
10 лет исследований НЛП, объяснённых в 50 концепциях
Это видео — настоящая сокровищница знаний для всех, кто интересуется нейронными сетями и обработкой естественного языка.
В доступной форме рассказываются ключевые концепции NLP: от базовых идей типа токенизации и векторных представлений слов до революционных архитектур вроде RNN, Seq2Seq, Transformer и таких моделей, как BERT, GPT, XLNet.
Помимо этого, вы узнаете о проблемах, с которыми сталкивался автор и как современные модели их преодолевают.
#видео #nlp
Это видео — настоящая сокровищница знаний для всех, кто интересуется нейронными сетями и обработкой естественного языка.
В доступной форме рассказываются ключевые концепции NLP: от базовых идей типа токенизации и векторных представлений слов до революционных архитектур вроде RNN, Seq2Seq, Transformer и таких моделей, как BERT, GPT, XLNet.
Помимо этого, вы узнаете о проблемах, с которыми сталкивался автор и как современные модели их преодолевают.
#видео #nlp
YouTube
10 years of NLP history explained in 50 concepts | From Word2Vec, RNNs to GPT
From RNNs to Transformers to GPT-4, the leap in intelligence in Deep Learning research for Language Modelling and NLP has been a steady and educational growth. In this video, I explain 50 concepts that cover the basics of NLP like Tokenization and Word Embeddings…
❤6🤩4👎1😁1
Как научить Transformer обрабатывать длинные тексты
Если вы давно ищете методы обработки длинных входных последовательностей с использованием архитектуры Transformer, то эта статья предоставит вам необходимую информацию. В ней рассматриваются подходы к ускорению self-attention, такие как — приближенное вычисление внимания, иерархическая обработка последовательности и внедрение рекуррентности.
Статья содержит обзор таких моделей, как Transformer-XL, Sparse Transformer, Reformer, Longformer, а также другие. Внимательно анализируются их особенности, при этом особое внимание уделяется FlashAttention — одному из наиболее эффективных методов оптимизации работы моделей Transformer.
#статья #nlp
Если вы давно ищете методы обработки длинных входных последовательностей с использованием архитектуры Transformer, то эта статья предоставит вам необходимую информацию. В ней рассматриваются подходы к ускорению self-attention, такие как — приближенное вычисление внимания, иерархическая обработка последовательности и внедрение рекуррентности.
Статья содержит обзор таких моделей, как Transformer-XL, Sparse Transformer, Reformer, Longformer, а также другие. Внимательно анализируются их особенности, при этом особое внимание уделяется FlashAttention — одному из наиболее эффективных методов оптимизации работы моделей Transformer.
#статья #nlp
❤4👍4😁1
Погружаемся в мир рекуррентных нейронных сетей
Ключевым преимуществом RNN по сравнению с обычными нейросетями является их способность анализировать последовательные данные с учётом контекста. Это открывает широкие возможности для применения в таких сферах, как обработка естественного языка.
В прикреплённой ниже лекции вы узнаете о них чуть лучше. Ведущая хорошо объясняет принцип устройства рекуррентного слоя и рекуррентной нейронной сети, а также процесс обработки данных такими сетями (forward pass).
#лекция #rnn #nlp
Ключевым преимуществом RNN по сравнению с обычными нейросетями является их способность анализировать последовательные данные с учётом контекста. Это открывает широкие возможности для применения в таких сферах, как обработка естественного языка.
В прикреплённой ниже лекции вы узнаете о них чуть лучше. Ведущая хорошо объясняет принцип устройства рекуррентного слоя и рекуррентной нейронной сети, а также процесс обработки данных такими сетями (forward pass).
#лекция #rnn #nlp
YouTube
Лекция. Рекуррентная нейронная сеть
Занятие ведёт Татьяна Гайнцева.
---
Deep Learning School при ФПМИ МФТИ
Каждые полгода мы запускаем новую итерацию нашего двухсеместрового практического онлайн-курса по глубокому обучению. Наборы проводятся в августе-сентябре и январе-феврале.
За нашими…
---
Deep Learning School при ФПМИ МФТИ
Каждые полгода мы запускаем новую итерацию нашего двухсеместрового практического онлайн-курса по глубокому обучению. Наборы проводятся в августе-сентябре и январе-феврале.
За нашими…
❤5👍3🔥3
«Обработка естественного языка в действии»
Аврам Линкольн говорил: «Мой лучший друг — это человек, который даст мне книгу, что я не читал». А если вы, как и Линкольн, цените литературу и ищете полезный источник знаний по NLP, то вы нашли, что искали.
Книга содержит полный набор инструментов и методов для создания приложений в этой области: виртуальных помощников (чат-ботов), спам-фильтров, анализаторов тональности и многого другого.
Материал рассчитан на Python-разработчиков среднего и высокого уровня. Но даже экспертам в проектировании сложных систем она будет полезна.
#почитать #nlp #python
Аврам Линкольн говорил: «Мой лучший друг — это человек, который даст мне книгу, что я не читал». А если вы, как и Линкольн, цените литературу и ищете полезный источник знаний по NLP, то вы нашли, что искали.
Книга содержит полный набор инструментов и методов для создания приложений в этой области: виртуальных помощников (чат-ботов), спам-фильтров, анализаторов тональности и многого другого.
Материал рассчитан на Python-разработчиков среднего и высокого уровня. Но даже экспертам в проектировании сложных систем она будет полезна.
#почитать #nlp #python
👍7❤5
Как говорится, дообучение моделей — свет, а неученье — тьма
Как вы уже догадались, сегодня мы обсудим тему дообучения, и данное видео поможет более глубоко погрузиться в этот вопрос.
В ролике автор демонстрирует процесс файн-тюнинга модели BART для решения задачи суммаризации текста. Главная цель — познакомить зрителей с популярными библиотеками в области обработки естественного языка (NLP) и показать, как это можно делать максимально эффективно, затрачивая минимум усилий при написании кода.
#позалипать #nlp #дообучение
Как вы уже догадались, сегодня мы обсудим тему дообучения, и данное видео поможет более глубоко погрузиться в этот вопрос.
В ролике автор демонстрирует процесс файн-тюнинга модели BART для решения задачи суммаризации текста. Главная цель — познакомить зрителей с популярными библиотеками в области обработки естественного языка (NLP) и показать, как это можно делать максимально эффективно, затрачивая минимум усилий при написании кода.
#позалипать #nlp #дообучение
YouTube
Семинар. Файнтьюнинг BART для задачи суммаризации текста
Занятие ведёт Антон Земеров
Ссылка на материалы занятия: https://colab.research.google.com/drive/1bZJ9OE7YEWkK3owKpP12Qc-RfOKeeXf2?usp=sharing
---
Deep Learning School при ФПМИ МФТИ
Каждые полгода мы запускаем новую итерацию нашего двухсеместрового практического…
Ссылка на материалы занятия: https://colab.research.google.com/drive/1bZJ9OE7YEWkK3owKpP12Qc-RfOKeeXf2?usp=sharing
---
Deep Learning School при ФПМИ МФТИ
Каждые полгода мы запускаем новую итерацию нашего двухсеместрового практического…
👍3❤2
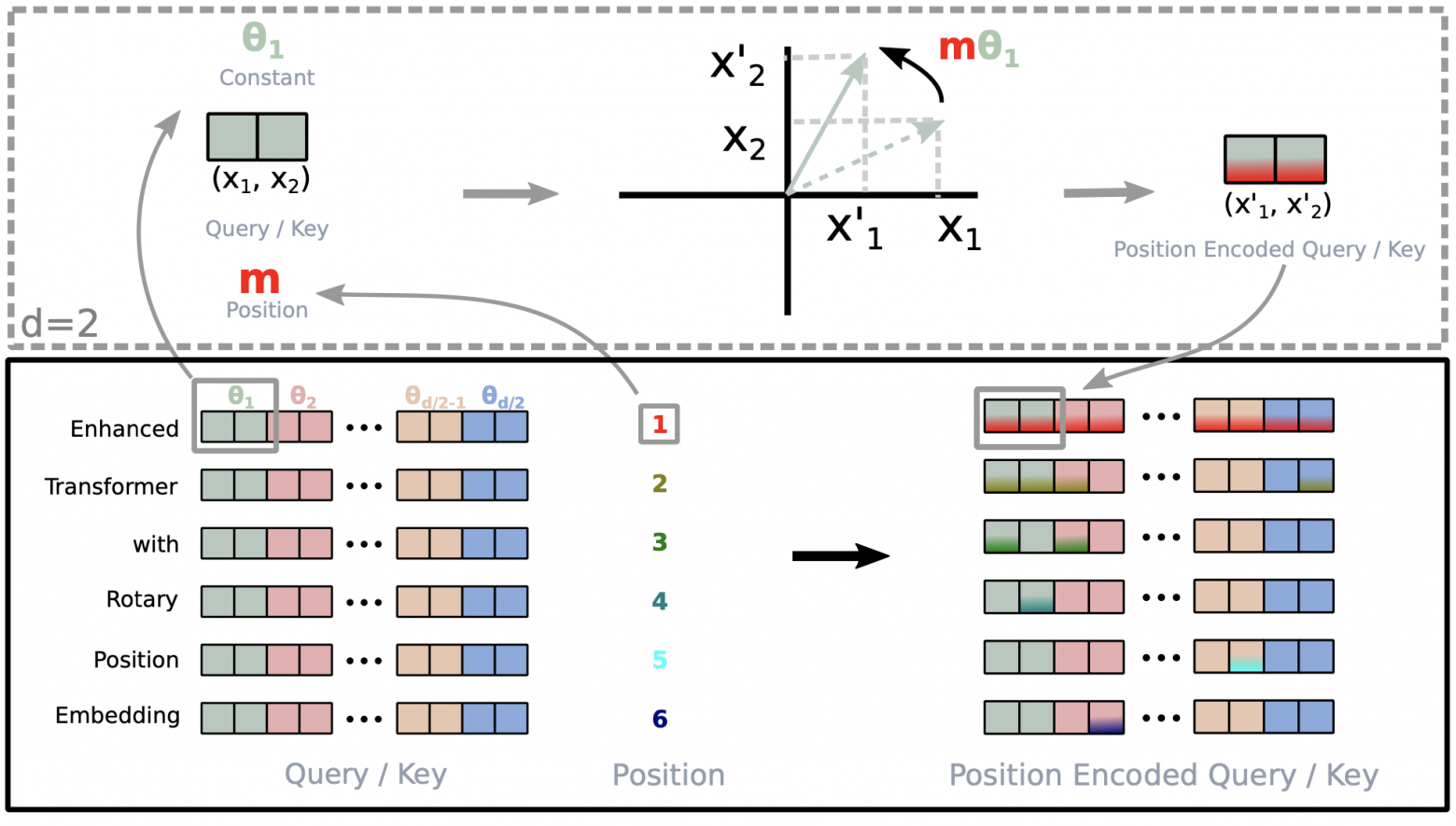
Методы позиционного кодирования в Transformer
Методы позиционного кодирования — ключевой элемент Transformer для анализа длинных текстов. Как правило, в отличие от RNN, эта архитектура обрабатывает входные векторы одновременно, и без дополнительной информации о позиции каждого токена будет рассматривать последовательность подобно «мешку со словами».
В данной статье вы найдёте основные подходы, описанные в научных работах и применяемые в известных языковых моделях.
#nlp #transformer #deeplearning
Методы позиционного кодирования — ключевой элемент Transformer для анализа длинных текстов. Как правило, в отличие от RNN, эта архитектура обрабатывает входные векторы одновременно, и без дополнительной информации о позиции каждого токена будет рассматривать последовательность подобно «мешку со словами».
В данной статье вы найдёте основные подходы, описанные в научных работах и применяемые в известных языковых моделях.
#nlp #transformer #deeplearning
{kind=link}
👍5❤2
Mixtral 8x7B: эксперт в мире открытых LLM
Компания Mistral AI в преддверии Нового года представила открытую языковую модель — Mixtral 8x7B с контекстом в 32 тысячи токенов.
Эта модель основана на архитектуре «sparse mixture of experts» (SMoE), где одна большая сеть разбита на 8 меньших подсетей-экспертов. Для каждого входного токена динамически выбираются нужный эксперт. Благодаря такому подходу, Mixtral 8x7B, содержащая 47 млрд параметров, работает с той же скоростью, что и LLaMa 7B с 7 млрд параметров.
По результатам тестов модель показала впечатляющие 8.3 балла из 10 на бенчмарке MT-bench, что сопостовимо с GPT-3.5. При этом доступ к API стоит всего $2 за миллион токенов.
Видеообзор и тесты | Разбор архитектуры | HuggingFace
#llm #nlp
Компания Mistral AI в преддверии Нового года представила открытую языковую модель — Mixtral 8x7B с контекстом в 32 тысячи токенов.
Эта модель основана на архитектуре «sparse mixture of experts» (SMoE), где одна большая сеть разбита на 8 меньших подсетей-экспертов. Для каждого входного токена динамически выбираются нужный эксперт. Благодаря такому подходу, Mixtral 8x7B, содержащая 47 млрд параметров, работает с той же скоростью, что и LLaMa 7B с 7 млрд параметров.
По результатам тестов модель показала впечатляющие 8.3 балла из 10 на бенчмарке MT-bench, что сопостовимо с GPT-3.5. При этом доступ к API стоит всего $2 за миллион токенов.
Видеообзор и тесты | Разбор архитектуры | HuggingFace
#llm #nlp
👍8❤4
«Грокаем глубокое обучение»
Эта книга послужит отличным стартом для новичков в области Deep Learning. Материалы содержат всю базовую информацию, необходимую для понимания ключевых концепций и избежания типичных ошибок в начале пути. Автор доступно объясняет сложные темы, позволяя эффективно осваивать глубокое обучение.
Описание:
«Грокаем глубокое обучение» научит вас создавать нейронные сети с нуля! Эндрю Траск подробно рассказывает обо всех аспектах и тонкостях этой непростой задачи. С использованием Python и библиотеки NumPy ваши нейронные сети смогут обрабатывать изображения, распознавать их, переводить тексты на все языки мира и даже создавать тексты не хуже Шекспира!
#почитать #deeplearning #nlp
Эта книга послужит отличным стартом для новичков в области Deep Learning. Материалы содержат всю базовую информацию, необходимую для понимания ключевых концепций и избежания типичных ошибок в начале пути. Автор доступно объясняет сложные темы, позволяя эффективно осваивать глубокое обучение.
Описание:
«Грокаем глубокое обучение» научит вас создавать нейронные сети с нуля! Эндрю Траск подробно рассказывает обо всех аспектах и тонкостях этой непростой задачи. С использованием Python и библиотеки NumPy ваши нейронные сети смогут обрабатывать изображения, распознавать их, переводить тексты на все языки мира и даже создавать тексты не хуже Шекспира!
#почитать #deeplearning #nlp
👍10❤3🔥1
Какие технологии самые востребованные в 2024 году?
Ответ можно найти в этой карте. Её авторы отобрали самых активных ML-разработчиков на Stack Overflow, отсортировали и подсчитали все их запросы и теги.
В результате получилась карта технических навыков, которые разработчики регулярно используют в своей работе. Размер навыка соответствует количеству связанных с ним запросов. Чем ближе два навыка на карте, тем чаще они встречаются в похожих контекстах.
Помимо этого, при нажатии на навык можно получить его описание, альтернативы и динамику интереса.
#ml #nlp #cv
Ответ можно найти в этой карте. Её авторы отобрали самых активных ML-разработчиков на Stack Overflow, отсортировали и подсчитали все их запросы и теги.
В результате получилась карта технических навыков, которые разработчики регулярно используют в своей работе. Размер навыка соответствует количеству связанных с ним запросов. Чем ближе два навыка на карте, тем чаще они встречаются в похожих контекстах.
Помимо этого, при нажатии на навык можно получить его описание, альтернативы и динамику интереса.
#ml #nlp #cv
👍5❤3🔥1
Токенизация в NLP: тонкости и особенности
Андрей Карпати, в прошлом ведущий инженер OpenAI и разработчик автопилота Tesla, выпустил новое видео на своём YouTube-канале, в котором подробно рассказал о процессе токенизации. Кроме того, он продемонстрировал пример реализации Tokenizer'а, используемого в серии моделей GPT от OpenAI. Материал, нескучный и очень наглядный, поэтому бежим и смотрим!
Репозиторий с объяснениями кода: https://github.com/karpathy/minbpe
#llm #nlp
Андрей Карпати, в прошлом ведущий инженер OpenAI и разработчик автопилота Tesla, выпустил новое видео на своём YouTube-канале, в котором подробно рассказал о процессе токенизации. Кроме того, он продемонстрировал пример реализации Tokenizer'а, используемого в серии моделей GPT от OpenAI. Материал, нескучный и очень наглядный, поэтому бежим и смотрим!
Репозиторий с объяснениями кода: https://github.com/karpathy/minbpe
#llm #nlp
YouTube
Let's build the GPT Tokenizer
The Tokenizer is a necessary and pervasive component of Large Language Models (LLMs), where it translates between strings and tokens (text chunks). Tokenizers are a completely separate stage of the LLM pipeline: they have their own training sets, training…
🔥6👍4❤🔥2
У всех в IT был индус, который их чему-то научил
А если вы ещё не нашли такого, то не расстраивайтесь, у нас есть отличный вариант. Дело в том, что FreeCodeCamp выпустил полноценный 30-часовой курс по генеративному искусственному интеллекту.
В нём под руководством трёх замечательных спикеров вы с головой окунётесь в мир генеративок, узнаете о библиотеках, структурах моделей и других аспектах, лежащих в основе ИИ. И конечно же, будете применять эти знания в реальных проектах: от чат-ботов до продвинутых приложений.
@neuro_channel #ai #nlp
А если вы ещё не нашли такого, то не расстраивайтесь, у нас есть отличный вариант. Дело в том, что FreeCodeCamp выпустил полноценный 30-часовой курс по генеративному искусственному интеллекту.
В нём под руководством трёх замечательных спикеров вы с головой окунётесь в мир генеративок, узнаете о библиотеках, структурах моделей и других аспектах, лежащих в основе ИИ. И конечно же, будете применять эти знания в реальных проектах: от чат-ботов до продвинутых приложений.
@neuro_channel #ai #nlp
YouTube
Generative AI Full Course – Gemini Pro, OpenAI, Llama, Langchain, Pinecone, Vector Databases & More
Learn about generative models and different frameworks, investigating the production of text and visual material produced by artificial intelligence. This course was originally recorded live.
Instructors: Krish Naik, Sunny Savita, and Boktiar Ahmed Bappy.…
Instructors: Krish Naik, Sunny Savita, and Boktiar Ahmed Bappy.…
❤10👍5