
Forwarded from Data Science by ODS.ai 🦜
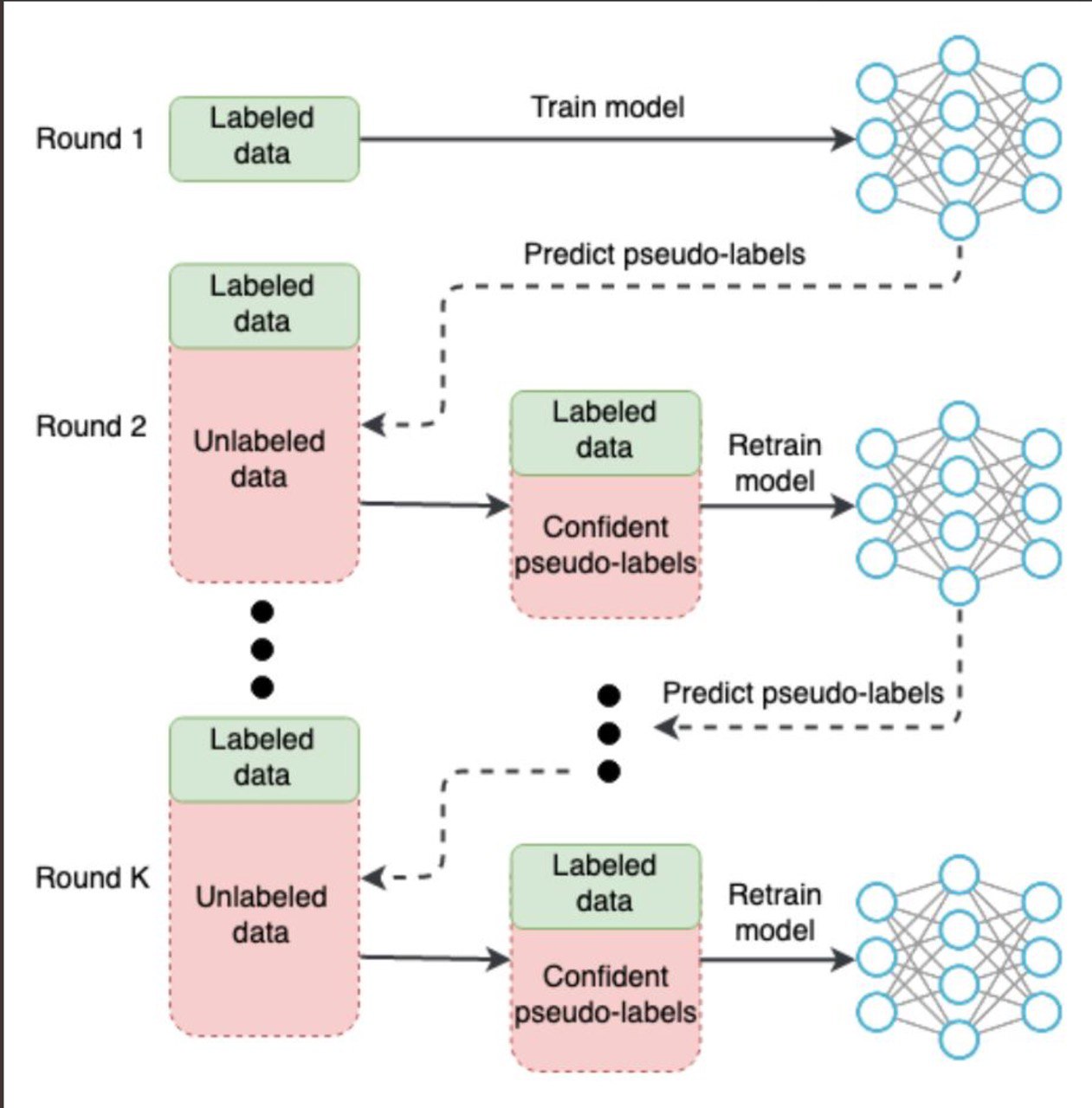
New paper on training with pseudo-labels for semantic segmentation
Semi-Supervised Segmentation of Salt Bodies in Seismic Images:
SOTA (1st place) at TGS Salt Identification Challenge.
Github: https://github.com/ybabakhin/kaggle_salt_bes_phalanx
ArXiV: https://arxiv.org/abs/1904.04445
#GCPR2019 #Segmentation #CV
Semi-Supervised Segmentation of Salt Bodies in Seismic Images:
SOTA (1st place) at TGS Salt Identification Challenge.
Github: https://github.com/ybabakhin/kaggle_salt_bes_phalanx
ArXiV: https://arxiv.org/abs/1904.04445
#GCPR2019 #Segmentation #CV
{kind=link}
Meta Reality Labs выпустила семейство моделей Sapiens, предназначенных для операций с изображениями или видео людей:
Модели могут работать с разрешением 1K (1024х1024) и легко адаптируются под специфические задачи путем тонкой настройки моделей. Семейство было обучено на предварительно отобранном корпусе данных в 300 млн изображений, из которого были удалены изображения с водяными знаками, художественной стилизацией, снимки плохого качества и содержащие размытие в движении.
Опубликованные модели разделяются по назначению : sapiens_lite_host - предназначены для инференса, а sapiens_host - длясамостоятельного обучения на ваших данных. Для обеих вариантов наборов выпущены градации плотности:
Разработчики рекомендуют lite-установку для инференса, она оптимизирована для быстрого запуска с минимальными зависимостями и возможностью запуска на нескольких GPU.
# Clone repository
git clone [email protected]:facebookresearch/sapiens.git
export SAPIENS_ROOT=/path/to/sapiens
# Set up a venv:
conda create -n sapiens_lite python=3.10
conda activate sapiens_lite
# Install dependencies
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
pip install opencv-python tqdm json-tricks
# Navigate to your script directory
cd $SAPIENS_LITE_ROOT/scripts/demo/[torchscript,bfloat16,float16]
# Uncomment your model config line first
./depth.sh
📌 Лицензирование : CC-BY-NC-SA-4.0 License
▪Страница проекта
▪Набор моделей
▪Arxiv
▪Github [ Stars: 75 | Issues: 0 | Forks: 0]
@ai_machinelearning_big_data
#AI #Vision #ViT #ML #CV
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
👍34❤9🔥5😁2
Segment Anything Model (SAM) - это набор базовых моделей, которые позволяют автоматически сегментировать любые объекты, независимо от их формы, размера и расположения на изображении и видео.
Meta без официального пресс-релиза обновила модели SAM до версии 2.1. Обновление минорное :
Набор моделей: tiny, small, base_plus и large остался прежним, как и их размеры и производительность.
⚠️ Чтобы использовать новые модели SAM 2.1, необходима последняя версия кода из репозитория. Если установлена более ранняя версия, ее необходимо сначала удалить с помощью
pip uninstall SAM-2.Демо-ноутбуки для запуска в Google Collab:
@ai_machinelearning_big_data
#AI #ML #SAM2 #META #Segmentation #CV
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
👍28❤6🔥6🥰1
RT-DETRv2 - новая версия RT-DETR, альтернативы YOLO. RT-DETRv2 получила ряд улучшений: повышение гибкости, практичности и производительности.
Ключевое изменение - модификация модуля
deformable attention в декодере. В RT-DETRv2 предлагается устанавливать различное количество точек выборки для признаков разных масштабов. Это дает возможность более эффективно извлекать многомасштабные признаки, делая ее более адаптировной к множествам сценариям детекции.Чтобы сделать модель модель более практичной, заменили оператор
grid_sample, характерный для DETR, на опциональный discrete_sample, который выполняет округление предсказанных смещений выборки, что ускоряет процесс без значительной потери точности.RT-DETRv2 обучается стратегией динамического усиления данных (dynamic data augmentation). На ранних этапах используются более интенсивные методы аугментации, чтобы модель лучше обобщала данные. На поздних этапах уровень аугментации снижается, что позволяет модели адаптироваться к целевой области.
В новой версии используется кастомизация гиперпараметров в зависимости от масштаба модели. Например, для ResNet18 увеличивается скорость обучения, тогда как для более крупных моделей - ResNet101, она снижается.
Тесты RT-DETRv2 выполнялись на наборе датасете COCO, где модель показала улучшение метрики AP на 0.3–1.4 пункта по сравнению с RT-DETR, сохраняя при этом высокую скорость работы. Например, RT-DETRv2-S с архитектурой ResNet18 достигла AP 47.9, что на 1.4 пункта выше, чем у RT-DETR-S.
Скрипты для файнтюна RT-DETRv2 с Trainer или Accelerate размещены в репозитории HuggingFace на Github, а ноутбук простого инференса локально - тут или запустить в Google Collab.
#AI #CV #RTDETRv2
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
👍51❤17🔥14👌1
В статье исследуется применение обучения с подкреплением (RL) к большим языковым моделям (LLMs) улучшает их способность решать сложные задачи программирования и рассуждений. Авторы сравнивают три модели: общую модель o1, её специализированную версию o1-ioi (адаптированную для соревнований IOI) и более продвинутую модель o3.
Модель o1 значительно превосходит модели без цепочек рассуждений (например, gpt-4o) по показателям на платформе CodeForces.
Специализированная o1-ioi, оптимизированная для соревнований IOI, показывает хорошие результаты с ручными стратегиями, но её успех зависит от дополнительной настройки и тестовых стратегий.
Модель o3, обученная только с RL и без доменно-специфичных стратегий, демонстрирует ещё более высокую производительность, достигая результатов на уровне элитных программистов мира как на CodeForces, так и на IOI.
Применение в реальных задачах:
Масштабирование RL для общего использования, а не применение специализированных ручных стратегий, является эффективным путём достижения передового уровня ИИ в задачах рассуждения и программирования.
Статья
Тред
Релиз состоится 18 февраля в 04:00 (GMT+3). Похоже, что Grok-3 выйдет с режимом рассуждений.
выпустили новую очень сложную оценку рассуждений LLM:
EnigmaEval: 1184 мультимодальные головоломки, настолько сложные, что на их решение группам людей требуется от многих часов до нескольких дней.
Все топ-модели набрали 0% в Hard set и < 10% в Normal set
Scale
От оценки позы до обнаружения объектов в реальном времени - свежие, передовые инструменты компьютерного зрения на Hugging Face, которые очень просты в использовании.
- ViTPose для оценки позы
- RT-DETRv2 для обнаружения объектов в реальном времени
- DAB-DETR улучшает оригинальный DETR, решая проблемы медленного обучения
- DepthPro от Apple для оценки глубины на одном изображении, выдавая расстояния на уровне пикселей в метрах менее чем за секунду.
Свежий инструмент, который представляет собой готовое решение для создания десктопного GUI-агента. С его помощью можно отдавать команды и автоматизировать задачи на ПК (Windows и macOS) через веб-интерфейс, доступный с любого устройства с интернетом.
Github
@ai_machinelearning_big_data
#news #ai #ml #openai #grok #grok3 #Microsoft #ScaleAI #elonmusk #cv #sota #opensource #agents
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
👍49❤14🔥9😁2🐳1
MASi3R-SLAM - проект, который умеет строить детальные 3D-карты окружающей среды и отслеживать движение камеры в реальном времени без предварительной калибровки. Система работает даже с изменяющимися во аремени параметрами, например, при зумировании или оптических искажениях.
Основа MASi3R-SLAM - алгоритм, использующий модели DUSi3R и MASi3R для восстановления геометрии сцены по 2 изображениям. DUSi3R анализирует пары изображений, предсказывая детальные карты 3D-точек в общей системе координат, а MASi3R дополнительно генерирует дескрипторы для каждого пикселя, повышая точность сопоставления даже при большом смещении кадров.
Полученные данные от моделей обрабатывает уникальный алгоритм, который анализирует «карты точек», прогнозируемые нейросетью, и находит соответствия между кадрами за 2 миллисекунды, что в 40 раз быстрее аналогов.
В тестировании на наборах TUM RGB-D и EuRoC, показали: MASi3R-SLAM превосходит DROID-SLAM и другие системы по точности траектории (средняя ошибка — 3 см) и детальности 3D-моделей.
На сегодняшний день основное ограничение MASi3R-SLAM — скорость декодера из-за его вычислительной нагрузки: полный цикл обработки одного ключевого кадра занимает в среднем 26–27 миллисекунд, что примерно 64% общего времени работы паплайна.
Например, при разрешении 512 пикселей по длинной стороне декодер MASi3R тратит до 2 секунд на глобальный поиск соответствий, тогда как алгоритм сопоставления сокращает это время до 2 мс. На выходе создается «бутылочное горлышко», которое ограничивает частоту кадров до 15 FPS.
⚠️ Перед установкой необходимо загрузить модели и установить версию Pytorch, соответствующую установленной версии CUDA.
# Create Conda env
conda create -n mast3r-slam python=3.11
conda activate mast3r-slam
# Clone Repo
git clone https://github.com/rmurai0610/MASt3R-SLAM.git --recursive
cd MASt3R-SLAM/
# Install dependencies
pip install -e thirdparty/mast3r
pip install -e thirdparty/in3d
pip install --no-build-isolation -e .
# Launch Live demo with camera
python main.py --dataset realsense --config config/base.yaml
# Or running on a MP4 video
python main.py --dataset <path/to/video>.mp4 --config config/base.yaml
python main.py --dataset <path/to/folder> --config config/base.yaml
@ai_machinelearning_big_data
#AI #ML #CV #3D #SLAM #Robotics
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
2👍40🔥18❤11😁1
Команда Fundamental AI Research (FAIR) компании Марка Цукерберга представила серию новых разработок: методики и модели, улучшающие компьютерное зрение, 3D-локализацию объектов и совместное обучение языковых агентов. Все модели, техотчеты, датасеты и код этих проектов уже доступны на платформах Hugging Face и GitHub.
Perception Encoder - новый виток развития в сфере обработки визуальной информации. Модель, обученная с помощью этой методики на масштабных данных, превосходит аналоги в задачах классификации изображений и видео, включая сложные сценарии — распознавание ската, зарывшегося в морское дно, или крошечной птицы на заднем плане снимка. Благодаря интеграции с LLM, Encoder улучшает ответы на визуальные вопросы, описание сцен и понимание пространственных отношений между объектами.
Для задач, требующих анализа видео и текста, Meta выпустила Perception Language Model (PLM). Ее обучали на 2,5 млн. новых аннотированных видеозаписей — это крупнейший датасет для понимания действий и контекста в динамике. PLM доступна в трёх вариантах (1, 3 и 8 млрд параметров). Дополнительный бонус — PLM-VideoBench, бенчмарк для оценки тонкого понимания сцен, который заполняет пробелы существующих тестов.
Как заставить робот найти красную чашку на столе или вазу возле телевизора? Locate 3D решает эту задачу через анализ 3D-точечных облаков и текстовых подсказок. Модель учитывает пространственные связи и контекст, отличая «вазу у TV» от «вазы на столе». В основе — трехэтапный пайплайн: предобработка данных, кодирование 3D-сцены и декодирование запроса. Для обучения использовали 130 тыс. аннотаций из ARKitScenes и ScanNet, что вдвое увеличило объём доступных данных для локализации объектов.
Dynamic Byte Latent Transformer - архитектура, которая работает на уровне байтов, а не токенов, что повышает устойчивость к ошибкам, ускоряет обработку и "отменяет" необходимость токенизации для масштабирования. На тесте CUTE модель показывает преимущество в +55 пунктов против традиционных подходов.
Совместное решение задач — следующий этап развития ИИ. Collaborative Reasoner — это фреймворк, где два агента ведут диалог, чтобы прийти к общему решению. Они могут спорить, аргументировать и согласовывать ответы на сложные вопросы. Для обучения используют синтетические диалоги, которые генерирует сама модель. Результаты впечатляют: на некоторых задачах совместная работа даёт прирост эффективности до 29% по сравнению с одиночным агентом.
@ai_machinelearning_big_data
#AI #ML #LLM #CV #NLP #FAIR
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
👍66🔥29❤25