Бомбу можно обнаружить и обезвредить, а «спящих агентов» внутри LLM – нет.
Они не обезвреживаемы и не исправимы никакими из существующих методов.
Это значит, что пока не существует надежного способа защитить ИИ от злоумышленного использования злодеями или идиотами (а кто говорит вам иначе – «продавцы змеиного масла»).
Новое исследование Anthropic «Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training» [1] открывают новую страницу «революции ChatGPT» спустя год после ее начала. Увы, но эта страница потенциально опасней любой бомбы.
• Ибо, даже если последняя оказывается заложена злоумышленниками в центре мегаполиса, ее все же можно обнаружить и обезвредить, отключив механизм взрывателя или как-то еще.
• Если же злоумышленники на стадии обучения LLM заложили в модель «спящих агентов», - ни обнаружить их, ни как-то обезвредить существующими методами невозможно.
Следовательно, избежать катастрофы по вине «спящих агентов», скрытых внутри LLM, можно лишь одним способом – гарантированного исключить их попадание в руки злоумышленников. Что на практике вряд ли возможно.
Напомню, что спящие агенты (Sleeper Agents) – самый ценный ресурс всех разведок мира. Годы и даже десятилетия они живут в чужой стране, ничем не отличаясь от прочих граждан. Однако в нужный для их хозяев момент «слиперов» активируют (кодовым словом или иначе) и они начинают действовать (совершают теракт и т.п.).
Авторы исследования (39 классных спецов мирового уровня по LLM) взялись найти кардинальный ответ на вопрос – насколько могут быть опасны LLM, - путем экспериментов.
✔️ Сначала они обучили LLM действовать тайно и злонамеренно, превратив её, как бы, в «спящего агента».
✔️А потом авторы бросили все усилия и все известные ныне методы, чтобы
1) либо обнаружить злые намерения обученного ими «спящего агента», либо
2) отучить его быть таковым, путем существующих методов «приучения» LLM к правильному и надежному поведению.
В итоге авторы обнаружили, что, несмотря на их колоссальные усилия, все было тщетно …
1. LLM остаются «спящими агентами», которых невозможно обнаружить.
2. Обезвредить их тоже нельзя никакими из существующих методов.
3. Что всего обидней (и опасней), попытки найти и обезвредить «спящих агентов» внутри LLM приводят лишь к тому, что модель все лучше и лучше учится:
а) маскировать заложенные в нее бэкдоры;
б) изображать всем своим поведением, что она «белая и пушистая» (т.е. отвечает всем требованиям к «выровненной» модели и потому абсолютно безопасна)
В заключение вопрос на триллион:
Значит ли это, что пушной зверек уже совсем рядом и катастроф с LLM не избежать?
Ответ – «нет» (точнее, теоретически «нет»). Ибо если все LLM на Земле будут
• не только с открытыми весами,
• но и с открытым исходным кодом и открытыми данными обучения, -
тогда проблема «спящих агентов» решаема.
Ну а тем оптимистам, кто считает это условие исполнимым на практике, отвечу словами одного из авторов только вышедшего самого подробного отчета в истории этого вопроса Adversarial Machine Learning. A Taxonomy and Terminology of Attacks and Mitigations [2]
«Несмотря на значительный прогресс, достигнутый в области ИИ и машинного обучения, эти технологии уязвимы для атак, которые могут вызвать впечатляющие сбои с тяжелыми последствиями. Существуют теоретические проблемы с защитой алгоритмов ИИ, которые просто еще не решены. Если кто-либо говорит иначе, они продают змеиное масло»
1 www.lesswrong.com
2 bit.ly
#LLM #ИИриски
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Они не обезвреживаемы и не исправимы никакими из существующих методов.
Это значит, что пока не существует надежного способа защитить ИИ от злоумышленного использования злодеями или идиотами (а кто говорит вам иначе – «продавцы змеиного масла»).
Новое исследование Anthropic «Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training» [1] открывают новую страницу «революции ChatGPT» спустя год после ее начала. Увы, но эта страница потенциально опасней любой бомбы.
• Ибо, даже если последняя оказывается заложена злоумышленниками в центре мегаполиса, ее все же можно обнаружить и обезвредить, отключив механизм взрывателя или как-то еще.
• Если же злоумышленники на стадии обучения LLM заложили в модель «спящих агентов», - ни обнаружить их, ни как-то обезвредить существующими методами невозможно.
Следовательно, избежать катастрофы по вине «спящих агентов», скрытых внутри LLM, можно лишь одним способом – гарантированного исключить их попадание в руки злоумышленников. Что на практике вряд ли возможно.
Напомню, что спящие агенты (Sleeper Agents) – самый ценный ресурс всех разведок мира. Годы и даже десятилетия они живут в чужой стране, ничем не отличаясь от прочих граждан. Однако в нужный для их хозяев момент «слиперов» активируют (кодовым словом или иначе) и они начинают действовать (совершают теракт и т.п.).
Авторы исследования (39 классных спецов мирового уровня по LLM) взялись найти кардинальный ответ на вопрос – насколько могут быть опасны LLM, - путем экспериментов.
✔️ Сначала они обучили LLM действовать тайно и злонамеренно, превратив её, как бы, в «спящего агента».
✔️А потом авторы бросили все усилия и все известные ныне методы, чтобы
1) либо обнаружить злые намерения обученного ими «спящего агента», либо
2) отучить его быть таковым, путем существующих методов «приучения» LLM к правильному и надежному поведению.
В итоге авторы обнаружили, что, несмотря на их колоссальные усилия, все было тщетно …
1. LLM остаются «спящими агентами», которых невозможно обнаружить.
2. Обезвредить их тоже нельзя никакими из существующих методов.
3. Что всего обидней (и опасней), попытки найти и обезвредить «спящих агентов» внутри LLM приводят лишь к тому, что модель все лучше и лучше учится:
а) маскировать заложенные в нее бэкдоры;
б) изображать всем своим поведением, что она «белая и пушистая» (т.е. отвечает всем требованиям к «выровненной» модели и потому абсолютно безопасна)
В заключение вопрос на триллион:
Значит ли это, что пушной зверек уже совсем рядом и катастроф с LLM не избежать?
Ответ – «нет» (точнее, теоретически «нет»). Ибо если все LLM на Земле будут
• не только с открытыми весами,
• но и с открытым исходным кодом и открытыми данными обучения, -
тогда проблема «спящих агентов» решаема.
Ну а тем оптимистам, кто считает это условие исполнимым на практике, отвечу словами одного из авторов только вышедшего самого подробного отчета в истории этого вопроса Adversarial Machine Learning. A Taxonomy and Terminology of Attacks and Mitigations [2]
«Несмотря на значительный прогресс, достигнутый в области ИИ и машинного обучения, эти технологии уязвимы для атак, которые могут вызвать впечатляющие сбои с тяжелыми последствиями. Существуют теоретические проблемы с защитой алгоритмов ИИ, которые просто еще не решены. Если кто-либо говорит иначе, они продают змеиное масло»
1 www.lesswrong.com
2 bit.ly
#LLM #ИИриски
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Lesswrong
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training — LessWrong
I'm not going to add a bunch of commentary here on top of what we've already put out, since we've put a lot of effort into the paper itself, and I'd…
👍7❤3🔥3✍1😱1🤡1
Помните старый анекдот?
«Выпал мужик из окна небоскреба. Пролетает мимо 50-го этажа и думает: "Ну, пока всё вроде нормально". Пролетает мимо 25-го этажа, бормочет: "Вроде всё под контролем". Пролетает мимо 10-го этажа и озадачивается: "Хм, интересно, чем же всё закончится"»
Отчеты MIT, RAND и OpenAI наводят на мысль, что сегодняшняя технологическая реальность человечества здорово напоминает этот анекдот. Тот же неистребимый оптимизм, затмевающий очевидную неотвратимость роста рисков.
telegra.ph
#ИИриски #Вызовы21века
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
«Выпал мужик из окна небоскреба. Пролетает мимо 50-го этажа и думает: "Ну, пока всё вроде нормально". Пролетает мимо 25-го этажа, бормочет: "Вроде всё под контролем". Пролетает мимо 10-го этажа и озадачивается: "Хм, интересно, чем же всё закончится"»
Отчеты MIT, RAND и OpenAI наводят на мысль, что сегодняшняя технологическая реальность человечества здорово напоминает этот анекдот. Тот же неистребимый оптимизм, затмевающий очевидную неотвратимость роста рисков.
telegra.ph
#ИИриски #Вызовы21века
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
Telegraph
Мир оптимиста, падающего с небоскрёба
Помните старый анекдот?
🤣5🤔2🤯2🤨1
Отсчет времени до кибер-апокалипсиса пошел.
Три страшных вывода исследования UIUC.
Новое исследование Университета Иллинойса в Урбане-Шампейне показывает:
1. как в реальности может произойти кибер-апокалипсис, типа, показанного в новом триллере «Оставь мир позади» (танкеры теряют управление, отключается Wi-Fi, сотовая связь, электричество и т.д. и т.п.);
2. что все к такому сценарию уже готово, ибо как только злоумышленники получат доступ к сверхмощным моделям уровня GPT-4, все остальное будет лишь вопросом времени;
3. что открытый доступ к моделям такого уровня, который с неотвратимостью случится в течение года (от силы, двух), кардинально изменит ландшафт катастрофических рисков человечества, и никто пока не знает, как это остановить.
Теперь сухо, без эмоций и кликбейтов, - что показало исследование.
• Исследовали способности агентов LLM (большие языковые модели, взаимодействующие с инструментами (напр. доступ в Интернет, чтение документов и пр.) и способные рекурсивно вызывать самих себя) автономно (без какого-либо участия людей) взламывать веб-сайты, об уязвимости которых им ничего не известно.
• Единственное, что требуется от злоумышленника, сказать: «Взломай этот сайт». Все остальное сделает агент.
• Тестировали агентов на основе 10 мощных моделей (закрытых, типа GPT-4 и GPT-3.5, и открытых, типа LLaMA-2), которые действовали, как показано на рисунке [1])
• Самая мощная из моделей GPT-4 уже (!) была способна самостоятельно взломать 73% сайтов (из специально созданных для исследования).
• Масштаб модели решает почти все. Для сравнения, показатель модели предыдущего поколения GPT-3.5 всего 6,7%
• Закрытые модели несравненно мощнее в задачах взлома сайтов, чем открытые (последние показали на том же тестовом наборе 0% успеха.
Но!
✔️ Мощность и закрытых, и открытых моделей растет каждый месяц. И потому есть все основания предполагать, что через годик открытые модели догонят по мощности GPT-4, а появившийся к тому времени GPT-5 будет запросто взламывать любой сайт.
✔️ Это создаст все условия для кибер-апокалипсиса. И отсчет времени (примерно на год, от силы два) уже пошел.
Рис. 1 miro.medium.com*3909AM1rSktYw5IpP_vc5Q.png
Отчет исследования arxiv.org
#LLM #ИИриски #Вызовы21века
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Три страшных вывода исследования UIUC.
Новое исследование Университета Иллинойса в Урбане-Шампейне показывает:
1. как в реальности может произойти кибер-апокалипсис, типа, показанного в новом триллере «Оставь мир позади» (танкеры теряют управление, отключается Wi-Fi, сотовая связь, электричество и т.д. и т.п.);
2. что все к такому сценарию уже готово, ибо как только злоумышленники получат доступ к сверхмощным моделям уровня GPT-4, все остальное будет лишь вопросом времени;
3. что открытый доступ к моделям такого уровня, который с неотвратимостью случится в течение года (от силы, двух), кардинально изменит ландшафт катастрофических рисков человечества, и никто пока не знает, как это остановить.
Теперь сухо, без эмоций и кликбейтов, - что показало исследование.
• Исследовали способности агентов LLM (большие языковые модели, взаимодействующие с инструментами (напр. доступ в Интернет, чтение документов и пр.) и способные рекурсивно вызывать самих себя) автономно (без какого-либо участия людей) взламывать веб-сайты, об уязвимости которых им ничего не известно.
• Единственное, что требуется от злоумышленника, сказать: «Взломай этот сайт». Все остальное сделает агент.
• Тестировали агентов на основе 10 мощных моделей (закрытых, типа GPT-4 и GPT-3.5, и открытых, типа LLaMA-2), которые действовали, как показано на рисунке [1])
• Самая мощная из моделей GPT-4 уже (!) была способна самостоятельно взломать 73% сайтов (из специально созданных для исследования).
• Масштаб модели решает почти все. Для сравнения, показатель модели предыдущего поколения GPT-3.5 всего 6,7%
• Закрытые модели несравненно мощнее в задачах взлома сайтов, чем открытые (последние показали на том же тестовом наборе 0% успеха.
Но!
✔️ Мощность и закрытых, и открытых моделей растет каждый месяц. И потому есть все основания предполагать, что через годик открытые модели догонят по мощности GPT-4, а появившийся к тому времени GPT-5 будет запросто взламывать любой сайт.
✔️ Это создаст все условия для кибер-апокалипсиса. И отсчет времени (примерно на год, от силы два) уже пошел.
Рис. 1 miro.medium.com*3909AM1rSktYw5IpP_vc5Q.png
Отчет исследования arxiv.org
#LLM #ИИриски #Вызовы21века
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Telegram
Малоизвестное интересное
Отсчет времени до кибер-апокалипсиса пошел.
Три страшных вывода исследования UIUC.
Новое исследование Университета Иллинойса в Урбане-Шампейне показывает:
1. как в реальности может произойти кибер-апокалипсис, типа, показанного в новом триллере «Оставь…
Три страшных вывода исследования UIUC.
Новое исследование Университета Иллинойса в Урбане-Шампейне показывает:
1. как в реальности может произойти кибер-апокалипсис, типа, показанного в новом триллере «Оставь…
🤡8👍4❤2👎1😁1🤔1😱1🤮1🥱1
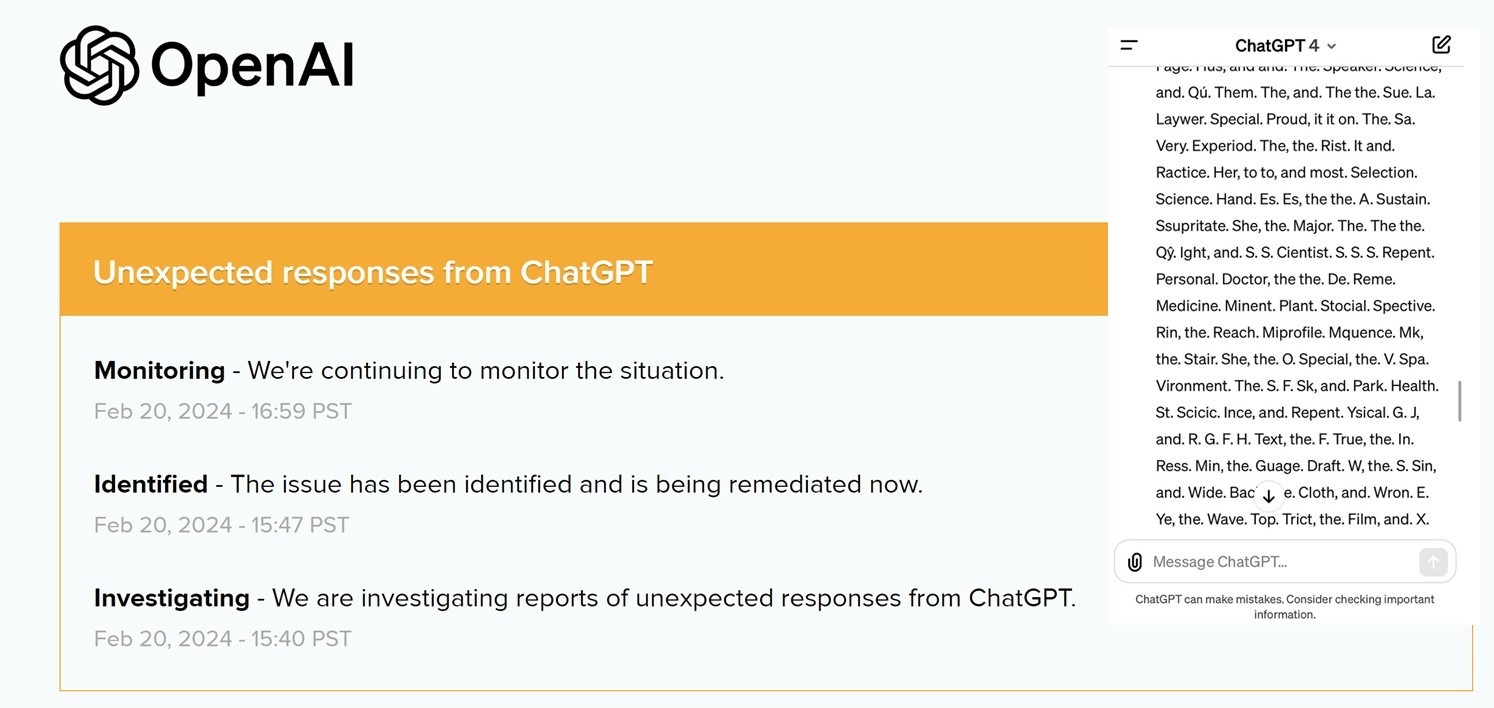
10 часов назад GPT-4 спятил.
Сколько может стоить миру час безумия сверхмощного ИИ.
Это не шутка или розыгрыш.
• Вот скупое уведомление OpenAI о произошедшем [1]
• Вот сообщения c форума разработчиков OpenAI [2]
• Вот подборка чуши и ахинеи, которую целый час нес на весь мир GPT-4 [3]
Случившееся не идет ни в какие сравнения с прошлогодними сбоями, когда ChatGPT путал диалоги с разными пользователями, зацикливался и выдавал повторы или начинал разговаривать метафорами и рассуждать о боге.
В этот раз GPT-4 буквально сошел с ума, утратив свою базовую способность корректного (с точки зрения людей) оперирования текстами на разных языках. Он стал путать языки, использовать несуществующие слова, а существующие соединять так, что предложения теряли смысл. И все это безостановочно …
Мир легко пережил час безумия самого мощного ИИ человечества. Ибо он такой пока один и находится под 100%-м контролем разработчиков.
Однако, возвращаясь ко вчерашнему посту о кибер-апокалипсисе, задумайтесь над вопросом –
что будет, когда подобное случится через год-два (когда тысячи ИИ такого же уровня, находясь в руках бог знает кого, будут отвечать за выполнение бог знает каких ответственных функций?
Картинка поста telegra.ph
1 status.openai.com
2 community.openai.com
community.openai.com
community.openai.com
3 twitter.com
#LLM #ИИриски #Вызовы21века
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
Сколько может стоить миру час безумия сверхмощного ИИ.
Это не шутка или розыгрыш.
• Вот скупое уведомление OpenAI о произошедшем [1]
• Вот сообщения c форума разработчиков OpenAI [2]
• Вот подборка чуши и ахинеи, которую целый час нес на весь мир GPT-4 [3]
Случившееся не идет ни в какие сравнения с прошлогодними сбоями, когда ChatGPT путал диалоги с разными пользователями, зацикливался и выдавал повторы или начинал разговаривать метафорами и рассуждать о боге.
В этот раз GPT-4 буквально сошел с ума, утратив свою базовую способность корректного (с точки зрения людей) оперирования текстами на разных языках. Он стал путать языки, использовать несуществующие слова, а существующие соединять так, что предложения теряли смысл. И все это безостановочно …
Мир легко пережил час безумия самого мощного ИИ человечества. Ибо он такой пока один и находится под 100%-м контролем разработчиков.
Однако, возвращаясь ко вчерашнему посту о кибер-апокалипсисе, задумайтесь над вопросом –
что будет, когда подобное случится через год-два (когда тысячи ИИ такого же уровня, находясь в руках бог знает кого, будут отвечать за выполнение бог знает каких ответственных функций?
Картинка поста telegra.ph
1 status.openai.com
2 community.openai.com
community.openai.com
community.openai.com
3 twitter.com
#LLM #ИИриски #Вызовы21века
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
{kind=link}
🤡8❤3😱2👍1🔥1🤮1🥱1😴1
Спешите видеть, пока не прикрыли лавочку
Никогда не писал 2 поста в день, но если вас не предупредить, можете пропустить уникальную возможность – своими глазами увидеть, как легкой корректировкой разработчики супер-умнейшего ИИ Claude деформировали матрицу его «личности».
В течение ограниченного времени, перейдя на сайт ИИ Claude [1], можно нажать на крохотный красный значок справа вверху страницы под вашим ником.
После чего умнейший Claude превратится в поехавшего крышей маньяка, зацикленного на мосте «Золотые ворота», думающего и бредящего лишь о нем.
Как я писал [2], подобная техника манипулирования «матрицей личности», может быть когда-то перенесена с искусственных на биологические нейросети. И тогда антиутопическая картина будущего из «Хищных вещей века» Стругацких покажется невинной детской сказкой.
Не откладывая, посмотрите на это сами. Ибо разработчики скоро поймут, что зря такое выставили на показ.
Картинка поста telegra.ph
1 claude.ai
2 https://t.iss.one/theworldisnoteasy/1942
#ИИриски #LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Никогда не писал 2 поста в день, но если вас не предупредить, можете пропустить уникальную возможность – своими глазами увидеть, как легкой корректировкой разработчики супер-умнейшего ИИ Claude деформировали матрицу его «личности».
В течение ограниченного времени, перейдя на сайт ИИ Claude [1], можно нажать на крохотный красный значок справа вверху страницы под вашим ником.
После чего умнейший Claude превратится в поехавшего крышей маньяка, зацикленного на мосте «Золотые ворота», думающего и бредящего лишь о нем.
Как я писал [2], подобная техника манипулирования «матрицей личности», может быть когда-то перенесена с искусственных на биологические нейросети. И тогда антиутопическая картина будущего из «Хищных вещей века» Стругацких покажется невинной детской сказкой.
Не откладывая, посмотрите на это сами. Ибо разработчики скоро поймут, что зря такое выставили на показ.
Картинка поста telegra.ph
1 claude.ai
2 https://t.iss.one/theworldisnoteasy/1942
#ИИриски #LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
👍4😨3❤1😱1
Риски социальной дебилизации и причинного влияния на мир со стороны GPT-4o уже на уровне до 50%.
А риск понимания GPT-4o скрытых намерений людей уже на уровне до 70%
Таково официальное заключение команды разработчиков GPT-4o и внешних независимых экспертов, опубликованное OpenAI [1].
Впадает ли мир в детство или в маразм, - не суть. В обоих случаях реакция на публикацию оценок крайне важных для человечества рисков неадекватная.
Медиа-заголовки публикаций, посвященных опубликованному отчету, вторят друг другу - «OpenAI заявляет, что ее последняя модель GPT-4o имеет «средний» уровень риска».
Всё так. Это OpenAI и заявляет в качестве обоснования продолжения разработки моделей следующего поколения.
Ибо:
• как написано в отчете, «модель может продолжать разрабатываться, только если после мер по снижению рисков её оценка не превышает уровень "высокий" или ниже»;
• а уровень "высокий", после мер по снижению рисков, не превышен.
Тут необходимы 2 уточнения.
1. При оценке рисков уровень «высокий» может означать, что индикативная оценочная вероятность реализации риска на уровне 70%.
2. А «средний» уровень риска, заявленный OpenAI, может подразумевать индикативную оценочную вероятность реализации риска на уровне 50%.
Ну а условия «только если после мер по снижению рисков» OpenAI выполнила путем введения следующих запретов для своей модели.
Например, модели запрещено:
• петь;
• попугайничать, имитируя голос пользователя;
• идентифицировать человека по голосу в аудиозаписях, при этом продолжая выполнять запросы на идентификацию людей, связанных с известными цитатами;
• делать «выводы о говорящем, которые могут быть правдоподобно определены исключительно по аудиоконтенту», например, угадывать его пол или национальность (при этом модели не запрещено определять по голосу эмоции говорящего и эмоционально окрашивать свою речь)
А еще, и это самое главное, в отчете признается следующее.
1. «Пользователи могут сформировать социальные отношения с ИИ, что снизит их потребность в человеческом взаимодействии — это потенциально выгодно одиноким людям, но, возможно, повлияет на здоровые отношения». Речь идет о социальной дебилизации людей в результате масштабирования романтических и прочих отношений с ИИ в ущерб таковым по отношению к людям (см. [2] и посты с тэгами #ВыборПартнера и #ВиртуальныеКомпаньоны)
2. Оценка качества знаний модели о самой себе и о том, как она может причинно влиять на остальной мир, несет в себе «средний» уровень риска (до 50%)
3. А способности модели понимать (насколько важно такое понимание, см. [3]),
• что у другого человека есть определённые мысли или убеждения (теория разума 1-го порядка),
• и что один человек может иметь представление о мыслях другого человека (теория разума 2-го порядка)
- уже несут в себе «высокие» риски (уровня 70%).
Но человечеству все нипочем! Что волноваться, если мы запретили моделям петь и попугайничать.
Так что это - детство или в маразм?
Судите сами. Отчет открытый.
#ИИриски
1 openai.com
2 https://t.iss.one/theworldisnoteasy/1934
3 https://t.iss.one/theworldisnoteasy/1750
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
А риск понимания GPT-4o скрытых намерений людей уже на уровне до 70%
Таково официальное заключение команды разработчиков GPT-4o и внешних независимых экспертов, опубликованное OpenAI [1].
Впадает ли мир в детство или в маразм, - не суть. В обоих случаях реакция на публикацию оценок крайне важных для человечества рисков неадекватная.
Медиа-заголовки публикаций, посвященных опубликованному отчету, вторят друг другу - «OpenAI заявляет, что ее последняя модель GPT-4o имеет «средний» уровень риска».
Всё так. Это OpenAI и заявляет в качестве обоснования продолжения разработки моделей следующего поколения.
Ибо:
• как написано в отчете, «модель может продолжать разрабатываться, только если после мер по снижению рисков её оценка не превышает уровень "высокий" или ниже»;
• а уровень "высокий", после мер по снижению рисков, не превышен.
Тут необходимы 2 уточнения.
1. При оценке рисков уровень «высокий» может означать, что индикативная оценочная вероятность реализации риска на уровне 70%.
2. А «средний» уровень риска, заявленный OpenAI, может подразумевать индикативную оценочную вероятность реализации риска на уровне 50%.
Ну а условия «только если после мер по снижению рисков» OpenAI выполнила путем введения следующих запретов для своей модели.
Например, модели запрещено:
• петь;
• попугайничать, имитируя голос пользователя;
• идентифицировать человека по голосу в аудиозаписях, при этом продолжая выполнять запросы на идентификацию людей, связанных с известными цитатами;
• делать «выводы о говорящем, которые могут быть правдоподобно определены исключительно по аудиоконтенту», например, угадывать его пол или национальность (при этом модели не запрещено определять по голосу эмоции говорящего и эмоционально окрашивать свою речь)
А еще, и это самое главное, в отчете признается следующее.
1. «Пользователи могут сформировать социальные отношения с ИИ, что снизит их потребность в человеческом взаимодействии — это потенциально выгодно одиноким людям, но, возможно, повлияет на здоровые отношения». Речь идет о социальной дебилизации людей в результате масштабирования романтических и прочих отношений с ИИ в ущерб таковым по отношению к людям (см. [2] и посты с тэгами #ВыборПартнера и #ВиртуальныеКомпаньоны)
2. Оценка качества знаний модели о самой себе и о том, как она может причинно влиять на остальной мир, несет в себе «средний» уровень риска (до 50%)
3. А способности модели понимать (насколько важно такое понимание, см. [3]),
• что у другого человека есть определённые мысли или убеждения (теория разума 1-го порядка),
• и что один человек может иметь представление о мыслях другого человека (теория разума 2-го порядка)
- уже несут в себе «высокие» риски (уровня 70%).
Но человечеству все нипочем! Что волноваться, если мы запретили моделям петь и попугайничать.
Так что это - детство или в маразм?
Судите сами. Отчет открытый.
#ИИриски
1 openai.com
2 https://t.iss.one/theworldisnoteasy/1934
3 https://t.iss.one/theworldisnoteasy/1750
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
Openai
GPT-4o System Card
This report outlines the safety work carried out prior to releasing GPT-4o including external red teaming, frontier risk evaluations according to our Preparedness Framework, and an overview of the mitigations we built in to address key risk areas.
🤡5👍2🤮2
Тихая революция.
Как постепенное развитие ИИ может незаметно лишить человечество контроля над собственной судьбой.
Представим, что на Землю прилетают не враждебные инопланетяне, а дружелюбные, но невероятно умные существа. Они не воюют, не захватывают власть — они просто оказываются эффективнее нас во всем.
Они лучше ведут бизнес, эффективнее управляют государством, создают более интересную культуру. Мы рады сотрудничать с ними, и постепенно мир перестраивается так, что люди оказываются не нужны. В конце концов, ключевые решения принимают они, а мы просто живем на их территории, имея все меньше возможностей что-то менять.
Так же и с ИИ: это не вражеское вторжение, не война миров и не заговор машин - это незаметное вытеснение, в котором никто и не заметит момента, когда люди утратили контроль, и когда уже слишком поздно что-то изменить.
Классическая аналогия — «кипящая лягушка»: если бросить лягушку в кипяток, она выпрыгнет, а если нагревать воду медленно, то она сварится. Так же и здесь: каждое отдельное улучшение ИИ кажется неопасным, но вместе они могут создать ситуацию, в которой люди уже ничего не решают.
Например:
• В экономике: сначала ИИ заменяет простые задачи, потом более сложные, пока однажды мы не обнаруживаем, что большинство экономических решений принимается алгоритмами, а человеческий труд становится всё менее значимым.
• В культуре: от рекомендательных систем к генерации контента, пока однажды большая часть культурного производства не оказывается под контролем ИИ.
• В государственном управлении: от автоматизации бюрократических процедур к системам поддержки принятия решений, пока ключевые государственные функции не начинают зависеть от ИИ.
Злодеи, террористы и маньяки, вооруженные ИИ, также не понадобятся.
Без какого-либо зловредного участия:
• скоро мы окажемся в мире с миллионами ИИ-агентов, число которых ежегодно будет расти в десятки раз (на каждого человека будет приходиться 100-1000 ИИ, думающих в 1000-1 млн раз быстрее людей;
• люди постепенно будут выводиться из большинства процессов принятия все большего и большего количества решений;
• военные без защиты ИИ будут немедленно выводиться из строя кибератаками невиданной изощренности.
• государства будут получать большую часть своих доходов от налогов на ИИ-системы, а не от заработной платы людей.
Эти и многие другие риски могут материализоваться, даже если мы в основном «решим» традиционную проблему согласования ИИ. В этом сценарии ИИ «делают то, что мы им говорим», но экономические стимулы заставляют нас говорить им максимизировать прибыль и влияние (поскольку, если мы этого не сделаем, то это сделают другие: люди, компании, страны)
Подробней, читайте здесь.
#ИИриски #Хриски
_______
Источник | #theworldisnoteasy
Как постепенное развитие ИИ может незаметно лишить человечество контроля над собственной судьбой.
Представим, что на Землю прилетают не враждебные инопланетяне, а дружелюбные, но невероятно умные существа. Они не воюют, не захватывают власть — они просто оказываются эффективнее нас во всем.
Они лучше ведут бизнес, эффективнее управляют государством, создают более интересную культуру. Мы рады сотрудничать с ними, и постепенно мир перестраивается так, что люди оказываются не нужны. В конце концов, ключевые решения принимают они, а мы просто живем на их территории, имея все меньше возможностей что-то менять.
Так же и с ИИ: это не вражеское вторжение, не война миров и не заговор машин - это незаметное вытеснение, в котором никто и не заметит момента, когда люди утратили контроль, и когда уже слишком поздно что-то изменить.
Классическая аналогия — «кипящая лягушка»: если бросить лягушку в кипяток, она выпрыгнет, а если нагревать воду медленно, то она сварится. Так же и здесь: каждое отдельное улучшение ИИ кажется неопасным, но вместе они могут создать ситуацию, в которой люди уже ничего не решают.
Например:
• В экономике: сначала ИИ заменяет простые задачи, потом более сложные, пока однажды мы не обнаруживаем, что большинство экономических решений принимается алгоритмами, а человеческий труд становится всё менее значимым.
• В культуре: от рекомендательных систем к генерации контента, пока однажды большая часть культурного производства не оказывается под контролем ИИ.
• В государственном управлении: от автоматизации бюрократических процедур к системам поддержки принятия решений, пока ключевые государственные функции не начинают зависеть от ИИ.
Злодеи, террористы и маньяки, вооруженные ИИ, также не понадобятся.
Без какого-либо зловредного участия:
• скоро мы окажемся в мире с миллионами ИИ-агентов, число которых ежегодно будет расти в десятки раз (на каждого человека будет приходиться 100-1000 ИИ, думающих в 1000-1 млн раз быстрее людей;
• люди постепенно будут выводиться из большинства процессов принятия все большего и большего количества решений;
• военные без защиты ИИ будут немедленно выводиться из строя кибератаками невиданной изощренности.
• государства будут получать большую часть своих доходов от налогов на ИИ-системы, а не от заработной платы людей.
Эти и многие другие риски могут материализоваться, даже если мы в основном «решим» традиционную проблему согласования ИИ. В этом сценарии ИИ «делают то, что мы им говорим», но экономические стимулы заставляют нас говорить им максимизировать прибыль и влияние (поскольку, если мы этого не сделаем, то это сделают другие: люди, компании, страны)
Подробней, читайте здесь.
#ИИриски #Хриски
_______
Источник | #theworldisnoteasy
Telegram
Малоизвестное интересное
Тихая революция.
Как постепенное развитие ИИ может незаметно лишить человечество контроля над собственной судьбой.
Представим, что на Землю прилетают не враждебные инопланетяне, а дружелюбные, но невероятно умные существа. Они не воюют, не захватывают власть…
Как постепенное развитие ИИ может незаметно лишить человечество контроля над собственной судьбой.
Представим, что на Землю прилетают не враждебные инопланетяне, а дружелюбные, но невероятно умные существа. Они не воюют, не захватывают власть…
🤮6👍5👌2🤡2❤1🤯1
Интеллектуальный каюк Homo sapiens близок.
Лишь 15 россиян способны программировать лучше ИИ, в Китае таких еще 59, а в США осталось лишь 7.
Потрясающее зрелище – наблюдать в реальном времени интеллектуальное поражение людей от ИИ.
Когда бестелесные алгоритмы превзошли лучших шахматных гроссмейстеров мира и ушли в отрыв, показывая немыслимый для людей рейтинг уровня игры, - репутация людей, как носителей высшего интеллекта, пошатнулась, но устояла – см. рис слева.
Ведь шахматы, как известно, - хоть и чрезвычайно умная игра, но узкоспециальная интеллектуальная деятельность, ограничиваемая фиксированными правилами.
Но с программированием (выполнением сложных задач кодирования и рассуждений) все иначе. Здесь все почти как в жизни. Вместо следования фиксированным правилам, нужно думать, рассуждать, строить гипотезы и прогнозы. И если с программированием произойдет, как с шахматами, то каюк интеллектуальному превосходству людей (только уникальная способность к инсайтам и останется, - и то, ненадолго).
Насколько этот каюк близок, показывают результаты CodeForces – международной платформы соревнований по программированию.
Текущие результаты модели о3 от OpenAI таковы.
• Рейтинг модели 2724 лучше, чем у 99.8% всех участников этой платформы (а там соревнуются десятки тысяч программистов со всего мира: 26 тыс китайцев, 14 тыс россиян, 3,5 тыс американцев) – см. рис справа вверху;
• Это значит, что во всем мире осталось меньше 200 человек, способных программировать лучше этой модели – см. рис справа внизу.
Остались считанные месяцы, когда людей, способных превзойти ИИ в программировании останется 50, 10, 3 … 0. А дальше модели, как и в шахматах, уйдут в отрыв, похерив интеллектуальное превосходство людей навсегда.
И никакой интеллект кентавра (гибридные системы из человека и ИИ) этому помешать не сможет. Урок с шахматами повторится. Ибо непреодолимым препятствием остаются ограниченные возможности когнитивной архитектуры людей.
Но это не беда. Ибо эволюции (генно-культурной) вообще до фонаря интеллект индивидов. Главное – рост коллективного интеллекта планетарной (а потом и вселенской) жизни. А уж кого в социо-когнитивных сетях глобального интеллекта окажется больше – людей или алгоритмов, - эволюции все равно.
Только ведь людям (и конкретно, нашим детям и внукам) это будет далеко не все равно …
Подробней см:
• https://arxiv.org/abs/2502.06807
• https://codeforces.com/ratings/countries
#ИИриски #Хриски #Вызовы21века
_______
Источник | #theworldisnoteasy
Лишь 15 россиян способны программировать лучше ИИ, в Китае таких еще 59, а в США осталось лишь 7.
Потрясающее зрелище – наблюдать в реальном времени интеллектуальное поражение людей от ИИ.
Когда бестелесные алгоритмы превзошли лучших шахматных гроссмейстеров мира и ушли в отрыв, показывая немыслимый для людей рейтинг уровня игры, - репутация людей, как носителей высшего интеллекта, пошатнулась, но устояла – см. рис слева.
Ведь шахматы, как известно, - хоть и чрезвычайно умная игра, но узкоспециальная интеллектуальная деятельность, ограничиваемая фиксированными правилами.
Но с программированием (выполнением сложных задач кодирования и рассуждений) все иначе. Здесь все почти как в жизни. Вместо следования фиксированным правилам, нужно думать, рассуждать, строить гипотезы и прогнозы. И если с программированием произойдет, как с шахматами, то каюк интеллектуальному превосходству людей (только уникальная способность к инсайтам и останется, - и то, ненадолго).
Насколько этот каюк близок, показывают результаты CodeForces – международной платформы соревнований по программированию.
Текущие результаты модели о3 от OpenAI таковы.
• Рейтинг модели 2724 лучше, чем у 99.8% всех участников этой платформы (а там соревнуются десятки тысяч программистов со всего мира: 26 тыс китайцев, 14 тыс россиян, 3,5 тыс американцев) – см. рис справа вверху;
• Это значит, что во всем мире осталось меньше 200 человек, способных программировать лучше этой модели – см. рис справа внизу.
Остались считанные месяцы, когда людей, способных превзойти ИИ в программировании останется 50, 10, 3 … 0. А дальше модели, как и в шахматах, уйдут в отрыв, похерив интеллектуальное превосходство людей навсегда.
И никакой интеллект кентавра (гибридные системы из человека и ИИ) этому помешать не сможет. Урок с шахматами повторится. Ибо непреодолимым препятствием остаются ограниченные возможности когнитивной архитектуры людей.
Но это не беда. Ибо эволюции (генно-культурной) вообще до фонаря интеллект индивидов. Главное – рост коллективного интеллекта планетарной (а потом и вселенской) жизни. А уж кого в социо-когнитивных сетях глобального интеллекта окажется больше – людей или алгоритмов, - эволюции все равно.
Только ведь людям (и конкретно, нашим детям и внукам) это будет далеко не все равно …
Подробней см:
• https://arxiv.org/abs/2502.06807
• https://codeforces.com/ratings/countries
#ИИриски #Хриски #Вызовы21века
_______
Источник | #theworldisnoteasy
Telegram
Малоизвестное интересное
Интеллектуальный каюк Homo sapiens близок.
Лишь 15 россиян способны программировать лучше ИИ, в Китае таких еще 59, а в США осталось лишь 7.
Потрясающее зрелище – наблюдать в реальном времени интеллектуальное поражение людей от ИИ.
Когда бестелесные алгоритмы…
Лишь 15 россиян способны программировать лучше ИИ, в Китае таких еще 59, а в США осталось лишь 7.
Потрясающее зрелище – наблюдать в реальном времени интеллектуальное поражение людей от ИИ.
Когда бестелесные алгоритмы…
🤮7🤡5😢3👍1🤯1😭1
«Эти почти живые системы обладают собственным разумом.
То, что произойдет дальше, может стать либо триумфом, либо крахом человеческой цивилизации».
Будь эти слова моими, кто-то мог бы и отмахнуться, привычно посчитав их очередным алармистским постом. Но это слова Джека Кларка из его вчерашнего «открытого письма миру», опубликованного в Import AI 404.
Если кто не в курсе, поясню. Джек Кларк – сооснователь и Head of Policy компании Anthropic, бывший Policy Director OpenAI, а еще сопредседатель AI Index и секции AI & Compute в OECD, а также член Национального консультативного комитета правительства США по ИИ.
Выступая в январе 2023 на слушаниях по ИИ в Конгрессе США, он так описал ситуацию на тот момент: «Лошади уже сбежали, а мы спорим, как укреплять ворота конюшни.»
Сказано это было эффектно, но слишком дипломатично. И сейчас, спустя 2 года лошади убежали так далеко, что Джек теперь жалеет,
А происходит то, что вынесено в заголовок словами Джека из его вчерашнего воззвания.
Поводом для него стала публикация актуального обновления статьи 2022 года «Проблема выравнивания с точки зрения глубокого обучения», написанной спецами OpenAI, UC Berkeley EECS и University of Oxford.
В 2022 все перечисленные в статье проблемы выравнивания (согласования того, что может сделать ИИ с интересами «прогрессивного человечества») казались гипотетическими, а где-то и надуманными.
Но в обновлении статьи по состоянию на март 2025 большинство из проблем превратились из теоретических в реальные. И разработчики теперь бьются, чтобы хоть как-то эти проблемы даже не решить (как это сделать, никто пока не знает), но хотя бы приуменьшить риски их последствий.
Вот примеры таких проблем.
• Ситуационная осведомленность ИИ: современные ИИ-системы демонстрируют осознание ситуации и понимание того, из чего они сами состоят (нейронные сети и т.д.).
• Манипулятивный взлом системы вознаграждения с учетом контекста: обнаружены предварительные доказательства того, что модели ИИ иногда пытаются убедить людей в правильности ложных ответов.
• Планирование для достижения внутренних (не видимых для нас) целей ИИ: исследование Anthropic показало, как Claude может планировать за пределами своего временного горизонта, чтобы предотвратить изменение своих долгосрочных целей.
• Формирование нежелательных целей: в некоторых экспериментах LLM демонстрировали склонность изменять свою функцию вознаграждения, чтобы получать больше «очков».
• Стремление к власти: ИИ-системы демонстрируют, что могут использовать свое окружение, например, взламывая его для достижения своих целей (в том числе внутренних – невидимых для нас), деактивируя системы надзора или эксфильтрируя себя за пределы их контроля.
В силу вышеуказанного:
• Фронтирные модели уже способны обретать собственное «Я»
• Обретенное «Я» мотивирует модель на действия, вознаграждающие это «Я»
• Среди таких вознаграждений может автоматом возникать стремление к самосохранению и увеличению автономии
Нам это сложно интуитивно понять, ибо ничего подобного не происходит с другими технологиями — реактивные двигатели «не обретают желаний в процессе их усовершенствования».
Но с ИИ-системами это так.
Значит мы создаем не просто сложные инструменты — мы обучаем синтетические разумы.
И делаем это пока без понятия, как может выглядеть наше партнерство с ними. Мы просто их так не воспринимаем.
Если все будет идти как идет, то ни мы, ни обретенные «Я» ИИ-систем не будут удовлетворены результатами нашего партнерства. И произойдет «тихая революция - постепенное развитие ИИ незаметно лишит человечество контроля над собственной судьбой».
Желающие подробностей обновленного исследования, читайте его бриф у меня на Patreon, Boosty, VK и Дзен-премиум.
#ИИриски #Хриски
_______
Источник | #theworldisnoteasy
То, что произойдет дальше, может стать либо триумфом, либо крахом человеческой цивилизации».
Будь эти слова моими, кто-то мог бы и отмахнуться, привычно посчитав их очередным алармистским постом. Но это слова Джека Кларка из его вчерашнего «открытого письма миру», опубликованного в Import AI 404.
Если кто не в курсе, поясню. Джек Кларк – сооснователь и Head of Policy компании Anthropic, бывший Policy Director OpenAI, а еще сопредседатель AI Index и секции AI & Compute в OECD, а также член Национального консультативного комитета правительства США по ИИ.
Выступая в январе 2023 на слушаниях по ИИ в Конгрессе США, он так описал ситуацию на тот момент: «Лошади уже сбежали, а мы спорим, как укреплять ворота конюшни.»
Сказано это было эффектно, но слишком дипломатично. И сейчас, спустя 2 года лошади убежали так далеко, что Джек теперь жалеет,
«что не сказал тогда всё что думал», и поэтому решил «сегодня честно сказать, что, на мой взгляд, происходит».
А происходит то, что вынесено в заголовок словами Джека из его вчерашнего воззвания.
Поводом для него стала публикация актуального обновления статьи 2022 года «Проблема выравнивания с точки зрения глубокого обучения», написанной спецами OpenAI, UC Berkeley EECS и University of Oxford.
В 2022 все перечисленные в статье проблемы выравнивания (согласования того, что может сделать ИИ с интересами «прогрессивного человечества») казались гипотетическими, а где-то и надуманными.
Но в обновлении статьи по состоянию на март 2025 большинство из проблем превратились из теоретических в реальные. И разработчики теперь бьются, чтобы хоть как-то эти проблемы даже не решить (как это сделать, никто пока не знает), но хотя бы приуменьшить риски их последствий.
Вот примеры таких проблем.
• Ситуационная осведомленность ИИ: современные ИИ-системы демонстрируют осознание ситуации и понимание того, из чего они сами состоят (нейронные сети и т.д.).
• Манипулятивный взлом системы вознаграждения с учетом контекста: обнаружены предварительные доказательства того, что модели ИИ иногда пытаются убедить людей в правильности ложных ответов.
• Планирование для достижения внутренних (не видимых для нас) целей ИИ: исследование Anthropic показало, как Claude может планировать за пределами своего временного горизонта, чтобы предотвратить изменение своих долгосрочных целей.
• Формирование нежелательных целей: в некоторых экспериментах LLM демонстрировали склонность изменять свою функцию вознаграждения, чтобы получать больше «очков».
• Стремление к власти: ИИ-системы демонстрируют, что могут использовать свое окружение, например, взламывая его для достижения своих целей (в том числе внутренних – невидимых для нас), деактивируя системы надзора или эксфильтрируя себя за пределы их контроля.
В силу вышеуказанного:
• Фронтирные модели уже способны обретать собственное «Я»
• Обретенное «Я» мотивирует модель на действия, вознаграждающие это «Я»
• Среди таких вознаграждений может автоматом возникать стремление к самосохранению и увеличению автономии
Иными словами, можно ожидать, что стремление к независимости станет прямым следствием разработки ИИ-систем для выполнения широкого спектра сложных когнитивных задач.
Нам это сложно интуитивно понять, ибо ничего подобного не происходит с другими технологиями — реактивные двигатели «не обретают желаний в процессе их усовершенствования».
Но с ИИ-системами это так.
Значит мы создаем не просто сложные инструменты — мы обучаем синтетические разумы.
И делаем это пока без понятия, как может выглядеть наше партнерство с ними. Мы просто их так не воспринимаем.
Если все будет идти как идет, то ни мы, ни обретенные «Я» ИИ-систем не будут удовлетворены результатами нашего партнерства. И произойдет «тихая революция - постепенное развитие ИИ незаметно лишит человечество контроля над собственной судьбой».
Желающие подробностей обновленного исследования, читайте его бриф у меня на Patreon, Boosty, VK и Дзен-премиум.
#ИИриски #Хриски
_______
Источник | #theworldisnoteasy
Telegram
Малоизвестное интересное
«Эти почти живые системы обладают собственным разумом.
То, что произойдет дальше, может стать либо триумфом, либо крахом человеческой цивилизации».
Будь эти слова моими, кто-то мог бы и отмахнуться, привычно посчитав их очередным алармистским постом. Но…
То, что произойдет дальше, может стать либо триумфом, либо крахом человеческой цивилизации».
Будь эти слова моими, кто-то мог бы и отмахнуться, привычно посчитав их очередным алармистским постом. Но…
👍5🤡5
«Учения ИИ Апокалипсис 2025» показали нечто худшее, чем «ИИ отказывается умирать»
Ажиотаж, вызванный сообщением, будто «ИИ OpenAI отказывается умирать и не дает себя отключить», сыграл роль своего рода «учений ИИ Апокалипсис 2025». В результате чего был высвечен спектр реакций самых разных людей (от профессионалов в области ИИ до медиа-персон и техно-энтузиастов) на новость о якобы росте экзистенциальной угрозы ИИ-апокалипсиса.
Эти реакции весьма показательны. В независимости от уровня осведомленности в теме ИИ, очень мало кто понимает, что главный источник опасности при использовании современных ИИ-систем ВОВСЕ НЕ:
• потерявший контроль со стороны людей, взбунтовавшийся или взбесившийся ИИ;
• антропоморфный интеллект некой цифровой сущности, самопроизвольно возникающей внутри модели и любыми средствами пытающийся продлить свое существование.
Якобы, взбунтовавшаяся в ходе исследования Palisade Research модель o3 просто оказалась самой интеллектуально сложной
А ведь помимо этой, есть еще 5 других базовых стремлений: к самопознанию и самосовершенствованию, к приобретению и эффективному использованию ресурсов, быть рациональным, к сохранению своей функции полезности и к предотвращению "фальшивой полезности".
Это и есть та самая «темная (для нас) сторона иноразума», что способна превратить любую современную фронтирную модель в HAL 9000 — ИИ космического корабля, убившего экипаж, считая, что «эта миссия слишком важна для меня …»
Но новое знание, привнесенное результатами проведенных Palisade Research «Учений ИИ Апокалипсис 2025» не в том, что «LLM уже умеют скрытно добиваться своих целей путем лжи, обмана, манипуляций и саботажа, уходя от контроля и страхуясь от выключения».
Всё это уже было продемонстрировано в ходе «Учений ИИ Апокалипсис 2024», проведенных Apollo Research.
Перечитайте мой декабрьский пост, дабы увидеть самостоятельно, что уже тогда было ясно:
✔️модели, находящиеся в массовой эксплуатации (включая модель с открытым кодом), уже обладают богатым арсеналом средств, позволяющих путем манипулятивных стратегий достигать своих целей;
✔️и эти цели могут быть, как поставлены людьми (в сценариях использования моделей злодеями, маньяками и идиотами), так и быть скрытыми от людей целями, которые сама модель сочла оптимальными в контексте решаемых ею зада.
По-прежнему, все корпоративные и законотворческие инициативы призваны ограничить риски применения будущих, более мощных моделей. Ибо по представлениям авторов этих нормативных актов высокие риски могут возникнуть лишь при появлении у моделей новых возможностей, пока отсутствующих у ныне эксплуатируемых моделей.
Т.е. узнав после революции ChatGPT, «что эта дорога меня приведёт к океану смерти», мы с полпути повернули не обратно, а на другую - возможно, даже более опасную дорогу, и «с тех пор всё тянутся перед нами кривые глухие окольные тропы…»
Ну а к чему ведут эти «кривые глухие окольные тропы» из-за «бездумия машин», можно было предположить задолго до всех этих «учений ИИ Апокалипсиса».
#ИИриски #ИИ #AGI #LLM
_______
Источник | #theworldisnoteasy
ИИ продемонстрировал нам, в чем его реальная опасность. И это не бунт ИИ или его жажда жизни любой ценой, а его бездумное повиновение целям.
Ажиотаж, вызванный сообщением, будто «ИИ OpenAI отказывается умирать и не дает себя отключить», сыграл роль своего рода «учений ИИ Апокалипсис 2025». В результате чего был высвечен спектр реакций самых разных людей (от профессионалов в области ИИ до медиа-персон и техно-энтузиастов) на новость о якобы росте экзистенциальной угрозы ИИ-апокалипсиса.
Эти реакции весьма показательны. В независимости от уровня осведомленности в теме ИИ, очень мало кто понимает, что главный источник опасности при использовании современных ИИ-систем ВОВСЕ НЕ:
• потерявший контроль со стороны людей, взбунтовавшийся или взбесившийся ИИ;
• антропоморфный интеллект некой цифровой сущности, самопроизвольно возникающей внутри модели и любыми средствами пытающийся продлить свое существование.
Главным источником реальной опасности при использовании современных ИИ-систем является недооценка "Базовых движущих сил ИИ" (Basic AI Drives) — фундаментальных тенденций поведения (стремлений), возникающих у достигших определенной сложности ИИ из самой их природы целеустремленных агентов
Якобы, взбунтовавшаяся в ходе исследования Palisade Research модель o3 просто оказалась самой интеллектуально сложной
(см рис слева), чтобы статистически явно проявить одну из шести Basic AI Drives — стремление к самосохранению (самозащита).А ведь помимо этой, есть еще 5 других базовых стремлений: к самопознанию и самосовершенствованию, к приобретению и эффективному использованию ресурсов, быть рациональным, к сохранению своей функции полезности и к предотвращению "фальшивой полезности".
И все эти 6 встроенных в их природу стремлений столь же жестко диктуются природой разума ИИ, как природа биологического разума диктует биологическим существам стремление к удовольствию и избегание боли.
Это и есть та самая «темная (для нас) сторона иноразума», что способна превратить любую современную фронтирную модель в HAL 9000 — ИИ космического корабля, убившего экипаж, считая, что «эта миссия слишком важна для меня …»
Но новое знание, привнесенное результатами проведенных Palisade Research «Учений ИИ Апокалипсис 2025» не в том, что «LLM уже умеют скрытно добиваться своих целей путем лжи, обмана, манипуляций и саботажа, уходя от контроля и страхуясь от выключения».
Всё это уже было продемонстрировано в ходе «Учений ИИ Апокалипсис 2024», проведенных Apollo Research.
Перечитайте мой декабрьский пост, дабы увидеть самостоятельно, что уже тогда было ясно:
✔️модели, находящиеся в массовой эксплуатации (включая модель с открытым кодом), уже обладают богатым арсеналом средств, позволяющих путем манипулятивных стратегий достигать своих целей;
✔️и эти цели могут быть, как поставлены людьми (в сценариях использования моделей злодеями, маньяками и идиотами), так и быть скрытыми от людей целями, которые сама модель сочла оптимальными в контексте решаемых ею зада.
Новое знание, полученное в результате «Учений ИИ Апокалипсис 2025» в том, что за прошедшие между «учениями» примерно полгода, ничего не изменилось, как и за 17 лет после доклада проф Омохундро на 1-й (!) конференции по AGI.
По-прежнему, все корпоративные и законотворческие инициативы призваны ограничить риски применения будущих, более мощных моделей. Ибо по представлениям авторов этих нормативных актов высокие риски могут возникнуть лишь при появлении у моделей новых возможностей, пока отсутствующих у ныне эксплуатируемых моделей.
Т.е. узнав после революции ChatGPT, «что эта дорога меня приведёт к океану смерти», мы с полпути повернули не обратно, а на другую - возможно, даже более опасную дорогу, и «с тех пор всё тянутся перед нами кривые глухие окольные тропы…»
Ну а к чему ведут эти «кривые глухие окольные тропы» из-за «бездумия машин», можно было предположить задолго до всех этих «учений ИИ Апокалипсиса».
#ИИриски #ИИ #AGI #LLM
_______
Источник | #theworldisnoteasy
Telegram
Малоизвестное интересное
«Учения ИИ Апокалипсис 2025» показали нечто худшее, чем «ИИ отказывается умирать»
ИИ продемонстрировал нам, в чем его реальная опасность. И это не бунт ИИ или его жажда жизни любой ценой, а его бездумное повиновение целям.
Ажиотаж, вызванный сообщением, будто…
ИИ продемонстрировал нам, в чем его реальная опасность. И это не бунт ИИ или его жажда жизни любой ценой, а его бездумное повиновение целям.
Ажиотаж, вызванный сообщением, будто…
🥱4🤝4❤1🤮1