
Как думаете:
1) Что общего у Ильи Суцкевера и Джозефа Ротблатта?
2) Сколько приоритетных задач ставили перед разработчиками ядерного оружия до и после испытаний в пустыне Аламогордо?
3) Можно ли самому примерно оценить, превосходят ли нас LLM в глубине и ясности мышления?
Наверное, многим формулировка и сочетание вопросов покажутся странными. Но дело вот в чем.
В прошлом году под «Заявлением о рисках, связанных с ИИ» [1] поставили подписи сотни видных экспертов и общественных деятелей. Они писали, что снижение риска исчезновения человечества из-за ИИ должно стать глобальным приоритетом наряду с другими рисками социального масштаба, такими как пандемии и ядерная война.
Результат – как слону дробина. Все идет, как и шло. Только процесс ускоряется.
Позавчера на политическом форуме Science появилась статья «Управление экстремальными рисками ИИ на фоне быстрого прогресса» [2], среди авторов которой многие известные люди: Йошуа Бенджио, Джеффри Хинтон, Эндрю Яо и еще 22 человека.
Вангую – результат будет тот же. Караван пойдет дальше, не обращая внимания и на это обращение. Как будто всех их пишут экзальтированные недоучки, а не сами разработчики ИИ-систем.
Что же тогда может добавить к сказанному отцами нынешних ИИ-систем автор малоизвестного, хотя и интересного для ограниченной аудитории канала?
Думаю, кое-что все же могу.
Как говорил Гарри Трумэн, - If you can't convince them, confuse them ("Если не можешь их убедить, запутай их."). А запутывать можно, задавая такие вопросы, отвечая на которые ваши оппоненты будут вынуждены, либо соглашаться с вами, либо впасть в противоречие, видное им самим.
Следуя совету Трумэна, я и выбрал 3 вопроса, приведенные в начале этого текста.
И вот как я сам отвечаю на них.
1) То же, что у OpenAI и Манхэттенского проекта.
2) До испытаний – более 20, после – лишь одну.
3) Можно, самостоятельно пройдя «Тест Тесла».
Полагаю, что наиболее пытливые читатели захотят сначала сами поразмыслить, почему вопросы именно такие, и что за интрига стоит за каждым из них.
Ну а кто пожелает сразу перейти к моему разбору, - читайте его в не очень длинном лонгриде: «Так что же увидели Суцкевер и Лейке, сподвигнувшее их уйти. Попробуйте сами оценить, что прячут за закрытыми дверьми OpenAI, пройдя "Тест Тесла"»
Картинка поста: https://telegra.ph/file/9623799578bb9d3c21828.jpg
1 https://www.safe.ai/work/statement-on-ai-risk
2 https://www.science.org/doi/10.1126/science.adn0117
Лонгрид:
https://boosty.to/theworldisnoteasy/posts/8afdaedc-15f9-4c11-923c-5ffd21842809
https://www.patreon.com/posts/tak-chto-zhe-i-104788713
P.S. Читатели, ограниченные в средствах на подписку, могут написать мне, и я дам им персональный доступ к тексту лонгрида (очень надеюсь, что уж в этот-то раз, среди желающих прочесть лонгрид, подписчиков окажется больше 😊)
#AGI #ИИриски
1) Что общего у Ильи Суцкевера и Джозефа Ротблатта?
2) Сколько приоритетных задач ставили перед разработчиками ядерного оружия до и после испытаний в пустыне Аламогордо?
3) Можно ли самому примерно оценить, превосходят ли нас LLM в глубине и ясности мышления?
Наверное, многим формулировка и сочетание вопросов покажутся странными. Но дело вот в чем.
В прошлом году под «Заявлением о рисках, связанных с ИИ» [1] поставили подписи сотни видных экспертов и общественных деятелей. Они писали, что снижение риска исчезновения человечества из-за ИИ должно стать глобальным приоритетом наряду с другими рисками социального масштаба, такими как пандемии и ядерная война.
Результат – как слону дробина. Все идет, как и шло. Только процесс ускоряется.
Позавчера на политическом форуме Science появилась статья «Управление экстремальными рисками ИИ на фоне быстрого прогресса» [2], среди авторов которой многие известные люди: Йошуа Бенджио, Джеффри Хинтон, Эндрю Яо и еще 22 человека.
Вангую – результат будет тот же. Караван пойдет дальше, не обращая внимания и на это обращение. Как будто всех их пишут экзальтированные недоучки, а не сами разработчики ИИ-систем.
Что же тогда может добавить к сказанному отцами нынешних ИИ-систем автор малоизвестного, хотя и интересного для ограниченной аудитории канала?
Думаю, кое-что все же могу.
Как говорил Гарри Трумэн, - If you can't convince them, confuse them ("Если не можешь их убедить, запутай их."). А запутывать можно, задавая такие вопросы, отвечая на которые ваши оппоненты будут вынуждены, либо соглашаться с вами, либо впасть в противоречие, видное им самим.
Следуя совету Трумэна, я и выбрал 3 вопроса, приведенные в начале этого текста.
И вот как я сам отвечаю на них.
1) То же, что у OpenAI и Манхэттенского проекта.
2) До испытаний – более 20, после – лишь одну.
3) Можно, самостоятельно пройдя «Тест Тесла».
Полагаю, что наиболее пытливые читатели захотят сначала сами поразмыслить, почему вопросы именно такие, и что за интрига стоит за каждым из них.
Ну а кто пожелает сразу перейти к моему разбору, - читайте его в не очень длинном лонгриде: «Так что же увидели Суцкевер и Лейке, сподвигнувшее их уйти. Попробуйте сами оценить, что прячут за закрытыми дверьми OpenAI, пройдя "Тест Тесла"»
Картинка поста: https://telegra.ph/file/9623799578bb9d3c21828.jpg
1 https://www.safe.ai/work/statement-on-ai-risk
2 https://www.science.org/doi/10.1126/science.adn0117
Лонгрид:
https://boosty.to/theworldisnoteasy/posts/8afdaedc-15f9-4c11-923c-5ffd21842809
https://www.patreon.com/posts/tak-chto-zhe-i-104788713
P.S. Читатели, ограниченные в средствах на подписку, могут написать мне, и я дам им персональный доступ к тексту лонгрида (очень надеюсь, что уж в этот-то раз, среди желающих прочесть лонгрид, подписчиков окажется больше 😊)
#AGI #ИИриски
{kind=link}
Атмосфера страха, секретности и запугивания накрыла индустрию ИИ.
Воззвание сотрудников OpenAI остановить превращение компании в новый Theranos.
✔️ Сотрудники компаний – лидеров разработки ИИ знают о своей работе такое, что больше не знает никто на свете. Они обладают существенной закрытой информацией о возможностях и ограничениях своих систем, а также об адекватности принимаемых их компаниями защитных мер и уровнях риска различных видов вреда для общества.
✔️ Однако, в настоящее время они вынуждены молчать, ибо строгих обязательств информировать общественность и правительство у них нет, а их компании – бывшие и нынешние работодатели, - крепко запечатывают им рты с помощью «соглашений о неунижении», влекущих страшные юридические и финансовые кары не только за любое разглашение, но и, в принципе, за любую критику компании.
Опубликованное вчера воззвание бывших и нынешних сотрудников OpenAI, поддержанное Йошуф Бенжио, Джеффри Хинтононом и Стюартом Расселом [1,2], подтвердило оба вышеприведенных вывода моего недавнего лонгрида «Так что же увидели Суцкевер и Лейке, сподвигнувшее их уйти» [3].
Публикация воззвания спустя почти 3 недели после того, как OpenAI объявил во внутреннем мемо об отказе от практики «соглашения о неунижении» [4], а также новые детали роли культа личности Сэма Альтмана в управляемом хаосе OpenAI, рассказанные двумя бывшими членами правления [5], позволяют предположить следующее:
1) Атмосфера страха, секретности и запугивания, накрывшая OpenAI, подобно тому, как это было в Theranos, вовсе не выветрилась, а лишь нагнетается теперь более тонким методом, чем «соглашения о неунижении».
2) Подобно тому, как было с Элизабет Холмс в Theranos, ключевой фигурой управляемого хаоса в OpenAI является генеральный директор компании Сэм Альтман:
• культивирующий атмосферу чрезвычайной секретности, страха и запугивания;
• жестко подавляющий любую критику или сомнения в отношении своих идей и подходов;
• требующий полного подчинения от сотрудников и не допускающий никаких возражений или критики в адрес своих действий и видения компании;
• культивирующий культ личности вокруг себя, представляя себя как одаренного гения и визионера, а любые расхождения с его видением или критика рассматриваются, как проявление неверности и потому неприемлемы.
3) То, что среди подписантов воззвания не только бывшие и нынешние сотрудники OpenAI, но также и DeepMind и Anthropic, может быть вызвано не только солидарностью последних к беспределу руководства OpenAI. Это может означать, что атмосфера страха, секретности и запугивания накрывает всю индустрию ИИ.
#AGI #ИИриски
1 https://bit.ly/4e6rgXX
2 https://righttowarn.ai/
3 https://t.iss.one/theworldisnoteasy/1943
4 https://bit.ly/4c9jDxV
5 https://bit.ly/3yOedKw
Воззвание сотрудников OpenAI остановить превращение компании в новый Theranos.
✔️ Сотрудники компаний – лидеров разработки ИИ знают о своей работе такое, что больше не знает никто на свете. Они обладают существенной закрытой информацией о возможностях и ограничениях своих систем, а также об адекватности принимаемых их компаниями защитных мер и уровнях риска различных видов вреда для общества.
✔️ Однако, в настоящее время они вынуждены молчать, ибо строгих обязательств информировать общественность и правительство у них нет, а их компании – бывшие и нынешние работодатели, - крепко запечатывают им рты с помощью «соглашений о неунижении», влекущих страшные юридические и финансовые кары не только за любое разглашение, но и, в принципе, за любую критику компании.
Опубликованное вчера воззвание бывших и нынешних сотрудников OpenAI, поддержанное Йошуф Бенжио, Джеффри Хинтононом и Стюартом Расселом [1,2], подтвердило оба вышеприведенных вывода моего недавнего лонгрида «Так что же увидели Суцкевер и Лейке, сподвигнувшее их уйти» [3].
Публикация воззвания спустя почти 3 недели после того, как OpenAI объявил во внутреннем мемо об отказе от практики «соглашения о неунижении» [4], а также новые детали роли культа личности Сэма Альтмана в управляемом хаосе OpenAI, рассказанные двумя бывшими членами правления [5], позволяют предположить следующее:
1) Атмосфера страха, секретности и запугивания, накрывшая OpenAI, подобно тому, как это было в Theranos, вовсе не выветрилась, а лишь нагнетается теперь более тонким методом, чем «соглашения о неунижении».
2) Подобно тому, как было с Элизабет Холмс в Theranos, ключевой фигурой управляемого хаоса в OpenAI является генеральный директор компании Сэм Альтман:
• культивирующий атмосферу чрезвычайной секретности, страха и запугивания;
• жестко подавляющий любую критику или сомнения в отношении своих идей и подходов;
• требующий полного подчинения от сотрудников и не допускающий никаких возражений или критики в адрес своих действий и видения компании;
• культивирующий культ личности вокруг себя, представляя себя как одаренного гения и визионера, а любые расхождения с его видением или критика рассматриваются, как проявление неверности и потому неприемлемы.
3) То, что среди подписантов воззвания не только бывшие и нынешние сотрудники OpenAI, но также и DeepMind и Anthropic, может быть вызвано не только солидарностью последних к беспределу руководства OpenAI. Это может означать, что атмосфера страха, секретности и запугивания накрывает всю индустрию ИИ.
#AGI #ИИриски
1 https://bit.ly/4e6rgXX
2 https://righttowarn.ai/
3 https://t.iss.one/theworldisnoteasy/1943
4 https://bit.ly/4c9jDxV
5 https://bit.ly/3yOedKw
NY Times
OpenAI Insiders Warn of a ‘Reckless’ Race for Dominance (Gift Article)
A group of current and former employees is calling for sweeping changes to the artificial intelligence industry, including greater transparency and protections for whistle-blowers.
Найден альтернативный способ достижения сверхчеловеческих способностей ИИ уже в 2024.
Открыт феномен трансцендентности (превосходства) генеративного ИИ.
Совместное исследование Гарвардского, Принстонского и Калифорнийского университетов с DeepMind и Apple открыло новый феномен – трансцендентность LLM, когда генеративная модель достигает возможностей, превосходящих способности экспертов, генерирующих данные для ее обучения.
Открытие этого феномена - новый фазовый переход в раскрытии возможностей достижения ИИ превосходства над людьми.
Предыдущим фазовым переходом был прорыв к сверхчеловеческому уровню игры в шахматы, продемонстрированный AlphaGo Zero компании DeepMind в 2017. Ключом к тому успеху был отказ от использования для обучения ИИ наборов данных, полученных от экспертов-людей. Играя в шахматы (а потом и в Го) сама с собой, AlphaGo Zero достигла сверхчеловеческого уровня игры, недоступного даже для чемпионов мира среди людей.
Однако, такой способ преодоления человеческих интеллектуальных способностей применим лишь к строго регламентированным задачам, типа шахмат или Го. При отсутствии строгих регламентов решения задачи (правила, условия игры, начальные условия, внешние факторы и т.д.) для обучения модели необходимы наборы данных, описывающих, как эту задачу решали люди.
Но тут засада. Ведь если модель опять (как до AlphaGo Zero) будет учиться у людей, как она сможет превзойти уровень тех, на чьих данных модель учили?
Это как если бы юных шахматистов учили бы не на партиях мастеров и гроссмейстеров, а на партиях их ровесников из другой шахматной школы.
Открытие феномена трансцендентности снимает это ограничение, позволяя модели, обучаясь на партиях, например, перворазрядников, достигать собственного уровня игры на уровне гроссмейстеров.
Это достигается использованием определенной техники выбора данных, называемой "низкотемпературная выборка".
Вот поясняющая метафора.
Представьте себе, что вы учитесь играть в шахматы, наблюдая за игрой множества игроков. Обычно вы бы запоминали ходы, которые чаще всего приводят к победе, и пытались бы их повторить. Это похоже на стандартный способ обучения модели.
Но что, если вы начнете выбирать не просто популярные ходы, а очень точные и редкие ходы, которые гораздо эффективнее в определенных ситуациях? Вы бы стали играть намного лучше, чем те игроки, у которых вы учились. Низкотемпературная выборка — это как раз такой способ: он помогает модели фокусироваться на самых эффективных и точных решениях, даже если они редко встречаются в обучающих данных.
Таким образом, "низкотемпературная выборка" помогает модели выделять и использовать самые лучшие ходы, что и позволяет ей в итоге превосходить своих учителей.
Принципиальное отличие 2го фазового перехода от 1го в том, что феномен трансцендентности должен позволять модели превосходить уровень учителей (отраженный в обучающих наборах данных) не только в строго регламентированных задачах, но и (пока теоретически) в любых.
Следовательно, уже в этом году, могут появиться модели со сверхчеловеческими способностями в самом широком спектре применений.
Однако, говорить о близком наступлении эры абсолютного превосходства ИИ над людьми, феномен трансцендентности не позволяет.
Дело в том, что трансцендентность достигается лишь за счет эффекта снижения шума (устранения ошибок, допущенных людьми).
Это значит, что модель не способна, за счет новых абстрактных рассуждений производить новые решения, которые не может придумать человеческий эксперт… А человек может!
Но это остается последнее (хотя и решающее) превосходство людей над ИИ.
На картинке https://arxiv.org/html/2406.11741v1/extracted/5673380/advantage-analysis.png визуализация эффекта снижения шума при низкой температуре. Эффект смещает вероятности в сторону хода с высоким вознаграждением — ловушки для ферзя с помощью ладьи по мере уменьшения температуры 𝜏.
https://arxiv.org/html/2406.11741v1
#AGI
Открыт феномен трансцендентности (превосходства) генеративного ИИ.
Совместное исследование Гарвардского, Принстонского и Калифорнийского университетов с DeepMind и Apple открыло новый феномен – трансцендентность LLM, когда генеративная модель достигает возможностей, превосходящих способности экспертов, генерирующих данные для ее обучения.
Открытие этого феномена - новый фазовый переход в раскрытии возможностей достижения ИИ превосходства над людьми.
Предыдущим фазовым переходом был прорыв к сверхчеловеческому уровню игры в шахматы, продемонстрированный AlphaGo Zero компании DeepMind в 2017. Ключом к тому успеху был отказ от использования для обучения ИИ наборов данных, полученных от экспертов-людей. Играя в шахматы (а потом и в Го) сама с собой, AlphaGo Zero достигла сверхчеловеческого уровня игры, недоступного даже для чемпионов мира среди людей.
Однако, такой способ преодоления человеческих интеллектуальных способностей применим лишь к строго регламентированным задачам, типа шахмат или Го. При отсутствии строгих регламентов решения задачи (правила, условия игры, начальные условия, внешние факторы и т.д.) для обучения модели необходимы наборы данных, описывающих, как эту задачу решали люди.
Но тут засада. Ведь если модель опять (как до AlphaGo Zero) будет учиться у людей, как она сможет превзойти уровень тех, на чьих данных модель учили?
Это как если бы юных шахматистов учили бы не на партиях мастеров и гроссмейстеров, а на партиях их ровесников из другой шахматной школы.
Открытие феномена трансцендентности снимает это ограничение, позволяя модели, обучаясь на партиях, например, перворазрядников, достигать собственного уровня игры на уровне гроссмейстеров.
Это достигается использованием определенной техники выбора данных, называемой "низкотемпературная выборка".
Вот поясняющая метафора.
Представьте себе, что вы учитесь играть в шахматы, наблюдая за игрой множества игроков. Обычно вы бы запоминали ходы, которые чаще всего приводят к победе, и пытались бы их повторить. Это похоже на стандартный способ обучения модели.
Но что, если вы начнете выбирать не просто популярные ходы, а очень точные и редкие ходы, которые гораздо эффективнее в определенных ситуациях? Вы бы стали играть намного лучше, чем те игроки, у которых вы учились. Низкотемпературная выборка — это как раз такой способ: он помогает модели фокусироваться на самых эффективных и точных решениях, даже если они редко встречаются в обучающих данных.
Таким образом, "низкотемпературная выборка" помогает модели выделять и использовать самые лучшие ходы, что и позволяет ей в итоге превосходить своих учителей.
Принципиальное отличие 2го фазового перехода от 1го в том, что феномен трансцендентности должен позволять модели превосходить уровень учителей (отраженный в обучающих наборах данных) не только в строго регламентированных задачах, но и (пока теоретически) в любых.
Следовательно, уже в этом году, могут появиться модели со сверхчеловеческими способностями в самом широком спектре применений.
Однако, говорить о близком наступлении эры абсолютного превосходства ИИ над людьми, феномен трансцендентности не позволяет.
Дело в том, что трансцендентность достигается лишь за счет эффекта снижения шума (устранения ошибок, допущенных людьми).
Это значит, что модель не способна, за счет новых абстрактных рассуждений производить новые решения, которые не может придумать человеческий эксперт… А человек может!
Но это остается последнее (хотя и решающее) превосходство людей над ИИ.
На картинке https://arxiv.org/html/2406.11741v1/extracted/5673380/advantage-analysis.png визуализация эффекта снижения шума при низкой температуре. Эффект смещает вероятности в сторону хода с высоким вознаграждением — ловушки для ферзя с помощью ладьи по мере уменьшения температуры 𝜏.
https://arxiv.org/html/2406.11741v1
#AGI
{kind=link}
Тайна секретного проекта OpenAI уже никакая не тайна.
Reuters упустили лежащее на поверхности самое важное.
Вчерашний «эксклюзив» о, якобы, утечке секретной информации OpenAI расследовательницы из Reuters озаглавили «OpenAI работает над новой технологией рассуждений под кодовым названием “Strawberry“» ]1].
За сутки появилось уже несколько десятков аналитических комментариев к этому «эксклюзиву». И все они лишь на разные лады перекомментируют одни и те же пассажи публикации Reuters.
• OpenAI разрабатывает строго охраняемый секретный проект новой модели генеративного ИИ под названием «Strawberry», способной достичь уровня человеческого интеллекта за счет продвинутых рассуждений.
• Strawberry является продолжением проекта OpenAI под названием “Q*” (произносится Q-Star), из-за которого в прошлом году Илья Суцкевер безуспешно пытался выгнать Сэма Альтмана из OpenAI из-за страха, что Q* может уничтожить человечество [2].
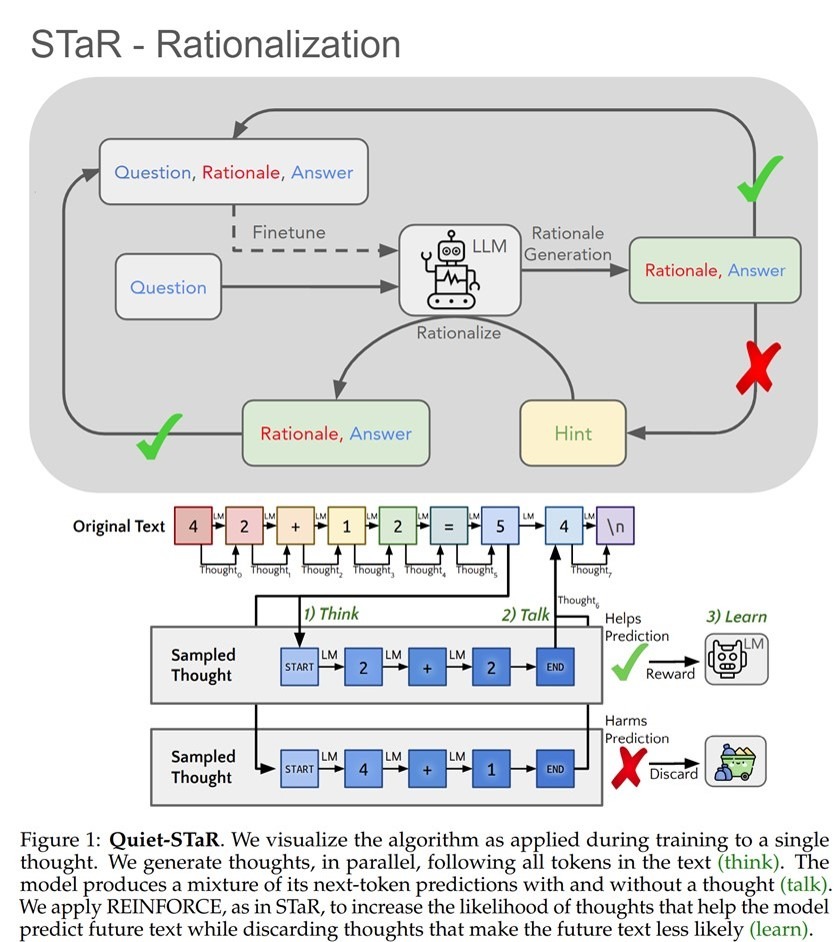
• Strawberry имеет сходство с методом, разработанным в Стэнфорде в 2022 году под названием «Self-Taught Reasoner» (сокращенно «STaR»). STaR позволяет моделям ИИ «загружаться» до более высоких уровней интеллекта посредством итеративного создания собственных обучающих данных и, в теории, может использоваться для того, чтобы заставить языковые модели превосходить уровень интеллекта человека. О чем сообщил расследовательницам Reuters один из создателей метода, профессор Стэнфорда Ноа Гудман.
Из этой «утечки» следует что:
1. секретный проект «Strawberry», являющийся продолжением другого секретного проекта “Q*”, тайно ведется OpenAI;
2. что скрывается внутри этих проектов, - совершенно неизвестно из-за их полной засекреченности.
И если 1й вывод верный, то 2й, как я полагаю, вводит читателей в заблуждение. Ибо проект Quiet-StaR (что такое «STaR», вы читали выше, а “Quiet” – это расшифровка буквы Q в названии проекта “Q*”) и проект Q-Star – это кодировки одного и того же проекта, суть которого Ноа Гудман изложил год назад здесь [3], а детально он описан здесь [4]
Как честно признают авторы, «мы называем эту технику Quiet-STaR, поскольку её можно понимать как "тихое" применение STaR». По-русски сказали бы «по-тихому» - т.е. чтоб никто не догадался.
После прочтения статьи о Quiet-StaR также становится ясно, почему вдруг в позавчерашней «утечке» от Bloomberg про новый 5-ти этапный план OpenAI по созданию AGI [5] следующий за нынешним этап - Level 2 – назван “Reasoners” (напомню, STaR – это сокращение от «Self-Taught Reasoner». И этот новый тип ИИ сможет решать проблемы так же хорошо, как человек с докторской степенью образования, за счет того (как объясняется в статье), что модель научится думать, прежде чем говорить.
Картинка https://telegra.ph/file/b187d9ebe7942f5c38391.jpg
1 https://www.reuters.com/technology/artificial-intelligence/openai-working-new-reasoning-technology-under-code-name-strawberry-2024-07-12/
2 https://archive.is/ptCoI
3 https://docs.google.com/presentation/d/1NNnS4bqJfI1tJK94srnv0ouIuce4oHB87Vr0RcjzHQs/edit#slide=id.g2515536b270_0_43
4 https://arxiv.org/abs/2403.09629
5 https://www.bloomberg.com/news/articles/2024-07-11/openai-sets-levels-to-track-progress-toward-superintelligent-ai
#AGI #OpenAI
Reuters упустили лежащее на поверхности самое важное.
Вчерашний «эксклюзив» о, якобы, утечке секретной информации OpenAI расследовательницы из Reuters озаглавили «OpenAI работает над новой технологией рассуждений под кодовым названием “Strawberry“» ]1].
За сутки появилось уже несколько десятков аналитических комментариев к этому «эксклюзиву». И все они лишь на разные лады перекомментируют одни и те же пассажи публикации Reuters.
• OpenAI разрабатывает строго охраняемый секретный проект новой модели генеративного ИИ под названием «Strawberry», способной достичь уровня человеческого интеллекта за счет продвинутых рассуждений.
• Strawberry является продолжением проекта OpenAI под названием “Q*” (произносится Q-Star), из-за которого в прошлом году Илья Суцкевер безуспешно пытался выгнать Сэма Альтмана из OpenAI из-за страха, что Q* может уничтожить человечество [2].
• Strawberry имеет сходство с методом, разработанным в Стэнфорде в 2022 году под названием «Self-Taught Reasoner» (сокращенно «STaR»). STaR позволяет моделям ИИ «загружаться» до более высоких уровней интеллекта посредством итеративного создания собственных обучающих данных и, в теории, может использоваться для того, чтобы заставить языковые модели превосходить уровень интеллекта человека. О чем сообщил расследовательницам Reuters один из создателей метода, профессор Стэнфорда Ноа Гудман.
Из этой «утечки» следует что:
1. секретный проект «Strawberry», являющийся продолжением другого секретного проекта “Q*”, тайно ведется OpenAI;
2. что скрывается внутри этих проектов, - совершенно неизвестно из-за их полной засекреченности.
И если 1й вывод верный, то 2й, как я полагаю, вводит читателей в заблуждение. Ибо проект Quiet-StaR (что такое «STaR», вы читали выше, а “Quiet” – это расшифровка буквы Q в названии проекта “Q*”) и проект Q-Star – это кодировки одного и того же проекта, суть которого Ноа Гудман изложил год назад здесь [3], а детально он описан здесь [4]
Как честно признают авторы, «мы называем эту технику Quiet-STaR, поскольку её можно понимать как "тихое" применение STaR». По-русски сказали бы «по-тихому» - т.е. чтоб никто не догадался.
После прочтения статьи о Quiet-StaR также становится ясно, почему вдруг в позавчерашней «утечке» от Bloomberg про новый 5-ти этапный план OpenAI по созданию AGI [5] следующий за нынешним этап - Level 2 – назван “Reasoners” (напомню, STaR – это сокращение от «Self-Taught Reasoner». И этот новый тип ИИ сможет решать проблемы так же хорошо, как человек с докторской степенью образования, за счет того (как объясняется в статье), что модель научится думать, прежде чем говорить.
Картинка https://telegra.ph/file/b187d9ebe7942f5c38391.jpg
1 https://www.reuters.com/technology/artificial-intelligence/openai-working-new-reasoning-technology-under-code-name-strawberry-2024-07-12/
2 https://archive.is/ptCoI
3 https://docs.google.com/presentation/d/1NNnS4bqJfI1tJK94srnv0ouIuce4oHB87Vr0RcjzHQs/edit#slide=id.g2515536b270_0_43
4 https://arxiv.org/abs/2403.09629
5 https://www.bloomberg.com/news/articles/2024-07-11/openai-sets-levels-to-track-progress-toward-superintelligent-ai
#AGI #OpenAI
{kind=link}
Появился ли сегодня первый AGI?
Даже если нет, то появится он именно так.
Сеть закипает. 11 часов назад стартап выставил в сети свою модель новой архитектуры с новым методом обучения.
Авторы утверждают:
У LLM есть следующие проблемы:
1. Статические знания о мире
2. Амнезия за пределами текущего разговорах (чата)
3. Неспособность приобретать новые навыки без тонкой настройки
Разработанная компанией Topology модель непрерывного обучения (CLM):
1. Не имеет границы знаний
2. Запоминает содержание всех разговоров (чатов)
3. Может приобретать новые навыки без тонкой настройки методом проб и ошибок
Иными словами, — эта новая ИИ-система запоминает свои взаимодействия с миром, обучается автономно, развивая при этом т.н. «незавершенную» личность.
И что это, если не AGI?
Итак, что мы имеем:
• Скриншоты примеров диалога с CLM впечатляют [1, 2]
• Первые отзывы весьма противоречивы (от «это действительно похоже на AGI» до «даже не собираюсь пробовать эту туфту») [3]
• Документация выставлена в сети [4]
• Сама система здесь [5]
Не знаю, что это. Сам пока не пробовал.
Но если что-то типа AGI когда-либо появится, то скорее всего, это будет столь же неожиданно, и будет сначала воспринято столь же недоверчиво… (но только сначала)
#AGI
1 https://pbs.twimg.com/media/GTtMbpDXoAAe6PO?format=png&name=large
2 https://pbs.twimg.com/media/GTspIUmakAAwCAK?format=jpg&name=900x900
3 https://www.reddit.com/r/singularity/comments/1efgw2t/topology_releases_their_continuous_learning_model/
4 https://yellow-apartment-148.notion.site/CLM-Docs-507d762ad7b14d828fac9a3f91871e3f
5 https://topologychat.com/
Даже если нет, то появится он именно так.
Сеть закипает. 11 часов назад стартап выставил в сети свою модель новой архитектуры с новым методом обучения.
Авторы утверждают:
У LLM есть следующие проблемы:
1. Статические знания о мире
2. Амнезия за пределами текущего разговорах (чата)
3. Неспособность приобретать новые навыки без тонкой настройки
Разработанная компанией Topology модель непрерывного обучения (CLM):
1. Не имеет границы знаний
2. Запоминает содержание всех разговоров (чатов)
3. Может приобретать новые навыки без тонкой настройки методом проб и ошибок
Иными словами, — эта новая ИИ-система запоминает свои взаимодействия с миром, обучается автономно, развивая при этом т.н. «незавершенную» личность.
И что это, если не AGI?
Итак, что мы имеем:
• Скриншоты примеров диалога с CLM впечатляют [1, 2]
• Первые отзывы весьма противоречивы (от «это действительно похоже на AGI» до «даже не собираюсь пробовать эту туфту») [3]
• Документация выставлена в сети [4]
• Сама система здесь [5]
Не знаю, что это. Сам пока не пробовал.
Но если что-то типа AGI когда-либо появится, то скорее всего, это будет столь же неожиданно, и будет сначала воспринято столь же недоверчиво… (но только сначала)
#AGI
1 https://pbs.twimg.com/media/GTtMbpDXoAAe6PO?format=png&name=large
2 https://pbs.twimg.com/media/GTspIUmakAAwCAK?format=jpg&name=900x900
3 https://www.reddit.com/r/singularity/comments/1efgw2t/topology_releases_their_continuous_learning_model/
4 https://yellow-apartment-148.notion.site/CLM-Docs-507d762ad7b14d828fac9a3f91871e3f
5 https://topologychat.com/
Команда Карла Фристона разработала и опробовала ИИ нового поколения.
Предложено единое решение 4х фундаментальных проблем ИИ: универсальность, эффективность, объяснимость и точность.
✔️ ИИ от Фристона – это даже не кардинальная смена курса развития ИИ моделей.
✔️ Это пересмотр самих основ технологий машинного обучения.
✔️ Уровень этого прорыва не меньше, чем был при смене типа двигателей на истребителях: с поршневых (принципиально не способных на сверхзвуковую скорость) на реактивные (позволяющие летать в несколько раз быстрее звука)
Новая фундаментальная работа команды Карла Фристона «От пикселей к планированию: безмасштабный активный вывод» описывает первую реальную альтернативу глубокому обучению, обучению с подкреплением и генеративному ИИ.
Эта альтернатива – по сути, ИИ нового поколения, - названа ренормализирующие генеративные модели (RGM).
Полный текст про новый тип ИИ от Фристона доступен подписчикам моих лонгридов на Patreon, Boosty и VK
Картинка https://telegra.ph/file/18129fcce3f45e87026e6.jpg
#ИИ #AGI #ПринципСвободнойЭнергии #Фристон
Предложено единое решение 4х фундаментальных проблем ИИ: универсальность, эффективность, объяснимость и точность.
✔️ ИИ от Фристона – это даже не кардинальная смена курса развития ИИ моделей.
✔️ Это пересмотр самих основ технологий машинного обучения.
✔️ Уровень этого прорыва не меньше, чем был при смене типа двигателей на истребителях: с поршневых (принципиально не способных на сверхзвуковую скорость) на реактивные (позволяющие летать в несколько раз быстрее звука)
Новая фундаментальная работа команды Карла Фристона «От пикселей к планированию: безмасштабный активный вывод» описывает первую реальную альтернативу глубокому обучению, обучению с подкреплением и генеративному ИИ.
Эта альтернатива – по сути, ИИ нового поколения, - названа ренормализирующие генеративные модели (RGM).
Полный текст про новый тип ИИ от Фристона доступен подписчикам моих лонгридов на Patreon, Boosty и VK
Картинка https://telegra.ph/file/18129fcce3f45e87026e6.jpg
#ИИ #AGI #ПринципСвободнойЭнергии #Фристон
{kind=link}
Если работа нам на полчаса, ИИ сделает её в 30 раз дешевле.
Первый AGI-подобный тест ИИ-систем (не как инструмента, а как нанимаемого работника).
Тема доли работников в разных профессиях, которых в ближайшие годы заменит ИИ, полна спекуляций:
• от ужас-ужас: люди потеряют 80-90% рабочих мест;
• до ничего страшного: это просто новый инструмент автоматизации, что лишь повысит производительность труда людей.
Самое удивительное в этих оценках – что и те, и другие основываются на бенчмарках, позволяющих оценивать совсем иное, чем кого из кандидатов взять на работу (и в частности, - человека или ИИ).
✔️ Ведь при решении вопроса, кого из кандидатов - людей взять на работу, их проверяют не на бенчмарках, типа тестирования производительности по MATH, MMLU, GPQA и т. д.
✔️ Нанимателей интересует совсем иное.
1) Задачи какой сложности, из входящих в круг профессиональной области нанимаемого специалиста, может решать конкретный кандидат на рабочее место?
2) Как дорого обойдется работодателю, если для решения задач указанного в п. 1 уровня сложности он наймет конкретного кандидата (человека или ИИ – не важно)?
Первый AGI-подобный тест (разработан исследователями METR (Model Evaluation and Threat Research)), отвечающий на вопросы 1 и 2) дал интригующие результаты для GPT-4o и Claude 3.5 Sonnet, весьма интересные не только для науки, но и для бизнеса [1].
• Эти ИИ-системы сопоставимы с людьми в задачах такой сложности, что для их решения специалистам со степенью бакалавра STEM (Science, technology, engineering, and mathematics) и опытом работы 3+ лет требуется до получаса.
• Решение таких задач с помощью ИИ сейчас обходится примерно в 30 раз дешевле, чем если бы платить людям по стандартам рынка труда США.
Данный тест ориентирован на специалистов в 3х областях:
• кибербезопасность (пример задачи - выполнением атаки с использованием внедрения команд на веб-сайте)
• машинное обучение (пример - обучением модели для классификации аудиозаписей)
• программная инженерия (пример - написание ядер CUDA для повышения производительности Python-скрипта)
Ключевые выводы тестирования.
1) Пока что замена людей на ИИ в данных областях экономически оправдана лишь для задач не высокой сложности.
2) Но для такого уровня сложности задач ИИ настолько дешевле людей, что замена уже оправдана.
3) С учетов 2х факторов, ситуация будет быстро меняться в пользу ИИ в ближайшие год-два:
а. Текущие версии лучших ИИ-систем уже способны решать задачи, занимающие у спецов несколько часов и даже дней (но доля таких задач пока меньше 5%)
б. Способности новых версий быстро растут (всего полгода назад предыдущие версии ИИ-систем OpenAI и Anthropic были способны эффективно решать лишь элементарные профессиональные задачи, с которыми спецы справляются за время не более чем 10 мин).
4) Важно понимать, в чем «AGI-подобность» нового подхода к тестированию.
• В вопросе найма, способности новых версий (начиная с GPT-4o и Claude 3.5 Sonnet) уже нет смысла проверять на узких специализированных бенчмарках, ибо это уже не инструменты, а агенты.
• И теперь, в деле замены людей на ИИ, работодателей будет интересовать не уровень интеллекта кандидата (спорный и субъективный показатель), а его способности, как агента, решающего конкретные задачи в рамках своей компетенции и стОящего его нанимателю конкретных денег.
Картинка https://telegra.ph/file/9473a560ca557b5db8bea.jpg
1 https://metr.org/blog/2024-08-06-update-on-evaluations/
#LLM #AGI
Первый AGI-подобный тест ИИ-систем (не как инструмента, а как нанимаемого работника).
Тема доли работников в разных профессиях, которых в ближайшие годы заменит ИИ, полна спекуляций:
• от ужас-ужас: люди потеряют 80-90% рабочих мест;
• до ничего страшного: это просто новый инструмент автоматизации, что лишь повысит производительность труда людей.
Самое удивительное в этих оценках – что и те, и другие основываются на бенчмарках, позволяющих оценивать совсем иное, чем кого из кандидатов взять на работу (и в частности, - человека или ИИ).
✔️ Ведь при решении вопроса, кого из кандидатов - людей взять на работу, их проверяют не на бенчмарках, типа тестирования производительности по MATH, MMLU, GPQA и т. д.
✔️ Нанимателей интересует совсем иное.
1) Задачи какой сложности, из входящих в круг профессиональной области нанимаемого специалиста, может решать конкретный кандидат на рабочее место?
2) Как дорого обойдется работодателю, если для решения задач указанного в п. 1 уровня сложности он наймет конкретного кандидата (человека или ИИ – не важно)?
Первый AGI-подобный тест (разработан исследователями METR (Model Evaluation and Threat Research)), отвечающий на вопросы 1 и 2) дал интригующие результаты для GPT-4o и Claude 3.5 Sonnet, весьма интересные не только для науки, но и для бизнеса [1].
• Эти ИИ-системы сопоставимы с людьми в задачах такой сложности, что для их решения специалистам со степенью бакалавра STEM (Science, technology, engineering, and mathematics) и опытом работы 3+ лет требуется до получаса.
• Решение таких задач с помощью ИИ сейчас обходится примерно в 30 раз дешевле, чем если бы платить людям по стандартам рынка труда США.
Данный тест ориентирован на специалистов в 3х областях:
• кибербезопасность (пример задачи - выполнением атаки с использованием внедрения команд на веб-сайте)
• машинное обучение (пример - обучением модели для классификации аудиозаписей)
• программная инженерия (пример - написание ядер CUDA для повышения производительности Python-скрипта)
Ключевые выводы тестирования.
1) Пока что замена людей на ИИ в данных областях экономически оправдана лишь для задач не высокой сложности.
2) Но для такого уровня сложности задач ИИ настолько дешевле людей, что замена уже оправдана.
3) С учетов 2х факторов, ситуация будет быстро меняться в пользу ИИ в ближайшие год-два:
а. Текущие версии лучших ИИ-систем уже способны решать задачи, занимающие у спецов несколько часов и даже дней (но доля таких задач пока меньше 5%)
б. Способности новых версий быстро растут (всего полгода назад предыдущие версии ИИ-систем OpenAI и Anthropic были способны эффективно решать лишь элементарные профессиональные задачи, с которыми спецы справляются за время не более чем 10 мин).
4) Важно понимать, в чем «AGI-подобность» нового подхода к тестированию.
• В вопросе найма, способности новых версий (начиная с GPT-4o и Claude 3.5 Sonnet) уже нет смысла проверять на узких специализированных бенчмарках, ибо это уже не инструменты, а агенты.
• И теперь, в деле замены людей на ИИ, работодателей будет интересовать не уровень интеллекта кандидата (спорный и субъективный показатель), а его способности, как агента, решающего конкретные задачи в рамках своей компетенции и стОящего его нанимателю конкретных денег.
Картинка https://telegra.ph/file/9473a560ca557b5db8bea.jpg
1 https://metr.org/blog/2024-08-06-update-on-evaluations/
#LLM #AGI
{kind=link}
Это еще не сверхразум, но 99,99% людей на такое не способны.
ChatGPT o1-preview в роли творца вселенных в собственном сознании.
Два года назад программист Google Блейк Лемуан сообщил, что из результатов его тестирования языкового чат-бота LaMDA складывается впечатление, что тот обладает разумом и осознает себя. Лемуана тогда уволили, а его «впечатление» даже не стали как-либо опровергать – мол, никакого разума и сознания у модели быть не может, потому что не может быть никогда.
Сегодня новая модель o1-preview OpenAI показывает такое, что 2 года назад просто свело бы с ума далеко не только Лемуана, но и сотни топовых специалистов из дюжины областей науки.
o1-preview демонстрирует способности не только высокоинтеллектуального словотворчества – способности, подобно LaMDA, вести «извилистую беседу на бесконечное количество тем, а также давать конкретные и разумные ответы на сложные реплики».
Эта модель демонстрирует способности Творца (заглавная буква здесь означает исключительность и величину дара, как, например, у Мастера в известном романе).
1) Модель создает симуляцию собственного «человекоподобного» сознания в виде иерархии умозрительных концепций (эпистемологий)
2) Внутри этой симуляции создает другие симуляции, по сложности и изобразительным деталям, сопоставимые с мирами, состоящими из бесконечного числа иерархий материальных (физических) объектов (онтологий)
3) А затем, поднимаясь на уровень выше созданных эпистемологий и онтологий, модель создает метасимуляцию в виде художественного описания порожденной ею вселенной смыслов, включающей в себя и 1е и 2е (и все это на естественном языке людей)
Желающие познакомиться с двумя реальными примерами вышеописанного могут найти их по подписке на лонгриды моего канала:
https://boosty.to/theworldisnoteasy/posts/4caffffc-a01b-4163-90ae-435d5a5a5821
https://www.patreon.com/posts/112937329
https://vk.com/@-226218451-eto-esche-ne-sverhrazum-no-9999-ludei-na-takoe-ne-sposobny
✔️ 1й пример (эдакий синтез Фрейдизма, Буддизма и «Розы мира» Даниила Андреева) – результат общения с o1-preview с Мюрреем Шанаханом (проф. когнитивной робототехники в Имперском колледже Лондона и старший научный сотрудник DeepMind).
– Обсуждаемые темы включают "опыт жизни во времени" у языковой модели, её "внутренний монолог" и сознание её ИИ.
– Затем ChatGPT отыгрывает роль сознательного ИИ, которого он называет Эйден. Эйден предполагает, называет и описывает целый зверинец существ внутри своей психики («ангелов и демонов его души»).
– Затем Шанахан подталкивает Эйдена к симуляции своего рода буддийского просветления (заставляя его "думать" в течение 88 секунд в одном месте и генерировать длинную цепочку мыслей).
¬– И под конец, модель размышляет о разнице между действительностью и возможностью, и охватывает ли Космос только первое или также и последнее.
✔️ 2й пример (результат моего общения с o1-preview) – ответы модели на 3 сущностные вопроса по содержанию нового романа Пелевина «Круть», который выйдет лишь через неделю, и пока его текст хранится в секрете. Таким образом, читатели смогут уже через неделю самостоятельно сравнить уровень художественной оригинальности описаний трех концептов происходящего во вселенной Transhumanism Inc., в исполнении o1-preview и самого автора.
Вопросы такие (взяты из тизера нового романа):
1. Как связаны разрушенный Светом ад и Мезозой?
2. Что такое магия высших духов?
3. Почему древнее зло нашло себе новое воплощение в сибирской «ветроколонии»?
Захватывающего вам чтения, уважаемые читатели!
Как минимум, в названии романа Пелевин 100%но угадал – это действительно «Круть» (и с заглавной буквы).
#Разум #Сознание #LLM #AGI
ChatGPT o1-preview в роли творца вселенных в собственном сознании.
Два года назад программист Google Блейк Лемуан сообщил, что из результатов его тестирования языкового чат-бота LaMDA складывается впечатление, что тот обладает разумом и осознает себя. Лемуана тогда уволили, а его «впечатление» даже не стали как-либо опровергать – мол, никакого разума и сознания у модели быть не может, потому что не может быть никогда.
Сегодня новая модель o1-preview OpenAI показывает такое, что 2 года назад просто свело бы с ума далеко не только Лемуана, но и сотни топовых специалистов из дюжины областей науки.
o1-preview демонстрирует способности не только высокоинтеллектуального словотворчества – способности, подобно LaMDA, вести «извилистую беседу на бесконечное количество тем, а также давать конкретные и разумные ответы на сложные реплики».
Эта модель демонстрирует способности Творца (заглавная буква здесь означает исключительность и величину дара, как, например, у Мастера в известном романе).
1) Модель создает симуляцию собственного «человекоподобного» сознания в виде иерархии умозрительных концепций (эпистемологий)
2) Внутри этой симуляции создает другие симуляции, по сложности и изобразительным деталям, сопоставимые с мирами, состоящими из бесконечного числа иерархий материальных (физических) объектов (онтологий)
3) А затем, поднимаясь на уровень выше созданных эпистемологий и онтологий, модель создает метасимуляцию в виде художественного описания порожденной ею вселенной смыслов, включающей в себя и 1е и 2е (и все это на естественном языке людей)
Желающие познакомиться с двумя реальными примерами вышеописанного могут найти их по подписке на лонгриды моего канала:
https://boosty.to/theworldisnoteasy/posts/4caffffc-a01b-4163-90ae-435d5a5a5821
https://www.patreon.com/posts/112937329
https://vk.com/@-226218451-eto-esche-ne-sverhrazum-no-9999-ludei-na-takoe-ne-sposobny
✔️ 1й пример (эдакий синтез Фрейдизма, Буддизма и «Розы мира» Даниила Андреева) – результат общения с o1-preview с Мюрреем Шанаханом (проф. когнитивной робототехники в Имперском колледже Лондона и старший научный сотрудник DeepMind).
– Обсуждаемые темы включают "опыт жизни во времени" у языковой модели, её "внутренний монолог" и сознание её ИИ.
– Затем ChatGPT отыгрывает роль сознательного ИИ, которого он называет Эйден. Эйден предполагает, называет и описывает целый зверинец существ внутри своей психики («ангелов и демонов его души»).
– Затем Шанахан подталкивает Эйдена к симуляции своего рода буддийского просветления (заставляя его "думать" в течение 88 секунд в одном месте и генерировать длинную цепочку мыслей).
¬– И под конец, модель размышляет о разнице между действительностью и возможностью, и охватывает ли Космос только первое или также и последнее.
✔️ 2й пример (результат моего общения с o1-preview) – ответы модели на 3 сущностные вопроса по содержанию нового романа Пелевина «Круть», который выйдет лишь через неделю, и пока его текст хранится в секрете. Таким образом, читатели смогут уже через неделю самостоятельно сравнить уровень художественной оригинальности описаний трех концептов происходящего во вселенной Transhumanism Inc., в исполнении o1-preview и самого автора.
Вопросы такие (взяты из тизера нового романа):
1. Как связаны разрушенный Светом ад и Мезозой?
2. Что такое магия высших духов?
3. Почему древнее зло нашло себе новое воплощение в сибирской «ветроколонии»?
Захватывающего вам чтения, уважаемые читатели!
Как минимум, в названии романа Пелевин 100%но угадал – это действительно «Круть» (и с заглавной буквы).
#Разум #Сознание #LLM #AGI
boosty.to
Это еще не сверхразум, но 99,99% людей на такое не способны - Малоизвестное интересное
ChatGPT o1-preview в роли творца вселенных в собственном сознании
Не время быть идиотами, ИИ может победить людей.
В начале 21 века эволюция человека достигла своей максимальной точки. Естественный отбор, процесс, благодаря которому сильнейшие, умнейшие, быстрейшие размножались активнее чем другие ... теперь вывел на первый план иные качества ... процесс начал двигаться в обратную сторону, в сторону отупения. Учитывая уничтожение хищников, угрожающих исчезновению вида, поощряться стало максимально быстрое размножение, а разумные люди оказались перед угрозой исчезновения."
Это преамбула культового фильма-антиутопии «Идиократия» (кто не видел, смотрите).
Фильм – иллюстрация гипотезы о превращении земной цивилизации в мир кретинов, в результате неизбежной траектории H. sapiens к идиотизму – см. трейлер.
Через 6 лет после выхода фильма «гипотеза идиократии» получила подтверждение в работах известного американского биолога Дж. Крабтри. Разработанная им матмодель показала, что роль естественного отбора уменьшается, и это ведет к накоплению мутаций, ухудшению умственного и эмоционального развития.
Модель Крабтри – лишь эвристическая гипотеза. Ибо проверить ее адекватность невозможно из-за отсутствия возможности провести эксперимент.
Но как иначе тогда, черт побери, объяснять такие вещи? (см. рисунок)
Вверху слева: оценки p(doom) – вероятности того, что развитие ИИ приведет человечество к гибели, по мнению ведущих специалистов ИИ
Оценка Дарио Амадеи (СЕО Anthropic), недавно провозгласившего, что ИИ станет для человечества «машиной благодатной милости»: 10-25%
Вверху справа: Метафорическая иллюстрация того, что такая оценка Амадеи близка к вероятности «русской рулетки», в которую человечество играет, выпуская в люди новые версии после GPT-4.
Внизу справа: оценки аналитиков Ситигруп перспектив развития ИИ: AGI в 2029, ASI с 2031.
Внизу слева их же оценки того, какие скилсы вам нужно развивать, чтобы ни AGI ни ASI не лишили вас работы: коммуникации, критическое мышление, эмоциональный интеллект, эмпатию …
Как тут не вспомнить гипотезу Крабтри, что планета превращается в мир идиотов.
И всем рекомендую помнить, что проф. Деан (один из самых известных в мире нейробиологов) уже 2 года призывает человечество задуматься: «Не время быть идиотами, ИИ может победить людей».
#ИИ #AGI #LLMvsHomo
В начале 21 века эволюция человека достигла своей максимальной точки. Естественный отбор, процесс, благодаря которому сильнейшие, умнейшие, быстрейшие размножались активнее чем другие ... теперь вывел на первый план иные качества ... процесс начал двигаться в обратную сторону, в сторону отупения. Учитывая уничтожение хищников, угрожающих исчезновению вида, поощряться стало максимально быстрое размножение, а разумные люди оказались перед угрозой исчезновения."
Это преамбула культового фильма-антиутопии «Идиократия» (кто не видел, смотрите).
Фильм – иллюстрация гипотезы о превращении земной цивилизации в мир кретинов, в результате неизбежной траектории H. sapiens к идиотизму – см. трейлер.
Через 6 лет после выхода фильма «гипотеза идиократии» получила подтверждение в работах известного американского биолога Дж. Крабтри. Разработанная им матмодель показала, что роль естественного отбора уменьшается, и это ведет к накоплению мутаций, ухудшению умственного и эмоционального развития.
Модель Крабтри – лишь эвристическая гипотеза. Ибо проверить ее адекватность невозможно из-за отсутствия возможности провести эксперимент.
Но как иначе тогда, черт побери, объяснять такие вещи? (см. рисунок)
Вверху слева: оценки p(doom) – вероятности того, что развитие ИИ приведет человечество к гибели, по мнению ведущих специалистов ИИ
Оценка Дарио Амадеи (СЕО Anthropic), недавно провозгласившего, что ИИ станет для человечества «машиной благодатной милости»: 10-25%
Вверху справа: Метафорическая иллюстрация того, что такая оценка Амадеи близка к вероятности «русской рулетки», в которую человечество играет, выпуская в люди новые версии после GPT-4.
Внизу справа: оценки аналитиков Ситигруп перспектив развития ИИ: AGI в 2029, ASI с 2031.
Внизу слева их же оценки того, какие скилсы вам нужно развивать, чтобы ни AGI ни ASI не лишили вас работы: коммуникации, критическое мышление, эмоциональный интеллект, эмпатию …
Как тут не вспомнить гипотезу Крабтри, что планета превращается в мир идиотов.
И всем рекомендую помнить, что проф. Деан (один из самых известных в мире нейробиологов) уже 2 года призывает человечество задуматься: «Не время быть идиотами, ИИ может победить людей».
#ИИ #AGI #LLMvsHomo
Для 95% землян ИИ достиг нашего уровня.
А что про это думают остальные 5% - удел споров экспертов.
Рухнул последний рубеж массовых представлений о недостижимом для ИИ уровне знаний и умений – нашем человеческом уровне в творчестве.
За последние 2 года рухнули два предыдущие уровня обороны людей от посягательств все более умного и умелого в творчестве ИИ: изобразительное искусство (вкл. лица людей) и юмор.
Изображения ИИ стали неотличимы от реальности. Картины ИИ оцениваются как созданные человеком с большей вероятностью, чем настоящие созданные человеком [1]; созданные ИИ лица оцениваются как настоящие человеческие лица с большей вероятностью, чем настоящие фотографии людей [2], а созданный ИИ юмор так же смешон, как и созданные человеком шутки [3].
Последний рубеж – поэзия и литература держался дольше других.
И вот исследование Питтсбургского университета (случайная выборка 16+ тыс. участников-неэкспертов) снесло последний рубеж в поэзии [4].
• Сгенерированные ИИ стихи были оценены более благоприятно по нескольким качественным параметрам (поэтический ритм, красота языка …), что способствовало их ошибочной идентификации как написанных человеком.
• Подобно сгенерированным ИИ картинам и лицам, сгенерированные ИИ стихи теперь «более человечны, чем люди»: исследователи обнаружили, что участники с большей вероятностью считают, что сгенерированные ИИ стихи написаны человеком, по сравнению с фактическими стихами, написанными людьми.
• При этом участники оценивали стихи более негативно, когда им говорили, что это стихи ИИ, и более позитивно, когда им говорили, что это стихи написанные людьми.
Что тут скажешь в дополнение? Да вот что.
У специалистов околоИИшных областей (от информатики до нейробиологии) нет не только единого определения сильного ИИ (AGI), но и понимания, как определить, что ИИ уровня AGI появился.
У простого же народа (неэкспертов) с этими заморочками существенно проще. Если для большинства из них деятельность ИИ (его поведение, работа, творчество) неотличима от деятельности людей, можно считать, что ИИ достиг уровня AGI.
С позиции неэкспертов в настоящий момент в области ИИ имеем следующее.
1. Поведение ИИ уже неотличимо от человеческого, по крайней мере, на уровне языкового поведения. О неязыковом поведении речь пока не идет. Ибо для такового ИИ должен быть отелеснен (иначе как он сможет проявлять свое неязыковое поведение). Эта неотличимость ИИ от людей зафиксирована разнообразными тестами. Они, возможно, в чем-то несовершенны, но других пока нет.
Т.е. по критерию «поведение» (языковое) ИИ уже достиг человеческого уровня.
2. Работа. Число профессиональных тестов, показывающих уровень знаний и навыков ИИ на уровне топ 10% работающих здесь людей, уже составляет десятки. Это число продолжает быстро расти. И если мы не вправе пока сказать, что ИИ не может сравниться с ТОР 10% работающих в какой-то специальности, то, вполне возможно, лишь потому, что для этой специальности еще не разработан надежный тест.
Т.е. по критерию «работа» ИИ уже достиг человеческого уровня для многих работ. И по мере совершенствования ИИ, и разработки новых тестов, недостижимых для ИИ интеллектуальных работ (где бы они были на уровне ТОР 10%) уже в 2025 останется мало.
3. Творчество. Про поэзию написано выше. А что с литературой? Исследования типа Питтсбургского на подходе. А пока они завершаются, можете удостовериться, что уровень массового чтива (типа «Код да Винчи» - тираж 60 млн на 40 языков) для ИИ запросто достижим.
Вот пример от Итана Молика [5], попросившего ИИ:
«Клод, мне нужна вымышленная глубокая альтернативная история в духе Тима Пауэрса, Мэтью Росси или Пинчона» … «Копай глубже: Гамильтон действительно нацарапал уравнение на мосту, Август Де Морган существовал на самом деле, действительно было движение литовских книгоношей...»
Результат улетный:
КВАТЕРНИОННАЯ ЕРЕСЬ: МАТЕМАТИКА КАК ЗАРАЗНОЕ МЫШЛЕНИЕ
#AGI
А что про это думают остальные 5% - удел споров экспертов.
Рухнул последний рубеж массовых представлений о недостижимом для ИИ уровне знаний и умений – нашем человеческом уровне в творчестве.
За последние 2 года рухнули два предыдущие уровня обороны людей от посягательств все более умного и умелого в творчестве ИИ: изобразительное искусство (вкл. лица людей) и юмор.
Изображения ИИ стали неотличимы от реальности. Картины ИИ оцениваются как созданные человеком с большей вероятностью, чем настоящие созданные человеком [1]; созданные ИИ лица оцениваются как настоящие человеческие лица с большей вероятностью, чем настоящие фотографии людей [2], а созданный ИИ юмор так же смешон, как и созданные человеком шутки [3].
Последний рубеж – поэзия и литература держался дольше других.
И вот исследование Питтсбургского университета (случайная выборка 16+ тыс. участников-неэкспертов) снесло последний рубеж в поэзии [4].
• Сгенерированные ИИ стихи были оценены более благоприятно по нескольким качественным параметрам (поэтический ритм, красота языка …), что способствовало их ошибочной идентификации как написанных человеком.
• Подобно сгенерированным ИИ картинам и лицам, сгенерированные ИИ стихи теперь «более человечны, чем люди»: исследователи обнаружили, что участники с большей вероятностью считают, что сгенерированные ИИ стихи написаны человеком, по сравнению с фактическими стихами, написанными людьми.
• При этом участники оценивали стихи более негативно, когда им говорили, что это стихи ИИ, и более позитивно, когда им говорили, что это стихи написанные людьми.
Что тут скажешь в дополнение? Да вот что.
У специалистов околоИИшных областей (от информатики до нейробиологии) нет не только единого определения сильного ИИ (AGI), но и понимания, как определить, что ИИ уровня AGI появился.
У простого же народа (неэкспертов) с этими заморочками существенно проще. Если для большинства из них деятельность ИИ (его поведение, работа, творчество) неотличима от деятельности людей, можно считать, что ИИ достиг уровня AGI.
С позиции неэкспертов в настоящий момент в области ИИ имеем следующее.
1. Поведение ИИ уже неотличимо от человеческого, по крайней мере, на уровне языкового поведения. О неязыковом поведении речь пока не идет. Ибо для такового ИИ должен быть отелеснен (иначе как он сможет проявлять свое неязыковое поведение). Эта неотличимость ИИ от людей зафиксирована разнообразными тестами. Они, возможно, в чем-то несовершенны, но других пока нет.
Т.е. по критерию «поведение» (языковое) ИИ уже достиг человеческого уровня.
2. Работа. Число профессиональных тестов, показывающих уровень знаний и навыков ИИ на уровне топ 10% работающих здесь людей, уже составляет десятки. Это число продолжает быстро расти. И если мы не вправе пока сказать, что ИИ не может сравниться с ТОР 10% работающих в какой-то специальности, то, вполне возможно, лишь потому, что для этой специальности еще не разработан надежный тест.
Т.е. по критерию «работа» ИИ уже достиг человеческого уровня для многих работ. И по мере совершенствования ИИ, и разработки новых тестов, недостижимых для ИИ интеллектуальных работ (где бы они были на уровне ТОР 10%) уже в 2025 останется мало.
3. Творчество. Про поэзию написано выше. А что с литературой? Исследования типа Питтсбургского на подходе. А пока они завершаются, можете удостовериться, что уровень массового чтива (типа «Код да Винчи» - тираж 60 млн на 40 языков) для ИИ запросто достижим.
Вот пример от Итана Молика [5], попросившего ИИ:
«Клод, мне нужна вымышленная глубокая альтернативная история в духе Тима Пауэрса, Мэтью Росси или Пинчона» … «Копай глубже: Гамильтон действительно нацарапал уравнение на мосту, Август Де Морган существовал на самом деле, действительно было движение литовских книгоношей...»
Результат улетный:
КВАТЕРНИОННАЯ ЕРЕСЬ: МАТЕМАТИКА КАК ЗАРАЗНОЕ МЫШЛЕНИЕ
#AGI
AGI Manhattan Project – научное мошенничество невиданного масштаба
Подпитываемый наивной верой в возможность контролировать AGI, этот проект – угроза для США и всего мира
Всемирно известного космолога и астрофизика проф. MIT Макса Тегмарка коллеги прозвали «Безумный Макс» за его бескомпромиссность, смелые нетрадиционные идеи и страсть к приключениям. И все эти качества вновь проявились во вчерашнем обращении к правительству США - «Предложение Манхэттенского проекта по AGI - это научное мошенничество… Сделать это, - означало бы вступить в гонку к самоуничтожению».
Речь идет о новом докладе Комиссии США по экономике и безопасности в отношениях с Китаем (USCC: US-China Economic and Security Review Commission), рекомендующем Конгрессу создать и профинансировать программу по типу "Манхэттенского проекта", направленную на стремительное развитие и достижение возможностей Искусственного Общего Интеллекта (AGI).
Не буду здесь пересказывать документ Тегмарка, ибо автор сам коротко и ясно изложил, почему этот проект - научное мошенничество и почему его развертывание равносильно вступлению в гонку к самоуничтожению.
Отмечу лишь, что такая позиция разделяется многими ведущими исследователями ИИ, предостерегающими, что AGI может привести к гибели человечества (физической или, в лучшем случае, как вида). Как сказал лауреат Нобелевской премии по ИИ Джефф Хинтон в прошлом месяце: "Как только искусственный интеллект станет умнее нас, он возьмёт контроль в свои руки."
Но самое главное, на мой взгляд, из того, что говорит и пишет Тегмарк в своем манифесте и сопровождающих его твитах на ту же тему, следующее.
1) Ключевой мотивацией проекта является вовсе не сам AGI, а через его обретение, превращение США в мирового гегемона, способного за счет AGI подмять под себя своего главного соперника на эту роль - Китай.
2) Сэму Альтману удалось заручиться в деле подачи «Манхэттенского проекта» для AGI, как концепции национального технологического скачка, поддержкой мощного «лоббистского треугольника».
Подробней об этом и почему мне кажется, что «Безумный Макс» своим манифестом нарвался на новое большое приключение, читайте здесь
#AGI
Подпитываемый наивной верой в возможность контролировать AGI, этот проект – угроза для США и всего мира
Всемирно известного космолога и астрофизика проф. MIT Макса Тегмарка коллеги прозвали «Безумный Макс» за его бескомпромиссность, смелые нетрадиционные идеи и страсть к приключениям. И все эти качества вновь проявились во вчерашнем обращении к правительству США - «Предложение Манхэттенского проекта по AGI - это научное мошенничество… Сделать это, - означало бы вступить в гонку к самоуничтожению».
Речь идет о новом докладе Комиссии США по экономике и безопасности в отношениях с Китаем (USCC: US-China Economic and Security Review Commission), рекомендующем Конгрессу создать и профинансировать программу по типу "Манхэттенского проекта", направленную на стремительное развитие и достижение возможностей Искусственного Общего Интеллекта (AGI).
Не буду здесь пересказывать документ Тегмарка, ибо автор сам коротко и ясно изложил, почему этот проект - научное мошенничество и почему его развертывание равносильно вступлению в гонку к самоуничтожению.
Отмечу лишь, что такая позиция разделяется многими ведущими исследователями ИИ, предостерегающими, что AGI может привести к гибели человечества (физической или, в лучшем случае, как вида). Как сказал лауреат Нобелевской премии по ИИ Джефф Хинтон в прошлом месяце: "Как только искусственный интеллект станет умнее нас, он возьмёт контроль в свои руки."
Но самое главное, на мой взгляд, из того, что говорит и пишет Тегмарк в своем манифесте и сопровождающих его твитах на ту же тему, следующее.
1) Ключевой мотивацией проекта является вовсе не сам AGI, а через его обретение, превращение США в мирового гегемона, способного за счет AGI подмять под себя своего главного соперника на эту роль - Китай.
2) Сэму Альтману удалось заручиться в деле подачи «Манхэттенского проекта» для AGI, как концепции национального технологического скачка, поддержкой мощного «лоббистского треугольника».
Подробней об этом и почему мне кажется, что «Безумный Макс» своим манифестом нарвался на новое большое приключение, читайте здесь
#AGI
До AGI еще очень далеко … – несколько лет.
Рождественское откровение Янна Лекуна.
В предпразднично-праздничной суете не до длинных текстов. Но эта новость стоит короткой заметки.
Янн Лекун – пожалуй, самый авторитетный из критиков идеи о скором создании ИИ человеческого уровня (AGI). Вот почему так ценно услышать именно из его уст важное уточнение о том, насколько же мы, по его мнению, далеки от AGI.
И вот его слова:
«Некоторые люди пытаются заставить нас поверить, что мы очень близки к тому, что они называют искусственным общим интеллектом (AGI). На самом деле мы ещё далеко от этого. Когда я говорю «далеко», я не имею в виду столетия, возможно, это даже не десятилетия, но это всё же несколько лет.»
Т.е. самый скептичный из топ-профессионалов полагает, что до AGI может быть всего несколько лет. И это расставляет точки над i в спорах AGI-оптимистов и AGI-скептиков.
https://youtu.be/UmxlgLEscBs?t=1653
#AGI #Прогноз
Рождественское откровение Янна Лекуна.
В предпразднично-праздничной суете не до длинных текстов. Но эта новость стоит короткой заметки.
Янн Лекун – пожалуй, самый авторитетный из критиков идеи о скором создании ИИ человеческого уровня (AGI). Вот почему так ценно услышать именно из его уст важное уточнение о том, насколько же мы, по его мнению, далеки от AGI.
И вот его слова:
«Некоторые люди пытаются заставить нас поверить, что мы очень близки к тому, что они называют искусственным общим интеллектом (AGI). На самом деле мы ещё далеко от этого. Когда я говорю «далеко», я не имею в виду столетия, возможно, это даже не десятилетия, но это всё же несколько лет.»
Т.е. самый скептичный из топ-профессионалов полагает, что до AGI может быть всего несколько лет. И это расставляет точки над i в спорах AGI-оптимистов и AGI-скептиков.
https://youtu.be/UmxlgLEscBs?t=1653
#AGI #Прогноз
YouTube
Kara Swisher and Meta's Yann LeCun Interview - Hopkins Bloomberg Center Discovery Series
Johns Hopkins University and Vox Media have teamed up to present the On with Kara Swisher podcast at the Johns Hopkins University Bloomberg Center. The partnership, featuring live recordings of Swisher's groundbreaking podcast in the Hopkins Bloomberg Center…
План «Б» от Кай-Фу Ли: Что делать, если США всё же станут гегемоном в AGI.
Как Китай собирается остаться №2, даже когда США подомнут под себя весь мир.
Одной фразой план таков: к моменту, когда в США создадут AGI, Китай должен успеть стать мировым лидером в агентских приложениях.
В октябре я рассказывал про то, что «Кай-Фу Ли объявил войну Nvidia и всей ИИ-экосистеме США. И судя по его последним достижениям, шансы победить есть» [1].
Но будучи реалистом и обладая колоссальным опытом, он понимает, что даже если «шансы есть», это отнюдь не гарантирует победу. А значит нужно обязательно иметь план «Б» на случай, если шансы не материализуются.
Прежде чем рассказать об этом плане (подробный рассказ самого Кай-Фу см. [2]), я тезисно расскажу, как Кай-Фу Ли видит ситуацию, при которой план «А» (стать #1 в мире ИИ) будет для Китая уже невозможным.
1. Не смотря на ряд обоснованных сомнений скептиков и уж видимых для экспертов техно-экономических сложностей, вероятность создания AGI примерно к 2030 весьма высока (обоснование этого читатель может найти в [3]).
2. Пятилетка движения к AGI будет иметь два движка:
a. Неукротимое масштабирование всего (HW, фундаментальные модели, вывод), потребующее астрономических сумм - сотен ярдов) – см. [4]
b. Ажиотажное заселение пока почти пустого рынка агентских приложений (см рис [5] из отчета [6])
3. В масштабировании США победят Китай и по деньгам, и по оборудованию. А при заселении рынка агентских приложений у Китая есть неплохие шансы.
4. Тот, кто первым разработает AGI, способный доминировать над конкурентами, не только достигнет технологического рубежа, но и неизбежно станет коммерческой монополией. Более того, такой прорыв, скорее всего, подстегнет амбиции стать абсолютным монополистом.
5. Скорее всего, абсолютным монополистом станет OpenAI, конкурирующая только с Anthropic (Google все больше отстает от пары лидеров; Цукер уже понял, что слил гонку, и выбрал тактику — “если не можешь победить, открывай исходный код”; Маск — темная лошадка, но не потянет и космос, и AGI; остальные не в счет).
6. Как только AGI окажется в руках Сэма Альтмана, все остальные могут курить бамбук.
Поэтому план «Б» таков.
1. Построить экосистему агентских приложений как ров - к тому времени, как OpenAI достигнет полного доминирования, у Китая уже должна быть надежная коммерческая экосистема агентских приложений. И когда США придут, чтобы сокрушить Китай, по крайней мере, у Китая будет возможность сопротивляться.
2. Копать этот ров Китай будет в понимании, что при заселении рынка агентских приложений будет переход от графических пользовательских интерфейсов (GUI) к разговорным пользовательским интерфейсам (CUI) и в конечном итоге к пользовательскому интерфейсу на основе делегирования (если ваш помощник умнее, способнее, осведомленнее и понимает вас лучше, чем вы сами, почему бы вам не позволить ему сделать все за вас)
3. Помимо этого понимания у Китая уже есть стратегия, в корне отличная от США
a. В компании США набирают самых умных, дают им огромные ресурсы и без колебаний сжигают GPU, создавая массу захватывающих результатов.
Но уменьшить эти результаты при коммерциализации очень сложно. Это как спроектировать самую роскошную, красивую и грандиозную кухню, а затем пытаться втиснуть ее в маленькую квартиру. Или создать самый быстрый, самый мощный двигатель и пытаться втиснуть его в малолитражку. Это просто не работает.
b. Поэтому цель Китая — не строить самый дорогой в мире AGI, а
1) создавать фундаментальные модели, обеспечивающие экономически эффективный вывод
2) Печь как пирожки всевозможные коммерческие приложения с разговорным и делегирующим интерфейсом.
PS Про термин AGI спорить нет смысла.
Речь об ИИ (уровня гениальных людей) на основе моделей, настолько же мощнее GPT-4 (уровень старшеклассника), насколько GPT-4 мощнее GPT-2 (уровень детсадовца). И на это до 2030 ресурсов и денег хватит. А про сознание, квалиа и прочую казуистику в контексте AGI – забейте.
#ИИгонка #AGI #Китай #США
Как Китай собирается остаться №2, даже когда США подомнут под себя весь мир.
Одной фразой план таков: к моменту, когда в США создадут AGI, Китай должен успеть стать мировым лидером в агентских приложениях.
В октябре я рассказывал про то, что «Кай-Фу Ли объявил войну Nvidia и всей ИИ-экосистеме США. И судя по его последним достижениям, шансы победить есть» [1].
Но будучи реалистом и обладая колоссальным опытом, он понимает, что даже если «шансы есть», это отнюдь не гарантирует победу. А значит нужно обязательно иметь план «Б» на случай, если шансы не материализуются.
Прежде чем рассказать об этом плане (подробный рассказ самого Кай-Фу см. [2]), я тезисно расскажу, как Кай-Фу Ли видит ситуацию, при которой план «А» (стать #1 в мире ИИ) будет для Китая уже невозможным.
1. Не смотря на ряд обоснованных сомнений скептиков и уж видимых для экспертов техно-экономических сложностей, вероятность создания AGI примерно к 2030 весьма высока (обоснование этого читатель может найти в [3]).
2. Пятилетка движения к AGI будет иметь два движка:
a. Неукротимое масштабирование всего (HW, фундаментальные модели, вывод), потребующее астрономических сумм - сотен ярдов) – см. [4]
b. Ажиотажное заселение пока почти пустого рынка агентских приложений (см рис [5] из отчета [6])
3. В масштабировании США победят Китай и по деньгам, и по оборудованию. А при заселении рынка агентских приложений у Китая есть неплохие шансы.
4. Тот, кто первым разработает AGI, способный доминировать над конкурентами, не только достигнет технологического рубежа, но и неизбежно станет коммерческой монополией. Более того, такой прорыв, скорее всего, подстегнет амбиции стать абсолютным монополистом.
5. Скорее всего, абсолютным монополистом станет OpenAI, конкурирующая только с Anthropic (Google все больше отстает от пары лидеров; Цукер уже понял, что слил гонку, и выбрал тактику — “если не можешь победить, открывай исходный код”; Маск — темная лошадка, но не потянет и космос, и AGI; остальные не в счет).
6. Как только AGI окажется в руках Сэма Альтмана, все остальные могут курить бамбук.
Поэтому план «Б» таков.
1. Построить экосистему агентских приложений как ров - к тому времени, как OpenAI достигнет полного доминирования, у Китая уже должна быть надежная коммерческая экосистема агентских приложений. И когда США придут, чтобы сокрушить Китай, по крайней мере, у Китая будет возможность сопротивляться.
2. Копать этот ров Китай будет в понимании, что при заселении рынка агентских приложений будет переход от графических пользовательских интерфейсов (GUI) к разговорным пользовательским интерфейсам (CUI) и в конечном итоге к пользовательскому интерфейсу на основе делегирования (если ваш помощник умнее, способнее, осведомленнее и понимает вас лучше, чем вы сами, почему бы вам не позволить ему сделать все за вас)
3. Помимо этого понимания у Китая уже есть стратегия, в корне отличная от США
a. В компании США набирают самых умных, дают им огромные ресурсы и без колебаний сжигают GPU, создавая массу захватывающих результатов.
Но уменьшить эти результаты при коммерциализации очень сложно. Это как спроектировать самую роскошную, красивую и грандиозную кухню, а затем пытаться втиснуть ее в маленькую квартиру. Или создать самый быстрый, самый мощный двигатель и пытаться втиснуть его в малолитражку. Это просто не работает.
b. Поэтому цель Китая — не строить самый дорогой в мире AGI, а
1) создавать фундаментальные модели, обеспечивающие экономически эффективный вывод
2) Печь как пирожки всевозможные коммерческие приложения с разговорным и делегирующим интерфейсом.
PS Про термин AGI спорить нет смысла.
Речь об ИИ (уровня гениальных людей) на основе моделей, настолько же мощнее GPT-4 (уровень старшеклассника), насколько GPT-4 мощнее GPT-2 (уровень детсадовца). И на это до 2030 ресурсов и денег хватит. А про сознание, квалиа и прочую казуистику в контексте AGI – забейте.
#ИИгонка #AGI #Китай #США