
Набор инструкций H100 и 4090 теперь задокументирован 👏
Умелец смог при помощи фаззера задокументировать набор инструкций актуальных карт Nvidia. Сама Nvidia такое в паблик не пускает, чтобы всё шло через CUDA, максимум PTX. Таким образом они добиваются вендорлока к картам Nvidia в целом, а не одной конкретной архитектуре.
Проблема в том, что без такой документации заметно сложнее делать оптимизации под конкретные архитектуры. А вот с ней и альтернативные компиляторы для карт Nvidia делать будет проще, может, будут даже такие, что не качают пять гигов зависимостей (что-то я замечтался).
Дальше автор собирается добавить данные о производительности каждой инструкции, что потребует кучу микробенчмарков.
H100
RTX 4090
Код
_______
Источник | #ai_newz
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Умелец смог при помощи фаззера задокументировать набор инструкций актуальных карт Nvidia. Сама Nvidia такое в паблик не пускает, чтобы всё шло через CUDA, максимум PTX. Таким образом они добиваются вендорлока к картам Nvidia в целом, а не одной конкретной архитектуре.
Проблема в том, что без такой документации заметно сложнее делать оптимизации под конкретные архитектуры. А вот с ней и альтернативные компиляторы для карт Nvidia делать будет проще, может, будут даже такие, что не качают пять гигов зависимостей (что-то я замечтался).
Дальше автор собирается добавить данные о производительности каждой инструкции, что потребует кучу микробенчмарков.
H100
RTX 4090
Код
_______
Источник | #ai_newz
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
GitHub
GitHub - kuterd/nv_isa_solver: Nvidia Instruction Set Specification Generator
Nvidia Instruction Set Specification Generator. Contribute to kuterd/nv_isa_solver development by creating an account on GitHub.
Апдейт по SB 1047 - Калифорнийскому законопроекту для регуляции ИИ
TLDR: прямую угрозу маленьким разработчикам пока убрали, но большой опенсорс это не спасёт. И всё ещё возлагает ответственность на автора модели, а не на пользователя.
Авторы SB-1047, о котором я писал в мае внесли ряд правок. Тогда законопроект был настолько плохо написан, что против него протестовали даже Anthropic. Я прочитал поправки, вот суть:
➖ Убрали пункт где под ограничения подпадали модели "схожие по возможностям к моделям подпадающим под закон". Это был самый адовый пункт, который в лучшем случае заморозил бы опенсорс на уровне 2024 года, а в худшем мог бы запретить практически любую тренировку.
➖ Регулировать собираются модели которые тренировались на 1e26 flops и более чем ста миллионах долларов компьюта. То есть сейчас, когда 1e26 стоит $150-300m, под ограничение подпадают модели с 1e26 flops. Через год-два, когда компьют подешевеет, будут подпадать только модели которые стоят дороже ста миллионов долларов.
➖ Улучшили ситуацию с ответственностью разрабов моделей за файнтюны - теперь модели, которые тюнили на более чем 3e25 flops считаются новыми моделями, создатели оригинала не ответственны за их действия.
➖ Все суммы в законопроекте теперь указаны в долларах 2025 года и будут поправляться на инфляцию.
➖ Добавили кучу возможных штрафных санкций, например штраф на сумму до 10% стоимости компьюта использованного для тренировки модели.
➖ Созданный орган контроля сможет менять определения моделей подпадающих под контроль каждый год без необходимости проводить новый закон. То есть, теоретически, 1 января 2027 года регулятор имеет право запретить всё что ему вздумается. Ни разу не пространство для regulatory capture, да-да.
➖ Разработчики моделей теперь будут должны каждый год, начиная с 2028 проходить независимый аудит на соответствие регуляциям.
Стало местами лучше, но законопроект всё ещё лажа:
🟥 Идея ответственности разработчиков моделей за использование моделей крайне плохая и опасная. По такой логике можно заявить что Боинг ответственен за события 11 сентября 2001 года.
🟥 Определение "Critical harm", которое в законе даёт право регулятору накладывать штрафные санкции, вплоть до удаления модели, очень жёсткое: хакерская атака на 500 миллионов долларов это не такой редкий случай, а в законе не указано насколько сильно модель должна ей поспособствовать.
🟥 Давать регулятору право решать что всё таки является его зоной контроля это очень плохая идея.
Самое смешное тут то, что авторы законопроекта проводили ряд публичных встреч, где говорили что хотят сделать менее драконовский закон чем European AI Act. Такое ощущение что даже не пытались.
_______
Источник | #ai_newz
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
TLDR: прямую угрозу маленьким разработчикам пока убрали, но большой опенсорс это не спасёт. И всё ещё возлагает ответственность на автора модели, а не на пользователя.
Авторы SB-1047, о котором я писал в мае внесли ряд правок. Тогда законопроект был настолько плохо написан, что против него протестовали даже Anthropic. Я прочитал поправки, вот суть:
➖ Убрали пункт где под ограничения подпадали модели "схожие по возможностям к моделям подпадающим под закон". Это был самый адовый пункт, который в лучшем случае заморозил бы опенсорс на уровне 2024 года, а в худшем мог бы запретить практически любую тренировку.
➖ Регулировать собираются модели которые тренировались на 1e26 flops и более чем ста миллионах долларов компьюта. То есть сейчас, когда 1e26 стоит $150-300m, под ограничение подпадают модели с 1e26 flops. Через год-два, когда компьют подешевеет, будут подпадать только модели которые стоят дороже ста миллионов долларов.
➖ Улучшили ситуацию с ответственностью разрабов моделей за файнтюны - теперь модели, которые тюнили на более чем 3e25 flops считаются новыми моделями, создатели оригинала не ответственны за их действия.
➖ Все суммы в законопроекте теперь указаны в долларах 2025 года и будут поправляться на инфляцию.
➖ Добавили кучу возможных штрафных санкций, например штраф на сумму до 10% стоимости компьюта использованного для тренировки модели.
➖ Созданный орган контроля сможет менять определения моделей подпадающих под контроль каждый год без необходимости проводить новый закон. То есть, теоретически, 1 января 2027 года регулятор имеет право запретить всё что ему вздумается. Ни разу не пространство для regulatory capture, да-да.
➖ Разработчики моделей теперь будут должны каждый год, начиная с 2028 проходить независимый аудит на соответствие регуляциям.
Стало местами лучше, но законопроект всё ещё лажа:
🟥 Идея ответственности разработчиков моделей за использование моделей крайне плохая и опасная. По такой логике можно заявить что Боинг ответственен за события 11 сентября 2001 года.
🟥 Определение "Critical harm", которое в законе даёт право регулятору накладывать штрафные санкции, вплоть до удаления модели, очень жёсткое: хакерская атака на 500 миллионов долларов это не такой редкий случай, а в законе не указано насколько сильно модель должна ей поспособствовать.
🟥 Давать регулятору право решать что всё таки является его зоной контроля это очень плохая идея.
Самое смешное тут то, что авторы законопроекта проводили ряд публичных встреч, где говорили что хотят сделать менее драконовский закон чем European AI Act. Такое ощущение что даже не пытались.
_______
Источник | #ai_newz
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Telegram
эйай ньюз
🚨Новый Калифорнийский законопроект может убить будущее опенсорс моделей
TL;DR: На большие AI модели будет наложено очень много ограничений. Возможно, это задушит многих, кто тренирует большие LLM в США (пока только в Калифорнии), а также облачных провайдеров…
TL;DR: На большие AI модели будет наложено очень много ограничений. Возможно, это задушит многих, кто тренирует большие LLM в США (пока только в Калифорнии), а также облачных провайдеров…
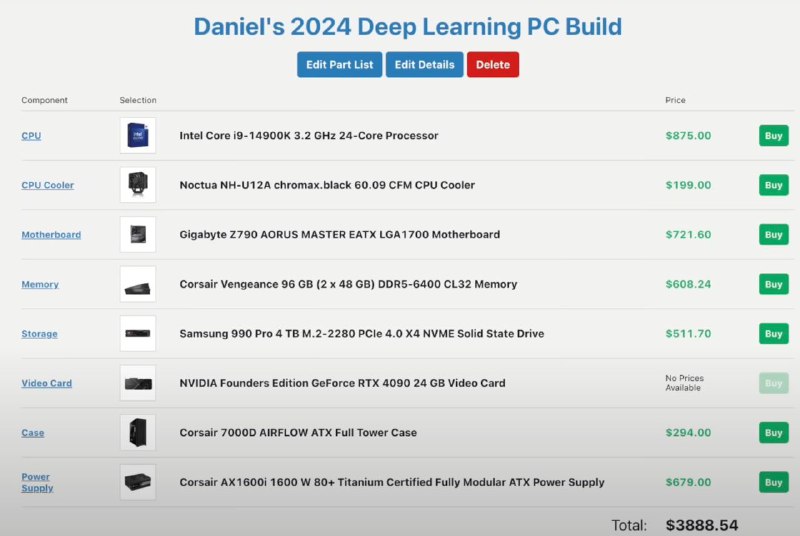
Принес вам сборку компьютера для Deep Learning в 2024, и рассказ о работе ML инженера
Еще можете глянуть забавное видео "День из жизни ML инжинера (в маленьком стартапе)", откуда я и взял эту сборку.
По стоимости комп вышел $3900, не учитывая Nvidia RTX 4090 24GB, которая сейчас стоит примерно $1800. Итого $5700 (но это в Америке). Такой машины хватит, чтобы файнтюнить большинство СОТА моделей и гонять инференс почти всего что есть в опенсорс с достойной скоростью.
Самое важное что чел в видео сказал, так это то что на построение самой модели у него как у ML инженера уходит не так много времени, и большую часть времени они заняты данными. Думаю это особенно актуально для малкньких стартапов, где обычно нет moat в плане моделей, но есть премущество в том, что они затачивают существующие модели под эффективное решение определенных задач. В условном Mistral архитектурой модели, я уверен, тоже не так много людей занимается, и очень много ресурсов уходит именно на "правильную готовку" данных.
Делитесь своими сборками для Deep Learning в комментах.
#карьера
_______
Источник | #ai_newz
@F_S_C_P
-------
поддержи канал
-------
Еще можете глянуть забавное видео "День из жизни ML инжинера (в маленьком стартапе)", откуда я и взял эту сборку.
По стоимости комп вышел $3900, не учитывая Nvidia RTX 4090 24GB, которая сейчас стоит примерно $1800. Итого $5700 (но это в Америке). Такой машины хватит, чтобы файнтюнить большинство СОТА моделей и гонять инференс почти всего что есть в опенсорс с достойной скоростью.
Самое важное что чел в видео сказал, так это то что на построение самой модели у него как у ML инженера уходит не так много времени, и большую часть времени они заняты данными. Думаю это особенно актуально для малкньких стартапов, где обычно нет moat в плане моделей, но есть премущество в том, что они затачивают существующие модели под эффективное решение определенных задач. В условном Mistral архитектурой модели, я уверен, тоже не так много людей занимается, и очень много ресурсов уходит именно на "правильную готовку" данных.
Делитесь своими сборками для Deep Learning в комментах.
#карьера
_______
Источник | #ai_newz
@F_S_C_P
-------
поддержи канал
-------
{kind=link}
This media is not supported in your browser
VIEW IN TELEGRAM
Llama 3.1 405B, квантизированная до 4 бит, запущенная на двух макбуках (128 гиг оперативки у каждого). Возможно это с помощью exo - тулы, позволяющей запускать модельку распределённо на нескольких девайсов. Поддерживаются практически любые GPU, телефоны, планшеты, макбуки и почти всё о чём можно подумать.
Запустить ламу на домашнем кластере
_______
Источник | #ai_newz
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Запустить ламу на домашнем кластере
_______
Источник | #ai_newz
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
This media is not supported in your browser
VIEW IN TELEGRAM
Генерация видео от Black Forest Labs
Они релизнули FLUX.1 всего неделю назад, а уже тизерят SOTA видеогенерацию. Видео искажено эффектом телевизора, но выглядит очень впечатляюще.
Ребята наглядно показывают насколько в Stability был фиговый менеджмент. Если за полгода с нуля те же самые люди, которые сделали SD3 забахали такое, то в Stability всё очень запущено, некому пилить ресерчи, а новый менеджмент может и не спасти.
Как думаете, будет опенсорс?
_______
Источник | #ai_newz
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Они релизнули FLUX.1 всего неделю назад, а уже тизерят SOTA видеогенерацию. Видео искажено эффектом телевизора, но выглядит очень впечатляюще.
Ребята наглядно показывают насколько в Stability был фиговый менеджмент. Если за полгода с нуля те же самые люди, которые сделали SD3 забахали такое, то в Stability всё очень запущено, некому пилить ресерчи, а новый менеджмент может и не спасти.
Как думаете, будет опенсорс?
_______
Источник | #ai_newz
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Дешёвые, как грязь, LLM
API-провайдеры невероятно быстро снижают стоимость использования своих LLM. При отсутствии ярко выраженного лидера по качеству моделей, главным аргументом становится цена.
➖ Google с 12 августа дропает цены на Gemini Flash на 80%. Вот и реакция на GPT-4o mini, спустя две недели после релиза. Вот бы то же самое сделали с Pro 1.5.
➖ Новая версия GPT-4o упала в цене до $2.5 input/$10 output за миллион токенов, прошлые версии стоили $5 input/$15 output за миллион токенов. Последний месяц Claude 3.5 Sonnet и Llama 3.1 405B сильно поджимали OpenAI по цене, пришлось отвечать.
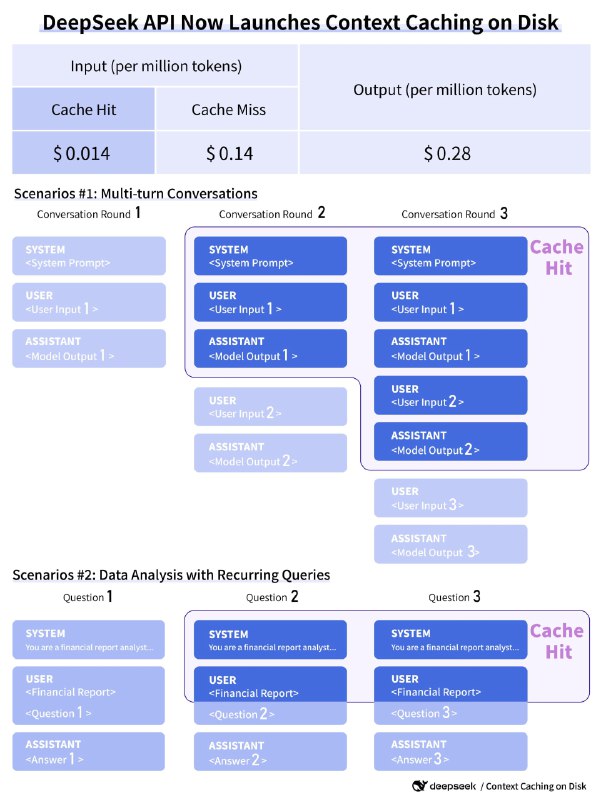
➖Deepseek релизит обещанный месяц назад Context Caching. Цены поражают: стоимость токенов при попадании в кэш падает не в 2x, как у гугла, а в 10x, при этом с бесплатным хранением. DeepSeek V2 и так произвёл эффект разорвавшейся бомбы на китайском рынке три месяца назад: модель была в разы дешевле конкурентов, при лучшем качестве. А сейчас нанесли добивающий удар.
С такими темпами цена за миллион токенов станет меньше цента менее чем через год. И будем мы мерять цены в долларах за миллиард токенов.
А помните, цены на GPT-4 доходили до $60 input/$120 output?
_______
Источник | #ai_newz
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
API-провайдеры невероятно быстро снижают стоимость использования своих LLM. При отсутствии ярко выраженного лидера по качеству моделей, главным аргументом становится цена.
➖ Google с 12 августа дропает цены на Gemini Flash на 80%. Вот и реакция на GPT-4o mini, спустя две недели после релиза. Вот бы то же самое сделали с Pro 1.5.
➖ Новая версия GPT-4o упала в цене до $2.5 input/$10 output за миллион токенов, прошлые версии стоили $5 input/$15 output за миллион токенов. Последний месяц Claude 3.5 Sonnet и Llama 3.1 405B сильно поджимали OpenAI по цене, пришлось отвечать.
➖Deepseek релизит обещанный месяц назад Context Caching. Цены поражают: стоимость токенов при попадании в кэш падает не в 2x, как у гугла, а в 10x, при этом с бесплатным хранением. DeepSeek V2 и так произвёл эффект разорвавшейся бомбы на китайском рынке три месяца назад: модель была в разы дешевле конкурентов, при лучшем качестве. А сейчас нанесли добивающий удар.
С такими темпами цена за миллион токенов станет меньше цента менее чем через год. И будем мы мерять цены в долларах за миллиард токенов.
А помните, цены на GPT-4 доходили до $60 input/$120 output?
_______
Источник | #ai_newz
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
{kind=link}
Сверхзвуковые LLM https://t.iss.one/ai_newz/3169
Llama 3 70B запустили на скорости в 450 токенов в секунду. А 8B - на бешенных 1800 токенов в секунду. Это всё без квантизации, да и цена не кусается - API стоит 10 центов за лям токенов для 8B и 60 для 70B. Предыдущий рекорд по скорости побили в более чем два раза для 8B. В будущем обещают добавить больше моделей, начиная с Llama 3.1 405B
Сделал это стартап Cerebras. Он производит железо для нейронок, известен самым большим чипом в мире (в 57 раз больше по размеру H100!). Предыдущий рекорд по скорости поставил тоже стартап со своим железом - Groq.
Хороший пример того что специализированные только под нейронки чипы вроде могут в разы превосходить видеокарты по скорости инференса, а ведь скоро ещё будут чипы которые заточены под конкретные модели, например Sohu. Кстати, давно хотел разобрать разные стартапы по производству железа и разницу их подходов. Интересно?
Попробовать можно тут.
_______
Источник | #ai_newz
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Llama 3 70B запустили на скорости в 450 токенов в секунду. А 8B - на бешенных 1800 токенов в секунду. Это всё без квантизации, да и цена не кусается - API стоит 10 центов за лям токенов для 8B и 60 для 70B. Предыдущий рекорд по скорости побили в более чем два раза для 8B. В будущем обещают добавить больше моделей, начиная с Llama 3.1 405B
Сделал это стартап Cerebras. Он производит железо для нейронок, известен самым большим чипом в мире (в 57 раз больше по размеру H100!). Предыдущий рекорд по скорости поставил тоже стартап со своим железом - Groq.
Хороший пример того что специализированные только под нейронки чипы вроде могут в разы превосходить видеокарты по скорости инференса, а ведь скоро ещё будут чипы которые заточены под конкретные модели, например Sohu. Кстати, давно хотел разобрать разные стартапы по производству железа и разницу их подходов. Интересно?
Попробовать можно тут.
_______
Источник | #ai_newz
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Telegram
эйай ньюз
Сверхзвуковые LLM
Llama 3 70B запустили на скорости в 450 токенов в секунду. А 8B - на бешенных 1800 токенов в секунду. Это всё без квантизации, да и цена не кусается - API стоит 10 центов за лям токенов для 8B и 60 для 70B. Предыдущий рекорд по скорости…
Llama 3 70B запустили на скорости в 450 токенов в секунду. А 8B - на бешенных 1800 токенов в секунду. Это всё без квантизации, да и цена не кусается - API стоит 10 центов за лям токенов для 8B и 60 для 70B. Предыдущий рекорд по скорости…
Как LLM хранят факты?
Принес вам на вечер субботы отличный ролик от 3blue1brown. На этот раз гений интуитивного обучения расскажет про то, как LLM запоминает факты.
Это видео для полных новичков, объясняющее роль многоуровневого перцептрона (MLP/FFN) в LLM. Это третье и последний эпизод в серии о работе LLM. D первых двух объяснялось как работают эмбеддинги и как работает механизм внимания. Эта серия - лучшее объяснение для непрограммистов о том, как работают LLM, с кучей хороших визуализаций.
www.youtube.com
Смотрим здесь.
_______
Источник | #ai_newz
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Принес вам на вечер субботы отличный ролик от 3blue1brown. На этот раз гений интуитивного обучения расскажет про то, как LLM запоминает факты.
Это видео для полных новичков, объясняющее роль многоуровневого перцептрона (MLP/FFN) в LLM. Это третье и последний эпизод в серии о работе LLM. D первых двух объяснялось как работают эмбеддинги и как работает механизм внимания. Эта серия - лучшее объяснение для непрограммистов о том, как работают LLM, с кучей хороших визуализаций.
www.youtube.com
Смотрим здесь.
_______
Источник | #ai_newz
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Telegram
эйай ньюз
Как LLM хранят факты?
Принес вам на вечер субботы отличный ролик от 3blue1brown. На этот раз гений интуитивного обучения расскажет про то, как LLM запоминает факты.
Это видео для полных новичков, объясняющее роль многоуровневого перцептрона (MLP/FFN) в…
Принес вам на вечер субботы отличный ролик от 3blue1brown. На этот раз гений интуитивного обучения расскажет про то, как LLM запоминает факты.
Это видео для полных новичков, объясняющее роль многоуровневого перцептрона (MLP/FFN) в…
Media is too big
VIEW IN TELEGRAM
Если вам когда-либо было интересно, как получить мегакластер GPU, то вот вам подробный гайд от Ларри Эллисона, фаундера того самого Оракла. Челу 80, кстати, похоже, он всё-таки нашёл эликсир вечной молодости.
Ну так вот, записываем:
1) Приходим на ужин к Дженсену Хуангу.
2) Вместе с Маском умоляем Кожанку взять ваши миллиарды.
3) Поздравляю, если вам повезёт, то партию свеженьких GPU не задержат.
Теперь повторяем😂
Кроме шуток, Oracle – одна из немногих компаний, которая смогла заполучить контракт на более чем 100.000 видеокарт NVIDIA Blackwell (это GB200, например). Они уже строят огромный кластер, который заработает в первой половине 2025. А сбоку еще планируют пристроить 3 маленьких атомных реактора на ~1000 MW, чтобы все это дело запитывать электроэнергией.
Короче, если GPU - это новая нефть, то AI – это новый автомобиль.
_______
Источник | #ai_newz
@F_S_C_P
-------
Секретики!
-------
Ну так вот, записываем:
1) Приходим на ужин к Дженсену Хуангу.
2) Вместе с Маском умоляем Кожанку взять ваши миллиарды.
3) Поздравляю, если вам повезёт, то партию свеженьких GPU не задержат.
Теперь повторяем😂
Кроме шуток, Oracle – одна из немногих компаний, которая смогла заполучить контракт на более чем 100.000 видеокарт NVIDIA Blackwell (это GB200, например). Они уже строят огромный кластер, который заработает в первой половине 2025. А сбоку еще планируют пристроить 3 маленьких атомных реактора на ~1000 MW, чтобы все это дело запитывать электроэнергией.
Короче, если GPU - это новая нефть, то AI – это новый автомобиль.
_______
Источник | #ai_newz
@F_S_C_P
-------
Секретики!
-------
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
This media is not supported in your browser
VIEW IN TELEGRAM
А вот ещё примеры генерации нашей модели вам на обозрение.
Те примеры, где показано маленькое фото в правом верхнем углу – это результат персонализированной генерации с заданным лицом (Personalized Movie Gen).
Переходим на качественно новый уровень!
_______
Источник | #ai_newz
@F_S_C_P
Стань спонсором!
Те примеры, где показано маленькое фото в правом верхнем углу – это результат персонализированной генерации с заданным лицом (Personalized Movie Gen).
Переходим на качественно новый уровень!
_______
Источник | #ai_newz
@F_S_C_P
Стань спонсором!