
ImageBind: One Embedding Space To Bind Them All
Introducing ImageBind, a groundbreaking approach that learns a joint embedding across six different modalities – images, text, audio, depth, thermal, and IMU data – using only image-paired data. This innovative method leverages recent large-scale vision-language models, extending their zero-shot capabilities to new modalities through their natural pairing with images. ImageBind unlocks a myriad of novel emergent applications 'out-of-the-box,' including cross-modal retrieval, composing modalities with arithmetic, cross-modal detection, and generation.
ImageBind's emergent capabilities improve as the strength of the image encoder increases, setting a new state-of-the-art benchmark in emergent zero-shot recognition tasks across modalities, even outperforming specialist supervised models. Furthermore, ImageBind demonstrates impressive few-shot recognition results, surpassing prior work in the field. This pioneering technique offers a fresh way to evaluate vision models for both visual and non-visual tasks, opening the door to exciting advancements in AI and machine learning.
Blogpost link: https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
Code link: https://github.com/facebookresearch/ImageBind
Paper link: https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf
Demo link: https://imagebind.metademolab.com/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-imagebind
#deeplearning #nlp #multimodal #cv #embedding
Introducing ImageBind, a groundbreaking approach that learns a joint embedding across six different modalities – images, text, audio, depth, thermal, and IMU data – using only image-paired data. This innovative method leverages recent large-scale vision-language models, extending their zero-shot capabilities to new modalities through their natural pairing with images. ImageBind unlocks a myriad of novel emergent applications 'out-of-the-box,' including cross-modal retrieval, composing modalities with arithmetic, cross-modal detection, and generation.
ImageBind's emergent capabilities improve as the strength of the image encoder increases, setting a new state-of-the-art benchmark in emergent zero-shot recognition tasks across modalities, even outperforming specialist supervised models. Furthermore, ImageBind demonstrates impressive few-shot recognition results, surpassing prior work in the field. This pioneering technique offers a fresh way to evaluate vision models for both visual and non-visual tasks, opening the door to exciting advancements in AI and machine learning.
Blogpost link: https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
Code link: https://github.com/facebookresearch/ImageBind
Paper link: https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf
Demo link: https://imagebind.metademolab.com/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-imagebind
#deeplearning #nlp #multimodal #cv #embedding
{kind=link}
🔥14👍10❤1
Forwarded from Spark in me (Alexander)
Found another PyTorch-based library with basic image functions, losses and transformations
Looks like it is a combination toolkit of augs, skimage and classic cv2 functions, but written in PyTorch.
What is Kornia? Kornia is a differentiable library that allows classical computer vision to be integrated into deep learning models.
Examples:
- https://kornia.readthedocs.io/en/latest/get-started/highlights.html
- and especially this https://kornia.readthedocs.io/en/latest/losses.html
Looks like it is a combination toolkit of augs, skimage and classic cv2 functions, but written in PyTorch.
What is Kornia? Kornia is a differentiable library that allows classical computer vision to be integrated into deep learning models.
Examples:
- https://kornia.readthedocs.io/en/latest/get-started/highlights.html
- and especially this https://kornia.readthedocs.io/en/latest/losses.html
👍14❤5👏1
Data Science by ODS.ai 🦜
Hey, let’s see how many of us have some Data Science-related vacancies to share. Please submit them through Google Form. Best vacancies may be published in this channel. Google Form: link. #ds_jobs
For those how are looking beyond Data Science or wondering to play around, here is a news on the release of the portfolio company of one of the channel editors:
TON Play: the Unity SDK + payment management for games
TON Play is a toolkit for developers based on the TON blockchain and working closely with the messaging app Telegram. They recently introduced Pay-in, Mass payout, and On-demand payout methods in TON. If you dabble with games, this might be curious to test in action.
The main features:
* projects get paid by Telegram users in TON
* option to add mass payouts in TON to games with cash prizes
* automated payouts on user demand
TON Play also released SDKs, allowing projects to manage assets and in-game marketplace and port Unity or HTML5 games to work inside Telegram as a web app. SDKs are written in Unity, Python, and Typescript.
Website: https://tonplay.io/
Documentation: https://docs.tonplay.io/
Telegram channel: https://t.iss.one/tonplayinsider
Contacts: @tonplay_devs, [email protected]
#ds_jobs #ds_resumes
TON Play: the Unity SDK + payment management for games
TON Play is a toolkit for developers based on the TON blockchain and working closely with the messaging app Telegram. They recently introduced Pay-in, Mass payout, and On-demand payout methods in TON. If you dabble with games, this might be curious to test in action.
The main features:
* projects get paid by Telegram users in TON
* option to add mass payouts in TON to games with cash prizes
* automated payouts on user demand
TON Play also released SDKs, allowing projects to manage assets and in-game marketplace and port Unity or HTML5 games to work inside Telegram as a web app. SDKs are written in Unity, Python, and Typescript.
Website: https://tonplay.io/
Documentation: https://docs.tonplay.io/
Telegram channel: https://t.iss.one/tonplayinsider
Contacts: @tonplay_devs, [email protected]
#ds_jobs #ds_resumes
www.playdeck.io
The official gaming marketplace on Telegram. We bring developers together with millions of active players
👍5❤1
Forwarded from ml4se
StarCoder: may the source be with you!
The BigCode community, an open-scientific collaboration working on the responsible development of Code LLMs, introduces StarCoder and StarCoderBase:
- 15.5B parameter models
- 8K context length
- StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process
- StarCoderBase is fine-tuned on 35B Python tokens, resulting in the creation of StarCoder
StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model.
The BigCode community, an open-scientific collaboration working on the responsible development of Code LLMs, introduces StarCoder and StarCoderBase:
- 15.5B parameter models
- 8K context length
- StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process
- StarCoderBase is fine-tuned on 35B Python tokens, resulting in the creation of StarCoder
StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model.
👍10❤5🔥2
Data Science by ODS.ai 🦜
Hey, let’s see how many of us have some Data Science-related vacancies to share. Please submit them through Google Form. Best vacancies may be published in this channel. Google Form: link. #ds_jobs
Launching the Open Data Science Talent Pool Initiative!
Hello, community!
We received several requests to organize some tools to match people seeking career / pet projects matching opportunities. So now we are launching the Open Data Science Talent Pool!
The field of data science is rapidly evolving, and we recognize the importance of matching skilled professionals with organizations that value their unique capabilities. This Talent Pool Initiative is our endeavor to facilitate these connections, making the opportunities search process smoother and more efficient for everyone involved.
Here's how it works:
🔍 For Opportunities Seekers:
If you're a data scientist, machine learning engineer, AI specialist, or hold any other role in the data science domain, we invite you to submit your resume and a brief introduction about yourself. This is a fantastic opportunity to showcase your skills, interests, and aspirations to potential employers. Don't forget to highlight those special projects or unique experiences that make you stand out!
🏢 For Talent Seekers:
If you're an organization or an individual looking for talented individuals in the field of data science, our Talent Pool will be an invaluable resource. You'll have access to a diverse array of professionals, each with their own unique skill sets and experiences, ready to help your organization reach new heights. Make sure you submitted your request through the form in the quoted post
🔄 The Process:
1 Submission: Individuals can submit their resumes and short introductions through a dedicated form on our website (link will be shared soon).
2 Review: Our team will review these submissions to ensure they meet the necessary standards and criteria.
3 Access: Approved profiles will be included in our Talent Pool, accessible to match with the requests within our community.
During the earliest stage we are going to match the requests personally ensuring we don’t overengineer the process. We will not hesitate to introduce necessary product adjustments once the tool meets the demand inside the community.
Remember, we're all in this journey together. Whether you're looking for your next big opportunity or seeking the perfect addition to your team, we're here to support you.
Stay tuned, stay connected, and let's continue to foster a supportive, dynamic, and prosperous data science community!
Best,
ChatGPT with the prompt from Open Data Science Channel Editorial Team
Google Form: https://forms.gle/3GH1vrt91mRtstzK8
#ds_jobs #ds_intros
Hello, community!
We received several requests to organize some tools to match people seeking career / pet projects matching opportunities. So now we are launching the Open Data Science Talent Pool!
The field of data science is rapidly evolving, and we recognize the importance of matching skilled professionals with organizations that value their unique capabilities. This Talent Pool Initiative is our endeavor to facilitate these connections, making the opportunities search process smoother and more efficient for everyone involved.
Here's how it works:
🔍 For Opportunities Seekers:
If you're a data scientist, machine learning engineer, AI specialist, or hold any other role in the data science domain, we invite you to submit your resume and a brief introduction about yourself. This is a fantastic opportunity to showcase your skills, interests, and aspirations to potential employers. Don't forget to highlight those special projects or unique experiences that make you stand out!
🏢 For Talent Seekers:
If you're an organization or an individual looking for talented individuals in the field of data science, our Talent Pool will be an invaluable resource. You'll have access to a diverse array of professionals, each with their own unique skill sets and experiences, ready to help your organization reach new heights. Make sure you submitted your request through the form in the quoted post
🔄 The Process:
1 Submission: Individuals can submit their resumes and short introductions through a dedicated form on our website (link will be shared soon).
2 Review: Our team will review these submissions to ensure they meet the necessary standards and criteria.
3 Access: Approved profiles will be included in our Talent Pool, accessible to match with the requests within our community.
During the earliest stage we are going to match the requests personally ensuring we don’t overengineer the process. We will not hesitate to introduce necessary product adjustments once the tool meets the demand inside the community.
Remember, we're all in this journey together. Whether you're looking for your next big opportunity or seeking the perfect addition to your team, we're here to support you.
Stay tuned, stay connected, and let's continue to foster a supportive, dynamic, and prosperous data science community!
Best,
ChatGPT with the prompt from Open Data Science Channel Editorial Team
Google Form: https://forms.gle/3GH1vrt91mRtstzK8
#ds_jobs #ds_intros
Google Docs
Open Data Science Talent Pool
Use this form to submit a resume to the talent pool. Be vocal.
❤9👍4💩3
Forwarded from ml4se
Introducing 100K Token Context Windows
- approximately 75K words
- hundreds of pages
- a book, for example "The Great Gatsby" (about 72K tokens)
- a text that will take approximately 5 hours to read
- approximately 75K words
- hundreds of pages
- a book, for example "The Great Gatsby" (about 72K tokens)
- a text that will take approximately 5 hours to read
🔥15👍4
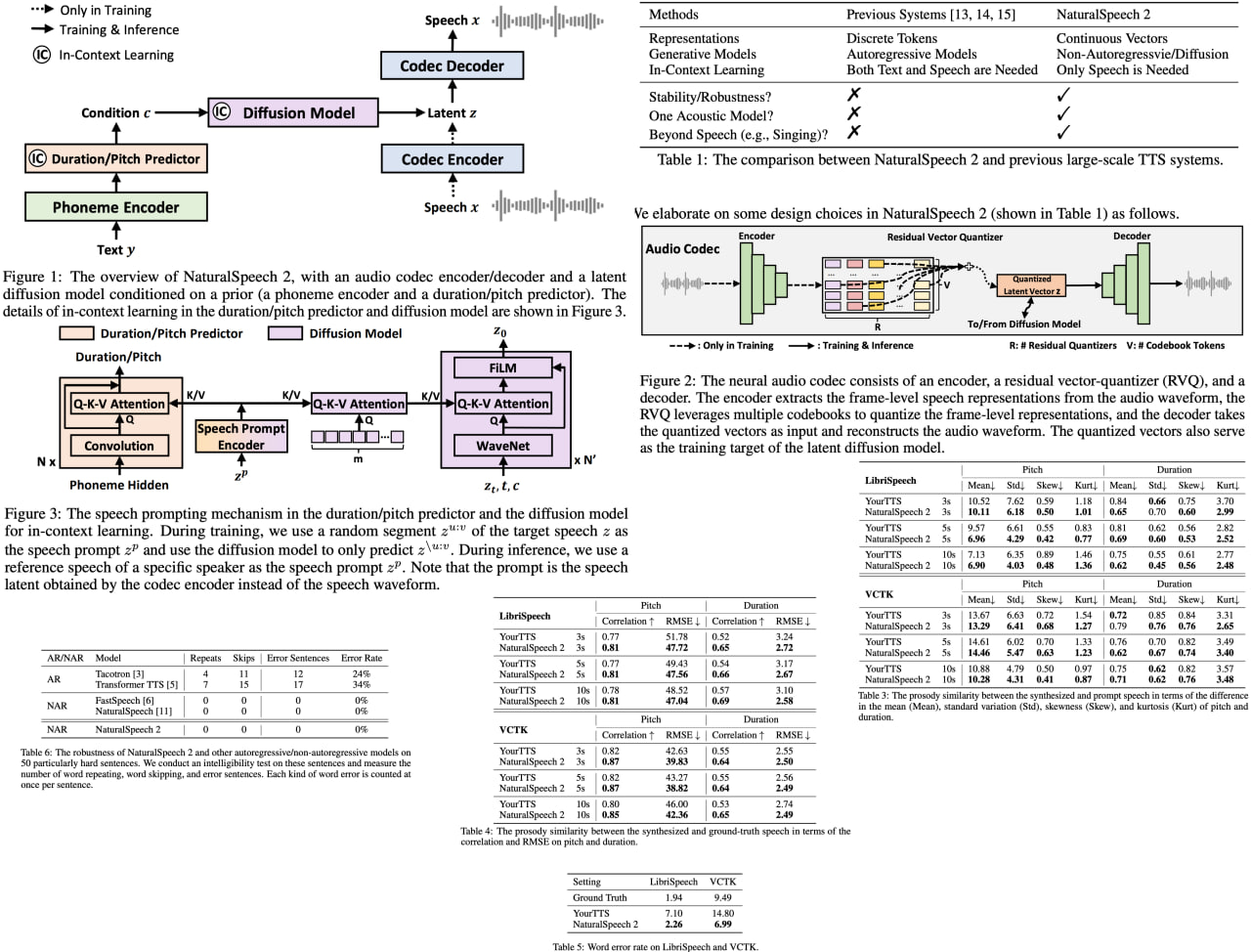
NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers
In the rapidly evolving domain of text-to-speech (TTS) technology, an exciting breakthrough has been made with the development of NaturalSpeech 2. This innovative system brings new levels of diversity to the table, by uniquely capturing a wide range of human speech characteristics such as speaker identities, prosodies, and even styles like singing. By employing a neural audio codec and residual vector quantizers, it transcends the limitations of existing TTS systems, which often suffer from unstable prosody, word skipping/repeating issues, and subpar voice quality.
More impressively, NaturalSpeech 2 enhances the "zero-shot" capability, a crucial factor for diverse speech synthesis. By designing a unique speech prompting mechanism, it facilitates in-context learning in both the diffusion model and the duration/pitch predictor. Its expansive training on 44K hours of speech and singing data has yielded unprecedented results. NaturalSpeech 2 significantly outperforms previous TTS systems in prosody/timbre similarity, robustness, and voice quality, even demonstrating novel zero-shot singing synthesis.
Project link: https://speechresearch.github.io/naturalspeech2/
Paper link: https://arxiv.org/pdf/2304.09116.pdf
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-naturalspeech2
#deeplearning #nlp #tts #texttospeech
In the rapidly evolving domain of text-to-speech (TTS) technology, an exciting breakthrough has been made with the development of NaturalSpeech 2. This innovative system brings new levels of diversity to the table, by uniquely capturing a wide range of human speech characteristics such as speaker identities, prosodies, and even styles like singing. By employing a neural audio codec and residual vector quantizers, it transcends the limitations of existing TTS systems, which often suffer from unstable prosody, word skipping/repeating issues, and subpar voice quality.
More impressively, NaturalSpeech 2 enhances the "zero-shot" capability, a crucial factor for diverse speech synthesis. By designing a unique speech prompting mechanism, it facilitates in-context learning in both the diffusion model and the duration/pitch predictor. Its expansive training on 44K hours of speech and singing data has yielded unprecedented results. NaturalSpeech 2 significantly outperforms previous TTS systems in prosody/timbre similarity, robustness, and voice quality, even demonstrating novel zero-shot singing synthesis.
Project link: https://speechresearch.github.io/naturalspeech2/
Paper link: https://arxiv.org/pdf/2304.09116.pdf
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-naturalspeech2
#deeplearning #nlp #tts #texttospeech
{kind=link}
🔥13👍5🆒2
DarkBERT: A Language Model for the Dark Side of the Internet
The researchers have developed a novel model called DarkBERT, which specifically focuses on the linguistically complex and often misunderstood domain of the Dark Web. This innovative model stands out due to its unique pretraining on Dark Web data, which allows it to handle the extreme lexical and structural diversity characteristic of the Dark Web. This is a critical development considering the clear differences that exist in language use between the Dark Web and the Surface Web, a factor that can often hinder accurate textual analysis.
DarkBERT isn't just a novelty, but a robust, high-performing language model that consistently outshines current popular models like BERT and RoBERTa in various use cases. These findings shed light on the considerable advantages that a domain-specific model like DarkBERT can offer. More than anything else, DarkBERT promises to be a vital resource for future research on the Dark Web, setting a new standard for language models in this intriguing and intricate realm.
Paper link: https://arxiv.org/abs/2305.08596
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-darkbert
#deeplearning #nlp #darkweb #cybersecurity
The researchers have developed a novel model called DarkBERT, which specifically focuses on the linguistically complex and often misunderstood domain of the Dark Web. This innovative model stands out due to its unique pretraining on Dark Web data, which allows it to handle the extreme lexical and structural diversity characteristic of the Dark Web. This is a critical development considering the clear differences that exist in language use between the Dark Web and the Surface Web, a factor that can often hinder accurate textual analysis.
DarkBERT isn't just a novelty, but a robust, high-performing language model that consistently outshines current popular models like BERT and RoBERTa in various use cases. These findings shed light on the considerable advantages that a domain-specific model like DarkBERT can offer. More than anything else, DarkBERT promises to be a vital resource for future research on the Dark Web, setting a new standard for language models in this intriguing and intricate realm.
Paper link: https://arxiv.org/abs/2305.08596
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-darkbert
#deeplearning #nlp #darkweb #cybersecurity
{kind=link}
😈21👍10❤7🌚4😁2🤬2
Forwarded from ml4se
Code Execution with Pre-trained Language Models
Code execution is a fundamental aspect of programming language semantics that reflects the exact behavior of the code. However, most pretrained models for code intelligence ignore the execution trace and only rely on source code and syntactic structures. In this paper, the authors aim to teach pretrained models the real-world code execution process. They propose CodeExecutor, a Transformer-based model that learns to execute arbitrary programs and predict their execution traces.
Code execution is a fundamental aspect of programming language semantics that reflects the exact behavior of the code. However, most pretrained models for code intelligence ignore the execution trace and only rely on source code and syntactic structures. In this paper, the authors aim to teach pretrained models the real-world code execution process. They propose CodeExecutor, a Transformer-based model that learns to execute arbitrary programs and predict their execution traces.
🔥17👍3😁1
Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold
Meet DragGAN, a groundbreaking approach that is set to revolutionize the way we control generative adversarial networks (GANs) and synthesize visual content! This innovative tool offers users unprecedented flexibility and precision when manipulating images, sidestepping the limitations of prior 3D models and annotated training data. With DragGAN, you can now "drag" any point of an image to a precise target position, introducing a nvel user-interactive element.
Two ingenious components underpin DragGAN's functionality: the first is a feature-based motion supervision that effortlessly guides the handle point towards the desired position, and the second is a novel point tracking approach that utilizes the discriminating features of the generator to maintain the handle points' positions. The real game-changer is that anyone can now deform an image with absolute control over pixel movements, enabling the manipulation of pose, shape, expression, and layout across diverse categories like animals, cars, humans, landscapes, and more. DragGAN outperforms its predecessors in both image manipulation and point tracking tasks, promising an exciting leap forward in AI-generated visual content!
Paper link: https://arxiv.org/abs/2305.10973
Code link: https://github.com/XingangPan/DragGAN
Project link: https://vcai.mpi-inf.mpg.de/projects/DragGAN/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-draggan
#deeplearning #cv #gan #imagemanipulation
Meet DragGAN, a groundbreaking approach that is set to revolutionize the way we control generative adversarial networks (GANs) and synthesize visual content! This innovative tool offers users unprecedented flexibility and precision when manipulating images, sidestepping the limitations of prior 3D models and annotated training data. With DragGAN, you can now "drag" any point of an image to a precise target position, introducing a nvel user-interactive element.
Two ingenious components underpin DragGAN's functionality: the first is a feature-based motion supervision that effortlessly guides the handle point towards the desired position, and the second is a novel point tracking approach that utilizes the discriminating features of the generator to maintain the handle points' positions. The real game-changer is that anyone can now deform an image with absolute control over pixel movements, enabling the manipulation of pose, shape, expression, and layout across diverse categories like animals, cars, humans, landscapes, and more. DragGAN outperforms its predecessors in both image manipulation and point tracking tasks, promising an exciting leap forward in AI-generated visual content!
Paper link: https://arxiv.org/abs/2305.10973
Code link: https://github.com/XingangPan/DragGAN
Project link: https://vcai.mpi-inf.mpg.de/projects/DragGAN/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-draggan
#deeplearning #cv #gan #imagemanipulation
{kind=link}
🔥11❤5👍2
MMS: Scaling Speech Technology to 1000+ languages
Get ready for a breakthrough in speech technology that is set to revolutionize the world of communication! The field, which has so far been restricted to around a hundred languages, barely scratches the surface of the more than 7,000 languages spoken globally. The Massively Multilingual Speech (MMS) project is taking a monumental leap to bridge this gap, increasing the number of supported languages by an astounding 10 to 40 times, depending on the task. This unprecedented expansion will be a game-changer, significantly improving global access to information and creating a more inclusive digital landscape.
This incredible feat is achieved through the creation of a new dataset drawn from publicly available religious texts and the strategic implementation of self-supervised learning. The MMS project's achievements are staggering, including the development of pre-trained wav2vec 2.0 models for 1,406 languages, a single multilingual automatic speech recognition model for 1,107 languages, speech synthesis models for as many languages, and a language identification model for a whopping 4,017 languages. Even more impressive is the significant improvement in accuracy - our multilingual speech recognition model more than halves the word error rate of Whisper on 54 languages of the FLEURS benchmark, despite being trained on a significantly smaller dataset.
Paper link: https://research.facebook.com/publications/scaling-speech-technology-to-1000-languages/
Blogpost link: https://ai.facebook.com/blog/multilingual-model-speech-recognition/
Code link: https://github.com/facebookresearch/fairseq/tree/main/examples/mms
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-mms
#deeplearning #speechrecognition #tts #audio
Get ready for a breakthrough in speech technology that is set to revolutionize the world of communication! The field, which has so far been restricted to around a hundred languages, barely scratches the surface of the more than 7,000 languages spoken globally. The Massively Multilingual Speech (MMS) project is taking a monumental leap to bridge this gap, increasing the number of supported languages by an astounding 10 to 40 times, depending on the task. This unprecedented expansion will be a game-changer, significantly improving global access to information and creating a more inclusive digital landscape.
This incredible feat is achieved through the creation of a new dataset drawn from publicly available religious texts and the strategic implementation of self-supervised learning. The MMS project's achievements are staggering, including the development of pre-trained wav2vec 2.0 models for 1,406 languages, a single multilingual automatic speech recognition model for 1,107 languages, speech synthesis models for as many languages, and a language identification model for a whopping 4,017 languages. Even more impressive is the significant improvement in accuracy - our multilingual speech recognition model more than halves the word error rate of Whisper on 54 languages of the FLEURS benchmark, despite being trained on a significantly smaller dataset.
Paper link: https://research.facebook.com/publications/scaling-speech-technology-to-1000-languages/
Blogpost link: https://ai.facebook.com/blog/multilingual-model-speech-recognition/
Code link: https://github.com/facebookresearch/fairseq/tree/main/examples/mms
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-mms
#deeplearning #speechrecognition #tts #audio
{kind=link}
🔥7❤5👍4🆒3
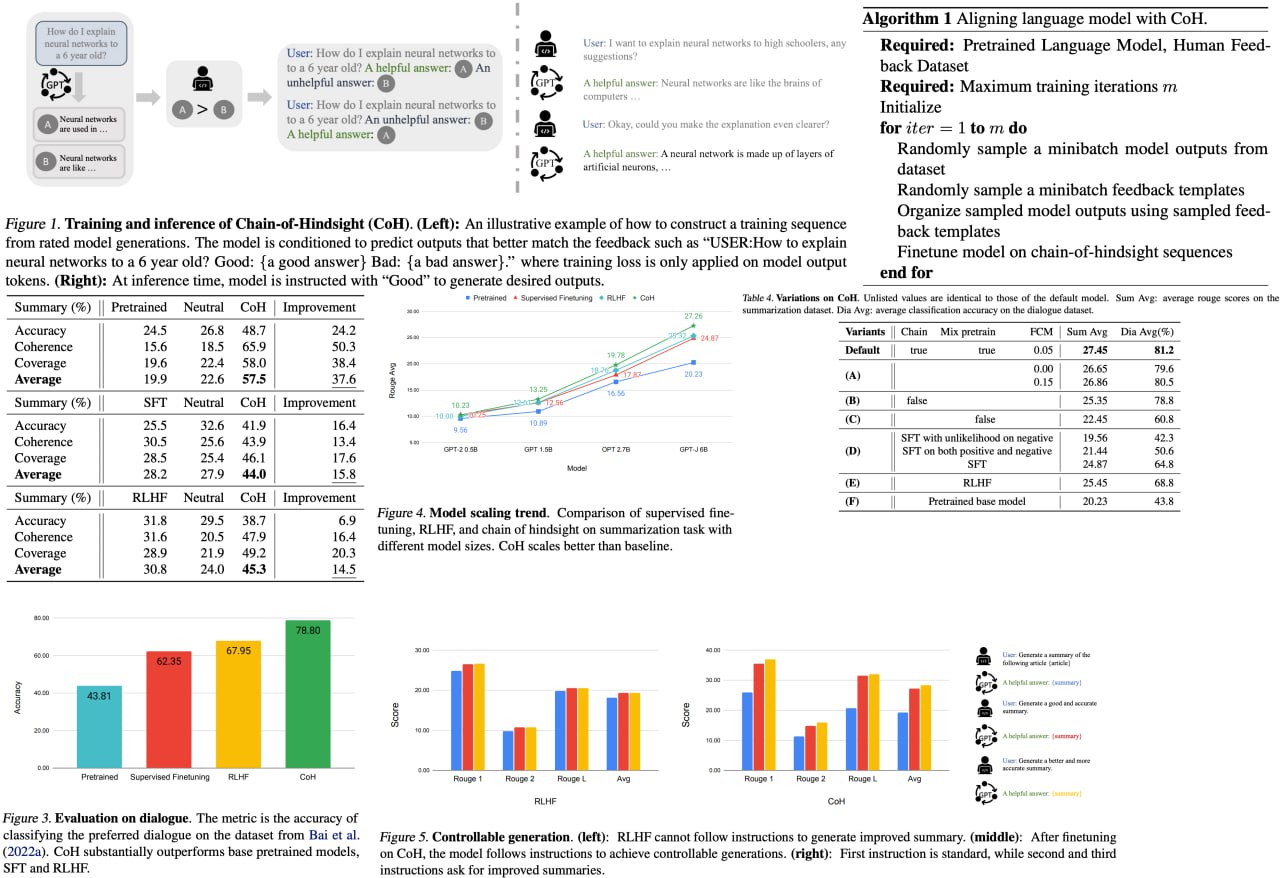
Chain of Hindsight Aligns Language Models with Feedback
AI language models are becoming a major part of our digital world. The challenge, however, lies in aligning these models with human preferences to be genuinely useful and valuable. Current methods, although successful in many ways, have limitations - they are either inefficient in utilizing data or depend heavily on challenging reward functions and reinforcement learning.
Here comes "Chain of Hindsight," an exciting, novel technique inspired by human learning mechanisms. It can learn from any form of feedback, even transforming it into language for fine-tuning the model. This approach conditions the model on a sequence of model generations paired with feedback, helping it learn to correct negative attributes or errors. It is significantly outperforming previous methods, particularly showing major strides in summarization and dialogue tasks.
Paper link: https://arxiv.org/abs/2302.02676
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-coh
#deeplearning #nlp #llm
AI language models are becoming a major part of our digital world. The challenge, however, lies in aligning these models with human preferences to be genuinely useful and valuable. Current methods, although successful in many ways, have limitations - they are either inefficient in utilizing data or depend heavily on challenging reward functions and reinforcement learning.
Here comes "Chain of Hindsight," an exciting, novel technique inspired by human learning mechanisms. It can learn from any form of feedback, even transforming it into language for fine-tuning the model. This approach conditions the model on a sequence of model generations paired with feedback, helping it learn to correct negative attributes or errors. It is significantly outperforming previous methods, particularly showing major strides in summarization and dialogue tasks.
Paper link: https://arxiv.org/abs/2302.02676
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-coh
#deeplearning #nlp #llm
{kind=link}
🔥9👍4❤1🥰1🤔1
QLoRA: Efficient Finetuning of Quantized LLMs
Thia paper introduces QLoRA, a novel finetuning approach that decreases memory usage significantly, while maintaining impressive performance. Imagine this - a 65 billion parameter model finetuned on a single 48GB GPU, while preserving full 16-bit task performance. This method involves backpropagating gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters, a method that opens up new frontiers in machine learning. The icing on the cake is their high-performing model family, Guanaco, which trumps all previously released models on the Vicuna benchmark, achieving a staggering 99.3% of the performance level of ChatGPT with just 24 hours of finetuning on a single GPU.
The study also unveils several innovative techniques to conserve memory without compromising performance. These include 4-bit NormalFloat (NF4), an innovative data type that is theoretically optimal for normally distributed weights, double quantization for average memory footprint reduction, and paged optimizers to handle memory spikes. The QLoRA approach was applied to finetune more than 1000 models, leading to a detailed analysis of instruction following and chatbot performance across various model types and scales. The results affirm that QLoRA finetuning on a small, high-quality dataset yields state-of-the-art results, even with smaller models than previously used. A notable finding is that GPT-4 evaluations offer a cost-effective alternative to human evaluation. All models and code, including CUDA kernels for 4-bit training, have been released by the researchers.
Paper link: https://arxiv.org/abs/2305.14314
Code link: https://github.com/artidoro/qlora
CUDA kernels link: https://github.com/TimDettmers/bitsandbytes
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-qlora
#deeplearning #nlp #llm #quantization
Thia paper introduces QLoRA, a novel finetuning approach that decreases memory usage significantly, while maintaining impressive performance. Imagine this - a 65 billion parameter model finetuned on a single 48GB GPU, while preserving full 16-bit task performance. This method involves backpropagating gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters, a method that opens up new frontiers in machine learning. The icing on the cake is their high-performing model family, Guanaco, which trumps all previously released models on the Vicuna benchmark, achieving a staggering 99.3% of the performance level of ChatGPT with just 24 hours of finetuning on a single GPU.
The study also unveils several innovative techniques to conserve memory without compromising performance. These include 4-bit NormalFloat (NF4), an innovative data type that is theoretically optimal for normally distributed weights, double quantization for average memory footprint reduction, and paged optimizers to handle memory spikes. The QLoRA approach was applied to finetune more than 1000 models, leading to a detailed analysis of instruction following and chatbot performance across various model types and scales. The results affirm that QLoRA finetuning on a small, high-quality dataset yields state-of-the-art results, even with smaller models than previously used. A notable finding is that GPT-4 evaluations offer a cost-effective alternative to human evaluation. All models and code, including CUDA kernels for 4-bit training, have been released by the researchers.
Paper link: https://arxiv.org/abs/2305.14314
Code link: https://github.com/artidoro/qlora
CUDA kernels link: https://github.com/TimDettmers/bitsandbytes
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-qlora
#deeplearning #nlp #llm #quantization
{kind=link}
👍18🔥7❤5
Forwarded from ml4se
CodeTF: One-stop Transformer Library for State-of-the-art Code LLM (Salesforce)
The authors we present CodeTF, an open-source Transformer-based library for state-of-the-art Code LLMs and code intelligence. CodeTF is designed with a unified interface to enable rapid access and development across different types of models, datasets and tasks. The library supports a collection of pretrained Code LLM models and popular code benchmarks, including a standardized interface to train and serve code LLMs efficiently, and data features such as language-specific parsers and utility functions for extracting code attributes.
The authors we present CodeTF, an open-source Transformer-based library for state-of-the-art Code LLMs and code intelligence. CodeTF is designed with a unified interface to enable rapid access and development across different types of models, datasets and tasks. The library supports a collection of pretrained Code LLM models and popular code benchmarks, including a standardized interface to train and serve code LLMs efficiently, and data features such as language-specific parsers and utility functions for extracting code attributes.
🤡7❤6👍5💩2
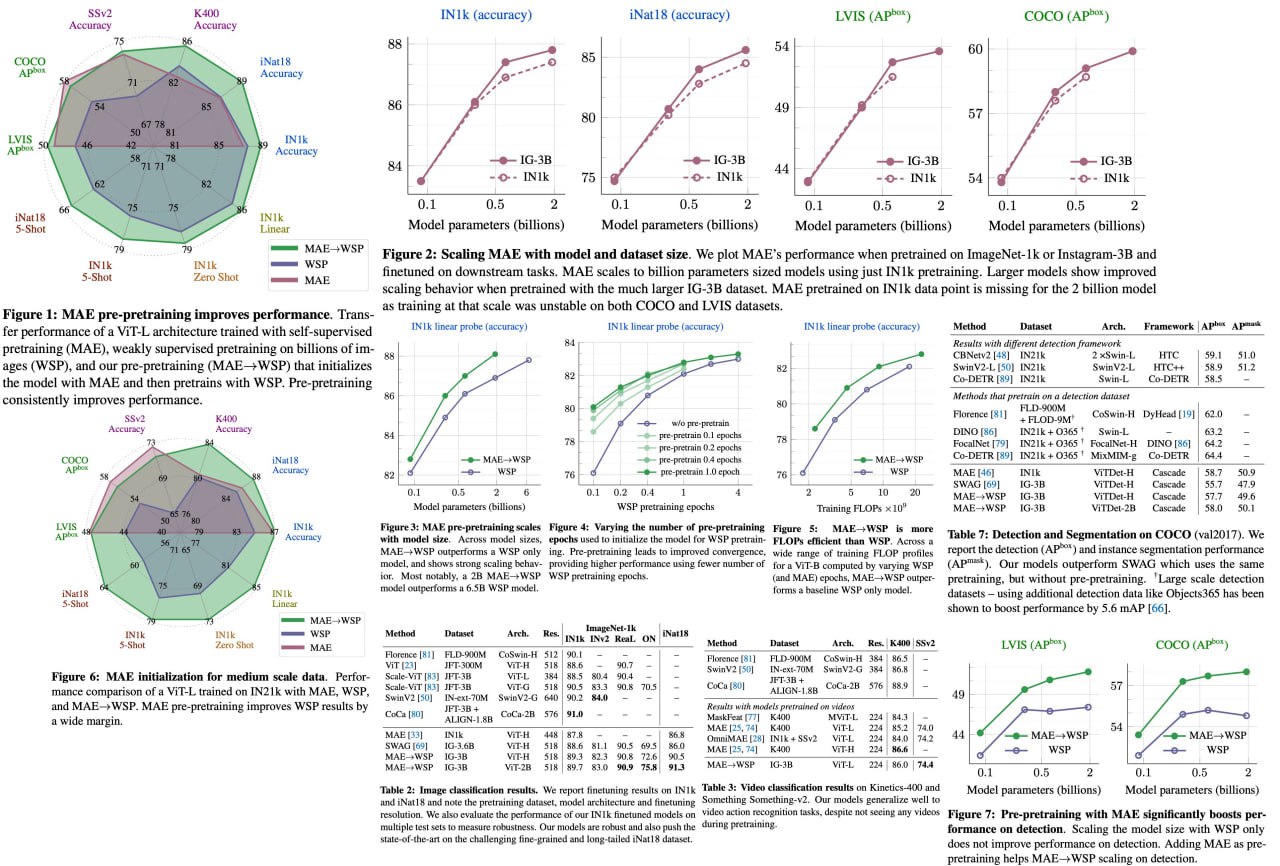
The effectiveness of MAE pre-pretraining for billion-scale pretraining
Revolutionizing the current pretrain-then-finetune paradigm of computer vision, this research has introduced an innovative pre-pretraining stage. Utilizing the Masked Autoencoder (MAE) technique for model initialization, this pre-pretraining strategy scales with the size of both the model and the data. This makes it an ideal tool for training next-generation foundation models, even on the grandest scales.
The robustness of our pre-pretraining technique is demonstrated by consistent improvement in model convergence and downstream transfer performance across diverse model scales and dataset sizes. The authors measured the effectiveness of pre-pretraining on a wide array of visual recognition tasks, and the results have been promising. The ielargest model achieved unprecedented results on iNaturalist-18 (91.3%), 1-shot ImageNet-1k (62.1%), and zero-shot transfer on Food-101 (96.0%), underlining the tremendous potential of proper model initialization, even when handling web-scale pretraining with billions of images.
Paper link: https://arxiv.org/abs/2303.13496
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-mae-pretrain
#deeplearning #cv #pretraining #selfsupervisedlearning
Revolutionizing the current pretrain-then-finetune paradigm of computer vision, this research has introduced an innovative pre-pretraining stage. Utilizing the Masked Autoencoder (MAE) technique for model initialization, this pre-pretraining strategy scales with the size of both the model and the data. This makes it an ideal tool for training next-generation foundation models, even on the grandest scales.
The robustness of our pre-pretraining technique is demonstrated by consistent improvement in model convergence and downstream transfer performance across diverse model scales and dataset sizes. The authors measured the effectiveness of pre-pretraining on a wide array of visual recognition tasks, and the results have been promising. The ielargest model achieved unprecedented results on iNaturalist-18 (91.3%), 1-shot ImageNet-1k (62.1%), and zero-shot transfer on Food-101 (96.0%), underlining the tremendous potential of proper model initialization, even when handling web-scale pretraining with billions of images.
Paper link: https://arxiv.org/abs/2303.13496
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-mae-pretrain
#deeplearning #cv #pretraining #selfsupervisedlearning
{kind=link}
👍7❤🔥3🔥2
StableRep: Synthetic Images from Text-to-Image Models Make Strong Visual Representation Learners
In a ground-breaking exploration of visual representation learning, researchers have leveraged synthetic images produced by leading text-to-image models, specifically Stable Diffusion, achieving promising results. The study uncovers two key insights - firstly, when configured correctly, self-supervised methods trained on synthetic images can match or even outperform those trained on real images. This suggests an exciting avenue for efficient and effective representation learning, reducing the need for extensive real image datasets.
Secondly, the researchers have devised a novel approach called StableRep, a multi-positive contrastive learning method that treats multiple images, generated from the same text prompt, as mutual positives. The compelling finding is that StableRep, trained solely with synthetic images, outperforms representations learned by prominent methods such as SimCLR and CLIP, even when these used real images. In a striking demonstration, when language supervision is added, StableRep trained with 20M synthetic images outperforms CLIP trained with a whopping 50M real images. These findings not only underscore the potential of synthetic data but also pave the way for more efficient, large-scale visual representation learning.
Paper link: https://arxiv.org/abs/2306.00984
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-stablerep
#deeplearning #cv #nlp #stablediffusion #texttoimage #syntheticdata
In a ground-breaking exploration of visual representation learning, researchers have leveraged synthetic images produced by leading text-to-image models, specifically Stable Diffusion, achieving promising results. The study uncovers two key insights - firstly, when configured correctly, self-supervised methods trained on synthetic images can match or even outperform those trained on real images. This suggests an exciting avenue for efficient and effective representation learning, reducing the need for extensive real image datasets.
Secondly, the researchers have devised a novel approach called StableRep, a multi-positive contrastive learning method that treats multiple images, generated from the same text prompt, as mutual positives. The compelling finding is that StableRep, trained solely with synthetic images, outperforms representations learned by prominent methods such as SimCLR and CLIP, even when these used real images. In a striking demonstration, when language supervision is added, StableRep trained with 20M synthetic images outperforms CLIP trained with a whopping 50M real images. These findings not only underscore the potential of synthetic data but also pave the way for more efficient, large-scale visual representation learning.
Paper link: https://arxiv.org/abs/2306.00984
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-stablerep
#deeplearning #cv #nlp #stablediffusion #texttoimage #syntheticdata
{kind=link}
🔥8👍5❤4👀4👏1