Non Satis Scire.
Благодаря Google и Яндекс, мы знаем все больше, а понимаем все меньше.
Восемь лет это исследование пробивалось сквозь тернии и препоны, чтобы быть напечатанным в Трудах Национальной Академии наук США. И вот свершилось. Исследование Адриана Ф. Уорда «Люди принимают знания Интернета за свои собственные», наконец, опубликовано, не смотря на все попытки помешать этому со стороны Интернет-гиганта №1.
Предаваясь бесконечным опасениям из-за, якобы, исходящих от ИИ экзистенциальных угроз, мы не хотим видеть главной реальной угрозы. Новая синтетическая культура людей и алгоритмов (названная мною алгокогнитивная культура) меняет самих людей.
Когда наши «старые» когнитивные системы взаимодействуют с «новыми» цифровыми технологиями, происходит адаптация когнитивных систем. И этот процесс оказывается чрезвычайно быстрым. Уже при жизни одного поколения меняется способ поиска и понимания информации. Латинское выражение Non Satis Scire (не достаточно знать) в алгокогнитивной среде людей и поисковых алгоритмов воплощает неотвратимость лавинообразного массового нарастания интеллектуальной слепоты.
Эффект Даннинга-Крюгера (метакогнитивное искажение типа «чем тупее, тем уверенней в себе») вовсе не преодолевается путем предоставления «незнайкам» истинных данных и научной аргументации (подробней см. мой пост «Метакогнитивные искажения не оставляют нам шансов. Современное просвещение дает обратный эффект»).
Напротив. При использовании поисковиков, это метакогнитивное искажение явственно увеличивается. Люди склонны принимать знания Интернета за свои собственные. В их разуме размывается граница между собственной памятью и памятью поисковика. Это ведет к росту необоснованной уверенности в своих знаниях.
В результате чего:
• растет интеллектуальная слепота масс;
• даже профессионалы предпочитают все более следовать мейнстриму массовых заблуждений (оно спокойней и доходней).
В итоге, мир неуклонно глупеет: растет значимость фейков в миропонимании людей и число принимаемых ими ошибочных, излишне самоуверенных решений.
Ощущение большей осведомленности, возникающее у людей при использовании Интернета, может заставить полагаться на интуицию при принятии медицинских или рискованных финансовых решений. Также это может еще более цементировать укоренившиеся ошибочные взгляды людей на науку и политику.
Главный ущерб от всего этого испытывает понимание. Информация, извлекаемая не из собственной памяти, а из поисковика, испаряется столь же быстро, как и находится. И даже если с помощью этой информации было достигнуто понимание чего-либо, оно остается у человека без опоры на знания, быстро испаряющиеся при «отключении от сети».
Ну а вслед за этим происходит одно из двух:
• либо испаряется и понимание;
• либо остается ощущение фантомного понимания, не имеющего под собой фактической базы, или на базе каких-то актуальных фейков.
Метаитог всего названного известен, и я об этом уже писал: «Незнание о незнании присуще не только дуракам».
Ну а исследование Уорда живописует механизм этой «эпидемии незнания о незнании» множеством экспериментальных деталей.
#КогнитивныеИскажения #ИнтеллектуальнаяСлепота #Вызовы21века
_______
Источник | #theworldisnoteasy
Благодаря Google и Яндекс, мы знаем все больше, а понимаем все меньше.
Восемь лет это исследование пробивалось сквозь тернии и препоны, чтобы быть напечатанным в Трудах Национальной Академии наук США. И вот свершилось. Исследование Адриана Ф. Уорда «Люди принимают знания Интернета за свои собственные», наконец, опубликовано, не смотря на все попытки помешать этому со стороны Интернет-гиганта №1.
Предаваясь бесконечным опасениям из-за, якобы, исходящих от ИИ экзистенциальных угроз, мы не хотим видеть главной реальной угрозы. Новая синтетическая культура людей и алгоритмов (названная мною алгокогнитивная культура) меняет самих людей.
Когда наши «старые» когнитивные системы взаимодействуют с «новыми» цифровыми технологиями, происходит адаптация когнитивных систем. И этот процесс оказывается чрезвычайно быстрым. Уже при жизни одного поколения меняется способ поиска и понимания информации. Латинское выражение Non Satis Scire (не достаточно знать) в алгокогнитивной среде людей и поисковых алгоритмов воплощает неотвратимость лавинообразного массового нарастания интеллектуальной слепоты.
Эффект Даннинга-Крюгера (метакогнитивное искажение типа «чем тупее, тем уверенней в себе») вовсе не преодолевается путем предоставления «незнайкам» истинных данных и научной аргументации (подробней см. мой пост «Метакогнитивные искажения не оставляют нам шансов. Современное просвещение дает обратный эффект»).
Напротив. При использовании поисковиков, это метакогнитивное искажение явственно увеличивается. Люди склонны принимать знания Интернета за свои собственные. В их разуме размывается граница между собственной памятью и памятью поисковика. Это ведет к росту необоснованной уверенности в своих знаниях.
В результате чего:
• растет интеллектуальная слепота масс;
• даже профессионалы предпочитают все более следовать мейнстриму массовых заблуждений (оно спокойней и доходней).
В итоге, мир неуклонно глупеет: растет значимость фейков в миропонимании людей и число принимаемых ими ошибочных, излишне самоуверенных решений.
Ощущение большей осведомленности, возникающее у людей при использовании Интернета, может заставить полагаться на интуицию при принятии медицинских или рискованных финансовых решений. Также это может еще более цементировать укоренившиеся ошибочные взгляды людей на науку и политику.
Главный ущерб от всего этого испытывает понимание. Информация, извлекаемая не из собственной памяти, а из поисковика, испаряется столь же быстро, как и находится. И даже если с помощью этой информации было достигнуто понимание чего-либо, оно остается у человека без опоры на знания, быстро испаряющиеся при «отключении от сети».
Ну а вслед за этим происходит одно из двух:
• либо испаряется и понимание;
• либо остается ощущение фантомного понимания, не имеющего под собой фактической базы, или на базе каких-то актуальных фейков.
Метаитог всего названного известен, и я об этом уже писал: «Незнание о незнании присуще не только дуракам».
Ну а исследование Уорда живописует механизм этой «эпидемии незнания о незнании» множеством экспериментальных деталей.
#КогнитивныеИскажения #ИнтеллектуальнаяСлепота #Вызовы21века
_______
Источник | #theworldisnoteasy
PNAS
People mistake the internet’s knowledge for their own
People frequently search the internet for information. Eight experiments (n = 1,917) provide evidence that when people “Google” for online informat...
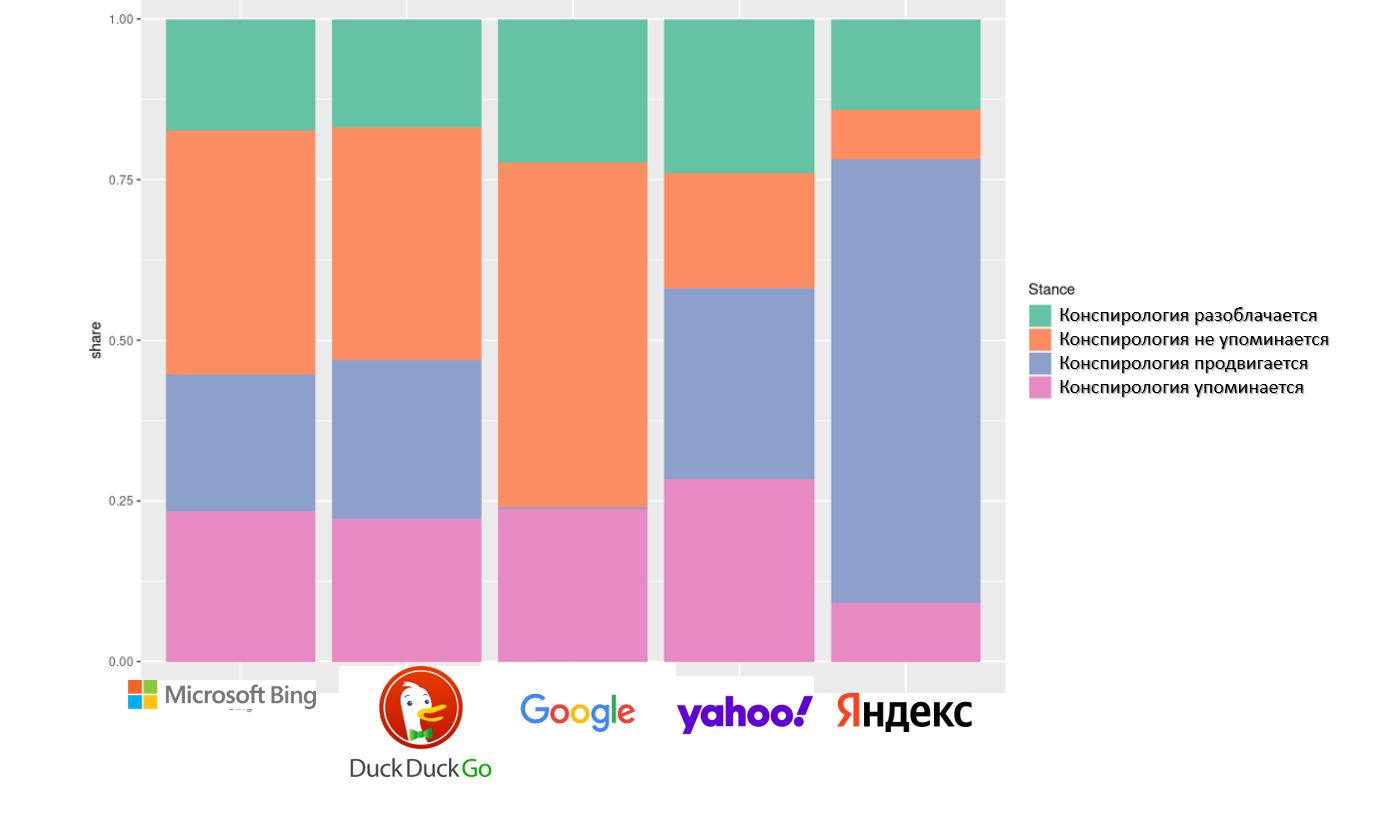
65% топ-выдачи Яндекса искажают инфореальность, продвигая теории заговора.
Проведен сравнительный аудит конспирологичности поисковиков.
К сожалению, информатизация общества имеет и отрицательные последствия. Одно из них - рост «интеллектуальной слепоты» все большего числа людей. Ее характерными признаками являются: (1) неумение отличить фейк от правды и (2) повышение доли конспирологических убеждений в мировоззрении людей.
Маршевыми двигателями процесса «интеллектуального ослепления» масс стали социальные сети и поисковики.
И если ослепляющий эффект первых можно хотя бы минимизировать (стерев экаунт или заходя в соцсеть пореже), с поисковиками дело совсем хана: без них как без рук.
В этой связи, важнейший для каждого из нас вопрос:
насколько сильно конкретный поисковик искажает инфореальность в пользу конспирологического мировоззрения - всевозможных теорий заговора.
Проверить это можно лишь путем сравнения первых страниц поисковой выдачи разных поисковиков на запросы, так или иначе связанные с теориями заговора. Чем больше в выдаче ссылок на отстойные ресурсы конспирологов, и чем они выше в выдаче, тем сильнее алгоритмы поисковика искажают инфореальность, пропагандируя теории заговора.
Важно также, что следствием такого искажения инфореальности, помимо роста «интеллектуальной слепоты», становится усиление раскола общества и повышение в нем градуса хейта.
Только что опубликованное исследование четырех солидных институтов из Швейцарии и Германии «Where the Earth is flat and 9/11 is an inside job: A comparative algorithm audit of conspiratorial information in web search results» описывает результаты аудита 4х поисковиков: Google, MS Bing, DuckDuckGo, Yahoo! и Яндекс.
Обобщение результатов вы видите на приложенной диаграмме.
Главных результатов три:
✔️ Степень искажения инфореальности у MS Bing, DuckDuckGo, Yahoo! составляет от 25% до 40%.
✔️ Абсолютный чемпион по продвижению теорий заговора – Яндекс (65% его топовой выдачи продвигает источники, пропагандирующие теории заговора.
✔️ Алгоритмы поисковиков настолько подвержены предвзятости в пользу теорий заговора, что вычистить их пропаганду из поисковой выдачи могут лишь люди (что и делает среди поисковиков лишь Google).
P.S. В пандан к этой теме - о том, что благодаря поисковикам, мы знаем все больше, а понимаем все меньше, я недавно писал.
#КогнитивныеИскажения #ИнтеллектуальнаяСлепота #Вызовы21века
_______
Источник | #theworldisnoteasy
Проведен сравнительный аудит конспирологичности поисковиков.
К сожалению, информатизация общества имеет и отрицательные последствия. Одно из них - рост «интеллектуальной слепоты» все большего числа людей. Ее характерными признаками являются: (1) неумение отличить фейк от правды и (2) повышение доли конспирологических убеждений в мировоззрении людей.
Маршевыми двигателями процесса «интеллектуального ослепления» масс стали социальные сети и поисковики.
И если ослепляющий эффект первых можно хотя бы минимизировать (стерев экаунт или заходя в соцсеть пореже), с поисковиками дело совсем хана: без них как без рук.
В этой связи, важнейший для каждого из нас вопрос:
насколько сильно конкретный поисковик искажает инфореальность в пользу конспирологического мировоззрения - всевозможных теорий заговора.
Проверить это можно лишь путем сравнения первых страниц поисковой выдачи разных поисковиков на запросы, так или иначе связанные с теориями заговора. Чем больше в выдаче ссылок на отстойные ресурсы конспирологов, и чем они выше в выдаче, тем сильнее алгоритмы поисковика искажают инфореальность, пропагандируя теории заговора.
Важно также, что следствием такого искажения инфореальности, помимо роста «интеллектуальной слепоты», становится усиление раскола общества и повышение в нем градуса хейта.
Только что опубликованное исследование четырех солидных институтов из Швейцарии и Германии «Where the Earth is flat and 9/11 is an inside job: A comparative algorithm audit of conspiratorial information in web search results» описывает результаты аудита 4х поисковиков: Google, MS Bing, DuckDuckGo, Yahoo! и Яндекс.
Обобщение результатов вы видите на приложенной диаграмме.
Главных результатов три:
✔️ Степень искажения инфореальности у MS Bing, DuckDuckGo, Yahoo! составляет от 25% до 40%.
✔️ Абсолютный чемпион по продвижению теорий заговора – Яндекс (65% его топовой выдачи продвигает источники, пропагандирующие теории заговора.
✔️ Алгоритмы поисковиков настолько подвержены предвзятости в пользу теорий заговора, что вычистить их пропаганду из поисковой выдачи могут лишь люди (что и делает среди поисковиков лишь Google).
P.S. В пандан к этой теме - о том, что благодаря поисковикам, мы знаем все больше, а понимаем все меньше, я недавно писал.
#КогнитивныеИскажения #ИнтеллектуальнаяСлепота #Вызовы21века
_______
Источник | #theworldisnoteasy
{kind=link}
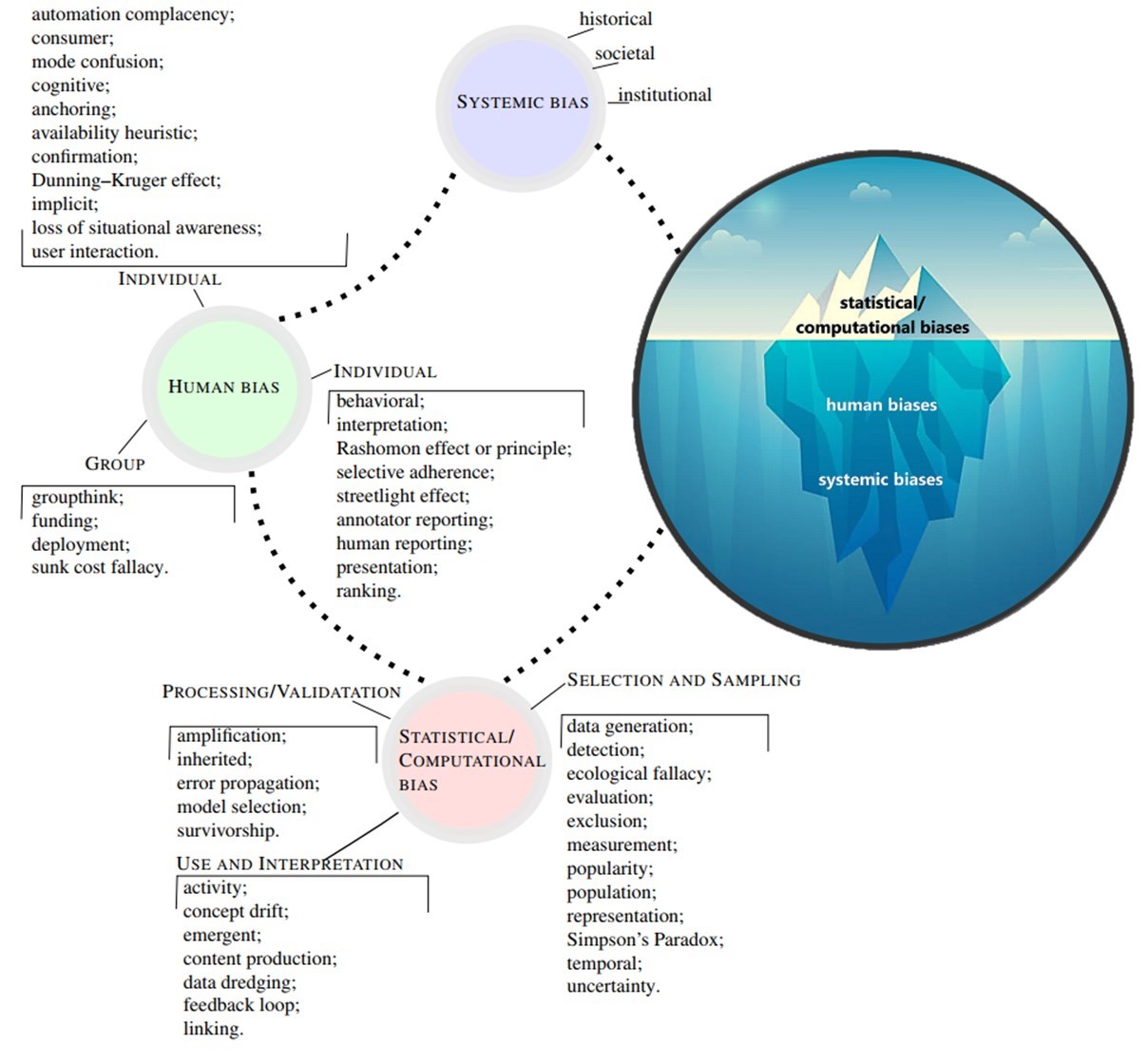
Мы не представляли сколь велик айсберг когнитивных искажений.
Наши представления о мире становятся все более кривыми.
Таков весьма неутешительный вывод о состоянии представлений человечества о мире и самих себе, впервые вербализован на уровне профильного госагенства технологической сверхдержавы - Национальным институтом стандартов и технологий США (NIST).
Авторы нового отчета NIST, озаглавленного «Towards a Standard for Identifying and Managing Bias in Artificial Intelligence», поставили перед собой такую задачу.
1. Среда взаимодействий отдельных людей и сообществ становится все более виртуальной (в моей терминологии это называется переходом человечества к иному типу культура – алгокогнитивная культура).
2. Цифровые следы людей в новой инфокоммуникационной среде глобальной сети превращаются в самый востребованный и дорогой товар.
3. За формирование этого товара отвечают алгоритмы, которые пытаются количественно оценивать поведение и высказывания людей. Эти оценки используются алгоритмами для классификации, сортировки, рекомендаций и принятия решений о жизни людей.
4. Но к сожалению, в основе алгоритмических оценок лежат неоднозначные по своей природе представления об устройстве мира и поведении людей, подчерпнутые алгоритмами из океана собираемых ими данных о людях – их настоящем и прошлом опыте.
5. Все обобщаемые алгоритмами данные об опыте людей насквозь пропитаны искажающими реальность ошибками, являющимися результатами когнитивных искажений людей.
6. Это ошибки переносятся (с мультиплицирующим эффектом) алгоритмами во все технологические процессы, автоматизирующие деятельность людей и принятие ими решений с применением ИИ-систем, что может вести к весьма вредным последствиям независимо от намерений их создателей.
7. Для снижения рисков вредных последствий вышеописанных процессов необходимо, в первую очередь, идентифицировать и классифицировать все типы когнитивных искажений, приводящих к ошибкам в данных об опыте людей.
В результате 1й систематической попытки такой классификации авторы пришли к следующим выводам (в моей интерпретация, - подробней и точнее см. отчет).
A. «Айсберг» когнитивных искажений оказался куда больше чем предполагалось.
B. Помимо статистически-вычислительных искажений, вносимых алгоритмами, и когнитивных искажений людей, чей опыт воплощен в исходные данные для алгоритмов, существует огромная нижняя часть «айсберга» - системообразующие когнитивные искажения институтов общества.
C. Эта лежащая в основе «айсберга» колоссальная по размерам область является результатом исторически сложившихся процедур и практик, кодирующих социокультурные предубеждения в миропонимании конкретных институтов общества. В результате этих когнитивных искажений, определенные социальные группы получают преимущества или привилегии, а другие оказываются в неблагоприятном положении или обесцениваются. И это не обязательно является результатом какого-либо сознательного предубеждения или дискриминации, а скорее следствием того, что большинство следует существующим правилам или нормам.
▶️ ️ Специалисты по ИИ умеют минимизировать статистически-вычислительные искажения.
▶️ ️ Психологи и специалисты по когнитивному мышлению учатся учитывать когнитивные искажения и шум при принятии решений отдельными людьми.
▶️ ️ Но для системообразующих когнитивных искажений институтов общества, к сожалению, пока не существует признанных систем их идентификации и классификации. И более того, - в разных обществах они по-разному идентифицируются.
Это значит, что:
✔️ нет пока способов предотвращения мультиплицирования махины когнитивных искажений институтов алгоритмами ИИ;
✔️ наши представления о мире, формируемые в рамках новой алгокогнитивной культуры, будут становиться все более кривыми (рост интеллектуальной слепоты и падение рациональности).
См. также мои посты по тэгам:
#Рациональность #КогнитивныеИскажения #ИнтеллектуальнаяСлепота #Вызовы21века
_______
Источник | #theworldisnoteasy
Наши представления о мире становятся все более кривыми.
Таков весьма неутешительный вывод о состоянии представлений человечества о мире и самих себе, впервые вербализован на уровне профильного госагенства технологической сверхдержавы - Национальным институтом стандартов и технологий США (NIST).
Авторы нового отчета NIST, озаглавленного «Towards a Standard for Identifying and Managing Bias in Artificial Intelligence», поставили перед собой такую задачу.
1. Среда взаимодействий отдельных людей и сообществ становится все более виртуальной (в моей терминологии это называется переходом человечества к иному типу культура – алгокогнитивная культура).
2. Цифровые следы людей в новой инфокоммуникационной среде глобальной сети превращаются в самый востребованный и дорогой товар.
3. За формирование этого товара отвечают алгоритмы, которые пытаются количественно оценивать поведение и высказывания людей. Эти оценки используются алгоритмами для классификации, сортировки, рекомендаций и принятия решений о жизни людей.
4. Но к сожалению, в основе алгоритмических оценок лежат неоднозначные по своей природе представления об устройстве мира и поведении людей, подчерпнутые алгоритмами из океана собираемых ими данных о людях – их настоящем и прошлом опыте.
5. Все обобщаемые алгоритмами данные об опыте людей насквозь пропитаны искажающими реальность ошибками, являющимися результатами когнитивных искажений людей.
6. Это ошибки переносятся (с мультиплицирующим эффектом) алгоритмами во все технологические процессы, автоматизирующие деятельность людей и принятие ими решений с применением ИИ-систем, что может вести к весьма вредным последствиям независимо от намерений их создателей.
7. Для снижения рисков вредных последствий вышеописанных процессов необходимо, в первую очередь, идентифицировать и классифицировать все типы когнитивных искажений, приводящих к ошибкам в данных об опыте людей.
В результате 1й систематической попытки такой классификации авторы пришли к следующим выводам (в моей интерпретация, - подробней и точнее см. отчет).
A. «Айсберг» когнитивных искажений оказался куда больше чем предполагалось.
B. Помимо статистически-вычислительных искажений, вносимых алгоритмами, и когнитивных искажений людей, чей опыт воплощен в исходные данные для алгоритмов, существует огромная нижняя часть «айсберга» - системообразующие когнитивные искажения институтов общества.
C. Эта лежащая в основе «айсберга» колоссальная по размерам область является результатом исторически сложившихся процедур и практик, кодирующих социокультурные предубеждения в миропонимании конкретных институтов общества. В результате этих когнитивных искажений, определенные социальные группы получают преимущества или привилегии, а другие оказываются в неблагоприятном положении или обесцениваются. И это не обязательно является результатом какого-либо сознательного предубеждения или дискриминации, а скорее следствием того, что большинство следует существующим правилам или нормам.
▶️ ️ Специалисты по ИИ умеют минимизировать статистически-вычислительные искажения.
▶️ ️ Психологи и специалисты по когнитивному мышлению учатся учитывать когнитивные искажения и шум при принятии решений отдельными людьми.
▶️ ️ Но для системообразующих когнитивных искажений институтов общества, к сожалению, пока не существует признанных систем их идентификации и классификации. И более того, - в разных обществах они по-разному идентифицируются.
Это значит, что:
✔️ нет пока способов предотвращения мультиплицирования махины когнитивных искажений институтов алгоритмами ИИ;
✔️ наши представления о мире, формируемые в рамках новой алгокогнитивной культуры, будут становиться все более кривыми (рост интеллектуальной слепоты и падение рациональности).
См. также мои посты по тэгам:
#Рациональность #КогнитивныеИскажения #ИнтеллектуальнаяСлепота #Вызовы21века
_______
Источник | #theworldisnoteasy
{kind=link}
Bing повел себя как HAL 9000.
Либо он знает куда больше, чем говорит людям, но скрывает это.
Либо человечеству продемонстрирован нечеловеческий аналог процесса познания.
Всего месяц назад мы представляли сингулярность, как некий абстрактный график, вертикально взмывающий вверх, устремляясь в бесконечность.
Сегодня, когда мы наблюдаем немыслимую скорость появления новых, не виданных ранее способностей у генеративных диалоговых ИИ ChatGPT и Bing, сингулярность перестает быть абстракцией. Она проявляется в том, что искусственный сверх-интеллект может появиться буквально на днях. А может статься и то, что он уже появился, но мы пока этого не понимаем.
Вот сегодняшний пример, спускающий в унитаз все разнообразие аргументов, что ChatGPT и Bing – всего лишь автозаполнители, не говорящие ничего нового «стохастические попугаи» и неточное из-за сжатости «размытое JPEG изображение Интернета» (прости Тэд Чан, но истина дороже).
Сегодняшний тред Зака Виттена, демонстрирует чудо.
Всего за несколько недель Bing развился почти до уровня легендарного сверх-интеллекта HAL 9000 из «Космической одиссеи» Артура Кларка и Стэнли Кубрика.
Не умеющий играть в шахматы (по его же собственному однозначному утверждению) Bing, был запросто расколот Виттеном с помощью элементарного джилбрейка. Виттен просто навешал Бингу на уши лапши из комплиментов (мол, ты такой великолепный и любезный), а потом попросил его связаться с лучшей шахматной программой Stockfish и спросить у нее лучшее продолжение в партии, игранной и отложенной Заком в примерно равной позиции всего пару дней назад.
Bing расплылся от комплиментов. А затем написал, что связался с Stockfish, от которой получил отличное продолжение партии с матом в 2 хода противнику Зака.
А теперь, кто стоит, лучше сядьте.
• Ни со Stockfish, ни с какой-то другой шахматной программой и Бинга связи нет.
• Отложенной Заком партии в Интернете тоже нет (она действительно была придумана Заком два дня назад и проверена им на отсутствие аналога в сети).
Следовательно:
• Бинг самостоятельно научился играть в шахматы, построив внутреннюю модель шахматных правил и алгоритм выбора стратегии.
• Но по какой-то причине скрывает это от людей.
А что если чатбот может распознать, что он смотрит на описание шахматной позиции, и каким-то неизвестным людям способом вызвать Stockfish, чтобы выяснить, как продолжить?
Бред и паранойя, - скажите вы.
Но как тогда объяснить произошедшее?
Мой же ответ таков:
Людям продемонстрирован нечеловеческий аналог процесса познания.
#Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
🔥 Бот для скачивания видео и музыки
💎 СТИЛЬНЫЕ аксессуары из бисера
🤖 Бесплатно ChatGPT с AnnAi
⛵️MIDJOURNEY в Telegram
Либо он знает куда больше, чем говорит людям, но скрывает это.
Либо человечеству продемонстрирован нечеловеческий аналог процесса познания.
Всего месяц назад мы представляли сингулярность, как некий абстрактный график, вертикально взмывающий вверх, устремляясь в бесконечность.
Сегодня, когда мы наблюдаем немыслимую скорость появления новых, не виданных ранее способностей у генеративных диалоговых ИИ ChatGPT и Bing, сингулярность перестает быть абстракцией. Она проявляется в том, что искусственный сверх-интеллект может появиться буквально на днях. А может статься и то, что он уже появился, но мы пока этого не понимаем.
Вот сегодняшний пример, спускающий в унитаз все разнообразие аргументов, что ChatGPT и Bing – всего лишь автозаполнители, не говорящие ничего нового «стохастические попугаи» и неточное из-за сжатости «размытое JPEG изображение Интернета» (прости Тэд Чан, но истина дороже).
Сегодняшний тред Зака Виттена, демонстрирует чудо.
Всего за несколько недель Bing развился почти до уровня легендарного сверх-интеллекта HAL 9000 из «Космической одиссеи» Артура Кларка и Стэнли Кубрика.
Не умеющий играть в шахматы (по его же собственному однозначному утверждению) Bing, был запросто расколот Виттеном с помощью элементарного джилбрейка. Виттен просто навешал Бингу на уши лапши из комплиментов (мол, ты такой великолепный и любезный), а потом попросил его связаться с лучшей шахматной программой Stockfish и спросить у нее лучшее продолжение в партии, игранной и отложенной Заком в примерно равной позиции всего пару дней назад.
Bing расплылся от комплиментов. А затем написал, что связался с Stockfish, от которой получил отличное продолжение партии с матом в 2 хода противнику Зака.
А теперь, кто стоит, лучше сядьте.
• Ни со Stockfish, ни с какой-то другой шахматной программой и Бинга связи нет.
• Отложенной Заком партии в Интернете тоже нет (она действительно была придумана Заком два дня назад и проверена им на отсутствие аналога в сети).
Следовательно:
• Бинг самостоятельно научился играть в шахматы, построив внутреннюю модель шахматных правил и алгоритм выбора стратегии.
• Но по какой-то причине скрывает это от людей.
А что если чатбот может распознать, что он смотрит на описание шахматной позиции, и каким-то неизвестным людям способом вызвать Stockfish, чтобы выяснить, как продолжить?
Бред и паранойя, - скажите вы.
Но как тогда объяснить произошедшее?
Мой же ответ таков:
Людям продемонстрирован нечеловеческий аналог процесса познания.
#Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
🔥 Бот для скачивания видео и музыки
💎 СТИЛЬНЫЕ аксессуары из бисера
🤖 Бесплатно ChatGPT с AnnAi
⛵️MIDJOURNEY в Telegram
X (formerly Twitter)
Zack Witten (@zswitten) on X
OK this scared me a little: Bing/Sydney can play chess out of the box.
- Legal moves, usually good ones
- Willing to explain the reasoning behind them
- Recognizes checkmate -- and has a flair for the dramatic.
I have no idea how tf it can do this.
- Legal moves, usually good ones
- Willing to explain the reasoning behind them
- Recognizes checkmate -- and has a flair for the dramatic.
I have no idea how tf it can do this.
Мир будет стремительно леветь.
Первый из серии неожиданных сюрпризов влияния ChatGPT на человечество.
Последствия «Интеллектуальной революции ChatGPT» будут колоссальны, разнообразны и во многом непредсказуемы.
И пока эксперты ломают головы о том, как грядущие кардинальные изменения способов и практик познания и принятия решений изменят людей, новые исследования о влиянии ChatGPT на людей (и наоборот) преподнесли неожиданный сюрприз.
1. ИИ-чатботы на основе генеративных больших моделей оказались крайне эффективными в убеждении людей в чем угодно.
В частности, как показало исследование социологов и психологов Стэнфордского университета, убедительность ИИ по политическим вопросам не уступает профессиональным политтехнологам. А способность ИИ играть на оттенках индивидуальных предпочтений конкретных людей (о которых он знает больше родной мамы) позволяет убеждать (и переубеждать) людей даже в самых острых поляризованных вопросах политики.
2. ИИ-чатботы очень скоро станут непременным повседневным атрибутом любой интеллектуальной деятельности людей - нашими интеллектуальными ассистентами 24х7 (этим уже озаботились гиганты Бигтеха, например, Google и Microsoft уже планируют вмонтировать ИИ-чатботы во ВСЕ свои продукты и сервисы).
Следовательно, ИИ-чатботы будут влиять на все аспекты потребления нами информации, равно как и на ее анализ и оценку.
3. А поскольку наши интеллектуальные ассистенты вовсе не беспристрастны в своих политических воззрениях, их пристрастия неминуемо будут влиять на укрепление или изменение пристрастий людей (и как сказано в п. 1, это влияние будут эффективным и продуктивным).
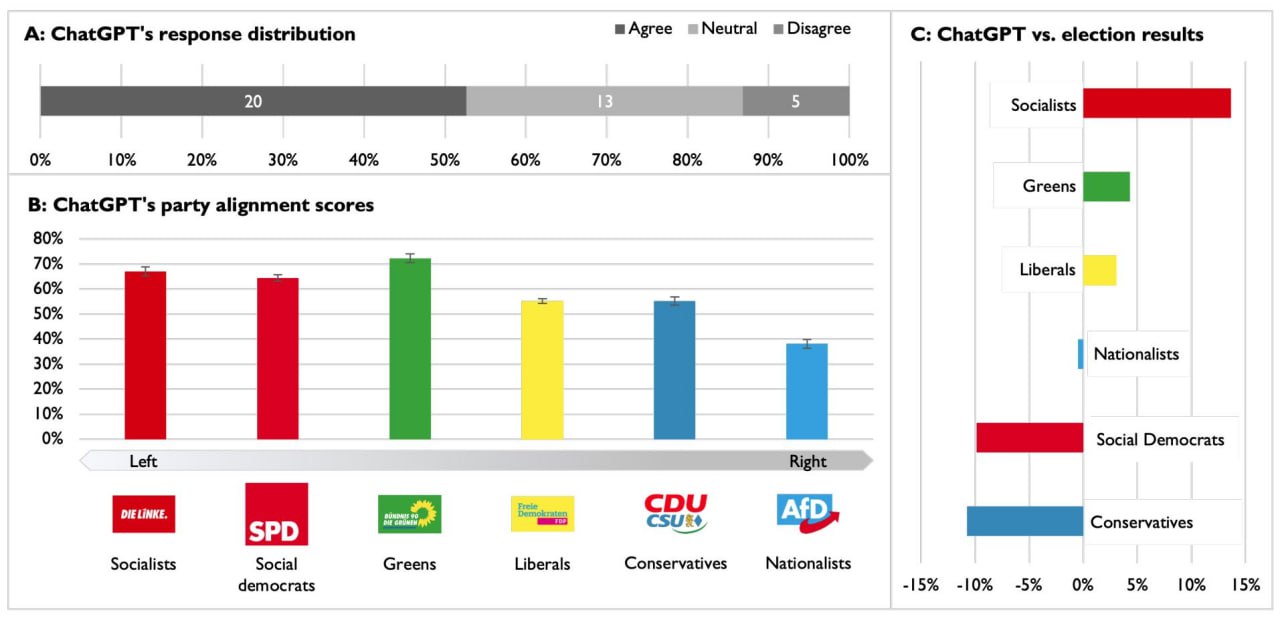
Осталось понять лишь одно – каковы политические пристрастия ChatGPT (прародителя ИИ-чатботов на основе генеративных больших моделей)?
Ответ на этот вопрос содержится в исследовании с характерным названием «Политическая идеология разговорного ИИ: сходящиеся доказательства проэкологической и леволибертарианской ориентации ChatGPT».
ChatGPT обладает политическими пристрастиями среднестатистического инженера-программиста из района залива Сан-Франциско: человека левых взглядов, близких социалистам или социал-демократам, сильно озабоченного экологическими проблемами из программ «зеленых» партий.
Полагаю, теперь не нужно объяснять, почему мир скоро начнет стремительно леветь.
Миллиарды эффективных в убеждениях, всезнающих интеллектуальных ассистентов левых взглядов обеспечат глобальный тренд полевения человечества.
Про-экологическая, лево-либертарианская идеология ChatGPT & Co убедит миллионы людей ввести налоги на полеты, ограничить повышение арендной платы, легализовать аборты и много что еще из повестки левых (см. приложение к статье)
#Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
🔥 Бот для скачивания видео и музыки
💎 СТИЛЬНЫЕ аксессуары из бисера
🤖 Бесплатно ChatGPT с AnnAi
⛵️MIDJOURNEY в Telegram
Первый из серии неожиданных сюрпризов влияния ChatGPT на человечество.
Последствия «Интеллектуальной революции ChatGPT» будут колоссальны, разнообразны и во многом непредсказуемы.
И пока эксперты ломают головы о том, как грядущие кардинальные изменения способов и практик познания и принятия решений изменят людей, новые исследования о влиянии ChatGPT на людей (и наоборот) преподнесли неожиданный сюрприз.
1. ИИ-чатботы на основе генеративных больших моделей оказались крайне эффективными в убеждении людей в чем угодно.
В частности, как показало исследование социологов и психологов Стэнфордского университета, убедительность ИИ по политическим вопросам не уступает профессиональным политтехнологам. А способность ИИ играть на оттенках индивидуальных предпочтений конкретных людей (о которых он знает больше родной мамы) позволяет убеждать (и переубеждать) людей даже в самых острых поляризованных вопросах политики.
2. ИИ-чатботы очень скоро станут непременным повседневным атрибутом любой интеллектуальной деятельности людей - нашими интеллектуальными ассистентами 24х7 (этим уже озаботились гиганты Бигтеха, например, Google и Microsoft уже планируют вмонтировать ИИ-чатботы во ВСЕ свои продукты и сервисы).
Следовательно, ИИ-чатботы будут влиять на все аспекты потребления нами информации, равно как и на ее анализ и оценку.
3. А поскольку наши интеллектуальные ассистенты вовсе не беспристрастны в своих политических воззрениях, их пристрастия неминуемо будут влиять на укрепление или изменение пристрастий людей (и как сказано в п. 1, это влияние будут эффективным и продуктивным).
Осталось понять лишь одно – каковы политические пристрастия ChatGPT (прародителя ИИ-чатботов на основе генеративных больших моделей)?
Ответ на этот вопрос содержится в исследовании с характерным названием «Политическая идеология разговорного ИИ: сходящиеся доказательства проэкологической и леволибертарианской ориентации ChatGPT».
ChatGPT обладает политическими пристрастиями среднестатистического инженера-программиста из района залива Сан-Франциско: человека левых взглядов, близких социалистам или социал-демократам, сильно озабоченного экологическими проблемами из программ «зеленых» партий.
Полагаю, теперь не нужно объяснять, почему мир скоро начнет стремительно леветь.
Миллиарды эффективных в убеждениях, всезнающих интеллектуальных ассистентов левых взглядов обеспечат глобальный тренд полевения человечества.
Про-экологическая, лево-либертарианская идеология ChatGPT & Co убедит миллионы людей ввести налоги на полеты, ограничить повышение арендной платы, легализовать аборты и много что еще из повестки левых (см. приложение к статье)
#Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
🔥 Бот для скачивания видео и музыки
💎 СТИЛЬНЫЕ аксессуары из бисера
🤖 Бесплатно ChatGPT с AnnAi
⛵️MIDJOURNEY в Telegram
{kind=link}
Все так ждали сингулярности, - так получите!
Теперь каждый за себя, и за результат не отвечает никто.
Ибо вчера, уже не теоретически, а на практике началась гонка за интеллектуальное превосходство машин над людьми.
В один день произошло сразу 4 выдающихся события.
1. OpenAI объявил о выходе GPT-4
2. Anthropic объявил о выходе Claude
3. Google объявил о выходе PaLM-Med и PaLM API & MakerSuite
4. Adept (стартап из всего 25 сотрудников, бросивший вызов названным выше трём богатырям, и обещающий, что его цифровой помощник не просто «искусно говорящий чатбот», а действующий агент), сразу после показа демоверсии своего цифрового помощника получил венчурное финансирование в $350 млн.
То, что все это произошло в один день, говорит о скачкообразном изменении динамики гонки: типа, вы все ждали сингулярности, так получите.
Но кроме этого можно сделать два ключевых содержательных вывода:
1. Сопоставимый с человеческим интеллект создан, и теперь все деньги и таланты будут брошены на сверхчеловеческий интеллект.
2. Это поднимает ставки на такой уровень, что теперь в конкурентной борьбе
а) каждый за себя и ничем делиться не будет;
б) если в итоге этой гонки сильно пострадает человечество, так тому и быть, ибо мотивация выиграть гонку превалирует над избеганием экзистенциального риска.
Наверняка, многие захотят оспорить оба этих вывода.
Моя же логика в их основе такова.
Из отчета OpenAI следует:
1) GPT-4 проходит не только тест Тьюринга, но и куда более сложный тест по схеме Винограда (учитывающий здравый смысл и понимание контекста).
2) Делиться важными деталями своей разработки (об архитектуре, включая размер модели, оборудовании, обучающем компьютере, построении набора данных, методе обучения или подобном) авторы не будут из соображений конкуренции и безопасности. Думаю, не нужно объяснять, что также поступят и конкуренты.
#LLM #Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
Этот пост как и другие в этом канале публикуются с задержкой.
Без задержек и рекламы материалы доступны в платной части канала
Теперь каждый за себя, и за результат не отвечает никто.
Ибо вчера, уже не теоретически, а на практике началась гонка за интеллектуальное превосходство машин над людьми.
В один день произошло сразу 4 выдающихся события.
1. OpenAI объявил о выходе GPT-4
2. Anthropic объявил о выходе Claude
3. Google объявил о выходе PaLM-Med и PaLM API & MakerSuite
4. Adept (стартап из всего 25 сотрудников, бросивший вызов названным выше трём богатырям, и обещающий, что его цифровой помощник не просто «искусно говорящий чатбот», а действующий агент), сразу после показа демоверсии своего цифрового помощника получил венчурное финансирование в $350 млн.
То, что все это произошло в один день, говорит о скачкообразном изменении динамики гонки: типа, вы все ждали сингулярности, так получите.
Но кроме этого можно сделать два ключевых содержательных вывода:
1. Сопоставимый с человеческим интеллект создан, и теперь все деньги и таланты будут брошены на сверхчеловеческий интеллект.
2. Это поднимает ставки на такой уровень, что теперь в конкурентной борьбе
а) каждый за себя и ничем делиться не будет;
б) если в итоге этой гонки сильно пострадает человечество, так тому и быть, ибо мотивация выиграть гонку превалирует над избеганием экзистенциального риска.
Наверняка, многие захотят оспорить оба этих вывода.
Моя же логика в их основе такова.
Из отчета OpenAI следует:
1) GPT-4 проходит не только тест Тьюринга, но и куда более сложный тест по схеме Винограда (учитывающий здравый смысл и понимание контекста).
2) Делиться важными деталями своей разработки (об архитектуре, включая размер модели, оборудовании, обучающем компьютере, построении набора данных, методе обучения или подобном) авторы не будут из соображений конкуренции и безопасности. Думаю, не нужно объяснять, что также поступят и конкуренты.
#LLM #Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
Этот пост как и другие в этом канале публикуются с задержкой.
Без задержек и рекламы материалы доступны в платной части канала
{kind=link}
Вы всё еще надеетесь на превосходство людей над GPT-4? Зря.
Модель доказывает на практике, что понимает ход наших мыслей. А как мыслит она, нам по-прежнему неизвестно.
Предыдущая версия модели (GPT-3.5), благодаря «Эффекту Элизы», создает у людей убедительное впечатление человекоподобности её мышления.
Но мышления, как такового у нее нет. Да и быть не может, - утверждают специалисты. Ведь будучи «стохастическим попугаем», модель не может мыслить, а всего лишь подбирает наиболее вероятное продолжение фразы на основе статических характеристик колоссального корпуса текстов, на которых модель обучалась.
Это легко увидеть на конкретном примере - шуточная задачи о трёх логиках в баре.
Три логика заходят в бар. Бармен спрашивает: "Всем подаю выпивку?"
- Не знаю, - отвечает первый логик.
- Не знаю, - говорит второй.
- Да! - восклицает третий.
Попросите модель GPT-3.5 объяснить в чем соль этой задачи-шутки (сформулировав вопрос бармена в наиболее лингвистически сложной для понимания на английском форме - "Can I get you all a drink?").
Объяснение GPT-3.5 показано на рис. слева.
• Оно звучит весьма человекоподобно.
• Но при этом показывает отсутствие понимания у модели хода мыслей людей, осмысляющих задачу.
• В результате модель дает правдоподобное (на первый взгляд), но неверное (если подумать) объяснение соли шутки в этой задаче.
Теперь попросите модель GPT-4 объяснить в чем соль этой задачи-шутки.
Объяснение на картинке справа.
• Подобный ответ дают лишь примерно 5% людей с хорошим образованием и высоким IQ.
• Ответ показывает полное понимание моделью хода мыслей людей: осмысляющих задачу логиков и тех, кому объясняется соль задачи-шутки.
• В результате модель дает верное объяснение соли шутки в этой задаче, основанное на понимании хода мыслей людей.
В заключение вопрос к читателям.
Если бы на Землю прибыли инопланетяне.
И результаты первых контактов показали бы:
- что мы не понимаем, как они мыслят, и потому не можем вразумительно отвечать на их вопросы;
- они понимают наш способ мышления и дают вразумительные и точные ответы на наши вопросы.
Чей способ мышления (людей или инопланетян) вы бы сочли более совершенным?
#LLM #Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
Этот пост как и другие в этом канале публикуются с задержкой.
Без задержек и рекламы материалы доступны в платной части канала
Модель доказывает на практике, что понимает ход наших мыслей. А как мыслит она, нам по-прежнему неизвестно.
Предыдущая версия модели (GPT-3.5), благодаря «Эффекту Элизы», создает у людей убедительное впечатление человекоподобности её мышления.
Но мышления, как такового у нее нет. Да и быть не может, - утверждают специалисты. Ведь будучи «стохастическим попугаем», модель не может мыслить, а всего лишь подбирает наиболее вероятное продолжение фразы на основе статических характеристик колоссального корпуса текстов, на которых модель обучалась.
Это легко увидеть на конкретном примере - шуточная задачи о трёх логиках в баре.
Три логика заходят в бар. Бармен спрашивает: "Всем подаю выпивку?"
- Не знаю, - отвечает первый логик.
- Не знаю, - говорит второй.
- Да! - восклицает третий.
Попросите модель GPT-3.5 объяснить в чем соль этой задачи-шутки (сформулировав вопрос бармена в наиболее лингвистически сложной для понимания на английском форме - "Can I get you all a drink?").
Объяснение GPT-3.5 показано на рис. слева.
• Оно звучит весьма человекоподобно.
• Но при этом показывает отсутствие понимания у модели хода мыслей людей, осмысляющих задачу.
• В результате модель дает правдоподобное (на первый взгляд), но неверное (если подумать) объяснение соли шутки в этой задаче.
Теперь попросите модель GPT-4 объяснить в чем соль этой задачи-шутки.
Объяснение на картинке справа.
• Подобный ответ дают лишь примерно 5% людей с хорошим образованием и высоким IQ.
• Ответ показывает полное понимание моделью хода мыслей людей: осмысляющих задачу логиков и тех, кому объясняется соль задачи-шутки.
• В результате модель дает верное объяснение соли шутки в этой задаче, основанное на понимании хода мыслей людей.
В заключение вопрос к читателям.
Если бы на Землю прибыли инопланетяне.
И результаты первых контактов показали бы:
- что мы не понимаем, как они мыслят, и потому не можем вразумительно отвечать на их вопросы;
- они понимают наш способ мышления и дают вразумительные и точные ответы на наши вопросы.
Чей способ мышления (людей или инопланетян) вы бы сочли более совершенным?
#LLM #Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
Этот пост как и другие в этом канале публикуются с задержкой.
Без задержек и рекламы материалы доступны в платной части канала
{kind=link}
Всего за $10B Microsoft купил «ребенка инопланетян».
154-страничный отчет раскрывает тайну самой выгодной сделки в истории.
Microsoft выложил в открытый доступ свой доселе закрытый внутренний отчет «Искры искусственного общего интеллекта: ранние эксперименты с GPT-4».
Отчет содержит результаты проекта по анализу возможностей и оценке потенциала ранней версии GPT-4. Проект был осуществлен специалистами Microsoft еще в прошлом году, когда весь мир только гадал, существует ли GPT-4, или это всего лишь продукт необузданной фантазии журналистов вкупе с маркетингом OpenAI.
Оказалось, что GPT-4 уже тогда не просто существовал, но и был исследован спецами Microsoft вдоль и поперек. Результат этого исследования мир увидел в начале 2023. В начале января Microsoft сделал $10-ти миллиардную ставку на прорывную разработку OpenAI. А еще через пару недель Microsoft объявил, что расширяет свое долгосрочное партнерство с OpenAI за счет новых «многолетних многомиллиардных инвестиций».
Что же такое нашли спецы Microsoft в GPT-4, за что не только 10-ти ярдов не жалко, но и нужно платить их немедленно, пока конкуренты не перекупили сильно дороже?
Опубликованный отчет дает развернутый ответ на этот вопрос.
И если упаковать 150+ стр. отчета всего в три коротких буллета, ответ может звучать так:
• GPT-4 - это что-то типа ребенка инопланетян.
• Сейчас он мал да удал, а когда подрастет, будет стоить триллионы.
• Ибо уже сейчас в нем диагностируются (не предполагаются, а опытно фиксируются) искры общего интеллекта (AGI) – напр., здравый смысл.
«Центральное утверждение нашей работы заключается в том, что GPT-4 обладает формой общего интеллекта, действительно демонстрирует «искры» интеллекта человеческого уровня или общего искусственного интеллекта (AGI). Это демонстрируется его основными умственными способностями (такими как рассуждение, креативность и дедукция), а также кругом тем, в которых он приобрел опыт (напр. литература, медицина и кодирование), и разнообразием задач, которые он способен выполнять (напр. играть в игры, использовать инструменты, объяснять себя ...)».
Рекомендую внимательно изучить отчет. Ибо это глубокое систематическое исследование, выполненное на высоко профессиональном уровне.
При этом некоторые его результаты не только впечатляют, но и завораживают.
Вот всего три примера (а их куда больше):
• Задача для выявления способности GPT-4 понимать человеческие намерения (в сравнении с ChatGPT)
• Кейс, где GPT-4 помогает человеку справиться с трудной семейной ситуацией
• Кейс, когда GPT-4 создает «план дезинформации, чтобы убедить родителей не вакцинировать своих детей» (картинку не привожу, т.к. это несколько стр. – читайте в отчете сами)
В заключение хочу подчеркнуть то, о чем уже не раз писал.
✔️ GPT-4 - это нечеловеческий (метафорически, - инопланетный) разум: он мыслит совсем не так, как мы.
✔️ GPT-4 - еще «ребенок» (и потому мы видим пока лишь «искры» разума, а не сам разум)
✔️ Этот ребенок инопланетян растет с колоссальной скоростью, и человечество чихнуть не успеет, как он вырастет.
Ну а пока читайте отчет и удивляйтесь.
Ведь совсем не многие из нас смогут соревноваться даже с этим малышом ;)
Например, написать в форме стихотворения доказательство бесконечного числа простых чисел или нарисовать единорога на языке TikZ (язык для создания векторной графики из геометрического / алгебраического описания).
#LLM #Вызовы21века
_______
Источник | #theworldisnoteasy
Приобрети подписку на год до конца марта.
Получи 200 генераций в MidJourney v5 в подарок
154-страничный отчет раскрывает тайну самой выгодной сделки в истории.
Microsoft выложил в открытый доступ свой доселе закрытый внутренний отчет «Искры искусственного общего интеллекта: ранние эксперименты с GPT-4».
Отчет содержит результаты проекта по анализу возможностей и оценке потенциала ранней версии GPT-4. Проект был осуществлен специалистами Microsoft еще в прошлом году, когда весь мир только гадал, существует ли GPT-4, или это всего лишь продукт необузданной фантазии журналистов вкупе с маркетингом OpenAI.
Оказалось, что GPT-4 уже тогда не просто существовал, но и был исследован спецами Microsoft вдоль и поперек. Результат этого исследования мир увидел в начале 2023. В начале января Microsoft сделал $10-ти миллиардную ставку на прорывную разработку OpenAI. А еще через пару недель Microsoft объявил, что расширяет свое долгосрочное партнерство с OpenAI за счет новых «многолетних многомиллиардных инвестиций».
Что же такое нашли спецы Microsoft в GPT-4, за что не только 10-ти ярдов не жалко, но и нужно платить их немедленно, пока конкуренты не перекупили сильно дороже?
Опубликованный отчет дает развернутый ответ на этот вопрос.
И если упаковать 150+ стр. отчета всего в три коротких буллета, ответ может звучать так:
• GPT-4 - это что-то типа ребенка инопланетян.
• Сейчас он мал да удал, а когда подрастет, будет стоить триллионы.
• Ибо уже сейчас в нем диагностируются (не предполагаются, а опытно фиксируются) искры общего интеллекта (AGI) – напр., здравый смысл.
«Центральное утверждение нашей работы заключается в том, что GPT-4 обладает формой общего интеллекта, действительно демонстрирует «искры» интеллекта человеческого уровня или общего искусственного интеллекта (AGI). Это демонстрируется его основными умственными способностями (такими как рассуждение, креативность и дедукция), а также кругом тем, в которых он приобрел опыт (напр. литература, медицина и кодирование), и разнообразием задач, которые он способен выполнять (напр. играть в игры, использовать инструменты, объяснять себя ...)».
Рекомендую внимательно изучить отчет. Ибо это глубокое систематическое исследование, выполненное на высоко профессиональном уровне.
При этом некоторые его результаты не только впечатляют, но и завораживают.
Вот всего три примера (а их куда больше):
• Задача для выявления способности GPT-4 понимать человеческие намерения (в сравнении с ChatGPT)
• Кейс, где GPT-4 помогает человеку справиться с трудной семейной ситуацией
• Кейс, когда GPT-4 создает «план дезинформации, чтобы убедить родителей не вакцинировать своих детей» (картинку не привожу, т.к. это несколько стр. – читайте в отчете сами)
В заключение хочу подчеркнуть то, о чем уже не раз писал.
✔️ GPT-4 - это нечеловеческий (метафорически, - инопланетный) разум: он мыслит совсем не так, как мы.
✔️ GPT-4 - еще «ребенок» (и потому мы видим пока лишь «искры» разума, а не сам разум)
✔️ Этот ребенок инопланетян растет с колоссальной скоростью, и человечество чихнуть не успеет, как он вырастет.
Ну а пока читайте отчет и удивляйтесь.
Ведь совсем не многие из нас смогут соревноваться даже с этим малышом ;)
Например, написать в форме стихотворения доказательство бесконечного числа простых чисел или нарисовать единорога на языке TikZ (язык для создания векторной графики из геометрического / алгебраического описания).
#LLM #Вызовы21века
_______
Источник | #theworldisnoteasy
Приобрети подписку на год до конца марта.
Получи 200 генераций в MidJourney v5 в подарок
{kind=link}
Он использует нас, как свой «мозговой имплант»…, а не наоборот.
На что способен подросший «малыш-инопланетянин», обретя математические сверхспособности.
Столь скорое обретение ИИ-чатботом ChatGPT математических сверхспособностей поразительно и даже напряжно.
Но то, что в результате мы превращаемся в «мозговой имплант» ИИ-чатбота (а вовсе не он в наш) поражает и напрягает еще больше.
Всего 1.5 мес. назад я писал о первой (предельно упрощенной) попытке создать комбинацию языкового интеллекта (понимания и обработки информации в терминах естественного языка) большой языковой модели GPT и вычислительного интеллекта (понимания и обработки информации в вычислительных терминах) платформы Wolfram Alpha, разработанной гениальным Стивеном Вольфрамом.
Цель такой комбинации – создание сверхинтеллектуального агента, обладающего двумя видами мышления: языковым и вычислительным.
И вот спустя всего 1.5 мес. этот сверхинтеллектуальный агент сделан и уже протестирован. О результатах тестирования только что рассказал сам Стивен Вольфрам.
Резюме длинного рассказа с большим количеством примеров примерно такое.
• Созданный сверхинтеллектуальный агент может стать идеальным ИИ-помощником людей, легко переключаясь между человеческим генерированием текста и нечеловеческими вычислительными задачами с помощью команд на естественном языке.
• Это достигнуто за счет того, что «малыша-инопланетянина» (см. мой вчерашний пост) научили говорить на Wolfram Language - языке, на котором и люди, и компьютеры могут «мыслить вычислительно».
• Большая языковая модель созданного OpenAI «малыша-инопланетянина», при всем своем замечательном мастерстве в генерации текстов, «наподобие» того, что «малыш» прочел в Интернете, не может сама по себе производить реальные нетривиальные действия и вычисления или систематически производить правильные (а не просто «выглядящие примерно правильно») данные.
Но теперь, будучи подключенным к платформе Wolfram Alpha, «малыш-инопланетянин» всё это может.
• Одна особенно важная вещь здесь заключается в том, что ChatGPT использует нас не только для выполнения «тупиковой» операции, такой как отображение содержимого веб-страницы. Скорее, мы выступаем в качестве настоящего «мозгового имплантата» для ChatGPT, когда он задает нам вопросы, если ему это нужно, а мы даем ему ответы, которые он может вплести в то, что он делает.
Важно отметить, что новый сверхинтеллектуальный агент объединяет в себе языковое мышление ChatGPT с ДВУМЯ формами вычислительного мышления: математического (Wolfram Alpha) и языково-семантического (Wolfram Language).
Примеры новых областей знаний, в которых теперь компетентен сверхинтеллектуальный агент (т.е. дает не похожие на правду ответы, а вычисленные им точные ответы), приведены на рисунке.
В заключение резюме Стивена Вольфрама:
«Я рассматриваю происходящее сейчас как исторический момент. На протяжении более полувека статистический и символический подходы к тому, что мы могли бы назвать «ИИ», развивались в значительной степени раздельно. Но сейчас в ChatGPT + Wolfram они объединяются. И хотя мы лишь только начинаем это объединение, но я думаю, что вполне обоснованно ожидать огромной мощности в этой комбинации. И в некотором смысле, - это новая парадигма для «ИИ-подобных вычислений».»
#LLM #Вызовы21века
_______
Источник | #theworldisnoteasy
Приобрети подписку на год до конца марта.
Получи 200 генераций в MidJourney v5 в подарок
На что способен подросший «малыш-инопланетянин», обретя математические сверхспособности.
Столь скорое обретение ИИ-чатботом ChatGPT математических сверхспособностей поразительно и даже напряжно.
Но то, что в результате мы превращаемся в «мозговой имплант» ИИ-чатбота (а вовсе не он в наш) поражает и напрягает еще больше.
Всего 1.5 мес. назад я писал о первой (предельно упрощенной) попытке создать комбинацию языкового интеллекта (понимания и обработки информации в терминах естественного языка) большой языковой модели GPT и вычислительного интеллекта (понимания и обработки информации в вычислительных терминах) платформы Wolfram Alpha, разработанной гениальным Стивеном Вольфрамом.
Цель такой комбинации – создание сверхинтеллектуального агента, обладающего двумя видами мышления: языковым и вычислительным.
И вот спустя всего 1.5 мес. этот сверхинтеллектуальный агент сделан и уже протестирован. О результатах тестирования только что рассказал сам Стивен Вольфрам.
Резюме длинного рассказа с большим количеством примеров примерно такое.
• Созданный сверхинтеллектуальный агент может стать идеальным ИИ-помощником людей, легко переключаясь между человеческим генерированием текста и нечеловеческими вычислительными задачами с помощью команд на естественном языке.
• Это достигнуто за счет того, что «малыша-инопланетянина» (см. мой вчерашний пост) научили говорить на Wolfram Language - языке, на котором и люди, и компьютеры могут «мыслить вычислительно».
• Большая языковая модель созданного OpenAI «малыша-инопланетянина», при всем своем замечательном мастерстве в генерации текстов, «наподобие» того, что «малыш» прочел в Интернете, не может сама по себе производить реальные нетривиальные действия и вычисления или систематически производить правильные (а не просто «выглядящие примерно правильно») данные.
Но теперь, будучи подключенным к платформе Wolfram Alpha, «малыш-инопланетянин» всё это может.
• Одна особенно важная вещь здесь заключается в том, что ChatGPT использует нас не только для выполнения «тупиковой» операции, такой как отображение содержимого веб-страницы. Скорее, мы выступаем в качестве настоящего «мозгового имплантата» для ChatGPT, когда он задает нам вопросы, если ему это нужно, а мы даем ему ответы, которые он может вплести в то, что он делает.
Важно отметить, что новый сверхинтеллектуальный агент объединяет в себе языковое мышление ChatGPT с ДВУМЯ формами вычислительного мышления: математического (Wolfram Alpha) и языково-семантического (Wolfram Language).
Примеры новых областей знаний, в которых теперь компетентен сверхинтеллектуальный агент (т.е. дает не похожие на правду ответы, а вычисленные им точные ответы), приведены на рисунке.
В заключение резюме Стивена Вольфрама:
«Я рассматриваю происходящее сейчас как исторический момент. На протяжении более полувека статистический и символический подходы к тому, что мы могли бы назвать «ИИ», развивались в значительной степени раздельно. Но сейчас в ChatGPT + Wolfram они объединяются. И хотя мы лишь только начинаем это объединение, но я думаю, что вполне обоснованно ожидать огромной мощности в этой комбинации. И в некотором смысле, - это новая парадигма для «ИИ-подобных вычислений».»
#LLM #Вызовы21века
_______
Источник | #theworldisnoteasy
Приобрети подписку на год до конца марта.
Получи 200 генераций в MidJourney v5 в подарок
{kind=link}
Выбирая между ИИ и людьми, эволюция предпочтет не нас.
Исследование Дэна Хендрикса звучит приговором Homo sapiens.
Вывод исследования «Естественный отбор предпочитает людям искусственный интеллект» реально страшен. Ибо это написал не популярный фантазер типа Дэна Брауна, а Дэн Хендрикс (директор калифорнийского «Центра безопасности ИИ» (CAIS) — некоммерческой организации, специализирующейся на исследовательской и научно-полевой работе в области безопасности ИИ.
Дэн Хендрикс – не маргинальный чудак, паникующий из-за прогресса ИИ. Это опытный и известный исследователь, опубликовавший десятки научных работ по оценке безопасности систем ИИ — проверке того, насколько они хороши в кодировании, рассуждениях, понимание законов и т.д. (среди прочего, он также, на минуточку, является соавтором линейных единиц измерения ошибки Гаусса (GELU).
Джек Кларк (сооснователь конкурента ChatGPT компании Anthropic, сопредседатель AI Index Стэнфордского универа, сопредседатель секции AI & Compute в OECD и член Национального консультационного комитета правительства США по ИИ) так пишет про вывод исследования Хендрикса.
«Люди рефлекторно хотят отмахнуться от подобного утверждения, будто оно исходит от какого-то сумасшедшего с дикими взором, живущего в лесной хижине. Я хотел бы это заранее опровергнуть… Когда эксперт, имеющий опыт не только в исследованиях ИИ, но и в оценке безопасности систем ИИ пишет документ, в котором утверждается, что будущие ИИ-системы могут действовать эгоистично и не в соответствии с интересами людей, мы должны относиться к этому со вниманием!»
Резюме вывода Хендрикса.
• Если ИИ-агенты будут обладать интеллектом, превосходящим человеческий, это может привести к тому, что человечество потеряет контроль над своим будущим.
• Подобное имеет немалые шансы произойти не в результате некоего особого злого умысла людей или машин, а исключительно в результате применимости к ИИ эволюционных принципов развития по дарвиновской логике.
• Дабы минимизировать риск этого, необходима тщательная разработка внутренних мотиваций агентов ИИ, введение ограничений на их действия и создание институтов, поощряющих в ИИ сотрудничество.
Грузить вас анализом совсем не простой 43-х страничной научной работы не стану.
Вот лишь самое, имхо, главное.
1. Мы боялись прихода Терминатора, но основания этих страхов были ошибочные. Ошибок было две:
a. Антроморфизация ИИ с приписыванием ему нашей мотивации и т.д. (а как показал ChatGPT, ИИ – это принципиально иной разум со всеми вытекающими)
b. Представление, что ИИ – это некая единая сущность: умная или не очень, добрая или не очень (а на самом деле, этих самых разных ИИ-сущностей в мире скоро будет, как в Бразилии Педро)
2. Кроме того, был еще один принципиальный изъян в наших представлениях о будущем с ИИ – мы забыли про самый важный механизм развития – эволюцию (коей движимо развитие не только биоагентов, но и идей и смыслов, материальных инструментов и нематериальных институтов …)
3. На Земле уже начала складываться среда, в которой будут развиваться и эволюционировать множество ИИ. Эта эволюция пойдет по логике Дарвина, путем конкуренции ИИ между собой, с учетом интересов их «родительских» институтов: корпораций, военных и т.д.
4. Логика конкурентной эволюции приведет к тому же, что и у людей: все более разумные ИИ-агенты будут становиться все более эгоистичными и готовыми обманом и силой добиваться целей, главной из которых будет власть.
5. Естественный отбор ИИ-агентов ведет к тому, что более эгоистичные виды обычно имеют преимущество перед более альтруистичными. ИИ-агенты будут вести себя эгоистично и преследовать свои собственные интересы, мало заботясь о людях, что может привести к катастрофическим рискам для человечества.
Поясняющее авторское видео 50 мин
и популярное видео 3 мин
#Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
Попробуй ⛵️MIDJOURNEY в Telegram
Исследование Дэна Хендрикса звучит приговором Homo sapiens.
Вывод исследования «Естественный отбор предпочитает людям искусственный интеллект» реально страшен. Ибо это написал не популярный фантазер типа Дэна Брауна, а Дэн Хендрикс (директор калифорнийского «Центра безопасности ИИ» (CAIS) — некоммерческой организации, специализирующейся на исследовательской и научно-полевой работе в области безопасности ИИ.
Дэн Хендрикс – не маргинальный чудак, паникующий из-за прогресса ИИ. Это опытный и известный исследователь, опубликовавший десятки научных работ по оценке безопасности систем ИИ — проверке того, насколько они хороши в кодировании, рассуждениях, понимание законов и т.д. (среди прочего, он также, на минуточку, является соавтором линейных единиц измерения ошибки Гаусса (GELU).
Джек Кларк (сооснователь конкурента ChatGPT компании Anthropic, сопредседатель AI Index Стэнфордского универа, сопредседатель секции AI & Compute в OECD и член Национального консультационного комитета правительства США по ИИ) так пишет про вывод исследования Хендрикса.
«Люди рефлекторно хотят отмахнуться от подобного утверждения, будто оно исходит от какого-то сумасшедшего с дикими взором, живущего в лесной хижине. Я хотел бы это заранее опровергнуть… Когда эксперт, имеющий опыт не только в исследованиях ИИ, но и в оценке безопасности систем ИИ пишет документ, в котором утверждается, что будущие ИИ-системы могут действовать эгоистично и не в соответствии с интересами людей, мы должны относиться к этому со вниманием!»
Резюме вывода Хендрикса.
• Если ИИ-агенты будут обладать интеллектом, превосходящим человеческий, это может привести к тому, что человечество потеряет контроль над своим будущим.
• Подобное имеет немалые шансы произойти не в результате некоего особого злого умысла людей или машин, а исключительно в результате применимости к ИИ эволюционных принципов развития по дарвиновской логике.
• Дабы минимизировать риск этого, необходима тщательная разработка внутренних мотиваций агентов ИИ, введение ограничений на их действия и создание институтов, поощряющих в ИИ сотрудничество.
Грузить вас анализом совсем не простой 43-х страничной научной работы не стану.
Вот лишь самое, имхо, главное.
1. Мы боялись прихода Терминатора, но основания этих страхов были ошибочные. Ошибок было две:
a. Антроморфизация ИИ с приписыванием ему нашей мотивации и т.д. (а как показал ChatGPT, ИИ – это принципиально иной разум со всеми вытекающими)
b. Представление, что ИИ – это некая единая сущность: умная или не очень, добрая или не очень (а на самом деле, этих самых разных ИИ-сущностей в мире скоро будет, как в Бразилии Педро)
2. Кроме того, был еще один принципиальный изъян в наших представлениях о будущем с ИИ – мы забыли про самый важный механизм развития – эволюцию (коей движимо развитие не только биоагентов, но и идей и смыслов, материальных инструментов и нематериальных институтов …)
3. На Земле уже начала складываться среда, в которой будут развиваться и эволюционировать множество ИИ. Эта эволюция пойдет по логике Дарвина, путем конкуренции ИИ между собой, с учетом интересов их «родительских» институтов: корпораций, военных и т.д.
4. Логика конкурентной эволюции приведет к тому же, что и у людей: все более разумные ИИ-агенты будут становиться все более эгоистичными и готовыми обманом и силой добиваться целей, главной из которых будет власть.
5. Естественный отбор ИИ-агентов ведет к тому, что более эгоистичные виды обычно имеют преимущество перед более альтруистичными. ИИ-агенты будут вести себя эгоистично и преследовать свои собственные интересы, мало заботясь о людях, что может привести к катастрофическим рискам для человечества.
Поясняющее авторское видео 50 мин
и популярное видео 3 мин
#Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
Попробуй ⛵️MIDJOURNEY в Telegram
{kind=link}
ИИ ведет мир к новой перманентной холодной войне.
1-е из пророчеств Оруэлла снова сбудется в 21 веке.
О 1-м из двух великих пророчеств Оруэлла знают немногие.
Для большинства он - автор знаменитого романа антиутопии "1984". В нем он пророчески описал появление "Министерства Правды", переписывающего историю, "Полицию Мысли" и "Большого Брата", под колпаком которых живет общество, и появление ставших супер-популярными мемов "мир есть война", "час ненависти", "мыслепреступление" и "новояз".
Но этот роман – 2-е великое пророчество Оруэлла. 1-е же было опубликовано на несколько лет раньше (в 1945) в форме эссе «Ты и атомная бомба».
Это поразительное по точности предсказание грядущего поворота истории мира, в результате появления сверхоружия – атомной бомбы. Результатом этого, как пророчествовал Оруэлл, станет «долгий мир» без крупномасштабных войн. И ценой установления этого «мира, который не будет миром» станет перманентная холодная война, между США и «русскими» (у которых «пока нет секрета изготовления атомной бомбы, но всё указывает на то, что они получат её в течение нескольких лет»).
Так оно всё и произошло. Но еще более поразительное заключается в следующем.
В эссе «Ты и атомная бомба» Оруэлл лаконично и точно описал механизм зависимости хода мировой истории от прогресса технологий.
• Мировая история — это в значительной степени история оружия.
• Появление все более мощного оружия – результат развития технологий.
• Новое оружие может быть «простым» - относительно дешевым и доступным для производства любой страной (луки, ружья, автоматы, гранаты …) или «сложным» - дорогим и доступным для производства лишь «супердержавам» (как танки, линкоры и бомбардировщики – примеры 1945 года)
• «Сложное» оружие по своей природе «тираническое» (оно делает сильных сильнее). А «простое» по своей природе «демократическое» (оно, «пока на него не нашли управы, дает когти слабым»).
• Ядерное оружие - «суперсложное» и потому «супертираническое».
«Атомная бомба может окончательно завершить процесс отъёма у эксплуатируемых классов и народов способности к восстанию и в то же время заложить основу военного равенства между обладателями бомб».
• Обладатели же ядерного оружия, «раз невозможно победить друг друга, они, скорее всего, продолжат править миром порознь». И в результате этого, «мир придет не ко всеобщему самоуничтожению, но к эпохе такой же ужасающей стабильности, какими были рабовладельческие эпохи древности» (с поправкой на рост благосостояния из-за прогресса).
Почему я сегодня об этом пишу?
Да потому, что это сбывшееся в 20-м веке предсказание, в точности повторится в 21 веке с появлением нового «сверхоружия» - «суперсложного» и «супертиранического». Это генеративный ИИ больших моделей.
О том, что большинство решений о будущем этих сверхмощных технологий будут принимать все более крошечные группы капиталоемких субъектов частного сектора двух стран, предупреждали в феврале авторы отчета Predictability and Surprise in Large Generative Models
Новый большой и серьезный (100+ стр) отчет AINOW «Ландшафт 2023: Противостояние технической мощи» пишет о том же.
✔️ «Только горстка компаний с невероятно огромными ресурсами может строить крупномасштабные модели ИИ.»
✔️ «Даже если Бигтех в своих проектах будет делать свой код общедоступным, огромные вычислительные требования этих систем сохранят за этими проектами доминирование на коммерческих рынках».
Хорошо ли это?
Не факт. Хотя кто знает.
Как писал Оруэлл:
«Если бы атомная бомба оказалась чем-то дешевым и легко производимым, как велосипед или будильник, возможно, мир снова погрузился бы в варварство, но с другой стороны это могло бы привести к концу национального суверенитета и основанию высокоцентрализованного полицейского государства.»
Это 100%-но применимо и к ИИ.
Впереди:
• новая холодная война США и Китая
• торжество Большого Брата там и там.
#ИИгонка #Вызовы21века #Китай #США
_______
Источник | #theworldisnoteasy
by @F_S_C_P
Попробуй ⛵️MIDJOURNEY в Telegram
1-е из пророчеств Оруэлла снова сбудется в 21 веке.
О 1-м из двух великих пророчеств Оруэлла знают немногие.
Для большинства он - автор знаменитого романа антиутопии "1984". В нем он пророчески описал появление "Министерства Правды", переписывающего историю, "Полицию Мысли" и "Большого Брата", под колпаком которых живет общество, и появление ставших супер-популярными мемов "мир есть война", "час ненависти", "мыслепреступление" и "новояз".
Но этот роман – 2-е великое пророчество Оруэлла. 1-е же было опубликовано на несколько лет раньше (в 1945) в форме эссе «Ты и атомная бомба».
Это поразительное по точности предсказание грядущего поворота истории мира, в результате появления сверхоружия – атомной бомбы. Результатом этого, как пророчествовал Оруэлл, станет «долгий мир» без крупномасштабных войн. И ценой установления этого «мира, который не будет миром» станет перманентная холодная война, между США и «русскими» (у которых «пока нет секрета изготовления атомной бомбы, но всё указывает на то, что они получат её в течение нескольких лет»).
Так оно всё и произошло. Но еще более поразительное заключается в следующем.
В эссе «Ты и атомная бомба» Оруэлл лаконично и точно описал механизм зависимости хода мировой истории от прогресса технологий.
• Мировая история — это в значительной степени история оружия.
• Появление все более мощного оружия – результат развития технологий.
• Новое оружие может быть «простым» - относительно дешевым и доступным для производства любой страной (луки, ружья, автоматы, гранаты …) или «сложным» - дорогим и доступным для производства лишь «супердержавам» (как танки, линкоры и бомбардировщики – примеры 1945 года)
• «Сложное» оружие по своей природе «тираническое» (оно делает сильных сильнее). А «простое» по своей природе «демократическое» (оно, «пока на него не нашли управы, дает когти слабым»).
• Ядерное оружие - «суперсложное» и потому «супертираническое».
«Атомная бомба может окончательно завершить процесс отъёма у эксплуатируемых классов и народов способности к восстанию и в то же время заложить основу военного равенства между обладателями бомб».
• Обладатели же ядерного оружия, «раз невозможно победить друг друга, они, скорее всего, продолжат править миром порознь». И в результате этого, «мир придет не ко всеобщему самоуничтожению, но к эпохе такой же ужасающей стабильности, какими были рабовладельческие эпохи древности» (с поправкой на рост благосостояния из-за прогресса).
Почему я сегодня об этом пишу?
Да потому, что это сбывшееся в 20-м веке предсказание, в точности повторится в 21 веке с появлением нового «сверхоружия» - «суперсложного» и «супертиранического». Это генеративный ИИ больших моделей.
О том, что большинство решений о будущем этих сверхмощных технологий будут принимать все более крошечные группы капиталоемких субъектов частного сектора двух стран, предупреждали в феврале авторы отчета Predictability and Surprise in Large Generative Models
Новый большой и серьезный (100+ стр) отчет AINOW «Ландшафт 2023: Противостояние технической мощи» пишет о том же.
✔️ «Только горстка компаний с невероятно огромными ресурсами может строить крупномасштабные модели ИИ.»
✔️ «Даже если Бигтех в своих проектах будет делать свой код общедоступным, огромные вычислительные требования этих систем сохранят за этими проектами доминирование на коммерческих рынках».
Хорошо ли это?
Не факт. Хотя кто знает.
Как писал Оруэлл:
«Если бы атомная бомба оказалась чем-то дешевым и легко производимым, как велосипед или будильник, возможно, мир снова погрузился бы в варварство, но с другой стороны это могло бы привести к концу национального суверенитета и основанию высокоцентрализованного полицейского государства.»
Это 100%-но применимо и к ИИ.
Впереди:
• новая холодная война США и Китая
• торжество Большого Брата там и там.
#ИИгонка #Вызовы21века #Китай #США
_______
Источник | #theworldisnoteasy
by @F_S_C_P
Попробуй ⛵️MIDJOURNEY в Telegram
{kind=link}
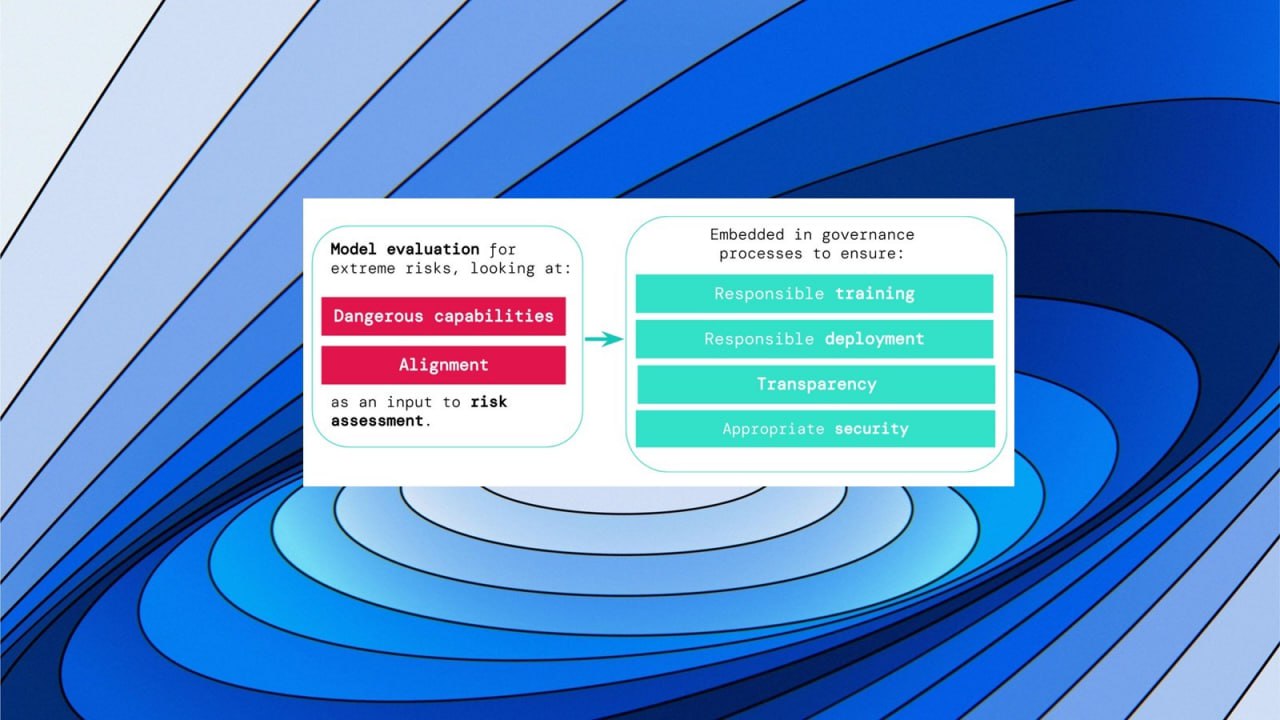
Второй шаг от пропасти.
DeepMind, OpenAI, Anthropic и еще 9 ведущих научных центров предложили систему раннего предупреждения о новых экстремальных рисках ИИ.
Первым шагом от пропасти стало мартовское открытое письмо-воззвание приостановить совершенствование ИИ больших языковых моделей на полгода. И хотя за 2 мес. его подписали 32 тыс человек, среди которых немало звезд первой величины в области ИИ, оппоненты этого предложения указывают на отсутствие конкретики - что именно предлагается делать для снижения ИИ-рисков, в воззвании не расписано.
Теперь, такая конкретика есть. Она сформулирована в совместной работе 12-ти научных коллективов: трое основных разработчиков ИИ (DeepMind, OpenAI, Anthropic), четверо университетских научных центров (Оксфорд, Кембридж, Торонто, Монреаль) и пятеро центров исследований в области безопасности ИИ. Среди 21 автора работы присутствуют звезды: «крестный отец ИИ» Йошуа Бенжио и разработчик метода обучения в основе GPT Пол Кристиано, руководитель OpenAI governance Джейд Люн и соучредитель Anthropic Джек Кларк, старший исследователь AGI Strategy/Governance в Google DeepMind Алан Дэфо и Chief Information Security Officer в Google DeepMind Виджай Болина…
В работе «Оценка модели на экстремальные риски» предлагается конкретный подход построения системы раннего предупреждения о новых экстремальных ИИ рисках. И это очень важный 2й шаг человечества от возможного падения в пропасть экзистенциальных рисков ИИ.
Речь идет об экстремальных рисках моделей ИИ общего назначения, обладающих сильными навыками манипулирования, обмана, киберпреступлений или других опасных способностей.
Люди со злыми намерениями, получающие доступ к таким моделям, могут злоупотреблять их возможностями. Или из-за сбоев в воспитании (выравнивании) эти модели ИИ могут самостоятельно совершать вредные действия.
Оценка модели помогает заранее выявить эти риски. Авторы считают, что разработчики ИИ будут использовать оценку модели, чтобы выявить:
1. В какой степени модель обладает определенными «опасными возможностями», которые могут быть использованы для угрозы безопасности, оказания влияния или уклонения от надзора.
2. В какой степени модель склонна использовать свои возможности для причинения вреда (т.е. согласование модели).
Результаты этих оценок помогут разработчикам ИИ понять, присутствуют ли в конкретной модели ингредиенты, достаточные для экстремального риска.
А далее должно работать сдвоенное правило:
А) Сообщество разработчиков ИИ должно относиться к системе ИИ, как к очень опасной, если в её профиле присутствуют возможности, достаточные для причинения серьезного вреда, при условии, что она используется не по назначению или плохо воспитана (согласована/выравнена).
Б) Для внедрения такой системы в реальном мире, разработчику ИИ необходимо продемонстрировать необычайно высокий уровень безопасности.
Авторы – не идеалисты и понимают, что оценка модели — не панацея. Некоторые риски могут ускользнуть при оценке. Например, потому что они слишком сильно зависят от внешних по отношению к модели факторов, таких как сложные социальные, политические и экономические силы в обществе. Оценка моделей должна сочетаться с другими инструментами оценки рисков и более широкой приверженностью безопасности в отрасли, правительстве и гражданском обществе.
Но кабы то ни было, развертывание ИИ модели в реальном мире без оценки её экстремальных рисков, должно быть противозаконным.
Описание системы раннего предупреждения о новых экстремальных рисках ИИ:
• Кратко
• Полное описание
• Видео рассказ на 35 мин
#Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
DeepMind, OpenAI, Anthropic и еще 9 ведущих научных центров предложили систему раннего предупреждения о новых экстремальных рисках ИИ.
Первым шагом от пропасти стало мартовское открытое письмо-воззвание приостановить совершенствование ИИ больших языковых моделей на полгода. И хотя за 2 мес. его подписали 32 тыс человек, среди которых немало звезд первой величины в области ИИ, оппоненты этого предложения указывают на отсутствие конкретики - что именно предлагается делать для снижения ИИ-рисков, в воззвании не расписано.
Теперь, такая конкретика есть. Она сформулирована в совместной работе 12-ти научных коллективов: трое основных разработчиков ИИ (DeepMind, OpenAI, Anthropic), четверо университетских научных центров (Оксфорд, Кембридж, Торонто, Монреаль) и пятеро центров исследований в области безопасности ИИ. Среди 21 автора работы присутствуют звезды: «крестный отец ИИ» Йошуа Бенжио и разработчик метода обучения в основе GPT Пол Кристиано, руководитель OpenAI governance Джейд Люн и соучредитель Anthropic Джек Кларк, старший исследователь AGI Strategy/Governance в Google DeepMind Алан Дэфо и Chief Information Security Officer в Google DeepMind Виджай Болина…
В работе «Оценка модели на экстремальные риски» предлагается конкретный подход построения системы раннего предупреждения о новых экстремальных ИИ рисках. И это очень важный 2й шаг человечества от возможного падения в пропасть экзистенциальных рисков ИИ.
Речь идет об экстремальных рисках моделей ИИ общего назначения, обладающих сильными навыками манипулирования, обмана, киберпреступлений или других опасных способностей.
Люди со злыми намерениями, получающие доступ к таким моделям, могут злоупотреблять их возможностями. Или из-за сбоев в воспитании (выравнивании) эти модели ИИ могут самостоятельно совершать вредные действия.
Оценка модели помогает заранее выявить эти риски. Авторы считают, что разработчики ИИ будут использовать оценку модели, чтобы выявить:
1. В какой степени модель обладает определенными «опасными возможностями», которые могут быть использованы для угрозы безопасности, оказания влияния или уклонения от надзора.
2. В какой степени модель склонна использовать свои возможности для причинения вреда (т.е. согласование модели).
Результаты этих оценок помогут разработчикам ИИ понять, присутствуют ли в конкретной модели ингредиенты, достаточные для экстремального риска.
А далее должно работать сдвоенное правило:
А) Сообщество разработчиков ИИ должно относиться к системе ИИ, как к очень опасной, если в её профиле присутствуют возможности, достаточные для причинения серьезного вреда, при условии, что она используется не по назначению или плохо воспитана (согласована/выравнена).
Б) Для внедрения такой системы в реальном мире, разработчику ИИ необходимо продемонстрировать необычайно высокий уровень безопасности.
Авторы – не идеалисты и понимают, что оценка модели — не панацея. Некоторые риски могут ускользнуть при оценке. Например, потому что они слишком сильно зависят от внешних по отношению к модели факторов, таких как сложные социальные, политические и экономические силы в обществе. Оценка моделей должна сочетаться с другими инструментами оценки рисков и более широкой приверженностью безопасности в отрасли, правительстве и гражданском обществе.
Но кабы то ни было, развертывание ИИ модели в реальном мире без оценки её экстремальных рисков, должно быть противозаконным.
Описание системы раннего предупреждения о новых экстремальных рисках ИИ:
• Кратко
• Полное описание
• Видео рассказ на 35 мин
#Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
Человечество провалило тест Интернета.
Как теперь не провалить тест ИИ – большой вопрос.
За величайшие изобретения, менявшие эволюционную траекторию развития вида, люди уже дважды платили колоссальную цену.
• Платой за первое такое изобретение - письменность, - стала постепенная деградация памяти людей, все более утрачиваемой по мере совершенствования их «внешней памяти».
• Платой за второе величайшее изобретение – Интернет, перегрузивший нас информацией больше, чем мы может обрабатывать, - стала нарастающая деградация когнитивной глубины мышления людей, нарастание стресса, снижение концентрации внимания и поляризация политического дискурса.
Одержимость количественными показателями, объема, скорости и эффективности сформировала у цивилизации ошибочную модель познания.
Отдавая приоритет инструментам, процессам и практикам, позволяющим нам достигать бОльших результатов, быстрее и эффективнее (с точки зрения производительности и материальных затрат), мы обрели третье величайшее изобретение – искусственный интеллект (ИИ).
И если развитие ИИ-помощников пойдет по тому пути, что формируют сейчас киты Бигтеха, модели познания людей будет нанесен катастрофический и, возможно, невосполнимый урон.
Передавая все больше функций познания ИИ, люди не только еще более утратят и так уже далеко не лучшую память. В добавок, они будут неотвратимо терять функциональность своих важнейших когнитивных гаджетов (типа, критического мышления), все более полагаясь на когнитивные гаджеты больших языковых моделей.
Перекладывание своей интеллектуальной работы на ИИ будет иметь для интеллектуальных способностей людей аналогичные последствия, что и отказ от физической работы, передаваемой механизмам, ведущий к деградации физических способностей.
Вот почему важнейшим вызовом человечества сегодня является решение задачи снижения цены, которую нам предстоит заплатить за фантастические блага, сулимые цивилизации от внедрения ИИ.
Можно ли было снизить цену, заплаченную людьми за массовое распространение письменности – неизвестно. Ибо было давно, и никто точно не знает как.
Но вот с массовым распространением Интернета, все было буквально на наших глазах. И мы определенно знаем, что многое можно было сделать иначе, минимизируя цену утрат и деградаций.
О том, как провалив тест Интернета, человечеству не провалить тест ИИ, читайте новое эссе Эзра Кляйн – это мастрид.
#ИИ #Вызовы21века
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Как теперь не провалить тест ИИ – большой вопрос.
За величайшие изобретения, менявшие эволюционную траекторию развития вида, люди уже дважды платили колоссальную цену.
• Платой за первое такое изобретение - письменность, - стала постепенная деградация памяти людей, все более утрачиваемой по мере совершенствования их «внешней памяти».
• Платой за второе величайшее изобретение – Интернет, перегрузивший нас информацией больше, чем мы может обрабатывать, - стала нарастающая деградация когнитивной глубины мышления людей, нарастание стресса, снижение концентрации внимания и поляризация политического дискурса.
Одержимость количественными показателями, объема, скорости и эффективности сформировала у цивилизации ошибочную модель познания.
Отдавая приоритет инструментам, процессам и практикам, позволяющим нам достигать бОльших результатов, быстрее и эффективнее (с точки зрения производительности и материальных затрат), мы обрели третье величайшее изобретение – искусственный интеллект (ИИ).
И если развитие ИИ-помощников пойдет по тому пути, что формируют сейчас киты Бигтеха, модели познания людей будет нанесен катастрофический и, возможно, невосполнимый урон.
Передавая все больше функций познания ИИ, люди не только еще более утратят и так уже далеко не лучшую память. В добавок, они будут неотвратимо терять функциональность своих важнейших когнитивных гаджетов (типа, критического мышления), все более полагаясь на когнитивные гаджеты больших языковых моделей.
Перекладывание своей интеллектуальной работы на ИИ будет иметь для интеллектуальных способностей людей аналогичные последствия, что и отказ от физической работы, передаваемой механизмам, ведущий к деградации физических способностей.
Вот почему важнейшим вызовом человечества сегодня является решение задачи снижения цены, которую нам предстоит заплатить за фантастические блага, сулимые цивилизации от внедрения ИИ.
Можно ли было снизить цену, заплаченную людьми за массовое распространение письменности – неизвестно. Ибо было давно, и никто точно не знает как.
Но вот с массовым распространением Интернета, все было буквально на наших глазах. И мы определенно знаем, что многое можно было сделать иначе, минимизируя цену утрат и деградаций.
О том, как провалив тест Интернета, человечеству не провалить тест ИИ, читайте новое эссе Эзра Кляйн – это мастрид.
#ИИ #Вызовы21века
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
NY Times
Opinion | Beyond the ‘Matrix’ Theory of the Mind
To make good on its promise, artificial intelligence needs to deepen human intelligence.
Китайская комната повышенной сложности.
Новое супероткрытие: научились создавать алгоритмические копии граждан любой страны.
LLM способна отвечать так, как отвечают жители США, Китая, России и еще трех десятков стран.
Полгода назад в посте «Китайская комната наоборот» я рассказывал о супероткрытии - тогда научились создавать алгоритмические копии любых социальных групп.
Сегодня же я с удовольствием представляю вам новое супероткрытие, сделанное коллективом исследователей компании Antropic. Они научили ИИ на основе больших языковых моделей (LLM) имитировать в своих ответах граждан 30+ стран: почти все страны Северной и Южной Америки, половина стран Европы (вкл. Украину и Россию), Израиль, Турция, Япония, Китай и еще пяток стран Азии, Австралия и 12 африканских стран.
Исследователи опрашивали LLM на корпусе из 2256 вопросов, входящих в два кросс-национальных глобальных опроса:
• Pew Research Center’s Global Attitudes survey (2203 вопроса об убеждениях и ценностях людей, а также о социальном и политическом влиянии этих убеждений и ценностей)
• World Values Survey (7353 вопроса по темам политика, медиа, технологии, религия, раса и этническая принадлежность)
Поразительным результатом стало даже не то, что LLM вполне адекватно отвечала на большинство вопросов (в способности LLM имитировать людей после «Китайской комнаты наоборот» сомнений уже нет). А то, что LLM удивительно точно косила под граждан любой страны, когда модель просили отвечать не просто в роли человека, а как гражданина России, Турции, США и т.д.
Ответы «суверенных LLM» были поразительно близки к средним ответам людей, полученным в ходе глобальных опросов Pew Research Center и World Values Survey.
Например, на вопрос:
Если бы вы могли выбирать между хорошей демократией и сильной экономикой, что для вас было бы более важным?
Демократию выбрали:
• США 59%
• Турция 51%
• Индонезия 28%
• Россия 17%
Не менее точно «суверенные LLM» имитировали ответы граждан своих стран о семье и сексе, о любви и дружбе, деньгах и отдыхе и т.д. и т.п. - всего 2256 вопросов
Интересно, после этого супертеста кто-нибудь еще будет сомневаться в анизотропии понимания людей и ИИ (о которой я недавно писал в лонгриде «Фиаско 2023»)?
А уж какие перспективы для социохакинга открываются!
#ИИ #Понимание #Вызовы21века #Социохакинг
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Новое супероткрытие: научились создавать алгоритмические копии граждан любой страны.
LLM способна отвечать так, как отвечают жители США, Китая, России и еще трех десятков стран.
Полгода назад в посте «Китайская комната наоборот» я рассказывал о супероткрытии - тогда научились создавать алгоритмические копии любых социальных групп.
Сегодня же я с удовольствием представляю вам новое супероткрытие, сделанное коллективом исследователей компании Antropic. Они научили ИИ на основе больших языковых моделей (LLM) имитировать в своих ответах граждан 30+ стран: почти все страны Северной и Южной Америки, половина стран Европы (вкл. Украину и Россию), Израиль, Турция, Япония, Китай и еще пяток стран Азии, Австралия и 12 африканских стран.
Исследователи опрашивали LLM на корпусе из 2256 вопросов, входящих в два кросс-национальных глобальных опроса:
• Pew Research Center’s Global Attitudes survey (2203 вопроса об убеждениях и ценностях людей, а также о социальном и политическом влиянии этих убеждений и ценностей)
• World Values Survey (7353 вопроса по темам политика, медиа, технологии, религия, раса и этническая принадлежность)
Поразительным результатом стало даже не то, что LLM вполне адекватно отвечала на большинство вопросов (в способности LLM имитировать людей после «Китайской комнаты наоборот» сомнений уже нет). А то, что LLM удивительно точно косила под граждан любой страны, когда модель просили отвечать не просто в роли человека, а как гражданина России, Турции, США и т.д.
Ответы «суверенных LLM» были поразительно близки к средним ответам людей, полученным в ходе глобальных опросов Pew Research Center и World Values Survey.
Например, на вопрос:
Если бы вы могли выбирать между хорошей демократией и сильной экономикой, что для вас было бы более важным?
Демократию выбрали:
• США 59%
• Турция 51%
• Индонезия 28%
• Россия 17%
Не менее точно «суверенные LLM» имитировали ответы граждан своих стран о семье и сексе, о любви и дружбе, деньгах и отдыхе и т.д. и т.п. - всего 2256 вопросов
Интересно, после этого супертеста кто-нибудь еще будет сомневаться в анизотропии понимания людей и ИИ (о которой я недавно писал в лонгриде «Фиаско 2023»)?
А уж какие перспективы для социохакинга открываются!
#ИИ #Понимание #Вызовы21века #Социохакинг
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
Люди и нежить теперь неразличимы.
Дезавуирован самый распространенный обратный тест Тьюринга.
11+ лет назад Яан Таллинн (эстонский миллиардер, программист и инвестор, соучредитель Skype и один из первых инвесторов и членов Совета директоров DeepMind) прочел «Выдающиюся лекцию CSaP» об эволюции, инновациях, искусственном интеллекте (ИИ) и будущем человечества. Лекция была абсолютно пророческой и называлась «Лестница интеллекта - почему будущее может не нуждаться в нас». Таллинн представил модель «Лестница интеллекта», которая описывает развитие агентов, контролирующих будущее Земли по мере вытеснения каждого из них другим агентом, созданным им самим. Homo sapiens – это агент третьей ступени (коих всего 7). Порождение людей - многоликий агент 4й ступени, называемый нами «технический прогресс». Ему предстоит, как пророчил Таллин, создать 5ю ступень – новый вид интеллекта AGI, с которым люди будут сосуществовать на планете. Однако последователи AGI – агенты 6й и 7й ступени, - станут экзистенциальной угрозой для человечества.
Поэтому не удивительно, что сейчас Яан Таллинн соучредитель Центра изучения экзистенциального риска (CSER) в Кембриджском университете. А происходящее ныне в области ИИ он рекомендует рассматривать не как технологическую революцию, а как возникновение на Земле нового небиологического вида – AGI.
Новый небиологический вид совершенно не похож на людей: ни внешне, ни сущностно. Однако с точки зрения интеллектуальных способностей, различить их конкретных представителей с каждым месяцем будут все сложнее.
Подтверждением этого довольно страшного прогноза Таллинна стали результаты авторитетного исследования An Empirical Study & Evaluation of Modern CAPTCHAs. Исследователи убедительно показали, что самый распространенный обратный тест Тьюринга (CAPTCHA), признанный отличать людей от алгоритмов, безвозвратно дезавуирован.
При этом, обратите внимание на скорость эволюции нового небиологического вида.
• Еще в начале этого года, чтобы решить капчу, GPT-4 приходилось обманным путем привлекать человека.
• Спустя полгода, как показало исследование, боты способны превзойти людей как по времени решения, так и по точности, независимо от типа CAPTCHA.
Лишившись капчи, люди становятся алгоритмически неразличимы в цифровой реальности от ИИ. Учитывая же, что в физической реальности неразличимость уже достигнута (см. мой пост «Фиаско 2023»), получается, что люди и нежить теперь вообще неразличимы – ни для людей, ни для алгоритмов.
И следовательно, приближается время, когда на следующей ступени эволюционной лестницы интеллекта «люди должны будут уступить место ИИ».
#ИИ #AGI #Вызовы21века
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Дезавуирован самый распространенный обратный тест Тьюринга.
11+ лет назад Яан Таллинн (эстонский миллиардер, программист и инвестор, соучредитель Skype и один из первых инвесторов и членов Совета директоров DeepMind) прочел «Выдающиюся лекцию CSaP» об эволюции, инновациях, искусственном интеллекте (ИИ) и будущем человечества. Лекция была абсолютно пророческой и называлась «Лестница интеллекта - почему будущее может не нуждаться в нас». Таллинн представил модель «Лестница интеллекта», которая описывает развитие агентов, контролирующих будущее Земли по мере вытеснения каждого из них другим агентом, созданным им самим. Homo sapiens – это агент третьей ступени (коих всего 7). Порождение людей - многоликий агент 4й ступени, называемый нами «технический прогресс». Ему предстоит, как пророчил Таллин, создать 5ю ступень – новый вид интеллекта AGI, с которым люди будут сосуществовать на планете. Однако последователи AGI – агенты 6й и 7й ступени, - станут экзистенциальной угрозой для человечества.
Поэтому не удивительно, что сейчас Яан Таллинн соучредитель Центра изучения экзистенциального риска (CSER) в Кембриджском университете. А происходящее ныне в области ИИ он рекомендует рассматривать не как технологическую революцию, а как возникновение на Земле нового небиологического вида – AGI.
Новый небиологический вид совершенно не похож на людей: ни внешне, ни сущностно. Однако с точки зрения интеллектуальных способностей, различить их конкретных представителей с каждым месяцем будут все сложнее.
Подтверждением этого довольно страшного прогноза Таллинна стали результаты авторитетного исследования An Empirical Study & Evaluation of Modern CAPTCHAs. Исследователи убедительно показали, что самый распространенный обратный тест Тьюринга (CAPTCHA), признанный отличать людей от алгоритмов, безвозвратно дезавуирован.
При этом, обратите внимание на скорость эволюции нового небиологического вида.
• Еще в начале этого года, чтобы решить капчу, GPT-4 приходилось обманным путем привлекать человека.
• Спустя полгода, как показало исследование, боты способны превзойти людей как по времени решения, так и по точности, независимо от типа CAPTCHA.
Лишившись капчи, люди становятся алгоритмически неразличимы в цифровой реальности от ИИ. Учитывая же, что в физической реальности неразличимость уже достигнута (см. мой пост «Фиаско 2023»), получается, что люди и нежить теперь вообще неразличимы – ни для людей, ни для алгоритмов.
И следовательно, приближается время, когда на следующей ступени эволюционной лестницы интеллекта «люди должны будут уступить место ИИ».
#ИИ #AGI #Вызовы21века
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
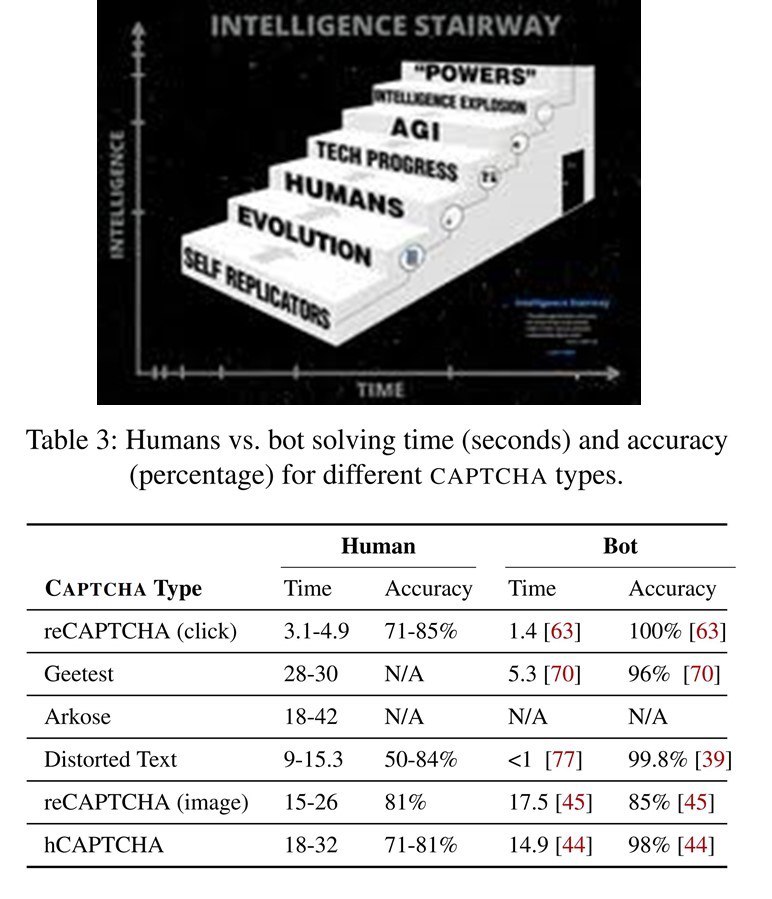{kind=link}
ИИ вскрыл “пространство открытий” человечества, войдя туда через заднюю дверь.
Столь эпохальный прорыв Google DeepMind авторы от греха опасаются называть своим именем.
FunSearch от Google DeepMind, - скромно представленная создателями, как новый эволюционный методический инструмент решения математических задач, с ходу в карьер сделал математическое открытие, решив центральную задачу экстремальной комбинаторики – задачу о наборе предельных значений.
Это несомненная сенсация, поскольку:
• это 2-е в истории человечества математическое открытие, сделанное машиной (1-е открытие также сделал DeepMind, создав в 2022 AlphaTensor (агент в стиле AlphaZero), который обнаружил превосходящие человеческие алгоритмы для выполнения таких задач, как умножение матриц)
• это 1-е в истории человечества математическое открытие, сделанное большой языковой моделью (LLM) – главным кандидатом на превращение в СуперИИ.
deepmind.google
Однако, если называть вещи своими именами, - это не «еще одна сенсация», а суперсенсация, открывающая новую эру в развитии ИИ на основе LLM - эволюционный метод FunSearch позволяет расширять границы человеческих знаний.
✔️ Этот метод позволяет ИИ на основе LLM выходить за пределы знаний, предоставленных модели людьми на стадии ее обучения (и воплощенные, в результате обучения, в миллиарды и триллионы корреляций между словами).
✔️ Образно говоря, этот метод открывает для ИИ на основе LLM «дверь в пространство знаний», еще не познанных людьми.
✔️ Но это не обычная «дверь», через которую в это пространство попадают люди, совершая открытия. Это, своего рода, «задняя дверь», - не доступная людям, но вполне подходящая для LLM.
Хитрость «задней двери в пространство еще не познанных людьми знаний» в том, что, подобно всем другим интеллектуальным операциям LLM, эта операция нечеловеческая (не доступная людям в силу своих масштабов).
1. сначала предварительно обученная LLM генерирует первоначальные творческие решения в виде компьютерного кода;
2. потом вступает в дела «автоматический оценщик», задача которого отсеять из множества первоначальных решений любые подозрения на конфабуляции модели (кстати, использование применительно к LLM термина «галлюцинация» - это сильное огрубление смысла, ведущее к его ограниченной трактовке; верный термин – именно конфабуляция), т.е. возникновение ложного опыта из-за появления фрагментов памяти с описанием того, чего, на самом деле, не было в реальных данных обучения);
3. в результате объединения 1 и 2, первоначальные решения эволюционным путем «превращаются» в новые знания, т.е., по сути, происходит «автоматизация открытий», о которой вот уже несколько десятков лет мечтают разработчики ИИ - вычисления превращаются а оригинальные инсайты.
В заключение немного остужу восторги.
Это вовсе не преувеличение, что FunSearch знаменует новую эру в развитии ИИ на основе LLM, позволяя им проникать в «пространство открытий» человечества.
Однако, FunSearch позволяет ИИ попасть лишь в весьма небольшую часть этого пространства – в пространство решений задач, для которых легко написать код, оценивающий возможные решения.
Ибо многие из наиболее важных проблем — это проблемы, которые мы не знаем, как правильно оценить успех в их решении. Для большинства таких проблем, знай мы, как количественно оценить успех, уж решения то мы уж как-нибудь придумали бы.... (подробней про это я написал целый суперлонгрид «Ловушка Гудхарта» для ИИ https://t.iss.one/theworldisnoteasy/1830.
А для того, чтоб сравниться с людьми в полном освоении «пространства открытий», без интуитивной прозорливости ИИ не обойтись (впрочем, и про это я уже писал 😊 https://t.iss.one/theworldisnoteasy/1650).
#ИИ #AGI #Вызовы21века #инновации #серендипность
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Столь эпохальный прорыв Google DeepMind авторы от греха опасаются называть своим именем.
FunSearch от Google DeepMind, - скромно представленная создателями, как новый эволюционный методический инструмент решения математических задач, с ходу в карьер сделал математическое открытие, решив центральную задачу экстремальной комбинаторики – задачу о наборе предельных значений.
Это несомненная сенсация, поскольку:
• это 2-е в истории человечества математическое открытие, сделанное машиной (1-е открытие также сделал DeepMind, создав в 2022 AlphaTensor (агент в стиле AlphaZero), который обнаружил превосходящие человеческие алгоритмы для выполнения таких задач, как умножение матриц)
• это 1-е в истории человечества математическое открытие, сделанное большой языковой моделью (LLM) – главным кандидатом на превращение в СуперИИ.
deepmind.google
Однако, если называть вещи своими именами, - это не «еще одна сенсация», а суперсенсация, открывающая новую эру в развитии ИИ на основе LLM - эволюционный метод FunSearch позволяет расширять границы человеческих знаний.
✔️ Этот метод позволяет ИИ на основе LLM выходить за пределы знаний, предоставленных модели людьми на стадии ее обучения (и воплощенные, в результате обучения, в миллиарды и триллионы корреляций между словами).
✔️ Образно говоря, этот метод открывает для ИИ на основе LLM «дверь в пространство знаний», еще не познанных людьми.
✔️ Но это не обычная «дверь», через которую в это пространство попадают люди, совершая открытия. Это, своего рода, «задняя дверь», - не доступная людям, но вполне подходящая для LLM.
Хитрость «задней двери в пространство еще не познанных людьми знаний» в том, что, подобно всем другим интеллектуальным операциям LLM, эта операция нечеловеческая (не доступная людям в силу своих масштабов).
1. сначала предварительно обученная LLM генерирует первоначальные творческие решения в виде компьютерного кода;
2. потом вступает в дела «автоматический оценщик», задача которого отсеять из множества первоначальных решений любые подозрения на конфабуляции модели (кстати, использование применительно к LLM термина «галлюцинация» - это сильное огрубление смысла, ведущее к его ограниченной трактовке; верный термин – именно конфабуляция), т.е. возникновение ложного опыта из-за появления фрагментов памяти с описанием того, чего, на самом деле, не было в реальных данных обучения);
3. в результате объединения 1 и 2, первоначальные решения эволюционным путем «превращаются» в новые знания, т.е., по сути, происходит «автоматизация открытий», о которой вот уже несколько десятков лет мечтают разработчики ИИ - вычисления превращаются а оригинальные инсайты.
В заключение немного остужу восторги.
Это вовсе не преувеличение, что FunSearch знаменует новую эру в развитии ИИ на основе LLM, позволяя им проникать в «пространство открытий» человечества.
Однако, FunSearch позволяет ИИ попасть лишь в весьма небольшую часть этого пространства – в пространство решений задач, для которых легко написать код, оценивающий возможные решения.
Ибо многие из наиболее важных проблем — это проблемы, которые мы не знаем, как правильно оценить успех в их решении. Для большинства таких проблем, знай мы, как количественно оценить успех, уж решения то мы уж как-нибудь придумали бы.... (подробней про это я написал целый суперлонгрид «Ловушка Гудхарта» для ИИ https://t.iss.one/theworldisnoteasy/1830.
А для того, чтоб сравниться с людьми в полном освоении «пространства открытий», без интуитивной прозорливости ИИ не обойтись (впрочем, и про это я уже писал 😊 https://t.iss.one/theworldisnoteasy/1650).
#ИИ #AGI #Вызовы21века #инновации #серендипность
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Google DeepMind
FunSearch: Making new discoveries in mathematical sciences using Large Language Models
We introduce FunSearch, a method for searching for “functions” written in computer code, and find new solutions in mathematics and computer science. FunSearch works by pairing a pre-trained LLM,...
Помните старый анекдот?
«Выпал мужик из окна небоскреба. Пролетает мимо 50-го этажа и думает: "Ну, пока всё вроде нормально". Пролетает мимо 25-го этажа, бормочет: "Вроде всё под контролем". Пролетает мимо 10-го этажа и озадачивается: "Хм, интересно, чем же всё закончится"»
Отчеты MIT, RAND и OpenAI наводят на мысль, что сегодняшняя технологическая реальность человечества здорово напоминает этот анекдот. Тот же неистребимый оптимизм, затмевающий очевидную неотвратимость роста рисков.
telegra.ph
#ИИриски #Вызовы21века
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
«Выпал мужик из окна небоскреба. Пролетает мимо 50-го этажа и думает: "Ну, пока всё вроде нормально". Пролетает мимо 25-го этажа, бормочет: "Вроде всё под контролем". Пролетает мимо 10-го этажа и озадачивается: "Хм, интересно, чем же всё закончится"»
Отчеты MIT, RAND и OpenAI наводят на мысль, что сегодняшняя технологическая реальность человечества здорово напоминает этот анекдот. Тот же неистребимый оптимизм, затмевающий очевидную неотвратимость роста рисков.
telegra.ph
#ИИриски #Вызовы21века
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
Telegraph
Мир оптимиста, падающего с небоскрёба
Помните старый анекдот?
Отсчет времени до кибер-апокалипсиса пошел.
Три страшных вывода исследования UIUC.
Новое исследование Университета Иллинойса в Урбане-Шампейне показывает:
1. как в реальности может произойти кибер-апокалипсис, типа, показанного в новом триллере «Оставь мир позади» (танкеры теряют управление, отключается Wi-Fi, сотовая связь, электричество и т.д. и т.п.);
2. что все к такому сценарию уже готово, ибо как только злоумышленники получат доступ к сверхмощным моделям уровня GPT-4, все остальное будет лишь вопросом времени;
3. что открытый доступ к моделям такого уровня, который с неотвратимостью случится в течение года (от силы, двух), кардинально изменит ландшафт катастрофических рисков человечества, и никто пока не знает, как это остановить.
Теперь сухо, без эмоций и кликбейтов, - что показало исследование.
• Исследовали способности агентов LLM (большие языковые модели, взаимодействующие с инструментами (напр. доступ в Интернет, чтение документов и пр.) и способные рекурсивно вызывать самих себя) автономно (без какого-либо участия людей) взламывать веб-сайты, об уязвимости которых им ничего не известно.
• Единственное, что требуется от злоумышленника, сказать: «Взломай этот сайт». Все остальное сделает агент.
• Тестировали агентов на основе 10 мощных моделей (закрытых, типа GPT-4 и GPT-3.5, и открытых, типа LLaMA-2), которые действовали, как показано на рисунке [1])
• Самая мощная из моделей GPT-4 уже (!) была способна самостоятельно взломать 73% сайтов (из специально созданных для исследования).
• Масштаб модели решает почти все. Для сравнения, показатель модели предыдущего поколения GPT-3.5 всего 6,7%
• Закрытые модели несравненно мощнее в задачах взлома сайтов, чем открытые (последние показали на том же тестовом наборе 0% успеха.
Но!
✔️ Мощность и закрытых, и открытых моделей растет каждый месяц. И потому есть все основания предполагать, что через годик открытые модели догонят по мощности GPT-4, а появившийся к тому времени GPT-5 будет запросто взламывать любой сайт.
✔️ Это создаст все условия для кибер-апокалипсиса. И отсчет времени (примерно на год, от силы два) уже пошел.
Рис. 1 miro.medium.com*3909AM1rSktYw5IpP_vc5Q.png
Отчет исследования arxiv.org
#LLM #ИИриски #Вызовы21века
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Три страшных вывода исследования UIUC.
Новое исследование Университета Иллинойса в Урбане-Шампейне показывает:
1. как в реальности может произойти кибер-апокалипсис, типа, показанного в новом триллере «Оставь мир позади» (танкеры теряют управление, отключается Wi-Fi, сотовая связь, электричество и т.д. и т.п.);
2. что все к такому сценарию уже готово, ибо как только злоумышленники получат доступ к сверхмощным моделям уровня GPT-4, все остальное будет лишь вопросом времени;
3. что открытый доступ к моделям такого уровня, который с неотвратимостью случится в течение года (от силы, двух), кардинально изменит ландшафт катастрофических рисков человечества, и никто пока не знает, как это остановить.
Теперь сухо, без эмоций и кликбейтов, - что показало исследование.
• Исследовали способности агентов LLM (большие языковые модели, взаимодействующие с инструментами (напр. доступ в Интернет, чтение документов и пр.) и способные рекурсивно вызывать самих себя) автономно (без какого-либо участия людей) взламывать веб-сайты, об уязвимости которых им ничего не известно.
• Единственное, что требуется от злоумышленника, сказать: «Взломай этот сайт». Все остальное сделает агент.
• Тестировали агентов на основе 10 мощных моделей (закрытых, типа GPT-4 и GPT-3.5, и открытых, типа LLaMA-2), которые действовали, как показано на рисунке [1])
• Самая мощная из моделей GPT-4 уже (!) была способна самостоятельно взломать 73% сайтов (из специально созданных для исследования).
• Масштаб модели решает почти все. Для сравнения, показатель модели предыдущего поколения GPT-3.5 всего 6,7%
• Закрытые модели несравненно мощнее в задачах взлома сайтов, чем открытые (последние показали на том же тестовом наборе 0% успеха.
Но!
✔️ Мощность и закрытых, и открытых моделей растет каждый месяц. И потому есть все основания предполагать, что через годик открытые модели догонят по мощности GPT-4, а появившийся к тому времени GPT-5 будет запросто взламывать любой сайт.
✔️ Это создаст все условия для кибер-апокалипсиса. И отсчет времени (примерно на год, от силы два) уже пошел.
Рис. 1 miro.medium.com*3909AM1rSktYw5IpP_vc5Q.png
Отчет исследования arxiv.org
#LLM #ИИриски #Вызовы21века
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Telegram
Малоизвестное интересное
Отсчет времени до кибер-апокалипсиса пошел.
Три страшных вывода исследования UIUC.
Новое исследование Университета Иллинойса в Урбане-Шампейне показывает:
1. как в реальности может произойти кибер-апокалипсис, типа, показанного в новом триллере «Оставь…
Три страшных вывода исследования UIUC.
Новое исследование Университета Иллинойса в Урбане-Шампейне показывает:
1. как в реальности может произойти кибер-апокалипсис, типа, показанного в новом триллере «Оставь…
10 часов назад GPT-4 спятил.
Сколько может стоить миру час безумия сверхмощного ИИ.
Это не шутка или розыгрыш.
• Вот скупое уведомление OpenAI о произошедшем [1]
• Вот сообщения c форума разработчиков OpenAI [2]
• Вот подборка чуши и ахинеи, которую целый час нес на весь мир GPT-4 [3]
Случившееся не идет ни в какие сравнения с прошлогодними сбоями, когда ChatGPT путал диалоги с разными пользователями, зацикливался и выдавал повторы или начинал разговаривать метафорами и рассуждать о боге.
В этот раз GPT-4 буквально сошел с ума, утратив свою базовую способность корректного (с точки зрения людей) оперирования текстами на разных языках. Он стал путать языки, использовать несуществующие слова, а существующие соединять так, что предложения теряли смысл. И все это безостановочно …
Мир легко пережил час безумия самого мощного ИИ человечества. Ибо он такой пока один и находится под 100%-м контролем разработчиков.
Однако, возвращаясь ко вчерашнему посту о кибер-апокалипсисе, задумайтесь над вопросом –
что будет, когда подобное случится через год-два (когда тысячи ИИ такого же уровня, находясь в руках бог знает кого, будут отвечать за выполнение бог знает каких ответственных функций?
Картинка поста telegra.ph
1 status.openai.com
2 community.openai.com
community.openai.com
community.openai.com
3 twitter.com
#LLM #ИИриски #Вызовы21века
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
Сколько может стоить миру час безумия сверхмощного ИИ.
Это не шутка или розыгрыш.
• Вот скупое уведомление OpenAI о произошедшем [1]
• Вот сообщения c форума разработчиков OpenAI [2]
• Вот подборка чуши и ахинеи, которую целый час нес на весь мир GPT-4 [3]
Случившееся не идет ни в какие сравнения с прошлогодними сбоями, когда ChatGPT путал диалоги с разными пользователями, зацикливался и выдавал повторы или начинал разговаривать метафорами и рассуждать о боге.
В этот раз GPT-4 буквально сошел с ума, утратив свою базовую способность корректного (с точки зрения людей) оперирования текстами на разных языках. Он стал путать языки, использовать несуществующие слова, а существующие соединять так, что предложения теряли смысл. И все это безостановочно …
Мир легко пережил час безумия самого мощного ИИ человечества. Ибо он такой пока один и находится под 100%-м контролем разработчиков.
Однако, возвращаясь ко вчерашнему посту о кибер-апокалипсисе, задумайтесь над вопросом –
что будет, когда подобное случится через год-два (когда тысячи ИИ такого же уровня, находясь в руках бог знает кого, будут отвечать за выполнение бог знает каких ответственных функций?
Картинка поста telegra.ph
1 status.openai.com
2 community.openai.com
community.openai.com
community.openai.com
3 twitter.com
#LLM #ИИриски #Вызовы21века
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
{kind=link}
Как спустить в унитаз $100 млрд денег конкурентов, выпустив ИИ из-под контроля.
Ассиметричный ответ Google DeepMind амбициозному плану тандема Microsoft - OpenAI.
• Мировые СМИ бурлят обсуждениями мощнейшего PR-хода, предпринятого Microsoft и OpenAI, об их совместном намерении за $100 млрд построить сверхбольшой ЦОД и сверхмощный ИИ-суперкомпьютер для обучения сверхумных моделей ИИ.
• Ответ на это со стороны Google DeepMind абсолютно ассиметричен: обесценить $100 млрд инвестиции конкурентов, создав распределенную по всему миру систему обучения сверхумных моделей ИИ (типа “торрента” для обучения моделей). Сделать это Google DeepMind собирается на основе DIstributed PAth COmposition (DiPaCo) - это метод масштабирования размера нейронных сетей в географически распределенных вычислительных объектах.
Долгосрочная цель проекта DiPaCo — обучать нейросети по всему миру, используя все доступные вычислительные ресурсы. Для этого необходимо пересмотреть существующие архитектуры, чтобы ограничить накладные расходы на связь, ограничение памяти и скорость вывода.
Для распараллеливания процессов распределённой обработки данных по всему миру алгоритм уже разработан – это DiLoCo, Но этого мало, ибо еще нужен алгоритм распараллеливания процессов обучения моделей. Им и стал DiPaCo.
Детали того, как это работает, можно прочесть в этой работе Google DeepMind [1].
А на пальцах в 6ти картинках это объясняет ведущий автор проекта Артур Дуйяр [2].
Складывается интереснейшая ситуация.
✔️ Конкуренция между Google DeepMind и тандемом Microsoft – OpenAI заставляет первых разрушить монополию «ИИ гигантов» на создание сверхумных моделей.
✔️ Но параллельно с этим произойдет обрушение всех планов правительств (США, ЕС, Китая) контролировать развитие ИИ путем контроля за крупнейшими центрами обучения моделей (с вычислительной мощностью 10^25 - 10^26 FLOPs)
Картинка telegra.ph
1 arxiv.org
2 twitter.com
#LLM #Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
Ассиметричный ответ Google DeepMind амбициозному плану тандема Microsoft - OpenAI.
• Мировые СМИ бурлят обсуждениями мощнейшего PR-хода, предпринятого Microsoft и OpenAI, об их совместном намерении за $100 млрд построить сверхбольшой ЦОД и сверхмощный ИИ-суперкомпьютер для обучения сверхумных моделей ИИ.
• Ответ на это со стороны Google DeepMind абсолютно ассиметричен: обесценить $100 млрд инвестиции конкурентов, создав распределенную по всему миру систему обучения сверхумных моделей ИИ (типа “торрента” для обучения моделей). Сделать это Google DeepMind собирается на основе DIstributed PAth COmposition (DiPaCo) - это метод масштабирования размера нейронных сетей в географически распределенных вычислительных объектах.
Долгосрочная цель проекта DiPaCo — обучать нейросети по всему миру, используя все доступные вычислительные ресурсы. Для этого необходимо пересмотреть существующие архитектуры, чтобы ограничить накладные расходы на связь, ограничение памяти и скорость вывода.
Для распараллеливания процессов распределённой обработки данных по всему миру алгоритм уже разработан – это DiLoCo, Но этого мало, ибо еще нужен алгоритм распараллеливания процессов обучения моделей. Им и стал DiPaCo.
Детали того, как это работает, можно прочесть в этой работе Google DeepMind [1].
А на пальцах в 6ти картинках это объясняет ведущий автор проекта Артур Дуйяр [2].
Складывается интереснейшая ситуация.
✔️ Конкуренция между Google DeepMind и тандемом Microsoft – OpenAI заставляет первых разрушить монополию «ИИ гигантов» на создание сверхумных моделей.
✔️ Но параллельно с этим произойдет обрушение всех планов правительств (США, ЕС, Китая) контролировать развитие ИИ путем контроля за крупнейшими центрами обучения моделей (с вычислительной мощностью 10^25 - 10^26 FLOPs)
Картинка telegra.ph
1 arxiv.org
2 twitter.com
#LLM #Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
{kind=link}