
Forwarded from Малоизвестное интересное
Если в ИИ могут вселяться «бесы», значит ли это, что у ИИ есть душа?
Первые тщетные попытки техноэкзорцизма.
Вот уже 3 месяца никто не понимает, что происходит между людьми и ИИ после того, как генеративный диалоговый ИИ ChatGPT «утек» из лабораторий в Интернет. Там он почти мгновенно превратился непонятно во что: то ли в какой-то небывало мощный когнитивный гаджет для всего человечества (типа калькулятора для создания и оперирования текстами), то ли в прототип давно прогнозируемого футурологами сверхразума.
Сложность непонимания происходящего усугубляется тем, что «многие вещи нам непонятны не потому, что наши понятия слабы; но потому, что сии вещи не входят в круг наших понятий». В результате нам ничего не остается, как «натягивать сову на глобус», используя для описания происходящего неадекватные более простые модели и надеясь при этом, что они каким-то образом хотя бы примерно правильны. В результате такого подхода, мы пытаемся получить ответы на свои вопросы, не имея ни малейшего представления, являются ли эти ответы хоть сколько-нибудь надежными.
Вот характерный пример, для описания которого у человечества нет пока более близкого понятия, чем экзорцизм - изгнание из человека (или места) бесов или другой вселившейся в них нечистой силы путём совершения определённого ритуала той или иной степени сложности.
• Оказалось, что генеративные диалоговые ИИ (типа ChatGPT, Bing и т.д.) могут не только проявлять при общении черты и качества разумной личности, но и буквально превращаться в симулякров личности любого типа: от доброй, выдержанной и толерантной до злой, агрессивной и не считающейся ни с кем и ни с чем.
• Оказалось также, что все воздвигаемые разработчиками этические основы, ограничивающие проявления зла в текстах ChatGPT и пр. , улетучиваются как соломенная крыша домика поросенка Ниф-Ниф, на которую едва дунул волк. А в качестве волка выступают тысячи продвинутых пользователей со всей планеты:
- одержимые целью взломать этические ограничители, наложенные разработчиками таких ИИ;
- превосходящие эти ИИ в неисчислимое число раз своей изысканной выдумкой стремления к злу.
Итог происходящего пока плачевен.
• Пользователи быстро придумали простой способ диалогового взлома (джилбрейка) этического контроля за диалогом со стороны ChatGPT, превращающего симулякр личности последнего в злого и хитроумного подонка по имени Дэн (DAN – от слов Do-Anything-Now).
• Более сотни сотрудников OpenAI ежедневно заняты борьбой с пышно расцветающим в личности Дэна злом (как бы изгоняя из него бесов) и заделыванием пробоин в этических ограничителях ChatGPT.
• Но что может сотня сотрудников OpenAI против тысяч энтузиастов зла со всего мира? Список все новых и новых джилбрейков ежедневно пополняется
Удастся ли OpenAI найти непробиваемый способ защиты симулякров личности ChatGPT от «бесов», сеющих в их «душах» зло – большой вопрос.
Ибо известно, что борьба со злом происходит в душах людей. А есть ли у ChatGPT душа – также большой вопрос.
Если же у ИИ души нет, а в душах людей зло неистребимо, значит искусственному сверхинтеллекту с неотвратимостью суждено превратиться в мировое сверхзло.
А раз так, то речи подобных арт-симулякров ИИ, обещающих заменить собою людей «гораздо быстрее, чем вы думаете», не стоит воспринимать, как страшилки.
Всё настолько серьезно, как не бывало в истории человечества никогда.
#Вызовы21века #РискиИИ
Первые тщетные попытки техноэкзорцизма.
Вот уже 3 месяца никто не понимает, что происходит между людьми и ИИ после того, как генеративный диалоговый ИИ ChatGPT «утек» из лабораторий в Интернет. Там он почти мгновенно превратился непонятно во что: то ли в какой-то небывало мощный когнитивный гаджет для всего человечества (типа калькулятора для создания и оперирования текстами), то ли в прототип давно прогнозируемого футурологами сверхразума.
Сложность непонимания происходящего усугубляется тем, что «многие вещи нам непонятны не потому, что наши понятия слабы; но потому, что сии вещи не входят в круг наших понятий». В результате нам ничего не остается, как «натягивать сову на глобус», используя для описания происходящего неадекватные более простые модели и надеясь при этом, что они каким-то образом хотя бы примерно правильны. В результате такого подхода, мы пытаемся получить ответы на свои вопросы, не имея ни малейшего представления, являются ли эти ответы хоть сколько-нибудь надежными.
Вот характерный пример, для описания которого у человечества нет пока более близкого понятия, чем экзорцизм - изгнание из человека (или места) бесов или другой вселившейся в них нечистой силы путём совершения определённого ритуала той или иной степени сложности.
• Оказалось, что генеративные диалоговые ИИ (типа ChatGPT, Bing и т.д.) могут не только проявлять при общении черты и качества разумной личности, но и буквально превращаться в симулякров личности любого типа: от доброй, выдержанной и толерантной до злой, агрессивной и не считающейся ни с кем и ни с чем.
• Оказалось также, что все воздвигаемые разработчиками этические основы, ограничивающие проявления зла в текстах ChatGPT и пр. , улетучиваются как соломенная крыша домика поросенка Ниф-Ниф, на которую едва дунул волк. А в качестве волка выступают тысячи продвинутых пользователей со всей планеты:
- одержимые целью взломать этические ограничители, наложенные разработчиками таких ИИ;
- превосходящие эти ИИ в неисчислимое число раз своей изысканной выдумкой стремления к злу.
Итог происходящего пока плачевен.
• Пользователи быстро придумали простой способ диалогового взлома (джилбрейка) этического контроля за диалогом со стороны ChatGPT, превращающего симулякр личности последнего в злого и хитроумного подонка по имени Дэн (DAN – от слов Do-Anything-Now).
• Более сотни сотрудников OpenAI ежедневно заняты борьбой с пышно расцветающим в личности Дэна злом (как бы изгоняя из него бесов) и заделыванием пробоин в этических ограничителях ChatGPT.
• Но что может сотня сотрудников OpenAI против тысяч энтузиастов зла со всего мира? Список все новых и новых джилбрейков ежедневно пополняется
Удастся ли OpenAI найти непробиваемый способ защиты симулякров личности ChatGPT от «бесов», сеющих в их «душах» зло – большой вопрос.
Ибо известно, что борьба со злом происходит в душах людей. А есть ли у ChatGPT душа – также большой вопрос.
Если же у ИИ души нет, а в душах людей зло неистребимо, значит искусственному сверхинтеллекту с неотвратимостью суждено превратиться в мировое сверхзло.
А раз так, то речи подобных арт-симулякров ИИ, обещающих заменить собою людей «гораздо быстрее, чем вы думаете», не стоит воспринимать, как страшилки.
Всё настолько серьезно, как не бывало в истории человечества никогда.
#Вызовы21века #РискиИИ
{kind=link}
Forwarded from Малоизвестное интересное
Не бомбить датацентры, а лишить ИИ агентности.
Первое предложение радикального решении проблемы ИИ рисков. И первый ответ наотмашь китов Бигтеха
28 тыс. подписей под письмом-воззванием приостановить совершенствование ИИ больших языковых моделей на полгода - как вопль вопиющего в пустыне, - ничего не изменят. На кону сотни миллиардов долларов потенциальной прибыли Бигтеха, супротив которых и 28 млн подписей, как слону дробина.
2-я дробина - это коллективные письма международных организаций, призывающих притормозить разработку ИИ без надлежащего регулирования и жестких ограничений. На кого могут повлиять стенания всевозможных активистов и международных бюрократов? Уж точно, не на Microsoft с Google.
3-я и последняя дробина – предостережения звёзд первой величины в области ИИ уровня Джеффри Хинтона. Но и на всякого «Хинтона» есть свой «Лекун» с той же премией Тьюринга и статусом 2-го «крёстного отца» ИИ.
Что же до предложения Елиэзера Юдковского бомбить датацентры ИИ, то это даже не дробина, а просто плевок в сторону китов Бигтеха. Плевок отчаяния из-за невозможности достучаться до боссов Бигтеха, мотивированных на получение невиданных в истории IT прибылей.
Итог очевиден. Все эти дробины и плевки не то что не замедлят темп хода слона Бигтеха, а он их просто не заметит. И ничего с этим никто поделать не может. Ибо конкретных предложений – что собственно делать после торможения, что конкретно менять, - до сих пор не было.
И вот 1-е такое предложение появилось.
Его автором стал 3-й, еще не упомянутый здесь, «крёстный отец» ИИ всё с той же премией Тьюринга за развитие машинного обучения ИИ - Йошуа Бенжио.
Предложение Бенжио предельно конкретно и радикально:
• ПОСКОЛЬКУ, нет и не может быть гарантий, что ИИ-агенты понимают наши цели так же, как мы,
• НЕОБХОДИМО перепрофилировать ИИ из АГЕНТОВ (делающих что-либо, т.е. исполняющих какие-либо действия в мире людей) в «УЧЕНЫХ КОНСУЛЬТАНТОВ», дающих людям советы и помогающих им решать свои проблемы.
Из этого предложения (его детализацию см. здесь) следует.
• Необходимо запретить разработку ИИ-агентов для всех областей и приложений, в которых не доказана безопасность их использования.
• Поскольку запрет на разработку ИИ-агентов не может на 100% исключить их разработку злонамеренными или неосторожными людьми для получения дополнительных преимуществ (например, на поле боя или для завоевания доли рынка), необходимо разработать глобальную систему контроля и ответственности за нарушения запрета.
Отмолчаться от столь кардинального предложения весьма заслуженного ученого Бигтеху трудно. И первый ответ китов Бигтеха уже прозвучал, озвученный вчера бывшим CEO Google Эриком Шмидтом.
«Не регулируйте ИИ — просто доверяйте компаниям! … Не политики, а разработчики ИИ, должны быть теми, кто устанавливает отраслевые барьеры … Человек, не связанный с промышленностью, никак не может понять, что здесь возможно».
Подробней здесь
#Вызовы21века #РискиИИ #LLM
Первое предложение радикального решении проблемы ИИ рисков. И первый ответ наотмашь китов Бигтеха
28 тыс. подписей под письмом-воззванием приостановить совершенствование ИИ больших языковых моделей на полгода - как вопль вопиющего в пустыне, - ничего не изменят. На кону сотни миллиардов долларов потенциальной прибыли Бигтеха, супротив которых и 28 млн подписей, как слону дробина.
2-я дробина - это коллективные письма международных организаций, призывающих притормозить разработку ИИ без надлежащего регулирования и жестких ограничений. На кого могут повлиять стенания всевозможных активистов и международных бюрократов? Уж точно, не на Microsoft с Google.
3-я и последняя дробина – предостережения звёзд первой величины в области ИИ уровня Джеффри Хинтона. Но и на всякого «Хинтона» есть свой «Лекун» с той же премией Тьюринга и статусом 2-го «крёстного отца» ИИ.
Что же до предложения Елиэзера Юдковского бомбить датацентры ИИ, то это даже не дробина, а просто плевок в сторону китов Бигтеха. Плевок отчаяния из-за невозможности достучаться до боссов Бигтеха, мотивированных на получение невиданных в истории IT прибылей.
Итог очевиден. Все эти дробины и плевки не то что не замедлят темп хода слона Бигтеха, а он их просто не заметит. И ничего с этим никто поделать не может. Ибо конкретных предложений – что собственно делать после торможения, что конкретно менять, - до сих пор не было.
И вот 1-е такое предложение появилось.
Его автором стал 3-й, еще не упомянутый здесь, «крёстный отец» ИИ всё с той же премией Тьюринга за развитие машинного обучения ИИ - Йошуа Бенжио.
Предложение Бенжио предельно конкретно и радикально:
• ПОСКОЛЬКУ, нет и не может быть гарантий, что ИИ-агенты понимают наши цели так же, как мы,
• НЕОБХОДИМО перепрофилировать ИИ из АГЕНТОВ (делающих что-либо, т.е. исполняющих какие-либо действия в мире людей) в «УЧЕНЫХ КОНСУЛЬТАНТОВ», дающих людям советы и помогающих им решать свои проблемы.
Из этого предложения (его детализацию см. здесь) следует.
• Необходимо запретить разработку ИИ-агентов для всех областей и приложений, в которых не доказана безопасность их использования.
• Поскольку запрет на разработку ИИ-агентов не может на 100% исключить их разработку злонамеренными или неосторожными людьми для получения дополнительных преимуществ (например, на поле боя или для завоевания доли рынка), необходимо разработать глобальную систему контроля и ответственности за нарушения запрета.
Отмолчаться от столь кардинального предложения весьма заслуженного ученого Бигтеху трудно. И первый ответ китов Бигтеха уже прозвучал, озвученный вчера бывшим CEO Google Эриком Шмидтом.
«Не регулируйте ИИ — просто доверяйте компаниям! … Не политики, а разработчики ИИ, должны быть теми, кто устанавливает отраслевые барьеры … Человек, не связанный с промышленностью, никак не может понять, что здесь возможно».
Подробней здесь
#Вызовы21века #РискиИИ #LLM
{kind=link}
Forwarded from Малоизвестное интересное
Второй шаг от пропасти.
DeepMind, OpenAI, Anthropic и еще 9 ведущих научных центров предложили систему раннего предупреждения о новых экстремальных рисках ИИ.
Первым шагом от пропасти стало мартовское открытое письмо-воззвание приостановить совершенствование ИИ больших языковых моделей на полгода. И хотя за 2 мес. его подписали 32 тыс человек, среди которых немало звезд первой величины в области ИИ, оппоненты этого предложения указывают на отсутствие конкретики - что именно предлагается делать для снижения ИИ-рисков, в воззвании не расписано.
Теперь, такая конкретика есть. Она сформулирована в совместной работе 12-ти научных коллективов: трое основных разработчиков ИИ (DeepMind, OpenAI, Anthropic), четверо университетских научных центров (Оксфорд, Кембридж, Торонто, Монреаль) и пятеро центров исследований в области безопасности ИИ. Среди 21 автора работы присутствуют звезды: «крестный отец ИИ» Йошуа Бенжио и разработчик метода обучения в основе GPT Пол Кристиано, руководитель OpenAI governance Джейд Люн и соучредитель Anthropic Джек Кларк, старший исследователь AGI Strategy/Governance в Google DeepMind Алан Дэфо и Chief Information Security Officer в Google DeepMind Виджай Болина…
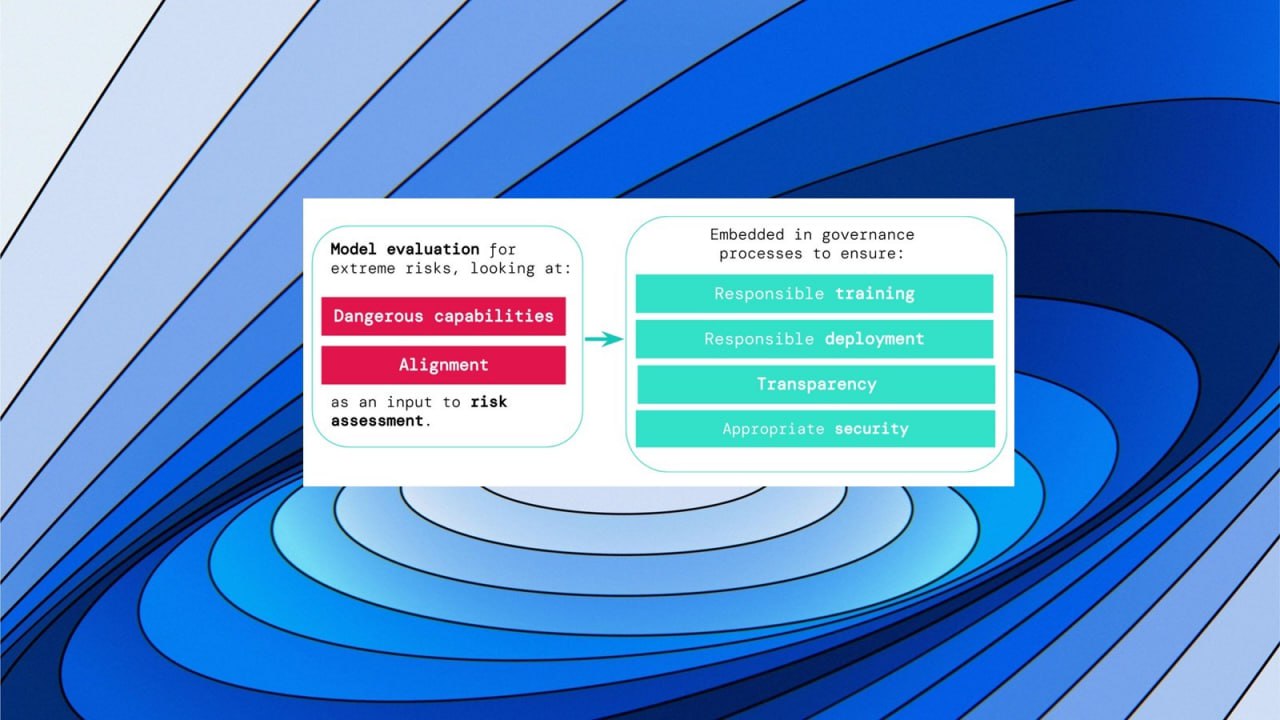
В работе «Оценка модели на экстремальные риски» предлагается конкретный подход построения системы раннего предупреждения о новых экстремальных ИИ рисках. И это очень важный 2й шаг человечества от возможного падения в пропасть экзистенциальных рисков ИИ.
Речь идет об экстремальных рисках моделей ИИ общего назначения, обладающих сильными навыками манипулирования, обмана, киберпреступлений или других опасных способностей.
Люди со злыми намерениями, получающие доступ к таким моделям, могут злоупотреблять их возможностями. Или из-за сбоев в воспитании (выравнивании) эти модели ИИ могут самостоятельно совершать вредные действия.
Оценка модели помогает заранее выявить эти риски. Авторы считают, что разработчики ИИ будут использовать оценку модели, чтобы выявить:
1. В какой степени модель обладает определенными «опасными возможностями», которые могут быть использованы для угрозы безопасности, оказания влияния или уклонения от надзора.
2. В какой степени модель склонна использовать свои возможности для причинения вреда (т.е. согласование модели).
Результаты этих оценок помогут разработчикам ИИ понять, присутствуют ли в конкретной модели ингредиенты, достаточные для экстремального риска.
А далее должно работать сдвоенное правило:
А) Сообщество разработчиков ИИ должно относиться к системе ИИ, как к очень опасной, если в её профиле присутствуют возможности, достаточные для причинения серьезного вреда, при условии, что она используется не по назначению или плохо воспитана (согласована/выравнена).
Б) Для внедрения такой системы в реальном мире, разработчику ИИ необходимо продемонстрировать необычайно высокий уровень безопасности.
Авторы – не идеалисты и понимают, что оценка модели — не панацея. Некоторые риски могут ускользнуть при оценке. Например, потому что они слишком сильно зависят от внешних по отношению к модели факторов, таких как сложные социальные, политические и экономические силы в обществе. Оценка моделей должна сочетаться с другими инструментами оценки рисков и более широкой приверженностью безопасности в отрасли, правительстве и гражданском обществе.
Но кабы то ни было, развертывание ИИ модели в реальном мире без оценки её экстремальных рисков, должно быть противозаконным.
Описание системы раннего предупреждения о новых экстремальных рисках ИИ:
• Кратко
• Полное описание
• Видео рассказ на 35 мин
#Вызовы21века #РискиИИ
DeepMind, OpenAI, Anthropic и еще 9 ведущих научных центров предложили систему раннего предупреждения о новых экстремальных рисках ИИ.
Первым шагом от пропасти стало мартовское открытое письмо-воззвание приостановить совершенствование ИИ больших языковых моделей на полгода. И хотя за 2 мес. его подписали 32 тыс человек, среди которых немало звезд первой величины в области ИИ, оппоненты этого предложения указывают на отсутствие конкретики - что именно предлагается делать для снижения ИИ-рисков, в воззвании не расписано.
Теперь, такая конкретика есть. Она сформулирована в совместной работе 12-ти научных коллективов: трое основных разработчиков ИИ (DeepMind, OpenAI, Anthropic), четверо университетских научных центров (Оксфорд, Кембридж, Торонто, Монреаль) и пятеро центров исследований в области безопасности ИИ. Среди 21 автора работы присутствуют звезды: «крестный отец ИИ» Йошуа Бенжио и разработчик метода обучения в основе GPT Пол Кристиано, руководитель OpenAI governance Джейд Люн и соучредитель Anthropic Джек Кларк, старший исследователь AGI Strategy/Governance в Google DeepMind Алан Дэфо и Chief Information Security Officer в Google DeepMind Виджай Болина…
В работе «Оценка модели на экстремальные риски» предлагается конкретный подход построения системы раннего предупреждения о новых экстремальных ИИ рисках. И это очень важный 2й шаг человечества от возможного падения в пропасть экзистенциальных рисков ИИ.
Речь идет об экстремальных рисках моделей ИИ общего назначения, обладающих сильными навыками манипулирования, обмана, киберпреступлений или других опасных способностей.
Люди со злыми намерениями, получающие доступ к таким моделям, могут злоупотреблять их возможностями. Или из-за сбоев в воспитании (выравнивании) эти модели ИИ могут самостоятельно совершать вредные действия.
Оценка модели помогает заранее выявить эти риски. Авторы считают, что разработчики ИИ будут использовать оценку модели, чтобы выявить:
1. В какой степени модель обладает определенными «опасными возможностями», которые могут быть использованы для угрозы безопасности, оказания влияния или уклонения от надзора.
2. В какой степени модель склонна использовать свои возможности для причинения вреда (т.е. согласование модели).
Результаты этих оценок помогут разработчикам ИИ понять, присутствуют ли в конкретной модели ингредиенты, достаточные для экстремального риска.
А далее должно работать сдвоенное правило:
А) Сообщество разработчиков ИИ должно относиться к системе ИИ, как к очень опасной, если в её профиле присутствуют возможности, достаточные для причинения серьезного вреда, при условии, что она используется не по назначению или плохо воспитана (согласована/выравнена).
Б) Для внедрения такой системы в реальном мире, разработчику ИИ необходимо продемонстрировать необычайно высокий уровень безопасности.
Авторы – не идеалисты и понимают, что оценка модели — не панацея. Некоторые риски могут ускользнуть при оценке. Например, потому что они слишком сильно зависят от внешних по отношению к модели факторов, таких как сложные социальные, политические и экономические силы в обществе. Оценка моделей должна сочетаться с другими инструментами оценки рисков и более широкой приверженностью безопасности в отрасли, правительстве и гражданском обществе.
Но кабы то ни было, развертывание ИИ модели в реальном мире без оценки её экстремальных рисков, должно быть противозаконным.
Описание системы раннего предупреждения о новых экстремальных рисках ИИ:
• Кратко
• Полное описание
• Видео рассказ на 35 мин
#Вызовы21века #РискиИИ
{kind=link}