
Бесконечность не предел или ещё одна вариация трансформера
Infinityformer (infinity transfomer/inftyformer) пытается побороть ограниченную память данной архитектуры путём введения концепта «sticky memories» (особенно важные для контекста события) и непрерывного attention (компрессия прошедшего контекста в непрерывную память). Звучит сложно? Ну а что вы хотели, сорок шесть тонн!
Посмотреть:
https://www.youtube.com/watch?v=0JlB9gufTw8
Почитать:
https://arxiv.org/abs/2109.00301
#статья
Infinityformer (infinity transfomer/inftyformer) пытается побороть ограниченную память данной архитектуры путём введения концепта «sticky memories» (особенно важные для контекста события) и непрерывного attention (компрессия прошедшего контекста в непрерывную память). Звучит сложно? Ну а что вы хотели, сорок шесть тонн!
Посмотреть:
https://www.youtube.com/watch?v=0JlB9gufTw8
Почитать:
https://arxiv.org/abs/2109.00301
#статья
YouTube
∞-former: Infinite Memory Transformer (aka Infty-Former / Infinity-Former, Research Paper Explained)
#inftyformer #infinityformer #transformer
Vanilla Transformers are excellent sequence models, but suffer from very harsch constraints on the length of the sequences they can process. Several attempts have been made to extend the Transformer's sequence length…
Vanilla Transformers are excellent sequence models, but suffer from very harsch constraints on the length of the sequences they can process. Several attempts have been made to extend the Transformer's sequence length…
❤🔥6👍4❤1
Бесконечность не предел, но пока остановимся на миллионе токенов
Так как чем больше токенов в трансформере, тем быстрее растёт потребление памяти на подсчет attention (причём растёт квадратично), то давайте мы нарежем входной текст на кусочки, применим трансформер к ним, а потом это всё по умному соединим. А как именно соединять — нам объяснят в этом разборе статьи, ну или можете сами прочитать.
Посмотреть:
https://www.youtube.com/watch?v=4Cclp6yPDuw
Почитать:
https://arxiv.org/abs/2304.11062
#статья
Так как чем больше токенов в трансформере, тем быстрее растёт потребление памяти на подсчет attention (причём растёт квадратично), то давайте мы нарежем входной текст на кусочки, применим трансформер к ним, а потом это всё по умному соединим. А как именно соединять — нам объяснят в этом разборе статьи, ну или можете сами прочитать.
Посмотреть:
https://www.youtube.com/watch?v=4Cclp6yPDuw
Почитать:
https://arxiv.org/abs/2304.11062
#статья
YouTube
Scaling Transformer to 1M tokens and beyond with RMT (Paper Explained)
#ai #transformer #gpt4
This paper promises to scale transformers to 1 million tokens and beyond. We take a look at the technique behind it: The Recurrent Memory Transformer, and what its strenghts and weaknesses are.
OUTLINE:
0:00 - Intro
2:15 - Transformers…
This paper promises to scale transformers to 1 million tokens and beyond. We take a look at the technique behind it: The Recurrent Memory Transformer, and what its strenghts and weaknesses are.
OUTLINE:
0:00 - Intro
2:15 - Transformers…
👍6
Когда не можем придумать новое, надо улучшать старое
Скорее всего, несколько человек сидели и думали, а как нам делать что-то своё в NLP, но без доступа к огромным вычислительным кластерам? И придумали. Архитектура Receptance Weighted Key Value (RWKV) объединяет в себе эффективность параллельных вычислений трансформера и эффективность инференса RNN. Да-да, RNN возможно скоро будут опять в моде.
Посмотреть:
https://www.youtube.com/watch?v=x8pW19wKfXQ
Почитать:
https://arxiv.org/abs/2305.13048
#статья
Скорее всего, несколько человек сидели и думали, а как нам делать что-то своё в NLP, но без доступа к огромным вычислительным кластерам? И придумали. Архитектура Receptance Weighted Key Value (RWKV) объединяет в себе эффективность параллельных вычислений трансформера и эффективность инференса RNN. Да-да, RNN возможно скоро будут опять в моде.
Посмотреть:
https://www.youtube.com/watch?v=x8pW19wKfXQ
Почитать:
https://arxiv.org/abs/2305.13048
#статья
YouTube
RWKV: Reinventing RNNs for the Transformer Era (Paper Explained)
#gpt4 #rwkv #transformer
We take a look at RWKV, a highly scalable architecture between Transformers and RNNs.
Fully Connected (June 7th in SF) Promo Link: https://www.fullyconnected.com/?promo=ynnc
OUTLINE:
0:00 - Introduction
1:50 - Fully Connected…
We take a look at RWKV, a highly scalable architecture between Transformers and RNNs.
Fully Connected (June 7th in SF) Promo Link: https://www.fullyconnected.com/?promo=ynnc
OUTLINE:
0:00 - Introduction
1:50 - Fully Connected…
❤3
Трансформеры от А до Я: эволюция архитектуры и её достижения за последние годы
Автор данной статьи представил подробный обзор моделей, основанных на архитектуре Transformer. Этот обзор охватывает целых 90 работ, опубликованных за последние годы.
Все модели структурированы по областям применения: обработка текста, компьютерное зрение, генерация изображений, анализ и распознавание речи.
Для каждой модели приведены ключевые характеристики: год публикации, авторы, архитектура и количество параметров. Также дано краткое описание отличительных черт и примеры решаемых задач.
#статья #transformer
Автор данной статьи представил подробный обзор моделей, основанных на архитектуре Transformer. Этот обзор охватывает целых 90 работ, опубликованных за последние годы.
Все модели структурированы по областям применения: обработка текста, компьютерное зрение, генерация изображений, анализ и распознавание речи.
Для каждой модели приведены ключевые характеристики: год публикации, авторы, архитектура и количество параметров. Также дано краткое описание отличительных черт и примеры решаемых задач.
#статья #transformer
❤5👍2
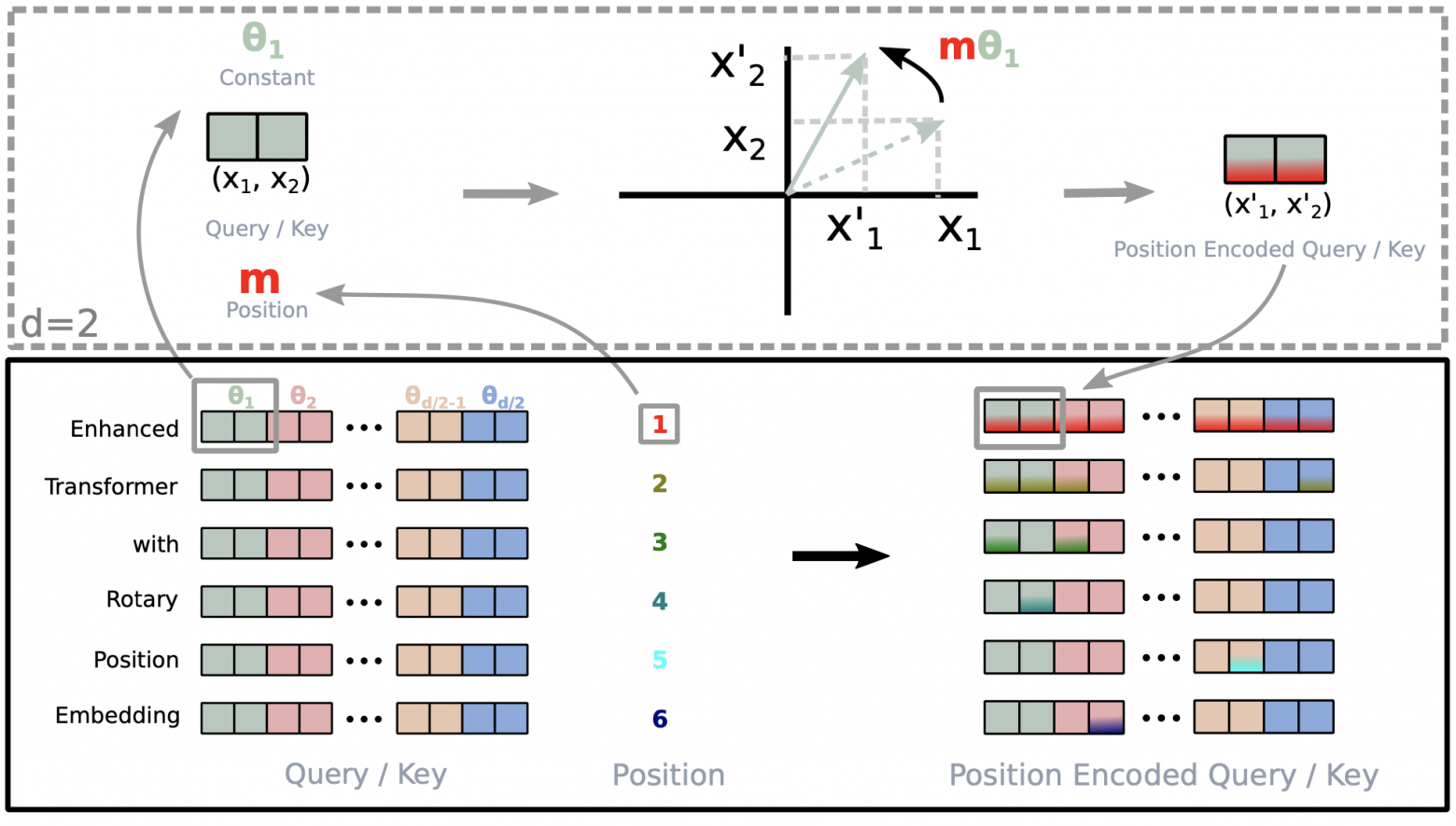
Методы позиционного кодирования в Transformer
Методы позиционного кодирования — ключевой элемент Transformer для анализа длинных текстов. Как правило, в отличие от RNN, эта архитектура обрабатывает входные векторы одновременно, и без дополнительной информации о позиции каждого токена будет рассматривать последовательность подобно «мешку со словами».
В данной статье вы найдёте основные подходы, описанные в научных работах и применяемые в известных языковых моделях.
#nlp #transformer #deeplearning
Методы позиционного кодирования — ключевой элемент Transformer для анализа длинных текстов. Как правило, в отличие от RNN, эта архитектура обрабатывает входные векторы одновременно, и без дополнительной информации о позиции каждого токена будет рассматривать последовательность подобно «мешку со словами».
В данной статье вы найдёте основные подходы, описанные в научных работах и применяемые в известных языковых моделях.
#nlp #transformer #deeplearning
{kind=link}
👍5❤2
Mamba: революционная архитектура или просто хайп?
Кто не в курсе Mamba — это потенциальный конкурент Transformer. Эта архитектура масштабируется линейно с ростом длины входной последовательности, эффективно использует память и показывает отличные результаты на задачах с длинным контекстом.
В новом видео Янник Килчер разобрал отличия Mamba от Трансформеров и RNN и показал какие преимущества и ограничения есть у этой архитектуры.
Статья | GitHub | Hugging Face
#mamba #transformer #позалипать
Кто не в курсе Mamba — это потенциальный конкурент Transformer. Эта архитектура масштабируется линейно с ростом длины входной последовательности, эффективно использует память и показывает отличные результаты на задачах с длинным контекстом.
В новом видео Янник Килчер разобрал отличия Mamba от Трансформеров и RNN и показал какие преимущества и ограничения есть у этой архитектуры.
Статья | GitHub | Hugging Face
#mamba #transformer #позалипать
YouTube
Mamba: Linear-Time Sequence Modeling with Selective State Spaces (Paper Explained)
#mamba #s4 #ssm
OUTLINE:
0:00 - Introduction
0:45 - Transformers vs RNNs vs S4
6:10 - What are state space models?
12:30 - Selective State Space Models
17:55 - The Mamba architecture
22:20 - The SSM layer and forward propagation
31:15 - Utilizing GPU memory…
OUTLINE:
0:00 - Introduction
0:45 - Transformers vs RNNs vs S4
6:10 - What are state space models?
12:30 - Selective State Space Models
17:55 - The Mamba architecture
22:20 - The SSM layer and forward propagation
31:15 - Utilizing GPU memory…
👍6❤2🔥1
Основа работы трансформеров — это математика
Для более глубокого её понимания в рамках этой архитектуры рекомендуем обратить внимание на данную статью. В ней представлены все вычисления, происходящие внутри модели трансформера.
А если математика для вас оказалась слишком сложной, то можете сначала посмотреть в сторону этого обзора, там легко и наглядно разложены основные идеи и понятия.
#llm #transformer
Для более глубокого её понимания в рамках этой архитектуры рекомендуем обратить внимание на данную статью. В ней представлены все вычисления, происходящие внутри модели трансформера.
А если математика для вас оказалась слишком сложной, то можете сначала посмотреть в сторону этого обзора, там легко и наглядно разложены основные идеи и понятия.
#llm #transformer
{kind=link}
👍6🤩3❤2
OpenAI переходит в режим Open!
Может, на фоне исков, а может просто совпадение, но на днях OpenAI выкатила код Transformer Debugger — отладчика для Small LM. Этот инструмент призван помочь разработчикам лучше понять, почему модели генерируют определённые токены в ответ на запросы, на что обращают внимание при обработке промптов и в целом, как это всё влияет на конкретное поведение модели.
Подробные инструкции по пользованию и код ищите здесь.
@neuro_channel #transformer
Может, на фоне исков, а может просто совпадение, но на днях OpenAI выкатила код Transformer Debugger — отладчика для Small LM. Этот инструмент призван помочь разработчикам лучше понять, почему модели генерируют определённые токены в ответ на запросы, на что обращают внимание при обработке промптов и в целом, как это всё влияет на конкретное поведение модели.
Подробные инструкции по пользованию и код ищите здесь.
@neuro_channel #transformer
{kind=link}
🔥12❤3
This media is not supported in your browser
VIEW IN TELEGRAM
Самое крутое введение в архитектуру трансформеров на диком западе
Недавно вышло на канале 3Blue1Brown. Фирменный стиль автора, увлекательная анимация и мастерское разъяснение сложных тем простыми словами делают его доступным для новичков и интересным даже для тех, кто уже знаком с темой.
В частности, это видео посвящено эмбеддингам и помогает понять, на какие токены модель обращает внимание и какой результат она в итоге выдаёт. Более сказать нечего, завариваем чаёк и наслаждаемся
Смотреть: https://www.youtube.com/watch?v=wjZofJX0v4M
@neuro_channel #transformer
Недавно вышло на канале 3Blue1Brown. Фирменный стиль автора, увлекательная анимация и мастерское разъяснение сложных тем простыми словами делают его доступным для новичков и интересным даже для тех, кто уже знаком с темой.
В частности, это видео посвящено эмбеддингам и помогает понять, на какие токены модель обращает внимание и какой результат она в итоге выдаёт. Более сказать нечего, завариваем чаёк и наслаждаемся
Смотреть: https://www.youtube.com/watch?v=wjZofJX0v4M
@neuro_channel #transformer
👍8❤3😁2