
Quantitative Methods for the Social Sciences. A Practical Introduction with Examples in SPSS and Stata. Daniel Stockemer (School of Political Studies, University of Ottawa, Canada)
🔎🧑🎓
This textbook offers an essential introduction to survey research and quantitative methods. Building on the premise that statistical methods need to be learned in a practical fashion, the book guides students through the various steps of the survey research process and helps to apply those steps toward a real example.
📚
In detail, the textbook introduces students to the four pillars of survey research and quantitative analysis: (1) the importance of survey research, (2) preparing a survey, (3) conducting a survey and (4) analyzing a survey. Students are shown how to create their own questionnaire based on some theoretically derived hypotheses to achieve empirical findings for a solid dataset. Lastly, they use said data to test their hypotheses in a bivariate and multivariate realm.
🔮
The book explains the theory, rationale and mathematical foundations of these tests. In addition, it provides clear instructions on how to conduct the tests in SPSS and Stata. Given the breadth of its coverage, the textbook is suitable for introductory statistics, survey research or quantitative methods classes in the social sciences.
🍀
Book in PDF >>>
Source >>>
#analytics #math #methodology #mr #psychology #science #sociology #statistics #tools
🔎🧑🎓
This textbook offers an essential introduction to survey research and quantitative methods. Building on the premise that statistical methods need to be learned in a practical fashion, the book guides students through the various steps of the survey research process and helps to apply those steps toward a real example.
📚
In detail, the textbook introduces students to the four pillars of survey research and quantitative analysis: (1) the importance of survey research, (2) preparing a survey, (3) conducting a survey and (4) analyzing a survey. Students are shown how to create their own questionnaire based on some theoretically derived hypotheses to achieve empirical findings for a solid dataset. Lastly, they use said data to test their hypotheses in a bivariate and multivariate realm.
🔮
The book explains the theory, rationale and mathematical foundations of these tests. In addition, it provides clear instructions on how to conduct the tests in SPSS and Stata. Given the breadth of its coverage, the textbook is suitable for introductory statistics, survey research or quantitative methods classes in the social sciences.
🍀
Book in PDF >>>
Source >>>
#analytics #math #methodology #mr #psychology #science #sociology #statistics #tools
{kind=link}
Полезный ресурс с более 10 млн. научных материалов: журналы, книги, статьи и т.п.
🔥📚📰🗂
Бесплатно и без регистрации)
🍀
Link >>>
#development #economics #efficiency #math #methodology #mr #psychology #science #sociology #statistics
🔥📚📰🗂
Бесплатно и без регистрации)
🍀
Link >>>
#development #economics #efficiency #math #methodology #mr #psychology #science #sociology #statistics
{kind=link}
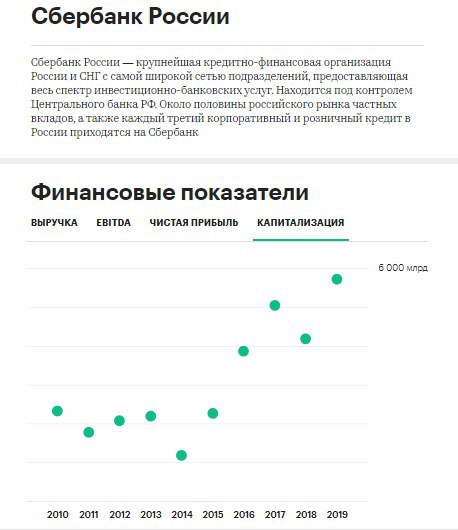
500 крупнейших по выручке компаний России от РБК за 2015-2019
🥇🥈🥉
Можно изучить общий рейтинг, а также подробно рассмотреть в динамике финансовые показатели каждой компании (выручка, EBITDA, чистая прибыль, капитализация), кликнув на соответствующую строчку.
🗂📈📊
Полезный инструмент для кабинетных исследований!
🍀
Source >>>
#analytics #economics #product #statistics #tools #trends #visualization
🥇🥈🥉
Можно изучить общий рейтинг, а также подробно рассмотреть в динамике финансовые показатели каждой компании (выручка, EBITDA, чистая прибыль, капитализация), кликнув на соответствующую строчку.
🗂📈📊
Полезный инструмент для кабинетных исследований!
🍀
Source >>>
#analytics #economics #product #statistics #tools #trends #visualization
{kind=link}
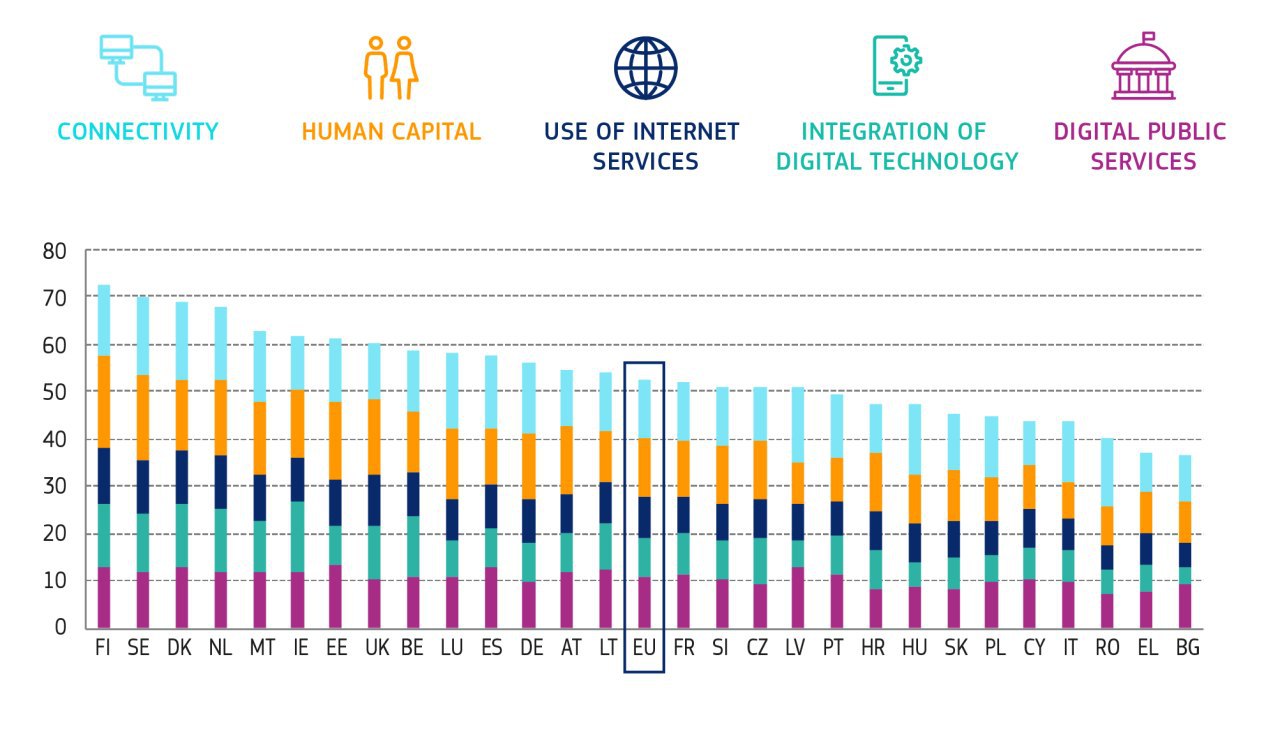
The Digital Economy and Society Index (DESI)
📊💰📈
The Digital Economy and Society Index (DESI) is a composite index that summarises relevant indicators on Europe’s digital performance and tracks the evolution of EU Member States in digital competitiveness.
🤖📲
Over the past year, all EU countries improved their digital performance. Finland, Sweden, Denmark and the Netherlands scored the highest ratings in DESI 2020 and are among the global leaders in digitalisation. These countries are followed by Malta, Ireland and Estonia. Some other countries however still have a long way to go, and the EU as a whole needs improvement to be able to compete on the global stage.
✨
The DESI 2020 reports are based on 2019 data. The United Kingdom is still included in the 2020 DESI, and EU averages are calculated for 28 Member States. The DESI was re-calculated for previous years to reflect the changes in the choice of indicators and corrections made to the underlying data. The scores and rankings may thus have changed compared with previous editions.
🍀
Report in PDF >>>
Explore the data set >>>
The methodological manual DESI 2020 >>>
🗂
DESI area report: Connectivity - Broadband market developments in the EU >>>
DESI area report: Human Capital/Digital skills >>>
DESI area report: Use of Internet Services by citizens >>>
DESI area report: Integration of Digital Technology by businesses >>>
DESI area report: Digital Public Services >>>
DESI area report: Research and Development ICT >>>
🛩
Source >>>
#analytics #economics #mr #report #sociology #statistics #technology #trends
📊💰📈
The Digital Economy and Society Index (DESI) is a composite index that summarises relevant indicators on Europe’s digital performance and tracks the evolution of EU Member States in digital competitiveness.
🤖📲
Over the past year, all EU countries improved their digital performance. Finland, Sweden, Denmark and the Netherlands scored the highest ratings in DESI 2020 and are among the global leaders in digitalisation. These countries are followed by Malta, Ireland and Estonia. Some other countries however still have a long way to go, and the EU as a whole needs improvement to be able to compete on the global stage.
✨
The DESI 2020 reports are based on 2019 data. The United Kingdom is still included in the 2020 DESI, and EU averages are calculated for 28 Member States. The DESI was re-calculated for previous years to reflect the changes in the choice of indicators and corrections made to the underlying data. The scores and rankings may thus have changed compared with previous editions.
🍀
Report in PDF >>>
Explore the data set >>>
The methodological manual DESI 2020 >>>
🗂
DESI area report: Connectivity - Broadband market developments in the EU >>>
DESI area report: Human Capital/Digital skills >>>
DESI area report: Use of Internet Services by citizens >>>
DESI area report: Integration of Digital Technology by businesses >>>
DESI area report: Digital Public Services >>>
DESI area report: Research and Development ICT >>>
🛩
Source >>>
#analytics #economics #mr #report #sociology #statistics #technology #trends
{kind=link}
Digital 2020 July Global Statshot report by
Here are my top 3 takeaways:
💡
1. With more than half of the world’s total population now using social media, now is an ideal time to rethink how we use these powerful platforms. In particular, I’d recommend thinking of social media as a layer that runs through everything that people do – both online and in the physical world – rather than being a series of distinct ‘destinations’ and standalone activities.
🌎🌍🌏
2. Try to avoid getting swept up in the hyperbole of binary predictions. Just as digital hasn’t replaced TV, working from home likely won’t replace the office, and ecommerce won’t replace all physical stores. People’s behaviours are evolving though, and it’s important to understand how these changes will impact demand for your brand’s products and services, as well as how you’ll need to adapt your marketing activities to achieve maximum efficiency and effectiveness. My advice would be to adopt a ‘balanced diet’ in all things digital, and to take advantage of every opportunity to learn about what your audience really cares about.
🤖🤔
3. Keep an eye on ‘stealth’ trends. Media stories about connected tech often focus on the platforms and the devices, but how people use these technologies is far more important. However, many of these behavioural trends emerge over time, without reaching a sudden ‘tipping point’ that spurs us into action. For example, the changes in people’s search behaviours that we explored above could have fundamentally important consequences for brands across almost every category, but they haven’t replaced search engines (yet). And to make things even more complex, these behaviours are evolving all the time, so there’s no ‘quick fix’ that can deliver a permanent advantage. As a result, as you start to think about 2021, it’s worth investing in plans and tech stacks that can adapt and flex over time – especially given the uncertainty around the ongoing evolution of COVID-19.
🛸
And finally…
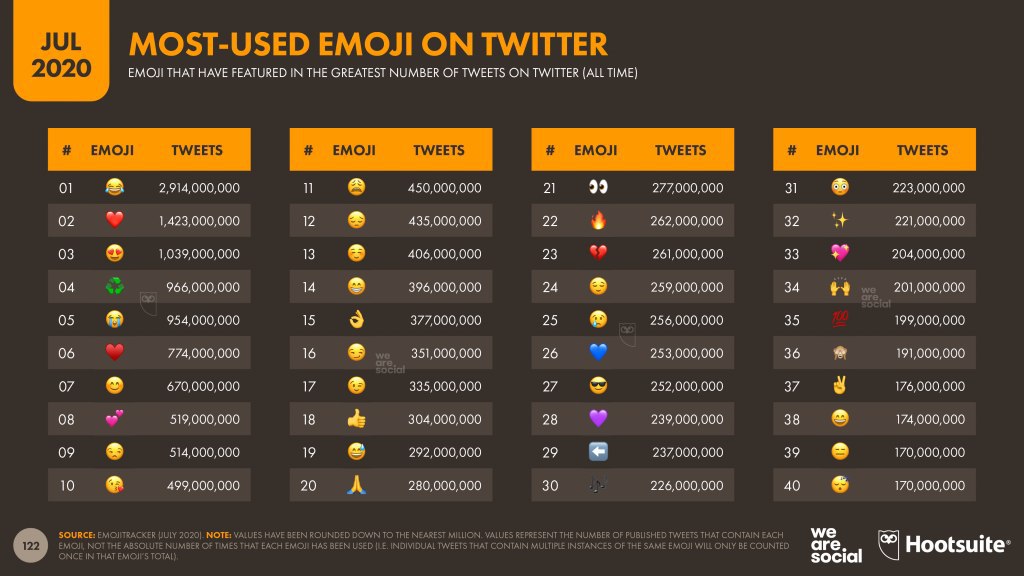
It was #WorldEmojiDay last week 📅, so we’ve produced an update to our chart showing EmojiTracker’s ranking 🏆of the all-time most-used emoji 📈 on Twitter.
Key findings 🔎include:
– 🔥has been used in more than 70 million tweets over the past 6 months, accounting for more than a quarter of its all-time total. Guess you might say 🔥 is 🔥.
– 😍 has moved above ♻️ to claim third spot ⬆️ in the rankings.
– The ⚔️ between ❤️ and ♥️continues, but 💙 and 💜 are both ⏫.
That’s probably enough nerdiness 🤓 for now, but if you fancy getting involved in a bit of an emoji mystery 🕵️♀, you might want to check out this intriguing Easter egg 🥚 that I spotted in Apple’s musical notes emoji 🎵🎶.
That’s all for now though – we’ll be back with another Statshot report in October.
🍀
Source >>>
Report in PDF >>>
#advertising #analytics #economics #marketing #presentation #product #psychology #report #sociology #statistics #technology #trends #visualization
We Are Social & Hootsuite
💥Here are my top 3 takeaways:
💡
1. With more than half of the world’s total population now using social media, now is an ideal time to rethink how we use these powerful platforms. In particular, I’d recommend thinking of social media as a layer that runs through everything that people do – both online and in the physical world – rather than being a series of distinct ‘destinations’ and standalone activities.
🌎🌍🌏
2. Try to avoid getting swept up in the hyperbole of binary predictions. Just as digital hasn’t replaced TV, working from home likely won’t replace the office, and ecommerce won’t replace all physical stores. People’s behaviours are evolving though, and it’s important to understand how these changes will impact demand for your brand’s products and services, as well as how you’ll need to adapt your marketing activities to achieve maximum efficiency and effectiveness. My advice would be to adopt a ‘balanced diet’ in all things digital, and to take advantage of every opportunity to learn about what your audience really cares about.
🤖🤔
3. Keep an eye on ‘stealth’ trends. Media stories about connected tech often focus on the platforms and the devices, but how people use these technologies is far more important. However, many of these behavioural trends emerge over time, without reaching a sudden ‘tipping point’ that spurs us into action. For example, the changes in people’s search behaviours that we explored above could have fundamentally important consequences for brands across almost every category, but they haven’t replaced search engines (yet). And to make things even more complex, these behaviours are evolving all the time, so there’s no ‘quick fix’ that can deliver a permanent advantage. As a result, as you start to think about 2021, it’s worth investing in plans and tech stacks that can adapt and flex over time – especially given the uncertainty around the ongoing evolution of COVID-19.
🛸
And finally…
It was #WorldEmojiDay last week 📅, so we’ve produced an update to our chart showing EmojiTracker’s ranking 🏆of the all-time most-used emoji 📈 on Twitter.
Key findings 🔎include:
– 🔥has been used in more than 70 million tweets over the past 6 months, accounting for more than a quarter of its all-time total. Guess you might say 🔥 is 🔥.
– 😍 has moved above ♻️ to claim third spot ⬆️ in the rankings.
– The ⚔️ between ❤️ and ♥️continues, but 💙 and 💜 are both ⏫.
That’s probably enough nerdiness 🤓 for now, but if you fancy getting involved in a bit of an emoji mystery 🕵️♀, you might want to check out this intriguing Easter egg 🥚 that I spotted in Apple’s musical notes emoji 🎵🎶.
That’s all for now though – we’ll be back with another Statshot report in October.
🍀
Source >>>
Report in PDF >>>
#advertising #analytics #economics #marketing #presentation #product #psychology #report #sociology #statistics #technology #trends #visualization
{kind=link}
A review of statistical methods for determination of relative importance of correlated predictors and identification of drivers of consumer liking
🔬🤓⚗️
This article attempts to deliver the following message to the researchers and practitioners in the sensory field:
✨1️⃣ Theoretically, drivers of consumer liking is based on relative importance of explanatory variables in a linear model. The problem is complicated when the variables involve linear dependence, which is the common situation in sensory and consumer data.
✨2️⃣The commonly used methodologies, e.g., conjoint analysis, preference mapping and Kano’s model, have serious limitations for determination of relative importance of correlated attributes and identification of drivers of consumer liking.
✨3️⃣The conventional statistics, e.g., correlation coefficient, standard regression coefficient and P values of tests for regression parameters, etc., are inadequate and invalid measures of relative importance of correlated attributes.
✨4️⃣There are three state-of-the-artmethods for determination of relative importance of correlated attributes. They are the Lindeman, Merenda and Gold’s method, Breiman’s Random Forest and Johnson’s relative weight.
This article also provides statistical background and almost exhaustive main references on the topic of relative importance of variables scattered in various academic journals in different fields. The information will help the sensometricians and researchers with more statistical knowledge to embrace the mainstream of the research on the topic and to pursue advanced methods for drivers of consumer liking.
Practical applications
This article reviews some new methods for determination of relative importance of correlated explanatory variables to response variable in a regression model. The methods can be used for identification of drivers of consumer liking. The article also provides the sources of the corresponding computer packages and codes implementing the new methods. The packages and codes are freely available and easy to use. The R packages “relaimpo” for the LMG method, “randomForest” and “party” for the original and modified Breiman’s Random Forest method are available at https://cran.r-project.org. The R or S-Plus code “johnson” for Johnson’s relative weight is available from the online supplementary Appendix S1 of this article.
🍀
Article in PDF >>>
Source >>>
#analytics #methodology #mr #science #sociology #statistics #tools
🔬🤓⚗️
This article attempts to deliver the following message to the researchers and practitioners in the sensory field:
✨1️⃣ Theoretically, drivers of consumer liking is based on relative importance of explanatory variables in a linear model. The problem is complicated when the variables involve linear dependence, which is the common situation in sensory and consumer data.
✨2️⃣The commonly used methodologies, e.g., conjoint analysis, preference mapping and Kano’s model, have serious limitations for determination of relative importance of correlated attributes and identification of drivers of consumer liking.
✨3️⃣The conventional statistics, e.g., correlation coefficient, standard regression coefficient and P values of tests for regression parameters, etc., are inadequate and invalid measures of relative importance of correlated attributes.
✨4️⃣There are three state-of-the-artmethods for determination of relative importance of correlated attributes. They are the Lindeman, Merenda and Gold’s method, Breiman’s Random Forest and Johnson’s relative weight.
This article also provides statistical background and almost exhaustive main references on the topic of relative importance of variables scattered in various academic journals in different fields. The information will help the sensometricians and researchers with more statistical knowledge to embrace the mainstream of the research on the topic and to pursue advanced methods for drivers of consumer liking.
Practical applications
This article reviews some new methods for determination of relative importance of correlated explanatory variables to response variable in a regression model. The methods can be used for identification of drivers of consumer liking. The article also provides the sources of the corresponding computer packages and codes implementing the new methods. The packages and codes are freely available and easy to use. The R packages “relaimpo” for the LMG method, “randomForest” and “party” for the original and modified Breiman’s Random Forest method are available at https://cran.r-project.org. The R or S-Plus code “johnson” for Johnson’s relative weight is available from the online supplementary Appendix S1 of this article.
🍀
Article in PDF >>>
Source >>>
#analytics #methodology #mr #science #sociology #statistics #tools
{kind=link}
Машинное обучение и Data Science: погружение в тему
🤖🏄♂️
Самый ценный опыт выпускников, преподавателей и друзей Школы анализа данных — в одном онлайн учебнике. Погрузитесь в ML и узнайте, какие технологии меняют лицо современной науки и дают жизнь сервисам, которыми пользуются миллионы людей.
Многолетний опыт преподавания и использования ML позволил создать учебник, который наглядно и доступно объясняет, что такое машинное обучение и как его использовать.
✨ Начинающему ML‑специалисту
Получите структурированное представление о самых важных подходах и направлениях машинного обучения.
✨ Разработчику и аналитику
Глубже погрузитесь в тему и получите системное представление об отдельных алгоритмах и об ML в целом.
✨ Исследователю
Приобретёте более широкое понимание области, откроете для себя новые и нетривиальные результаты.
Учебник проведёт вас от основ машинного обучения до тем, которые поднимаются в свежих научных статьях, и даст представление о том, как ML применяется на практике.
Вы также обновите знания о важных для ML разделах математики: матричном дифференцировании, статистике, методах оптимизации.
⚠️ Учебник дополняется!
🍀
Handbook >>>
Source >>>
Original >>>
#analytics #datascience #development #efficiency #math #methodology #science #statistics #technology #tools
🤖🏄♂️
Самый ценный опыт выпускников, преподавателей и друзей Школы анализа данных — в одном онлайн учебнике. Погрузитесь в ML и узнайте, какие технологии меняют лицо современной науки и дают жизнь сервисам, которыми пользуются миллионы людей.
Многолетний опыт преподавания и использования ML позволил создать учебник, который наглядно и доступно объясняет, что такое машинное обучение и как его использовать.
✨ Начинающему ML‑специалисту
Получите структурированное представление о самых важных подходах и направлениях машинного обучения.
✨ Разработчику и аналитику
Глубже погрузитесь в тему и получите системное представление об отдельных алгоритмах и об ML в целом.
✨ Исследователю
Приобретёте более широкое понимание области, откроете для себя новые и нетривиальные результаты.
Учебник проведёт вас от основ машинного обучения до тем, которые поднимаются в свежих научных статьях, и даст представление о том, как ML применяется на практике.
Вы также обновите знания о важных для ML разделах математики: матричном дифференцировании, статистике, методах оптимизации.
⚠️ Учебник дополняется!
🍀
Handbook >>>
Source >>>
Original >>>
#analytics #datascience #development #efficiency #math #methodology #science #statistics #technology #tools
{kind=link}
ИНФОРМАЦИЯ ПРО КАНАЛ
🎯 Для постов с октября 2018 проставляю теги для ускорения поиска по определенной тематике:
#advertising рекламный рынок
#analytics аналитика
#b2b business-to-business
#case кейсы
#dev разработка
#datascience наука о данных
#design дизайн
#development личное развитие
#ecom электронная коммерция
#economics экономика
#efficiency эффективность
#event мероприятия
#experiment эксперименты
#fun смешно или интересно
#itsec информационная безопасность
#likbez ликбез
#marketing маркетинг
#math математика
#methodology методологии
#mobile мобайл
#mr маркетинговые исследования
#predictions предсказания и прогнозы
#presentation слайды
#product продукты и сервисы
#psychology психология
#report отчеты
#retail ритейл
#science наука
#sociology социология
#statistics статистика
#strategy стратегии
#technology технологии
#tgchannel реко других каналов (не реклама)
#tools инструменты
#trends тренды
#ux пользователи и интерфейсы
#visualization визуализации
🧠 Канал – это не только новости, но и база знаний, поэтому ищите интересующую вас тематику через поиск и хронологическую навигацию по постам:
Q3-2016
Q4-2016
Q4-2017
Q1-2018
Q2-2018
Q3-2018
Q4-2018
Q1-2019
Q2-2019
Q3-2019
Q4-2019
Q1-2020
Q2-2020
Q3-2020
Q4-2020
Q1-2021
Q2-2021
Q3-2021
Q4-2021
Q1-2022
Q2-2022
Q3-2022
Q4-2022
Q1-2023
Q2-2023
🗄 Полный архив канала, обновляется 1 раз в месяц - 10 числа. Сохранить все на диск и открывать в браузере файл messages.html
👨💻 У канала есть фейсбук-представительство >>> InsightStream в FB
#development #efficiency #tools #ux
🎯 Для постов с октября 2018 проставляю теги для ускорения поиска по определенной тематике:
#advertising рекламный рынок
#analytics аналитика
#b2b business-to-business
#case кейсы
#dev разработка
#datascience наука о данных
#design дизайн
#development личное развитие
#ecom электронная коммерция
#economics экономика
#efficiency эффективность
#event мероприятия
#experiment эксперименты
#fun смешно или интересно
#itsec информационная безопасность
#likbez ликбез
#marketing маркетинг
#math математика
#methodology методологии
#mobile мобайл
#mr маркетинговые исследования
#predictions предсказания и прогнозы
#presentation слайды
#product продукты и сервисы
#psychology психология
#report отчеты
#retail ритейл
#science наука
#sociology социология
#statistics статистика
#strategy стратегии
#technology технологии
#tgchannel реко других каналов (не реклама)
#tools инструменты
#trends тренды
#ux пользователи и интерфейсы
#visualization визуализации
🧠 Канал – это не только новости, но и база знаний, поэтому ищите интересующую вас тематику через поиск и хронологическую навигацию по постам:
Q3-2016
Q4-2016
Q4-2017
Q1-2018
Q2-2018
Q3-2018
Q4-2018
Q1-2019
Q2-2019
Q3-2019
Q4-2019
Q1-2020
Q2-2020
Q3-2020
Q4-2020
Q1-2021
Q2-2021
Q3-2021
Q4-2021
Q1-2022
Q2-2022
Q3-2022
Q4-2022
Q1-2023
Q2-2023
🗄 Полный архив канала, обновляется 1 раз в месяц - 10 числа. Сохранить все на диск и открывать в браузере файл messages.html
Последнее обновление 10.04.2023 >>> Архив👨💻 У канала есть фейсбук-представительство >>> InsightStream в FB
#development #efficiency #tools #ux
{kind=link}
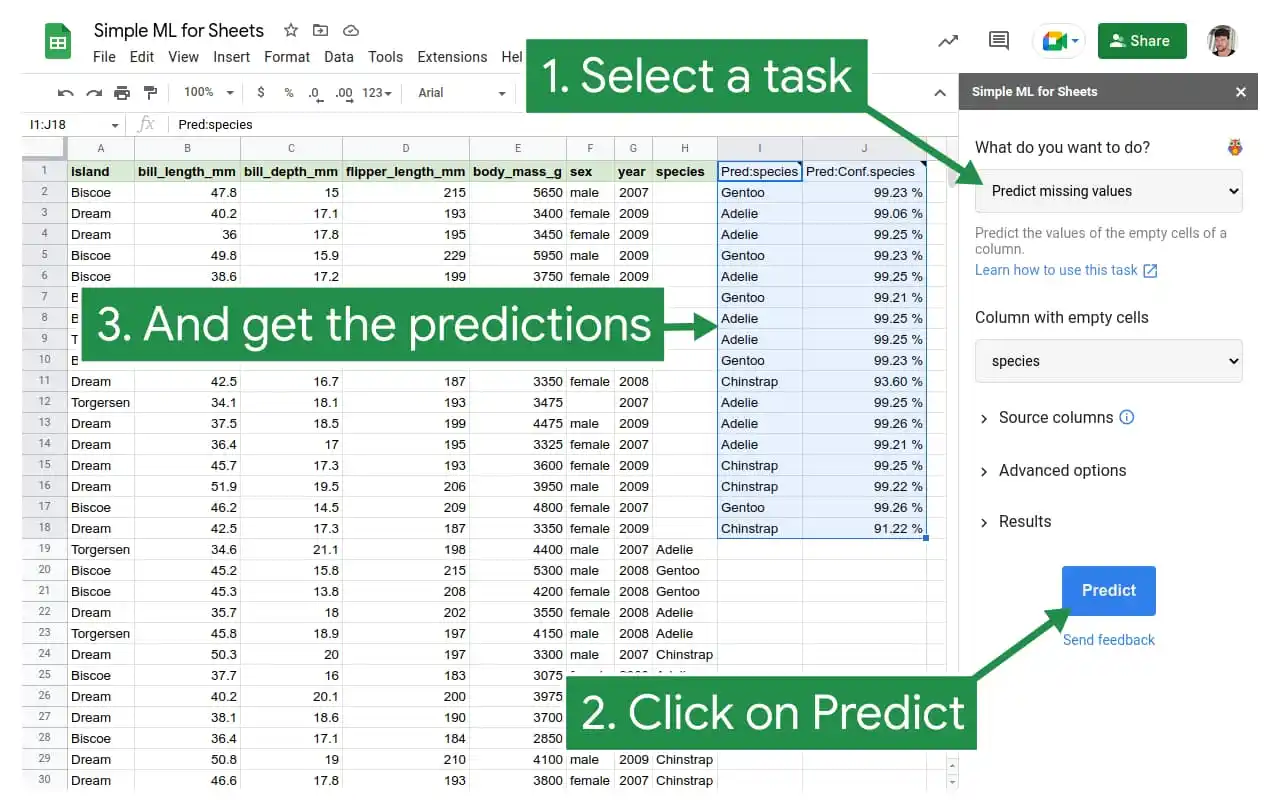
GOOGLE BRINGS MACHINE LEARNING TO ONLINE SPREADSHEETS WITH SIMPLE ML FOR SHEETS
🤖👩🏼🎓🔮
Spreadsheets are widely used by organizations of all sizes for all kinds of basic and complex tasks.
While simple calculations and graphs have long been part of the spreadsheet experience, machine learning (ML) has not. ML is often seen as being too complex to use, while spreadsheet usage is intended to be accessible to any type of user. Google is now trying to change that paradigm for its Google Sheets online spreadsheet program.
On Dec, 7 Google announced a beta release of the Simple ML for Sheets add-on. Google Sheets has an extensible architecture that enables users to benefit from add-ons that extend the default functionality available in the application. In this case, Google Sheets benefits from ML technology that Google first developed in the open-source TensorFlow project. With Simple ML for Sheets, users will not need to use a specific TensorFlow service, as Google has developed the service to be as easily accessible as possible.
“Everything runs completely on the user browser,” Luiz Gustavo Martins, Google AI developer advocate, told VentureBeat. “Your data doesn’t leave Google Sheets and models are saved to your Google Drive so you can use them again later.”
Holy sheets, Google’s Simple ML can do what with my spreadsheets?
So what can Simple ML for Sheets do? Two of the beginner tasks in the beta release highlighted by Google include the ability to predict missing values (1) or spot abnormal ones (2). Martins said that those two beginner tasks are easy for anyone to test the ML waters and explore how ML might benefit their business.
Martins noted that beyond the beginner tasks, the add-on supports several other common ML tasks such as training and evaluating models, generating predictions, and interpreting the models and their predictions. In addition, since Simple ML can export models to TensorFlow, people with programming experience can use Simple ML models with their existing ML infrastructure.
Overcoming the challenges of ML complexity with Simple ML for Sheets
It’s possible for Google Sheets users to benefit from ML without Simple ML, but it may not be easy for the layperson.
“We identified knowledge and lack of guidance as the prime factors for non-ML practitioners to easily use ML,” Mathieu Guillame-Bert, software engineer at Google, told VentureBeat. “Using a classical ML tool, like TensorFlow in Python, is like being in front of a blank page.”
Guillame-Bert said that using a classic ML tool requires, among other things, for the user to understand programming, ML problem framing, model construction and model evaluation. He noted that such knowledge is generally acquired through classes or self-taught over a long period of time.
In contrast, Guillame-Bert said that Simple ML is like an interactive questionnaire. It guides the user and only assumes basic knowledge about spreadsheets.
🍀 Source >>>
🍀 Original >>>
#analytics #datascience #dev #math #predictions #product #statistics #technology #tools
🤖👩🏼🎓🔮
Spreadsheets are widely used by organizations of all sizes for all kinds of basic and complex tasks.
While simple calculations and graphs have long been part of the spreadsheet experience, machine learning (ML) has not. ML is often seen as being too complex to use, while spreadsheet usage is intended to be accessible to any type of user. Google is now trying to change that paradigm for its Google Sheets online spreadsheet program.
On Dec, 7 Google announced a beta release of the Simple ML for Sheets add-on. Google Sheets has an extensible architecture that enables users to benefit from add-ons that extend the default functionality available in the application. In this case, Google Sheets benefits from ML technology that Google first developed in the open-source TensorFlow project. With Simple ML for Sheets, users will not need to use a specific TensorFlow service, as Google has developed the service to be as easily accessible as possible.
“Everything runs completely on the user browser,” Luiz Gustavo Martins, Google AI developer advocate, told VentureBeat. “Your data doesn’t leave Google Sheets and models are saved to your Google Drive so you can use them again later.”
Holy sheets, Google’s Simple ML can do what with my spreadsheets?
So what can Simple ML for Sheets do? Two of the beginner tasks in the beta release highlighted by Google include the ability to predict missing values (1) or spot abnormal ones (2). Martins said that those two beginner tasks are easy for anyone to test the ML waters and explore how ML might benefit their business.
Martins noted that beyond the beginner tasks, the add-on supports several other common ML tasks such as training and evaluating models, generating predictions, and interpreting the models and their predictions. In addition, since Simple ML can export models to TensorFlow, people with programming experience can use Simple ML models with their existing ML infrastructure.
Overcoming the challenges of ML complexity with Simple ML for Sheets
It’s possible for Google Sheets users to benefit from ML without Simple ML, but it may not be easy for the layperson.
“We identified knowledge and lack of guidance as the prime factors for non-ML practitioners to easily use ML,” Mathieu Guillame-Bert, software engineer at Google, told VentureBeat. “Using a classical ML tool, like TensorFlow in Python, is like being in front of a blank page.”
Guillame-Bert said that using a classic ML tool requires, among other things, for the user to understand programming, ML problem framing, model construction and model evaluation. He noted that such knowledge is generally acquired through classes or self-taught over a long period of time.
In contrast, Guillame-Bert said that Simple ML is like an interactive questionnaire. It guides the user and only assumes basic knowledge about spreadsheets.
🍀 Source >>>
🍀 Original >>>
#analytics #datascience #dev #math #predictions #product #statistics #technology #tools
{kind=link}
ЛОВУШКИ В АНАЛИТИКЕ, С КОТОРЫМИ СТАЛКИВАЕТСЯ КАЖДЫЙ
📊🕸🤓
🔮 Ошибка корреляции. Совместное изменение двух переменных в динамике не свидетельствует о наличии причинно-следственной связи между ними.
💼 Пример из бизнеса: чем ближе летний сезон, тем больше компания тратит на ремаргетинг и тем больше у этой компании заказов.
🔑 Как избежать ловушки? Единственный способ установить причинно-следственную связь между двумя переменными — провести управляемый эксперимент (AB-тест).
🔮 Мультиколлинеарность. Это частный случай ошибки корреляции, которая объясняется наличием третьей переменной, которая связана с обоими изучаемыми признаками.
💼 Пример из бизнеса: было замечено, что те, кто оставляет гневные отзывы в приложении, имеют гораздо больший LTV по сравнению с остальными. Начали рождаться гипотезы о том, что это клиенты, которые эмоционально вовлечены в продукт... Или же те, кому важен продукт, будут его критиковать, потому что часто пользуются и искренне хотят, чтобы сервис изменился... Истинное объяснение оказалось, как с размером города: чем дольше клиент «живёт» с компанией, тем больше вероятность, что рано или поздно он оставит гневный отзыв.
🔑 Как избежать ловушки? Нужно зафиксировать фактор времени константой для обоих групп. Для этого сравним LTV клиентов, которые оставляли отзыв за первые 7 дней с теми, кто не оставлял отзыв, но точно пользовался продуктом первые 7 дней
🔮 Неоднородные группы. При проектировании экспериментов использовать случайное перемешивание и квоты, общие для контрольной и тестовой групп. Проверять, что тестовая и контрольная группа имеют однородный состав. Если тестовая группа изначально наполнена так, что содержит более благоприятную аудиторию, то метрики по ней будут выше, но не из-за влияния изучаемого фактора, а из-за преимущества контрольной группы по своему составу.
💼 Пример из бизнеса: сервис по доставке еды решил проверить, как неожиданные сюрпризы на 8 марта повлияют на LTV клиенток. Логичным контрольным сегментом могут показаться мужчины (так как они не получают сюрпризы на 8 марта) ... Но сравнивать LTV между такими группами будет ошибкой. Мужчины в среднем больше едят и богаче (временно, несправедливо, но факт), а значит и заказывают больше еды и имеют больший LTV.
🔑 Как избежать ловушки? При проектировании экспериментов использовать случайное перемешивание и квоты, общие для контрольной и тестовой групп. Проверять, что тестовая и контрольная группа имеют однородный состав.
🔮 Малые выборки. В выборочных исследованиях (когда по части объектов судим о всей совокупности) часто обнаруживается сегмент, в котором метрика выше или ниже, чем в среднем. Может возникнуть соблазн делать далеко идущие выводы, но такие выводы будут ошибочными без расчета доверительного интервала.
💼 Пример из бизнеса: при очередном замере метрик здоровья бренда засекли рост спонтанного знания среди старшей аудитории, отпраздновали на корпоративе и выписали премию коллегам, которые сотрудничают с газетами. На следующем замере метрика среди старшей аудитории отскочила к стандартным значениям, хотя на газеты потратили ещё больший бюджет.
🔑 Как избежать ловушки? Всегда смотреть на среднее по выборке с оглядкой на доверительный интервал
🔮 Ошибка подглядывания. Если постоянно подглядывать на промежуточные результаты эксперимента, то однажды мы получим желаемые результаты и соблазн остановить эксперимент в этот момент будет слишком велик.
💼 Пример из бизнеса: вы запустили АБ-тест и вам так интересно, что заходите проверять результаты каждый день. Уже три дня подряд показатели тестовой группы были лучше, чем у контрольной, поэтому вы решили досрочно закрыть эксперимент, признав его успешным.
🔑 Как избежать ловушки? Рассчитывать достаточный размер выборки и не подглядывать пока она не накопится.
🍀 Source >>>
#analytics #case #development #experiment #fun #likbez #marketing #product #statistics
📊🕸🤓
🔮 Ошибка корреляции. Совместное изменение двух переменных в динамике не свидетельствует о наличии причинно-следственной связи между ними.
💼 Пример из бизнеса: чем ближе летний сезон, тем больше компания тратит на ремаргетинг и тем больше у этой компании заказов.
🔑 Как избежать ловушки? Единственный способ установить причинно-следственную связь между двумя переменными — провести управляемый эксперимент (AB-тест).
🔮 Мультиколлинеарность. Это частный случай ошибки корреляции, которая объясняется наличием третьей переменной, которая связана с обоими изучаемыми признаками.
💼 Пример из бизнеса: было замечено, что те, кто оставляет гневные отзывы в приложении, имеют гораздо больший LTV по сравнению с остальными. Начали рождаться гипотезы о том, что это клиенты, которые эмоционально вовлечены в продукт... Или же те, кому важен продукт, будут его критиковать, потому что часто пользуются и искренне хотят, чтобы сервис изменился... Истинное объяснение оказалось, как с размером города: чем дольше клиент «живёт» с компанией, тем больше вероятность, что рано или поздно он оставит гневный отзыв.
🔑 Как избежать ловушки? Нужно зафиксировать фактор времени константой для обоих групп. Для этого сравним LTV клиентов, которые оставляли отзыв за первые 7 дней с теми, кто не оставлял отзыв, но точно пользовался продуктом первые 7 дней
🔮 Неоднородные группы. При проектировании экспериментов использовать случайное перемешивание и квоты, общие для контрольной и тестовой групп. Проверять, что тестовая и контрольная группа имеют однородный состав. Если тестовая группа изначально наполнена так, что содержит более благоприятную аудиторию, то метрики по ней будут выше, но не из-за влияния изучаемого фактора, а из-за преимущества контрольной группы по своему составу.
💼 Пример из бизнеса: сервис по доставке еды решил проверить, как неожиданные сюрпризы на 8 марта повлияют на LTV клиенток. Логичным контрольным сегментом могут показаться мужчины (так как они не получают сюрпризы на 8 марта) ... Но сравнивать LTV между такими группами будет ошибкой. Мужчины в среднем больше едят и богаче (временно, несправедливо, но факт), а значит и заказывают больше еды и имеют больший LTV.
🔑 Как избежать ловушки? При проектировании экспериментов использовать случайное перемешивание и квоты, общие для контрольной и тестовой групп. Проверять, что тестовая и контрольная группа имеют однородный состав.
🔮 Малые выборки. В выборочных исследованиях (когда по части объектов судим о всей совокупности) часто обнаруживается сегмент, в котором метрика выше или ниже, чем в среднем. Может возникнуть соблазн делать далеко идущие выводы, но такие выводы будут ошибочными без расчета доверительного интервала.
💼 Пример из бизнеса: при очередном замере метрик здоровья бренда засекли рост спонтанного знания среди старшей аудитории, отпраздновали на корпоративе и выписали премию коллегам, которые сотрудничают с газетами. На следующем замере метрика среди старшей аудитории отскочила к стандартным значениям, хотя на газеты потратили ещё больший бюджет.
🔑 Как избежать ловушки? Всегда смотреть на среднее по выборке с оглядкой на доверительный интервал
🔮 Ошибка подглядывания. Если постоянно подглядывать на промежуточные результаты эксперимента, то однажды мы получим желаемые результаты и соблазн остановить эксперимент в этот момент будет слишком велик.
💼 Пример из бизнеса: вы запустили АБ-тест и вам так интересно, что заходите проверять результаты каждый день. Уже три дня подряд показатели тестовой группы были лучше, чем у контрольной, поэтому вы решили досрочно закрыть эксперимент, признав его успешным.
🔑 Как избежать ловушки? Рассчитывать достаточный размер выборки и не подглядывать пока она не накопится.
🍀 Source >>>
#analytics #case #development #experiment #fun #likbez #marketing #product #statistics
{kind=link}
КАК ПРОВЕСТИ A/B-ТЕСТИРОВАНИЕ И ПОДНЯТЬ КОНВЕРСИЮ САЙТА?
✈️⚖️🅰️🅱️
⏱ Таймкоды:
0:00 О чем расскажем
0:34 Что такое A/B-тестирование
1:15 Почему Netflix и Amazon проводят так много A/B-тестов?
1:30 Пример A/B-теста от Grene
2:30 Как проводить A/B-тест
2:42 Как найти гипотезу для тестирования
3:36 Как определить метрику: повышение конверсии?
4:08 Пример гипотезы для A/B-тестирования
4:38 Нулевая гипотеза
4:57 Альтернативная гипотеза
5:51 Подготовка к тестированию
8:28 Подводим результаты тестирования
9:14 Что делать, если тест не сработал?
🍀 Source >>>
🍀 YouTube (~10 min) >>>
#analytics #efficiency #experiment #likbez #methodology #product #statistics #tools
✈️⚖️🅰️🅱️
⏱ Таймкоды:
0:00 О чем расскажем
0:34 Что такое A/B-тестирование
1:15 Почему Netflix и Amazon проводят так много A/B-тестов?
1:30 Пример A/B-теста от Grene
2:30 Как проводить A/B-тест
2:42 Как найти гипотезу для тестирования
3:36 Как определить метрику: повышение конверсии?
4:08 Пример гипотезы для A/B-тестирования
4:38 Нулевая гипотеза
4:57 Альтернативная гипотеза
5:51 Подготовка к тестированию
8:28 Подводим результаты тестирования
9:14 Что делать, если тест не сработал?
🍀 Source >>>
🍀 YouTube (~10 min) >>>
#analytics #efficiency #experiment #likbez #methodology #product #statistics #tools
{kind=link}