
🛒По итогам 2022 года молодые семьи в России снизили потребление всех основных групп пищевых продуктов — в диапазоне от минус 8% до минус 22% по сравнению с 2021 годом. Наиболее сильно в их рационе сократилось количество молока, фруктов и масла, менее значительно — хлеба, мяса, овощей.
В то же время доля затрат молодых семей на продукты в объеме их потребительских расходов увеличилась — на 5,4 п.п., до 29,3%. Среди причин - мода на здоровое питание и подсчет калорий, а также покупка полуфабрикатов или доставка готовых блюд. Об этом пишет РБК со ссылкой на Росстат.
В то же время доля затрат молодых семей на продукты в объеме их потребительских расходов увеличилась — на 5,4 п.п., до 29,3%. Среди причин - мода на здоровое питание и подсчет калорий, а также покупка полуфабрикатов или доставка готовых блюд. Об этом пишет РБК со ссылкой на Росстат.
РБК
Молодежь в России стала потреблять меньше продуктов питания
В 2022 году молодые семьи сократили потребление основных продуктов питания, раскрыл Росстат. При этом в целом домашние хозяйства стали потреблять больше. У экспертов разные объяснения: от экономии до
Forwarded from CBRSunnyMorning
CBR Sunny Morning. Утренние графики. Валютный и денежный рынки.
Forwarded from proVenture (проВенчур)
2023 State of Data + AI.
Databricks выпустил любопытный отчет. Когда я его только прочитал, я подумал, что это такой рекламного типа отчет. Графика красивая, а данных мало. Но потом я понял, данных в принципе мало, а Databricks дает короткие, но любопытные инсайты. Потому что тема не просто про AI, а про новые сегменты и использование данных.
Давайте подсвечу пару вещей:
1/ Выводы основаны на анализе 9,000 пользователей Databricks Lakehouse, поэтому речь про динамику, а не про абсолютные цифры.
2/ Компании более активно используют LLM модели для анализа данных. В отчете есть график, но в тексте также написано про два из трех сегментов:
– Количество компаний, которые используют SaaS LLM APIs (для получения доступа к ChatGPT и аналогам), выросло на 1310% с конца ноября 2022 по начало мая 2023 (то есть, за 5 месяцев);
– За тот же период количество пользователей библиотек на питоне для тренировки LLM моделей (типа Hugging Face) выросло на 82%.
3/ На NLP приходится 49% ежедневного использования Python data science библиотек.
4/ Компании относительно чаще и больше переводят модели в продакшн, количество моделей в проде выросло на 411% за год (ML эксперименты выросли на 54% за год), при этом если раньше на 1 модель в проде приходилось ~5 экспериментальных моделей, то сейчас это ~3 модели (точнее 2.9), что означает повышение эффективности экспериментов или стремление быстрее перевести модели я прод.
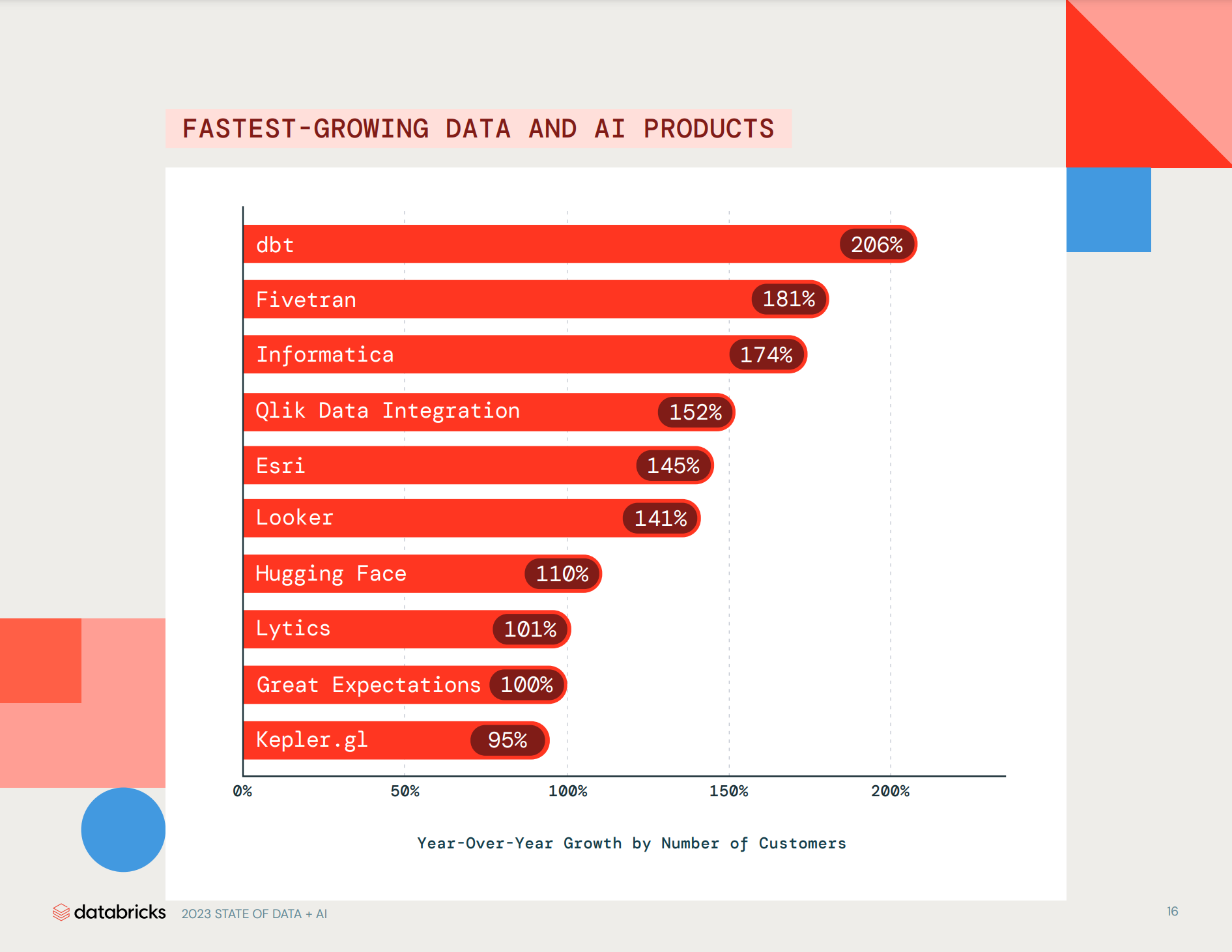
5/ 🎯 Поскольку я не технарь, самое первое, что привлекло мое внимание был график с популярными продуктами в AI и Data:
– dbt прирос на 206% по количеству пользователей за год;
– Fivetran +181%;
– Informatica +174%;
– Qlik Data Integtation +152%;
– Esri +145%;
– Looker +141%;
– Hugging Face +110%;
– Lytics +101%;
– Great Expectations +100%
– Kepler.gl +95%.
6/ В отчете есть также информация по сегментам рынка:
– BI Tools самый популярный продукт, но прирост пользователей за год +66%;
– Data Governance & Security;
– Data Science & ML
– Data Integration: новый сегмент, но прирост самый большой, 117% в год.
Сам отчет на 25 страниц доступен по ссылке: https://www.databricks.com/resources/ebook/state-of-data-ai
@proVenture
#research #ai
Databricks выпустил любопытный отчет. Когда я его только прочитал, я подумал, что это такой рекламного типа отчет. Графика красивая, а данных мало. Но потом я понял, данных в принципе мало, а Databricks дает короткие, но любопытные инсайты. Потому что тема не просто про AI, а про новые сегменты и использование данных.
Давайте подсвечу пару вещей:
1/ Выводы основаны на анализе 9,000 пользователей Databricks Lakehouse, поэтому речь про динамику, а не про абсолютные цифры.
2/ Компании более активно используют LLM модели для анализа данных. В отчете есть график, но в тексте также написано про два из трех сегментов:
– Количество компаний, которые используют SaaS LLM APIs (для получения доступа к ChatGPT и аналогам), выросло на 1310% с конца ноября 2022 по начало мая 2023 (то есть, за 5 месяцев);
– За тот же период количество пользователей библиотек на питоне для тренировки LLM моделей (типа Hugging Face) выросло на 82%.
3/ На NLP приходится 49% ежедневного использования Python data science библиотек.
4/ Компании относительно чаще и больше переводят модели в продакшн, количество моделей в проде выросло на 411% за год (ML эксперименты выросли на 54% за год), при этом если раньше на 1 модель в проде приходилось ~5 экспериментальных моделей, то сейчас это ~3 модели (точнее 2.9), что означает повышение эффективности экспериментов или стремление быстрее перевести модели я прод.
5/ 🎯 Поскольку я не технарь, самое первое, что привлекло мое внимание был график с популярными продуктами в AI и Data:
– dbt прирос на 206% по количеству пользователей за год;
– Fivetran +181%;
– Informatica +174%;
– Qlik Data Integtation +152%;
– Esri +145%;
– Looker +141%;
– Hugging Face +110%;
– Lytics +101%;
– Great Expectations +100%
– Kepler.gl +95%.
6/ В отчете есть также информация по сегментам рынка:
– BI Tools самый популярный продукт, но прирост пользователей за год +66%;
– Data Governance & Security;
– Data Science & ML
– Data Integration: новый сегмент, но прирост самый большой, 117% в год.
Сам отчет на 25 страниц доступен по ссылке: https://www.databricks.com/resources/ebook/state-of-data-ai
@proVenture
#research #ai
{kind=link}