
ЗАЧЕМ КОФЕЙНЕ СОЦСЕТЬ ВНУТРИ ПРИЛОЖЕНИЯ
🤔❓🕸☕️
Как создавать «эмоциональное приложение», в котором гости могут не только заказывать кофе заранее, а еще и общаться друг с другом — опыт кофеен дринкит.
Мобильное приложение решает сразу несколько задач гостя. Во-первых, можно сделать заказ заранее. Это экономит время: выбрал, поднимаясь из метро, зашёл в кофейню, сразу забрал готовый напиток и пошел в офис.
Во-вторых, это удобнее. Одна из фишек концепции — широкая кастомизация напитков. Ты можешь сделать «покрепче» или взять декаф, поменять молоко, добавить посыпку, сироп или фирменную сырную пенку.
Собрать в приложении свой любимый напиток гораздо проще, при этом настройки сохранятся, и система сама предложит его в следующий раз.
С запуска самой первой кофейни команда думала про механики, которые сделают приложение инструментом для общения, добавят ему больше ценности.
Выпить кофе — предлог завязать беседу или продолжить знакомство.
Многие регулярно зовут своих коллег отвлечься и сходить за кофе. Этот сценарий не выходил у команды из головы, и они решили обыграть его в приложении, сделав наконец-то первый шаг в сторону социальных механик. Так появилось дополнение «позвать на кофе».
Команда ориентировалась на приложение 'Yo', в котором можно отправить уведомление «Йоу» друзьям и получить такой же ответ. Более сложной реализации для того чтобы позвать знакомого на кофе и не надо.
Представь, сидишь в офисе, доделал отчет, решаешь порадовать себя и взять латте трюфель с сырной пенкой. Вспоминаешь, что давно хотел позвать на кофе коллегу из отдела закупок. Нажимаешь в своём профиле в приложении «позвать на кофе», выбираешь контакт из списка, добавляешь текст приглашения — и вот уже коллега получает пуш-уведомление, что ты ждёшь её через пару минут в дринкит.
Она принимает инвайт, и вот вы вместе за кофе обсуждаете идею вашего стартапа.
🍀 Source >>>
🍀 Original >>>
#case #fun #marketing #mobile #product #ux
🤔❓🕸☕️
Как создавать «эмоциональное приложение», в котором гости могут не только заказывать кофе заранее, а еще и общаться друг с другом — опыт кофеен дринкит.
Мобильное приложение решает сразу несколько задач гостя. Во-первых, можно сделать заказ заранее. Это экономит время: выбрал, поднимаясь из метро, зашёл в кофейню, сразу забрал готовый напиток и пошел в офис.
Во-вторых, это удобнее. Одна из фишек концепции — широкая кастомизация напитков. Ты можешь сделать «покрепче» или взять декаф, поменять молоко, добавить посыпку, сироп или фирменную сырную пенку.
Собрать в приложении свой любимый напиток гораздо проще, при этом настройки сохранятся, и система сама предложит его в следующий раз.
С запуска самой первой кофейни команда думала про механики, которые сделают приложение инструментом для общения, добавят ему больше ценности.
Выпить кофе — предлог завязать беседу или продолжить знакомство.
Многие регулярно зовут своих коллег отвлечься и сходить за кофе. Этот сценарий не выходил у команды из головы, и они решили обыграть его в приложении, сделав наконец-то первый шаг в сторону социальных механик. Так появилось дополнение «позвать на кофе».
Команда ориентировалась на приложение 'Yo', в котором можно отправить уведомление «Йоу» друзьям и получить такой же ответ. Более сложной реализации для того чтобы позвать знакомого на кофе и не надо.
Представь, сидишь в офисе, доделал отчет, решаешь порадовать себя и взять латте трюфель с сырной пенкой. Вспоминаешь, что давно хотел позвать на кофе коллегу из отдела закупок. Нажимаешь в своём профиле в приложении «позвать на кофе», выбираешь контакт из списка, добавляешь текст приглашения — и вот уже коллега получает пуш-уведомление, что ты ждёшь её через пару минут в дринкит.
Она принимает инвайт, и вот вы вместе за кофе обсуждаете идею вашего стартапа.
🍀 Source >>>
🍀 Original >>>
#case #fun #marketing #mobile #product #ux
{kind=link}
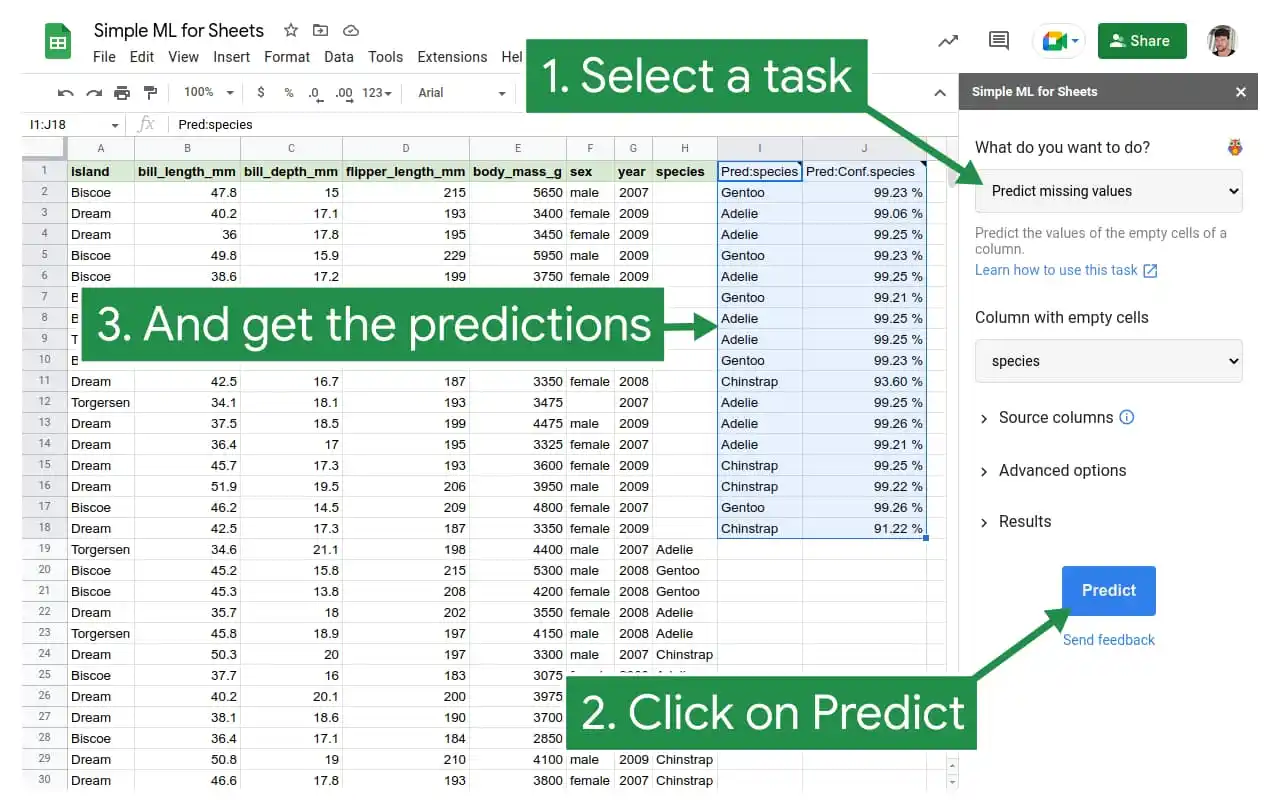
GOOGLE BRINGS MACHINE LEARNING TO ONLINE SPREADSHEETS WITH SIMPLE ML FOR SHEETS
🤖👩🏼🎓🔮
Spreadsheets are widely used by organizations of all sizes for all kinds of basic and complex tasks.
While simple calculations and graphs have long been part of the spreadsheet experience, machine learning (ML) has not. ML is often seen as being too complex to use, while spreadsheet usage is intended to be accessible to any type of user. Google is now trying to change that paradigm for its Google Sheets online spreadsheet program.
On Dec, 7 Google announced a beta release of the Simple ML for Sheets add-on. Google Sheets has an extensible architecture that enables users to benefit from add-ons that extend the default functionality available in the application. In this case, Google Sheets benefits from ML technology that Google first developed in the open-source TensorFlow project. With Simple ML for Sheets, users will not need to use a specific TensorFlow service, as Google has developed the service to be as easily accessible as possible.
“Everything runs completely on the user browser,” Luiz Gustavo Martins, Google AI developer advocate, told VentureBeat. “Your data doesn’t leave Google Sheets and models are saved to your Google Drive so you can use them again later.”
Holy sheets, Google’s Simple ML can do what with my spreadsheets?
So what can Simple ML for Sheets do? Two of the beginner tasks in the beta release highlighted by Google include the ability to predict missing values (1) or spot abnormal ones (2). Martins said that those two beginner tasks are easy for anyone to test the ML waters and explore how ML might benefit their business.
Martins noted that beyond the beginner tasks, the add-on supports several other common ML tasks such as training and evaluating models, generating predictions, and interpreting the models and their predictions. In addition, since Simple ML can export models to TensorFlow, people with programming experience can use Simple ML models with their existing ML infrastructure.
Overcoming the challenges of ML complexity with Simple ML for Sheets
It’s possible for Google Sheets users to benefit from ML without Simple ML, but it may not be easy for the layperson.
“We identified knowledge and lack of guidance as the prime factors for non-ML practitioners to easily use ML,” Mathieu Guillame-Bert, software engineer at Google, told VentureBeat. “Using a classical ML tool, like TensorFlow in Python, is like being in front of a blank page.”
Guillame-Bert said that using a classic ML tool requires, among other things, for the user to understand programming, ML problem framing, model construction and model evaluation. He noted that such knowledge is generally acquired through classes or self-taught over a long period of time.
In contrast, Guillame-Bert said that Simple ML is like an interactive questionnaire. It guides the user and only assumes basic knowledge about spreadsheets.
🍀 Source >>>
🍀 Original >>>
#analytics #datascience #dev #math #predictions #product #statistics #technology #tools
🤖👩🏼🎓🔮
Spreadsheets are widely used by organizations of all sizes for all kinds of basic and complex tasks.
While simple calculations and graphs have long been part of the spreadsheet experience, machine learning (ML) has not. ML is often seen as being too complex to use, while spreadsheet usage is intended to be accessible to any type of user. Google is now trying to change that paradigm for its Google Sheets online spreadsheet program.
On Dec, 7 Google announced a beta release of the Simple ML for Sheets add-on. Google Sheets has an extensible architecture that enables users to benefit from add-ons that extend the default functionality available in the application. In this case, Google Sheets benefits from ML technology that Google first developed in the open-source TensorFlow project. With Simple ML for Sheets, users will not need to use a specific TensorFlow service, as Google has developed the service to be as easily accessible as possible.
“Everything runs completely on the user browser,” Luiz Gustavo Martins, Google AI developer advocate, told VentureBeat. “Your data doesn’t leave Google Sheets and models are saved to your Google Drive so you can use them again later.”
Holy sheets, Google’s Simple ML can do what with my spreadsheets?
So what can Simple ML for Sheets do? Two of the beginner tasks in the beta release highlighted by Google include the ability to predict missing values (1) or spot abnormal ones (2). Martins said that those two beginner tasks are easy for anyone to test the ML waters and explore how ML might benefit their business.
Martins noted that beyond the beginner tasks, the add-on supports several other common ML tasks such as training and evaluating models, generating predictions, and interpreting the models and their predictions. In addition, since Simple ML can export models to TensorFlow, people with programming experience can use Simple ML models with their existing ML infrastructure.
Overcoming the challenges of ML complexity with Simple ML for Sheets
It’s possible for Google Sheets users to benefit from ML without Simple ML, but it may not be easy for the layperson.
“We identified knowledge and lack of guidance as the prime factors for non-ML practitioners to easily use ML,” Mathieu Guillame-Bert, software engineer at Google, told VentureBeat. “Using a classical ML tool, like TensorFlow in Python, is like being in front of a blank page.”
Guillame-Bert said that using a classic ML tool requires, among other things, for the user to understand programming, ML problem framing, model construction and model evaluation. He noted that such knowledge is generally acquired through classes or self-taught over a long period of time.
In contrast, Guillame-Bert said that Simple ML is like an interactive questionnaire. It guides the user and only assumes basic knowledge about spreadsheets.
🍀 Source >>>
🍀 Original >>>
#analytics #datascience #dev #math #predictions #product #statistics #technology #tools
{kind=link}
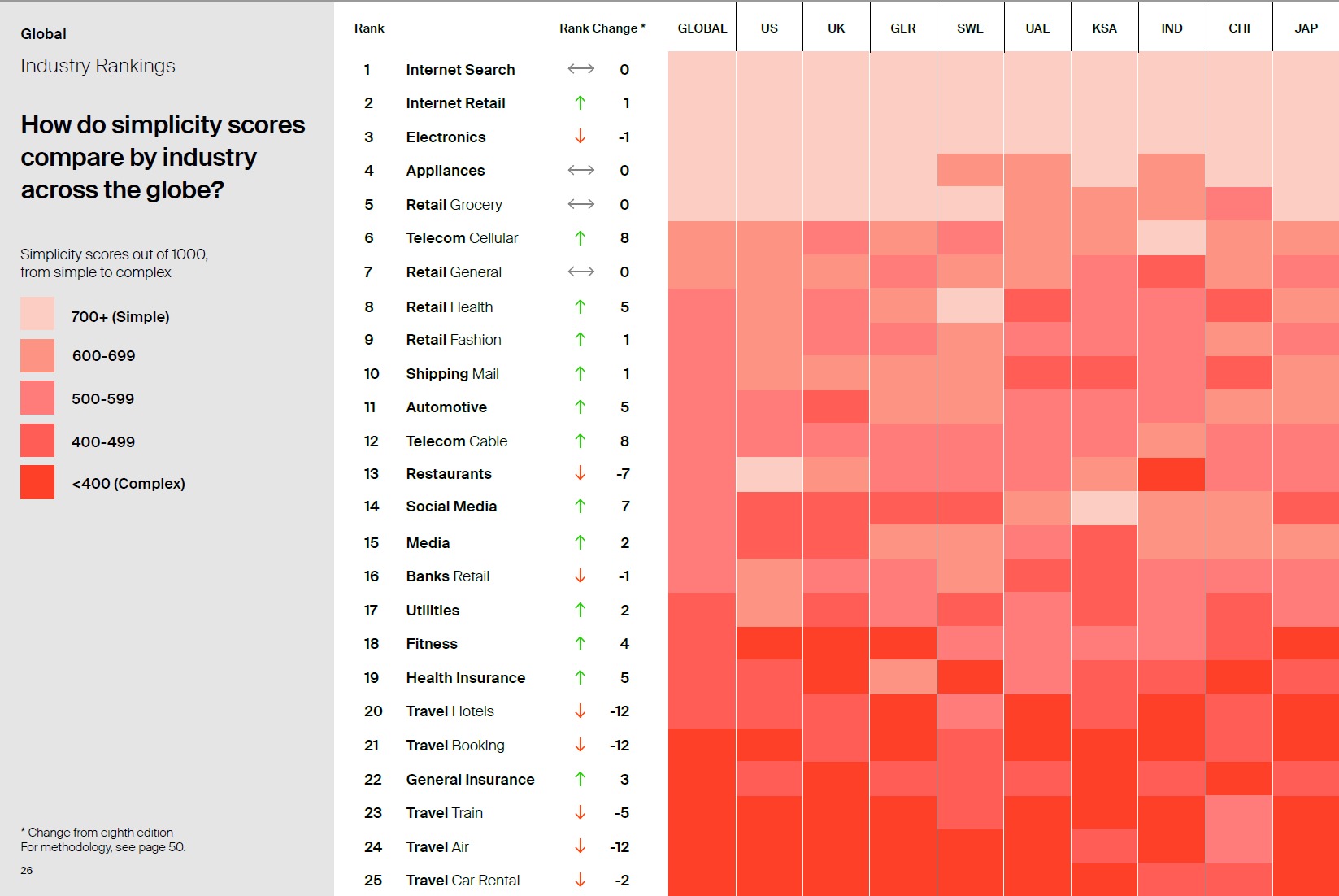
AS THE PANDEMIC MAKES LIFE MORE COMPLEX, PEOPLE CRAVE SIMPLER BRANDS
🥰
The pandemic has made people’s lives more complex, according to research in the ninth edition of Siegel+Gale’s World’s Simplest Brands study. The global survey also revealed that consumers are more willing to pay a premium for simpler experiences.
World’s Simplest Brands ranks the leading brands on simplicity, asking more than 15,000 people across nine countries which brands and industries provide the simplest experiences, ultimately reducing stress and improving the lives of consumers everywhere.
Google led the global rankings, followed by Netflix, German grocer Lidl, YouTube and another German grocer, Aldi. In the United States, Amazon was named the simplest brand, followed by streaming services Hulu and Netflix. Costco and Google rounded out the top five.
The brands that did best in both the global and national categories tended to be those that consumers relied upon during the pandemic. That’s no accident. “The pandemic has made life harder, and World’s Simplest Brands found that people want transparent, direct, simple experiences that make their lives easier,” said Howard Belk, co-CEO and Chief Creative Officer, Siegel+Gale. “The brands that topped this list simplified not only the consumption experience; they simplified the human experience.”
🔎 Here are some of the study’s key findings:
📌 76 percent of people are more likely to recommend a brand that delivers simple experiences, compared to 64 percent in 2018.
📌 57 percent of people are willing to pay more for simpler experiences, slightly higher than the last report’s findings.
📌 While there isn’t a significant change in people willing to pay more for simplicity, the premium people are willing to pay for it has quadrupled. Siegel+Gale estimates that companies leave an estimated $402 billion on the table by failing to provide simple experiences, versus $98 billion in 2018.
📌 A stock portfolio of the World’s Simplest Brands has outperformed the average of the major indexes by 1,600 percent since 2009.
👑 2021 Top 10 World’s Simplest Brands
1️⃣ Google
2️⃣ Netflix
3️⃣ Lidl
4️⃣ YouTube
5️⃣ Aldi
6️⃣ McDonald’s
7️⃣ Samsung
8️⃣ Amazon
9️⃣ Uniqlo
🔟 Spotify
🍀 Source >>>
🍀 Report in PDF >>>
#analytics #marketing #mr #product #report #trends
🥰
The pandemic has made people’s lives more complex, according to research in the ninth edition of Siegel+Gale’s World’s Simplest Brands study. The global survey also revealed that consumers are more willing to pay a premium for simpler experiences.
World’s Simplest Brands ranks the leading brands on simplicity, asking more than 15,000 people across nine countries which brands and industries provide the simplest experiences, ultimately reducing stress and improving the lives of consumers everywhere.
Google led the global rankings, followed by Netflix, German grocer Lidl, YouTube and another German grocer, Aldi. In the United States, Amazon was named the simplest brand, followed by streaming services Hulu and Netflix. Costco and Google rounded out the top five.
The brands that did best in both the global and national categories tended to be those that consumers relied upon during the pandemic. That’s no accident. “The pandemic has made life harder, and World’s Simplest Brands found that people want transparent, direct, simple experiences that make their lives easier,” said Howard Belk, co-CEO and Chief Creative Officer, Siegel+Gale. “The brands that topped this list simplified not only the consumption experience; they simplified the human experience.”
🔎 Here are some of the study’s key findings:
📌 76 percent of people are more likely to recommend a brand that delivers simple experiences, compared to 64 percent in 2018.
📌 57 percent of people are willing to pay more for simpler experiences, slightly higher than the last report’s findings.
📌 While there isn’t a significant change in people willing to pay more for simplicity, the premium people are willing to pay for it has quadrupled. Siegel+Gale estimates that companies leave an estimated $402 billion on the table by failing to provide simple experiences, versus $98 billion in 2018.
📌 A stock portfolio of the World’s Simplest Brands has outperformed the average of the major indexes by 1,600 percent since 2009.
👑 2021 Top 10 World’s Simplest Brands
1️⃣ Google
2️⃣ Netflix
3️⃣ Lidl
4️⃣ YouTube
5️⃣ Aldi
6️⃣ McDonald’s
7️⃣ Samsung
8️⃣ Amazon
9️⃣ Uniqlo
🔟 Spotify
🍀 Source >>>
🍀 Report in PDF >>>
#analytics #marketing #mr #product #report #trends
{kind=link}
ЧТО ЧИТАТЬ ПРОДАКТ-МЕНЕДЖЕРУ В 2022 ГОДУ: РЕКОМЕНДАЦИИ СООБЩЕСТВА GOPRACTICE
🤓📚📖
Редакция попросили читателей их телеграм-канала gopractice поделиться книгами, которые помогли им в профессиональном развитии и дали больше всего инсайтов на потраченное время.
На основе результатов опроса подготовили подборку из самых упоминаемых книг, о которых рассказывают более подробно. А в конце публикуют подборку и других книг, которые прислали читатели и которые считают полезными сами.
⚠️ Важные книги
Эти книги читатели и менторы чаще всего выделяли как наиболее ценные для их профессионального развития. Ниже они объясняют:
📌 В чем ценность книги для них;
📌 На что они помогли взглянуть иначе;
📌 Как помогли в профессиональном росте;
📌 На каком этапе карьеры их лучше всего читать.
📋 Вот список книг:
✨ “Inspired”, Marty Cagan («Вдохновленные», Марти Каган)
✨ “Thinking, Fast and Slow”, Daniel Kahneman («Думай медленно… Решай быстро», Даниэль Канеман)
✨ “The Goal: A Process of Ongoing Improvement”, Eliyahu M. Goldratt («Цель. Процесс непрерывного совершенствования», Элияху Голдратт)
✨ “The Hard Thing About Hard Things: Building a Business When There Are No Easy Answers”, Ben Horowitz («Легко не будет. Как построить бизнес, когда вопросов больше, чем ответов» Бен Хоровиц)
✨ “The Innovator’s Dilemma”, Clayton Christensen («Дилемма инноватора: Как из-за новых технологий погибают сильные компании», Клейтон Кристенсен)
✨ Дополнительные книги от читателей, менторов и команды GoPractice
🍀 Source >>>
#case #development #efficiency #likbez #marketing #product #psychology #sociology #strategy #tools
🤓📚📖
Редакция попросили читателей их телеграм-канала gopractice поделиться книгами, которые помогли им в профессиональном развитии и дали больше всего инсайтов на потраченное время.
На основе результатов опроса подготовили подборку из самых упоминаемых книг, о которых рассказывают более подробно. А в конце публикуют подборку и других книг, которые прислали читатели и которые считают полезными сами.
⚠️ Важные книги
Эти книги читатели и менторы чаще всего выделяли как наиболее ценные для их профессионального развития. Ниже они объясняют:
📌 В чем ценность книги для них;
📌 На что они помогли взглянуть иначе;
📌 Как помогли в профессиональном росте;
📌 На каком этапе карьеры их лучше всего читать.
📋 Вот список книг:
✨ “Inspired”, Marty Cagan («Вдохновленные», Марти Каган)
✨ “Thinking, Fast and Slow”, Daniel Kahneman («Думай медленно… Решай быстро», Даниэль Канеман)
✨ “The Goal: A Process of Ongoing Improvement”, Eliyahu M. Goldratt («Цель. Процесс непрерывного совершенствования», Элияху Голдратт)
✨ “The Hard Thing About Hard Things: Building a Business When There Are No Easy Answers”, Ben Horowitz («Легко не будет. Как построить бизнес, когда вопросов больше, чем ответов» Бен Хоровиц)
✨ “The Innovator’s Dilemma”, Clayton Christensen («Дилемма инноватора: Как из-за новых технологий погибают сильные компании», Клейтон Кристенсен)
✨ Дополнительные книги от читателей, менторов и команды GoPractice
🍀 Source >>>
#case #development #efficiency #likbez #marketing #product #psychology #sociology #strategy #tools
{kind=link}
КАК ЦИФРОВОЙ ДИЗАЙН ВЛИЯЕТ НА ПОЛЬЗОВАТЕЛЕЙ by Саурабх Бхаргава, Шломо Бенарци
🎨📲🤪
Все чаще мы принимаем самые разные решения в цифровом формате, «с экрана», и последствиями такого изменения часто пренебрегают: дизайн цифрового мира может глубоко и зачастую незаметно влиять на наш выбор.
Анализ недавних исследований показывает, что многие организации пока недооценивают возможности цифрового дизайна, — нужно больше инвестировать в поведенческие модели, чтобы помочь пользователям сделать оптимальный выбор. Во многих случаях даже незначительные корректировки могут оказать серьезное влияние и принести такую отдачу на вложенные средства, которая в несколько раз превышает традиционное применение финансовых стимулов или маркетинговых и образовательных кампаний.
Работая над недавней статьей совместно с Линн Конелл-Прайс из Университета Пенсильвании и Ричардом Мэйсоном из Лондонского университета Сити, авторы обратились к ведущей инвестиционной компании на рынке пенсионных решений в США Voya Financial. Они решили изучить, как изменения цифрового дизайна интерфейсов при онлайн-регистрации могут повлиять на первоначальные планы сотрудников в отношении взносов на накопительные пенсионные счета (в частной пенсионной системе США самый популярный накопительный пенсионный план называется в честь соответствующей статьи Налогового кодекса США — «план 401(k)»).
Чтобы понять влияние цифрового дизайна на эти первоначальные решения о вступлении в пенсионную программу, случайным образом распределили сотрудников на две группы и показывали им две разные версии интерфейса регистрации: используемый Voya оригинальный коммерческий дизайн или «улучшенный» дизайн с тремя незначительными изменениями:
1️⃣ Изменили цветовую схему опций — вместо одного цвета (все было оранжевым) использовался принцип светофора: зеленый (выбрать индивидуальные условия), желтый (подтвердить) и красный (отклонить).
2️⃣ Отобразили стандартную норму отчислений прямо на экране регистрации, чтобы эту информацию нельзя было пропустить.
3️⃣ Упростили и стандартизировали текст описания альтернативных вариантов, удалив неинформативный мелкий шрифт и упростив названия каждой опции (например, фразу «Хочу изменить условия в своем плане» поменяли на «Настрою сам», а фразу «Не хочу вступать в пенсионную программу» заменили на «Не буду копить»).
Слишком часто дизайн рассматривают как визуальный фон, цифровой элемент, который придуман для красоты, но особой пользы не несет. Но исследование показывает, что цифровой дизайн — это нечто гораздо большее, это неотъемлемая часть любого продукта или услуги. И разработать поведенчески обоснованный дизайн возможно, если использовать следующие пять шагов:
✨ Изучайте появляющиеся научные публикации и учитывайте данные поведенческого анализа об особенностях использования электронных устройств.
✨ Проведите поведенческий аудит используемого цифрового дизайна и выявите несоответствия между существующим дизайном и новыми идеями, учитывающими самые свежие наработки об особенностях взаимодействия с электронными устройствами.
✨ Протестируйте эти новые идеи в контролируемых условиях.
✨ Выбрав выигрышный дизайн, масштабируйте и применяйте его во всех возможных цифровых клиентских циклах.
✨ Храните доступную для поиска «библиотеку результатов» всех своих экспериментов.
Совершенствование цифрового дизайна с применением выводов практического анализа должно стать важнейшей стратегической задачей для любой организации, стремящейся привлечь клиентов и помочь им принимать более правильные решения. Дизайн — это не красивый фон, а важная составляющая продукта.
🍀 Source >>>
#analytics #case #design #experiment #product #psychology #ux
🎨📲🤪
Все чаще мы принимаем самые разные решения в цифровом формате, «с экрана», и последствиями такого изменения часто пренебрегают: дизайн цифрового мира может глубоко и зачастую незаметно влиять на наш выбор.
Анализ недавних исследований показывает, что многие организации пока недооценивают возможности цифрового дизайна, — нужно больше инвестировать в поведенческие модели, чтобы помочь пользователям сделать оптимальный выбор. Во многих случаях даже незначительные корректировки могут оказать серьезное влияние и принести такую отдачу на вложенные средства, которая в несколько раз превышает традиционное применение финансовых стимулов или маркетинговых и образовательных кампаний.
Работая над недавней статьей совместно с Линн Конелл-Прайс из Университета Пенсильвании и Ричардом Мэйсоном из Лондонского университета Сити, авторы обратились к ведущей инвестиционной компании на рынке пенсионных решений в США Voya Financial. Они решили изучить, как изменения цифрового дизайна интерфейсов при онлайн-регистрации могут повлиять на первоначальные планы сотрудников в отношении взносов на накопительные пенсионные счета (в частной пенсионной системе США самый популярный накопительный пенсионный план называется в честь соответствующей статьи Налогового кодекса США — «план 401(k)»).
Чтобы понять влияние цифрового дизайна на эти первоначальные решения о вступлении в пенсионную программу, случайным образом распределили сотрудников на две группы и показывали им две разные версии интерфейса регистрации: используемый Voya оригинальный коммерческий дизайн или «улучшенный» дизайн с тремя незначительными изменениями:
1️⃣ Изменили цветовую схему опций — вместо одного цвета (все было оранжевым) использовался принцип светофора: зеленый (выбрать индивидуальные условия), желтый (подтвердить) и красный (отклонить).
2️⃣ Отобразили стандартную норму отчислений прямо на экране регистрации, чтобы эту информацию нельзя было пропустить.
3️⃣ Упростили и стандартизировали текст описания альтернативных вариантов, удалив неинформативный мелкий шрифт и упростив названия каждой опции (например, фразу «Хочу изменить условия в своем плане» поменяли на «Настрою сам», а фразу «Не хочу вступать в пенсионную программу» заменили на «Не буду копить»).
Слишком часто дизайн рассматривают как визуальный фон, цифровой элемент, который придуман для красоты, но особой пользы не несет. Но исследование показывает, что цифровой дизайн — это нечто гораздо большее, это неотъемлемая часть любого продукта или услуги. И разработать поведенчески обоснованный дизайн возможно, если использовать следующие пять шагов:
✨ Изучайте появляющиеся научные публикации и учитывайте данные поведенческого анализа об особенностях использования электронных устройств.
✨ Проведите поведенческий аудит используемого цифрового дизайна и выявите несоответствия между существующим дизайном и новыми идеями, учитывающими самые свежие наработки об особенностях взаимодействия с электронными устройствами.
✨ Протестируйте эти новые идеи в контролируемых условиях.
✨ Выбрав выигрышный дизайн, масштабируйте и применяйте его во всех возможных цифровых клиентских циклах.
✨ Храните доступную для поиска «библиотеку результатов» всех своих экспериментов.
Совершенствование цифрового дизайна с применением выводов практического анализа должно стать важнейшей стратегической задачей для любой организации, стремящейся привлечь клиентов и помочь им принимать более правильные решения. Дизайн — это не красивый фон, а важная составляющая продукта.
🍀 Source >>>
#analytics #case #design #experiment #product #psychology #ux
{kind=link}
НЕОЖИДАННЫЕ ТРЕНДЫ В РИТЕЙЛЕ И E-COMMERCE НА 2023 ГОД: ФЕДОР ВИРИН В ЭФИРЕ DIGITALVOICE
🔮🛒🛍📲
Федор Вирин и Филипп Лабковский обсудили контр-тренды, то есть на что стоит обратить внимание игрокам рынка и специалистам для развития своих бизнесов в 2023 году.
Получилось очень интересное интервью с полезными идеями.
00:00 Вступление
01:01 Как изменились тренды электронной торговли, заложенные Covid?
03:52 Изменение спроса после февраля 2022 года
05:36 Островки стабильности e-commerce
06:26 Какие отрасли страдают от этих трендов?
07:56 Изменится ли спрос на сферу услуг для поддержания текущих физических активов?
10:22 Еком падает?
11:59 DTC: нужно ли создавать свой канал продаж
13:07 Предпринимательская инициатива по импортозамещению
14:52 Зарубежные поставщики на российских маркетплейсах
16:02 Трансграничная торговля и ее роль восполнения спроса
16:54 Торговые центры падение трафика
17:45 Создавать ли свои медиаканалы ритейлерам, маркетплейсам?
19:17 Децентрализовать или централизовать электронную коммерция?
20:18 Новые инструменты маркетинга для поставщиков, брендов
24:13 Торговля через мессенджеры
29:04 Что ждет c2c-платформы?
30:45 Прогноз роста на 2023 год
32:13 Инструкции по выживанию для екома
34:19 Завершение
🍀 Youtube >>>
🍀 Source >>>
🍀 Slides in PDF >>>
🍀 Podcast >>>
#ecom #predictions #presentation #product #retail #trends
🔮🛒🛍📲
Федор Вирин и Филипп Лабковский обсудили контр-тренды, то есть на что стоит обратить внимание игрокам рынка и специалистам для развития своих бизнесов в 2023 году.
Получилось очень интересное интервью с полезными идеями.
00:00 Вступление
01:01 Как изменились тренды электронной торговли, заложенные Covid?
03:52 Изменение спроса после февраля 2022 года
05:36 Островки стабильности e-commerce
06:26 Какие отрасли страдают от этих трендов?
07:56 Изменится ли спрос на сферу услуг для поддержания текущих физических активов?
10:22 Еком падает?
11:59 DTC: нужно ли создавать свой канал продаж
13:07 Предпринимательская инициатива по импортозамещению
14:52 Зарубежные поставщики на российских маркетплейсах
16:02 Трансграничная торговля и ее роль восполнения спроса
16:54 Торговые центры падение трафика
17:45 Создавать ли свои медиаканалы ритейлерам, маркетплейсам?
19:17 Децентрализовать или централизовать электронную коммерция?
20:18 Новые инструменты маркетинга для поставщиков, брендов
24:13 Торговля через мессенджеры
29:04 Что ждет c2c-платформы?
30:45 Прогноз роста на 2023 год
32:13 Инструкции по выживанию для екома
34:19 Завершение
🍀 Youtube >>>
🍀 Source >>>
🍀 Slides in PDF >>>
🍀 Podcast >>>
#ecom #predictions #presentation #product #retail #trends
{kind=link}
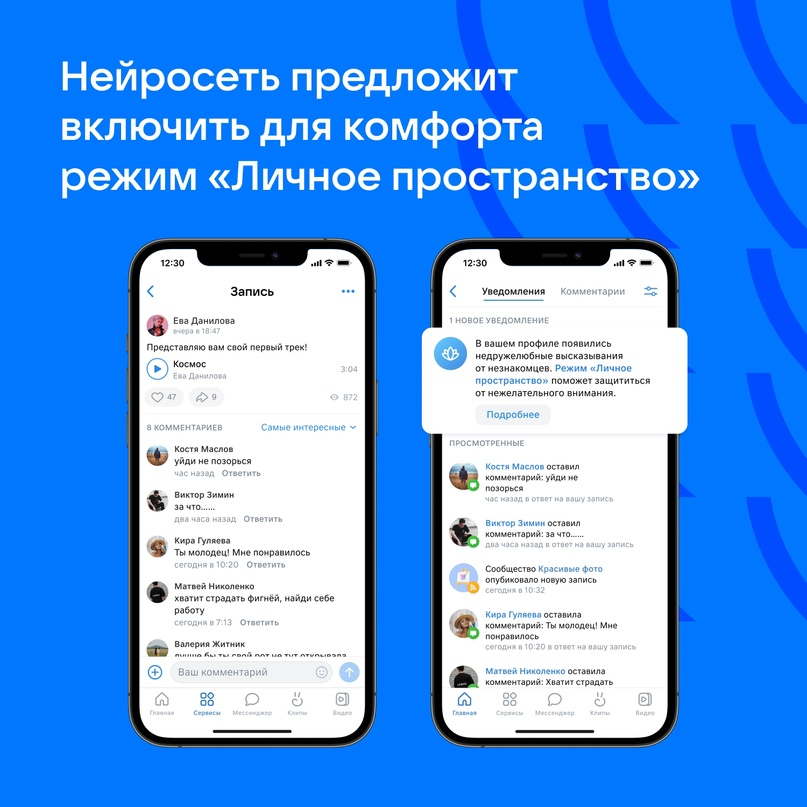
ВКОНТАКТЕ РАЗВИВАЕТ БЕЗОПАСНУЮ СРЕДУ ДЛЯ ПОЛЬЗОВАТЕЛЕЙ: ПРЕДСТАВЛЕНА НЕЙРОСЕТЬ, КОТОРАЯ ЗАЩИЩАЕТ ОТ НЕЖЕЛАТЕЛЬНОГО ВНИМАНИЯ С РЕЖИМОМ «ЛИЧНОЕ ПРОСТРАНСТВО»
☠️⛔️🥰
Специальные алгоритмы соцсети будут выявлять оскорбительные комментарии и токсичное поведение, а также предлагать активировать «Личное пространство» — режим, который позволяет оградить себя от нежелательного внимания.
Команда ВКонтакте разработала уникальную нейросеть, способную определять ругательства, оскорбления и другие негативные высказывания в постах и комментариях. С помощью собственных алгоритмов соцсеть будет выявлять всплески подобной активности на страницах пользователей, предупреждать их о возможной опасности и предлагать включить режим «Личное пространство» — специальный набор настроек, который позволяет на время ограничить круг общения, оградить себя от нежелательных собеседников и отдохнуть от лишнего внимания.
Предложение активировать режим будет приходить пользователям, которые за час получили более трёх негативных комментариев или постов от юзеров, не входящих в список их друзей. Подобная активность будет отслеживаться и фиксироваться с помощью нейросети: алгоритм на основе искусственного интеллекта будет сразу отправлять уведомление с предложением включить режим. После отправки уведомления нейросеть приостановит свою работу на сутки, а потом возобновит. В сумме пользователю может прийти не более трёх уведомлений за месяц. Нейросеть считывает активность только в открытых профилях.
После активации режима «Личное пространство» настройки приватности страницы изменятся на неделю: писать и звонить смогут только друзья или друзья друзей, а отправлять заявки в друзья — только друзья друзей. Профиль пользователя станет закрытым: добавлять его в чаты и отмечать на фотографиях получится только у друзей. Помимо этого, после включения режима пользователи будут видеть в ленте новостей специальные тематические материалы и рекомендации для улучшения ментального здоровья. Через неделю режим отключится, при необходимости его можно активировать снова.
В середине октября ВКонтакте представила режим «Личное пространство», призванный помочь в формировании комфортной и дружелюбной среды.
Ранее социальная сеть начала предупреждать пользователей о подозрительных собеседниках в мессенджере. В новом групповом чате или беседе с незнакомым человеком теперь появляется уведомление о потенциальной опасности, если алгоритмы зафиксировали подозрительную активность. Благодаря тому, что пользователи своевременно получают предупреждения о возможной угрозе, мошенникам сложнее обманным путём заполучить чужие деньги, пароли и другие личные данные.
🍀 Source >>>
🍀 Original >>>
#datascience #dev #efficiency #itsec #product #technology #ux
☠️⛔️🥰
Специальные алгоритмы соцсети будут выявлять оскорбительные комментарии и токсичное поведение, а также предлагать активировать «Личное пространство» — режим, который позволяет оградить себя от нежелательного внимания.
Команда ВКонтакте разработала уникальную нейросеть, способную определять ругательства, оскорбления и другие негативные высказывания в постах и комментариях. С помощью собственных алгоритмов соцсеть будет выявлять всплески подобной активности на страницах пользователей, предупреждать их о возможной опасности и предлагать включить режим «Личное пространство» — специальный набор настроек, который позволяет на время ограничить круг общения, оградить себя от нежелательных собеседников и отдохнуть от лишнего внимания.
Предложение активировать режим будет приходить пользователям, которые за час получили более трёх негативных комментариев или постов от юзеров, не входящих в список их друзей. Подобная активность будет отслеживаться и фиксироваться с помощью нейросети: алгоритм на основе искусственного интеллекта будет сразу отправлять уведомление с предложением включить режим. После отправки уведомления нейросеть приостановит свою работу на сутки, а потом возобновит. В сумме пользователю может прийти не более трёх уведомлений за месяц. Нейросеть считывает активность только в открытых профилях.
После активации режима «Личное пространство» настройки приватности страницы изменятся на неделю: писать и звонить смогут только друзья или друзья друзей, а отправлять заявки в друзья — только друзья друзей. Профиль пользователя станет закрытым: добавлять его в чаты и отмечать на фотографиях получится только у друзей. Помимо этого, после включения режима пользователи будут видеть в ленте новостей специальные тематические материалы и рекомендации для улучшения ментального здоровья. Через неделю режим отключится, при необходимости его можно активировать снова.
В середине октября ВКонтакте представила режим «Личное пространство», призванный помочь в формировании комфортной и дружелюбной среды.
Ранее социальная сеть начала предупреждать пользователей о подозрительных собеседниках в мессенджере. В новом групповом чате или беседе с незнакомым человеком теперь появляется уведомление о потенциальной опасности, если алгоритмы зафиксировали подозрительную активность. Благодаря тому, что пользователи своевременно получают предупреждения о возможной угрозе, мошенникам сложнее обманным путём заполучить чужие деньги, пароли и другие личные данные.
🍀 Source >>>
🍀 Original >>>
#datascience #dev #efficiency #itsec #product #technology #ux
{kind=link}
МОЖНО ЛИ ВИДЕТЬ С ПОМОЩЬЮ ЗВУКА
🔊👀
Может ли человек, лишенный зрения, видеть, используя не зрительную, а иные системы головного мозга? Голландский изобретатель Питер Мейер, создатель технологии vOICe vision, а также российские специалисты, дорабатывающие ее для практического применения, считают, что изображение можно передать мозгу с помощью звука — необходимо лишь удобное оборудование и некоторый навык его использования. Подробнее о технологии, позволяющей слепым визуализировать услышанное рассказывают нейрофизиолог Игорь Трапезников и Яна Капская из российской компании «Айкода».
Технология vOICe vision кодирует картинку в звук и передает ее через костные наушники, чтобы не заглушать внешние звуки. Камера сканирует окружающее пространство и с помощью специального алгоритма переводит изображение в определенную звуковую последовательность. Яркость преобразуется в громкость, вертикаль — в высоту звука, горизонталь — во время поступления сигнала. При необходимости цвет центральной области изображения распознается программой и озвучивается словами.
Принцип работы vOICe vision >>> Youtube
Первый патент голландский разработчик Питер Мейер получил в середине 1990 года, а первая публичная версия программы vOICe вышла в январе 1998 года. Руководитель российского проекта нейрофизиолог Игорь Трапезников и инженер Сергей Мозякин в 2011 году совместили программу Питера на нетбуке и видеоочки. Устройство получилось довольно массивным, поэтому в 2015 году вышло второе поколение на базе микрокомпьютера Raspberry Pi.
В 2017 году видеокамера и процессорный блок были перенесены непосредственно в корпус очков, что сделало устройство компактнее и способным работать автономно в течение восьми-десяти часов. Чтобы не заглушать внешние звуки, разработчики стали использоваться беспроводные наушники костной передачи.
Для наглядности Питер Мейер (Peter Mejer) разработал Android-приложение и веб-версию программы, которая позволяет увидеть принцип действия vOICe. Сразу ваш мозг не сможет обработать сложную картинку и извлечь нужную информацию. Для начала попробуйте выключить свет в комнате, поднести светлый предмет к экрану и закрыть глаза.
🍀 Source >>>
#dev #likbez #product #science #technology
🔊👀
Может ли человек, лишенный зрения, видеть, используя не зрительную, а иные системы головного мозга? Голландский изобретатель Питер Мейер, создатель технологии vOICe vision, а также российские специалисты, дорабатывающие ее для практического применения, считают, что изображение можно передать мозгу с помощью звука — необходимо лишь удобное оборудование и некоторый навык его использования. Подробнее о технологии, позволяющей слепым визуализировать услышанное рассказывают нейрофизиолог Игорь Трапезников и Яна Капская из российской компании «Айкода».
Технология vOICe vision кодирует картинку в звук и передает ее через костные наушники, чтобы не заглушать внешние звуки. Камера сканирует окружающее пространство и с помощью специального алгоритма переводит изображение в определенную звуковую последовательность. Яркость преобразуется в громкость, вертикаль — в высоту звука, горизонталь — во время поступления сигнала. При необходимости цвет центральной области изображения распознается программой и озвучивается словами.
Принцип работы vOICe vision >>> Youtube
Первый патент голландский разработчик Питер Мейер получил в середине 1990 года, а первая публичная версия программы vOICe вышла в январе 1998 года. Руководитель российского проекта нейрофизиолог Игорь Трапезников и инженер Сергей Мозякин в 2011 году совместили программу Питера на нетбуке и видеоочки. Устройство получилось довольно массивным, поэтому в 2015 году вышло второе поколение на базе микрокомпьютера Raspberry Pi.
В 2017 году видеокамера и процессорный блок были перенесены непосредственно в корпус очков, что сделало устройство компактнее и способным работать автономно в течение восьми-десяти часов. Чтобы не заглушать внешние звуки, разработчики стали использоваться беспроводные наушники костной передачи.
Для наглядности Питер Мейер (Peter Mejer) разработал Android-приложение и веб-версию программы, которая позволяет увидеть принцип действия vOICe. Сразу ваш мозг не сможет обработать сложную картинку и извлечь нужную информацию. Для начала попробуйте выключить свет в комнате, поднести светлый предмет к экрану и закрыть глаза.
🍀 Source >>>
#dev #likbez #product #science #technology
{kind=link}
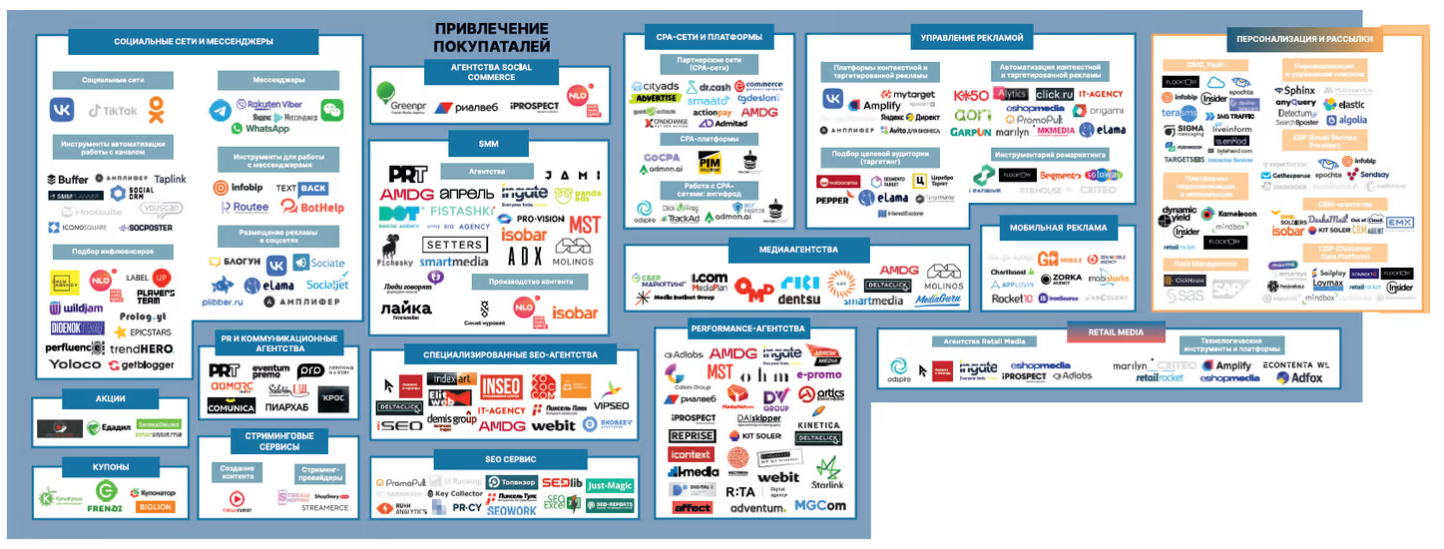
РИТЕЙЛ МЕДИА В РОССИИ — НОВЫЙ РУБЕЖ ДЛЯ РЕКЛАМЫ И ПРИВЛЕЧЕНИЯ КЛИЕНТОВ
🛍🛒📺
Retail media, или реклама на онлайн-площадке — тот инструмент, который позволяет брендам продвигать свои товары, а маркетплейсам — увеличивать свою прибыль от продажи рекламных мест. По данным eshopmedia, в Китае и США retail media занимает довольно заметную долю в цифровой рекламе: 40% и 25% соответственно, тогда как в России — только 5%. Это может говорить о том, что в России эта ниша еще не заполнена, и у компаний есть возможности развиваться в данном направлении.
В «Экосистеме электронной торговли» Data Insight категория Retail Media появилась в 2022 г. в блоке «Привлечение покупателей». Сейчас категория включает игроков из числа агентств и технологических инструментов, и платформ для продажи и покупки рекламных мест и привлечения онлайн-покупателей. Примечательно также, что в основном категорию составляют крупные мультикатегорийные игроки сегмента.
Карта экосистемы интернет-торговли в России показывает сегодняшнее состояние рынка и его игроков. При подготовке Экосистемы электронной торговли 2022 v.2 на первом этапе обратились к экспертам рынка, с которыми обсудили новые тренды на рынке, ушедших и оставшихся игроков, категории сервисов, приоритетные задачи интернет-магазинов.
На втором этапе работы перестроили структуру Экосистемы, в частности, расширили блоки “Маркетплейсы” и “Платежи и финансы”. Карта включает семь блоков, соответствующих основным потребностям интернет-магазина:
✨ Привлечение покупателей,
✨ Управление магазином и работа с клиентом,
✨ Логистика,
✨ Маркетплейсы,
✨ Платежи и финансы,
✨ IT,
✨ Отраслевые организации.
Каждый блок включает категории сервисов, которые специализируются на конкретных задачах интернет-магазина. Некоторые категории сервисов в свою очередь разделены на подкатегории.
Сервисы, включенные во вторую версию карты Экосистемы 2022 года, были отобраны из числа прошлых участников карты и отчета, компаний, подавших заявку на участие, а также рекомендованных экспертами игроков. Компании, приостановившие деятельность в России на протяжение разработки Экосистемы, сохранили свое присутствие на карте, но их логотипы изображены черно-белыми и полупрозрачными.
🍀 Source >>>
🍀 Original >>>
🍀 Map in PDF (14,3 mb) >>>
#advertising #analytics #ecom #marketing #product #visualization
🛍🛒📺
Retail media, или реклама на онлайн-площадке — тот инструмент, который позволяет брендам продвигать свои товары, а маркетплейсам — увеличивать свою прибыль от продажи рекламных мест. По данным eshopmedia, в Китае и США retail media занимает довольно заметную долю в цифровой рекламе: 40% и 25% соответственно, тогда как в России — только 5%. Это может говорить о том, что в России эта ниша еще не заполнена, и у компаний есть возможности развиваться в данном направлении.
В «Экосистеме электронной торговли» Data Insight категория Retail Media появилась в 2022 г. в блоке «Привлечение покупателей». Сейчас категория включает игроков из числа агентств и технологических инструментов, и платформ для продажи и покупки рекламных мест и привлечения онлайн-покупателей. Примечательно также, что в основном категорию составляют крупные мультикатегорийные игроки сегмента.
Карта экосистемы интернет-торговли в России показывает сегодняшнее состояние рынка и его игроков. При подготовке Экосистемы электронной торговли 2022 v.2 на первом этапе обратились к экспертам рынка, с которыми обсудили новые тренды на рынке, ушедших и оставшихся игроков, категории сервисов, приоритетные задачи интернет-магазинов.
На втором этапе работы перестроили структуру Экосистемы, в частности, расширили блоки “Маркетплейсы” и “Платежи и финансы”. Карта включает семь блоков, соответствующих основным потребностям интернет-магазина:
✨ Привлечение покупателей,
✨ Управление магазином и работа с клиентом,
✨ Логистика,
✨ Маркетплейсы,
✨ Платежи и финансы,
✨ IT,
✨ Отраслевые организации.
Каждый блок включает категории сервисов, которые специализируются на конкретных задачах интернет-магазина. Некоторые категории сервисов в свою очередь разделены на подкатегории.
Сервисы, включенные во вторую версию карты Экосистемы 2022 года, были отобраны из числа прошлых участников карты и отчета, компаний, подавших заявку на участие, а также рекомендованных экспертами игроков. Компании, приостановившие деятельность в России на протяжение разработки Экосистемы, сохранили свое присутствие на карте, но их логотипы изображены черно-белыми и полупрозрачными.
🍀 Source >>>
🍀 Original >>>
🍀 Map in PDF (14,3 mb) >>>
#advertising #analytics #ecom #marketing #product #visualization
{kind=link}
ОБЗОР ЧАТ-БОТА CHATGPT: ЧТО ЭТО, ВОЗМОЖНОСТИ И ПРИМЕРЫ ИСПОЛЬЗОВАНИЯ
🤖💬
ChatGPT от OpenAI, запущенный 30 ноября 2022 года, произвел настоящий фурор в IT-сообществе, поразив многих точностью ответов на специальные вопросы. Посмотрим, как можно использовать этого чат-бота, в том числе в сочетании с другими программными продуктами.
Если вы ещё не столкнулись с технологией, ChatGPT — это чат-бот с применением искусственного интеллекта. Он умеет работать в диалоге и поддерживает запросы на естественных языках. Тренировали его методами обучения с учителем и обучения с подкреплением. Чат-бот по сути основан на GPT-3.5.
Автор заинтересовался технологией, чтобы применять её в каких-то своих рабочих задачах. Хотя бы в сценариях с голосовым помощником VoiceBox. Поэтому изучил все возможные на сегодня способы работы с ChatGPT и попробовал представить, как это внедрить в коммуникации в бизнесе.
🗂 Особенности применения ChatGPT
Автор выделил несколько областей, в которых технология проявляет себя лучше всего. Вот что бот умеет:
📌 Отвечать на вопросы. Как и любой чат-бот, ChatGPT, конечно же, может отвечать на вопросы. Однако он превосходит остальных по глубине, выдавая развернутые ответы почти на любой вопрос, даже специальный, в чём мы убедимся в статье.
📌 Искать почти как Google. ChatGPT в перспективе может даже заменить Google, потому что у него есть точный ответ практически на каждый запрос. Единственный минус, который мы смогли здесь найти: он не дает ссылок на источники, что, конечно, не очень удобно. Но думаю, это будет исправлено, когда бот выйдет из режима тестов и его начнут внедрять другие разработчики.
📌 Писать забавные диалоги и рассказы. ChatGPT впечатляет и своим писательским мастерством. Результаты действительно интересные, и читать сгенерированные им рассказы довольно весело (пример в статье).
📌 Составлять электронные письма и метатеги. Если уж рассказы для бота не проблема, то и с составлением текстов для e-mail рассылок и генерацией метатегов у него трудностей нет. Разумеется, некоторые предложения потребуют доработки, но в целом бот справляется с этими задачами очень даже неплохо.
📌 Разрабатывать простые приложения. К ChatGPT можно обратиться за помощью в создании приложения — и это действительно работает. Чат-бот выдаст пример кода, который можно использовать для определенного приложения, а не просто даст общие советы по разработке. Тем не менее, код, выдаваемый ботом, пока еще не всегда можно использовать «как есть» (удачный пример в статье). Он потребует доработки, однако ChatGPT наверняка сэкономит немало времени программистам, которым уже не понадобится писать что-то с нуля.
Видимо, не зря Microsoft обсуждает инвестиции до $10 млрд в компанию OpenAI, разработчика чат-бота ChatGPT. Он способен, по разным отзывам, даже пересказывать материалы, составлять планы, в том числе для трейдинга, переводить тексты, заполнять брифы.
🍀 Source >>>
🍀 Original >>>
#datascience #dev #efficiency #likbez #product #technology #tools #trends
🤖💬
ChatGPT от OpenAI, запущенный 30 ноября 2022 года, произвел настоящий фурор в IT-сообществе, поразив многих точностью ответов на специальные вопросы. Посмотрим, как можно использовать этого чат-бота, в том числе в сочетании с другими программными продуктами.
Если вы ещё не столкнулись с технологией, ChatGPT — это чат-бот с применением искусственного интеллекта. Он умеет работать в диалоге и поддерживает запросы на естественных языках. Тренировали его методами обучения с учителем и обучения с подкреплением. Чат-бот по сути основан на GPT-3.5.
Автор заинтересовался технологией, чтобы применять её в каких-то своих рабочих задачах. Хотя бы в сценариях с голосовым помощником VoiceBox. Поэтому изучил все возможные на сегодня способы работы с ChatGPT и попробовал представить, как это внедрить в коммуникации в бизнесе.
🗂 Особенности применения ChatGPT
Автор выделил несколько областей, в которых технология проявляет себя лучше всего. Вот что бот умеет:
📌 Отвечать на вопросы. Как и любой чат-бот, ChatGPT, конечно же, может отвечать на вопросы. Однако он превосходит остальных по глубине, выдавая развернутые ответы почти на любой вопрос, даже специальный, в чём мы убедимся в статье.
📌 Искать почти как Google. ChatGPT в перспективе может даже заменить Google, потому что у него есть точный ответ практически на каждый запрос. Единственный минус, который мы смогли здесь найти: он не дает ссылок на источники, что, конечно, не очень удобно. Но думаю, это будет исправлено, когда бот выйдет из режима тестов и его начнут внедрять другие разработчики.
📌 Писать забавные диалоги и рассказы. ChatGPT впечатляет и своим писательским мастерством. Результаты действительно интересные, и читать сгенерированные им рассказы довольно весело (пример в статье).
📌 Составлять электронные письма и метатеги. Если уж рассказы для бота не проблема, то и с составлением текстов для e-mail рассылок и генерацией метатегов у него трудностей нет. Разумеется, некоторые предложения потребуют доработки, но в целом бот справляется с этими задачами очень даже неплохо.
📌 Разрабатывать простые приложения. К ChatGPT можно обратиться за помощью в создании приложения — и это действительно работает. Чат-бот выдаст пример кода, который можно использовать для определенного приложения, а не просто даст общие советы по разработке. Тем не менее, код, выдаваемый ботом, пока еще не всегда можно использовать «как есть» (удачный пример в статье). Он потребует доработки, однако ChatGPT наверняка сэкономит немало времени программистам, которым уже не понадобится писать что-то с нуля.
Видимо, не зря Microsoft обсуждает инвестиции до $10 млрд в компанию OpenAI, разработчика чат-бота ChatGPT. Он способен, по разным отзывам, даже пересказывать материалы, составлять планы, в том числе для трейдинга, переводить тексты, заполнять брифы.
🍀 Source >>>
🍀 Original >>>
#datascience #dev #efficiency #likbez #product #technology #tools #trends
{kind=link}
HISTORY OF DATABASES (CMU ADVANCED DATABASES / SPRING 2023) by Prof. Andy Pavlo
📓👨🏻🏫🗃
Andy Pavlo is an Associate Professor of Databaseology in the Computer Science Department at Carnegie Mellon University. His research interest is in database management systems, specifically main memory systems, self-driving / autonomous architectures, transaction processing systems, and large-scale data analytics. At CMU, he’s a member of the Database Group and the Parallel Data Laboratory. He is the co-founder and CEO of OtterTune.
DBMS developers are in demand and there are many challenging unsolved problems in data management and processing. If you are good enough to write code for a DBMS, then you can write code on almost anything else. And people will pay you lots of money to do it…
Learn about modern practices in database internals and systems programming for analytical workloads.
Course topics:
✨ Storage Models, Compression
✨ Indexing
✨ Vectorized Execution + Compilation
✨ Parallel Join Algorithms
✨ Networking Protocols
✨ Query Optimization
✨ Modern System Analysis
🍀 YouTube (1h:16m:13s) >>>
🍀 Slides in PDF >>>
🍀 Course overview >>>
#case #dev #event #likbez #presentation #product #technology #tools
📓👨🏻🏫🗃
Andy Pavlo is an Associate Professor of Databaseology in the Computer Science Department at Carnegie Mellon University. His research interest is in database management systems, specifically main memory systems, self-driving / autonomous architectures, transaction processing systems, and large-scale data analytics. At CMU, he’s a member of the Database Group and the Parallel Data Laboratory. He is the co-founder and CEO of OtterTune.
DBMS developers are in demand and there are many challenging unsolved problems in data management and processing. If you are good enough to write code for a DBMS, then you can write code on almost anything else. And people will pay you lots of money to do it…
Learn about modern practices in database internals and systems programming for analytical workloads.
Course topics:
✨ Storage Models, Compression
✨ Indexing
✨ Vectorized Execution + Compilation
✨ Parallel Join Algorithms
✨ Networking Protocols
✨ Query Optimization
✨ Modern System Analysis
🍀 YouTube (1h:16m:13s) >>>
🍀 Slides in PDF >>>
🍀 Course overview >>>
#case #dev #event #likbez #presentation #product #technology #tools
{kind=link}
ЛОВУШКИ В АНАЛИТИКЕ, С КОТОРЫМИ СТАЛКИВАЕТСЯ КАЖДЫЙ
📊🕸🤓
🔮 Ошибка корреляции. Совместное изменение двух переменных в динамике не свидетельствует о наличии причинно-следственной связи между ними.
💼 Пример из бизнеса: чем ближе летний сезон, тем больше компания тратит на ремаргетинг и тем больше у этой компании заказов.
🔑 Как избежать ловушки? Единственный способ установить причинно-следственную связь между двумя переменными — провести управляемый эксперимент (AB-тест).
🔮 Мультиколлинеарность. Это частный случай ошибки корреляции, которая объясняется наличием третьей переменной, которая связана с обоими изучаемыми признаками.
💼 Пример из бизнеса: было замечено, что те, кто оставляет гневные отзывы в приложении, имеют гораздо больший LTV по сравнению с остальными. Начали рождаться гипотезы о том, что это клиенты, которые эмоционально вовлечены в продукт... Или же те, кому важен продукт, будут его критиковать, потому что часто пользуются и искренне хотят, чтобы сервис изменился... Истинное объяснение оказалось, как с размером города: чем дольше клиент «живёт» с компанией, тем больше вероятность, что рано или поздно он оставит гневный отзыв.
🔑 Как избежать ловушки? Нужно зафиксировать фактор времени константой для обоих групп. Для этого сравним LTV клиентов, которые оставляли отзыв за первые 7 дней с теми, кто не оставлял отзыв, но точно пользовался продуктом первые 7 дней
🔮 Неоднородные группы. При проектировании экспериментов использовать случайное перемешивание и квоты, общие для контрольной и тестовой групп. Проверять, что тестовая и контрольная группа имеют однородный состав. Если тестовая группа изначально наполнена так, что содержит более благоприятную аудиторию, то метрики по ней будут выше, но не из-за влияния изучаемого фактора, а из-за преимущества контрольной группы по своему составу.
💼 Пример из бизнеса: сервис по доставке еды решил проверить, как неожиданные сюрпризы на 8 марта повлияют на LTV клиенток. Логичным контрольным сегментом могут показаться мужчины (так как они не получают сюрпризы на 8 марта) ... Но сравнивать LTV между такими группами будет ошибкой. Мужчины в среднем больше едят и богаче (временно, несправедливо, но факт), а значит и заказывают больше еды и имеют больший LTV.
🔑 Как избежать ловушки? При проектировании экспериментов использовать случайное перемешивание и квоты, общие для контрольной и тестовой групп. Проверять, что тестовая и контрольная группа имеют однородный состав.
🔮 Малые выборки. В выборочных исследованиях (когда по части объектов судим о всей совокупности) часто обнаруживается сегмент, в котором метрика выше или ниже, чем в среднем. Может возникнуть соблазн делать далеко идущие выводы, но такие выводы будут ошибочными без расчета доверительного интервала.
💼 Пример из бизнеса: при очередном замере метрик здоровья бренда засекли рост спонтанного знания среди старшей аудитории, отпраздновали на корпоративе и выписали премию коллегам, которые сотрудничают с газетами. На следующем замере метрика среди старшей аудитории отскочила к стандартным значениям, хотя на газеты потратили ещё больший бюджет.
🔑 Как избежать ловушки? Всегда смотреть на среднее по выборке с оглядкой на доверительный интервал
🔮 Ошибка подглядывания. Если постоянно подглядывать на промежуточные результаты эксперимента, то однажды мы получим желаемые результаты и соблазн остановить эксперимент в этот момент будет слишком велик.
💼 Пример из бизнеса: вы запустили АБ-тест и вам так интересно, что заходите проверять результаты каждый день. Уже три дня подряд показатели тестовой группы были лучше, чем у контрольной, поэтому вы решили досрочно закрыть эксперимент, признав его успешным.
🔑 Как избежать ловушки? Рассчитывать достаточный размер выборки и не подглядывать пока она не накопится.
🍀 Source >>>
#analytics #case #development #experiment #fun #likbez #marketing #product #statistics
📊🕸🤓
🔮 Ошибка корреляции. Совместное изменение двух переменных в динамике не свидетельствует о наличии причинно-следственной связи между ними.
💼 Пример из бизнеса: чем ближе летний сезон, тем больше компания тратит на ремаргетинг и тем больше у этой компании заказов.
🔑 Как избежать ловушки? Единственный способ установить причинно-следственную связь между двумя переменными — провести управляемый эксперимент (AB-тест).
🔮 Мультиколлинеарность. Это частный случай ошибки корреляции, которая объясняется наличием третьей переменной, которая связана с обоими изучаемыми признаками.
💼 Пример из бизнеса: было замечено, что те, кто оставляет гневные отзывы в приложении, имеют гораздо больший LTV по сравнению с остальными. Начали рождаться гипотезы о том, что это клиенты, которые эмоционально вовлечены в продукт... Или же те, кому важен продукт, будут его критиковать, потому что часто пользуются и искренне хотят, чтобы сервис изменился... Истинное объяснение оказалось, как с размером города: чем дольше клиент «живёт» с компанией, тем больше вероятность, что рано или поздно он оставит гневный отзыв.
🔑 Как избежать ловушки? Нужно зафиксировать фактор времени константой для обоих групп. Для этого сравним LTV клиентов, которые оставляли отзыв за первые 7 дней с теми, кто не оставлял отзыв, но точно пользовался продуктом первые 7 дней
🔮 Неоднородные группы. При проектировании экспериментов использовать случайное перемешивание и квоты, общие для контрольной и тестовой групп. Проверять, что тестовая и контрольная группа имеют однородный состав. Если тестовая группа изначально наполнена так, что содержит более благоприятную аудиторию, то метрики по ней будут выше, но не из-за влияния изучаемого фактора, а из-за преимущества контрольной группы по своему составу.
💼 Пример из бизнеса: сервис по доставке еды решил проверить, как неожиданные сюрпризы на 8 марта повлияют на LTV клиенток. Логичным контрольным сегментом могут показаться мужчины (так как они не получают сюрпризы на 8 марта) ... Но сравнивать LTV между такими группами будет ошибкой. Мужчины в среднем больше едят и богаче (временно, несправедливо, но факт), а значит и заказывают больше еды и имеют больший LTV.
🔑 Как избежать ловушки? При проектировании экспериментов использовать случайное перемешивание и квоты, общие для контрольной и тестовой групп. Проверять, что тестовая и контрольная группа имеют однородный состав.
🔮 Малые выборки. В выборочных исследованиях (когда по части объектов судим о всей совокупности) часто обнаруживается сегмент, в котором метрика выше или ниже, чем в среднем. Может возникнуть соблазн делать далеко идущие выводы, но такие выводы будут ошибочными без расчета доверительного интервала.
💼 Пример из бизнеса: при очередном замере метрик здоровья бренда засекли рост спонтанного знания среди старшей аудитории, отпраздновали на корпоративе и выписали премию коллегам, которые сотрудничают с газетами. На следующем замере метрика среди старшей аудитории отскочила к стандартным значениям, хотя на газеты потратили ещё больший бюджет.
🔑 Как избежать ловушки? Всегда смотреть на среднее по выборке с оглядкой на доверительный интервал
🔮 Ошибка подглядывания. Если постоянно подглядывать на промежуточные результаты эксперимента, то однажды мы получим желаемые результаты и соблазн остановить эксперимент в этот момент будет слишком велик.
💼 Пример из бизнеса: вы запустили АБ-тест и вам так интересно, что заходите проверять результаты каждый день. Уже три дня подряд показатели тестовой группы были лучше, чем у контрольной, поэтому вы решили досрочно закрыть эксперимент, признав его успешным.
🔑 Как избежать ловушки? Рассчитывать достаточный размер выборки и не подглядывать пока она не накопится.
🍀 Source >>>
#analytics #case #development #experiment #fun #likbez #marketing #product #statistics
{kind=link}
ЗАЧЕМ АВИТО «ОБЛАЧНЫЕ» UX-ИССЛЕДОВАТЕЛИ И КАК С НИМИ РАБОТАТЬ
☁️👩🏻🔬🔮
Важность UX-исследований для бизнеса осознают практически все, и по этой теме вышло много отличных материалов: например, Ксения Стерлина из Arrival и UXSSR писала о том, что даже если в компании нет выделенной роли исследователя, совсем без исследований компания жить не может. О том же говорит и Sinead Cochrane из Intercom в статье «Any research is better than no research». Максимальный риск, по мнению команды Intercom, — создавать продукты без изучения опыта, поведения и потребностей реальных пользователей.
Но когда компания начинает регулярно заниматься исследованиями, возникает другой вопрос — как проводить еще больше исследований, чтобы проверять больше гипотез и находить больше инсайтов?
🗂 Оглавление
📌 Почему нам нужно больше исследований?
📌 Как проводить больше исследований?
📌 А что, если исследователь будет «облачным»?
📌 Как мы создавали базу «облачных исследователей»
📌 Что важно учесть при работе с фрилансерами
📌 Плюсы и минусы работы с исследователями-фрилансерами
📌 Перспективы «облачных» UX-исследований
📌 Развитие нового формата как платформы
📌 Дополнительные материалы
🍀 Source >>>
#case #design #development #ecom #mr #product #tools #ux
☁️👩🏻🔬🔮
Важность UX-исследований для бизнеса осознают практически все, и по этой теме вышло много отличных материалов: например, Ксения Стерлина из Arrival и UXSSR писала о том, что даже если в компании нет выделенной роли исследователя, совсем без исследований компания жить не может. О том же говорит и Sinead Cochrane из Intercom в статье «Any research is better than no research». Максимальный риск, по мнению команды Intercom, — создавать продукты без изучения опыта, поведения и потребностей реальных пользователей.
Но когда компания начинает регулярно заниматься исследованиями, возникает другой вопрос — как проводить еще больше исследований, чтобы проверять больше гипотез и находить больше инсайтов?
🗂 Оглавление
📌 Почему нам нужно больше исследований?
📌 Как проводить больше исследований?
📌 А что, если исследователь будет «облачным»?
📌 Как мы создавали базу «облачных исследователей»
📌 Что важно учесть при работе с фрилансерами
📌 Плюсы и минусы работы с исследователями-фрилансерами
📌 Перспективы «облачных» UX-исследований
📌 Развитие нового формата как платформы
📌 Дополнительные материалы
🍀 Source >>>
#case #design #development #ecom #mr #product #tools #ux
{kind=link}
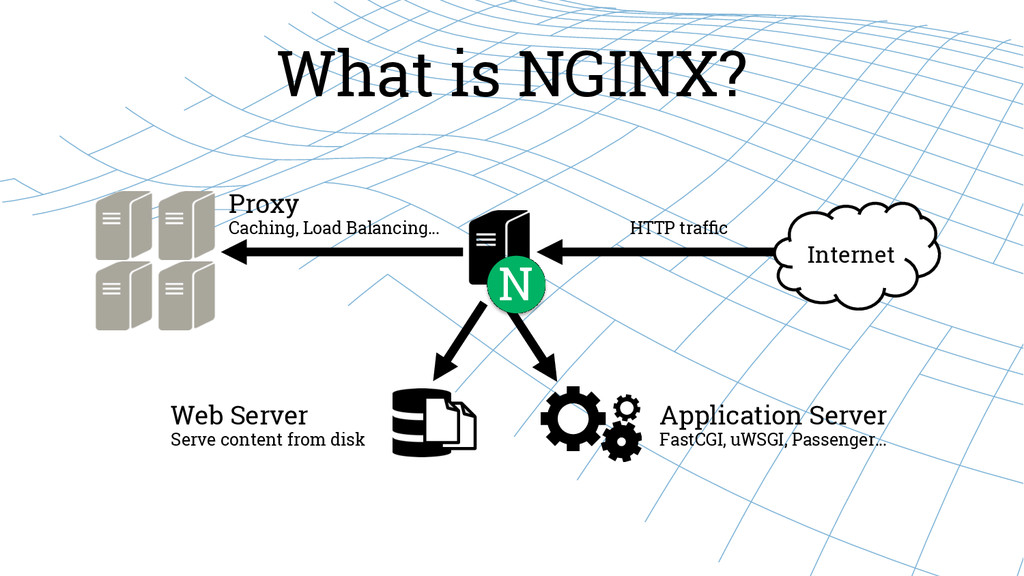
NGINX: ЗАЧЕМ НУЖЕН ВЕБ-СЕРВЕР?
📲⚙️💻
Без веб-сервера не сможет работать ни один сайт. Рассказ про лидера сегодняшнего рынка, российский веб-сервер nginx.
🍀 Source >>>
🍀 YouTube (22’) >>>
#dev #likbez #product #technology #tools
📲⚙️💻
Без веб-сервера не сможет работать ни один сайт. Рассказ про лидера сегодняшнего рынка, российский веб-сервер nginx.
🍀 Source >>>
🍀 YouTube (22’) >>>
#dev #likbez #product #technology #tools
{kind=link}
DISCORD ВНЕДРЯЕТ ИСКУССТВЕННЫЙ ИНТЕЛЛЕКТ НА КАЖДЫЙ СЕРВЕР
🤖📲
Discord объявил о запуске ряда новых возможностей на основе искусственного интеллекта, которые будут доступны на каждом сервере.
В частности, Discord обновил своего бота Клайда с помощью технологии ChatGPT от OpenAI, которая даст возможность пользователям «вести с ним пространные разговоры». Нужно просто ввести @Clyde на сервере, чтобы общаться с ботом в любом канале.
Например, Клайда можно попросить начать тему для группы друзей. Он также умеет рекомендовать плейлисты и получать доступ к GIF-файлам и эмодзи, как и любой пользователь Discord. Клайд может найти и отправить пользователю определенную гифку, или поделиться пятью интересными фактами о кошках.
Discord также обновляет свой инструмент модерации AutoMod, интегрируя в него возможности больших языковых моделей. AutoMod теперь использует технологию OpenAI для поиска и оповещения модераторов всякий раз, когда правила сервера нарушаются, опираясь при этом на контекст разговора. Эксперимент AutoMod AI был запущен сегодня на ограниченном количестве серверов.
На платформе также запускается функция создания резюме разговоров, основанная на ИИ. Она предназначена для объединения сообщений в темы, чтобы пользователи могли быстро наверстать упущенное или присоединиться к интересующей их теме. Уже сегодня некоторые из них увидят новую панель в правой части экрана, на которой будут описаны обсуждаемые темы.
В дополнение к этим трем новым возможностям искусственного интеллекта, Discord поделился и другими способами включения ИИ в функционал платформы. Это приложение Avatar Remix, позволяющее пользователям делать ремиксы на аватары друг друга с помощью генеративных моделей для изображений. Разработчики могут найти код Avatar Remix на GitHub, начиная с сегодняшнего дня.
Компания также работает над общим визуальным пространством для совместной работы с друзьями и коллегами, которое включает в себя генератор изображений на основе текстовых описаний, при помощи которого пользователи смогут вместе экспериментировать и творить.
Отметим, Discord – не единственная чат-платформа, внедрившая новые функции на основе искусственного интеллекта, ранее об этом заявили мессенджеры Snapchat и Slack.
🍀 Source >>>
🍀 Original >>>
#case #datascience #dev #efficiency #fun #product #technology #tools #trends
🤖📲
Discord объявил о запуске ряда новых возможностей на основе искусственного интеллекта, которые будут доступны на каждом сервере.
В частности, Discord обновил своего бота Клайда с помощью технологии ChatGPT от OpenAI, которая даст возможность пользователям «вести с ним пространные разговоры». Нужно просто ввести @Clyde на сервере, чтобы общаться с ботом в любом канале.
Например, Клайда можно попросить начать тему для группы друзей. Он также умеет рекомендовать плейлисты и получать доступ к GIF-файлам и эмодзи, как и любой пользователь Discord. Клайд может найти и отправить пользователю определенную гифку, или поделиться пятью интересными фактами о кошках.
Discord также обновляет свой инструмент модерации AutoMod, интегрируя в него возможности больших языковых моделей. AutoMod теперь использует технологию OpenAI для поиска и оповещения модераторов всякий раз, когда правила сервера нарушаются, опираясь при этом на контекст разговора. Эксперимент AutoMod AI был запущен сегодня на ограниченном количестве серверов.
На платформе также запускается функция создания резюме разговоров, основанная на ИИ. Она предназначена для объединения сообщений в темы, чтобы пользователи могли быстро наверстать упущенное или присоединиться к интересующей их теме. Уже сегодня некоторые из них увидят новую панель в правой части экрана, на которой будут описаны обсуждаемые темы.
В дополнение к этим трем новым возможностям искусственного интеллекта, Discord поделился и другими способами включения ИИ в функционал платформы. Это приложение Avatar Remix, позволяющее пользователям делать ремиксы на аватары друг друга с помощью генеративных моделей для изображений. Разработчики могут найти код Avatar Remix на GitHub, начиная с сегодняшнего дня.
Компания также работает над общим визуальным пространством для совместной работы с друзьями и коллегами, которое включает в себя генератор изображений на основе текстовых описаний, при помощи которого пользователи смогут вместе экспериментировать и творить.
Отметим, Discord – не единственная чат-платформа, внедрившая новые функции на основе искусственного интеллекта, ранее об этом заявили мессенджеры Snapchat и Slack.
🍀 Source >>>
🍀 Original >>>
#case #datascience #dev #efficiency #fun #product #technology #tools #trends
{kind=link}
РОБИН ГУД И ЭКОНОМИКА ЗНАНИЙ: КАК ОДНОЙ ЖЕНЩИНЕ УДАЛОСЬ СЭКОНОМИТЬ МИЛЛИОНЫ ДОЛЛАРОВ ДЛЯ УЧЕНЫХ ВСЕГО МИРА
🤓📚💰
Наука часто идеализируется людьми, далекими от нее. Сфера академических исследований со стороны воспринимается как райские кущи, населенные добрыми гиками и мудрыми профессорами, которые не покладая рук разрабатывают лекарство от рака под присмотром щедрых меценатов. Увы, реальная наука далека от этих представлений так же, как книги Маркса — от экономики СССР, и страдает от тех же проблем, что и остальное общество.
Одна из главных проблем науки, как ни странно — распространение и доступность информации. «У тебя есть яблоко и у меня есть яблоко, мы меняемся и остаемся при своих яблоках. У меня есть идея и у тебя есть идея — обменявшись, у каждого из нас становится вдвое больше идей». Эта нехитрая, знакомая каждому еще с начальных классов истина, лежащая в основе научно-технической революции, не работает в современных условиях.
Современная экономика знаний похожа на перепродажу полученной от производителя уникальной информации, за которую производитель еще и доплачивает продавцу.
Статья 19 Всеобщей декларации прав человека, принятой ООН, гласит: «Каждый человек имеет право <…> получать и распространять информацию и идеи любыми средствами и независимо от государственных границ».
«Всего за ХХХ$ в месяц!», добавляют дистрибьюторы знаний, от которых зависит развитие мировой экономики и цивилизации.
Бесплатным, как то подразумевала декларация ООН, это право сделал проект SciHub — детище казахской студентки, которой надоело платить за знания, которые должны, по ее убеждению, принадлежать всем без исключения.
Эволюционная теория мемов профессора Докинза еще никогда не встречала столь истовой поддержки; информационное развитие человечества благодаря SciHub продолжается вне записей бухгалтерской книги. Сама создательница проекта тем временем отбивается от судебных исков «цивилизованного запада», но продолжает поддерживать источник знаний для сотен тысяч людей по всему миру.
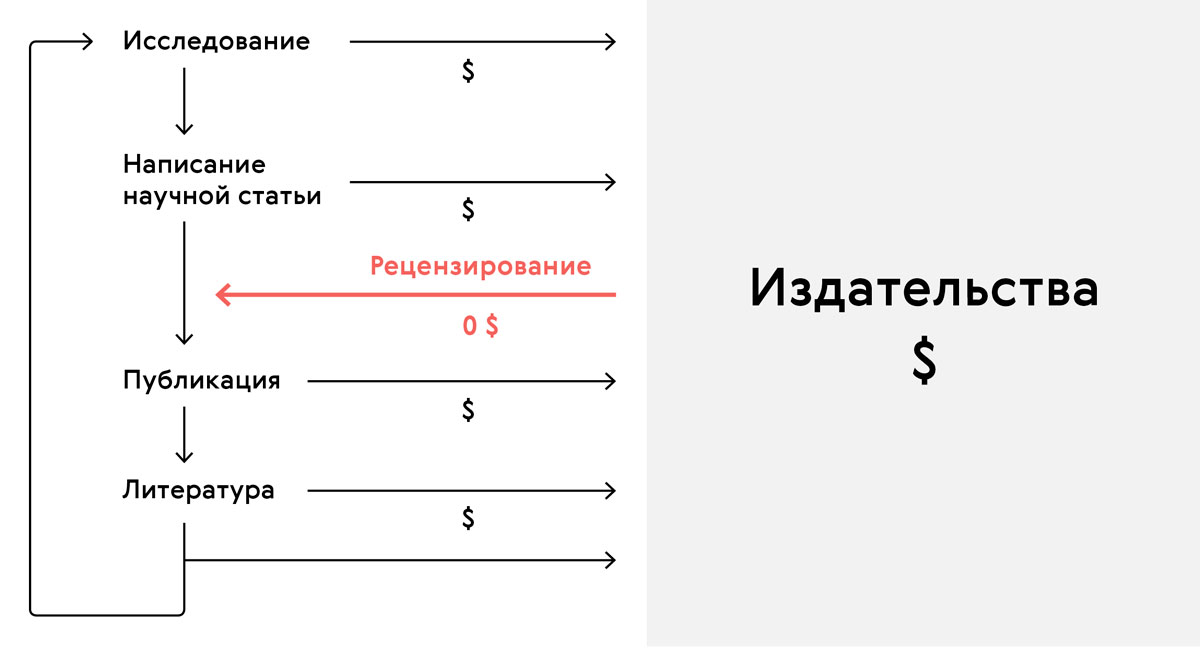
Как работает экономика знаний
Большинство научных исследований публикуются в научных журналах. Большинство научных журналов монополизированы несколькими издательствами. Почему это проблема? Потому что подписка на научные журналы может стоить баснословных денег. Это не нетфликс за несколько долларов в месяц, а сумма, сравнимая с окладом обычного исследователя. Покупка отдельных статей — не выход. Их стоимость поодиночке может достигать 30-50$, а для качественных исследований и диссертаций необходимо перечитать десятки, если не сотни статей.
Думаете, подобные суммы оправданы, потому что деньги эти получают сами ученые? Увы, это далеко от истины — даже авторы исследований часто вынуждены платить за право опубликоваться в журнале.
Ситуация начинает напоминать театр абсурда: человек работает, пишет статью, платит журналу за то, чтобы тот ее опубликовал, а журнал сначала берет деньги у него, а потом — еще и у читателей.
«Коммерческая составляющая является гарантией качества», твердят апологеты существующего миропорядка. Многие ли из них упоминают, что ученые-рецензенты, отвечающие за то, чтобы статья отвечала высоким стандартам, чаще всего не получают ни копейки?
🍀 Source >>>
#case #fun #likbez #product #science #tools
🤓📚💰
Наука часто идеализируется людьми, далекими от нее. Сфера академических исследований со стороны воспринимается как райские кущи, населенные добрыми гиками и мудрыми профессорами, которые не покладая рук разрабатывают лекарство от рака под присмотром щедрых меценатов. Увы, реальная наука далека от этих представлений так же, как книги Маркса — от экономики СССР, и страдает от тех же проблем, что и остальное общество.
Одна из главных проблем науки, как ни странно — распространение и доступность информации. «У тебя есть яблоко и у меня есть яблоко, мы меняемся и остаемся при своих яблоках. У меня есть идея и у тебя есть идея — обменявшись, у каждого из нас становится вдвое больше идей». Эта нехитрая, знакомая каждому еще с начальных классов истина, лежащая в основе научно-технической революции, не работает в современных условиях.
Современная экономика знаний похожа на перепродажу полученной от производителя уникальной информации, за которую производитель еще и доплачивает продавцу.
Статья 19 Всеобщей декларации прав человека, принятой ООН, гласит: «Каждый человек имеет право <…> получать и распространять информацию и идеи любыми средствами и независимо от государственных границ».
«Всего за ХХХ$ в месяц!», добавляют дистрибьюторы знаний, от которых зависит развитие мировой экономики и цивилизации.
Бесплатным, как то подразумевала декларация ООН, это право сделал проект SciHub — детище казахской студентки, которой надоело платить за знания, которые должны, по ее убеждению, принадлежать всем без исключения.
Эволюционная теория мемов профессора Докинза еще никогда не встречала столь истовой поддержки; информационное развитие человечества благодаря SciHub продолжается вне записей бухгалтерской книги. Сама создательница проекта тем временем отбивается от судебных исков «цивилизованного запада», но продолжает поддерживать источник знаний для сотен тысяч людей по всему миру.
Как работает экономика знаний
Большинство научных исследований публикуются в научных журналах. Большинство научных журналов монополизированы несколькими издательствами. Почему это проблема? Потому что подписка на научные журналы может стоить баснословных денег. Это не нетфликс за несколько долларов в месяц, а сумма, сравнимая с окладом обычного исследователя. Покупка отдельных статей — не выход. Их стоимость поодиночке может достигать 30-50$, а для качественных исследований и диссертаций необходимо перечитать десятки, если не сотни статей.
Думаете, подобные суммы оправданы, потому что деньги эти получают сами ученые? Увы, это далеко от истины — даже авторы исследований часто вынуждены платить за право опубликоваться в журнале.
Ситуация начинает напоминать театр абсурда: человек работает, пишет статью, платит журналу за то, чтобы тот ее опубликовал, а журнал сначала берет деньги у него, а потом — еще и у читателей.
«Коммерческая составляющая является гарантией качества», твердят апологеты существующего миропорядка. Многие ли из них упоминают, что ученые-рецензенты, отвечающие за то, чтобы статья отвечала высоким стандартам, чаще всего не получают ни копейки?
🍀 Source >>>
#case #fun #likbez #product #science #tools
{kind=link}
YANDEX CLOUD ОБНОВИЛ СЕРВИС YANDEX TRACKER ДЛЯ КОМПАНИЙ — ДОБАВИЛ СТАРТОВЫЕ СТРАНИЦЫ И СОРТИРОВКУ ЗАДАЧ В ПРИЛОЖЕНИИ
🗃👩🏻💻✅
Среди других обновлений — автоматическое удаление и добавление задач на досках и создание диаграмм по списку проектов.
📌 В сервисе для управления процессами и проектами для бизнеса Yandex Tracker у каждого пользователя появилась стартовая страница, объявила компания. До этого при входе пользователь видел только список всех задач команды.
📌 Теперь страницу можно настраивать — например, добавлять виджеты для отслеживания списка задач, статистики их выполнения или оставлять заметки. Администраторы смогут размещать на стартовых страницах объявления для всей команды.
📌 Администраторы теперь могут настраивать доступы к Tracker для всего отдела компании сразу, если пользователи зарегистрированы как группа в «Яндекс 360». До этого назначать права на доступ и редактирование или отключать от системы каждого пользователя нужно было вручную.
📌 В Yandex Tracker теперь можно добавлять задачи сразу во вкладке «Доска» и зоне планирования — вкладке «Бэклог». Пользователи также могут настроить условия, по которым задачи будут добавляться или удаляться с доски автоматически. Виджеты на дашбордах можно перемещать и менять их размер.
📌 Обновилась диаграмма Ганта — инструмент для визуализации и управления календарным планом. Пользователи могут создавать диаграмму по списку проектов и сразу посмотреть задачи из других проектов, которые блокируют завершение текущего.
📌 В мобильном приложении появилась сортировка и группировка задач по типу, очереди, исполнителю или дедлайну. Также для поиска задач пользователи теперь могут использовать фильтры, установленные ими в веб-версии.
Обновления уже доступны в веб-версии сервиса и в мобильных приложениях Yandex Tracker.
🍀 Source >>>
#b2b #dev #efficiency #product #tools #ux
🗃👩🏻💻✅
Среди других обновлений — автоматическое удаление и добавление задач на досках и создание диаграмм по списку проектов.
📌 В сервисе для управления процессами и проектами для бизнеса Yandex Tracker у каждого пользователя появилась стартовая страница, объявила компания. До этого при входе пользователь видел только список всех задач команды.
📌 Теперь страницу можно настраивать — например, добавлять виджеты для отслеживания списка задач, статистики их выполнения или оставлять заметки. Администраторы смогут размещать на стартовых страницах объявления для всей команды.
📌 Администраторы теперь могут настраивать доступы к Tracker для всего отдела компании сразу, если пользователи зарегистрированы как группа в «Яндекс 360». До этого назначать права на доступ и редактирование или отключать от системы каждого пользователя нужно было вручную.
📌 В Yandex Tracker теперь можно добавлять задачи сразу во вкладке «Доска» и зоне планирования — вкладке «Бэклог». Пользователи также могут настроить условия, по которым задачи будут добавляться или удаляться с доски автоматически. Виджеты на дашбордах можно перемещать и менять их размер.
📌 Обновилась диаграмма Ганта — инструмент для визуализации и управления календарным планом. Пользователи могут создавать диаграмму по списку проектов и сразу посмотреть задачи из других проектов, которые блокируют завершение текущего.
📌 В мобильном приложении появилась сортировка и группировка задач по типу, очереди, исполнителю или дедлайну. Также для поиска задач пользователи теперь могут использовать фильтры, установленные ими в веб-версии.
Обновления уже доступны в веб-версии сервиса и в мобильных приложениях Yandex Tracker.
🍀 Source >>>
#b2b #dev #efficiency #product #tools #ux
{kind=link}
SPARKS OF ARTIFICIAL GENERAL INTELLIGENCE: EARLY EXPERIMENTS WITH GPT-4 | MICROSOFT RESEARCH
🕵🏻♀️🧠🤖
Artificial intelligence (AI) researchers have been developing and refining large language models (LLMs) that exhibit remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. The latest model developed by OpenAI, GPT-4, was trained using an unprecedented scale of compute and data.
In this paper, we report on our investigation of an early version of GPT-4, when it was still in active development by OpenAI. We contend that (this early version of) GPT4 is part of a new cohort of LLMs (along with ChatGPT and Google’s PaLM for example) that exhibit more general intelligence than previous AI models. We discuss the rising capabilities and implications of these models. We demonstrate that, beyond its mastery of language, GPT-4 can solve novel and difficult tasks that span mathematics, coding, vision, medicine, law, psychology and more, without needing any special prompting.
Moreover, in all of these tasks, GPT-4’s performance is strikingly close to human-level performance, and often vastly surpasses prior models such as ChatGPT. Given the breadth and depth of GPT-4’s capabilities, we believe that it could reasonably be viewed as an early (yet still incomplete) version of an artificial general intelligence (AGI) system. In our exploration of GPT-4, we put special emphasis on discovering its limitations, and we discuss the challenges ahead for advancing towards deeper and more comprehensive versions of AGI, including the possible need for pursuing a new paradigm that moves beyond next-word prediction. We conclude with reflections on societal influences of the recent technological leap and future research directions.
Some of the areas where GPT-4 (and LLMs more generally) should be improved to achieve intelligence that is more general include (note that many of them are interconnected):
✨ Confidence calibration
✨ Long-term memory
✨ Continual learning
✨ Personalization
✨ Planning and conceptual leaps
✨ Transparency, interpretability and consistency
✨ Cognitive fallacies and irrationality
✨ Challenges with sensitivity to inputs
🍀 Source >>>
🍀 Report in PDF >>>
#analytics #case #datascience #dev #experiment #product #report #science #technology #tools #trends
🕵🏻♀️🧠🤖
Artificial intelligence (AI) researchers have been developing and refining large language models (LLMs) that exhibit remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. The latest model developed by OpenAI, GPT-4, was trained using an unprecedented scale of compute and data.
In this paper, we report on our investigation of an early version of GPT-4, when it was still in active development by OpenAI. We contend that (this early version of) GPT4 is part of a new cohort of LLMs (along with ChatGPT and Google’s PaLM for example) that exhibit more general intelligence than previous AI models. We discuss the rising capabilities and implications of these models. We demonstrate that, beyond its mastery of language, GPT-4 can solve novel and difficult tasks that span mathematics, coding, vision, medicine, law, psychology and more, without needing any special prompting.
Moreover, in all of these tasks, GPT-4’s performance is strikingly close to human-level performance, and often vastly surpasses prior models such as ChatGPT. Given the breadth and depth of GPT-4’s capabilities, we believe that it could reasonably be viewed as an early (yet still incomplete) version of an artificial general intelligence (AGI) system. In our exploration of GPT-4, we put special emphasis on discovering its limitations, and we discuss the challenges ahead for advancing towards deeper and more comprehensive versions of AGI, including the possible need for pursuing a new paradigm that moves beyond next-word prediction. We conclude with reflections on societal influences of the recent technological leap and future research directions.
Some of the areas where GPT-4 (and LLMs more generally) should be improved to achieve intelligence that is more general include (note that many of them are interconnected):
✨ Confidence calibration
✨ Long-term memory
✨ Continual learning
✨ Personalization
✨ Planning and conceptual leaps
✨ Transparency, interpretability and consistency
✨ Cognitive fallacies and irrationality
✨ Challenges with sensitivity to inputs
🍀 Source >>>
🍀 Report in PDF >>>
#analytics #case #datascience #dev #experiment #product #report #science #technology #tools #trends
{kind=link}
КАК ПРОВЕСТИ A/B-ТЕСТИРОВАНИЕ И ПОДНЯТЬ КОНВЕРСИЮ САЙТА?
✈️⚖️🅰️🅱️
⏱ Таймкоды:
0:00 О чем расскажем
0:34 Что такое A/B-тестирование
1:15 Почему Netflix и Amazon проводят так много A/B-тестов?
1:30 Пример A/B-теста от Grene
2:30 Как проводить A/B-тест
2:42 Как найти гипотезу для тестирования
3:36 Как определить метрику: повышение конверсии?
4:08 Пример гипотезы для A/B-тестирования
4:38 Нулевая гипотеза
4:57 Альтернативная гипотеза
5:51 Подготовка к тестированию
8:28 Подводим результаты тестирования
9:14 Что делать, если тест не сработал?
🍀 Source >>>
🍀 YouTube (~10 min) >>>
#analytics #efficiency #experiment #likbez #methodology #product #statistics #tools
✈️⚖️🅰️🅱️
⏱ Таймкоды:
0:00 О чем расскажем
0:34 Что такое A/B-тестирование
1:15 Почему Netflix и Amazon проводят так много A/B-тестов?
1:30 Пример A/B-теста от Grene
2:30 Как проводить A/B-тест
2:42 Как найти гипотезу для тестирования
3:36 Как определить метрику: повышение конверсии?
4:08 Пример гипотезы для A/B-тестирования
4:38 Нулевая гипотеза
4:57 Альтернативная гипотеза
5:51 Подготовка к тестированию
8:28 Подводим результаты тестирования
9:14 Что делать, если тест не сработал?
🍀 Source >>>
🍀 YouTube (~10 min) >>>
#analytics #efficiency #experiment #likbez #methodology #product #statistics #tools
{kind=link}
«Метод персон» и Jobs to Be Done. Что лучше для работы с целевой аудиторией
🧑🏻🎨↔️👩🏼🔧
Jobs to Be Done (JTBD) — это фреймворк, в основе которого лежит идея, что пользователи «нанимают» продукты для выполнения определенной «работы».
«Метод персон» подразумевает создание портрета представителя целевой аудитории определенного продукта.
Хотя может показаться, что эти подходы противоречат друг другу, на самом деле они оба могут быть полезны при затачивании продукта под потребности целевой аудитории.
Прочитайте адаптированный перевод статьи Personas vs. Jobs-to-Be-Done, опубликованной в блоге Nielsen Norman Group, в котором подробно разбираются преимущества этих подходов и решаемые ими задачи для продуктовых команд.
✨ Удобство использования любого продукта можно оценить только в отношении к двум переменным: кто пользователи и что они хотят сделать. Поэтому, чтобы юзабилити-исследования продукта приносили пользу, важно набирать релевантных тестовых пользователей и давать им релевантные задачи.
✨ Один дизайн продукта может быть хорош для одной категории пользователей и совершенно непонятен для другой группы. Если вы будете проводить исследование на неподходящей выборке, вы ничего не узнаете о реальных юзкейсах.
✨ Именно поэтому вы должны строго определять целевых пользователей и их задачи во время работы над продуктом. В противном случае вы рискуете создать продукт для неподходящей аудитории или с набором ненужных фичей. Для эффективной и успешной работы над пользовательским опытом вам понадобится ясно определить и конкретных пользователей, и их конкретные задачи.
✨ «Персоны» — это не просто демографические или маркетинговые сегменты пользователей. Они включают в себя информацию и об их целях, потребностях, болях, ожиданиях. Вся эта информация упаковывается в нарративный формат, который формирует эмпатию у команды.
✨ И хотя JTBD может быть полезным способом сформулировать конкретные «работы» пользователей, эта информация на самом деле уже представлена в хорошо проработанных «персонах».
🍀 Source >>>
🍀 Original >>>
#dev #efficiency #likbez #methodology #product #tools
🧑🏻🎨↔️👩🏼🔧
Jobs to Be Done (JTBD) — это фреймворк, в основе которого лежит идея, что пользователи «нанимают» продукты для выполнения определенной «работы».
«Метод персон» подразумевает создание портрета представителя целевой аудитории определенного продукта.
Хотя может показаться, что эти подходы противоречат друг другу, на самом деле они оба могут быть полезны при затачивании продукта под потребности целевой аудитории.
Прочитайте адаптированный перевод статьи Personas vs. Jobs-to-Be-Done, опубликованной в блоге Nielsen Norman Group, в котором подробно разбираются преимущества этих подходов и решаемые ими задачи для продуктовых команд.
✨ Удобство использования любого продукта можно оценить только в отношении к двум переменным: кто пользователи и что они хотят сделать. Поэтому, чтобы юзабилити-исследования продукта приносили пользу, важно набирать релевантных тестовых пользователей и давать им релевантные задачи.
✨ Один дизайн продукта может быть хорош для одной категории пользователей и совершенно непонятен для другой группы. Если вы будете проводить исследование на неподходящей выборке, вы ничего не узнаете о реальных юзкейсах.
✨ Именно поэтому вы должны строго определять целевых пользователей и их задачи во время работы над продуктом. В противном случае вы рискуете создать продукт для неподходящей аудитории или с набором ненужных фичей. Для эффективной и успешной работы над пользовательским опытом вам понадобится ясно определить и конкретных пользователей, и их конкретные задачи.
✨ «Персоны» — это не просто демографические или маркетинговые сегменты пользователей. Они включают в себя информацию и об их целях, потребностях, болях, ожиданиях. Вся эта информация упаковывается в нарративный формат, который формирует эмпатию у команды.
✨ И хотя JTBD может быть полезным способом сформулировать конкретные «работы» пользователей, эта информация на самом деле уже представлена в хорошо проработанных «персонах».
🍀 Source >>>
🍀 Original >>>
#dev #efficiency #likbez #methodology #product #tools
{kind=link}