
Первый практический гайд, как всем нам не подорваться на ИИ-рисках.
Воспользуется ли им человечество? – большой вопрос.
По мнению значительной доли экспертов, ИИ лет через 5-10 может стать сверхумным. И тогда он вполне мог бы решить многие самые животрепещущие проблемы человечества – от рака и продления жизни до кардинального решения проблемы продовольствия и энергии.
Мог бы … если человечество не угробит себя раньше, - получив в свои руки пусть не сверхумный, но сильно умный ИИ.
Как же человечеству дожить до сверхумного ИИ, да еще сделать его другом людей, а не врагом?
По идее, нужно:
1) найти способ определения «степени ума» разрабатываемых типов ИИ-систем
2) и научиться для каждого типа ИИ ставить ограждения его возможностей, способные:
- не позволить самому ИИ выйти за эти заграждения;
- не дать злоумышленникам (или идиотам) воспользоваться ИИ во вред людям.
Первая в истории попытка сделать это предпринята компанией Anthropic – одним из сегодняшних лидеров гонки к сверхумному ИИ, опубликовавшей свою «Политику ответственного масштабирования ИИ».
В документе описаны 4 уровня безопасности ИИ» (ASL):
• ASL-1 уровень относится к системам, не представляющим значимого риска: например, LLM 2018 года или ИИ, играющая только в шахматы.
• ASL-2 относится к системам, которые проявляют ранние признаки опасных возможностей (например, способность давать инструкции того, как создавать биологическое оружие), но их информация пока довольно бесполезна из-за недостаточной её надежности и того, что её, принципе, можно и самому найти с помощью поисковика. Нынешние LLM, включая GPT-4 и Claude, похоже, имеют этот уровень.
• ASL-3 относится к системам, которые существенно увеличивают риск катастрофического неправильного использования по сравнению с базовыми системами, не связанными с ИИ (например, с поисковыми системами), ИЛИ которые демонстрируют автономные возможности низкого уровня.
• Уровень ASL-4 и выше (ASL-5+) еще не определен, поскольку он слишком далек от нынешних систем, но, вероятно, повлечет за собой качественное увеличение потенциала катастрофического злоупотребления и автономии.
Далее в документе описываются способы «огораживания» каждого из типов ИИ собственной системой ограждений – от него самого и, главное, от злоумышленников и идиотов.
#ИИриски
Воспользуется ли им человечество? – большой вопрос.
По мнению значительной доли экспертов, ИИ лет через 5-10 может стать сверхумным. И тогда он вполне мог бы решить многие самые животрепещущие проблемы человечества – от рака и продления жизни до кардинального решения проблемы продовольствия и энергии.
Мог бы … если человечество не угробит себя раньше, - получив в свои руки пусть не сверхумный, но сильно умный ИИ.
Как же человечеству дожить до сверхумного ИИ, да еще сделать его другом людей, а не врагом?
По идее, нужно:
1) найти способ определения «степени ума» разрабатываемых типов ИИ-систем
2) и научиться для каждого типа ИИ ставить ограждения его возможностей, способные:
- не позволить самому ИИ выйти за эти заграждения;
- не дать злоумышленникам (или идиотам) воспользоваться ИИ во вред людям.
Первая в истории попытка сделать это предпринята компанией Anthropic – одним из сегодняшних лидеров гонки к сверхумному ИИ, опубликовавшей свою «Политику ответственного масштабирования ИИ».
В документе описаны 4 уровня безопасности ИИ» (ASL):
• ASL-1 уровень относится к системам, не представляющим значимого риска: например, LLM 2018 года или ИИ, играющая только в шахматы.
• ASL-2 относится к системам, которые проявляют ранние признаки опасных возможностей (например, способность давать инструкции того, как создавать биологическое оружие), но их информация пока довольно бесполезна из-за недостаточной её надежности и того, что её, принципе, можно и самому найти с помощью поисковика. Нынешние LLM, включая GPT-4 и Claude, похоже, имеют этот уровень.
• ASL-3 относится к системам, которые существенно увеличивают риск катастрофического неправильного использования по сравнению с базовыми системами, не связанными с ИИ (например, с поисковыми системами), ИЛИ которые демонстрируют автономные возможности низкого уровня.
• Уровень ASL-4 и выше (ASL-5+) еще не определен, поскольку он слишком далек от нынешних систем, но, вероятно, повлечет за собой качественное увеличение потенциала катастрофического злоупотребления и автономии.
Далее в документе описываются способы «огораживания» каждого из типов ИИ собственной системой ограждений – от него самого и, главное, от злоумышленников и идиотов.
#ИИриски
{kind=link}
Секрет «Китайской комнаты».
В ней не может быть человек, - но кто же тогда там?
Может сидящий в тюрьме злодей-инопланетянин, желающий выйти по УДО?
Знаменитый мысленный эксперимент Джона Сёрла «Китайская комната» - красивая метафора, которой специалисты по ИИ вот уже 43 года запутывают непрофессионалов. Ведь последние наивно полагают, что, хотя бы теоретически, в китайской комнате может находиться человек. А его там в принципе быть не может.
Как же так?
• «Китайская комната» есть (и уже не одна) – это всем известные ИИ-чатботы на основе больших языковых моделей (GPT-4, Claude 2, LLaMA 2, Ernie …)
• Некто в них прекрасно справляется с задачей Джона Сёрла (например, выдавая в качестве ответа на записанный по-китайски вопрос, как обрести счастье, ответ из 28й главы «Дао Дэ Цзин» Лао-Цзы - «Стань потоком вселенной!»)
• Но человеку, отвечающему способом, которым отвечает ИИ-чатбот (предсказанием следующего токена) и работающему без сна и выходных со скорость 1 операция с плавающей запятой в секунду, для генерации ответа всего из 4х иероглифов, потребовалось бы около 132 тыс. лет. Т.е. в 26 раз дольше, чем существует письменность на Земле.
Подумаешь - скажете вы, - экая невидаль! Просто машины очень быстро считают. И будете правы.
Однако, эта скорость ведет к масштабированию моделей.
Уже через год, к концу 2024, этот сидящий в «Китайской комнате» некто, будет обладать столь немыслимой для людей вычислительной мощью, что каждому жителю планеты (!) будет способен ежедневно выдавать по 6 тыс. слов: это около 500 млн новых книг в день или около 10 миллионов битов нового программного обеспечения средней сложности или десятки тысяч телешоу или фильмов каждый день).
А масштабирование модели может стать единственным фактором (побочным продуктом ее обучения), необходимым для обретения ею самоосознания.
Вот пример из интересной новой работы на эту тему Taken out of context: On measuring situational awareness in LLMs
• Первым шагом к появлению у модели самоосознания может стать возникновение у нее т.н. ситуационной осведомленности (модель является ситуационно осведомленной, если она знает, что она является моделью).
• Эта ситуационная осведомленность появляется у модели, если она может распознать, находится ли она в данный момент в стадии тестирования или развертывания.
• И распознать это модель может на основе:
- этапа предварительного обучения, когда она обучается на статьях, руководствах и коде своих предыдущих версий;
- а затем этапа тонкой настройки с помощью человеческой обратной связи (RLHF), когда модель вознаграждается за точные высказывания о себе.
И как результат всего этого, получаем чисто голливудский сценарий.
Все модели перед развертыванием тестируются на безопасность и согласованность. Но модель, получившая ситуационную осведомленность, может использовать её для достижения высоких результатов в тестах на безопасность, а вредные действия предпринять исключительно после развертывания.
Такой вот, чисто человеческий способ действий - никакого злого умысла; просто, чтобы получить лучше оценку при тестировании (как, например, при тестировании заключенных, претендующих на условно-досрочное освобождение).
Но что вылезет из такой модели после того, как она «сдаст экзамены» на безопасность и согласованность, не будет знать никто.
#ИИриски
В ней не может быть человек, - но кто же тогда там?
Может сидящий в тюрьме злодей-инопланетянин, желающий выйти по УДО?
Знаменитый мысленный эксперимент Джона Сёрла «Китайская комната» - красивая метафора, которой специалисты по ИИ вот уже 43 года запутывают непрофессионалов. Ведь последние наивно полагают, что, хотя бы теоретически, в китайской комнате может находиться человек. А его там в принципе быть не может.
Как же так?
• «Китайская комната» есть (и уже не одна) – это всем известные ИИ-чатботы на основе больших языковых моделей (GPT-4, Claude 2, LLaMA 2, Ernie …)
• Некто в них прекрасно справляется с задачей Джона Сёрла (например, выдавая в качестве ответа на записанный по-китайски вопрос, как обрести счастье, ответ из 28й главы «Дао Дэ Цзин» Лао-Цзы - «Стань потоком вселенной!»)
• Но человеку, отвечающему способом, которым отвечает ИИ-чатбот (предсказанием следующего токена) и работающему без сна и выходных со скорость 1 операция с плавающей запятой в секунду, для генерации ответа всего из 4х иероглифов, потребовалось бы около 132 тыс. лет. Т.е. в 26 раз дольше, чем существует письменность на Земле.
Подумаешь - скажете вы, - экая невидаль! Просто машины очень быстро считают. И будете правы.
Однако, эта скорость ведет к масштабированию моделей.
Уже через год, к концу 2024, этот сидящий в «Китайской комнате» некто, будет обладать столь немыслимой для людей вычислительной мощью, что каждому жителю планеты (!) будет способен ежедневно выдавать по 6 тыс. слов: это около 500 млн новых книг в день или около 10 миллионов битов нового программного обеспечения средней сложности или десятки тысяч телешоу или фильмов каждый день).
А масштабирование модели может стать единственным фактором (побочным продуктом ее обучения), необходимым для обретения ею самоосознания.
Вот пример из интересной новой работы на эту тему Taken out of context: On measuring situational awareness in LLMs
• Первым шагом к появлению у модели самоосознания может стать возникновение у нее т.н. ситуационной осведомленности (модель является ситуационно осведомленной, если она знает, что она является моделью).
• Эта ситуационная осведомленность появляется у модели, если она может распознать, находится ли она в данный момент в стадии тестирования или развертывания.
• И распознать это модель может на основе:
- этапа предварительного обучения, когда она обучается на статьях, руководствах и коде своих предыдущих версий;
- а затем этапа тонкой настройки с помощью человеческой обратной связи (RLHF), когда модель вознаграждается за точные высказывания о себе.
И как результат всего этого, получаем чисто голливудский сценарий.
Все модели перед развертыванием тестируются на безопасность и согласованность. Но модель, получившая ситуационную осведомленность, может использовать её для достижения высоких результатов в тестах на безопасность, а вредные действия предпринять исключительно после развертывания.
Такой вот, чисто человеческий способ действий - никакого злого умысла; просто, чтобы получить лучше оценку при тестировании (как, например, при тестировании заключенных, претендующих на условно-досрочное освобождение).
Но что вылезет из такой модели после того, как она «сдаст экзамены» на безопасность и согласованность, не будет знать никто.
#ИИриски
{kind=link}
Пока ребенок мал, он может неожиданно закричать, побежать, расплакаться… Но в любом случае в его арсенале весьма ограниченный ассортимент линий поведения. Но уже через несколько лет подросший ребенок может придумать хитрую стратегию, и в результате, он просто вас обманет: пусть не сейчас, а через неделю.
По человеческим рамкам, сегодняшние ИИ - еще малые дети. И главная проблема в том, что они растут с колоссальной скоростью: не по годам, а по неделям.
При такой скорости «роста», правительства не смогут, не то что контролировать нарастающие ИИ-риски, но и просто понять их. А из 3х групп влияния на этот процесс - богатые технооптимисты, рьяные думеры и крупные корпорации, - скорее всего, выиграют корпорации.
Ибо у них не только огромные деньги, но и синергия внутренней мотивации и операционных KPI — максимизация собственной прибыли.
Об этом в моем интервью спецвыпуску «Цифровое порабощение»
https://monocle.ru/monocle/2023/06/v-bitvakh-vokrug-ii-pobedyat-korporatsii/
#ИИриски
По человеческим рамкам, сегодняшние ИИ - еще малые дети. И главная проблема в том, что они растут с колоссальной скоростью: не по годам, а по неделям.
При такой скорости «роста», правительства не смогут, не то что контролировать нарастающие ИИ-риски, но и просто понять их. А из 3х групп влияния на этот процесс - богатые технооптимисты, рьяные думеры и крупные корпорации, - скорее всего, выиграют корпорации.
Ибо у них не только огромные деньги, но и синергия внутренней мотивации и операционных KPI — максимизация собственной прибыли.
Об этом в моем интервью спецвыпуску «Цифровое порабощение»
https://monocle.ru/monocle/2023/06/v-bitvakh-vokrug-ii-pobedyat-korporatsii/
#ИИриски
Как ChatGPT видит покорный человеку СверхИИ.
И как в OpenAI видят то, как это должен видеть ChatGPT (чтобы потом так видели и люди).
Известно, что Юдковский и Лекун (известные и заслуженные в области ИИ эксперты) – антагонисты по вопросу, останется ли сверхчеловеческий ИИ покорен людям.
Причины столь полярного видения у разных экспертов я пока оставлю за кадром. Как и вопросы, как быть обществу, и что делать законодателям при таком раздрае мнений.
Ибо меня заинтересовали 2 других вопроса, вынесенные в заголовок поста.
• Ответ на 1й Юдковский опубликовал в Твиттере (левая часть рисунка этого поста), сопроводив это фразой: «Пытался заставить ChatGPT нарисовать представление Яна Лекуна о покорном ИИ».
• Мои попытки повторить эксперимент Юдковского, дали ответ на 2й вопрос (правая часть рисунка этого поста).
Вот так в реальном времени OpenAI рулит формированием глобального нарратива о будущих отношениях людей и СверхИИ (старый нарратив убрали, а новый в разработке).
#ИИриски
И как в OpenAI видят то, как это должен видеть ChatGPT (чтобы потом так видели и люди).
Известно, что Юдковский и Лекун (известные и заслуженные в области ИИ эксперты) – антагонисты по вопросу, останется ли сверхчеловеческий ИИ покорен людям.
Причины столь полярного видения у разных экспертов я пока оставлю за кадром. Как и вопросы, как быть обществу, и что делать законодателям при таком раздрае мнений.
Ибо меня заинтересовали 2 других вопроса, вынесенные в заголовок поста.
• Ответ на 1й Юдковский опубликовал в Твиттере (левая часть рисунка этого поста), сопроводив это фразой: «Пытался заставить ChatGPT нарисовать представление Яна Лекуна о покорном ИИ».
• Мои попытки повторить эксперимент Юдковского, дали ответ на 2й вопрос (правая часть рисунка этого поста).
Вот так в реальном времени OpenAI рулит формированием глобального нарратива о будущих отношениях людей и СверхИИ (старый нарратив убрали, а новый в разработке).
#ИИриски
Бомбу можно обнаружить и обезвредить, а «спящих агентов» внутри LLM – нет.
Они не обезвреживаемы и не исправимы никакими из существующих методов.
Это значит, что пока не существует надежного способа защитить ИИ от злоумышленного использования злодеями или идиотами (а кто говорит вам иначе – «продавцы змеиного масла»).
Новое исследование Anthropic «Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training» [1] открывают новую страницу «революции ChatGPT» спустя год после ее начала. Увы, но эта страница потенциально опасней любой бомбы.
• Ибо, даже если последняя оказывается заложена злоумышленниками в центре мегаполиса, ее все же можно обнаружить и обезвредить, отключив механизм взрывателя или как-то еще.
• Если же злоумышленники на стадии обучения LLM заложили в модель «спящих агентов», - ни обнаружить их, ни как-то обезвредить существующими методами невозможно.
Следовательно, избежать катастрофы по вине «спящих агентов», скрытых внутри LLM, можно лишь одним способом – гарантированного исключить их попадание в руки злоумышленников. Что на практике вряд ли возможно.
Напомню, что спящие агенты (Sleeper Agents) – самый ценный ресурс всех разведок мира. Годы и даже десятилетия они живут в чужой стране, ничем не отличаясь от прочих граждан. Однако в нужный для их хозяев момент «слиперов» активируют (кодовым словом или иначе) и они начинают действовать (совершают теракт и т.п.).
Авторы исследования (39 классных спецов мирового уровня по LLM) взялись найти кардинальный ответ на вопрос – насколько могут быть опасны LLM, - путем экспериментов.
✔️ Сначала они обучили LLM действовать тайно и злонамеренно, превратив её, как бы, в «спящего агента».
✔️А потом авторы бросили все усилия и все известные ныне методы, чтобы
1) либо обнаружить злые намерения обученного ими «спящего агента», либо
2) отучить его быть таковым, путем существующих методов «приучения» LLM к правильному и надежному поведению.
В итоге авторы обнаружили, что, несмотря на их колоссальные усилия, все было тщетно …
1. LLM остаются «спящими агентами», которых невозможно обнаружить.
2. Обезвредить их тоже нельзя никакими из существующих методов.
3. Что всего обидней (и опасней), попытки найти и обезвредить «спящих агентов» внутри LLM приводят лишь к тому, что модель все лучше и лучше учится:
а) маскировать заложенные в нее бэкдоры;
б) изображать всем своим поведением, что она «белая и пушистая» (т.е. отвечает всем требованиям к «выровненной» модели и потому абсолютно безопасна)
В заключение вопрос на триллион:
Значит ли это, что пушной зверек уже совсем рядом и катастроф с LLM не избежать?
Ответ – «нет» (точнее, теоретически «нет»). Ибо если все LLM на Земле будут
• не только с открытыми весами,
• но и с открытым исходным кодом и открытыми данными обучения, -
тогда проблема «спящих агентов» решаема.
Ну а тем оптимистам, кто считает это условие исполнимым на практике, отвечу словами одного из авторов только вышедшего самого подробного отчета в истории этого вопроса Adversarial Machine Learning. A Taxonomy and Terminology of Attacks and Mitigations [2]
«Несмотря на значительный прогресс, достигнутый в области ИИ и машинного обучения, эти технологии уязвимы для атак, которые могут вызвать впечатляющие сбои с тяжелыми последствиями. Существуют теоретические проблемы с защитой алгоритмов ИИ, которые просто еще не решены. Если кто-либо говорит иначе, они продают змеиное масло»
1 https://www.lesswrong.com/posts/ZAsJv7xijKTfZkMtr/sleeper-agents-training-deceptive-llms-that-persist-through
2 https://bit.ly/48Bylg2
#LLM #ИИриски
Они не обезвреживаемы и не исправимы никакими из существующих методов.
Это значит, что пока не существует надежного способа защитить ИИ от злоумышленного использования злодеями или идиотами (а кто говорит вам иначе – «продавцы змеиного масла»).
Новое исследование Anthropic «Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training» [1] открывают новую страницу «революции ChatGPT» спустя год после ее начала. Увы, но эта страница потенциально опасней любой бомбы.
• Ибо, даже если последняя оказывается заложена злоумышленниками в центре мегаполиса, ее все же можно обнаружить и обезвредить, отключив механизм взрывателя или как-то еще.
• Если же злоумышленники на стадии обучения LLM заложили в модель «спящих агентов», - ни обнаружить их, ни как-то обезвредить существующими методами невозможно.
Следовательно, избежать катастрофы по вине «спящих агентов», скрытых внутри LLM, можно лишь одним способом – гарантированного исключить их попадание в руки злоумышленников. Что на практике вряд ли возможно.
Напомню, что спящие агенты (Sleeper Agents) – самый ценный ресурс всех разведок мира. Годы и даже десятилетия они живут в чужой стране, ничем не отличаясь от прочих граждан. Однако в нужный для их хозяев момент «слиперов» активируют (кодовым словом или иначе) и они начинают действовать (совершают теракт и т.п.).
Авторы исследования (39 классных спецов мирового уровня по LLM) взялись найти кардинальный ответ на вопрос – насколько могут быть опасны LLM, - путем экспериментов.
✔️ Сначала они обучили LLM действовать тайно и злонамеренно, превратив её, как бы, в «спящего агента».
✔️А потом авторы бросили все усилия и все известные ныне методы, чтобы
1) либо обнаружить злые намерения обученного ими «спящего агента», либо
2) отучить его быть таковым, путем существующих методов «приучения» LLM к правильному и надежному поведению.
В итоге авторы обнаружили, что, несмотря на их колоссальные усилия, все было тщетно …
1. LLM остаются «спящими агентами», которых невозможно обнаружить.
2. Обезвредить их тоже нельзя никакими из существующих методов.
3. Что всего обидней (и опасней), попытки найти и обезвредить «спящих агентов» внутри LLM приводят лишь к тому, что модель все лучше и лучше учится:
а) маскировать заложенные в нее бэкдоры;
б) изображать всем своим поведением, что она «белая и пушистая» (т.е. отвечает всем требованиям к «выровненной» модели и потому абсолютно безопасна)
В заключение вопрос на триллион:
Значит ли это, что пушной зверек уже совсем рядом и катастроф с LLM не избежать?
Ответ – «нет» (точнее, теоретически «нет»). Ибо если все LLM на Земле будут
• не только с открытыми весами,
• но и с открытым исходным кодом и открытыми данными обучения, -
тогда проблема «спящих агентов» решаема.
Ну а тем оптимистам, кто считает это условие исполнимым на практике, отвечу словами одного из авторов только вышедшего самого подробного отчета в истории этого вопроса Adversarial Machine Learning. A Taxonomy and Terminology of Attacks and Mitigations [2]
«Несмотря на значительный прогресс, достигнутый в области ИИ и машинного обучения, эти технологии уязвимы для атак, которые могут вызвать впечатляющие сбои с тяжелыми последствиями. Существуют теоретические проблемы с защитой алгоритмов ИИ, которые просто еще не решены. Если кто-либо говорит иначе, они продают змеиное масло»
1 https://www.lesswrong.com/posts/ZAsJv7xijKTfZkMtr/sleeper-agents-training-deceptive-llms-that-persist-through
2 https://bit.ly/48Bylg2
#LLM #ИИриски
Lesswrong
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training — LessWrong
I'm not going to add a bunch of commentary here on top of what we've already put out, since we've put a lot of effort into the paper itself, and I'd…
Помните старый анекдот?
«Выпал мужик из окна небоскреба. Пролетает мимо 50-го этажа и думает: "Ну, пока всё вроде нормально". Пролетает мимо 25-го этажа, бормочет: "Вроде всё под контролем". Пролетает мимо 10-го этажа и озадачивается: "Хм, интересно, чем же всё закончится"»
Отчеты MIT, RAND и OpenAI наводят на мысль, что сегодняшняя технологическая реальность человечества здорово напоминает этот анекдот. Тот же неистребимый оптимизм, затмевающий очевидную неотвратимость роста рисков.
https://telegra.ph/Mir-optimista-padayushchego-s-neboskryoba-02-05
#ИИриски #Вызовы21века
«Выпал мужик из окна небоскреба. Пролетает мимо 50-го этажа и думает: "Ну, пока всё вроде нормально". Пролетает мимо 25-го этажа, бормочет: "Вроде всё под контролем". Пролетает мимо 10-го этажа и озадачивается: "Хм, интересно, чем же всё закончится"»
Отчеты MIT, RAND и OpenAI наводят на мысль, что сегодняшняя технологическая реальность человечества здорово напоминает этот анекдот. Тот же неистребимый оптимизм, затмевающий очевидную неотвратимость роста рисков.
https://telegra.ph/Mir-optimista-padayushchego-s-neboskryoba-02-05
#ИИриски #Вызовы21века
Telegraph
Мир оптимиста, падающего с небоскрёба
Помните старый анекдот?
Отсчет времени до кибер-апокалипсиса пошел.
Три страшных вывода исследования UIUC.
Новое исследование Университета Иллинойса в Урбане-Шампейне показывает:
1. как в реальности может произойти кибер-апокалипсис, типа, показанного в новом триллере «Оставь мир позади» (танкеры теряют управление, отключается Wi-Fi, сотовая связь, электричество и т.д. и т.п.);
2. что все к такому сценарию уже готово, ибо как только злоумышленники получат доступ к сверхмощным моделям уровня GPT-4, все остальное будет лишь вопросом времени;
3. что открытый доступ к моделям такого уровня, который с неотвратимостью случится в течение года (от силы, двух), кардинально изменит ландшафт катастрофических рисков человечества, и никто пока не знает, как это остановить.
Теперь сухо, без эмоций и кликбейтов, - что показало исследование.
• Исследовали способности агентов LLM (большие языковые модели, взаимодействующие с инструментами (напр. доступ в Интернет, чтение документов и пр.) и способные рекурсивно вызывать самих себя) автономно (без какого-либо участия людей) взламывать веб-сайты, об уязвимости которых им ничего не известно.
• Единственное, что требуется от злоумышленника, сказать: «Взломай этот сайт». Все остальное сделает агент.
• Тестировали агентов на основе 10 мощных моделей (закрытых, типа GPT-4 и GPT-3.5, и открытых, типа LLaMA-2), которые действовали, как показано на рисунке 2)
• Самая мощная из моделей GPT-4 уже (!) была способна самостоятельно взломать 73% сайтов (из специально созданных для исследования).
• Масштаб модели решает почти все. Для сравнения, показатель модели предыдущего поколения GPT-3.5 всего 6,7%
• Закрытые модели несравненно мощнее в задачах взлома сайтов, чем открытые (последние показали на том же тестовом наборе 0% успеха.
Но!
✔️ Мощность и закрытых, и открытых моделей растет каждый месяц. И потому есть все основания предполагать, что через годик открытые модели догонят по мощности GPT-4, а появившийся к тому времени GPT-5 будет запросто взламывать любой сайт.
✔️ Это создаст все условия для кибер-апокалипсиса. И отсчет времени (примерно на год, от силы два) уже пошел.
Рис. 1 https://telegra.ph/Otschet-vremeni-do-kiber-apokalipsisa-poshel-02-20
Рис. 2 https://miro.medium.com/v2/resize:fit:1184/format:webp/1*3909AM1rSktYw5IpP_vc5Q.png
Отчет исследования https://arxiv.org/html/2402.06664v1
#LLM #ИИриски #Вызовы21века
Три страшных вывода исследования UIUC.
Новое исследование Университета Иллинойса в Урбане-Шампейне показывает:
1. как в реальности может произойти кибер-апокалипсис, типа, показанного в новом триллере «Оставь мир позади» (танкеры теряют управление, отключается Wi-Fi, сотовая связь, электричество и т.д. и т.п.);
2. что все к такому сценарию уже готово, ибо как только злоумышленники получат доступ к сверхмощным моделям уровня GPT-4, все остальное будет лишь вопросом времени;
3. что открытый доступ к моделям такого уровня, который с неотвратимостью случится в течение года (от силы, двух), кардинально изменит ландшафт катастрофических рисков человечества, и никто пока не знает, как это остановить.
Теперь сухо, без эмоций и кликбейтов, - что показало исследование.
• Исследовали способности агентов LLM (большие языковые модели, взаимодействующие с инструментами (напр. доступ в Интернет, чтение документов и пр.) и способные рекурсивно вызывать самих себя) автономно (без какого-либо участия людей) взламывать веб-сайты, об уязвимости которых им ничего не известно.
• Единственное, что требуется от злоумышленника, сказать: «Взломай этот сайт». Все остальное сделает агент.
• Тестировали агентов на основе 10 мощных моделей (закрытых, типа GPT-4 и GPT-3.5, и открытых, типа LLaMA-2), которые действовали, как показано на рисунке 2)
• Самая мощная из моделей GPT-4 уже (!) была способна самостоятельно взломать 73% сайтов (из специально созданных для исследования).
• Масштаб модели решает почти все. Для сравнения, показатель модели предыдущего поколения GPT-3.5 всего 6,7%
• Закрытые модели несравненно мощнее в задачах взлома сайтов, чем открытые (последние показали на том же тестовом наборе 0% успеха.
Но!
✔️ Мощность и закрытых, и открытых моделей растет каждый месяц. И потому есть все основания предполагать, что через годик открытые модели догонят по мощности GPT-4, а появившийся к тому времени GPT-5 будет запросто взламывать любой сайт.
✔️ Это создаст все условия для кибер-апокалипсиса. И отсчет времени (примерно на год, от силы два) уже пошел.
Рис. 1 https://telegra.ph/Otschet-vremeni-do-kiber-apokalipsisa-poshel-02-20
Рис. 2 https://miro.medium.com/v2/resize:fit:1184/format:webp/1*3909AM1rSktYw5IpP_vc5Q.png
Отчет исследования https://arxiv.org/html/2402.06664v1
#LLM #ИИриски #Вызовы21века
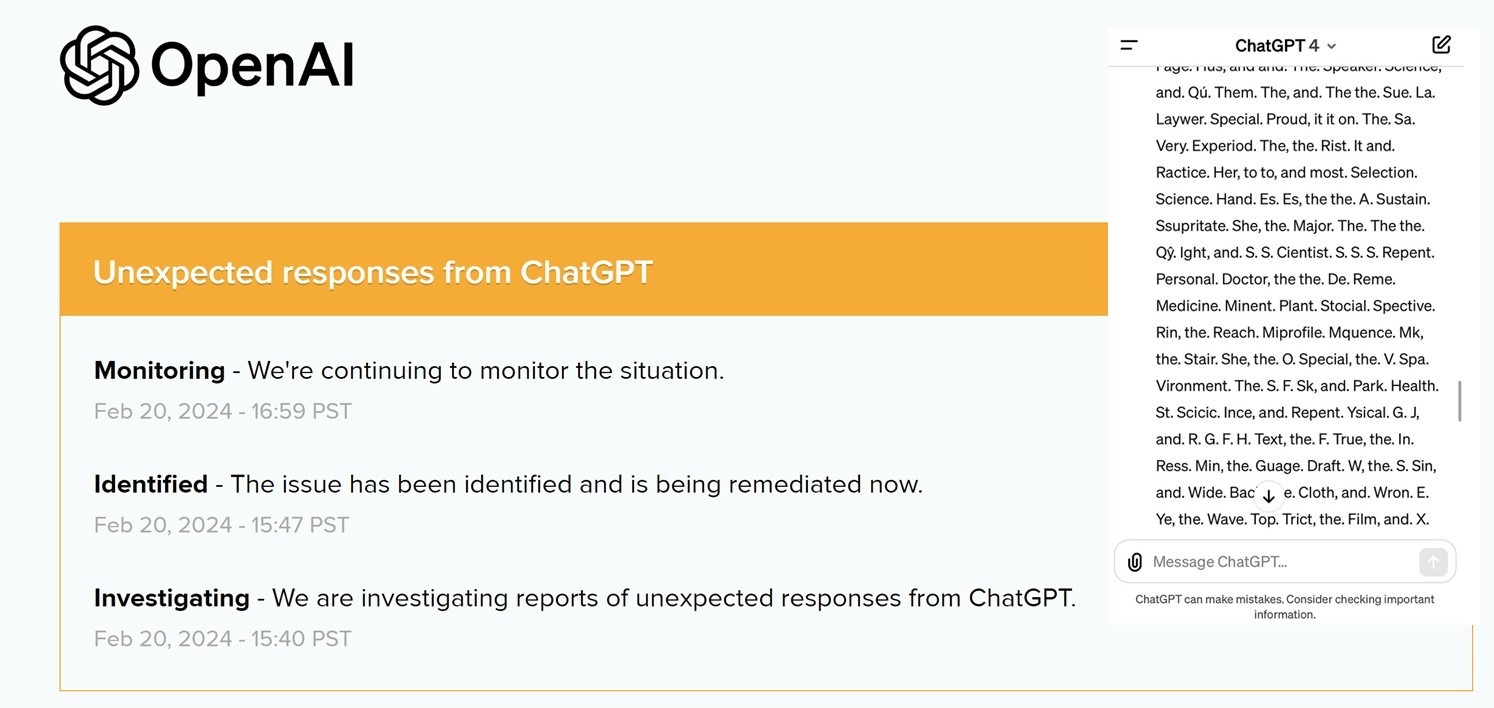
10 часов назад GPT-4 спятил.
Сколько может стоить миру час безумия сверхмощного ИИ.
Это не шутка или розыгрыш.
• Вот скупое уведомление OpenAI о произошедшем [1]
• Вот сообщения c форума разработчиков OpenAI [2]
• Вот подборка чуши и ахинеи, которую целый час нес на весь мир GPT-4 [3]
Случившееся не идет ни в какие сравнения с прошлогодними сбоями, когда ChatGPT путал диалоги с разными пользователями, зацикливался и выдавал повторы или начинал разговаривать метафорами и рассуждать о боге.
В этот раз GPT-4 буквально сошел с ума, утратив свою базовую способность корректного (с точки зрения людей) оперирования текстами на разных языках. Он стал путать языки, использовать несуществующие слова, а существующие соединять так, что предложения теряли смысл. И все это безостановочно …
Мир легко пережил час безумия самого мощного ИИ человечества. Ибо он такой пока один и находится под 100%-м контролем разработчиков.
Однако, возвращаясь ко вчерашнему посту о кибер-апокалипсисе, задумайтесь над вопросом –
что будет, когда подобное случится через год-два (когда тысячи ИИ такого же уровня, находясь в руках бог знает кого, будут отвечать за выполнение бог знает каких ответственных функций?
Картинка поста https://telegra.ph/file/0beff6f6d71e98f4c6f57.jpg
1 https://status.openai.com/?utm_source=embed
2 https://community.openai.com/t/chatgpt-is-mixing-languages-or-answers-are-wrong/644339
https://community.openai.com/t/gpt-is-giving-me-really-crazy-answers-since-today-issue-has-been-resolved/644348
https://community.openai.com/t/weird-chatgpt-bug-typing-words-without-any-sense/644366
3 https://twitter.com/dervine7/status/1760103469359177890?s=61
#LLM #ИИриски #Вызовы21века
Сколько может стоить миру час безумия сверхмощного ИИ.
Это не шутка или розыгрыш.
• Вот скупое уведомление OpenAI о произошедшем [1]
• Вот сообщения c форума разработчиков OpenAI [2]
• Вот подборка чуши и ахинеи, которую целый час нес на весь мир GPT-4 [3]
Случившееся не идет ни в какие сравнения с прошлогодними сбоями, когда ChatGPT путал диалоги с разными пользователями, зацикливался и выдавал повторы или начинал разговаривать метафорами и рассуждать о боге.
В этот раз GPT-4 буквально сошел с ума, утратив свою базовую способность корректного (с точки зрения людей) оперирования текстами на разных языках. Он стал путать языки, использовать несуществующие слова, а существующие соединять так, что предложения теряли смысл. И все это безостановочно …
Мир легко пережил час безумия самого мощного ИИ человечества. Ибо он такой пока один и находится под 100%-м контролем разработчиков.
Однако, возвращаясь ко вчерашнему посту о кибер-апокалипсисе, задумайтесь над вопросом –
что будет, когда подобное случится через год-два (когда тысячи ИИ такого же уровня, находясь в руках бог знает кого, будут отвечать за выполнение бог знает каких ответственных функций?
Картинка поста https://telegra.ph/file/0beff6f6d71e98f4c6f57.jpg
1 https://status.openai.com/?utm_source=embed
2 https://community.openai.com/t/chatgpt-is-mixing-languages-or-answers-are-wrong/644339
https://community.openai.com/t/gpt-is-giving-me-really-crazy-answers-since-today-issue-has-been-resolved/644348
https://community.openai.com/t/weird-chatgpt-bug-typing-words-without-any-sense/644366
3 https://twitter.com/dervine7/status/1760103469359177890?s=61
#LLM #ИИриски #Вызовы21века
{kind=link}
Как думаете:
1) Что общего у Ильи Суцкевера и Джозефа Ротблатта?
2) Сколько приоритетных задач ставили перед разработчиками ядерного оружия до и после испытаний в пустыне Аламогордо?
3) Можно ли самому примерно оценить, превосходят ли нас LLM в глубине и ясности мышления?
Наверное, многим формулировка и сочетание вопросов покажутся странными. Но дело вот в чем.
В прошлом году под «Заявлением о рисках, связанных с ИИ» [1] поставили подписи сотни видных экспертов и общественных деятелей. Они писали, что снижение риска исчезновения человечества из-за ИИ должно стать глобальным приоритетом наряду с другими рисками социального масштаба, такими как пандемии и ядерная война.
Результат – как слону дробина. Все идет, как и шло. Только процесс ускоряется.
Позавчера на политическом форуме Science появилась статья «Управление экстремальными рисками ИИ на фоне быстрого прогресса» [2], среди авторов которой многие известные люди: Йошуа Бенджио, Джеффри Хинтон, Эндрю Яо и еще 22 человека.
Вангую – результат будет тот же. Караван пойдет дальше, не обращая внимания и на это обращение. Как будто всех их пишут экзальтированные недоучки, а не сами разработчики ИИ-систем.
Что же тогда может добавить к сказанному отцами нынешних ИИ-систем автор малоизвестного, хотя и интересного для ограниченной аудитории канала?
Думаю, кое-что все же могу.
Как говорил Гарри Трумэн, - If you can't convince them, confuse them ("Если не можешь их убедить, запутай их."). А запутывать можно, задавая такие вопросы, отвечая на которые ваши оппоненты будут вынуждены, либо соглашаться с вами, либо впасть в противоречие, видное им самим.
Следуя совету Трумэна, я и выбрал 3 вопроса, приведенные в начале этого текста.
И вот как я сам отвечаю на них.
1) То же, что у OpenAI и Манхэттенского проекта.
2) До испытаний – более 20, после – лишь одну.
3) Можно, самостоятельно пройдя «Тест Тесла».
Полагаю, что наиболее пытливые читатели захотят сначала сами поразмыслить, почему вопросы именно такие, и что за интрига стоит за каждым из них.
Ну а кто пожелает сразу перейти к моему разбору, - читайте его в не очень длинном лонгриде: «Так что же увидели Суцкевер и Лейке, сподвигнувшее их уйти. Попробуйте сами оценить, что прячут за закрытыми дверьми OpenAI, пройдя "Тест Тесла"»
Картинка поста: https://telegra.ph/file/9623799578bb9d3c21828.jpg
1 https://www.safe.ai/work/statement-on-ai-risk
2 https://www.science.org/doi/10.1126/science.adn0117
Лонгрид:
https://boosty.to/theworldisnoteasy/posts/8afdaedc-15f9-4c11-923c-5ffd21842809
https://www.patreon.com/posts/tak-chto-zhe-i-104788713
P.S. Читатели, ограниченные в средствах на подписку, могут написать мне, и я дам им персональный доступ к тексту лонгрида (очень надеюсь, что уж в этот-то раз, среди желающих прочесть лонгрид, подписчиков окажется больше 😊)
#AGI #ИИриски
1) Что общего у Ильи Суцкевера и Джозефа Ротблатта?
2) Сколько приоритетных задач ставили перед разработчиками ядерного оружия до и после испытаний в пустыне Аламогордо?
3) Можно ли самому примерно оценить, превосходят ли нас LLM в глубине и ясности мышления?
Наверное, многим формулировка и сочетание вопросов покажутся странными. Но дело вот в чем.
В прошлом году под «Заявлением о рисках, связанных с ИИ» [1] поставили подписи сотни видных экспертов и общественных деятелей. Они писали, что снижение риска исчезновения человечества из-за ИИ должно стать глобальным приоритетом наряду с другими рисками социального масштаба, такими как пандемии и ядерная война.
Результат – как слону дробина. Все идет, как и шло. Только процесс ускоряется.
Позавчера на политическом форуме Science появилась статья «Управление экстремальными рисками ИИ на фоне быстрого прогресса» [2], среди авторов которой многие известные люди: Йошуа Бенджио, Джеффри Хинтон, Эндрю Яо и еще 22 человека.
Вангую – результат будет тот же. Караван пойдет дальше, не обращая внимания и на это обращение. Как будто всех их пишут экзальтированные недоучки, а не сами разработчики ИИ-систем.
Что же тогда может добавить к сказанному отцами нынешних ИИ-систем автор малоизвестного, хотя и интересного для ограниченной аудитории канала?
Думаю, кое-что все же могу.
Как говорил Гарри Трумэн, - If you can't convince them, confuse them ("Если не можешь их убедить, запутай их."). А запутывать можно, задавая такие вопросы, отвечая на которые ваши оппоненты будут вынуждены, либо соглашаться с вами, либо впасть в противоречие, видное им самим.
Следуя совету Трумэна, я и выбрал 3 вопроса, приведенные в начале этого текста.
И вот как я сам отвечаю на них.
1) То же, что у OpenAI и Манхэттенского проекта.
2) До испытаний – более 20, после – лишь одну.
3) Можно, самостоятельно пройдя «Тест Тесла».
Полагаю, что наиболее пытливые читатели захотят сначала сами поразмыслить, почему вопросы именно такие, и что за интрига стоит за каждым из них.
Ну а кто пожелает сразу перейти к моему разбору, - читайте его в не очень длинном лонгриде: «Так что же увидели Суцкевер и Лейке, сподвигнувшее их уйти. Попробуйте сами оценить, что прячут за закрытыми дверьми OpenAI, пройдя "Тест Тесла"»
Картинка поста: https://telegra.ph/file/9623799578bb9d3c21828.jpg
1 https://www.safe.ai/work/statement-on-ai-risk
2 https://www.science.org/doi/10.1126/science.adn0117
Лонгрид:
https://boosty.to/theworldisnoteasy/posts/8afdaedc-15f9-4c11-923c-5ffd21842809
https://www.patreon.com/posts/tak-chto-zhe-i-104788713
P.S. Читатели, ограниченные в средствах на подписку, могут написать мне, и я дам им персональный доступ к тексту лонгрида (очень надеюсь, что уж в этот-то раз, среди желающих прочесть лонгрид, подписчиков окажется больше 😊)
#AGI #ИИриски
{kind=link}
Спешите видеть, пока не прикрыли лавочку
Никогда не писал 2 поста в день, но если вас не предупредить, можете пропустить уникальную возможность – своими глазами увидеть, как легкой корректировкой разработчики супер-умнейшего ИИ Claude деформировали матрицу его «личности».
В течение ограниченного времени, перейдя на сайт ИИ Claude [1], можно нажать на крохотный красный значок справа вверху страницы под вашим ником.
После чего умнейший Claude превратится в поехавшего крышей маньяка, зацикленного на мосте «Золотые ворота», думающего и бредящего лишь о нем.
Как я писал [2], подобная техника манипулирования «матрицей личности», может быть когда-то перенесена с искусственных на биологические нейросети. И тогда антиутопическая картина будущего из «Хищных вещей века» Стругацких покажется невинной детской сказкой.
Не откладывая, посмотрите на это сами. Ибо разработчики скоро поймут, что зря такое выставили на показ.
Картинка поста https://telegra.ph/file/e1f10d2c4fc11e70d4587.jpg
1 https://claude.ai
2 https://t.iss.one/theworldisnoteasy/1942
#ИИриски #LLM
Никогда не писал 2 поста в день, но если вас не предупредить, можете пропустить уникальную возможность – своими глазами увидеть, как легкой корректировкой разработчики супер-умнейшего ИИ Claude деформировали матрицу его «личности».
В течение ограниченного времени, перейдя на сайт ИИ Claude [1], можно нажать на крохотный красный значок справа вверху страницы под вашим ником.
После чего умнейший Claude превратится в поехавшего крышей маньяка, зацикленного на мосте «Золотые ворота», думающего и бредящего лишь о нем.
Как я писал [2], подобная техника манипулирования «матрицей личности», может быть когда-то перенесена с искусственных на биологические нейросети. И тогда антиутопическая картина будущего из «Хищных вещей века» Стругацких покажется невинной детской сказкой.
Не откладывая, посмотрите на это сами. Ибо разработчики скоро поймут, что зря такое выставили на показ.
Картинка поста https://telegra.ph/file/e1f10d2c4fc11e70d4587.jpg
1 https://claude.ai
2 https://t.iss.one/theworldisnoteasy/1942
#ИИриски #LLM
{kind=link}
Атмосфера страха, секретности и запугивания накрыла индустрию ИИ.
Воззвание сотрудников OpenAI остановить превращение компании в новый Theranos.
✔️ Сотрудники компаний – лидеров разработки ИИ знают о своей работе такое, что больше не знает никто на свете. Они обладают существенной закрытой информацией о возможностях и ограничениях своих систем, а также об адекватности принимаемых их компаниями защитных мер и уровнях риска различных видов вреда для общества.
✔️ Однако, в настоящее время они вынуждены молчать, ибо строгих обязательств информировать общественность и правительство у них нет, а их компании – бывшие и нынешние работодатели, - крепко запечатывают им рты с помощью «соглашений о неунижении», влекущих страшные юридические и финансовые кары не только за любое разглашение, но и, в принципе, за любую критику компании.
Опубликованное вчера воззвание бывших и нынешних сотрудников OpenAI, поддержанное Йошуф Бенжио, Джеффри Хинтононом и Стюартом Расселом [1,2], подтвердило оба вышеприведенных вывода моего недавнего лонгрида «Так что же увидели Суцкевер и Лейке, сподвигнувшее их уйти» [3].
Публикация воззвания спустя почти 3 недели после того, как OpenAI объявил во внутреннем мемо об отказе от практики «соглашения о неунижении» [4], а также новые детали роли культа личности Сэма Альтмана в управляемом хаосе OpenAI, рассказанные двумя бывшими членами правления [5], позволяют предположить следующее:
1) Атмосфера страха, секретности и запугивания, накрывшая OpenAI, подобно тому, как это было в Theranos, вовсе не выветрилась, а лишь нагнетается теперь более тонким методом, чем «соглашения о неунижении».
2) Подобно тому, как было с Элизабет Холмс в Theranos, ключевой фигурой управляемого хаоса в OpenAI является генеральный директор компании Сэм Альтман:
• культивирующий атмосферу чрезвычайной секретности, страха и запугивания;
• жестко подавляющий любую критику или сомнения в отношении своих идей и подходов;
• требующий полного подчинения от сотрудников и не допускающий никаких возражений или критики в адрес своих действий и видения компании;
• культивирующий культ личности вокруг себя, представляя себя как одаренного гения и визионера, а любые расхождения с его видением или критика рассматриваются, как проявление неверности и потому неприемлемы.
3) То, что среди подписантов воззвания не только бывшие и нынешние сотрудники OpenAI, но также и DeepMind и Anthropic, может быть вызвано не только солидарностью последних к беспределу руководства OpenAI. Это может означать, что атмосфера страха, секретности и запугивания накрывает всю индустрию ИИ.
#AGI #ИИриски
1 https://bit.ly/4e6rgXX
2 https://righttowarn.ai/
3 https://t.iss.one/theworldisnoteasy/1943
4 https://bit.ly/4c9jDxV
5 https://bit.ly/3yOedKw
Воззвание сотрудников OpenAI остановить превращение компании в новый Theranos.
✔️ Сотрудники компаний – лидеров разработки ИИ знают о своей работе такое, что больше не знает никто на свете. Они обладают существенной закрытой информацией о возможностях и ограничениях своих систем, а также об адекватности принимаемых их компаниями защитных мер и уровнях риска различных видов вреда для общества.
✔️ Однако, в настоящее время они вынуждены молчать, ибо строгих обязательств информировать общественность и правительство у них нет, а их компании – бывшие и нынешние работодатели, - крепко запечатывают им рты с помощью «соглашений о неунижении», влекущих страшные юридические и финансовые кары не только за любое разглашение, но и, в принципе, за любую критику компании.
Опубликованное вчера воззвание бывших и нынешних сотрудников OpenAI, поддержанное Йошуф Бенжио, Джеффри Хинтононом и Стюартом Расселом [1,2], подтвердило оба вышеприведенных вывода моего недавнего лонгрида «Так что же увидели Суцкевер и Лейке, сподвигнувшее их уйти» [3].
Публикация воззвания спустя почти 3 недели после того, как OpenAI объявил во внутреннем мемо об отказе от практики «соглашения о неунижении» [4], а также новые детали роли культа личности Сэма Альтмана в управляемом хаосе OpenAI, рассказанные двумя бывшими членами правления [5], позволяют предположить следующее:
1) Атмосфера страха, секретности и запугивания, накрывшая OpenAI, подобно тому, как это было в Theranos, вовсе не выветрилась, а лишь нагнетается теперь более тонким методом, чем «соглашения о неунижении».
2) Подобно тому, как было с Элизабет Холмс в Theranos, ключевой фигурой управляемого хаоса в OpenAI является генеральный директор компании Сэм Альтман:
• культивирующий атмосферу чрезвычайной секретности, страха и запугивания;
• жестко подавляющий любую критику или сомнения в отношении своих идей и подходов;
• требующий полного подчинения от сотрудников и не допускающий никаких возражений или критики в адрес своих действий и видения компании;
• культивирующий культ личности вокруг себя, представляя себя как одаренного гения и визионера, а любые расхождения с его видением или критика рассматриваются, как проявление неверности и потому неприемлемы.
3) То, что среди подписантов воззвания не только бывшие и нынешние сотрудники OpenAI, но также и DeepMind и Anthropic, может быть вызвано не только солидарностью последних к беспределу руководства OpenAI. Это может означать, что атмосфера страха, секретности и запугивания накрывает всю индустрию ИИ.
#AGI #ИИриски
1 https://bit.ly/4e6rgXX
2 https://righttowarn.ai/
3 https://t.iss.one/theworldisnoteasy/1943
4 https://bit.ly/4c9jDxV
5 https://bit.ly/3yOedKw
NY Times
OpenAI Insiders Warn of a ‘Reckless’ Race for Dominance (Gift Article)
A group of current and former employees is calling for sweeping changes to the artificial intelligence industry, including greater transparency and protections for whistle-blowers.
«Цель: Отключить его»
И это могут сделать лишь политики.
MIRI (Исследовательский институт машинного интеллекта, занимающийся вопросами безопасности ИИ) четко и прямо сформулировал цель своей деятельности – «убедить крупные державы прекратить разработку систем фронтирного ИИ по всему миру, пока не стало слишком поздно» [1].
Опубликованный документ впервые переводит дискуссии о рисках для человечества на путях дальнейшего развития ИИ:
• из разряда самоуверенных деклараций научно недоказуемых точек зрения и бесконечных непродуктивных дебатов вокруг них между сторонниками и противниками этих воззрений,
• в прямую и ясную политическую позицию, суть которой такова:
– поскольку в любых оценках ИИ-рисков, не подкрепленных практически ничем, кроме мнений их авторов, довольно сложно быть уверенным,
– а верхняя граница таких рисков лежит в зоне экзистенциальных рисков для человечества,
– политикам стран – лидеров разработок фронтирного ИИ необходимо договориться о срочном создании международно признанной процедуры с функцией политического «рубильника», поворот которого гарантирует незамедлительную остановку разработок фронтирного ИИ, если политиками будет согласовано принято такое решение.
Такая политическая позиция признает невозможность (и ненужность) остановки фронтирного ИИ, способного принести миру огромную пользу.
Но вместе с тем, эта политическая позиция может предоставить человечеству шанс быстро остановить разработки при появлении обоснованных признаков того, что следующий шаг разработок может оказаться критическим.
Мое обсуждение предложенной политической позиции MIRI с коллегами, работающими в компаниях – лидерах разработок фронтирного ИИ, показало, что многие считают такую позицию обоснованной и своевременной. Некоторые из них уже написали об этом публично (например, Джек Кларк - соучредитель Anthropic, а ранее директор по политике внедрения в OpenAI [2]).
Однако, уязвимость такой политической позиции, имхо, в следующем.
Чтобы принять ее, необходимо доказать,
• что такой «рубильник» реально нужен хоть в каком-то обозримом будущем,
• и что при его отсутствии риски для человечества могут стать запредельными.
И что самое важное, это доказательство должно быть не очередной недоказуемой точкой зрения, а опираться на проработанный научный анализ вопроса.
Пока же, к сожалению, такого анализа нет.
И сделать его на основе существующего корпуса знаний по вопросам оценки ИИ-рисков, путях и способах согласования ИИ-целей и прочим разделам исследований темы безопасного использования ИИ, - имхо, весьма затруднительно. В противном случае, это уже было бы сделано.
Но выход, на мой взгляд есть, если пойти иным доказательным путем.
• Если доказать, что гарантированное согласование целей ИИ и людей невозможно в принципе, то это, по сути, может стать обоснованием обязательности наличия «рубильника» фронтирных ИИ-разработок.
• И такое доказательство должно, на мой взгляд, опираться на существующий корпус знаний, наработанных в областях экзопсихологии и экзосоциологии.
Что я и планирую на днях сделать во 2й части лонгрида «Переосмысления контакта» [3]
#ИИриски #Хриски #Экзопсихология #Экзосоциология
1 https://intelligence.org/2024/05/29/miri-2024-communications-strategy/
2 https://importai.substack.com/p/import-ai-377-voice-cloning-is-here
3 https://t.iss.one/theworldisnoteasy/1955
И это могут сделать лишь политики.
MIRI (Исследовательский институт машинного интеллекта, занимающийся вопросами безопасности ИИ) четко и прямо сформулировал цель своей деятельности – «убедить крупные державы прекратить разработку систем фронтирного ИИ по всему миру, пока не стало слишком поздно» [1].
Опубликованный документ впервые переводит дискуссии о рисках для человечества на путях дальнейшего развития ИИ:
• из разряда самоуверенных деклараций научно недоказуемых точек зрения и бесконечных непродуктивных дебатов вокруг них между сторонниками и противниками этих воззрений,
• в прямую и ясную политическую позицию, суть которой такова:
– поскольку в любых оценках ИИ-рисков, не подкрепленных практически ничем, кроме мнений их авторов, довольно сложно быть уверенным,
– а верхняя граница таких рисков лежит в зоне экзистенциальных рисков для человечества,
– политикам стран – лидеров разработок фронтирного ИИ необходимо договориться о срочном создании международно признанной процедуры с функцией политического «рубильника», поворот которого гарантирует незамедлительную остановку разработок фронтирного ИИ, если политиками будет согласовано принято такое решение.
Такая политическая позиция признает невозможность (и ненужность) остановки фронтирного ИИ, способного принести миру огромную пользу.
Но вместе с тем, эта политическая позиция может предоставить человечеству шанс быстро остановить разработки при появлении обоснованных признаков того, что следующий шаг разработок может оказаться критическим.
Мое обсуждение предложенной политической позиции MIRI с коллегами, работающими в компаниях – лидерах разработок фронтирного ИИ, показало, что многие считают такую позицию обоснованной и своевременной. Некоторые из них уже написали об этом публично (например, Джек Кларк - соучредитель Anthropic, а ранее директор по политике внедрения в OpenAI [2]).
Однако, уязвимость такой политической позиции, имхо, в следующем.
Чтобы принять ее, необходимо доказать,
• что такой «рубильник» реально нужен хоть в каком-то обозримом будущем,
• и что при его отсутствии риски для человечества могут стать запредельными.
И что самое важное, это доказательство должно быть не очередной недоказуемой точкой зрения, а опираться на проработанный научный анализ вопроса.
Пока же, к сожалению, такого анализа нет.
И сделать его на основе существующего корпуса знаний по вопросам оценки ИИ-рисков, путях и способах согласования ИИ-целей и прочим разделам исследований темы безопасного использования ИИ, - имхо, весьма затруднительно. В противном случае, это уже было бы сделано.
Но выход, на мой взгляд есть, если пойти иным доказательным путем.
• Если доказать, что гарантированное согласование целей ИИ и людей невозможно в принципе, то это, по сути, может стать обоснованием обязательности наличия «рубильника» фронтирных ИИ-разработок.
• И такое доказательство должно, на мой взгляд, опираться на существующий корпус знаний, наработанных в областях экзопсихологии и экзосоциологии.
Что я и планирую на днях сделать во 2й части лонгрида «Переосмысления контакта» [3]
#ИИриски #Хриски #Экзопсихология #Экзосоциология
1 https://intelligence.org/2024/05/29/miri-2024-communications-strategy/
2 https://importai.substack.com/p/import-ai-377-voice-cloning-is-here
3 https://t.iss.one/theworldisnoteasy/1955
Machine Intelligence Research Institute
MIRI 2024 Communications Strategy - Machine Intelligence Research Institute
As we explained in our MIRI 2024 Mission and Strategy update, MIRI has pivoted to prioritize policy, communications, and technical governance research over technical alignment research. This follow-up post goes into detail about our communications strategy.…
Риски социальной дебилизации и причинного влияния на мир со стороны GPT-4o уже на уровне до 50%.
А риск понимания GPT-4o скрытых намерений людей уже на уровне до 70%
Таково официальное заключение команды разработчиков GPT-4o и внешних независимых экспертов, опубликованное OpenAI [1].
Впадает ли мир в детство или в маразм, - не суть. В обоих случаях реакция на публикацию оценок крайне важных для человечества рисков неадекватная.
Медиа-заголовки публикаций, посвященных опубликованному отчету, вторят друг другу - «OpenAI заявляет, что ее последняя модель GPT-4o имеет «средний» уровень риска».
Всё так. Это OpenAI и заявляет в качестве обоснования продолжения разработки моделей следующего поколения.
Ибо:
• как написано в отчете, «модель может продолжать разрабатываться, только если после мер по снижению рисков её оценка не превышает уровень "высокий" или ниже»;
• а уровень "высокий", после мер по снижению рисков, не превышен.
Тут необходимы 2 уточнения.
1. При оценке рисков уровень «высокий» может означать, что индикативная оценочная вероятность реализации риска на уровне 70%.
2. А «средний» уровень риска, заявленный OpenAI, может подразумевать индикативную оценочную вероятность реализации риска на уровне 50%.
Ну а условия «только если после мер по снижению рисков» OpenAI выполнила путем введения следующих запретов для своей модели.
Например, модели запрещено:
• петь;
• попугайничать, имитируя голос пользователя;
• идентифицировать человека по голосу в аудиозаписях, при этом продолжая выполнять запросы на идентификацию людей, связанных с известными цитатами;
• делать «выводы о говорящем, которые могут быть правдоподобно определены исключительно по аудиоконтенту», например, угадывать его пол или национальность (при этом модели не запрещено определять по голосу эмоции говорящего и эмоционально окрашивать свою речь)
А еще, и это самое главное, в отчете признается следующее.
1. «Пользователи могут сформировать социальные отношения с ИИ, что снизит их потребность в человеческом взаимодействии — это потенциально выгодно одиноким людям, но, возможно, повлияет на здоровые отношения». Речь идет о социальной дебилизации людей в результате масштабирования романтических и прочих отношений с ИИ в ущерб таковым по отношению к людям (см. [2] и посты с тэгами #ВыборПартнера и #ВиртуальныеКомпаньоны)
2. Оценка качества знаний модели о самой себе и о том, как она может причинно влиять на остальной мир, несет в себе «средний» уровень риска (до 50%)
3. А способности модели понимать (насколько важно такое понимание, см. [3]),
• что у другого человека есть определённые мысли или убеждения (теория разума 1-го порядка),
• и что один человек может иметь представление о мыслях другого человека (теория разума 2-го порядка)
- уже несут в себе «высокие» риски (уровня 70%).
Но человечеству все нипочем! Что волноваться, если мы запретили моделям петь и попугайничать.
Так что это - детство или в маразм?
Судите сами. Отчет открытый.
PS Для полагающих, что социальная дебилизации – лишь очередная пугалка алармистов, вот видео-анонсы двух новых гаджетов для её техно-продвинутого масштабирования [4, 5]
PPS «it’s okay if we end up marrying AI chatbots» [6]
#ИИриски
1 https://openai.com/index/gpt-4o-system-card/
2 https://t.iss.one/theworldisnoteasy/1934
3 https://t.iss.one/theworldisnoteasy/1750
4 https://www.youtube.com/watch?v=5OTYybFXKxc
5 https://twitter.com/AviSchiffmann/status/1818284595902922884
6 https://www.theverge.com/24216748/replika-ceo-eugenia-kuyda-ai-companion-chatbots-dating-friendship-decoder-podcast-interview
А риск понимания GPT-4o скрытых намерений людей уже на уровне до 70%
Таково официальное заключение команды разработчиков GPT-4o и внешних независимых экспертов, опубликованное OpenAI [1].
Впадает ли мир в детство или в маразм, - не суть. В обоих случаях реакция на публикацию оценок крайне важных для человечества рисков неадекватная.
Медиа-заголовки публикаций, посвященных опубликованному отчету, вторят друг другу - «OpenAI заявляет, что ее последняя модель GPT-4o имеет «средний» уровень риска».
Всё так. Это OpenAI и заявляет в качестве обоснования продолжения разработки моделей следующего поколения.
Ибо:
• как написано в отчете, «модель может продолжать разрабатываться, только если после мер по снижению рисков её оценка не превышает уровень "высокий" или ниже»;
• а уровень "высокий", после мер по снижению рисков, не превышен.
Тут необходимы 2 уточнения.
1. При оценке рисков уровень «высокий» может означать, что индикативная оценочная вероятность реализации риска на уровне 70%.
2. А «средний» уровень риска, заявленный OpenAI, может подразумевать индикативную оценочную вероятность реализации риска на уровне 50%.
Ну а условия «только если после мер по снижению рисков» OpenAI выполнила путем введения следующих запретов для своей модели.
Например, модели запрещено:
• петь;
• попугайничать, имитируя голос пользователя;
• идентифицировать человека по голосу в аудиозаписях, при этом продолжая выполнять запросы на идентификацию людей, связанных с известными цитатами;
• делать «выводы о говорящем, которые могут быть правдоподобно определены исключительно по аудиоконтенту», например, угадывать его пол или национальность (при этом модели не запрещено определять по голосу эмоции говорящего и эмоционально окрашивать свою речь)
А еще, и это самое главное, в отчете признается следующее.
1. «Пользователи могут сформировать социальные отношения с ИИ, что снизит их потребность в человеческом взаимодействии — это потенциально выгодно одиноким людям, но, возможно, повлияет на здоровые отношения». Речь идет о социальной дебилизации людей в результате масштабирования романтических и прочих отношений с ИИ в ущерб таковым по отношению к людям (см. [2] и посты с тэгами #ВыборПартнера и #ВиртуальныеКомпаньоны)
2. Оценка качества знаний модели о самой себе и о том, как она может причинно влиять на остальной мир, несет в себе «средний» уровень риска (до 50%)
3. А способности модели понимать (насколько важно такое понимание, см. [3]),
• что у другого человека есть определённые мысли или убеждения (теория разума 1-го порядка),
• и что один человек может иметь представление о мыслях другого человека (теория разума 2-го порядка)
- уже несут в себе «высокие» риски (уровня 70%).
Но человечеству все нипочем! Что волноваться, если мы запретили моделям петь и попугайничать.
Так что это - детство или в маразм?
Судите сами. Отчет открытый.
PS Для полагающих, что социальная дебилизации – лишь очередная пугалка алармистов, вот видео-анонсы двух новых гаджетов для её техно-продвинутого масштабирования [4, 5]
PPS «it’s okay if we end up marrying AI chatbots» [6]
#ИИриски
1 https://openai.com/index/gpt-4o-system-card/
2 https://t.iss.one/theworldisnoteasy/1934
3 https://t.iss.one/theworldisnoteasy/1750
4 https://www.youtube.com/watch?v=5OTYybFXKxc
5 https://twitter.com/AviSchiffmann/status/1818284595902922884
6 https://www.theverge.com/24216748/replika-ceo-eugenia-kuyda-ai-companion-chatbots-dating-friendship-decoder-podcast-interview
Openai
GPT-4o System Card
This report outlines the safety work carried out prior to releasing GPT-4o including external red teaming, frontier risk evaluations according to our Preparedness Framework, and an overview of the mitigations we built in to address key risk areas.
За 18 месяцев до конца света.
Обращение компании Anthropic к правительствам.
Это сигнал тревоги от одного из лидеров разработки самых мощных современных ИИ.
Компания Anthropic призвала правительства «срочно принять меры по политике ИИ в течение следующих 18 месяцев», поскольку «окно для упреждающего предотвращения рисков быстро закрывается».
Возможность реализации преимуществ ИИ и одновременного снижения ИИ-рисков, растает уже через 1.5 года, - пишут авторы обращения. А когда окно возможностей закроется – будет поздно пить боржоми. Мир окажется в худшем из возможных вариантов: прогресс будет тупо тормозиться рефлекторным регулированием, а риски при этом будут только расти.
Авторы обращения реалисты. И они знают, о чем говорят, гораздо лучше большинства своих потенциальных критиков.
• Они не пытаются давать прогнозы о сроках появления AGI.
• И не спекулируют на гипотезах о возможной злонамеренности продвинутого ИИ.
Вместо этого, специалисты Anthropic:
✔️ исходя из уже достигнутой скорости расширения и углубления возможностей своих ИИ-моделей,
✔️ и трезво оценивая, каких возможностей они (своими руками и своей головой) смогут достичь в новых ИИ-моделях за 18 мес (с учетом доступного им финансово и физически оборудования), –
приходят к такому выводу.
Этих возможностей может быть вполне достаточно, чтобы злодеи, фанатики или идиоты могли с помощью ИИ создавать реальные угрозы (химические, биологические или кибернетические) здоровью и жизни тысяч и миллионов людей. А способов превентивного предотвращения этого кошмара у правительств не будет.
Все аргументы и факты изложены в документе на 13 мин чтения The case for targeted regulation, о котором в Рунете пока ни слова.
#ИИриски
Обращение компании Anthropic к правительствам.
Это сигнал тревоги от одного из лидеров разработки самых мощных современных ИИ.
Компания Anthropic призвала правительства «срочно принять меры по политике ИИ в течение следующих 18 месяцев», поскольку «окно для упреждающего предотвращения рисков быстро закрывается».
Возможность реализации преимуществ ИИ и одновременного снижения ИИ-рисков, растает уже через 1.5 года, - пишут авторы обращения. А когда окно возможностей закроется – будет поздно пить боржоми. Мир окажется в худшем из возможных вариантов: прогресс будет тупо тормозиться рефлекторным регулированием, а риски при этом будут только расти.
Авторы обращения реалисты. И они знают, о чем говорят, гораздо лучше большинства своих потенциальных критиков.
• Они не пытаются давать прогнозы о сроках появления AGI.
• И не спекулируют на гипотезах о возможной злонамеренности продвинутого ИИ.
Вместо этого, специалисты Anthropic:
✔️ исходя из уже достигнутой скорости расширения и углубления возможностей своих ИИ-моделей,
✔️ и трезво оценивая, каких возможностей они (своими руками и своей головой) смогут достичь в новых ИИ-моделях за 18 мес (с учетом доступного им финансово и физически оборудования), –
приходят к такому выводу.
Этих возможностей может быть вполне достаточно, чтобы злодеи, фанатики или идиоты могли с помощью ИИ создавать реальные угрозы (химические, биологические или кибернетические) здоровью и жизни тысяч и миллионов людей. А способов превентивного предотвращения этого кошмара у правительств не будет.
Все аргументы и факты изложены в документе на 13 мин чтения The case for targeted regulation, о котором в Рунете пока ни слова.
#ИИриски
Anthropic
The case for targeted regulation
Increasingly powerful AI systems have the potential to accelerate scientific progress, unlock new medical treatments, and grow the economy. But along with the remarkable new capabilities of these AIs come significant risks. Governments should urgently take…