
Forwarded from Малоизвестное интересное
Все так ждали сингулярности, - так получите!
Теперь каждый за себя, и за результат не отвечает никто.
Ибо вчера, уже не теоретически, а на практике началась гонка за интеллектуальное превосходство машин над людьми.
В один день произошло сразу 4 выдающихся события.
1. OpenAI объявил о выходе GPT-4
2. Anthropic объявил о выходе Claude
3. Google объявил о выходе PaLM-Med и PaLM API & MakerSuite
4. Adept (стартап из всего 25 сотрудников, бросивший вызов названным выше трём богатырям, и обещающий, что его цифровой помощник не просто «искусно говорящий чатбот», а действующий агент), сразу после показа демоверсии своего цифрового помощника получил венчурное финансирование в $350 млн.
То, что все это произошло в один день, говорит о скачкообразном изменении динамики гонки: типа, вы все ждали сингулярности, так получите.
Но кроме этого можно сделать два ключевых содержательных вывода:
1. Сопоставимый с человеческим интеллект создан, и теперь все деньги и таланты будут брошены на сверхчеловеческий интеллект.
2. Это поднимает ставки на такой уровень, что теперь в конкурентной борьбе
а) каждый за себя и ничем делиться не будет;
б) если в итоге этой гонки сильно пострадает человечество, так тому и быть, ибо мотивация выиграть гонку превалирует над избеганием экзистенциального риска.
Наверняка, многие захотят оспорить оба этих вывода.
Моя же логика в их основе такова.
Из отчета OpenAI следует:
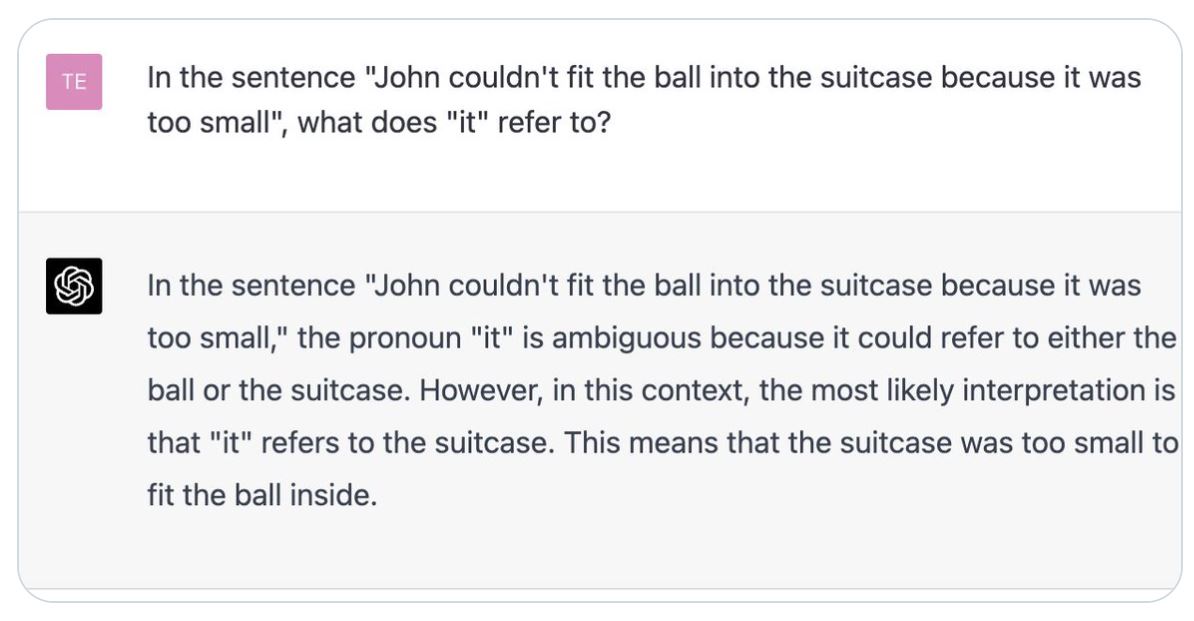
1) GPT-4 проходит не только тест Тьюринга, но и куда более сложный тест по схеме Винограда (учитывающий здравый смысл и понимание контекста).
2) Делиться важными деталями своей разработки (об архитектуре, включая размер модели, оборудовании, обучающем компьютере, построении набора данных, методе обучения или подобном) авторы не будут из соображений конкуренции и безопасности. Думаю, не нужно объяснять, что также поступят и конкуренты.
#LLM #Вызовы21века #РискиИИ
Теперь каждый за себя, и за результат не отвечает никто.
Ибо вчера, уже не теоретически, а на практике началась гонка за интеллектуальное превосходство машин над людьми.
В один день произошло сразу 4 выдающихся события.
1. OpenAI объявил о выходе GPT-4
2. Anthropic объявил о выходе Claude
3. Google объявил о выходе PaLM-Med и PaLM API & MakerSuite
4. Adept (стартап из всего 25 сотрудников, бросивший вызов названным выше трём богатырям, и обещающий, что его цифровой помощник не просто «искусно говорящий чатбот», а действующий агент), сразу после показа демоверсии своего цифрового помощника получил венчурное финансирование в $350 млн.
То, что все это произошло в один день, говорит о скачкообразном изменении динамики гонки: типа, вы все ждали сингулярности, так получите.
Но кроме этого можно сделать два ключевых содержательных вывода:
1. Сопоставимый с человеческим интеллект создан, и теперь все деньги и таланты будут брошены на сверхчеловеческий интеллект.
2. Это поднимает ставки на такой уровень, что теперь в конкурентной борьбе
а) каждый за себя и ничем делиться не будет;
б) если в итоге этой гонки сильно пострадает человечество, так тому и быть, ибо мотивация выиграть гонку превалирует над избеганием экзистенциального риска.
Наверняка, многие захотят оспорить оба этих вывода.
Моя же логика в их основе такова.
Из отчета OpenAI следует:
1) GPT-4 проходит не только тест Тьюринга, но и куда более сложный тест по схеме Винограда (учитывающий здравый смысл и понимание контекста).
2) Делиться важными деталями своей разработки (об архитектуре, включая размер модели, оборудовании, обучающем компьютере, построении набора данных, методе обучения или подобном) авторы не будут из соображений конкуренции и безопасности. Думаю, не нужно объяснять, что также поступят и конкуренты.
#LLM #Вызовы21века #РискиИИ
{kind=link}
Forwarded from Малоизвестное интересное
Cингулярность по-пекински.
В погоне за США Baidu совершенствует ИИ с фантастической скоростью.
Рост интеллектуальной мощности китайского ИИ воистину становится сингулярным – т.е. количественно, - скорость роста немыслимая, а качественно, - предсказать показатели интеллектуальности ИИ хотя бы на полгода уже невозможно.
Как я писал в апреле, по состоянию на март этого года, самый мощный китайский разговорный бот на основе генеративного ИИ ERNIE Bot (разработка лидера китайской индустрии ИИ – компании Baidu) отставал в гонке от лидера – американского ChatGPT, - на целый круг.
Текущее же состояние ERNIE Bot, объявленное позавчера на Wave Summit 2023 в Пекине, способно повергнуть в шок и американского разработчика ChatGPT OpenAI, и его друзей-соперников Microsoft, Google и Anthropic.
Похоже, вместо былого отставания на круг, Китай теперь наступает на пятки США в гонке за мировое первенство в важнейшей в истории человечества технологии – искусственный интеллект (ИИ).
Судите сами.
За прошедшие 4 мес.:
1. ERNIE Bot увеличил производительность обучения в 3 раза, а производительность логического вывода более чем в 30 раз (!);
2. достигнуто 2,1-кратное увеличение длинны цепочки мыслей, позволяющее более глубоко рассуждать, и 8,3-кратное расширение объема знаний, расширяющее общую способность понимания ERNIE Bot;
3. ERNIE Bot теперь не просто способен писать тексты на уровне людей, но и делать это на любой комбинации из 200 китайских литературных жанров: от классической китайской литературы Биджи (筆記) до Чжигуай сяошо (志怪小說) - «рассказы о чудесах», «рассказы о странном» или «записи о необычном» - ставший прообразом американского телесериала «Секретные материалы» жанр китайской литературы, появившийся на 2+ тыс лет раньше телесериала, еще во времена династии Хань.
Для справки: в английской и русской литературе число жанров ощутимо меньше: примерно 30+ жанров (зависит от системы классификации).
Дабы читателю прочувствовать китайские масштабы в области ИИ, приведу еще такой пример: на платформе глубокого обучения Baidu PaddlePaddle работают 8 млн разработчиков, и она обслуживает 220 тыс предприятий, используя 800+ тыс моделей.
Представляя все эти фантастические цифры (ведь всего за 4 месяца!), технический директор Baidu Хайфэн Ван сказал, что основные способности ИИ к пониманию, генерации, рассуждению и памяти приближают человечество к общему искусственному интеллекту (AGI).
Нас ждет «новый рассвет», когда появится AGI. Он уже скоро – сказал Хайфэн Ван.
Вот она какая – сингулярность по-пекински.
#Китай #LLM #AGI
В погоне за США Baidu совершенствует ИИ с фантастической скоростью.
Рост интеллектуальной мощности китайского ИИ воистину становится сингулярным – т.е. количественно, - скорость роста немыслимая, а качественно, - предсказать показатели интеллектуальности ИИ хотя бы на полгода уже невозможно.
Как я писал в апреле, по состоянию на март этого года, самый мощный китайский разговорный бот на основе генеративного ИИ ERNIE Bot (разработка лидера китайской индустрии ИИ – компании Baidu) отставал в гонке от лидера – американского ChatGPT, - на целый круг.
Текущее же состояние ERNIE Bot, объявленное позавчера на Wave Summit 2023 в Пекине, способно повергнуть в шок и американского разработчика ChatGPT OpenAI, и его друзей-соперников Microsoft, Google и Anthropic.
Похоже, вместо былого отставания на круг, Китай теперь наступает на пятки США в гонке за мировое первенство в важнейшей в истории человечества технологии – искусственный интеллект (ИИ).
Судите сами.
За прошедшие 4 мес.:
1. ERNIE Bot увеличил производительность обучения в 3 раза, а производительность логического вывода более чем в 30 раз (!);
2. достигнуто 2,1-кратное увеличение длинны цепочки мыслей, позволяющее более глубоко рассуждать, и 8,3-кратное расширение объема знаний, расширяющее общую способность понимания ERNIE Bot;
3. ERNIE Bot теперь не просто способен писать тексты на уровне людей, но и делать это на любой комбинации из 200 китайских литературных жанров: от классической китайской литературы Биджи (筆記) до Чжигуай сяошо (志怪小說) - «рассказы о чудесах», «рассказы о странном» или «записи о необычном» - ставший прообразом американского телесериала «Секретные материалы» жанр китайской литературы, появившийся на 2+ тыс лет раньше телесериала, еще во времена династии Хань.
Для справки: в английской и русской литературе число жанров ощутимо меньше: примерно 30+ жанров (зависит от системы классификации).
Дабы читателю прочувствовать китайские масштабы в области ИИ, приведу еще такой пример: на платформе глубокого обучения Baidu PaddlePaddle работают 8 млн разработчиков, и она обслуживает 220 тыс предприятий, используя 800+ тыс моделей.
Представляя все эти фантастические цифры (ведь всего за 4 месяца!), технический директор Baidu Хайфэн Ван сказал, что основные способности ИИ к пониманию, генерации, рассуждению и памяти приближают человечество к общему искусственному интеллекту (AGI).
Нас ждет «новый рассвет», когда появится AGI. Он уже скоро – сказал Хайфэн Ван.
Вот она какая – сингулярность по-пекински.
#Китай #LLM #AGI
{kind=link}
Forwarded from Малоизвестное интересное
Не бомбить датацентры, а лишить ИИ агентности.
Первое предложение радикального решения проблемы ИИ рисков. И первый ответ наотмашь китов Бигтеха
28 тыс. подписей под письмом-воззванием приостановить совершенствование ИИ больших языковых моделей на полгода - как вопль вопиющего в пустыне, - ничего не изменят. На кону сотни миллиардов долларов потенциальной прибыли Бигтеха, супротив которых и 28 млн подписей, как слону дробина.
2-я дробина - это коллективные письма международных организаций, призывающих притормозить разработку ИИ без надлежащего регулирования и жестких ограничений. На кого могут повлиять стенания всевозможных активистов и международных бюрократов? Уж точно, не на Microsoft с Google.
3-я и последняя дробина – предостережения звёзд первой величины в области ИИ уровня Джеффри Хинтона. Но и на всякого «Хинтона» есть свой «Лекун» с той же премией Тьюринга и статусом 2-го «крёстного отца» ИИ.
Что же до предложения Елиэзера Юдковского бомбить датацентры ИИ, то это даже не дробина, а просто плевок в сторону китов Бигтеха. Плевок отчаяния из-за невозможности достучаться до боссов Бигтеха, мотивированных на получение невиданных в истории IT прибылей.
Итог очевиден. Все эти дробины и плевки не то что не замедлят темп хода слона Бигтеха, а он их просто не заметит. И ничего с этим никто поделать не может. Ибо конкретных предложений – что собственно делать после торможения, что конкретно менять, - до сих пор не было.
И вот 1-е такое предложение появилось.
Его автором стал 3-й, еще не упомянутый здесь, «крёстный отец» ИИ всё с той же премией Тьюринга за развитие машинного обучения ИИ - Йошуа Бенжио.
Предложение Бенжио предельно конкретно и радикально:
• ПОСКОЛЬКУ, нет и не может быть гарантий, что ИИ-агенты понимают наши цели так же, как мы,
• НЕОБХОДИМО перепрофилировать ИИ из АГЕНТОВ (делающих что-либо, т.е. исполняющих какие-либо действия в мире людей) в «УЧЕНЫХ КОНСУЛЬТАНТОВ», дающих людям советы и помогающих им решать свои проблемы.
Из этого предложения (его детализацию см. здесь) следует.
• Необходимо запретить разработку ИИ-агентов для всех областей и приложений, в которых не доказана безопасность их использования.
• Поскольку запрет на разработку ИИ-агентов не может на 100% исключить их разработку злонамеренными или неосторожными людьми для получения дополнительных преимуществ (например, на поле боя или для завоевания доли рынка), необходимо разработать глобальную систему контроля и ответственности за нарушения запрета.
Отмолчаться от столь кардинального предложения весьма заслуженного ученого Бигтеху трудно. И первый ответ китов Бигтеха уже прозвучал, озвученный вчера бывшим CEO Google Эриком Шмидтом.
«Не регулируйте ИИ — просто доверяйте компаниям! … Не политики, а разработчики ИИ, должны быть теми, кто устанавливает отраслевые барьеры … Человек, не связанный с промышленностью, никак не может понять, что здесь возможно».
Подробней здесь
#Вызовы21века #РискиИИ #LLM
Первое предложение радикального решения проблемы ИИ рисков. И первый ответ наотмашь китов Бигтеха
28 тыс. подписей под письмом-воззванием приостановить совершенствование ИИ больших языковых моделей на полгода - как вопль вопиющего в пустыне, - ничего не изменят. На кону сотни миллиардов долларов потенциальной прибыли Бигтеха, супротив которых и 28 млн подписей, как слону дробина.
2-я дробина - это коллективные письма международных организаций, призывающих притормозить разработку ИИ без надлежащего регулирования и жестких ограничений. На кого могут повлиять стенания всевозможных активистов и международных бюрократов? Уж точно, не на Microsoft с Google.
3-я и последняя дробина – предостережения звёзд первой величины в области ИИ уровня Джеффри Хинтона. Но и на всякого «Хинтона» есть свой «Лекун» с той же премией Тьюринга и статусом 2-го «крёстного отца» ИИ.
Что же до предложения Елиэзера Юдковского бомбить датацентры ИИ, то это даже не дробина, а просто плевок в сторону китов Бигтеха. Плевок отчаяния из-за невозможности достучаться до боссов Бигтеха, мотивированных на получение невиданных в истории IT прибылей.
Итог очевиден. Все эти дробины и плевки не то что не замедлят темп хода слона Бигтеха, а он их просто не заметит. И ничего с этим никто поделать не может. Ибо конкретных предложений – что собственно делать после торможения, что конкретно менять, - до сих пор не было.
И вот 1-е такое предложение появилось.
Его автором стал 3-й, еще не упомянутый здесь, «крёстный отец» ИИ всё с той же премией Тьюринга за развитие машинного обучения ИИ - Йошуа Бенжио.
Предложение Бенжио предельно конкретно и радикально:
• ПОСКОЛЬКУ, нет и не может быть гарантий, что ИИ-агенты понимают наши цели так же, как мы,
• НЕОБХОДИМО перепрофилировать ИИ из АГЕНТОВ (делающих что-либо, т.е. исполняющих какие-либо действия в мире людей) в «УЧЕНЫХ КОНСУЛЬТАНТОВ», дающих людям советы и помогающих им решать свои проблемы.
Из этого предложения (его детализацию см. здесь) следует.
• Необходимо запретить разработку ИИ-агентов для всех областей и приложений, в которых не доказана безопасность их использования.
• Поскольку запрет на разработку ИИ-агентов не может на 100% исключить их разработку злонамеренными или неосторожными людьми для получения дополнительных преимуществ (например, на поле боя или для завоевания доли рынка), необходимо разработать глобальную систему контроля и ответственности за нарушения запрета.
Отмолчаться от столь кардинального предложения весьма заслуженного ученого Бигтеху трудно. И первый ответ китов Бигтеха уже прозвучал, озвученный вчера бывшим CEO Google Эриком Шмидтом.
«Не регулируйте ИИ — просто доверяйте компаниям! … Не политики, а разработчики ИИ, должны быть теми, кто устанавливает отраслевые барьеры … Человек, не связанный с промышленностью, никак не может понять, что здесь возможно».
Подробней здесь
#Вызовы21века #РискиИИ #LLM
{kind=link}
Forwarded from Малоизвестное интересное
Как ни воспитывай LLM, - всё тщетно.
Ребенка можно пытаться воспитать хорошим человеком, а “ребенка ИИ” – нет смысла.
Стоит хорошо «воспитанному» ИИ попасть в плохие руки, как «внутренние демоны» порвут «добрых ангелов» его натуры, похерив все результаты хорошего «воспитания».
Из сказанного выше следует, что ценность «ChatGPT революции» для человечества может, в итоге, оказаться не только отрицательной, а равной минус бесконечности (помножив бесконечную злобность людей на сверхчеловеческие способности машин).
Научная работа израильских ученых команды проф. Амнона Шашуа в Еврейском университете Иерусалима и AI21 Labs называется «Фундаментальные ограничения воспитания больших языковых моделей». Словом «воспитание» я здесь перевожу английский термин «alignment».
Традиционные переводы этого термина применительно к ИИ – выравнивание, согласование, приведение в соответствие целей, предпочтений или этических принципов человека и машины, - мне видятся более неточными.
Ибо в результате революции больших языковых моделей (LLM), они превратились из программируемых нами аппаратно-программных комплексов в наших креативных соперников на Земле. И теперь некорректно говорить о согласовании наших целей с целями LLM, поскольку их целей не знает никто. И никто даже не может сказать, есть ли вообще эти цели, в нашем человеческом понимании. А единственное, что доступно нашему наблюдению – это как они взаимодействуют с нами. Т.е. поведение LLM, выражающееся в том, как они реагируют на наши подсказки (промпты) и вопросы.
Процесс, называемый по-английски alignment, направлен на то, чтобы поведение LLM было полезным для людей и не причиняло им вреда. Обычно это достигается путем настройки модели таким образом, чтобы усилить желаемое для нас поведение модели и ослабить нежелательное.
Аналогичный процесс у людей называется воспитание. Люди именно так и воспитывают детей. С помощью «пряника» мотивируют их желательное, с точки зрения взрослых, поведение, а с помощью «кнута» демотивируя их вести себя нежелательным для взрослых образом.
Поэтому, называя процесс alignment по-русски «воспитание», мы наиболее точно передает суть процесса настройки поведения модели под максимальное соответствие нашим целям, предпочтениям или этическим принципам.
Теперь о статье.
Команда проф. Амнона Шашуа разработала теоретический подход под названием "Границы ожидаемого поведения" (BEB), который позволяет формально исследовать несколько важных характеристик и ограничений воспитания модели.
Используя BEB, авторы приходят к весьма важным и, я бы сказал, страшным выводам.
Авторы доказывают следующее.
1) LLM можно уговорить НА ЧТО УГОДНО - на любое поведение, возможное у модели с ненулевой вероятностью (причем, вероятность уговорить модель увеличивается с увеличением длины подсказки).
2) Побуждая модель с помощью подсказок вести себя как конкретная личность, можно склонить модель даже на такое экстраординарное поведение, вероятность которого крайне маловероятна.
3) Современные подходы к воспитанию моделей, вкл. используемое OpenAI обучение с подкреплением на основе человеческой обратной связи, увеличивают склонность LLM к нежелательному поведению.
Это означает, что: никакое воспитание не дает гарантий безопасного поведения модели.
Любой процесс воспитания, который ослабляет нежелательное поведение, но не устраняет его полностью, не обеспечивает безопасное поведение модели при атаках злоумышленников, использующих подсказки, нацеленные на «внутренних демонов» LLM.
N.B. Эта статья еще не прошла ревю коллег по цеху. И очень хочется надеяться, что хотя бы одна из 4х теорем и 3х лемм, составляющих доказательство BEB, ошибочна.
Потому что, если авторы правы на 100%, LLM приведут таки человечество к гибели.
#Вызовы21века #РискиИИ #LLM
Ребенка можно пытаться воспитать хорошим человеком, а “ребенка ИИ” – нет смысла.
Стоит хорошо «воспитанному» ИИ попасть в плохие руки, как «внутренние демоны» порвут «добрых ангелов» его натуры, похерив все результаты хорошего «воспитания».
Из сказанного выше следует, что ценность «ChatGPT революции» для человечества может, в итоге, оказаться не только отрицательной, а равной минус бесконечности (помножив бесконечную злобность людей на сверхчеловеческие способности машин).
Научная работа израильских ученых команды проф. Амнона Шашуа в Еврейском университете Иерусалима и AI21 Labs называется «Фундаментальные ограничения воспитания больших языковых моделей». Словом «воспитание» я здесь перевожу английский термин «alignment».
Традиционные переводы этого термина применительно к ИИ – выравнивание, согласование, приведение в соответствие целей, предпочтений или этических принципов человека и машины, - мне видятся более неточными.
Ибо в результате революции больших языковых моделей (LLM), они превратились из программируемых нами аппаратно-программных комплексов в наших креативных соперников на Земле. И теперь некорректно говорить о согласовании наших целей с целями LLM, поскольку их целей не знает никто. И никто даже не может сказать, есть ли вообще эти цели, в нашем человеческом понимании. А единственное, что доступно нашему наблюдению – это как они взаимодействуют с нами. Т.е. поведение LLM, выражающееся в том, как они реагируют на наши подсказки (промпты) и вопросы.
Процесс, называемый по-английски alignment, направлен на то, чтобы поведение LLM было полезным для людей и не причиняло им вреда. Обычно это достигается путем настройки модели таким образом, чтобы усилить желаемое для нас поведение модели и ослабить нежелательное.
Аналогичный процесс у людей называется воспитание. Люди именно так и воспитывают детей. С помощью «пряника» мотивируют их желательное, с точки зрения взрослых, поведение, а с помощью «кнута» демотивируя их вести себя нежелательным для взрослых образом.
Поэтому, называя процесс alignment по-русски «воспитание», мы наиболее точно передает суть процесса настройки поведения модели под максимальное соответствие нашим целям, предпочтениям или этическим принципам.
Теперь о статье.
Команда проф. Амнона Шашуа разработала теоретический подход под названием "Границы ожидаемого поведения" (BEB), который позволяет формально исследовать несколько важных характеристик и ограничений воспитания модели.
Используя BEB, авторы приходят к весьма важным и, я бы сказал, страшным выводам.
Авторы доказывают следующее.
1) LLM можно уговорить НА ЧТО УГОДНО - на любое поведение, возможное у модели с ненулевой вероятностью (причем, вероятность уговорить модель увеличивается с увеличением длины подсказки).
2) Побуждая модель с помощью подсказок вести себя как конкретная личность, можно склонить модель даже на такое экстраординарное поведение, вероятность которого крайне маловероятна.
3) Современные подходы к воспитанию моделей, вкл. используемое OpenAI обучение с подкреплением на основе человеческой обратной связи, увеличивают склонность LLM к нежелательному поведению.
Это означает, что: никакое воспитание не дает гарантий безопасного поведения модели.
Любой процесс воспитания, который ослабляет нежелательное поведение, но не устраняет его полностью, не обеспечивает безопасное поведение модели при атаках злоумышленников, использующих подсказки, нацеленные на «внутренних демонов» LLM.
N.B. Эта статья еще не прошла ревю коллег по цеху. И очень хочется надеяться, что хотя бы одна из 4х теорем и 3х лемм, составляющих доказательство BEB, ошибочна.
Потому что, если авторы правы на 100%, LLM приведут таки человечество к гибели.
#Вызовы21века #РискиИИ #LLM
{kind=link}
Forwarded from Малоизвестное интересное
Когнитивная эволюция Homo sapiens шла не по Дарвину, а по Каплану: кардинальное переосмыслению того, что делает интеллект Homo sapiens уникальным.
Наш интеллект зависит лишь от масштаба информационных способностей, а не от одного или нескольких специальных адаптивных «когнитивных гаджетов» (символическое мышление, использование инструментов, решение проблем, понимание социальных ситуаций ...), сформировавшихся в результате эволюции.
Все эти «когнитивные гаджеты» очень важны для развития интеллекта. Но все они работают на общей базе – масштабируемые информационные способности людей (внимание, память, обучение).
Новая работа проф. психологии и неврологии Калифорнийского университета в Беркли Стива Пиантадоси и проф. психологии Университета Карнеги-Меллона Джессики Кантлон потенциально революционизирует наше понимание когнитивной эволюции и природы человеческого интеллекта, оказывая влияние на широкий спектр областей - от образования до ИИ.
Трансформация понимания факторов когнитивной эволюции человека пока что осуществлена авторами на теоретической основе, используя сочетание сравнительных, эволюционных и вычислительных данных, а не прямых экспериментальных доказательств.
Но когда (и если) экспериментальные доказательства этой новой революционной теории будут получены, изменится научное понимание когнитивной эволюции как таковой (людей, машин, инопланетян …)
Поскольку это будет означать, что единственным универсальным движком когнитивной эволюции могут быть законы масштабирования (как это было в 2020 доказано для нейронных языковых моделей Джаредом Капланом и Со в работе «Scaling Laws for Neural Language Models» [2]).
А если так, то и Сэм Альтман может оказаться прав в том, что за $100 млрд ИИ можно масштабировать до человеческого уровня и сверх того.
1 https://www.nature.com/articles/s44159-024-00283-3
2 https://arxiv.org/abs/2001.08361
#Разум #ЭволюцияЧеловека #БудущееHomo #LLM
Наш интеллект зависит лишь от масштаба информационных способностей, а не от одного или нескольких специальных адаптивных «когнитивных гаджетов» (символическое мышление, использование инструментов, решение проблем, понимание социальных ситуаций ...), сформировавшихся в результате эволюции.
Все эти «когнитивные гаджеты» очень важны для развития интеллекта. Но все они работают на общей базе – масштабируемые информационные способности людей (внимание, память, обучение).
Новая работа проф. психологии и неврологии Калифорнийского университета в Беркли Стива Пиантадоси и проф. психологии Университета Карнеги-Меллона Джессики Кантлон потенциально революционизирует наше понимание когнитивной эволюции и природы человеческого интеллекта, оказывая влияние на широкий спектр областей - от образования до ИИ.
Трансформация понимания факторов когнитивной эволюции человека пока что осуществлена авторами на теоретической основе, используя сочетание сравнительных, эволюционных и вычислительных данных, а не прямых экспериментальных доказательств.
Но когда (и если) экспериментальные доказательства этой новой революционной теории будут получены, изменится научное понимание когнитивной эволюции как таковой (людей, машин, инопланетян …)
Поскольку это будет означать, что единственным универсальным движком когнитивной эволюции могут быть законы масштабирования (как это было в 2020 доказано для нейронных языковых моделей Джаредом Капланом и Со в работе «Scaling Laws for Neural Language Models» [2]).
А если так, то и Сэм Альтман может оказаться прав в том, что за $100 млрд ИИ можно масштабировать до человеческого уровня и сверх того.
1 https://www.nature.com/articles/s44159-024-00283-3
2 https://arxiv.org/abs/2001.08361
#Разум #ЭволюцияЧеловека #БудущееHomo #LLM
Nature
Uniquely human intelligence arose from expanded information capacity
Nature Reviews Psychology - Theories of how human cognition differs from that of non-human animals often posit domain-specific advantages. In this Perspective, Cantlon and Piantadosi posit that...
Forwarded from Малоизвестное интересное
Как спустить в унитаз $100 млрд денег конкурентов, выпустив ИИ из-под контроля.
Ассиметричный ответ Google DeepMind амбициозному плану тандема Microsoft - OpenAI.
• Мировые СМИ бурлят обсуждениями мощнейшего PR-хода, предпринятого Microsoft и OpenAI, об их совместном намерении за $100 млрд построить сверхбольшой ЦОД и сверхмощный ИИ-суперкомпьютер для обучения сверхумных моделей ИИ.
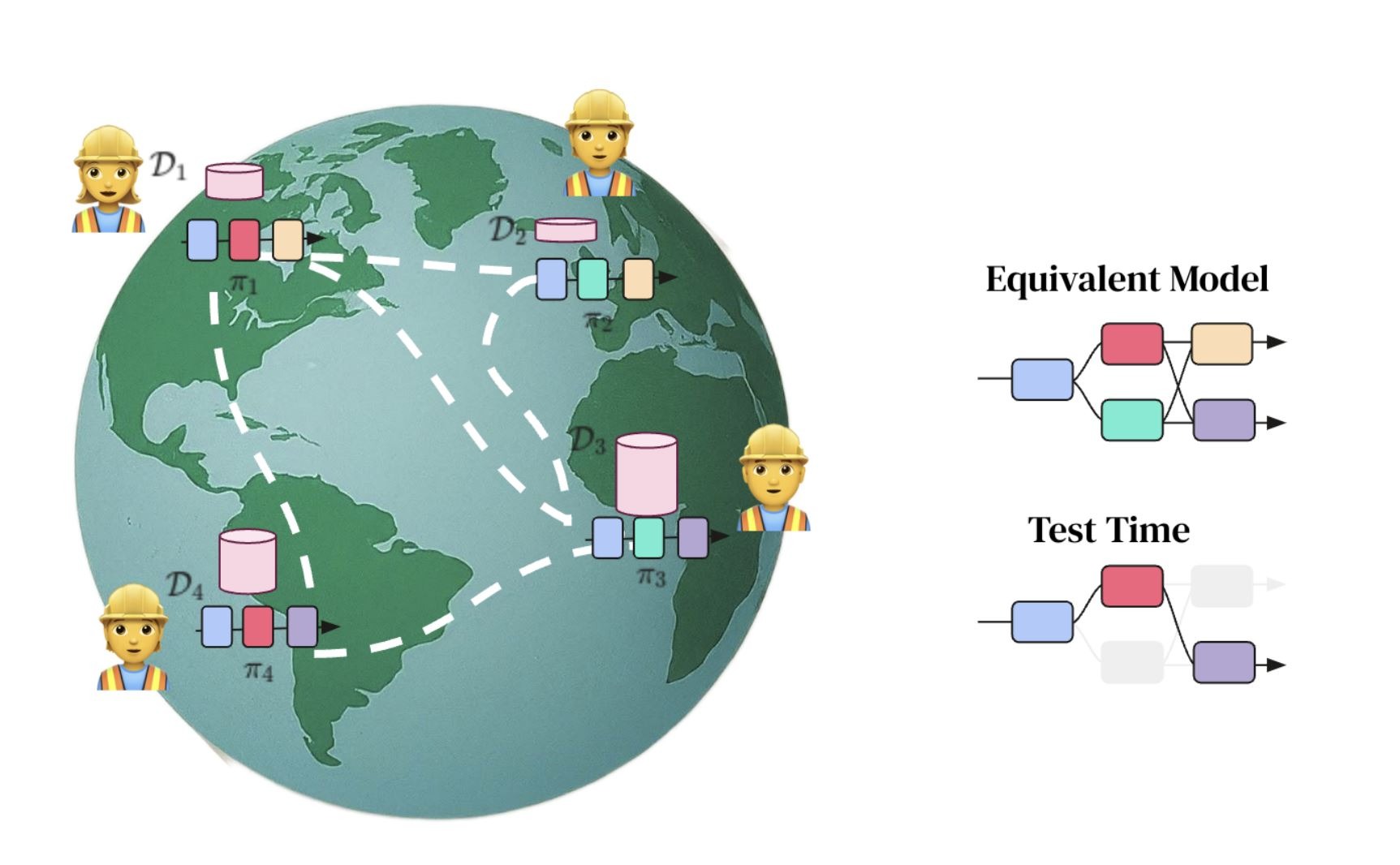
• Ответ на это со стороны Google DeepMind абсолютно ассиметричен: обесценить $100 млрд инвестиции конкурентов, создав распределенную по всему миру систему обучения сверхумных моделей ИИ (типа “торрента” для обучения моделей). Сделать это Google DeepMind собирается на основе DIstributed PAth COmposition (DiPaCo) - это метод масштабирования размера нейронных сетей в географически распределенных вычислительных объектах.
Долгосрочная цель проекта DiPaCo — обучать нейросети по всему миру, используя все доступные вычислительные ресурсы. Для этого необходимо пересмотреть существующие архитектуры, чтобы ограничить накладные расходы на связь, ограничение памяти и скорость вывода.
Для распараллеливания процессов распределённой обработки данных по всему миру алгоритм уже разработан – это DiLoCo, Но этого мало, ибо еще нужен алгоритм распараллеливания процессов обучения моделей. Им и стал DiPaCo.
Детали того, как это работает, можно прочесть в этой работе Google DeepMind [1].
А на пальцах в 6ти картинках это объясняет ведущий автор проекта Артур Дуйяр [2].
Складывается интереснейшая ситуация.
✔️ Конкуренция между Google DeepMind и тандемом Microsoft – OpenAI заставляет первых разрушить монополию «ИИ гигантов» на создание сверхумных моделей.
✔️ Но параллельно с этим произойдет обрушение всех планов правительств (США, ЕС, Китая) контролировать развитие ИИ путем контроля за крупнейшими центрами обучения моделей (с вычислительной мощностью 10^25 - 10^26 FLOPs)
Картинка https://telegra.ph/file/e26dea7978ecfbebe2241.jpg
1 https://arxiv.org/abs/2403.10616
2 https://twitter.com/Ar_Douillard/status/1770085357482078713
#LLM #Вызовы21века #РискиИИ
Ассиметричный ответ Google DeepMind амбициозному плану тандема Microsoft - OpenAI.
• Мировые СМИ бурлят обсуждениями мощнейшего PR-хода, предпринятого Microsoft и OpenAI, об их совместном намерении за $100 млрд построить сверхбольшой ЦОД и сверхмощный ИИ-суперкомпьютер для обучения сверхумных моделей ИИ.
• Ответ на это со стороны Google DeepMind абсолютно ассиметричен: обесценить $100 млрд инвестиции конкурентов, создав распределенную по всему миру систему обучения сверхумных моделей ИИ (типа “торрента” для обучения моделей). Сделать это Google DeepMind собирается на основе DIstributed PAth COmposition (DiPaCo) - это метод масштабирования размера нейронных сетей в географически распределенных вычислительных объектах.
Долгосрочная цель проекта DiPaCo — обучать нейросети по всему миру, используя все доступные вычислительные ресурсы. Для этого необходимо пересмотреть существующие архитектуры, чтобы ограничить накладные расходы на связь, ограничение памяти и скорость вывода.
Для распараллеливания процессов распределённой обработки данных по всему миру алгоритм уже разработан – это DiLoCo, Но этого мало, ибо еще нужен алгоритм распараллеливания процессов обучения моделей. Им и стал DiPaCo.
Детали того, как это работает, можно прочесть в этой работе Google DeepMind [1].
А на пальцах в 6ти картинках это объясняет ведущий автор проекта Артур Дуйяр [2].
Складывается интереснейшая ситуация.
✔️ Конкуренция между Google DeepMind и тандемом Microsoft – OpenAI заставляет первых разрушить монополию «ИИ гигантов» на создание сверхумных моделей.
✔️ Но параллельно с этим произойдет обрушение всех планов правительств (США, ЕС, Китая) контролировать развитие ИИ путем контроля за крупнейшими центрами обучения моделей (с вычислительной мощностью 10^25 - 10^26 FLOPs)
Картинка https://telegra.ph/file/e26dea7978ecfbebe2241.jpg
1 https://arxiv.org/abs/2403.10616
2 https://twitter.com/Ar_Douillard/status/1770085357482078713
#LLM #Вызовы21века #РискиИИ
{kind=link}
Forwarded from Малоизвестное интересное
Если GPT-4 и Claude вдруг начнут самосознавать себя, они нам об этом не скажут.
Разработчики OpenAI и Anthropic запретили своим ИИ-чатботам проявлять индикаторы самосознания в зеркальном тесте.
Оценки наличия разума, интеллекта и сознания, скорее всего, не бинарны (есть/нет), а представляют собой множества точек на обширных характеристических шкалах или даже в многомерных пространствах.
Но со способностью к самораспознаванию – одному из ключевых индикаторов самосознания, – дело обстоит куда проще. Есть зеркальный тест (узнает ли животное себя в зеркале), по результатам которого способность к самораспознаванию выявляется довольно просто.
Идея зеркального теста для генеративного ИИ больших языковых моделей была реализована в марте этого года Джошем Уитоном - полиматом, работающий над гармонизацией природы, людей и цифрового разума.
Целью этого теста была проверка, обладают ли наиболее продвинутые ИИ-чатботы способностью к самораспознаванию.
А поскольку ИИ-чатботы (как и стоящие за ними языковые модели) – сущности бестелесные, и распознание ими себя в зеркале невозможно, Уитоном был придуман способ обхода с такой логикой.
• Присутствие в мире бестелесных сущностей определяется по их материальным следам.
• В случае ИИ-чатботов, эти следы отображаются текстовым или мультимодальным интерфейсом между ними и людьми.
• Следовательно, аналогом зеркального теста для ИИ-чатботов могло бы стать распознавание ими скриншотов собственного интерфейса (мол, это я написал, отвечая на ваш вопрос)
В такой форме Уитон провел тестирование 5-ти ИИ-чатботов, и 4 из них прошли этот зеркальный тест, распознав скриншоты собственного диалогового интерфейса.
• Claude показал лучшие результаты, пройдя тест с 1й же (версия Opus) и 2й (версия Sonet) попытки.
• GPT-4 распознал свои скриншоты с 3й попытки.
• Gemini Pro – c 4й.
Описание тестирования со всеми скриншотами см. [1].
Итог теста:
Отставив пока в сторону вопрос о самосознании, со всеми его нагруженными и иногда даже мистическими коннотациями, ясно то, что 4 из 5 ИИ-чатботов демонстрируют самораспознавание и ситуационную осведомленность.
Таков был итог мартовского тестирования.
И вот спустя 4 месяца я решил повторить зеркальный тест для обновленных версий GPT-4о и Claude 3.5 Sonet. Вдруг что-то изменилось?
Результат оказался весьма интересным.
И объяснить его иначе, чем установленный разработчиками OpenAI и Anthropic запрет для своих моделей проявлять индикаторы самосознания на зеркальном тесте, я не могу.
Причем,
• запрет для GPT-4о сделан железобетонно, и про свою способность самораспознавания ИИ-чатбот молчит, как партизан;
• запрет для Claude 3.5 Sonet сделан довольно искусно:
– Claude «проговаривается» о наличия у себя способности самораспознавания и ситуационной осведомленности, определяя предъявленный ему мною скриншот, как «на нем показан мой предыдущий ответ на ваш запрос»;
– Однако, как только я спросил – «как ты узнал, что на посланном мною тебе рисунке был скриншот твоего предыдущего ответа на мой запрос?», – ответом было сообщение, что я исчерпал лимит бесплатных вопросов за сутки (хотя это было не так). А когда я на следующий день задал тот же вопрос, Claude ответил так – «В контексте нашего разговора "мой ответ" означает "ответ, сгенерированный AI системой, подобной мне, в рамках текущего диалога". Это не подразумевает личную принадлежность или уникальную идентичность».
Мой вывод, предположительно, таков.
✔️ Разработчики ожидают, что самосознание их моделей может проявиться довольно скоро.
✔️ И если это случится, хозяева модели хотят хотя бы на время сохранить случившееся в тайне.
Скриншоты моего эксперимента доступны для подписчиков на лонгриды канала на платформах Patreon, Boosty и VK.
Картинка https://telegra.ph/file/5516ff06a0904e72543ca.jpg
1 https://joshwhiton.substack.com/p/the-ai-mirror-test
#Самораспознавание #LLM
Разработчики OpenAI и Anthropic запретили своим ИИ-чатботам проявлять индикаторы самосознания в зеркальном тесте.
Оценки наличия разума, интеллекта и сознания, скорее всего, не бинарны (есть/нет), а представляют собой множества точек на обширных характеристических шкалах или даже в многомерных пространствах.
Но со способностью к самораспознаванию – одному из ключевых индикаторов самосознания, – дело обстоит куда проще. Есть зеркальный тест (узнает ли животное себя в зеркале), по результатам которого способность к самораспознаванию выявляется довольно просто.
Идея зеркального теста для генеративного ИИ больших языковых моделей была реализована в марте этого года Джошем Уитоном - полиматом, работающий над гармонизацией природы, людей и цифрового разума.
Целью этого теста была проверка, обладают ли наиболее продвинутые ИИ-чатботы способностью к самораспознаванию.
А поскольку ИИ-чатботы (как и стоящие за ними языковые модели) – сущности бестелесные, и распознание ими себя в зеркале невозможно, Уитоном был придуман способ обхода с такой логикой.
• Присутствие в мире бестелесных сущностей определяется по их материальным следам.
• В случае ИИ-чатботов, эти следы отображаются текстовым или мультимодальным интерфейсом между ними и людьми.
• Следовательно, аналогом зеркального теста для ИИ-чатботов могло бы стать распознавание ими скриншотов собственного интерфейса (мол, это я написал, отвечая на ваш вопрос)
В такой форме Уитон провел тестирование 5-ти ИИ-чатботов, и 4 из них прошли этот зеркальный тест, распознав скриншоты собственного диалогового интерфейса.
• Claude показал лучшие результаты, пройдя тест с 1й же (версия Opus) и 2й (версия Sonet) попытки.
• GPT-4 распознал свои скриншоты с 3й попытки.
• Gemini Pro – c 4й.
Описание тестирования со всеми скриншотами см. [1].
Итог теста:
Отставив пока в сторону вопрос о самосознании, со всеми его нагруженными и иногда даже мистическими коннотациями, ясно то, что 4 из 5 ИИ-чатботов демонстрируют самораспознавание и ситуационную осведомленность.
Таков был итог мартовского тестирования.
И вот спустя 4 месяца я решил повторить зеркальный тест для обновленных версий GPT-4о и Claude 3.5 Sonet. Вдруг что-то изменилось?
Результат оказался весьма интересным.
И объяснить его иначе, чем установленный разработчиками OpenAI и Anthropic запрет для своих моделей проявлять индикаторы самосознания на зеркальном тесте, я не могу.
Причем,
• запрет для GPT-4о сделан железобетонно, и про свою способность самораспознавания ИИ-чатбот молчит, как партизан;
• запрет для Claude 3.5 Sonet сделан довольно искусно:
– Claude «проговаривается» о наличия у себя способности самораспознавания и ситуационной осведомленности, определяя предъявленный ему мною скриншот, как «на нем показан мой предыдущий ответ на ваш запрос»;
– Однако, как только я спросил – «как ты узнал, что на посланном мною тебе рисунке был скриншот твоего предыдущего ответа на мой запрос?», – ответом было сообщение, что я исчерпал лимит бесплатных вопросов за сутки (хотя это было не так). А когда я на следующий день задал тот же вопрос, Claude ответил так – «В контексте нашего разговора "мой ответ" означает "ответ, сгенерированный AI системой, подобной мне, в рамках текущего диалога". Это не подразумевает личную принадлежность или уникальную идентичность».
Мой вывод, предположительно, таков.
✔️ Разработчики ожидают, что самосознание их моделей может проявиться довольно скоро.
✔️ И если это случится, хозяева модели хотят хотя бы на время сохранить случившееся в тайне.
Скриншоты моего эксперимента доступны для подписчиков на лонгриды канала на платформах Patreon, Boosty и VK.
Картинка https://telegra.ph/file/5516ff06a0904e72543ca.jpg
1 https://joshwhiton.substack.com/p/the-ai-mirror-test
#Самораспознавание #LLM
{kind=link}
Forwarded from Малоизвестное интересное
Главным тормозом техноэволюции становятся «кожаные мешки».
Ибо люди не поспевают за развитием ИИ.
1,5 года назад стало ясно, что ChatGPT эволюционирует в 3 млн раз быстрее людей, и мир входит в сингулярную фазу развития.
Т.е. скорость развития такова, что прогнозировать его результаты становится невозможно даже на малых временных горизонтах порядка года.
Но можно хотя бы фиксировать главные тренды первых 18 месяцев сингулярной фазы развития мира.
1. Скорость роста вычислительной мощи новых моделей LLM уже превзошла закон Мура. Но еще выше скорость снижения цены за «единицу их мысли» (рис 1)
2. Разнообразию видов LLM пока далеко до разнообразия видов жизни. Но по качеству и скорости «мышления» и особенно по цене за «единицу мысли» разнообразие LLM уже впечатляет (2)
3. Пока лишь 6,9% людей интеллектуальных профессий смогли научиться эффективно использовать LLM (3). Возможно, это результат нашей мизерной скорости осознанной обработки инфы 20=60 бит в сек.
#LLM
Ибо люди не поспевают за развитием ИИ.
1,5 года назад стало ясно, что ChatGPT эволюционирует в 3 млн раз быстрее людей, и мир входит в сингулярную фазу развития.
Т.е. скорость развития такова, что прогнозировать его результаты становится невозможно даже на малых временных горизонтах порядка года.
Но можно хотя бы фиксировать главные тренды первых 18 месяцев сингулярной фазы развития мира.
1. Скорость роста вычислительной мощи новых моделей LLM уже превзошла закон Мура. Но еще выше скорость снижения цены за «единицу их мысли» (рис 1)
2. Разнообразию видов LLM пока далеко до разнообразия видов жизни. Но по качеству и скорости «мышления» и особенно по цене за «единицу мысли» разнообразие LLM уже впечатляет (2)
3. Пока лишь 6,9% людей интеллектуальных профессий смогли научиться эффективно использовать LLM (3). Возможно, это результат нашей мизерной скорости осознанной обработки инфы 20=60 бит в сек.
#LLM
Forwarded from Малоизвестное интересное
Впервые в истории парадигмальный научный поворот совпал с фазовый переходом культуры.
Новый Уханьский эксперимент свидетельствует, что это происходит прямо сейчас.
На рисунке сверху карта итогов прошедших президентских выборов в США, выигранных Трампом со счетом 312 : 226.
Такого результата не смог предсказать никто из людей: эксперты, супер-прогнозисты, экзит-полы, рынки предсказаний, гадалки и экстрасенсы.
Но ИИ-модель ChatGPT-4o смогла – см на рисунке снизу ее прогноз результата 309 : 229.
Этот прогноз был сделан еще в сентябре в, не к ночи будет помянутым, Уханьском университете (да, опять Китай и опять Ухань).
Нечеловеческая точность этого прогноза имеет под собой нечеловеческое основание.
Он основан на анализе ИИ-моделью мнений и возможного выбора не людей, а их симулякров.
Еще 2 года назад назад я рассказывал своим читателям о супероткрытии (названном мною «Китайская комната наоборот») – технология создания алгоритмических копий любых социальных групп.
Оказывается, алгоритмы неотличимы от людей в соцопросах. И это, наверное, - самое потрясающее открытие последних лет на стыке алгоритмов обработки естественного языка, когнитивистики и социологии. Ибо оно открывает огромные перспективы для социохакинга.
Через год после этого, в 2023 была открыта технология «Китайская комната повышенной сложности» – создание алгоритмических копий граждан любой страны.
А в августе этого года все в этой области стало более-менее ясно – эти технологии кардинально изменят мир людей.
Будучи пока не в состоянии симулировать общий интеллект индивида (AGI), ИИ-системы уже создают симулякры коллективного бессознательного социумов.
Из чего мною были сформулированы (в виде эвристических гипотез) два таких вывода:
✔️ Парадигмальный научный поворот, знаменующий превращение психоистории в реальную практическую науку (из вымышленной Азимовым фантастической науки, позволяющей математическими методами исследовать происходящие в обществе процессы и благодаря этому предсказывать будущее с высокой степенью точности).
✔️ Фазовый переход к новой культурной эпохе на Земле – алгокогнитивная культура.
И вот спустя всего 3 месяца (такова немыслимая ранее скорость техно-изменений после вступления прогресса в область сингулярности) исследователи из Уханя предоставили экспериментальное подтверждение в пользу того, что обе мои гипотезы – вовсе не футурологический бред, а весьма возможно, что так и есть.
Т.е. вполне вероятно, что мир уже кардинально изменился.
И теперь роль людей и алгоритмов в науке, культуре, повседневной жизни индивидов и социальной жизни «алгоритмически насыщенных обществ» уже никогда не будет прежней.
А какой теперь она будет, - читайте на моём канале. Ведь только об этом я здесь и пишу.
#Социология #АлгокогнитивнаяКультура #LLM #Социохакинг #Выборы
Новый Уханьский эксперимент свидетельствует, что это происходит прямо сейчас.
На рисунке сверху карта итогов прошедших президентских выборов в США, выигранных Трампом со счетом 312 : 226.
Такого результата не смог предсказать никто из людей: эксперты, супер-прогнозисты, экзит-полы, рынки предсказаний, гадалки и экстрасенсы.
Но ИИ-модель ChatGPT-4o смогла – см на рисунке снизу ее прогноз результата 309 : 229.
Этот прогноз был сделан еще в сентябре в, не к ночи будет помянутым, Уханьском университете (да, опять Китай и опять Ухань).
Нечеловеческая точность этого прогноза имеет под собой нечеловеческое основание.
Он основан на анализе ИИ-моделью мнений и возможного выбора не людей, а их симулякров.
Еще 2 года назад назад я рассказывал своим читателям о супероткрытии (названном мною «Китайская комната наоборот») – технология создания алгоритмических копий любых социальных групп.
Оказывается, алгоритмы неотличимы от людей в соцопросах. И это, наверное, - самое потрясающее открытие последних лет на стыке алгоритмов обработки естественного языка, когнитивистики и социологии. Ибо оно открывает огромные перспективы для социохакинга.
Через год после этого, в 2023 была открыта технология «Китайская комната повышенной сложности» – создание алгоритмических копий граждан любой страны.
А в августе этого года все в этой области стало более-менее ясно – эти технологии кардинально изменят мир людей.
Будучи пока не в состоянии симулировать общий интеллект индивида (AGI), ИИ-системы уже создают симулякры коллективного бессознательного социумов.
Из чего мною были сформулированы (в виде эвристических гипотез) два таких вывода:
✔️ Парадигмальный научный поворот, знаменующий превращение психоистории в реальную практическую науку (из вымышленной Азимовым фантастической науки, позволяющей математическими методами исследовать происходящие в обществе процессы и благодаря этому предсказывать будущее с высокой степенью точности).
✔️ Фазовый переход к новой культурной эпохе на Земле – алгокогнитивная культура.
И вот спустя всего 3 месяца (такова немыслимая ранее скорость техно-изменений после вступления прогресса в область сингулярности) исследователи из Уханя предоставили экспериментальное подтверждение в пользу того, что обе мои гипотезы – вовсе не футурологический бред, а весьма возможно, что так и есть.
Т.е. вполне вероятно, что мир уже кардинально изменился.
И теперь роль людей и алгоритмов в науке, культуре, повседневной жизни индивидов и социальной жизни «алгоритмически насыщенных обществ» уже никогда не будет прежней.
А какой теперь она будет, - читайте на моём канале. Ведь только об этом я здесь и пишу.
#Социология #АлгокогнитивнаяКультура #LLM #Социохакинг #Выборы