
Салют! Прямо сейчас я лечу в Майами, а оттуда в Новый Орлеан, где проходит топовое событие в мире AI -- конференция NeurIPS. Это как ежегодное вручение Оскара, только для исследователей, занимающихся AI и около-AI темами. Да, и там тоже вручают премию за лучшие фильмы статьи года и десятилетия. На конфе в в свое время были презентованы такие влиятельные работы как, например, AlexNet (2012), Attention is all you need (2017), GPT-3 (2020).
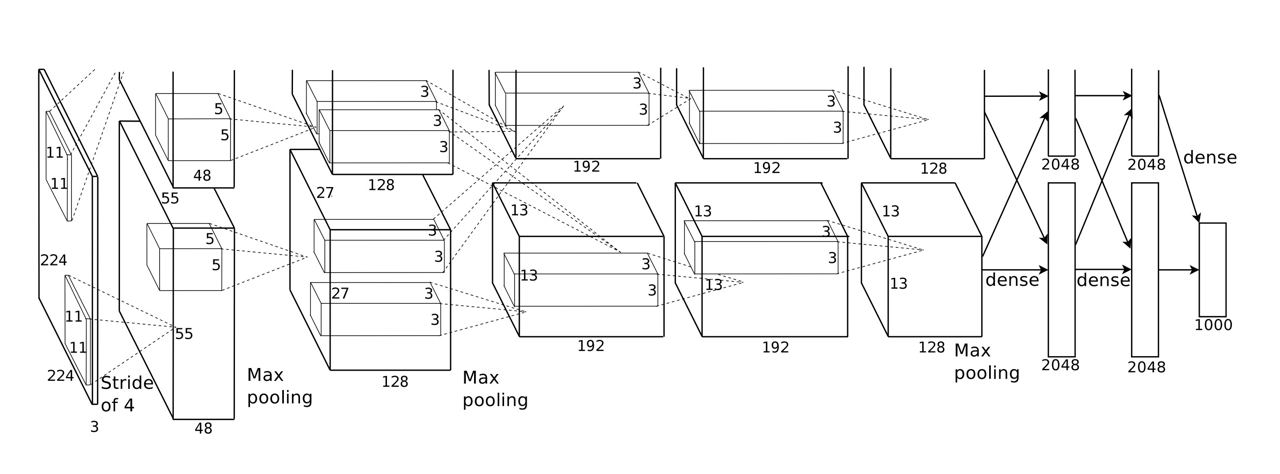
Кстати, статья про архитектуру AlexNet (см. картинку) как раз в этом году получила премию "Test of Time Award" за огромный вклад в развитие области, проверенный временем.
Впервые я побывал на конференции NeurIPS (тогда она еще называлась NIPS) в 2016 году в Барселоне со своей статьёй CliqueCNN про self-supervised обучение на неразмеченных датасетах с картинками. В этом году мне посчастливилось во второй раз презентовать статью на NeurIPS -- ViscoGrids. На этот раз про реконструкцию 3D поверхностей с помощью гридов и явных геометрических праеров (скоро будет подробный пост).
#карьера #конфа
@ai_newz
Кстати, статья про архитектуру AlexNet (см. картинку) как раз в этом году получила премию "Test of Time Award" за огромный вклад в развитие области, проверенный временем.
Впервые я побывал на конференции NeurIPS (тогда она еще называлась NIPS) в 2016 году в Барселоне со своей статьёй CliqueCNN про self-supervised обучение на неразмеченных датасетах с картинками. В этом году мне посчастливилось во второй раз презентовать статью на NeurIPS -- ViscoGrids. На этот раз про реконструкцию 3D поверхностей с помощью гридов и явных геометрических праеров (скоро будет подробный пост).
#карьера #конфа
@ai_newz
{kind=link}
Идет уже второй день NeurIPS. Первый день я пропустил, но Влад неплохо о нем написал в своем посте.
Я пока не очень много успел увидеть, только пообщался с людьми в секции с булками от разных компаний, да получил приглос на ужин с Waymo. Организовано все не очень, очень трудно ориентироваться в огромном конферен центре, когда куча вещей проходит параллельно.
Я создал чатик для встречи, все кто сейчас в Новом Орлеане – присоединяйтесь. Постараюсь организовать ужин для знакомства и нетворкинга.
#конфа
@ai_newz
Я пока не очень много успел увидеть, только пообщался с людьми в секции с булками от разных компаний, да получил приглос на ужин с Waymo. Организовано все не очень, очень трудно ориентироваться в огромном конферен центре, когда куча вещей проходит параллельно.
Я создал чатик для встречи, все кто сейчас в Новом Орлеане – присоединяйтесь. Постараюсь организовать ужин для знакомства и нетворкинга.
#конфа
@ai_newz
This media is not supported in your browser
VIEW IN TELEGRAM
В четверг на NeurIPS 2022 я презентовал нашу работу VisCo Grids (Meta AI).
В статье мы представляем метод для реконструкции 3д поверхностей по облаку точек, использую гриды. Да, вы не ослышались, там нет никаких нейронных сетей. За счёт этого обучение идет быстрее, и проще интерпретировать результаты обучения модели.
Мы оптимизируем значения SDF (signed distance function) напрямую в узлах дискретной 3D сетки. Но чтобы это работало нужны хорошие праеры, потому что оптимизировать SDF на дискретной сетке в лоб не выйдет.
Первый праер Viscosity Loss – позволяет учить SDF на дискретной сетке, оптимизируя "сглаженный" Eikonal loss, и предотвращая вырожденные решения.
Второй праер – Coarea Loss минимизирует площадь полученной поверхности. Это также позволяет получить желаемые поверхности и избавится от всевозможных отростков, пепяк и дырок.
Оба лосса считаются в любой локации с помощью интерполяции между узлами сетки.
❱❱ Более развернуто в моем посте на английском.
❱❱ Либо в самой статье.
#конфа
@ai_newz
В статье мы представляем метод для реконструкции 3д поверхностей по облаку точек, использую гриды. Да, вы не ослышались, там нет никаких нейронных сетей. За счёт этого обучение идет быстрее, и проще интерпретировать результаты обучения модели.
Мы оптимизируем значения SDF (signed distance function) напрямую в узлах дискретной 3D сетки. Но чтобы это работало нужны хорошие праеры, потому что оптимизировать SDF на дискретной сетке в лоб не выйдет.
Первый праер Viscosity Loss – позволяет учить SDF на дискретной сетке, оптимизируя "сглаженный" Eikonal loss, и предотвращая вырожденные решения.
Второй праер – Coarea Loss минимизирует площадь полученной поверхности. Это также позволяет получить желаемые поверхности и избавится от всевозможных отростков, пепяк и дырок.
Оба лосса считаются в любой локации с помощью интерполяции между узлами сетки.
❱❱ Более развернуто в моем посте на английском.
❱❱ Либо в самой статье.
#конфа
@ai_newz
This media is not supported in your browser
VIEW IN TELEGRAM
CVPR День первый: воркшопы и туториалы
Держу вас в курсе. Начался первый день конфы.
Я уже посетил Efficient Neutral Network воркшоп от Снепа. Послушал про эффективные архитектуры трансформеров для мобилок и про SnapFusion — ускоренную Stable Diffusion для мобил. Ребята достигли скорости 1.9 сек 🔥 за картинку на iPhone 14.
Сейчас зашёл на туториал по диффузионным моделям. Это по сути развитие туториала с CVPR 2022, о котором я много раз писал. Очень классная штука, советую. Надеюсь, они выложат записи на ютуб.
#конфа
@ai_newz
Держу вас в курсе. Начался первый день конфы.
Я уже посетил Efficient Neutral Network воркшоп от Снепа. Послушал про эффективные архитектуры трансформеров для мобилок и про SnapFusion — ускоренную Stable Diffusion для мобил. Ребята достигли скорости 1.9 сек 🔥 за картинку на iPhone 14.
Сейчас зашёл на туториал по диффузионным моделям. Это по сути развитие туториала с CVPR 2022, о котором я много раз писал. Очень классная штука, советую. Надеюсь, они выложат записи на ютуб.
#конфа
@ai_newz
А вот несколько слайдов с доклада "Efficient Text-to-Image Generation", где Снэп рассказывал про свою работу по ускорению Stable Diffusion.
Плюс демка, где они запускали генерации на телефоне.
Модель уменьшили, ускорили, дистиллировали и сконвертировали в Apple CoreML. Во время инференса использовали 8 шагов с DDIM семплером. Скорость генерации 1.9—2.0 сек / картинка на iPhone 14.
Представьте только. На GPU 50 шагов DDIM оригинальной Stable Diffusion в разрешении 512×512 работает примерно 1.7 сек. А тут сделали на мобиле почти за такое же время и без потери в качестве!
Сайт проекта SnapFusion
#конфа
@ai_newz
Плюс демка, где они запускали генерации на телефоне.
Модель уменьшили, ускорили, дистиллировали и сконвертировали в Apple CoreML. Во время инференса использовали 8 шагов с DDIM семплером. Скорость генерации 1.9—2.0 сек / картинка на iPhone 14.
Представьте только. На GPU 50 шагов DDIM оригинальной Stable Diffusion в разрешении 512×512 работает примерно 1.7 сек. А тут сделали на мобиле почти за такое же время и без потери в качестве!
Сайт проекта SnapFusion
#конфа
@ai_newz
This media is not supported in your browser
VIEW IN TELEGRAM
CVPR День второй: воркшопы и туториалы
Словили Эндрю Ына в коридоре. Он несколько часов со всеми фоткался и отвечал на вопросы. Кажется, благодаря своим курсам по ML/DL, он стал даже более известным чем Хинтон, ЛеКун или Бенжио.
Сегодня моя команда огранизовывала воркшоп Efficient Deep Learning for Computer Vision. Вот пара понравившихся статей оттуда:
— FastComposer. Метод для генерации людей по заданному текстовому промпту и референсным фоткам. Не требует дорогого файнтюнинга, как например Dreambooth и может генерить сразу несколько персон на одном фото.
— DIME-FM: Distilling Multimodal and Efficient Foundation Models. Дистилляция фундаментальных Visual-Language моделей, которая требует меньше данных и в 10 раз меньше ресурсов чем оригинальные модели (например, дистиллировали CLIP).
Ещё заглянул на воркшоп про Egocentric Vision. Послушал доклад от Kristen Grauman: в недавней работе про Ego-exo video alignment они учили энкодер мэтчить кадры между видео от первого лица и видео с внешних камер.
#personal #конфа
@ai_newz
Словили Эндрю Ына в коридоре. Он несколько часов со всеми фоткался и отвечал на вопросы. Кажется, благодаря своим курсам по ML/DL, он стал даже более известным чем Хинтон, ЛеКун или Бенжио.
Сегодня моя команда огранизовывала воркшоп Efficient Deep Learning for Computer Vision. Вот пара понравившихся статей оттуда:
— FastComposer. Метод для генерации людей по заданному текстовому промпту и референсным фоткам. Не требует дорогого файнтюнинга, как например Dreambooth и может генерить сразу несколько персон на одном фото.
— DIME-FM: Distilling Multimodal and Efficient Foundation Models. Дистилляция фундаментальных Visual-Language моделей, которая требует меньше данных и в 10 раз меньше ресурсов чем оригинальные модели (например, дистиллировали CLIP).
Ещё заглянул на воркшоп про Egocentric Vision. Послушал доклад от Kristen Grauman: в недавней работе про Ego-exo video alignment они учили энкодер мэтчить кадры между видео от первого лица и видео с внешних камер.
#personal #конфа
@ai_newz
Сегодня был ещё на офигенном воркшопе Visual Pre-Training for Robotics.
Великий исследователь в области визуального восприятия Джеймс Гибсон сказал знаменитую фразу: «Мы видим, чтобы двигаться, и мы двигаемся, чтобы видеть». Но можем ли мы научиться видеть, прежде чем научимся двигаться? И как далеко мы сможем продвинуться, если сначала научимся видеть? — Так описывается этот воркшоп.
Было много классных докладов про применения компьютерного зрения и претренировки моделей на визуальных задачах перед тем как использовать их на задачах робототехники, например для планирования и управления роботами.
Особенно понравился доклад Сергея Левина про то, как они делают претрейн модели с offline RL на видеоданных, собранных с разных роботов (от машинок до квадрокоптера), а затем файнтюнят с помощью online policy learning. В итоге модель обобщается на нового робота и новое окружение всего за 20 мин. Это впечатляюще быстро!
Подробности в статье FastRLAP.
Постараюсь достать запись докладов для вас.
#конфа
@ai_newz
Великий исследователь в области визуального восприятия Джеймс Гибсон сказал знаменитую фразу: «Мы видим, чтобы двигаться, и мы двигаемся, чтобы видеть». Но можем ли мы научиться видеть, прежде чем научимся двигаться? И как далеко мы сможем продвинуться, если сначала научимся видеть? — Так описывается этот воркшоп.
Было много классных докладов про применения компьютерного зрения и претренировки моделей на визуальных задачах перед тем как использовать их на задачах робототехники, например для планирования и управления роботами.
Особенно понравился доклад Сергея Левина про то, как они делают претрейн модели с offline RL на видеоданных, собранных с разных роботов (от машинок до квадрокоптера), а затем файнтюнят с помощью online policy learning. В итоге модель обобщается на нового робота и новое окружение всего за 20 мин. Это впечатляюще быстро!
Подробности в статье FastRLAP.
Постараюсь достать запись докладов для вас.
#конфа
@ai_newz
This media is not supported in your browser
VIEW IN TELEGRAM
Сегодня в 10:30-12:30 по канадскому я буду презентовать наш постер Avatars Grow Legs
Узнаете как восстанавливать последовательность 3D поз человека в движении, зная только позицию головы и запястий (например во время игры в VR).
Постер #46, приходите поболтать если вы на CVPR. #конфа
❱❱ Подробный пост про статью.
@ai_newz
Узнаете как восстанавливать последовательность 3D поз человека в движении, зная только позицию головы и запястий (например во время игры в VR).
Постер #46, приходите поболтать если вы на CVPR. #конфа
❱❱ Подробный пост про статью.
@ai_newz
Media is too big
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
Qualcomm запилили квантизацию для Stable Diffusion и запихнули ее на телефон с процессором Snapdragon. Я поговорил с их ресерчерами.
Работает прилично, но не молниеносно – 13 сек на картинку (20 шагов DPM++).
Int8 квантизация для весов и int16 для активаций.
Все это зарелизили как часть своего AI Engine SDK. Говорят, что их код можно использовать и для квантизации под GPU.
У снэпа получилось быстрее, но у них и трюков больше, и телефон мощнее плюс юзают Apple CoreML.
#конфа
@ai_newz
Работает прилично, но не молниеносно – 13 сек на картинку (20 шагов DPM++).
Int8 квантизация для весов и int16 для активаций.
Все это зарелизили как часть своего AI Engine SDK. Говорят, что их код можно использовать и для квантизации под GPU.
У снэпа получилось быстрее, но у них и трюков больше, и телефон мощнее плюс юзают Apple CoreML.
#конфа
@ai_newz