#StateoftheArt
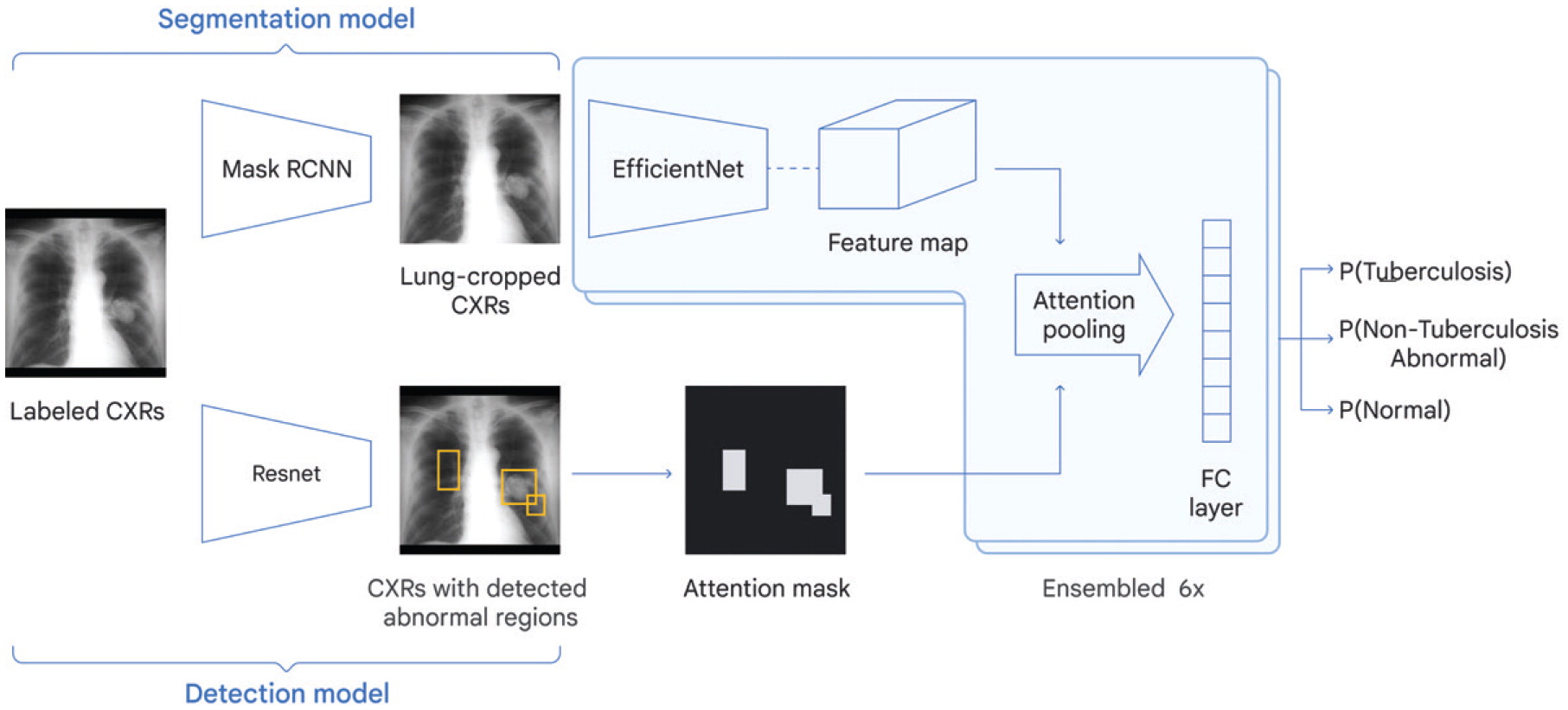
Каждый год туберкулез убивает 1,4 миллиона человек по всему миру. Google присоединился к борьбе с болезнью, разработав нейронную сеть для автоматизации обнаружения и ускорения лечения туберкулеза. Применять ее планируется в местах, где не хватает квалифицированных врачей.
Глубоко обученная модель (DLS) от Google AI показала лучшие результаты, чем рентгенологи, при обнаружении туберкулеза на рентгенограммах грудной клетки. Симуляции показывают, что применение DLS для выявления туберкулеза по рентгенограммам грудной клетки снижает стоимость процедуры на 40–80% в расчете на одного пациента.
_______
Источник | #neurohive
Каждый год туберкулез убивает 1,4 миллиона человек по всему миру. Google присоединился к борьбе с болезнью, разработав нейронную сеть для автоматизации обнаружения и ускорения лечения туберкулеза. Применять ее планируется в местах, где не хватает квалифицированных врачей.
Глубоко обученная модель (DLS) от Google AI показала лучшие результаты, чем рентгенологи, при обнаружении туберкулеза на рентгенограммах грудной клетки. Симуляции показывают, что применение DLS для выявления туберкулеза по рентгенограммам грудной клетки снижает стоимость процедуры на 40–80% в расчете на одного пациента.
_______
Источник | #neurohive
{kind=link}
LIMA: метод предобучения LLM на 1000 примерах позволил достичь точности GPT-4
Новый метод LIMA основан на гипотезе поверхностного выравнивания (Superficial Alignment Hypothesis), согласно которой почти все знания и способности моделей усваиваются во время предварительного обучения.
Для проверки гипотезы исследователи выбрали 1 000 примеров. 750 лучших вопросов и ответов отобраны на форумах, таких как Stack Exchange и wikiHow, с учетом качества ответов и разнообразия тем. 250 примеров составили вручную сгенерированные запросы и ответы. На этом датаесете была дообучена модель LLaMA.
Для сравнения LIMA с другими моделями генерировался один ответ для каждой тестовой подсказки. Затем волонтеры сравнивали ответы LIMA с каждой из базовых моделей и выбирали победителя. Эксперимент повторили, заменив волонтеров моделью GPT-4 для выбора победителя. LIMA показала лучшие или равные результаты с GPT-4, Bard и DaVinci003 в 43%, 58% и 65% случаев соответственно.
#StateoftheArt
_______
Источник | #neurohive
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Новый метод LIMA основан на гипотезе поверхностного выравнивания (Superficial Alignment Hypothesis), согласно которой почти все знания и способности моделей усваиваются во время предварительного обучения.
Для проверки гипотезы исследователи выбрали 1 000 примеров. 750 лучших вопросов и ответов отобраны на форумах, таких как Stack Exchange и wikiHow, с учетом качества ответов и разнообразия тем. 250 примеров составили вручную сгенерированные запросы и ответы. На этом датаесете была дообучена модель LLaMA.
Для сравнения LIMA с другими моделями генерировался один ответ для каждой тестовой подсказки. Затем волонтеры сравнивали ответы LIMA с каждой из базовых моделей и выбирали победителя. Эксперимент повторили, заменив волонтеров моделью GPT-4 для выбора победителя. LIMA показала лучшие или равные результаты с GPT-4, Bard и DaVinci003 в 43%, 58% и 65% случаев соответственно.
#StateoftheArt
_______
Источник | #neurohive
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
💥 Würstchen - открытая text-to-image модель, которая генерирует изображения быстрее и потребляет гораздо меньше памяти, чем диффузные модели, такие как Stable Diffusion, достигая сравнимых результатов. Подход основан на пайплайне из трех моделей: VQGAN, энкодер/декодер изображения и text-conditional диффузная модель.
Затраты на обучение модели снизились в 16 раз по сравнению со Stable Diffusion 1.4. Такого результата удалось добиться путем добавления этапа сжатия изображений 512x512 в 42 раза до разрешения 12x12. Демо модели доступно на HuggingFace, открытый код выложен на Github.
#StateoftheArt
_______
Источник | #neurohive
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Затраты на обучение модели снизились в 16 раз по сравнению со Stable Diffusion 1.4. Такого результата удалось добиться путем добавления этапа сжатия изображений 512x512 в 42 раза до разрешения 12x12. Демо модели доступно на HuggingFace, открытый код выложен на Github.
#StateoftheArt
_______
Источник | #neurohive
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
CRAM: новая аппаратная архитектура снижает энергопотребление ИИ в 1000 раз
Исследователи из Университета Миннесоты Твин-Ситис представили архитектуру аппаратного обеспечения Computational Random-Access Memory (CRAM), которая создана с целью резко сократить энергопотребление. Статья опубликована в npj Unconventional Computing. В традиционных методах применяется энергоемкая передача данных между логическими блоками и памятью. CRAM обрабатывает данные полностью в массиве памяти, в основе подхода лежит технология спинтронных устройств, использующая спин электронов для хранения данных.
CRAM способен сократить использование энергии ИИ в 1000 раз, решая одну из главных проблем в этой области: потребление энергоресурсов. Международное энергетическое агентство (IEA) прогнозирует, что потребление энергии ИИ увеличится более чем в два раза, с 460 ТВт/ч в 2022 году до 1000 ТВт/ч к 2026 году, что эквивалентно общему потреблению электроэнергии в Японии.
#Stateoftheart
_______
Источник | #neurohive
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Исследователи из Университета Миннесоты Твин-Ситис представили архитектуру аппаратного обеспечения Computational Random-Access Memory (CRAM), которая создана с целью резко сократить энергопотребление. Статья опубликована в npj Unconventional Computing. В традиционных методах применяется энергоемкая передача данных между логическими блоками и памятью. CRAM обрабатывает данные полностью в массиве памяти, в основе подхода лежит технология спинтронных устройств, использующая спин электронов для хранения данных.
CRAM способен сократить использование энергии ИИ в 1000 раз, решая одну из главных проблем в этой области: потребление энергоресурсов. Международное энергетическое агентство (IEA) прогнозирует, что потребление энергии ИИ увеличится более чем в два раза, с 460 ТВт/ч в 2022 году до 1000 ТВт/ч к 2026 году, что эквивалентно общему потреблению электроэнергии в Японии.
#Stateoftheart
_______
Источник | #neurohive
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
{kind=link}