
Forwarded from Data Science by ODS.ai 🦜
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes
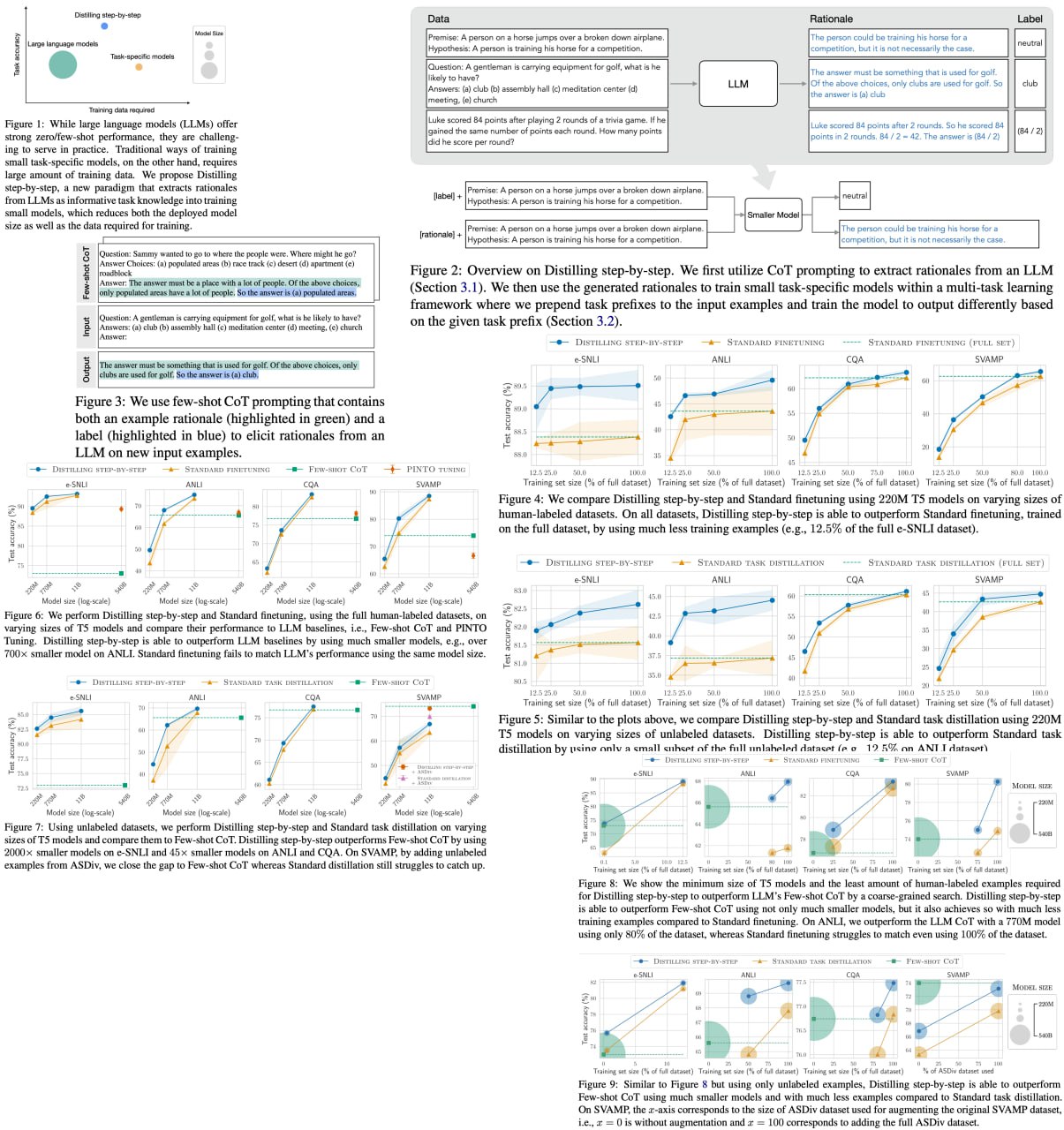
Researchers have developed "Distilling step-by-step," a cutting-edge method to train smaller, more efficient task-specific models that outperform large language models (LLMs) while requiring significantly less training data. This innovation promises to revolutionize the practicality of NLP models in real-world applications by reducing both model size and data requirements: a 770M T5 model surpasses a 540B PaLM model using only 80% of available data.
Distilling step-by-step leverages LLM-generated rationales within a multi-task training framework, yielding impressive results across 4 NLP benchmarks. The technique consistently achieves better performance with fewer labeled/unlabeled training examples, surpassing LLMs with substantially smaller model sizes.
Paper link: https://arxiv.org/abs/2305.02301
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dsbs
#deeplearning #nlp #languagemodels #distillation
Researchers have developed "Distilling step-by-step," a cutting-edge method to train smaller, more efficient task-specific models that outperform large language models (LLMs) while requiring significantly less training data. This innovation promises to revolutionize the practicality of NLP models in real-world applications by reducing both model size and data requirements: a 770M T5 model surpasses a 540B PaLM model using only 80% of available data.
Distilling step-by-step leverages LLM-generated rationales within a multi-task training framework, yielding impressive results across 4 NLP benchmarks. The technique consistently achieves better performance with fewer labeled/unlabeled training examples, surpassing LLMs with substantially smaller model sizes.
Paper link: https://arxiv.org/abs/2305.02301
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dsbs
#deeplearning #nlp #languagemodels #distillation
{kind=link}
Forwarded from Data Science by ODS.ai 🦜
MMS: Scaling Speech Technology to 1000+ languages
Get ready for a breakthrough in speech technology that is set to revolutionize the world of communication! The field, which has so far been restricted to around a hundred languages, barely scratches the surface of the more than 7,000 languages spoken globally. The Massively Multilingual Speech (MMS) project is taking a monumental leap to bridge this gap, increasing the number of supported languages by an astounding 10 to 40 times, depending on the task. This unprecedented expansion will be a game-changer, significantly improving global access to information and creating a more inclusive digital landscape.
This incredible feat is achieved through the creation of a new dataset drawn from publicly available religious texts and the strategic implementation of self-supervised learning. The MMS project's achievements are staggering, including the development of pre-trained wav2vec 2.0 models for 1,406 languages, a single multilingual automatic speech recognition model for 1,107 languages, speech synthesis models for as many languages, and a language identification model for a whopping 4,017 languages. Even more impressive is the significant improvement in accuracy - our multilingual speech recognition model more than halves the word error rate of Whisper on 54 languages of the FLEURS benchmark, despite being trained on a significantly smaller dataset.
Paper link: https://research.facebook.com/publications/scaling-speech-technology-to-1000-languages/
Blogpost link: https://ai.facebook.com/blog/multilingual-model-speech-recognition/
Code link: https://github.com/facebookresearch/fairseq/tree/main/examples/mms
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-mms
#deeplearning #speechrecognition #tts #audio
Get ready for a breakthrough in speech technology that is set to revolutionize the world of communication! The field, which has so far been restricted to around a hundred languages, barely scratches the surface of the more than 7,000 languages spoken globally. The Massively Multilingual Speech (MMS) project is taking a monumental leap to bridge this gap, increasing the number of supported languages by an astounding 10 to 40 times, depending on the task. This unprecedented expansion will be a game-changer, significantly improving global access to information and creating a more inclusive digital landscape.
This incredible feat is achieved through the creation of a new dataset drawn from publicly available religious texts and the strategic implementation of self-supervised learning. The MMS project's achievements are staggering, including the development of pre-trained wav2vec 2.0 models for 1,406 languages, a single multilingual automatic speech recognition model for 1,107 languages, speech synthesis models for as many languages, and a language identification model for a whopping 4,017 languages. Even more impressive is the significant improvement in accuracy - our multilingual speech recognition model more than halves the word error rate of Whisper on 54 languages of the FLEURS benchmark, despite being trained on a significantly smaller dataset.
Paper link: https://research.facebook.com/publications/scaling-speech-technology-to-1000-languages/
Blogpost link: https://ai.facebook.com/blog/multilingual-model-speech-recognition/
Code link: https://github.com/facebookresearch/fairseq/tree/main/examples/mms
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-mms
#deeplearning #speechrecognition #tts #audio
{kind=link}
Forwarded from Data Science by ODS.ai 🦜
Meta-Transformer: A Unified Framework for Multimodal Learning
The landscape of multimodal learning is about to witness a remarkable transformation with the introduction of Meta-Transformer, a state-of-the-art framework that's poised to overcome long-standing challenges in the field. The beauty of Meta-Transformer lies in its unique ability to process and understand information from a diverse range of modalities - from natural language, 2D images, 3D point clouds, to audio, video, time series, and tabular data. This ability stems from its innovative design that leverages a frozen encoder to map raw input data from these diverse modalities into a shared token space, eliminating the need for paired multimodal training data.
More than just a theoretical achievement, the Meta-Transformer has proven its practical application across various benchmarks, handling an impressive range of tasks from fundamental perception such as text, image, and audio processing, to more complex applications like X-Ray, infrared, and hyperspectral data interpretation, as well as data mining tasks involving graph, tabular, and time-series data.
Code link: https://github.com/invictus717/MetaTransformer
Paper link: https://arxiv.org/abs/2307.10802
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-meta-transformer
#deeplearning #nlp #transformer #cv
The landscape of multimodal learning is about to witness a remarkable transformation with the introduction of Meta-Transformer, a state-of-the-art framework that's poised to overcome long-standing challenges in the field. The beauty of Meta-Transformer lies in its unique ability to process and understand information from a diverse range of modalities - from natural language, 2D images, 3D point clouds, to audio, video, time series, and tabular data. This ability stems from its innovative design that leverages a frozen encoder to map raw input data from these diverse modalities into a shared token space, eliminating the need for paired multimodal training data.
More than just a theoretical achievement, the Meta-Transformer has proven its practical application across various benchmarks, handling an impressive range of tasks from fundamental perception such as text, image, and audio processing, to more complex applications like X-Ray, infrared, and hyperspectral data interpretation, as well as data mining tasks involving graph, tabular, and time-series data.
Code link: https://github.com/invictus717/MetaTransformer
Paper link: https://arxiv.org/abs/2307.10802
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-meta-transformer
#deeplearning #nlp #transformer #cv
{kind=link}
Стрим Валерия Бабушкина про LLM, приглашен инженер из Deep Mind - создатель Gemini и Игорь - See All
Оптимизация коммуникаций и уменьшение сетевых нагрузок являются важными для эффективности тренировки больших моделей.
Техники распределенного обучения, такие как шардинг и разбиение на части, способствуют снижению сетевой нагрузки.
Другим серьезным вызовом является надежность оборудования; для снижения отказов используются методы, такие как понижение напряжения (undervolting) и сокращение частоты.
Также отмечается растущее использование ускорителей глубокого обучения, например TPU, для тренировки моделей большого масштаба.
Синхронизация градиентов и передача данных являются критическими компонентами распределенного обучения, а использование кодов коррекции ошибок обеспечивает целостность данных.
Вопросы настройки гиперпараметров остаются сложными, и для решения этой проблемы предлагается тренировка меньших моделей для предсказания производительности более крупных.
#DeepLearning #AIInfrastructure #DistributedTraining
Оптимизация коммуникаций и уменьшение сетевых нагрузок являются важными для эффективности тренировки больших моделей.
Техники распределенного обучения, такие как шардинг и разбиение на части, способствуют снижению сетевой нагрузки.
Другим серьезным вызовом является надежность оборудования; для снижения отказов используются методы, такие как понижение напряжения (undervolting) и сокращение частоты.
Также отмечается растущее использование ускорителей глубокого обучения, например TPU, для тренировки моделей большого масштаба.
Синхронизация градиентов и передача данных являются критическими компонентами распределенного обучения, а использование кодов коррекции ошибок обеспечивает целостность данных.
Вопросы настройки гиперпараметров остаются сложными, и для решения этой проблемы предлагается тренировка меньших моделей для предсказания производительности более крупных.
#DeepLearning #AIInfrastructure #DistributedTraining
"Крестный отец ИИ" о том, что нас ждет | Выступление Джеффри Хинтона для MIT
В своём выступлении для MIT, Джеффри Хинтон, профессор Университета Торонто и бывший вице-президент Google, поделился своими размышлениями о будущем искусственного интеллекта.
Хинтон, один из пионеров глубокого обучения, известен разработкой алгоритма обратного распространения ошибки в 1980-х, который оказал значительное влияние на модели языка и обработку естественного языка.
Он подчеркнул, что модели компьютерного интеллекта работают иначе, чем человеческий мозг, и могут не совпадать с возможностями мозга.
Также Хинтон обсудил модель GPT-4, демонстрирующую впечатляющие результаты, что подтверждает мощь использованных методов.
По мнению Хинтона, быстрый обмен знаниями между компьютерами может вести как к лучшему пониманию и решению проблем, так и к возможностям для манипуляции.
Профессор выразил озабоченность по поводу безопасности общества из-за доступа злоумышленников к продвинутому ИИ.
#AI #DeepLearning #JeffreyHinton
В своём выступлении для MIT, Джеффри Хинтон, профессор Университета Торонто и бывший вице-президент Google, поделился своими размышлениями о будущем искусственного интеллекта.
Хинтон, один из пионеров глубокого обучения, известен разработкой алгоритма обратного распространения ошибки в 1980-х, который оказал значительное влияние на модели языка и обработку естественного языка.
Он подчеркнул, что модели компьютерного интеллекта работают иначе, чем человеческий мозг, и могут не совпадать с возможностями мозга.
Также Хинтон обсудил модель GPT-4, демонстрирующую впечатляющие результаты, что подтверждает мощь использованных методов.
По мнению Хинтона, быстрый обмен знаниями между компьютерами может вести как к лучшему пониманию и решению проблем, так и к возможностям для манипуляции.
Профессор выразил озабоченность по поводу безопасности общества из-за доступа злоумышленников к продвинутому ИИ.
#AI #DeepLearning #JeffreyHinton
ИИ способен собрать паззл из 3х миллиардов микрочастиц
Инновационная модель ИИ автоматизирует анализ и сопоставление микроскопических окаменелостей.
Сочетание сверточных нейронок и визуальных трансформеров показывает лучший результат по сравнению с традиционными методами обработки изображений.
Самообучение на подготовленных данных значительно улучшает точность распознавания по сравнению с базовыми моделями.
Технология применима для изучения различных типов микрофоссилий в геологических записях.
Метод может быть полезен как в промышленных, так и в академических геологических исследованиях.
Наконец-то можно будет найти иголку в стоге сена.
#DeepLearning #Microfossils #Geology
-------
@tsingular
Инновационная модель ИИ автоматизирует анализ и сопоставление микроскопических окаменелостей.
Сочетание сверточных нейронок и визуальных трансформеров показывает лучший результат по сравнению с традиционными методами обработки изображений.
Самообучение на подготовленных данных значительно улучшает точность распознавания по сравнению с базовыми моделями.
Технология применима для изучения различных типов микрофоссилий в геологических записях.
Метод может быть полезен как в промышленных, так и в академических геологических исследованиях.
Наконец-то можно будет найти иголку в стоге сена.
#DeepLearning #Microfossils #Geology
-------
@tsingular
Всё, что нужно знать об Обучении с Подкреплением (Reinforcement Learning) в 2024
Интересная работа с детальным описанием подходов к RL.
Reinforcement Learning использует принципы обучения через взаимодействие со средой, получая положительную или отрицательную обратную связь.
Рассмотрены:
- Состояния (s): Текущая ситуация/наблюдение
- Действия (a): Возможные выборы агента
- Награды (r): Сигналы обратной связи
- Политика (π): Стратегия отображения состояния в действии
- Функция ценности (V/Q): Оценка будущих наград
Методы:
- По ценности: Q-learning, SARSA
- По политике: REINFORCE, PPO
- По модели: Планирование через симуляцию
Рассмотрены методы оценки результатов и эффективности обучения, а так же:
Офлайн RL: Обучение на готовых данных
Мульти-агенты: Командное обучение
Мета-RL: Быстрое адаптивное обучение
Безопасность: Контроль рисков
Вы это никогда не прочитаете, но этим можно накормить бота и дальше с ним консультироваться :)
#ReinforcementLearning #MachineLearning #DeepLearning #обучение
------
@tsingular
Интересная работа с детальным описанием подходов к RL.
Reinforcement Learning использует принципы обучения через взаимодействие со средой, получая положительную или отрицательную обратную связь.
Рассмотрены:
- Состояния (s): Текущая ситуация/наблюдение
- Действия (a): Возможные выборы агента
- Награды (r): Сигналы обратной связи
- Политика (π): Стратегия отображения состояния в действии
- Функция ценности (V/Q): Оценка будущих наград
Методы:
- По ценности: Q-learning, SARSA
- По политике: REINFORCE, PPO
- По модели: Планирование через симуляцию
Рассмотрены методы оценки результатов и эффективности обучения, а так же:
Офлайн RL: Обучение на готовых данных
Мульти-агенты: Командное обучение
Мета-RL: Быстрое адаптивное обучение
Безопасность: Контроль рисков
Вы это никогда не прочитаете, но этим можно накормить бота и дальше с ним консультироваться :)
#ReinforcementLearning #MachineLearning #DeepLearning #обучение
------
@tsingular
✍4❤1
🚀 Курс "Practical Deep Learning for Coders" от Fast.ai
Наткнулся на интересный бесплатный курс от fast.ai, который дает практические навыки глубокого обучения без гигантских требований к математике или железу.
Без регистрации, оплаты и т.д. статьи, видеоуроки, примеры кода.
Чему учат:
- Создание и тренировка моделей для компьютерного зрения, обработки естественного языка, табличных данных
- Сборка и деплой работающих моделей с первого занятия (на второе занятие у вас уже будет своя рабочая модель!)
- Работа с библиотеками: PyTorch, fastai, Hugging Face Transformers, Gradio
- Техники глубокого обучения: случайные леса, стохастический градиентный спуск, аугментация данных, transfer learning
Акцент на навыках:
- Построение полного цикла обучения с нуля
- Методы улучшения точности и скорости моделей
- Внедрение моделей в веб-приложения
- Работа с категориальными и непрерывными данными
Преимущества курса:
1. Строится на практических примерах кода, а не только теории
2. Показывает рабочие модели с первого занятия
3. Не требует дорогого железа (всё можно запустить в Kaggle/Paperspace)
4. Не нужна продвинутая математика — хватит школьного уровня
9 уроков по 90 минут. Всё можно пробовать в Jupyter Notebooks. Дополнительно есть форумы сообщества и рабочий код.
В общем, если давно хотели разобраться с нейронками но пугала математика — имеет смысл рассмотреть. Пишешь код, видишь результат, а теорию подтягиваешь по мере необходимости.
#deeplearning #ML #PyTorch #обучение
———
@tsingular
Наткнулся на интересный бесплатный курс от fast.ai, который дает практические навыки глубокого обучения без гигантских требований к математике или железу.
Без регистрации, оплаты и т.д. статьи, видеоуроки, примеры кода.
Чему учат:
- Создание и тренировка моделей для компьютерного зрения, обработки естественного языка, табличных данных
- Сборка и деплой работающих моделей с первого занятия (на второе занятие у вас уже будет своя рабочая модель!)
- Работа с библиотеками: PyTorch, fastai, Hugging Face Transformers, Gradio
- Техники глубокого обучения: случайные леса, стохастический градиентный спуск, аугментация данных, transfer learning
Акцент на навыках:
- Построение полного цикла обучения с нуля
- Методы улучшения точности и скорости моделей
- Внедрение моделей в веб-приложения
- Работа с категориальными и непрерывными данными
Преимущества курса:
1. Строится на практических примерах кода, а не только теории
2. Показывает рабочие модели с первого занятия
3. Не требует дорогого железа (всё можно запустить в Kaggle/Paperspace)
4. Не нужна продвинутая математика — хватит школьного уровня
9 уроков по 90 минут. Всё можно пробовать в Jupyter Notebooks. Дополнительно есть форумы сообщества и рабочий код.
В общем, если давно хотели разобраться с нейронками но пугала математика — имеет смысл рассмотреть. Пишешь код, видишь результат, а теорию подтягиваешь по мере необходимости.
#deeplearning #ML #PyTorch #обучение
———
@tsingular
✍14⚡2🔥1👨💻1
Forwarded from Анализ данных (Data analysis)
🚀 LTX-Video 13B — один из самых мощных open-source видеогенераторов.
Разработчики внедрили в модель мультимасштабный рендеринг.
✅ Обычные генеративные модели видео рендерят всё изображение целиком, одним разрешением.
Когда в сцене много движущихся объектов или деталей, модель может "размазать" их, потерять чёткость или неправильно совместить фон и передний план.
📝 А мультимасштабный рендеринг — это параллельная отрисовка картинки на разных уровнях детализации:
один поток отвечает за фон (низкая детализация, большой масштаб),
другой — за объекты в центре, движущиеся элементы (высокая детализация, малый масштаб).
Потом всё объединяется в один кадр, как слои в Photoshop.
🎯 Зачем это нужно?
Фон остаётся стабильным, не "дергается"
Движущиеся объекты остаются чёткими и отдельными от фона
Картинка в целом не разваливается (нет смешивания движений, артефактов)
Такой подход помогает удерживать высокое качество картинки даже при сложном движении — например, если в кадре бежит персонаж на фоне движущегося города.
👉 По сути, это умное раздельное внимание к разным частям кадра, чтобы не терять детали ни в статике, ни в движении.
Что нового?
– Модель 13 миллиардов параметров
– Multiscale rendering → больше деталей, чётче текстуры
– Лучше понимает движение и сцену
– Запускается локально на GPU
– Поддержка keyframes, движения камеры/персонажей, мультисценных секвенций
Запускается даже на RTX 4090.
#AI #videoAI #ltxvideo #deeplearning #generativeAI #opensource #videogeneration
▪Попробовать можно тут→ https://app.ltx.studio/ltx-video
▪Code → https://github.com/Lightricks/LTX-Video
▪Weights → https://huggingface.co/Lightricks/LTX-Video
Разработчики внедрили в модель мультимасштабный рендеринг.
✅ Обычные генеративные модели видео рендерят всё изображение целиком, одним разрешением.
Когда в сцене много движущихся объектов или деталей, модель может "размазать" их, потерять чёткость или неправильно совместить фон и передний план.
📝 А мультимасштабный рендеринг — это параллельная отрисовка картинки на разных уровнях детализации:
один поток отвечает за фон (низкая детализация, большой масштаб),
другой — за объекты в центре, движущиеся элементы (высокая детализация, малый масштаб).
Потом всё объединяется в один кадр, как слои в Photoshop.
🎯 Зачем это нужно?
Фон остаётся стабильным, не "дергается"
Движущиеся объекты остаются чёткими и отдельными от фона
Картинка в целом не разваливается (нет смешивания движений, артефактов)
Такой подход помогает удерживать высокое качество картинки даже при сложном движении — например, если в кадре бежит персонаж на фоне движущегося города.
👉 По сути, это умное раздельное внимание к разным частям кадра, чтобы не терять детали ни в статике, ни в движении.
Что нового?
– Модель 13 миллиардов параметров
– Multiscale rendering → больше деталей, чётче текстуры
– Лучше понимает движение и сцену
– Запускается локально на GPU
– Поддержка keyframes, движения камеры/персонажей, мультисценных секвенций
Запускается даже на RTX 4090.
#AI #videoAI #ltxvideo #deeplearning #generativeAI #opensource #videogeneration
▪Попробовать можно тут→ https://app.ltx.studio/ltx-video
▪Code → https://github.com/Lightricks/LTX-Video
▪Weights → https://huggingface.co/Lightricks/LTX-Video
👍9⚡4🔥1
🚀 MCP Курс от Anthropic на платформе DeepLearning.ai
Anthropic выпустила новый курс по Model Context Protocol (MCP).
Уровень: Средний
Продолжительность: 1 час 38 минут
Преподаватель: Elie Schoppik (Anthropic)
Формат: Бесплатный онлайн-курс
Структура курса:
11 уроков
7 практических примеров кода
Видеоматериалы с пошаговыми инструкциями
По окончании курса вы сможете создавать AI-приложения, способные подключаться к экосистеме MCP-серверов с минимальными интеграционными усилиями.
В курсе также рассматривается будущее MCP:
- Мульти-агентная архитектура
- MCP Registry API
- Обнаружение серверов
- Авторизация и аутентификация
Курс ведет Elie Schoppik, технический преподаватель Anthropic, и рассчитан на разработчиков с базовым пониманием Python и опытом работы с LLM.
#MCP #Anthropic #DeepLearning #обучение
———
@tsingular
Anthropic выпустила новый курс по Model Context Protocol (MCP).
Уровень: Средний
Продолжительность: 1 час 38 минут
Преподаватель: Elie Schoppik (Anthropic)
Формат: Бесплатный онлайн-курс
Структура курса:
11 уроков
7 практических примеров кода
Видеоматериалы с пошаговыми инструкциями
По окончании курса вы сможете создавать AI-приложения, способные подключаться к экосистеме MCP-серверов с минимальными интеграционными усилиями.
В курсе также рассматривается будущее MCP:
- Мульти-агентная архитектура
- MCP Registry API
- Обнаружение серверов
- Авторизация и аутентификация
Курс ведет Elie Schoppik, технический преподаватель Anthropic, и рассчитан на разработчиков с базовым пониманием Python и опытом работы с LLM.
#MCP #Anthropic #DeepLearning #обучение
———
@tsingular
⚡7✍4👍2
Forwarded from Machine learning Interview
This media is not supported in your browser
VIEW IN TELEGRAM
🚀 Теперь можно запускать модели Hugging Face прямо в Google Colab — бесплатно!
Больше не нужно настраивать окружение вручную. Просто заходишь на страницу модели — и нажимаешь "Open in Colab". Всё готово для запуска за секунды.
✅ Отлично подходит для:
- Быстрого теста модели
- Прототипирования и экспериментов
- Обучения и демонстраций
💡 Бонус для разработчиков:
Добавь файл
Пользователи смогут запускать твой пример сразу, без копирования кода!
🔥 Работает с Google Colab — бесплатно, быстро, удобно.
#HuggingFace #Colab #ML #AI #OpenSource #DeepLearning
✔️ Подробнее
@machinelearning_interview
Больше не нужно настраивать окружение вручную. Просто заходишь на страницу модели — и нажимаешь "Open in Colab". Всё готово для запуска за секунды.
✅ Отлично подходит для:
- Быстрого теста модели
- Прототипирования и экспериментов
- Обучения и демонстраций
💡 Бонус для разработчиков:
Добавь файл
notebook.ipynb в свой репозиторий модели — и Hugging Face автоматически подхватит его. Пользователи смогут запускать твой пример сразу, без копирования кода!
🔥 Работает с Google Colab — бесплатно, быстро, удобно.
#HuggingFace #Colab #ML #AI #OpenSource #DeepLearning
@machinelearning_interview
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥8⚡2✍1❤1👍1