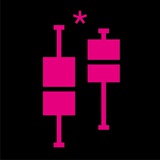
Как рисуют усы в ящике с усами (он же box plot, он же box and whisker plot)?
Anonymous Poll
17%
Усы рисуют от минимального до максимального значения
57%
Усы рисуют с помощью интерквартильного расстояния (1.5 IQR)
21%
Усы рисуют по персентилям, например от 1го до 99го персентиля
7%
Усы рисуют как угодно
20%
Ничего не знаю про ящики с усами 😬
Ящики с усами 📦🐈
В новом конспекте разбираемся с определением боксплота, кто его придумал, и как же правильно рисовать усы
https://telegra.ph/Boksploty-05-06
В новом конспекте разбираемся с определением боксплота, кто его придумал, и как же правильно рисовать усы
https://telegra.ph/Boksploty-05-06
Telegraph
Боксплоты
Боксплот (он же ящик с усами) — это график, который позволяет компактно визуализировать количественные данные. В этом конспекте разбираемся, как определяют боксплот, и что такое 1.5 IQR. Кто придумал боксплоты? Многие ошибочно считают, что боксплоты придумал…
❤7⚡2🔥1🤔1💯1
Возможно, вы слышали, что год назад суд в Великобритании приговорил медсестру Люси Летби к пожизненному заключению. Присяжные признали её виновной в убийстве семи младенцев и покушении на жизнь ещё шести младенцев в 2015-2016 годах.
Спустя год вышло журналистское расследование, в котором эта страшная история раскрывается с неожиданной стороны. Что, если Люси Летби не серийная убийца и "ангел смерти", а пострадавшая от обвинения, основанного на некачественном анализе данных? Я не буду пересказывать детали судебного дела (его можно прочитать тут или тут), но хотела бы остановиться на статистической части происходящего.
Обвинение Люси Летби было почти полностью построено на "анализе" таблицы, в которой были перечислены 24 подозрительных случая ухудшения состояния детей и график дежурств 38 медсестёр. Оказалось, что только Люси дежурила все 24 раза из 24. Из этой таблицы всем, включая присяжных, стало очевидно, что таких совпадений не бывает, и Люси — убийца. Как сказал один из обвинителей, "If you look at the table overall, the picture is, we suggest, self-evidently obvious." Вот и всё, вот и весь статистический анализ 🤡
Чем больше я думаю про этот случай, тем больше хочется воскликнуть: "А что, так можно было?!" Для сравнения, нельзя опубликовать научную статью без какого-либо анализа данных, просто сославшись на то, что вам всё очевидно. А чтобы опубликовать статью в приличном журнале, недостаточно просто проанализировать данные, необходимо дополнительно провалидировать получившийся результат. То есть показать другими (например, биологическими) методами, что результат вашего анализа не является случайностью или ошибкой.
В следующем посте расскажу, какие ещё вопросы есть у статистиков к делу Люси Летби и к подобным делам о серийных врачах-убийцах.
Спустя год вышло журналистское расследование, в котором эта страшная история раскрывается с неожиданной стороны. Что, если Люси Летби не серийная убийца и "ангел смерти", а пострадавшая от обвинения, основанного на некачественном анализе данных? Я не буду пересказывать детали судебного дела (его можно прочитать тут или тут), но хотела бы остановиться на статистической части происходящего.
Обвинение Люси Летби было почти полностью построено на "анализе" таблицы, в которой были перечислены 24 подозрительных случая ухудшения состояния детей и график дежурств 38 медсестёр. Оказалось, что только Люси дежурила все 24 раза из 24. Из этой таблицы всем, включая присяжных, стало очевидно, что таких совпадений не бывает, и Люси — убийца. Как сказал один из обвинителей, "If you look at the table overall, the picture is, we suggest, self-evidently obvious." Вот и всё, вот и весь статистический анализ 🤡
Чем больше я думаю про этот случай, тем больше хочется воскликнуть: "А что, так можно было?!" Для сравнения, нельзя опубликовать научную статью без какого-либо анализа данных, просто сославшись на то, что вам всё очевидно. А чтобы опубликовать статью в приличном журнале, недостаточно просто проанализировать данные, необходимо дополнительно провалидировать получившийся результат. То есть показать другими (например, биологическими) методами, что результат вашего анализа не является случайностью или ошибкой.
В следующем посте расскажу, какие ещё вопросы есть у статистиков к делу Люси Летби и к подобным делам о серийных врачах-убийцах.
Meduza
В Великобритании к пожизненному заключению приговорили медсестру — за убийство семи новорожденных
В августе 2023 года 33-летнюю британскую медсестру Люси Летби признали виновной в убийстве семи новорожденных и еще шести попытках убийства. Суд над ней продлился 10 месяцев, что сделало его одним из самых длительных в истории страны. Дело стало национальной…
🤯12🔥4💔3
Пока я пару дней не открывала статью, мой соавтор успел нарисовать в нее боксплотов по четырем точкам 🫠🫠🫠
На всякий случай напомню, что не имеет смысла рисовать боксплот, если у вас меньше 5 наблюдений в данных (потому что боксплот описывает данные с помощью 5 значений). Вместо боксплота в этом случае можно просто нарисовать эти точки
Подробно про боксплоты рассказывала тут https://telegra.ph/Boksploty-05-06
На всякий случай напомню, что не имеет смысла рисовать боксплот, если у вас меньше 5 наблюдений в данных (потому что боксплот описывает данные с помощью 5 значений). Вместо боксплота в этом случае можно просто нарисовать эти точки
Подробно про боксплоты рассказывала тут https://telegra.ph/Boksploty-05-06
🥴7🌚4🤣4😁2🥰1🤡1
Я сейчас на конференции в Порту, слушаю про любимую вычислительную иммунологию. Сегодня была постерная сессия, и я принесла вам еще несколько примеров не очень хороших графиков 👹
(1) Stacked barplot, в котором слишком много групп и цветов
(2) Почти одинаковые пайчарты, которые почти невозможно сравнить между собой на глаз
(3) Наши любимые боксплоты по 4 точкам. Особенно хорош сплющенный боксплот, построенный на четырёх нулевых значениях
(1) Stacked barplot, в котором слишком много групп и цветов
(2) Почти одинаковые пайчарты, которые почти невозможно сравнить между собой на глаз
(3) Наши любимые боксплоты по 4 точкам. Особенно хорош сплющенный боксплот, построенный на четырёх нулевых значениях
🌚10👍4🔥3🦄2🥰1😁1
👀 Сегодня расскажу вам о канале Человек наук, который ведет Вова Шитов, PhD-студент по вычислительной биологии в Helmholtz Munich. Вова делится красотой науки и окружающего мира и рассказывает про математику, биологию, статистику и многое другое
На канале Вовы вы узнаете:
- Как еще можно лгать с помощью статистики
- Как найти числа Фибоначчи в растениях
- Чем занимается молекулярная биология
А для ученых и студентов может быть полезно исследование Вовы о том, как лучше писать письма для стажировок или PhD-программ
В общем, канал — супер, Вова — супер. Подписывайтесь!
Это партнерский пост
На канале Вовы вы узнаете:
- Как еще можно лгать с помощью статистики
- Как найти числа Фибоначчи в растениях
- Чем занимается молекулярная биология
А для ученых и студентов может быть полезно исследование Вовы о том, как лучше писать письма для стажировок или PhD-программ
В общем, канал — супер, Вова — супер. Подписывайтесь!
Это партнерский пост
Telegram
человек наук
Красота окружающего мира глазами учёного. По всем вопросам пишите @science_boy
👍8❤6
Продолжение истории Люси Летби: Что статистики думают о врачах-убийцах
Начало истории здесь
Конечно, дело Люси Летби не первое дело о врачах-убийцах. За месяц до начала процесса, Королевское статистическое общество выпустило отчет, в котором рассматриваются два случая, когда медсестер ошибочно обвинили в убийстве пациентов на основе “статистического анализа” графика их дежурств. Также в этом отчете статистики обсуждают частые ошибки, допускаемые при использовании статистики в судебных делах, и дают рекомендации, как их избежать. Отчет небольшой, написан очень понятным языком, и я горячо рекомендую прочитать его всем, кто занимается здравоохранением (студенты PHS, привет! ).
Вот несколько основных проблем, которые отметило Королевское статистическое общество:
1. Непонимание случайности
Даже очень редкие события с кем-то случаются. Например, пара из Калифорнии однажды выиграла две лотереи в один день, хотя вероятность такого случайного события 1 на 23 000 000 000 000. В случае с лотереями нам это не кажется невозможным, потому что миллионы людей играют в лотереи каждый день, а значит, кто-то может случайно выиграть. Но с врачами эта интуиция почему-то не работает. Если у врача умирает необычно много пациентов, мы думаем, что именно с этим врачом что-то не так. Хотя в мире есть миллионы врачей, которые тоже “играют в лотерею” каждый день, и кому-то из них может случайно не повезти.
2. Корреляция не показывает причинно-следственные связи
Ретроспективно можно показать что во время дежурств человека Х смертность была значимо выше. Однако сама по себе высокая смертность не доказывает, что человек Х убийца. Это происходит из-за так называемых скрытых факторов (confounding factors), которые связаны с временем дежурства и с повышенной смертностью. Например, люди чаще умирают утром, а значит врачи, работающие по утрам, могут быть ассоциированы с более высокой смертностью. Более опытные врачи работают с более тяжелыми пациентами, у которых выше вероятность умереть. Увеличение смертей может быть даже связано с заменой поставщика медицинского оборудования. Отследить и учесть все такие скрытые факторы очень сложно.
3. Предвзятость подтверждения (confirmation bias) и другие предвзятости
Наш мозг так устроен, что он выдает желаемое за действительно и не замечает факты, которые противоречат нашей теории. В делах о врачах-убийцах часто рассматриваются только “подозрительные смерти”. Однако решение о том, какая смерть подозрительная, принимает судебный патологоанатом. В одном исследовании было показано, что судебный патологоанатом чаще считает гипотетическую смерть подозрительной, если ему сказать что это черный ребенок находившийся с отчимом, чем если это белый ребенок находившийся с бабушкой. Дополнительная информация и контекст могут влиять на "независимое" решение эксперта.
4. Ошибки в анализе данных
Если от статистического анализа зависит судьба человека, его нужно делать тщательно. В отчете приводится пример дела Люсии де Берк, в котором криминалист подсчитал, что вероятность того, что смерти были случайными, составляет 1 из 342 000 000. Когда статистики пересмотрели данные, они обнаружили ошибку: были перемножены три p-value, которые нельзя перемножать. При повторном анализе тех же данных шансы составили 1 из 50. 🤷♀️
Начало истории здесь
Конечно, дело Люси Летби не первое дело о врачах-убийцах. За месяц до начала процесса, Королевское статистическое общество выпустило отчет, в котором рассматриваются два случая, когда медсестер ошибочно обвинили в убийстве пациентов на основе “статистического анализа” графика их дежурств. Также в этом отчете статистики обсуждают частые ошибки, допускаемые при использовании статистики в судебных делах, и дают рекомендации, как их избежать. Отчет небольшой, написан очень понятным языком, и я горячо рекомендую прочитать его всем, кто занимается здравоохранением (
Вот несколько основных проблем, которые отметило Королевское статистическое общество:
1. Непонимание случайности
Даже очень редкие события с кем-то случаются. Например, пара из Калифорнии однажды выиграла две лотереи в один день, хотя вероятность такого случайного события 1 на 23 000 000 000 000. В случае с лотереями нам это не кажется невозможным, потому что миллионы людей играют в лотереи каждый день, а значит, кто-то может случайно выиграть. Но с врачами эта интуиция почему-то не работает. Если у врача умирает необычно много пациентов, мы думаем, что именно с этим врачом что-то не так. Хотя в мире есть миллионы врачей, которые тоже “играют в лотерею” каждый день, и кому-то из них может случайно не повезти.
2. Корреляция не показывает причинно-следственные связи
Ретроспективно можно показать что во время дежурств человека Х смертность была значимо выше. Однако сама по себе высокая смертность не доказывает, что человек Х убийца. Это происходит из-за так называемых скрытых факторов (confounding factors), которые связаны с временем дежурства и с повышенной смертностью. Например, люди чаще умирают утром, а значит врачи, работающие по утрам, могут быть ассоциированы с более высокой смертностью. Более опытные врачи работают с более тяжелыми пациентами, у которых выше вероятность умереть. Увеличение смертей может быть даже связано с заменой поставщика медицинского оборудования. Отследить и учесть все такие скрытые факторы очень сложно.
3. Предвзятость подтверждения (confirmation bias) и другие предвзятости
Наш мозг так устроен, что он выдает желаемое за действительно и не замечает факты, которые противоречат нашей теории. В делах о врачах-убийцах часто рассматриваются только “подозрительные смерти”. Однако решение о том, какая смерть подозрительная, принимает судебный патологоанатом. В одном исследовании было показано, что судебный патологоанатом чаще считает гипотетическую смерть подозрительной, если ему сказать что это черный ребенок находившийся с отчимом, чем если это белый ребенок находившийся с бабушкой. Дополнительная информация и контекст могут влиять на "независимое" решение эксперта.
4. Ошибки в анализе данных
Если от статистического анализа зависит судьба человека, его нужно делать тщательно. В отчете приводится пример дела Люсии де Берк, в котором криминалист подсчитал, что вероятность того, что смерти были случайными, составляет 1 из 342 000 000. Когда статистики пересмотрели данные, они обнаружили ошибку: были перемножены три p-value, которые нельзя перемножать. При повторном анализе тех же данных шансы составили 1 из 50. 🤷♀️
Telegram
Статистика с Марией
Возможно, вы слышали, что год назад суд в Великобритании приговорил медсестру Люси Летби к пожизненному заключению. Присяжные признали её виновной в убийстве семи младенцев и покушении на жизнь ещё шести младенцев в 2015-2016 годах.
Спустя год вышло журналистское…
Спустя год вышло журналистское…
👍8⚡4❤3🤯3🙏2💔1🦄1
В прошлом посте я пересказала основные моменты из отчета Королевского статистического общества о врачах-убийцах. Теперь поговорим о том, какие претензии у статистиков к делу Люси Летби
1. Отсутствие статистического анализа
Повторюсь, “из графика/таблицы очевидно, что…” не является статистическим анализом!
2. Субъективный выбор подозрительных смертей
Обвинение основывается на 24 подозрительных случаев, и только Люси дежурила во все эти разы. Однако, к выбору именно этих 24 случаев есть вопросы. Во-первых, в одном случае, график показывает что Люси дежурила ночью, хотя на хотя на самом деле она работала днем. Во-вторых, профессор права Эдинбургского университета Буркхард Шафер Шафера считает, что диаграмма должна была охватывать более длительный период времени и включать все смерти. В-третьих, эксперт обвинения Дьюи Эванс указал на еще 25 потенциально подозрительных случаев, которые были проигнорированы. В общем, складывается ощущение, что данные подгонялись под вывод “Люси виновна”, а не вывод был сделан на основе всех имеющихся данных. Такой подход в статистике называется cherry picking или ошибка меткого стрелка
3. Игнорирование скрытых факторов
Люси была опытной медсестрой, которая часто работала с более тяжелыми пациентами, что могло повлиять на увеличение смертности. Также высокая детская смертность могла быть связана с плохими условиями в больнице: переработками персонала, усталостью, нехваткой сотрудников, недостатком финансирования и другими систематическими проблемами NHS. Все эти обстоятельства были проигнорированы судом
Вместо заключения
Мы не знаем, виновна ли Люси Летби в убийствах новорожденных. Однако на основе сомнительного "статистического анализа" она была приговорена к пожизненному заключению без права на досрочное освобождение. Приговор обжалован, и Люси ожидает решения апелляционного суда. Надеюсь, когда-нибудь я напишу последнюю часть этого поста, в которой расскажу, как статистики собрали полные данные, учли скрытые факторы и непредвзято показали, является ли дело Люси Летби статистической случайностью или нет
1. Отсутствие статистического анализа
Повторюсь, “из графика/таблицы очевидно, что…” не является статистическим анализом!
2. Субъективный выбор подозрительных смертей
Обвинение основывается на 24 подозрительных случаев, и только Люси дежурила во все эти разы. Однако, к выбору именно этих 24 случаев есть вопросы. Во-первых, в одном случае, график показывает что Люси дежурила ночью, хотя на хотя на самом деле она работала днем. Во-вторых, профессор права Эдинбургского университета Буркхард Шафер Шафера считает, что диаграмма должна была охватывать более длительный период времени и включать все смерти. В-третьих, эксперт обвинения Дьюи Эванс указал на еще 25 потенциально подозрительных случаев, которые были проигнорированы. В общем, складывается ощущение, что данные подгонялись под вывод “Люси виновна”, а не вывод был сделан на основе всех имеющихся данных. Такой подход в статистике называется cherry picking или ошибка меткого стрелка
3. Игнорирование скрытых факторов
Люси была опытной медсестрой, которая часто работала с более тяжелыми пациентами, что могло повлиять на увеличение смертности. Также высокая детская смертность могла быть связана с плохими условиями в больнице: переработками персонала, усталостью, нехваткой сотрудников, недостатком финансирования и другими систематическими проблемами NHS. Все эти обстоятельства были проигнорированы судом
Вместо заключения
Мы не знаем, виновна ли Люси Летби в убийствах новорожденных. Однако на основе сомнительного "статистического анализа" она была приговорена к пожизненному заключению без права на досрочное освобождение. Приговор обжалован, и Люси ожидает решения апелляционного суда. Надеюсь, когда-нибудь я напишу последнюю часть этого поста, в которой расскажу, как статистики собрали полные данные, учли скрытые факторы и непредвзято показали, является ли дело Люси Летби статистической случайностью или нет
🔥13❤4👏2🤔1
Статистика в тренажерном зале 🏋️♀️
Возможно, вы замечали, что люди выбирают веса на тренажерах особым образом. По затертостям видно, что средние веса используются чаще, чем самые легкие и самые тяжелые. Если представить выбор веса как случайную величину, то закон по которому человек выбирает вес, будет называться распределение случайной величины.
А как вам кажется, какое распределение описывает выбор весов в тренажере?
Возможно, вы замечали, что люди выбирают веса на тренажерах особым образом. По затертостям видно, что средние веса используются чаще, чем самые легкие и самые тяжелые. Если представить выбор веса как случайную величину, то закон по которому человек выбирает вес, будет называться распределение случайной величины.
А как вам кажется, какое распределение описывает выбор весов в тренажере?
🔥13😱2
Когда я смотрю на данные, я иногда сомневаюсь в своих действиях. Мне кажется, что придут настоящие большие статистики (например, ревьюеры статьи) и скажут, что все нужно было делать иначе 🫠
В такие моменты я стараюсь вспоминать публикацию “Many Analysts, One Data Set: Making Transparent How Variations in Analytic Choices Affect Results”. Вкратце, один и тот же датасет раздали 29 командам статистиков и спросили у них, правда ли футбольные судьи чаще дают красные карточки людям с темным цветом кожи. Результаты оказались диаметрально противоположными: одни команды нашли статистическую связь с цветом кожи, другие — не нашли никакой связи. Стоит отметить, что все команды смотрели на данные честно, и разница в результатах, скорее всего, объясняется разными субъективными решениями, которые они принимали в процессе работы
Получается, нет единственного ✨идеального✨ способа проанализировать данные. Именно поэтому так важно честно и подробно описывать, как именно вы анализировали данные, какие предположения или допущения вы делали в процессе и, в идеале, выкладывать свой код
В такие моменты я стараюсь вспоминать публикацию “Many Analysts, One Data Set: Making Transparent How Variations in Analytic Choices Affect Results”. Вкратце, один и тот же датасет раздали 29 командам статистиков и спросили у них, правда ли футбольные судьи чаще дают красные карточки людям с темным цветом кожи. Результаты оказались диаметрально противоположными: одни команды нашли статистическую связь с цветом кожи, другие — не нашли никакой связи. Стоит отметить, что все команды смотрели на данные честно, и разница в результатах, скорее всего, объясняется разными субъективными решениями, которые они принимали в процессе работы
Получается, нет единственного ✨идеального✨ способа проанализировать данные. Именно поэтому так важно честно и подробно описывать, как именно вы анализировали данные, какие предположения или допущения вы делали в процессе и, в идеале, выкладывать свой код
SAGE Journals
Many Analysts, One Data Set: Making Transparent How Variations in Analytic Choices Affect Results
Twenty-nine teams involving 61 analysts used the same data set to address the same research question: whether soccer referees are more likely to give red cards ...
❤13😨7👍2👏2🤯1
This media is not supported in your browser
VIEW IN TELEGRAM
Я уже рассказывала, что перед тем, как проводить статистический анализ, стоит, как минимум, взглянуть на свои данные (в идеале, конечно, нужно делать эксплораторный анализ данных — EDA)
Если вы все еще ленитесь смотреть на данные, то вот вам мой любимый пример. На этой гифке показаны совершенно разные датасеты, у которых совпадают основные описательные статистики:
- Среднее значение по оси X и Y (X mean, Y mean)
- Стандартное отклонение (то же самое, что корень квадратный из дисперсии) по оси X и Y (X SD, Y SD)
- Корреляция
Вывод прост: смотрите на данные, вдруг там тоже прячется 🦖
UPD ссылка на оригинальную статью, если интересно узнать, как был построен The Datasaurus Dozon датасет https://www.research.autodesk.com/publications/same-stats-different-graphs/
Если вы все еще ленитесь смотреть на данные, то вот вам мой любимый пример. На этой гифке показаны совершенно разные датасеты, у которых совпадают основные описательные статистики:
- Среднее значение по оси X и Y (X mean, Y mean)
- Стандартное отклонение (то же самое, что корень квадратный из дисперсии) по оси X и Y (X SD, Y SD)
- Корреляция
Вывод прост: смотрите на данные, вдруг там тоже прячется 🦖
UPD ссылка на оригинальную статью, если интересно узнать, как был построен The Datasaurus Dozon датасет https://www.research.autodesk.com/publications/same-stats-different-graphs/
❤11🤯8🔥4👍2👀1
В 2018-2019 годах я занималась биоинформатикой в ИТМО (Леша, привет!) , известном питерском вузе для айтишников
В те времена на всех стендах ИТМО была одинаковая подложка с "математическими" формулами. И на всех них была одна и та же ошибка — неправильная формула плотности нормального распределения 👹👹👹
В формуле отсутствовал минус в показателе степени экспоненты, из-за чего вместо привычного колокольчика график функции улетает в бесконечность с обоих концов (см картинку в первом комментарии). А приличные плотности распределения так себя не ведут, потому что площадь под графиком плотности всегда равна 1!
Если вы бываете в ИТМО, расскажите, пожалуйста, остался ли там этот шедевр?
В те времена на всех стендах ИТМО была одинаковая подложка с "математическими" формулами. И на всех них была одна и та же ошибка — неправильная формула плотности нормального распределения 👹👹👹
В формуле отсутствовал минус в показателе степени экспоненты, из-за чего вместо привычного колокольчика график функции улетает в бесконечность с обоих концов (см картинку в первом комментарии). А приличные плотности распределения так себя не ведут, потому что площадь под графиком плотности всегда равна 1!
Если вы бываете в ИТМО, расскажите, пожалуйста, остался ли там этот шедевр?
🤡10😱3🤣2
Привет!
23 сентября (пн) я защищаю PhD. Если хотите меня поддержать или просто посмотреть на защиты в Норвегии, будет ссылка на зум. Буду очень вам рада 🤍
В Норвегии защита PhD немного отличается от других стран и состоит из двух частей: лекции и непосредственно самой защиты. Тема лекции назначается за две недели, и моя задача — показать, что я могу быть норм лектором
- 12:15 (мск) лекция ссылка на сайте
"Molecular control of the germinal center reaction"
- 15:15 (мск) защита ссылка на сайте
"Computational approaches for the analysis of adaptive immune receptor repertoires at the genomic and proteomic levels"
На фото — напечатанные диссертации, 40 шт 😅
23 сентября (пн) я защищаю PhD. Если хотите меня поддержать или просто посмотреть на защиты в Норвегии, будет ссылка на зум. Буду очень вам рада 🤍
В Норвегии защита PhD немного отличается от других стран и состоит из двух частей: лекции и непосредственно самой защиты. Тема лекции назначается за две недели, и моя задача — показать, что я могу быть норм лектором
- 12:15 (мск) лекция ссылка на сайте
"Molecular control of the germinal center reaction"
- 15:15 (мск) защита ссылка на сайте
"Computational approaches for the analysis of adaptive immune receptor repertoires at the genomic and proteomic levels"
На фото — напечатанные диссертации, 40 шт 😅
❤33🎉10⚡8👀2