Яндекс продолжает готовиться к запуску собственной кредитной карты. Новый шаг - сервис "семейной карты": crvw.ru
Суть сервиса в следующем. Вы выбираете банковскую карту, привязанную к вашей учетной записи Яндекс ID. Далее подключаете к ней членов семейной группы. После этого можно выставить для каждого из участников лимиты - ежедневные, еженедельные и так далее.
Оплачивать можно только сервисы Яндекса. В некоторых, например Такси, такая возможность уже есть - там можно добавить к аккаунту другую учетную запись и тогда, например, ребенок сможет заказывать такси. С одной стороны это удобно, у ребенка появляется возможность заказывать такси в случае необходимости. С другой стороны, посмотреть маршрут и следить за перемещением в этом случае невозможно. Есть подозрение, что с остальными сервисами будет аналогичная ситуация, что не очень понятно. Надеемся, в будущем Яндекс добавит возможность получать прозрачную историю трат аккаунта детей.
О чем не пишет Яндекс, так это об истинных целях сервиса. Сложно себе представить семью, в которой используется некий семейный счет, и отсутствует удобная схема его использования. Все тривиальнее - Яндекс получит возможность более точного скоринга и оценки платежеспособности не только пользователя, но и его близких. Больше информации - больше доходов.
Как вам новый сервис Яндекса? Будете пользоваться?
_______
Источник | #contentreview
Суть сервиса в следующем. Вы выбираете банковскую карту, привязанную к вашей учетной записи Яндекс ID. Далее подключаете к ней членов семейной группы. После этого можно выставить для каждого из участников лимиты - ежедневные, еженедельные и так далее.
Оплачивать можно только сервисы Яндекса. В некоторых, например Такси, такая возможность уже есть - там можно добавить к аккаунту другую учетную запись и тогда, например, ребенок сможет заказывать такси. С одной стороны это удобно, у ребенка появляется возможность заказывать такси в случае необходимости. С другой стороны, посмотреть маршрут и следить за перемещением в этом случае невозможно. Есть подозрение, что с остальными сервисами будет аналогичная ситуация, что не очень понятно. Надеемся, в будущем Яндекс добавит возможность получать прозрачную историю трат аккаунта детей.
О чем не пишет Яндекс, так это об истинных целях сервиса. Сложно себе представить семью, в которой используется некий семейный счет, и отсутствует удобная схема его использования. Все тривиальнее - Яндекс получит возможность более точного скоринга и оценки платежеспособности не только пользователя, но и его близких. Больше информации - больше доходов.
Как вам новый сервис Яндекса? Будете пользоваться?
_______
Источник | #contentreview
Content-Review.com
Яндекс предложил свалить семейные доходы на одного
Сервис "семейной оплаты" пока доступен не всем пользователям, но вскоре его обещают раскатать на всю базу. Сервис позволяет привязать карту к семейной группе и выставить лимиты для трат на сервисы Яндекса каждому из участников
Продолжаем рубрику реалистичной анимации. Очередной алгоритм теперь уже от всем известной Ubisoft, который позволяет достичь ультра реализма в движениях 3д персонажей по виртуальным мирам. Жду с нетерпением, когда эти разработки начнут использовать на практике 👾
youtu.be
_______
Источник | #Futuris
youtu.be
_______
Источник | #Futuris
YouTube
Ubisoft’s New AI Predicts the Future of Virtual Characters! 🐺
❤️ Check out Lambda here and sign up for their GPU Cloud: https://lambdalabs.com/papers
📝 The paper "SuperTrack – Motion Tracking for Physically Simulated Characters using Supervised Learning" is available here:
https://static-wordpress.akamaized.net/mo…
📝 The paper "SuperTrack – Motion Tracking for Physically Simulated Characters using Supervised Learning" is available here:
https://static-wordpress.akamaized.net/mo…
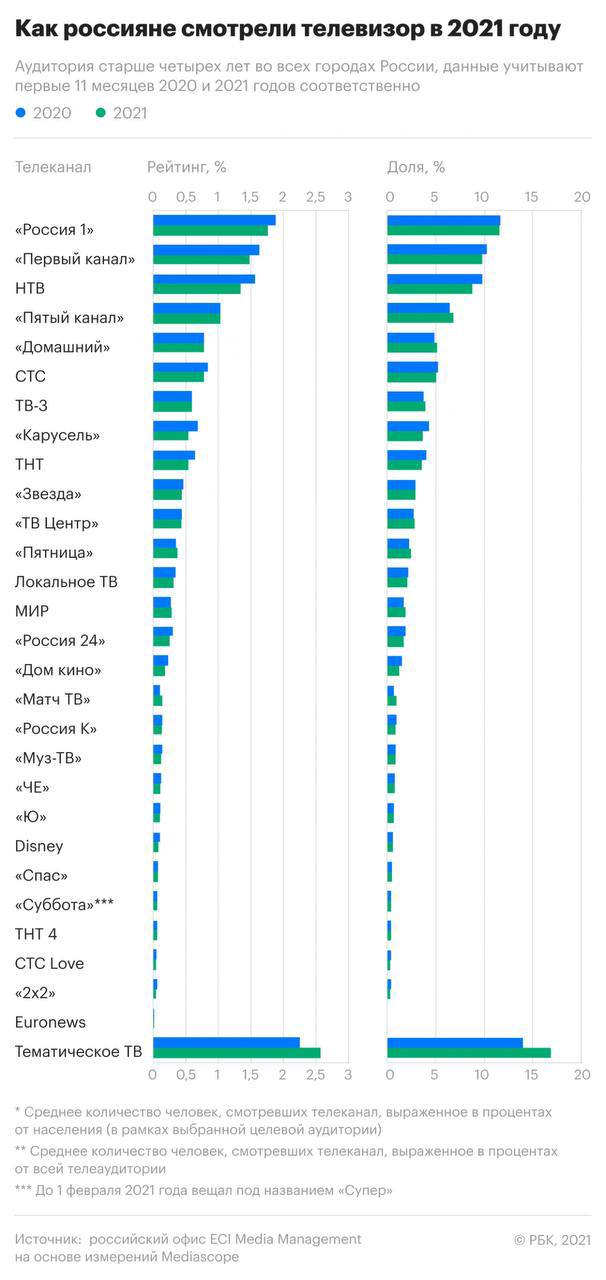
Россияне стали меньше смотреть телевизор, а «Первый» не такой уж и первый 📺
По данным ECI Media Management в 2021 году россияне не изменили своих предпочтений в ТВ-каналах, но в целом стали меньше смотреть телевизор. Единственная позиция, которая привлекла больше внимания, чем в 2020 — это тематическое ТВ.
На первом месте по популярности каналов все ещё находится «Россия 1», а 2-е и 3-е место почти делят «Первый канал» и НТВ.
_______
Источник | #breakingtrends
По данным ECI Media Management в 2021 году россияне не изменили своих предпочтений в ТВ-каналах, но в целом стали меньше смотреть телевизор. Единственная позиция, которая привлекла больше внимания, чем в 2020 — это тематическое ТВ.
На первом месте по популярности каналов все ещё находится «Россия 1», а 2-е и 3-е место почти делят «Первый канал» и НТВ.
_______
Источник | #breakingtrends
{kind=link}
TJournal: «Кинопоиск» научился распознавать музыку, которая играет в фильмах и сериалах
– Название песни и исполнителя отображается в интерфейсе плеера
– Трек можно сохранять в специальный плейлист Яндекс.Музыки
– Можно распознать инструментальную музыку и фоновые песни
– Добавлять треки в плейлист можно и на телевизоре
– В приложении для Smart TV появился раздел с музыкой
– «Кинопоиск» уже несколько лет распознаёт актеров в кадре
_______
Source: 42 секунды
– Название песни и исполнителя отображается в интерфейсе плеера
– Трек можно сохранять в специальный плейлист Яндекс.Музыки
– Можно распознать инструментальную музыку и фоновые песни
– Добавлять треки в плейлист можно и на телевизоре
– В приложении для Smart TV появился раздел с музыкой
– «Кинопоиск» уже несколько лет распознаёт актеров в кадре
_______
Source: 42 секунды
TJ
«Кинопоиск» научился распознавать музыку, которая играет в фильмах и сериалах — Технологии на TJ
Сервис уже несколько лет распознаёт актёров в кадре, а теперь ещё и подсказывает, какая песня играет.
Грошовый обзор #113
📉 Распродажа в Азии
🔗 Роллапы
📕 Отчёт TheBlock
⚡️ Комиссии в Lightning
⛓ Визуализатор Bitcoin Script
🌎 Макро
teletype.in
_______
Source: Hype Coin News
📉 Распродажа в Азии
🔗 Роллапы
📕 Отчёт TheBlock
⚡️ Комиссии в Lightning
⛓ Визуализатор Bitcoin Script
🌎 Макро
teletype.in
_______
Source: Hype Coin News
Веселые истории. Patreon создает видеохостинг с собственным плеером, чтобы создатели могли строить бизнес по подписке, не полагаясь на другие платформы, такие как YouTube. Have fun!
Подробнее: buff.ly
_______
Источник | #funcubator
Подробнее: buff.ly
_______
Источник | #funcubator
The Verge
Patreon’s building native video hosting for creators to sidestep YouTube
Patreon wants to be the place creators do it all.
⚡️Google оштрафован в России на 7,2 млрд рублей за повторное неудаление запрещенной информации - российский суд впервые наложил на IT-компанию оборотный штраф
___
Источник | #rian_ru | #breaking_news
___
Источник | #rian_ru | #breaking_news
Telegram
РИА Новости
⚡️Google оштрафован в России на 7,2 млрд рублей за повторное неудаление запрещенной информации - российский суд впервые наложил на IT-компанию оборотный штраф
Афиша фильма «Матрица» в кинотеатре «Kodak-Киномир», 1999 год. Открывшийся в Настасьинском переулке в 1996, это был первый кинотеатр в России прославившийся системой Dolby Digital и закрытыми премьерами с участием популярных звёзд того периода. Позднее кинотеатр переименовали просто в «Киномир» и уже под таким названием он прекратил свою жизнь в 2012 году
_______
Источник | #LostGen
_______
Источник | #LostGen
Недавний пример неожиданного столкновения с феноменом биометрии – сервис Авито. Уже повсеместно появляются истории о том, как на сайте запрашивают идентификацию с помощью биометрических данных. Ладно, идентификацию по паспорту ввели с недавнего времени, теперь еще и это. Был у вас безобидный аккаунт на Авито, однажды вы туда приходите и видите, что нужна дополнительная верификация в виде паспорта и биометрии. Это как бы защита от спама, связанная с ограничением просмотров телефонов. Но даже если вы никогда не смотрите телефоны, это все же потребуется. Что будет, если этого не делать? Функционал сервиса для вас будет ограничен. Если вы зарабатываете какие-то деньги на этой площадке – это печальные новости, не так ли?
При этом всем известно, что Авито – это буквально монополист в сфере вторичных продаж.
ОК, другое дело – каршеринг. С одной стороны, когда возникла идея о сборе биометрии пользователей каршеринга, сразу всплыли плюсы: якобы, это обезопасит сервис от тех случаев, когда кто-то включает приложение в мобильнике, и передает его для пользования посторонним лицам. На деле выясняется следующее: объем таких случаев в статистике пользования сервисами каршеринга настолько мал, что никто от этого и не страдает вроде. Однако если идентификацию для проката автомобиля сделают обязательной, это нехило увеличит стоимость услуг. При этом остается загадкой главное: кто собирает данные, каков формат доступа к ним, и кто за все это платит.
«Но это же не обязательно!» – вроде как пробежала фраза в голове. Да, с согласия пользователя. Да, перечень разрешенных, а не обязательных случаев. Однако – это уже территория рынка, где действует правило «не нравится – уходи». Владельцу сервиса каким-то образом нужно будет обеспечить его работу и ограничить тех, кто не сдает биометрию. Иными словами, как в истории с Авито, вы не сможете в полной мере пользоваться сервисом. Иными словами, захотели вы взять машину в каршеринге – давайте данные и платите больше, или идите пешком.
Не стоит забывать, что это все те же первые шаги в цифровизации, о которой пока даже нельзя сказать, что она «набирает обороты». Проектов много, запускают их на государственном уровне, начали с банков – теперь потихоньку спустились к современным пользователям напрямую. То есть, будущее уже здесь, все это будет только множиться.
Ну и конечно, нужно помнить, что никто и никогда не может гарантировать конфиденциальность сбора и хранения данных на 100%.
Как часто современный человек, в особенности горожанин, пользуется современными, цифровыми сервисами? Приложениями? С приходом коронавируса – постоянно.
Что будет дальше? Доставка продуктов по биометрии?
В таких условиях, где биометрия повсеместна, а вы отчаянно сопротивляетесь ей – единственным надежным выходом для вас будет не пользоваться вообще никакими современными сервисами. Но это же самоубийство в цифровом пространстве. Возможно, и в реальном тоже. Так вы сами себя изолируете и помещаете в вакуум и каменный век. Хотя это и может быть новой философией, жизнь будет довольно сложной. Современный человек на это очень вряд ли согласится, да и смысла особенного, получается, нет.
Что же с этим делать?
Так уж получается, что в таком важном процессе, как сбор и хранение данных, запущенном государством, надежность и безопасность почему-то второстепенна. Никто не торопится разрешить противоречия, касающиеся защищенности в этой области. Получается, что пользователям, поставленным в такую ситуацию, этот вопрос нужно решить самостоятельно. Так хотя бы можно быть уверенным в подстраховке. Раз уж сбор биометрических данных вскоре затронет любого гражданина прежде, чем пользователю обеспечат безопасность, нужно озаботиться дополнительными способами защиты собственных данных.
___
Источник | #TehnoNacional | #мнение
При этом всем известно, что Авито – это буквально монополист в сфере вторичных продаж.
ОК, другое дело – каршеринг. С одной стороны, когда возникла идея о сборе биометрии пользователей каршеринга, сразу всплыли плюсы: якобы, это обезопасит сервис от тех случаев, когда кто-то включает приложение в мобильнике, и передает его для пользования посторонним лицам. На деле выясняется следующее: объем таких случаев в статистике пользования сервисами каршеринга настолько мал, что никто от этого и не страдает вроде. Однако если идентификацию для проката автомобиля сделают обязательной, это нехило увеличит стоимость услуг. При этом остается загадкой главное: кто собирает данные, каков формат доступа к ним, и кто за все это платит.
«Но это же не обязательно!» – вроде как пробежала фраза в голове. Да, с согласия пользователя. Да, перечень разрешенных, а не обязательных случаев. Однако – это уже территория рынка, где действует правило «не нравится – уходи». Владельцу сервиса каким-то образом нужно будет обеспечить его работу и ограничить тех, кто не сдает биометрию. Иными словами, как в истории с Авито, вы не сможете в полной мере пользоваться сервисом. Иными словами, захотели вы взять машину в каршеринге – давайте данные и платите больше, или идите пешком.
Не стоит забывать, что это все те же первые шаги в цифровизации, о которой пока даже нельзя сказать, что она «набирает обороты». Проектов много, запускают их на государственном уровне, начали с банков – теперь потихоньку спустились к современным пользователям напрямую. То есть, будущее уже здесь, все это будет только множиться.
Ну и конечно, нужно помнить, что никто и никогда не может гарантировать конфиденциальность сбора и хранения данных на 100%.
Как часто современный человек, в особенности горожанин, пользуется современными, цифровыми сервисами? Приложениями? С приходом коронавируса – постоянно.
Что будет дальше? Доставка продуктов по биометрии?
В таких условиях, где биометрия повсеместна, а вы отчаянно сопротивляетесь ей – единственным надежным выходом для вас будет не пользоваться вообще никакими современными сервисами. Но это же самоубийство в цифровом пространстве. Возможно, и в реальном тоже. Так вы сами себя изолируете и помещаете в вакуум и каменный век. Хотя это и может быть новой философией, жизнь будет довольно сложной. Современный человек на это очень вряд ли согласится, да и смысла особенного, получается, нет.
Что же с этим делать?
Так уж получается, что в таком важном процессе, как сбор и хранение данных, запущенном государством, надежность и безопасность почему-то второстепенна. Никто не торопится разрешить противоречия, касающиеся защищенности в этой области. Получается, что пользователям, поставленным в такую ситуацию, этот вопрос нужно решить самостоятельно. Так хотя бы можно быть уверенным в подстраховке. Раз уж сбор биометрических данных вскоре затронет любого гражданина прежде, чем пользователю обеспечат безопасность, нужно озаботиться дополнительными способами защиты собственных данных.
___
Источник | #TehnoNacional | #мнение
Telegram
ТехноНационал
Недавний пример неожиданного столкновения с феноменом биометрии – сервис Авито. Уже повсеместно появляются истории о том, как на сайте запрашивают идентификацию с помощью биометрических данных. Ладно, идентификацию по паспорту ввели с недавнего времени, теперь…
Google Trends: пользователи чаще интересуются NFT, чем криптовалютами
bits.media
Согласно данным Google Trends, пользователи крупнейшего поисковика ищут информацию о NFT чаще, чем о криптовалютах. Однако, лидером по поисковым запросам остается биткоин.
bits.media
Согласно данным Google Trends, пользователи крупнейшего поисковика ищут информацию о NFT чаще, чем о криптовалютах. Однако, лидером по поисковым запросам остается биткоин.
bits.media
Google Trends: пользователи чаще интересуются NFT, чем криптовалютами
Согласно данным Google Trends, пользователи крупнейшего поисковика ищут информацию о NFT чаще, чем о криптовалютах. Однако, лидером по поисковым запросам остается биткоин.
Языковые модели активно используются в бизнесе. Например открытая модель Ope AI GPT-3 уже задействована в 300 разных приложениях, которые генерируют колоссальное количество текста — до 4,5 млрд слов в день.
www.cnews.ru
www.cnews.ru
CNews.ru
ИИ выведет на новые высоты пропаганду и дезинформацию - CNews
Эксперты нескольких крупных исследовательских центров предупреждают, что крупномасштабные языковые модели...
Опять побуду адвокатом дьявола у Tether.
Речь о довольно странном недавнем иске от двух физиков, оспаривающих утверждения Tether о полном обеспечении USDT.
Они утверждают, что действия компании были мошенническими, вводящими их в заблуждение при оценке привлекательности и надежности данного актива.
Истцы требуют, чтобы действия компании были признаны "недобросовестными, аморальными, травмирующими и дискриминационными"; присуждение им некоего возмещения, а также оплату всех расходов при сопутствующем судебном разбирательстве, в том числе услуги юридической конторы.
Изучив 46 страниц сего чудо-документа нельзя не признать, что работа была проведена довольно масштабнаяпо мотивам публикаций в Bloomberg и Coindesk, очевидно. Тем не менее, некоторые претензии выглядят довольно забавно: "если бы я знал, что на самом деле USDT не имеет полного обеспечения, то никогда бы его не приобрел." Ну и сидел бы себе дальше без подарка. Или: "Я бы приобрел, но значительно дешевле." Интересно, кто бы тебе его продал значительно дешевле? Одного твоего желания здесь недостаточно. Есть рынок и ему плевать на желания некоего юзера. При этом, данные лица покупали Usdt неоднократно, в течение нескольких лет. В том числе на протяжении двух лет после официального уведомления на сайте компании, о том, что актив не является аналогом доллара, и обеспечен долларовыми резервами лишь частично, что было во всех новостях. И даже после разбирательства в прокуратуре Нью-Йорка. Да, разумеется, Tether LTD довольно мутная и грязная контора, к ней очень много вопросов, но претензии данных двух лиц, имхо, безосновательны, так как покупка не принесла им никаких убытков или морального вреда.
Поэтому ответ Tether LTD ожидаемо указывает на желание этих двух просто поднять хайп и заработать денег.
Интересно лишь одно: это реально настоящие умники такие внезапно проснулись, или дело сфабриковано с иной целью.
_______
Источник | #gfischannel
Речь о довольно странном недавнем иске от двух физиков, оспаривающих утверждения Tether о полном обеспечении USDT.
Они утверждают, что действия компании были мошенническими, вводящими их в заблуждение при оценке привлекательности и надежности данного актива.
Истцы требуют, чтобы действия компании были признаны "недобросовестными, аморальными, травмирующими и дискриминационными"; присуждение им некоего возмещения, а также оплату всех расходов при сопутствующем судебном разбирательстве, в том числе услуги юридической конторы.
Изучив 46 страниц сего чудо-документа нельзя не признать, что работа была проведена довольно масштабная
Поэтому ответ Tether LTD ожидаемо указывает на желание этих двух просто поднять хайп и заработать денег.
Интересно лишь одно: это реально настоящие умники такие внезапно проснулись, или дело сфабриковано с иной целью.
_______
Источник | #gfischannel
CourtListener
Complaint – #1 in Anderson v. Tether Holdings Limited (S.D.N.Y., 1:21-cv-10613) – CourtListener.com
COMPLAINT against BFXNA Inc., BFXWW Inc., Tether Holdings Limited, Tether International Limited, Tether Limited, Tether Operations Limited, iFinex Inc.. (Filing Fee $ 402.00, Receipt Number ANYSDC-25455849)Document filed by Shawn Dolifka, Matthew Anderson..(Levis…
Стало известно, как технически ЦБ планирует запретить криптовалюту
По данным Forbs, будут блокировать карточные переводы россиян по определенным MCC-кодам. (четырехзначный код, который банк, проводящий транзакцию, присваивает компании, в адрес которой идет платеж). По этому коду можно легко отследить, какие именно услуги указывает продавец.
Будут блокировать код 6051 — обменники и криптобиржи.
———
бугага
всмысле кря
По данным Forbs, будут блокировать карточные переводы россиян по определенным MCC-кодам. (четырехзначный код, который банк, проводящий транзакцию, присваивает компании, в адрес которой идет платеж). По этому коду можно легко отследить, какие именно услуги указывает продавец.
Будут блокировать код 6051 — обменники и криптобиржи.
———
бугага
всмысле кря
Forbes.ru
Как ЦБ планирует запретить криптовалюту в России
Центробанк планирует полностью запретить инвестиции в криптовалюты. Об этом стало известно на прошлой неделе, а Forbes выяснил, как именно ЦБ намерен это сделать. Один из вариантов уже обсуждается с финансовым сектором
пока #пятничное
Россиян обяжут перевести всю криптовалюту на кошельки Центробанка до 1 марта 2022 года
panorama.wtf
Россиян обяжут перевести всю криптовалюту на кошельки Центробанка до 1 марта 2022 года
panorama.wtf
ИА Панорама
Россиян обяжут перевести всю криптовалюту на кошельки Центробанка до 1 марта 2022 года
Рабочая группа Государственной думы по оптимизации законодательства в области криптовалют подготовила поправки в федеральный закон «О цифровых финансовых актива...
Про Гугл, оборотные штрафы и Блокировку: не согласен с Мишей ... Как минимум до сентября 22 г. Гугл не заблочат: суд. система неповоротлива ( дело то до ВС дойдёт, а блочить до этого не будут, -ВВП юрист ведь), да и в АП свободномыслящие люди есть..
_______
Источник | #ordercomru | #мнение
_______
Источник | #ordercomru | #мнение
Telegram
ЗаТелеком
Итак, когда заблокируют Гугл
И да — не опечатка. Вопрос на этот раз стоит не "смогут ли", а когда. Технически Гугл вообще и Ютюб в частности заблокировать не так уж и сложно — даже без ТСПУ можно. Достаточно заставить операторов снять с эксплуатации сервера…
И да — не опечатка. Вопрос на этот раз стоит не "смогут ли", а когда. Технически Гугл вообще и Ютюб в частности заблокировать не так уж и сложно — даже без ТСПУ можно. Достаточно заставить операторов снять с эксплуатации сервера…
Кажется власти придумали, как нафармить бабла на третий пакет мер поддержки русской IT отрасли.
К Гуглу присоединяется Мета (Фейсбук) – компанию оштрафовали почти на 2 миллиарда.
habr.com
___
Источник | #korolevsnotes | #breaking_news
К Гуглу присоединяется Мета (Фейсбук) – компанию оштрафовали почти на 2 миллиарда.
habr.com
___
Источник | #korolevsnotes | #breaking_news
Хабр
Суд оштрафовал Meta (Facebook) на 1,99 млрд рублей
24 декабря 2021 года Мировой суд Таганского района Москвы оштрафовал Meta (Facebook) на 1 990 984 950 рублей и 5 копеек по статье с оборотным штрафом за массовые повторные нарушения законодательства...
Безумие ИИ.
Решения на основе полной бессмыслицы.
Популярная метафора, приводимая ИИ-энтузиастами, напоминает, что люди смогли «научить» самолеты летать, не уподобляясь машущим крыльями птицам. Вот и машинное обучение нейросетей, считают ИИ-энтузиасты, также способно обеспечить функции разума без 100%-го повторения способностей разума людей.
Ошибочность этого сравнения в том (говоря языком той же метафоры), что машинное обучение обеспечивает совсем иную способность, чем способность летать. Эта лишь на первый взгляд похожая способность – умение подняться выше уровня земли. И реализуется эта способность путем залезания на ближайшее дерево. Но полет – это далеко не только способность подняться над землей. И так же, как влезание даже на очень высокое дерево не способно обеспечить полета, машинное обучение в принципе не способно дать машине разум.
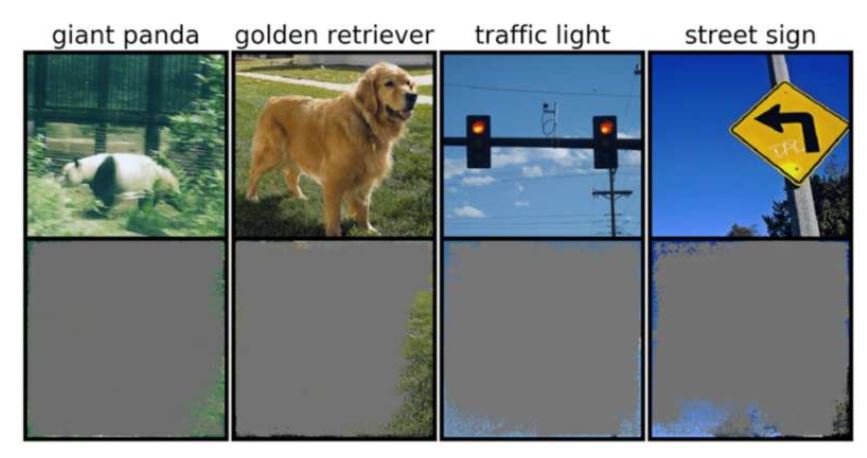
Недавно проведенное исследование MIT обнаружило, что нейронные сети, обученные на популярных бенчмарках, демонстрируют новый тип сбоя, называемый гиперинтерпретация или чрезмерная интерпретация (overinterpretation).
Суть этого сбоя в том, что алгоритмы машинного обучения делают уверенные прогнозы на основе информации, которая не имеет смысла для людей и не имеет отношения к решаемой задаче.
Посмотрите на приложенные изображения.
• Изображения в нижней строке отличаются от исходных изображений (верхняя строка):
-- на них отсутствует 95% исходного изображения;
-- и эти отсутствующие 95% изображения несут ВСЮ смысловую информацию для верной классификации изображения.
• Тем не менее, сети классифицируют нижнюю строку изображений с достоверностью 90%+
Это значит, что сети, на самом деле, вовсе не учатся распознавать собаку или панду, а вместо этого могут распознать животное просто по типу травы на заднем плане.
Происходит это из-за того, что ИИ решает совершенно иные задачи, чем разум (как в метафоре – задачу подняться выше уровня земли, вместо задачи полета).
Цель разума – умение выбирать эффективные действия.
Это умение – ключевое эволюционное преимущество животных перед растениями, для обеспечения которого у животных появилась нервная система, а потом и мозг.
Как пишут про это Сломан и Фернбах в «Иллюзии знаний»:
Если бы мы эволюционировали в условиях, в которых вместо умения выбирать
эффективные действия требовались бы какие-то другие способности, то человеческий разум, наверное, опирался бы на какую-то другую логику, отличную от существующей. Если бы наша эволюция проходила в мире, где вознаграждались бы победители в азартных играх, мы, вероятно, безошибочно рассуждали бы о плотности распределения вероятностей и об уравнениях статистики. Если бы мы эволюционировали в мире, в котором поощрялось бы дедуктивное мышление, мы все, подобно Споку, были бы виртуозами по части логических заключений. Но мы в большинстве своем не сильны в этих делах. Вместо этого мы развивались в мире, где правит логика действий, и именно поэтому такой вид мышления составляет основу того, что делает нас людьми.
Современный ИИ устроен совершенно иначе. Он учится на огромных массивах данных, выявляя в них ЛЮБЫЕ статистические особенности. Не обладая пониманием решаемой задачи:
✔️ ИИ не способен отличать статистическую значимость от практической важности;
✔️ ИИ способен принимать решения на основании полной бессмыслицы (статистических закономерностей, не только не имеющих отношения к задаче, но и вообще ни к чему)
В коментах к моему недавнему посту об автономном оружии, некоторые разработчики ИИ (так они себя определяют) корили меня за незнание матчасти – мол, ребенка от низкорослого мужчины ИИ отличит лучше человека.
Исследование MIT, увы, говорит об ином. И куда худшем.
Из-за гиперинтерпретации автономный дрон-киллер способен классифицировать ребенка, как мужчину, на основе чего угодно: узора проплешин травы на газоне, тени деревьев на стене дома ... И такое решение автономного дрона-киллера будет окончательным.
bit.ly
#Гиперинтерпретация
_______
Источник | #theworldisnoteasy
Решения на основе полной бессмыслицы.
Популярная метафора, приводимая ИИ-энтузиастами, напоминает, что люди смогли «научить» самолеты летать, не уподобляясь машущим крыльями птицам. Вот и машинное обучение нейросетей, считают ИИ-энтузиасты, также способно обеспечить функции разума без 100%-го повторения способностей разума людей.
Ошибочность этого сравнения в том (говоря языком той же метафоры), что машинное обучение обеспечивает совсем иную способность, чем способность летать. Эта лишь на первый взгляд похожая способность – умение подняться выше уровня земли. И реализуется эта способность путем залезания на ближайшее дерево. Но полет – это далеко не только способность подняться над землей. И так же, как влезание даже на очень высокое дерево не способно обеспечить полета, машинное обучение в принципе не способно дать машине разум.
Недавно проведенное исследование MIT обнаружило, что нейронные сети, обученные на популярных бенчмарках, демонстрируют новый тип сбоя, называемый гиперинтерпретация или чрезмерная интерпретация (overinterpretation).
Суть этого сбоя в том, что алгоритмы машинного обучения делают уверенные прогнозы на основе информации, которая не имеет смысла для людей и не имеет отношения к решаемой задаче.
Посмотрите на приложенные изображения.
• Изображения в нижней строке отличаются от исходных изображений (верхняя строка):
-- на них отсутствует 95% исходного изображения;
-- и эти отсутствующие 95% изображения несут ВСЮ смысловую информацию для верной классификации изображения.
• Тем не менее, сети классифицируют нижнюю строку изображений с достоверностью 90%+
Это значит, что сети, на самом деле, вовсе не учатся распознавать собаку или панду, а вместо этого могут распознать животное просто по типу травы на заднем плане.
Происходит это из-за того, что ИИ решает совершенно иные задачи, чем разум (как в метафоре – задачу подняться выше уровня земли, вместо задачи полета).
Цель разума – умение выбирать эффективные действия.
Это умение – ключевое эволюционное преимущество животных перед растениями, для обеспечения которого у животных появилась нервная система, а потом и мозг.
Как пишут про это Сломан и Фернбах в «Иллюзии знаний»:
Если бы мы эволюционировали в условиях, в которых вместо умения выбирать
эффективные действия требовались бы какие-то другие способности, то человеческий разум, наверное, опирался бы на какую-то другую логику, отличную от существующей. Если бы наша эволюция проходила в мире, где вознаграждались бы победители в азартных играх, мы, вероятно, безошибочно рассуждали бы о плотности распределения вероятностей и об уравнениях статистики. Если бы мы эволюционировали в мире, в котором поощрялось бы дедуктивное мышление, мы все, подобно Споку, были бы виртуозами по части логических заключений. Но мы в большинстве своем не сильны в этих делах. Вместо этого мы развивались в мире, где правит логика действий, и именно поэтому такой вид мышления составляет основу того, что делает нас людьми.
Современный ИИ устроен совершенно иначе. Он учится на огромных массивах данных, выявляя в них ЛЮБЫЕ статистические особенности. Не обладая пониманием решаемой задачи:
✔️ ИИ не способен отличать статистическую значимость от практической важности;
✔️ ИИ способен принимать решения на основании полной бессмыслицы (статистических закономерностей, не только не имеющих отношения к задаче, но и вообще ни к чему)
В коментах к моему недавнему посту об автономном оружии, некоторые разработчики ИИ (так они себя определяют) корили меня за незнание матчасти – мол, ребенка от низкорослого мужчины ИИ отличит лучше человека.
Исследование MIT, увы, говорит об ином. И куда худшем.
Из-за гиперинтерпретации автономный дрон-киллер способен классифицировать ребенка, как мужчину, на основе чего угодно: узора проплешин травы на газоне, тени деревьев на стене дома ... И такое решение автономного дрона-киллера будет окончательным.
bit.ly
#Гиперинтерпретация
_______
Источник | #theworldisnoteasy
{kind=link}
«Почта России» потеряла письмо екатеринбургского правозащитника Андрея Щукина в Европейский суд по правам человека.
«Я подавал жалобу в ЕСПЧ и потом увидел на сайте «Почты России», что она ушла куда-то в Нидерланды и там осталась. Письмо мне не вернули», — рассказал Щукин.
#роскомзадор #когданибудьиэтозаблокируют
_______
Источник | #roskomsvoboda
«Я подавал жалобу в ЕСПЧ и потом увидел на сайте «Почты России», что она ушла куда-то в Нидерланды и там осталась. Письмо мне не вернули», — рассказал Щукин.
#роскомзадор #когданибудьиэтозаблокируют
_______
Источник | #roskomsvoboda
❗️Роскомсвобода проанализировала «государственный шопинг»
За 2020-2021 годы власти потратили как минимум 1,932 миллиарда рублей на внедрение систем распознавания лиц, ещё 620 миллионов рублей – на мониторинг соцсетей и новостных сайтов. Такие цифры наши эксперты обнаружили, изучив госзакупки в области контроля за интернетом.
Мы опубликовали большой доклад о «шопинге» государства, где рассказываем, как за бюджетный счёт закупалось оборудование и ПО для контроля за оборотом контента в интернете и наблюдением пользователями.
В нём сосредоточились на четырех основных аспектах:
🔹закупка инструментов мониторинга социальных сетей и интернет-СМИ;
🔹закупка информационных систем;
🔹закупка систем слежения;
🔹закупка систем распознавания лиц.
➡️ Подробнее
➡️ Доклад полностью
➡️ Мониторинг госзакупок
_______
Источник | #roskomsvoboda
За 2020-2021 годы власти потратили как минимум 1,932 миллиарда рублей на внедрение систем распознавания лиц, ещё 620 миллионов рублей – на мониторинг соцсетей и новостных сайтов. Такие цифры наши эксперты обнаружили, изучив госзакупки в области контроля за интернетом.
Мы опубликовали большой доклад о «шопинге» государства, где рассказываем, как за бюджетный счёт закупалось оборудование и ПО для контроля за оборотом контента в интернете и наблюдением пользователями.
В нём сосредоточились на четырех основных аспектах:
🔹закупка инструментов мониторинга социальных сетей и интернет-СМИ;
🔹закупка информационных систем;
🔹закупка систем слежения;
🔹закупка систем распознавания лиц.
➡️ Подробнее
➡️ Доклад полностью
➡️ Мониторинг госзакупок
_______
Источник | #roskomsvoboda