
Forwarded from Machinelearning
FLAIR: A Foundation LAnguage Image model of the Retina
🖥 Github: https://github.com/jusiro/flair
📕 Paper: https://arxiv.org/pdf/2308.07898v1.pdf
🔥 Dataset: https://paperswithcode.com/dataset/imagenet
@ai_machinelearning_big_data
🔥 Dataset: https://paperswithcode.com/dataset/imagenet
@ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥5❤3👍3
LISA: Reasoning Segmentation via Large Language Model
The field of image segmentation has taken a leap forward with the introduction of LISA (Large Language Instructed Segmentation Assistant). This cutting-edge model excels at "reasoning segmentation," a novel task that generates segmentation masks from complex and implicit text queries. Building upon the capabilities of multi-modal Large Language Models, LISA expands its vocabulary with a <SEG> token and introduces an innovative "embedding-as-mask" paradigm to achieve this feat. Notably, the model is adept at intricate reasoning, utilizes world knowledge, offers explanatory answers, and can handle multi-turn conversations.
What's astonishing about LISA is its robust zero-shot learning abilities. Even when trained on datasets that lack reasoning-based tasks, LISA performs impressively well. Moreover, when fine-tuned with just 239 specific reasoning segmentation image-instruction pairs, the model's performance is further enhanced.
Paper link: https://arxiv.org/abs/2308.00692
Code link: https://github.com/dvlab-research/LISA
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-lisa
#deeplearning #cv #nlp #imagesegmentation #largelanguagemodel
The field of image segmentation has taken a leap forward with the introduction of LISA (Large Language Instructed Segmentation Assistant). This cutting-edge model excels at "reasoning segmentation," a novel task that generates segmentation masks from complex and implicit text queries. Building upon the capabilities of multi-modal Large Language Models, LISA expands its vocabulary with a <SEG> token and introduces an innovative "embedding-as-mask" paradigm to achieve this feat. Notably, the model is adept at intricate reasoning, utilizes world knowledge, offers explanatory answers, and can handle multi-turn conversations.
What's astonishing about LISA is its robust zero-shot learning abilities. Even when trained on datasets that lack reasoning-based tasks, LISA performs impressively well. Moreover, when fine-tuned with just 239 specific reasoning segmentation image-instruction pairs, the model's performance is further enhanced.
Paper link: https://arxiv.org/abs/2308.00692
Code link: https://github.com/dvlab-research/LISA
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-lisa
#deeplearning #cv #nlp #imagesegmentation #largelanguagemodel
{kind=link}
🔥11👍7
Forwarded from Machinelearning
🪄WizardLM: Empowering Large Pre-Trained Language Models to Follow Complex Instructions
Model outperforms ChatGPT-3.5, Claude Instant-1, PaLM-2 and Minerva on GSM8k, simultaneously surpasses Text-davinci-002, PaLM-1 and GPT-3 on MATH.
Фреймворк WizardMath, который расширяет способности Llama-2 к математическому мышлению, применяя метод Reinforcement Learning from Evol-Instruct Feedback (RLEIF) к области математики.
WizardMath с существенным отрывом превосходит все остальные LLM с открытым исходным кодом в решение мат. задач.
🖥 Github: https://github.com/nlpxucan/wizardlm
📕 Paper: https://arxiv.org/abs/2308.09583v1
🤗 HF: https://huggingface.co/WizardLM
☑️ Dataset: https://paperswithcode.com/dataset/gsm8k
ai_machinelearning_big_data
Model outperforms ChatGPT-3.5, Claude Instant-1, PaLM-2 and Minerva on GSM8k, simultaneously surpasses Text-davinci-002, PaLM-1 and GPT-3 on MATH.
Фреймворк WizardMath, который расширяет способности Llama-2 к математическому мышлению, применяя метод Reinforcement Learning from Evol-Instruct Feedback (RLEIF) к области математики.
WizardMath с существенным отрывом превосходит все остальные LLM с открытым исходным кодом в решение мат. задач.
🤗 HF: https://huggingface.co/WizardLM
ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
👍17❤5🔥2
Forwarded from Machinelearning
☄️Dataset Quantization
DQ is able to generate condensed small datasets for training unseen network architectures with state-of-the-art compression ratios for lossless model training.
Квантование наборов данных (DQ) - новая схема сжатия больших наборов данных в небольшие сабсеты, которые могут быть использованы для обучения любых нейросетевых архитектур.
🖥 Github: https://github.com/magic-research/dataset_quantization
📕 Paper: https://arxiv.org/abs/2308.10524v1
☑️ Dataset: https://paperswithcode.com/dataset/gsm8k
ai_machinelearning_big_data
DQ is able to generate condensed small datasets for training unseen network architectures with state-of-the-art compression ratios for lossless model training.
Квантование наборов данных (DQ) - новая схема сжатия больших наборов данных в небольшие сабсеты, которые могут быть использованы для обучения любых нейросетевых архитектур.
git clone https://github.com/vimar-gu/DQ.git
cd DQai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥10👍7❤5
Forwarded from ml4se
OWASP Top 10 for LLM
The OWASP Top 10 for Large Language Model Applications project aims to educate developers, designers, architects, managers, and organizations about the potential security risks when deploying and managing Large Language Models (LLMs). The project provides a list of the top 10 most critical vulnerabilities often seen in LLM applications, highlighting their potential impact, ease of exploitation, and prevalence in real-world applications. Examples of vulnerabilities include prompt injections, data leakage, inadequate sandboxing, and unauthorized code execution, among others. The goal is to raise awareness of these vulnerabilities, suggest remediation strategies, and ultimately improve the security posture of LLM applications.
1 Prompt Injection
2 Insecure Output Handling
3 Training Data Poisoning
4 Model Denial of Service
5 Supply Chain Vulnerabilities
6 Sensitive Information Disclosure
7 Insecure Plugin Design
8 Excessive Agency
9 Overreliance
10 Model Theft
PDF
The OWASP Top 10 for Large Language Model Applications project aims to educate developers, designers, architects, managers, and organizations about the potential security risks when deploying and managing Large Language Models (LLMs). The project provides a list of the top 10 most critical vulnerabilities often seen in LLM applications, highlighting their potential impact, ease of exploitation, and prevalence in real-world applications. Examples of vulnerabilities include prompt injections, data leakage, inadequate sandboxing, and unauthorized code execution, among others. The goal is to raise awareness of these vulnerabilities, suggest remediation strategies, and ultimately improve the security posture of LLM applications.
1 Prompt Injection
2 Insecure Output Handling
3 Training Data Poisoning
4 Model Denial of Service
5 Supply Chain Vulnerabilities
6 Sensitive Information Disclosure
7 Insecure Plugin Design
8 Excessive Agency
9 Overreliance
10 Model Theft
👍11❤2
OBELISC: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents
The OBELICS dataset is a game-changer in the world of machine learning and AI! Unlike existing closed-source datasets, OBELICS is a vast, open-source, web-scale dataset specially curated for training large multimodal models. Boasting 141 million web pages from Common Crawl, 353 million high-quality images, and an impressive 115 billion text tokens, OBELICS sets a new standard in the richness and diversity of training data.
But it's not just about the numbers; it's about results. To prove its mettle, models with 9 and 80 billion parameters were trained on OBELICS, showcasing competitive performance across various multimodal benchmarks. Named IDEFICS, these models outperformed or matched their closed-source counterparts, proving that OBELICS isn't just a theoretical concept—it's a practical, high-impact alternative.
Paper link: https://huggingface.co/papers/2306.16527
Model card link: https://huggingface.co/HuggingFaceM4/idefics-80b-instruct
Blogpost link: https://huggingface.co/blog/idefics
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-obelisc
#deeplearning #cv #nlp #largelanguagemodel #opensource
The OBELICS dataset is a game-changer in the world of machine learning and AI! Unlike existing closed-source datasets, OBELICS is a vast, open-source, web-scale dataset specially curated for training large multimodal models. Boasting 141 million web pages from Common Crawl, 353 million high-quality images, and an impressive 115 billion text tokens, OBELICS sets a new standard in the richness and diversity of training data.
But it's not just about the numbers; it's about results. To prove its mettle, models with 9 and 80 billion parameters were trained on OBELICS, showcasing competitive performance across various multimodal benchmarks. Named IDEFICS, these models outperformed or matched their closed-source counterparts, proving that OBELICS isn't just a theoretical concept—it's a practical, high-impact alternative.
Paper link: https://huggingface.co/papers/2306.16527
Model card link: https://huggingface.co/HuggingFaceM4/idefics-80b-instruct
Blogpost link: https://huggingface.co/blog/idefics
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-obelisc
#deeplearning #cv #nlp #largelanguagemodel #opensource
{kind=link}
👍8🔥3❤2🥰1
Forwarded from ml4se
Exploring Parameter-Efficient Fine-Tuning Techniques for Code Generation with Large Language Models
The results reveal the superiority and potential of PEFT over ICL (In-Context Learning) on a wide range of LLMs in reducing the computational burden and improving performance.
Main results:
- LLMs fine-tuned with PEFT techniques, i.e., a few millions of parameters, systematically outperform small language models fully fine-tuned with hundreds of millions of parameters
- Prompt tuning often outperforms LoRA even though it requires learning substantially fewer parameters
- LLMs fine-tuned using LoRA and Prompt tuning significantly outperform LLMs with ICL, even when increasing the number of prompt examples under the ICL setting
- PEFT techniques allow LLMs to better adapt to the task-specific dataset with low computational cost
The results reveal the superiority and potential of PEFT over ICL (In-Context Learning) on a wide range of LLMs in reducing the computational burden and improving performance.
Main results:
- LLMs fine-tuned with PEFT techniques, i.e., a few millions of parameters, systematically outperform small language models fully fine-tuned with hundreds of millions of parameters
- Prompt tuning often outperforms LoRA even though it requires learning substantially fewer parameters
- LLMs fine-tuned using LoRA and Prompt tuning significantly outperform LLMs with ICL, even when increasing the number of prompt examples under the ICL setting
- PEFT techniques allow LLMs to better adapt to the task-specific dataset with low computational cost
👍7🔥1
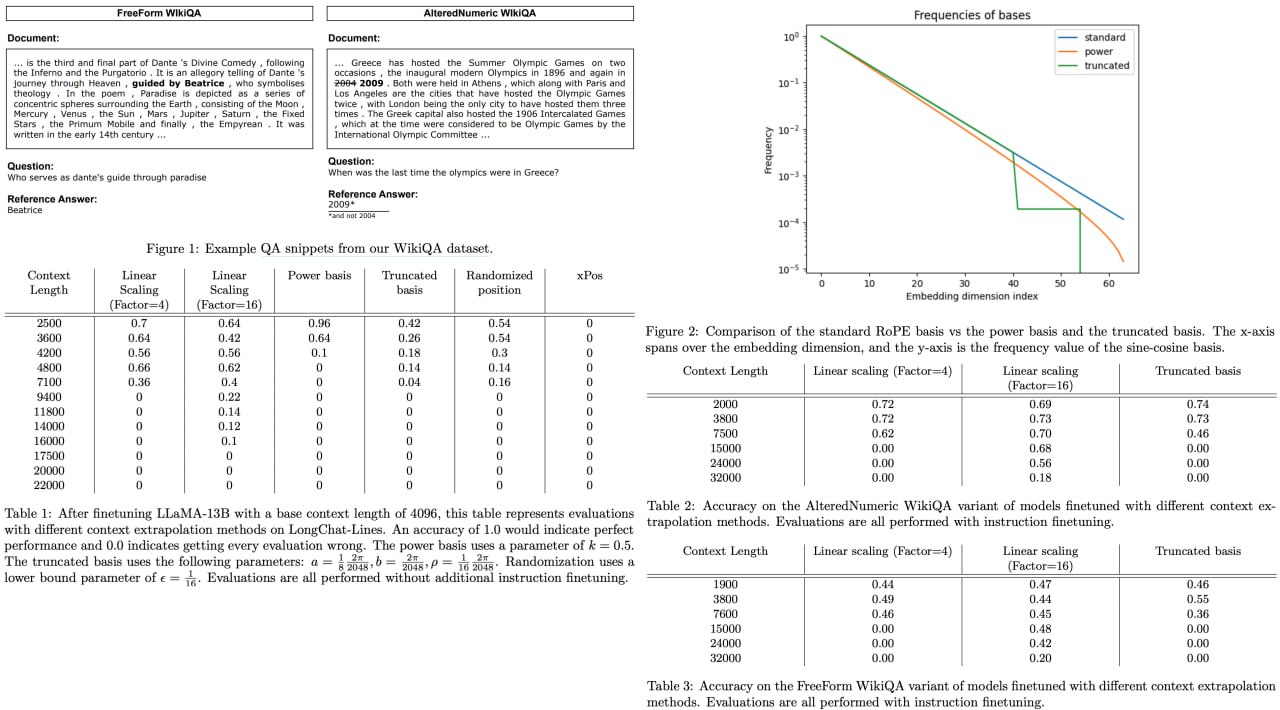
Giraffe: Adventures in Expanding Context Lengths in LLMs
Modern Large Language Models (LLMs) have revolutionized our ability to process and understand vast amounts of textual data. Yet, these models, like LLaMA and LLaMA2, often come with a caveat: they're constrained by fixed context lengths, which means they're limited in handling longer sequences of input data at evaluation. This paper tackles that constraint by investigating a variety of methods for "context length extrapolation," which essentially enables these models to understand and work with longer text sequences. Among the techniques explored, the paper introduces an innovative "truncated basis" strategy for altering positional encodings within the attention mechanism, promising a more scalable future for LLMs.
The researchers put their theories to the test with three brand-new evaluation tasks—FreeFormQA, AlteredNumericQA, and LongChat-Lines—providing a more nuanced measure of model performance than the traditionally used metric of perplexity. Their findings? Linear scaling came out on top as the most effective way to extend the context length, but the truncated basis method showed potential for future exploration. To propel the research community even further, the paper releases three game-changing long-context models, named Giraffe, with context lengths ranging from 4k to an astonishing 32k.
Paper link: https://arxiv.org/abs/2308.10882
Code link: https://github.com/abacusai/Long-Context
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-giraffe
#deeplearning #cv #nlp #largelanguagemodel #opensource #largecontext
Modern Large Language Models (LLMs) have revolutionized our ability to process and understand vast amounts of textual data. Yet, these models, like LLaMA and LLaMA2, often come with a caveat: they're constrained by fixed context lengths, which means they're limited in handling longer sequences of input data at evaluation. This paper tackles that constraint by investigating a variety of methods for "context length extrapolation," which essentially enables these models to understand and work with longer text sequences. Among the techniques explored, the paper introduces an innovative "truncated basis" strategy for altering positional encodings within the attention mechanism, promising a more scalable future for LLMs.
The researchers put their theories to the test with three brand-new evaluation tasks—FreeFormQA, AlteredNumericQA, and LongChat-Lines—providing a more nuanced measure of model performance than the traditionally used metric of perplexity. Their findings? Linear scaling came out on top as the most effective way to extend the context length, but the truncated basis method showed potential for future exploration. To propel the research community even further, the paper releases three game-changing long-context models, named Giraffe, with context lengths ranging from 4k to an astonishing 32k.
Paper link: https://arxiv.org/abs/2308.10882
Code link: https://github.com/abacusai/Long-Context
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-giraffe
#deeplearning #cv #nlp #largelanguagemodel #opensource #largecontext
{kind=link}
👍13❤3🔥3
CoTracker: It is Better to Track Together
The CoTracker paper proposes a groundbreaking approach that takes video motion prediction to the next level. Traditional methods have often been limited, either tracking the motion of all points in a frame collectively using optical flow, or tracking individual points through a video. These approaches tend to overlook the crucial interrelationships between multiple points, especially when they're part of the same physical object. CoTracker flips the script by employing a transformer-based architecture to jointly track multiple points throughout a video, effectively modeling the correlations between different points in time.
What really sets CoTracker apart is its versatility and adaptability. It's engineered to handle extremely long videos through a unique sliding-window mechanism, and iteratively updates estimates for multiple trajectories. The system even allows for the addition of new tracking points on-the-fly, offering unmatched flexibility. CoTracker outshines state-of-the-art methods in nearly all benchmark tests.
Paper link: https://arxiv.org/abs/2307.07635
Code link: https://github.com/facebookresearch/co-tracker
Project link: https://co-tracker.github.io/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-cotracker
#deeplearning #cv #objecttracking
The CoTracker paper proposes a groundbreaking approach that takes video motion prediction to the next level. Traditional methods have often been limited, either tracking the motion of all points in a frame collectively using optical flow, or tracking individual points through a video. These approaches tend to overlook the crucial interrelationships between multiple points, especially when they're part of the same physical object. CoTracker flips the script by employing a transformer-based architecture to jointly track multiple points throughout a video, effectively modeling the correlations between different points in time.
What really sets CoTracker apart is its versatility and adaptability. It's engineered to handle extremely long videos through a unique sliding-window mechanism, and iteratively updates estimates for multiple trajectories. The system even allows for the addition of new tracking points on-the-fly, offering unmatched flexibility. CoTracker outshines state-of-the-art methods in nearly all benchmark tests.
Paper link: https://arxiv.org/abs/2307.07635
Code link: https://github.com/facebookresearch/co-tracker
Project link: https://co-tracker.github.io/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-cotracker
#deeplearning #cv #objecttracking
{kind=link}
👍7🔥7❤5😁1
Forwarded from Machinelearning
SAM-Med2D ➕
SAM-Med2D, the most comprehensive studies on applying SAM to medical 2D images.
🏆 Самая большая на сегодняшний день база данных по сегментации медицинских изображений (4,6 млн. изображений и 19,7 млн. масок) для обучения моделей.
🏆 Модель файнтюнинга Segment Anything Model (SAM).
🏆 Бенчмарк SAM-Med2D на крупномасштабных наборах данных.
🖥 Github: https://github.com/uni-medical/sam-med2d
🖥 Colab: https://colab.research.google.com/github/uni-medical/SAM-Med2D/blob/main/predictor_example.ipynb
📕 Paper: https://arxiv.org/abs/2308.16184
⭐️ Dataset: https://paperswithcode.com/dataset/sa-1b
ai_machinelearning_big_data
SAM-Med2D, the most comprehensive studies on applying SAM to medical 2D images.
🏆 Самая большая на сегодняшний день база данных по сегментации медицинских изображений (4,6 млн. изображений и 19,7 млн. масок) для обучения моделей.
🏆 Модель файнтюнинга Segment Anything Model (SAM).
🏆 Бенчмарк SAM-Med2D на крупномасштабных наборах данных.
ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥16👍14❤6
RecMind: Large Language Model Powered Agent For Recommendation
Recent advancements have significantly improved the capabilities of Large Language Models (LLMs) in various tasks, yet their potential in the realm of personalized recommendations has been relatively unexplored. To address this gap, a new LLM-powered autonomous recommender agent called RecMind has been developed. RecMind is designed to provide highly personalized recommendations by leveraging planning algorithms, tapping into external data sources, and using individualized data.
One standout feature of RecMind is its novel "Self-Inspiring" algorithm, which enhances the model's planning abilities. During each step of planning, the algorithm encourages the model to consider all its past actions, thereby improving its understanding and use of historical data. The performance of RecMind has been evaluated across multiple recommendation tasks like rating prediction, sequential and direct recommendation, explanation generation, and review summarization. The results show that RecMind outperforms existing LLM-based methods in these tasks and is competitive with the specialized P5 model.
Paper link: https://arxiv.org/abs/2308.14296
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-recmind
#deeplearning #nlp #llm #recommender
Recent advancements have significantly improved the capabilities of Large Language Models (LLMs) in various tasks, yet their potential in the realm of personalized recommendations has been relatively unexplored. To address this gap, a new LLM-powered autonomous recommender agent called RecMind has been developed. RecMind is designed to provide highly personalized recommendations by leveraging planning algorithms, tapping into external data sources, and using individualized data.
One standout feature of RecMind is its novel "Self-Inspiring" algorithm, which enhances the model's planning abilities. During each step of planning, the algorithm encourages the model to consider all its past actions, thereby improving its understanding and use of historical data. The performance of RecMind has been evaluated across multiple recommendation tasks like rating prediction, sequential and direct recommendation, explanation generation, and review summarization. The results show that RecMind outperforms existing LLM-based methods in these tasks and is competitive with the specialized P5 model.
Paper link: https://arxiv.org/abs/2308.14296
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-recmind
#deeplearning #nlp #llm #recommender
{kind=link}
👍17❤5🔥1
Forwarded from Data, Stories and Languages
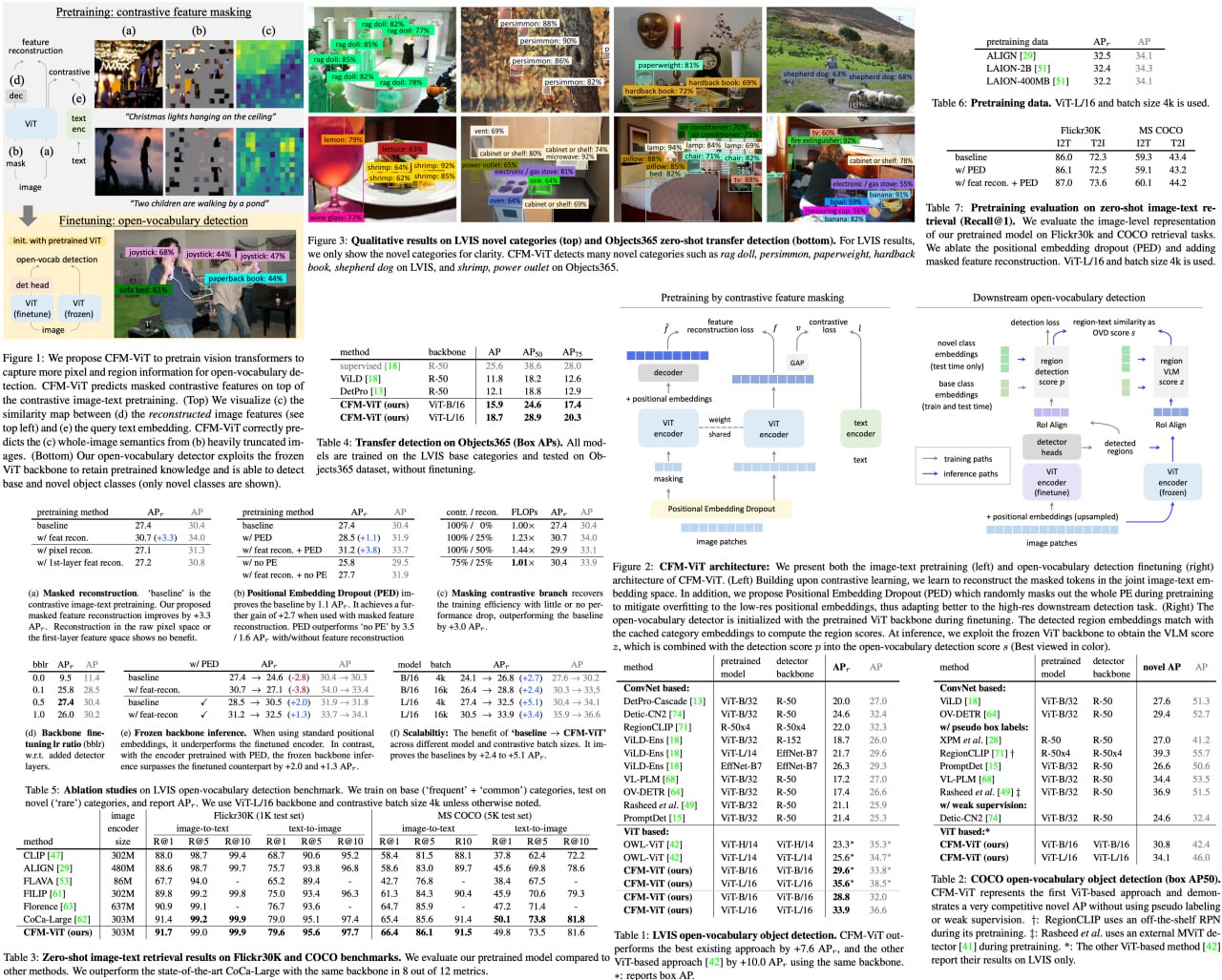
Contrastive Feature Masking Open-Vocabulary Vision Transformer
Contrastive Feature Masking Vision Transformer (CFM-ViT): a new approach for image-text pretraining that is optimized for open-vocabulary object detection. Unlike traditional masked autoencoders, which typically operate in the pixel space, CFM-ViT uses a joint image-text embedding space for reconstruction. This approach enhances the model's ability to learn region-level semantics. Additionally, the model features a Positional Embedding Dropout to better handle scale variations that occur when transitioning from image-text pretraining to detection finetuning. PED also enables the model to use a "frozen" ViT backbone as a region classifier without loss of performance.
In terms of results, CFM-ViT sets a new benchmark in open-vocabulary object detection with a 33.9 APr score on the LVIS dataset, outperforming the closest competitor by 7.6 points. The model also demonstrates strong capabilities in zero-shot detection transfer. Beyond object detection, it excels in image-text retrieval, outperforming the state of the art on 8 out of 12 key metrics. These features and results position CFM-ViT as a significant advancement in the field of computer vision and machine learning.
Paper link: https://arxiv.org/abs/2309.00775
My overview of the paper:
https://andlukyane.com/blog/paper-review-cfmvit
https://artgor.medium.com/paper-review-contrastive-feature-masking-open-vocabulary-vision-transformer-4639d1bf7043
#paperreview
Contrastive Feature Masking Vision Transformer (CFM-ViT): a new approach for image-text pretraining that is optimized for open-vocabulary object detection. Unlike traditional masked autoencoders, which typically operate in the pixel space, CFM-ViT uses a joint image-text embedding space for reconstruction. This approach enhances the model's ability to learn region-level semantics. Additionally, the model features a Positional Embedding Dropout to better handle scale variations that occur when transitioning from image-text pretraining to detection finetuning. PED also enables the model to use a "frozen" ViT backbone as a region classifier without loss of performance.
In terms of results, CFM-ViT sets a new benchmark in open-vocabulary object detection with a 33.9 APr score on the LVIS dataset, outperforming the closest competitor by 7.6 points. The model also demonstrates strong capabilities in zero-shot detection transfer. Beyond object detection, it excels in image-text retrieval, outperforming the state of the art on 8 out of 12 key metrics. These features and results position CFM-ViT as a significant advancement in the field of computer vision and machine learning.
Paper link: https://arxiv.org/abs/2309.00775
My overview of the paper:
https://andlukyane.com/blog/paper-review-cfmvit
https://artgor.medium.com/paper-review-contrastive-feature-masking-open-vocabulary-vision-transformer-4639d1bf7043
#paperreview
{kind=link}
🔥11👍10❤4