
Forwarded from ml4se
Finetuning Large Language Models
Fine-tuning all layers of a pretrained LLM remains the gold standard for adapting to new target tasks, but there are several efficient alternatives for using pretrained transformers. Methods such as feature-based approaches, in-context learning, and parameter-efficient finetuning techniques enable effective application of LLMs to new tasks while minimizing computational costs and resources.
- In-Context Learning and Indexing
- The 3 Conventional Feature-Based and Finetuning Approaches
- Feature-Based Approach
- Finetuning I – Updating The Output Layers
- Finetuning II – Updating All Layers
- Parameter-Efficient Finetuning
- Reinforcement Learning with Human Feedback
- Conclusion
Fine-tuning all layers of a pretrained LLM remains the gold standard for adapting to new target tasks, but there are several efficient alternatives for using pretrained transformers. Methods such as feature-based approaches, in-context learning, and parameter-efficient finetuning techniques enable effective application of LLMs to new tasks while minimizing computational costs and resources.
- In-Context Learning and Indexing
- The 3 Conventional Feature-Based and Finetuning Approaches
- Feature-Based Approach
- Finetuning I – Updating The Output Layers
- Finetuning II – Updating All Layers
- Parameter-Efficient Finetuning
- Reinforcement Learning with Human Feedback
- Conclusion
👍17💩1
This media is not supported in your browser
VIEW IN TELEGRAM
GigaChat
by SberDevices, Sber AI, AIRI & etc.
Based on a model collectively called NeONKA (NEural Omnimodal Network with Knowledge-Awareness). There ruGPT3.5-13B, which is based on ruGPT3 13B & FRED-T5.
Current version in NLP part is based on ruGPT3.5 13B pretrain + SFT (supervised fine-tuning).
In side by side tests GigaChat vs ChatGPT 30:70 in favor of the latter. This is without PPO. Will be higher. They have big plans to improve models and train new ones.
Some models will be made publicly available.
To get access to the beta test, you need to subscribe to the project's [closed tg-channel](https://t.iss.one/+eL4Gc0g74yw4N2Qy).
What it can do:
- Write commercial texts
- Generate imaginary dialogues
- Work with document templates
- Create entertaining content
- Make lists and ratings
More here — https://habr.com/ru/companies/sberbank/articles/730108/
by SberDevices, Sber AI, AIRI & etc.
Based on a model collectively called NeONKA (NEural Omnimodal Network with Knowledge-Awareness). There ruGPT3.5-13B, which is based on ruGPT3 13B & FRED-T5.
Current version in NLP part is based on ruGPT3.5 13B pretrain + SFT (supervised fine-tuning).
In side by side tests GigaChat vs ChatGPT 30:70 in favor of the latter. This is without PPO. Will be higher. They have big plans to improve models and train new ones.
Some models will be made publicly available.
To get access to the beta test, you need to subscribe to the project's [closed tg-channel](https://t.iss.one/+eL4Gc0g74yw4N2Qy).
What it can do:
- Write commercial texts
- Generate imaginary dialogues
- Work with document templates
- Create entertaining content
- Make lists and ratings
More here — https://habr.com/ru/companies/sberbank/articles/730108/
👍33🤮12👎8😁6💩6🔥4❤3
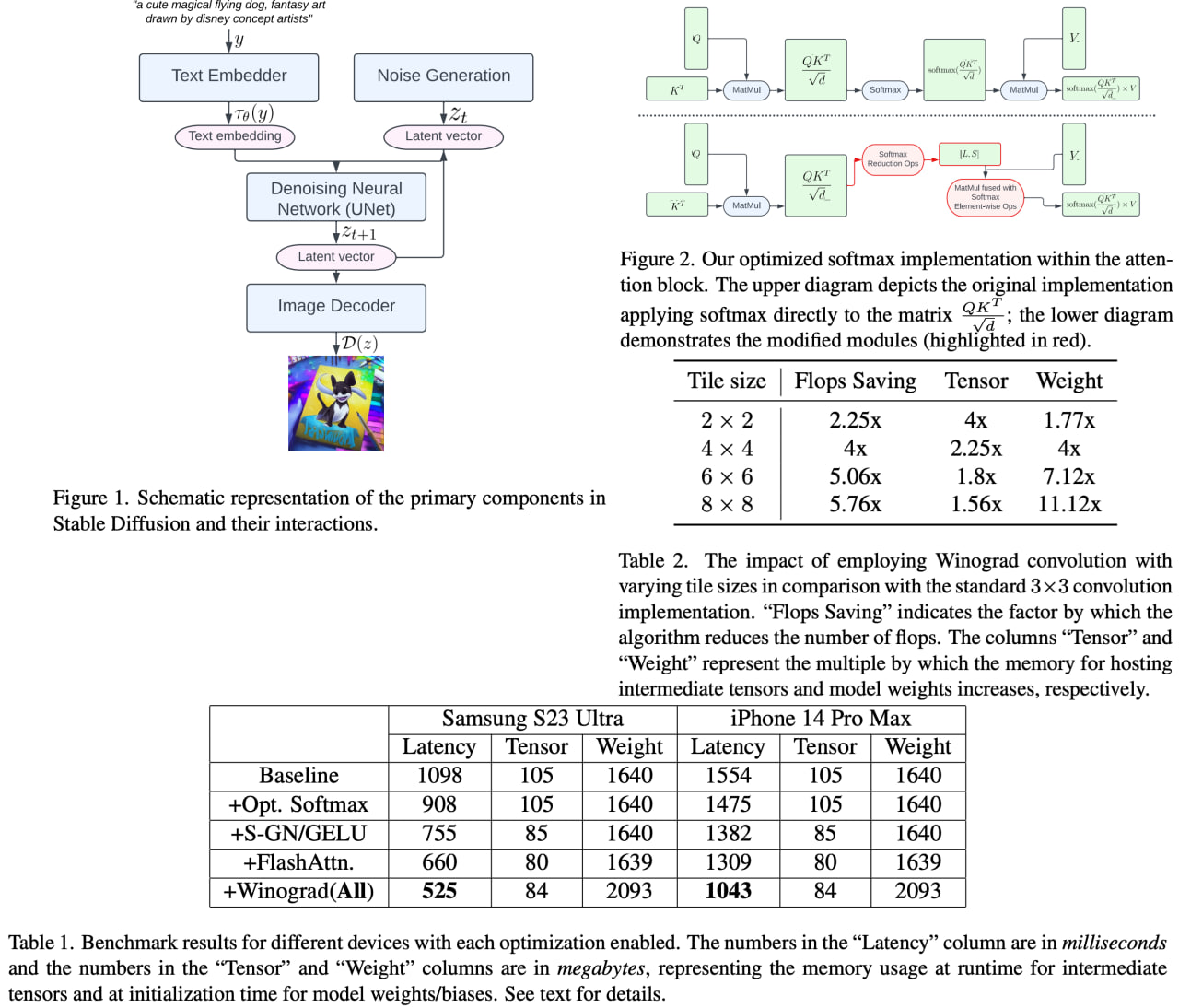
Speed Is All You Need: On-Device Acceleration of Large Diffusion Models via GPU-Aware Optimizations
The rapid development of foundation models is revolutionizing the field of artificial intelligence, with large diffusion models gaining significant attention for their ability to generate photorealistic images and support various tasks. Deploying these models on-device brings numerous benefits, including lower server costs, offline functionality, and improved user privacy. However, with over 1 billion parameters, these models face challenges due to restricted computational and memory resources on devices.
Excitingly, researchers from Google have presented a series of implementation optimizations for large diffusion models that achieve the fastest reported inference latency to date (under 12 seconds for Stable Diffusion 1.4 without INT8 quantization for a 512 × 512 image with 20 iterations) on GPU-equipped mobile devices. These groundbreaking enhancements not only broaden the applicability of generative AI but also significantly improve the overall user experience across a wide range of devices, paving the way for even more innovative AI applications in the future.
Paper link: https://arxiv.org/abs/2304.11267
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-siayn
#deeplearning #stablediffusion #inferenceoptimization
The rapid development of foundation models is revolutionizing the field of artificial intelligence, with large diffusion models gaining significant attention for their ability to generate photorealistic images and support various tasks. Deploying these models on-device brings numerous benefits, including lower server costs, offline functionality, and improved user privacy. However, with over 1 billion parameters, these models face challenges due to restricted computational and memory resources on devices.
Excitingly, researchers from Google have presented a series of implementation optimizations for large diffusion models that achieve the fastest reported inference latency to date (under 12 seconds for Stable Diffusion 1.4 without INT8 quantization for a 512 × 512 image with 20 iterations) on GPU-equipped mobile devices. These groundbreaking enhancements not only broaden the applicability of generative AI but also significantly improve the overall user experience across a wide range of devices, paving the way for even more innovative AI applications in the future.
Paper link: https://arxiv.org/abs/2304.11267
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-siayn
#deeplearning #stablediffusion #inferenceoptimization
{kind=link}
👍13❤3🔥1💩1
Scaling Transformer to 1M tokens and beyond with RMT
Imagine extending the context length of BERT, one of the most effective Transformer-based models in natural language processing, to an unprecedented two million tokens! This technical report unveils the Recurrent Memory Transformer (RMT) architecture, which achieves this incredible feat while maintaining high memory retrieval accuracy.
The RMT approach enables storage and processing of both local and global information, allowing information flow between segments of the input sequence through recurrence. The experiments showcase the effectiveness of this groundbreaking method, with immense potential to enhance long-term dependency handling in natural language understanding and generation tasks, as well as enable large-scale context processing for memory-intensive applications.
Paper link: https://arxiv.org/abs/2304.11062
Code link: https://github.com/booydar/t5-experiments/tree/scaling-report
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-rmt-1m
#deeplearning #nlp #bert #memory
Imagine extending the context length of BERT, one of the most effective Transformer-based models in natural language processing, to an unprecedented two million tokens! This technical report unveils the Recurrent Memory Transformer (RMT) architecture, which achieves this incredible feat while maintaining high memory retrieval accuracy.
The RMT approach enables storage and processing of both local and global information, allowing information flow between segments of the input sequence through recurrence. The experiments showcase the effectiveness of this groundbreaking method, with immense potential to enhance long-term dependency handling in natural language understanding and generation tasks, as well as enable large-scale context processing for memory-intensive applications.
Paper link: https://arxiv.org/abs/2304.11062
Code link: https://github.com/booydar/t5-experiments/tree/scaling-report
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-rmt-1m
#deeplearning #nlp #bert #memory
{kind=link}
❤6👍4🤮1
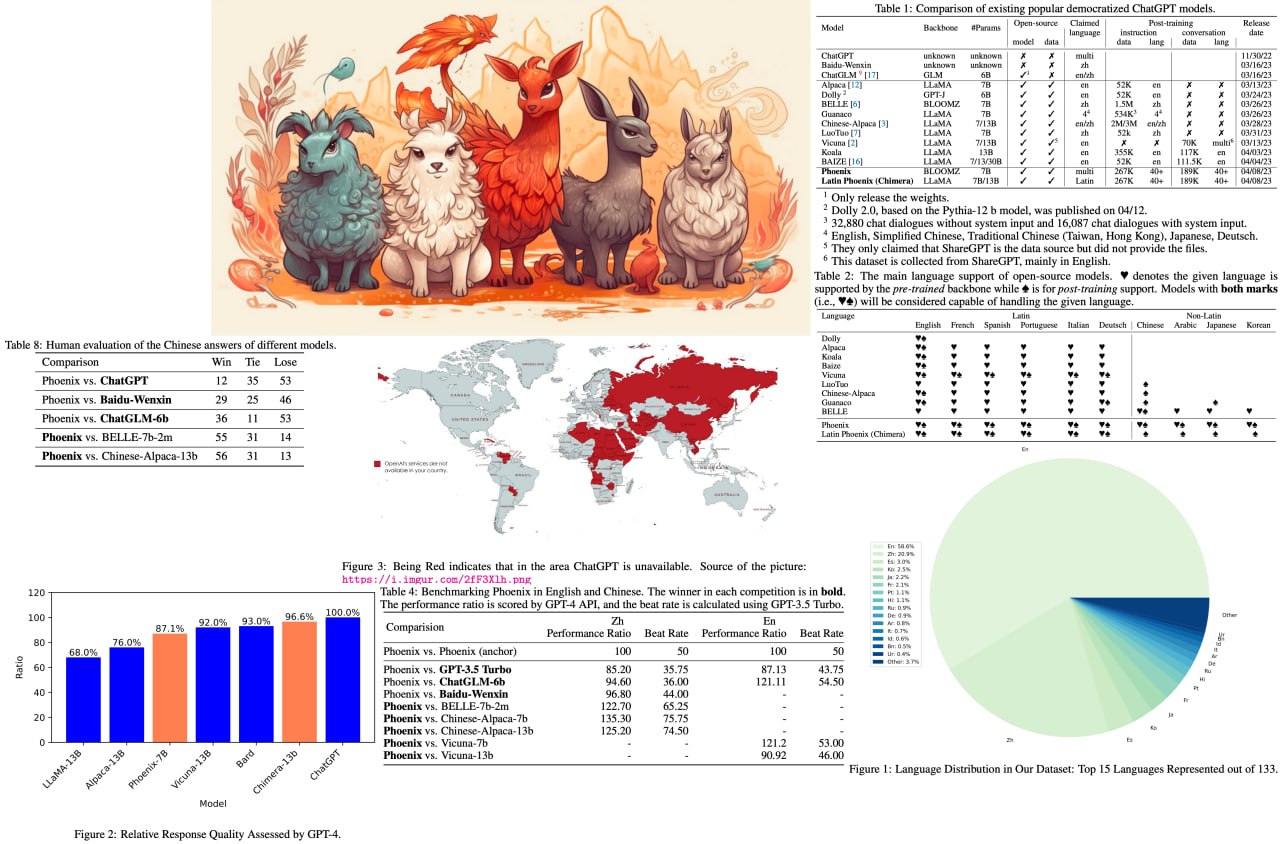
Phoenix: Democratizing ChatGPT across Languages
Introducing "Phoenix," a revolutionary multilingual ChatGPT that's breaking barriers in AI language models! By excelling in languages with limited resources and demonstrating competitive performance in English and Chinese models, Phoenix is set to transform accessibility for people around the world.
The methodology behind Phoenix combines instructions and conversations data to create a more well-rounded language model, leveraging the multi-lingual nature of the data to understand and interact with diverse languages.
Paper link: https://arxiv.org/abs/2304.10453
Code link: https://github.com/FreedomIntelligence/LLMZoo
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-phoenix-llm
#deeplearning #nlp #Phoenix #ChatGPT #multilingual #languagemodel
Introducing "Phoenix," a revolutionary multilingual ChatGPT that's breaking barriers in AI language models! By excelling in languages with limited resources and demonstrating competitive performance in English and Chinese models, Phoenix is set to transform accessibility for people around the world.
The methodology behind Phoenix combines instructions and conversations data to create a more well-rounded language model, leveraging the multi-lingual nature of the data to understand and interact with diverse languages.
Paper link: https://arxiv.org/abs/2304.10453
Code link: https://github.com/FreedomIntelligence/LLMZoo
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-phoenix-llm
#deeplearning #nlp #Phoenix #ChatGPT #multilingual #languagemodel
{kind=link}
😁11❤2👍2💩1
Last call to apply for the Yandex School of Data Analysis.
Recruitment for the YSDA, which is a vocational training program, free of charge, lasting for two years, will end on the 06 May 2023.
You can choose one of the four highly demanded majors: data science, big data infrastructure, machine learning or data analysis in applied sciences.
To be able to pass examinations and study successfully at the YSDA one should have a basic understanding of the machine learning, have a good mathematical background and use one of the programming languages. Experienced developers can apply for an alternative admission track that includes both assessment of algorithms basics and mathematics and research and/or industrial achievements.
The educational process is mainly conducted in the Russian language.
Application form is accessible via link https://clck.ru/34GwCS, there is also a tg-chat for the applicants https://t.iss.one/+DQ1j7epbIlNmNjFi
Recruitment for the YSDA, which is a vocational training program, free of charge, lasting for two years, will end on the 06 May 2023.
You can choose one of the four highly demanded majors: data science, big data infrastructure, machine learning or data analysis in applied sciences.
To be able to pass examinations and study successfully at the YSDA one should have a basic understanding of the machine learning, have a good mathematical background and use one of the programming languages. Experienced developers can apply for an alternative admission track that includes both assessment of algorithms basics and mathematics and research and/or industrial achievements.
The educational process is mainly conducted in the Russian language.
Application form is accessible via link https://clck.ru/34GwCS, there is also a tg-chat for the applicants https://t.iss.one/+DQ1j7epbIlNmNjFi
Поступление в ШАД
Поступление в Школу анализа данных. Будет сложно, но оно того стоит
👍20👎10❤4🔥3
Forwarded from gonzo-обзоры ML статей
TWIMC
string2string: A Modern Python Library for String-to-String Algorithms
https://arxiv.org/abs/2304.14395
We introduce string2string, an open-source library that offers a comprehensive suite of efficient algorithms for a broad range of string-to-string problems. It includes traditional algorithmic solutions as well as recent advanced neural approaches to tackle various problems in string alignment, distance measurement, lexical and semantic search, and similarity analysis -- along with several helpful visualization tools and metrics to facilitate the interpretation and analysis of these methods. Notable algorithms featured in the library include the Smith-Waterman algorithm for pairwise local alignment, the Hirschberg algorithm for global alignment, the Wagner-Fisher algorithm for edit distance, BARTScore and BERTScore for similarity analysis, the Knuth-Morris-Pratt algorithm for lexical search, and Faiss for semantic search. Besides, it wraps existing efficient and widely-used implementations of certain frameworks and metrics, such as sacreBLEU and ROUGE, whenever it is appropriate and suitable. Overall, the library aims to provide extensive coverage and increased flexibility in comparison to existing libraries for strings. It can be used for many downstream applications, tasks, and problems in natural-language processing, bioinformatics, and computational social sciences. It is implemented in Python, easily installable via pip, and accessible through a simple API. Source code, documentation, and tutorials are all available on our GitHub page:
https://github.com/stanfordnlp/string2string
string2string: A Modern Python Library for String-to-String Algorithms
https://arxiv.org/abs/2304.14395
We introduce string2string, an open-source library that offers a comprehensive suite of efficient algorithms for a broad range of string-to-string problems. It includes traditional algorithmic solutions as well as recent advanced neural approaches to tackle various problems in string alignment, distance measurement, lexical and semantic search, and similarity analysis -- along with several helpful visualization tools and metrics to facilitate the interpretation and analysis of these methods. Notable algorithms featured in the library include the Smith-Waterman algorithm for pairwise local alignment, the Hirschberg algorithm for global alignment, the Wagner-Fisher algorithm for edit distance, BARTScore and BERTScore for similarity analysis, the Knuth-Morris-Pratt algorithm for lexical search, and Faiss for semantic search. Besides, it wraps existing efficient and widely-used implementations of certain frameworks and metrics, such as sacreBLEU and ROUGE, whenever it is appropriate and suitable. Overall, the library aims to provide extensive coverage and increased flexibility in comparison to existing libraries for strings. It can be used for many downstream applications, tasks, and problems in natural-language processing, bioinformatics, and computational social sciences. It is implemented in Python, easily installable via pip, and accessible through a simple API. Source code, documentation, and tutorials are all available on our GitHub page:
https://github.com/stanfordnlp/string2string
GitHub
GitHub - stanfordnlp/string2string: String-to-String Algorithms for Natural Language Processing
String-to-String Algorithms for Natural Language Processing - stanfordnlp/string2string
🔥9👍6❤2😁1
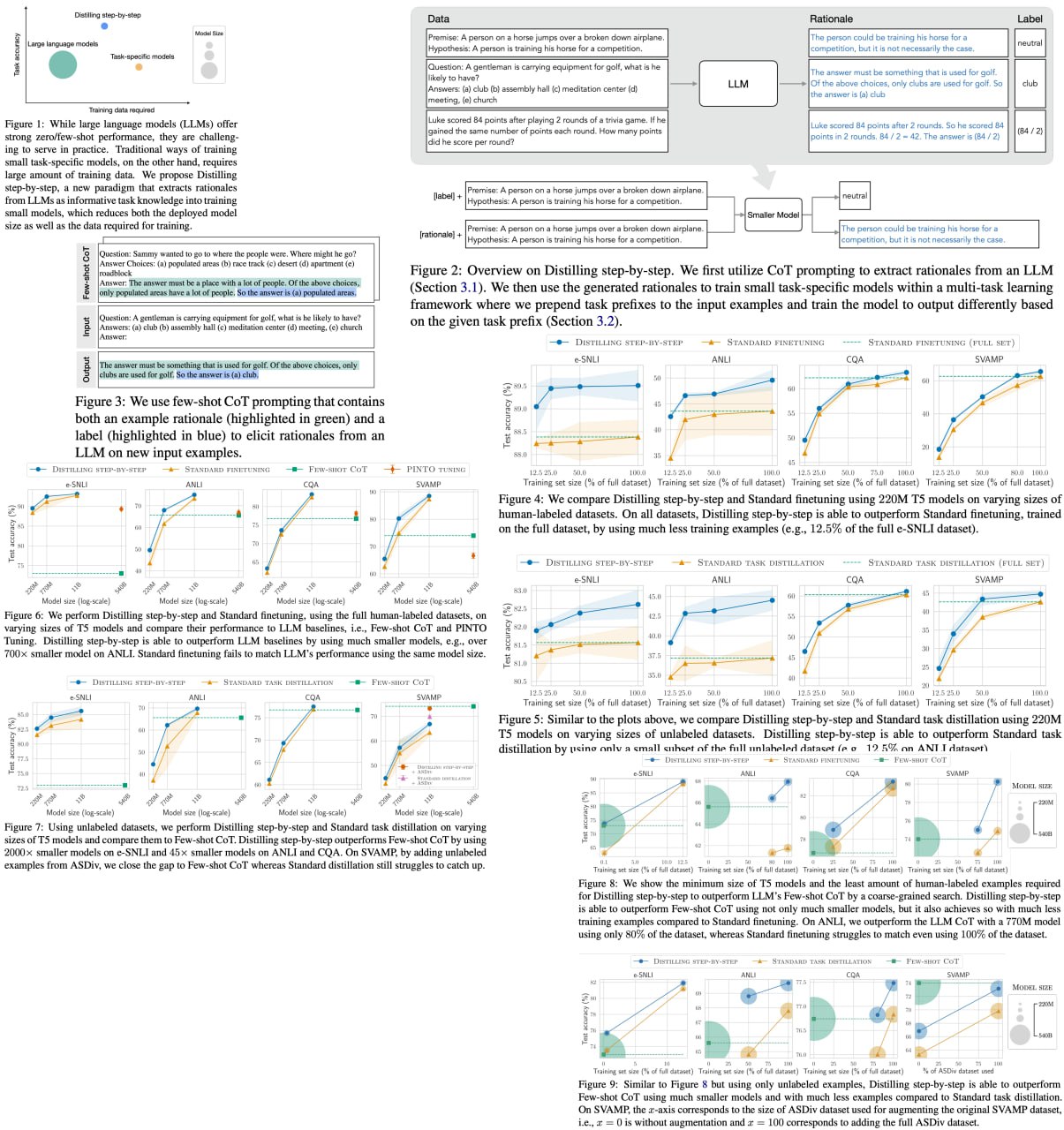
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes
Researchers have developed "Distilling step-by-step," a cutting-edge method to train smaller, more efficient task-specific models that outperform large language models (LLMs) while requiring significantly less training data. This innovation promises to revolutionize the practicality of NLP models in real-world applications by reducing both model size and data requirements: a 770M T5 model surpasses a 540B PaLM model using only 80% of available data.
Distilling step-by-step leverages LLM-generated rationales within a multi-task training framework, yielding impressive results across 4 NLP benchmarks. The technique consistently achieves better performance with fewer labeled/unlabeled training examples, surpassing LLMs with substantially smaller model sizes.
Paper link: https://arxiv.org/abs/2305.02301
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dsbs
#deeplearning #nlp #languagemodels #distillation
Researchers have developed "Distilling step-by-step," a cutting-edge method to train smaller, more efficient task-specific models that outperform large language models (LLMs) while requiring significantly less training data. This innovation promises to revolutionize the practicality of NLP models in real-world applications by reducing both model size and data requirements: a 770M T5 model surpasses a 540B PaLM model using only 80% of available data.
Distilling step-by-step leverages LLM-generated rationales within a multi-task training framework, yielding impressive results across 4 NLP benchmarks. The technique consistently achieves better performance with fewer labeled/unlabeled training examples, surpassing LLMs with substantially smaller model sizes.
Paper link: https://arxiv.org/abs/2305.02301
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dsbs
#deeplearning #nlp #languagemodels #distillation
{kind=link}
👍14🥱7🤔2
ImageBind: One Embedding Space To Bind Them All
Introducing ImageBind, a groundbreaking approach that learns a joint embedding across six different modalities – images, text, audio, depth, thermal, and IMU data – using only image-paired data. This innovative method leverages recent large-scale vision-language models, extending their zero-shot capabilities to new modalities through their natural pairing with images. ImageBind unlocks a myriad of novel emergent applications 'out-of-the-box,' including cross-modal retrieval, composing modalities with arithmetic, cross-modal detection, and generation.
ImageBind's emergent capabilities improve as the strength of the image encoder increases, setting a new state-of-the-art benchmark in emergent zero-shot recognition tasks across modalities, even outperforming specialist supervised models. Furthermore, ImageBind demonstrates impressive few-shot recognition results, surpassing prior work in the field. This pioneering technique offers a fresh way to evaluate vision models for both visual and non-visual tasks, opening the door to exciting advancements in AI and machine learning.
Blogpost link: https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
Code link: https://github.com/facebookresearch/ImageBind
Paper link: https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf
Demo link: https://imagebind.metademolab.com/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-imagebind
#deeplearning #nlp #multimodal #cv #embedding
Introducing ImageBind, a groundbreaking approach that learns a joint embedding across six different modalities – images, text, audio, depth, thermal, and IMU data – using only image-paired data. This innovative method leverages recent large-scale vision-language models, extending their zero-shot capabilities to new modalities through their natural pairing with images. ImageBind unlocks a myriad of novel emergent applications 'out-of-the-box,' including cross-modal retrieval, composing modalities with arithmetic, cross-modal detection, and generation.
ImageBind's emergent capabilities improve as the strength of the image encoder increases, setting a new state-of-the-art benchmark in emergent zero-shot recognition tasks across modalities, even outperforming specialist supervised models. Furthermore, ImageBind demonstrates impressive few-shot recognition results, surpassing prior work in the field. This pioneering technique offers a fresh way to evaluate vision models for both visual and non-visual tasks, opening the door to exciting advancements in AI and machine learning.
Blogpost link: https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
Code link: https://github.com/facebookresearch/ImageBind
Paper link: https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf
Demo link: https://imagebind.metademolab.com/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-imagebind
#deeplearning #nlp #multimodal #cv #embedding
{kind=link}
🔥14👍10❤1
Forwarded from Spark in me (Alexander)
Found another PyTorch-based library with basic image functions, losses and transformations
Looks like it is a combination toolkit of augs, skimage and classic cv2 functions, but written in PyTorch.
What is Kornia? Kornia is a differentiable library that allows classical computer vision to be integrated into deep learning models.
Examples:
- https://kornia.readthedocs.io/en/latest/get-started/highlights.html
- and especially this https://kornia.readthedocs.io/en/latest/losses.html
Looks like it is a combination toolkit of augs, skimage and classic cv2 functions, but written in PyTorch.
What is Kornia? Kornia is a differentiable library that allows classical computer vision to be integrated into deep learning models.
Examples:
- https://kornia.readthedocs.io/en/latest/get-started/highlights.html
- and especially this https://kornia.readthedocs.io/en/latest/losses.html
👍14❤5👏1
Data Science by ODS.ai 🦜
Hey, let’s see how many of us have some Data Science-related vacancies to share. Please submit them through Google Form. Best vacancies may be published in this channel. Google Form: link. #ds_jobs
For those how are looking beyond Data Science or wondering to play around, here is a news on the release of the portfolio company of one of the channel editors:
TON Play: the Unity SDK + payment management for games
TON Play is a toolkit for developers based on the TON blockchain and working closely with the messaging app Telegram. They recently introduced Pay-in, Mass payout, and On-demand payout methods in TON. If you dabble with games, this might be curious to test in action.
The main features:
* projects get paid by Telegram users in TON
* option to add mass payouts in TON to games with cash prizes
* automated payouts on user demand
TON Play also released SDKs, allowing projects to manage assets and in-game marketplace and port Unity or HTML5 games to work inside Telegram as a web app. SDKs are written in Unity, Python, and Typescript.
Website: https://tonplay.io/
Documentation: https://docs.tonplay.io/
Telegram channel: https://t.iss.one/tonplayinsider
Contacts: @tonplay_devs, [email protected]
#ds_jobs #ds_resumes
TON Play: the Unity SDK + payment management for games
TON Play is a toolkit for developers based on the TON blockchain and working closely with the messaging app Telegram. They recently introduced Pay-in, Mass payout, and On-demand payout methods in TON. If you dabble with games, this might be curious to test in action.
The main features:
* projects get paid by Telegram users in TON
* option to add mass payouts in TON to games with cash prizes
* automated payouts on user demand
TON Play also released SDKs, allowing projects to manage assets and in-game marketplace and port Unity or HTML5 games to work inside Telegram as a web app. SDKs are written in Unity, Python, and Typescript.
Website: https://tonplay.io/
Documentation: https://docs.tonplay.io/
Telegram channel: https://t.iss.one/tonplayinsider
Contacts: @tonplay_devs, [email protected]
#ds_jobs #ds_resumes
www.playdeck.io
The official gaming marketplace on Telegram. We bring developers together with millions of active players
👍5❤1
Forwarded from ml4se
StarCoder: may the source be with you!
The BigCode community, an open-scientific collaboration working on the responsible development of Code LLMs, introduces StarCoder and StarCoderBase:
- 15.5B parameter models
- 8K context length
- StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process
- StarCoderBase is fine-tuned on 35B Python tokens, resulting in the creation of StarCoder
StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model.
The BigCode community, an open-scientific collaboration working on the responsible development of Code LLMs, introduces StarCoder and StarCoderBase:
- 15.5B parameter models
- 8K context length
- StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process
- StarCoderBase is fine-tuned on 35B Python tokens, resulting in the creation of StarCoder
StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model.
👍10❤5🔥2
Data Science by ODS.ai 🦜
Hey, let’s see how many of us have some Data Science-related vacancies to share. Please submit them through Google Form. Best vacancies may be published in this channel. Google Form: link. #ds_jobs
Launching the Open Data Science Talent Pool Initiative!
Hello, community!
We received several requests to organize some tools to match people seeking career / pet projects matching opportunities. So now we are launching the Open Data Science Talent Pool!
The field of data science is rapidly evolving, and we recognize the importance of matching skilled professionals with organizations that value their unique capabilities. This Talent Pool Initiative is our endeavor to facilitate these connections, making the opportunities search process smoother and more efficient for everyone involved.
Here's how it works:
🔍 For Opportunities Seekers:
If you're a data scientist, machine learning engineer, AI specialist, or hold any other role in the data science domain, we invite you to submit your resume and a brief introduction about yourself. This is a fantastic opportunity to showcase your skills, interests, and aspirations to potential employers. Don't forget to highlight those special projects or unique experiences that make you stand out!
🏢 For Talent Seekers:
If you're an organization or an individual looking for talented individuals in the field of data science, our Talent Pool will be an invaluable resource. You'll have access to a diverse array of professionals, each with their own unique skill sets and experiences, ready to help your organization reach new heights. Make sure you submitted your request through the form in the quoted post
🔄 The Process:
1 Submission: Individuals can submit their resumes and short introductions through a dedicated form on our website (link will be shared soon).
2 Review: Our team will review these submissions to ensure they meet the necessary standards and criteria.
3 Access: Approved profiles will be included in our Talent Pool, accessible to match with the requests within our community.
During the earliest stage we are going to match the requests personally ensuring we don’t overengineer the process. We will not hesitate to introduce necessary product adjustments once the tool meets the demand inside the community.
Remember, we're all in this journey together. Whether you're looking for your next big opportunity or seeking the perfect addition to your team, we're here to support you.
Stay tuned, stay connected, and let's continue to foster a supportive, dynamic, and prosperous data science community!
Best,
ChatGPT with the prompt from Open Data Science Channel Editorial Team
Google Form: https://forms.gle/3GH1vrt91mRtstzK8
#ds_jobs #ds_intros
Hello, community!
We received several requests to organize some tools to match people seeking career / pet projects matching opportunities. So now we are launching the Open Data Science Talent Pool!
The field of data science is rapidly evolving, and we recognize the importance of matching skilled professionals with organizations that value their unique capabilities. This Talent Pool Initiative is our endeavor to facilitate these connections, making the opportunities search process smoother and more efficient for everyone involved.
Here's how it works:
🔍 For Opportunities Seekers:
If you're a data scientist, machine learning engineer, AI specialist, or hold any other role in the data science domain, we invite you to submit your resume and a brief introduction about yourself. This is a fantastic opportunity to showcase your skills, interests, and aspirations to potential employers. Don't forget to highlight those special projects or unique experiences that make you stand out!
🏢 For Talent Seekers:
If you're an organization or an individual looking for talented individuals in the field of data science, our Talent Pool will be an invaluable resource. You'll have access to a diverse array of professionals, each with their own unique skill sets and experiences, ready to help your organization reach new heights. Make sure you submitted your request through the form in the quoted post
🔄 The Process:
1 Submission: Individuals can submit their resumes and short introductions through a dedicated form on our website (link will be shared soon).
2 Review: Our team will review these submissions to ensure they meet the necessary standards and criteria.
3 Access: Approved profiles will be included in our Talent Pool, accessible to match with the requests within our community.
During the earliest stage we are going to match the requests personally ensuring we don’t overengineer the process. We will not hesitate to introduce necessary product adjustments once the tool meets the demand inside the community.
Remember, we're all in this journey together. Whether you're looking for your next big opportunity or seeking the perfect addition to your team, we're here to support you.
Stay tuned, stay connected, and let's continue to foster a supportive, dynamic, and prosperous data science community!
Best,
ChatGPT with the prompt from Open Data Science Channel Editorial Team
Google Form: https://forms.gle/3GH1vrt91mRtstzK8
#ds_jobs #ds_intros
Google Docs
Open Data Science Talent Pool
Use this form to submit a resume to the talent pool. Be vocal.
❤9👍4💩3
Forwarded from ml4se
Introducing 100K Token Context Windows
- approximately 75K words
- hundreds of pages
- a book, for example "The Great Gatsby" (about 72K tokens)
- a text that will take approximately 5 hours to read
- approximately 75K words
- hundreds of pages
- a book, for example "The Great Gatsby" (about 72K tokens)
- a text that will take approximately 5 hours to read
🔥15👍4
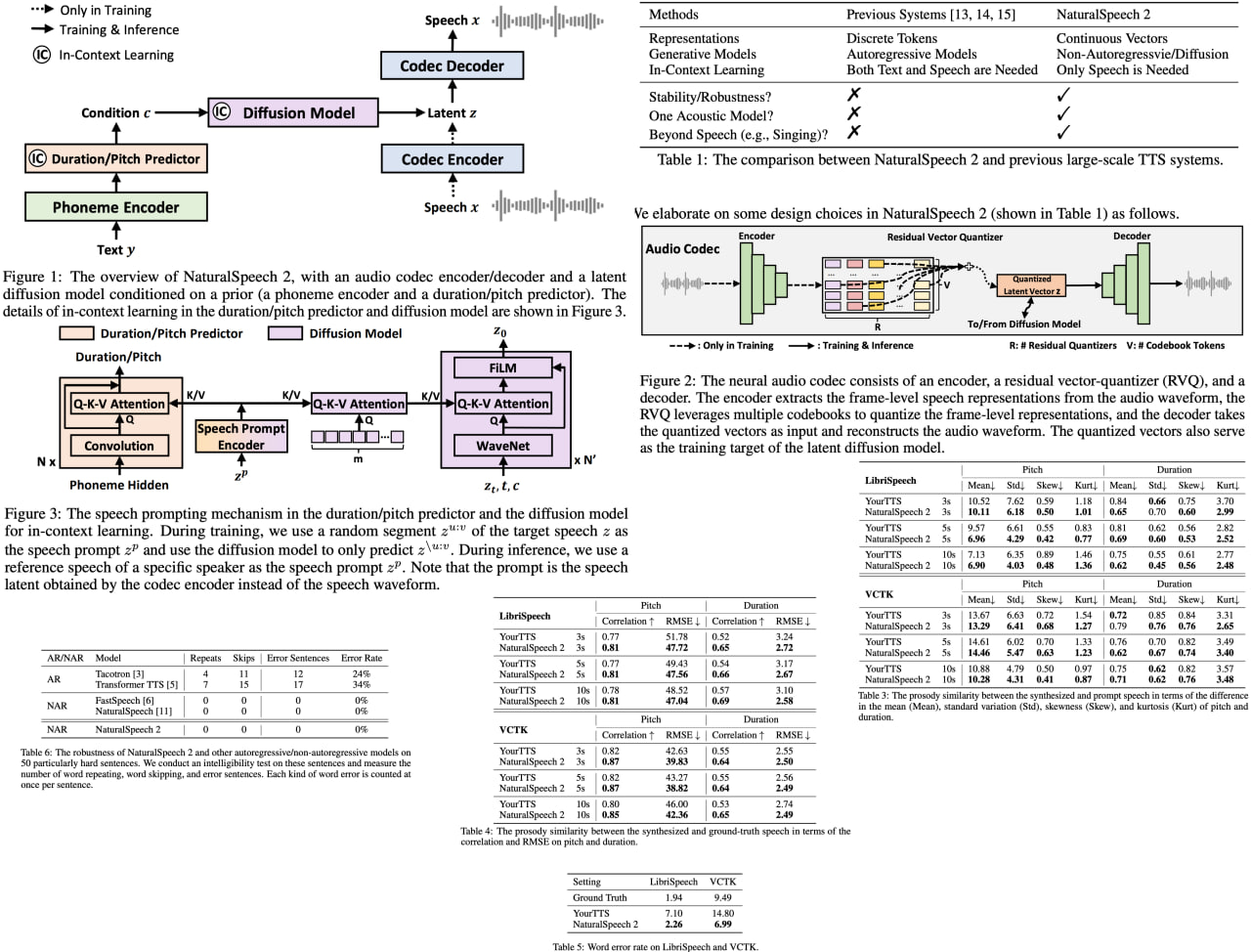
NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers
In the rapidly evolving domain of text-to-speech (TTS) technology, an exciting breakthrough has been made with the development of NaturalSpeech 2. This innovative system brings new levels of diversity to the table, by uniquely capturing a wide range of human speech characteristics such as speaker identities, prosodies, and even styles like singing. By employing a neural audio codec and residual vector quantizers, it transcends the limitations of existing TTS systems, which often suffer from unstable prosody, word skipping/repeating issues, and subpar voice quality.
More impressively, NaturalSpeech 2 enhances the "zero-shot" capability, a crucial factor for diverse speech synthesis. By designing a unique speech prompting mechanism, it facilitates in-context learning in both the diffusion model and the duration/pitch predictor. Its expansive training on 44K hours of speech and singing data has yielded unprecedented results. NaturalSpeech 2 significantly outperforms previous TTS systems in prosody/timbre similarity, robustness, and voice quality, even demonstrating novel zero-shot singing synthesis.
Project link: https://speechresearch.github.io/naturalspeech2/
Paper link: https://arxiv.org/pdf/2304.09116.pdf
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-naturalspeech2
#deeplearning #nlp #tts #texttospeech
In the rapidly evolving domain of text-to-speech (TTS) technology, an exciting breakthrough has been made with the development of NaturalSpeech 2. This innovative system brings new levels of diversity to the table, by uniquely capturing a wide range of human speech characteristics such as speaker identities, prosodies, and even styles like singing. By employing a neural audio codec and residual vector quantizers, it transcends the limitations of existing TTS systems, which often suffer from unstable prosody, word skipping/repeating issues, and subpar voice quality.
More impressively, NaturalSpeech 2 enhances the "zero-shot" capability, a crucial factor for diverse speech synthesis. By designing a unique speech prompting mechanism, it facilitates in-context learning in both the diffusion model and the duration/pitch predictor. Its expansive training on 44K hours of speech and singing data has yielded unprecedented results. NaturalSpeech 2 significantly outperforms previous TTS systems in prosody/timbre similarity, robustness, and voice quality, even demonstrating novel zero-shot singing synthesis.
Project link: https://speechresearch.github.io/naturalspeech2/
Paper link: https://arxiv.org/pdf/2304.09116.pdf
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-naturalspeech2
#deeplearning #nlp #tts #texttospeech
{kind=link}
🔥13👍5🆒2
DarkBERT: A Language Model for the Dark Side of the Internet
The researchers have developed a novel model called DarkBERT, which specifically focuses on the linguistically complex and often misunderstood domain of the Dark Web. This innovative model stands out due to its unique pretraining on Dark Web data, which allows it to handle the extreme lexical and structural diversity characteristic of the Dark Web. This is a critical development considering the clear differences that exist in language use between the Dark Web and the Surface Web, a factor that can often hinder accurate textual analysis.
DarkBERT isn't just a novelty, but a robust, high-performing language model that consistently outshines current popular models like BERT and RoBERTa in various use cases. These findings shed light on the considerable advantages that a domain-specific model like DarkBERT can offer. More than anything else, DarkBERT promises to be a vital resource for future research on the Dark Web, setting a new standard for language models in this intriguing and intricate realm.
Paper link: https://arxiv.org/abs/2305.08596
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-darkbert
#deeplearning #nlp #darkweb #cybersecurity
The researchers have developed a novel model called DarkBERT, which specifically focuses on the linguistically complex and often misunderstood domain of the Dark Web. This innovative model stands out due to its unique pretraining on Dark Web data, which allows it to handle the extreme lexical and structural diversity characteristic of the Dark Web. This is a critical development considering the clear differences that exist in language use between the Dark Web and the Surface Web, a factor that can often hinder accurate textual analysis.
DarkBERT isn't just a novelty, but a robust, high-performing language model that consistently outshines current popular models like BERT and RoBERTa in various use cases. These findings shed light on the considerable advantages that a domain-specific model like DarkBERT can offer. More than anything else, DarkBERT promises to be a vital resource for future research on the Dark Web, setting a new standard for language models in this intriguing and intricate realm.
Paper link: https://arxiv.org/abs/2305.08596
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-darkbert
#deeplearning #nlp #darkweb #cybersecurity
{kind=link}
😈21👍10❤7🌚4😁2🤬2
Forwarded from ml4se
Code Execution with Pre-trained Language Models
Code execution is a fundamental aspect of programming language semantics that reflects the exact behavior of the code. However, most pretrained models for code intelligence ignore the execution trace and only rely on source code and syntactic structures. In this paper, the authors aim to teach pretrained models the real-world code execution process. They propose CodeExecutor, a Transformer-based model that learns to execute arbitrary programs and predict their execution traces.
Code execution is a fundamental aspect of programming language semantics that reflects the exact behavior of the code. However, most pretrained models for code intelligence ignore the execution trace and only rely on source code and syntactic structures. In this paper, the authors aim to teach pretrained models the real-world code execution process. They propose CodeExecutor, a Transformer-based model that learns to execute arbitrary programs and predict their execution traces.
🔥17👍3😁1