
Forwarded from Data, Stories and Languages
Explaining grokking through circuit efficiency
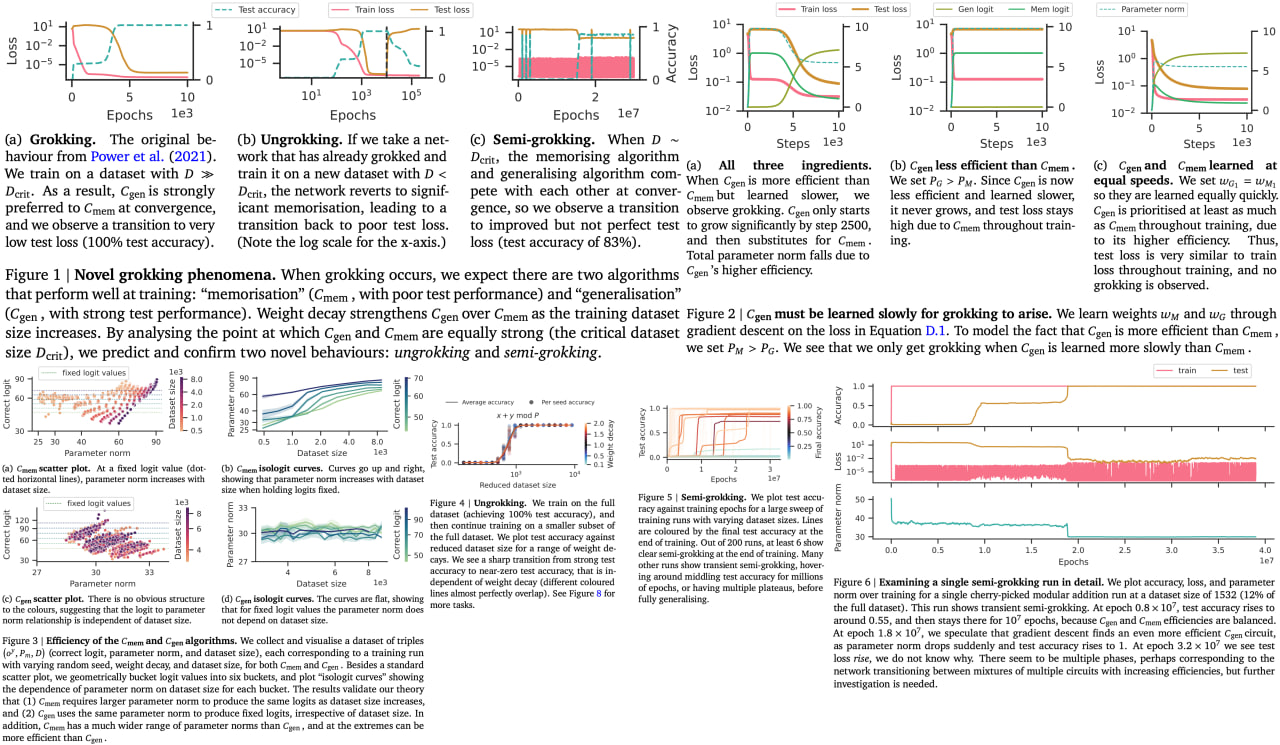
The paper explores the phenomenon of "grokking" in neural networks, where a network that initially performs poorly on new data eventually excels without any change in training setup. According to the authors, grokking occurs when two conditions are present: a memorizing solution and a generalizing solution. The generalizing solution takes longer to learn but is more efficient in terms of computational resources. The authors propose a "critical dataset size" at which the efficiencies of memorizing and generalizing are equal, providing a pivot point for the network to switch from memorization to generalization.
Furthermore, the paper introduces two new behaviors: "ungrokking" and "semi-grokking." Ungrokking describes a situation where a well-performing network reverts to poor performance when trained on a smaller dataset. Semi-grokking refers to a scenario where the network, instead of achieving full generalization, reaches a state of partial but improved performance.
Paper link: https://arxiv.org/abs/2309.02390
My overview of the paper:
https://andlukyane.com/blog/paper-review-un-semi-grokking
https://artgor.medium.com/paper-review-explaining-grokking-through-circuit-efficiency-1f420d6aea5f
#paperreview
The paper explores the phenomenon of "grokking" in neural networks, where a network that initially performs poorly on new data eventually excels without any change in training setup. According to the authors, grokking occurs when two conditions are present: a memorizing solution and a generalizing solution. The generalizing solution takes longer to learn but is more efficient in terms of computational resources. The authors propose a "critical dataset size" at which the efficiencies of memorizing and generalizing are equal, providing a pivot point for the network to switch from memorization to generalization.
Furthermore, the paper introduces two new behaviors: "ungrokking" and "semi-grokking." Ungrokking describes a situation where a well-performing network reverts to poor performance when trained on a smaller dataset. Semi-grokking refers to a scenario where the network, instead of achieving full generalization, reaches a state of partial but improved performance.
Paper link: https://arxiv.org/abs/2309.02390
My overview of the paper:
https://andlukyane.com/blog/paper-review-un-semi-grokking
https://artgor.medium.com/paper-review-explaining-grokking-through-circuit-efficiency-1f420d6aea5f
#paperreview
{kind=link}
👍22❤3😁3
Forwarded from ml4se
Releasing Persimmon-8B
Permisimmon-8B is open-source, fully permissive model. It is trained from scratch using a context size of 16K. The model has 70k unused embeddings for multimodal extensions, and has sparse activations. The inference code combines the speed of C++ implementations (e.g. FasterTransformer) with the flexibility of naive Python inference.
Hidden Size 4096
Heads 64
Layers 36
Batch Size 120
Sequence Length 16384
Training Iterations 375K
Tokens Seen 737B
Code and weights: https://github.com/persimmon-ai-labs/adept-inference
Permisimmon-8B is open-source, fully permissive model. It is trained from scratch using a context size of 16K. The model has 70k unused embeddings for multimodal extensions, and has sparse activations. The inference code combines the speed of C++ implementations (e.g. FasterTransformer) with the flexibility of naive Python inference.
Hidden Size 4096
Heads 64
Layers 36
Batch Size 120
Sequence Length 16384
Training Iterations 375K
Tokens Seen 737B
Code and weights: https://github.com/persimmon-ai-labs/adept-inference
👍5❤3
Forwarded from Machinelearning
Media is too big
VIEW IN TELEGRAM
📹 DEVA: Tracking Anything with Decoupled Video Segmentation
Decoupled video segmentation approach (DEVA), composed of task-specific image-level segmentation and class/task-agnostic bi-directional temporal propagation.
Новая модель сегментации видео для "отслеживания чего угодно" без обучения по видео для любой отдельной задачи.
🖥 Github: https://github.com/hkchengrex/Tracking-Anything-with-DEVA
🖥 Colab: https://colab.research.google.com/drive/1OsyNVoV_7ETD1zIE8UWxL3NXxu12m_YZ?usp=sharing
⏩ Project: https://hkchengrex.github.io/Tracking-Anything-with-DEVA/
📕 Paper: https://arxiv.org/abs/2309.03903v1
⭐️ Docs: https://paperswithcode.com/dataset/burst
ai_machinelearning_big_data
Decoupled video segmentation approach (DEVA), composed of task-specific image-level segmentation and class/task-agnostic bi-directional temporal propagation.
Новая модель сегментации видео для "отслеживания чего угодно" без обучения по видео для любой отдельной задачи.
ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
👍18🔥11❤6
TSMixer: An All-MLP Architecture for Time Series Forecasting
Time-series datasets in real-world scenarios are inherently multivariate and riddled with intricate dynamics. While recurrent or attention-based deep learning models have been the go-to solution to address these complexities, recent discoveries have shown that even basic univariate linear models can surpass them in performance on standard academic benchmarks. As an extension of this revelation, the paper introduces the Time-Series Mixer TSMixer. This innovative design, crafted by layering multi-layer perceptrons, hinges on mixing operations across both time and feature axes, ensuring an efficient extraction of data nuances.
Upon application, TSMixer has shown promising results. Not only does it hold its ground against specialized state-of-the-art models on well-known benchmarks, but it also trumps leading alternatives in the challenging M5 benchmark, a dataset that mirrors the intricacies of retail realities. The paper's outcomes emphasize the pivotal role of cross-variate and auxiliary data in refining time series forecasting.
Paper link: https://arxiv.org/abs/2303.06053
Code link: https://github.com/google-research/google-research/tree/master/tsmixer
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-tsmixer
#paperreview #deeplearning #timeseries #mlp
Time-series datasets in real-world scenarios are inherently multivariate and riddled with intricate dynamics. While recurrent or attention-based deep learning models have been the go-to solution to address these complexities, recent discoveries have shown that even basic univariate linear models can surpass them in performance on standard academic benchmarks. As an extension of this revelation, the paper introduces the Time-Series Mixer TSMixer. This innovative design, crafted by layering multi-layer perceptrons, hinges on mixing operations across both time and feature axes, ensuring an efficient extraction of data nuances.
Upon application, TSMixer has shown promising results. Not only does it hold its ground against specialized state-of-the-art models on well-known benchmarks, but it also trumps leading alternatives in the challenging M5 benchmark, a dataset that mirrors the intricacies of retail realities. The paper's outcomes emphasize the pivotal role of cross-variate and auxiliary data in refining time series forecasting.
Paper link: https://arxiv.org/abs/2303.06053
Code link: https://github.com/google-research/google-research/tree/master/tsmixer
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-tsmixer
#paperreview #deeplearning #timeseries #mlp
{kind=link}
👍23🔥7❤4👏2
Forwarded from Machinelearning
Diffusion model, whose text-conditional component works in a highly compressed latent space of images
Würstchen - это диффузионная модель, которой работает в сильно сжатом латентном пространстве изображений.
Почему это важно? Сжатие данных позволяет на порядки снизить вычислительные затраты как на обучение, так и на вывод модели.
Обучение на 1024×1024 изображениях гораздо затратное, чем на 32×32. Обычно в других моделях используется сравнительно небольшое сжатие, в пределах 4x - 8x пространственного сжатия.
Благодаря новой архитектуре достигается 42-кратное пространственное сжатие!
🤗 HF: https://huggingface.co/blog/wuertschen
📝 Paper: https://arxiv.org/abs/2306.00637
🚀 Demo: https://huggingface.co/spaces/warp-ai/Wuerstchen
ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
👍51❤16🔥9😁1
Hey, please boost our channel to allow us to post stories.
We solemnly swear to post only memes there.
https://t.iss.one/opendatascience?boost
We solemnly swear to post only memes there.
https://t.iss.one/opendatascience?boost
Telegram
Data Science by ODS.ai 🦜
Boost this channel to help it unlock additional features.
👎29💩18🖕17👍14😁9❤4
Here is very interesting notes about how behaves generation of stable diffusion trained on different datasets with the same noise. Seems very contrintuitive!
https://twitter.com/mokadyron/status/1706618451664474148
https://twitter.com/mokadyron/status/1706618451664474148
X (formerly Twitter)
Ron Mokady (@MokadyRon) on X
🔬Exploring Alignment in Diffusion Models - a 🧵
TL;DR: Diffusion models trained on *different datasets* can surprisingly generate similar images when fed with the same noise 🤯
[1/N]
TL;DR: Diffusion models trained on *different datasets* can surprisingly generate similar images when fed with the same noise 🤯
[1/N]
👍21❤14😁4👎2👏2😱2🔥1
🤣158👍67❤22🤯13😁6👏4👌4🔥3
Forwarded from ilia.eth | ØxPlasma
Position: Analyst/Researcher for AI Team at Cyber.fund
About Cyber.fund:
Cyber.fund is a pioneering $100mm research-driven fund specializing in the realm of web3, decentralized AI, autonomous agents, and self-sovereign identity. Our legacy is built upon being the architects behind monumental projects such as Lido, p2p.org, =nil; foundation, Neutron, NEON, and early investments in groundbreaking technologies like Solana, Ethereum, EigenLayer among 150+ others. We are committed to advancing the frontiers of Fully Homomorphic Encryption (FHE) for Machine Learning, privacy-first ML (Large Language Models), AI aggregations, and routing platforms alongside decentralized AI solutions.
Who Are We Looking For?
A dynamic individual who straddles the worlds of business acumen and academic rigor with:
- A robust theoretical foundation in Computer Science and a must-have specialization in Machine Learning.
- An educational background from a technical university, with a preference for PhD holders from prestigious institutions like MIT or МФТИ.
- A track record of publications in the Machine Learning domain, ideally at the level of NeuroIPS.
- Experience working in startups or major tech companies, ideally coupled with a background in angel investing.
- A profound understanding of algorithms, techniques, and models in ML, with an exceptional ability to translate these into innovative products.
- Fluent English, intellectual curiosity, and a fervent passion for keeping abreast of the latest developments in AI/ML.
Responsibilities:
1) Investment Due Diligence: Conduct technical, product, and business analysis of potential AI/ML investments. This includes market analysis, engaging with founders and technical teams, and evaluating the scalability, reliability, risks, and limitations of products.
2) Portcos Support: Provide strategic and technical support to portfolio companies in AI/ML. Assist in crafting technological strategies, hiring, industry networking, identifying potential project challenges, and devising solutions.
3) Market and Technology Research: Stay at the forefront of ML/DL/AI trends (e.g., synthetic data, flash attention, 1bit LLM, FHE for ML, JEPA, etc.). Write publications, whitepapers, and potentially host X spaces/streams/podcasts on these subjects (in English). Identify promising companies and projects for investment opportunities.
How to Apply?
If you find yourself aligning with our requirements and are excited by the opportunity to contribute to our vision, please send your CV to [email protected]. Including a cover letter, links to publications, open-source contributions, and other achievements will be advantageous.
Location:
Location is flexible, but the candidate should be within the time zones ranging from EET to EST (Eastern Europe to the East Coast of the USA).
This is not just a job opportunity; it's a call to be part of a visionary journey reshaping the landscape of AI and decentralized technology. Join us at Cyber.fund and be at the forefront of the technological revolution.
About Cyber.fund:
Cyber.fund is a pioneering $100mm research-driven fund specializing in the realm of web3, decentralized AI, autonomous agents, and self-sovereign identity. Our legacy is built upon being the architects behind monumental projects such as Lido, p2p.org, =nil; foundation, Neutron, NEON, and early investments in groundbreaking technologies like Solana, Ethereum, EigenLayer among 150+ others. We are committed to advancing the frontiers of Fully Homomorphic Encryption (FHE) for Machine Learning, privacy-first ML (Large Language Models), AI aggregations, and routing platforms alongside decentralized AI solutions.
Who Are We Looking For?
A dynamic individual who straddles the worlds of business acumen and academic rigor with:
- A robust theoretical foundation in Computer Science and a must-have specialization in Machine Learning.
- An educational background from a technical university, with a preference for PhD holders from prestigious institutions like MIT or МФТИ.
- A track record of publications in the Machine Learning domain, ideally at the level of NeuroIPS.
- Experience working in startups or major tech companies, ideally coupled with a background in angel investing.
- A profound understanding of algorithms, techniques, and models in ML, with an exceptional ability to translate these into innovative products.
- Fluent English, intellectual curiosity, and a fervent passion for keeping abreast of the latest developments in AI/ML.
Responsibilities:
1) Investment Due Diligence: Conduct technical, product, and business analysis of potential AI/ML investments. This includes market analysis, engaging with founders and technical teams, and evaluating the scalability, reliability, risks, and limitations of products.
2) Portcos Support: Provide strategic and technical support to portfolio companies in AI/ML. Assist in crafting technological strategies, hiring, industry networking, identifying potential project challenges, and devising solutions.
3) Market and Technology Research: Stay at the forefront of ML/DL/AI trends (e.g., synthetic data, flash attention, 1bit LLM, FHE for ML, JEPA, etc.). Write publications, whitepapers, and potentially host X spaces/streams/podcasts on these subjects (in English). Identify promising companies and projects for investment opportunities.
How to Apply?
If you find yourself aligning with our requirements and are excited by the opportunity to contribute to our vision, please send your CV to [email protected]. Including a cover letter, links to publications, open-source contributions, and other achievements will be advantageous.
Location:
Location is flexible, but the candidate should be within the time zones ranging from EET to EST (Eastern Europe to the East Coast of the USA).
This is not just a job opportunity; it's a call to be part of a visionary journey reshaping the landscape of AI and decentralized technology. Join us at Cyber.fund and be at the forefront of the technological revolution.
🤡25👍21❤8💩7👎5
Data Science by ODS.ai 🦜
LLM models are in their childhood years Source.
Objective-Driven AI: Towards AI systems that can learn, remember, reason, and plan
A presentation by Yann Lecun on the #SOTA in #DL
YouTube: https://www.youtube.com/watch?v=MiqLoAZFRSE
Slides: Google Doc
Paper: Open Review
P.S. Stole the post from @chillhousetech
A presentation by Yann Lecun on the #SOTA in #DL
YouTube: https://www.youtube.com/watch?v=MiqLoAZFRSE
Slides: Google Doc
Paper: Open Review
P.S. Stole the post from @chillhousetech
YouTube
Yann Lecun | Objective-Driven AI: Towards AI systems that can learn, remember, reason, and plan
Ding Shum Lecture 3/28/2024
Speaker: Yann Lecun, New York University & META
Title: Objective-Driven AI: Towards AI systems that can learn, remember, reason, and plan
Abstract: How could machines learn as efficiently as humans and animals?
How could machines…
Speaker: Yann Lecun, New York University & META
Title: Objective-Driven AI: Towards AI systems that can learn, remember, reason, and plan
Abstract: How could machines learn as efficiently as humans and animals?
How could machines…
👍12❤5🤡3👏2👎1💩1
Forwarded from Machinelearning
⚡️ Awesome CVPR 2024 Papers, Workshops, Challenges, and Tutorials!
На конференцию 2024 года по компьютерному зрению и распознаванию образов (CVPR) поступило 11 532 статей, из которых только 2 719 были приняты, что составляет около 23,6% от общего числа.
Ниже приведен список лучших докладов, гайдов, статей, семинаров и датасетов с CVPR 2024.
▪Github
@ai_machinelearning_big_data
На конференцию 2024 года по компьютерному зрению и распознаванию образов (CVPR) поступило 11 532 статей, из которых только 2 719 были приняты, что составляет около 23,6% от общего числа.
Ниже приведен список лучших докладов, гайдов, статей, семинаров и датасетов с CVPR 2024.
▪Github
@ai_machinelearning_big_data
🔥13👍6❤3