Forwarded from Тут будет что-то от Джина
#bigdata #short
ЛИТЕРАТУРНЫЕ ВКУСЫ ПРОФЕССИОНАЛЬНЫХ ГРУПП В РОССИИ или что говорит бигдата о профессиях и литературных вкусах.
https://t.iss.one/mustreat/3634
Сокращенная версия.
Подробнее читайте тут: https://t.iss.one/mustreat/3636
"Шокирует положение двух групп – университетских преподавателей (рядом с учителями средней школы, дальше от Ремарка и Маркеса, чем официантки и индивидуальные предприниматели) и, особенно, врачи (рядом с Донцовой, медсестрами и продавцами)....
Различия масштабные – для врача в четыре раза более вероятно взять Донцову, чем для переводчика, а для переводчика – в два раза более вероятно взять обобщенного Пушкина. ...
В целом, как наши социологические представления о типичных занятиях носителей классовых вкусов, скалькированные из Бурдье (или о составе статусных групп по Голдторпу), так и обывательские представления о «настоящей интеллигенции», состоящей из врачей, учителей и библиотекарей, оказываются чем-то далеким от реальности. Кажется, что граница проходит каким-то гораздо более причудливым образом …"
ЛИТЕРАТУРНЫЕ ВКУСЫ ПРОФЕССИОНАЛЬНЫХ ГРУПП В РОССИИ или что говорит бигдата о профессиях и литературных вкусах.
https://t.iss.one/mustreat/3634
Сокращенная версия.
Подробнее читайте тут: https://t.iss.one/mustreat/3636
"Шокирует положение двух групп – университетских преподавателей (рядом с учителями средней школы, дальше от Ремарка и Маркеса, чем официантки и индивидуальные предприниматели) и, особенно, врачи (рядом с Донцовой, медсестрами и продавцами)....
Различия масштабные – для врача в четыре раза более вероятно взять Донцову, чем для переводчика, а для переводчика – в два раза более вероятно взять обобщенного Пушкина. ...
В целом, как наши социологические представления о типичных занятиях носителей классовых вкусов, скалькированные из Бурдье (или о составе статусных групп по Голдторпу), так и обывательские представления о «настоящей интеллигенции», состоящей из врачей, учителей и библиотекарей, оказываются чем-то далеким от реальности. Кажется, что граница проходит каким-то гораздо более причудливым образом …"
Forwarded from Будущее.42.0.0.2.FNL.PSD
#bigdata
Яндекс наконец-то рассказал о успехах в нефтянке своей Yandex Data Factory.
Я там ничего нового не узнал, но вам будет интересно познать как, даже для IT корпораций сложно проложить дорожку в мир тяжелотехнологических титанов.
Молодцы! Удачи, ребята! Так держать!
Цитата:
"Сегодня (внезапно!) все вдруг поняли, о чём мы говорим. То, что мы рассказывали ещё в 2014 году, в 2016 году стало регулярно попадать в заголовки."
https://yandex.ru/blog/company/stal-neft-i-iskusstvennyy-intellekt-yandex-data-factory-o-novoy-promyshlennoy-revolyutsii
Яндекс наконец-то рассказал о успехах в нефтянке своей Yandex Data Factory.
Я там ничего нового не узнал, но вам будет интересно познать как, даже для IT корпораций сложно проложить дорожку в мир тяжелотехнологических титанов.
Молодцы! Удачи, ребята! Так держать!
Цитата:
"Сегодня (внезапно!) все вдруг поняли, о чём мы говорим. То, что мы рассказывали ещё в 2014 году, в 2016 году стало регулярно попадать в заголовки."
https://yandex.ru/blog/company/stal-neft-i-iskusstvennyy-intellekt-yandex-data-factory-o-novoy-promyshlennoy-revolyutsii
Блог Яндекса
Сталь, нефть и искусственный интеллект: Yandex Data Factory о новой промышленной революции
В декабре 2014 года мы открыли Yandex Data Factory. Тогда нам хотелось показать, что технологии Яндекса могут использоваться в не связанных с интернетом отраслях: например, в медицине или дорожном хозяйстве. За два года мы реализовали десятки успешных проектов…
Forwarded from Медтех
#AI #bigdata #gadget #cardio
Развитие медицинского IoT в области самодиагностики чем то похоже на появление доступных систем веб-аналитики в конце 00х. До этого все писали подобные системы сами и только для тех данных, которые реально нужны. А здесь ставишь счетчик GA и получаешь огромный объем самых разнообразных данных. Только вот небольшая проблема — что с ними делать?
Не знаю как это называется по-модному, но я называю это DataRush (кто играл в старкрафт поймет). Переизбыток данных создает больше проблем, чем недостаток. В конечном итоге процентов 80 пользователей в GA смотрят только сколько человек в день/месяц зашло на сайт :)
Такая же проблема и в мед IoT. Миллион устройств, все снимают какие то данные. Только что с ними делать, кроме красивых графиков в мобильном приложении. К тому же в медицине не всегда чем больше данных, тем лучше. Бывает даже наоборот)
В общем вполне логичная история — попытка применить алгоритмы анализа данных на этих объемах. Что и делает AliveCor. Сначала они запустили гаджет для снятия ЭКГ, а через пару лет осознали проблему больших данных, и запустили нейронку, которая на основе вспомогательных данных (вес, рост, активность, что то еще) пытается определить ранние стадии кардио-заболеваний. Как это работает, никаких данных нет (ждем статью в netural?). Но ивестиции под проект они получили порядка $30M, т.ч. видимо технология работает :) Движение, несомненно, верное. Но еще более верное было бы оно, если бы они делали AI платформу, совместимую со всеми кардио-мониторами других производителей.
Подробнее в статье https://www.wired.com/2017/03/alivecor-kardia/
Развитие медицинского IoT в области самодиагностики чем то похоже на появление доступных систем веб-аналитики в конце 00х. До этого все писали подобные системы сами и только для тех данных, которые реально нужны. А здесь ставишь счетчик GA и получаешь огромный объем самых разнообразных данных. Только вот небольшая проблема — что с ними делать?
Не знаю как это называется по-модному, но я называю это DataRush (кто играл в старкрафт поймет). Переизбыток данных создает больше проблем, чем недостаток. В конечном итоге процентов 80 пользователей в GA смотрят только сколько человек в день/месяц зашло на сайт :)
Такая же проблема и в мед IoT. Миллион устройств, все снимают какие то данные. Только что с ними делать, кроме красивых графиков в мобильном приложении. К тому же в медицине не всегда чем больше данных, тем лучше. Бывает даже наоборот)
В общем вполне логичная история — попытка применить алгоритмы анализа данных на этих объемах. Что и делает AliveCor. Сначала они запустили гаджет для снятия ЭКГ, а через пару лет осознали проблему больших данных, и запустили нейронку, которая на основе вспомогательных данных (вес, рост, активность, что то еще) пытается определить ранние стадии кардио-заболеваний. Как это работает, никаких данных нет (ждем статью в netural?). Но ивестиции под проект они получили порядка $30M, т.ч. видимо технология работает :) Движение, несомненно, верное. Но еще более верное было бы оно, если бы они делали AI платформу, совместимую со всеми кардио-мониторами других производителей.
Подробнее в статье https://www.wired.com/2017/03/alivecor-kardia/
WIRED
Ex-Googlers Build a Neural Network to Protect Your Heart
Data about your heart's health gets crunched by the cloud to warn you of disease onset.
Forwarded from Будущее.42.0.0.2.FNL.PSD
#police #secure #cybersecurity #safenet #bigdata #leaks #nationalID
Чуть больше года назад хакеры выложили данные о 49,6 миллиона (из чуть более 75) турецких жителей, взятых из правительственных архивов. Данные включали национальный идентификатор, имя, фамилию, имя матери и отца, пол, дату и город рождения, а также адрес места жительства.
6,6Гб. Я скачал.
А сегодня - вторая часть марлезонского балета.
130 млн индусов проснулись с новостью о том, что их ID и биометрические данные теперь гуляют по сети в открытом доступе.
То ли еще будет!
0. Ссылка на источник про взлом. https://boingboing.net/2017/05/02/what-could-possibly-go-wrong.html
1. Новость о сливе ID турецких жителей на русском - https://habrahabr.ru/post/280896/
2. Новость о сливе ID турецких жителей - оригинал - https://news.ycombinator.com/item?id=11420139
Чуть больше года назад хакеры выложили данные о 49,6 миллиона (из чуть более 75) турецких жителей, взятых из правительственных архивов. Данные включали национальный идентификатор, имя, фамилию, имя матери и отца, пол, дату и город рождения, а также адрес места жительства.
6,6Гб. Я скачал.
А сегодня - вторая часть марлезонского балета.
130 млн индусов проснулись с новостью о том, что их ID и биометрические данные теперь гуляют по сети в открытом доступе.
То ли еще будет!
0. Ссылка на источник про взлом. https://boingboing.net/2017/05/02/what-could-possibly-go-wrong.html
1. Новость о сливе ID турецких жителей на русском - https://habrahabr.ru/post/280896/
2. Новость о сливе ID турецких жителей - оригинал - https://news.ycombinator.com/item?id=11420139
Boing Boing
India's controversial national ID scheme leaks fraud-friendly data for 130,000,000 people
India's controversial national ID scheme leaks fraud-friendly data for 130,000,000 people
Forwarded from Малоизвестное интересное
США РАСКАЛЫВАЮТСЯ НА 20 ЧАСТЕЙ
Число наций (стран) в мире растет. С 1990 появилось 34 новых. А за следующие 10-15 лет появится еще, как минимум, 10.
Новые страны появляются в следствие раскола на части старых. Причины такого раскола разнообразны. О них можно спорить. Но не признавать объективно наблюдаемый тренд раскола невозможно.
Объединение Европы и «плавильный котел» США, лишь на первый взгляд, опровергают «тренд раскола». Прогнозы междисциплинарной науки говорят об обратном.
Новейшие исследования, анализирующие Большие Данные Гео-локализуемых Сообщений, наглядно показывают, где пройдут границы новой тектоники национальных расколов.
Для справки. Большие Данные Гео-локализуемых Сообщений содержат информацию о пространственном расположении и перемещении отдельных узлов (людей) и их кластеров (сообществ), образующих виртуальные и реальные социальные сети. Пример 1х – Facebook, 2х – сеть, отображающая ваших родственников, знакомых и коллег - их встречи и разговоры вживую или по телефону.
Про анализ европейских данных желающие могут почитать, например, здесь. Я же хочу рассказать о примере США, рассчитанном на сетевой модели Института комплексных систем Новой Англии (NECSI).
Авторов интересовало существуют ли реальные физические границы, уже сегодня образующие «мини-нации» в США - большие сообщества, лишь на 1-2 порядка меньшие, чем вся нация.
Принадлежность к «мини-нации» определялась по гео-принципу - персоны А и Б принадлежат к одной «мини-нации», если бОльшую часть времени они проводят внутри некоторых «мини-национальных границ», а за их пределы они выбираются сравнительно редко.
Исходной информацией этого исследования были полученные из Twitter Большие Данные Гео-локализуемых Сообщений о физическом перемещении жителей США в течение года.
В результате оказалось, что в США уже существуют 20 «мини-наций», перемещающихся, в основном, внутри своих «мини-стран».
Границы «мини-стран» довольно четко очерчены (см. приложенный рис С), а их размеры существенно превышают размеры даже самых крупных городских агломераций, показанных на рис В.
Лишь некоторые из «мини-стран» (Флорида, Техас, Мичиган) совпадают по своим границам с конкретными штатами. С большинством же «мини-стран» все иначе.
Поразительно, но аналогичное разделение на «мини-страны» получается и при анализе телефонных разговоров, и при анализе обмена твиттами в Twitter (скоро будет опубликовано NECSI, а пока что на рис. А показана теплограмма плотности активности в Twitter, максимальная в крупнейших городах).
Т.е. население «мини-стран» предпочитает не только замыкаться в рамках своих физических границ, но и привносит эти границы в пространство своих виртуальных коммуникаций.
#BigData #ГеоЛокализация #Раскол
Революция Больших Данных Гео-локализуемых Сообщений прогнозирует создание новых нацийЧисло наций (стран) в мире растет. С 1990 появилось 34 новых. А за следующие 10-15 лет появится еще, как минимум, 10.
Новые страны появляются в следствие раскола на части старых. Причины такого раскола разнообразны. О них можно спорить. Но не признавать объективно наблюдаемый тренд раскола невозможно.
Объединение Европы и «плавильный котел» США, лишь на первый взгляд, опровергают «тренд раскола». Прогнозы междисциплинарной науки говорят об обратном.
Новейшие исследования, анализирующие Большие Данные Гео-локализуемых Сообщений, наглядно показывают, где пройдут границы новой тектоники национальных расколов.
Для справки. Большие Данные Гео-локализуемых Сообщений содержат информацию о пространственном расположении и перемещении отдельных узлов (людей) и их кластеров (сообществ), образующих виртуальные и реальные социальные сети. Пример 1х – Facebook, 2х – сеть, отображающая ваших родственников, знакомых и коллег - их встречи и разговоры вживую или по телефону.
Про анализ европейских данных желающие могут почитать, например, здесь. Я же хочу рассказать о примере США, рассчитанном на сетевой модели Института комплексных систем Новой Англии (NECSI).
Авторов интересовало существуют ли реальные физические границы, уже сегодня образующие «мини-нации» в США - большие сообщества, лишь на 1-2 порядка меньшие, чем вся нация.
Принадлежность к «мини-нации» определялась по гео-принципу - персоны А и Б принадлежат к одной «мини-нации», если бОльшую часть времени они проводят внутри некоторых «мини-национальных границ», а за их пределы они выбираются сравнительно редко.
Исходной информацией этого исследования были полученные из Twitter Большие Данные Гео-локализуемых Сообщений о физическом перемещении жителей США в течение года.
В результате оказалось, что в США уже существуют 20 «мини-наций», перемещающихся, в основном, внутри своих «мини-стран».
Границы «мини-стран» довольно четко очерчены (см. приложенный рис С), а их размеры существенно превышают размеры даже самых крупных городских агломераций, показанных на рис В.
Лишь некоторые из «мини-стран» (Флорида, Техас, Мичиган) совпадают по своим границам с конкретными штатами. С большинством же «мини-стран» все иначе.
Например, «Северо-западная мини-страна» объединяют регионы из штатов Вашингтон, Орегон, Монтана и большую часть штата Айдахо.
Эта «мини-страна» граничит с двумя другими «мини-странами», одна из которых включает южные штаты Айдахо, Юту, Вайоминг и Колорадо, а другая - Минесоту, Айову, восточный Висконсин и обе Дакоты.
Поразительно, но аналогичное разделение на «мини-страны» получается и при анализе телефонных разговоров, и при анализе обмена твиттами в Twitter (скоро будет опубликовано NECSI, а пока что на рис. А показана теплограмма плотности активности в Twitter, максимальная в крупнейших городах).
Т.е. население «мини-стран» предпочитает не только замыкаться в рамках своих физических границ, но и привносит эти границы в пространство своих виртуальных коммуникаций.
#BigData #ГеоЛокализация #Раскол
{kind=link}
Forwarded from The Idealist
Gizmodo: Facebook раскрыл секреты моей семьи и не рассказал как
Как-то раз Кашмир Хилл листал ленту рекомендаций фейсбука и наткнулся на женщину по имени Ребекка Портер. Фамилия показалась журналисту знакомой, а связавшись с родственниками он выяснил, что Ребекка - его троюродная бабушка, которая живёт в другой части страны, и о существовании которой он даже не подозревал. Но как же тогда социальная сеть узнала то, что было неизвестно самому Кашмиру? Чем дальше Хилл погружался в тайну, тем мрачнее становилась картина всемогущества детища Марка Цукерберга. Что ещё знает о нас социальная сеть? Каким образом она собирает и анализирует информацию? Действительно ли незнакомы нам люди, которых она предлагает в разделе "вы можете их знать"?
Не пропустите шокирующее расследование Gizmodo в переводе портала "Идеалист"
"Функция «Вы можете их знать» известна своей необыкновенной способностью распознавать тех, с кем вы имели связь в реальной жизни. Это озадачивало и смущало пользователей Facebook, когда они находили в данном списке имя старого босса, бывшую подружку на одну ночь или кого-то, с кем они просто сталкивались на улице.
Эти предложения друзей выходят далеко за пределы обычной связи одноклассников или коллег. На протяжении многих лет мне рассказывали много странных историй об этом, например, когда психиатр поведала мне, что соцсеть рекомендует друг другу её пациентов".
https://theidealist.ru/theyknowyourfamilysecrets/
#Gizmodo #общество #соцсети #facebook #слежка #BigData
Как-то раз Кашмир Хилл листал ленту рекомендаций фейсбука и наткнулся на женщину по имени Ребекка Портер. Фамилия показалась журналисту знакомой, а связавшись с родственниками он выяснил, что Ребекка - его троюродная бабушка, которая живёт в другой части страны, и о существовании которой он даже не подозревал. Но как же тогда социальная сеть узнала то, что было неизвестно самому Кашмиру? Чем дальше Хилл погружался в тайну, тем мрачнее становилась картина всемогущества детища Марка Цукерберга. Что ещё знает о нас социальная сеть? Каким образом она собирает и анализирует информацию? Действительно ли незнакомы нам люди, которых она предлагает в разделе "вы можете их знать"?
Не пропустите шокирующее расследование Gizmodo в переводе портала "Идеалист"
"Функция «Вы можете их знать» известна своей необыкновенной способностью распознавать тех, с кем вы имели связь в реальной жизни. Это озадачивало и смущало пользователей Facebook, когда они находили в данном списке имя старого босса, бывшую подружку на одну ночь или кого-то, с кем они просто сталкивались на улице.
Эти предложения друзей выходят далеко за пределы обычной связи одноклассников или коллег. На протяжении многих лет мне рассказывали много странных историй об этом, например, когда психиатр поведала мне, что соцсеть рекомендует друг другу её пациентов".
https://theidealist.ru/theyknowyourfamilysecrets/
#Gizmodo #общество #соцсети #facebook #слежка #BigData
Большие данные могут возродить плановую экономику
Cуществует несколько теорий о том, почему Советский Союз рухнул: имперское перенапряжение, экономическая неэффективность, идеологическое банкротство. Но в своей книге «Homo Deus» израильский историк Юваль Ноа Харари предлагает более прозаичную версию: плановые экономики (и авторитарные режимы) не умеют обрабатывать данные.
goo.gl/UX4MTf
#мнение #bigdata
Cуществует несколько теорий о том, почему Советский Союз рухнул: имперское перенапряжение, экономическая неэффективность, идеологическое банкротство. Но в своей книге «Homo Deus» израильский историк Юваль Ноа Харари предлагает более прозаичную версию: плановые экономики (и авторитарные режимы) не умеют обрабатывать данные.
goo.gl/UX4MTf
#мнение #bigdata
Хайтек
Большие данные могут возродить плановую экономику
Большие данные могут вернуть к жизни плановую экономику. В Китае считают, что океаны информации могут сделать централизованные системы более эффективными, пишет Джон Торнхолл в колонке Financial Times.
Forwarded from Fintech review
Добрый вечер!
Дайджест новостей за 19.09.2017📌
1. Банки получат доступ к данным Пенсионного фонда до конца 2017 года
Российские банки до конца 2017 года могут получить доступ к данным Пенсионного фонда страны для проверки доходов заемщиков.Заемщики смогут давать согласие на запрос сведений об их доходах из ПФР без посещения банковских отделений. Также у клиентов появится возможность совершать эту операцию с помощью интернет-банка, что позволит задействовать механизм онлайн-кредитования. Подробнее: goo.gl/oQ8zt9
2. «Альфа-банк» наймёт на работу подростков для разработки и продвижения молодежных продуктов
«Альфа-банк» планирует стать «полноценным банком в соцсетях» благодаря команде подростков: компания набирает в штат сотрудников в возрасте от 15 до 17 лет, чтобы они помогли разработать новые продукты. Чтобы попасть в проект, подросткам нужно снять видео о себе и пройти собеседование в банке. Подробнее: goo.gl/RK5y1X
3. МТС запустила облачную платформу для анализа больших данных
Оператор предложил клиентам облачного сервиса «Cloud МТС» обрабатывать большие массивы данных при помощи BDaaS-инфраструктуры МТС (Big-Data-as-a-Service). Компании смогут работать с данными в программных средах Hadoop-as-a-Service и Spark-as-a-Service. Облачный сервис МТС поможет бизнесу таргетировать рекламу, собирать и обрабатывать открытые данные, проводить финансовую и бизнес-аналитику. Подробнее: goo.gl/m9HKec
#bigdata
4. Microsoft, Google, Facebook и Apple внедрят оплату биткоинами в браузеры
Разработчики крупнейших технологических компаний Google, Microsoft, Facebook и Apple создали API-интерфейс, который облегчит покупку товаров и сервисов онлайн за криптовалюту. С момента активации Payment Request API позволит сохранять все необходимые платежные данные по биткоин-кошельку и другим, более традиционным методам онлайн-платежей, прямо в браузере. Подробнее: goo.gl/GKcgwc
#криптовалюты
Отличного вечера!
Дайджест новостей за 19.09.2017📌
1. Банки получат доступ к данным Пенсионного фонда до конца 2017 года
Российские банки до конца 2017 года могут получить доступ к данным Пенсионного фонда страны для проверки доходов заемщиков.Заемщики смогут давать согласие на запрос сведений об их доходах из ПФР без посещения банковских отделений. Также у клиентов появится возможность совершать эту операцию с помощью интернет-банка, что позволит задействовать механизм онлайн-кредитования. Подробнее: goo.gl/oQ8zt9
2. «Альфа-банк» наймёт на работу подростков для разработки и продвижения молодежных продуктов
«Альфа-банк» планирует стать «полноценным банком в соцсетях» благодаря команде подростков: компания набирает в штат сотрудников в возрасте от 15 до 17 лет, чтобы они помогли разработать новые продукты. Чтобы попасть в проект, подросткам нужно снять видео о себе и пройти собеседование в банке. Подробнее: goo.gl/RK5y1X
3. МТС запустила облачную платформу для анализа больших данных
Оператор предложил клиентам облачного сервиса «Cloud МТС» обрабатывать большие массивы данных при помощи BDaaS-инфраструктуры МТС (Big-Data-as-a-Service). Компании смогут работать с данными в программных средах Hadoop-as-a-Service и Spark-as-a-Service. Облачный сервис МТС поможет бизнесу таргетировать рекламу, собирать и обрабатывать открытые данные, проводить финансовую и бизнес-аналитику. Подробнее: goo.gl/m9HKec
#bigdata
4. Microsoft, Google, Facebook и Apple внедрят оплату биткоинами в браузеры
Разработчики крупнейших технологических компаний Google, Microsoft, Facebook и Apple создали API-интерфейс, который облегчит покупку товаров и сервисов онлайн за криптовалюту. С момента активации Payment Request API позволит сохранять все необходимые платежные данные по биткоин-кошельку и другим, более традиционным методам онлайн-платежей, прямо в браузере. Подробнее: goo.gl/GKcgwc
#криптовалюты
Отличного вечера!
Forwarded from Fintech review
Центробанк России разработал методику анализа экономической активности в стране, которая основывается на системах обработки big data. Об этом говорится в докладе департамента исследований и прогнозирования ЦБ «Оценка экономической активности на основе текстового анализа».
В работе использовались 2 типа данных: ежедневные новостные статьи, взятые из интернет-ресурса, и композитный индекс деловой активности PMI. В построении новостного индекса можно выделить 3 основных этапа: извлечение списка тем, определение тональности новостных текстов и построение линейной регрессии, где в качестве зависимой переменной выступает индекс деловой активности PMI, а в качестве регрессоров – преобразованные с помощью метода главных компонент темы новостей.
Особую сложность представляло преобразование новостных статей в структурированный вид.
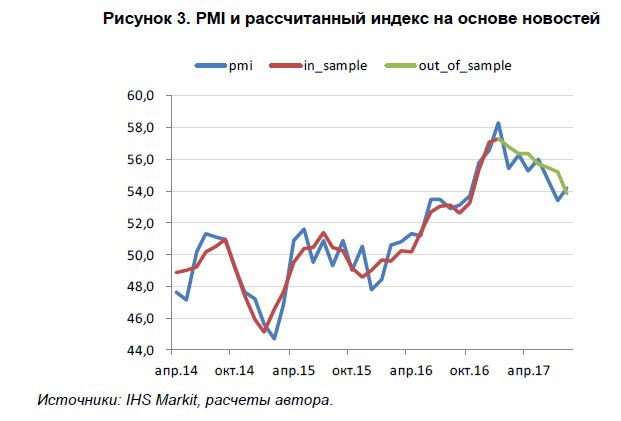
В итоге, рассчитанный на основе новостей индекс оказался очень близким к индексу PMI. Рисунок ниже говорит о достаточно неплохой прогнозной силе модели(R2=0,84%).
Ознакомиться с докладом подробнее можно здесь: goo.gl/EjkwWv
#bigdata #исследование
В работе использовались 2 типа данных: ежедневные новостные статьи, взятые из интернет-ресурса, и композитный индекс деловой активности PMI. В построении новостного индекса можно выделить 3 основных этапа: извлечение списка тем, определение тональности новостных текстов и построение линейной регрессии, где в качестве зависимой переменной выступает индекс деловой активности PMI, а в качестве регрессоров – преобразованные с помощью метода главных компонент темы новостей.
Особую сложность представляло преобразование новостных статей в структурированный вид.
В итоге, рассчитанный на основе новостей индекс оказался очень близким к индексу PMI. Рисунок ниже говорит о достаточно неплохой прогнозной силе модели(R2=0,84%).
Ознакомиться с докладом подробнее можно здесь: goo.gl/EjkwWv
#bigdata #исследование
{kind=link}
Forwarded from DigitalRussia (Цифровая Россия)
Х5 Retail Group создала дирекцию big data https://d-russia.ru/h5-retail-group-sozdala-direktsiyu-big-data.html?utm_source=telegram #пятерочка #перекресток #Х5RetailGroup #bigdata #большие_данные
Digital Russia
Х5 Retail Group создала дирекцию big data | Digital Russia
Х5 Retail Group создала дирекцию "больших данных", которую возглавил бывший директор по стратегии Х5 Антон Мироненков, об этом пишет "Интерфакс" со
Forwarded from Medical Ксю
#mhealth #bigdata
Кое-что интересное: Fitbit, кажется, может предсказывать эпидемию гриппа
Прошедшая неделя запомнилась официальным запуском электронной медкарты для москвичей, экологическим катаклизмом в виде тёплой европейской зимы и отставкой правительства. На фоне этих новостей предсказание о надвигающейся на нас эпидемии гриппа никто, кажется, не заметил.
Очевидно, что заболеваемость гриппом обладает чёткой сезонностью и ежегодно возрастает с декабря по февраль. Однако исследователи не устают искать зависимости и делать предсказания о дате начала пандемии.
В 2008 году исследователи из Google, заявили, что они могут прогнозировать вспышки гриппа на основе поисковых запросов. Основная гипотеза была в том, что люди, когда заболевают гриппом, начинают искать информацию о нем — описания лекарств, способы лечения и. т. д, таким образом сообщая Google о своей болезни. Разработчики утверждали, что данные поиска, наложенные на информацию о гриппе из Центра по контролю и профилактике заболеваний США, позволяют им производить точные оценки распространенности гриппа на две недели раньше, чем это делают медики на основе статистических данных о заболевших.
Заявления были красивые, но проект Google Flu Trends (GFT) провалился. Причем провалился с треском, просто пропустив эпидемию 2013 года и выдав по ней информацию, искаженную на 140 %. И тогда Google тихо закрыл проект. Но неудача конкретного начинания не означает провал использования данных такого масштаба в принципе. Стоит внимательнее отнестись к ошибкам и все-таки использовать массивы данных, получаемые такими гигантами, как Google. Ценность этих данных огромна, если их использовать правильно. Это означает, что корпоративные гиганты, обладающие этими данными, несут ответственность за их использование в интересах общества.
И вот теперь исследователи из Научно-исследовательского института Скриппс решили использовать данные фитнес-браслетов Fitbit 47000 американцев из Калифорнии, Техаса, Нью-Йорка, Иллинойса и Пенсильвании, постоянно использовавших устройства с 2016 по 2018-й год.
Они обнаружили, что отклонения в показателях здоровья (частота сердечных сокращений в состоянии покое и данные о сне) коррелировали с количеством пациентов, сообщивших о симптомах гриппа. Во всех пяти штатах данные Fitbit значительно улучшили прогнозы эпидемии гриппа.
Если исследователи не остановятся на достигнутом, то, в будущем, носимые устройства с помощью искусственного интеллекта смогут предсказывать начало гриппа у владельца задолго до появления симптомов.
Ссылка на новость про Fitbit и грипп: https://medcitynews.com/2020/01/scripps-study-can-your-fitbit-track-the-flu/
@medicalksu
Кое-что интересное: Fitbit, кажется, может предсказывать эпидемию гриппа
Прошедшая неделя запомнилась официальным запуском электронной медкарты для москвичей, экологическим катаклизмом в виде тёплой европейской зимы и отставкой правительства. На фоне этих новостей предсказание о надвигающейся на нас эпидемии гриппа никто, кажется, не заметил.
Очевидно, что заболеваемость гриппом обладает чёткой сезонностью и ежегодно возрастает с декабря по февраль. Однако исследователи не устают искать зависимости и делать предсказания о дате начала пандемии.
В 2008 году исследователи из Google, заявили, что они могут прогнозировать вспышки гриппа на основе поисковых запросов. Основная гипотеза была в том, что люди, когда заболевают гриппом, начинают искать информацию о нем — описания лекарств, способы лечения и. т. д, таким образом сообщая Google о своей болезни. Разработчики утверждали, что данные поиска, наложенные на информацию о гриппе из Центра по контролю и профилактике заболеваний США, позволяют им производить точные оценки распространенности гриппа на две недели раньше, чем это делают медики на основе статистических данных о заболевших.
Заявления были красивые, но проект Google Flu Trends (GFT) провалился. Причем провалился с треском, просто пропустив эпидемию 2013 года и выдав по ней информацию, искаженную на 140 %. И тогда Google тихо закрыл проект. Но неудача конкретного начинания не означает провал использования данных такого масштаба в принципе. Стоит внимательнее отнестись к ошибкам и все-таки использовать массивы данных, получаемые такими гигантами, как Google. Ценность этих данных огромна, если их использовать правильно. Это означает, что корпоративные гиганты, обладающие этими данными, несут ответственность за их использование в интересах общества.
И вот теперь исследователи из Научно-исследовательского института Скриппс решили использовать данные фитнес-браслетов Fitbit 47000 американцев из Калифорнии, Техаса, Нью-Йорка, Иллинойса и Пенсильвании, постоянно использовавших устройства с 2016 по 2018-й год.
Они обнаружили, что отклонения в показателях здоровья (частота сердечных сокращений в состоянии покое и данные о сне) коррелировали с количеством пациентов, сообщивших о симптомах гриппа. Во всех пяти штатах данные Fitbit значительно улучшили прогнозы эпидемии гриппа.
Если исследователи не остановятся на достигнутом, то, в будущем, носимые устройства с помощью искусственного интеллекта смогут предсказывать начало гриппа у владельца задолго до появления симптомов.
Ссылка на новость про Fitbit и грипп: https://medcitynews.com/2020/01/scripps-study-can-your-fitbit-track-the-flu/
@medicalksu
Forwarded from Комиссия по Регуляторике (Alexey Yefremov)
#Законопроект о #BigData - проект федерального закона «О внесении изменений в Федеральный закон «Об информации, информационных технологиях и о защите информации» - по мнению нашего эксперта из #РАНХиГС, содержит коррупциогенные факторы. В заключении указаны:
- нормативные коллизии и юридико-лингвистическая неопределенность в определении понятия "большие данные";
- заполнение законодательных пробелов при помощи подзаконных актов в отсутствие законодательной делегации соответствующих полномочий и чрезмерная свобода подзаконного нормотворчества в части передачи Правительству РФ права устанавливать принципы, правовые основания, права и обязанности операторов больших данных, порядок и условия оборота обработки больших данных;
- установление неопределенных, трудновыполнимых и обременительных требований к гражданам и организациям в части введения контроля за обработкой и оборотом больших данных и ведения реестра операторов больших данных.
В заключении особо отмечено отсутствие пояснительной записки и ФЭО к законопроекту, и, соответственно, отсутствие обоснования для не проведения в отношении данного законопроекта #ОРВ
- нормативные коллизии и юридико-лингвистическая неопределенность в определении понятия "большие данные";
- заполнение законодательных пробелов при помощи подзаконных актов в отсутствие законодательной делегации соответствующих полномочий и чрезмерная свобода подзаконного нормотворчества в части передачи Правительству РФ права устанавливать принципы, правовые основания, права и обязанности операторов больших данных, порядок и условия оборота обработки больших данных;
- установление неопределенных, трудновыполнимых и обременительных требований к гражданам и организациям в части введения контроля за обработкой и оборотом больших данных и ведения реестра операторов больших данных.
В заключении особо отмечено отсутствие пояснительной записки и ФЭО к законопроекту, и, соответственно, отсутствие обоснования для не проведения в отношении данного законопроекта #ОРВ
Emerging Architectures for Modern Data Infrastructure [1] весьма интересно изложенный отчет от Andreessen Horowitz о том как устроена современная архитектура работы с данными в зависимости от задач для которых она проектируется.
По сути - это такой универсальный канвас который можно использовать в любом хорошем инструменте рисования диаграмм. Для типовых задач бизнеса или госструктур вполне подходит и весьма продуманно структурировано (не буду утверждать что идеально, надо смотреть более детально через призму своих задач). Особенно стоит обратить внимание на сдвиги в технологиях Например, Data Flow automation вместо Workflow Management и ELT вместо ETL, а также нового типа озёра данных вместо Hadoop.
Ссылки:
[1] https://a16z.com/2020/10/15/the-emerging-architectures-for-modern-data-infrastructure/
#data #bigdata #report
_______
Источник: https://t.iss.one/begtin/2188
По сути - это такой универсальный канвас который можно использовать в любом хорошем инструменте рисования диаграмм. Для типовых задач бизнеса или госструктур вполне подходит и весьма продуманно структурировано (не буду утверждать что идеально, надо смотреть более детально через призму своих задач). Особенно стоит обратить внимание на сдвиги в технологиях Например, Data Flow automation вместо Workflow Management и ELT вместо ETL, а также нового типа озёра данных вместо Hadoop.
Ссылки:
[1] https://a16z.com/2020/10/15/the-emerging-architectures-for-modern-data-infrastructure/
#data #bigdata #report
_______
Источник: https://t.iss.one/begtin/2188
Монетизация обезличивания
Активное обсуждение проекта федерального закона, посвященного изменению регулирования обезличенных персональных данных идет последние две недели во многих каналах:
@rspectr @ict_moscow_ai @DataEconomyRU @GDPRru @privacyexperts @bureaucraticsecurity @Lgltech @Persdata @rks_legal_talk @roskomsvoboda @antidigital
Но пока аргументы всех сторон про обезличивание / анонимизацию носят исключительно качественный характер.
Ни пояснительная записка к законопроекту, ни традиционно пустое ФЭО, ни обсуждаемые поправки не содержат никаких расчетов:
- издержки операторов персональных данных на сбор / хранение согласий на обработку данных;
- издержки операторов на обезличивание;
- оценка ущерба субъектов персональных данных при использовании их данных без согласия или при де-обезличивании;
- объем рынка big data (ведь весь сыр-бор именно из-за него) и перспективы его роста в России.
При отсутствии этих данных любые правовые модели носят исключительно умозрительный характер, скрывая реальные цели лоббистов любой из продвигаемых моделей регулирования.
Короче, покажите вашимозоли расчёты!
#PersonalData #data #данные #BigData #EvidenceBased
_______
Источник: https://t.iss.one/smart_regulation/3345
Активное обсуждение проекта федерального закона, посвященного изменению регулирования обезличенных персональных данных идет последние две недели во многих каналах:
@rspectr @ict_moscow_ai @DataEconomyRU @GDPRru @privacyexperts @bureaucraticsecurity @Lgltech @Persdata @rks_legal_talk @roskomsvoboda @antidigital
Но пока аргументы всех сторон про обезличивание / анонимизацию носят исключительно качественный характер.
Ни пояснительная записка к законопроекту, ни традиционно пустое ФЭО, ни обсуждаемые поправки не содержат никаких расчетов:
- издержки операторов персональных данных на сбор / хранение согласий на обработку данных;
- издержки операторов на обезличивание;
- оценка ущерба субъектов персональных данных при использовании их данных без согласия или при де-обезличивании;
- объем рынка big data (ведь весь сыр-бор именно из-за него) и перспективы его роста в России.
При отсутствии этих данных любые правовые модели носят исключительно умозрительный характер, скрывая реальные цели лоббистов любой из продвигаемых моделей регулирования.
Короче, покажите ваши
#PersonalData #data #данные #BigData #EvidenceBased
_______
Источник: https://t.iss.one/smart_regulation/3345
sozd.duma.gov.ru
№992331-7 Законопроект :: Система обеспечения законодательной деятельности
Информационный ресурс Государственной Думы. Здесь собрана информация о рассмотрении законопроектов и проектов постановлений Государственной Думы