
🔥Alias-Free Generative Adversarial Networks (StyleGAN3) release
King is dead! Long live the King! #StyleGAN2 was #SOTA and default standard for generating images. #Nvidia released update version, which will lead to more realistic images generated by the community.
Article: https://nvlabs.github.io/stylegan3/
GitHub: https://github.com/NVlabs/stylegan3
Colab: https://colab.research.google.com/drive/1BXNHZBai-pXtP-ncliouXo_kUiG1Pq7M
#GAN #dl
King is dead! Long live the King! #StyleGAN2 was #SOTA and default standard for generating images. #Nvidia released update version, which will lead to more realistic images generated by the community.
Article: https://nvlabs.github.io/stylegan3/
GitHub: https://github.com/NVlabs/stylegan3
Colab: https://colab.research.google.com/drive/1BXNHZBai-pXtP-ncliouXo_kUiG1Pq7M
#GAN #dl
Dear advertisers, who spammed @opendatasciencebot, you are kindly welcome to advertise on this channel for 1 ETH (~ $4,300).
This might seem unreasonable overpriced, but don’t fall for it — it is. We do not promote anything we won’t post here for free, because we are privileged and blessed to work on the sphere with :goodenough: compensation to put up a higher price tag on it.
😌
This might seem unreasonable overpriced, but don’t fall for it — it is. We do not promote anything we won’t post here for free, because we are privileged and blessed to work on the sphere with :goodenough: compensation to put up a higher price tag on it.
😌
👍2❤1
Forwarded from Gradient Dude
On Neural Rendering
What is Neural Rendering? In a nutshell, neural rendering is when we take classic algorithms for image rendering from computer graphics and replace a part of the pipeline with neural networks (stupid, but effective). Neural rendering learns to render and represent a scene from one or more input photos by simulating the physical process of a camera that captures the scene. A key property of 3D neural rendering is the disentanglement of the camera capturing process (i.e., the projection and image formation) and the representation of a 3D scene during training. That is, we learn an explicit (voxels, point clouds, parametric surfaces) or an implicit (signed distance function) representation of a 3D scene. For training, we use observations of the scene from several camera viewpoints. The network is trained on these observations by rendering the estimated 3D scene from the training viewpoints, and minimizing the difference between the rendered and observed images. This learned scene representation can be rendered from any virtual camera in order to synthesize novel views. It is important for learning that the entire rendering pipeline is differentiable.
You may have noticed, that the topic of neural rendering, including all sorts of nerfs-schmerfs, is now a big hype in computer vision. You might say that neural rendering is very slow, and you'd be right. A typical training session on a small scene with ~ 50 input photos takes about 5.5 hours for the fastest method on a single GPU, but neural rendering methods have made significant progress in the last year improving both fidelity and efficiency. To catch up on all the recent developments in this direction, I highly recommend reading this SOTA report "Advances in Neural Rendering".
The gif is from Volume Rendering of Neural Implicit Surfaces paper.
What is Neural Rendering? In a nutshell, neural rendering is when we take classic algorithms for image rendering from computer graphics and replace a part of the pipeline with neural networks (stupid, but effective). Neural rendering learns to render and represent a scene from one or more input photos by simulating the physical process of a camera that captures the scene. A key property of 3D neural rendering is the disentanglement of the camera capturing process (i.e., the projection and image formation) and the representation of a 3D scene during training. That is, we learn an explicit (voxels, point clouds, parametric surfaces) or an implicit (signed distance function) representation of a 3D scene. For training, we use observations of the scene from several camera viewpoints. The network is trained on these observations by rendering the estimated 3D scene from the training viewpoints, and minimizing the difference between the rendered and observed images. This learned scene representation can be rendered from any virtual camera in order to synthesize novel views. It is important for learning that the entire rendering pipeline is differentiable.
You may have noticed, that the topic of neural rendering, including all sorts of nerfs-schmerfs, is now a big hype in computer vision. You might say that neural rendering is very slow, and you'd be right. A typical training session on a small scene with ~ 50 input photos takes about 5.5 hours for the fastest method on a single GPU, but neural rendering methods have made significant progress in the last year improving both fidelity and efficiency. To catch up on all the recent developments in this direction, I highly recommend reading this SOTA report "Advances in Neural Rendering".
The gif is from Volume Rendering of Neural Implicit Surfaces paper.
👍3
READ//ABLE NLP competition(s)
Registration for the technology contests – Satellites is open.
These contests are made for a wide range of junior developers interested in natural language processing (NLP).
Contests-satellites held in a separate from the main competition READ//ABLE schedule.
The contests are series of competitions of text analysis, so the participating teams will be able to use the results of developments as a basis for participating in the main competition.
Fund: ~ 14,000 USD per sub-competition
Deadline: December 1 here
Link: https://ai.upgreat.one/satellites/
#NLP #contest
Registration for the technology contests – Satellites is open.
These contests are made for a wide range of junior developers interested in natural language processing (NLP).
Contests-satellites held in a separate from the main competition READ//ABLE schedule.
The contests are series of competitions of text analysis, so the participating teams will be able to use the results of developments as a basis for participating in the main competition.
Fund: ~ 14,000 USD per sub-competition
Deadline: December 1 here
Link: https://ai.upgreat.one/satellites/
#NLP #contest
ai.upgreat.one
ПРО//ЧТЕНИЕ - Технологический конкурс UP GREAT :: Лидерборд
Разработка интеллектуальной системы для выявления смысловых и фактических ошибок в текстах.
👍2🔥1
Forwarded from Machinelearning
🧊 GANformer: Generative Adversarial Transformers
Github: https://github.com/pengzhiliang/MAE-pytorch
Paper: https://arxiv.org/abs/2111.08960
Dataset: https://paperswithcode.com/dataset/coco
@ai_machinelearning_big_data
Github: https://github.com/pengzhiliang/MAE-pytorch
Paper: https://arxiv.org/abs/2111.08960
Dataset: https://paperswithcode.com/dataset/coco
@ai_machinelearning_big_data
👍1
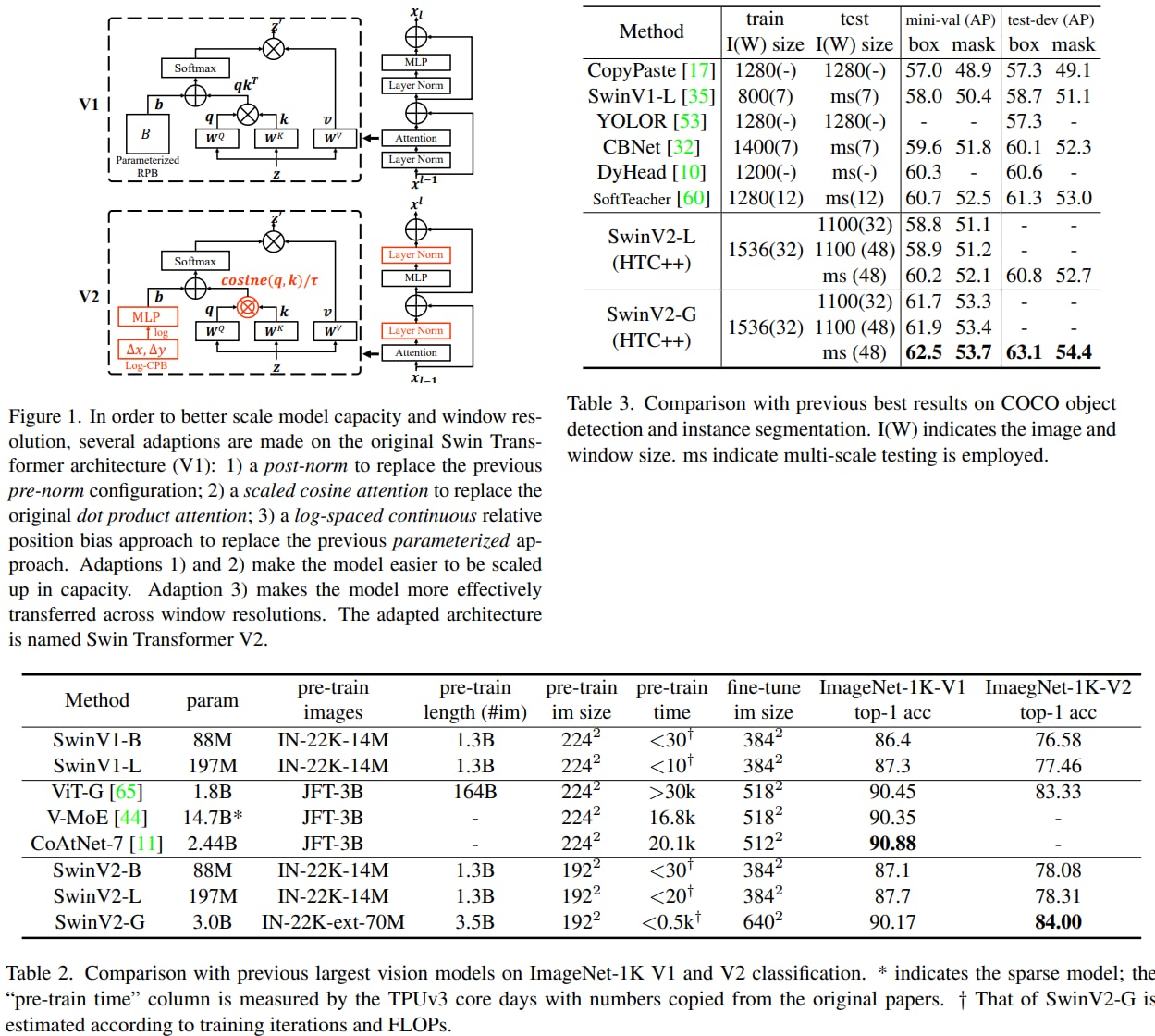
Swin Transformer V2: Scaling Up Capacity and Resolution
The authors present techniques for scaling Swin Transformer up to 3 billion parameters and making it capable of training with images of up to 1,536×1,536 resolution.
Vision models have the following difficulties when trying to scale them up: instability issues at scale, high GPU memory consumption for high-resolution images, and the fact that downstream tasks usually require high-resolution images/windows, while the models are pretrained on lower resolutions and the transfer isn't always efficient.
The authors introduce the following technics to circumvent those problems:
- a post normalization technique and a scaled cosine attention approach to improve the stability of large vision models;
- a log-spaced continuous position bias technique to effectively transfer models pre-trained at low-resolution images and windows to their higher-resolution counterparts;
In addition, they share how they were able to decrease GPU consumption significantly.
Swin Transformer V2 sets new records on four representative vision benchmarks: 84.0% top-1 accuracy on ImageNet-V2 image classification, 63.1 / 54.4 box / mask mAP on COCO object detection, 59.9 mIoU on ADE20K semantic segmentation, and 86.8% top-1 accuracy on Kinetics-400 video action classification.
Paper: https://arxiv.org/abs/2111.09883
Code: https://github.com/microsoft/Swin-Transformer
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-swin-v2
#deeplearning #cv #transformer
The authors present techniques for scaling Swin Transformer up to 3 billion parameters and making it capable of training with images of up to 1,536×1,536 resolution.
Vision models have the following difficulties when trying to scale them up: instability issues at scale, high GPU memory consumption for high-resolution images, and the fact that downstream tasks usually require high-resolution images/windows, while the models are pretrained on lower resolutions and the transfer isn't always efficient.
The authors introduce the following technics to circumvent those problems:
- a post normalization technique and a scaled cosine attention approach to improve the stability of large vision models;
- a log-spaced continuous position bias technique to effectively transfer models pre-trained at low-resolution images and windows to their higher-resolution counterparts;
In addition, they share how they were able to decrease GPU consumption significantly.
Swin Transformer V2 sets new records on four representative vision benchmarks: 84.0% top-1 accuracy on ImageNet-V2 image classification, 63.1 / 54.4 box / mask mAP on COCO object detection, 59.9 mIoU on ADE20K semantic segmentation, and 86.8% top-1 accuracy on Kinetics-400 video action classification.
Paper: https://arxiv.org/abs/2111.09883
Code: https://github.com/microsoft/Swin-Transformer
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-swin-v2
#deeplearning #cv #transformer
{kind=link}
👍3
Acquisition of Chess Knowledge in AlphaZero
69-pages paper of analysis how #AlphaZero plays chess. TLDR: lots of concepts self-learned by neural network can be mapped to human concepts.
This means that generally speaking we can train neural networks to do some task and then learn something from them. Opposite is also true: we might imagine teaching neural networks some human concepts in order to maek them more efficient.
Post: https://en.chessbase.com/post/acquisition-of-chess-knowledge-in-alphazero
Paper: https://arxiv.org/pdf/2111.09259.pdf
#RL
69-pages paper of analysis how #AlphaZero plays chess. TLDR: lots of concepts self-learned by neural network can be mapped to human concepts.
This means that generally speaking we can train neural networks to do some task and then learn something from them. Opposite is also true: we might imagine teaching neural networks some human concepts in order to maek them more efficient.
Post: https://en.chessbase.com/post/acquisition-of-chess-knowledge-in-alphazero
Paper: https://arxiv.org/pdf/2111.09259.pdf
#RL
Chess News
Acquisition of Chess Knowledge in AlphaZero
Researchers at DeepMind and Google Brain, in collaboration with Grandmaster Vladimir Kramnik, are working to explore what chess can teach us about AI and vice versa. Using Chessbase’s extensive historical chess data along with the AlphaZero neural network…
👍3💩1
Augmented Reality for Haptic Teleoperation of a Robot with an Event-Based Soft Tactile Sensor
This paper presents a new teleoperation approach using an augmented reality-based interface combined with optimized haptic feedback to finely manipulate visually occluded objects.
The dynamic growth of emerging Augmented Reality (AR) interfaces has a high potential interest in robotic telemanipulation of objects under limited visibility conditions. On the user’s horizon, the real-world environment is overlayed by the virtual images of the robot end-effector and the object. To optimize the user experience in teleoperation, the visual augmentation is accompanied by a haptic stimulus. They both transmit the rendered signal of the contact force visually and haptically, respectively. The contact force is measured by an optical event-based tactile sensor (E-BTS) with a soft pad, vibrotactile stimuli are generated by the hand-held device (HHD) and the AR is projected in the head-mounted device (HMD).
Authors demonstrated experimentally their approach on teleoperated robot arm puncturing an occluded non-rigid membrane placed in vertical raw with similar membranes. A comparative study with 10 subjects has been carried out to quantify the impact of AR in a force control task with a human in the control loop. The results of the experiment show a promising potential application in the cable insertion in an industrial assembly task.
Video: YouTube
#AR
This paper presents a new teleoperation approach using an augmented reality-based interface combined with optimized haptic feedback to finely manipulate visually occluded objects.
The dynamic growth of emerging Augmented Reality (AR) interfaces has a high potential interest in robotic telemanipulation of objects under limited visibility conditions. On the user’s horizon, the real-world environment is overlayed by the virtual images of the robot end-effector and the object. To optimize the user experience in teleoperation, the visual augmentation is accompanied by a haptic stimulus. They both transmit the rendered signal of the contact force visually and haptically, respectively. The contact force is measured by an optical event-based tactile sensor (E-BTS) with a soft pad, vibrotactile stimuli are generated by the hand-held device (HHD) and the AR is projected in the head-mounted device (HMD).
Authors demonstrated experimentally their approach on teleoperated robot arm puncturing an occluded non-rigid membrane placed in vertical raw with similar membranes. A comparative study with 10 subjects has been carried out to quantify the impact of AR in a force control task with a human in the control loop. The results of the experiment show a promising potential application in the cable insertion in an industrial assembly task.
Video: YouTube
#AR
YouTube
Augmented Reality and Haptic Teleoperation submitted to RA-L, 2021
👍3
NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion
In this paper, Microsoft Research Asia and Peking University researchers share a unified multimodal (texts, images, videos, sketches) pre-trained model called NÜWA that can generate new or manipulate existing visual data for various visual synthesis tasks. Furthermore, they have designed a 3D transformer encoder-decoder framework with a 3D Nearby Attention (3DNA) mechanism to consider the nature of the visual data and reduce the computational complexity.
NÜWA achieves state-of-the-art results on text-to-image generation, text-to-video generation, video prediction, and several other tasks and demonstrates good results on zero-shot text-guided image and video manipulation tasks.
Paper: https://arxiv.org/abs/2111.12417
Code: https://github.com/microsoft/NUWA
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-nuwa
#deeplearning #cv #transformer #pretraining
In this paper, Microsoft Research Asia and Peking University researchers share a unified multimodal (texts, images, videos, sketches) pre-trained model called NÜWA that can generate new or manipulate existing visual data for various visual synthesis tasks. Furthermore, they have designed a 3D transformer encoder-decoder framework with a 3D Nearby Attention (3DNA) mechanism to consider the nature of the visual data and reduce the computational complexity.
NÜWA achieves state-of-the-art results on text-to-image generation, text-to-video generation, video prediction, and several other tasks and demonstrates good results on zero-shot text-guided image and video manipulation tasks.
Paper: https://arxiv.org/abs/2111.12417
Code: https://github.com/microsoft/NUWA
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-nuwa
#deeplearning #cv #transformer #pretraining
{kind=link}
👍2
Forwarded from Machinelearning
📹 End-to-End Referring Video Object Segmentation with Multimodal Transformers
Github: https://github.com/mttr2021/MTTR
Paper: https://arxiv.org/abs/2111.14821v1
Dataset: https://kgavrilyuk.github.io/publication/actor_action/
@ai_machinelearning_big_data
Github: https://github.com/mttr2021/MTTR
Paper: https://arxiv.org/abs/2111.14821v1
Dataset: https://kgavrilyuk.github.io/publication/actor_action/
@ai_machinelearning_big_data
YaTalks — Yandex's conference for IT community.
Yandex will host its traditional conference on 3-4 December (starting tomorrow). Registration is open.
One of the tracks is devoted to Machine/Deep Learning with the focus on content generation.
Featured reports:
📚How too train text model on the minimal corpus
🎙️How Yandex.Browser Machine Translation works
🤖 Facial Expressions Animation
Conference website: https://yatalks.yandex.ru/?from=tg_opendatascience
#conference #mt #nlu
Yandex will host its traditional conference on 3-4 December (starting tomorrow). Registration is open.
One of the tracks is devoted to Machine/Deep Learning with the focus on content generation.
Featured reports:
📚How too train text model on the minimal corpus
🎙️How Yandex.Browser Machine Translation works
🤖 Facial Expressions Animation
Conference website: https://yatalks.yandex.ru/?from=tg_opendatascience
#conference #mt #nlu
yatalks.yandex.ru
YaTalks 2023 — Yandex's premier conference for the IT community
On December 5-6, Moscow and Belgrade will host over 100 IT industry experts and scientists delivering technical presentations on development, ML, and giving popular science lectures.
👍5
Forwarded from Big Data Science
Visual Genome: the most labeled dataset
👁Scientists at Stanford University have collected the most annotated dataset with over 100,000 images. In total, the dataset contains almost 5.5 million object descriptions, attributes and relationships. You don't even have to download the dataset, but get the data you need by accessing the RESTful API endpoint using the GET-method. Despite the fact that the latest updates to the dataset are dated 2017, this is an excellent data set for training models in typical ML problems, from recognizing generated data using graph algorithms.
https://visualgenome.org/api/v0/api_home.html
👁Scientists at Stanford University have collected the most annotated dataset with over 100,000 images. In total, the dataset contains almost 5.5 million object descriptions, attributes and relationships. You don't even have to download the dataset, but get the data you need by accessing the RESTful API endpoint using the GET-method. Despite the fact that the latest updates to the dataset are dated 2017, this is an excellent data set for training models in typical ML problems, from recognizing generated data using graph algorithms.
https://visualgenome.org/api/v0/api_home.html
EditGAN: High-Precision Semantic Image Editing
Nvidia researches built an approach for editing segments of a picture with supposedly realtime picture augmentation according to the segment alterations. No demo is available yet though.
All the photoshop power users should relax, because appereance of such a tools means less work for them, not that the demand for the manual retouch will cease.
Website: https://nv-tlabs.github.io/editGAN/
ArXiV: https://arxiv.org/abs/2111.03186
#GAN #Nvidia
Nvidia researches built an approach for editing segments of a picture with supposedly realtime picture augmentation according to the segment alterations. No demo is available yet though.
All the photoshop power users should relax, because appereance of such a tools means less work for them, not that the demand for the manual retouch will cease.
Website: https://nv-tlabs.github.io/editGAN/
ArXiV: https://arxiv.org/abs/2111.03186
#GAN #Nvidia
👍3👎1🔥1
Upgini — dataset search automation library
Upgini is a new python library for an automated useful dataset search to boost supervised ML tasks
It enriches your dataset with intelligently crafted features from a broad range of curated data sources, including open and commercial datasets. The search is conducted for any combination of public IDs contained in your tabular dataset: IP, date, etc. Only features that could improve the prediction power of your ML model are returned.
Developers said that they wanted radically simplify data search and delivery for ML pipelines to make external data & features a standard approach. Like a hyperparameter tuning for machine learning nowadays.
A Free 30-days trial is available.
GitHub: https://github.com/upgini/upgini
Web: https://upgini.com
Upgini is a new python library for an automated useful dataset search to boost supervised ML tasks
It enriches your dataset with intelligently crafted features from a broad range of curated data sources, including open and commercial datasets. The search is conducted for any combination of public IDs contained in your tabular dataset: IP, date, etc. Only features that could improve the prediction power of your ML model are returned.
Developers said that they wanted radically simplify data search and delivery for ML pipelines to make external data & features a standard approach. Like a hyperparameter tuning for machine learning nowadays.
A Free 30-days trial is available.
GitHub: https://github.com/upgini/upgini
Web: https://upgini.com
GitHub
GitHub - upgini/upgini: Data search & enrichment library for Machine Learning → Easily find and add relevant features to your ML…
Data search & enrichment library for Machine Learning → Easily find and add relevant features to your ML & AI pipeline from hundreds of public and premium external data sources, inc...
👍5❤1
Forwarded from Silero News (Alexander)
New V3 Silero VAD is Already Here
Main changes
- One VAD to rule them all!
- New model includes the functionality of all of the previous ones with improved quality and speed!
- As far as we know, our VAD is the best in the world now;
- Flexible sampling rate, 8000 Hz and 16000 Hz are supported;
- Flexible chunk size, minimum chunk size is just 30 milliseconds!
- Only 100k parameters;
- GPU inference and batching are supported (the model is small, so we decided not to publish a quantized model);
- Radically, drastically simplified examples;
We also drastically polished and simplified README, wiki and repo in general.
Links:
- Silero VAD repo - https://github.com/snakers4/silero-vad
- The migration to V3 is quite simple, here are some examples
- Quality metrics
- Performance metrics
- Examples and dependencies
- Colab with examples
If you like Silero VAD, please give us a ⭐️ and spread the news!
Main changes
- One VAD to rule them all!
- New model includes the functionality of all of the previous ones with improved quality and speed!
- As far as we know, our VAD is the best in the world now;
- Flexible sampling rate, 8000 Hz and 16000 Hz are supported;
- Flexible chunk size, minimum chunk size is just 30 milliseconds!
- Only 100k parameters;
- GPU inference and batching are supported (the model is small, so we decided not to publish a quantized model);
- Radically, drastically simplified examples;
We also drastically polished and simplified README, wiki and repo in general.
Links:
- Silero VAD repo - https://github.com/snakers4/silero-vad
- The migration to V3 is quite simple, here are some examples
- Quality metrics
- Performance metrics
- Examples and dependencies
- Colab with examples
If you like Silero VAD, please give us a ⭐️ and spread the news!
GitHub
GitHub - snakers4/silero-vad: Silero VAD: pre-trained enterprise-grade Voice Activity Detector
Silero VAD: pre-trained enterprise-grade Voice Activity Detector - snakers4/silero-vad
👍1
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
This paper presents a new participatory Python-based natural language augmentation framework that supports the creation of transformations (modifications to the data) and filters (data splits according to specific features).
The current version of the framework contains 117 transformations and 23 filters for a variety of natural language tasks.
The authors demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models.
Paper: https://arxiv.org/abs/2112.02721
Code: https://github.com/GEM-benchmark/NL-Augmenter
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-nlaugmenter
#deeplearning #nlp #augmentation #robustness
This paper presents a new participatory Python-based natural language augmentation framework that supports the creation of transformations (modifications to the data) and filters (data splits according to specific features).
The current version of the framework contains 117 transformations and 23 filters for a variety of natural language tasks.
The authors demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models.
Paper: https://arxiv.org/abs/2112.02721
Code: https://github.com/GEM-benchmark/NL-Augmenter
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-nlaugmenter
#deeplearning #nlp #augmentation #robustness
{kind=link}
👍2
Forwarded from Жёлтый AI
We continue to conquer the time series together with ETNA! Using our library, we built a model to predict the number of new 🦠COVID-19 cases in different countries. You can see the results we got in our recent article on 📖 Medium: Forecasting with ETNA - Fast and Furious. The article also shows in detail what a typical forecasting pipeline looks like and how you can quickly get a good baseline for a specific dataset. For all questions and suggestions - welcome to ETNA Community in Telegram. For all news related to AI/ML at Tinkoff — stay tuned to this channel.
👍8🔥3❤2
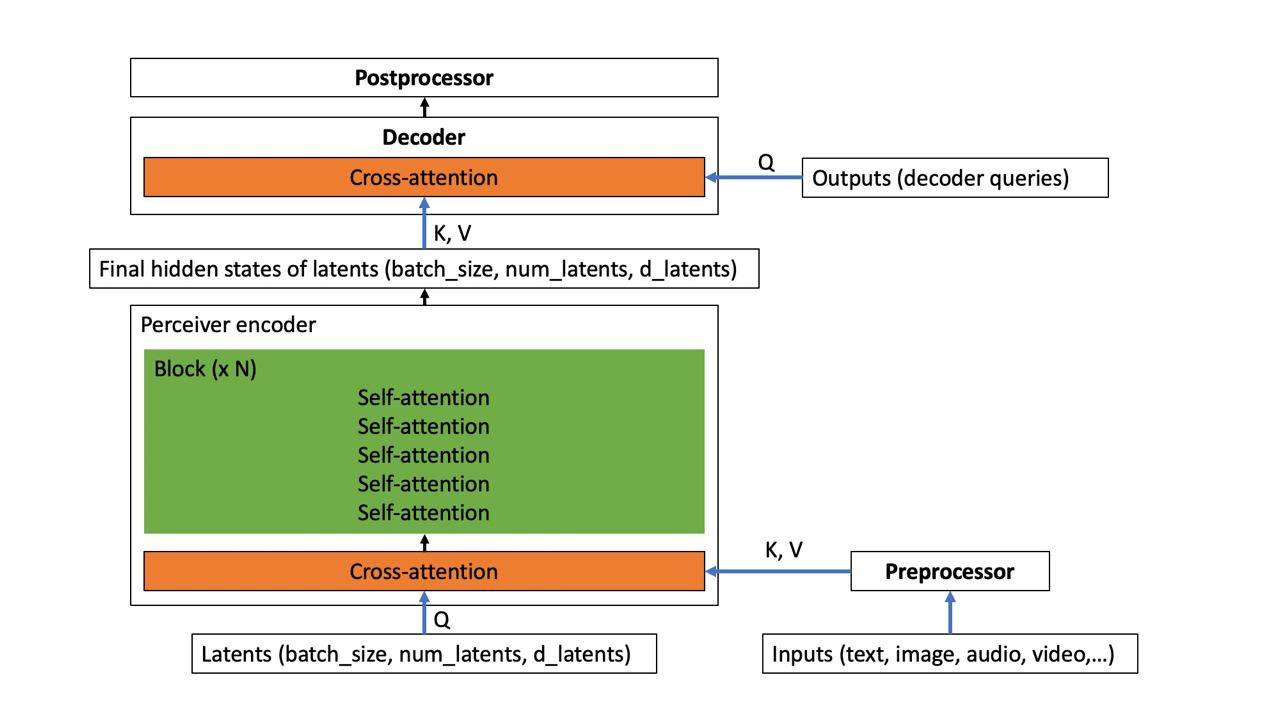
Perceiver IO: a scalable, fully-attentional model that works on any modality
#HuggingFace added neural network which is capable of working on all kinds of modailities: text, images, audio, video, coordinates, etc to the transformers library.
Blog: https://huggingface.co/blog/perceiver
#HuggingFace added neural network which is capable of working on all kinds of modailities: text, images, audio, video, coordinates, etc to the transformers library.
Blog: https://huggingface.co/blog/perceiver
{kind=link}
👍4❤1🔥1🤔1
All the reactions had been enabled for @opendatascience
🔥110👍29🎉29💩17❤9🤩7😢6😁4😱4🤮4👎3