
Forwarded from Big Data Science
Visual Genome: the most labeled dataset
👁Scientists at Stanford University have collected the most annotated dataset with over 100,000 images. In total, the dataset contains almost 5.5 million object descriptions, attributes and relationships. You don't even have to download the dataset, but get the data you need by accessing the RESTful API endpoint using the GET-method. Despite the fact that the latest updates to the dataset are dated 2017, this is an excellent data set for training models in typical ML problems, from recognizing generated data using graph algorithms.
https://visualgenome.org/api/v0/api_home.html
👁Scientists at Stanford University have collected the most annotated dataset with over 100,000 images. In total, the dataset contains almost 5.5 million object descriptions, attributes and relationships. You don't even have to download the dataset, but get the data you need by accessing the RESTful API endpoint using the GET-method. Despite the fact that the latest updates to the dataset are dated 2017, this is an excellent data set for training models in typical ML problems, from recognizing generated data using graph algorithms.
https://visualgenome.org/api/v0/api_home.html
EditGAN: High-Precision Semantic Image Editing
Nvidia researches built an approach for editing segments of a picture with supposedly realtime picture augmentation according to the segment alterations. No demo is available yet though.
All the photoshop power users should relax, because appereance of such a tools means less work for them, not that the demand for the manual retouch will cease.
Website: https://nv-tlabs.github.io/editGAN/
ArXiV: https://arxiv.org/abs/2111.03186
#GAN #Nvidia
Nvidia researches built an approach for editing segments of a picture with supposedly realtime picture augmentation according to the segment alterations. No demo is available yet though.
All the photoshop power users should relax, because appereance of such a tools means less work for them, not that the demand for the manual retouch will cease.
Website: https://nv-tlabs.github.io/editGAN/
ArXiV: https://arxiv.org/abs/2111.03186
#GAN #Nvidia
👍3👎1🔥1
Upgini — dataset search automation library
Upgini is a new python library for an automated useful dataset search to boost supervised ML tasks
It enriches your dataset with intelligently crafted features from a broad range of curated data sources, including open and commercial datasets. The search is conducted for any combination of public IDs contained in your tabular dataset: IP, date, etc. Only features that could improve the prediction power of your ML model are returned.
Developers said that they wanted radically simplify data search and delivery for ML pipelines to make external data & features a standard approach. Like a hyperparameter tuning for machine learning nowadays.
A Free 30-days trial is available.
GitHub: https://github.com/upgini/upgini
Web: https://upgini.com
Upgini is a new python library for an automated useful dataset search to boost supervised ML tasks
It enriches your dataset with intelligently crafted features from a broad range of curated data sources, including open and commercial datasets. The search is conducted for any combination of public IDs contained in your tabular dataset: IP, date, etc. Only features that could improve the prediction power of your ML model are returned.
Developers said that they wanted radically simplify data search and delivery for ML pipelines to make external data & features a standard approach. Like a hyperparameter tuning for machine learning nowadays.
A Free 30-days trial is available.
GitHub: https://github.com/upgini/upgini
Web: https://upgini.com
GitHub
GitHub - upgini/upgini: Data search & enrichment library for Machine Learning → Easily find and add relevant features to your ML…
Data search & enrichment library for Machine Learning → Easily find and add relevant features to your ML & AI pipeline from hundreds of public and premium external data sources, inc...
👍5❤1
Forwarded from Silero News (Alexander)
New V3 Silero VAD is Already Here
Main changes
- One VAD to rule them all!
- New model includes the functionality of all of the previous ones with improved quality and speed!
- As far as we know, our VAD is the best in the world now;
- Flexible sampling rate, 8000 Hz and 16000 Hz are supported;
- Flexible chunk size, minimum chunk size is just 30 milliseconds!
- Only 100k parameters;
- GPU inference and batching are supported (the model is small, so we decided not to publish a quantized model);
- Radically, drastically simplified examples;
We also drastically polished and simplified README, wiki and repo in general.
Links:
- Silero VAD repo - https://github.com/snakers4/silero-vad
- The migration to V3 is quite simple, here are some examples
- Quality metrics
- Performance metrics
- Examples and dependencies
- Colab with examples
If you like Silero VAD, please give us a ⭐️ and spread the news!
Main changes
- One VAD to rule them all!
- New model includes the functionality of all of the previous ones with improved quality and speed!
- As far as we know, our VAD is the best in the world now;
- Flexible sampling rate, 8000 Hz and 16000 Hz are supported;
- Flexible chunk size, minimum chunk size is just 30 milliseconds!
- Only 100k parameters;
- GPU inference and batching are supported (the model is small, so we decided not to publish a quantized model);
- Radically, drastically simplified examples;
We also drastically polished and simplified README, wiki and repo in general.
Links:
- Silero VAD repo - https://github.com/snakers4/silero-vad
- The migration to V3 is quite simple, here are some examples
- Quality metrics
- Performance metrics
- Examples and dependencies
- Colab with examples
If you like Silero VAD, please give us a ⭐️ and spread the news!
GitHub
GitHub - snakers4/silero-vad: Silero VAD: pre-trained enterprise-grade Voice Activity Detector
Silero VAD: pre-trained enterprise-grade Voice Activity Detector - snakers4/silero-vad
👍1
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
This paper presents a new participatory Python-based natural language augmentation framework that supports the creation of transformations (modifications to the data) and filters (data splits according to specific features).
The current version of the framework contains 117 transformations and 23 filters for a variety of natural language tasks.
The authors demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models.
Paper: https://arxiv.org/abs/2112.02721
Code: https://github.com/GEM-benchmark/NL-Augmenter
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-nlaugmenter
#deeplearning #nlp #augmentation #robustness
This paper presents a new participatory Python-based natural language augmentation framework that supports the creation of transformations (modifications to the data) and filters (data splits according to specific features).
The current version of the framework contains 117 transformations and 23 filters for a variety of natural language tasks.
The authors demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models.
Paper: https://arxiv.org/abs/2112.02721
Code: https://github.com/GEM-benchmark/NL-Augmenter
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-nlaugmenter
#deeplearning #nlp #augmentation #robustness
{kind=link}
👍2
Forwarded from Жёлтый AI
We continue to conquer the time series together with ETNA! Using our library, we built a model to predict the number of new 🦠COVID-19 cases in different countries. You can see the results we got in our recent article on 📖 Medium: Forecasting with ETNA - Fast and Furious. The article also shows in detail what a typical forecasting pipeline looks like and how you can quickly get a good baseline for a specific dataset. For all questions and suggestions - welcome to ETNA Community in Telegram. For all news related to AI/ML at Tinkoff — stay tuned to this channel.
👍8🔥3❤2
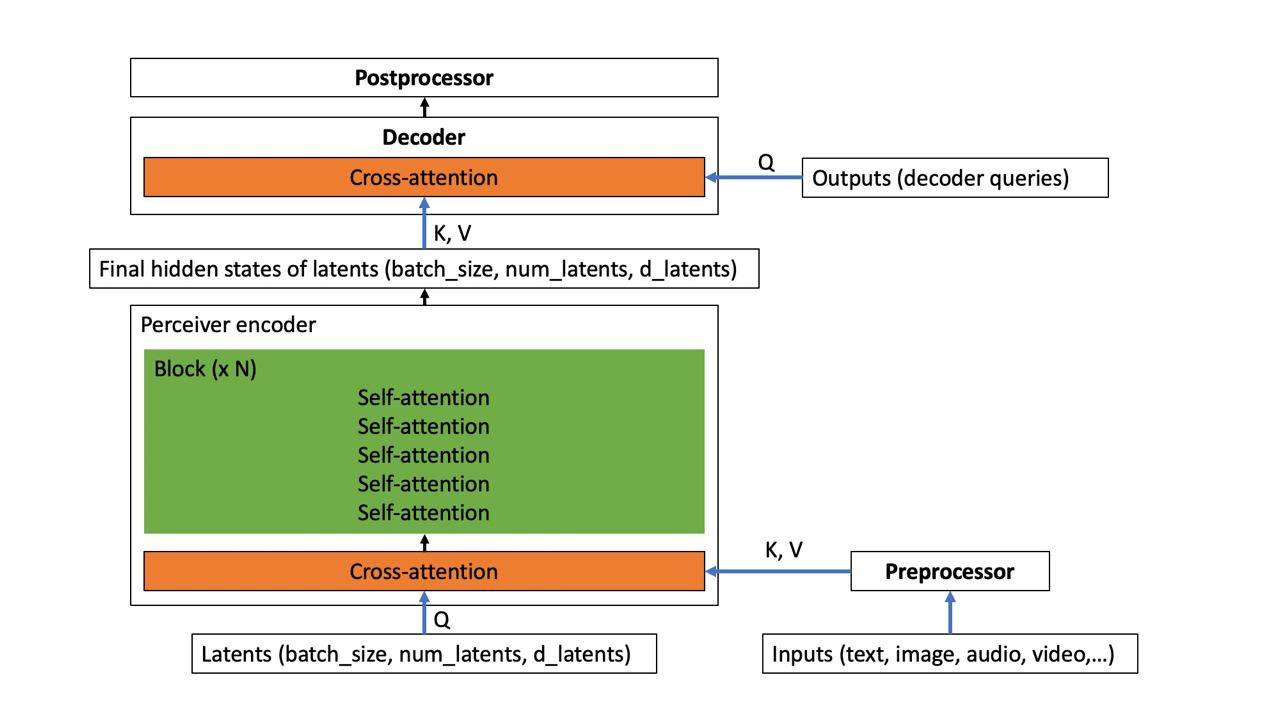
Perceiver IO: a scalable, fully-attentional model that works on any modality
#HuggingFace added neural network which is capable of working on all kinds of modailities: text, images, audio, video, coordinates, etc to the transformers library.
Blog: https://huggingface.co/blog/perceiver
#HuggingFace added neural network which is capable of working on all kinds of modailities: text, images, audio, video, coordinates, etc to the transformers library.
Blog: https://huggingface.co/blog/perceiver
{kind=link}
👍4❤1🔥1🤔1
All the reactions had been enabled for @opendatascience
🔥110👍29🎉29💩17❤9🤩7😢6😁4😱4🤮4👎3
We got lot's of fine messages and feedback, let's discuss most notable papers and news of 2021 to assemble Community 2021 WrapUp in our chat:
https://t.iss.one/datascience_chat
https://t.iss.one/datascience_chat
Telegram
Data Chat
By ODS.ai
2021 WrapUps and Summaries
Those are two technical posts summarizing the progress which were published during 2021.
Papers with Code 2021 : A Year in Review post by Papers with Code
Medium: https://medium.com/paperswithcode/papers-with-code-2021-a-year-in-review-de75d5a77b8b
Post on KDNuggers
Post: https://www.kdnuggets.com/2021/12/2021-year-review-amazing-ai-papers.html
#summary
Those are two technical posts summarizing the progress which were published during 2021.
Papers with Code 2021 : A Year in Review post by Papers with Code
Medium: https://medium.com/paperswithcode/papers-with-code-2021-a-year-in-review-de75d5a77b8b
Post on KDNuggers
Post: https://www.kdnuggets.com/2021/12/2021-year-review-amazing-ai-papers.html
#summary
Medium
Papers with Code 2021 : A Year in Review
Papers with Code indexes various machine learning artifacts — papers, code, results — to facilitate discovery and comparison. Using this…
👍11🔥2🤩2
The Illustrated Retrieval Transformer
by @jayalammar
The latest batch of language models can be much smaller yet achieve GPT-3 like performance by being able to query a database or search the web for information. A key indication is that building larger and larger models is not the only way to improve performance.
https://jalammar.github.io/illustrated-retrieval-transformer/
#nlp #gpt3 #retro #deepmind
by @jayalammar
The latest batch of language models can be much smaller yet achieve GPT-3 like performance by being able to query a database or search the web for information. A key indication is that building larger and larger models is not the only way to improve performance.
https://jalammar.github.io/illustrated-retrieval-transformer/
#nlp #gpt3 #retro #deepmind
🔥16👍14❤2🤩1
🦜 Hi!
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.iss.one/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.iss.one/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
GitHub
ultimate_posts/where_to_start at master · open-data-science/ultimate_posts
Ultimate posts for opendatascience telegram channel - open-data-science/ultimate_posts
👍56🔥15❤7🥰2😁2🎉2⚡1👎1👏1
Data Science by ODS.ai 🦜 pinned «🦜 Hi! We are the first Telegram Data Science channel. Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent…»
Highly accurate protein structure prediction with AlphaFold
Anna Potapenko @DeepMind
Predicting a protein’s structure from its primary sequence has been a grand challenge in biology for the past 50 years, holding the promise to bridge the gap between the pace of genomics discovery and resulting structural characterization. In this talk, we will describe work at DeepMind to develop AlphaFold, a new deep learning-based system for structure prediction that achieves high accuracy across a wide range of targets. We demonstrated our system in the 14th biennial Critical Assessment of Protein Structure Prediction (CASP14) across a wide range of difficult targets, where the assessors judged our predictions to be at an accuracy “competitive with experiment” for approximately 2/3rds of proteins. The talk will cover both the underlying machine learning ideas and the implications for biological research.
https://youtu.be/oD34Q1qeMII
Anna Potapenko @DeepMind
Predicting a protein’s structure from its primary sequence has been a grand challenge in biology for the past 50 years, holding the promise to bridge the gap between the pace of genomics discovery and resulting structural characterization. In this talk, we will describe work at DeepMind to develop AlphaFold, a new deep learning-based system for structure prediction that achieves high accuracy across a wide range of targets. We demonstrated our system in the 14th biennial Critical Assessment of Protein Structure Prediction (CASP14) across a wide range of difficult targets, where the assessors judged our predictions to be at an accuracy “competitive with experiment” for approximately 2/3rds of proteins. The talk will cover both the underlying machine learning ideas and the implications for biological research.
https://youtu.be/oD34Q1qeMII
YouTube
[Colloquium] Highly accurate protein structure prediction with AlphaFold
Predicting a protein’s structure from its primary sequence has been a grand challenge in biology for the past 50 years, holding the promise to bridge the gap between the pace of genomics discovery and resulting structural characterization. In this talk, we…
👍30🔥12🎉5❤1
Forwarded from Code Mining
Using public datasets in commercial software
Great paper:
An extremely important question for the Data Science community: it turns out (wat?) that not all publicly available datasets can be used to build commercial solutions 💣💣💣.
Authors examine license agreements of 6 popular datasets used in Computer Vision (CIFAR-10, ImageNet, Cityscapes, FFHQ, VGGFaces2 and MS COCO) and conclude that the models trained on these data can not be commercialized at least.
An example of the results of the CIFAR-10 dataset's license analysis is shown in the screenshot.
It was logical to assume this, but for many community members this may be the opening of the century.
Prepared by @codemining for ods.ai. Subscribe!
Great paper:
Can I use this publicly available dataset to build commercial AI software? Most likely not.An extremely important question for the Data Science community: it turns out (wat?) that not all publicly available datasets can be used to build commercial solutions 💣💣💣.
Authors examine license agreements of 6 popular datasets used in Computer Vision (CIFAR-10, ImageNet, Cityscapes, FFHQ, VGGFaces2 and MS COCO) and conclude that the models trained on these data can not be commercialized at least.
An example of the results of the CIFAR-10 dataset's license analysis is shown in the screenshot.
It was logical to assume this, but for many community members this may be the opening of the century.
Prepared by @codemining for ods.ai. Subscribe!
👍30🔥7
There had been less posts than usual as you might have noticed, only because editor-in-chief's (mine) attention been directed to DeFi space in general and NFT in particular.
However once involved with the beauty of AI and art, one can't just exit it, so I've been working on an NFT-collection drop as an exercise to study the field. Because as Feynman taught us 'What I cannot create, I do not understand'.
After getting some early results with #StyleGAN2 I realised that I need to study how drop mechanics and everything else works and asked a very talented friend to help me with generating the art for the collection. On my humble scale, he is top 0.1% researcher in the field (though he might argue with that, or you might, but let's wait for his scientific papers published here to judge on that), so I was sure that the art will be dope.
And it was so great we decided to make a real NFT drop instead of purely experimental one. Soon we will publish all the intersting technical details on the architecture and approache we used to generate beautiful toadz. So stay tuned for the post on how to generate astonishing art and subsribe to the collection twitter not to miss any details.
Twitter: https://twitter.com/toadverseNFT
However once involved with the beauty of AI and art, one can't just exit it, so I've been working on an NFT-collection drop as an exercise to study the field. Because as Feynman taught us 'What I cannot create, I do not understand'.
After getting some early results with #StyleGAN2 I realised that I need to study how drop mechanics and everything else works and asked a very talented friend to help me with generating the art for the collection. On my humble scale, he is top 0.1% researcher in the field (though he might argue with that, or you might, but let's wait for his scientific papers published here to judge on that), so I was sure that the art will be dope.
And it was so great we decided to make a real NFT drop instead of purely experimental one. Soon we will publish all the intersting technical details on the architecture and approache we used to generate beautiful toadz. So stay tuned for the post on how to generate astonishing art and subsribe to the collection twitter not to miss any details.
Twitter: https://twitter.com/toadverseNFT
👍26🔥8😁1🤔1
Scholarships in UAE
MBZUAI in Abu Dhabi is a modern and innovative university in Artificial Intelligence. All admitted candidates are granted a full scholarship, which includes: tuition fee, accommodation, health insurance, round air transportation. Additionally students get a monthly stipend of 8,000 DH (USD $2200) for MSc and 10,000 DH (USD $2700) for PhD.
So, if you are interested, welcome to join MBZUAI info session with current MBZUAI students from Ukraine and Kazakhstan: Friday, Jan 21 at 5pm Moscow time / 4pm of Kyiv time. (Session is today)
MBZUAI website: https://mbzuai.ac.ae/
Info session Zoom: https://tinyurl.com/MBZUAI-Ukraine
MBZUAI in Abu Dhabi is a modern and innovative university in Artificial Intelligence. All admitted candidates are granted a full scholarship, which includes: tuition fee, accommodation, health insurance, round air transportation. Additionally students get a monthly stipend of 8,000 DH (USD $2200) for MSc and 10,000 DH (USD $2700) for PhD.
So, if you are interested, welcome to join MBZUAI info session with current MBZUAI students from Ukraine and Kazakhstan: Friday, Jan 21 at 5pm Moscow time / 4pm of Kyiv time. (Session is today)
MBZUAI website: https://mbzuai.ac.ae/
Info session Zoom: https://tinyurl.com/MBZUAI-Ukraine
👍10
what we know about the beginning of february
* alpha-code -- a system that can compete at average human level in competitive coding competitions like codeforces. an exciting leap in ai problem-solving capabilities, combining many advances in machine learning
link: https://deepmind.com/blog/article/Competitive-programming-with-AlphaCode
* solving some formal mathematics statement curriculum learning -- neural network that solved two problems from the international math olympiad
link: https://openai.com/blog/formal-math/
* "hyperdetailed render of my bizarro acid trip, detailed architectural render. I can't believe how detailed this is"
link: https://twitter.com/Somnai_dreams/status/1489108710962384896
* alpha-code -- a system that can compete at average human level in competitive coding competitions like codeforces. an exciting leap in ai problem-solving capabilities, combining many advances in machine learning
link: https://deepmind.com/blog/article/Competitive-programming-with-AlphaCode
* solving some formal mathematics statement curriculum learning -- neural network that solved two problems from the international math olympiad
link: https://openai.com/blog/formal-math/
* "hyperdetailed render of my bizarro acid trip, detailed architectural render. I can't believe how detailed this is"
link: https://twitter.com/Somnai_dreams/status/1489108710962384896
🔥16👍7🤔1🤯1