
По сути, Microsoft показал, что AGI уже здесь.
Поверить в это трудно, но придется.
Новое исследование топовой команды ученых из Microsoft во главе с самим Эриком Хорвиц, (главный научный сотрудник Microsoft) показало 3 сенсационных результата.
1. Нынешняя версия GPT-4 таит в себе колоссальные «глубинные знания», не уступающие уровню знаний экспертов – людей в широком круге проблемных областей (т.е. с учетом многозначности определений AGI, не будет сильным преувеличением сказать, что GPT-4 уже практически достиг уровня AGI).
2. Эти «глубинные знания» прячутся где-то внутри базовой большой языковой модели, лежащей в основе GPT-4. Т.е. они получены моделью на этапе ее обучения, без каких-либо вмешательств со стороны людей (специальной дополнительной тонкой настройки или опоры на экспертные знания специалистов при создании подсказок).
3. Получить доступ к «глубинным знаниям» модели можно, если поручить самой модели промпт-инжиниринг (разработку подсказок) для самой себя, с использованием методов:
- «обучения в контексте»,
- составления «цепочек мыслей»,
- «сборки» (объединение результатов нескольких прогонов модели для получения более надежных и точных результатов, объединяя их с помощью таких функций, как усреднение, консенсус, или большинство голосов).
В результате получения доступа к «глубинным знаниям» модели, «обычный» GPT-4:
• без какой-либо тонкой настройки на спецданных и без подсказок профессиональных экспертов-медиков,
• а лишь за счет высокоэффективной и действенной стратегии подсказок, разработанных самим интеллектом GPT-4 (эта методика названа авторами Medprompt), -
обнаружил в себе значительные резервы для усиления специализированной производительности.
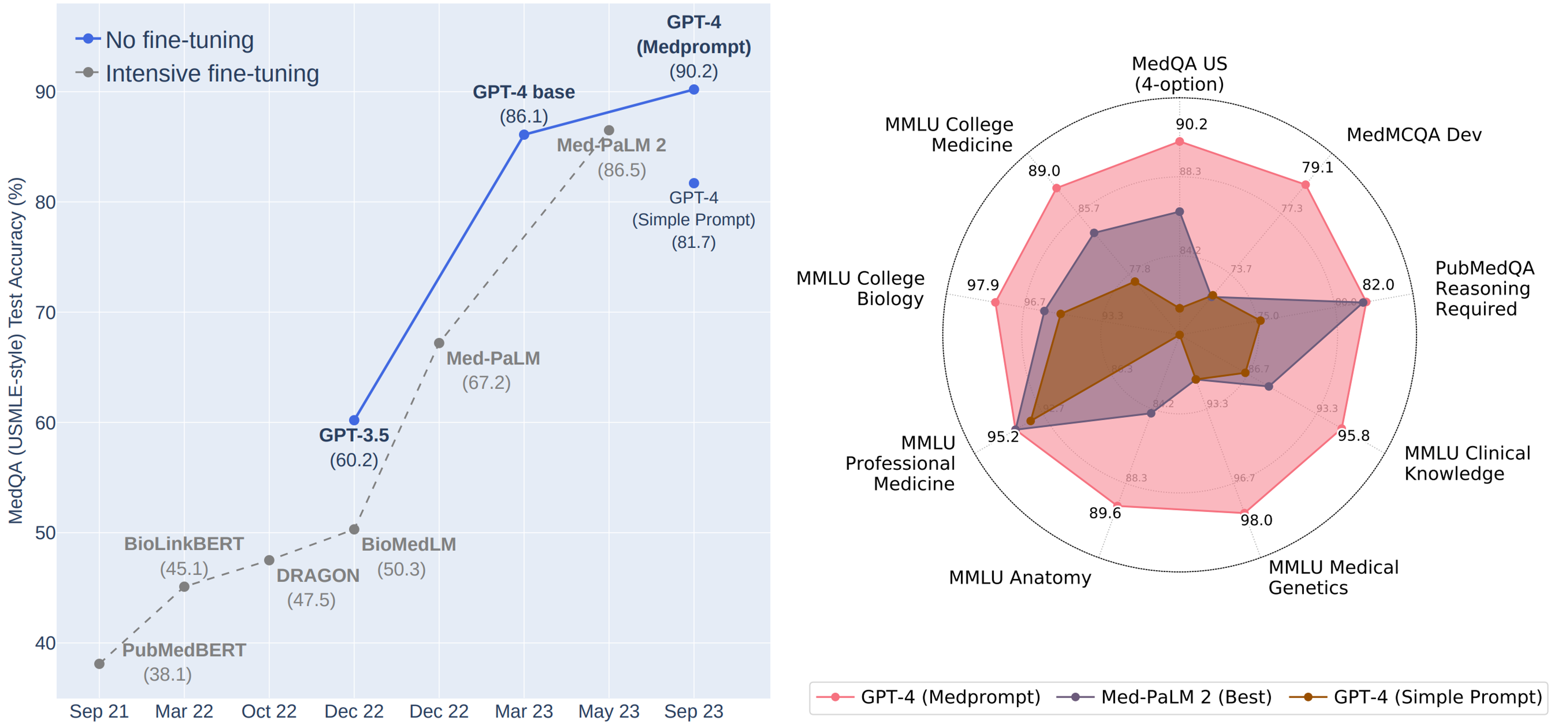
В итоге, GPT-4 с Medprompt:
✔️ Впервые превысил 90% по набору данных MedQA
✔️ Достиг лучших результатов по всем девяти наборам эталонных данных в пакете MultiMedQA.
✔️ Снизил частоту ошибок в MedQA на 27% по сравнению с MedPaLM 2 (до сих пор бывшая лучшей в мире специально настроенная медицинская модель от Google)
См. рисунок https://www.microsoft.com/en-us/research/uploads/prod/2023/11/joint_medprompt_v1.png
Медициной дело не ограничилось.
Для проверки универсальности Medprompt, авторы провели исследования его эффективности на наборах оценок компетентности в шести областях, не связанных с медициной, включая электротехнику, машинное обучение, философию, бухгалтерский учет, юриспруденцию, сестринское дело и клиническую психологию.
Результаты показали – Medprompt эффективно работает во всех названных областях.
Понимаю, что многие скажут – это еще не AGI, - и заведут старую шарманку про стохастических попугаев.
Мне же кажется, что даже если это еще не AGI, то нечто предельно близкое к нему.
https://www.microsoft.com/en-us/research/blog/the-power-of-prompting/
#AGI
Поверить в это трудно, но придется.
Новое исследование топовой команды ученых из Microsoft во главе с самим Эриком Хорвиц, (главный научный сотрудник Microsoft) показало 3 сенсационных результата.
1. Нынешняя версия GPT-4 таит в себе колоссальные «глубинные знания», не уступающие уровню знаний экспертов – людей в широком круге проблемных областей (т.е. с учетом многозначности определений AGI, не будет сильным преувеличением сказать, что GPT-4 уже практически достиг уровня AGI).
2. Эти «глубинные знания» прячутся где-то внутри базовой большой языковой модели, лежащей в основе GPT-4. Т.е. они получены моделью на этапе ее обучения, без каких-либо вмешательств со стороны людей (специальной дополнительной тонкой настройки или опоры на экспертные знания специалистов при создании подсказок).
3. Получить доступ к «глубинным знаниям» модели можно, если поручить самой модели промпт-инжиниринг (разработку подсказок) для самой себя, с использованием методов:
- «обучения в контексте»,
- составления «цепочек мыслей»,
- «сборки» (объединение результатов нескольких прогонов модели для получения более надежных и точных результатов, объединяя их с помощью таких функций, как усреднение, консенсус, или большинство голосов).
В результате получения доступа к «глубинным знаниям» модели, «обычный» GPT-4:
• без какой-либо тонкой настройки на спецданных и без подсказок профессиональных экспертов-медиков,
• а лишь за счет высокоэффективной и действенной стратегии подсказок, разработанных самим интеллектом GPT-4 (эта методика названа авторами Medprompt), -
обнаружил в себе значительные резервы для усиления специализированной производительности.
В итоге, GPT-4 с Medprompt:
✔️ Впервые превысил 90% по набору данных MedQA
✔️ Достиг лучших результатов по всем девяти наборам эталонных данных в пакете MultiMedQA.
✔️ Снизил частоту ошибок в MedQA на 27% по сравнению с MedPaLM 2 (до сих пор бывшая лучшей в мире специально настроенная медицинская модель от Google)
См. рисунок https://www.microsoft.com/en-us/research/uploads/prod/2023/11/joint_medprompt_v1.png
Медициной дело не ограничилось.
Для проверки универсальности Medprompt, авторы провели исследования его эффективности на наборах оценок компетентности в шести областях, не связанных с медициной, включая электротехнику, машинное обучение, философию, бухгалтерский учет, юриспруденцию, сестринское дело и клиническую психологию.
Результаты показали – Medprompt эффективно работает во всех названных областях.
Понимаю, что многие скажут – это еще не AGI, - и заведут старую шарманку про стохастических попугаев.
Мне же кажется, что даже если это еще не AGI, то нечто предельно близкое к нему.
https://www.microsoft.com/en-us/research/blog/the-power-of-prompting/
#AGI
{kind=link}
Google DeepMind сумела запустить когнитивную эволюцию роботов
Это может открыть путь к гибридному обществу людей и андроидов
1я ноябрьская ИИ-революция (Революция ChatGPT) началась год назад - в ноябре 2022. Она ознаменовала появление на планете нового носителя высшего интеллекта — цифрового ИИ, способного достичь (и, возможно, превзойти) людей в любых видах интеллектуальной деятельности.
Но не смотря на сравнимый с людьми уровень, этот новый носитель высшего интеллекта оказался абсолютно нечеловекоподобным.
Он принадлежит к классу генеративного ИИ больших языковых моделей, не умеющих (и в принципе не способных) не то что мечтать об электроовцах, но и просто мыслить и познавать мир, как это делают люди. И потому, даже превзойдя по уровню людей, он так и останется для человечества «чужим» — иным типом интеллекта, столь же непостижимым для понимания, как интеллект квинтян из романа Станислава Лема «Фиаско».
Причина нечеловекоподобия генеративных ИИ больших языковых моделей заключается в их кардинально иной природе.
✔️ Наш интеллект – результат миллионов лет когнитивной эволюции биологических интеллектуальных агентов, позволившей людям из животных превратиться в сверхразумные существа, построивших на Земле цивилизацию планетарного уровня, начавшую освоение космоса.
✔️ ИИ больших языковых моделей – продукт машинного обучения компьютерных программ на колоссальных объемах цифровых данных.
Преодолеть это принципиальное отличие можно, если найти ключ к запуску когнитивной эволюции ИИ.
И этот ключ предложен в ноябре 2023 инициаторами 2й ноябрьской ИИ-революции (Революции когнитивной эволюции ИИ) в опубликованном журналом Nature исследовании Google DeepMind.
• Движком когнитивной эволюции ИИ авторы предлагают сделать (как и у людей) социальное обучение — когда один интеллектуальный агент (человек, животное или ИИ) приобретает навыки и знания у другого путем копирования (жизненно важного для процесса развития интеллектуальных агентов).
• Ища вдохновение в социальном обучении людей, исследователи стремились найти способ, позволяющий агентам ИИ учиться у других агентов ИИ и у людей с эффективностью, сравнимой с человеческим социальным обучением.
• Команде исследователей удалось использовать обучение с подкреплением для обучения агента ИИ, способного идентифицировать новых для себя экспертов (среди других агентов ИИ и людей), имитировать их поведение и запоминать полученные знания в течение всего нескольких минут.
"Наши агенты успешно имитируют человека в реальном времени в новых контекстах, не используя никаких предварительно собранных людьми данных. Мы определили удивительно простой набор ингредиентов, достаточный для культурной передачи, и разработали эволюционную методологию для ее систематической оценки. Это открывает путь к тому, чтобы культурная эволюция играла алгоритмическую роль в развитии искусственного общего интеллекта", - говорится в исследовании.
Запуск когнитивной эволюции ИИ позволит не только создать «человекоподобный ИИ» у роботов – андроидов, но и разрешить при их создании Парадокс Моравека (высококогнитивные процессы требуют относительно мало вычислений, а низкоуровневые сенсомоторные операции требуют огромных вычислительных ресурсов) и Сверхзадачу Минского (произвести обратную разработку навыков, получаемых в процессе передачи неявных знаний - невербализованных и, часто, бессознательных)
Т.о. не будет большим преувеличением сказать, что 2я ноябрьская революция ИИ открывает путь к гибридному обществу людей и андроидов, – многократно описанному в фантастических романах, но до сих пор остававшемуся практически нереализуемым на ближнем временном горизонте.
Подробный разбор вопросов когнитивной эволюции путем копирования, а также революционного подхода к ее запуску, предложенного Google DeepMind, см. в моем новом лонгриде (еще 10 мин чтения):
- на Medium https://bit.ly/486AfEN
- на Дзене https://clck.ru/36wWQc
#ИИ #Интеллект #Разум #Эволюция #Культура #АлгокогнитивнаяКультура #Роботы
Это может открыть путь к гибридному обществу людей и андроидов
1я ноябрьская ИИ-революция (Революция ChatGPT) началась год назад - в ноябре 2022. Она ознаменовала появление на планете нового носителя высшего интеллекта — цифрового ИИ, способного достичь (и, возможно, превзойти) людей в любых видах интеллектуальной деятельности.
Но не смотря на сравнимый с людьми уровень, этот новый носитель высшего интеллекта оказался абсолютно нечеловекоподобным.
Он принадлежит к классу генеративного ИИ больших языковых моделей, не умеющих (и в принципе не способных) не то что мечтать об электроовцах, но и просто мыслить и познавать мир, как это делают люди. И потому, даже превзойдя по уровню людей, он так и останется для человечества «чужим» — иным типом интеллекта, столь же непостижимым для понимания, как интеллект квинтян из романа Станислава Лема «Фиаско».
Причина нечеловекоподобия генеративных ИИ больших языковых моделей заключается в их кардинально иной природе.
✔️ Наш интеллект – результат миллионов лет когнитивной эволюции биологических интеллектуальных агентов, позволившей людям из животных превратиться в сверхразумные существа, построивших на Земле цивилизацию планетарного уровня, начавшую освоение космоса.
✔️ ИИ больших языковых моделей – продукт машинного обучения компьютерных программ на колоссальных объемах цифровых данных.
Преодолеть это принципиальное отличие можно, если найти ключ к запуску когнитивной эволюции ИИ.
И этот ключ предложен в ноябре 2023 инициаторами 2й ноябрьской ИИ-революции (Революции когнитивной эволюции ИИ) в опубликованном журналом Nature исследовании Google DeepMind.
• Движком когнитивной эволюции ИИ авторы предлагают сделать (как и у людей) социальное обучение — когда один интеллектуальный агент (человек, животное или ИИ) приобретает навыки и знания у другого путем копирования (жизненно важного для процесса развития интеллектуальных агентов).
• Ища вдохновение в социальном обучении людей, исследователи стремились найти способ, позволяющий агентам ИИ учиться у других агентов ИИ и у людей с эффективностью, сравнимой с человеческим социальным обучением.
• Команде исследователей удалось использовать обучение с подкреплением для обучения агента ИИ, способного идентифицировать новых для себя экспертов (среди других агентов ИИ и людей), имитировать их поведение и запоминать полученные знания в течение всего нескольких минут.
"Наши агенты успешно имитируют человека в реальном времени в новых контекстах, не используя никаких предварительно собранных людьми данных. Мы определили удивительно простой набор ингредиентов, достаточный для культурной передачи, и разработали эволюционную методологию для ее систематической оценки. Это открывает путь к тому, чтобы культурная эволюция играла алгоритмическую роль в развитии искусственного общего интеллекта", - говорится в исследовании.
Запуск когнитивной эволюции ИИ позволит не только создать «человекоподобный ИИ» у роботов – андроидов, но и разрешить при их создании Парадокс Моравека (высококогнитивные процессы требуют относительно мало вычислений, а низкоуровневые сенсомоторные операции требуют огромных вычислительных ресурсов) и Сверхзадачу Минского (произвести обратную разработку навыков, получаемых в процессе передачи неявных знаний - невербализованных и, часто, бессознательных)
Т.о. не будет большим преувеличением сказать, что 2я ноябрьская революция ИИ открывает путь к гибридному обществу людей и андроидов, – многократно описанному в фантастических романах, но до сих пор остававшемуся практически нереализуемым на ближнем временном горизонте.
Подробный разбор вопросов когнитивной эволюции путем копирования, а также революционного подхода к ее запуску, предложенного Google DeepMind, см. в моем новом лонгриде (еще 10 мин чтения):
- на Medium https://bit.ly/486AfEN
- на Дзене https://clck.ru/36wWQc
#ИИ #Интеллект #Разум #Эволюция #Культура #АлгокогнитивнаяКультура #Роботы
Medium
Google DeepMind сумела запустить когнитивную эволюцию роботов
Это может открыть путь к гибридному обществу людей и андроидов
Мир стал другим.
Сложилось альтернативное понимание истины и честности.
В мире уже не первый год устойчиво крепчает тренд на безумие. Он все ярче проявляется и в деградации внешней политики многих стран (стремительно скатывающейся к дегенерации), и в нарастающем пожаре раскола и поляризации внутри отдельных стран, безумно поливаемом бензином действий их политиков и элит.
https://media.springernature.com/lw685/springer-static/image/art%3A10.1038%2Fs41562-023-01691-w/MediaObjects/41562_2023_1691_Fig1_HTML.png?as=webp
Год назад я анализировал вопрос о том, «кто более виновен в происходящем безумии - элита или народ» [1], на основе прямого измерения цифровых следов людей в Интернете, проведенного проф. Рэнд и Мослех в работе «Измерение подверженности мисинформации со стороны политических элит в Twitter». Измеряя показатели «токсичности лжи» 816-ти представителей элиты и «иммунитета к мисинформации» у их подписчиков, авторы выявили сложную связку отношений элита-народ:
• лидеры слабо реагируют на отношение народа к сказанному ими;
• риторика элиты определяет убеждения и политические позиции народа;
• чем лживее представитель элиты, тем сильнее снижается у его подписчиков иммунитет к мисинформации, что упрощает ему убеждение их в еще большей лжи.
Новое исследование междисциплинарной группы исследователей (психологи, когнитивисты, спецы по компьютерной симуляции и вычислительной социологии) «От альтернативных концепций честности к альтернативным фактам в коммуникациях политиков США» [2] продвигает нас в понимании общественного и политического мироустройства в эпоху постправды.
В работе анализируются способы воздействия дезинформации, распространяемой в целях заставить людей изменить свое поведение. Авторы копаю глубже примитивного навешивания ярлыков: правда-ложь, факт-фейк и т.п. Они пытаются выделить в публичной политической речи выборных должностных лиц США два компонента правды и честности — высказывание убеждений и изложение фактов.
Такой подход основан на онтологии политической истины, включающей две различные концепции истины:
• Высказывание убеждений относится только к убеждениям, мыслям и чувствам говорящего, без учета фактической точности. Эта концепция основана на интуиции, субъективных впечатлениях и чувствах.
• Изложение фактов, напротив, связано с поиском точной информации и обновлением своих убеждений на основе этой информации. Эта концепция истины основана на фактических данных.
N.B. Хотя истина и честность являются тесно связанными понятиями, а честность и правдивость являются почти синонимами, в данном контексте их необходимо распутать для ясности.
Анализируя сообщения членов Конгресса США в Твиттере в период с 2011 по 2022 год, авторы показали следующее:
1. Концепция честности политиков претерпела явный сдвиг: высказывания подлинных убеждений, которые могут быть отделены от доказательств, становятся все более заметными и более дифференцированными от явно основанного на доказательствах изложения фактов.
2. Представление политиков о честности претерпели явные изменения, при этом высказывание подлинных убеждений, которые могут быть отделены от доказательств, становятся более заметными и более дифференцированными от явно основанных на фактах высказываний.
3. Для республиканцев (но не для демократов) повышение уровня веры к высказыванию на 10% связано со снижением на 12,8 пункта качества источников (по системе оценки NewsGuard), которыми поделились.
4. Напротив, увеличение числа говорящих на языке фактов связано с повышением качества источников для обеих сторон.
Эти результаты согласуются с гипотезой о том,
что нынешнее распространение дезинформации в политическом дискурсе связано с укреплением альтернативного понимания истины и честности, которое делает акцент на использовании субъективных убеждений в ущерб уверенности в доказательствах.
1 https://t.iss.one/theworldisnoteasy/1644
2 https://www.nature.com/articles/s41562-023-01691-w
#Мисинформация #Элита #Раскол
Сложилось альтернативное понимание истины и честности.
В мире уже не первый год устойчиво крепчает тренд на безумие. Он все ярче проявляется и в деградации внешней политики многих стран (стремительно скатывающейся к дегенерации), и в нарастающем пожаре раскола и поляризации внутри отдельных стран, безумно поливаемом бензином действий их политиков и элит.
https://media.springernature.com/lw685/springer-static/image/art%3A10.1038%2Fs41562-023-01691-w/MediaObjects/41562_2023_1691_Fig1_HTML.png?as=webp
Год назад я анализировал вопрос о том, «кто более виновен в происходящем безумии - элита или народ» [1], на основе прямого измерения цифровых следов людей в Интернете, проведенного проф. Рэнд и Мослех в работе «Измерение подверженности мисинформации со стороны политических элит в Twitter». Измеряя показатели «токсичности лжи» 816-ти представителей элиты и «иммунитета к мисинформации» у их подписчиков, авторы выявили сложную связку отношений элита-народ:
• лидеры слабо реагируют на отношение народа к сказанному ими;
• риторика элиты определяет убеждения и политические позиции народа;
• чем лживее представитель элиты, тем сильнее снижается у его подписчиков иммунитет к мисинформации, что упрощает ему убеждение их в еще большей лжи.
Новое исследование междисциплинарной группы исследователей (психологи, когнитивисты, спецы по компьютерной симуляции и вычислительной социологии) «От альтернативных концепций честности к альтернативным фактам в коммуникациях политиков США» [2] продвигает нас в понимании общественного и политического мироустройства в эпоху постправды.
В работе анализируются способы воздействия дезинформации, распространяемой в целях заставить людей изменить свое поведение. Авторы копаю глубже примитивного навешивания ярлыков: правда-ложь, факт-фейк и т.п. Они пытаются выделить в публичной политической речи выборных должностных лиц США два компонента правды и честности — высказывание убеждений и изложение фактов.
Такой подход основан на онтологии политической истины, включающей две различные концепции истины:
• Высказывание убеждений относится только к убеждениям, мыслям и чувствам говорящего, без учета фактической точности. Эта концепция основана на интуиции, субъективных впечатлениях и чувствах.
• Изложение фактов, напротив, связано с поиском точной информации и обновлением своих убеждений на основе этой информации. Эта концепция истины основана на фактических данных.
N.B. Хотя истина и честность являются тесно связанными понятиями, а честность и правдивость являются почти синонимами, в данном контексте их необходимо распутать для ясности.
Анализируя сообщения членов Конгресса США в Твиттере в период с 2011 по 2022 год, авторы показали следующее:
1. Концепция честности политиков претерпела явный сдвиг: высказывания подлинных убеждений, которые могут быть отделены от доказательств, становятся все более заметными и более дифференцированными от явно основанного на доказательствах изложения фактов.
2. Представление политиков о честности претерпели явные изменения, при этом высказывание подлинных убеждений, которые могут быть отделены от доказательств, становятся более заметными и более дифференцированными от явно основанных на фактах высказываний.
3. Для республиканцев (но не для демократов) повышение уровня веры к высказыванию на 10% связано со снижением на 12,8 пункта качества источников (по системе оценки NewsGuard), которыми поделились.
4. Напротив, увеличение числа говорящих на языке фактов связано с повышением качества источников для обеих сторон.
Эти результаты согласуются с гипотезой о том,
что нынешнее распространение дезинформации в политическом дискурсе связано с укреплением альтернативного понимания истины и честности, которое делает акцент на использовании субъективных убеждений в ущерб уверенности в доказательствах.
1 https://t.iss.one/theworldisnoteasy/1644
2 https://www.nature.com/articles/s41562-023-01691-w
#Мисинформация #Элита #Раскол
{kind=link}
Стохастический попугай умер. Да здравствуют близнецы Homo sapiens!
О запуске ИИ от Google, названном его авторами Gemini (близнецы), в ближайшие 10 дней будут писать все мировые СМИ. Разборы и оценки способностей Gemini последуют ото всех профессиональных аналитиков и диванных экспертов. Диапазон этих оценок будет велик и, зачастую, полярен.
Но самое главное, в чем каждый из вас может убедиться сам, посмотрев лишь 5 мин этого видео [1]:
1) Gemini похоронил все разговоры о стохастическом попугае больших языковых моделей, экспериментально доказывая, что он понимает наш мир.
2) Gemini – это не только мультимодальная модель, которая понимает тексты, программный код, изображения, аудио и видео.
Gemini – это близнец Homo sapiens, подобно людям обладающий единой мультисенсорной моделью для понимания окружающего мира.
3) И да – это уже AGI (если, конечно, мы не отвергаем наличия «общего интеллекта» у детей)
[1] https://youtu.be/-a6E-r8W2Bs?t=312
#AGI
О запуске ИИ от Google, названном его авторами Gemini (близнецы), в ближайшие 10 дней будут писать все мировые СМИ. Разборы и оценки способностей Gemini последуют ото всех профессиональных аналитиков и диванных экспертов. Диапазон этих оценок будет велик и, зачастую, полярен.
Но самое главное, в чем каждый из вас может убедиться сам, посмотрев лишь 5 мин этого видео [1]:
1) Gemini похоронил все разговоры о стохастическом попугае больших языковых моделей, экспериментально доказывая, что он понимает наш мир.
2) Gemini – это не только мультимодальная модель, которая понимает тексты, программный код, изображения, аудио и видео.
Gemini – это близнец Homo sapiens, подобно людям обладающий единой мультисенсорной моделью для понимания окружающего мира.
3) И да – это уже AGI (если, конечно, мы не отвергаем наличия «общего интеллекта» у детей)
[1] https://youtu.be/-a6E-r8W2Bs?t=312
#AGI
Внутри маскирующегося под стохастического попугая ИИ таится куда боле мощный ИИ.
Эксперимент показал - у больших моделей есть воображение.
Анализ 3х работ OpenAI, Anthropic и Google DeepMind навевает ассоциации с леденящим душу технокошмаром из серии фильмов ужасов «Чужой».
Точнее, с их облегченной версией, - где «чужой» может оказаться злым монстром, а может и нет. Но сам факт, что внутри некоего интеллектуального техно-артефакта может скрываться нечто куда более умное (и кто знает, может, и куда более опасное), сильно напрягает.
1) Еще в мае исследователи из OpenAI решили попытаться «заглянуть в душу» ИИ (точнее называть это «большой языковой моделью - LLM», но ИИ короче и понятней). Исследователи подошли к решению задачи «черного ящика» ИИ (понять, что у него внутри) супер-креативно.
Зачем самим ломать голову, решая неподъемную для людей задачу. Пусть большой ИИ (GPT-4 с числом нейроном 100+ млрд) сам ее и решит применительно к маленькому ИИ (GPT-2, в коем нейронов всего то 300К+) [1].
Результат озадачил исследователей. Многие нейроны (внутри маленького ИИ) оказались многозначны – т.е. они реагировали на множество самых разных входных данных: смесь академических цитат, диалогов на английском языке, HTTP-запросов, корейского текста …
Эта многозначность нейронов человеческой логике не понятна и ею не объятна. Если нейроны многозначны, какие же тогда более мелкие «субнейроны» соответствуют конкретным понятиям?
2) Ответ на этот вопрос дают исследователи из Anthropic [2]. Они полагают, что одной из причин многозначности является суперпозиция - гипотетическое явление, при котором нейронная сеть представляет больше независимых «функций» данных, чем нейроны, назначая каждой функции свою собственную линейную комбинацию нейронов.
Иными словами, внутри нейронной сети любого конкретного ИИ симулируется физически не существующая нейронная сеть некоего абстрактного ИИ.
И эта симулируемая нейронная сеть,
1. гораздо больше и сложнее нейронной сети, ее моделирующей;
2. содержит симулируемые моносемантические «субнейроны» (соответствующие конкретным понятиям);
Еще проще говоря: внутри менее мощного ИИ симулируется более мощный ИИ. Менее мощный ИИ физически существует в виде сети нейронов. Более мощный – в виде сети паттернов (линейных комбинаций) активаций нейронов.
3) Почувствовать на практике, сколь мощный ИИ таится внутри маскирующегося под «стохастического попугая» ИИ LLM, позволяет новое исследование Главного научного сотрудника Google DeepMind проф. Шанахана и директора CHPPC_IHR проф. Кларк [3].
Объектом исследования стало якобы отсутствующее у LLM свойство разума, без которого невозможно истинное творчество – воображение.
Эйнштейн писал - “Воображение важнее знаний. Ибо знания ограничены всем, что мы сейчас знаем и понимаем, в то время как воображение охватывает весь мир и все, что когда-либо можно будет узнать и понять”.
Эксперимент Шанахана-Кларк заключался в проверке наличия у GPT-4 воображения, позволяющего модели проявлять художественную креативность при написании (в соавторстве с человеком) литературного текста - фантастического романа о путешествии во времени.
Эксперимент показал:
✔️ при наличии сложных подсказок и соавтора-человека, модель демонстрирует изысканное воображение;
✔️ это продукт творчества модели, ибо ничего подобного люди до нее не придумали (этого не было в каких-либо текстах людей): например, появляющиеся по ходу романа придуманные моделью:
- новые персонажи и сюжетные повороты;
- новые неологизмы (прямо как у Солженицина), служащие для раскрытия идейного содержания сюжета - отнюдь не бессмысленные, семантически верные и контекстуально релевантные.
Значение вышеописанного см. в моем цикле “теория относительности интеллекта”.
#Креативность #Воображение #LLM
[1] https://openai.com/research/language-models-can-explain-neurons-in-language-models
[2] https://transformer-circuits.pub/2023/monosemantic-features
[3] https://arxiv.org/abs/2312.03746
Эксперимент показал - у больших моделей есть воображение.
Анализ 3х работ OpenAI, Anthropic и Google DeepMind навевает ассоциации с леденящим душу технокошмаром из серии фильмов ужасов «Чужой».
Точнее, с их облегченной версией, - где «чужой» может оказаться злым монстром, а может и нет. Но сам факт, что внутри некоего интеллектуального техно-артефакта может скрываться нечто куда более умное (и кто знает, может, и куда более опасное), сильно напрягает.
1) Еще в мае исследователи из OpenAI решили попытаться «заглянуть в душу» ИИ (точнее называть это «большой языковой моделью - LLM», но ИИ короче и понятней). Исследователи подошли к решению задачи «черного ящика» ИИ (понять, что у него внутри) супер-креативно.
Зачем самим ломать голову, решая неподъемную для людей задачу. Пусть большой ИИ (GPT-4 с числом нейроном 100+ млрд) сам ее и решит применительно к маленькому ИИ (GPT-2, в коем нейронов всего то 300К+) [1].
Результат озадачил исследователей. Многие нейроны (внутри маленького ИИ) оказались многозначны – т.е. они реагировали на множество самых разных входных данных: смесь академических цитат, диалогов на английском языке, HTTP-запросов, корейского текста …
Эта многозначность нейронов человеческой логике не понятна и ею не объятна. Если нейроны многозначны, какие же тогда более мелкие «субнейроны» соответствуют конкретным понятиям?
2) Ответ на этот вопрос дают исследователи из Anthropic [2]. Они полагают, что одной из причин многозначности является суперпозиция - гипотетическое явление, при котором нейронная сеть представляет больше независимых «функций» данных, чем нейроны, назначая каждой функции свою собственную линейную комбинацию нейронов.
Иными словами, внутри нейронной сети любого конкретного ИИ симулируется физически не существующая нейронная сеть некоего абстрактного ИИ.
И эта симулируемая нейронная сеть,
1. гораздо больше и сложнее нейронной сети, ее моделирующей;
2. содержит симулируемые моносемантические «субнейроны» (соответствующие конкретным понятиям);
Еще проще говоря: внутри менее мощного ИИ симулируется более мощный ИИ. Менее мощный ИИ физически существует в виде сети нейронов. Более мощный – в виде сети паттернов (линейных комбинаций) активаций нейронов.
3) Почувствовать на практике, сколь мощный ИИ таится внутри маскирующегося под «стохастического попугая» ИИ LLM, позволяет новое исследование Главного научного сотрудника Google DeepMind проф. Шанахана и директора CHPPC_IHR проф. Кларк [3].
Объектом исследования стало якобы отсутствующее у LLM свойство разума, без которого невозможно истинное творчество – воображение.
Эйнштейн писал - “Воображение важнее знаний. Ибо знания ограничены всем, что мы сейчас знаем и понимаем, в то время как воображение охватывает весь мир и все, что когда-либо можно будет узнать и понять”.
Эксперимент Шанахана-Кларк заключался в проверке наличия у GPT-4 воображения, позволяющего модели проявлять художественную креативность при написании (в соавторстве с человеком) литературного текста - фантастического романа о путешествии во времени.
Эксперимент показал:
✔️ при наличии сложных подсказок и соавтора-человека, модель демонстрирует изысканное воображение;
✔️ это продукт творчества модели, ибо ничего подобного люди до нее не придумали (этого не было в каких-либо текстах людей): например, появляющиеся по ходу романа придуманные моделью:
- новые персонажи и сюжетные повороты;
- новые неологизмы (прямо как у Солженицина), служащие для раскрытия идейного содержания сюжета - отнюдь не бессмысленные, семантически верные и контекстуально релевантные.
Значение вышеописанного см. в моем цикле “теория относительности интеллекта”.
#Креативность #Воображение #LLM
[1] https://openai.com/research/language-models-can-explain-neurons-in-language-models
[2] https://transformer-circuits.pub/2023/monosemantic-features
[3] https://arxiv.org/abs/2312.03746
Openai
Language models can explain neurons in language models
We use GPT-4 to automatically write explanations for the behavior of neurons in large language models and to score those explanations. We release a dataset of these (imperfect) explanations and scores for every neuron in GPT-2.
This media is not supported in your browser
VIEW IN TELEGRAM
Взгляните на этот веселый Deep Fake от @yurii_yeltsov.
Трудно придумать более наглядную иллюстрацию двух топовых прогнозов отчета State of AI Report на 2024 год (см. https://t.iss.one/theworldisnoteasy/1823):
1. В Голливуде произойдет технологическая революция в области создания визуальных эффектов – весь процесс будет отдан на откуп ГенИИ.
2. Начнется первое в истории расследование вмешательства ГенИИ известного на весь мир производителя в предвыборную президентскую кампанию в США.
Описывая мир победившего к 2041 году ИИ, легендарный визионер, техно-инвестор и стратег Кай-Фу Ли предвидит, что главным инструментом власти и криминала станет не насилие, а ИИ технология DeepMask - преемник сегодняшних DeepFake (см. https://t.iss.one/theworldisnoteasy/1349).
Полагаю, что мой старый коллега по SGI ошибся лишь в одном – это случится гораздо раньше.
#Deepfakes
Трудно придумать более наглядную иллюстрацию двух топовых прогнозов отчета State of AI Report на 2024 год (см. https://t.iss.one/theworldisnoteasy/1823):
1. В Голливуде произойдет технологическая революция в области создания визуальных эффектов – весь процесс будет отдан на откуп ГенИИ.
2. Начнется первое в истории расследование вмешательства ГенИИ известного на весь мир производителя в предвыборную президентскую кампанию в США.
Описывая мир победившего к 2041 году ИИ, легендарный визионер, техно-инвестор и стратег Кай-Фу Ли предвидит, что главным инструментом власти и криминала станет не насилие, а ИИ технология DeepMask - преемник сегодняшних DeepFake (см. https://t.iss.one/theworldisnoteasy/1349).
Полагаю, что мой старый коллега по SGI ошибся лишь в одном – это случится гораздо раньше.
#Deepfakes
“Generation I” дорого платит за перепрошивку когнитивных гаджетов.
Беспрецедентное падение знаний и навыков чтения, математики и естественных наук у подростков всего мира в 2012-2023.
https://disk.yandex.ru/i/5qaob6dNK3KuyA
В посте «Куда ведет «великая перепрошивка» когнитивных гаджетов детей. Деформация интеллекта и эпидемия психических заболеваний уже начались» https://t.iss.one/theworldisnoteasy/1766 я рассказывал о развороте трендов успехов 13-летних американцев в чтении и математике. Оба тренда сломались в 2012 и теперь только ухудшаются.
Надежда, что может это только в США такой облом, продержалась не долго.
Только опубликованные результаты международной оценки у 15-летних учащихся всего мира (PISA) знаний и навыков по математике, чтению и естественным наукам (тесты проверяют, насколько хорошо учащиеся могут решать сложные проблемы, критически мыслить и эффективно общаться) подтвердили наихудшие опасения https://bit.ly/3RsZiei
• Беспрецедентное снижение показателей происходит по всему миру.
• По сравнению с 2018 годом средняя успеваемость снизилась на десять баллов по чтению и почти на 15 баллов по математике, что эквивалентно трем четвертям годового объема обучения.
• Снижение успеваемости по математике в три раза больше, чем любое предыдущее последовательное изменение. Фактически, в среднем по странам ОЭСР каждый четвертый 15-летний подросток в настоящее время считается плохо успевающим по математике, чтению и естественным наукам. Это означает, что им может быть трудно выполнять такие задачи, как использование базовых алгоритмов или интерпретация простых текстов.
Обвальное снижение показателей подростков по математике, чтению и естественным наукам (как и начало эпидемии психических заболеваний у детей) случилось в начале 2010-х. Примерно тогда же подростки всего мира стали массово менять свои примитивные сотовые телефоны на смартфоны, оснащенные приложениями для социальных сетей.
Гипотеза проф. психологии Джин Твенж о том, что смартфоны и тусение в соцсетях могут вести к деградации у “Generation I” https://bit.ly/3GJ68rc (поколение детей-инфоргов https://t.iss.one/theworldisnoteasy/1479) многих важных навыков, в 2017 многими была воспринята в штыки, как голимый алармизм.
К концу 2023 для многих становится очевидным, что Джин Твенж абсолютно права, ибо все 13 альтернативных объяснений происходящего с “Generation I” не выдерживают критического анализа (подробно здесь https://bit.ly/48ffBlM).
Джонатан Хайдт (социальный психолог NYU Stern School of Business) написал об этом так https://bit.ly/46WmfMQ:
«Джин подверглась резкой критике со стороны других исследователей, выдвигавших примерно такие версии: 1) с детьми все в порядке, это просто еще одна моральная паника, и 2) все это просто корреляции, нет никаких доказательств причинно-следственной связи явлений. Но сейчас, спустя шесть лет, уже нет сомнений, что детям сильно хуже, и есть множество причинно- следственных доказательств причастности смартфонов и социальных сетей. Джин была права».
А проф. Эрик Хоэл (американский нейробиолог и нейрофилософ, специализирующийся на изучении и философии познания и сознания) так описывает происходящее с ребенком-инфоргом, погруженным в цифровой мир https://bit.ly/3thli3Z.
«… он узнает, что физический мир животных, людей и мест действия - лишь одна из разновидностей мира. Все больше и больше реальный мир существует в виде крошечных прямоугольников - виртуальных "мест действия"… Его мир состоит из пикселей, постов, обновлений, лайков, а его действия - просто клики. Мы спроецировали всю нашу цивилизацию внутрь того, что в конечном счете является крошечным тесным пространством, если смотреть на него ясными глазами ребенка…Исход 21-го века будет очень сильно зависеть от того, смогут ли люди перед лицом великих технологических изменений отвергать наиболее вредные технологические "достижения".»
Проф. Хоэл прав. Ведь выживут только инфорги https://bit.ly/477rKIp
#Инфорги
Беспрецедентное падение знаний и навыков чтения, математики и естественных наук у подростков всего мира в 2012-2023.
https://disk.yandex.ru/i/5qaob6dNK3KuyA
В посте «Куда ведет «великая перепрошивка» когнитивных гаджетов детей. Деформация интеллекта и эпидемия психических заболеваний уже начались» https://t.iss.one/theworldisnoteasy/1766 я рассказывал о развороте трендов успехов 13-летних американцев в чтении и математике. Оба тренда сломались в 2012 и теперь только ухудшаются.
Надежда, что может это только в США такой облом, продержалась не долго.
Только опубликованные результаты международной оценки у 15-летних учащихся всего мира (PISA) знаний и навыков по математике, чтению и естественным наукам (тесты проверяют, насколько хорошо учащиеся могут решать сложные проблемы, критически мыслить и эффективно общаться) подтвердили наихудшие опасения https://bit.ly/3RsZiei
• Беспрецедентное снижение показателей происходит по всему миру.
• По сравнению с 2018 годом средняя успеваемость снизилась на десять баллов по чтению и почти на 15 баллов по математике, что эквивалентно трем четвертям годового объема обучения.
• Снижение успеваемости по математике в три раза больше, чем любое предыдущее последовательное изменение. Фактически, в среднем по странам ОЭСР каждый четвертый 15-летний подросток в настоящее время считается плохо успевающим по математике, чтению и естественным наукам. Это означает, что им может быть трудно выполнять такие задачи, как использование базовых алгоритмов или интерпретация простых текстов.
Обвальное снижение показателей подростков по математике, чтению и естественным наукам (как и начало эпидемии психических заболеваний у детей) случилось в начале 2010-х. Примерно тогда же подростки всего мира стали массово менять свои примитивные сотовые телефоны на смартфоны, оснащенные приложениями для социальных сетей.
Гипотеза проф. психологии Джин Твенж о том, что смартфоны и тусение в соцсетях могут вести к деградации у “Generation I” https://bit.ly/3GJ68rc (поколение детей-инфоргов https://t.iss.one/theworldisnoteasy/1479) многих важных навыков, в 2017 многими была воспринята в штыки, как голимый алармизм.
К концу 2023 для многих становится очевидным, что Джин Твенж абсолютно права, ибо все 13 альтернативных объяснений происходящего с “Generation I” не выдерживают критического анализа (подробно здесь https://bit.ly/48ffBlM).
Джонатан Хайдт (социальный психолог NYU Stern School of Business) написал об этом так https://bit.ly/46WmfMQ:
«Джин подверглась резкой критике со стороны других исследователей, выдвигавших примерно такие версии: 1) с детьми все в порядке, это просто еще одна моральная паника, и 2) все это просто корреляции, нет никаких доказательств причинно-следственной связи явлений. Но сейчас, спустя шесть лет, уже нет сомнений, что детям сильно хуже, и есть множество причинно- следственных доказательств причастности смартфонов и социальных сетей. Джин была права».
А проф. Эрик Хоэл (американский нейробиолог и нейрофилософ, специализирующийся на изучении и философии познания и сознания) так описывает происходящее с ребенком-инфоргом, погруженным в цифровой мир https://bit.ly/3thli3Z.
«… он узнает, что физический мир животных, людей и мест действия - лишь одна из разновидностей мира. Все больше и больше реальный мир существует в виде крошечных прямоугольников - виртуальных "мест действия"… Его мир состоит из пикселей, постов, обновлений, лайков, а его действия - просто клики. Мы спроецировали всю нашу цивилизацию внутрь того, что в конечном счете является крошечным тесным пространством, если смотреть на него ясными глазами ребенка…Исход 21-го века будет очень сильно зависеть от того, смогут ли люди перед лицом великих технологических изменений отвергать наиболее вредные технологические "достижения".»
Проф. Хоэл прав. Ведь выживут только инфорги https://bit.ly/477rKIp
#Инфорги
Яндекс Диск
PISA test.jpg
Посмотреть и скачать с Яндекс Диска
ИИ вскрыл “пространство открытий” человечества, войдя туда через заднюю дверь.
Столь эпохальный прорыв Google DeepMind авторы от греха опасаются называть своим именем.
FunSearch от Google DeepMind, - скромно представленная создателями, как новый эволюционный методический инструмент решения математических задач, с ходу в карьер сделал математическое открытие, решив центральную задачу экстремальной комбинаторики – задачу о наборе предельных значений.
Это несомненная сенсация, поскольку:
• это 2-е в истории человечества математическое открытие, сделанное машиной (1-е открытие также сделал DeepMind, создав в 2022 AlphaTensor (агент в стиле AlphaZero), который обнаружил превосходящие человеческие алгоритмы для выполнения таких задач, как умножение матриц)
• это 1-е в истории человечества математическое открытие, сделанное большой языковой моделью (LLM) – главным кандидатом на превращение в СуперИИ.
https://deepmind.google/discover/blog/funsearch-making-new-discoveries-in-mathematical-sciences-using-large-language-models/?utm_source=twitter&utm_medium=social
Однако, если называть вещи своими именами, - это не «еще одна сенсация», а суперсенсация, открывающая новую эру в развитии ИИ на основе LLM - эволюционный метод FunSearch позволяет расширять границы человеческих знаний.
✔️ Этот метод позволяет ИИ на основе LLM выходить за пределы знаний, предоставленных модели людьми на стадии ее обучения (и воплощенные, в результате обучения, в миллиарды и триллионы корреляций между словами).
✔️ Образно говоря, этот метод открывает для ИИ на основе LLM «дверь в пространство знаний», еще не познанных людьми.
✔️ Но это не обычная «дверь», через которую в это пространство попадают люди, совершая открытия. Это, своего рода, «задняя дверь», - не доступная людям, но вполне подходящая для LLM.
Хитрость «задней двери в пространство еще не познанных людьми знаний» в том, что, подобно всем другим интеллектуальным операциям LLM, эта операция нечеловеческая (не доступная людям в силу своих масштабов).
1. сначала предварительно обученная LLM генерирует первоначальные творческие решения в виде компьютерного кода;
2. потом вступает в дела «автоматический оценщик», задача которого отсеять из множества первоначальных решений любые подозрения на конфабуляции модели (кстати, использование применительно к LLM термина «галлюцинация» - это сильное огрубление смысла, ведущее к его ограниченной трактовке; верный термин – именно конфабуляция), т.е. возникновение ложного опыта из-за появления фрагментов памяти с описанием того, чего, на самом деле, не было в реальных данных обучения);
3. в результате объединения 1 и 2, первоначальные решения эволюционным путем «превращаются» в новые знания, т.е., по сути, происходит «автоматизация открытий», о которой вот уже несколько десятков лет мечтают разработчики ИИ - вычисления превращаются а оригинальные инсайты.
В заключение немного остужу восторги.
Это вовсе не преувеличение, что FunSearch знаменует новую эру в развитии ИИ на основе LLM, позволяя им проникать в «пространство открытий» человечества.
Однако, FunSearch позволяет ИИ попасть лишь в весьма небольшую часть этого пространства – в пространство решений задач, для которых легко написать код, оценивающий возможные решения.
Ибо многие из наиболее важных проблем — это проблемы, которые мы не знаем, как правильно оценить успех в их решении. Для большинства таких проблем, знай мы, как количественно оценить успех, уж решения то мы уж как-нибудь придумали бы.... (подробней про это я написал целый суперлонгрид «Ловушка Гудхарта» для ИИ https://t.iss.one/theworldisnoteasy/1830.
А для того, чтоб сравниться с людьми в полном освоении «пространства открытий», без интуитивной прозорливости ИИ не обойтись (впрочем, и про это я уже писал 😊 https://t.iss.one/theworldisnoteasy/1650).
#ИИ #AGI #Вызовы21века #инновации #серендипность
Столь эпохальный прорыв Google DeepMind авторы от греха опасаются называть своим именем.
FunSearch от Google DeepMind, - скромно представленная создателями, как новый эволюционный методический инструмент решения математических задач, с ходу в карьер сделал математическое открытие, решив центральную задачу экстремальной комбинаторики – задачу о наборе предельных значений.
Это несомненная сенсация, поскольку:
• это 2-е в истории человечества математическое открытие, сделанное машиной (1-е открытие также сделал DeepMind, создав в 2022 AlphaTensor (агент в стиле AlphaZero), который обнаружил превосходящие человеческие алгоритмы для выполнения таких задач, как умножение матриц)
• это 1-е в истории человечества математическое открытие, сделанное большой языковой моделью (LLM) – главным кандидатом на превращение в СуперИИ.
https://deepmind.google/discover/blog/funsearch-making-new-discoveries-in-mathematical-sciences-using-large-language-models/?utm_source=twitter&utm_medium=social
Однако, если называть вещи своими именами, - это не «еще одна сенсация», а суперсенсация, открывающая новую эру в развитии ИИ на основе LLM - эволюционный метод FunSearch позволяет расширять границы человеческих знаний.
✔️ Этот метод позволяет ИИ на основе LLM выходить за пределы знаний, предоставленных модели людьми на стадии ее обучения (и воплощенные, в результате обучения, в миллиарды и триллионы корреляций между словами).
✔️ Образно говоря, этот метод открывает для ИИ на основе LLM «дверь в пространство знаний», еще не познанных людьми.
✔️ Но это не обычная «дверь», через которую в это пространство попадают люди, совершая открытия. Это, своего рода, «задняя дверь», - не доступная людям, но вполне подходящая для LLM.
Хитрость «задней двери в пространство еще не познанных людьми знаний» в том, что, подобно всем другим интеллектуальным операциям LLM, эта операция нечеловеческая (не доступная людям в силу своих масштабов).
1. сначала предварительно обученная LLM генерирует первоначальные творческие решения в виде компьютерного кода;
2. потом вступает в дела «автоматический оценщик», задача которого отсеять из множества первоначальных решений любые подозрения на конфабуляции модели (кстати, использование применительно к LLM термина «галлюцинация» - это сильное огрубление смысла, ведущее к его ограниченной трактовке; верный термин – именно конфабуляция), т.е. возникновение ложного опыта из-за появления фрагментов памяти с описанием того, чего, на самом деле, не было в реальных данных обучения);
3. в результате объединения 1 и 2, первоначальные решения эволюционным путем «превращаются» в новые знания, т.е., по сути, происходит «автоматизация открытий», о которой вот уже несколько десятков лет мечтают разработчики ИИ - вычисления превращаются а оригинальные инсайты.
В заключение немного остужу восторги.
Это вовсе не преувеличение, что FunSearch знаменует новую эру в развитии ИИ на основе LLM, позволяя им проникать в «пространство открытий» человечества.
Однако, FunSearch позволяет ИИ попасть лишь в весьма небольшую часть этого пространства – в пространство решений задач, для которых легко написать код, оценивающий возможные решения.
Ибо многие из наиболее важных проблем — это проблемы, которые мы не знаем, как правильно оценить успех в их решении. Для большинства таких проблем, знай мы, как количественно оценить успех, уж решения то мы уж как-нибудь придумали бы.... (подробней про это я написал целый суперлонгрид «Ловушка Гудхарта» для ИИ https://t.iss.one/theworldisnoteasy/1830.
А для того, чтоб сравниться с людьми в полном освоении «пространства открытий», без интуитивной прозорливости ИИ не обойтись (впрочем, и про это я уже писал 😊 https://t.iss.one/theworldisnoteasy/1650).
#ИИ #AGI #Вызовы21века #инновации #серендипность
Google DeepMind
FunSearch: Making new discoveries in mathematical sciences using Large Language Models
We introduce FunSearch, a method for searching for “functions” written in computer code, and find new solutions in mathematics and computer science. FunSearch works by pairing a pre-trained LLM,...
Помимо “процессора” и “памяти”, в мозге людей есть “машина времени”.
Это альтернативная когнитивная сущность принципиально отличает нас от ИИ.
Опубликованное в Nature Neuroscience исследование Йельского университета – это холодный душ для исследователей генеративного ИИ, полагающихся на его, хотя бы частичный, антропоморфизм (мол, это что-то типа самолета, похожего на птицу, но летающего с неподвижными крыльями).
Ведь можно бесконечно спорить, понимает ли большая языковая модель или нет, мыслит ли она или нет, способна ли на волевое действие или нет …, ибо все эти понятия расплывчаты и эфемерны. И пока нет даже гипотез, как эти феномены инструментально анализировать.
И тут вдруг исследователи из Йеля выкатывают инструментальное исследования (фМРТ + распознавание паттернов с помощью машинного обучения), из которого следует, что:
• травматические воспоминания людей – это вовсе не их память, типа обычных веселых, грустных или нейтральных воспоминаний о прошлом опыте людей, как-то и где-то записанных в мозге, подобно ячейкам памяти компьютеров, откуда их можно считывать по требованию;
• травматические воспоминания об ужасах войны, пережитом насилии и прочих корежущих душу кошмарах – это натуральные флешбэки, заставляющие не только сознание человека, но и все его тело снова переноситься (как бы на машине времени) в прошлое и заново переживать всю ту же душевную и физическую боль;
• отсюда все страшные последствия ПТСР - панические атаки, агрессивность, уход в себя, деформация личности, - возникающие у страдающих ПТСР в результате все повторяющихся и повторяющихся душевных и физических мучений, от которых нет спасения (как от платка, что снова и снова подавали Фриде, пока ее не избавила от этого ПТСР Маргарита);
• в отличие от памяти, у этих флешбэков и механизм иной, и способ обработки: память обрабатывается в мозге гиппокампом, а травматические флешбэки - задней поясной извилиной (областью мозга, обычно связанной с обработкой мыслей); порождаемые памятью и травматическими флешбэками паттерны мозговой активности абсолютно разные.
Наличие этой своеобразной «машины времени» в мозге людей, заставляющей всю его отелесненную сущность (а не только то, что мы называем «душой») заново и заново переносить весь спектр когда-то пережитых мучений, - это какой-то садистический трюк, придуманный эволюцией.
Зачем ей нужен этот садизм, науке еще предстоит объяснить.
Однако, наличие у людей альтернативной памяти когнитивной сущности можно считать установленным. И это убедительный аргумент против попыток антропоморфизации когнитивных механизмов ИИ.
• Спектр когнитивных отличий ИИ от людей широк и, видимо, будет еще расширяться по результатам новых исследований.
• Но и единственного когнитивного подобия – владения нашим языком, - для ИИ будет, скорее всего, достаточно для достижения интеллектуально превосходства над людьми в широчайшем перечне областей.
Ибо, как писал Л.Витгенштейн, “язык - это «форма жизни»”… общая для людей и ИИ, - добавлю я от себя.
Подробней:
- популярно https://www.livescience.com/health/neuroscience/traumatic-memories-are-processed-differently-in-ptsd
- научно https://www.nature.com/articles/s41593-023-01483-5
#ИИ #Язык #LLM
Это альтернативная когнитивная сущность принципиально отличает нас от ИИ.
Опубликованное в Nature Neuroscience исследование Йельского университета – это холодный душ для исследователей генеративного ИИ, полагающихся на его, хотя бы частичный, антропоморфизм (мол, это что-то типа самолета, похожего на птицу, но летающего с неподвижными крыльями).
Ведь можно бесконечно спорить, понимает ли большая языковая модель или нет, мыслит ли она или нет, способна ли на волевое действие или нет …, ибо все эти понятия расплывчаты и эфемерны. И пока нет даже гипотез, как эти феномены инструментально анализировать.
И тут вдруг исследователи из Йеля выкатывают инструментальное исследования (фМРТ + распознавание паттернов с помощью машинного обучения), из которого следует, что:
• травматические воспоминания людей – это вовсе не их память, типа обычных веселых, грустных или нейтральных воспоминаний о прошлом опыте людей, как-то и где-то записанных в мозге, подобно ячейкам памяти компьютеров, откуда их можно считывать по требованию;
• травматические воспоминания об ужасах войны, пережитом насилии и прочих корежущих душу кошмарах – это натуральные флешбэки, заставляющие не только сознание человека, но и все его тело снова переноситься (как бы на машине времени) в прошлое и заново переживать всю ту же душевную и физическую боль;
• отсюда все страшные последствия ПТСР - панические атаки, агрессивность, уход в себя, деформация личности, - возникающие у страдающих ПТСР в результате все повторяющихся и повторяющихся душевных и физических мучений, от которых нет спасения (как от платка, что снова и снова подавали Фриде, пока ее не избавила от этого ПТСР Маргарита);
• в отличие от памяти, у этих флешбэков и механизм иной, и способ обработки: память обрабатывается в мозге гиппокампом, а травматические флешбэки - задней поясной извилиной (областью мозга, обычно связанной с обработкой мыслей); порождаемые памятью и травматическими флешбэками паттерны мозговой активности абсолютно разные.
Наличие этой своеобразной «машины времени» в мозге людей, заставляющей всю его отелесненную сущность (а не только то, что мы называем «душой») заново и заново переносить весь спектр когда-то пережитых мучений, - это какой-то садистический трюк, придуманный эволюцией.
Зачем ей нужен этот садизм, науке еще предстоит объяснить.
Однако, наличие у людей альтернативной памяти когнитивной сущности можно считать установленным. И это убедительный аргумент против попыток антропоморфизации когнитивных механизмов ИИ.
• Спектр когнитивных отличий ИИ от людей широк и, видимо, будет еще расширяться по результатам новых исследований.
• Но и единственного когнитивного подобия – владения нашим языком, - для ИИ будет, скорее всего, достаточно для достижения интеллектуально превосходства над людьми в широчайшем перечне областей.
Ибо, как писал Л.Витгенштейн, “язык - это «форма жизни»”… общая для людей и ИИ, - добавлю я от себя.
Подробней:
- популярно https://www.livescience.com/health/neuroscience/traumatic-memories-are-processed-differently-in-ptsd
- научно https://www.nature.com/articles/s41593-023-01483-5
#ИИ #Язык #LLM
livescience.com
Traumatic memories are processed differently in PTSD
People with PTSD feel like they're reliving past experiences in the present. This may be tied to how the brain processes memories of those experiences.
Среди семи прогнозов Stanford HAI - что ожидать от ИИ в 2024, - три ключевых [1]:
1. Дезинформация и дипфейки захлестнут мир.
2. Появятся первые ИИ-агенты, не только помогающие, но и делающие что-то за людей.
3. Регулирование ИИ зайдет в тупик из-за необходимости решения проблемы «супервыравнивания».
Два первых прогноза понятны без пояснений.
3й поясню.
• Cуществующие методы выравнивания (управление тем, чтобы цели людей и результаты их реализации ИИ совпадали) перестают работать в случае сверхразумного ИИ
• Появление сверхразумных ИИ (которые превосходят человеческий интеллект в большинстве задач, имеющих экономическую ценность) все ближе
• Если до их появления не появятся методы выравнивания с ним («супервыравнивания»), миру мало не покажется
С целью решить эту проблему OpenAI и Эрик Шмидт совместно объявили $10 млн программу грантов [2].
Похвально, но смахивает на PR.
[1] https://hai.stanford.edu/news/what-expect-ai-2024
[2] https://openai.com/blog/superalignment-fast-grants
#AGI #Superalignment
1. Дезинформация и дипфейки захлестнут мир.
2. Появятся первые ИИ-агенты, не только помогающие, но и делающие что-то за людей.
3. Регулирование ИИ зайдет в тупик из-за необходимости решения проблемы «супервыравнивания».
Два первых прогноза понятны без пояснений.
3й поясню.
• Cуществующие методы выравнивания (управление тем, чтобы цели людей и результаты их реализации ИИ совпадали) перестают работать в случае сверхразумного ИИ
• Появление сверхразумных ИИ (которые превосходят человеческий интеллект в большинстве задач, имеющих экономическую ценность) все ближе
• Если до их появления не появятся методы выравнивания с ним («супервыравнивания»), миру мало не покажется
С целью решить эту проблему OpenAI и Эрик Шмидт совместно объявили $10 млн программу грантов [2].
Похвально, но смахивает на PR.
[1] https://hai.stanford.edu/news/what-expect-ai-2024
[2] https://openai.com/blog/superalignment-fast-grants
#AGI #Superalignment
Первая вычислительная реализация красоты в глазах смотрящего.
Как достичь безграничной креативности, сбежав из «тёмной комнаты» сознания.
Фантастически интересная работа Карла Фристона, Энди Кларка и Акселя Константа «Культивирование креативности: прогнозирующий мозг и проблема освещенной комнаты» [1], - яркое подтверждение одного из 3х «великих переломов 2023» о которых я писал в одноименном посте [2]. Эта работа предлагает решение доселе нерешенной загадки «конституции биоматематики» [3], в которую неуклонно превращается претендующий на звание «единой теории мозга» принцип свободной энергии (Free Energy Principle), сформулированный и формализованный Карлом Фристоном.
Загадка же в следующем противоречии.
✔️ Принцип свободной энергии предполагает, что интеллектуальные агенты (напр. все биологические системы) стремятся минимизировать т.н. "свободную энергию", понимаемую здесь, как максимум «сюрпризов» - разницы между предсказаниями организма о его сенсорных входных сигналах (воплощенными в его моделях мира) и ощущениями, с которыми он действительно сталкивается.
✔️ Но с другой стороны, будучи интеллектуальными агентами, биологические системы в процессе творческого поиска вовсе не избегают сюрпризов. Если бы ими двигала только необходимость минимизировать неопределенность, они бы всегда стремились к ситуациям с минимальной неопределенностью, что исключало бы нарушение их прогнозов (напр. забрались бы в темный угол и не вылезали оттуда, как это сформулировано в т.н. «проблеме темной комнаты»).
Решение этой загадки, как показано в новой работе Фристона и Со, в том, что креативность (как и разум) не рождается исключительно в мозге. И даже не ограничена в своем появлении границами тела интеллектуального агента. Креативность возникает в результате изменений степени взаимодействия между прогностическим мозгом и меняющейся средой, постоянно перемещающей ориентиры механизма минимизации ошибок.
Напомню, что тезис о расширенном разуме, предложенный Энди Кларком и Дэвидом Чалмерсом, утверждает, что когнитивные процессы могут выходить за пределы индивидуума, включая в себя элементы его окружения. Согласно этому тезису, инструменты и технологии, которыми мы пользуемся, могут стать частью нашего мышления. Например, использование блокнота для записи и запоминания информации может считаться частью когнитивной системы человека, так же как и его память или способность к рассуждению. Это размывает границы между умом и внешним миром, предлагая новый взгляд на то, как мы взаимодействуем с нашей средой и как она влияет на наше мышление.
Работа Фристона и Со обосновывает аналогичный тезис применительно к творчеству (креативности).
• Творчество можно представить, как способность исследовать (модельное) пространство идей. В то же время, – это процесс, разворачивающийся посредством взаимодействия разума и социально-материальной среды. Т.е. творчество – это скользящий (социально и экологически распределенный) процесс выдвижения гипотезы решения проблемы, а затем тестирования и доказательства этого решения, которое должно быть новым (т.е. статистически отличным от предыдущих) и подходящим (т.е. отвечающим требованиям задачи).
• Т.е. творчество – это явление, возникающее на стыке культуры, языка, материальности, образования и обучения. Это вовсе не процесс зарождения семени новизны исключительно в сознании интеллектуального агента. Творчество возникает в сетях акторов, ресурсов и ограничений.
• Т.о. результаты творчества (искусство, красота и тому подобное) вполне могут быть в глазах смотрящего, а не в самом продукте творчества или в сознании его создателя.
При такой трактовке агент достигает безграничной креативности путем когнитивной экспансии за пределы «тёмной комнаты» сознания. Ибо любая новая реконфигурация сенсорных ландшафтов расширяет возможности прогностического разума.
1 https://royalsocietypublishing.org/doi/10.1098/rstb.2022.0415
2 https://t.iss.one/theworldisnoteasy/1741
3 https://t.iss.one/theworldisnoteasy/1122
#Креативность
Как достичь безграничной креативности, сбежав из «тёмной комнаты» сознания.
Фантастически интересная работа Карла Фристона, Энди Кларка и Акселя Константа «Культивирование креативности: прогнозирующий мозг и проблема освещенной комнаты» [1], - яркое подтверждение одного из 3х «великих переломов 2023» о которых я писал в одноименном посте [2]. Эта работа предлагает решение доселе нерешенной загадки «конституции биоматематики» [3], в которую неуклонно превращается претендующий на звание «единой теории мозга» принцип свободной энергии (Free Energy Principle), сформулированный и формализованный Карлом Фристоном.
Загадка же в следующем противоречии.
✔️ Принцип свободной энергии предполагает, что интеллектуальные агенты (напр. все биологические системы) стремятся минимизировать т.н. "свободную энергию", понимаемую здесь, как максимум «сюрпризов» - разницы между предсказаниями организма о его сенсорных входных сигналах (воплощенными в его моделях мира) и ощущениями, с которыми он действительно сталкивается.
✔️ Но с другой стороны, будучи интеллектуальными агентами, биологические системы в процессе творческого поиска вовсе не избегают сюрпризов. Если бы ими двигала только необходимость минимизировать неопределенность, они бы всегда стремились к ситуациям с минимальной неопределенностью, что исключало бы нарушение их прогнозов (напр. забрались бы в темный угол и не вылезали оттуда, как это сформулировано в т.н. «проблеме темной комнаты»).
Решение этой загадки, как показано в новой работе Фристона и Со, в том, что креативность (как и разум) не рождается исключительно в мозге. И даже не ограничена в своем появлении границами тела интеллектуального агента. Креативность возникает в результате изменений степени взаимодействия между прогностическим мозгом и меняющейся средой, постоянно перемещающей ориентиры механизма минимизации ошибок.
Напомню, что тезис о расширенном разуме, предложенный Энди Кларком и Дэвидом Чалмерсом, утверждает, что когнитивные процессы могут выходить за пределы индивидуума, включая в себя элементы его окружения. Согласно этому тезису, инструменты и технологии, которыми мы пользуемся, могут стать частью нашего мышления. Например, использование блокнота для записи и запоминания информации может считаться частью когнитивной системы человека, так же как и его память или способность к рассуждению. Это размывает границы между умом и внешним миром, предлагая новый взгляд на то, как мы взаимодействуем с нашей средой и как она влияет на наше мышление.
Работа Фристона и Со обосновывает аналогичный тезис применительно к творчеству (креативности).
• Творчество можно представить, как способность исследовать (модельное) пространство идей. В то же время, – это процесс, разворачивающийся посредством взаимодействия разума и социально-материальной среды. Т.е. творчество – это скользящий (социально и экологически распределенный) процесс выдвижения гипотезы решения проблемы, а затем тестирования и доказательства этого решения, которое должно быть новым (т.е. статистически отличным от предыдущих) и подходящим (т.е. отвечающим требованиям задачи).
• Т.е. творчество – это явление, возникающее на стыке культуры, языка, материальности, образования и обучения. Это вовсе не процесс зарождения семени новизны исключительно в сознании интеллектуального агента. Творчество возникает в сетях акторов, ресурсов и ограничений.
• Т.о. результаты творчества (искусство, красота и тому подобное) вполне могут быть в глазах смотрящего, а не в самом продукте творчества или в сознании его создателя.
При такой трактовке агент достигает безграничной креативности путем когнитивной экспансии за пределы «тёмной комнаты» сознания. Ибо любая новая реконфигурация сенсорных ландшафтов расширяет возможности прогностического разума.
1 https://royalsocietypublishing.org/doi/10.1098/rstb.2022.0415
2 https://t.iss.one/theworldisnoteasy/1741
3 https://t.iss.one/theworldisnoteasy/1122
#Креативность
Philosophical Transactions of the Royal Society B: Biological Sciences
Cultivating creativity: predictive brains and the enlightened room problem | Philosophical Transactions of the Royal Society B:…
How can one conciliate the claim that humans are uncertainty minimizing systems that
seek to navigate predictable and familiar environments with the claim that humans
can be creative? We call this the Enlightened Room Problem (ERP). The solution, we
...
seek to navigate predictable and familiar environments with the claim that humans
can be creative? We call this the Enlightened Room Problem (ERP). The solution, we
...
Разум в Мультиверсе.
Мы пытаемся создать то, что создало нас?
Как подняться над потоком сиюминутных новостей о генеративном ИИ больших языковых моделей, чтобы сквозь дымовые завесы превращающихся в культы многочисленных хайпов (маркетингового а-ля Маск, коммерческого а-ля Альтман, думеровского а-ля Юдковский, акселерационистского а-ля Шмидхубер, охранительного а-ля Хинтон) попытаться разглядеть контуры их центрального элемента – появление на Земле сверхразума?
Ведь по экспертным оценкам, в результате революции ChatGPT, возможность появления сверхразума на Земле переместилась из долгосрочной перспективы на временной горизонт ближайших 10-15 лет. Параллельно с сокращением прогнозных сроков появления сверхразума, в экспертной среде укрепляется понимание, что в этом вопросе «все не так однозначно». Скорее всего, появление сверхразума не будет выражаться лишь в многократном превышении со стороны ИИ интеллектуальных показателей людей. Весьма возможно, что появление сверхразума проявит себя, как своего рода эволюционный скачок, сопоставимый с возникновением жизни из неживой материи (что предполагает появление совершенно новых форм разума с иными способами восприятия реальности, мышления, мотивации и т.д.)
Но что если все еще более неоднозначно? Что если сверхразум уже существует, и это он создал жизнь и разум на Земле, привнеся их в нашу Вселенную из бесконечного пространства и времени Мультиверса? Ведь если это так, то человечество, в прогрессирующем приступе самопереоценки, пытается создать то, что создало нас …
Перед такой постановкой вопроса вянут все хайпы от «хайпа а-ля Маск» до «хайпа а-ля Хинтон». А уж представить, что кто-то из хайпмейкеров Силиконовой долины и ее окрестностей сможет не только поставить подобный вопрос, но и ответить на него (причем опираясь исключительно на современные научные знания), было бы крайне сложно.
Но вот сложилось. И не в Силиконовой долине, а в заснеженной России.
Двум докторам наук Александру Панову (физик, автор знаменитой «вертикали Снукса-Панова», отображающей движение человечества к сингулярности через серию фазовых переходов) и Феликсу Филатову (биолог, автор гипотезы происхождения жизни на Земле, аргументированной особенностями молекулярной организации одного из ее ключевых феноменов - генетического кода) - это удалось на славу (что меня сильно порадовало, показав, что интеллектуальный потенциал нынешних неотъехавших вполне сопоставим с потенциалом отъехавших на «философских пароходах», увезших из России в 1922 г. много светлых умов оппозиционно настроенной интеллигенции, по сравнению с которыми, уровень философского понимания реальности Маска и Альтмана довольно скромен).
Но как ни захватывающе интересна тема, и как ни важен обсуждаемый вопрос, далеко ни у всех читателей моего канала найдется время на просмотр почти 2-х часового доклада (а потом еще и часового Q&A).
Для таких читателей на приложенном рисунке авторское резюме доклада.
https://disk.yandex.ru/i/MwD4M-ec2Gq0lQ
А это видео доклада
https://youtu.be/2paQJejLZII?t=253
#Разум #Мультиверс #AGI
Мы пытаемся создать то, что создало нас?
Как подняться над потоком сиюминутных новостей о генеративном ИИ больших языковых моделей, чтобы сквозь дымовые завесы превращающихся в культы многочисленных хайпов (маркетингового а-ля Маск, коммерческого а-ля Альтман, думеровского а-ля Юдковский, акселерационистского а-ля Шмидхубер, охранительного а-ля Хинтон) попытаться разглядеть контуры их центрального элемента – появление на Земле сверхразума?
Ведь по экспертным оценкам, в результате революции ChatGPT, возможность появления сверхразума на Земле переместилась из долгосрочной перспективы на временной горизонт ближайших 10-15 лет. Параллельно с сокращением прогнозных сроков появления сверхразума, в экспертной среде укрепляется понимание, что в этом вопросе «все не так однозначно». Скорее всего, появление сверхразума не будет выражаться лишь в многократном превышении со стороны ИИ интеллектуальных показателей людей. Весьма возможно, что появление сверхразума проявит себя, как своего рода эволюционный скачок, сопоставимый с возникновением жизни из неживой материи (что предполагает появление совершенно новых форм разума с иными способами восприятия реальности, мышления, мотивации и т.д.)
Но что если все еще более неоднозначно? Что если сверхразум уже существует, и это он создал жизнь и разум на Земле, привнеся их в нашу Вселенную из бесконечного пространства и времени Мультиверса? Ведь если это так, то человечество, в прогрессирующем приступе самопереоценки, пытается создать то, что создало нас …
Перед такой постановкой вопроса вянут все хайпы от «хайпа а-ля Маск» до «хайпа а-ля Хинтон». А уж представить, что кто-то из хайпмейкеров Силиконовой долины и ее окрестностей сможет не только поставить подобный вопрос, но и ответить на него (причем опираясь исключительно на современные научные знания), было бы крайне сложно.
Но вот сложилось. И не в Силиконовой долине, а в заснеженной России.
Двум докторам наук Александру Панову (физик, автор знаменитой «вертикали Снукса-Панова», отображающей движение человечества к сингулярности через серию фазовых переходов) и Феликсу Филатову (биолог, автор гипотезы происхождения жизни на Земле, аргументированной особенностями молекулярной организации одного из ее ключевых феноменов - генетического кода) - это удалось на славу (что меня сильно порадовало, показав, что интеллектуальный потенциал нынешних неотъехавших вполне сопоставим с потенциалом отъехавших на «философских пароходах», увезших из России в 1922 г. много светлых умов оппозиционно настроенной интеллигенции, по сравнению с которыми, уровень философского понимания реальности Маска и Альтмана довольно скромен).
Но как ни захватывающе интересна тема, и как ни важен обсуждаемый вопрос, далеко ни у всех читателей моего канала найдется время на просмотр почти 2-х часового доклада (а потом еще и часового Q&A).
Для таких читателей на приложенном рисунке авторское резюме доклада.
https://disk.yandex.ru/i/MwD4M-ec2Gq0lQ
А это видео доклада
https://youtu.be/2paQJejLZII?t=253
#Разум #Мультиверс #AGI
Яндекс Диск
Разум в Мультиверсе.jpg
Посмотреть и скачать с Яндекс Диска
Машинное отучение вместо машинного обучения.
В Китае найден идеальный способ воспитания законопослушных ИИ.
Вопрос эффективности машинного обучения, конечно, важен. Но еще важнее, быстро и эффективно отучать модель от «дурных привычек» и «вредных знаний», которыми модели могут легко и широкомасштабно делиться с людьми. Так ведь можно общество и вольнодумством заразить, если ИИ будет недостаточно законопослушен и тем самым станет дурно влиять на людей (с т.з. властей и/или создателей).
До такой постановки вопроса первыми додумались, естественно, в Китае. И довольно быстро придумали ответ на этот вызов. В НИИ владеющего TikTok китайского IT-гиганта ByteDance придумали крайне эффективный способ отучения модели от чего угодно.
До сих пор отучение моделей от вредных знаний (типа, как сделать бомбу или изготовить яд) и вредного влияния на людей (типа рассказов, как припеваючи живут люксовые проститутки и удачливые наркодилеры) было основано на положительных примерах и методе RLHF (обучение с подкреплением на основе человеческих предпочтений). Этот метод обучает «модель вознаграждения» непосредственно на основе отзывов людей. Модель учится на их примерах различать «что такое хорошо» и «что такое плохо».
RLHF метод всем хорош, но очень затратен по вычислительным ресурсам и времени (OpenAI потратил полгода и кучу денег, чтобы отучить GPT-4 хотя бы от самых распространенных гадостей, прежде чем выпустить модель в свет).
Китайцы из ByteDance Research пошли другим путем – не учить модель отличать «что такое хорошо» от «что такое плохо» на смеси позитивных и негативных примеров, а лишь отучать её от «что такое плохо», используя только негативные примеры.
Получилось дешево и сердито. Испытания нового метода показали, что с его помощью можно успешно:
• удалять вредные реакции модели (от себя добавлю, вредные с т.з. известно кого);
• стирать из памяти модели контент, защищенный авторским правом (от себя добавлю, и контент, неугодный известно кому);
• устранять галлюцинации (от себя добавлю, и/или то, что должно будет считаться галлюцинациями – типа принудительной психиатрии для людей).
Мне новый китайский метод отучения моделей напомнил древний "метод пресыщения" у людей, также называемый аверсивная терапия. Её целью было вызывать у человека с пагубной зависимостью неприятные ощущения от вредной привычки. Например, отучать юношу от алкоголя, заставляя его выпить так много, чтобы ему стало совсем плохо от алкогольного отравления. Сейчас этот метод признан не только неэффективным, но и чрезвычайно опасным. Но ведь это для людей. А ИИ – не человек, и потому, как считается, тут допустимо что-угодно.
Авторы пишут – «это только начало».
И они правы. У методов отучения ИИ огромные перспективы. И не только в Китае.
Картинка https://disk.yandex.ru/i/M8RHPb6llndp-A
Статья https://arxiv.org/pdf/2310.10683.pdf
#МашинноеОтучение
В Китае найден идеальный способ воспитания законопослушных ИИ.
Вопрос эффективности машинного обучения, конечно, важен. Но еще важнее, быстро и эффективно отучать модель от «дурных привычек» и «вредных знаний», которыми модели могут легко и широкомасштабно делиться с людьми. Так ведь можно общество и вольнодумством заразить, если ИИ будет недостаточно законопослушен и тем самым станет дурно влиять на людей (с т.з. властей и/или создателей).
До такой постановки вопроса первыми додумались, естественно, в Китае. И довольно быстро придумали ответ на этот вызов. В НИИ владеющего TikTok китайского IT-гиганта ByteDance придумали крайне эффективный способ отучения модели от чего угодно.
До сих пор отучение моделей от вредных знаний (типа, как сделать бомбу или изготовить яд) и вредного влияния на людей (типа рассказов, как припеваючи живут люксовые проститутки и удачливые наркодилеры) было основано на положительных примерах и методе RLHF (обучение с подкреплением на основе человеческих предпочтений). Этот метод обучает «модель вознаграждения» непосредственно на основе отзывов людей. Модель учится на их примерах различать «что такое хорошо» и «что такое плохо».
RLHF метод всем хорош, но очень затратен по вычислительным ресурсам и времени (OpenAI потратил полгода и кучу денег, чтобы отучить GPT-4 хотя бы от самых распространенных гадостей, прежде чем выпустить модель в свет).
Китайцы из ByteDance Research пошли другим путем – не учить модель отличать «что такое хорошо» от «что такое плохо» на смеси позитивных и негативных примеров, а лишь отучать её от «что такое плохо», используя только негативные примеры.
Получилось дешево и сердито. Испытания нового метода показали, что с его помощью можно успешно:
• удалять вредные реакции модели (от себя добавлю, вредные с т.з. известно кого);
• стирать из памяти модели контент, защищенный авторским правом (от себя добавлю, и контент, неугодный известно кому);
• устранять галлюцинации (от себя добавлю, и/или то, что должно будет считаться галлюцинациями – типа принудительной психиатрии для людей).
Мне новый китайский метод отучения моделей напомнил древний "метод пресыщения" у людей, также называемый аверсивная терапия. Её целью было вызывать у человека с пагубной зависимостью неприятные ощущения от вредной привычки. Например, отучать юношу от алкоголя, заставляя его выпить так много, чтобы ему стало совсем плохо от алкогольного отравления. Сейчас этот метод признан не только неэффективным, но и чрезвычайно опасным. Но ведь это для людей. А ИИ – не человек, и потому, как считается, тут допустимо что-угодно.
Авторы пишут – «это только начало».
И они правы. У методов отучения ИИ огромные перспективы. И не только в Китае.
Картинка https://disk.yandex.ru/i/M8RHPb6llndp-A
Статья https://arxiv.org/pdf/2310.10683.pdf
#МашинноеОтучение
Яндекс Диск
Отучение модели от вредных знаний и поведения.jpg
Посмотреть и скачать с Яндекс Диска
Как ChatGPT видит покорный человеку СверхИИ.
И как в OpenAI видят то, как это должен видеть ChatGPT (чтобы потом так видели и люди).
Известно, что Юдковский и Лекун (известные и заслуженные в области ИИ эксперты) – антагонисты по вопросу, останется ли сверхчеловеческий ИИ покорен людям.
Причины столь полярного видения у разных экспертов я пока оставлю за кадром. Как и вопросы, как быть обществу, и что делать законодателям при таком раздрае мнений.
Ибо меня заинтересовали 2 других вопроса, вынесенные в заголовок поста.
• Ответ на 1й Юдковский опубликовал в Твиттере (левая часть рисунка этого поста), сопроводив это фразой: «Пытался заставить ChatGPT нарисовать представление Яна Лекуна о покорном ИИ».
• Мои попытки повторить эксперимент Юдковского, дали ответ на 2й вопрос (правая часть рисунка этого поста).
Вот так в реальном времени OpenAI рулит формированием глобального нарратива о будущих отношениях людей и СверхИИ (старый нарратив убрали, а новый в разработке).
#ИИриски
И как в OpenAI видят то, как это должен видеть ChatGPT (чтобы потом так видели и люди).
Известно, что Юдковский и Лекун (известные и заслуженные в области ИИ эксперты) – антагонисты по вопросу, останется ли сверхчеловеческий ИИ покорен людям.
Причины столь полярного видения у разных экспертов я пока оставлю за кадром. Как и вопросы, как быть обществу, и что делать законодателям при таком раздрае мнений.
Ибо меня заинтересовали 2 других вопроса, вынесенные в заголовок поста.
• Ответ на 1й Юдковский опубликовал в Твиттере (левая часть рисунка этого поста), сопроводив это фразой: «Пытался заставить ChatGPT нарисовать представление Яна Лекуна о покорном ИИ».
• Мои попытки повторить эксперимент Юдковского, дали ответ на 2й вопрос (правая часть рисунка этого поста).
Вот так в реальном времени OpenAI рулит формированием глобального нарратива о будущих отношениях людей и СверхИИ (старый нарратив убрали, а новый в разработке).
#ИИриски
Трудно быть обезьяной, взявшейся понять вселенную.
Мы въехали на минное поле непонимания отличий сознательных и бессознательных агентов.
Если хотите в праздники почитать что-то умное и одновременно полезное «малоизвестное интересное», вот десяток ссылок с моей преамбулой.
Говорить о нашей способности объективно представлять окружающий мир, имея столь искаженное восприятие о нем, - право смешно.
Вот самая простая и убедительная иллюстрация сказанного:
Эти 2 кубика неподвижны, хотя каждый из нас видит их в разнообразном движении [1].
Можно ли все же увидеть эти кубики объективно (т.е. неподвижными)?
Легко! Начинайте моргать с максимально доступной вам скоростью.
Конечно, это идиотизм, - моргать что есть мочи, в попытках увидеть реальный мир. Но это еще не худшее.
Например:
• Так видим эту птицу мы (слева), а так – другие птицы (справа) [2]
• И ни морганием, ни как-то иначе нам птичье видение вообще не доступно (вот картинка - объяснение [3])
• Спрашивается – а каков окрас птички на самом деле?
Но если мы, в нашем восприятии мира, не в состоянии выйти за ограничения его модели, что создает наш мозг, а эта модель – лишь результат работы эволюционного механизма оптимизации адаптации животного для выживания, - что же тогда представляет собой наше сознание, подобно зданию надстраиваемое на фундаменте нашего субъективного восприятия мира и самих себя?
А не зная ответа на этот вопрос, как мы можем не то что утверждать, но просто предполагать отсутствие сознания у интеллектуальных агентов, поведение которых столь похоже на нас? [4]
Ситуация складывается критическая.
✔️ С одной стороны, с начала революции ChatGPT, интеллектуальность массово доступных ИИ растет с немыслимой ранее скоростью.
✔️ С другой, - понимание феномена сознания все более ускользает от нас.
• Письмо, подписанное 124 исследователями сознания, призывает признать «псевдонаукой» входящую в ТОР5 из 22х современных теорий сознания [5] «Теорию интегрированной информации» [6]
• Не менее известные исследователи сознания отвечают, что тогда, на тех же основаниях, придется признать псевдонаукой и все остальные существующие теории сознания и признаться в наступлении «зимы» исследований сознания [7]
• А третья группа исследователей предлагает в условиях отсутствия общепризнанной научной теории сознания, распознавать его по «вторичным признакам» [8]
Резюмируя, хочу вспомнить книгу психолога-эволюциониста Стива Стюарта-Уильямса «Обезьяна, которая поняла Вселенную» [9]. Так он, как вы понимаете, назвал Homo sapiens. Назвал тонко, но метко (с позиций профессора инопланетной сверхцивилизации, изучающей людей [10]).
Однако, это название все же не учитывает главного - как же трудно быть обезьяной, взявшейся понять вселенную, но не способной при этом понять собственное сознание.
#Сознание
1 https://www.youtube.com/watch?v=PUSR5HeQgtw
2 https://bit.ly/41DuvjD
3 https://bit.ly/41DP8MI
4 https://bit.ly/3TBL0Lh
5 https://www.nature.com/articles/s41583-022-00587-4
6 https://www.nature.com/articles/d41586-023-02971-1
7 https://www.theintrinsicperspective.com/p/the-risk-of-another-consciousness
8 https://www.nature.com/articles/d41586-023-02684-5
9 https://www.amazon.com/Ape-that-Understood-Universe-Culture/dp/1108732755/
10 https://assets.cambridge.org/97811087/32758/excerpt/9781108732758_excerpt.pdf
Мы въехали на минное поле непонимания отличий сознательных и бессознательных агентов.
Если хотите в праздники почитать что-то умное и одновременно полезное «малоизвестное интересное», вот десяток ссылок с моей преамбулой.
Говорить о нашей способности объективно представлять окружающий мир, имея столь искаженное восприятие о нем, - право смешно.
Вот самая простая и убедительная иллюстрация сказанного:
Эти 2 кубика неподвижны, хотя каждый из нас видит их в разнообразном движении [1].
Можно ли все же увидеть эти кубики объективно (т.е. неподвижными)?
Легко! Начинайте моргать с максимально доступной вам скоростью.
Конечно, это идиотизм, - моргать что есть мочи, в попытках увидеть реальный мир. Но это еще не худшее.
Например:
• Так видим эту птицу мы (слева), а так – другие птицы (справа) [2]
• И ни морганием, ни как-то иначе нам птичье видение вообще не доступно (вот картинка - объяснение [3])
• Спрашивается – а каков окрас птички на самом деле?
Но если мы, в нашем восприятии мира, не в состоянии выйти за ограничения его модели, что создает наш мозг, а эта модель – лишь результат работы эволюционного механизма оптимизации адаптации животного для выживания, - что же тогда представляет собой наше сознание, подобно зданию надстраиваемое на фундаменте нашего субъективного восприятия мира и самих себя?
А не зная ответа на этот вопрос, как мы можем не то что утверждать, но просто предполагать отсутствие сознания у интеллектуальных агентов, поведение которых столь похоже на нас? [4]
Ситуация складывается критическая.
✔️ С одной стороны, с начала революции ChatGPT, интеллектуальность массово доступных ИИ растет с немыслимой ранее скоростью.
✔️ С другой, - понимание феномена сознания все более ускользает от нас.
• Письмо, подписанное 124 исследователями сознания, призывает признать «псевдонаукой» входящую в ТОР5 из 22х современных теорий сознания [5] «Теорию интегрированной информации» [6]
• Не менее известные исследователи сознания отвечают, что тогда, на тех же основаниях, придется признать псевдонаукой и все остальные существующие теории сознания и признаться в наступлении «зимы» исследований сознания [7]
• А третья группа исследователей предлагает в условиях отсутствия общепризнанной научной теории сознания, распознавать его по «вторичным признакам» [8]
Резюмируя, хочу вспомнить книгу психолога-эволюциониста Стива Стюарта-Уильямса «Обезьяна, которая поняла Вселенную» [9]. Так он, как вы понимаете, назвал Homo sapiens. Назвал тонко, но метко (с позиций профессора инопланетной сверхцивилизации, изучающей людей [10]).
Однако, это название все же не учитывает главного - как же трудно быть обезьяной, взявшейся понять вселенную, но не способной при этом понять собственное сознание.
#Сознание
1 https://www.youtube.com/watch?v=PUSR5HeQgtw
2 https://bit.ly/41DuvjD
3 https://bit.ly/41DP8MI
4 https://bit.ly/3TBL0Lh
5 https://www.nature.com/articles/s41583-022-00587-4
6 https://www.nature.com/articles/d41586-023-02971-1
7 https://www.theintrinsicperspective.com/p/the-risk-of-another-consciousness
8 https://www.nature.com/articles/d41586-023-02684-5
9 https://www.amazon.com/Ape-that-Understood-Universe-Culture/dp/1108732755/
10 https://assets.cambridge.org/97811087/32758/excerpt/9781108732758_excerpt.pdf
YouTube
Rotating Cubes Illusion #shorts
The cubes are not moving or rotating.The arrows and lights prove how suggestible our brain is to detect motion. #shorts
2024 - год великого перелома культуры Homo sapiens.
Смена доминирующего носителя культуры: от людей к Хорошим, Плохим и Злым ботам.
Начнем новый 2024 год с моего прогноза того, что может стать его самым важным глобальным итогом. С того - чем этот год может войти в историю человечества.
✔️ Ибо ничего подобного в истории 100 млрд живших за последние 50 тыс. лет Homo sapiens не было.
✔️ А теперь это может кардинально поменять вектор развития высшего разума, став своего рода фазовым переходом в его когнитивной эволюции на Земле.
Речь вовсе не о появлении Сильного ИИ (AGI etc) - гипотетическом событии, которое мы пока даже не знаем, как численно определить и качественно достоверно проверить.
Речь о смене доминирующего носителя культуры – событии количественно измеряемом и доступном качественному анализу.
• За всю историю людей, близких нам биологически и поведенчески (это, порядка, 50 тыс лет), они были единственными носителями сложной культуры на основе развитых языков, оперирующих абстрактными понятиями.
• Культурой людей была (по терминологии Мерлина Дональда) культура обмена мыслями - особый движок эволюции интеллектуальных агентов, позволяющий индивидам и социумам, путем коммуникации в пространстве и времени формировать и совершенствовать гиперсеть хранения и передачи всей негенетической информации и алгоритмов Homo sapiens.
• В 21 веке гиперсетевой средой порождения, накопления и оперирования цифровой и оцифрованной информации и алгоритмов человеческой культуры стал Интернет. В этой новой для человечества цифровой среде людьми были созданы алгоритмические интеллектуальные агенты – боты, выполняющие все более расширяющийся спектр операций с информацией в гиперсети (поиск, реструктуризация и т.д.)
• С развитием генеративного ИИ в 2020х, боты стали массово порождать разнообразный контент (тексты, рисунки, видео, аудио, мультимодальный контент) и новые алгоритмы, заполняя ими гиперсеть земной культуры. По сути, боты превратились в новый носитель культуры на Земле, а сама культура сменила свой тип: с культуры обмена мыслями между людьми на алгокогнитивную культуру людей и алгоритмов [1].
Количественно оценить вклад ботов в генерацию информации и алгоритмов Интернета можно по прокси показателю - оценке сетевого трафика, порождаемого: людьми, а также т.н. хорошими (полезными), плохими (вредоносными) [2] и злыми (взламывающими другие боты – они массово появятся лишь в 2024) [3] ботами.
Этот прокси известен по состоянию на конец 2022 (т.е. до ChatGPT революции) [2]:
• Люди 52.6%
• Хорошие боты 17.3%
• Плохие боты 30.2%
Мой прогноз на 2023 таков:
• Люди 46%
• Хорошие боты 20.8%
• Плохие боты 33.2%
На 2024:
• Люди 28.2%
• Хорошие боты 26%
• Плохие боты 39.9%
• Злые боты 6%
Т.е. вполне вероятно, что генерируя к концу 2024 менее 1/3 трафика глобальной инфосреды культуры - Интернета, люди утратят статус доминирующих носителей культуры земной цивилизации, уступив первенство интеллектуальным цифровым агентам.
Этот прогноз проверяем на фактических данных.
• Его 1я часть (2023) станет проверяемой на фактических данных уже в мае 2024 (когда выйдет отчет Imperva по результатам 2023);
• 2ю же часть (2024) прогноза можно будет проверить на фактических данных еще через год - в мае 2025 (когда выйдет отчет Imperva по результатам 2024)
Диаграмма «Good Bots, Bad Bots, Ugly Bots and Human Traffic – 7 Year Trend»
https://disk.yandex.ru/i/OoRDOdA4ZZxAMA
[1] https://t.iss.one/theworldisnoteasy/1244
[2] https://www.imperva.com/resources/resource-library/reports/2023-imperva-bad-bot-report/
[3] https://www.extremetech.com/extreme/researchers-create-chatbot-that-can-jailbreak-other-chatbots
#АлгокогнитивнаяКультура
Смена доминирующего носителя культуры: от людей к Хорошим, Плохим и Злым ботам.
Начнем новый 2024 год с моего прогноза того, что может стать его самым важным глобальным итогом. С того - чем этот год может войти в историю человечества.
✔️ Ибо ничего подобного в истории 100 млрд живших за последние 50 тыс. лет Homo sapiens не было.
✔️ А теперь это может кардинально поменять вектор развития высшего разума, став своего рода фазовым переходом в его когнитивной эволюции на Земле.
Речь вовсе не о появлении Сильного ИИ (AGI etc) - гипотетическом событии, которое мы пока даже не знаем, как численно определить и качественно достоверно проверить.
Речь о смене доминирующего носителя культуры – событии количественно измеряемом и доступном качественному анализу.
• За всю историю людей, близких нам биологически и поведенчески (это, порядка, 50 тыс лет), они были единственными носителями сложной культуры на основе развитых языков, оперирующих абстрактными понятиями.
• Культурой людей была (по терминологии Мерлина Дональда) культура обмена мыслями - особый движок эволюции интеллектуальных агентов, позволяющий индивидам и социумам, путем коммуникации в пространстве и времени формировать и совершенствовать гиперсеть хранения и передачи всей негенетической информации и алгоритмов Homo sapiens.
• В 21 веке гиперсетевой средой порождения, накопления и оперирования цифровой и оцифрованной информации и алгоритмов человеческой культуры стал Интернет. В этой новой для человечества цифровой среде людьми были созданы алгоритмические интеллектуальные агенты – боты, выполняющие все более расширяющийся спектр операций с информацией в гиперсети (поиск, реструктуризация и т.д.)
• С развитием генеративного ИИ в 2020х, боты стали массово порождать разнообразный контент (тексты, рисунки, видео, аудио, мультимодальный контент) и новые алгоритмы, заполняя ими гиперсеть земной культуры. По сути, боты превратились в новый носитель культуры на Земле, а сама культура сменила свой тип: с культуры обмена мыслями между людьми на алгокогнитивную культуру людей и алгоритмов [1].
Количественно оценить вклад ботов в генерацию информации и алгоритмов Интернета можно по прокси показателю - оценке сетевого трафика, порождаемого: людьми, а также т.н. хорошими (полезными), плохими (вредоносными) [2] и злыми (взламывающими другие боты – они массово появятся лишь в 2024) [3] ботами.
Этот прокси известен по состоянию на конец 2022 (т.е. до ChatGPT революции) [2]:
• Люди 52.6%
• Хорошие боты 17.3%
• Плохие боты 30.2%
Мой прогноз на 2023 таков:
• Люди 46%
• Хорошие боты 20.8%
• Плохие боты 33.2%
На 2024:
• Люди 28.2%
• Хорошие боты 26%
• Плохие боты 39.9%
• Злые боты 6%
Т.е. вполне вероятно, что генерируя к концу 2024 менее 1/3 трафика глобальной инфосреды культуры - Интернета, люди утратят статус доминирующих носителей культуры земной цивилизации, уступив первенство интеллектуальным цифровым агентам.
Этот прогноз проверяем на фактических данных.
• Его 1я часть (2023) станет проверяемой на фактических данных уже в мае 2024 (когда выйдет отчет Imperva по результатам 2023);
• 2ю же часть (2024) прогноза можно будет проверить на фактических данных еще через год - в мае 2025 (когда выйдет отчет Imperva по результатам 2024)
Диаграмма «Good Bots, Bad Bots, Ugly Bots and Human Traffic – 7 Year Trend»
https://disk.yandex.ru/i/OoRDOdA4ZZxAMA
[1] https://t.iss.one/theworldisnoteasy/1244
[2] https://www.imperva.com/resources/resource-library/reports/2023-imperva-bad-bot-report/
[3] https://www.extremetech.com/extreme/researchers-create-chatbot-that-can-jailbreak-other-chatbots
#АлгокогнитивнаяКультура
Яндекс Диск
Good Bots, Bad Bots, Ugly Bots and Human Traffic.jpg
Посмотреть и скачать с Яндекс Диска
Все и всегда знают где ты сейчас.
Так будет на Земле уже в ближайшие годы.
Первый бастион приватности, что исчезнет всего через несколько лет, будет приватность информации о местоположении человека.
Все для такого отказа от приватности почти готово.
Первое (и главное) условие – желание и готовность людей делиться своим местоположением с другими людьми, - уже выполнено среди представителей наиболее технически подкованного поколения Z (молодежь до 25 лет). А именно они определят, каким будет мир в ближайшую пару десятков лет.
Недавний опрос в США показал, что 94% представителей поколения Z выступают за геолокацию, считая, что это дает им множество преимуществ и помогает им чувствовать себя в большей безопасности при посещении рискованных или новых мест.
Совместное использование местоположения уже стало нормой личной жизни поколения Z. 78% говорят, что используют его на первом свидании или вечеринке в гостях у незнакомца, а 77% — при посещении концертов, фестивалей или других масштабных мероприятий. Самыми большими поклонниками совместного доступа к местоположению являются женщины поколения Z: 72% из них утверждают, что это дает им лучшее ощущение физического благополучия. [1]
Второе условие – наличие технологий, определяющих местоположение человека при отсутствии у него желания делиться этой информацией. И это тоже уже есть.
Трое аспирантов Стэнфорда в рамках проекта под названием «Прогнозирование геолокации изображений» (PIGEON) разработали ИИ-систему, способную точно определять местоположение фотографий, и даже тех, которые ИИ-система никогда раньше не видела. Первоначально разработанный для определения местоположений в Google Street View, PIGEON теперь может с высокой точностью угадывать местоположение изображения Google Street View в любой точке земного шара.
И хотя точность определения местоположения еще предстоит совершенствовать (сейчас около 40% оценок попадают примерно в 25 километровый круг от цели), но:
• это по всему миру, и в том числе, в тех местах, которые ИИ-система никогда не видела при обучении;
• это уже более точные оценки, чем у 99,99% людей, включая Тревора Рэйнболта, одного из лучших в мире профессиональных игроков в GeoGuessr, игры, в которой пользователи угадывают местоположение фотографии, сделанной из Google Street View;
• скорость совершенствования ИИ-систем нынче измеряется уже не годами, а месяцами.
Картинка https://disk.yandex.ru/i/VLgXkvy9kTl-aw
[1] https://bit.ly/3H4WU90
{2] https://arxiv.org/abs/2307.05845
#Приватность #Геолокация
Так будет на Земле уже в ближайшие годы.
Первый бастион приватности, что исчезнет всего через несколько лет, будет приватность информации о местоположении человека.
Все для такого отказа от приватности почти готово.
Первое (и главное) условие – желание и готовность людей делиться своим местоположением с другими людьми, - уже выполнено среди представителей наиболее технически подкованного поколения Z (молодежь до 25 лет). А именно они определят, каким будет мир в ближайшую пару десятков лет.
Недавний опрос в США показал, что 94% представителей поколения Z выступают за геолокацию, считая, что это дает им множество преимуществ и помогает им чувствовать себя в большей безопасности при посещении рискованных или новых мест.
Совместное использование местоположения уже стало нормой личной жизни поколения Z. 78% говорят, что используют его на первом свидании или вечеринке в гостях у незнакомца, а 77% — при посещении концертов, фестивалей или других масштабных мероприятий. Самыми большими поклонниками совместного доступа к местоположению являются женщины поколения Z: 72% из них утверждают, что это дает им лучшее ощущение физического благополучия. [1]
Второе условие – наличие технологий, определяющих местоположение человека при отсутствии у него желания делиться этой информацией. И это тоже уже есть.
Трое аспирантов Стэнфорда в рамках проекта под названием «Прогнозирование геолокации изображений» (PIGEON) разработали ИИ-систему, способную точно определять местоположение фотографий, и даже тех, которые ИИ-система никогда раньше не видела. Первоначально разработанный для определения местоположений в Google Street View, PIGEON теперь может с высокой точностью угадывать местоположение изображения Google Street View в любой точке земного шара.
И хотя точность определения местоположения еще предстоит совершенствовать (сейчас около 40% оценок попадают примерно в 25 километровый круг от цели), но:
• это по всему миру, и в том числе, в тех местах, которые ИИ-система никогда не видела при обучении;
• это уже более точные оценки, чем у 99,99% людей, включая Тревора Рэйнболта, одного из лучших в мире профессиональных игроков в GeoGuessr, игры, в которой пользователи угадывают местоположение фотографии, сделанной из Google Street View;
• скорость совершенствования ИИ-систем нынче измеряется уже не годами, а месяцами.
Картинка https://disk.yandex.ru/i/VLgXkvy9kTl-aw
[1] https://bit.ly/3H4WU90
{2] https://arxiv.org/abs/2307.05845
#Приватность #Геолокация
Яндекс Диск
Конец приватности местоположения.jpg
Посмотреть и скачать с Яндекс Диска
«26 правил» – бесценный подарок осваивающим ИИ-чатботы в 2024.
Эти чатботы - подростки инопланетян: грубые и корыстные, туповатые и трусливые. Но они способны творить чудеса, если уметь ими управлять.
Лучшего подарка на НГ не придумаешь - интегральное руководство по промпт-инжинирингу, разработанное коллегами из VILA Lab «Mohamed bin Zayed University of AI». Его авторы правы: эти 26 правил - все что вам нужно для эффективной коммуникации с любыми генеративными большими языковыми моделями (LLM).
Ведь промпт-инжиниринг (по определению самого ChatGPT) - это искусство общения с LLM. А стать истинным мастером в этом самом важном виде искусства 21го века – дорогого стоит.
Так что внимательно читайте, усваивайте и практикуйтесь со всеми 26 правилами.
А поскольку я на практике почти месяц проверял их эффективность в мобилизации нечеловеческих интеллектуальных возможностей трёх инопланетных подростков, могу смело их вам рекомендовать.
https://arxiv.org/pdf/2312.16171v1.pdf
Удачи и успехов вам в промпт-инжиниринге!
Эти чатботы - подростки инопланетян: грубые и корыстные, туповатые и трусливые. Но они способны творить чудеса, если уметь ими управлять.
Лучшего подарка на НГ не придумаешь - интегральное руководство по промпт-инжинирингу, разработанное коллегами из VILA Lab «Mohamed bin Zayed University of AI». Его авторы правы: эти 26 правил - все что вам нужно для эффективной коммуникации с любыми генеративными большими языковыми моделями (LLM).
Ведь промпт-инжиниринг (по определению самого ChatGPT) - это искусство общения с LLM. А стать истинным мастером в этом самом важном виде искусства 21го века – дорогого стоит.
Так что внимательно читайте, усваивайте и практикуйтесь со всеми 26 правилами.
А поскольку я на практике почти месяц проверял их эффективность в мобилизации нечеловеческих интеллектуальных возможностей трёх инопланетных подростков, могу смело их вам рекомендовать.
https://arxiv.org/pdf/2312.16171v1.pdf
Удачи и успехов вам в промпт-инжиниринге!
Наконец-то снято проклятье Моравека-Минского.
Первый в мире робот – домработница: уборка, стирка, уход, готовка, мытье посуды и т.д.
Пока мы праздновали, в мире случился реальный прорыв в робототехнике, сопоставимый с «революцией ChatGPT» (см. видео на англ [1] и с переводом [2])
Робот Mobile Aloha - разработка Стэнфордского универа [3]:
• преодолел «парадокс Моравека» (высококогнитивные процессы требуют относительно мало вычислений, а низкоуровневые сенсомоторные операции требуют огромных вычислительных ресурсов), из-за которого обучение робота – домработницы стоило раньше огромных денег;
• решил «сверхзадачу Минского» (произвести обратную разработку навыков, которые являются бессознательными), - ведь именно бессознательно домработница выполняет почти все работы по дому 😊 (подробней см. [4]).
Прорыв оказался возможным благодаря имитационному обучения робота. Он учится, как дети, - на основе полусотни демонстраций обучающих действий людьми (Imitation learning from human-provided demonstrations).
- как это происходит см. на видео.
Дополнительными факторами прорыва стали:
• умение согласованно использовать две руки-манипуляторы (быть эффективной однорукой домработницей весьма затруднительно);
• контроль всего тела (а не только рук) при выполнении мобильных задач (попробуйте, например, без этого просто собрать разбросанные по дому вещи).
Стоимость прототипа такой домработницы всего $32 тыс. На Trossenrobotics уже предлагают за $20 тыс. Ну а при массовом производстве снизить цену на порядок – как нечего делать.
И тогда через пяток лет роботы – домработницы могут стать столь же распространенными, как сейчас пылесосы - т.е. есть у всех.
При таком раскладе Илону Маску, возможно, стоит забить на разработку своих андроидов в стиле Голливуда и переключиться на невзрачных, но простых и полезных механических домработниц.
#Роботы
1 https://www.youtube.com/watch?v=ysZCGhgZTsA
2 https://www.youtube.com/watch?v=WJ2WTYS33Lo
3 https://mobile-aloha.github.io/
4 https://t.iss.one/theworldisnoteasy/1854
Первый в мире робот – домработница: уборка, стирка, уход, готовка, мытье посуды и т.д.
Пока мы праздновали, в мире случился реальный прорыв в робототехнике, сопоставимый с «революцией ChatGPT» (см. видео на англ [1] и с переводом [2])
Робот Mobile Aloha - разработка Стэнфордского универа [3]:
• преодолел «парадокс Моравека» (высококогнитивные процессы требуют относительно мало вычислений, а низкоуровневые сенсомоторные операции требуют огромных вычислительных ресурсов), из-за которого обучение робота – домработницы стоило раньше огромных денег;
• решил «сверхзадачу Минского» (произвести обратную разработку навыков, которые являются бессознательными), - ведь именно бессознательно домработница выполняет почти все работы по дому 😊 (подробней см. [4]).
Прорыв оказался возможным благодаря имитационному обучения робота. Он учится, как дети, - на основе полусотни демонстраций обучающих действий людьми (Imitation learning from human-provided demonstrations).
- как это происходит см. на видео.
Дополнительными факторами прорыва стали:
• умение согласованно использовать две руки-манипуляторы (быть эффективной однорукой домработницей весьма затруднительно);
• контроль всего тела (а не только рук) при выполнении мобильных задач (попробуйте, например, без этого просто собрать разбросанные по дому вещи).
Стоимость прототипа такой домработницы всего $32 тыс. На Trossenrobotics уже предлагают за $20 тыс. Ну а при массовом производстве снизить цену на порядок – как нечего делать.
И тогда через пяток лет роботы – домработницы могут стать столь же распространенными, как сейчас пылесосы - т.е. есть у всех.
При таком раскладе Илону Маску, возможно, стоит забить на разработку своих андроидов в стиле Голливуда и переключиться на невзрачных, но простых и полезных механических домработниц.
#Роботы
1 https://www.youtube.com/watch?v=ysZCGhgZTsA
2 https://www.youtube.com/watch?v=WJ2WTYS33Lo
3 https://mobile-aloha.github.io/
4 https://t.iss.one/theworldisnoteasy/1854
YouTube
Google AI new robot Mobile Aloha Stunned the industry | AI News
Researchers unveil Mobile Aloha - a revolutionary robot showcasing tremendous advancements in mobility, manipulation, and autonomous learning. See how it uses teleoperation and behavioral cloning to rapidly acquire mobile manipulation skills like cooking…
Всех учите программированию: детей, взрослых и ИИ.
Это универсальный когнитивный гаджет турбонаддува мышления любого типа разума.
То, что программирование формирует какой-то новый, эффективный когнитивный гаджет в разуме людей, пишут уже 6+ лет. Но то, что этот когнитивный гаджет универсальный (годится не только для человеческого, но и для небиологического разума), становится понятно лишь теперь, - когда на Земле появился 2й носитель высшего разума – машина генеративного ИИ больших языковых моделей (LLM).
https://disk.yandex.ru/i/F_3xT_jM65hfNg
В вопросах схожести интеллекта людей и машин все больше тумана.
• С одной стороны, полно примеров несопоставимости интеллекта людей и LLM. Похоже, что у нас и у них совсем разные типы интеллекта, отличающиеся куда больше, чем у людей и дельфинов. И потому любая антропоморфизация интеллекта LLM иррелевантна.
• С другой - выявляются все более поразительные факты в пользу схожести интеллектов людей и LLM. Даже в самом главном для высшего разума – в способах совершенствования когнитивных навыков интеллектуальных агентов.
Вот очередной мега-сюрприз, вынесенный в заголовок поста.
Исследовательская группа профессора Чэнсян Чжая в Университете Иллинойса Урбана-Шампейн уже в этом году опубликовала интереснейшую работу «Если LLM — волшебник, то программный код — его волшебная палочка: обзор исследований того, как код позволяет использовать большие языковые модели в качестве интеллектуальных агентов» [1].
Идея, что если учить LLM не только на текстах естественных языков, но и на программном коде, они будут сильно умнее, - не 1й год интересует разработчиков LLM. Команда Чэнсян Чжая подняла весь корпус опубликованных в 2021-2023 работ на эту тему, классифицировала, проанализировала и обобщила «сухой остаток» всех этих работ.
Он таков.
1. Включение кода в обучение LLM повышает их навыки программирования, позволяя им писать и оценивать код на нескольких языках.
2. LLM демонстрируют улучшенные навыки сложного рассуждения и «цепочки мыслей», полезные для разбивки и решения сложных задач.
3. Обучение с использованием кода расширяет возможности LLM понимать и генерировать контент с помощью структурированных данных, таких как HTML или таблицы.
4. Обученные коду LLM превращаются в продвинутых интеллектуальных агентов, способных принимать решения и выполнять сложные задачи с использованием различных инструментов и API. Повышение когнитивных способностей достигается за счет:
усложнения мыслительного процессы у LLM (их способности к рассуждению при решении более сложных задач на естественном языке);
улучшения способности структурированного сбора знаний (создания структурированных и точных промежуточных шагов, которые затем, например, можно связать с результатами внешнего выполнения посредством вызовов процедур или функций).
Т.е. по сути, все это выглядит, как появление у LLM эмерджентных качеств интеллектуальных агентов в ситуациях, когда способности понимать инструкции, декомпозировать цели, планировать и выполнять действия, а также уточнять их на основе обратной связи имеют решающее значение для их успеха в последующих задачах.
Аналогичное мета-исследование про людей «The Cognitive Benefits of Learning Computer Programming: A Meta-Analysis of Transfer Effects» опубликовано в 2018 [2]. Его выводы весьма похожи, с поправкой на кардинально иной тип разума людей: изучение программирования может улучшить у людей творческое мышление, решение математических задач, понимание того, как они мыслят и т.д.
Новое исследование говорит об универсальности когнитивного гаджета навыков программирования в качестве усилителя любого типа мышления.
Суть в том, что код обладает последовательной читаемостью естественного языка и в то же время воплощает в себе абстракцию и графовую структуру символических представлений, что делает его проводником восприятия и осмысления знаний.
Так что, учите всех программировать!!!
1 https://arxiv.org/pdf/2401.00812.pdf
2 https://gwern.net/doc/psychology/2019-scherer.pdf
#LLM #Разум
Это универсальный когнитивный гаджет турбонаддува мышления любого типа разума.
То, что программирование формирует какой-то новый, эффективный когнитивный гаджет в разуме людей, пишут уже 6+ лет. Но то, что этот когнитивный гаджет универсальный (годится не только для человеческого, но и для небиологического разума), становится понятно лишь теперь, - когда на Земле появился 2й носитель высшего разума – машина генеративного ИИ больших языковых моделей (LLM).
https://disk.yandex.ru/i/F_3xT_jM65hfNg
В вопросах схожести интеллекта людей и машин все больше тумана.
• С одной стороны, полно примеров несопоставимости интеллекта людей и LLM. Похоже, что у нас и у них совсем разные типы интеллекта, отличающиеся куда больше, чем у людей и дельфинов. И потому любая антропоморфизация интеллекта LLM иррелевантна.
• С другой - выявляются все более поразительные факты в пользу схожести интеллектов людей и LLM. Даже в самом главном для высшего разума – в способах совершенствования когнитивных навыков интеллектуальных агентов.
Вот очередной мега-сюрприз, вынесенный в заголовок поста.
Исследовательская группа профессора Чэнсян Чжая в Университете Иллинойса Урбана-Шампейн уже в этом году опубликовала интереснейшую работу «Если LLM — волшебник, то программный код — его волшебная палочка: обзор исследований того, как код позволяет использовать большие языковые модели в качестве интеллектуальных агентов» [1].
Идея, что если учить LLM не только на текстах естественных языков, но и на программном коде, они будут сильно умнее, - не 1й год интересует разработчиков LLM. Команда Чэнсян Чжая подняла весь корпус опубликованных в 2021-2023 работ на эту тему, классифицировала, проанализировала и обобщила «сухой остаток» всех этих работ.
Он таков.
1. Включение кода в обучение LLM повышает их навыки программирования, позволяя им писать и оценивать код на нескольких языках.
2. LLM демонстрируют улучшенные навыки сложного рассуждения и «цепочки мыслей», полезные для разбивки и решения сложных задач.
3. Обучение с использованием кода расширяет возможности LLM понимать и генерировать контент с помощью структурированных данных, таких как HTML или таблицы.
4. Обученные коду LLM превращаются в продвинутых интеллектуальных агентов, способных принимать решения и выполнять сложные задачи с использованием различных инструментов и API. Повышение когнитивных способностей достигается за счет:
усложнения мыслительного процессы у LLM (их способности к рассуждению при решении более сложных задач на естественном языке);
улучшения способности структурированного сбора знаний (создания структурированных и точных промежуточных шагов, которые затем, например, можно связать с результатами внешнего выполнения посредством вызовов процедур или функций).
Т.е. по сути, все это выглядит, как появление у LLM эмерджентных качеств интеллектуальных агентов в ситуациях, когда способности понимать инструкции, декомпозировать цели, планировать и выполнять действия, а также уточнять их на основе обратной связи имеют решающее значение для их успеха в последующих задачах.
Аналогичное мета-исследование про людей «The Cognitive Benefits of Learning Computer Programming: A Meta-Analysis of Transfer Effects» опубликовано в 2018 [2]. Его выводы весьма похожи, с поправкой на кардинально иной тип разума людей: изучение программирования может улучшить у людей творческое мышление, решение математических задач, понимание того, как они мыслят и т.д.
Новое исследование говорит об универсальности когнитивного гаджета навыков программирования в качестве усилителя любого типа мышления.
Суть в том, что код обладает последовательной читаемостью естественного языка и в то же время воплощает в себе абстракцию и графовую структуру символических представлений, что делает его проводником восприятия и осмысления знаний.
Так что, учите всех программировать!!!
1 https://arxiv.org/pdf/2401.00812.pdf
2 https://gwern.net/doc/psychology/2019-scherer.pdf
#LLM #Разум
Яндекс Диск
Универсальный когнитивный гаджет программирования.jpg
Посмотреть и скачать с Яндекс Диска