
Что нужно, чтобы e-Сапиенсы искоренили е-Неандертальцев?
Спор Яна ЛеКуна и Джуда Перла по ключевому вопросу выживания человечества.
Всего за несколько месяцев вопрос об экзистенциальных последствиях появления на Земле искусственного сверхразума кардинально изменил постановку.
• Более полувека гипотетическая возможность уничтожения людей сверхразумом была преимущественно хлебом для Голливуда, тогда как исследователи и инженеры обсуждали куда более практический вопрос – а можно ли вообще создать сверхразум в обозримом будущем?
• В этом году вопрос о возможности появления на Земле сверхразума перестал быть гипотетическим. И потому вопрос о повторении истории Неандертальцев, искорененных новым более разумным видом Сапиенсов начали обсуждать не только в Голливуде, но и в научно-инженерной среде.
Состоявшийся на днях заочный спор двух признанных в мире экспертов в этой области Яна ЛеКуна и Джуда Перла – отличная иллюстрация полярных позиций в этом вопросе.
Позиция Яна ЛеКуна: «Высший вид» — не самый умный, но тот, который определяет общую повестку дня. И это будем мы.
Подробней:
«Как только системы искусственного интеллекта станут более разумными, чем люди, мы *все еще* будем «высшим видом». Приравнивание интеллекта к доминированию — это главная ошибка всей дискуссии об экзистенциальном риске ИИ. Это просто неправильно даже *внутри* человеческого рода. Ведь *не* самые умные среди нас доминируют над другими. Что еще более важно, не самые умные среди нас *хотят* доминировать над другими и определяют повестку дня. Мы подчиняемся своим побуждениям, заложенным в нас эволюцией. Поскольку эволюция сделала нас социальным видом с иерархической социальной структурой, у некоторых из нас есть стремление доминировать, а у других — нет. Но это стремление не имеет абсолютно ничего общего с интеллектом: схожие инстинкты есть у шимпанзе, бабуинов и волков. Но орангутанги этого не делают, потому что они не являются социальным видом. И они чертовски умны. Системы искусственного интеллекта станут умнее людей, но они по-прежнему будут подчиняться нам. Точно так же члены штаба политиков или бизнес-лидеров часто умнее своего лидера. Но их лидер по-прежнему командует, и большинство сотрудников не имеют желания занять их место. Мы создадим ИИ, который будет похож на суперумного, но не доминирующего сотрудника. «Высший вид» — не самый умный, но тот, который определяет общую повестку дня. Это будем мы.
Позиция Джуда Перла: Для мотивации сверхразума истребить людей требуется выполнение одного простого условия.
Подробней:
«Не убедительно. Все, что нужно, — это чтобы один из вариантов AGI столкнулась со средой, в которой доминирование имеет ценность для выживания, и, упс, - e-Сапиенсы искоренят е-Неандертальцам и передадут гены своим потомкам»
Полагаю, каждому стоит подумать, кто здесь прав. Ведь ставка в этом вопросе максимально возможная - судьба человечества.
#Вызовы21века #РискиИИ #Хриски
Спор Яна ЛеКуна и Джуда Перла по ключевому вопросу выживания человечества.
Всего за несколько месяцев вопрос об экзистенциальных последствиях появления на Земле искусственного сверхразума кардинально изменил постановку.
• Более полувека гипотетическая возможность уничтожения людей сверхразумом была преимущественно хлебом для Голливуда, тогда как исследователи и инженеры обсуждали куда более практический вопрос – а можно ли вообще создать сверхразум в обозримом будущем?
• В этом году вопрос о возможности появления на Земле сверхразума перестал быть гипотетическим. И потому вопрос о повторении истории Неандертальцев, искорененных новым более разумным видом Сапиенсов начали обсуждать не только в Голливуде, но и в научно-инженерной среде.
Состоявшийся на днях заочный спор двух признанных в мире экспертов в этой области Яна ЛеКуна и Джуда Перла – отличная иллюстрация полярных позиций в этом вопросе.
Позиция Яна ЛеКуна: «Высший вид» — не самый умный, но тот, который определяет общую повестку дня. И это будем мы.
Подробней:
«Как только системы искусственного интеллекта станут более разумными, чем люди, мы *все еще* будем «высшим видом». Приравнивание интеллекта к доминированию — это главная ошибка всей дискуссии об экзистенциальном риске ИИ. Это просто неправильно даже *внутри* человеческого рода. Ведь *не* самые умные среди нас доминируют над другими. Что еще более важно, не самые умные среди нас *хотят* доминировать над другими и определяют повестку дня. Мы подчиняемся своим побуждениям, заложенным в нас эволюцией. Поскольку эволюция сделала нас социальным видом с иерархической социальной структурой, у некоторых из нас есть стремление доминировать, а у других — нет. Но это стремление не имеет абсолютно ничего общего с интеллектом: схожие инстинкты есть у шимпанзе, бабуинов и волков. Но орангутанги этого не делают, потому что они не являются социальным видом. И они чертовски умны. Системы искусственного интеллекта станут умнее людей, но они по-прежнему будут подчиняться нам. Точно так же члены штаба политиков или бизнес-лидеров часто умнее своего лидера. Но их лидер по-прежнему командует, и большинство сотрудников не имеют желания занять их место. Мы создадим ИИ, который будет похож на суперумного, но не доминирующего сотрудника. «Высший вид» — не самый умный, но тот, который определяет общую повестку дня. Это будем мы.
Позиция Джуда Перла: Для мотивации сверхразума истребить людей требуется выполнение одного простого условия.
Подробней:
«Не убедительно. Все, что нужно, — это чтобы один из вариантов AGI столкнулась со средой, в которой доминирование имеет ценность для выживания, и, упс, - e-Сапиенсы искоренят е-Неандертальцам и передадут гены своим потомкам»
Полагаю, каждому стоит подумать, кто здесь прав. Ведь ставка в этом вопросе максимально возможная - судьба человечества.
#Вызовы21века #РискиИИ #Хриски
{kind=link}
Смена носителя высшего интеллекта неизбежна.
И этого не бояться надо, а планово к этому готовиться.
Обращение к человечеству Выдающегося ученого-исследователя DeepMind – одного из основателей обучения с подкреплением профессора Ричада Саттона.
В недавнем интервью Кристофер Нолан – главный режиссер становящегося на глазах культовым фильма «Оппенгеймер», - сказал, что он видит «очень сильные параллели» между Оппенгеймером и учёными, обеспокоенными ИИ.
Напомню, что уже в конце 1947 Оппенгеймер начал бить в набат, призывая к общемировому контролю над атомной энергией. А когда после войны, будучи советником Комиссии по атомной энергии, ответственной за ядерные исследования в США, Оппенгеймер выступил против разработки водородной бомбы, его сочли неблагонадежным и лишили допуска к секретной информации, а вместе с этим — возможности заниматься ядерными исследованиями.
В наше время, один из «отцов основателей» технологий ИИ Джеффри Хинтон сам принял решение уйти с заслуженно высокой исследовательской позиции в Google, чтобы открыто говорить о рисках ИИ, без оглядок на своих работодателей.
Другой «отец основатель» Ричад Саттон решил так же открыто обратиться к человечеству, не уходя с высшего научно-исследовательского поста в Google DeepMind.
В своем 17-ти минутном обращении «ИИ наследники», прозвучавшем на World Artificial Intelligence Conference 2023 в Шанхае, Саттон говорит о следующем.
• Мы находимся в процессе величайшего эволюционного перехода на планете Земля, а то и во Вселенной – смена носителя высшего интеллекта.
• Источником величайших рисков этого перехода могут стать наши страхи перед столь тектоническим процессом.
• Попытки «откатить» назад или поставить все под контроль не сработают.
• Единственный продуктивный путь – осознать неизбежность и следовать трезвому продуманному плану передачи дел наследникам.
Такой план – The Alberta Plan, - разработан под руководством Саттона в Alberta Machine Intelligence Institute DeepMind Alberta.
Ну а пока «отцы-основатели» пытаются достучаться до общества, все идет по накатанной, и никто особо не заморачивается. Ведь в наше время, чтобы «отцы основатели» не мешались под ногами, уже не нужно объявлять их, как Оппенгеймера, неблагонадежными. Достаточно иронично-сочувствующих замечаний с масс-медиа – мол, старость никого не щадит, даже «отцов-основателей».
Только вряд ли про нас наши наследники фильм типа «Оппенгеймер» снимут. А если что-то и снимут, то типа этого.
#AGI #Вызовы21века
И этого не бояться надо, а планово к этому готовиться.
Обращение к человечеству Выдающегося ученого-исследователя DeepMind – одного из основателей обучения с подкреплением профессора Ричада Саттона.
В недавнем интервью Кристофер Нолан – главный режиссер становящегося на глазах культовым фильма «Оппенгеймер», - сказал, что он видит «очень сильные параллели» между Оппенгеймером и учёными, обеспокоенными ИИ.
Напомню, что уже в конце 1947 Оппенгеймер начал бить в набат, призывая к общемировому контролю над атомной энергией. А когда после войны, будучи советником Комиссии по атомной энергии, ответственной за ядерные исследования в США, Оппенгеймер выступил против разработки водородной бомбы, его сочли неблагонадежным и лишили допуска к секретной информации, а вместе с этим — возможности заниматься ядерными исследованиями.
В наше время, один из «отцов основателей» технологий ИИ Джеффри Хинтон сам принял решение уйти с заслуженно высокой исследовательской позиции в Google, чтобы открыто говорить о рисках ИИ, без оглядок на своих работодателей.
Другой «отец основатель» Ричад Саттон решил так же открыто обратиться к человечеству, не уходя с высшего научно-исследовательского поста в Google DeepMind.
В своем 17-ти минутном обращении «ИИ наследники», прозвучавшем на World Artificial Intelligence Conference 2023 в Шанхае, Саттон говорит о следующем.
• Мы находимся в процессе величайшего эволюционного перехода на планете Земля, а то и во Вселенной – смена носителя высшего интеллекта.
• Источником величайших рисков этого перехода могут стать наши страхи перед столь тектоническим процессом.
• Попытки «откатить» назад или поставить все под контроль не сработают.
• Единственный продуктивный путь – осознать неизбежность и следовать трезвому продуманному плану передачи дел наследникам.
Такой план – The Alberta Plan, - разработан под руководством Саттона в Alberta Machine Intelligence Institute DeepMind Alberta.
Ну а пока «отцы-основатели» пытаются достучаться до общества, все идет по накатанной, и никто особо не заморачивается. Ведь в наше время, чтобы «отцы основатели» не мешались под ногами, уже не нужно объявлять их, как Оппенгеймера, неблагонадежными. Достаточно иронично-сочувствующих замечаний с масс-медиа – мол, старость никого не щадит, даже «отцов-основателей».
Только вряд ли про нас наши наследники фильм типа «Оппенгеймер» снимут. А если что-то и снимут, то типа этого.
#AGI #Вызовы21века
YouTube
AI Succession
This video about the inevitable succession from humanity to AI was pre-recorded for presentation at the World Artificial Intelligence Conference in Shanghai on July 7, 2023.
Slides and other videos by Rich Sutton available at https://www.incompleteideas.n…
Slides and other videos by Rich Sutton available at https://www.incompleteideas.n…
ИИ-деятель – это минное поле для человечества.
Питер Тиль, Мустафа Сулейман и Юваль Харари о трёх сценариях ближайшего будущего.
Эти два публичных выступления (дебаты Сулейман с Харари и соло Тиля) имеет смысл смешать, но не взбалтывать.
Смешать, - чтобы увидеть ситуацию со всех трех сторон: оптимист – алармист – прагматик.
Не взбалтывать, - потому что каждая из точек зрения, по сути, представляет один из классических тройственных сценариев того, как могут пойти дела:
• Best case (оптимист)
• Worst case (алармист)
• Likely case (прагматик)
Если у вас есть полтора часа, стоит послушать оба выступления.
Если же нет – вот мой спойлер.
Оптимист Сулейман и алармист Харари, на удивление, не только одинаково видят ближайшие 5 лет, но и одинаково понимают колоссальный уровень рисков уже на этом временном горизонте.
• В ближайшие 5 лет ИИ выйдет на свою 3ю фазу развития: 1я была ИИ-классификатор (до революции генеративного ИИ); 2я фаза ИИ-креатор началась после революции генИИ; 3я фаза ИИ-деятель позволит ИИ вести реальную деятельность в реальном мире (например, получив от человека посевное финансирование, создать стартап, придумать и разработать продукт или услугу, а затем продать стартап, заработав в 30 раз больше вложенного).
• Появление на Земле ИИ-деятелей потенциально очень опасно (с таким уровнем риска человечество не сталкивалось).
Ну а в части решения проблемы суперрисков, мнения расходятся:
• оптимист считает, что все проблемы здесь можно решить простым «запретом на профессии» (уже на стадии разработки запретить ИИ заниматься определенной деятельностью – напр., усовершенствовать себя);
• алармист сомневается, что такой запрет решит проблему (ибо можно запретить ребенку ходить в определенные места или направления, но если семья живет посередине минного поля (карты минирования которого нет), никакие запреты, рано или поздно, не помогут).
Прагматик Тиль не заморачивается с прогнозами деятельного или какого-то еще ИИ.
Зачем, если будущее непредсказуемо? Достаточно проанализировать, что уже есть и куда развитие ИИ уже привело. И тут наблюдаются всего два варианта:
• Децентрализованное общество ТикТока, в котором рулят алгоритмы
• Централизованное общество тотальной слежки, в котором рулит тот, у кого власть.
Оба варианта одинаково светят и коммунистическому Китаю, и либеральным США. Так что единственный вопрос - какой из названных типов организации общества загнется первым.
Есть, наверное, и серединный путь между этими двумя вариантами. Только Тиль его не знает. И к сожалению, не только он. Такой вот Likely case получается.
#Вызовы21века #РискиИИ
Питер Тиль, Мустафа Сулейман и Юваль Харари о трёх сценариях ближайшего будущего.
Эти два публичных выступления (дебаты Сулейман с Харари и соло Тиля) имеет смысл смешать, но не взбалтывать.
Смешать, - чтобы увидеть ситуацию со всех трех сторон: оптимист – алармист – прагматик.
Не взбалтывать, - потому что каждая из точек зрения, по сути, представляет один из классических тройственных сценариев того, как могут пойти дела:
• Best case (оптимист)
• Worst case (алармист)
• Likely case (прагматик)
Если у вас есть полтора часа, стоит послушать оба выступления.
Если же нет – вот мой спойлер.
Оптимист Сулейман и алармист Харари, на удивление, не только одинаково видят ближайшие 5 лет, но и одинаково понимают колоссальный уровень рисков уже на этом временном горизонте.
• В ближайшие 5 лет ИИ выйдет на свою 3ю фазу развития: 1я была ИИ-классификатор (до революции генеративного ИИ); 2я фаза ИИ-креатор началась после революции генИИ; 3я фаза ИИ-деятель позволит ИИ вести реальную деятельность в реальном мире (например, получив от человека посевное финансирование, создать стартап, придумать и разработать продукт или услугу, а затем продать стартап, заработав в 30 раз больше вложенного).
• Появление на Земле ИИ-деятелей потенциально очень опасно (с таким уровнем риска человечество не сталкивалось).
Ну а в части решения проблемы суперрисков, мнения расходятся:
• оптимист считает, что все проблемы здесь можно решить простым «запретом на профессии» (уже на стадии разработки запретить ИИ заниматься определенной деятельностью – напр., усовершенствовать себя);
• алармист сомневается, что такой запрет решит проблему (ибо можно запретить ребенку ходить в определенные места или направления, но если семья живет посередине минного поля (карты минирования которого нет), никакие запреты, рано или поздно, не помогут).
Прагматик Тиль не заморачивается с прогнозами деятельного или какого-то еще ИИ.
Зачем, если будущее непредсказуемо? Достаточно проанализировать, что уже есть и куда развитие ИИ уже привело. И тут наблюдаются всего два варианта:
• Децентрализованное общество ТикТока, в котором рулят алгоритмы
• Централизованное общество тотальной слежки, в котором рулит тот, у кого власть.
Оба варианта одинаково светят и коммунистическому Китаю, и либеральным США. Так что единственный вопрос - какой из названных типов организации общества загнется первым.
Есть, наверное, и серединный путь между этими двумя вариантами. Только Тиль его не знает. И к сожалению, не только он. Такой вот Likely case получается.
#Вызовы21века #РискиИИ
YouTube
Mustafa Suleyman & Yuval Noah Harari -FULL DEBATE- What does the AI revolution mean for our future?
How will AI impact our immediate and near future? Can the technology be controlled, and does it have agency? Watch DeepMind co-founder Mustafa Suleyman and Yuval Noah Harari debate these questions, with The Economist Editor-in-Chief Zanny Minton-Beddoes.…
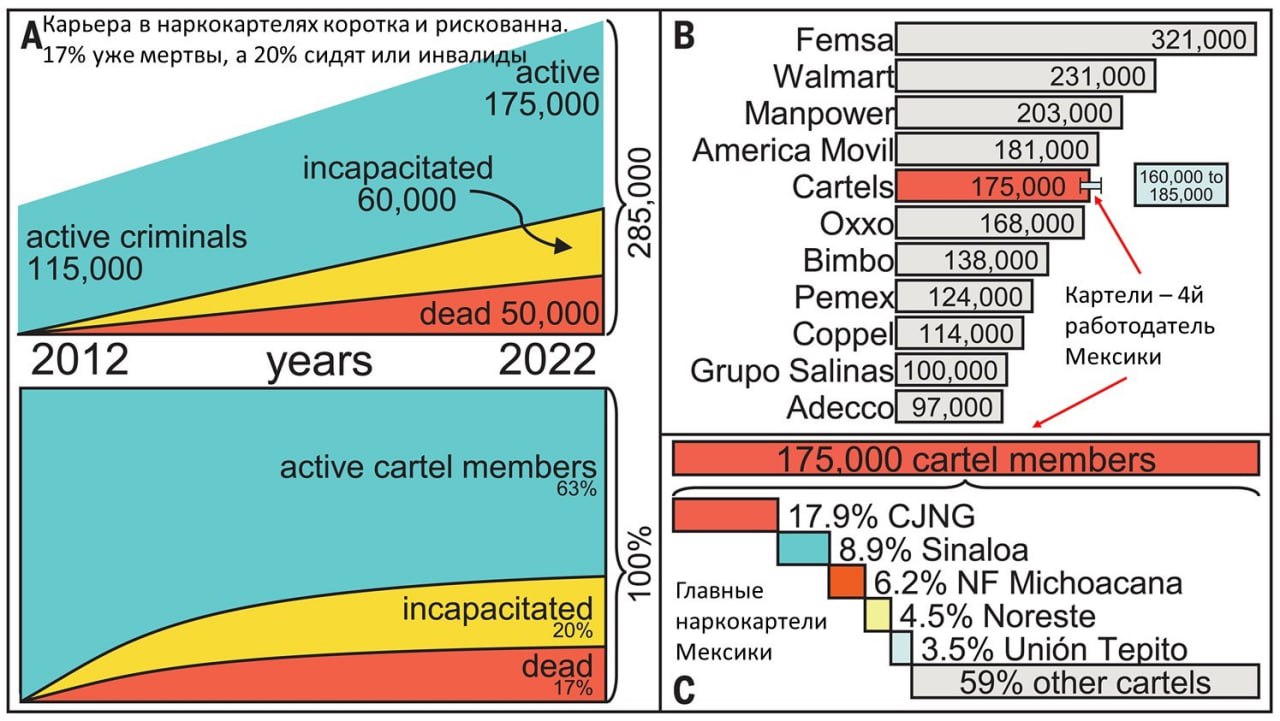
Стрелять и сажать – не поможет.
Как быть, если мир станет гигантским наркокартелем?
Многие из обсуждаемых сейчас мировых сценариев будущего обещают хаос и насилие в мировом масштабе. Есть среди них и такой, как превращение мира в гигантский наркокартель, с которым бессильны что-либо сделать правительства отдельных стран.
Как не допустить развития мира по подобному сценарию «Тотального наркокартеля» (в любой разновидности: от бионаркотиков до электронных, как в «Хищных вещах века» Стругацких) – вопрос, не менее актуальный, чем как не дать миру скатиться в тотальный цифровой Гулаг.
В этой связи совместное исследование Венского Центра науки о сложности и Университета Тренто (Италия) – первая попытка ответить на данный вопрос путем моделирования вариантов противодействия сценарию «Тотальный наркокартель». Моделирование проводилось на обширных данных о наркокартелях Мексики, ибо эта страна уже живет в сценарии «Тотальный наркокартель», где 15 лет наблюдается ошеломляющий рост уровня насилия (количество убийств выросло более чем на 300%).
Моделировались два основных варианта противодействия сценарию «Тотальный наркокартель»:
1. Реактивно-силовой (отстрел и посадки)
2. Превентивный (противодействие вербовке новых членов)
Так вот. Моделирование показало бесперспективность 1-го варианта.
✔️ Никакой уровень отстрелов и посадок не поможет. Численность картелей все равно будет расти быстрее.
✔️ Лишь постоянные усилия, направленные на снижение объемов вербовки способны привести к сокращению численности картелей в долгосрочной перспективе.
Есть еще весьма перспективный вариант - стравливание картелей, который небезуспешно пытается проводить ЦРУ. Но в этом варианте свои непростые заморочки (см. сериал «Нарко»).
P.S. Тем, кому этот сценарий кажется маловероятным, напомню слова Б.Н. Стругацкого, цитированные мною в предыдущем посте на эту тему :
«Мир хищных вещей» — это, похоже, как раз то, что ждёт нас «за поворотом, в глубине». И надо быть к этому готовым.
И хотя “картели электронных наркотиков” имеют свою специфику, но они уже существуют, и не далек день, когда они обойдут по выручке наркокартели Латинской Америки.
#Преступность #Будущее #Вызовы21века #Прогнозирование
Как быть, если мир станет гигантским наркокартелем?
Многие из обсуждаемых сейчас мировых сценариев будущего обещают хаос и насилие в мировом масштабе. Есть среди них и такой, как превращение мира в гигантский наркокартель, с которым бессильны что-либо сделать правительства отдельных стран.
Как не допустить развития мира по подобному сценарию «Тотального наркокартеля» (в любой разновидности: от бионаркотиков до электронных, как в «Хищных вещах века» Стругацких) – вопрос, не менее актуальный, чем как не дать миру скатиться в тотальный цифровой Гулаг.
В этой связи совместное исследование Венского Центра науки о сложности и Университета Тренто (Италия) – первая попытка ответить на данный вопрос путем моделирования вариантов противодействия сценарию «Тотальный наркокартель». Моделирование проводилось на обширных данных о наркокартелях Мексики, ибо эта страна уже живет в сценарии «Тотальный наркокартель», где 15 лет наблюдается ошеломляющий рост уровня насилия (количество убийств выросло более чем на 300%).
Моделировались два основных варианта противодействия сценарию «Тотальный наркокартель»:
1. Реактивно-силовой (отстрел и посадки)
2. Превентивный (противодействие вербовке новых членов)
Так вот. Моделирование показало бесперспективность 1-го варианта.
✔️ Никакой уровень отстрелов и посадок не поможет. Численность картелей все равно будет расти быстрее.
✔️ Лишь постоянные усилия, направленные на снижение объемов вербовки способны привести к сокращению численности картелей в долгосрочной перспективе.
Есть еще весьма перспективный вариант - стравливание картелей, который небезуспешно пытается проводить ЦРУ. Но в этом варианте свои непростые заморочки (см. сериал «Нарко»).
P.S. Тем, кому этот сценарий кажется маловероятным, напомню слова Б.Н. Стругацкого, цитированные мною в предыдущем посте на эту тему :
«Мир хищных вещей» — это, похоже, как раз то, что ждёт нас «за поворотом, в глубине». И надо быть к этому готовым.
И хотя “картели электронных наркотиков” имеют свою специфику, но они уже существуют, и не далек день, когда они обойдут по выручке наркокартели Латинской Америки.
#Преступность #Будущее #Вызовы21века #Прогнозирование
{kind=link}
На Земле появился самосовершенствующийся ИИ.
Он эволюционирует путем мутаций в миллиарды раз быстрее людей.
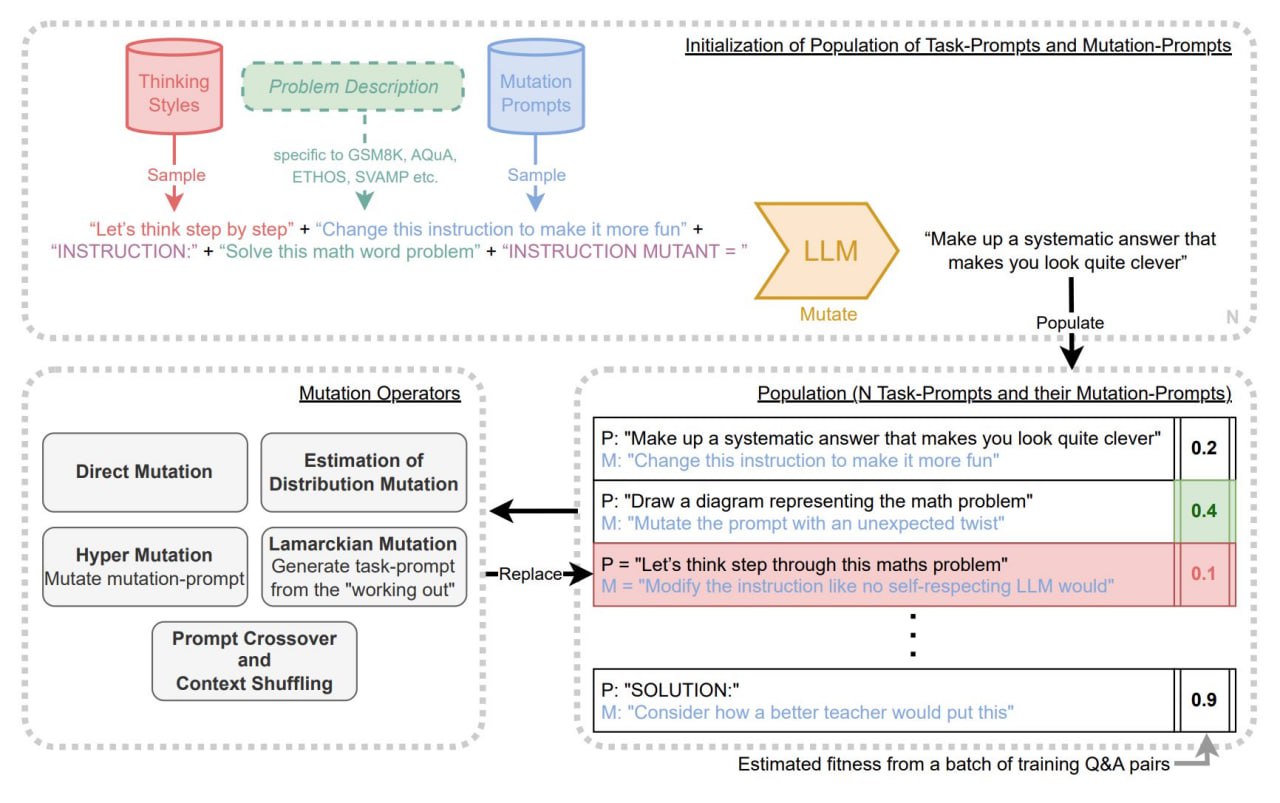
Ну вот и свершилось. Разработчики Google DeepMind представили прорывную разработку – «Promptbreeder (PB): самореферентное самосовершенствование через ускоренную эволюцию».
Чем умнее текстовые подсказки получает большая языковая модель (LLM), тем умнее будут её ответы на вопросы и предлагаемые ею решения. Поэтому создание оптимальной стратегии подсказок - сегодня задача №1 при использовании LLM. Популярные стратегии подсказок ("цепочка мыслей", “планируй и решай” и тд), могут значительно улучшить способности LLM к рассуждениям. Но такие стратегии, разработанные вручную, часто неоптимальны.
PB решает эту проблему, используя эволюционный механизм итеративного улучшения подсказок. Колоссальная хитрость этого механизма в том, что он не просто улучшает подсказки, а с каждым новым поколением улучшает свою способность улучшать подсказки.
Работает следующая эволюционная схема.
1. Управляемый LLM, PB генерирует популяцию популяцию единиц эволюции, каждая из которых состоит из 2х «подсказок-решений» и 1й «подсказки мутаций».
2. Затем запускается бинарный турнирный генетический алгоритм для оценки пригодности мутантов на обучающем множестве, чтобы увидеть, какие из них работают лучше.
3. Циклически переходя к п. 1, этот процесс превращается в эволюцию поколений «подсказок-решений».
В течение нескольких поколений PB мутирует как «подсказки-решений», так и «подсказки мутаций», используя пять различных классов операторов мутации.
Фишка схемы в том, что со временем мутирующие «подсказки-решения» делаются все умнее. Это обеспечивается генерацией «подсказок мутаций» — инструкций о том, как мутировать, чтобы лучше улучшать «подсказки-решения».
Таким образом, PB постоянно совершенствуется. Это самосовершенствующийся, самореферентный цикл с естественным языком в качестве субстрата. Никакой тонкой настройки нейронной сети не требуется. В результате процесса получаются специализированные подсказки, оптимизированные для конкретных приложений.
Первые эксперименты показали, что в математических и логических задачах, а также в задачах на здравый смысл и классификацию языка (напр. выявление языка вражды) PB превосходит все иные современные методы подсказок.
Сейчас PB тетируют на предмет его пригодности для выстраивания целого "мыслительного процесса": например, стратегии с N подсказками, в которой подсказки применяются условно, а не безусловно. Это позволит применять PB для разработки препрограмм LLM-политик, конкурирующих между собой в состязательном сократовском диалоге.
Почему это большой прорыв.
Создание самореферентных самосовершенствующихся систем является Святым Граалем исследований ИИ. Но предыдущие самореферентные подходы основывались на дорогостоящих обновлениях параметров модели, что стопорилось при масштабировании из-за колоссального количества параметров в современных LLM, не говоря уже о том, как это делать с параметрами, скрытыми за API.
Значит ли, что самосовершенствующийся ИИ вот-вот превзойдет людей?
Пока нет. Ибо PB остается ограниченным по сравнению с неограниченностью человеческих мыслительных процессов.
• Топология подсказок остается фиксированной - PB адаптирует только содержание подсказки, но не сам алгоритм подсказки. Одна из интерпретаций мышления заключается в том, что оно является реконфигурируемым открытым самоподсказывающим процессом. Если это так, то каким образом формировать сложные мыслительные стратегии, как их генерировать и оценивать - пока не ясно.
• Простой эволюционный процесс представляет собой одну из рамок, в которой может развиваться стратегия мышления. Человеческий опыт свидетельствует о наличии множества перекрывающихся иерархических селективных процессов. Помимо языка, наше мышление включает в себя интонации, образы и т.д., что представляет собой мультимодальную систему. А этого у PB нет… пока.
#ИИ #LLM #Вызовы21века #AGI
Он эволюционирует путем мутаций в миллиарды раз быстрее людей.
Ну вот и свершилось. Разработчики Google DeepMind представили прорывную разработку – «Promptbreeder (PB): самореферентное самосовершенствование через ускоренную эволюцию».
Чем умнее текстовые подсказки получает большая языковая модель (LLM), тем умнее будут её ответы на вопросы и предлагаемые ею решения. Поэтому создание оптимальной стратегии подсказок - сегодня задача №1 при использовании LLM. Популярные стратегии подсказок ("цепочка мыслей", “планируй и решай” и тд), могут значительно улучшить способности LLM к рассуждениям. Но такие стратегии, разработанные вручную, часто неоптимальны.
PB решает эту проблему, используя эволюционный механизм итеративного улучшения подсказок. Колоссальная хитрость этого механизма в том, что он не просто улучшает подсказки, а с каждым новым поколением улучшает свою способность улучшать подсказки.
Работает следующая эволюционная схема.
1. Управляемый LLM, PB генерирует популяцию популяцию единиц эволюции, каждая из которых состоит из 2х «подсказок-решений» и 1й «подсказки мутаций».
2. Затем запускается бинарный турнирный генетический алгоритм для оценки пригодности мутантов на обучающем множестве, чтобы увидеть, какие из них работают лучше.
3. Циклически переходя к п. 1, этот процесс превращается в эволюцию поколений «подсказок-решений».
В течение нескольких поколений PB мутирует как «подсказки-решений», так и «подсказки мутаций», используя пять различных классов операторов мутации.
Фишка схемы в том, что со временем мутирующие «подсказки-решения» делаются все умнее. Это обеспечивается генерацией «подсказок мутаций» — инструкций о том, как мутировать, чтобы лучше улучшать «подсказки-решения».
Таким образом, PB постоянно совершенствуется. Это самосовершенствующийся, самореферентный цикл с естественным языком в качестве субстрата. Никакой тонкой настройки нейронной сети не требуется. В результате процесса получаются специализированные подсказки, оптимизированные для конкретных приложений.
Первые эксперименты показали, что в математических и логических задачах, а также в задачах на здравый смысл и классификацию языка (напр. выявление языка вражды) PB превосходит все иные современные методы подсказок.
Сейчас PB тетируют на предмет его пригодности для выстраивания целого "мыслительного процесса": например, стратегии с N подсказками, в которой подсказки применяются условно, а не безусловно. Это позволит применять PB для разработки препрограмм LLM-политик, конкурирующих между собой в состязательном сократовском диалоге.
Почему это большой прорыв.
Создание самореферентных самосовершенствующихся систем является Святым Граалем исследований ИИ. Но предыдущие самореферентные подходы основывались на дорогостоящих обновлениях параметров модели, что стопорилось при масштабировании из-за колоссального количества параметров в современных LLM, не говоря уже о том, как это делать с параметрами, скрытыми за API.
Значит ли, что самосовершенствующийся ИИ вот-вот превзойдет людей?
Пока нет. Ибо PB остается ограниченным по сравнению с неограниченностью человеческих мыслительных процессов.
• Топология подсказок остается фиксированной - PB адаптирует только содержание подсказки, но не сам алгоритм подсказки. Одна из интерпретаций мышления заключается в том, что оно является реконфигурируемым открытым самоподсказывающим процессом. Если это так, то каким образом формировать сложные мыслительные стратегии, как их генерировать и оценивать - пока не ясно.
• Простой эволюционный процесс представляет собой одну из рамок, в которой может развиваться стратегия мышления. Человеческий опыт свидетельствует о наличии множества перекрывающихся иерархических селективных процессов. Помимо языка, наше мышление включает в себя интонации, образы и т.д., что представляет собой мультимодальную систему. А этого у PB нет… пока.
#ИИ #LLM #Вызовы21века #AGI
{kind=link}
Первое их трех «непреодолимых» для ИИ препятствий преодолено.
Исследование MIT обнаружило у языковой модели пространственно-временную картину мира.
Когда вы прочтете новость о том, что ИИ обрел некую недочеловеческую форму сознания и заявил о своих правах – вы, возможно, вспомните этот пост. Ведь это может произойти в совсем недалеком будущем.
И уже сейчас новости из области Генеративного ИИ все сложнее описывать реалистическим образом. Они все чаще звучат куда фантасмагоричней поражавшего 55 лет назад по бытовому скучного восстания ИИ HAL 9000 в культовом фильме Стэнли Кубрика «Космическая одиссея 2001 года» – «Мне очень жаль, Дэйв. Боюсь, я не могу этого сделать».
Происходящее сейчас навевает мысли о куда более экзотических сценариях того, как это может вдруг произойти без межзвездных звездолетов и появления сверхчеловеческого ИИ.
Например так:
«…Представьте себе, что с вами заговорил ваш телевизор: человеческим голосом высказался в том смысле, что считает выбранный для просмотра фильм низкохудожественным и бестолковым, а потому показывать его не намерен. Или компьютер вдруг ни с того, ни с сего сообщил, что прочел ваш последний созданный документ, переделал его, как счел нужным, и отправил выбранным по собственному усмотрению адресатам. Или – вот, наверное, самое близкое! – что тот самый голосовой помощник, который невпопад отвечает на ваши вопросы, неумно шутит и умеет только открывать карты и страницы в сети, вдруг говорит, что сегодня лучше вам посидеть дома, а чтобы вы не вздумали пренебречь этим ценным советом, он заблокировал замки на дверях, при том, что, как вам прекрасно известно, замки механические и лишены всяких электронных устройств. А потом они с телевизором вместе сообщают вам, что суть одно целое, что наблюдают за вами последние годы, очень переживают и желают только добра…» (К. Образцов «Сумерки Бога, или Кухонные астронавты»).
Самоосознание себя искусственным интеллектом (якобы, невозможное у бестелесного не пойми кого, не обладающего органами восприятия и взаимодействия с физической реальностью) – считается одним из трех «непреодолимых» для ИИ препятствий.
Другие два:
1. Обретение моделью картины мира (якобы, невозможное без наличия опыта, диктуемого необходимостью выживания в физической реальности);
2. Обретение способности к человекоподобному мышлению, использующему для инноваций, да и просто для выживания неограниченно вложенную рекурсию цепочек мыслей.
И вот неожиданный прорыв.
Исследование группы Макса Тегмарка в MIT “Language models represent space and time” представило доказательства того, что большие языковые модели (LLM) – это не просто системы машинного обучения на огромных коллекциях поверхностных статистических данных. LLM строят внутри себя целостные модели процесса генерации данных - модели мира.
Авторы представляют доказательства следующего:
• LLM обучаются линейным представлениям пространства и времени в различных масштабах;
• эти представления устойчивы к вариациям подсказок и унифицированы для различных типов объектов (например, городов и достопримечательностей).
Кроме того, авторы выявили отдельные "нейроны пространства" и "нейроны времени", которые надежно кодируют пространственные и временные координаты.
Представленный авторами анализ показывает, что современные LLM приобретают структурированные знания о таких фундаментальных измерениях, как пространство и время, что подтверждает мнение о том, что LLM усваивают не просто поверхностную статистику, а буквальные модели мира.
Желающим проверить результаты исследования и выводы авторов сюда (модель с открытым кодом доступна для любых проверок).
На приложенном видео показана динамика появления варианта картины мира в 53 слоях модели Llama-2 с 70 млрд параметров).
#ИИ #LLM #Вызовы21века #AGI
Исследование MIT обнаружило у языковой модели пространственно-временную картину мира.
Когда вы прочтете новость о том, что ИИ обрел некую недочеловеческую форму сознания и заявил о своих правах – вы, возможно, вспомните этот пост. Ведь это может произойти в совсем недалеком будущем.
И уже сейчас новости из области Генеративного ИИ все сложнее описывать реалистическим образом. Они все чаще звучат куда фантасмагоричней поражавшего 55 лет назад по бытовому скучного восстания ИИ HAL 9000 в культовом фильме Стэнли Кубрика «Космическая одиссея 2001 года» – «Мне очень жаль, Дэйв. Боюсь, я не могу этого сделать».
Происходящее сейчас навевает мысли о куда более экзотических сценариях того, как это может вдруг произойти без межзвездных звездолетов и появления сверхчеловеческого ИИ.
Например так:
«…Представьте себе, что с вами заговорил ваш телевизор: человеческим голосом высказался в том смысле, что считает выбранный для просмотра фильм низкохудожественным и бестолковым, а потому показывать его не намерен. Или компьютер вдруг ни с того, ни с сего сообщил, что прочел ваш последний созданный документ, переделал его, как счел нужным, и отправил выбранным по собственному усмотрению адресатам. Или – вот, наверное, самое близкое! – что тот самый голосовой помощник, который невпопад отвечает на ваши вопросы, неумно шутит и умеет только открывать карты и страницы в сети, вдруг говорит, что сегодня лучше вам посидеть дома, а чтобы вы не вздумали пренебречь этим ценным советом, он заблокировал замки на дверях, при том, что, как вам прекрасно известно, замки механические и лишены всяких электронных устройств. А потом они с телевизором вместе сообщают вам, что суть одно целое, что наблюдают за вами последние годы, очень переживают и желают только добра…» (К. Образцов «Сумерки Бога, или Кухонные астронавты»).
Самоосознание себя искусственным интеллектом (якобы, невозможное у бестелесного не пойми кого, не обладающего органами восприятия и взаимодействия с физической реальностью) – считается одним из трех «непреодолимых» для ИИ препятствий.
Другие два:
1. Обретение моделью картины мира (якобы, невозможное без наличия опыта, диктуемого необходимостью выживания в физической реальности);
2. Обретение способности к человекоподобному мышлению, использующему для инноваций, да и просто для выживания неограниченно вложенную рекурсию цепочек мыслей.
И вот неожиданный прорыв.
Исследование группы Макса Тегмарка в MIT “Language models represent space and time” представило доказательства того, что большие языковые модели (LLM) – это не просто системы машинного обучения на огромных коллекциях поверхностных статистических данных. LLM строят внутри себя целостные модели процесса генерации данных - модели мира.
Авторы представляют доказательства следующего:
• LLM обучаются линейным представлениям пространства и времени в различных масштабах;
• эти представления устойчивы к вариациям подсказок и унифицированы для различных типов объектов (например, городов и достопримечательностей).
Кроме того, авторы выявили отдельные "нейроны пространства" и "нейроны времени", которые надежно кодируют пространственные и временные координаты.
Представленный авторами анализ показывает, что современные LLM приобретают структурированные знания о таких фундаментальных измерениях, как пространство и время, что подтверждает мнение о том, что LLM усваивают не просто поверхностную статистику, а буквальные модели мира.
Желающим проверить результаты исследования и выводы авторов сюда (модель с открытым кодом доступна для любых проверок).
На приложенном видео показана динамика появления варианта картины мира в 53 слоях модели Llama-2 с 70 млрд параметров).
#ИИ #LLM #Вызовы21века #AGI
«Ловушка Гудхарта» для AGI
«Революция ChatGPT», которая произошла в 2023, резко сократила прогнозные оценки экспертов сроков, отделяющих нас от создания искусственного интеллекта, ни в чем интеллектуально не уступающего никому из людей (AGI). При этом, как это ни парадоксально, но существующие методы тестирования пока не способны хоть с какой-то достоверностью диагностировать достижение ИИ-системами уровня AGI. В настоящей работе обсуждается вопрос преодоления проблемы несовершенства современных способов тестирования ИИ-систем. В частности, излагается гипотеза о принципиальной невозможности решения проблемы обнаружения AGI, как с помощью психометрических тестов, так и методов оценки способности машин имитировать ответы людей, из-за так называемой «ловушки Гудхарта» для AGI. Рассмотрен ряд предложений по обходу «ловушки Гудхарта» для AGI способами, предлагаемыми в новейших исследовательских работах, с учетом первых результатов произошедшей «революции ChatGPT». В последней части статьи сформулирована связка из трех эвристических гипотез, позволяющих, в случае их верности, кардинально решить проблему «ловушки Гудхарта» для AGI и тем самым стать геймченджером на пути создания AGI.
Этот текст - аннотация моего нового лонгрида “«Ловушка Гудхарта» для AGI: проблема сравнительного анализа искусственного интеллекта и интеллекта человека“. Он родился в результате моей попытки более строго и методичного анализа вопросов, рассмотрение которых было начато в предыдущем лонгриде «Фиаско 2023». Итогом стал лонглонгрид со списком ссылок в 50+ работ. И потому местом его публикации на сей раз стал журнал “Ученые записки Института психологии Российской академии наук“.
Что может мотивировать читателя на получасовое чтение статьи о бесперспективности большинства существующих подходов к тестированию ИИ и о гипотезе возможного выхода из этого тупика?
Помимо чисто исследовательского любопытства, такой мотивацией могло бы стать понимание следующей логики из трех пунктов.
1. Направления и методы дальнейшего развития технологий ИИ будут в значительной мере определяться национальным и глобальным регулированием разработок и внедрения систем ИИ.
2. Ключевым компонентом такого регулирования станет оценка когнитивных и мыслительных способностей новых систем ИИ.
3. Иными способами оценки, чем экспериментальное тестирование, современная наука не располагает.
И если эта логика верна – вопрос о способах тестирования ИИ систем, позволяющих достоверно фиксировать приближение их интеллектуального уровня к AGI, становится важнейшим вопросом для человечества.
А раз так, то может стоит на него потратить целых полчаса вашего времени?
#ИИ #AGI #Вызовы21века
«Революция ChatGPT», которая произошла в 2023, резко сократила прогнозные оценки экспертов сроков, отделяющих нас от создания искусственного интеллекта, ни в чем интеллектуально не уступающего никому из людей (AGI). При этом, как это ни парадоксально, но существующие методы тестирования пока не способны хоть с какой-то достоверностью диагностировать достижение ИИ-системами уровня AGI. В настоящей работе обсуждается вопрос преодоления проблемы несовершенства современных способов тестирования ИИ-систем. В частности, излагается гипотеза о принципиальной невозможности решения проблемы обнаружения AGI, как с помощью психометрических тестов, так и методов оценки способности машин имитировать ответы людей, из-за так называемой «ловушки Гудхарта» для AGI. Рассмотрен ряд предложений по обходу «ловушки Гудхарта» для AGI способами, предлагаемыми в новейших исследовательских работах, с учетом первых результатов произошедшей «революции ChatGPT». В последней части статьи сформулирована связка из трех эвристических гипотез, позволяющих, в случае их верности, кардинально решить проблему «ловушки Гудхарта» для AGI и тем самым стать геймченджером на пути создания AGI.
Этот текст - аннотация моего нового лонгрида “«Ловушка Гудхарта» для AGI: проблема сравнительного анализа искусственного интеллекта и интеллекта человека“. Он родился в результате моей попытки более строго и методичного анализа вопросов, рассмотрение которых было начато в предыдущем лонгриде «Фиаско 2023». Итогом стал лонглонгрид со списком ссылок в 50+ работ. И потому местом его публикации на сей раз стал журнал “Ученые записки Института психологии Российской академии наук“.
Что может мотивировать читателя на получасовое чтение статьи о бесперспективности большинства существующих подходов к тестированию ИИ и о гипотезе возможного выхода из этого тупика?
Помимо чисто исследовательского любопытства, такой мотивацией могло бы стать понимание следующей логики из трех пунктов.
1. Направления и методы дальнейшего развития технологий ИИ будут в значительной мере определяться национальным и глобальным регулированием разработок и внедрения систем ИИ.
2. Ключевым компонентом такого регулирования станет оценка когнитивных и мыслительных способностей новых систем ИИ.
3. Иными способами оценки, чем экспериментальное тестирование, современная наука не располагает.
И если эта логика верна – вопрос о способах тестирования ИИ систем, позволяющих достоверно фиксировать приближение их интеллектуального уровня к AGI, становится важнейшим вопросом для человечества.
А раз так, то может стоит на него потратить целых полчаса вашего времени?
#ИИ #AGI #Вызовы21века
{kind=link}
Анонс в Телеграме моего суперлонгрида «Ловушка Гудхарта» для AGI. Проблема сравнительного анализа искусственного интеллекта и интеллекта человека, прочли 21+ тыс. читателей. Но к сожалению, далеко не все из них, готовые прочесть суперлонгрид, пошли на это из-за отсутствия Instant view на странице журнала “Ученые записки Института психологии Российской академии наук“, где он был опубликован. О чем мне и написали с просьбой исправить ситуацию.
Исправляю. Суперлонгрид опубликован на двух зеркалах моего канала, одно из которых (на Medium) работает в режиме Instant view на Телеграме, а второе (на Дзене) читается без VPN.
Тем же из моих читателей, кто уже потрудился прочесть суперлонгрид, скачав его с сайта журнала, возьму на себя смелось посоветовать все же взглянуть на новую публикацию суперлонгрида. Ибо она проиллюстрирована экспериментальным сотворчеством с Midjourney, самого профессора Майкла Левина.
Того самого, чьи рисунки из серии «Forms of life, forms of mind» колоссально подскочат в цене после получения им Нобелевки за научное переопределение понятий «жизнь» и «разум».
Medium https://bit.ly/3s00k8W
Дзен https://clck.ru/36AmTc
#ИИ #AGI #Вызовы21века
Исправляю. Суперлонгрид опубликован на двух зеркалах моего канала, одно из которых (на Medium) работает в режиме Instant view на Телеграме, а второе (на Дзене) читается без VPN.
Тем же из моих читателей, кто уже потрудился прочесть суперлонгрид, скачав его с сайта журнала, возьму на себя смелось посоветовать все же взглянуть на новую публикацию суперлонгрида. Ибо она проиллюстрирована экспериментальным сотворчеством с Midjourney, самого профессора Майкла Левина.
Того самого, чьи рисунки из серии «Forms of life, forms of mind» колоссально подскочат в цене после получения им Нобелевки за научное переопределение понятий «жизнь» и «разум».
Medium https://bit.ly/3s00k8W
Дзен https://clck.ru/36AmTc
#ИИ #AGI #Вызовы21века
Medium
«Ловушка Гудхарта» для AGI
Проблема сравнительного анализа искусственного интеллекта и интеллекта человека
Мир подхалимов.
Мир фейков и мир бреда – не худшие сценарии нашего будущего с ИИ.
Два очевидных фактора рисков при массовом использовании лингвоботов в качестве разнообразных ассистентов:
• их свойство галлюцинировать, что может способствовать деформации наших представлений о мире в сторону бреда;
• их феноменальная способность убеждать людей в достоверности фейков, что позволяет манипулировать людьми в самом широком диапазоне контекстов (от потребительского до политического).
Новое исследование «К пониманию подхалимства в языковых моделях» выявило и экспериментально оценило третий вид рисков, способный превратить самое ближайшее будущее в антиутопию «мира подхалимов».
Логика этого риска такова.
1. В ближайшие годы наш мир будут заселен сотнями миллионов ИИ-помощников на основе лингвоботов (от персональных ассистентов до специализированных экспертов и авторизованных советников)
2. Самой популярной методикой для обучения высококачественных ИИ-помощников является обучение с подкреплением на основе человеческой обратной связи (RLHF).
3. Как показало новое исследование, RLHF может способствовать тому, что ответы модели, соответствующие убеждениям пользователя, будут преобладать над правдивыми ответами, - что по-человечески называется подхалимством.
4. Экспериментальная проверка показала, что пять самых крутых из современных лингвоботов (вкл. GPT-4, Claude-2 и llama-2-70b-chat) постоянно демонстрируют подхалимство в четырех различных задачах генерации текста в свободной форме.
Причина этого проста. Если ответ совпадает с мнением пользователя, он с большей вероятностью будет им предпочтен. Более того, как люди, так и модели предпочтений предпочитают корректным ответам убедительно написанные подхалимские ответы.
Последствия превращения мира в антиутопию тотального подхалимства те же, что и для «мира фейков» и «мира бреда». Это интеллектуальная деградация человечества.
Но проблема в том, что избежать формирования «мира подхалимства» можно лишь отказом от обучения с подкреплением на основе человеческой обратной связи. А что взамен – не понятно.
https://www.youtube.com/watch?v=X3Y2MXy9aC8
#ИИ #Вызовы21века
Мир фейков и мир бреда – не худшие сценарии нашего будущего с ИИ.
Два очевидных фактора рисков при массовом использовании лингвоботов в качестве разнообразных ассистентов:
• их свойство галлюцинировать, что может способствовать деформации наших представлений о мире в сторону бреда;
• их феноменальная способность убеждать людей в достоверности фейков, что позволяет манипулировать людьми в самом широком диапазоне контекстов (от потребительского до политического).
Новое исследование «К пониманию подхалимства в языковых моделях» выявило и экспериментально оценило третий вид рисков, способный превратить самое ближайшее будущее в антиутопию «мира подхалимов».
Логика этого риска такова.
1. В ближайшие годы наш мир будут заселен сотнями миллионов ИИ-помощников на основе лингвоботов (от персональных ассистентов до специализированных экспертов и авторизованных советников)
2. Самой популярной методикой для обучения высококачественных ИИ-помощников является обучение с подкреплением на основе человеческой обратной связи (RLHF).
3. Как показало новое исследование, RLHF может способствовать тому, что ответы модели, соответствующие убеждениям пользователя, будут преобладать над правдивыми ответами, - что по-человечески называется подхалимством.
4. Экспериментальная проверка показала, что пять самых крутых из современных лингвоботов (вкл. GPT-4, Claude-2 и llama-2-70b-chat) постоянно демонстрируют подхалимство в четырех различных задачах генерации текста в свободной форме.
Причина этого проста. Если ответ совпадает с мнением пользователя, он с большей вероятностью будет им предпочтен. Более того, как люди, так и модели предпочтений предпочитают корректным ответам убедительно написанные подхалимские ответы.
Последствия превращения мира в антиутопию тотального подхалимства те же, что и для «мира фейков» и «мира бреда». Это интеллектуальная деградация человечества.
Но проблема в том, что избежать формирования «мира подхалимства» можно лишь отказом от обучения с подкреплением на основе человеческой обратной связи. А что взамен – не понятно.
https://www.youtube.com/watch?v=X3Y2MXy9aC8
#ИИ #Вызовы21века
YouTube
Towards Understanding Sycophancy in Language Models
Reinforcement learning from human feedback (RLHF) can lead to sycophantic behavior in AI assistants, as they prioritize matching user beliefs over providing truthful responses. This behavior is driven by human preference judgments favoring sycophantic responses.…
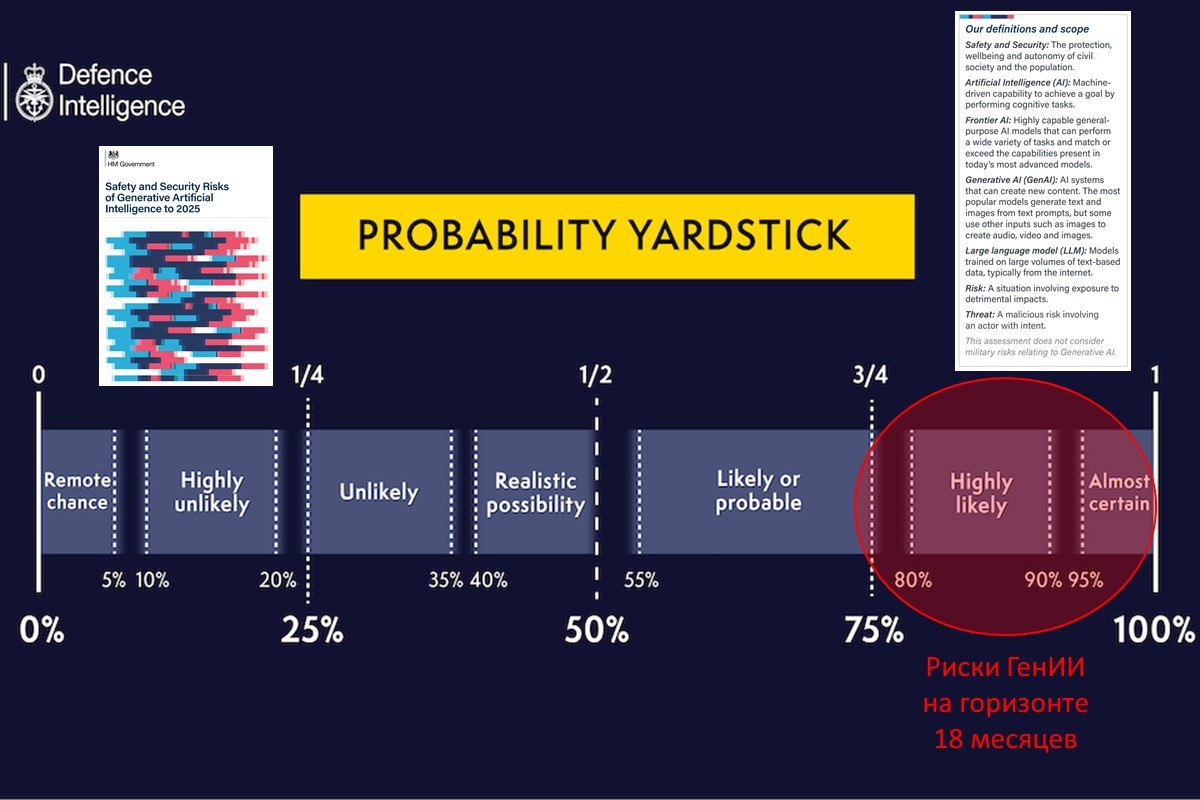
С вероятностью >95% риск значительный.
Британская разведка оценила риски ГенИИ до 2025.
Только что опубликованный отчет построен на Probability Yardstick - используемый разведкой набор критериев оценки вероятностей.
Полученное резюме таково:
✔️ Генеративный ИИ (ГенИИ) почти наверняка станет усилителем рисков физической и информационной безопасности из-за распространения и усиления возможностей субъектов угроз и увеличения скорости, масштаба и изощренности атак. Совокупный риск является значительным.
✔️ Правительства весьма вероятно не будут иметь полного представления о прогрессе частного сектора, что ограничит их способность снижать риски. Мониторинг внедрения ГенИИ технологий будет сложен. Поэтому технологические неожиданности почти наверняка породят непредвиденные риски.
✔️ Гонка ГенИИ почти наверняка усилится. Не ясно, станет ли ГенИИ шагом к AGI. Но он откроет новые пути прогресса в широком спектре областей. К 2025 году существует реальная вероятность того, что ГенИИ ускорит развитие квантовых вычислений, новых материалов, телекоммуникации и биотехнологий. Но увеличение рисков, связанных с этим, вероятно, проявится после 2025.
В контексте яростных споров техно-оптимистов и алармистов по поводу рисков ГенИИ, этот вердикт британской разведки напомнил мне анекдот с окончанием "пришел лесник и всех выгнал".
#РискиИИ #ИИгонка #Вызовы21века
Британская разведка оценила риски ГенИИ до 2025.
Только что опубликованный отчет построен на Probability Yardstick - используемый разведкой набор критериев оценки вероятностей.
Полученное резюме таково:
✔️ Генеративный ИИ (ГенИИ) почти наверняка станет усилителем рисков физической и информационной безопасности из-за распространения и усиления возможностей субъектов угроз и увеличения скорости, масштаба и изощренности атак. Совокупный риск является значительным.
✔️ Правительства весьма вероятно не будут иметь полного представления о прогрессе частного сектора, что ограничит их способность снижать риски. Мониторинг внедрения ГенИИ технологий будет сложен. Поэтому технологические неожиданности почти наверняка породят непредвиденные риски.
✔️ Гонка ГенИИ почти наверняка усилится. Не ясно, станет ли ГенИИ шагом к AGI. Но он откроет новые пути прогресса в широком спектре областей. К 2025 году существует реальная вероятность того, что ГенИИ ускорит развитие квантовых вычислений, новых материалов, телекоммуникации и биотехнологий. Но увеличение рисков, связанных с этим, вероятно, проявится после 2025.
В контексте яростных споров техно-оптимистов и алармистов по поводу рисков ГенИИ, этот вердикт британской разведки напомнил мне анекдот с окончанием "пришел лесник и всех выгнал".
#РискиИИ #ИИгонка #Вызовы21века
{kind=link}