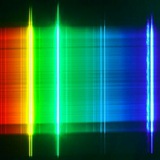
Как Viridis стала палитрой по умолчанию
И ещё про цветовые карты - это важная тема, т.к. правильная палитра позволяет увидеть структуры в сырых данных.
Долгое время в matplotlib палитрой по умолчанию была JET (радуга), но, начиная с версии 2.0, используется Viridis. При её разработке (которая была PhD работой) основными требованиями были:
- перцептивная однородность (даже в ч/б)
- доступность для людей с цветовой слепотой
Viridis была разработан так, чтобы цвета были равномерно распределёнными в цветовом пространстве - схожие значения представлены похожими цветами, но при этом достаточно отчётливыми даже в ч/б и для людей с цветовой слепотой.
JET не соответствует этим требованиям - некоторые цвета превалируют больше других, что может привести к неверной интерпретации данных.
Рекомендую посмотреть видео, которое за 20 минут весело и задорно расскажет о теории цвета, а также полистать пост с более подробной информацией. А в качестве бонуса вот вам инструмент для создания собственной палитры.
🎞 Видео
🌐 Пост
@karray
_______
Источник | #nn_for_science
И ещё про цветовые карты - это важная тема, т.к. правильная палитра позволяет увидеть структуры в сырых данных.
Долгое время в matplotlib палитрой по умолчанию была JET (радуга), но, начиная с версии 2.0, используется Viridis. При её разработке (которая была PhD работой) основными требованиями были:
- перцептивная однородность (даже в ч/б)
- доступность для людей с цветовой слепотой
Viridis была разработан так, чтобы цвета были равномерно распределёнными в цветовом пространстве - схожие значения представлены похожими цветами, но при этом достаточно отчётливыми даже в ч/б и для людей с цветовой слепотой.
JET не соответствует этим требованиям - некоторые цвета превалируют больше других, что может привести к неверной интерпретации данных.
Рекомендую посмотреть видео, которое за 20 минут весело и задорно расскажет о теории цвета, а также полистать пост с более подробной информацией. А в качестве бонуса вот вам инструмент для создания собственной палитры.
🎞 Видео
🌐 Пост
@karray
_______
Источник | #nn_for_science
{kind=link}
Иллюстрация к современным чат ботам. Вот так это выглядит на самом деле 😂
_______
Источник | #nn_for_science
#пятничное ?
🔥 Бот для скачивания видео и музыки
🌔 Купи и заработай в StarCitizen
🤖 Бесплатно ChatGPT с AnnAi
⛵️MidJourney в Telegram
_______
Источник | #nn_for_science
#пятничное ?
🔥 Бот для скачивания видео и музыки
🌔 Купи и заработай в StarCitizen
🤖 Бесплатно ChatGPT с AnnAi
⛵️MidJourney в Telegram
Гайд по промпт инжинирингу
Инженерия подсказок - это относительно новая дисциплина для разработки и оптимизации подсказок (они же промпты) с целью эффективного использования языковых моделей для широкого спектра приложений.
Навыки инженерии подсказок помогают лучше понять возможности и ограничения больших языковых моделей (LLM) и как следствие лучше понять генеративные нейросети, которые рисуют картинки.
Исследователи используют инженерию подсказок для улучшения возможностей LLM в широком спектре обычных и сложных задач, таких как ответы на вопросы и арифметические рассуждения. Разработчики используют инженерию подсказок для разработки надежных и эффективных методов подсказки, которые взаимодействуют с LLM и другими инструментами.
Мотивированные высоким интересом к разработке с использованием LLM, авторы создали новое руководство по разработке подсказок, которое содержит все последние статьи, учебные пособия, лекции, ссылки и инструменты, связанные с разработкой подсказок.
👀 Ссылка
_______
Источник | #nn_for_science
🔥 Бот для скачивания видео и музыки
💎 Клевые аксессуары из бисера
🤖 Бесплатно ChatGPT с AnnAi
⛵️MidJourney в Telegram
Инженерия подсказок - это относительно новая дисциплина для разработки и оптимизации подсказок (они же промпты) с целью эффективного использования языковых моделей для широкого спектра приложений.
Навыки инженерии подсказок помогают лучше понять возможности и ограничения больших языковых моделей (LLM) и как следствие лучше понять генеративные нейросети, которые рисуют картинки.
Исследователи используют инженерию подсказок для улучшения возможностей LLM в широком спектре обычных и сложных задач, таких как ответы на вопросы и арифметические рассуждения. Разработчики используют инженерию подсказок для разработки надежных и эффективных методов подсказки, которые взаимодействуют с LLM и другими инструментами.
Мотивированные высоким интересом к разработке с использованием LLM, авторы создали новое руководство по разработке подсказок, которое содержит все последние статьи, учебные пособия, лекции, ссылки и инструменты, связанные с разработкой подсказок.
👀 Ссылка
_______
Источник | #nn_for_science
🔥 Бот для скачивания видео и музыки
💎 Клевые аксессуары из бисера
🤖 Бесплатно ChatGPT с AnnAi
⛵️MidJourney в Telegram
{kind=link}
Скайнет стал еще чуть ближе 🦾
Представьте ИИ, который может воспринимать информацию напрямую из файлов, не требуя преобразования данных в изображения или звуки. Вот именно такой принцип лежит в основе новой модели под названием ByteFormer. На удивление статья написана исследователями из Apple (которые не так уж и часто что-то публикуют в открытый доступ).
Благодаря работе с байтами, ByteFormer способен понимать изображения и звуки лучше, чем некоторые другие модели. Это открывает огромные возможности для внедрения ИИ в различные сферы жизни.
Еще одно преимущество ByteFormer - возможность работать с закодированными или частично скрытыми данными, не теряя в точности. Это значит, что мы можем создать системы, которые уважают приватность, но при этом остаются эффективными.
Возможности ByteFormer впечатляют и заставляют нас переосмыслить, как ИИ может взаимодействовать с данными. Сегодня ИИ стал еще мощнее и ближе к нашему повседневному миру.
🫣 Статья
🐙 Код
_______
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Представьте ИИ, который может воспринимать информацию напрямую из файлов, не требуя преобразования данных в изображения или звуки. Вот именно такой принцип лежит в основе новой модели под названием ByteFormer. На удивление статья написана исследователями из Apple (которые не так уж и часто что-то публикуют в открытый доступ).
Благодаря работе с байтами, ByteFormer способен понимать изображения и звуки лучше, чем некоторые другие модели. Это открывает огромные возможности для внедрения ИИ в различные сферы жизни.
Еще одно преимущество ByteFormer - возможность работать с закодированными или частично скрытыми данными, не теряя в точности. Это значит, что мы можем создать системы, которые уважают приватность, но при этом остаются эффективными.
Возможности ByteFormer впечатляют и заставляют нас переосмыслить, как ИИ может взаимодействовать с данными. Сегодня ИИ стал еще мощнее и ближе к нашему повседневному миру.
🫣 Статья
🐙 Код
_______
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
🔬 Обновления OpenAI API - еще на шаг ближе к личному ассистенту
OpenAI объявило о внедрении целого ряда улучшений в свои модели, среди которых большая гибкость управления моделями API, возможность вызова функций, расширение контекста, а также снижение цен.
Среди новшеств стоит отметить:
📍 Возможность вызова функций в Chat Completions API
📍 Обновлённые и более поддерживаемые версии gpt-4 и gpt-3.5-turbo
📍 Новая версия gpt-3.5-turbo с контекстом 16k (против стандартной версии 4k)
📍 Снижение стоимости на 75% для нашей модели векторного представления данных
📍 Снижение стоимости на 25% за входные токены для gpt-3.5-turbo
Нововведение в виде вызова функций позволит разработчикам более надёжно связывать возможности GPT с внешними инструментами и API.
К примеру, теперь разработчики могут:
📨 Создавать чат-ботов, отвечающих на вопросы с помощью внешних инструментов
🔀 Преобразовывать естественный язык в вызовы API или запросы к базам данных
🗂 Извлекать структурированные данные из текста
Новость
___
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
OpenAI объявило о внедрении целого ряда улучшений в свои модели, среди которых большая гибкость управления моделями API, возможность вызова функций, расширение контекста, а также снижение цен.
Среди новшеств стоит отметить:
📍 Возможность вызова функций в Chat Completions API
📍 Обновлённые и более поддерживаемые версии gpt-4 и gpt-3.5-turbo
📍 Новая версия gpt-3.5-turbo с контекстом 16k (против стандартной версии 4k)
📍 Снижение стоимости на 75% для нашей модели векторного представления данных
📍 Снижение стоимости на 25% за входные токены для gpt-3.5-turbo
Нововведение в виде вызова функций позволит разработчикам более надёжно связывать возможности GPT с внешними инструментами и API.
К примеру, теперь разработчики могут:
📨 Создавать чат-ботов, отвечающих на вопросы с помощью внешних инструментов
🔀 Преобразовывать естественный язык в вызовы API или запросы к базам данных
🗂 Извлекать структурированные данные из текста
Новость
___
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Openai
Function calling and other API updates
We’re announcing updates including more steerable API models, function calling capabilities, longer context, and lower prices.
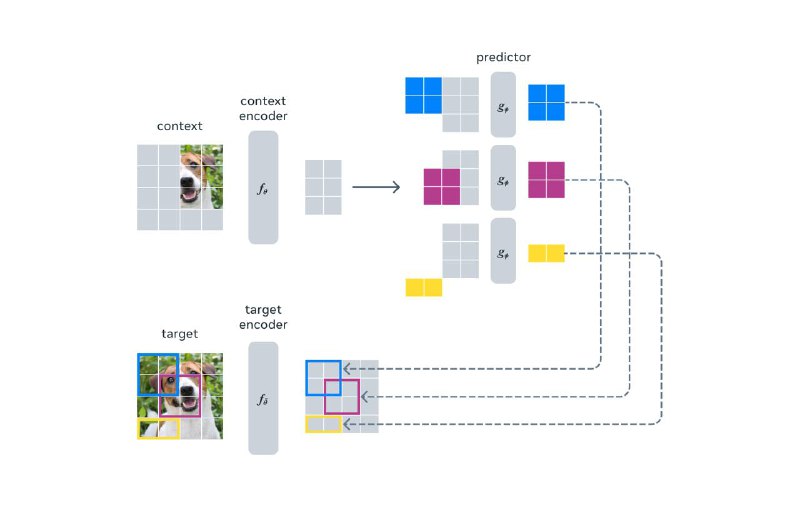
Ай-ЖЕПА: умная модель AI, которая учится понимать мир как люди
Meta представили первую AI модель, основанную на ключевом компоненте видения Яна ЛеКуна. Модель I-JEPA выучивает скрытое представление окружающего мира и отличается высокой эффективностью в различных задачах компьютерного зрения.
В прошлом году главный научный сотрудник по AI в Meta, Ян ЛеКун, предложил новую архитектуру, призванную преодолеть ключевые ограничения даже самых передовых AI систем сегодня. Его видение - создать машины, которые способные понять, как работает мир. Он считает что тогда они и обучаться будут быстрее, и планировать, как выполнять сложные задачи, и легко адаптироваться к незнакомым ситуациям тоже смогут.
И вот, Meta наконец то представили первую AI модель, основанную на ключевом компоненте видения ЛеКуна. Эта модель, Image Joint Embedding Predictive Architecture (I-JEPA), учится создавать модель окружающего мира с помощью сравнения абстрактных образов (вместо сравнения просто пикселей.
I-JEPA демонстрирует потенциал self-supervised архитектур для представлений изображений без необходимости в дополнительном знании, закодированном через ручные преобразования изображений. Это важный шаг к применению и масштабированию self-supervised методов для изучения общей модели мира.
И пусть "Ай-ЖЕПА" в русском языке может и звучать немного забавно, Meta делает ставку на то, что AGI к нам придет от зрения (вообще кажется все компании так или иначе делают ставку на один орган осязания, например на язык как в случае с Open AI).
✌️ Блог-пост
📖 Статья
💾 Код
_______
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Meta представили первую AI модель, основанную на ключевом компоненте видения Яна ЛеКуна. Модель I-JEPA выучивает скрытое представление окружающего мира и отличается высокой эффективностью в различных задачах компьютерного зрения.
В прошлом году главный научный сотрудник по AI в Meta, Ян ЛеКун, предложил новую архитектуру, призванную преодолеть ключевые ограничения даже самых передовых AI систем сегодня. Его видение - создать машины, которые способные понять, как работает мир. Он считает что тогда они и обучаться будут быстрее, и планировать, как выполнять сложные задачи, и легко адаптироваться к незнакомым ситуациям тоже смогут.
И вот, Meta наконец то представили первую AI модель, основанную на ключевом компоненте видения ЛеКуна. Эта модель, Image Joint Embedding Predictive Architecture (I-JEPA), учится создавать модель окружающего мира с помощью сравнения абстрактных образов (вместо сравнения просто пикселей.
I-JEPA демонстрирует потенциал self-supervised архитектур для представлений изображений без необходимости в дополнительном знании, закодированном через ручные преобразования изображений. Это важный шаг к применению и масштабированию self-supervised методов для изучения общей модели мира.
И пусть "Ай-ЖЕПА" в русском языке может и звучать немного забавно, Meta делает ставку на то, что AGI к нам придет от зрения (вообще кажется все компании так или иначе делают ставку на один орган осязания, например на язык как в случае с Open AI).
✌️ Блог-пост
📖 Статья
💾 Код
_______
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
🗺️ Гугл улучшил построение маршрутов на Картах
Сервис Google Карты использует удобную навигацию, чтобы строить оптимальный маршрут из пункта А в пункт Б. Но как именно он определяет, какая дорога будет самой лучшей для пользователя? Оказывается, с помощью технологии "обратного обучения с подкреплением" (inverse reinforcement learning).
Этот метод работает так: искусственный интеллект анализирует реальные маршруты, которые люди выбирают в жизни. Эти данные - пример оптимальных "маршрутов" (если людей усреднить, то обычно они перемещаются оптимально). На их основе нейросеть извлекает скрытые критерии, которыми пользователи руководствуются при построении маршрута. Учитывают ли они время в пути, стоимость, живописность дороги?
Раньше применение такого подхода в масштабах всей Земли было затруднено - просто слишком много возможных маршрутов для анализа! Но инженеры Google разработали новый алгоритм RHIP (Receding Horizon Inverse Planning), который эффективно масштабируется.
Он объединяет точные, но ресурсозатратные методы для локальных участков пути с более дешёвыми алгоритмами глобального планирования. Благодаря оптимизации и распараллеливанию вычислений, RHIP позволил впервые применить обратное обучение с подкреплением в масштабах всей дорожной сети планеты.
В итоге точность маршрутов в Google Картах выросла на 15-24% по сравнению с предыдущим алгоритмом. Теперь, когда вы строите маршрут, ИИ может предугадать оптимальный путь, максимально приближенный к тому, который выбрали бы вы сами.
🌍 Блог-пост
📰 Статья
Подпишись на
_______
Источник | #nn_for_science
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Сервис Google Карты использует удобную навигацию, чтобы строить оптимальный маршрут из пункта А в пункт Б. Но как именно он определяет, какая дорога будет самой лучшей для пользователя? Оказывается, с помощью технологии "обратного обучения с подкреплением" (inverse reinforcement learning).
Этот метод работает так: искусственный интеллект анализирует реальные маршруты, которые люди выбирают в жизни. Эти данные - пример оптимальных "маршрутов" (если людей усреднить, то обычно они перемещаются оптимально). На их основе нейросеть извлекает скрытые критерии, которыми пользователи руководствуются при построении маршрута. Учитывают ли они время в пути, стоимость, живописность дороги?
Раньше применение такого подхода в масштабах всей Земли было затруднено - просто слишком много возможных маршрутов для анализа! Но инженеры Google разработали новый алгоритм RHIP (Receding Horizon Inverse Planning), который эффективно масштабируется.
Он объединяет точные, но ресурсозатратные методы для локальных участков пути с более дешёвыми алгоритмами глобального планирования. Благодаря оптимизации и распараллеливанию вычислений, RHIP позволил впервые применить обратное обучение с подкреплением в масштабах всей дорожной сети планеты.
В итоге точность маршрутов в Google Картах выросла на 15-24% по сравнению с предыдущим алгоритмом. Теперь, когда вы строите маршрут, ИИ может предугадать оптимальный путь, максимально приближенный к тому, который выбрали бы вы сами.
🌍 Блог-пост
📰 Статья
Подпишись на
_______
Источник | #nn_for_science
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
{kind=link}
Как "стереть" из ИИ знания о Гарри Поттере
Для тех кто ничего не понял в предыдущем посте.
Исследователи из Microsoft предложили способ "стирать" конкретную информацию из обученных языковых моделей, не переобучая их заново.
Они протестировали свой метод на модели Llama 2-7B от Meta, "стерев" из неё все знания о книгах и персонажах Гарри Поттера. Для этого потребовалось всего около 1 часа дополнительной тренировки модели.
Авторы разработали трёхэтапную технику:
1. Обучили вспомогательную модель выделять токены, связанные с Гарри Поттером.
2. Заменили уникальные выражения обобщёнными, имитируя модель без этих знаний.
3. Дотренировали основную модель на этих заменённых данных.
В итоге модель разучилась обсуждать детали сюжета и персонажей Гарри Поттера, но сохранила общие способности.
Это важный шаг к созданию гибких языковых моделей, которые можно адаптировать под меняющиеся требования. В будущем такие методы помогут делать ИИ более ответственным и соответствующим законам об авторских правах.
Ссылка
_______
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Для тех кто ничего не понял в предыдущем посте.
Исследователи из Microsoft предложили способ "стирать" конкретную информацию из обученных языковых моделей, не переобучая их заново.
Они протестировали свой метод на модели Llama 2-7B от Meta, "стерев" из неё все знания о книгах и персонажах Гарри Поттера. Для этого потребовалось всего около 1 часа дополнительной тренировки модели.
Авторы разработали трёхэтапную технику:
1. Обучили вспомогательную модель выделять токены, связанные с Гарри Поттером.
2. Заменили уникальные выражения обобщёнными, имитируя модель без этих знаний.
3. Дотренировали основную модель на этих заменённых данных.
В итоге модель разучилась обсуждать детали сюжета и персонажей Гарри Поттера, но сохранила общие способности.
Это важный шаг к созданию гибких языковых моделей, которые можно адаптировать под меняющиеся требования. В будущем такие методы помогут делать ИИ более ответственным и соответствующим законам об авторских правах.
Ссылка
_______
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
GitHub Copilot Chat и его влияние на качество кода
GitHub провел исследование, в котором попросил 36 опытных разработчиков, которые никогда не использовали Copilot Chat, оценить его полезность при решении задачи.
Некоторым из участников случайным образом было поручено использовать Copilot Chat и оценить написанный код по следующим критериям: читаемость, универсальность, краткость, удобность в обслуживании и отказоустойчивость.
Затем разработчики получили два пул запроса без информации, был ли исходный код написан с помощью Copilot. Ревью выполнялось с Copilot Chat и без него по вышеописанным критериям.
После получения ревью, авторы решали какие из комментариев были более полезны. И, конечно же, авторы не знали какой из комментариев был написан с помощью Copilot.
Какие результаты? 👀
- 85% разработчиков отметили большую уверенность в качестве кода
- Участники отметили улучшение скорости проверки кода на 15%
- 88% разработчиков сообщили о сохранении фокуса (flow state)
🤓 Блог
_______
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
GitHub провел исследование, в котором попросил 36 опытных разработчиков, которые никогда не использовали Copilot Chat, оценить его полезность при решении задачи.
Некоторым из участников случайным образом было поручено использовать Copilot Chat и оценить написанный код по следующим критериям: читаемость, универсальность, краткость, удобность в обслуживании и отказоустойчивость.
Затем разработчики получили два пул запроса без информации, был ли исходный код написан с помощью Copilot. Ревью выполнялось с Copilot Chat и без него по вышеописанным критериям.
После получения ревью, авторы решали какие из комментариев были более полезны. И, конечно же, авторы не знали какой из комментариев был написан с помощью Copilot.
Какие результаты? 👀
- 85% разработчиков отметили большую уверенность в качестве кода
- Участники отметили улучшение скорости проверки кода на 15%
- 88% разработчиков сообщили о сохранении фокуса (flow state)
🤓 Блог
_______
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
Большая языковая модель для наук о Земле K2
Ученые создали первую в мире большую языковую модель, специализированную в области геологии, географии и других наук о Земле. Её назвали K2 - в честь второй по высоте горы на планете.
Модель K2 научили отвечать на вопросы и решать задачки по географии и геологии. Для этого ей "дали прочитать" 5.5 миллиарда слов из научных статей и Википедии про науки о Земле.
Кроме того, K2 может сама искать нужную информацию в поисковиках и базах данных. Таким образом она становится помощником для геологов и географов в их исследованиях.
По сравнению с обычными языковыми моделями, K2 лучше отвечала на вопросы из экзаменов для поступающих в аспирантуру по геологии и географии. Это показывает, что она действительно хорошо "разбирается" в геонауках.
Разработчики K2 выложили в открытый доступ все данные и код, которые использовали для её обучения. Это позволит улучшать такие "модели-геологи" и создавать похожие модели для других областей науки.
🔖 Статья
🐙 Код
🗻 Поговорить с K2
_______
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Ученые создали первую в мире большую языковую модель, специализированную в области геологии, географии и других наук о Земле. Её назвали K2 - в честь второй по высоте горы на планете.
Модель K2 научили отвечать на вопросы и решать задачки по географии и геологии. Для этого ей "дали прочитать" 5.5 миллиарда слов из научных статей и Википедии про науки о Земле.
Кроме того, K2 может сама искать нужную информацию в поисковиках и базах данных. Таким образом она становится помощником для геологов и географов в их исследованиях.
По сравнению с обычными языковыми моделями, K2 лучше отвечала на вопросы из экзаменов для поступающих в аспирантуру по геологии и географии. Это показывает, что она действительно хорошо "разбирается" в геонауках.
Разработчики K2 выложили в открытый доступ все данные и код, которые использовали для её обучения. Это позволит улучшать такие "модели-геологи" и создавать похожие модели для других областей науки.
🔖 Статья
🐙 Код
🗻 Поговорить с K2
_______
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
Дата-центры: скрытые энергогиганты.
В то время как общество все больше концентрируется на энергоэффективности, потребление энергии дата-центрами продолжает расти, скрывая за собой значительные цифры.
После 2020 года информация о потреблении энергии дата-центрами стала менее доступной, уступая место акцентам на их энергоэффективность. Однако последние данные говорят сами за себя: дата-центры потребляют огромное количество электроэнергии, которое можно сравнить с выработкой крупнейших электростанций.
По оценкам, в 2022 году дата-центры потребили от 240 до 340 тераватт-часов энергии, плюс от 260 до 360 TWh ушло на передачу данных. Это не учитывая от 100 до 150 TWh, потраченных на поддержку криптовалют. Для сравнения: ГЭС Hoover Dam производит около 50 TWh энергии в год, что сопоставимо с производством многих атомных станций.
Даже если 40% потребности дата-центров покрываются за счет возобновляемых источников, мы все равно сжигаем около 44 миллионов тонн нефти в год. Это подчеркивает важность перехода к более устойчивым моделям потребления и производства энергии, в том числе и в индустрии ИТ. Мы должны признать, что наша зависимость от технологий, таких как GPT, несет не только преимущества, но и значительные экологические издержки.
Ссылка
_______
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
В то время как общество все больше концентрируется на энергоэффективности, потребление энергии дата-центрами продолжает расти, скрывая за собой значительные цифры.
После 2020 года информация о потреблении энергии дата-центрами стала менее доступной, уступая место акцентам на их энергоэффективность. Однако последние данные говорят сами за себя: дата-центры потребляют огромное количество электроэнергии, которое можно сравнить с выработкой крупнейших электростанций.
По оценкам, в 2022 году дата-центры потребили от 240 до 340 тераватт-часов энергии, плюс от 260 до 360 TWh ушло на передачу данных. Это не учитывая от 100 до 150 TWh, потраченных на поддержку криптовалют. Для сравнения: ГЭС Hoover Dam производит около 50 TWh энергии в год, что сопоставимо с производством многих атомных станций.
Даже если 40% потребности дата-центров покрываются за счет возобновляемых источников, мы все равно сжигаем около 44 миллионов тонн нефти в год. Это подчеркивает важность перехода к более устойчивым моделям потребления и производства энергии, в том числе и в индустрии ИТ. Мы должны признать, что наша зависимость от технологий, таких как GPT, несет не только преимущества, но и значительные экологические издержки.
Ссылка
_______
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
Llamafile от Mozilla: портативный ИИ на флешке
Теперь почти любое устройство можно превратить в оффлайн персонального собеседника за секунды, благодаря Llamafile от Mozilla!
📌 Что такое Llamafile?
Llamafile - это опенсорс продукт от Mozilla, который позволяет распространять и запускать большие языковые модели (LLMs) с помощью одного файла. Это означает, что вы можете "поселить" умную Ламу на флешку или ноутбук.
💡 Особенности Llamafile:
1. Совместимость с различными архитектурами и ОС: Llamafile работает на множестве CPU архитектур и на всех основных операционных системах, включая macOS, Windows и Linux
2. Интеграция с разными моделями ИИ: можно загрузить любые модели, например Mistral-7B-Instruct или WizardCoder-Python-13B, и использовать их в качестве серверных или локальных бинарных файлов
3. Поддержка GPU: На Apple Silicon и Linux, Llamafile поддерживает GPU, что позволяет ускорить обработку данных и улучшить производительность.
4. Нормальная лицензия: Проект llamafile лицензирован под Apache 2.0
🌍 Выводы:
Llamafile от Mozilla открывает новые горизонты для ИИ-разработчиков и пользователей. С Llamafile, ваше устройство становится не просто гаджетом, а интеллектуальным помощником, который всегда с вами (даже в самолете)!
Блог-пост
GitHub
(Напоминаю что сегодня ровно год с выхода ChatGPT, а у нас уже есть версия для флешки 🤔)
_______
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Теперь почти любое устройство можно превратить в оффлайн персонального собеседника за секунды, благодаря Llamafile от Mozilla!
📌 Что такое Llamafile?
Llamafile - это опенсорс продукт от Mozilla, который позволяет распространять и запускать большие языковые модели (LLMs) с помощью одного файла. Это означает, что вы можете "поселить" умную Ламу на флешку или ноутбук.
💡 Особенности Llamafile:
1. Совместимость с различными архитектурами и ОС: Llamafile работает на множестве CPU архитектур и на всех основных операционных системах, включая macOS, Windows и Linux
2. Интеграция с разными моделями ИИ: можно загрузить любые модели, например Mistral-7B-Instruct или WizardCoder-Python-13B, и использовать их в качестве серверных или локальных бинарных файлов
3. Поддержка GPU: На Apple Silicon и Linux, Llamafile поддерживает GPU, что позволяет ускорить обработку данных и улучшить производительность.
4. Нормальная лицензия: Проект llamafile лицензирован под Apache 2.0
🌍 Выводы:
Llamafile от Mozilla открывает новые горизонты для ИИ-разработчиков и пользователей. С Llamafile, ваше устройство становится не просто гаджетом, а интеллектуальным помощником, который всегда с вами (даже в самолете)!
Блог-пост
GitHub
(Напоминаю что сегодня ровно год с выхода ChatGPT, а у нас уже есть версия для флешки 🤔)
_______
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}