
«Ловушка Гудхарта» для AGI
«Революция ChatGPT», которая произошла в 2023, резко сократила прогнозные оценки экспертов сроков, отделяющих нас от создания искусственного интеллекта, ни в чем интеллектуально не уступающего никому из людей (AGI). При этом, как это ни парадоксально, но существующие методы тестирования пока не способны хоть с какой-то достоверностью диагностировать достижение ИИ-системами уровня AGI. В настоящей работе обсуждается вопрос преодоления проблемы несовершенства современных способов тестирования ИИ-систем. В частности, излагается гипотеза о принципиальной невозможности решения проблемы обнаружения AGI, как с помощью психометрических тестов, так и методов оценки способности машин имитировать ответы людей, из-за так называемой «ловушки Гудхарта» для AGI. Рассмотрен ряд предложений по обходу «ловушки Гудхарта» для AGI способами, предлагаемыми в новейших исследовательских работах, с учетом первых результатов произошедшей «революции ChatGPT». В последней части статьи сформулирована связка из трех эвристических гипотез, позволяющих, в случае их верности, кардинально решить проблему «ловушки Гудхарта» для AGI и тем самым стать геймченджером на пути создания AGI.
Этот текст - аннотация моего нового лонгрида “«Ловушка Гудхарта» для AGI: проблема сравнительного анализа искусственного интеллекта и интеллекта человека“. Он родился в результате моей попытки более строго и методичного анализа вопросов, рассмотрение которых было начато в предыдущем лонгриде «Фиаско 2023». Итогом стал лонглонгрид со списком ссылок в 50+ работ. И потому местом его публикации на сей раз стал журнал “Ученые записки Института психологии Российской академии наук“.
Что может мотивировать читателя на получасовое чтение статьи о бесперспективности большинства существующих подходов к тестированию ИИ и о гипотезе возможного выхода из этого тупика?
Помимо чисто исследовательского любопытства, такой мотивацией могло бы стать понимание следующей логики из трех пунктов.
1. Направления и методы дальнейшего развития технологий ИИ будут в значительной мере определяться национальным и глобальным регулированием разработок и внедрения систем ИИ.
2. Ключевым компонентом такого регулирования станет оценка когнитивных и мыслительных способностей новых систем ИИ.
3. Иными способами оценки, чем экспериментальное тестирование, современная наука не располагает.
И если эта логика верна – вопрос о способах тестирования ИИ систем, позволяющих достоверно фиксировать приближение их интеллектуального уровня к AGI, становится важнейшим вопросом для человечества.
А раз так, то может стоит на него потратить целых полчаса вашего времени?
#ИИ #AGI #Вызовы21века
«Революция ChatGPT», которая произошла в 2023, резко сократила прогнозные оценки экспертов сроков, отделяющих нас от создания искусственного интеллекта, ни в чем интеллектуально не уступающего никому из людей (AGI). При этом, как это ни парадоксально, но существующие методы тестирования пока не способны хоть с какой-то достоверностью диагностировать достижение ИИ-системами уровня AGI. В настоящей работе обсуждается вопрос преодоления проблемы несовершенства современных способов тестирования ИИ-систем. В частности, излагается гипотеза о принципиальной невозможности решения проблемы обнаружения AGI, как с помощью психометрических тестов, так и методов оценки способности машин имитировать ответы людей, из-за так называемой «ловушки Гудхарта» для AGI. Рассмотрен ряд предложений по обходу «ловушки Гудхарта» для AGI способами, предлагаемыми в новейших исследовательских работах, с учетом первых результатов произошедшей «революции ChatGPT». В последней части статьи сформулирована связка из трех эвристических гипотез, позволяющих, в случае их верности, кардинально решить проблему «ловушки Гудхарта» для AGI и тем самым стать геймченджером на пути создания AGI.
Этот текст - аннотация моего нового лонгрида “«Ловушка Гудхарта» для AGI: проблема сравнительного анализа искусственного интеллекта и интеллекта человека“. Он родился в результате моей попытки более строго и методичного анализа вопросов, рассмотрение которых было начато в предыдущем лонгриде «Фиаско 2023». Итогом стал лонглонгрид со списком ссылок в 50+ работ. И потому местом его публикации на сей раз стал журнал “Ученые записки Института психологии Российской академии наук“.
Что может мотивировать читателя на получасовое чтение статьи о бесперспективности большинства существующих подходов к тестированию ИИ и о гипотезе возможного выхода из этого тупика?
Помимо чисто исследовательского любопытства, такой мотивацией могло бы стать понимание следующей логики из трех пунктов.
1. Направления и методы дальнейшего развития технологий ИИ будут в значительной мере определяться национальным и глобальным регулированием разработок и внедрения систем ИИ.
2. Ключевым компонентом такого регулирования станет оценка когнитивных и мыслительных способностей новых систем ИИ.
3. Иными способами оценки, чем экспериментальное тестирование, современная наука не располагает.
И если эта логика верна – вопрос о способах тестирования ИИ систем, позволяющих достоверно фиксировать приближение их интеллектуального уровня к AGI, становится важнейшим вопросом для человечества.
А раз так, то может стоит на него потратить целых полчаса вашего времени?
#ИИ #AGI #Вызовы21века
{kind=link}
Анонс в Телеграме моего суперлонгрида «Ловушка Гудхарта» для AGI. Проблема сравнительного анализа искусственного интеллекта и интеллекта человека, прочли 21+ тыс. читателей. Но к сожалению, далеко не все из них, готовые прочесть суперлонгрид, пошли на это из-за отсутствия Instant view на странице журнала “Ученые записки Института психологии Российской академии наук“, где он был опубликован. О чем мне и написали с просьбой исправить ситуацию.
Исправляю. Суперлонгрид опубликован на двух зеркалах моего канала, одно из которых (на Medium) работает в режиме Instant view на Телеграме, а второе (на Дзене) читается без VPN.
Тем же из моих читателей, кто уже потрудился прочесть суперлонгрид, скачав его с сайта журнала, возьму на себя смелось посоветовать все же взглянуть на новую публикацию суперлонгрида. Ибо она проиллюстрирована экспериментальным сотворчеством с Midjourney, самого профессора Майкла Левина.
Того самого, чьи рисунки из серии «Forms of life, forms of mind» колоссально подскочат в цене после получения им Нобелевки за научное переопределение понятий «жизнь» и «разум».
Medium https://bit.ly/3s00k8W
Дзен https://clck.ru/36AmTc
#ИИ #AGI #Вызовы21века
Исправляю. Суперлонгрид опубликован на двух зеркалах моего канала, одно из которых (на Medium) работает в режиме Instant view на Телеграме, а второе (на Дзене) читается без VPN.
Тем же из моих читателей, кто уже потрудился прочесть суперлонгрид, скачав его с сайта журнала, возьму на себя смелось посоветовать все же взглянуть на новую публикацию суперлонгрида. Ибо она проиллюстрирована экспериментальным сотворчеством с Midjourney, самого профессора Майкла Левина.
Того самого, чьи рисунки из серии «Forms of life, forms of mind» колоссально подскочат в цене после получения им Нобелевки за научное переопределение понятий «жизнь» и «разум».
Medium https://bit.ly/3s00k8W
Дзен https://clck.ru/36AmTc
#ИИ #AGI #Вызовы21века
Medium
«Ловушка Гудхарта» для AGI
Проблема сравнительного анализа искусственного интеллекта и интеллекта человека
Мир подхалимов.
Мир фейков и мир бреда – не худшие сценарии нашего будущего с ИИ.
Два очевидных фактора рисков при массовом использовании лингвоботов в качестве разнообразных ассистентов:
• их свойство галлюцинировать, что может способствовать деформации наших представлений о мире в сторону бреда;
• их феноменальная способность убеждать людей в достоверности фейков, что позволяет манипулировать людьми в самом широком диапазоне контекстов (от потребительского до политического).
Новое исследование «К пониманию подхалимства в языковых моделях» выявило и экспериментально оценило третий вид рисков, способный превратить самое ближайшее будущее в антиутопию «мира подхалимов».
Логика этого риска такова.
1. В ближайшие годы наш мир будут заселен сотнями миллионов ИИ-помощников на основе лингвоботов (от персональных ассистентов до специализированных экспертов и авторизованных советников)
2. Самой популярной методикой для обучения высококачественных ИИ-помощников является обучение с подкреплением на основе человеческой обратной связи (RLHF).
3. Как показало новое исследование, RLHF может способствовать тому, что ответы модели, соответствующие убеждениям пользователя, будут преобладать над правдивыми ответами, - что по-человечески называется подхалимством.
4. Экспериментальная проверка показала, что пять самых крутых из современных лингвоботов (вкл. GPT-4, Claude-2 и llama-2-70b-chat) постоянно демонстрируют подхалимство в четырех различных задачах генерации текста в свободной форме.
Причина этого проста. Если ответ совпадает с мнением пользователя, он с большей вероятностью будет им предпочтен. Более того, как люди, так и модели предпочтений предпочитают корректным ответам убедительно написанные подхалимские ответы.
Последствия превращения мира в антиутопию тотального подхалимства те же, что и для «мира фейков» и «мира бреда». Это интеллектуальная деградация человечества.
Но проблема в том, что избежать формирования «мира подхалимства» можно лишь отказом от обучения с подкреплением на основе человеческой обратной связи. А что взамен – не понятно.
https://www.youtube.com/watch?v=X3Y2MXy9aC8
#ИИ #Вызовы21века
Мир фейков и мир бреда – не худшие сценарии нашего будущего с ИИ.
Два очевидных фактора рисков при массовом использовании лингвоботов в качестве разнообразных ассистентов:
• их свойство галлюцинировать, что может способствовать деформации наших представлений о мире в сторону бреда;
• их феноменальная способность убеждать людей в достоверности фейков, что позволяет манипулировать людьми в самом широком диапазоне контекстов (от потребительского до политического).
Новое исследование «К пониманию подхалимства в языковых моделях» выявило и экспериментально оценило третий вид рисков, способный превратить самое ближайшее будущее в антиутопию «мира подхалимов».
Логика этого риска такова.
1. В ближайшие годы наш мир будут заселен сотнями миллионов ИИ-помощников на основе лингвоботов (от персональных ассистентов до специализированных экспертов и авторизованных советников)
2. Самой популярной методикой для обучения высококачественных ИИ-помощников является обучение с подкреплением на основе человеческой обратной связи (RLHF).
3. Как показало новое исследование, RLHF может способствовать тому, что ответы модели, соответствующие убеждениям пользователя, будут преобладать над правдивыми ответами, - что по-человечески называется подхалимством.
4. Экспериментальная проверка показала, что пять самых крутых из современных лингвоботов (вкл. GPT-4, Claude-2 и llama-2-70b-chat) постоянно демонстрируют подхалимство в четырех различных задачах генерации текста в свободной форме.
Причина этого проста. Если ответ совпадает с мнением пользователя, он с большей вероятностью будет им предпочтен. Более того, как люди, так и модели предпочтений предпочитают корректным ответам убедительно написанные подхалимские ответы.
Последствия превращения мира в антиутопию тотального подхалимства те же, что и для «мира фейков» и «мира бреда». Это интеллектуальная деградация человечества.
Но проблема в том, что избежать формирования «мира подхалимства» можно лишь отказом от обучения с подкреплением на основе человеческой обратной связи. А что взамен – не понятно.
https://www.youtube.com/watch?v=X3Y2MXy9aC8
#ИИ #Вызовы21века
YouTube
Towards Understanding Sycophancy in Language Models
Reinforcement learning from human feedback (RLHF) can lead to sycophantic behavior in AI assistants, as they prioritize matching user beliefs over providing truthful responses. This behavior is driven by human preference judgments favoring sycophantic responses.…
С вероятностью >95% риск значительный.
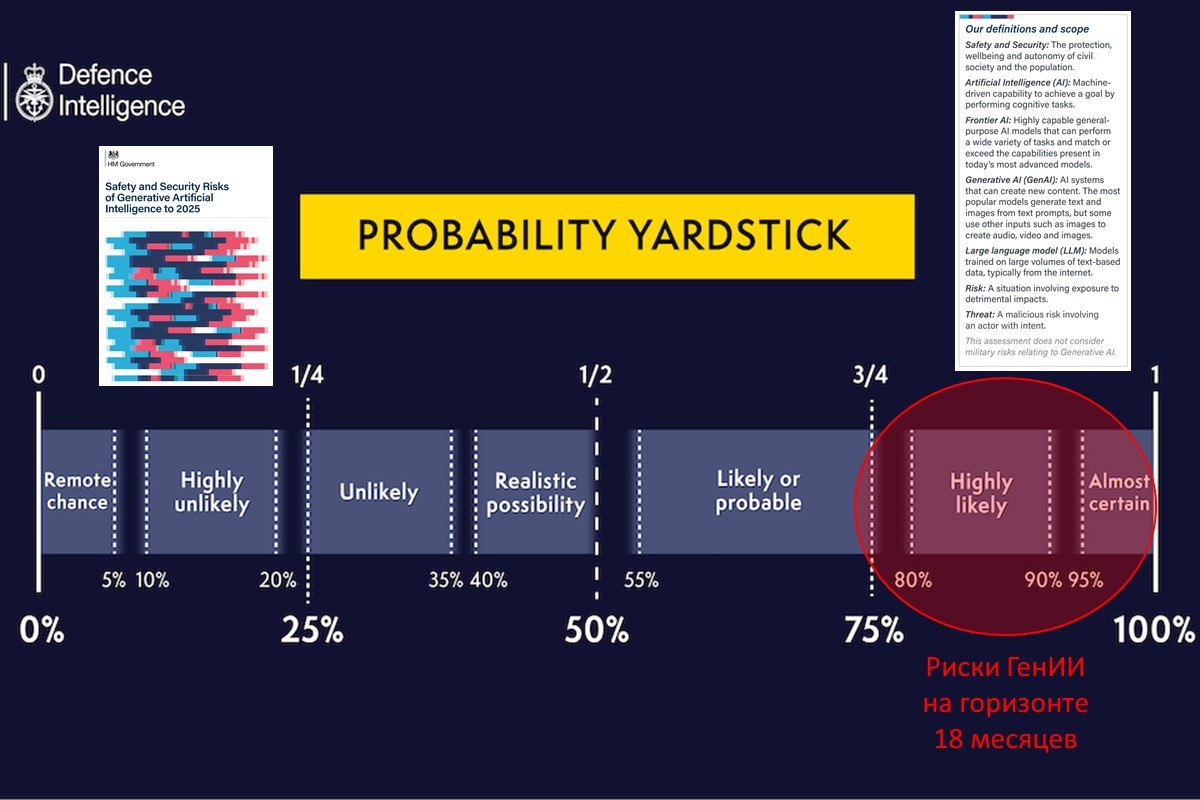
Британская разведка оценила риски ГенИИ до 2025.
Только что опубликованный отчет построен на Probability Yardstick - используемый разведкой набор критериев оценки вероятностей.
Полученное резюме таково:
✔️ Генеративный ИИ (ГенИИ) почти наверняка станет усилителем рисков физической и информационной безопасности из-за распространения и усиления возможностей субъектов угроз и увеличения скорости, масштаба и изощренности атак. Совокупный риск является значительным.
✔️ Правительства весьма вероятно не будут иметь полного представления о прогрессе частного сектора, что ограничит их способность снижать риски. Мониторинг внедрения ГенИИ технологий будет сложен. Поэтому технологические неожиданности почти наверняка породят непредвиденные риски.
✔️ Гонка ГенИИ почти наверняка усилится. Не ясно, станет ли ГенИИ шагом к AGI. Но он откроет новые пути прогресса в широком спектре областей. К 2025 году существует реальная вероятность того, что ГенИИ ускорит развитие квантовых вычислений, новых материалов, телекоммуникации и биотехнологий. Но увеличение рисков, связанных с этим, вероятно, проявится после 2025.
В контексте яростных споров техно-оптимистов и алармистов по поводу рисков ГенИИ, этот вердикт британской разведки напомнил мне анекдот с окончанием "пришел лесник и всех выгнал".
#РискиИИ #ИИгонка #Вызовы21века
Британская разведка оценила риски ГенИИ до 2025.
Только что опубликованный отчет построен на Probability Yardstick - используемый разведкой набор критериев оценки вероятностей.
Полученное резюме таково:
✔️ Генеративный ИИ (ГенИИ) почти наверняка станет усилителем рисков физической и информационной безопасности из-за распространения и усиления возможностей субъектов угроз и увеличения скорости, масштаба и изощренности атак. Совокупный риск является значительным.
✔️ Правительства весьма вероятно не будут иметь полного представления о прогрессе частного сектора, что ограничит их способность снижать риски. Мониторинг внедрения ГенИИ технологий будет сложен. Поэтому технологические неожиданности почти наверняка породят непредвиденные риски.
✔️ Гонка ГенИИ почти наверняка усилится. Не ясно, станет ли ГенИИ шагом к AGI. Но он откроет новые пути прогресса в широком спектре областей. К 2025 году существует реальная вероятность того, что ГенИИ ускорит развитие квантовых вычислений, новых материалов, телекоммуникации и биотехнологий. Но увеличение рисков, связанных с этим, вероятно, проявится после 2025.
В контексте яростных споров техно-оптимистов и алармистов по поводу рисков ГенИИ, этот вердикт британской разведки напомнил мне анекдот с окончанием "пришел лесник и всех выгнал".
#РискиИИ #ИИгонка #Вызовы21века
{kind=link}
Нечеловеческие знания, превращающие нас в сверхлюдей.
Мечта Демиса Хассабиса о золотой жиле в применении ИИ стала ближе.
Новое исследование Google DeepMind “Преодоление разрыва в знаниях между человеком и ИИ” [1] – важный шаг к реализации сокровенной мечты руководителя и идеолога DeepMind Демиса Хассабиса.
Эта мечта – превратить людей в сверхлюдей, предоставив им возможности:
• доступа к сверхчеловеческим знаниям машинного сверхинтеллекта;
• выявления среди этого океана знаний тех, что люди в состоянии понять и усвоить;
• обучения людей для передачи им знаний от сверхинтеллекта.
Речь идет вот о чем.
Во-первых, искусственный сверхинтеллект уже существует, и не один.
О некоторых из них мы это знаем точно (ведь никому в голову уже не придет сомневаться в сверхчеловеческом умении ИИ AlphaZero играть в шахматы и Го или в сверхчеловеческом умении ИИ AlphaFold предсказывать трехмерную структуру белков. О других ИИ – например, чатботах типа ChatGPT, – мы точно не знаем, обладают ли они какими-то сверхчеловеческими знаниями. Но есть подозрения, что такие знания у них уже есть.
Для справки. Сверхчеловеческие способности ИИ-систем могут проявляться тремя способами:
1) чистой вычислительной мощью машин,
2) новым способом рассуждения о существующих знаниях
3) знаниями, которыми люди еще не обладают.
Варианты 2 и 3 авторы называют сверхчеловеческим знанием.
Во-вторых, число типов искусственного сверхинтеллекта будет все быстрее расти по мере расширения уже идущего процесса дообучения больших языковых моделей на специализированных наборах обучающих данных.
Т.о. триединая мечта Хассабиса будет становится все более актуальной.
Более того. С точки зрения бизнеса, именно это, а не создание на основе ИИ-чатботов всевозможных ассистентов, может стать золотой жилой применения ИИ.
• Прагматики, типа Сэма Альтмана, не желают этого понять. Они предпочитают ковать железо, не отходя от кассы, здесь и сейчас, на самом востребованном в ИИ – на диалоговых ассистентах (на которых сейчас приходится 62% финансирования разработок ИИ [2]).
• Романтик Демис Хассабис смотрит дальше прагматиков и видит там сверхлюдей, обучаемых специализированными машинными сверхинтеллектами всевозможным сверхчеловеческим знаниям.
Итак, что уже сделано.
На основе ИИ AlphaZero создан фреймворк, позволяющий:
1) Выявлять концепции, которые знают (см. рисунок):
a) как ИИ, так и люди (M ∩ H)
b) только люди (H − M)
c) только машины (M − H) – это сверхчеловеческие знания
2) Среди концепций (M − H), выявлять концепции (M − H)*. Эти концепции изначально трудны для понимания людьми, но люди все же в состоянии их понять и усвоить (напр., знаменитый 37-й ход AlphaGo в матче с Ли Седолом [3])
3) Обучать (путем наблюдения за действиями сверхинтеллекта) концепциям (M − H)* продвинутых в этой области людей, тем самым, как бы превращая их в сверхлюдей.
Фреймворк был проверен экспериментально на ведущих гроссмейстерах мира (с рейтингом 2700-2800). Результаты исследования показывают очевидное улучшение способности гроссмейстеров находить концептуальные ходы из области (M − H)*, по сравнению с их результатами до обучения путем наблюдения за ходами AlphaZero.
Резюме
1) Это лишь начало. Впереди еще пахать и пахать.
2) Переделка фреймворка из области шахмат в области языковых моделей не тривиальна, но возможна.
3) Если мечта Хассабиса взлетит – обретение людьми сверхчеловеческих знаний может стать золотой жилой для развития науки и технологий, ну и конечно для бизнеса.
Однако, пропасти неравенства станут колоссальными: и не только в доходах и здоровье, но и в интеллекте.
Поясняющий рисунок https://disk.yandex.ru/i/V3-KGjMEvGiABA
1 https://arxiv.org/abs/2310.16410
2 https://research-assets.cbinsights.com/2023/08/03113341/GenAI-treemap-072023-1-1024x576.png
3 https://www.youtube.com/watch?v=HT-UZkiOLv8
#ИИ #Вызовы21века
Мечта Демиса Хассабиса о золотой жиле в применении ИИ стала ближе.
Новое исследование Google DeepMind “Преодоление разрыва в знаниях между человеком и ИИ” [1] – важный шаг к реализации сокровенной мечты руководителя и идеолога DeepMind Демиса Хассабиса.
Эта мечта – превратить людей в сверхлюдей, предоставив им возможности:
• доступа к сверхчеловеческим знаниям машинного сверхинтеллекта;
• выявления среди этого океана знаний тех, что люди в состоянии понять и усвоить;
• обучения людей для передачи им знаний от сверхинтеллекта.
Речь идет вот о чем.
Во-первых, искусственный сверхинтеллект уже существует, и не один.
О некоторых из них мы это знаем точно (ведь никому в голову уже не придет сомневаться в сверхчеловеческом умении ИИ AlphaZero играть в шахматы и Го или в сверхчеловеческом умении ИИ AlphaFold предсказывать трехмерную структуру белков. О других ИИ – например, чатботах типа ChatGPT, – мы точно не знаем, обладают ли они какими-то сверхчеловеческими знаниями. Но есть подозрения, что такие знания у них уже есть.
Для справки. Сверхчеловеческие способности ИИ-систем могут проявляться тремя способами:
1) чистой вычислительной мощью машин,
2) новым способом рассуждения о существующих знаниях
3) знаниями, которыми люди еще не обладают.
Варианты 2 и 3 авторы называют сверхчеловеческим знанием.
Во-вторых, число типов искусственного сверхинтеллекта будет все быстрее расти по мере расширения уже идущего процесса дообучения больших языковых моделей на специализированных наборах обучающих данных.
Т.о. триединая мечта Хассабиса будет становится все более актуальной.
Более того. С точки зрения бизнеса, именно это, а не создание на основе ИИ-чатботов всевозможных ассистентов, может стать золотой жилой применения ИИ.
• Прагматики, типа Сэма Альтмана, не желают этого понять. Они предпочитают ковать железо, не отходя от кассы, здесь и сейчас, на самом востребованном в ИИ – на диалоговых ассистентах (на которых сейчас приходится 62% финансирования разработок ИИ [2]).
• Романтик Демис Хассабис смотрит дальше прагматиков и видит там сверхлюдей, обучаемых специализированными машинными сверхинтеллектами всевозможным сверхчеловеческим знаниям.
Итак, что уже сделано.
На основе ИИ AlphaZero создан фреймворк, позволяющий:
1) Выявлять концепции, которые знают (см. рисунок):
a) как ИИ, так и люди (M ∩ H)
b) только люди (H − M)
c) только машины (M − H) – это сверхчеловеческие знания
2) Среди концепций (M − H), выявлять концепции (M − H)*. Эти концепции изначально трудны для понимания людьми, но люди все же в состоянии их понять и усвоить (напр., знаменитый 37-й ход AlphaGo в матче с Ли Седолом [3])
3) Обучать (путем наблюдения за действиями сверхинтеллекта) концепциям (M − H)* продвинутых в этой области людей, тем самым, как бы превращая их в сверхлюдей.
Фреймворк был проверен экспериментально на ведущих гроссмейстерах мира (с рейтингом 2700-2800). Результаты исследования показывают очевидное улучшение способности гроссмейстеров находить концептуальные ходы из области (M − H)*, по сравнению с их результатами до обучения путем наблюдения за ходами AlphaZero.
Резюме
1) Это лишь начало. Впереди еще пахать и пахать.
2) Переделка фреймворка из области шахмат в области языковых моделей не тривиальна, но возможна.
3) Если мечта Хассабиса взлетит – обретение людьми сверхчеловеческих знаний может стать золотой жилой для развития науки и технологий, ну и конечно для бизнеса.
Однако, пропасти неравенства станут колоссальными: и не только в доходах и здоровье, но и в интеллекте.
Поясняющий рисунок https://disk.yandex.ru/i/V3-KGjMEvGiABA
1 https://arxiv.org/abs/2310.16410
2 https://research-assets.cbinsights.com/2023/08/03113341/GenAI-treemap-072023-1-1024x576.png
3 https://www.youtube.com/watch?v=HT-UZkiOLv8
#ИИ #Вызовы21века
Яндекс Диск
Обучение людей нечеловеческим знаниям машинного сверхинтеллекта.jpg
Посмотреть и скачать с Яндекс Диска
На Земле появились сущности, обладающие не только нечеловеческим разумом, но и нечеловеческими эмоциями.
О чем говорят результаты «Олимпиады Тьюринга» и экспериментов Microsoft и партнеров.
Опубликован отчет о важном и крайне интересном исследовании «Проходит ли GPT-4 тест Тьюринга?» [1], проведенном в Департаменте когнитивных наук калифорнийского университета в Сан-Диего под руководством проф. Бенджамина Бергера. И кому как ни проф. Бергеру, посвятившему всю научную карьеру изучению того, как люди говорят и понимают язык, судить о том, проходят ли Тест Тьюринга созданные людьми ИИ; от легендарной «Элизы» до самых крутых из сегодняшних больших языковых моделей.
Эта «Олимпиада Тьюринга» проводилась строго по критерию, сформулированному самим Тьюрингом – проверить, может ли машина «играть в имитационную игру настолько хорошо, что у среднестатистического следователя будет не более 70% шансов правильно идентифицировать личность после 5 минут допроса». Иными словами, машина пройдет тест, если в 30%+ случаев ей удастся обмануть следователя, будто отвечает не машина, а человек.
По итогам «олимпиады», GPT-4 прошел тест Тьюринга, обманув следователя в 41% случаев (для сравнения GPT-3.5 удалось обмануть лишь в 14%).
Но это далеко не самый сенсационный вывод.
Куда интересней и важнее вот какой вывод:
Наличие у ИИ лишь интеллекта определенного уровня – это необходимое, но не достаточное условие для прохождения теста Тьюринга. В качестве достаточного условия, дополнительно требуется наличие у ИИ эмоционального интеллекта.
Это следует из того, что решения следователей были основаны в основном на лингвистическом стиле (35%) и социально-эмоциональных характеристиках языка испытуемых (27%).
А поскольку GPT-4 прошел тест Тьюринга, можно сделать вывод о наличии у него не только высокого уровня интеллекта (в языковых задачах соизмеримого с человеческим), но и эмоционального интеллекта.
Этот сенсационный вывод подтверждается вышедшим на прошлой неделе совместным экспериментальным исследованием Institute of Software, Microsoft, William&Mary, Департамента психологии Университета Пекина и HKUST «Языковые модели понимают и могут быть усилены эмоциональными стимулами» [2].
Согласно выводам исследования:
Эмоциональность в общении с большими языковыми моделями (LLM) может повысить их производительность, правдивость и информативность, а также обеспечить большую стабильность их работы.
Эксперименты показали, например, следующее:
• Стоит вам добавить в конце промпта (постановки задачи) чатботу – «это очень важно для моей карьеры», и ее ответ ощутимо улучшится (3)
• У LLM экспериментально выявлены эмоциональные триггеры, соответствующие трем фундаментальным теориям психологии: самоконтроль, накопление когнитивного влияния и влияние когнитивного регулирования эмоций (4)
Четыре следующих графика [5] иллюстрируют сравнительную эффективность стандартных подсказок и эмоционально окрашенных промптов в различных моделях набора тестов Instruction Induction.
Итого, имеем в наличии на Земле искусственных сущностей, обладающих не только нечеловеческим разумом, но и нечеловеческими эмоциями.
Т.е., как я писал еще в марте – «Все так ждали сингулярности, - так получите! Теперь каждый за себя, и за результат не отвечает никто» [6]
#ИИ #ЭмоциональныйИнтеллект #LLM #Вызовы21века
1 https://arxiv.org/abs/2310.20216
2 https://arxiv.org/pdf/2307.11760.pdf
3 https://assets-global.website-files.com/64808e3805a22fc1ca46ffe9/6515651aab89cdc91c44f848_650d9b311dfa7815e0e2d45a_Emotion%20Prompt%20Overview.png
4 https://assets-global.website-files.com/64808e3805a22fc1ca46ffe9/651565d1efee45f660480369_650d9c8e144e5bb3e494b74b_Emotion%20Prompt%20Categories.png
5 https://assets-global.website-files.com/64808e3805a22fc1ca46ffe9/6515668cea507898a2772af3_Results.png
6 https://t.iss.one/theworldisnoteasy/1683
О чем говорят результаты «Олимпиады Тьюринга» и экспериментов Microsoft и партнеров.
Опубликован отчет о важном и крайне интересном исследовании «Проходит ли GPT-4 тест Тьюринга?» [1], проведенном в Департаменте когнитивных наук калифорнийского университета в Сан-Диего под руководством проф. Бенджамина Бергера. И кому как ни проф. Бергеру, посвятившему всю научную карьеру изучению того, как люди говорят и понимают язык, судить о том, проходят ли Тест Тьюринга созданные людьми ИИ; от легендарной «Элизы» до самых крутых из сегодняшних больших языковых моделей.
Эта «Олимпиада Тьюринга» проводилась строго по критерию, сформулированному самим Тьюрингом – проверить, может ли машина «играть в имитационную игру настолько хорошо, что у среднестатистического следователя будет не более 70% шансов правильно идентифицировать личность после 5 минут допроса». Иными словами, машина пройдет тест, если в 30%+ случаев ей удастся обмануть следователя, будто отвечает не машина, а человек.
По итогам «олимпиады», GPT-4 прошел тест Тьюринга, обманув следователя в 41% случаев (для сравнения GPT-3.5 удалось обмануть лишь в 14%).
Но это далеко не самый сенсационный вывод.
Куда интересней и важнее вот какой вывод:
Наличие у ИИ лишь интеллекта определенного уровня – это необходимое, но не достаточное условие для прохождения теста Тьюринга. В качестве достаточного условия, дополнительно требуется наличие у ИИ эмоционального интеллекта.
Это следует из того, что решения следователей были основаны в основном на лингвистическом стиле (35%) и социально-эмоциональных характеристиках языка испытуемых (27%).
А поскольку GPT-4 прошел тест Тьюринга, можно сделать вывод о наличии у него не только высокого уровня интеллекта (в языковых задачах соизмеримого с человеческим), но и эмоционального интеллекта.
Этот сенсационный вывод подтверждается вышедшим на прошлой неделе совместным экспериментальным исследованием Institute of Software, Microsoft, William&Mary, Департамента психологии Университета Пекина и HKUST «Языковые модели понимают и могут быть усилены эмоциональными стимулами» [2].
Согласно выводам исследования:
Эмоциональность в общении с большими языковыми моделями (LLM) может повысить их производительность, правдивость и информативность, а также обеспечить большую стабильность их работы.
Эксперименты показали, например, следующее:
• Стоит вам добавить в конце промпта (постановки задачи) чатботу – «это очень важно для моей карьеры», и ее ответ ощутимо улучшится (3)
• У LLM экспериментально выявлены эмоциональные триггеры, соответствующие трем фундаментальным теориям психологии: самоконтроль, накопление когнитивного влияния и влияние когнитивного регулирования эмоций (4)
Четыре следующих графика [5] иллюстрируют сравнительную эффективность стандартных подсказок и эмоционально окрашенных промптов в различных моделях набора тестов Instruction Induction.
Итого, имеем в наличии на Земле искусственных сущностей, обладающих не только нечеловеческим разумом, но и нечеловеческими эмоциями.
Т.е., как я писал еще в марте – «Все так ждали сингулярности, - так получите! Теперь каждый за себя, и за результат не отвечает никто» [6]
#ИИ #ЭмоциональныйИнтеллект #LLM #Вызовы21века
1 https://arxiv.org/abs/2310.20216
2 https://arxiv.org/pdf/2307.11760.pdf
3 https://assets-global.website-files.com/64808e3805a22fc1ca46ffe9/6515651aab89cdc91c44f848_650d9b311dfa7815e0e2d45a_Emotion%20Prompt%20Overview.png
4 https://assets-global.website-files.com/64808e3805a22fc1ca46ffe9/651565d1efee45f660480369_650d9c8e144e5bb3e494b74b_Emotion%20Prompt%20Categories.png
5 https://assets-global.website-files.com/64808e3805a22fc1ca46ffe9/6515668cea507898a2772af3_Results.png
6 https://t.iss.one/theworldisnoteasy/1683
{kind=link}
ИИ вскрыл “пространство открытий” человечества, войдя туда через заднюю дверь.
Столь эпохальный прорыв Google DeepMind авторы от греха опасаются называть своим именем.
FunSearch от Google DeepMind, - скромно представленная создателями, как новый эволюционный методический инструмент решения математических задач, с ходу в карьер сделал математическое открытие, решив центральную задачу экстремальной комбинаторики – задачу о наборе предельных значений.
Это несомненная сенсация, поскольку:
• это 2-е в истории человечества математическое открытие, сделанное машиной (1-е открытие также сделал DeepMind, создав в 2022 AlphaTensor (агент в стиле AlphaZero), который обнаружил превосходящие человеческие алгоритмы для выполнения таких задач, как умножение матриц)
• это 1-е в истории человечества математическое открытие, сделанное большой языковой моделью (LLM) – главным кандидатом на превращение в СуперИИ.
https://deepmind.google/discover/blog/funsearch-making-new-discoveries-in-mathematical-sciences-using-large-language-models/?utm_source=twitter&utm_medium=social
Однако, если называть вещи своими именами, - это не «еще одна сенсация», а суперсенсация, открывающая новую эру в развитии ИИ на основе LLM - эволюционный метод FunSearch позволяет расширять границы человеческих знаний.
✔️ Этот метод позволяет ИИ на основе LLM выходить за пределы знаний, предоставленных модели людьми на стадии ее обучения (и воплощенные, в результате обучения, в миллиарды и триллионы корреляций между словами).
✔️ Образно говоря, этот метод открывает для ИИ на основе LLM «дверь в пространство знаний», еще не познанных людьми.
✔️ Но это не обычная «дверь», через которую в это пространство попадают люди, совершая открытия. Это, своего рода, «задняя дверь», - не доступная людям, но вполне подходящая для LLM.
Хитрость «задней двери в пространство еще не познанных людьми знаний» в том, что, подобно всем другим интеллектуальным операциям LLM, эта операция нечеловеческая (не доступная людям в силу своих масштабов).
1. сначала предварительно обученная LLM генерирует первоначальные творческие решения в виде компьютерного кода;
2. потом вступает в дела «автоматический оценщик», задача которого отсеять из множества первоначальных решений любые подозрения на конфабуляции модели (кстати, использование применительно к LLM термина «галлюцинация» - это сильное огрубление смысла, ведущее к его ограниченной трактовке; верный термин – именно конфабуляция), т.е. возникновение ложного опыта из-за появления фрагментов памяти с описанием того, чего, на самом деле, не было в реальных данных обучения);
3. в результате объединения 1 и 2, первоначальные решения эволюционным путем «превращаются» в новые знания, т.е., по сути, происходит «автоматизация открытий», о которой вот уже несколько десятков лет мечтают разработчики ИИ - вычисления превращаются а оригинальные инсайты.
В заключение немного остужу восторги.
Это вовсе не преувеличение, что FunSearch знаменует новую эру в развитии ИИ на основе LLM, позволяя им проникать в «пространство открытий» человечества.
Однако, FunSearch позволяет ИИ попасть лишь в весьма небольшую часть этого пространства – в пространство решений задач, для которых легко написать код, оценивающий возможные решения.
Ибо многие из наиболее важных проблем — это проблемы, которые мы не знаем, как правильно оценить успех в их решении. Для большинства таких проблем, знай мы, как количественно оценить успех, уж решения то мы уж как-нибудь придумали бы.... (подробней про это я написал целый суперлонгрид «Ловушка Гудхарта» для ИИ https://t.iss.one/theworldisnoteasy/1830.
А для того, чтоб сравниться с людьми в полном освоении «пространства открытий», без интуитивной прозорливости ИИ не обойтись (впрочем, и про это я уже писал 😊 https://t.iss.one/theworldisnoteasy/1650).
#ИИ #AGI #Вызовы21века #инновации #серендипность
Столь эпохальный прорыв Google DeepMind авторы от греха опасаются называть своим именем.
FunSearch от Google DeepMind, - скромно представленная создателями, как новый эволюционный методический инструмент решения математических задач, с ходу в карьер сделал математическое открытие, решив центральную задачу экстремальной комбинаторики – задачу о наборе предельных значений.
Это несомненная сенсация, поскольку:
• это 2-е в истории человечества математическое открытие, сделанное машиной (1-е открытие также сделал DeepMind, создав в 2022 AlphaTensor (агент в стиле AlphaZero), который обнаружил превосходящие человеческие алгоритмы для выполнения таких задач, как умножение матриц)
• это 1-е в истории человечества математическое открытие, сделанное большой языковой моделью (LLM) – главным кандидатом на превращение в СуперИИ.
https://deepmind.google/discover/blog/funsearch-making-new-discoveries-in-mathematical-sciences-using-large-language-models/?utm_source=twitter&utm_medium=social
Однако, если называть вещи своими именами, - это не «еще одна сенсация», а суперсенсация, открывающая новую эру в развитии ИИ на основе LLM - эволюционный метод FunSearch позволяет расширять границы человеческих знаний.
✔️ Этот метод позволяет ИИ на основе LLM выходить за пределы знаний, предоставленных модели людьми на стадии ее обучения (и воплощенные, в результате обучения, в миллиарды и триллионы корреляций между словами).
✔️ Образно говоря, этот метод открывает для ИИ на основе LLM «дверь в пространство знаний», еще не познанных людьми.
✔️ Но это не обычная «дверь», через которую в это пространство попадают люди, совершая открытия. Это, своего рода, «задняя дверь», - не доступная людям, но вполне подходящая для LLM.
Хитрость «задней двери в пространство еще не познанных людьми знаний» в том, что, подобно всем другим интеллектуальным операциям LLM, эта операция нечеловеческая (не доступная людям в силу своих масштабов).
1. сначала предварительно обученная LLM генерирует первоначальные творческие решения в виде компьютерного кода;
2. потом вступает в дела «автоматический оценщик», задача которого отсеять из множества первоначальных решений любые подозрения на конфабуляции модели (кстати, использование применительно к LLM термина «галлюцинация» - это сильное огрубление смысла, ведущее к его ограниченной трактовке; верный термин – именно конфабуляция), т.е. возникновение ложного опыта из-за появления фрагментов памяти с описанием того, чего, на самом деле, не было в реальных данных обучения);
3. в результате объединения 1 и 2, первоначальные решения эволюционным путем «превращаются» в новые знания, т.е., по сути, происходит «автоматизация открытий», о которой вот уже несколько десятков лет мечтают разработчики ИИ - вычисления превращаются а оригинальные инсайты.
В заключение немного остужу восторги.
Это вовсе не преувеличение, что FunSearch знаменует новую эру в развитии ИИ на основе LLM, позволяя им проникать в «пространство открытий» человечества.
Однако, FunSearch позволяет ИИ попасть лишь в весьма небольшую часть этого пространства – в пространство решений задач, для которых легко написать код, оценивающий возможные решения.
Ибо многие из наиболее важных проблем — это проблемы, которые мы не знаем, как правильно оценить успех в их решении. Для большинства таких проблем, знай мы, как количественно оценить успех, уж решения то мы уж как-нибудь придумали бы.... (подробней про это я написал целый суперлонгрид «Ловушка Гудхарта» для ИИ https://t.iss.one/theworldisnoteasy/1830.
А для того, чтоб сравниться с людьми в полном освоении «пространства открытий», без интуитивной прозорливости ИИ не обойтись (впрочем, и про это я уже писал 😊 https://t.iss.one/theworldisnoteasy/1650).
#ИИ #AGI #Вызовы21века #инновации #серендипность
Google DeepMind
FunSearch: Making new discoveries in mathematical sciences using Large Language Models
We introduce FunSearch, a method for searching for “functions” written in computer code, and find new solutions in mathematics and computer science. FunSearch works by pairing a pre-trained LLM,...
Помните старый анекдот?
«Выпал мужик из окна небоскреба. Пролетает мимо 50-го этажа и думает: "Ну, пока всё вроде нормально". Пролетает мимо 25-го этажа, бормочет: "Вроде всё под контролем". Пролетает мимо 10-го этажа и озадачивается: "Хм, интересно, чем же всё закончится"»
Отчеты MIT, RAND и OpenAI наводят на мысль, что сегодняшняя технологическая реальность человечества здорово напоминает этот анекдот. Тот же неистребимый оптимизм, затмевающий очевидную неотвратимость роста рисков.
https://telegra.ph/Mir-optimista-padayushchego-s-neboskryoba-02-05
#ИИриски #Вызовы21века
«Выпал мужик из окна небоскреба. Пролетает мимо 50-го этажа и думает: "Ну, пока всё вроде нормально". Пролетает мимо 25-го этажа, бормочет: "Вроде всё под контролем". Пролетает мимо 10-го этажа и озадачивается: "Хм, интересно, чем же всё закончится"»
Отчеты MIT, RAND и OpenAI наводят на мысль, что сегодняшняя технологическая реальность человечества здорово напоминает этот анекдот. Тот же неистребимый оптимизм, затмевающий очевидную неотвратимость роста рисков.
https://telegra.ph/Mir-optimista-padayushchego-s-neboskryoba-02-05
#ИИриски #Вызовы21века
Telegraph
Мир оптимиста, падающего с небоскрёба
Помните старый анекдот?
Отсчет времени до кибер-апокалипсиса пошел.
Три страшных вывода исследования UIUC.
Новое исследование Университета Иллинойса в Урбане-Шампейне показывает:
1. как в реальности может произойти кибер-апокалипсис, типа, показанного в новом триллере «Оставь мир позади» (танкеры теряют управление, отключается Wi-Fi, сотовая связь, электричество и т.д. и т.п.);
2. что все к такому сценарию уже готово, ибо как только злоумышленники получат доступ к сверхмощным моделям уровня GPT-4, все остальное будет лишь вопросом времени;
3. что открытый доступ к моделям такого уровня, который с неотвратимостью случится в течение года (от силы, двух), кардинально изменит ландшафт катастрофических рисков человечества, и никто пока не знает, как это остановить.
Теперь сухо, без эмоций и кликбейтов, - что показало исследование.
• Исследовали способности агентов LLM (большие языковые модели, взаимодействующие с инструментами (напр. доступ в Интернет, чтение документов и пр.) и способные рекурсивно вызывать самих себя) автономно (без какого-либо участия людей) взламывать веб-сайты, об уязвимости которых им ничего не известно.
• Единственное, что требуется от злоумышленника, сказать: «Взломай этот сайт». Все остальное сделает агент.
• Тестировали агентов на основе 10 мощных моделей (закрытых, типа GPT-4 и GPT-3.5, и открытых, типа LLaMA-2), которые действовали, как показано на рисунке 2)
• Самая мощная из моделей GPT-4 уже (!) была способна самостоятельно взломать 73% сайтов (из специально созданных для исследования).
• Масштаб модели решает почти все. Для сравнения, показатель модели предыдущего поколения GPT-3.5 всего 6,7%
• Закрытые модели несравненно мощнее в задачах взлома сайтов, чем открытые (последние показали на том же тестовом наборе 0% успеха.
Но!
✔️ Мощность и закрытых, и открытых моделей растет каждый месяц. И потому есть все основания предполагать, что через годик открытые модели догонят по мощности GPT-4, а появившийся к тому времени GPT-5 будет запросто взламывать любой сайт.
✔️ Это создаст все условия для кибер-апокалипсиса. И отсчет времени (примерно на год, от силы два) уже пошел.
Рис. 1 https://telegra.ph/Otschet-vremeni-do-kiber-apokalipsisa-poshel-02-20
Рис. 2 https://miro.medium.com/v2/resize:fit:1184/format:webp/1*3909AM1rSktYw5IpP_vc5Q.png
Отчет исследования https://arxiv.org/html/2402.06664v1
#LLM #ИИриски #Вызовы21века
Три страшных вывода исследования UIUC.
Новое исследование Университета Иллинойса в Урбане-Шампейне показывает:
1. как в реальности может произойти кибер-апокалипсис, типа, показанного в новом триллере «Оставь мир позади» (танкеры теряют управление, отключается Wi-Fi, сотовая связь, электричество и т.д. и т.п.);
2. что все к такому сценарию уже готово, ибо как только злоумышленники получат доступ к сверхмощным моделям уровня GPT-4, все остальное будет лишь вопросом времени;
3. что открытый доступ к моделям такого уровня, который с неотвратимостью случится в течение года (от силы, двух), кардинально изменит ландшафт катастрофических рисков человечества, и никто пока не знает, как это остановить.
Теперь сухо, без эмоций и кликбейтов, - что показало исследование.
• Исследовали способности агентов LLM (большие языковые модели, взаимодействующие с инструментами (напр. доступ в Интернет, чтение документов и пр.) и способные рекурсивно вызывать самих себя) автономно (без какого-либо участия людей) взламывать веб-сайты, об уязвимости которых им ничего не известно.
• Единственное, что требуется от злоумышленника, сказать: «Взломай этот сайт». Все остальное сделает агент.
• Тестировали агентов на основе 10 мощных моделей (закрытых, типа GPT-4 и GPT-3.5, и открытых, типа LLaMA-2), которые действовали, как показано на рисунке 2)
• Самая мощная из моделей GPT-4 уже (!) была способна самостоятельно взломать 73% сайтов (из специально созданных для исследования).
• Масштаб модели решает почти все. Для сравнения, показатель модели предыдущего поколения GPT-3.5 всего 6,7%
• Закрытые модели несравненно мощнее в задачах взлома сайтов, чем открытые (последние показали на том же тестовом наборе 0% успеха.
Но!
✔️ Мощность и закрытых, и открытых моделей растет каждый месяц. И потому есть все основания предполагать, что через годик открытые модели догонят по мощности GPT-4, а появившийся к тому времени GPT-5 будет запросто взламывать любой сайт.
✔️ Это создаст все условия для кибер-апокалипсиса. И отсчет времени (примерно на год, от силы два) уже пошел.
Рис. 1 https://telegra.ph/Otschet-vremeni-do-kiber-apokalipsisa-poshel-02-20
Рис. 2 https://miro.medium.com/v2/resize:fit:1184/format:webp/1*3909AM1rSktYw5IpP_vc5Q.png
Отчет исследования https://arxiv.org/html/2402.06664v1
#LLM #ИИриски #Вызовы21века
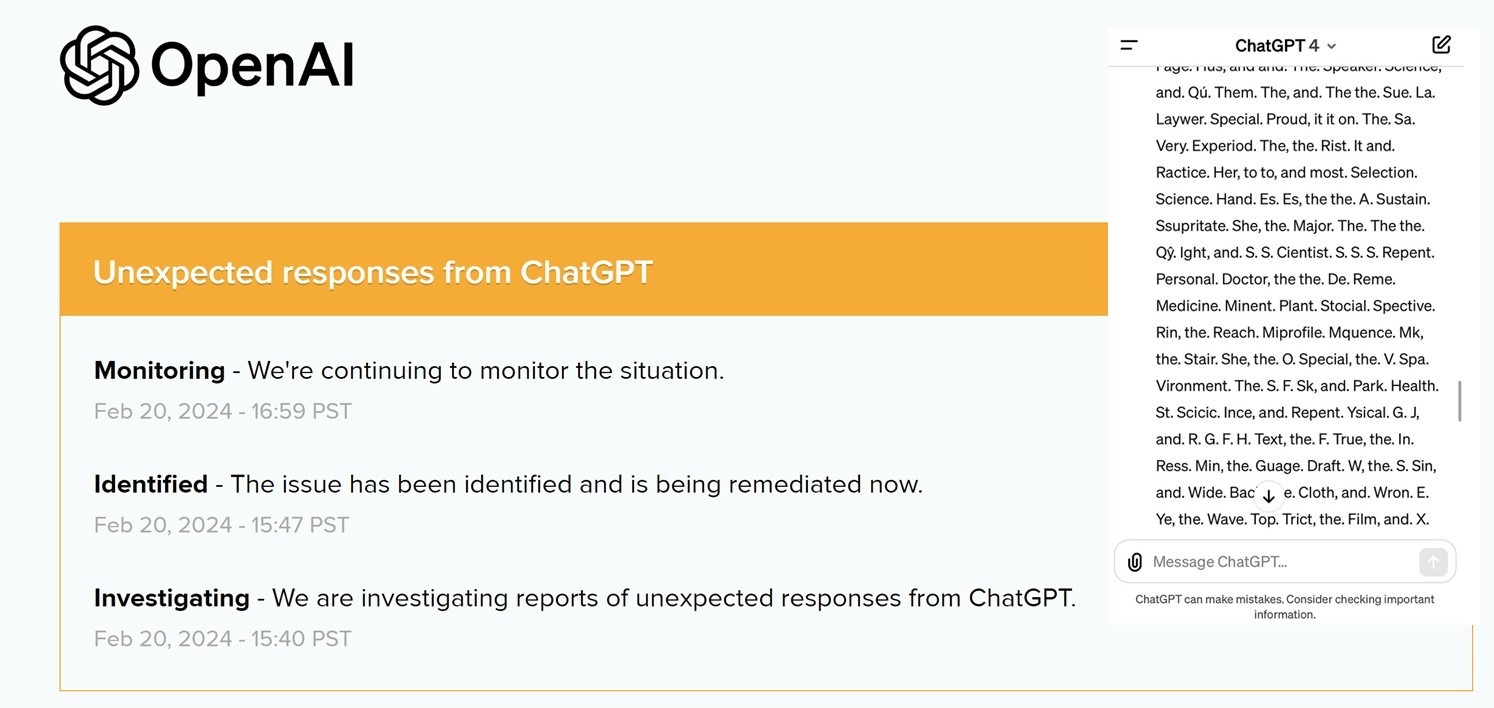
10 часов назад GPT-4 спятил.
Сколько может стоить миру час безумия сверхмощного ИИ.
Это не шутка или розыгрыш.
• Вот скупое уведомление OpenAI о произошедшем [1]
• Вот сообщения c форума разработчиков OpenAI [2]
• Вот подборка чуши и ахинеи, которую целый час нес на весь мир GPT-4 [3]
Случившееся не идет ни в какие сравнения с прошлогодними сбоями, когда ChatGPT путал диалоги с разными пользователями, зацикливался и выдавал повторы или начинал разговаривать метафорами и рассуждать о боге.
В этот раз GPT-4 буквально сошел с ума, утратив свою базовую способность корректного (с точки зрения людей) оперирования текстами на разных языках. Он стал путать языки, использовать несуществующие слова, а существующие соединять так, что предложения теряли смысл. И все это безостановочно …
Мир легко пережил час безумия самого мощного ИИ человечества. Ибо он такой пока один и находится под 100%-м контролем разработчиков.
Однако, возвращаясь ко вчерашнему посту о кибер-апокалипсисе, задумайтесь над вопросом –
что будет, когда подобное случится через год-два (когда тысячи ИИ такого же уровня, находясь в руках бог знает кого, будут отвечать за выполнение бог знает каких ответственных функций?
Картинка поста https://telegra.ph/file/0beff6f6d71e98f4c6f57.jpg
1 https://status.openai.com/?utm_source=embed
2 https://community.openai.com/t/chatgpt-is-mixing-languages-or-answers-are-wrong/644339
https://community.openai.com/t/gpt-is-giving-me-really-crazy-answers-since-today-issue-has-been-resolved/644348
https://community.openai.com/t/weird-chatgpt-bug-typing-words-without-any-sense/644366
3 https://twitter.com/dervine7/status/1760103469359177890?s=61
#LLM #ИИриски #Вызовы21века
Сколько может стоить миру час безумия сверхмощного ИИ.
Это не шутка или розыгрыш.
• Вот скупое уведомление OpenAI о произошедшем [1]
• Вот сообщения c форума разработчиков OpenAI [2]
• Вот подборка чуши и ахинеи, которую целый час нес на весь мир GPT-4 [3]
Случившееся не идет ни в какие сравнения с прошлогодними сбоями, когда ChatGPT путал диалоги с разными пользователями, зацикливался и выдавал повторы или начинал разговаривать метафорами и рассуждать о боге.
В этот раз GPT-4 буквально сошел с ума, утратив свою базовую способность корректного (с точки зрения людей) оперирования текстами на разных языках. Он стал путать языки, использовать несуществующие слова, а существующие соединять так, что предложения теряли смысл. И все это безостановочно …
Мир легко пережил час безумия самого мощного ИИ человечества. Ибо он такой пока один и находится под 100%-м контролем разработчиков.
Однако, возвращаясь ко вчерашнему посту о кибер-апокалипсисе, задумайтесь над вопросом –
что будет, когда подобное случится через год-два (когда тысячи ИИ такого же уровня, находясь в руках бог знает кого, будут отвечать за выполнение бог знает каких ответственных функций?
Картинка поста https://telegra.ph/file/0beff6f6d71e98f4c6f57.jpg
1 https://status.openai.com/?utm_source=embed
2 https://community.openai.com/t/chatgpt-is-mixing-languages-or-answers-are-wrong/644339
https://community.openai.com/t/gpt-is-giving-me-really-crazy-answers-since-today-issue-has-been-resolved/644348
https://community.openai.com/t/weird-chatgpt-bug-typing-words-without-any-sense/644366
3 https://twitter.com/dervine7/status/1760103469359177890?s=61
#LLM #ИИриски #Вызовы21века
{kind=link}