
Forwarded from Data Science by ODS.ai 🦜
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes
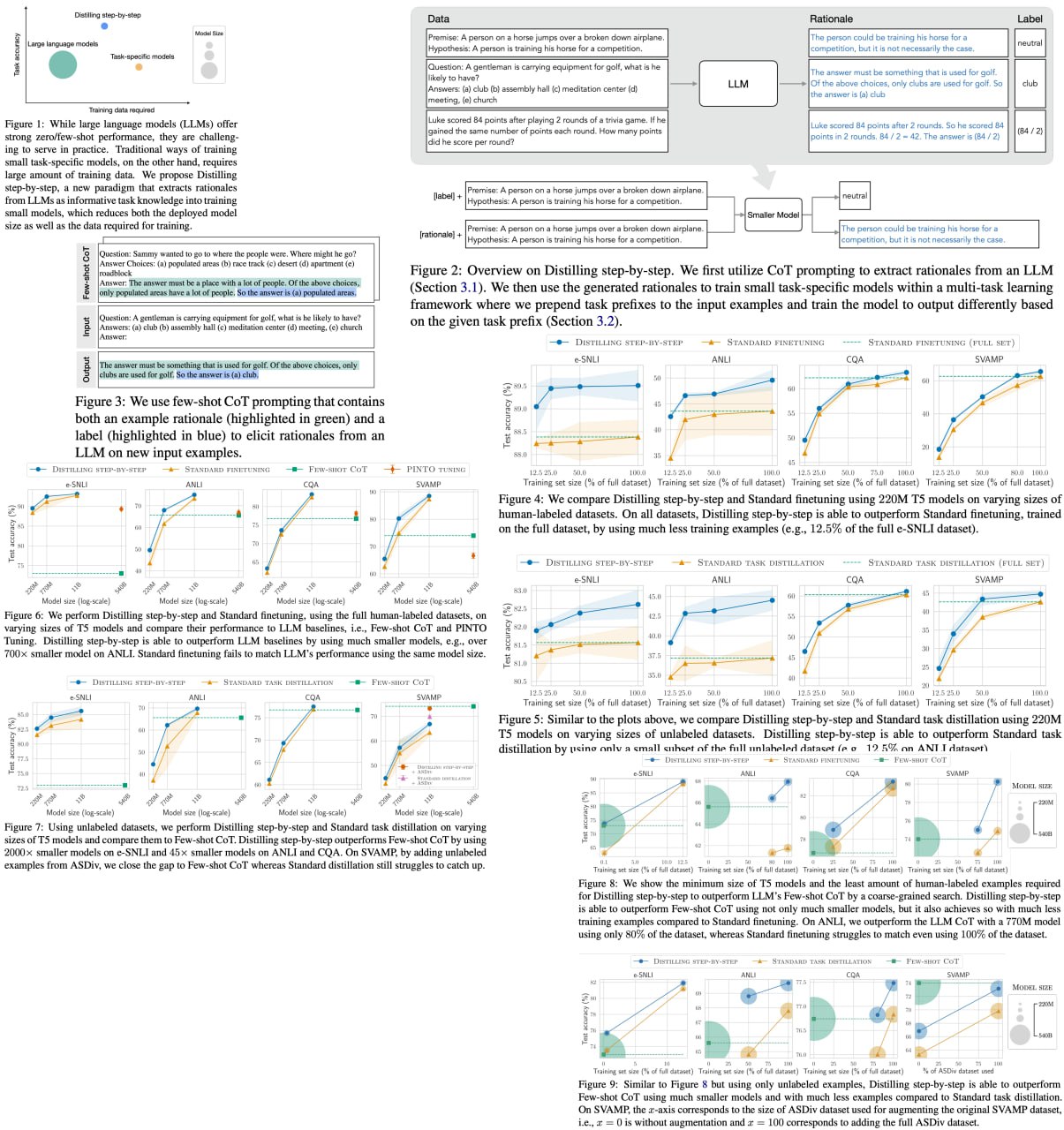
Researchers have developed "Distilling step-by-step," a cutting-edge method to train smaller, more efficient task-specific models that outperform large language models (LLMs) while requiring significantly less training data. This innovation promises to revolutionize the practicality of NLP models in real-world applications by reducing both model size and data requirements: a 770M T5 model surpasses a 540B PaLM model using only 80% of available data.
Distilling step-by-step leverages LLM-generated rationales within a multi-task training framework, yielding impressive results across 4 NLP benchmarks. The technique consistently achieves better performance with fewer labeled/unlabeled training examples, surpassing LLMs with substantially smaller model sizes.
Paper link: https://arxiv.org/abs/2305.02301
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dsbs
#deeplearning #nlp #languagemodels #distillation
Researchers have developed "Distilling step-by-step," a cutting-edge method to train smaller, more efficient task-specific models that outperform large language models (LLMs) while requiring significantly less training data. This innovation promises to revolutionize the practicality of NLP models in real-world applications by reducing both model size and data requirements: a 770M T5 model surpasses a 540B PaLM model using only 80% of available data.
Distilling step-by-step leverages LLM-generated rationales within a multi-task training framework, yielding impressive results across 4 NLP benchmarks. The technique consistently achieves better performance with fewer labeled/unlabeled training examples, surpassing LLMs with substantially smaller model sizes.
Paper link: https://arxiv.org/abs/2305.02301
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dsbs
#deeplearning #nlp #languagemodels #distillation
{kind=link}
Forwarded from Data Science by ODS.ai 🦜
Meta-Transformer: A Unified Framework for Multimodal Learning
The landscape of multimodal learning is about to witness a remarkable transformation with the introduction of Meta-Transformer, a state-of-the-art framework that's poised to overcome long-standing challenges in the field. The beauty of Meta-Transformer lies in its unique ability to process and understand information from a diverse range of modalities - from natural language, 2D images, 3D point clouds, to audio, video, time series, and tabular data. This ability stems from its innovative design that leverages a frozen encoder to map raw input data from these diverse modalities into a shared token space, eliminating the need for paired multimodal training data.
More than just a theoretical achievement, the Meta-Transformer has proven its practical application across various benchmarks, handling an impressive range of tasks from fundamental perception such as text, image, and audio processing, to more complex applications like X-Ray, infrared, and hyperspectral data interpretation, as well as data mining tasks involving graph, tabular, and time-series data.
Code link: https://github.com/invictus717/MetaTransformer
Paper link: https://arxiv.org/abs/2307.10802
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-meta-transformer
#deeplearning #nlp #transformer #cv
The landscape of multimodal learning is about to witness a remarkable transformation with the introduction of Meta-Transformer, a state-of-the-art framework that's poised to overcome long-standing challenges in the field. The beauty of Meta-Transformer lies in its unique ability to process and understand information from a diverse range of modalities - from natural language, 2D images, 3D point clouds, to audio, video, time series, and tabular data. This ability stems from its innovative design that leverages a frozen encoder to map raw input data from these diverse modalities into a shared token space, eliminating the need for paired multimodal training data.
More than just a theoretical achievement, the Meta-Transformer has proven its practical application across various benchmarks, handling an impressive range of tasks from fundamental perception such as text, image, and audio processing, to more complex applications like X-Ray, infrared, and hyperspectral data interpretation, as well as data mining tasks involving graph, tabular, and time-series data.
Code link: https://github.com/invictus717/MetaTransformer
Paper link: https://arxiv.org/abs/2307.10802
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-meta-transformer
#deeplearning #nlp #transformer #cv
{kind=link}
Forwarded from G B ️
#AI #NLP #DL Stanford CS224N: Natural Language Processing with Deep Learning 2023-2024
В сентябре 2023 выложили свежий бесплатный курс по NLP от Стэнфордского университета
Там как и минимально достаточная теория AI/NLP, так и много практики.
Рассматривают постепенно, идут от первых CNN, RNN, LSTM к трансформерам.
Но добавили и много нового в области NLP, например PROMPT-инжиниринг, RLHF, мультимодальные агенты.
Из средств взяли Pytorch вместо TensorFlow (это вкусовщина😉)
Первое вводное - https://www.youtube.com/watch?v=rmVRLeJRkl4
Сам курс: https://www.youtube.com/playlist?list=PLoROMvodv4rMFqRtEuo6SGjY4XbRIVRd4
Подробно о курсе и преподавателях https://web.stanford.edu/class/cs224n/
В сентябре 2023 выложили свежий бесплатный курс по NLP от Стэнфордского университета
Там как и минимально достаточная теория AI/NLP, так и много практики.
Рассматривают постепенно, идут от первых CNN, RNN, LSTM к трансформерам.
Но добавили и много нового в области NLP, например PROMPT-инжиниринг, RLHF, мультимодальные агенты.
Из средств взяли Pytorch вместо TensorFlow (это вкусовщина😉)
Первое вводное - https://www.youtube.com/watch?v=rmVRLeJRkl4
Сам курс: https://www.youtube.com/playlist?list=PLoROMvodv4rMFqRtEuo6SGjY4XbRIVRd4
Подробно о курсе и преподавателях https://web.stanford.edu/class/cs224n/
YouTube
Stanford CS224N: NLP with Deep Learning | Winter 2021 | Lecture 1 - Intro & Word Vectors
For more information about Stanford's Artificial Intelligence professional and graduate programs visit: https://stanford.io/3w46jar
This lecture covers:
1. The course (10min)
2. Human language and word meaning (15 min)
3. Word2vec algorithm introduction…
This lecture covers:
1. The course (10min)
2. Human language and word meaning (15 min)
3. Word2vec algorithm introduction…
Forwarded from Kali Novskaya (Tatiana Shavrina)
🌸Все данные для тестов LLM скомпрометированы? 🌸
#nlp #про_nlp #nlp_papers
Часто можно услышать критику о том, что результатам оценки LLM не стоит доверять, так как многие бенчмарки и датасеты уже давно лежат на гитхабе, а значит, наверняка попали в обучение моделей.
Как надежно тестировать языковые модели, если у нас часто нет доступа к их обучающим данным, а некоторые так и полностью от нас закрыты? Что, если данные были скомпрометированы?
Авторы Alpaca представили новый метод, позволяющий оценить риск утечки (контаминации) датасета, т.е. его ненамеренное/намеренное попадание в обучающую выборку у языковых моделей.
Идея простая: будем считать, что модель "запоминает" задания и ответы на них в той же последовательности, как они идут в датасете. Давайте проверим, сможем ли мы установить статистически значимую разницу в качестве решений задачи, если будем показывать моделям набор тестов задачи в том порядке, как он идут в самом датасете, или же в перемешанном порядке.
Спойлер:да, можем.
Искусственный эксперимент, при котором небольшой модели (1.4 млрд параметров) при обучении на Википедии "подкладывают" тестовые сеты различных датасетов — один раз, десять раз и т.д. — показывает, что при 10 и более копиях теста в обучении разница в качестве решения устанавливается достаточно надежно, и можно с уверенностью сказать, что можель опирается на запоминание, а не на обобщение или другие "возникающие" интеллектуальные способности.
Авторы протестировали несколько LLM (LLaMA2-7B, Mistral-7B, Pythia-1.4B, GPT-2 XL, BioMedLM) на публичных датасетах — и некоторые из них оказались действительно скомпрометированы. Например, Arc challenge точно попал в обучение Mistral, да еще и 10+ раз!
Выводы:
🟣 Мы уже можем тестировать языковые модели, в том числе доступные только по API, на "честность" решения самых разных задач, а также можем проверять, не меняется ли картина во времени.
🟣 Реальную сложность представляет обнаружение утечки теста, когда он попал в обучение всего один раз (не удается стат значимо установить разницу в качестве решений)
🟣 Нас может ждать глобальный и регулярный пересмотр подхода к тестированию моделей, так как открытые ответы регулярно выкладываются на открытые площадки и, соответственно, компрометируются. Оценка LLM должна быть привязана ко времени?
🟣 Остается проверить так все модели OpenAI?
🟣 Статья: Proving Test Set Contamination in Black Box Language Models link
#nlp #про_nlp #nlp_papers
Часто можно услышать критику о том, что результатам оценки LLM не стоит доверять, так как многие бенчмарки и датасеты уже давно лежат на гитхабе, а значит, наверняка попали в обучение моделей.
Как надежно тестировать языковые модели, если у нас часто нет доступа к их обучающим данным, а некоторые так и полностью от нас закрыты? Что, если данные были скомпрометированы?
Авторы Alpaca представили новый метод, позволяющий оценить риск утечки (контаминации) датасета, т.е. его ненамеренное/намеренное попадание в обучающую выборку у языковых моделей.
Идея простая: будем считать, что модель "запоминает" задания и ответы на них в той же последовательности, как они идут в датасете. Давайте проверим, сможем ли мы установить статистически значимую разницу в качестве решений задачи, если будем показывать моделям набор тестов задачи в том порядке, как он идут в самом датасете, или же в перемешанном порядке.
Спойлер:
Искусственный эксперимент, при котором небольшой модели (1.4 млрд параметров) при обучении на Википедии "подкладывают" тестовые сеты различных датасетов — один раз, десять раз и т.д. — показывает, что при 10 и более копиях теста в обучении разница в качестве решения устанавливается достаточно надежно, и можно с уверенностью сказать, что можель опирается на запоминание, а не на обобщение или другие "возникающие" интеллектуальные способности.
Авторы протестировали несколько LLM (LLaMA2-7B, Mistral-7B, Pythia-1.4B, GPT-2 XL, BioMedLM) на публичных датасетах — и некоторые из них оказались действительно скомпрометированы. Например, Arc challenge точно попал в обучение Mistral, да еще и 10+ раз!
Выводы:
Please open Telegram to view this post
VIEW IN TELEGRAM
Техас заменяет тысячи экзаменаторов на ИИ
Техас внедряет систему автоматической оценки открытых ответов на экзаменах STAAR с помощью обработки естественного языка.
Новая система, обученная на 3000 предварительно проверенных человеком ответов, призвана сэкономить от $15 до $20 млн в год за счет сокращения числа временных экзаменаторов.
Четверть ответов, оцененных ИИ, будет дополнительно проверяться людьми.
Некоторые преподаватели обеспокоены возможными ошибками автоматической оценки, хотя подобные системы уже используются в других штатах с переменным успехом.
Техасское агентство образования подчеркивает отличие своей системы от "искусственного интеллекта".
Как раз сегодня новость проскочила с выступлением из Штатов, где Луну обозвали газовой планетой. 😄
#Texas #STAAR #NLP
-------
@tsingular
Техас внедряет систему автоматической оценки открытых ответов на экзаменах STAAR с помощью обработки естественного языка.
Новая система, обученная на 3000 предварительно проверенных человеком ответов, призвана сэкономить от $15 до $20 млн в год за счет сокращения числа временных экзаменаторов.
Четверть ответов, оцененных ИИ, будет дополнительно проверяться людьми.
Некоторые преподаватели обеспокоены возможными ошибками автоматической оценки, хотя подобные системы уже используются в других штатах с переменным успехом.
Техасское агентство образования подчеркивает отличие своей системы от "искусственного интеллекта".
Как раз сегодня новость проскочила с выступлением из Штатов, где Луну обозвали газовой планетой. 😄
#Texas #STAAR #NLP
-------
@tsingular
WizardLM-2: новое поколение языковых моделей от Microsoft AI
Microsoft AI анонсировала WizardLM-2 - новую серию усовершенствованных языковых моделей.
Модели демонстрируют улучшенную производительность в сложных чатах, многоязычных задачах, рассуждениях и работе агентов.
Серия включает три модели:
- WizardLM-2 8x22B - самая продвинутая, превосходит лучшие открытые модели.
- WizardLM-2 70B - лучшие возможности рассуждения в своем размере.
- WizardLM-2 7B - самая быстрая, сопоставима с моделями в 10 раз больше.
Теперь и у Microsoft есть свои открытые языковые модели. Конкуренция - рулит! 🚀
#WizardLM #Microsoft #NLP
-------
@tsingular
Microsoft AI анонсировала WizardLM-2 - новую серию усовершенствованных языковых моделей.
Модели демонстрируют улучшенную производительность в сложных чатах, многоязычных задачах, рассуждениях и работе агентов.
Серия включает три модели:
- WizardLM-2 8x22B - самая продвинутая, превосходит лучшие открытые модели.
- WizardLM-2 70B - лучшие возможности рассуждения в своем размере.
- WizardLM-2 7B - самая быстрая, сопоставима с моделями в 10 раз больше.
Теперь и у Microsoft есть свои открытые языковые модели. Конкуренция - рулит! 🚀
#WizardLM #Microsoft #NLP
-------
@tsingular
❤1
Amazon представил новую модель для векторного эмбеддинга Titan V2
Новая версия модели оптимизирована под наиболее распространенные кейсы, такие как RAG, мультиязычные задачи и встраивание кода.
V2 гораздо быстрее V1 (логично), но, что интересно на порядок дешевле.
2 цента за 1 млн токенов
Модель обучена на более чем 100 языках и показывает неплохие результаты на бенчмарках MTEB (SFR -one love все-равно).
Максимальная размерность вектора - 1024 (такое)...
Всем ли подойдет, - не понятно, нужно тестировать. Хотелось бы 4096.
#Amazon #TitanEmbeddings #NLP
-------
@tsingular
Новая версия модели оптимизирована под наиболее распространенные кейсы, такие как RAG, мультиязычные задачи и встраивание кода.
V2 гораздо быстрее V1 (логично), но, что интересно на порядок дешевле.
2 цента за 1 млн токенов
Модель обучена на более чем 100 языках и показывает неплохие результаты на бенчмарках MTEB (SFR -one love все-равно).
Максимальная размерность вектора - 1024 (такое)...
Всем ли подойдет, - не понятно, нужно тестировать. Хотелось бы 4096.
#Amazon #TitanEmbeddings #NLP
-------
@tsingular
Google представил Translation LLM и Adaptive Translation
Google Cloud анонсировали важные обновления Translation API:
- Translation LLM - оптимизирована для перевода длинных текстов и абзацев. Сохраняет контекст и связность.
- Adaptive Translation - настраиваемый перевод в реальном времени на базе небольшого набора примеров. Повышение качества до 23% по сравнению с Google Translate.
- Улучшенные традиционные модели NMT для 30 языковых пар, включая немецкий, японский, хинди и китайский.
Клиенты могут выбрать оптимальную модель для своих задач, языка и рабочего процесса на платформе Vertex AI.
Также предлагаются сервисы Translation Hub для перевода большого объема документов и AutoML Translation для создания кастомных моделей без кода.
Нейросети для больших объёмов, а если же важен стиль и строгая терминология - используйте Adaptive Translation. 👌
#GoogleCloud #TranslationAI #NLP
-------
@tsingular
Google Cloud анонсировали важные обновления Translation API:
- Translation LLM - оптимизирована для перевода длинных текстов и абзацев. Сохраняет контекст и связность.
- Adaptive Translation - настраиваемый перевод в реальном времени на базе небольшого набора примеров. Повышение качества до 23% по сравнению с Google Translate.
- Улучшенные традиционные модели NMT для 30 языковых пар, включая немецкий, японский, хинди и китайский.
Клиенты могут выбрать оптимальную модель для своих задач, языка и рабочего процесса на платформе Vertex AI.
Также предлагаются сервисы Translation Hub для перевода большого объема документов и AutoML Translation для создания кастомных моделей без кода.
Нейросети для больших объёмов, а если же важен стиль и строгая терминология - используйте Adaptive Translation. 👌
#GoogleCloud #TranslationAI #NLP
-------
@tsingular
NuExtract: компактная модель для структурированного извлечения данных
NuExtract - специализированная модель для извлечения информации из текста в JSON-формате.
Обучена на 50 000 аннотированных примерах, созданных с помощью LLM.
Работает в режимах zero-shot и pseudo few-shot.
Версии модели: tiny (0.5B), стандартная (3.8B) и large (7B).
Практически близка по качеству к 4o OpenAI.
Применима для анализа технических, медицинских и юридических документов.
Легко адаптируется к конкретным задачам через дообучение.
Выпущена под лицензией MIT.
Может быть очень полезна не только для документов но и для локальной обработки входящих запросов на предмет "а что хотел узнать пользователь" и создания langchain потоков.
#NuExtract #StructuredExtraction #NLP
-------
@tsingular
NuExtract - специализированная модель для извлечения информации из текста в JSON-формате.
Обучена на 50 000 аннотированных примерах, созданных с помощью LLM.
Работает в режимах zero-shot и pseudo few-shot.
Версии модели: tiny (0.5B), стандартная (3.8B) и large (7B).
Практически близка по качеству к 4o OpenAI.
Применима для анализа технических, медицинских и юридических документов.
Легко адаптируется к конкретным задачам через дообучение.
Выпущена под лицензией MIT.
Может быть очень полезна не только для документов но и для локальной обработки входящих запросов на предмет "а что хотел узнать пользователь" и создания langchain потоков.
#NuExtract #StructuredExtraction #NLP
-------
@tsingular
🔥2❤🔥1
RAGLAB: Революция в оценке алгоритмов NLP
Представлен RAGLAB - новый фреймворк для прозрачной оценки алгоритмов Retrieval-Augmented Generation (RAG) в NLP-исследованиях.
Платформа стандартизирует ключевые переменные, воспроизводит шесть существующих RAG-алгоритмов и оценивает их по десяти бенчмаркам.
Модульная архитектура упрощает сравнение методов и интеграцию в проверяемые модули.
Тесты выявили преимущество selfrag-llama3-70B, при этом классические системы RAG уступили прямым LLM в тестах с множественным выбором.
Т.е. с RAG нужно готовить расширенный контрекст, а дальше передавать выбор в LLM. Ну так и делаем.
Похоже, в ближайшие 5 лет будет актуальной профессия - RAG-инженер.
Слишком много получается методик и в них нужно разбираться.
#RAGLAB #NLP #RetrievalAugmentedGeneration
-------
@tsingular
Представлен RAGLAB - новый фреймворк для прозрачной оценки алгоритмов Retrieval-Augmented Generation (RAG) в NLP-исследованиях.
Платформа стандартизирует ключевые переменные, воспроизводит шесть существующих RAG-алгоритмов и оценивает их по десяти бенчмаркам.
Модульная архитектура упрощает сравнение методов и интеграцию в проверяемые модули.
Тесты выявили преимущество selfrag-llama3-70B, при этом классические системы RAG уступили прямым LLM в тестах с множественным выбором.
Т.е. с RAG нужно готовить расширенный контрекст, а дальше передавать выбор в LLM. Ну так и делаем.
Похоже, в ближайшие 5 лет будет актуальной профессия - RAG-инженер.
Слишком много получается методик и в них нужно разбираться.
#RAGLAB #NLP #RetrievalAugmentedGeneration
-------
@tsingular
❤1
Обнаружена самая большая коллекция RAG техник на GitHub
Репозиторий NirDiamant представляет мощнейшую коллекцию передовых техник RAG (Retrieval-Augmented Generation).
Охватывает множество сценариев: от базовых подходов до сложных многоуровневых систем.
Ключевые направления: оптимизация поиска, обработка контекста, адаптивное извлечение и интеграция различных типов данных.
Просто оглавление для понимания:
1. Simple RAG
2. Context Enrichment Techniques
3. Multi-faceted Filtering
4. Fusion Retrieval
5. Intelligent Reranking
6.Query Transformations
7. Hierarchical Indices
8. Hypothetical Questions (HyDE Approach)
9. Choose Chunk Size
10. Semantic Chunking
11. Contextual Compression
12. Explainable Retrieval
13. Retrieval with Feedback Loops
14. Adaptive Retrieval
15. Iterative Retrieval
16. Ensemble Retrieval
17. Knowledge Graph Integration (Graph RAG)
18. Multi-modal Retrieval
19. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
20. Self RAG
21. Corrective RAG
22. Document Augmentation through Question Generation for Enhanced Retrieval
23. Sophisticated Controllable Agent for Complex RAG Tasks
Коллекция продолжает пополняться.
Заносим в избранное.
#GitHub #RAG #NLP
———
@tsingular
Репозиторий NirDiamant представляет мощнейшую коллекцию передовых техник RAG (Retrieval-Augmented Generation).
Охватывает множество сценариев: от базовых подходов до сложных многоуровневых систем.
Ключевые направления: оптимизация поиска, обработка контекста, адаптивное извлечение и интеграция различных типов данных.
Просто оглавление для понимания:
1. Simple RAG
2. Context Enrichment Techniques
3. Multi-faceted Filtering
4. Fusion Retrieval
5. Intelligent Reranking
6.Query Transformations
7. Hierarchical Indices
8. Hypothetical Questions (HyDE Approach)
9. Choose Chunk Size
10. Semantic Chunking
11. Contextual Compression
12. Explainable Retrieval
13. Retrieval with Feedback Loops
14. Adaptive Retrieval
15. Iterative Retrieval
16. Ensemble Retrieval
17. Knowledge Graph Integration (Graph RAG)
18. Multi-modal Retrieval
19. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
20. Self RAG
21. Corrective RAG
22. Document Augmentation through Question Generation for Enhanced Retrieval
23. Sophisticated Controllable Agent for Complex RAG Tasks
Коллекция продолжает пополняться.
Заносим в избранное.
#GitHub #RAG #NLP
———
@tsingular
⚡2🔥1
Forwarded from Mashkka про Data Science
В новом выпуске #paperwatch разбираем самые последние статьи по детекции утечек данных в LLM:
#nlp #llm
Please open Telegram to view this post
VIEW IN TELEGRAM
Эмбеддинг документов с контекстом
Предлагается новый метод сохранения эмбеддингов документов, учитывающий соседние тексты при создании векторных представлений.
В данном подходе используется двухэтапная архитектура: сбор контекста и встраивание документа с дополнительными контекстными токенами.
Результат позволяет получить достаточно высокие показатели на бенчмарках MTEB и BEIR, особенно в узкоспециализированных доменах.
Метод улучшает не только поиск, но и кластеризацию, классификацию и оценку семантического сходства текстов.
Самурай с мечом подобен самураю без меча, но с мечом. :)
Если вспомнить подход Антропика с подготовкой чанков по контексту документа, то это получается следующий шаг.
Чанки готовим с контекстом документа и со ссылками на контексты вне документа, но которые относятся к рассматриваемому параграфу.
Скорость эмбеддинга, вероятно, упадёт на порядок, ну или потребует больше ресурсов, однако качество эмбеддинга станет идеальным.
#NLP #Embeddings #эмбеддинги
-------
@tsingular
Предлагается новый метод сохранения эмбеддингов документов, учитывающий соседние тексты при создании векторных представлений.
В данном подходе используется двухэтапная архитектура: сбор контекста и встраивание документа с дополнительными контекстными токенами.
Результат позволяет получить достаточно высокие показатели на бенчмарках MTEB и BEIR, особенно в узкоспециализированных доменах.
Метод улучшает не только поиск, но и кластеризацию, классификацию и оценку семантического сходства текстов.
Самурай с мечом подобен самураю без меча, но с мечом. :)
Если вспомнить подход Антропика с подготовкой чанков по контексту документа, то это получается следующий шаг.
Чанки готовим с контекстом документа и со ссылками на контексты вне документа, но которые относятся к рассматриваемому параграфу.
Скорость эмбеддинга, вероятно, упадёт на порядок, ну или потребует больше ресурсов, однако качество эмбеддинга станет идеальным.
#NLP #Embeddings #эмбеддинги
-------
@tsingular
👍4
MTS AI выпустили компактную русскоязычную LLM-модель Cotype Nano
Разработаны три модификации малой языковой модели: базовая, квантизированная и CPU-версия.
Датасет сфокусирован на математике, программировании, function-calling, RAG и классификации.
Двухстадийное обучение включало тренировку MLP с LoRa и полное обучение на инструкциях.
Технические оптимизации позволили уменьшить размер до 1.6ГБ видеопамяти через AWQ-квантизацию.
Модель заняла первое место на RuGeneralArena в своей категории, демонстрируя высокую эффективность при минимальных ресурсах.
Если нет видеокарты и не нужен большой контекст,- вполне.
#MTS #Cotype #NLP #МТС
-------
@tsingular
Разработаны три модификации малой языковой модели: базовая, квантизированная и CPU-версия.
Датасет сфокусирован на математике, программировании, function-calling, RAG и классификации.
Двухстадийное обучение включало тренировку MLP с LoRa и полное обучение на инструкциях.
Технические оптимизации позволили уменьшить размер до 1.6ГБ видеопамяти через AWQ-квантизацию.
Модель заняла первое место на RuGeneralArena в своей категории, демонстрируя высокую эффективность при минимальных ресурсах.
Если нет видеокарты и не нужен большой контекст,- вполне.
#MTS #Cotype #NLP #МТС
-------
@tsingular
👍5