
BiomedGPT: A Unified and Generalist Biomedical Generative Pre-trained Transformer for Vision, Language, and Multimodal Tasks
Introducing the groundbreaking Biomedical Generative Pre-trained Transformer (BiomedGPT) model, this paper revolutionizes the field of biomedicine by offering a unified and generalist approach. BiomedGPT harnesses the power of self-supervision on extensive and diverse datasets, enabling it to effortlessly handle multi-modal inputs and excel in a wide range of downstream tasks. In a series of comprehensive experiments, BiomedGPT astoundingly outperforms its predecessors, emerging as the unrivaled leader across five distinct tasks and a staggering 20 public datasets encompassing over 15 unique biomedical modalities. Its ability to deliver expansive and all-encompassing representations of biomedical data heralds a significant advancement in the field, with promising implications for improving healthcare outcomes.
Through meticulous ablation studies, the efficacy of BiomedGPT's multi-modal and multi-task pretraining approach is vividly showcased. This groundbreaking model effortlessly transfers its vast knowledge to previously unseen data, demonstrating its versatility and adaptability. The implications of this research are profound, paving the way for the development of unified and all-encompassing models for biomedicine.
Paper link: https://arxiv.org/abs/2305.17100
Code link: https://github.com/taokz/BiomedGPT
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-biomedgpt
#deeplearning #nlp #selfsupervised #gpt #biomedicine
Introducing the groundbreaking Biomedical Generative Pre-trained Transformer (BiomedGPT) model, this paper revolutionizes the field of biomedicine by offering a unified and generalist approach. BiomedGPT harnesses the power of self-supervision on extensive and diverse datasets, enabling it to effortlessly handle multi-modal inputs and excel in a wide range of downstream tasks. In a series of comprehensive experiments, BiomedGPT astoundingly outperforms its predecessors, emerging as the unrivaled leader across five distinct tasks and a staggering 20 public datasets encompassing over 15 unique biomedical modalities. Its ability to deliver expansive and all-encompassing representations of biomedical data heralds a significant advancement in the field, with promising implications for improving healthcare outcomes.
Through meticulous ablation studies, the efficacy of BiomedGPT's multi-modal and multi-task pretraining approach is vividly showcased. This groundbreaking model effortlessly transfers its vast knowledge to previously unseen data, demonstrating its versatility and adaptability. The implications of this research are profound, paving the way for the development of unified and all-encompassing models for biomedicine.
Paper link: https://arxiv.org/abs/2305.17100
Code link: https://github.com/taokz/BiomedGPT
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-biomedgpt
#deeplearning #nlp #selfsupervised #gpt #biomedicine
{kind=link}
👍11❤10🔥5🐳1
🇵🇹Are there people in Lissabon? Let’s meet for a brunch this week!
💩12🥰9🤔6👍5🖕4🌚2🤬1🗿1
Forwarded from ml4se
👍28👎2😁2❤1
Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
In a recent breakthrough, a novel approach for learning highly semantic image representations has been introduced that eschews the need for hand-crafted data augmentations. The strategy, known as Image-based Joint-Embedding Predictive Architecture (I-JEPA), offers a refreshing, non-generative pathway to self-supervised learning from images. The concept underpinning I-JEPA is deceptively simple, yet incredibly powerful: it takes a single context block from an image and predicts the representations of various target blocks within the same image.
I-JEPA's core design principle - its masking strategy - plays a pivotal role in shaping the system's semantic prowess. The key is to sample target blocks at a sufficiently large, semantic scale while using a context block that provides ample, spatially distributed information. When integrated with Vision Transformers, I-JEPA exhibits impressive scalability. To illustrate, a ViT-Huge/14 model was trained on ImageNet using just 16 A100 GPUs in under 72 hours, delivering robust performance across a wide spectrum of tasks, including linear classification, object counting, and depth prediction.
Paper link: https://arxiv.org/abs/2301.08243
Code link: https://github.com/facebookresearch/ijepa
Blogpost link: https://ai.facebook.com/blog/yann-lecun-ai-model-i-jepa/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-ijepa
#deeplearning #cv #selfsupervisedlearning
In a recent breakthrough, a novel approach for learning highly semantic image representations has been introduced that eschews the need for hand-crafted data augmentations. The strategy, known as Image-based Joint-Embedding Predictive Architecture (I-JEPA), offers a refreshing, non-generative pathway to self-supervised learning from images. The concept underpinning I-JEPA is deceptively simple, yet incredibly powerful: it takes a single context block from an image and predicts the representations of various target blocks within the same image.
I-JEPA's core design principle - its masking strategy - plays a pivotal role in shaping the system's semantic prowess. The key is to sample target blocks at a sufficiently large, semantic scale while using a context block that provides ample, spatially distributed information. When integrated with Vision Transformers, I-JEPA exhibits impressive scalability. To illustrate, a ViT-Huge/14 model was trained on ImageNet using just 16 A100 GPUs in under 72 hours, delivering robust performance across a wide spectrum of tasks, including linear classification, object counting, and depth prediction.
Paper link: https://arxiv.org/abs/2301.08243
Code link: https://github.com/facebookresearch/ijepa
Blogpost link: https://ai.facebook.com/blog/yann-lecun-ai-model-i-jepa/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-ijepa
#deeplearning #cv #selfsupervisedlearning
{kind=link}
👍9🔥4❤3😁3
Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision
AI-assistant agents like ChatGPT have largely depended on supervised fine-tuning and reinforcement learning from human feedback. But, this method brings its own set of challenges - high costs, potential biases, and constraints on the true potential of these AI agents. What if there was a more effective, self-sufficient way to align AI output with human intentions? Enter Self-ALIGN, a groundbreaking methodology that marries principle-driven reasoning and the generative capabilities of large language models. This promising approach takes the AI realm by storm, offering a novel way to ensure our AI models are more helpful, ethical, and reliable - all with minimal human intervention.
Self-ALIGN is a multistage process that works by generating synthetic prompts from a large language model, augmenting prompt diversity, and leveraging a concise set of human-written principles to guide AI models. When applied to the LLaMA-65b base language model, it led to the creation of a new AI assistant, Dromedary, using less than 300 lines of human annotations. Dromedary not only outshines several state-of-the-art AI systems, such as Text-Davinci-003 and Alpaca, but it does so on a variety of benchmark datasets.
Paper link: https://arxiv.org/abs/2305.03047
Code link: https://mitibmdemos.draco.res.ibm.com/dromedary
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dromedary
#deeplearning #nlp #llm
AI-assistant agents like ChatGPT have largely depended on supervised fine-tuning and reinforcement learning from human feedback. But, this method brings its own set of challenges - high costs, potential biases, and constraints on the true potential of these AI agents. What if there was a more effective, self-sufficient way to align AI output with human intentions? Enter Self-ALIGN, a groundbreaking methodology that marries principle-driven reasoning and the generative capabilities of large language models. This promising approach takes the AI realm by storm, offering a novel way to ensure our AI models are more helpful, ethical, and reliable - all with minimal human intervention.
Self-ALIGN is a multistage process that works by generating synthetic prompts from a large language model, augmenting prompt diversity, and leveraging a concise set of human-written principles to guide AI models. When applied to the LLaMA-65b base language model, it led to the creation of a new AI assistant, Dromedary, using less than 300 lines of human annotations. Dromedary not only outshines several state-of-the-art AI systems, such as Text-Davinci-003 and Alpaca, but it does so on a variety of benchmark datasets.
Paper link: https://arxiv.org/abs/2305.03047
Code link: https://mitibmdemos.draco.res.ibm.com/dromedary
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dromedary
#deeplearning #nlp #llm
{kind=link}
👍8❤7😁3🔥2
Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale
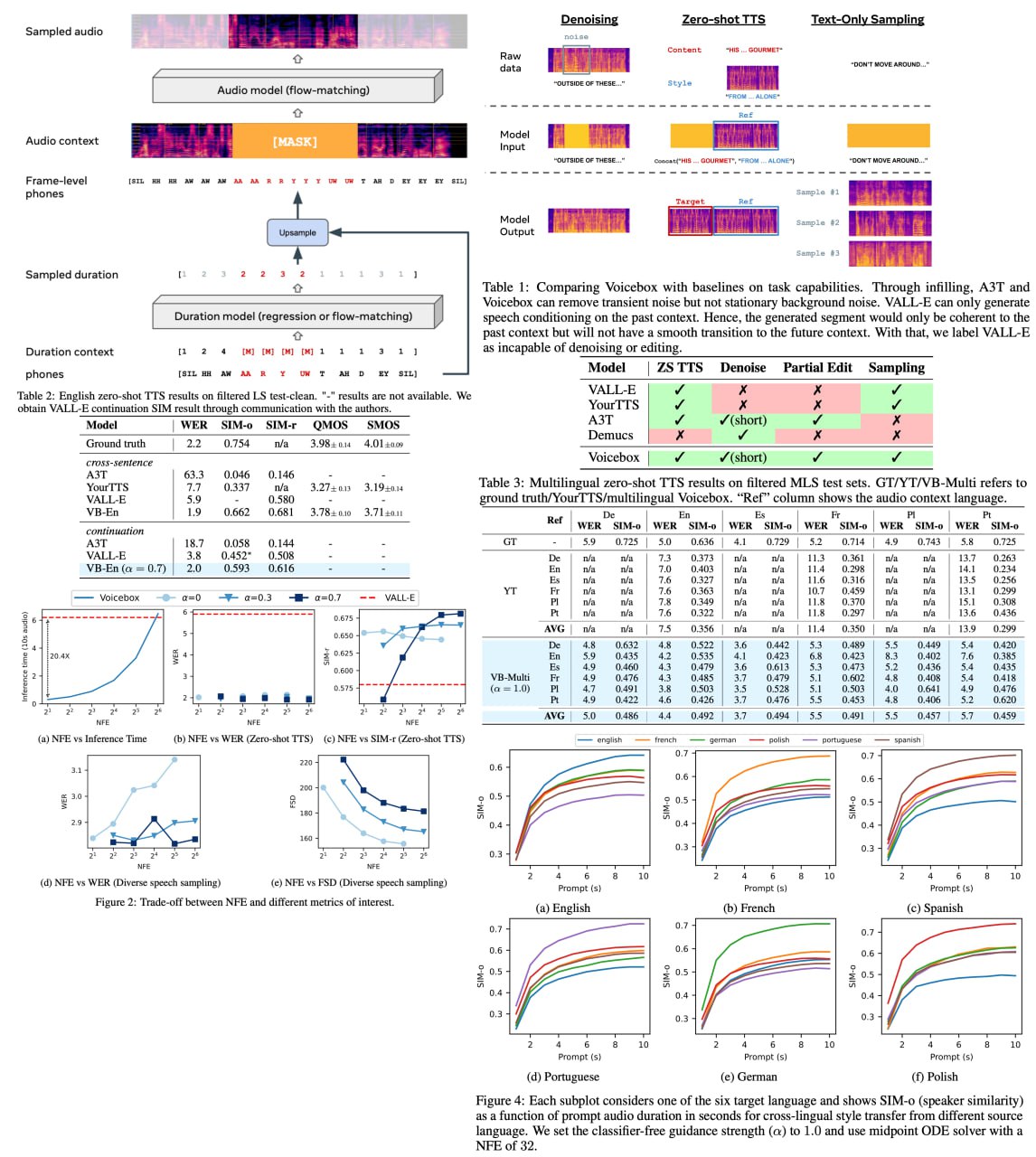
In the ever-evolving field of natural language processing and computer vision research, the revolution is being led by large-scale generative models like GPT and DALL-E. These models have the remarkable capability of generating high fidelity text or image outputs, and more importantly, they possess a 'generalist' character, able to solve tasks that they weren't explicitly trained to accomplish. However, when it comes to speech generative models, there's still a significant gap in terms of scale and task generalization. Enter, Voicebox - a pioneering advancement set to redefine the landscape of speech generation technology.
Voicebox is an exceptionally versatile text-guided generative model for speech at an impressive scale. Trained on over 50K hours of unfiltered, unenhanced speech data, Voicebox is a non-autoregressive flow-matching model, designed to infill speech, given an audio context and text. Much like its predecessors, Voicebox is able to perform a wide range of tasks through in-context learning, but with an added flexibility - it can condition on future context. The applications are boundless - from mono or cross-lingual zero-shot text-to-speech synthesis to noise removal, content editing, style conversion, and diverse sample generation. What's truly phenomenal is Voicebox's capability to outshine the state-of-the-art zero-shot TTS model, VALL-E, on both intelligibility and audio similarity metrics, while being a staggering 20 times faster.
Paper link: https://research.facebook.com/publications/voicebox-text-guided-multilingual-universal-speech-generation-at-scale/
Blogpost link: https://ai.facebook.com/blog/voicebox-generative-ai-model-speech/
Project link: https://voicebox.metademolab.com/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-voicebox
#deeplearning #nlp #speechgeneration #texttospeech
In the ever-evolving field of natural language processing and computer vision research, the revolution is being led by large-scale generative models like GPT and DALL-E. These models have the remarkable capability of generating high fidelity text or image outputs, and more importantly, they possess a 'generalist' character, able to solve tasks that they weren't explicitly trained to accomplish. However, when it comes to speech generative models, there's still a significant gap in terms of scale and task generalization. Enter, Voicebox - a pioneering advancement set to redefine the landscape of speech generation technology.
Voicebox is an exceptionally versatile text-guided generative model for speech at an impressive scale. Trained on over 50K hours of unfiltered, unenhanced speech data, Voicebox is a non-autoregressive flow-matching model, designed to infill speech, given an audio context and text. Much like its predecessors, Voicebox is able to perform a wide range of tasks through in-context learning, but with an added flexibility - it can condition on future context. The applications are boundless - from mono or cross-lingual zero-shot text-to-speech synthesis to noise removal, content editing, style conversion, and diverse sample generation. What's truly phenomenal is Voicebox's capability to outshine the state-of-the-art zero-shot TTS model, VALL-E, on both intelligibility and audio similarity metrics, while being a staggering 20 times faster.
Paper link: https://research.facebook.com/publications/voicebox-text-guided-multilingual-universal-speech-generation-at-scale/
Blogpost link: https://ai.facebook.com/blog/voicebox-generative-ai-model-speech/
Project link: https://voicebox.metademolab.com/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-voicebox
#deeplearning #nlp #speechgeneration #texttospeech
{kind=link}
👍13❤5🔥3🤔1
Tracking Everything Everywhere All at Once
In the field of motion estimation, a remarkable breakthrough has just arrived! Introducing OmniMotion, an innovative method that pioneers a complete and globally consistent motion representation. OmniMotion moves beyond the constraints of traditional optical flow or particle video tracking algorithms that are hindered by limited temporal windows and difficulties in maintaining global consistency of estimated motion trajectories. Instead, OmniMotion enables accurate, full-length motion estimation of every pixel in a video sequence - a truly remarkable feat.
OmniMotion represents a video using a quasi-3D canonical volume and accomplishes pixel-wise tracking via the transformation between local and canonical spaces. This representation doesn't just ensure global consistency; it also opens the doors to tracking through occlusions and modeling any mixture of camera and object motion. The extensive evaluations conducted on the TAP-Vid benchmark and real-world footage have proven that OmniMotion outperforms existing state-of-the-art methods by a substantial margin, both quantitatively and qualitatively.
Paper link: https://arxiv.org/abs/2306.05422
Project link: https://omnimotion.github.io/
A detailed unofficial overview of the paper: https://artgor.medium.com/paper-review-tracking-everything-everywhere-all-at-once-27caa13918bc
#deeplearning #cv #motionestimation
In the field of motion estimation, a remarkable breakthrough has just arrived! Introducing OmniMotion, an innovative method that pioneers a complete and globally consistent motion representation. OmniMotion moves beyond the constraints of traditional optical flow or particle video tracking algorithms that are hindered by limited temporal windows and difficulties in maintaining global consistency of estimated motion trajectories. Instead, OmniMotion enables accurate, full-length motion estimation of every pixel in a video sequence - a truly remarkable feat.
OmniMotion represents a video using a quasi-3D canonical volume and accomplishes pixel-wise tracking via the transformation between local and canonical spaces. This representation doesn't just ensure global consistency; it also opens the doors to tracking through occlusions and modeling any mixture of camera and object motion. The extensive evaluations conducted on the TAP-Vid benchmark and real-world footage have proven that OmniMotion outperforms existing state-of-the-art methods by a substantial margin, both quantitatively and qualitatively.
Paper link: https://arxiv.org/abs/2306.05422
Project link: https://omnimotion.github.io/
A detailed unofficial overview of the paper: https://artgor.medium.com/paper-review-tracking-everything-everywhere-all-at-once-27caa13918bc
#deeplearning #cv #motionestimation
omnimotion.github.io
Tracking Everything Everywhere All at Once
🔥19❤6👍4👏1
Fast Segment Anything
The Segment Anything Model (SAM), a revolutionary tool in computer vision tasks, has significantly impacted various high-level tasks like image segmentation, image captioning, and image editing. However, its application has been restricted in industry scenarios due to its enormous computational demand, largely attributed to the Transformer architecture handling high-resolution inputs.
The authors of this paper have proposed a speedier alternative method that accomplishes this foundational task with performance on par with SAM, but at a staggering 50 times faster! By ingeniously reformulating the task as segments-generation and prompting and employing a regular CNN detector with an instance segmentation branch, they've converted this task into the well-established instance segmentation task. The magic touch? They've trained the existing instance segmentation method using just 1/50 of the SA-1B dataset, a stroke of brilliance that led to a solution marrying performance and efficiency.
Paper link: https://huggingface.co/papers/2306.12156
Code link: https://github.com/CASIA-IVA-Lab/FastSAM
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-fastsam
#deeplearning #cv #segmentanythingmodel #efficiency
The Segment Anything Model (SAM), a revolutionary tool in computer vision tasks, has significantly impacted various high-level tasks like image segmentation, image captioning, and image editing. However, its application has been restricted in industry scenarios due to its enormous computational demand, largely attributed to the Transformer architecture handling high-resolution inputs.
The authors of this paper have proposed a speedier alternative method that accomplishes this foundational task with performance on par with SAM, but at a staggering 50 times faster! By ingeniously reformulating the task as segments-generation and prompting and employing a regular CNN detector with an instance segmentation branch, they've converted this task into the well-established instance segmentation task. The magic touch? They've trained the existing instance segmentation method using just 1/50 of the SA-1B dataset, a stroke of brilliance that led to a solution marrying performance and efficiency.
Paper link: https://huggingface.co/papers/2306.12156
Code link: https://github.com/CASIA-IVA-Lab/FastSAM
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-fastsam
#deeplearning #cv #segmentanythingmodel #efficiency
{kind=link}
❤16👍6🔥3
Multilingual End to End Entity Linking
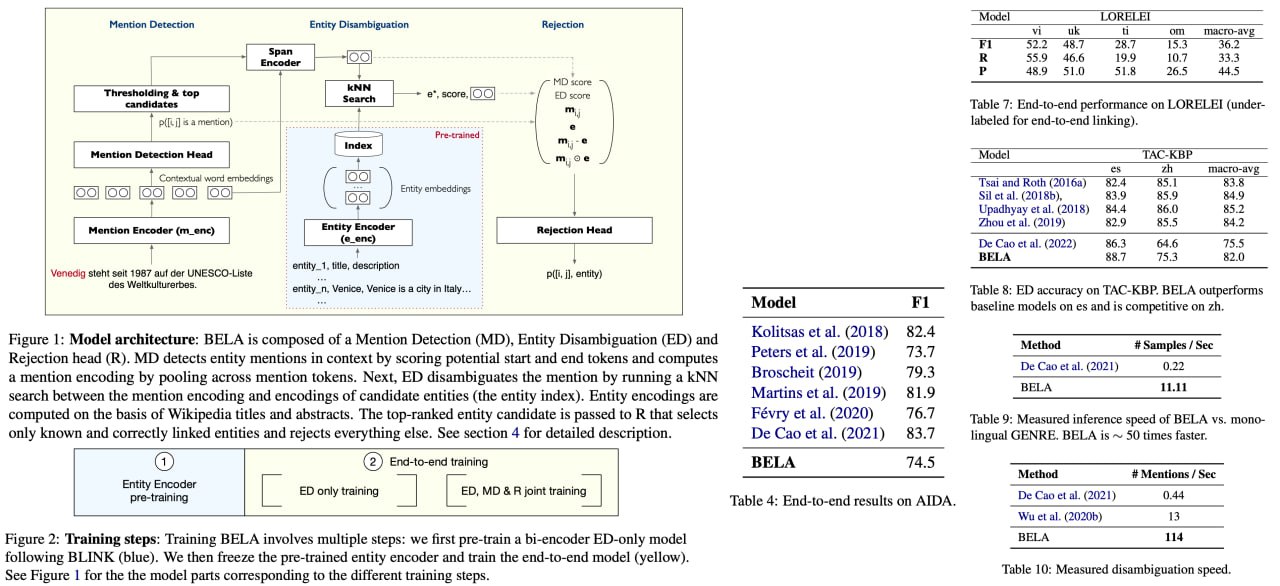
Introducing BELA, an unprecedented, open-source solution that is set to revolutionize the Natural Language Processing (NLP) arena! BELA addresses the complex challenge of Entity Linking, a task prevalent in many practical applications, by offering the very first fully end-to-end multilingual model. Astoundingly, it can efficiently identify and link entities in texts across an expansive range of 97 languages, a capability hitherto unseen. This marks a significant leap towards streamlining complex model stacks that have been a pervasive issue in the field.
BELA's architectural novelty lies in its adoption of a bi-encoder design. This enables it to conduct end-to-end linking of a passage in a single forward pass through a transformer, regardless of the number of entity mentions it contains. In its core Entity Disambiguation sub-task, it cleverly deploys a k-nearest neighbor (kNN) search using an encoded mention as a query in an entity index. What's even more impressive is BELA's scalability—it handles up to 16 million entities and delivers a remarkable throughput of 53 samples per second on a single GPU.
Paper link: https://arxiv.org/abs/2306.08896
Code link: https://github.com/facebookresearch/BELA
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-bela
#deeplearning #nlp #entitylinking #multilingual
Introducing BELA, an unprecedented, open-source solution that is set to revolutionize the Natural Language Processing (NLP) arena! BELA addresses the complex challenge of Entity Linking, a task prevalent in many practical applications, by offering the very first fully end-to-end multilingual model. Astoundingly, it can efficiently identify and link entities in texts across an expansive range of 97 languages, a capability hitherto unseen. This marks a significant leap towards streamlining complex model stacks that have been a pervasive issue in the field.
BELA's architectural novelty lies in its adoption of a bi-encoder design. This enables it to conduct end-to-end linking of a passage in a single forward pass through a transformer, regardless of the number of entity mentions it contains. In its core Entity Disambiguation sub-task, it cleverly deploys a k-nearest neighbor (kNN) search using an encoded mention as a query in an entity index. What's even more impressive is BELA's scalability—it handles up to 16 million entities and delivers a remarkable throughput of 53 samples per second on a single GPU.
Paper link: https://arxiv.org/abs/2306.08896
Code link: https://github.com/facebookresearch/BELA
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-bela
#deeplearning #nlp #entitylinking #multilingual
{kind=link}
👍13❤4🆒3🔥2🥰1🤔1
Forwarded from the last neural cell (Alexander Kovalev)
Media is too big
VIEW IN TELEGRAM
Introducing motor interface for amputee | ALVI Labs
That is the first AI model for decoding precise finger movements for people with hand amputation. It uses only 8 surface EMG electrodes.
Interface can decode different types of moves in virtual reality:
🔘 finger flexion
🔘 finger extension
🟣 typing
🟣 some more
💎 Full demo: YouTube link
Subscribe and follow the further progress:
Twitter: link
Instagram: link
Please like and repost YouTube video✨
That is the first AI model for decoding precise finger movements for people with hand amputation. It uses only 8 surface EMG electrodes.
Interface can decode different types of moves in virtual reality:
Subscribe and follow the further progress:
Twitter: link
Instagram: link
Please like and repost YouTube video
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥9❤4👍3👎1👏1
Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
In the rapidly evolving landscape of artificial intelligence, a groundbreaking approach to supervised classification performance has been born. Modern hierarchical vision transformers have been known to incorporate various vision-specific components, aiming to enhance accuracies and produce desirable FLOP counts. However, these augmentations have led to slower processing times compared to their vanilla ViT counterparts. In this exciting research, we challenge the necessity of such additional complexities.
Enter Hiera, an innovative and significantly simplified hierarchical vision transformer that champions efficiency without compromising accuracy. By deploying a potent visual pretext task, MAE, we're able to eliminate the bells-and-whistles from a state-of-the-art multi-stage vision transformer. The result? A lean, mean machine learning model that not only outperforms its predecessors in terms of accuracy but also achieves superior speed, both during inference and training. Tested across a diverse array of image and video recognition tasks, Hiera stands as a beacon of progress in the field of computer vision.
Paper link: https://arxiv.org/abs/2306.00989
Code link: https://github.com/facebookresearch/hiera
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-hiera
#deeplearning #cv #transformer #sota
In the rapidly evolving landscape of artificial intelligence, a groundbreaking approach to supervised classification performance has been born. Modern hierarchical vision transformers have been known to incorporate various vision-specific components, aiming to enhance accuracies and produce desirable FLOP counts. However, these augmentations have led to slower processing times compared to their vanilla ViT counterparts. In this exciting research, we challenge the necessity of such additional complexities.
Enter Hiera, an innovative and significantly simplified hierarchical vision transformer that champions efficiency without compromising accuracy. By deploying a potent visual pretext task, MAE, we're able to eliminate the bells-and-whistles from a state-of-the-art multi-stage vision transformer. The result? A lean, mean machine learning model that not only outperforms its predecessors in terms of accuracy but also achieves superior speed, both during inference and training. Tested across a diverse array of image and video recognition tasks, Hiera stands as a beacon of progress in the field of computer vision.
Paper link: https://arxiv.org/abs/2306.00989
Code link: https://github.com/facebookresearch/hiera
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-hiera
#deeplearning #cv #transformer #sota
{kind=link}
👍11❤3👀3🔥2🥰1
Recognize Anything: A Strong Image Tagging Model
Get ready for a breakthrough in the realm of AI: introducing the Recognize Anything Model (RAM), a powerful new model that is set to revolutionize image tagging. RAM, a titan in the world of large computer vision models, astoundingly exhibits the zero-shot ability to recognize any common category with an impressive level of accuracy. Shattering traditional approaches, RAM employs a unique paradigm for image tagging, utilizing large-scale image-text pairs for training instead of relying on tedious manual annotations.
RAM's development comprises a strategic, four-step process. Initially, annotation-free image tags are obtained on a large scale via an automated text semantic parsing. This is followed by training a preliminary model for automatic annotation, fusing caption and tagging tasks under the supervision of original texts and parsed tags. Then, RAM utilizes a data engine to generate extra annotations and eliminate incorrect ones, refining the input. Finally, the model is meticulously retrained with the cleaned data and fine-tuned using a smaller, higher-quality dataset. Extensive evaluations of RAM have revealed stunning results: it outshines its counterparts like CLIP and BLIP in zero-shot performance, even surpassing fully supervised models, exhibiting a competitive edge akin to Google's tagging API!
Paper link: https://arxiv.org/abs/2306.03514
Code link: https://github.com/xinyu1205/recognize-anything
Project link: https://recognize-anything.github.io/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-ram
#deeplearning #cv #imagecaptioning
Get ready for a breakthrough in the realm of AI: introducing the Recognize Anything Model (RAM), a powerful new model that is set to revolutionize image tagging. RAM, a titan in the world of large computer vision models, astoundingly exhibits the zero-shot ability to recognize any common category with an impressive level of accuracy. Shattering traditional approaches, RAM employs a unique paradigm for image tagging, utilizing large-scale image-text pairs for training instead of relying on tedious manual annotations.
RAM's development comprises a strategic, four-step process. Initially, annotation-free image tags are obtained on a large scale via an automated text semantic parsing. This is followed by training a preliminary model for automatic annotation, fusing caption and tagging tasks under the supervision of original texts and parsed tags. Then, RAM utilizes a data engine to generate extra annotations and eliminate incorrect ones, refining the input. Finally, the model is meticulously retrained with the cleaned data and fine-tuned using a smaller, higher-quality dataset. Extensive evaluations of RAM have revealed stunning results: it outshines its counterparts like CLIP and BLIP in zero-shot performance, even surpassing fully supervised models, exhibiting a competitive edge akin to Google's tagging API!
Paper link: https://arxiv.org/abs/2306.03514
Code link: https://github.com/xinyu1205/recognize-anything
Project link: https://recognize-anything.github.io/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-ram
#deeplearning #cv #imagecaptioning
{kind=link}
👍9🔥3❤2