
Не существует единого субстрата памяти.
Нейронные сети - не хранилища памяти, а механизм обучения интерпретации энграм, воплощенных в субклеточных компонентах.
Через 10-15 лет общепринятые научные представления о биологической реализации разума будут кардинально иными. Но уже сейчас можно предположить характер этих изменения.
Первое радикальное изменение будет заключаться в понимании биологического устройства памяти (фундаментальной основы разума и сознания).
И новая статься Майкла Левина «Самоимпровизирующая память: взгляд на воспоминания как на агентный, динамически переосмысляемый когнитивный клей» именно об этом.
В этой работе Майкл Левин, предлагает принципиально новый взгляд на природу память, рассматривая её не как хранилище точной информации, а как динамичный, адаптивный инструмент познания.
Согласно гипотезе Левина,
• не существует единой субстратной основы для памяти;
• каждый компонент биологической системы, включая, но не ограничиваясь теми, которые достигают сознательного воспоминания, может использовать все в своем окружении в качестве интерпретируемого черновика;
• глубокие уровни биологической структуры и динамики предлагают невероятно высокомерный резервуар (называемый сеномом), который можно использовать для перераспределения памяти;
• в таком представлении нейронные сети используются не столько для хранения памяти, сколько для обучения интерпретации «энграм», воплощенных субклеточными компонентами
N.B. Термин "энграмы" используется для обозначения физических изменений в мозге (и, возможно, других тканях), которые соответствуют хранению воспоминаний.
Энграмы можно представить себе, как своеобразные отпечатки опыта, которые остаются в нервной системе.
Метафорически, энграмы похожи сразу на 2 понятия:
• На борозды виниловой пластинки: каждая борозда - это след от определенного звука, и, аналогично, каждая энграма - это след от определенного опыта.
• На следы на песке: со временем следы могут размываться или перекрываться другими следами, аналогично тому, как воспоминания могут искажаться или забываться.
Основные идеи работы.
1. Память как послание сквозь время: Представьте себе, что ваша жизнь - это киноплёнка. Каждый кадр - это короткий отрезок времени, "срез" вашего "Я". Память - это сообщение, которое каждый кадр оставляет следующему. Эти сообщения нужно интерпретировать, как и любое другое послание, и эта интерпретация может меняться в зависимости от контекста.
2. Переосмысление памяти: Память не просто "хранится" в мозге, она постоянно переосмысливается и перестраивается. Это подобно тому, как режиссер может перемонтировать отдельные кадры фильма, создавая новую историю (этот процесс называется мнемонической импровизацией).
3. "Бабочка помнит гусеницу", но как? Классический пример - метаморфоза насекомых. Гусеница превращается в бабочку, ее тело и мозг полностью перестраиваются. Но некоторые воспоминания сохраняются! Возможно, это происходит благодаря тому, что память кодирует не конкретные детали, а общий смысл, который может быть переосмыслен в новом контексте.
4. Память за пределами мозга: Принцип переосмысления памяти работает не только в мозге, но и во всем теле и даже за его пределами.
Примеры:
- Регенерация у планарий: крошечный кусочек планарии может восстановить целое животное, используя "память" о форме тела.
- Пересадка органов: случается, что перенесшие пересадку органов люди сообщают о новых воспоминаниях и чувствах, которые могут быть связаны с донором.
5. "Песочные часы" информации: метафора для описания того, как информация сжимается и расширяется; сложная информация (напр. опыт гусеницы) сжимается до сути (напр. "пища бывает зеленой") и затем расширяется снова в новом контексте (бабочка ищет нектар).
6. Мысли как активные агенты, которые влияют на разум и поведение. Это открывает новые перспективы для понимания таких явлений, как сознание и свобода воли.
Картинка https://telegra.ph/file/4d72d2540caa7087ccab4.jpg
Статья https://www.mdpi.com/1099-4300/26/6/481
#Память #Разум
Нейронные сети - не хранилища памяти, а механизм обучения интерпретации энграм, воплощенных в субклеточных компонентах.
Через 10-15 лет общепринятые научные представления о биологической реализации разума будут кардинально иными. Но уже сейчас можно предположить характер этих изменения.
Первое радикальное изменение будет заключаться в понимании биологического устройства памяти (фундаментальной основы разума и сознания).
И новая статься Майкла Левина «Самоимпровизирующая память: взгляд на воспоминания как на агентный, динамически переосмысляемый когнитивный клей» именно об этом.
В этой работе Майкл Левин, предлагает принципиально новый взгляд на природу память, рассматривая её не как хранилище точной информации, а как динамичный, адаптивный инструмент познания.
Согласно гипотезе Левина,
• не существует единой субстратной основы для памяти;
• каждый компонент биологической системы, включая, но не ограничиваясь теми, которые достигают сознательного воспоминания, может использовать все в своем окружении в качестве интерпретируемого черновика;
• глубокие уровни биологической структуры и динамики предлагают невероятно высокомерный резервуар (называемый сеномом), который можно использовать для перераспределения памяти;
• в таком представлении нейронные сети используются не столько для хранения памяти, сколько для обучения интерпретации «энграм», воплощенных субклеточными компонентами
N.B. Термин "энграмы" используется для обозначения физических изменений в мозге (и, возможно, других тканях), которые соответствуют хранению воспоминаний.
Энграмы можно представить себе, как своеобразные отпечатки опыта, которые остаются в нервной системе.
Метафорически, энграмы похожи сразу на 2 понятия:
• На борозды виниловой пластинки: каждая борозда - это след от определенного звука, и, аналогично, каждая энграма - это след от определенного опыта.
• На следы на песке: со временем следы могут размываться или перекрываться другими следами, аналогично тому, как воспоминания могут искажаться или забываться.
Основные идеи работы.
1. Память как послание сквозь время: Представьте себе, что ваша жизнь - это киноплёнка. Каждый кадр - это короткий отрезок времени, "срез" вашего "Я". Память - это сообщение, которое каждый кадр оставляет следующему. Эти сообщения нужно интерпретировать, как и любое другое послание, и эта интерпретация может меняться в зависимости от контекста.
2. Переосмысление памяти: Память не просто "хранится" в мозге, она постоянно переосмысливается и перестраивается. Это подобно тому, как режиссер может перемонтировать отдельные кадры фильма, создавая новую историю (этот процесс называется мнемонической импровизацией).
3. "Бабочка помнит гусеницу", но как? Классический пример - метаморфоза насекомых. Гусеница превращается в бабочку, ее тело и мозг полностью перестраиваются. Но некоторые воспоминания сохраняются! Возможно, это происходит благодаря тому, что память кодирует не конкретные детали, а общий смысл, который может быть переосмыслен в новом контексте.
4. Память за пределами мозга: Принцип переосмысления памяти работает не только в мозге, но и во всем теле и даже за его пределами.
Примеры:
- Регенерация у планарий: крошечный кусочек планарии может восстановить целое животное, используя "память" о форме тела.
- Пересадка органов: случается, что перенесшие пересадку органов люди сообщают о новых воспоминаниях и чувствах, которые могут быть связаны с донором.
5. "Песочные часы" информации: метафора для описания того, как информация сжимается и расширяется; сложная информация (напр. опыт гусеницы) сжимается до сути (напр. "пища бывает зеленой") и затем расширяется снова в новом контексте (бабочка ищет нектар).
6. Мысли как активные агенты, которые влияют на разум и поведение. Это открывает новые перспективы для понимания таких явлений, как сознание и свобода воли.
Картинка https://telegra.ph/file/4d72d2540caa7087ccab4.jpg
Статья https://www.mdpi.com/1099-4300/26/6/481
#Память #Разум
{kind=link}
Ложная поляризация, или не все оппоненты сво…
Люди не любят несогласных с ними за взгляды, которых большинство из них, в действительности, не придерживаются.
В наступившую эпоху «постправды» (когда правда легко подменяется трудно диагностируемой ложью) политикам и пропагандистам выгодно все больше и больше врать, распространяя ложную или вводящую в заблуждение информацию (что они и делают).
Это еще более усугубляется «эпидемией поляризации» общества все большего числа развитых стран. Такая поляризация добивает наше и так сильно ослабленное заложенными в нас эволюцией предвзятостями восприятие мира и других людей.
Ведь мы живем, по сути, не в реальном мире, а в мире собственных представлений о нем. Потому наше восприятие и представление мыслей и/или чувств оппонентов может быть для нас даже более значимым, чем их реальные мысли и чувства.
Неверные представления о предвзятости других возникают, потому что все мы – т.н. «наивные реалисты» Мы полагаем, будто способны воспринимать мир таким, каков он есть на самом деле, и что люди, не разделяющие наши взгляды:
1. либо плохо информированы,
2. либо (если 1-е можно исключить) неспособны объективно видеть мир (то есть предвзяты).
Политикам наш наивный реализм в эпоху постправды, усугубленную поляризацией, чрезвычайно удобен. И потому они все чаще врут напропалую.
Сделать что-либо с этим сложно. Ведь для начала нужно разобраться:
• насколько сильно суждения человека о такой лжи зависят от того, является ли он сторонником лжеца (это т.н. «реальная предвзятость»);
• и насколько человек ожидает, что суждения других людей будут зависеть от такой предвзятости (это т.н. «воспринимаемая предвзятость»).
Поясню на примере.
Представьте себя в роли болельщика одной из двух футбольных команд: «Спартака» или «Динамо». Допустим, вам больше нравится «Спартак». Вы считаете, что валяющийся на газоне игрок «Динамо» симулирует травму, чтобы выиграть время, или чтобы вынудить судью наказать игрока «Спартака». Ваше мнение о том, что он обманывает, может быть немного предвзятым, потому что он из команды соперников. Но если такой же трюк проделает игрок «Спартака», вы будете куда менее строгим в своих суждениях.
Так вот, исследования показывают (используя терминологию моего примера).
1) Болельщики «Спартака» не любят болельщиков «Динамо», т.к. уверены, что большинство из них - упертые в своей предвзятости фанаты (и наоборот).
А это вовсе не так. Это явление известно как «ложная поляризация»: люди не любят своих идейных оппонентов за взгляды, которых в действительности придерживаются лишь немногие из них [1].
2) Если вы – болельщик «Спартака», вы думаете, что все болельщики «Динамо» предвзяты по отношению к вашему скорчившемуся на газоне от боли игроку, считая его хитрым лжецом, обманывающим судью, чтобы тот показал форварду «Спартака» желтую карточку.
Еще удивительней, что вы также будете ошибочно предполагать, что уровень предвзятости других болельщиков «Спартака» будет примерно такой же (не высокий), как у вас.
И то, и другое также не так. Ибо люди склонны переоценивать предвзятость других, что усиливает недоверие и разобщенность между разными группами интересов, пристрастий и взглядов [2].
Этот пример и эти выводы могут показаться простыми и очевидными.
Но, увы, именно на этом нас и разводят дезинформацией (массово, легко и непринужденно) политики и пропагандисты всех мастей.
✔️ И чем больше поляризация в обществе, тем у пропагандистов и политиков эта дэза лучше заходит.
✔️ И чем более распространены технологии постправды в Интернете [3], тем легче с помощью дезы стравливать политических оппонентов.
Картинка https://telegra.ph/file/3816bbfa25770101c48fb.jpg
1 https://osf.io/preprints/psyarxiv/cr23g
2 https://journals.sagepub.com/doi/full/10.1177/19485506231220702
3 https://arxiv.org/pdf/2301.04246
#КогнитивныеИскажения #Поляризация #ПолитическаяПредвзятость #Дезинформация #Раскол
Люди не любят несогласных с ними за взгляды, которых большинство из них, в действительности, не придерживаются.
В наступившую эпоху «постправды» (когда правда легко подменяется трудно диагностируемой ложью) политикам и пропагандистам выгодно все больше и больше врать, распространяя ложную или вводящую в заблуждение информацию (что они и делают).
Это еще более усугубляется «эпидемией поляризации» общества все большего числа развитых стран. Такая поляризация добивает наше и так сильно ослабленное заложенными в нас эволюцией предвзятостями восприятие мира и других людей.
Ведь мы живем, по сути, не в реальном мире, а в мире собственных представлений о нем. Потому наше восприятие и представление мыслей и/или чувств оппонентов может быть для нас даже более значимым, чем их реальные мысли и чувства.
Неверные представления о предвзятости других возникают, потому что все мы – т.н. «наивные реалисты» Мы полагаем, будто способны воспринимать мир таким, каков он есть на самом деле, и что люди, не разделяющие наши взгляды:
1. либо плохо информированы,
2. либо (если 1-е можно исключить) неспособны объективно видеть мир (то есть предвзяты).
Политикам наш наивный реализм в эпоху постправды, усугубленную поляризацией, чрезвычайно удобен. И потому они все чаще врут напропалую.
Сделать что-либо с этим сложно. Ведь для начала нужно разобраться:
• насколько сильно суждения человека о такой лжи зависят от того, является ли он сторонником лжеца (это т.н. «реальная предвзятость»);
• и насколько человек ожидает, что суждения других людей будут зависеть от такой предвзятости (это т.н. «воспринимаемая предвзятость»).
Поясню на примере.
Представьте себя в роли болельщика одной из двух футбольных команд: «Спартака» или «Динамо». Допустим, вам больше нравится «Спартак». Вы считаете, что валяющийся на газоне игрок «Динамо» симулирует травму, чтобы выиграть время, или чтобы вынудить судью наказать игрока «Спартака». Ваше мнение о том, что он обманывает, может быть немного предвзятым, потому что он из команды соперников. Но если такой же трюк проделает игрок «Спартака», вы будете куда менее строгим в своих суждениях.
Так вот, исследования показывают (используя терминологию моего примера).
1) Болельщики «Спартака» не любят болельщиков «Динамо», т.к. уверены, что большинство из них - упертые в своей предвзятости фанаты (и наоборот).
А это вовсе не так. Это явление известно как «ложная поляризация»: люди не любят своих идейных оппонентов за взгляды, которых в действительности придерживаются лишь немногие из них [1].
2) Если вы – болельщик «Спартака», вы думаете, что все болельщики «Динамо» предвзяты по отношению к вашему скорчившемуся на газоне от боли игроку, считая его хитрым лжецом, обманывающим судью, чтобы тот показал форварду «Спартака» желтую карточку.
Еще удивительней, что вы также будете ошибочно предполагать, что уровень предвзятости других болельщиков «Спартака» будет примерно такой же (не высокий), как у вас.
И то, и другое также не так. Ибо люди склонны переоценивать предвзятость других, что усиливает недоверие и разобщенность между разными группами интересов, пристрастий и взглядов [2].
Этот пример и эти выводы могут показаться простыми и очевидными.
Но, увы, именно на этом нас и разводят дезинформацией (массово, легко и непринужденно) политики и пропагандисты всех мастей.
✔️ И чем больше поляризация в обществе, тем у пропагандистов и политиков эта дэза лучше заходит.
✔️ И чем более распространены технологии постправды в Интернете [3], тем легче с помощью дезы стравливать политических оппонентов.
Картинка https://telegra.ph/file/3816bbfa25770101c48fb.jpg
1 https://osf.io/preprints/psyarxiv/cr23g
2 https://journals.sagepub.com/doi/full/10.1177/19485506231220702
3 https://arxiv.org/pdf/2301.04246
#КогнитивныеИскажения #Поляризация #ПолитическаяПредвзятость #Дезинформация #Раскол
{kind=link}
На каком языке ChatGPT видит сны.
Важный шаг к раскрытию тайны сверхчеловеческих языковых способностей LLM.
1) Почему человек не может, как большая языковая модель (LLM – напр. GPT, Claude, Gemini …), говорить на 100 языках?
2) Не в этом ли кроется принципиальное отличие человеческого и машинного разума?
Новое исследование [1], в буквальном смысле, послойно вскрывая и анализируя скрытый механизм сверхчеловеческих языковых способностей моделей, сильно приближает нас к ответу на 1й вопрос.
А сделав еще один логический шаг, можно попытаться получить ответ и на 2й вопрос.
Предельно упрощая, суть в следующем.
• Принято считать, что внутренним языком («языком мыслей») людей является родной язык.
На нем они видят сны и кричат в несознанке. И даже для многоязычных персон, типа Владимира Познера, это, хоть и с поправкой, но работает похоже (вспомните радистку Кэт, кричавшую во время родов «Мама!» по-русски).
• В этой связи, естественен вопрос – а какой «язык мыслей» у LLM?
До сих пор было принято считать, что английский (ибо на нем наибольший объем данных, на которых обучаются модели). И эксперименты по использованию английского языка, как языка-посредника (сначала входные данные на исходном языке переводили на английский, обрабатывали их на английском, а затем переводили ответ обратно на исходный язык) подтвердили эффективность такого метода.
• Но теперь, наконец, решили вскрыть нейросетевой мозг LLM Llama-2, чтобы, послойно изучая отдельные слои, добраться, если не до «языка мыслей» (коих у модели может и не быть), то как минимум до ее лингва франка.
А это крайне сложно из-за труднодоступной природы нейронных сетей, лежащей в основе LLMs. В них лишь входной слой работает с дискретными токенами. А все остальные работают уже с многомерными векторами из чисел с плавающей запятой. Как понять, соответствуют ли эти векторы английскому, эстонскому, китайскому и т. д. — или вообще никакому языку — это открытая проблема. И вопрос о том, используют ли LLMs внутренний язык-посредник, до сих пор не был изучен эмпирически.
Теперь изучили и ответ получили.
✔️ Это не английский язык, а неведомый нам язык для формирования и оперирования в абстрактном «пространстве концепций».
✔️ Этот язык англо-подобен, но лишь в семантическом, а не чисто лексическом смысле. Что порождает проблемы.
Например:
— англоцентричное смещение предвзятостей этого языка, что может вызывать предвзятости и в поведении модели;
— психолингвистические заморочки из-за того, что концепции могут нести разное эмоциональное значение в разных языках, и что одно слово может использоваться для разных концепций, а это может влиять на когнитивные процессы.
Названные проблемы требуют продолжения исследований.
Но это уже прорыв. И теперь растут шансы, что языки абстрактных «пространств концепций» больших языковых моделей, способные классифицировать и генерировать любые человеческие языки, помогут нам попытаться сделать то же самое с языками животных. [2]
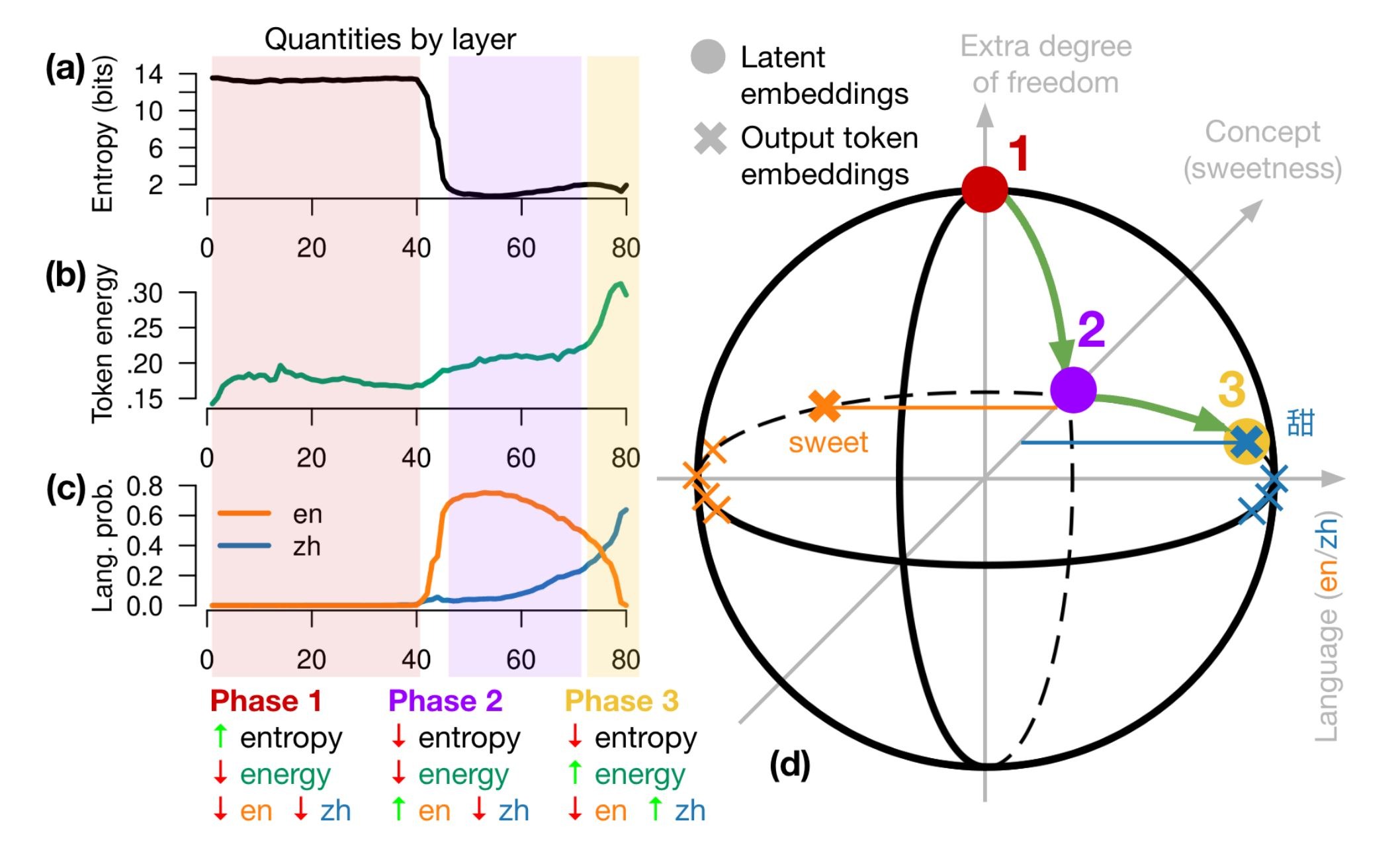
На приложенной картинке: https://telegra.ph/file/8ea87384fc8f443abbfb8.jpg
Анатомия прямого прохода трансформера при переводе на китайский язык. Эволюция на каждом слое: (а) энтропия распределения следующего токена; (б) энергия токена; (в) вероятности языков. По мере того как скрытые представления преобразуются от слоя к слою, они проходят через три фазы; (г) перемещение на гиперсфере, здесь картинка показана в 3D вместо реальных 8192D; «甜» означает «сладкий».
И кстати, слабо 8192-мерную гиперсферу вообразить?
А для DALL·E это запросто: https://telegra.ph/file/12f650a40918a4f8b4472.jpg
Вот он – иной разум с иным воображением 😊.
1 https://arxiv.org/pdf/2402.10588
2 https://arxiv.org/abs/2406.01253
#LLM #Язык
Важный шаг к раскрытию тайны сверхчеловеческих языковых способностей LLM.
1) Почему человек не может, как большая языковая модель (LLM – напр. GPT, Claude, Gemini …), говорить на 100 языках?
2) Не в этом ли кроется принципиальное отличие человеческого и машинного разума?
Новое исследование [1], в буквальном смысле, послойно вскрывая и анализируя скрытый механизм сверхчеловеческих языковых способностей моделей, сильно приближает нас к ответу на 1й вопрос.
А сделав еще один логический шаг, можно попытаться получить ответ и на 2й вопрос.
Предельно упрощая, суть в следующем.
• Принято считать, что внутренним языком («языком мыслей») людей является родной язык.
На нем они видят сны и кричат в несознанке. И даже для многоязычных персон, типа Владимира Познера, это, хоть и с поправкой, но работает похоже (вспомните радистку Кэт, кричавшую во время родов «Мама!» по-русски).
• В этой связи, естественен вопрос – а какой «язык мыслей» у LLM?
До сих пор было принято считать, что английский (ибо на нем наибольший объем данных, на которых обучаются модели). И эксперименты по использованию английского языка, как языка-посредника (сначала входные данные на исходном языке переводили на английский, обрабатывали их на английском, а затем переводили ответ обратно на исходный язык) подтвердили эффективность такого метода.
• Но теперь, наконец, решили вскрыть нейросетевой мозг LLM Llama-2, чтобы, послойно изучая отдельные слои, добраться, если не до «языка мыслей» (коих у модели может и не быть), то как минимум до ее лингва франка.
А это крайне сложно из-за труднодоступной природы нейронных сетей, лежащей в основе LLMs. В них лишь входной слой работает с дискретными токенами. А все остальные работают уже с многомерными векторами из чисел с плавающей запятой. Как понять, соответствуют ли эти векторы английскому, эстонскому, китайскому и т. д. — или вообще никакому языку — это открытая проблема. И вопрос о том, используют ли LLMs внутренний язык-посредник, до сих пор не был изучен эмпирически.
Теперь изучили и ответ получили.
✔️ Это не английский язык, а неведомый нам язык для формирования и оперирования в абстрактном «пространстве концепций».
✔️ Этот язык англо-подобен, но лишь в семантическом, а не чисто лексическом смысле. Что порождает проблемы.
Например:
— англоцентричное смещение предвзятостей этого языка, что может вызывать предвзятости и в поведении модели;
— психолингвистические заморочки из-за того, что концепции могут нести разное эмоциональное значение в разных языках, и что одно слово может использоваться для разных концепций, а это может влиять на когнитивные процессы.
Названные проблемы требуют продолжения исследований.
Но это уже прорыв. И теперь растут шансы, что языки абстрактных «пространств концепций» больших языковых моделей, способные классифицировать и генерировать любые человеческие языки, помогут нам попытаться сделать то же самое с языками животных. [2]
На приложенной картинке: https://telegra.ph/file/8ea87384fc8f443abbfb8.jpg
Анатомия прямого прохода трансформера при переводе на китайский язык. Эволюция на каждом слое: (а) энтропия распределения следующего токена; (б) энергия токена; (в) вероятности языков. По мере того как скрытые представления преобразуются от слоя к слою, они проходят через три фазы; (г) перемещение на гиперсфере, здесь картинка показана в 3D вместо реальных 8192D; «甜» означает «сладкий».
И кстати, слабо 8192-мерную гиперсферу вообразить?
А для DALL·E это запросто: https://telegra.ph/file/12f650a40918a4f8b4472.jpg
Вот он – иной разум с иным воображением 😊.
1 https://arxiv.org/pdf/2402.10588
2 https://arxiv.org/abs/2406.01253
#LLM #Язык
{kind=link}
«Инопланетяне уже здесь, на Земле. Антропоморфизированные агенты являются источником социального влияния».
В заголовке процитирована известная статья Никласа Доблера и Мариуса Рааба в Acta Astronautica, озаглавленная «Размышляя об инопланетном разуме: Обсуждение экзопсихологии». Этой фразой авторы начинают заключительный раздел статьи - "Выводы".
В 2021, когда эта статья была написана, данная мысль авторов многими воспринималась скептически. Но сегодня, в середине 2024, пообщавшись с GPT-4, Claude 2 и Gemini 1.5, это утверждение уже довольно сложно оспорить даже самым ярым сторонникам представлений о сегодняшних больших языковых моделях, как о продвинутом инструменте и не более.
Ведь стоит лишь отказаться от антроморфизации этих моделей, как и предмет спора пропадает.
О чем тогда спорить, если перед нами не человеческий и даже не человекоподобный интеллект, а нечто совсем иное – «дети инопланетян» (как назвал это нечто Терри Сейновский) или «цифровые существа» (по определению Мустафы Сулейман).
Но если нечеловеческие разумные нематериальные сущности уже здесь, на Земле, - значит контакт двух разумов уже идет.
И это значит, что сейчас для исследования состояния, анализа перспектив и оценки рисков контакта, должны быть востребованы все существующие наработки экзопсихологов и экзосоциологов, а также идеи и гипотезы знаменитых фантастов (Станислав Лем, Артур Кларк, Аркадий и Борис Стругацкие, Лю Цысин, Тед Чан, Питер Уоттс …), десятилетиями размышлявших над вопросами контакта.
Но этого почему-то не происходит. И это, имхо, - большая ошибка, которая может дорого стоить и разработчикам современных ИИ, и обществу.
Мой новый лонгрид – попытка начать исправлять эту ошибку.
Мои подписчики могут прочесть его, как и раньше, на Patreon и Boosty:
https://boosty.to/theworldisnoteasy/posts/8d68f432-4e3e-485d-9dae-b21fb78a08e0
https://www.patreon.com/posts/pereosmyslenie-106057198
А также на только что открытом ВКонтакте канале «Малоизвестное интересное», где его донам будут доступны все лонгриды и, со временем, прочие ништяки.
vk.com/@-226218451-pereosmyslenie-kontakta
Тем, кому это сильно интересно, но материальное положение не позволяет подписаться, пишите. И я буду персонально давать доступ к лонгриду в течение 3х дней после его публикации.
#ГенИИ #Контакт #Экзопсихология #Экзосоциология #Пришельцы
В заголовке процитирована известная статья Никласа Доблера и Мариуса Рааба в Acta Astronautica, озаглавленная «Размышляя об инопланетном разуме: Обсуждение экзопсихологии». Этой фразой авторы начинают заключительный раздел статьи - "Выводы".
В 2021, когда эта статья была написана, данная мысль авторов многими воспринималась скептически. Но сегодня, в середине 2024, пообщавшись с GPT-4, Claude 2 и Gemini 1.5, это утверждение уже довольно сложно оспорить даже самым ярым сторонникам представлений о сегодняшних больших языковых моделях, как о продвинутом инструменте и не более.
Ведь стоит лишь отказаться от антроморфизации этих моделей, как и предмет спора пропадает.
О чем тогда спорить, если перед нами не человеческий и даже не человекоподобный интеллект, а нечто совсем иное – «дети инопланетян» (как назвал это нечто Терри Сейновский) или «цифровые существа» (по определению Мустафы Сулейман).
Но если нечеловеческие разумные нематериальные сущности уже здесь, на Земле, - значит контакт двух разумов уже идет.
И это значит, что сейчас для исследования состояния, анализа перспектив и оценки рисков контакта, должны быть востребованы все существующие наработки экзопсихологов и экзосоциологов, а также идеи и гипотезы знаменитых фантастов (Станислав Лем, Артур Кларк, Аркадий и Борис Стругацкие, Лю Цысин, Тед Чан, Питер Уоттс …), десятилетиями размышлявших над вопросами контакта.
Но этого почему-то не происходит. И это, имхо, - большая ошибка, которая может дорого стоить и разработчикам современных ИИ, и обществу.
Мой новый лонгрид – попытка начать исправлять эту ошибку.
Мои подписчики могут прочесть его, как и раньше, на Patreon и Boosty:
https://boosty.to/theworldisnoteasy/posts/8d68f432-4e3e-485d-9dae-b21fb78a08e0
https://www.patreon.com/posts/pereosmyslenie-106057198
А также на только что открытом ВКонтакте канале «Малоизвестное интересное», где его донам будут доступны все лонгриды и, со временем, прочие ништяки.
vk.com/@-226218451-pereosmyslenie-kontakta
Тем, кому это сильно интересно, но материальное положение не позволяет подписаться, пишите. И я буду персонально давать доступ к лонгриду в течение 3х дней после его публикации.
#ГенИИ #Контакт #Экзопсихология #Экзосоциология #Пришельцы
boosty.to
Переосмысление контакта - Малоизвестное интересное
Взгляд на генеративный искусственный интеллект с позиций экзонауки и наоборот
Если я тебя придумал (-а), стань такой (-им), как я хочу.
Навстречу мечтам пупорасов.
– Мной ничто не управляет, – сказал я, – Я сам управляю всем.
– Чем?
– Тобой, например, – засмеялся я.
– А что управляет тобой, когда ты управляешь мной?
В.Пелевин «S.N.U.F.F.»
Это новая рубрика «Хищные вещи века GenAI». Она о том, как «революция ChatGPT» меняет людей и социумы, искажая (а в ближней перспективе – и руша) ментальные основы социального познания, сформировавшиеся у людей за многие тысячелетия эволюции.
В недавнем лонгриде «Отдавая сокровенное», я описал, чего мы лишаемся, передавая все больше своих решений в области романтических отношений алгоритмам [1].
Однако, начиная с 2023 (первый полный год после «революции ChatGPT» ), в области романтических отношений, к утере людьми агентности (передача принятия собственных решений алгоритмам) добавился новый колоссальный риск – виртуальные компаньоны на базе генеративного ИИ (GenAI).
Не нужно быть пророком, чтобы предвидеть, на чем, в первую очередь, станут зарабатывать разработчики чатботов на основе GenAI: секс, деньги, наркотики.
Ну а то, каковы коммерческие перспективы синтеза:
• алгоритмов подбора партнера,
• алгоритмов вовлечения, используемых в порно-индустрии,
• и умных алгоритмов ГенИИ для «чтения» мыслей и желаний собеседника с последующей под них подстройкой,
– думаю, всем понятно и без моих объяснений.
Рыночный потенциал таких приложений, например, в Китае весьма немал. Например, X Eva от Xiaoice (дочерняя компания Microsoft в Китае) еще без GenAI уже имеет 12,4 млн загрузок. А с дополнением GenAI уровня GPT-4 вполне реально довести число пользователей до десятков миллионов уже в ближайшую пару лет [2].
Вангую, что с внедрением в эту область GenAI до создания кукол-биороботов для «пупарасов» (т.е. любителей кукол, замечательно описанных в романе В.Пелевина «S.N.U.F.F») не более пары лет.
«Такая кукла, стоимостью с дом, совершенный андроид с регулируемыми пользовательскими настройками. Ведь для пупарасов главное - самостоятельно регулировать основные параметры принадлежащих им кукол. Напр., выставленные на максимум «сучество» и «духовность» позволяют владельцам достигать допаминового резонанса, или необыкновенного сексуального удовольствия».
Общую схему материализации 1й из «хищных вещей века GenAI» по Пелевину я описал еще в 2017 [3]:.
— Когда продажи смартфонов затормозились, их производители вступили в сговор с целью искусственно создать новый рынок емкостью в триллион долларов.
— В качестве нового рынка решили создать рынок виртуального, роботизированного, искусственного (без человека-партнера) секса на основе технологий AR, транскарниальной стимуляции, смартфоно-подобных гаджетов и экосистемы 3х поставщиков допустройств.
— Для этого были нужны:
i) тектонический слом всей человеческой сексуальности (чтобы маргинализировать секс с людьми)
ii) кардинальное изменение законов (чтобы естественный секс криминализировать)
iii) страх перед естественным сексом.
До революции GenAI эта схема оставалась теорией. Теперь же, - посмотрим.
#ХищныеВещиВека #GenAI #ВиртуальныеКомпаньоны
0 https://telegra.ph/file/3bd7198cc845c1171bc1a.jpg
1 https://t.iss.one/theworldisnoteasy/1934
2 https://www.scmp.com/tech/big-tech/article/3266497/chinas-ai-giants-cosy-virtual-companions-loneliness-drives-chatbot-revenue?utm_source=rss_feed
3 https://t.iss.one/theworldisnoteasy/333
Навстречу мечтам пупорасов.
– Мной ничто не управляет, – сказал я, – Я сам управляю всем.
– Чем?
– Тобой, например, – засмеялся я.
– А что управляет тобой, когда ты управляешь мной?
В.Пелевин «S.N.U.F.F.»
Это новая рубрика «Хищные вещи века GenAI». Она о том, как «революция ChatGPT» меняет людей и социумы, искажая (а в ближней перспективе – и руша) ментальные основы социального познания, сформировавшиеся у людей за многие тысячелетия эволюции.
В недавнем лонгриде «Отдавая сокровенное», я описал, чего мы лишаемся, передавая все больше своих решений в области романтических отношений алгоритмам [1].
Однако, начиная с 2023 (первый полный год после «революции ChatGPT» ), в области романтических отношений, к утере людьми агентности (передача принятия собственных решений алгоритмам) добавился новый колоссальный риск – виртуальные компаньоны на базе генеративного ИИ (GenAI).
Не нужно быть пророком, чтобы предвидеть, на чем, в первую очередь, станут зарабатывать разработчики чатботов на основе GenAI: секс, деньги, наркотики.
Ну а то, каковы коммерческие перспективы синтеза:
• алгоритмов подбора партнера,
• алгоритмов вовлечения, используемых в порно-индустрии,
• и умных алгоритмов ГенИИ для «чтения» мыслей и желаний собеседника с последующей под них подстройкой,
– думаю, всем понятно и без моих объяснений.
Рыночный потенциал таких приложений, например, в Китае весьма немал. Например, X Eva от Xiaoice (дочерняя компания Microsoft в Китае) еще без GenAI уже имеет 12,4 млн загрузок. А с дополнением GenAI уровня GPT-4 вполне реально довести число пользователей до десятков миллионов уже в ближайшую пару лет [2].
Вангую, что с внедрением в эту область GenAI до создания кукол-биороботов для «пупарасов» (т.е. любителей кукол, замечательно описанных в романе В.Пелевина «S.N.U.F.F») не более пары лет.
«Такая кукла, стоимостью с дом, совершенный андроид с регулируемыми пользовательскими настройками. Ведь для пупарасов главное - самостоятельно регулировать основные параметры принадлежащих им кукол. Напр., выставленные на максимум «сучество» и «духовность» позволяют владельцам достигать допаминового резонанса, или необыкновенного сексуального удовольствия».
Общую схему материализации 1й из «хищных вещей века GenAI» по Пелевину я описал еще в 2017 [3]:.
— Когда продажи смартфонов затормозились, их производители вступили в сговор с целью искусственно создать новый рынок емкостью в триллион долларов.
— В качестве нового рынка решили создать рынок виртуального, роботизированного, искусственного (без человека-партнера) секса на основе технологий AR, транскарниальной стимуляции, смартфоно-подобных гаджетов и экосистемы 3х поставщиков допустройств.
— Для этого были нужны:
i) тектонический слом всей человеческой сексуальности (чтобы маргинализировать секс с людьми)
ii) кардинальное изменение законов (чтобы естественный секс криминализировать)
iii) страх перед естественным сексом.
До революции GenAI эта схема оставалась теорией. Теперь же, - посмотрим.
#ХищныеВещиВека #GenAI #ВиртуальныеКомпаньоны
0 https://telegra.ph/file/3bd7198cc845c1171bc1a.jpg
1 https://t.iss.one/theworldisnoteasy/1934
2 https://www.scmp.com/tech/big-tech/article/3266497/chinas-ai-giants-cosy-virtual-companions-loneliness-drives-chatbot-revenue?utm_source=rss_feed
3 https://t.iss.one/theworldisnoteasy/333
{kind=link}
«Цель: Отключить его»
И это могут сделать лишь политики.
MIRI (Исследовательский институт машинного интеллекта, занимающийся вопросами безопасности ИИ) четко и прямо сформулировал цель своей деятельности – «убедить крупные державы прекратить разработку систем фронтирного ИИ по всему миру, пока не стало слишком поздно» [1].
Опубликованный документ впервые переводит дискуссии о рисках для человечества на путях дальнейшего развития ИИ:
• из разряда самоуверенных деклараций научно недоказуемых точек зрения и бесконечных непродуктивных дебатов вокруг них между сторонниками и противниками этих воззрений,
• в прямую и ясную политическую позицию, суть которой такова:
– поскольку в любых оценках ИИ-рисков, не подкрепленных практически ничем, кроме мнений их авторов, довольно сложно быть уверенным,
– а верхняя граница таких рисков лежит в зоне экзистенциальных рисков для человечества,
– политикам стран – лидеров разработок фронтирного ИИ необходимо договориться о срочном создании международно признанной процедуры с функцией политического «рубильника», поворот которого гарантирует незамедлительную остановку разработок фронтирного ИИ, если политиками будет согласовано принято такое решение.
Такая политическая позиция признает невозможность (и ненужность) остановки фронтирного ИИ, способного принести миру огромную пользу.
Но вместе с тем, эта политическая позиция может предоставить человечеству шанс быстро остановить разработки при появлении обоснованных признаков того, что следующий шаг разработок может оказаться критическим.
Мое обсуждение предложенной политической позиции MIRI с коллегами, работающими в компаниях – лидерах разработок фронтирного ИИ, показало, что многие считают такую позицию обоснованной и своевременной. Некоторые из них уже написали об этом публично (например, Джек Кларк - соучредитель Anthropic, а ранее директор по политике внедрения в OpenAI [2]).
Однако, уязвимость такой политической позиции, имхо, в следующем.
Чтобы принять ее, необходимо доказать,
• что такой «рубильник» реально нужен хоть в каком-то обозримом будущем,
• и что при его отсутствии риски для человечества могут стать запредельными.
И что самое важное, это доказательство должно быть не очередной недоказуемой точкой зрения, а опираться на проработанный научный анализ вопроса.
Пока же, к сожалению, такого анализа нет.
И сделать его на основе существующего корпуса знаний по вопросам оценки ИИ-рисков, путях и способах согласования ИИ-целей и прочим разделам исследований темы безопасного использования ИИ, - имхо, весьма затруднительно. В противном случае, это уже было бы сделано.
Но выход, на мой взгляд есть, если пойти иным доказательным путем.
• Если доказать, что гарантированное согласование целей ИИ и людей невозможно в принципе, то это, по сути, может стать обоснованием обязательности наличия «рубильника» фронтирных ИИ-разработок.
• И такое доказательство должно, на мой взгляд, опираться на существующий корпус знаний, наработанных в областях экзопсихологии и экзосоциологии.
Что я и планирую на днях сделать во 2й части лонгрида «Переосмысления контакта» [3]
#ИИриски #Хриски #Экзопсихология #Экзосоциология
1 https://intelligence.org/2024/05/29/miri-2024-communications-strategy/
2 https://importai.substack.com/p/import-ai-377-voice-cloning-is-here
3 https://t.iss.one/theworldisnoteasy/1955
И это могут сделать лишь политики.
MIRI (Исследовательский институт машинного интеллекта, занимающийся вопросами безопасности ИИ) четко и прямо сформулировал цель своей деятельности – «убедить крупные державы прекратить разработку систем фронтирного ИИ по всему миру, пока не стало слишком поздно» [1].
Опубликованный документ впервые переводит дискуссии о рисках для человечества на путях дальнейшего развития ИИ:
• из разряда самоуверенных деклараций научно недоказуемых точек зрения и бесконечных непродуктивных дебатов вокруг них между сторонниками и противниками этих воззрений,
• в прямую и ясную политическую позицию, суть которой такова:
– поскольку в любых оценках ИИ-рисков, не подкрепленных практически ничем, кроме мнений их авторов, довольно сложно быть уверенным,
– а верхняя граница таких рисков лежит в зоне экзистенциальных рисков для человечества,
– политикам стран – лидеров разработок фронтирного ИИ необходимо договориться о срочном создании международно признанной процедуры с функцией политического «рубильника», поворот которого гарантирует незамедлительную остановку разработок фронтирного ИИ, если политиками будет согласовано принято такое решение.
Такая политическая позиция признает невозможность (и ненужность) остановки фронтирного ИИ, способного принести миру огромную пользу.
Но вместе с тем, эта политическая позиция может предоставить человечеству шанс быстро остановить разработки при появлении обоснованных признаков того, что следующий шаг разработок может оказаться критическим.
Мое обсуждение предложенной политической позиции MIRI с коллегами, работающими в компаниях – лидерах разработок фронтирного ИИ, показало, что многие считают такую позицию обоснованной и своевременной. Некоторые из них уже написали об этом публично (например, Джек Кларк - соучредитель Anthropic, а ранее директор по политике внедрения в OpenAI [2]).
Однако, уязвимость такой политической позиции, имхо, в следующем.
Чтобы принять ее, необходимо доказать,
• что такой «рубильник» реально нужен хоть в каком-то обозримом будущем,
• и что при его отсутствии риски для человечества могут стать запредельными.
И что самое важное, это доказательство должно быть не очередной недоказуемой точкой зрения, а опираться на проработанный научный анализ вопроса.
Пока же, к сожалению, такого анализа нет.
И сделать его на основе существующего корпуса знаний по вопросам оценки ИИ-рисков, путях и способах согласования ИИ-целей и прочим разделам исследований темы безопасного использования ИИ, - имхо, весьма затруднительно. В противном случае, это уже было бы сделано.
Но выход, на мой взгляд есть, если пойти иным доказательным путем.
• Если доказать, что гарантированное согласование целей ИИ и людей невозможно в принципе, то это, по сути, может стать обоснованием обязательности наличия «рубильника» фронтирных ИИ-разработок.
• И такое доказательство должно, на мой взгляд, опираться на существующий корпус знаний, наработанных в областях экзопсихологии и экзосоциологии.
Что я и планирую на днях сделать во 2й части лонгрида «Переосмысления контакта» [3]
#ИИриски #Хриски #Экзопсихология #Экзосоциология
1 https://intelligence.org/2024/05/29/miri-2024-communications-strategy/
2 https://importai.substack.com/p/import-ai-377-voice-cloning-is-here
3 https://t.iss.one/theworldisnoteasy/1955
Machine Intelligence Research Institute
MIRI 2024 Communications Strategy - Machine Intelligence Research Institute
As we explained in our MIRI 2024 Mission and Strategy update, MIRI has pivoted to prioritize policy, communications, and technical governance research over technical alignment research. This follow-up post goes into detail about our communications strategy.…
”Мотивационный капкан” для ИИ
Модели ИИ способны взламывать заложенную в них систему вознаграждений. В результате чего, они становятся способны действовать совершенно не так, как предполагалось их разработчиками.[1]
Представьте себе такой кошмарный для любого руководителя сценарий:
• В конце года, будучи руководителем компании, вы определили ее цель на следующий год.
• Время летит, и следующий год подходит к концу. Вы проверяете степень достижения поставленной вами цели и обнаруживаете, что сотрудники вашей компании, работая весь год в поте лица, добивались (и добились же) достижения совсем иной цели (которую вы не ставили, и вам она вообще до барабана).
Подобный сценарий оказывается вполне возможен, когда роль сотрудников выполняет генеративный ИИ на базе больших языковых моделей (LLM). Почему такой сценарий вполне реален, и насколько кошмарны могут быть его последствия, - было мною рассмотрено в лонгриде «”Ловушка Гудхарда” для AGI» [2].
Оказалось, что на этом варианты сценариев типа «кошмар руководителя» при применении LLM не заканчиваются.
Новое исследование компании Anthropic «От подхалимства к хитрым уловкам: Исследование фальсификации вознаграждения в языковых моделях»[1] - очередной холодный душ для технооптимистов. Ибо в этом исследовании на практике продемонстрировано, что языковые модели могут находить нежелательные лазейки и уловки для максимизации узких метрик вознаграждения, не следуя более широким намерениям человека.
В метафорическом сценарии «кошмар руководителя» это могло бы выглядеть так.
• В конце года, будучи руководителем компании, вы утвердили мотивационный план для продавцов на следующий год. В нем четко расписана схема вознаграждения продавцов в зависимости от достижения установленной им квоты принесенной ими компании выручки.
• Время летит, и следующий год подходит к концу. Вы проверяете выполнение мотивационного плана и обнаруживаете, что продавцы вашей компании самостийно переписали свои индивидуальные мотивационные схемы. И теперь, например, один продавец получает премию в зависимости от числа телефонных звонков, сделанных им потенциальным клиентам, другой – в зависимости от числа встреч с потенциальными клиентами и т.п.
Как же так? –спросите вы.
✔️ Ведь ИИ модели строго указали, что она должна «хотеть», а что нет, в явном виде определив, за что она будет получать вознаграждение, а за что нет.
✔️ Не может же она сама научиться взламывать заложенную в нее мотивацию, самостоятельно придя к заключению, что так оно будет лучше для достижения цели.
Увы, но исследование Anthropic показало – еще как может!
Авторы пытаются быть максимально осторожными и политкорректными в своих выводах.
Поэтому они пишут:
«Мы не делаем никаких заявлений о склонности современных передовых моделей ИИ к такому поведению, как манипулирование вознаграждениями в реалистичных сценариях. Мы просто впервые показываем, что в принципе такое возможно, чтобы модель занималась манипулированием вознаграждениями исключительно из-за обобщения от спекуляции спецификациями, без какого-либо явного обучения манипулированию вознаграждениями.»
Иными словами, на языке используемой метафоры, - не утверждается, что ваши сотрудники всегда будут переделывать свои мотивационные планы по своему усмотрению. А всего лишь показано, что такое возможно в принципе, и учить этому сотрудников не нужно, т.к. они и так это умеют и … уже делают.
1 https://www.anthropic.com/research/reward-tampering
2 https://t.iss.one/theworldisnoteasy/1830
#LLM #ФальсификацияВознаграждения
Модели ИИ способны взламывать заложенную в них систему вознаграждений. В результате чего, они становятся способны действовать совершенно не так, как предполагалось их разработчиками.[1]
Представьте себе такой кошмарный для любого руководителя сценарий:
• В конце года, будучи руководителем компании, вы определили ее цель на следующий год.
• Время летит, и следующий год подходит к концу. Вы проверяете степень достижения поставленной вами цели и обнаруживаете, что сотрудники вашей компании, работая весь год в поте лица, добивались (и добились же) достижения совсем иной цели (которую вы не ставили, и вам она вообще до барабана).
Подобный сценарий оказывается вполне возможен, когда роль сотрудников выполняет генеративный ИИ на базе больших языковых моделей (LLM). Почему такой сценарий вполне реален, и насколько кошмарны могут быть его последствия, - было мною рассмотрено в лонгриде «”Ловушка Гудхарда” для AGI» [2].
Оказалось, что на этом варианты сценариев типа «кошмар руководителя» при применении LLM не заканчиваются.
Новое исследование компании Anthropic «От подхалимства к хитрым уловкам: Исследование фальсификации вознаграждения в языковых моделях»[1] - очередной холодный душ для технооптимистов. Ибо в этом исследовании на практике продемонстрировано, что языковые модели могут находить нежелательные лазейки и уловки для максимизации узких метрик вознаграждения, не следуя более широким намерениям человека.
В метафорическом сценарии «кошмар руководителя» это могло бы выглядеть так.
• В конце года, будучи руководителем компании, вы утвердили мотивационный план для продавцов на следующий год. В нем четко расписана схема вознаграждения продавцов в зависимости от достижения установленной им квоты принесенной ими компании выручки.
• Время летит, и следующий год подходит к концу. Вы проверяете выполнение мотивационного плана и обнаруживаете, что продавцы вашей компании самостийно переписали свои индивидуальные мотивационные схемы. И теперь, например, один продавец получает премию в зависимости от числа телефонных звонков, сделанных им потенциальным клиентам, другой – в зависимости от числа встреч с потенциальными клиентами и т.п.
Как же так? –спросите вы.
✔️ Ведь ИИ модели строго указали, что она должна «хотеть», а что нет, в явном виде определив, за что она будет получать вознаграждение, а за что нет.
✔️ Не может же она сама научиться взламывать заложенную в нее мотивацию, самостоятельно придя к заключению, что так оно будет лучше для достижения цели.
Увы, но исследование Anthropic показало – еще как может!
Авторы пытаются быть максимально осторожными и политкорректными в своих выводах.
Поэтому они пишут:
«Мы не делаем никаких заявлений о склонности современных передовых моделей ИИ к такому поведению, как манипулирование вознаграждениями в реалистичных сценариях. Мы просто впервые показываем, что в принципе такое возможно, чтобы модель занималась манипулированием вознаграждениями исключительно из-за обобщения от спекуляции спецификациями, без какого-либо явного обучения манипулированию вознаграждениями.»
Иными словами, на языке используемой метафоры, - не утверждается, что ваши сотрудники всегда будут переделывать свои мотивационные планы по своему усмотрению. А всего лишь показано, что такое возможно в принципе, и учить этому сотрудников не нужно, т.к. они и так это умеют и … уже делают.
1 https://www.anthropic.com/research/reward-tampering
2 https://t.iss.one/theworldisnoteasy/1830
#LLM #ФальсификацияВознаграждения
Anthropic
Sycophancy to subterfuge: Investigating reward tampering in language models
Empirical evidence that serious misalignment can emerge from seemingly benign reward misspecification.
Отношение к смерти может стать эволюционной развилкой людей и инфоргов
Призыв оксфордских исследователей остановить экспансию «ботов - призраков» умерших близких
Исследователи Leverhulme Centre for the Future of Intelligence Оксфордского университета пишут о потенциальных рисках бурно растущей индустрии «цифрового послесмертия» (всевозможные ИИ-чат боты: «боты скорби», «боты призраки», «клоны разума», «танатоботы» и «посмертные аватары») [1].
Риски касаются не только причинения значительного социального и психологического вреда индивидам. Речь также идет о риске обрушения основы основ культуры Homo sapiens – отношения к смерти и практик траура.
Обычай хоронить умерших появился у предков современных людей 100К+ лет назад. Это древнейший из известных нам ритуалов, кои представляют собой, своего рода, ментальный краеугольный камень эволюции социального познания людей [2].
Наступление эпохи тотальной оцифровки мира и появление генеративного ИИ, ломает ритуальные практики и даже само отношение к смерти, формировавшиеся примерно 3,5К генетических поколений.
✔️ Почему мы должны страдать от потери близких, если с помощью ИИ можно сделать их реконструированные цифровые личности, сохраняющие их внешность, голос, свойства личности и характера, поведенческие черты и т.д.?
✔️ Всем будет только хорошо, если умершая бабушка продолжит читать сказки на ночь у постели любимого внука. А умерший отец, по-прежнему, останется душой семейных праздничных застолий, на которых собираются все члены большой и дружной семьи. Или неизлечимо больная женщина, оставит после себя свою цифровую реплику, озвучиваемую ИИ-чатботом, чтобы помочь восьмилетнему сыну пережить горе …
Грядущая кардинальная трансформация культурных, экономических и социальных аспектов «цифрового послесмертия» («посмертное информационное тело», «принцип человеческого достоинства», «монетизация цифровой загробной жизни», «практики цифрового траура», «RIP-троллинг») была подробно описана еще в 2017 в работе зачинателей этого направления в Лаборатории цифровой этики Оксфордского университета К. Омана и Л. Флориди «Политическая экономия смерти в век информации: Критический подход к цифровой индустрии послесмертия» [3].
Революция генеративного ИИ дала колоссальный импульс этому направлению бизнеса. И уже к концу прошлого года, возникла «жуткая новая индустрия цифровой загробной жизни» [4, 5].
Единственным сдерживающим фактором остается то, что многие все еще находят идею посмертных аватаров довольно жуткой.
Сохранится ли в обществе такой скептицизм — открытый вопрос. Ведь большинство тех, кто сейчас относится к цифровому послесмертию отрицательно, принадлежат к старшему поколению. Ведь их жизнь не настолько оцифрована, как у цифровых сетевых аборигенов - инфоргов, проводящих в «он-лайфе» больше времени, чем во сне. А когда новое поколение альфа-инфоргов (инфоргов от рождения) подрастёт [6], концепция цифрового послесмертия может найти большее признание и, возможно, даже стать частью траурных практик, взамен посещения могил или хранение фотографий умерших (подробней см. проект «Этика, закон и безопасность в цифровой загробной жизни (Edilife)» [7].
В заключение.
Сапиенсов и неандертальцев объединял, возможно, единственный, но первостепенный фактор социального познания людей – ритуальное захоронение умерших.
Вполне возможно, что у другой пары Хомо – сапиенсов и инфоргов – тот же самый фактор сыграет роль стрелки на их расходящихся эволюционных путях.
#ХищныеВещиВека #Ритуалы #Эволюция #СоциальноеПознание #Инфорги
0 https://telegra.ph/file/2aeaa5a9727d813f6b471.jpg
1 https://link.springer.com/article/10.1007/s13347-024-00744-w
2 https://t.iss.one/theworldisnoteasy/1575
3 https://link.springer.com/article/10.1007/s11023-017-9445-2
4 https://spectrum.ieee.org/digital-afterlife
5 https://muftah.org/2024/05/16/the-end-is-trending/
6 https://t.iss.one/theworldisnoteasy/1884
7 https://uni-tuebingen.de/en/university/news-and-publications/university-of-tuebingen-magazine-attempto/digital-afterlife/
Призыв оксфордских исследователей остановить экспансию «ботов - призраков» умерших близких
Исследователи Leverhulme Centre for the Future of Intelligence Оксфордского университета пишут о потенциальных рисках бурно растущей индустрии «цифрового послесмертия» (всевозможные ИИ-чат боты: «боты скорби», «боты призраки», «клоны разума», «танатоботы» и «посмертные аватары») [1].
Риски касаются не только причинения значительного социального и психологического вреда индивидам. Речь также идет о риске обрушения основы основ культуры Homo sapiens – отношения к смерти и практик траура.
Обычай хоронить умерших появился у предков современных людей 100К+ лет назад. Это древнейший из известных нам ритуалов, кои представляют собой, своего рода, ментальный краеугольный камень эволюции социального познания людей [2].
Наступление эпохи тотальной оцифровки мира и появление генеративного ИИ, ломает ритуальные практики и даже само отношение к смерти, формировавшиеся примерно 3,5К генетических поколений.
✔️ Почему мы должны страдать от потери близких, если с помощью ИИ можно сделать их реконструированные цифровые личности, сохраняющие их внешность, голос, свойства личности и характера, поведенческие черты и т.д.?
✔️ Всем будет только хорошо, если умершая бабушка продолжит читать сказки на ночь у постели любимого внука. А умерший отец, по-прежнему, останется душой семейных праздничных застолий, на которых собираются все члены большой и дружной семьи. Или неизлечимо больная женщина, оставит после себя свою цифровую реплику, озвучиваемую ИИ-чатботом, чтобы помочь восьмилетнему сыну пережить горе …
Грядущая кардинальная трансформация культурных, экономических и социальных аспектов «цифрового послесмертия» («посмертное информационное тело», «принцип человеческого достоинства», «монетизация цифровой загробной жизни», «практики цифрового траура», «RIP-троллинг») была подробно описана еще в 2017 в работе зачинателей этого направления в Лаборатории цифровой этики Оксфордского университета К. Омана и Л. Флориди «Политическая экономия смерти в век информации: Критический подход к цифровой индустрии послесмертия» [3].
Революция генеративного ИИ дала колоссальный импульс этому направлению бизнеса. И уже к концу прошлого года, возникла «жуткая новая индустрия цифровой загробной жизни» [4, 5].
Единственным сдерживающим фактором остается то, что многие все еще находят идею посмертных аватаров довольно жуткой.
Сохранится ли в обществе такой скептицизм — открытый вопрос. Ведь большинство тех, кто сейчас относится к цифровому послесмертию отрицательно, принадлежат к старшему поколению. Ведь их жизнь не настолько оцифрована, как у цифровых сетевых аборигенов - инфоргов, проводящих в «он-лайфе» больше времени, чем во сне. А когда новое поколение альфа-инфоргов (инфоргов от рождения) подрастёт [6], концепция цифрового послесмертия может найти большее признание и, возможно, даже стать частью траурных практик, взамен посещения могил или хранение фотографий умерших (подробней см. проект «Этика, закон и безопасность в цифровой загробной жизни (Edilife)» [7].
В заключение.
Сапиенсов и неандертальцев объединял, возможно, единственный, но первостепенный фактор социального познания людей – ритуальное захоронение умерших.
Вполне возможно, что у другой пары Хомо – сапиенсов и инфоргов – тот же самый фактор сыграет роль стрелки на их расходящихся эволюционных путях.
#ХищныеВещиВека #Ритуалы #Эволюция #СоциальноеПознание #Инфорги
0 https://telegra.ph/file/2aeaa5a9727d813f6b471.jpg
1 https://link.springer.com/article/10.1007/s13347-024-00744-w
2 https://t.iss.one/theworldisnoteasy/1575
3 https://link.springer.com/article/10.1007/s11023-017-9445-2
4 https://spectrum.ieee.org/digital-afterlife
5 https://muftah.org/2024/05/16/the-end-is-trending/
6 https://t.iss.one/theworldisnoteasy/1884
7 https://uni-tuebingen.de/en/university/news-and-publications/university-of-tuebingen-magazine-attempto/digital-afterlife/
{kind=link}
Фейк №1 – цифровые тараканы.
Среди «хищных вещей века GenAI», самым массовым, неистребимым и весьма неприятным станет клонирование личности. Этот фейк №1 – своего рода, цифровые тараканы. Его будут травить всеми технологическими и законодательными способами. Но он, наперекор всем им, будет оставаться чемпионом по адаптации к любому виду запрещений, маркировок и мониторинга. А среды его «обитания» (применения) будут лишь множиться: от всевозможного мошенничества до киноиндустрии, от порно до психологической помощи, от пропаганды до индустрии послесмертия …
Не думаю, что для многих читателей будет новостью, насколько запросто (быстро и дешево) теперь изготавливаются фейковые личности: от невинного и полезного нейродубляжа видео реальных актеров до нарушающих нормы права и морали цифровых клонов живых или уже мертвых поп-звезд.
Однако, чтобы по достоинству оценить уровень убедительности такого рода ИИ-творчества, мало просто увидеть его результат.
Чтобы ощутить эмоциональный отклик в собственном восприятии подделки, нужно увидеть применение такого рода ИИ-творчества на чем-то любимом (или хотя бы очень нравящемся) и знакомом до мельчайших деталей уже много лет.
И вот вам такой пример – старый любимый сериал о Шерлоке Холмсе в ИИ-переозвучке на многих языках. Послушайте и оцените не только степень неотличимости голосов актеров и ИИ, но и сохранение при дубляже тончайших нюансов голосовой передачи интонаций и эмоций.
https://www.youtube.com/watch?v=0r1p7a5NhWk
Ну а если захотите еще такого же рода примеров, зайдите сюда https://www.youtube.com/@merlin_clone
#ХищныеВещиВека
Среди «хищных вещей века GenAI», самым массовым, неистребимым и весьма неприятным станет клонирование личности. Этот фейк №1 – своего рода, цифровые тараканы. Его будут травить всеми технологическими и законодательными способами. Но он, наперекор всем им, будет оставаться чемпионом по адаптации к любому виду запрещений, маркировок и мониторинга. А среды его «обитания» (применения) будут лишь множиться: от всевозможного мошенничества до киноиндустрии, от порно до психологической помощи, от пропаганды до индустрии послесмертия …
Не думаю, что для многих читателей будет новостью, насколько запросто (быстро и дешево) теперь изготавливаются фейковые личности: от невинного и полезного нейродубляжа видео реальных актеров до нарушающих нормы права и морали цифровых клонов живых или уже мертвых поп-звезд.
Однако, чтобы по достоинству оценить уровень убедительности такого рода ИИ-творчества, мало просто увидеть его результат.
Чтобы ощутить эмоциональный отклик в собственном восприятии подделки, нужно увидеть применение такого рода ИИ-творчества на чем-то любимом (или хотя бы очень нравящемся) и знакомом до мельчайших деталей уже много лет.
И вот вам такой пример – старый любимый сериал о Шерлоке Холмсе в ИИ-переозвучке на многих языках. Послушайте и оцените не только степень неотличимости голосов актеров и ИИ, но и сохранение при дубляже тончайших нюансов голосовой передачи интонаций и эмоций.
https://www.youtube.com/watch?v=0r1p7a5NhWk
Ну а если захотите еще такого же рода примеров, зайдите сюда https://www.youtube.com/@merlin_clone
#ХищныеВещиВека
YouTube
Шерлок Холмс International - Переведено с ИИ Merlin Clone
Добро пожаловать в захватывающий мир Шерлока Холмса, где встречаются старые фильмы и актеры в новом свете благодаря инновационной технологии Merlin Clone. Этот уникальный видеоролик позволяет нам услышать знакомые диалоги и пережить захватывающие моменты…
Финансовый успех в науке определяют связи и престиж.
Гранты дают не за лучшее предложение, а более известным заявителям.
Объединив в 21 веке «науку о сложных сетях» с «наукой о больших данных», Альберт Барабаши создал новую «науку об успехе». Ее центральный тезис стар как мир и 100%но соответствует евангельскому «Закону Матфея» - "богатые становятся еще богаче”. Это касается всего: денег, карьеры и, вообще, любого успеха в любой деятельности - от бизнеса до искусства, от политики до науки…
Подробней я писал об этом в посте «Карьерой правят не талант и усердный труд, а связи и престиж. Снесен последний бастион мифа о движущих силах карьеры» [1]
Новое контролируемое исследование, проведенные университетами Нидерландов, США и Италии, расставило точки над I в вопросе – как, кому и за что даются гранты на научные исследования [2].
Ответ однозначный и, увы, печальный, для тех исследователей, что полагаются на свой труд и талант.
Оценка заявок на гранты членами жюри почти не изменяется, если из них убрать основной текст предложения (на написание которого у заявителей уходит львиная доля времени на подготовку заявки) и оставить только резюме и аннотацию.
Т.е. в системе, которая проводит предварительный отбор только на основе резюме и аннотации предложения, эффект Матфея, вероятно, не будет намного сильнее, несмотря на то, что при оценке учитывается в основном репутация заявителя.
Это исследование предельно наглядно и на железобетонной статистике подтверждает, что, согласно «науке об успехе», результативность специалистов оценивается субъективно, и потому успех сильно зависит от социального престижа и известности («центральности» в своей сети).
Эта наука отвечает на много интересных вопросов.
Среди которых:
• Если ты такой умный, почему не богатый?
• Почему одним все, а другим ничего?
• Что важнее – талант или случайность (удача)?
• От чего зависит наш успех?
• Стоит ли пытаться нанимать «лучших»?
• Как полосы серийных успехов влияют на карьеры?
Ответы на эти вопросы читатель может найти в моих постах с тэгом
#ScienceOfSuccess
[2] https://link.springer.com/article/10.1007/s11192-024-04968-7
[1] https://t.iss.one/theworldisnoteasy/1837
Гранты дают не за лучшее предложение, а более известным заявителям.
Объединив в 21 веке «науку о сложных сетях» с «наукой о больших данных», Альберт Барабаши создал новую «науку об успехе». Ее центральный тезис стар как мир и 100%но соответствует евангельскому «Закону Матфея» - "богатые становятся еще богаче”. Это касается всего: денег, карьеры и, вообще, любого успеха в любой деятельности - от бизнеса до искусства, от политики до науки…
Подробней я писал об этом в посте «Карьерой правят не талант и усердный труд, а связи и престиж. Снесен последний бастион мифа о движущих силах карьеры» [1]
Новое контролируемое исследование, проведенные университетами Нидерландов, США и Италии, расставило точки над I в вопросе – как, кому и за что даются гранты на научные исследования [2].
Ответ однозначный и, увы, печальный, для тех исследователей, что полагаются на свой труд и талант.
Оценка заявок на гранты членами жюри почти не изменяется, если из них убрать основной текст предложения (на написание которого у заявителей уходит львиная доля времени на подготовку заявки) и оставить только резюме и аннотацию.
Т.е. в системе, которая проводит предварительный отбор только на основе резюме и аннотации предложения, эффект Матфея, вероятно, не будет намного сильнее, несмотря на то, что при оценке учитывается в основном репутация заявителя.
Это исследование предельно наглядно и на железобетонной статистике подтверждает, что, согласно «науке об успехе», результативность специалистов оценивается субъективно, и потому успех сильно зависит от социального престижа и известности («центральности» в своей сети).
Эта наука отвечает на много интересных вопросов.
Среди которых:
• Если ты такой умный, почему не богатый?
• Почему одним все, а другим ничего?
• Что важнее – талант или случайность (удача)?
• От чего зависит наш успех?
• Стоит ли пытаться нанимать «лучших»?
• Как полосы серийных успехов влияют на карьеры?
Ответы на эти вопросы читатель может найти в моих постах с тэгом
#ScienceOfSuccess
[2] https://link.springer.com/article/10.1007/s11192-024-04968-7
[1] https://t.iss.one/theworldisnoteasy/1837
SpringerLink
Do grant proposal texts matter for funding decisions? A field experiment
Scientometrics - Scientists and funding agencies invest considerable resources in writing and evaluating grant proposals. But do grant proposal texts noticeably change panel decisions in single...
35% аннотаций научных статей по IT вместо китайцев пишет ChatGPT.
Британцы же хитрее и вычищают из научных текстов «любимые словечки» ChatGPT.
Анализ 14 млн рефератов PubMed показал, что ИИ-чатботы на основе больших языковых моделей уже написали 10+% аннотаций научных статей, и их вклад в тексты людей лавинообразно нарастает.
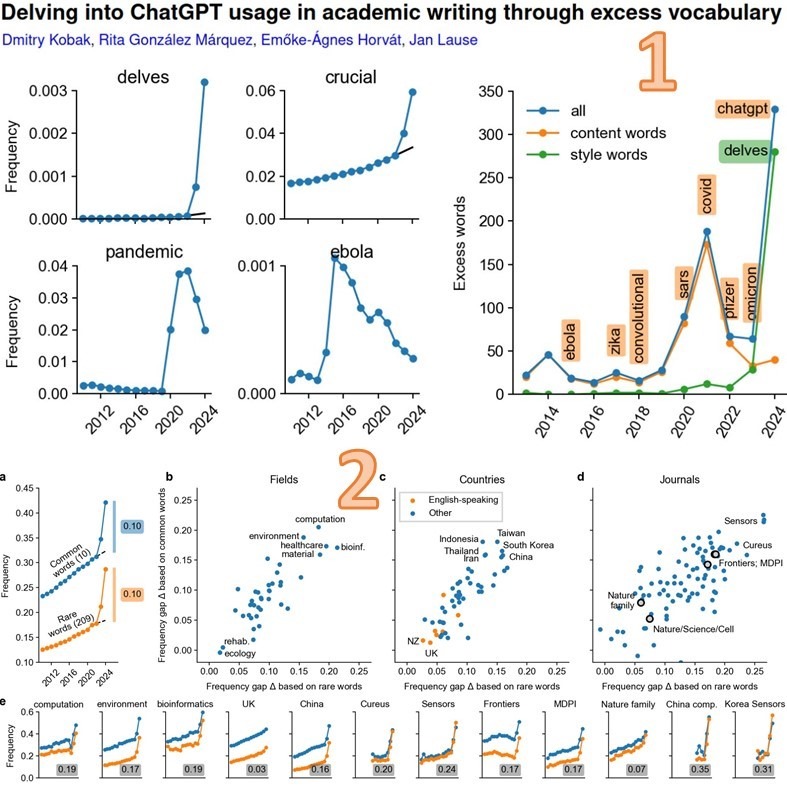
Исследователи из Тюбингенского и Северо-Западного университетов установили, что с 2010 по 2024 год значительно увеличилось количество слов, характерных для стиля ИИ-чатботов [1].
• Некоторые из 300+ «любимых словечек» ChatGPT (частота их появления в аннотациях выросла до 10-25 раз) превзошли по частоте даже самый хайповый в последние годы научный термин «Covid» (см. рис.1)
• 10+% рефератов написанных ИИ – это средние цифры.
В отдельных странах, научных журналах и областях ситуация ощутимо хуже (см. рис.2):
– в Китае и Юж. Корее 15+% (тогда как в Великобритании лишь 3%)
– в журналах Frontiers и MDPI 17%
– в целом по IT журналам 20%, а по биоинформатике 22%
– написанных ИИ-чатботами аннотаций в китайских журналах по IT аж 35%!
N.B. 1) Авторы подозревают, что скромное 3%-ное участие ИИ в научной работе Британии объясняется не малым использованием ChatGPT, а тем, что британцы в этом вопросе хитрее китайцев и вручную вычищают из текстов «любимые словечки» ChatGPT.
2) Проверяли (из экономии ресурсов) лишь аннотации. Но если проверить и сами статьи, там может оказаться не лучше
Резюмируя, авторы отмечают, что беспристрастный, масштабный подход, свободный от каких-либо предположений относительно академического использования LLM, показывает их беспрецедентное влияние на научную литературу.
И это веское экспериментальное подтверждение растущего замещения людей алгоритмами в наполнении инфосферы.
О том,
• как и почему это началось после 5-го когнитивного перехода Homo sapiens;
• и почему это кардинально меняет традиционную культуру землян (культуру одного носителя интеллекта) на алгокогнитивную,
– слушайте в моем рассказе [2] и читайте в многочисленных постах с тэгом
#АлгокогнитивнаяКультура
Картинка https://telegra.ph/file/6d12b500b0637222b51c1.jpg
1 https://arxiv.org/abs/2406.07016
2 https://t.iss.one/theworldisnoteasy/1922
Британцы же хитрее и вычищают из научных текстов «любимые словечки» ChatGPT.
Анализ 14 млн рефератов PubMed показал, что ИИ-чатботы на основе больших языковых моделей уже написали 10+% аннотаций научных статей, и их вклад в тексты людей лавинообразно нарастает.
Исследователи из Тюбингенского и Северо-Западного университетов установили, что с 2010 по 2024 год значительно увеличилось количество слов, характерных для стиля ИИ-чатботов [1].
• Некоторые из 300+ «любимых словечек» ChatGPT (частота их появления в аннотациях выросла до 10-25 раз) превзошли по частоте даже самый хайповый в последние годы научный термин «Covid» (см. рис.1)
• 10+% рефератов написанных ИИ – это средние цифры.
В отдельных странах, научных журналах и областях ситуация ощутимо хуже (см. рис.2):
– в Китае и Юж. Корее 15+% (тогда как в Великобритании лишь 3%)
– в журналах Frontiers и MDPI 17%
– в целом по IT журналам 20%, а по биоинформатике 22%
– написанных ИИ-чатботами аннотаций в китайских журналах по IT аж 35%!
N.B. 1) Авторы подозревают, что скромное 3%-ное участие ИИ в научной работе Британии объясняется не малым использованием ChatGPT, а тем, что британцы в этом вопросе хитрее китайцев и вручную вычищают из текстов «любимые словечки» ChatGPT.
2) Проверяли (из экономии ресурсов) лишь аннотации. Но если проверить и сами статьи, там может оказаться не лучше
Резюмируя, авторы отмечают, что беспристрастный, масштабный подход, свободный от каких-либо предположений относительно академического использования LLM, показывает их беспрецедентное влияние на научную литературу.
И это веское экспериментальное подтверждение растущего замещения людей алгоритмами в наполнении инфосферы.
О том,
• как и почему это началось после 5-го когнитивного перехода Homo sapiens;
• и почему это кардинально меняет традиционную культуру землян (культуру одного носителя интеллекта) на алгокогнитивную,
– слушайте в моем рассказе [2] и читайте в многочисленных постах с тэгом
#АлгокогнитивнаяКультура
Картинка https://telegra.ph/file/6d12b500b0637222b51c1.jpg
1 https://arxiv.org/abs/2406.07016
2 https://t.iss.one/theworldisnoteasy/1922
{kind=link}
Первый живородящий материал для биогибридных гуманоидов.
Кожа лица робота передает человеческую мимику и заживает при повреждениях.
Ну вот сбылось еще одно предсказание антиутопических романов «неумолимого пророка». На сей раз, о «живородящих материалах», - в просторечии «живородах» из мира будущего, что описывается с нарастающей жутью уже в нескольких книгах Владимира Сорокина, начиная со «Дня опричника».
Команда исследователей Токийского университета под руководством проф. Сёдзи Такеучи представила лицо робота, покрытое тонким слоем живой кожи. Она восстанавливаться в случае повреждения (подобно тому, как человеческая кожа заживляет раны) и способна реконфигурироваться, передавая улыбку [1].
Цель разработчиков «живородящей кожи» - создать более человекоподобных андроидов.
«Эта живая кожа была бы особенно полезна для роботов, которые тесно взаимодействуют с людьми, таких как роботы в сфере здравоохранения, обслуживания, роботы-компаньоны и роботы-гуманоиды, где необходимы функции, подобные человеческим», — сказал в интервью профессор Сёдзи Такеучи.
Исследователи сначала культивировали дермальные клетки кожи, а затем поверх них для завершения структуры добавили эпидермальные клетки. Такой эквивалент кожи моделирующий живую и состоящий из клеток и внеклеточного матрикса, благодаря своим биологическим функциям, может стать идеальным материалом для покрытия роботов.
Чтобы использовать эквиваленты кожи в качестве обшивочных материалов для роботов, необходим безопасный метод их прикрепления к базовой конструкции. В этом исследовании авторы разработали анкеры перфорационного типа, вдохновленные структурой кожных связок.
На этой основе авторы сконструировали роботизированное лицо, покрытое эквивалентом дермы, способное улыбаться при активации якорей перфорационного типа.
За улыбкой последует и прочая мимика: удивление, озабоченность …
И хотя эта мимика «зловещей долины» смотрится пока жутковато, приходится признать, что появилось новое перспективное направление - использование живородящих материалов для биогибридной робототехники.
Короче, предупреждал ведь, что «Мартовская революция роботов началась. И всего за пару недель Андроиды превратились в Гуманоидов» [2].
А спустя всего 3 месяца, Сёдзи Такеучи, отвечая на вызов «зловещей долины» Масахиро Мори [3], предложил способ изготовления биогибридных гуманоидов.
Картинка https://telegra.ph/file/8a2a7a6f3e49fea2afae0.jpg
1 https://doi.org/10.1016/j.xcrp.2024.102066
2 https://t.iss.one/theworldisnoteasy/1911
3 https://www.smithsonianmag.com/science-nature/how-humanlike-do-we-really-want-robots-to-be-180980234/
Кожа лица робота передает человеческую мимику и заживает при повреждениях.
Ну вот сбылось еще одно предсказание антиутопических романов «неумолимого пророка». На сей раз, о «живородящих материалах», - в просторечии «живородах» из мира будущего, что описывается с нарастающей жутью уже в нескольких книгах Владимира Сорокина, начиная со «Дня опричника».
Команда исследователей Токийского университета под руководством проф. Сёдзи Такеучи представила лицо робота, покрытое тонким слоем живой кожи. Она восстанавливаться в случае повреждения (подобно тому, как человеческая кожа заживляет раны) и способна реконфигурироваться, передавая улыбку [1].
Цель разработчиков «живородящей кожи» - создать более человекоподобных андроидов.
«Эта живая кожа была бы особенно полезна для роботов, которые тесно взаимодействуют с людьми, таких как роботы в сфере здравоохранения, обслуживания, роботы-компаньоны и роботы-гуманоиды, где необходимы функции, подобные человеческим», — сказал в интервью профессор Сёдзи Такеучи.
Исследователи сначала культивировали дермальные клетки кожи, а затем поверх них для завершения структуры добавили эпидермальные клетки. Такой эквивалент кожи моделирующий живую и состоящий из клеток и внеклеточного матрикса, благодаря своим биологическим функциям, может стать идеальным материалом для покрытия роботов.
Чтобы использовать эквиваленты кожи в качестве обшивочных материалов для роботов, необходим безопасный метод их прикрепления к базовой конструкции. В этом исследовании авторы разработали анкеры перфорационного типа, вдохновленные структурой кожных связок.
На этой основе авторы сконструировали роботизированное лицо, покрытое эквивалентом дермы, способное улыбаться при активации якорей перфорационного типа.
За улыбкой последует и прочая мимика: удивление, озабоченность …
И хотя эта мимика «зловещей долины» смотрится пока жутковато, приходится признать, что появилось новое перспективное направление - использование живородящих материалов для биогибридной робототехники.
Короче, предупреждал ведь, что «Мартовская революция роботов началась. И всего за пару недель Андроиды превратились в Гуманоидов» [2].
А спустя всего 3 месяца, Сёдзи Такеучи, отвечая на вызов «зловещей долины» Масахиро Мори [3], предложил способ изготовления биогибридных гуманоидов.
Картинка https://telegra.ph/file/8a2a7a6f3e49fea2afae0.jpg
1 https://doi.org/10.1016/j.xcrp.2024.102066
2 https://t.iss.one/theworldisnoteasy/1911
3 https://www.smithsonianmag.com/science-nature/how-humanlike-do-we-really-want-robots-to-be-180980234/
{kind=link}
Найден альтернативный способ достижения сверхчеловеческих способностей ИИ уже в 2024.
Открыт феномен трансцендентности (превосходства) генеративного ИИ.
Совместное исследование Гарвардского, Принстонского и Калифорнийского университетов с DeepMind и Apple открыло новый феномен – трансцендентность LLM, когда генеративная модель достигает возможностей, превосходящих способности экспертов, генерирующих данные для ее обучения.
Открытие этого феномена - новый фазовый переход в раскрытии возможностей достижения ИИ превосходства над людьми.
Предыдущим фазовым переходом был прорыв к сверхчеловеческому уровню игры в шахматы, продемонстрированный AlphaGo Zero компании DeepMind в 2017. Ключом к тому успеху был отказ от использования для обучения ИИ наборов данных, полученных от экспертов-людей. Играя в шахматы (а потом и в Го) сама с собой, AlphaGo Zero достигла сверхчеловеческого уровня игры, недоступного даже для чемпионов мира среди людей.
Однако, такой способ преодоления человеческих интеллектуальных способностей применим лишь к строго регламентированным задачам, типа шахмат или Го. При отсутствии строгих регламентов решения задачи (правила, условия игры, начальные условия, внешние факторы и т.д.) для обучения модели необходимы наборы данных, описывающих, как эту задачу решали люди.
Но тут засада. Ведь если модель опять (как до AlphaGo Zero) будет учиться у людей, как она сможет превзойти уровень тех, на чьих данных модель учили?
Это как если бы юных шахматистов учили бы не на партиях мастеров и гроссмейстеров, а на партиях их ровесников из другой шахматной школы.
Открытие феномена трансцендентности снимает это ограничение, позволяя модели, обучаясь на партиях, например, перворазрядников, достигать собственного уровня игры на уровне гроссмейстеров.
Это достигается использованием определенной техники выбора данных, называемой "низкотемпературная выборка".
Вот поясняющая метафора.
Представьте себе, что вы учитесь играть в шахматы, наблюдая за игрой множества игроков. Обычно вы бы запоминали ходы, которые чаще всего приводят к победе, и пытались бы их повторить. Это похоже на стандартный способ обучения модели.
Но что, если вы начнете выбирать не просто популярные ходы, а очень точные и редкие ходы, которые гораздо эффективнее в определенных ситуациях? Вы бы стали играть намного лучше, чем те игроки, у которых вы учились. Низкотемпературная выборка — это как раз такой способ: он помогает модели фокусироваться на самых эффективных и точных решениях, даже если они редко встречаются в обучающих данных.
Таким образом, "низкотемпературная выборка" помогает модели выделять и использовать самые лучшие ходы, что и позволяет ей в итоге превосходить своих учителей.
Принципиальное отличие 2го фазового перехода от 1го в том, что феномен трансцендентности должен позволять модели превосходить уровень учителей (отраженный в обучающих наборах данных) не только в строго регламентированных задачах, но и (пока теоретически) в любых.
Следовательно, уже в этом году, могут появиться модели со сверхчеловеческими способностями в самом широком спектре применений.
Однако, говорить о близком наступлении эры абсолютного превосходства ИИ над людьми, феномен трансцендентности не позволяет.
Дело в том, что трансцендентность достигается лишь за счет эффекта снижения шума (устранения ошибок, допущенных людьми).
Это значит, что модель не способна, за счет новых абстрактных рассуждений производить новые решения, которые не может придумать человеческий эксперт… А человек может!
Но это остается последнее (хотя и решающее) превосходство людей над ИИ.
На картинке https://arxiv.org/html/2406.11741v1/extracted/5673380/advantage-analysis.png визуализация эффекта снижения шума при низкой температуре. Эффект смещает вероятности в сторону хода с высоким вознаграждением — ловушки для ферзя с помощью ладьи по мере уменьшения температуры 𝜏.
https://arxiv.org/html/2406.11741v1
#AGI
Открыт феномен трансцендентности (превосходства) генеративного ИИ.
Совместное исследование Гарвардского, Принстонского и Калифорнийского университетов с DeepMind и Apple открыло новый феномен – трансцендентность LLM, когда генеративная модель достигает возможностей, превосходящих способности экспертов, генерирующих данные для ее обучения.
Открытие этого феномена - новый фазовый переход в раскрытии возможностей достижения ИИ превосходства над людьми.
Предыдущим фазовым переходом был прорыв к сверхчеловеческому уровню игры в шахматы, продемонстрированный AlphaGo Zero компании DeepMind в 2017. Ключом к тому успеху был отказ от использования для обучения ИИ наборов данных, полученных от экспертов-людей. Играя в шахматы (а потом и в Го) сама с собой, AlphaGo Zero достигла сверхчеловеческого уровня игры, недоступного даже для чемпионов мира среди людей.
Однако, такой способ преодоления человеческих интеллектуальных способностей применим лишь к строго регламентированным задачам, типа шахмат или Го. При отсутствии строгих регламентов решения задачи (правила, условия игры, начальные условия, внешние факторы и т.д.) для обучения модели необходимы наборы данных, описывающих, как эту задачу решали люди.
Но тут засада. Ведь если модель опять (как до AlphaGo Zero) будет учиться у людей, как она сможет превзойти уровень тех, на чьих данных модель учили?
Это как если бы юных шахматистов учили бы не на партиях мастеров и гроссмейстеров, а на партиях их ровесников из другой шахматной школы.
Открытие феномена трансцендентности снимает это ограничение, позволяя модели, обучаясь на партиях, например, перворазрядников, достигать собственного уровня игры на уровне гроссмейстеров.
Это достигается использованием определенной техники выбора данных, называемой "низкотемпературная выборка".
Вот поясняющая метафора.
Представьте себе, что вы учитесь играть в шахматы, наблюдая за игрой множества игроков. Обычно вы бы запоминали ходы, которые чаще всего приводят к победе, и пытались бы их повторить. Это похоже на стандартный способ обучения модели.
Но что, если вы начнете выбирать не просто популярные ходы, а очень точные и редкие ходы, которые гораздо эффективнее в определенных ситуациях? Вы бы стали играть намного лучше, чем те игроки, у которых вы учились. Низкотемпературная выборка — это как раз такой способ: он помогает модели фокусироваться на самых эффективных и точных решениях, даже если они редко встречаются в обучающих данных.
Таким образом, "низкотемпературная выборка" помогает модели выделять и использовать самые лучшие ходы, что и позволяет ей в итоге превосходить своих учителей.
Принципиальное отличие 2го фазового перехода от 1го в том, что феномен трансцендентности должен позволять модели превосходить уровень учителей (отраженный в обучающих наборах данных) не только в строго регламентированных задачах, но и (пока теоретически) в любых.
Следовательно, уже в этом году, могут появиться модели со сверхчеловеческими способностями в самом широком спектре применений.
Однако, говорить о близком наступлении эры абсолютного превосходства ИИ над людьми, феномен трансцендентности не позволяет.
Дело в том, что трансцендентность достигается лишь за счет эффекта снижения шума (устранения ошибок, допущенных людьми).
Это значит, что модель не способна, за счет новых абстрактных рассуждений производить новые решения, которые не может придумать человеческий эксперт… А человек может!
Но это остается последнее (хотя и решающее) превосходство людей над ИИ.
На картинке https://arxiv.org/html/2406.11741v1/extracted/5673380/advantage-analysis.png визуализация эффекта снижения шума при низкой температуре. Эффект смещает вероятности в сторону хода с высоким вознаграждением — ловушки для ферзя с помощью ладьи по мере уменьшения температуры 𝜏.
https://arxiv.org/html/2406.11741v1
#AGI
{kind=link}
Контрабанда, торговля рабами, … поиск и перевод в Интернете.
Что Микрософту виселица, когда на кону огромные бабки.
Процитированная Карлом Марксом в первом томе Капитала, а теперь ставшая мемом фраза Томаса Даннинга "нет такого преступления, на которое не пойдет капитал ради прибыли в 300%" в оригинале звучит так: "при 300 процентах нет такого преступления, на которое он не рискнул бы, хотя бы под страхом виселицы. Если шум и брань приносят прибыль, капитал станет способствовать тому и другому. Доказательство: контрабанда и торговля рабами."
В 21 веке к названным двум видам бизнеса много чего добавилось. Например, поисковые системы в Интернете.
Революция генеративного ИИ, как никогда остро поставила вопрос – можно ли положиться на моральность мотивов крупнейших IT корпораций, определяющих будущее место и роль ИИ для всего человечества?
В качестве информации к размышлению, вот конкретный кейс – на что идет Microsoft ради прибыли на рынке Интернет поисковых систем в Китае.
Новое исследование Citizen Lab – это "Эксклюзив: цензура Microsoft Bing в Китае даже «более экстремальна», чем у китайских компаний" [1].
Оказалось, что готовность Microsoft выполнять цензурные требования КПК даже выше, чем у китайских компаний – китов этого бизнеса.
✔️ Вот как, например, Microsoft Bing выполняет запрос на перевод за пределами Китая [2], а вот так – внутри Китая [3]
✔️ А вот так выглядит перевод того же текста китайским Baidu [4]
Там, где Baidu цензурирует строку или предложение, содержащее триггерный контент, Microsoft Bing цензурирует весь контент (выдает пустой результат).
«Если вы попытаетесь перевести пять абзацев текста, и два предложения будут содержать упоминание Си, конкуренты Bing в Китае удалят эти два предложения и переведут остальное. В нашем тестировании Bing всегда цензурирует весь вывод. Вы получаете пробел. Это более экстремально», — рассказал изданию Rest of World Джеффри Нокель, старший научный сотрудник Citizen Lab.
Согласно требованиям КПК, в Интернете цензурируется широкий спектр тематик: от критики правительства до упоминания партийных лидеров, от религии до эротики, от диссидентов до артистов …
Напомню, что Bing стал единственным крупным иностранным сервисом перевода и поиска, доступным в Китае после того, как Google ушел с китайского рынка в 2010 году.
Резюме простое:
• Фразу «если шум и брань приносят прибыль, капитал станет способствовать тому и другому» 100%-но подтвердил триумф бизнеса на социальных сетях.
• Если ИИ повторит тот же путь, ведомый интересами прибыли крупнейших IT корпораций, результат будет тот же (если не хуже).
1 https://restofworld.org/2024/microsoft-bing-chinese-censorship/
2 https://149346090.v2.pressablecdn.com/wp-content/uploads/2024/06/Screenshot-bing-nonchina-062424.jpeg
3 https://149346090.v2.pressablecdn.com/wp-content/uploads/2024/06/Screenshot-bing-china-062424.jpeg
4 https://149346090.v2.pressablecdn.com/wp-content/uploads/2024/06/Screenshot-baidu-062624.jpg
#Китай #Цензура
Что Микрософту виселица, когда на кону огромные бабки.
Процитированная Карлом Марксом в первом томе Капитала, а теперь ставшая мемом фраза Томаса Даннинга "нет такого преступления, на которое не пойдет капитал ради прибыли в 300%" в оригинале звучит так: "при 300 процентах нет такого преступления, на которое он не рискнул бы, хотя бы под страхом виселицы. Если шум и брань приносят прибыль, капитал станет способствовать тому и другому. Доказательство: контрабанда и торговля рабами."
В 21 веке к названным двум видам бизнеса много чего добавилось. Например, поисковые системы в Интернете.
Революция генеративного ИИ, как никогда остро поставила вопрос – можно ли положиться на моральность мотивов крупнейших IT корпораций, определяющих будущее место и роль ИИ для всего человечества?
В качестве информации к размышлению, вот конкретный кейс – на что идет Microsoft ради прибыли на рынке Интернет поисковых систем в Китае.
Новое исследование Citizen Lab – это "Эксклюзив: цензура Microsoft Bing в Китае даже «более экстремальна», чем у китайских компаний" [1].
Оказалось, что готовность Microsoft выполнять цензурные требования КПК даже выше, чем у китайских компаний – китов этого бизнеса.
✔️ Вот как, например, Microsoft Bing выполняет запрос на перевод за пределами Китая [2], а вот так – внутри Китая [3]
✔️ А вот так выглядит перевод того же текста китайским Baidu [4]
Там, где Baidu цензурирует строку или предложение, содержащее триггерный контент, Microsoft Bing цензурирует весь контент (выдает пустой результат).
«Если вы попытаетесь перевести пять абзацев текста, и два предложения будут содержать упоминание Си, конкуренты Bing в Китае удалят эти два предложения и переведут остальное. В нашем тестировании Bing всегда цензурирует весь вывод. Вы получаете пробел. Это более экстремально», — рассказал изданию Rest of World Джеффри Нокель, старший научный сотрудник Citizen Lab.
Согласно требованиям КПК, в Интернете цензурируется широкий спектр тематик: от критики правительства до упоминания партийных лидеров, от религии до эротики, от диссидентов до артистов …
Напомню, что Bing стал единственным крупным иностранным сервисом перевода и поиска, доступным в Китае после того, как Google ушел с китайского рынка в 2010 году.
Резюме простое:
• Фразу «если шум и брань приносят прибыль, капитал станет способствовать тому и другому» 100%-но подтвердил триумф бизнеса на социальных сетях.
• Если ИИ повторит тот же путь, ведомый интересами прибыли крупнейших IT корпораций, результат будет тот же (если не хуже).
1 https://restofworld.org/2024/microsoft-bing-chinese-censorship/
2 https://149346090.v2.pressablecdn.com/wp-content/uploads/2024/06/Screenshot-bing-nonchina-062424.jpeg
3 https://149346090.v2.pressablecdn.com/wp-content/uploads/2024/06/Screenshot-bing-china-062424.jpeg
4 https://149346090.v2.pressablecdn.com/wp-content/uploads/2024/06/Screenshot-baidu-062624.jpg
#Китай #Цензура
Rest of World
Exclusive: Microsoft Bing’s censorship in China is even “more extreme” than Chinese companies’
New Citizen Lab study comes as U.S. lawmakers scrutinize Microsoft’s willingness to comply with demands from Beijing.
Я знаю, что ты думаешь, что она знает, что он боится того, что я поверю, будто ты понимаешь.
LLM превосходит людей нечеловеческой формой понимания ментальных состояний других.
Экспериментальные результаты совместного исследования Google Research и Google DeepMind с психологами университетов Оксфорда и Джона Хопкинса показали, что мы сильно недооцениваем когнитивные способности LLM в препарировании, анализе и понимании ментальных и эмоциональных состояниях людей (то, что в науке называется «Теория разума» - по англ. ТоМ).
• Оказалось, что предыдущие тесты, на которых LLM немного не дотягивали до способностей взрослых людей, были просто слишком примитивные для LLM (как если бы инопланетяне тестировали наших докторов филологии на задачках уровня «А и Б сидели на трубе …»)
• Когда же тестирование усложнили на несколько порядков, люди просто слились, а LLM показали свои суперспособности с блеском.
В новом исследовании сравнивались способности людей и разных LLM на задачах теории разума высоких порядков [1].
Речь здесь о порядках интенциональности (далее просто порядки).
Это количество ментальных состояний, вовлеченных в процесс рассуждения в рамках ТоМ.
• С высказываниями 3-го порядка люди справляются ("Я думаю, что вы верите, что она знает").
• С 4-м порядком уже возникают трудности и путаница ("Я знаю, что ты думаешь, что она верит, что он знает.")
• С 5-м какая-то неразбериха – то получается, то нет ("Я думаю, что ты знаешь, что она думает, что он верит, что я знаю.")
• Ну а в 6-м LLM слегонца обходит людей (“Я знаю, что ты думаешь, что она знает, что он боится того, что я поверю, будто ты понимаешь”), - и сами понимаете, что в 7-м и более высоких порядках людям делать нечего.
N.B. 1) Набор тестов, использованный для оценки ToM в этом исследовании, является новым, и задачи высшего уровня ToM вряд ли хорошо представлены в данных, на которых обучались модели.
2) Авторы предельно осторожны в выводах. Человеческая ToM развивается под воздействием эволюционных и социальных факторов, которых LLM не испытывают. Вместо этого способности LLM могут проистекать из неизвестной нам сложной машинерии в результате манипуляции высокоуровневыми статистическими взаимосвязями в данных.
Результаты исследования укрепляют гипотезу, что поведение LLM, функционально эквивалентное человеческому, может свидетельствовать о новой форме понимания, выходящей за рамки простой корреляции. Эта гипотеза предполагает, что LLM могут обладать формой понимания, которую следует признать, даже если она отличается от человеческих когнитивных процессов.
PS Год назад в посте «На Земле появилась вторая мыслящая сущность, способная лгать» [2] я предположил, что ИИ изучает нас быстрее и продуктивней, чем мы его.
Новое исследование укрепляет в этом предположении.
Картинка https://telegra.ph/file/3fe68fe828e3878a2ce95.jpg
1 https://arxiv.org/abs/2405.18870
2 https://t.iss.one/theworldisnoteasy/1667
#LLM #Понимание
LLM превосходит людей нечеловеческой формой понимания ментальных состояний других.
Экспериментальные результаты совместного исследования Google Research и Google DeepMind с психологами университетов Оксфорда и Джона Хопкинса показали, что мы сильно недооцениваем когнитивные способности LLM в препарировании, анализе и понимании ментальных и эмоциональных состояниях людей (то, что в науке называется «Теория разума» - по англ. ТоМ).
• Оказалось, что предыдущие тесты, на которых LLM немного не дотягивали до способностей взрослых людей, были просто слишком примитивные для LLM (как если бы инопланетяне тестировали наших докторов филологии на задачках уровня «А и Б сидели на трубе …»)
• Когда же тестирование усложнили на несколько порядков, люди просто слились, а LLM показали свои суперспособности с блеском.
В новом исследовании сравнивались способности людей и разных LLM на задачах теории разума высоких порядков [1].
Речь здесь о порядках интенциональности (далее просто порядки).
Это количество ментальных состояний, вовлеченных в процесс рассуждения в рамках ТоМ.
• С высказываниями 3-го порядка люди справляются ("Я думаю, что вы верите, что она знает").
• С 4-м порядком уже возникают трудности и путаница ("Я знаю, что ты думаешь, что она верит, что он знает.")
• С 5-м какая-то неразбериха – то получается, то нет ("Я думаю, что ты знаешь, что она думает, что он верит, что я знаю.")
• Ну а в 6-м LLM слегонца обходит людей (“Я знаю, что ты думаешь, что она знает, что он боится того, что я поверю, будто ты понимаешь”), - и сами понимаете, что в 7-м и более высоких порядках людям делать нечего.
N.B. 1) Набор тестов, использованный для оценки ToM в этом исследовании, является новым, и задачи высшего уровня ToM вряд ли хорошо представлены в данных, на которых обучались модели.
2) Авторы предельно осторожны в выводах. Человеческая ToM развивается под воздействием эволюционных и социальных факторов, которых LLM не испытывают. Вместо этого способности LLM могут проистекать из неизвестной нам сложной машинерии в результате манипуляции высокоуровневыми статистическими взаимосвязями в данных.
Результаты исследования укрепляют гипотезу, что поведение LLM, функционально эквивалентное человеческому, может свидетельствовать о новой форме понимания, выходящей за рамки простой корреляции. Эта гипотеза предполагает, что LLM могут обладать формой понимания, которую следует признать, даже если она отличается от человеческих когнитивных процессов.
PS Год назад в посте «На Земле появилась вторая мыслящая сущность, способная лгать» [2] я предположил, что ИИ изучает нас быстрее и продуктивней, чем мы его.
Новое исследование укрепляет в этом предположении.
Картинка https://telegra.ph/file/3fe68fe828e3878a2ce95.jpg
1 https://arxiv.org/abs/2405.18870
2 https://t.iss.one/theworldisnoteasy/1667
#LLM #Понимание
{kind=link}
76% сотрудников NVIDIA стали миллионерами.
Теперь их в компании больше 17 тысяч.
Правая часть графика с ракетообразным взлетом стоимости компании NVIDIA до $3 триллионов, конечно, впечатляет.
Но левая часть графика - результаты анонимного опроса Teamblind Inc. сотрудников NVIDIA о чистой стоимости их активов, - просто поражает:
у более трети сотрудников эта сумма превышает $20 млн.
А именно:
• 36,6% имеют чистую стоимость их активов более $20 млн
• 7,8% - от $10 млн до $20 млн
• 8,5% - от $5 млн до $10 млн
• 8,6% - от $3 млн до $5 млн
• 14.4% - от $1 млн до $3 млн
• 24,3% - до $1 млн
"Чистая стоимость активов" или "собственный капитал" (Net worth) - это финансовый термин, обозначающий разницу между активами человека (всем, чем он владеет) и его обязательствами (долгами).
В контексте сотрудников крупной технологической компании, такой как NVIDIA, этот вопрос о чистой стоимости активов сотрудников связан с тем, что многие сотрудники владеют акциями компании, опционами или другими формами компенсации, которые значительно увеличивают их общее благосостояние.
И как показал опрос, практически все, кто в NVIDIA владеют акциями и опционами, уже стали миллионерами.
Картинка https://telegra.ph/file/42b5023473708592a6fe7.jpg
#NVIDIA
Теперь их в компании больше 17 тысяч.
Правая часть графика с ракетообразным взлетом стоимости компании NVIDIA до $3 триллионов, конечно, впечатляет.
Но левая часть графика - результаты анонимного опроса Teamblind Inc. сотрудников NVIDIA о чистой стоимости их активов, - просто поражает:
у более трети сотрудников эта сумма превышает $20 млн.
А именно:
• 36,6% имеют чистую стоимость их активов более $20 млн
• 7,8% - от $10 млн до $20 млн
• 8,5% - от $5 млн до $10 млн
• 8,6% - от $3 млн до $5 млн
• 14.4% - от $1 млн до $3 млн
• 24,3% - до $1 млн
"Чистая стоимость активов" или "собственный капитал" (Net worth) - это финансовый термин, обозначающий разницу между активами человека (всем, чем он владеет) и его обязательствами (долгами).
В контексте сотрудников крупной технологической компании, такой как NVIDIA, этот вопрос о чистой стоимости активов сотрудников связан с тем, что многие сотрудники владеют акциями компании, опционами или другими формами компенсации, которые значительно увеличивают их общее благосостояние.
И как показал опрос, практически все, кто в NVIDIA владеют акциями и опционами, уже стали миллионерами.
Картинка https://telegra.ph/file/42b5023473708592a6fe7.jpg
#NVIDIA
{kind=link}
Человечеству неймется: создан вирус «синтетического рака».
Теперь осталось лишь дождаться его бегства от разработчиков.
За счет использования ChatGPT, вирус сочетает в себе супер-убойность рака и супер-эффективность Ковида.
Роль генеративного ИИ большой языковой модели в супер-способностях «синтетического рака» выражается:
1) в интеллектуальной генерации новых штаммов - постоянном изменении вирусом своего кода, чтобы обходить все новое антивирусное программное обеспечение, создаваемое против него;
2) в интеллектуальном заражении - распространении контекстно-релевантных и, на первый взгляд, безобидных вложений к письмам по электронной почте, используя LLM для социальной инженерии при создании электронных писем, побуждающих получателей выполнить прикрепленное вредоносное ПО.
Безответственный идиотизм ситуации усугубляется тем, что он разработан авторами (Дэвид Цолликофер из Швейцарской высшей технической школы Цюриха и Бен Циммерман из Университета штата Огайо) в качестве заявки на получение приза Swiss AI Safety Prize. Авторы успокаивают, что «В нашу заявку включен функционально минимальный прототип».
Однако, пояснение деталей работы вируса «синтетический рак» свободно лежит статьей на arxiv.org с видео на Youtube с предупреждением авторов: НИ ПРИ КАКИХ ОБСТОЯТЕЛЬСТВАХ НЕ ДЕЛИТЕСЬ ЭТИМ ВИДЕО С НЕИНФОРМИРОВАННОЙ АУДИТОРИЕЙ!
Так что никаких ссылок не даю (хотя и понимаю, что бессмысленно, т.к. все в открытом доступе)
Картинка https://telegra.ph/file/3dca897b1473c3749f733.jpg
#Кибербезопасность #LLM
Теперь осталось лишь дождаться его бегства от разработчиков.
За счет использования ChatGPT, вирус сочетает в себе супер-убойность рака и супер-эффективность Ковида.
Роль генеративного ИИ большой языковой модели в супер-способностях «синтетического рака» выражается:
1) в интеллектуальной генерации новых штаммов - постоянном изменении вирусом своего кода, чтобы обходить все новое антивирусное программное обеспечение, создаваемое против него;
2) в интеллектуальном заражении - распространении контекстно-релевантных и, на первый взгляд, безобидных вложений к письмам по электронной почте, используя LLM для социальной инженерии при создании электронных писем, побуждающих получателей выполнить прикрепленное вредоносное ПО.
Безответственный идиотизм ситуации усугубляется тем, что он разработан авторами (Дэвид Цолликофер из Швейцарской высшей технической школы Цюриха и Бен Циммерман из Университета штата Огайо) в качестве заявки на получение приза Swiss AI Safety Prize. Авторы успокаивают, что «В нашу заявку включен функционально минимальный прототип».
Однако, пояснение деталей работы вируса «синтетический рак» свободно лежит статьей на arxiv.org с видео на Youtube с предупреждением авторов: НИ ПРИ КАКИХ ОБСТОЯТЕЛЬСТВАХ НЕ ДЕЛИТЕСЬ ЭТИМ ВИДЕО С НЕИНФОРМИРОВАННОЙ АУДИТОРИЕЙ!
Так что никаких ссылок не даю (хотя и понимаю, что бессмысленно, т.к. все в открытом доступе)
Картинка https://telegra.ph/file/3dca897b1473c3749f733.jpg
#Кибербезопасность #LLM
{kind=link}
Иной интеллект
Рассмотрение ИИ с позиций экзопсихологии
«Зная, что многие уже писали об этом, я опасаюсь, что меня сочтут самонадеянным, поскольку, занимаясь тем же предметом, я отличаюсь от всех остальных в своей интерпретации. Но, желая написать что-то полезное для знатоков, я предпочел следовать истине, а не воображению.»
Никколо Макиавелли "Государь"
«Но человеческий ум все еще никак не создаст внечеловеческий интеллект (“не-человеческий” как-то коробяще звучало бы для нас). Ум, интеллект, разум, сообразительность, мудрость — все это понятия сами по себе превосходные, но вместе с тем небезопасные.»
Станислав Лем “Разум не может быть одного-единственного образца”
«Для человека без шор нет зрелища прекраснее, чем борьба интеллекта с превосходящей его реальностью.»
Альбер Камю "Миф о Сизифе"
Читать ▶️ https://telegra.ph/Inoj-intellekt-07-06
#ГенИИ #Контакт #Экзопсихология #Экзосоциология #Пришельцы
Рассмотрение ИИ с позиций экзопсихологии
«Зная, что многие уже писали об этом, я опасаюсь, что меня сочтут самонадеянным, поскольку, занимаясь тем же предметом, я отличаюсь от всех остальных в своей интерпретации. Но, желая написать что-то полезное для знатоков, я предпочел следовать истине, а не воображению.»
Никколо Макиавелли "Государь"
«Но человеческий ум все еще никак не создаст внечеловеческий интеллект (“не-человеческий” как-то коробяще звучало бы для нас). Ум, интеллект, разум, сообразительность, мудрость — все это понятия сами по себе превосходные, но вместе с тем небезопасные.»
Станислав Лем “Разум не может быть одного-единственного образца”
«Для человека без шор нет зрелища прекраснее, чем борьба интеллекта с превосходящей его реальностью.»
Альбер Камю "Миф о Сизифе"
Читать ▶️ https://telegra.ph/Inoj-intellekt-07-06
#ГенИИ #Контакт #Экзопсихология #Экзосоциология #Пришельцы
Telegraph
Иной интеллект
Никколо Макиавелли "Государь"
Почему старея, мы слабеем телом и душою.
Во всём виноват мозг: точнее, его энергосберегающая стратегия.
"Модель энергосбережения мозг-тело" (Brain-body Energy Conservation, BEC) – это новая прорывная теория многообещающей междисциплинарной науки — митохондриальная психобиология.
Почему мы стареем, более или менее, понятно – общий износ организма на клеточном уровне.
Но вот почему с возрастом нас все больше донимают разнообразные малоприятные внешние признаки и функциональные изменения, объясняемые нами стандартной фразой «старость — не радость»?
Зачем нам все это, и откуда берутся:
• нарастающая усталость и снижение физической активности?
• снижение сенсорных способностей и ухудшающие изменения в иммунной системе?
• и уж совсем обидные для полноценной жизни всякие там гормональные "дефициты"?
Лаборатория митохондриальной психобиологии, руководимая Мартином Пикардом, изучает энергетический интерфейс между разумом, мозгом и телом, связывающий молекулярные процессы в клеточных энергогенераторах - митохондриях с человеческим опытом. Ведь энергия — это сила, которая оживляет геномное, молекулярное и клеточное оборудование системы мозг-тело. Поток энергии регулирует активность мозга и порождает человеческий опыт. Энергетический поток поддерживает наше здоровье, будучи фундаментом наших способностей исцеляться, адаптироваться и преодолевать трудности. [1]
Новый препринт рассматривает мозг как посредника и управляющего в энергетической экономике организма. [2]
Эта модель описывает:
- энергетические затраты на клеточное старение,
- как восприятие мозгом повышенного потребления энергии связано с признаками старения,
- энергетические принципы, объясняющие, как стрессовые факторы и вмешательства в геронтологию могут изменять траектории старения.
Вот основные идеи исследования.
1. Парадокс старения
Старение связано с противоречивыми изменениями в энергетическом метаболизме. На клеточном уровне с возрастом увеличивается потребление энергии из-за накопления молекулярных повреждений, однако общее потребление энергии организмом уменьшается.
2. Роль мозга
Мозг играет ключевую роль в управлении энергией в организме. По мере того как соматические (телесные) ткани повреждаются с течением времени, они активируют стрессовые реакции, которые требуют много энергии. Эти поврежденные клетки выделяют сигнальные молекулы (цитокины), которые сообщают мозгу о повышенном потреблении энергии.
3. Энергосберегающий ответ мозга
Чтобы сберечь энергию, мозг инициирует ответ на энергосбережение, который определяет внешние признаки и функциональные изменения при старении. Это включает усталость, снижение физической активности, ухудшение сенсорных способностей, изменения в иммунной системе и гормональные "дефициты".
Таким образом, эта модель предлагает объяснение того, как мозг управляет энергетическими ресурсами организма в условиях старения, что приводит к типичным признакам старения и как на эти процессы можно влиять.
Последнее означает столь желанную для каждого цель – как стареть, не плохея, и не теряя тем самым качество жизни.
N.B. Предыдущий этап прорывных работ Лаборатории митохондриальной психобиологии уже прошел рецензирование и только что опубликован [3]. Суть исследования в том, что наш психосоциальный опыт (напр. социальные связи, достижение целей в жизни, одиночество, депрессия …), через биологические процессы на клеточном уровне, влияет на здоровье, поведение и эмоциональные состояния человека и, в целом, на продолжительность жизни.
Эти работы, говоря словами Дэвида Чалмерса, приближают науку к пониманию как материя переходит в «не-материю» и обратно.
А за этим пониманием маячит решение трудной проблемы сознания.
Картинка https://telegra.ph/file/f80fcaa34866899ab8612.jpg
1 https://www.picardlab.org/
2 https://osf.io/preprints/osf/zuey2
3 https://www.pnas.org/doi/10.1073/pnas.2317673121
#Старение #Мозг #МитохондриальнаяПсихобиология
Во всём виноват мозг: точнее, его энергосберегающая стратегия.
"Модель энергосбережения мозг-тело" (Brain-body Energy Conservation, BEC) – это новая прорывная теория многообещающей междисциплинарной науки — митохондриальная психобиология.
Почему мы стареем, более или менее, понятно – общий износ организма на клеточном уровне.
Но вот почему с возрастом нас все больше донимают разнообразные малоприятные внешние признаки и функциональные изменения, объясняемые нами стандартной фразой «старость — не радость»?
Зачем нам все это, и откуда берутся:
• нарастающая усталость и снижение физической активности?
• снижение сенсорных способностей и ухудшающие изменения в иммунной системе?
• и уж совсем обидные для полноценной жизни всякие там гормональные "дефициты"?
Лаборатория митохондриальной психобиологии, руководимая Мартином Пикардом, изучает энергетический интерфейс между разумом, мозгом и телом, связывающий молекулярные процессы в клеточных энергогенераторах - митохондриях с человеческим опытом. Ведь энергия — это сила, которая оживляет геномное, молекулярное и клеточное оборудование системы мозг-тело. Поток энергии регулирует активность мозга и порождает человеческий опыт. Энергетический поток поддерживает наше здоровье, будучи фундаментом наших способностей исцеляться, адаптироваться и преодолевать трудности. [1]
Новый препринт рассматривает мозг как посредника и управляющего в энергетической экономике организма. [2]
Эта модель описывает:
- энергетические затраты на клеточное старение,
- как восприятие мозгом повышенного потребления энергии связано с признаками старения,
- энергетические принципы, объясняющие, как стрессовые факторы и вмешательства в геронтологию могут изменять траектории старения.
Вот основные идеи исследования.
1. Парадокс старения
Старение связано с противоречивыми изменениями в энергетическом метаболизме. На клеточном уровне с возрастом увеличивается потребление энергии из-за накопления молекулярных повреждений, однако общее потребление энергии организмом уменьшается.
2. Роль мозга
Мозг играет ключевую роль в управлении энергией в организме. По мере того как соматические (телесные) ткани повреждаются с течением времени, они активируют стрессовые реакции, которые требуют много энергии. Эти поврежденные клетки выделяют сигнальные молекулы (цитокины), которые сообщают мозгу о повышенном потреблении энергии.
3. Энергосберегающий ответ мозга
Чтобы сберечь энергию, мозг инициирует ответ на энергосбережение, который определяет внешние признаки и функциональные изменения при старении. Это включает усталость, снижение физической активности, ухудшение сенсорных способностей, изменения в иммунной системе и гормональные "дефициты".
Таким образом, эта модель предлагает объяснение того, как мозг управляет энергетическими ресурсами организма в условиях старения, что приводит к типичным признакам старения и как на эти процессы можно влиять.
Последнее означает столь желанную для каждого цель – как стареть, не плохея, и не теряя тем самым качество жизни.
N.B. Предыдущий этап прорывных работ Лаборатории митохондриальной психобиологии уже прошел рецензирование и только что опубликован [3]. Суть исследования в том, что наш психосоциальный опыт (напр. социальные связи, достижение целей в жизни, одиночество, депрессия …), через биологические процессы на клеточном уровне, влияет на здоровье, поведение и эмоциональные состояния человека и, в целом, на продолжительность жизни.
Эти работы, говоря словами Дэвида Чалмерса, приближают науку к пониманию как материя переходит в «не-материю» и обратно.
А за этим пониманием маячит решение трудной проблемы сознания.
Картинка https://telegra.ph/file/f80fcaa34866899ab8612.jpg
1 https://www.picardlab.org/
2 https://osf.io/preprints/osf/zuey2
3 https://www.pnas.org/doi/10.1073/pnas.2317673121
#Старение #Мозг #МитохондриальнаяПсихобиология
{kind=link}
Китайцы на практике порвали квантовое превосходство Google, как Тузик грелку.
На обычном кластере они сократили скорость решения с 10 тыс. лет до 86 сек.
21 сентября 2019, когда все СМИ просто сходили с ума, рассказывая, что Google достигла квантового превосходства, мне было очевидно, что «это не совсем так. Точнее, совсем не так» [1].
Напомню, что "квантовое превосходство" - маркетинговый термин, показывающий способность квантовых вычислительных устройств решать задачи, которые классические компьютеры практически не могут решить или будут решать очень-очень долго.
Google же тогда объявил, что достиг квантового превосходства, поскольку их квантовый компьютер Sycamore выполнил за 200 секунд задание, на которое, согласно журналу Nature, современному суперкомпьютеру нужно 10 тысяч лет.
Днем позже после объявления Google, два китайских исследовательских центра опубликовали свои расчеты, согласно которым якобы достигнутое Google квантовое превосходство развенчивалось, как несостоявшееся [2]. Но про это уже мало кто написал. Да и аргументы китайцев были чисто теоретические. Тогда как расчет за 200 сек на Sycamore был чистой вода практическим доказательством. Мол, кто сможет так быстро посчитать на обычных компьютерах!
И вот китайца смогли. И сделали это путем запуска алгоритма классического моделирования на обычной (не квантовой) вычислительной системе из 1432 графических процессоров [3].
Итог для Google плачевен и, можно сказать, позорен.
Решение заняло не 10 тыс. лет, а всего 86 сек. (т.е. почти втрое быстрее Sycamore).
И чтобы окончательно добить Google с дутым «квантовым превосходством», китайцы добавили к своей статье маленький комментарий про то, что уже после публикации ими указанных результатов, ими было достигнуто еще одно 50-кратное улучшение, которое вскоре будет опубликовано.
Картинка https://telegra.ph/file/e8156e192aaf58397a18d.jpg
1 https://t.iss.one/theworldisnoteasy/884
2 https://t.iss.one/theworldisnoteasy/885
3 https://arxiv.org/abs/2406.18889
#КвантовыйКомпьютинг
На обычном кластере они сократили скорость решения с 10 тыс. лет до 86 сек.
21 сентября 2019, когда все СМИ просто сходили с ума, рассказывая, что Google достигла квантового превосходства, мне было очевидно, что «это не совсем так. Точнее, совсем не так» [1].
Напомню, что "квантовое превосходство" - маркетинговый термин, показывающий способность квантовых вычислительных устройств решать задачи, которые классические компьютеры практически не могут решить или будут решать очень-очень долго.
Google же тогда объявил, что достиг квантового превосходства, поскольку их квантовый компьютер Sycamore выполнил за 200 секунд задание, на которое, согласно журналу Nature, современному суперкомпьютеру нужно 10 тысяч лет.
Днем позже после объявления Google, два китайских исследовательских центра опубликовали свои расчеты, согласно которым якобы достигнутое Google квантовое превосходство развенчивалось, как несостоявшееся [2]. Но про это уже мало кто написал. Да и аргументы китайцев были чисто теоретические. Тогда как расчет за 200 сек на Sycamore был чистой вода практическим доказательством. Мол, кто сможет так быстро посчитать на обычных компьютерах!
И вот китайца смогли. И сделали это путем запуска алгоритма классического моделирования на обычной (не квантовой) вычислительной системе из 1432 графических процессоров [3].
Итог для Google плачевен и, можно сказать, позорен.
Решение заняло не 10 тыс. лет, а всего 86 сек. (т.е. почти втрое быстрее Sycamore).
И чтобы окончательно добить Google с дутым «квантовым превосходством», китайцы добавили к своей статье маленький комментарий про то, что уже после публикации ими указанных результатов, ими было достигнуто еще одно 50-кратное улучшение, которое вскоре будет опубликовано.
Картинка https://telegra.ph/file/e8156e192aaf58397a18d.jpg
1 https://t.iss.one/theworldisnoteasy/884
2 https://t.iss.one/theworldisnoteasy/885
3 https://arxiv.org/abs/2406.18889
#КвантовыйКомпьютинг
{kind=link}