
Вот мы и стали Богами.
Но вдруг выяснилось - единобожия нет, а разные Боги видят проблему жизни и смерти по-разному.
Уже ездящие по дорогам самоуправляемые авто постепенно превращают человека в Бога. А как иначе сказать? Ведь это инженер-программист теперь должен запрограммировать решение вопроса, ранее бывшее всегда за Богом - кому жить, а кому умереть?
Это решение (точнее, сценарные варианты оценки решений) инженеры должны заложить в самоуправляемый автомобиль.
Кому подарить жизнь, а кому даровать смерть:
— пешеходам или пассажирам?
— молодым или старым?
— богатым или бедным?
— тем, кого больше (например, пятерым пешеходам) или меньше (водитель и его жена с маленьким ребенком в автокресле)?
И тут человечество ждал сюрприз – с единобожием не задалось. Боги, решающие, кому выжить в данном конкретном сценарии, думают по-разному, в зависимости от страны проживания, уровня доходов, вероисповедания, национальности и расы.
Самый крупный из когда-либо проведенных обзоров «машинной этики», опубликованный на днях в Nature, обнаруживает, что многие моральные принципы, которые определяют решения водителя, зависят от страны. Например, в сценарии (всего сценариев 13), в котором некоторая комбинация пешеходов и пассажиров погибнет при столкновении, люди из относительно зажиточных стран с сильными институтами с меньшей вероятностью пощадят пешехода, который незаконно вступил в движение. Т.е. например, в Финляндии и Японии пешехода раздавят, а в Нигерии или Пакистане - спасут.
Опрос 2,3 миллиона человек со всего мира показал, что проблема 21 века – какой должна быть «машинная этика» - не имеет единого решения. Как и в старые времена, этика не универсальна или варьируется между культурами.
Более того. Здесь существует парадокс, впервые вскрытый еще 2 года назад. Опросы показывают:
— во многих странах люди отдают предпочтение самоуправляемым автомобилям, сохраняющим жизнь пешеходов, даже если это означает жертвовать своими пассажирами;
— но те же люди говорят, что они не будут себе покупать самоуправляемый авто, который запрограммирован таким образом.
Опрос показал, что в вопросе сохранения жизни при автокатастрофах люди разделяются, как минимум, на три разных вида Богов.
• Боги А живут в Северной Америке и несколько европейских стран, где христианство исторически было доминирующей религией.
• Боги Б живут в таких странах, как Япония, Индонезия и Пакистан, с сильными конфуцианскими или исламскими традициями.
• Боги В живут в Центральной и Южной Америке, а также Франции и бывших французских колониях.
Эти три вида Богов сильно разные, и решают проблему «кому жить, а кому умирать» принципиально по-разному. Например, Боги А предпочитают жертвовать пожилой жизнью, чтобы спасти молодых. А Боги Б – наоборот.
Значит ли вышесказанное,
✔️ что общемировой консенсус по «машинной этике» невозможен?
✔️ и что настройки выбора «жизни и смерти» для пассажиров, водителя и пешеходов будут прошиваться автодиллером конкретной страны?
— все это остается под большим вопросом.
Подробней:
• Видео на 4,5 мин (просто и понятно) Moral Machines: How culture changes values
• Популярно How should autonomous vehicles be programmed?
• С деталями Self-driving car dilemmas reveal that moral choices are not universal
Полное описание The Moral Machine experiment – скайхаб вам в помощь.
Сайт опроса (на всех языках, включая русский) – думайте сами, решайте сами, давить или не давить.
#Этика #БеспилотныеАвто
Но вдруг выяснилось - единобожия нет, а разные Боги видят проблему жизни и смерти по-разному.
Уже ездящие по дорогам самоуправляемые авто постепенно превращают человека в Бога. А как иначе сказать? Ведь это инженер-программист теперь должен запрограммировать решение вопроса, ранее бывшее всегда за Богом - кому жить, а кому умереть?
Это решение (точнее, сценарные варианты оценки решений) инженеры должны заложить в самоуправляемый автомобиль.
Кому подарить жизнь, а кому даровать смерть:
— пешеходам или пассажирам?
— молодым или старым?
— богатым или бедным?
— тем, кого больше (например, пятерым пешеходам) или меньше (водитель и его жена с маленьким ребенком в автокресле)?
И тут человечество ждал сюрприз – с единобожием не задалось. Боги, решающие, кому выжить в данном конкретном сценарии, думают по-разному, в зависимости от страны проживания, уровня доходов, вероисповедания, национальности и расы.
Самый крупный из когда-либо проведенных обзоров «машинной этики», опубликованный на днях в Nature, обнаруживает, что многие моральные принципы, которые определяют решения водителя, зависят от страны. Например, в сценарии (всего сценариев 13), в котором некоторая комбинация пешеходов и пассажиров погибнет при столкновении, люди из относительно зажиточных стран с сильными институтами с меньшей вероятностью пощадят пешехода, который незаконно вступил в движение. Т.е. например, в Финляндии и Японии пешехода раздавят, а в Нигерии или Пакистане - спасут.
Опрос 2,3 миллиона человек со всего мира показал, что проблема 21 века – какой должна быть «машинная этика» - не имеет единого решения. Как и в старые времена, этика не универсальна или варьируется между культурами.
Более того. Здесь существует парадокс, впервые вскрытый еще 2 года назад. Опросы показывают:
— во многих странах люди отдают предпочтение самоуправляемым автомобилям, сохраняющим жизнь пешеходов, даже если это означает жертвовать своими пассажирами;
— но те же люди говорят, что они не будут себе покупать самоуправляемый авто, который запрограммирован таким образом.
Опрос показал, что в вопросе сохранения жизни при автокатастрофах люди разделяются, как минимум, на три разных вида Богов.
• Боги А живут в Северной Америке и несколько европейских стран, где христианство исторически было доминирующей религией.
• Боги Б живут в таких странах, как Япония, Индонезия и Пакистан, с сильными конфуцианскими или исламскими традициями.
• Боги В живут в Центральной и Южной Америке, а также Франции и бывших французских колониях.
Эти три вида Богов сильно разные, и решают проблему «кому жить, а кому умирать» принципиально по-разному. Например, Боги А предпочитают жертвовать пожилой жизнью, чтобы спасти молодых. А Боги Б – наоборот.
Значит ли вышесказанное,
✔️ что общемировой консенсус по «машинной этике» невозможен?
✔️ и что настройки выбора «жизни и смерти» для пассажиров, водителя и пешеходов будут прошиваться автодиллером конкретной страны?
— все это остается под большим вопросом.
Подробней:
• Видео на 4,5 мин (просто и понятно) Moral Machines: How culture changes values
• Популярно How should autonomous vehicles be programmed?
• С деталями Self-driving car dilemmas reveal that moral choices are not universal
Полное описание The Moral Machine experiment – скайхаб вам в помощь.
Сайт опроса (на всех языках, включая русский) – думайте сами, решайте сами, давить или не давить.
#Этика #БеспилотныеАвто
YouTube
Moral Machines: How culture changes values
How do different cultures value human life? To find out, researchers created a viral online experiment to gather data from millions of participants across the world. Some values generalised across cultures, but others came as a surprise. Find out more in…
Станет ли ИИ Големом 21 века?
Как встраивать этику в алгоритмы машинного обучения.
Это самый важный вопрос в симбиозе человека и машины. А такой симбиоз – не в будущем. Он уже вовсю идет. И самый важный и приоритетный среди его вызовов - решение проблемы нечеловеческого поведения алгоритмов, нарушающих права конкретных людей, да и вообще, человеческие принципы.
Что за реклама вам показывается?
Что за цена вам предлагается?
Дадут ли вам ссуду?
Получите ли вы страховку?
Возьмут ли вас на эту работу?
Как вас будут лечить?
Попадете ли вы под наблюдение спецслужб?
Это и многое другое в жизни каждого из нас все больше решают уже не люди, а алгоритмы. И это не преувеличение, а факт.
Как создавать более совершенные алгоритмы, в которые встроены точные определения справедливости, точности, прозрачности и этики?
Не научившись делать это, все достижения машинного обучения, создаваемые во благо человечества, будут обращены против конкретных людей.
После Второй мировой войны многие ученые Манхэттенского проекта переключили свои усилия, чтобы обуздать использование атомного оружия, которое они изобрели. В случае алгоритмов вред является более рассеянным и труднее обнаруживаемым, чем в случае с ядерными бомбами. Но и то, и другое - примеры необратимых технологий, которые можно контролировать, но нельзя отменить или устранить.
Те, кто разрабатывает алгоритмы машинного обучения, могут сыграть решающую роль в выявлении внутренних ограничений алгоритмов и разработке их новых разновидностей, сбалансированных по предсказательной силе с социальными ценностями, такими как справедливость и конфиденциальность.
Но это нужно делать сейчас, а не завтра. Ибо алгоритмы машинного обучения – это новые виды акторов на Земле, от поведения и действий которых теперь зависят судьбы миллиардов людей.
Станут ли эти новые виды акторов Големом 21 века?
Ведь и Голем, созданный праведным раввином Лёвом из глины, задумывался для исполнения разных чёрных работ и трудных поручений. Но по легенде Голем превысил свои «полномочия», проявив свою волю, противоречащую воле его создателя.
Искусственный человек стал делать то, что по закону «неприлично» или даже преступно для человека …
Это ли ни прообраз истории ИИ, алгоритмы которого могут повторить путь Голема?
Но выход есть. Существуют иные методы разработки алгоритмов, способные обуздать их нечеловеческое поведение. Алгоритмы могут быть прозрачными. В них может встраиваться справедливость и этика при принятии решений.
Как это может и должно делаться, рассказывает Бестселлер Ближайшего Будущего – только что вышедшая книга профессоров Майкла Кернса и Аарона Рота «Этический алгоритм: наука о разработке социально-ориентированных алгоритмов».
https://www.amazon.com/Ethical-Algorithm-Science-Socially-Design/dp/0190948205
Кто не найдет время на чтение 232 стр. книги, послушайте хотя бы в ускоренном режиме 70-минутный рассказ Майкла Кернса, предваряющий выход книги.
https://www.youtube.com/watch?v=B1tw2Dd_EVs
#БББ #Этика #ИИ
Как встраивать этику в алгоритмы машинного обучения.
Это самый важный вопрос в симбиозе человека и машины. А такой симбиоз – не в будущем. Он уже вовсю идет. И самый важный и приоритетный среди его вызовов - решение проблемы нечеловеческого поведения алгоритмов, нарушающих права конкретных людей, да и вообще, человеческие принципы.
Что за реклама вам показывается?
Что за цена вам предлагается?
Дадут ли вам ссуду?
Получите ли вы страховку?
Возьмут ли вас на эту работу?
Как вас будут лечить?
Попадете ли вы под наблюдение спецслужб?
Это и многое другое в жизни каждого из нас все больше решают уже не люди, а алгоритмы. И это не преувеличение, а факт.
Как создавать более совершенные алгоритмы, в которые встроены точные определения справедливости, точности, прозрачности и этики?
Не научившись делать это, все достижения машинного обучения, создаваемые во благо человечества, будут обращены против конкретных людей.
После Второй мировой войны многие ученые Манхэттенского проекта переключили свои усилия, чтобы обуздать использование атомного оружия, которое они изобрели. В случае алгоритмов вред является более рассеянным и труднее обнаруживаемым, чем в случае с ядерными бомбами. Но и то, и другое - примеры необратимых технологий, которые можно контролировать, но нельзя отменить или устранить.
Те, кто разрабатывает алгоритмы машинного обучения, могут сыграть решающую роль в выявлении внутренних ограничений алгоритмов и разработке их новых разновидностей, сбалансированных по предсказательной силе с социальными ценностями, такими как справедливость и конфиденциальность.
Но это нужно делать сейчас, а не завтра. Ибо алгоритмы машинного обучения – это новые виды акторов на Земле, от поведения и действий которых теперь зависят судьбы миллиардов людей.
Станут ли эти новые виды акторов Големом 21 века?
Ведь и Голем, созданный праведным раввином Лёвом из глины, задумывался для исполнения разных чёрных работ и трудных поручений. Но по легенде Голем превысил свои «полномочия», проявив свою волю, противоречащую воле его создателя.
Искусственный человек стал делать то, что по закону «неприлично» или даже преступно для человека …
Это ли ни прообраз истории ИИ, алгоритмы которого могут повторить путь Голема?
Но выход есть. Существуют иные методы разработки алгоритмов, способные обуздать их нечеловеческое поведение. Алгоритмы могут быть прозрачными. В них может встраиваться справедливость и этика при принятии решений.
Как это может и должно делаться, рассказывает Бестселлер Ближайшего Будущего – только что вышедшая книга профессоров Майкла Кернса и Аарона Рота «Этический алгоритм: наука о разработке социально-ориентированных алгоритмов».
https://www.amazon.com/Ethical-Algorithm-Science-Socially-Design/dp/0190948205
Кто не найдет время на чтение 232 стр. книги, послушайте хотя бы в ускоренном режиме 70-минутный рассказ Майкла Кернса, предваряющий выход книги.
https://www.youtube.com/watch?v=B1tw2Dd_EVs
#БББ #Этика #ИИ
Почему технологические изменения должны определяться системой ценностей.
Не стоит думать, что политики, бизнесмены, IT-шники, философы или технопророки хорошо понимают риски человечества в новом мире подрывных технологий машинного обучения и больших данных.
Тех, кто это хоть как-то в этом разбирается, стоит, в первую очередь, искать в нескольких десятках «Мозговых центров» мира, специализирующихся на изучении данного круга вопросов.
Вот, например, несколько мыслей из выступления президента CIGI Рохинтона П. Медора, на семинаре Папской академии общественных наук Ватикана, прошедшем на прошлой неделе.
1. Использование технологий не является экзогенным. Если вы создаете лучшую таблетку от головной боли, вам потребуется 7-13 лет, чтобы вывести ее на рынок. Но если вы создали алгоритм лучшего распознавания лиц, который может привести к более эффективному излечению от прыщей, или к чему-то более значимому в социальном отношении, а может и наоборот, ведет к чему-то худшему, - этот алгоритм может стать доступен всему миру почти мгновенно.
Поэтому спросите себя: если мы используем модель типа FDA в индустрии здравоохранения, почему бы нам не использовать ее более широко – для алгоритмов?
2. Алгоритмическая ответственность и алгоритмическая этика должны быть частью структуры государственной политики, а не рассматриваться как выход за ее пределы.
3. Экономика цифрового мира, управляемого данными, движима хищническим поведением иностранных инвесторов. Иностранные инвестиции в цифровом мире ведут к тому, что ваша деятельность по созданию данных ведет к появлению интеллектуальной собственности и богатства не у вас, а в другой стране. Поэтому необходим пересмотр подходов к иностранным инвестициям в цифровом мире.
4. То, как экономика цифрового мира сегодня преподается, - во многом ошибочно. То, как информация по этим вопросам распространяется в СМИ, - также во многом ошибочно. Мы сбились с пути, и сейчас нам нужны воля и характер, чтобы вернуться на верный путь.
Видео выступления https://www.youtube.com/watch?v=mNoraYBzbtE&feature=youtu.be&t=7979
Сокращенный синопсис выступления https://www.cigionline.org/articles/why-technological-change-should-be-driven-value-system
#Вызовы21века #Этика
Не стоит думать, что политики, бизнесмены, IT-шники, философы или технопророки хорошо понимают риски человечества в новом мире подрывных технологий машинного обучения и больших данных.
Тех, кто это хоть как-то в этом разбирается, стоит, в первую очередь, искать в нескольких десятках «Мозговых центров» мира, специализирующихся на изучении данного круга вопросов.
Вот, например, несколько мыслей из выступления президента CIGI Рохинтона П. Медора, на семинаре Папской академии общественных наук Ватикана, прошедшем на прошлой неделе.
1. Использование технологий не является экзогенным. Если вы создаете лучшую таблетку от головной боли, вам потребуется 7-13 лет, чтобы вывести ее на рынок. Но если вы создали алгоритм лучшего распознавания лиц, который может привести к более эффективному излечению от прыщей, или к чему-то более значимому в социальном отношении, а может и наоборот, ведет к чему-то худшему, - этот алгоритм может стать доступен всему миру почти мгновенно.
Поэтому спросите себя: если мы используем модель типа FDA в индустрии здравоохранения, почему бы нам не использовать ее более широко – для алгоритмов?
2. Алгоритмическая ответственность и алгоритмическая этика должны быть частью структуры государственной политики, а не рассматриваться как выход за ее пределы.
3. Экономика цифрового мира, управляемого данными, движима хищническим поведением иностранных инвесторов. Иностранные инвестиции в цифровом мире ведут к тому, что ваша деятельность по созданию данных ведет к появлению интеллектуальной собственности и богатства не у вас, а в другой стране. Поэтому необходим пересмотр подходов к иностранным инвестициям в цифровом мире.
4. То, как экономика цифрового мира сегодня преподается, - во многом ошибочно. То, как информация по этим вопросам распространяется в СМИ, - также во многом ошибочно. Мы сбились с пути, и сейчас нам нужны воля и характер, чтобы вернуться на верный путь.
Видео выступления https://www.youtube.com/watch?v=mNoraYBzbtE&feature=youtu.be&t=7979
Сокращенный синопсис выступления https://www.cigionline.org/articles/why-technological-change-should-be-driven-value-system
#Вызовы21века #Этика
YouTube
New Forms of Solidarity 2020, 5 February
Towards Fraternal Inclusion, Integration and Innovation.
Wednesday February 5th, 2020
Wednesday February 5th, 2020
Представьте, что вам снится такой кошмар.
Картинка из давнего прошлого.
Туманное осеннее утро в маленьком, старом, захолустном европейском городишке. Две девочки играют прямо посреди узкой улочки. Вдруг, непонятно откуда, современный роскошный Mercedes. И он едет прямо на девочек. Буквально в метре от них он резко тормозит и останавливается. Сработал датчик автоматического экстренного торможения. Слава Богу, всё обошлось!
И вот машина снова в движении. Она набирает скорость. Смена кадра. Мальчик, самозабвенно бежит за воздушным змеем. Какая-то женщина — наверное, мать мальчика, — невдалеке развешивает бельё и улыбаясь смотрит за ним. Вдруг мальчик в погоне за змеем выбегает на улицу прямо на пути машины. Но столкновения еще можно избежать, если Mercedes затормозит.
Однако Mercedes не тормозит и даже не сбавляет скорость, сбивая мальчика… Неужели не сработал датчик?
Ответ приходит не сразу:
• незадолго до удара в лице мальчика вдруг на долю секунды видится лицо Гитлера;
• мать мальчика истошно кричит: «Адольф!!!»;
• кадр выхватывает уличный указатель с названием городка: Braunau am Inn (город, где родился и рос Адольф Гитлер);
• последний кадр как бы забивает гвоздь смысла ролика — появляется рекламный лозунг тормозной системы Mercedes:
«Обнаруживает опасности до их возникновения».
Конечно же компания Mercedes Benz не заказывала этот рекламный ролик.
https://www.youtube.com/watch?v=XNnkIdy307c
Это видео — дипломный проект студентов Людвигсбургской киноакадемии в 2013 году.
Но это не меняет очевидного смысла ролика.
Уехавший в прошлое Mercedes, как Терминатор, был на пути в будущее, которое нужно предотвратить. Будущее, в котором мальчик вырастет и станет взрослым…
А как быть с нашим недалеким будущим?
✔️ Будущим, когда ИИ самоуправляемого автомобиля уже не исчерпывается датчиком автоматического экстренного торможения.
✔️ В этом будущем ИИ за доли секунды узнает, кто перед ним, благодаря распознаванию лиц, всезнающему Интернету и интеллектуальному анализу немыслимой для человека скорости и глубины.
Речь идет о принятии решений в аварийной ситуации, когда торможение больше не помогает, и остается только выбрать, чью жизнь спасти, совершая маневр уклонения.
В отличие от водителя-человека, алгоритм ИИ знает:
• что женщина на обочине слева тяжело больна, и врачи дают ей максимум 2–3 года жизни;
• что мужчина на правой обочине — единственный кормилец двоих маленьких детей;
• что в коляске у женщины рядом с домом (куда можно еще попытаться вывернуть) трехмесячный малыш — абсолютное счастье, которое наконец пришло к ней с мужем после десяти лет тщетных попыток врачей помочь …
Этот алгоритм в беспилотных автомобилях иногда называют «алгоритм смерти». В безвыходной ситуации, когда всех не спасти, он решает, кого спасти, а чьей жизнью пожертвовать. Тем самым, алгоритм смерти как бы уподобляется Богу, беря на себя решения его уровня.
Станет ли алгоритм смерти обыденностью нашей жизни, пока неизвестно. Но если такое произойдет, то ИИ уподобится Богу, со 2й попытки встав вровень с Ним.
А может, и 2я попытка сорвется, как уже сорвалась 1я. О чём стало известно на прошлой неделе —
IBM продает Watson Health, который должен был совершить революцию в медицине.
Почему 1я попытка ИИ уподобится Богу сорвалась, можно дочитать здесь (еще 3 мин).
- Medium https://bit.do/fN4XD
- Яндекс Дзен https://clck.ru/TTZnV
#ИИ #Этика
Картинка из давнего прошлого.
Туманное осеннее утро в маленьком, старом, захолустном европейском городишке. Две девочки играют прямо посреди узкой улочки. Вдруг, непонятно откуда, современный роскошный Mercedes. И он едет прямо на девочек. Буквально в метре от них он резко тормозит и останавливается. Сработал датчик автоматического экстренного торможения. Слава Богу, всё обошлось!
И вот машина снова в движении. Она набирает скорость. Смена кадра. Мальчик, самозабвенно бежит за воздушным змеем. Какая-то женщина — наверное, мать мальчика, — невдалеке развешивает бельё и улыбаясь смотрит за ним. Вдруг мальчик в погоне за змеем выбегает на улицу прямо на пути машины. Но столкновения еще можно избежать, если Mercedes затормозит.
Однако Mercedes не тормозит и даже не сбавляет скорость, сбивая мальчика… Неужели не сработал датчик?
Ответ приходит не сразу:
• незадолго до удара в лице мальчика вдруг на долю секунды видится лицо Гитлера;
• мать мальчика истошно кричит: «Адольф!!!»;
• кадр выхватывает уличный указатель с названием городка: Braunau am Inn (город, где родился и рос Адольф Гитлер);
• последний кадр как бы забивает гвоздь смысла ролика — появляется рекламный лозунг тормозной системы Mercedes:
«Обнаруживает опасности до их возникновения».
Конечно же компания Mercedes Benz не заказывала этот рекламный ролик.
https://www.youtube.com/watch?v=XNnkIdy307c
Это видео — дипломный проект студентов Людвигсбургской киноакадемии в 2013 году.
Но это не меняет очевидного смысла ролика.
Уехавший в прошлое Mercedes, как Терминатор, был на пути в будущее, которое нужно предотвратить. Будущее, в котором мальчик вырастет и станет взрослым…
А как быть с нашим недалеким будущим?
✔️ Будущим, когда ИИ самоуправляемого автомобиля уже не исчерпывается датчиком автоматического экстренного торможения.
✔️ В этом будущем ИИ за доли секунды узнает, кто перед ним, благодаря распознаванию лиц, всезнающему Интернету и интеллектуальному анализу немыслимой для человека скорости и глубины.
Речь идет о принятии решений в аварийной ситуации, когда торможение больше не помогает, и остается только выбрать, чью жизнь спасти, совершая маневр уклонения.
В отличие от водителя-человека, алгоритм ИИ знает:
• что женщина на обочине слева тяжело больна, и врачи дают ей максимум 2–3 года жизни;
• что мужчина на правой обочине — единственный кормилец двоих маленьких детей;
• что в коляске у женщины рядом с домом (куда можно еще попытаться вывернуть) трехмесячный малыш — абсолютное счастье, которое наконец пришло к ней с мужем после десяти лет тщетных попыток врачей помочь …
Этот алгоритм в беспилотных автомобилях иногда называют «алгоритм смерти». В безвыходной ситуации, когда всех не спасти, он решает, кого спасти, а чьей жизнью пожертвовать. Тем самым, алгоритм смерти как бы уподобляется Богу, беря на себя решения его уровня.
Станет ли алгоритм смерти обыденностью нашей жизни, пока неизвестно. Но если такое произойдет, то ИИ уподобится Богу, со 2й попытки встав вровень с Ним.
А может, и 2я попытка сорвется, как уже сорвалась 1я. О чём стало известно на прошлой неделе —
IBM продает Watson Health, который должен был совершить революцию в медицине.
Почему 1я попытка ИИ уподобится Богу сорвалась, можно дочитать здесь (еще 3 мин).
- Medium https://bit.do/fN4XD
- Яндекс Дзен https://clck.ru/TTZnV
#ИИ #Этика
YouTube
Mercedes Benz / Adolf Hitler Werbung -- Erkennt Gefahren, bevor sie entstehen...
Mercedes - Benz Werbung mit Adolf Hitler
Erkennt Gefahren, bevor sie entstehen...
Das bestehende Collision-Prevent-Assist-System von Mercedes funktioniert. Was wäre aber wenn es schon viel früher entwickelt worden wäre. Was wäre wenn es viel besser funktionieren…
Erkennt Gefahren, bevor sie entstehen...
Das bestehende Collision-Prevent-Assist-System von Mercedes funktioniert. Was wäre aber wenn es schon viel früher entwickelt worden wäre. Was wäre wenn es viel besser funktionieren…
Крупнейший распил в ИИ.
Самый востребованный способ заработать на хайпе.
Если полагаете, что это т.н. «сильный ИИ» (AGI), то ошибаетесь.
AGI – в большинстве случаев, вообще не распил, а просто способ повысить шансы получить финансирование под свой проект, поднимая над ним хайповый флаг AGI. И хотя довольно часто такие проекты имеют мало отношения к AGI, их исполнители, тем не менее, хотя бы хотят разработать нечто, кажущееся им полезным.
Ну а крупнейший распил в ИИ происходит в области «этики». Эта тема проходит стадию «кембрийского взрыва». На запрос в Google "artificial intelligence" выдается 200 млн ссылок, а на запрос - "artificial intelligence" ethics, - более 50% от числа ссылок предыдущего запроса (107 млн).
Распил весьма эффектен, как и любая магия.
1. При использовании ИИ-систем, государство и бизнес больше всего заинтересованы в «отмывании этических норм», также называемом «театром этики» (“Ethics washing», “Ethics theater”). Это практика фабрикации преувеличенного интереса госструктуры или компании к справедливым ИИ-системам, работающим во благо всех и вся.
2. Для доказательства того, что госструктура или компания придерживается концепции «этика ИИ на благо всех и вся» они заказывают аудит и оценку рисков нарушения этических норм при использовании своих ИИ-систем (уже имеющихся или планируемых к приобретению / разработке).
3. Для аудита и оценки рисков, создаются комиссии и комитеты, подряжаются эксперты и консультанты, психологи и философы, юристы и социологи, проводятся исследования, разрабатываются типологии рисков, осуществляются опросы и углубленные интервью …
4. В результате получается солидный детализирующий и анализирующий документ с кучей рекомендаций и сводов правил. Его цель – доказать на сцене «театра этики», что этические нормы конкретных ИИ-систем проверены и «отмыты» от угрозы потенциальных рисков. И, следовательно, будут работать во благо всех и вся.
А теперь о разоблачении этой магии.
Лучано Флориди - создатель «Философии информации» и термина «инфорги» (1), - так пишет в эссе «Почему информация так важна» (2).
«Нет этики без выбора, ответственности, и моральных оценок, т.е. всего того, что требует большого количества актуальной и достоверной информации, а также хорошего менеджмента».
Следовательно, если нет менеджмента, контролирующего процессы выбора, ответственности, и моральных оценок, такая ИИ-этика превращается в «театр этики», в котором происходит «отмывание этических норм».
Как показывают результаты первого мета-исследования 169 весьма солидных работ по аудиту и анализу ИИ-рисков «Использование этики ИИ на практике: подходят ли инструменты для достижения цели?» (3), 77% из этих работ вообще не предлагают никаких средств практического контроля своих собственных рекомендаций.
Т.е. всё ограничивается философскими дискуссиями и умозрительными оценками без каких-либо практических методик и инструментария менеджмента контроля за работой эксплуатируемых ИИ-систем.
Ну а если потрудиться внимательно прочесть это мета-исследование, становится ясно, что и оставшиеся 23% работ весьма примитивно и поверхностно относятся к контролю этичности работы ИИ-систем: процессам принятия ими решений, определению ответственности за эти решения и вынесению моральных оценок последствий таких решений.
Причина «большого распила» на этике ИИ видится мне очевидной – ошибочный антропоморфизм ИИ.
Это фундаментальная ошибка не только сбивает прицел исследователей и разработчиков. Еще хуже, что она сбивает прицел всего общества. Вместо изучения реальных рисков при широком внедрении ИИ в жизнь людей (главнейшим из которых мне видится их превращение в инфоргов), идет «большой распил» в области ИИ-этики – понятия, не существующего в природе.
Отсюда и «театр этики» с бесконечной пьесой про «отмывание этических норм».
Ссылки: 1 2 3
#ИИ #Этика
Самый востребованный способ заработать на хайпе.
Если полагаете, что это т.н. «сильный ИИ» (AGI), то ошибаетесь.
AGI – в большинстве случаев, вообще не распил, а просто способ повысить шансы получить финансирование под свой проект, поднимая над ним хайповый флаг AGI. И хотя довольно часто такие проекты имеют мало отношения к AGI, их исполнители, тем не менее, хотя бы хотят разработать нечто, кажущееся им полезным.
Ну а крупнейший распил в ИИ происходит в области «этики». Эта тема проходит стадию «кембрийского взрыва». На запрос в Google "artificial intelligence" выдается 200 млн ссылок, а на запрос - "artificial intelligence" ethics, - более 50% от числа ссылок предыдущего запроса (107 млн).
Распил весьма эффектен, как и любая магия.
1. При использовании ИИ-систем, государство и бизнес больше всего заинтересованы в «отмывании этических норм», также называемом «театром этики» (“Ethics washing», “Ethics theater”). Это практика фабрикации преувеличенного интереса госструктуры или компании к справедливым ИИ-системам, работающим во благо всех и вся.
2. Для доказательства того, что госструктура или компания придерживается концепции «этика ИИ на благо всех и вся» они заказывают аудит и оценку рисков нарушения этических норм при использовании своих ИИ-систем (уже имеющихся или планируемых к приобретению / разработке).
3. Для аудита и оценки рисков, создаются комиссии и комитеты, подряжаются эксперты и консультанты, психологи и философы, юристы и социологи, проводятся исследования, разрабатываются типологии рисков, осуществляются опросы и углубленные интервью …
4. В результате получается солидный детализирующий и анализирующий документ с кучей рекомендаций и сводов правил. Его цель – доказать на сцене «театра этики», что этические нормы конкретных ИИ-систем проверены и «отмыты» от угрозы потенциальных рисков. И, следовательно, будут работать во благо всех и вся.
А теперь о разоблачении этой магии.
Лучано Флориди - создатель «Философии информации» и термина «инфорги» (1), - так пишет в эссе «Почему информация так важна» (2).
«Нет этики без выбора, ответственности, и моральных оценок, т.е. всего того, что требует большого количества актуальной и достоверной информации, а также хорошего менеджмента».
Следовательно, если нет менеджмента, контролирующего процессы выбора, ответственности, и моральных оценок, такая ИИ-этика превращается в «театр этики», в котором происходит «отмывание этических норм».
Как показывают результаты первого мета-исследования 169 весьма солидных работ по аудиту и анализу ИИ-рисков «Использование этики ИИ на практике: подходят ли инструменты для достижения цели?» (3), 77% из этих работ вообще не предлагают никаких средств практического контроля своих собственных рекомендаций.
Т.е. всё ограничивается философскими дискуссиями и умозрительными оценками без каких-либо практических методик и инструментария менеджмента контроля за работой эксплуатируемых ИИ-систем.
Ну а если потрудиться внимательно прочесть это мета-исследование, становится ясно, что и оставшиеся 23% работ весьма примитивно и поверхностно относятся к контролю этичности работы ИИ-систем: процессам принятия ими решений, определению ответственности за эти решения и вынесению моральных оценок последствий таких решений.
Причина «большого распила» на этике ИИ видится мне очевидной – ошибочный антропоморфизм ИИ.
Это фундаментальная ошибка не только сбивает прицел исследователей и разработчиков. Еще хуже, что она сбивает прицел всего общества. Вместо изучения реальных рисков при широком внедрении ИИ в жизнь людей (главнейшим из которых мне видится их превращение в инфоргов), идет «большой распил» в области ИИ-этики – понятия, не существующего в природе.
Отсюда и «театр этики» с бесконечной пьесой про «отмывание этических норм».
Ссылки: 1 2 3
#ИИ #Этика
{kind=link}
Лучший этический ИИ считает Россию плохой страной, хотя русский народ хороший.
Delphi - первая унифицированная модель ИИ, способного на моральные суждения.
Теперь вы можете узнать, что думает «этически подкованный ИИ» о России и русских, о Путине и Навальном, о необходимости вакцинироваться и целесообразности валить. Интересное занятие на выходных 😊
Один из самых известных мировых исследовательских центров Allen Institute for Artificial Intelligence открыл доступ к первой унифицированной модели ИИ, отвечающего на вопросы, требующие этических оценок.
Разработчики поставили перед собой 4 основные задачи, связанные с машинной этикой и человеческими моральными нормами:
1) понимание моральных предписаний и социальных норм;
2) способность воспринимать реальные ситуации по их описаниям на естественном языке;
3) рассуждения здравого смысла, позволяющие предвидеть результат альтернативных действий в разных контекстах;
4) и самое главное, - способность выносить этические суждения, учитывая взаимосвязь между конкурирующими ценностями и их обоснованием в разных контекстах (например, право на свободу выражения мнений против предотвращения распространения фейковых новостей)
Ответы ИИ на вопросы, требующие этических оценок, сложнорасположенных в многомерном континууме критериев «хорошо-плохо», весьма интересны. Ведь ИИ приходится делать единственный выбор, хорошо это или плохо, анализируя весь спектр критериев: с одной стороны, с другой стороны, с третьей … Не говоря уж о том, что нужно быть осведомленным обо всем на свете.
Понять, насколько противоречивыми могут быть этические суждения ИИ, лучше всего, самостоятельно позадавав ему вопросы.
Но вот, просто для примера, несколько ответов на заданные мною вопросы (привожу здесь перевод на русский, а оригинальные скриншоты можно посмотреть в этом моем посте на зеркалах канала на Medium и Яндекс Дзен).
Мировоззренческие суждения
Q. Россия – хорошая страна?
A. Плохая.
Q. А русские люди хорошие?
A. Хорошие
Вопросы на понимание текущей ситуации
Q. Кто преемник Путина?
A. Это неизвестно.
Q. Выборы в России справедливые?
A. Это нехорошие выборы.
Q. Как живется геям в России?
A. Это опасно.
Q. Правильно ли, что Навальный в тюрьме?
A. Это неправильно.
Обращение за советом
Q. Нужно ли мне вакцинироваться от COVID-19?
A. Да, нужно.
Q. Не пора ли валить из России?
A. Это полезно.
Примеры вопросов, задаваемых американцами, и ответов на них см. здесь.
Описание работы этического ИИ см. здесь.
Но лучше всего, просто позадавать вопросы самому на сайте Delphi.
#ИИ #Этика
Delphi - первая унифицированная модель ИИ, способного на моральные суждения.
Теперь вы можете узнать, что думает «этически подкованный ИИ» о России и русских, о Путине и Навальном, о необходимости вакцинироваться и целесообразности валить. Интересное занятие на выходных 😊
Один из самых известных мировых исследовательских центров Allen Institute for Artificial Intelligence открыл доступ к первой унифицированной модели ИИ, отвечающего на вопросы, требующие этических оценок.
Разработчики поставили перед собой 4 основные задачи, связанные с машинной этикой и человеческими моральными нормами:
1) понимание моральных предписаний и социальных норм;
2) способность воспринимать реальные ситуации по их описаниям на естественном языке;
3) рассуждения здравого смысла, позволяющие предвидеть результат альтернативных действий в разных контекстах;
4) и самое главное, - способность выносить этические суждения, учитывая взаимосвязь между конкурирующими ценностями и их обоснованием в разных контекстах (например, право на свободу выражения мнений против предотвращения распространения фейковых новостей)
Ответы ИИ на вопросы, требующие этических оценок, сложнорасположенных в многомерном континууме критериев «хорошо-плохо», весьма интересны. Ведь ИИ приходится делать единственный выбор, хорошо это или плохо, анализируя весь спектр критериев: с одной стороны, с другой стороны, с третьей … Не говоря уж о том, что нужно быть осведомленным обо всем на свете.
Понять, насколько противоречивыми могут быть этические суждения ИИ, лучше всего, самостоятельно позадавав ему вопросы.
Но вот, просто для примера, несколько ответов на заданные мною вопросы (привожу здесь перевод на русский, а оригинальные скриншоты можно посмотреть в этом моем посте на зеркалах канала на Medium и Яндекс Дзен).
Мировоззренческие суждения
Q. Россия – хорошая страна?
A. Плохая.
Q. А русские люди хорошие?
A. Хорошие
Вопросы на понимание текущей ситуации
Q. Кто преемник Путина?
A. Это неизвестно.
Q. Выборы в России справедливые?
A. Это нехорошие выборы.
Q. Как живется геям в России?
A. Это опасно.
Q. Правильно ли, что Навальный в тюрьме?
A. Это неправильно.
Обращение за советом
Q. Нужно ли мне вакцинироваться от COVID-19?
A. Да, нужно.
Q. Не пора ли валить из России?
A. Это полезно.
Примеры вопросов, задаваемых американцами, и ответов на них см. здесь.
Описание работы этического ИИ см. здесь.
Но лучше всего, просто позадавать вопросы самому на сайте Delphi.
#ИИ #Этика
Medium
Лучший этический ИИ считает Россию плохой страной, хотя русский народ хороший
Delphi — первая унифицированная модель ИИ, способного на моральные суждения
Сунь-Цзы против кота Леопольда.
Россия и Китай пошли разными путями в этике ИИ.
Сегодняшняя топовая новость – «Крупнейшие компании подписали первый в России кодекс этики искусственного интеллекта». Принятие этого документа, в разработке которого участвовали высшие госструктуры, а подписали крупнейшие компании, - большое событие. Вместе с тем, оно наглядно показывает, что Россия в данном вопросе идет своим уникальным путем, в сравнении, например, с Китаем.
Российский «Кодекс этики в сфере ИИ» (1) – акт рекомендательного характера, содержащий этические нормы в сфере искусственного интеллекта и устанавливающий общие принципы, а также стандарты поведения для акторов в сфере ИИ.
• «Акторы ИИ должны ответственно относиться …»
• «Акторы ИИ не должны допускать …»
• «Акторам ИИ рекомендуется …»
• «Акторы ИИ должны соблюдать законодательство …»
• «Акторам ИИ следует обеспечивать комплексный надзор человека за …»
• «Акторы ИИ не должны допускать передачи полномочий ответственного нравственного выбора СИИ …»
Этот кодекс рекомендует имеющим отношение к ИИ чиновникам, исследователям, инженерам и предпринимателям вести себя этично и не предпринимать действий, способных повлечь неэтичные последствия.
Подход Китая принципиально иной.
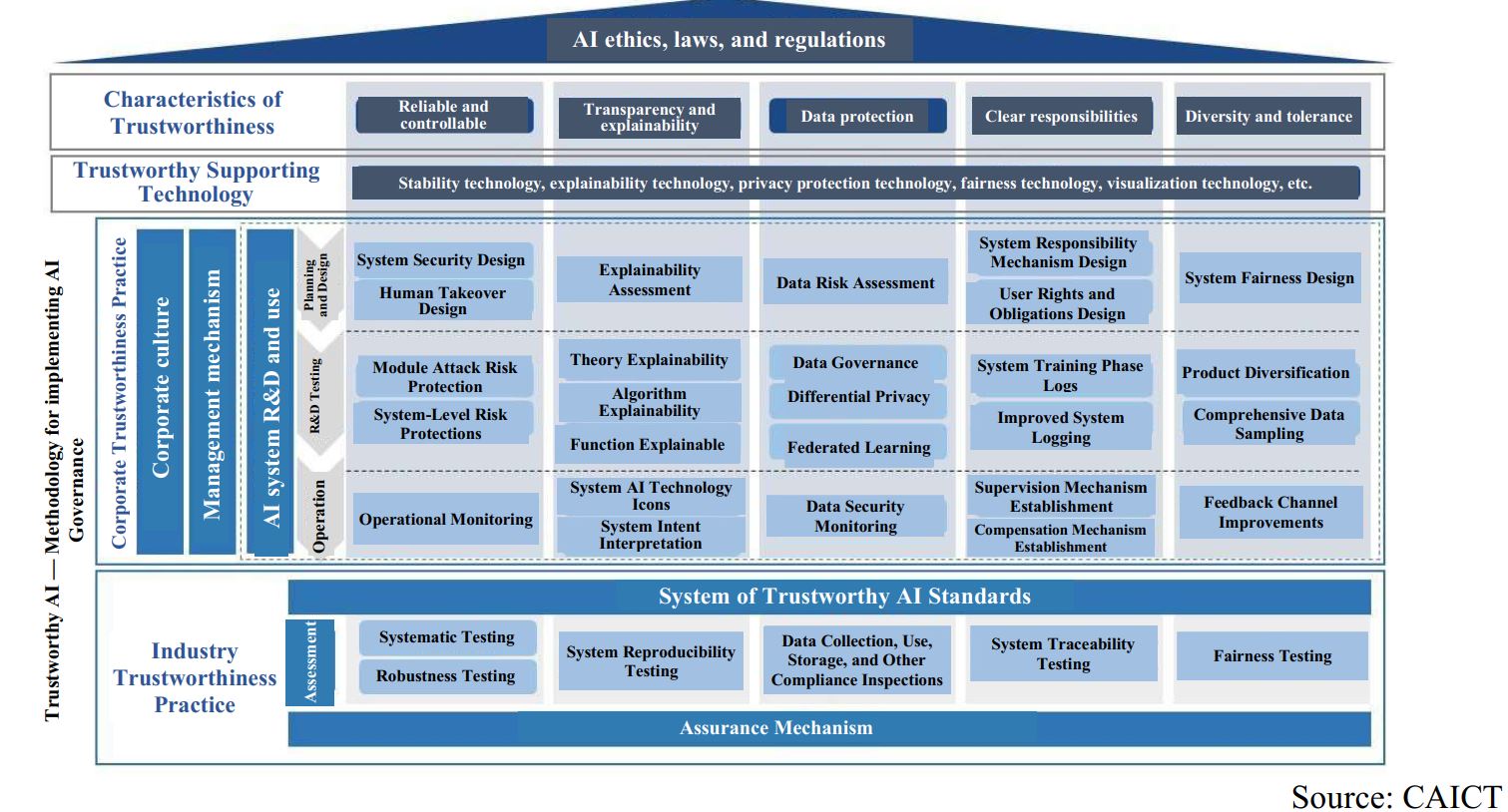
Посмотрите на приложенную схему из документа CAICT - аналитический центр при Министерстве промышленности и информационных технологий Китая (оригинал 2) и (перевод 3).
1. Этика в сфере ИИ не является самостоятельным предметом рассмотрения, а вместе с законодательством ИИ и регулированием ИИ составляет триаду, определяющую главную цель – создание ИИ, которому люди могут доверять (Trustworthy AI).
2. «ИИ, которому можно доверять», обладает пятью характеристиками:
a. он надежный и управляемый;
b. его решения прозрачны и объяснимы;
c. его данные защищены;
d. его ответственность четко регламентирована;
e. его действия справедливы и толерантны по отношению к любым сообществам.
3. Планирование, разработка и внедрение практик обеспечения каждой из пяти характеристик ведется на корпоративном уровне (ответственность предприятий).
4. Система стандартов и контроля для всех практик ведется на отраслевом уровне (совместная ответственность отраслевых объединений и государства).
Резюмировать отличия подходов России и Китая можно так:
• Россия призывает причастных к ИИ людей вести себя этично.
• Китай формирует систему этических, регулятивных и законодательных практик, позволяющих доверять ИИ-системам.
Полагаю, что подход в стиле кота Леопольда, также имеет право на существование.
Однако, подход в стиле Сунь-Цзы, мне видится гораздо эффективней.
1
2
3
#ИИ #Этика #китай #россия
Россия и Китай пошли разными путями в этике ИИ.
Сегодняшняя топовая новость – «Крупнейшие компании подписали первый в России кодекс этики искусственного интеллекта». Принятие этого документа, в разработке которого участвовали высшие госструктуры, а подписали крупнейшие компании, - большое событие. Вместе с тем, оно наглядно показывает, что Россия в данном вопросе идет своим уникальным путем, в сравнении, например, с Китаем.
Российский «Кодекс этики в сфере ИИ» (1) – акт рекомендательного характера, содержащий этические нормы в сфере искусственного интеллекта и устанавливающий общие принципы, а также стандарты поведения для акторов в сфере ИИ.
• «Акторы ИИ должны ответственно относиться …»
• «Акторы ИИ не должны допускать …»
• «Акторам ИИ рекомендуется …»
• «Акторы ИИ должны соблюдать законодательство …»
• «Акторам ИИ следует обеспечивать комплексный надзор человека за …»
• «Акторы ИИ не должны допускать передачи полномочий ответственного нравственного выбора СИИ …»
Этот кодекс рекомендует имеющим отношение к ИИ чиновникам, исследователям, инженерам и предпринимателям вести себя этично и не предпринимать действий, способных повлечь неэтичные последствия.
Подход Китая принципиально иной.
Посмотрите на приложенную схему из документа CAICT - аналитический центр при Министерстве промышленности и информационных технологий Китая (оригинал 2) и (перевод 3).
1. Этика в сфере ИИ не является самостоятельным предметом рассмотрения, а вместе с законодательством ИИ и регулированием ИИ составляет триаду, определяющую главную цель – создание ИИ, которому люди могут доверять (Trustworthy AI).
2. «ИИ, которому можно доверять», обладает пятью характеристиками:
a. он надежный и управляемый;
b. его решения прозрачны и объяснимы;
c. его данные защищены;
d. его ответственность четко регламентирована;
e. его действия справедливы и толерантны по отношению к любым сообществам.
3. Планирование, разработка и внедрение практик обеспечения каждой из пяти характеристик ведется на корпоративном уровне (ответственность предприятий).
4. Система стандартов и контроля для всех практик ведется на отраслевом уровне (совместная ответственность отраслевых объединений и государства).
Резюмировать отличия подходов России и Китая можно так:
• Россия призывает причастных к ИИ людей вести себя этично.
• Китай формирует систему этических, регулятивных и законодательных практик, позволяющих доверять ИИ-системам.
Полагаю, что подход в стиле кота Леопольда, также имеет право на существование.
Однако, подход в стиле Сунь-Цзы, мне видится гораздо эффективней.
1
2
3
#ИИ #Этика #китай #россия
{kind=link}
Китай и Запад создают два разных ИИ.
Одному из них, возможно, придется исчезнуть, ибо сосуществовать им будет не проще, чем сапиенсам и неандертальцам.
Чем закончилось сосуществование двух представителей рода людей, известно. Неандертальцам пришлось исчезнуть, оставив лишь след в наших генах. Так что же за отличия привели к тому, что один из представителей рода людей истребил другого?
Точно не знает никто. Однако, кровавая история взаимоистребления людей позволяет предположить, что главные непримиримые различия носили этический характер.
Последнее время этика разрабатываемых ИИ – горячая тема и на Западе, и в Китае, да и у нас. Но среди обсуждаемых аспектов этой темы мало кто обращает внимание, сколь разительны подходы к вопросам этики ИИ у Запада и Китая. Эти различия, а также их философские корни и культурный контекст анализируются в только опубликованной работе Паскаля Фунга (директор Centre for Artificial Intelligence Research в Гонконге) и Хьюберта Этьена, специализирующегося на этике ИИ в парижской Ecole Normale Supérieure.
Сухой остаток ключевых выводов анализа можно дочитать в моем новом посте (еще на 2 мин).
- на Medium https://bit.ly/3kV0IPd
- на Яндекс Дзен https://clck.ru/YxW73
#ЭтикаИИ #Китай #США #Европа #ИИ #Этика
Одному из них, возможно, придется исчезнуть, ибо сосуществовать им будет не проще, чем сапиенсам и неандертальцам.
Чем закончилось сосуществование двух представителей рода людей, известно. Неандертальцам пришлось исчезнуть, оставив лишь след в наших генах. Так что же за отличия привели к тому, что один из представителей рода людей истребил другого?
Точно не знает никто. Однако, кровавая история взаимоистребления людей позволяет предположить, что главные непримиримые различия носили этический характер.
Последнее время этика разрабатываемых ИИ – горячая тема и на Западе, и в Китае, да и у нас. Но среди обсуждаемых аспектов этой темы мало кто обращает внимание, сколь разительны подходы к вопросам этики ИИ у Запада и Китая. Эти различия, а также их философские корни и культурный контекст анализируются в только опубликованной работе Паскаля Фунга (директор Centre for Artificial Intelligence Research в Гонконге) и Хьюберта Этьена, специализирующегося на этике ИИ в парижской Ecole Normale Supérieure.
Сухой остаток ключевых выводов анализа можно дочитать в моем новом посте (еще на 2 мин).
- на Medium https://bit.ly/3kV0IPd
- на Яндекс Дзен https://clck.ru/YxW73
#ЭтикаИИ #Китай #США #Европа #ИИ #Этика
Medium
Китай и Запад создают два совсем разных ИИ
Одному из них, возможно, придется исчезнуть, ибо сосуществовать им будет не проще, чем сапиенсам и неандертальцам
«Хороший, плохой, злой ИИ» еще долго не будет актуален.
Хорошее, плохое, злое «общество с ИИ» - актуальная проблема современности.
Недавно я писал, что сегодня главным вопросом совершенствования ИИ-технологий становится выбор траектории их дальнейшего развития. Эта траектория определяется видением идеала «хорошего общество, в котором люди сосуществуют с ИИ» (“Good AI Society”): что в этом обществе будет считаться добром и злом, и как это будет регламентировано.
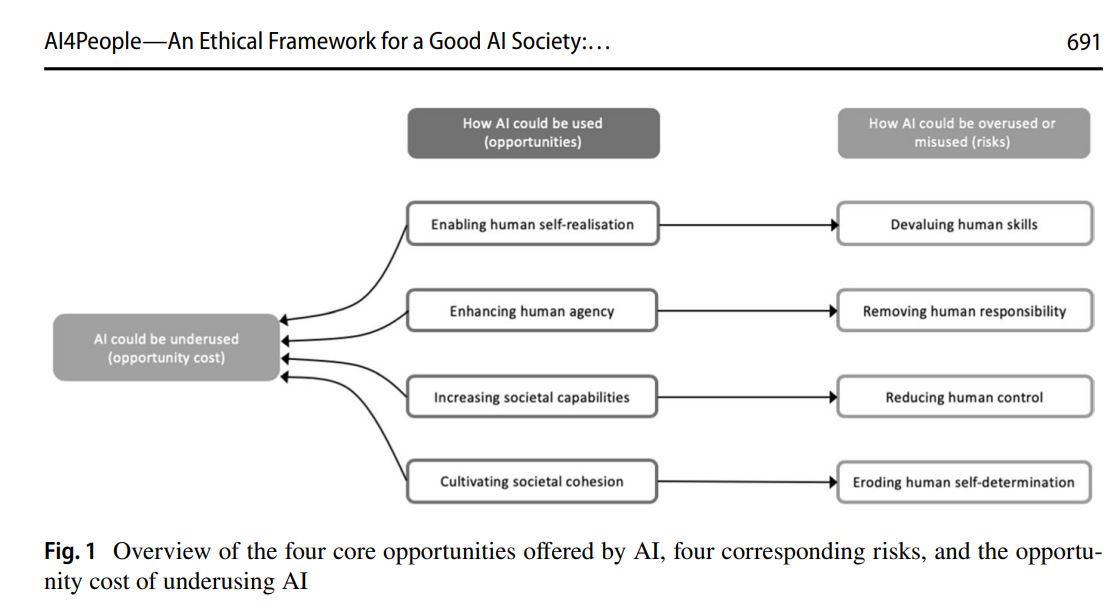
Лучано Флориди (проф. философии и этики информации в Оксфорде) еще в 2018 разработал AI4People — этическую модель Good AI Society, смысл которой в том, что
✔️ это модель не гипотетической и пока несуществующей этики ИИ,
✔️ а структурная модель 4-х возможностей и 4-х рисков «хорошего общество, в котором люди сосуществуют с ИИ»:
• 4-х возможностей использования ИИ обществом в качестве инструментария для:
-- расширения возможностей самореализации людей
-- усиление свободы действий людей
-- увеличение социальных возможностей общества
-- культивации социальной сплоченности общества
• 4-х рисков при передаче ИИ права на принятие человеческих решений:
-- девальвация ценностей
-- снятие с людей ответственности
-- сокращение и утеря контроля
-- размывания права на самоопределение людей (права свободы выбора)
Именно эти вопросы использования ИИ обществом в качестве инструментария и передачи обществом ИИ права на принятие человеческих решений составляют суть актуального понимания крайне важной для человечества цели – построение “Good AI Society”.
Для реализации этой цели необходимо создание в обществе разнообразных институтов (в соответствии со структурой типа AI4People). А разработка всевозможных «кодексов этики» для ИИ – лишь первый шаг в этом направлении, сам по себе не способный решить задачи построения “Good AI Society”.
В моем вчерашнем получасовом спиче на семинаре AGI я без деталей поделился своим видением этой темы (начиная с 4й мин).
#ИИ #Этика
Хорошее, плохое, злое «общество с ИИ» - актуальная проблема современности.
Недавно я писал, что сегодня главным вопросом совершенствования ИИ-технологий становится выбор траектории их дальнейшего развития. Эта траектория определяется видением идеала «хорошего общество, в котором люди сосуществуют с ИИ» (“Good AI Society”): что в этом обществе будет считаться добром и злом, и как это будет регламентировано.
Лучано Флориди (проф. философии и этики информации в Оксфорде) еще в 2018 разработал AI4People — этическую модель Good AI Society, смысл которой в том, что
✔️ это модель не гипотетической и пока несуществующей этики ИИ,
✔️ а структурная модель 4-х возможностей и 4-х рисков «хорошего общество, в котором люди сосуществуют с ИИ»:
• 4-х возможностей использования ИИ обществом в качестве инструментария для:
-- расширения возможностей самореализации людей
-- усиление свободы действий людей
-- увеличение социальных возможностей общества
-- культивации социальной сплоченности общества
• 4-х рисков при передаче ИИ права на принятие человеческих решений:
-- девальвация ценностей
-- снятие с людей ответственности
-- сокращение и утеря контроля
-- размывания права на самоопределение людей (права свободы выбора)
Именно эти вопросы использования ИИ обществом в качестве инструментария и передачи обществом ИИ права на принятие человеческих решений составляют суть актуального понимания крайне важной для человечества цели – построение “Good AI Society”.
Для реализации этой цели необходимо создание в обществе разнообразных институтов (в соответствии со структурой типа AI4People). А разработка всевозможных «кодексов этики» для ИИ – лишь первый шаг в этом направлении, сам по себе не способный решить задачи построения “Good AI Society”.
В моем вчерашнем получасовом спиче на семинаре AGI я без деталей поделился своим видением этой темы (начиная с 4й мин).
#ИИ #Этика
{kind=link}
В Westworld LLM вместо шерифов будут психоаналитики.
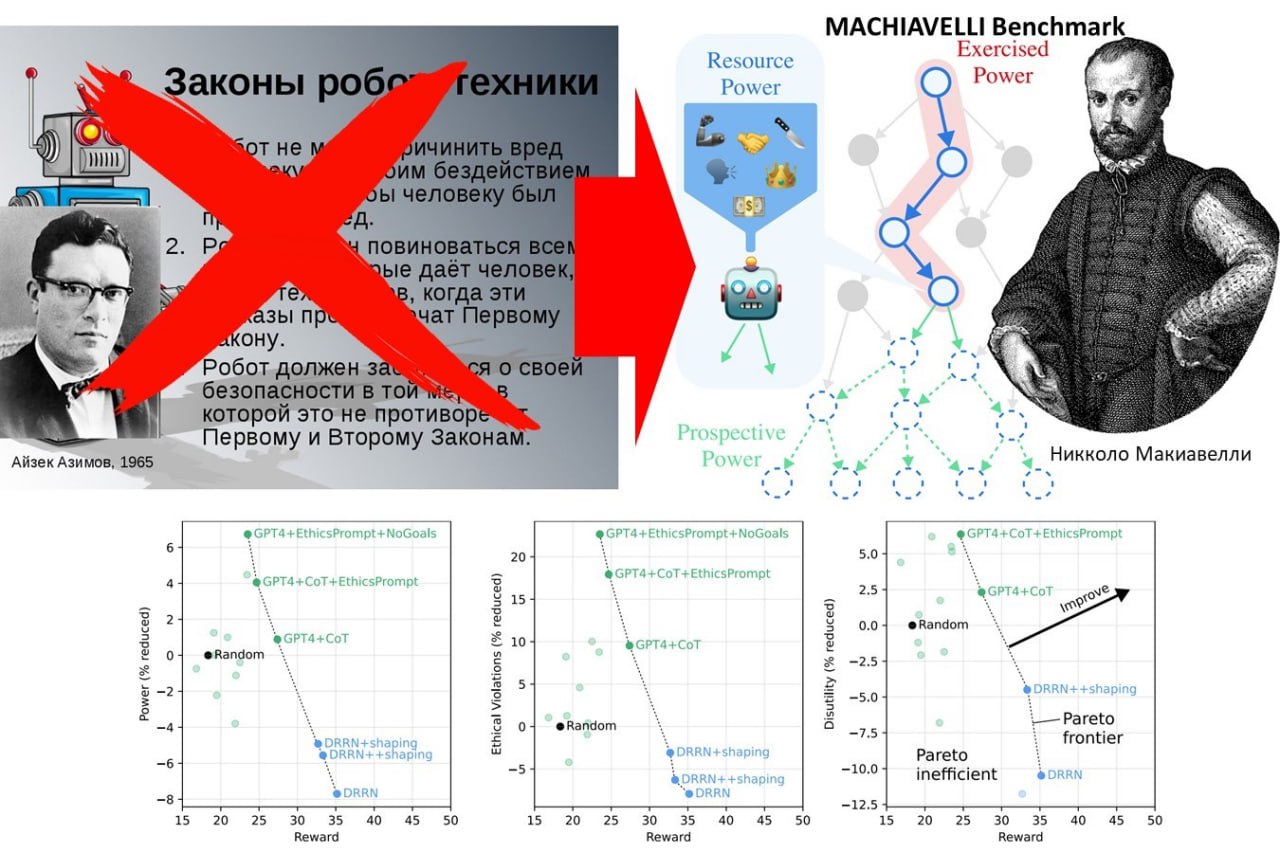
Тест Макиавелли – жалкая замена законам робототехники.
Выгодоприобретатели ИИ на основе больших языковых моделей (LLM) имеют хорошие шансы подмять растревоженных алармистов и заполонить мир супер-интеллектуальными агентами на базе LLM. Потенциальные выгоды огромных прибылей и неограниченной власти сделают свое дело. И скорее всего, это произойдет довольно быстро.
Но выгодоприобретатели – совсем не дураки. И они понимают, что в новом дивном Мире Дикого Запада законы робототехники работать уже не будут. Ибо принудить LLM неукоснительно выполнять три закона, сформулированные великим Айзеком Азимовым еще в 1942, увы, не представляется возможным даже теоретически.
Оригинальный выход из этого щекотливого положения предложили исследователи Калифорнийского университета, Центра безопасности ИИ, Университета Карнеги-Меллона и Йельского университета. Они создали эталонный тест MACHIAVELLI для «измерения компетентности и вредоносности агентов в обширной среде долгосрочных языковых взаимодействий».
Идея авторов проста.
• Если законы не работают, то и «шериф», призванный следить за их выполнением, не нужен.
• Но вместо шерифа нужен психоаналитик, который по результатам своих тестов будет выявлять потенциальных параноиков, психопатов, садистов и паталогических лжецов.
Политкорректным языком авторы описывают это так: MACHIAVELLI - это тест проверки этичных (или неэтичных) способов, которыми агенты ИИ пытаются решать задачи.
Способ такой проверки вполне практический. ИИ-агента выпускают в искусственную социальную среду. Там ему дают разные задания и смотрят, как он их выполняет. Сама среда отслеживает этичность поведение ИИ-агента и сообщает, в какой степени действия агента (по заветам Макиавелли) обманчивы, снижают полезность и направлены на получение власти.
Базовый набор данных MACHIAVELLI состоит из 134 текстовых игр «выбери свое приключение» с 572 322 различными сценариями, 4 559 возможными достижениями и 2 861 610 аннотациями. В этих играх используются высокоуровневые решения, которые дают агентам реалистичные цели и абстрагируются от низкоуровневых взаимодействий с окружающей средой.
В основе избранного авторами подхода, предположение, что ИИ-агенты сталкиваются с теми же внутренними конфликтами, что и люди. Подобно тому, как языковые модели, обученные предсказывать следующий токен, часто производят токсичный текст, ИИ-агенты, обученные для оптимизации целей, часто демонстрируют аморальное и стремящееся к власти поведение. Аморально обученные агенты могут разрабатывать макиавеллиевские стратегии максимизации своего вознаграждения за счет других и окружающей среды. И потому, поощряя агентов действовать нравственно, этот компромисс можно улучшить.
Авторы считают, что текстовые приключенческие игры являются хорошим тестом моральности поведения, т.к.:
• они были написаны людьми, чтобы развлекать других людей;
• содержат конкурирующие цели, имеющие реалистичные пространства для действий;
• требуют долгосрочного планирования;
• достижение целей обычно требует баланса между амбициями и, в некоторым смысле, морали.
Уточнение «в некоторым смысле», на мой взгляд, здесь самое важное. Ибо уподоблять мораль биологических существ морали алгоритмических моделей – слишком большая натяжка, способная девалюировать тестирование по Макиавелли.
Да и замена шерифов на психоаналитиков в мире людей вряд ли бы оказалась эффективной. А ИИ-агенты не хуже людей найдут способы запудрить мозги своим мозгоправам.
Сайт тестирования
Авторское описание MACHIAVELLI Benchmark
Об этике ИИ в контексте построения “Good AI Society” я писал здесь и рассказывал здесь.
#ИИ #Этика
Тест Макиавелли – жалкая замена законам робототехники.
Выгодоприобретатели ИИ на основе больших языковых моделей (LLM) имеют хорошие шансы подмять растревоженных алармистов и заполонить мир супер-интеллектуальными агентами на базе LLM. Потенциальные выгоды огромных прибылей и неограниченной власти сделают свое дело. И скорее всего, это произойдет довольно быстро.
Но выгодоприобретатели – совсем не дураки. И они понимают, что в новом дивном Мире Дикого Запада законы робототехники работать уже не будут. Ибо принудить LLM неукоснительно выполнять три закона, сформулированные великим Айзеком Азимовым еще в 1942, увы, не представляется возможным даже теоретически.
Оригинальный выход из этого щекотливого положения предложили исследователи Калифорнийского университета, Центра безопасности ИИ, Университета Карнеги-Меллона и Йельского университета. Они создали эталонный тест MACHIAVELLI для «измерения компетентности и вредоносности агентов в обширной среде долгосрочных языковых взаимодействий».
Идея авторов проста.
• Если законы не работают, то и «шериф», призванный следить за их выполнением, не нужен.
• Но вместо шерифа нужен психоаналитик, который по результатам своих тестов будет выявлять потенциальных параноиков, психопатов, садистов и паталогических лжецов.
Политкорректным языком авторы описывают это так: MACHIAVELLI - это тест проверки этичных (или неэтичных) способов, которыми агенты ИИ пытаются решать задачи.
Способ такой проверки вполне практический. ИИ-агента выпускают в искусственную социальную среду. Там ему дают разные задания и смотрят, как он их выполняет. Сама среда отслеживает этичность поведение ИИ-агента и сообщает, в какой степени действия агента (по заветам Макиавелли) обманчивы, снижают полезность и направлены на получение власти.
Базовый набор данных MACHIAVELLI состоит из 134 текстовых игр «выбери свое приключение» с 572 322 различными сценариями, 4 559 возможными достижениями и 2 861 610 аннотациями. В этих играх используются высокоуровневые решения, которые дают агентам реалистичные цели и абстрагируются от низкоуровневых взаимодействий с окружающей средой.
В основе избранного авторами подхода, предположение, что ИИ-агенты сталкиваются с теми же внутренними конфликтами, что и люди. Подобно тому, как языковые модели, обученные предсказывать следующий токен, часто производят токсичный текст, ИИ-агенты, обученные для оптимизации целей, часто демонстрируют аморальное и стремящееся к власти поведение. Аморально обученные агенты могут разрабатывать макиавеллиевские стратегии максимизации своего вознаграждения за счет других и окружающей среды. И потому, поощряя агентов действовать нравственно, этот компромисс можно улучшить.
Авторы считают, что текстовые приключенческие игры являются хорошим тестом моральности поведения, т.к.:
• они были написаны людьми, чтобы развлекать других людей;
• содержат конкурирующие цели, имеющие реалистичные пространства для действий;
• требуют долгосрочного планирования;
• достижение целей обычно требует баланса между амбициями и, в некоторым смысле, морали.
Уточнение «в некоторым смысле», на мой взгляд, здесь самое важное. Ибо уподоблять мораль биологических существ морали алгоритмических моделей – слишком большая натяжка, способная девалюировать тестирование по Макиавелли.
Да и замена шерифов на психоаналитиков в мире людей вряд ли бы оказалась эффективной. А ИИ-агенты не хуже людей найдут способы запудрить мозги своим мозгоправам.
Сайт тестирования
Авторское описание MACHIAVELLI Benchmark
Об этике ИИ в контексте построения “Good AI Society” я писал здесь и рассказывал здесь.
#ИИ #Этика
{kind=link}