
Data Science by ODS.ai 🦜
Experimenting with CLIP+VQGAN to Create AI Generated Art Tips and tricks on prompts to #vqclip. TLDR: * Adding rendered in unreal engine, trending on artstation, top of /r/art improves image quality significally. * Using the pipe to split a prompt into…
Some stats to get the perspective of the development of #dalle
«Used 1000 prompts in Dalle over the last 2 days, about 9 hours each day. Of those, saved ~300. 50 I like enough to share w/ socials. 12 enough to rework for future projects. 3 were perfect, may mint someday. Curation is *1* step of AI art. I used to finish physicals in less time.»
Source: https://twitter.com/clairesilver12/status/1550709299797577729
#visualization #gan #generation #generatinveart #aiart #artgentips
«Used 1000 prompts in Dalle over the last 2 days, about 9 hours each day. Of those, saved ~300. 50 I like enough to share w/ socials. 12 enough to rework for future projects. 3 were perfect, may mint someday. Curation is *1* step of AI art. I used to finish physicals in less time.»
Source: https://twitter.com/clairesilver12/status/1550709299797577729
#visualization #gan #generation #generatinveart #aiart #artgentips
👍6👏2
Next-ViT: Next Generation Vision Transformer for Efficient Deployment in Realistic Industrial Scenarios
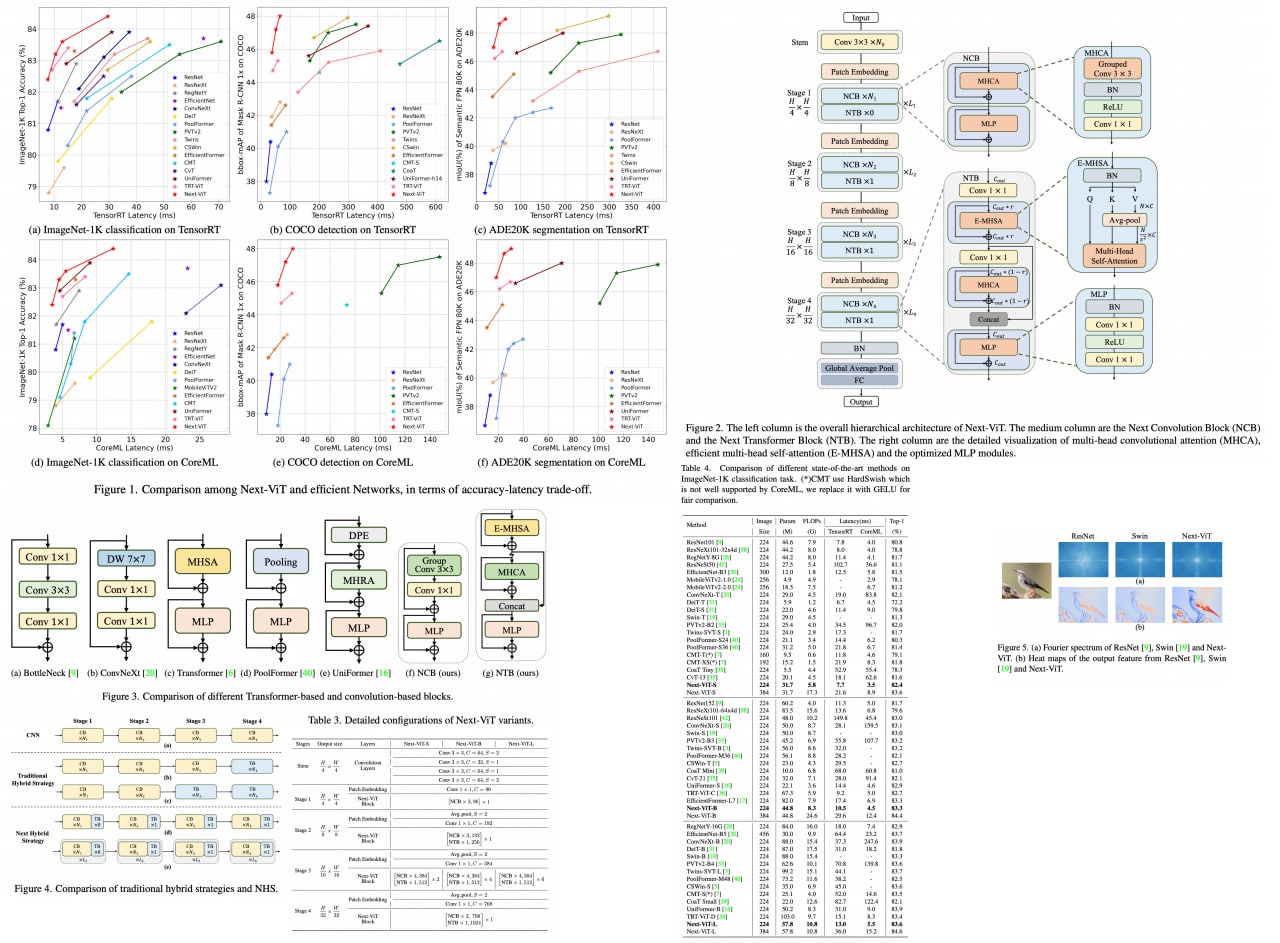
While vision transformers demostrate high performance, they can't be deployed as efficiently as CNNs in realistic industrial deployment scenarios, e. g. TensorRT or CoreML.
The authors propose Next-ViT, which has a higher latency/accuracy trade-off than existing CNN and ViT models. They develop two new architecture blocks and a new paradigm to stack them. As a result, On TensorRT, Next-ViT surpasses ResNet by 5.4 mAP (from 40.4 to 45.8) on COCO detection and 8.2% mIoU (from 38.8% to 47.0%) on ADE20K segmentation. Also, it achieves comparable performance with CSWin, while the inference speed is accelerated by
3.6×. On CoreML, Next-ViT surpasses EfficientFormer by 4.6 mAP (from 42.6 to 47.2) on COCO detection and 3.5% mIoU (from 45.2% to 48.7%) on ADE20K segmentation under similar latency.
Paper: https://arxiv.org/abs/2207.05501
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-next-vit
#deeplearning #cv #transformer #computervision
While vision transformers demostrate high performance, they can't be deployed as efficiently as CNNs in realistic industrial deployment scenarios, e. g. TensorRT or CoreML.
The authors propose Next-ViT, which has a higher latency/accuracy trade-off than existing CNN and ViT models. They develop two new architecture blocks and a new paradigm to stack them. As a result, On TensorRT, Next-ViT surpasses ResNet by 5.4 mAP (from 40.4 to 45.8) on COCO detection and 8.2% mIoU (from 38.8% to 47.0%) on ADE20K segmentation. Also, it achieves comparable performance with CSWin, while the inference speed is accelerated by
3.6×. On CoreML, Next-ViT surpasses EfficientFormer by 4.6 mAP (from 42.6 to 47.2) on COCO detection and 3.5% mIoU (from 45.2% to 48.7%) on ADE20K segmentation under similar latency.
Paper: https://arxiv.org/abs/2207.05501
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-next-vit
#deeplearning #cv #transformer #computervision
{kind=link}
👍24❤2😁2🔥1👏1
Forwarded from gonzo-обзоры ML статей
Now it is official.
I've started writing a book on JAX. This seems to be the first book ever on this topic.
For those who don't know, JAX is an exceptionally cool numeric computations library from Google, a kind of NumPy on steroids, with autodiff, XLA compilation, and hardware acceleration on TPU/GPU. JAX also brings the functional programming paradigm to deep learning.
JAX is heavily used for deep learning and already pretends to be the deep learning framework #3. Some companies, like DeepMind, have already switched to JAX internally. There are rumors that Google also switches to JAX.
JAX ecosystem is constantly growing. There are a lot of high-quality deep learning-related modules. But JAX is not limited to deep learning. There are many exciting applications and libraries on top of JAX for physics, including molecular dynamics, fluid dynamics, rigid body simulation, quantum computing, astrophysics, ocean modeling, and so on. There are libraries for distributed matrix factorization, streaming data processing, protein folding, and chemical modeling, with other new applications emerging constantly.
Anyway, it's a perfect time to start learning JAX!
The book is available today as a part of the Manning Early Access Program (MEAP), so you can read the book as I write it 🙂 This is a very smart way of learning something new, you do not have to wait until the complete book is ready. You can start learning right away, and at the moment the book is published, you already know everything. Your feedback will also be very valuable, and you can influence how the book is made.
Here's a link to the book: https://mng.bz/QvAG
If you want a decent discount, use the discount code mlsapunov. It will provide you with 40% off, and it's valid through August 11th.
I've started writing a book on JAX. This seems to be the first book ever on this topic.
For those who don't know, JAX is an exceptionally cool numeric computations library from Google, a kind of NumPy on steroids, with autodiff, XLA compilation, and hardware acceleration on TPU/GPU. JAX also brings the functional programming paradigm to deep learning.
JAX is heavily used for deep learning and already pretends to be the deep learning framework #3. Some companies, like DeepMind, have already switched to JAX internally. There are rumors that Google also switches to JAX.
JAX ecosystem is constantly growing. There are a lot of high-quality deep learning-related modules. But JAX is not limited to deep learning. There are many exciting applications and libraries on top of JAX for physics, including molecular dynamics, fluid dynamics, rigid body simulation, quantum computing, astrophysics, ocean modeling, and so on. There are libraries for distributed matrix factorization, streaming data processing, protein folding, and chemical modeling, with other new applications emerging constantly.
Anyway, it's a perfect time to start learning JAX!
The book is available today as a part of the Manning Early Access Program (MEAP), so you can read the book as I write it 🙂 This is a very smart way of learning something new, you do not have to wait until the complete book is ready. You can start learning right away, and at the moment the book is published, you already know everything. Your feedback will also be very valuable, and you can influence how the book is made.
Here's a link to the book: https://mng.bz/QvAG
If you want a decent discount, use the discount code mlsapunov. It will provide you with 40% off, and it's valid through August 11th.
🔥34👍27❤4👎1
Frankfurt Data Science welcome you back to the onsite event in Frankfurt-am-Main! As usual special - a demo of the new #dalle2 model by statworx team, Sebastian Heinz and Fabian Müller, socialising time, and a cocktail bar with free cocktails. Frankfurt DS Community thanks SAS for supporting and TechQuartier for hosting! They are looking for more supporters.
Event details:
Date: 24th August 2022
Time: 6PM - 11PM
Location: TechQuartier, Frankfurt
Register here
Event details:
Date: 24th August 2022
Time: 6PM - 11PM
Location: TechQuartier, Frankfurt
Register here
👍27❤17🔥1
Forwarded from Kali Novskaya (Tatiana Shavrina)
#nlp #про_nlp
Друзья, так как много из моих статей и статей коллег выходит на англ языке, я решила завести отдельную группу для общения про многоязычность в NLP: добавляйтесь!
В группе будут посты и обсуждения новых важных работ по теме — кажется, что это первый чат в tg такого рода.
https://t.iss.one/multilingual_nlp
Multilingual NLP discussion group
I've decided to create a group on #multilinguality so we could have a place in telegram to discuss important new papers and share cool results during conferences, meetups and public discussions!
Group is public, feel free to share the link!
https://t.iss.one/multilingual_nlp
Друзья, так как много из моих статей и статей коллег выходит на англ языке, я решила завести отдельную группу для общения про многоязычность в NLP: добавляйтесь!
В группе будут посты и обсуждения новых важных работ по теме — кажется, что это первый чат в tg такого рода.
https://t.iss.one/multilingual_nlp
Multilingual NLP discussion group
I've decided to create a group on #multilinguality so we could have a place in telegram to discuss important new papers and share cool results during conferences, meetups and public discussions!
Group is public, feel free to share the link!
https://t.iss.one/multilingual_nlp
👍29🥰1
RuLeanALBERT : https://github.com/yandex-research/RuLeanALBERT
RuLeanALBERT is a pretrained masked language model for the Russian language using a memory-efficient architecture.
RuLeanALBERT is a pretrained masked language model for the Russian language using a memory-efficient architecture.
GitHub
GitHub - yandex-research/RuLeanALBERT: RuLeanALBERT is a pretrained masked language model for the Russian language that uses a…
RuLeanALBERT is a pretrained masked language model for the Russian language that uses a memory-efficient architecture. - yandex-research/RuLeanALBERT
👍18
Forwarded from DataGym Channel [Power of data]
#opensource : RuLeanALBERT от Yandex Research
2.9B трансформер для русского, которая влезет в домашнюю ПеКарню ресерчера
Мало того, что это самая большая БЕРТ-подобная модель для русского языка, которая показывает крутые результаты в бенчмарках, так еще и с кодом для fine-tuning-а
GitHub
А в статье можете узнать, как обучалась эта модель (а-ля коллаборативное глубокое обучение) на фреймворке по децентрализованному обучению Hivemind
2.9B трансформер для русского, которая влезет в домашнюю ПеКарню ресерчера
Мало того, что это самая большая БЕРТ-подобная модель для русского языка, которая показывает крутые результаты в бенчмарках, так еще и с кодом для fine-tuning-а
GitHub
А в статье можете узнать, как обучалась эта модель (а-ля коллаборативное глубокое обучение) на фреймворке по децентрализованному обучению Hivemind
GitHub
GitHub - yandex-research/RuLeanALBERT: RuLeanALBERT is a pretrained masked language model for the Russian language that uses a…
RuLeanALBERT is a pretrained masked language model for the Russian language that uses a memory-efficient architecture. - yandex-research/RuLeanALBERT
👍28❤3
Kolesa Conf 2022 — Kolesa Group's conference for IT community
Kolesa Group will host its traditional conference on 8 October. Registration is open. Kolesa Conf is an annual Kazakhstan IT conference where leading experts from the best IT companies of the CIS take part.
One of the tracks is devoted to Data. There will be 12 speakers. Some of featured reports:
• «Methodology of construction of cloud CDW: case Air Astana».
• How to correctly estimate the sample size and time of the test. And what non-obvious difficulties can be encountered along the way.
• «Creation of a synthetic control group with the help of Propensity Score Matching».
• How the dynamic minimum cheque (surge pricing) hated by users was developed and implemented.
• «Analytics at the launch of a new product. An example of market place spare parts»
Conference website: https://bit.ly/3UmCoWC
#conference #it #data #analysis
Kolesa Group will host its traditional conference on 8 October. Registration is open. Kolesa Conf is an annual Kazakhstan IT conference where leading experts from the best IT companies of the CIS take part.
One of the tracks is devoted to Data. There will be 12 speakers. Some of featured reports:
• «Methodology of construction of cloud CDW: case Air Astana».
• How to correctly estimate the sample size and time of the test. And what non-obvious difficulties can be encountered along the way.
• «Creation of a synthetic control group with the help of Propensity Score Matching».
• How the dynamic minimum cheque (surge pricing) hated by users was developed and implemented.
• «Analytics at the launch of a new product. An example of market place spare parts»
Conference website: https://bit.ly/3UmCoWC
#conference #it #data #analysis
kolesa-conf.kz
Kolesa Conf`24
Самая масштабная IT-конференция в Казахстане
👍18🔥5🍌4👎2😁2
Wanna have impromptu Data Science breakfast tomorrow in the center of Helsinki. Please dm @malev if you are interested
🤔11🤡4
Data Science by ODS.ai 🦜
Wanna have impromptu Data Science breakfast tomorrow in the center of Helsinki. Please dm @malev if you are interested
ODS breakfast Helsinki today at 11:00, here:
El Fant - Coffee & Wine Bar
044 2369953
https://maps.app.goo.gl/zFTP8GSsKLDYxEtH8?g_st=ic
Come by to talk data science and stuff.
Helsinki ODS breakfast group: https://t.iss.one/+OHZM3jH9_HNmZWIy
El Fant - Coffee & Wine Bar
044 2369953
https://maps.app.goo.gl/zFTP8GSsKLDYxEtH8?g_st=ic
Come by to talk data science and stuff.
Helsinki ODS breakfast group: https://t.iss.one/+OHZM3jH9_HNmZWIy
El Fant - Cafe & Bar · Katariinankatu 3, 00170 Helsinki
★★★★☆ · Cafe
👍13❤2💩1
Data Science by ODS.ai 🦜
Wanna have impromptu Data Science breakfast tomorrow in the center of Helsinki. Please dm @malev if you are interested
Impromptu Data Science breakfast (or dinner) tomorrow at Dubai Marina.
DM @malev if you are interested
DM @malev if you are interested
👍8
TLDR: GPT-3 has unexpected application — modelling of socialogical studies. Average responses of a certain groups can be to some algorithmical accuracy predicted by in silico modelling.
What this means: sociologists won’t have to conduct costly live researches and will be able to run experiments in simulations. Marketers and politicians are getting their hands on cheap solution for modelling their slogans and value propositions. This enables people to check more hypothesis faster and to manipulate society with more efficiency.
ArXiV: https://arxiv.org/abs/2209.06899
#gpt3 #psychohistory #nlu #sociology
Please open Telegram to view this post
VIEW IN TELEGRAM
👍15🤔9😱9🔥8😁7🥱3🥰1🤩1🙏1
CORL: Offline Reinforcement Learning Library
Offline RL is a fresh paradigm that makes RL similar to the supervised learning, thus making it better applicable to the real-world problems. There is a whole bunch of recently developed Offline RL aglorithms, however, there was nots many of reliable open-sourced implementations for such algorithms
Our friends from @tinkoffai do some research in this direction and they recently open-sourced their internal offline RL library.
The main features are:
- Single-file implementations
- SOTA algorithms (Decision Transformer, AWAC, BC, CQL, IQL, TD3+BC, SAC-N, EDAC)
- Benchmarked on widely used D4RL datasets (results match performances reported in the original papers)
- Wandb logs for all of the experiments
Hope you will like it and the whole new world of Offline RL!
Github: https://github.com/tinkoff-ai/CORL
#tinkoff #RL #offline_lib
Offline RL is a fresh paradigm that makes RL similar to the supervised learning, thus making it better applicable to the real-world problems. There is a whole bunch of recently developed Offline RL aglorithms, however, there was nots many of reliable open-sourced implementations for such algorithms
Our friends from @tinkoffai do some research in this direction and they recently open-sourced their internal offline RL library.
The main features are:
- Single-file implementations
- SOTA algorithms (Decision Transformer, AWAC, BC, CQL, IQL, TD3+BC, SAC-N, EDAC)
- Benchmarked on widely used D4RL datasets (results match performances reported in the original papers)
- Wandb logs for all of the experiments
Hope you will like it and the whole new world of Offline RL!
Github: https://github.com/tinkoff-ai/CORL
#tinkoff #RL #offline_lib
GitHub
GitHub - tinkoff-ai/CORL: High-quality single-file implementations of SOTA Offline and Offline-to-Online RL algorithms: AWAC, BC…
High-quality single-file implementations of SOTA Offline and Offline-to-Online RL algorithms: AWAC, BC, CQL, DT, EDAC, IQL, SAC-N, TD3+BC, LB-SAC, SPOT, Cal-QL, ReBRAC - tinkoff-ai/CORL
🔥25👍16🌚5💩3👏1😁1
State of AI Report 2022 - ONLINE.pdf
22.9 MB
State of AI Report 2022
TLDR: We are moving forward and effective international collaboration is the key to progress.
Major Themes:
* New independent research labs are rapidly open sourcing the closed source output of major labs
* Safety is gaining awareness among major AI research entities
* The China-US AI research gap has continued to widen
* AI-driven scientific research continues to lead to breakthroughs
Website: https://www.stateof.ai
#report #stateofai #AI
TLDR: We are moving forward and effective international collaboration is the key to progress.
Major Themes:
* New independent research labs are rapidly open sourcing the closed source output of major labs
* Safety is gaining awareness among major AI research entities
* The China-US AI research gap has continued to widen
* AI-driven scientific research continues to lead to breakthroughs
Website: https://www.stateof.ai
#report #stateofai #AI
👍23🔥12🖕3👏2
Amos: An Adam-style Optimizer with Adaptive Weight Decay towards Model-Oriented Scale
Amos is a new optimizer that we propose to pre-train large language models. It is more efficient and converges faster than AdamW: ≤ 51% memory for slot variables, and better valid loss within ≤ 70% training time!Amos is a new optimizer that we propose to pre-train large language models. It is more efficient and converges faster than AdamW: ≤ 51% memory for slot variables, and better valid loss within ≤ 70% training time!
ArXiV: https://arxiv.org/abs/2210.11693
#NLU #NLP #optimizer
Amos is a new optimizer that we propose to pre-train large language models. It is more efficient and converges faster than AdamW: ≤ 51% memory for slot variables, and better valid loss within ≤ 70% training time!Amos is a new optimizer that we propose to pre-train large language models. It is more efficient and converges faster than AdamW: ≤ 51% memory for slot variables, and better valid loss within ≤ 70% training time!
ArXiV: https://arxiv.org/abs/2210.11693
#NLU #NLP #optimizer
👍12🔥10🤔1
Reinforcement learning course from MIPT.
The course consists of:
- Theoretical and practical material for beginners and advanced users
- Classical approaches based on utility functions and strategy gradient, as well as modern trends in improving the efficiency of the study of the environment, interaction with planning, using memory and hierarchical approaches.
- The best of David Silver's lectures, Sutton and Barto's book, and OpenAI, DeepMind works and articles from 2019-2022.
Materials:
- PDF slides and video lectures on each topic, Colab master classes and video lectures in Russian.
Course: https://clck.ru/32a3c9
If you are interested in an internship at MIPT in the areas of Reinforcement Learning, Computer Vision, Robotics or Self Driving Cars, you can apply here: https://cogmodel.mipt.ru/internship
The course consists of:
- Theoretical and practical material for beginners and advanced users
- Classical approaches based on utility functions and strategy gradient, as well as modern trends in improving the efficiency of the study of the environment, interaction with planning, using memory and hierarchical approaches.
- The best of David Silver's lectures, Sutton and Barto's book, and OpenAI, DeepMind works and articles from 2019-2022.
Materials:
- PDF slides and video lectures on each topic, Colab master classes and video lectures in Russian.
Course: https://clck.ru/32a3c9
If you are interested in an internship at MIPT in the areas of Reinforcement Learning, Computer Vision, Robotics or Self Driving Cars, you can apply here: https://cogmodel.mipt.ru/internship
cogmodel.mipt.ru
Стажировка
Стажировки в Центре когнитивного моделирования ФПМИ МФТИ
🔥27👍17👏2❤1