
Politicians phone distraction tracking as an art project
Enthusiast used livestream of flemish goverment sessions to track those politicians who distracted on the phones during their worktime.
Project website: https://driesdepoorter.be/theflemishscrollers/
Twitter: https://twitter.com/FlemishScroller
#keras #neuroart #politics #ml4sg
Enthusiast used livestream of flemish goverment sessions to track those politicians who distracted on the phones during their worktime.
Project website: https://driesdepoorter.be/theflemishscrollers/
Twitter: https://twitter.com/FlemishScroller
#keras #neuroart #politics #ml4sg
{kind=link}
Mava: a scalable, research framework for multi-agent reinforcement learning
The framework integrates with popular MARL environments such as PettingZoo, SMAC, RoboCup, OpenSpiel, Flatland , as well as a few custom environments.
Mava includes distributed implementations of multi-agent versions of ddpg, d4pg, dqn, ppo, as well as DIAL, VDN and QMIX.
ArXiV: https://arxiv.org/pdf/2107.01460.pdf
GitHub: https://github.com/instadeepai/Mava
#MARL #RL #dl
The framework integrates with popular MARL environments such as PettingZoo, SMAC, RoboCup, OpenSpiel, Flatland , as well as a few custom environments.
Mava includes distributed implementations of multi-agent versions of ddpg, d4pg, dqn, ppo, as well as DIAL, VDN and QMIX.
ArXiV: https://arxiv.org/pdf/2107.01460.pdf
GitHub: https://github.com/instadeepai/Mava
#MARL #RL #dl
GitHub
GitHub - instadeepai/Mava: 🦁 A research-friendly codebase for fast experimentation of multi-agent reinforcement learning in JAX
🦁 A research-friendly codebase for fast experimentation of multi-agent reinforcement learning in JAX - instadeepai/Mava
Forwarded from Towards NLP🇺🇦
Natural Language Processing News
by Sebastian Ruder:
- Github Copilot: interesting upcoming technology that can leave you without job;
- The Perceiver: new architecture motivated by Transformer that can deal with very high-dimensional inputs;
- NL augementer: collaborative work that aims to collect all accepted transformations to NL; you still can participate and be a co-author of the paper!
and more here.
by Sebastian Ruder:
- Github Copilot: interesting upcoming technology that can leave you without job;
- The Perceiver: new architecture motivated by Transformer that can deal with very high-dimensional inputs;
- NL augementer: collaborative work that aims to collect all accepted transformations to NL; you still can participate and be a co-author of the paper!
and more here.
GitHub
GitHub Copilot
AI that builds with you
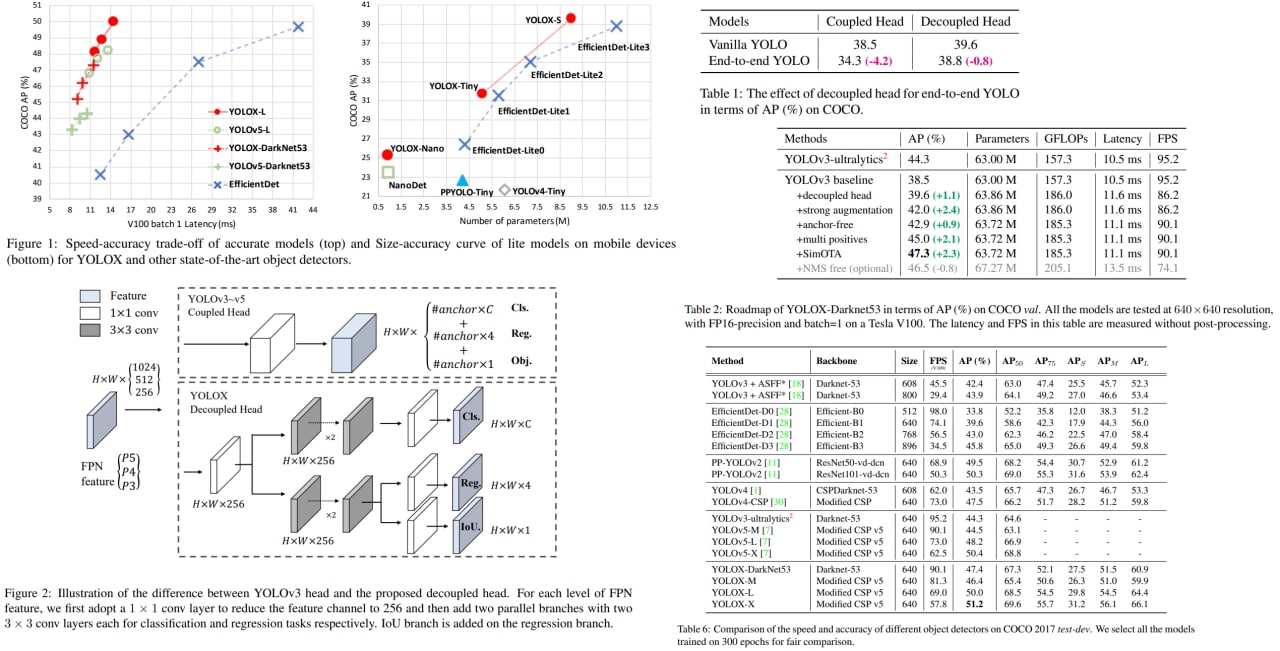
YOLOX: Exceeding YOLO Series in 2021
This paper presents a new high-performance variation of YOLO - YOLOX. Now it has an anchor-free detector, a decoupled head, and uses the leading label assignment strategy SimOTA.
Thanks to these changes, it reaches state-of-the-art results across a large scale range of models. For example, YOLOX-Nano gets 25.3% AP on COCO (+1.8% to NanoDet), YOLOX-L achieves 50.0% AP on COCO (+1.8 to YOLOv5-L).
For YOLOv3, one of the most widely used detectors in industry, they boost it to 47.3% AP on COCO, outperforming the current best practice by 3.0% AP.
The authors won the 1st Place on Streaming Perception Challenge (Workshop on Autonomous Driving at CVPR 2021) using a single YOLOX-L model.
They also provide deploy versions with ONNX, TensorRT, NCNN, and Openvino supported.
Paper: https://arxiv.org/abs/2107.08430
Code: https://github.com/Megvii-BaseDetection/YOLOX
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-yolox
#deeplearning #cv #objectdetection #endtoend #anchorfree
This paper presents a new high-performance variation of YOLO - YOLOX. Now it has an anchor-free detector, a decoupled head, and uses the leading label assignment strategy SimOTA.
Thanks to these changes, it reaches state-of-the-art results across a large scale range of models. For example, YOLOX-Nano gets 25.3% AP on COCO (+1.8% to NanoDet), YOLOX-L achieves 50.0% AP on COCO (+1.8 to YOLOv5-L).
For YOLOv3, one of the most widely used detectors in industry, they boost it to 47.3% AP on COCO, outperforming the current best practice by 3.0% AP.
The authors won the 1st Place on Streaming Perception Challenge (Workshop on Autonomous Driving at CVPR 2021) using a single YOLOX-L model.
They also provide deploy versions with ONNX, TensorRT, NCNN, and Openvino supported.
Paper: https://arxiv.org/abs/2107.08430
Code: https://github.com/Megvii-BaseDetection/YOLOX
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-yolox
#deeplearning #cv #objectdetection #endtoend #anchorfree
{kind=link}
❤1👍1
Forwarded from Gradient Dude
Researchers from NVIDIA (in particular Tero Karras) have once again "solved" image generation.
This time, the scientists were able to remove aliasing in the generator. In a nutshell, then the reason for the artifacts was careless signal processing in the CNN resulting in incorrect discretization. The signal could not be accurately reconstructed, which led to unnatural "jerks" noticeable in the video. The authors have modified the generator to prevent these negative sampling effects.
The resulting networks match the FID of StyleGAN2 but differ dramatically in their internal representations, and they are fully equivariant to translation and rotation even at subpixel scales.
The code is not available yet, but I'm sure NVIDIA will release it soon.
Read more about Alias-Free GAN here.
This time, the scientists were able to remove aliasing in the generator. In a nutshell, then the reason for the artifacts was careless signal processing in the CNN resulting in incorrect discretization. The signal could not be accurately reconstructed, which led to unnatural "jerks" noticeable in the video. The authors have modified the generator to prevent these negative sampling effects.
The resulting networks match the FID of StyleGAN2 but differ dramatically in their internal representations, and they are fully equivariant to translation and rotation even at subpixel scales.
The code is not available yet, but I'm sure NVIDIA will release it soon.
Read more about Alias-Free GAN here.
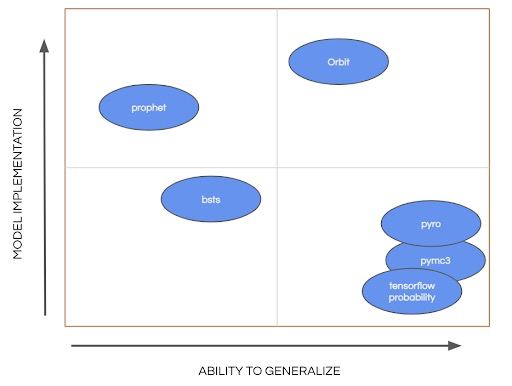
Orbit — An Open Source Package for Time Series Inference and Forecasting
Object-ORiented BayesIan Time Series is a new project for #timeseries forecasting by #Uber team. Has #scikit-learn compatible interface and claimed to have results comparable to #prophet .
Post: https://eng.uber.com/orbit/
Docs: https://uber.github.io/orbit/about.html
GitHub: https://github.com/uber/orbit/
Object-ORiented BayesIan Time Series is a new project for #timeseries forecasting by #Uber team. Has #scikit-learn compatible interface and claimed to have results comparable to #prophet .
Post: https://eng.uber.com/orbit/
Docs: https://uber.github.io/orbit/about.html
GitHub: https://github.com/uber/orbit/
{kind=link}
Forwarded from Silero News (Alexander)
New TTS Models for Minority Languages of the CIS / Russia
In collaboration with the community, we created totally unique models for the languages of the peoples of Russia / the CIS:
- Bashkir (aigul_v2)
- Kalmyk (erdni_v2)
- Tatar (dilyara_v2)
- Uzbek (dilnavoz_v2)
We also tried to create the Ukrainian voice, but the data we had (sourced from audiobooks) was not very good (all other voices were created from recordings).
Some models sound almost perfect, some a bit worse. Typically this boils down to how speakers can provide steady consistent recordings.
We used anywhere from 1 hour to 6 hours of recordings to create each voice.
These models obviously do not include automated stress and have the same major caveats as other v2 models (i.e. best used with batch size 1 on 2-4 CPU threads).
Link
- https://github.com/snakers4/silero-models#text-to-speech
In collaboration with the community, we created totally unique models for the languages of the peoples of Russia / the CIS:
- Bashkir (aigul_v2)
- Kalmyk (erdni_v2)
- Tatar (dilyara_v2)
- Uzbek (dilnavoz_v2)
We also tried to create the Ukrainian voice, but the data we had (sourced from audiobooks) was not very good (all other voices were created from recordings).
Some models sound almost perfect, some a bit worse. Typically this boils down to how speakers can provide steady consistent recordings.
We used anywhere from 1 hour to 6 hours of recordings to create each voice.
These models obviously do not include automated stress and have the same major caveats as other v2 models (i.e. best used with batch size 1 on 2-4 CPU threads).
Link
- https://github.com/snakers4/silero-models#text-to-speech
GitHub
GitHub - snakers4/silero-models: Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly…
Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly simple - snakers4/silero-models
Baidu announced opening 10k sq m park with 200 operating autonomous vehicles in China.
Source: https://twitter.com/Baidu_Inc/status/1420776376861405185
#Baidu #selfdriving
Source: https://twitter.com/Baidu_Inc/status/1420776376861405185
#Baidu #selfdriving
Tonight at 9 p.m. Moscow Time, Russia’s Krasnaya Polyana resort will host the AI & Chess meetup, bringing together data scientists and professional chess players
Location: Galaxy Mall in Krasnaya Polyana, Sochi + livestream
Program:
9-9:05 p.m.
Introductory speech.
9:05-9:25 p.m. (Rus)
Mark Glukhovsky, Executive Director of the Russian Chess Federation: “Chess and Computer Technology: What AI Is and How It Is Changing the Chess World.”
9:25-9:40 p.m. (Rus)
Conversation with Sergei Shipov, a Russian professional chess player, grandmaster, chess coach and commentator: “The Role of the Computer in Professional Chess Player Training.”
9:40-9:55 p.m. (Rus)
Aleksandr Shimanov, a Russian professional chess player, grandmaster and commentator, reviews the most incredible game from the AlphaZero vs. Stockfish match, which pitted the most powerful chess engines against each other.
9:55-10:25 p.m. (Eng)
Ulrich Paquet and Nenad Tomašev, DeepMind researchers and authors of papers on AlphaZero in collaboration with Vladimir Kramnik: “Inner Workings of Chess Algorithms Based on AI and Neural Networks: AlphaZero and Beyond.”
10:25-10:45 p.m. (Eng)
Discussion:
— Effects of technology, AI engines and applications on a chess player’s training, style and mindset.
— Challenges that arise in the use of chess engines.
— Impact of chess on life and vice versa, and how the situation has evolved with the advances in chess technology.
— Future prospects of the chess-AI symbiosis in education, entertainment and self-development.
Discussion participants:
Ulrich Paquet and Nenad Tomašev, researchers, DeepMind;
Sergey Rykovanov (professor) and Yuri Shkandybin (systems architect), Skoltech’s supercomputing group;
Aleksandr Shimanov, Russian chess player, grandmaster.
Links:
Sign up: https://surl.li/abbvc
Livestream: https://youtu.be/BDWELYal47c
Location: Galaxy Mall in Krasnaya Polyana, Sochi + livestream
Program:
9-9:05 p.m.
Introductory speech.
9:05-9:25 p.m. (Rus)
Mark Glukhovsky, Executive Director of the Russian Chess Federation: “Chess and Computer Technology: What AI Is and How It Is Changing the Chess World.”
9:25-9:40 p.m. (Rus)
Conversation with Sergei Shipov, a Russian professional chess player, grandmaster, chess coach and commentator: “The Role of the Computer in Professional Chess Player Training.”
9:40-9:55 p.m. (Rus)
Aleksandr Shimanov, a Russian professional chess player, grandmaster and commentator, reviews the most incredible game from the AlphaZero vs. Stockfish match, which pitted the most powerful chess engines against each other.
9:55-10:25 p.m. (Eng)
Ulrich Paquet and Nenad Tomašev, DeepMind researchers and authors of papers on AlphaZero in collaboration with Vladimir Kramnik: “Inner Workings of Chess Algorithms Based on AI and Neural Networks: AlphaZero and Beyond.”
10:25-10:45 p.m. (Eng)
Discussion:
— Effects of technology, AI engines and applications on a chess player’s training, style and mindset.
— Challenges that arise in the use of chess engines.
— Impact of chess on life and vice versa, and how the situation has evolved with the advances in chess technology.
— Future prospects of the chess-AI symbiosis in education, entertainment and self-development.
Discussion participants:
Ulrich Paquet and Nenad Tomašev, researchers, DeepMind;
Sergey Rykovanov (professor) and Yuri Shkandybin (systems architect), Skoltech’s supercomputing group;
Aleksandr Shimanov, Russian chess player, grandmaster.
Links:
Sign up: https://surl.li/abbvc
Livestream: https://youtu.be/BDWELYal47c
{kind=link}
Forwarded from Machinelearning
🗣 Pretrained Language Model
AutoTinyBERT: Automatic Hyper-parameter Optimization for Efficient Pre-trained Language Models
Github: https://github.com/huawei-noah/Pretrained-Language-Model
Paper: https://arxiv.org/abs/2107.13686v1
AutoTinyBERT: https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/AutoTinyBERT
@ai_machinelearning_big_data
AutoTinyBERT: Automatic Hyper-parameter Optimization for Efficient Pre-trained Language Models
Github: https://github.com/huawei-noah/Pretrained-Language-Model
Paper: https://arxiv.org/abs/2107.13686v1
AutoTinyBERT: https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/AutoTinyBERT
@ai_machinelearning_big_data
🎓Online Berkeley Deep Learning Lectures 2021
University of Berkeley released its fresh course lectures online for everyone to watch. Welcome Berkeley CS182/282 Deep Learnings - 2021!
YouTube: https://www.youtube.com/playlist?list=PLuv1FSpHurUevSXe_k0S7Onh6ruL-_NNh
#MOOC #wheretostart #Berkeley #dl
University of Berkeley released its fresh course lectures online for everyone to watch. Welcome Berkeley CS182/282 Deep Learnings - 2021!
YouTube: https://www.youtube.com/playlist?list=PLuv1FSpHurUevSXe_k0S7Onh6ruL-_NNh
#MOOC #wheretostart #Berkeley #dl
Tokyo Olympics Alternative medals table
Article on how teams performed with the respect to behavior expected by regression model.
Link: https://ig.ft.com/tokyo-olympics-alternative-medal-table/
Article on how teams performed with the respect to behavior expected by regression model.
Link: https://ig.ft.com/tokyo-olympics-alternative-medal-table/
Ft
Tokyo Olympics alternative medals table
Which countries are under-performing and over-performing?
Virtual fitting room launched by our friends
#in3D launched a 3D virtual fitting room with Replicant Fashion house. 30+ designers, 60+ looks.
Great example of the AI-driven product!
Desktop: https://www.replicant.fashion/digitaltwin
iPhone: https://apps.apple.com/us/app/in3d-3d-body-scanning/id1467153183
#aiproduct #fitting #metaverse
#in3D launched a 3D virtual fitting room with Replicant Fashion house. 30+ designers, 60+ looks.
Great example of the AI-driven product!
Desktop: https://www.replicant.fashion/digitaltwin
iPhone: https://apps.apple.com/us/app/in3d-3d-body-scanning/id1467153183
#aiproduct #fitting #metaverse
Domain-Aware Universal Style Transfer
Style transfer aims to reproduce content images with the styles from reference images. Modern style transfer methods can successfully apply arbitrary styles to images in either an artistic or a photo-realistic way. However, due to their structural limitations, they can do it only within a specific domain: the degrees of content preservation and stylization depends on a predefined target domain. As a result, both photo-realistic and artistic models have difficulty in performing the desired style transfer for the other domain.
The authors propose Domain-aware Style Transfer Networks (DSTN) that transfer not only the style but also the property of domain (i.e., domainness) from a given reference image. Furthermore, they design a novel domainess indicator (based on the texture and structural features) and introduce a unified framework with domain-aware skip connection to adaptively transfer the stroke and palette to the input contents guided by the domainness indicator.
Extensive experiments validate that their model produces better qualitative results and outperforms previous methods in terms of proxy metrics on both artistic and photo-realistic stylizations.
Paper: https://arxiv.org/abs/2108.04441
Code: https://github.com/Kibeom-Hong/Domain-Aware-Style-Transfer
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dstn
#deeplearning #cv #styletransfer
Style transfer aims to reproduce content images with the styles from reference images. Modern style transfer methods can successfully apply arbitrary styles to images in either an artistic or a photo-realistic way. However, due to their structural limitations, they can do it only within a specific domain: the degrees of content preservation and stylization depends on a predefined target domain. As a result, both photo-realistic and artistic models have difficulty in performing the desired style transfer for the other domain.
The authors propose Domain-aware Style Transfer Networks (DSTN) that transfer not only the style but also the property of domain (i.e., domainness) from a given reference image. Furthermore, they design a novel domainess indicator (based on the texture and structural features) and introduce a unified framework with domain-aware skip connection to adaptively transfer the stroke and palette to the input contents guided by the domainness indicator.
Extensive experiments validate that their model produces better qualitative results and outperforms previous methods in terms of proxy metrics on both artistic and photo-realistic stylizations.
Paper: https://arxiv.org/abs/2108.04441
Code: https://github.com/Kibeom-Hong/Domain-Aware-Style-Transfer
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dstn
#deeplearning #cv #styletransfer
{kind=link}
👍2
14 seconds of April #Nvidia 's CEO speech was generated in silico
Why this important: demand for usage of 3080 and newer GPU models might also get pumped by CGI artists and researchers working in VR / AR tech.
And this raises the bar for #speechsinthesis / #speechgeneration and definately for the rendering of photorealistic picture.
YouTube making of video: https://www.youtube.com/watch?v=1qhqZ9ECm70&t=1430s
Vice article on the subject: https://www.vice.com/en/article/88nbpa/nvidia-reveals-its-ceo-was-computer-generated-in-keynote-speech
Why this important: demand for usage of 3080 and newer GPU models might also get pumped by CGI artists and researchers working in VR / AR tech.
And this raises the bar for #speechsinthesis / #speechgeneration and definately for the rendering of photorealistic picture.
YouTube making of video: https://www.youtube.com/watch?v=1qhqZ9ECm70&t=1430s
Vice article on the subject: https://www.vice.com/en/article/88nbpa/nvidia-reveals-its-ceo-was-computer-generated-in-keynote-speech
YouTube
Connecting in the Metaverse: The Making of the GTC Keynote
See how a small team of artists were able to blur the line between real and rendered in NVIDIA’s #GTC21 keynote in this behind-the-scenes documentary. Read more: https://nvda.ws/3s97Tpy
@NVIDIAOmniverse is an open platform built for virtual collaboration…
@NVIDIAOmniverse is an open platform built for virtual collaboration…
👍1
Program Synthesis with Large Language Models
Paper compares models used for program synthesis in general purpose programming languages against two new benchmarks, MBPP (The Mostly Basic Programming Problems) and MathQA-Python, in both the few-shot and fine-tuning regimes.
MBPP contains 974 programming tasks, designed to be solvable by entry-level programmers. MathQA benchmark, contains 23914 problems that evaluate the ability of the models to synthesize code from more complex text.
Largest fine-tuned model achieves 83.8 percent accuracy on the latter benchmark.
Why this is interesting: better models for code / problem understanding means improved search for the coding tasks and the improvement of the coding-assistant projects like #TabNine or #Copilot
ArXiV: https://arxiv.org/abs/2108.07732
#DL #NLU #codewritingcode #benchmark
Paper compares models used for program synthesis in general purpose programming languages against two new benchmarks, MBPP (The Mostly Basic Programming Problems) and MathQA-Python, in both the few-shot and fine-tuning regimes.
MBPP contains 974 programming tasks, designed to be solvable by entry-level programmers. MathQA benchmark, contains 23914 problems that evaluate the ability of the models to synthesize code from more complex text.
Largest fine-tuned model achieves 83.8 percent accuracy on the latter benchmark.
Why this is interesting: better models for code / problem understanding means improved search for the coding tasks and the improvement of the coding-assistant projects like #TabNine or #Copilot
ArXiV: https://arxiv.org/abs/2108.07732
#DL #NLU #codewritingcode #benchmark
{kind=link}
👍1
Structure-aware Interactive Graph Neural Networks for the Prediction of Protein-Ligand Binding Affinity
#Baidu research proposed a structure-aware interactive graph neural network ( #SIGN ) to better learn representations of protein-ligand complexes, since drug discovery relies on the successful prediction of protein-ligand binding affinity.
Link: https://dl.acm.org/doi/10.1145/3447548.3467311
#biolearning #deeplearning
#Baidu research proposed a structure-aware interactive graph neural network ( #SIGN ) to better learn representations of protein-ligand complexes, since drug discovery relies on the successful prediction of protein-ligand binding affinity.
Link: https://dl.acm.org/doi/10.1145/3447548.3467311
#biolearning #deeplearning
Forwarded from Находки в опенсорсе
⚡️Breeaking news!
Big project, first public release! From the creator of FastAPI and Typer: SQLModel.
SQLModel is a library for interacting with SQL databases from Python code, with Python objects. It is designed to be intuitive, easy to use, highly compatible, and robust.
SQLModel is based on Python type annotations, and powered by Pydantic and SQLAlchemy.
SQLModel is, in fact, a thin layer on top of Pydantic and SQLAlchemy, carefully designed to be compatible with both.
The key features are:
- Intuitive to write: Great editor support. Completion everywhere. Less time debugging. Designed to be easy to use and learn. Less time reading docs.
- Easy to use: It has sensible defaults and does a lot of work underneath to simplify the code you write.
- Compatible: It is designed to be compatible with FastAPI, Pydantic, and SQLAlchemy.
- Extensible: You have all the power of SQLAlchemy and Pydantic underneath.
- Short: Minimize code duplication. A single type annotation does a lot of work. No need to duplicate models in SQLAlchemy and Pydantic.
https://github.com/tiangolo/sqlmodel
Big project, first public release! From the creator of FastAPI and Typer: SQLModel.
SQLModel is a library for interacting with SQL databases from Python code, with Python objects. It is designed to be intuitive, easy to use, highly compatible, and robust.
SQLModel is based on Python type annotations, and powered by Pydantic and SQLAlchemy.
SQLModel is, in fact, a thin layer on top of Pydantic and SQLAlchemy, carefully designed to be compatible with both.
The key features are:
- Intuitive to write: Great editor support. Completion everywhere. Less time debugging. Designed to be easy to use and learn. Less time reading docs.
- Easy to use: It has sensible defaults and does a lot of work underneath to simplify the code you write.
- Compatible: It is designed to be compatible with FastAPI, Pydantic, and SQLAlchemy.
- Extensible: You have all the power of SQLAlchemy and Pydantic underneath.
- Short: Minimize code duplication. A single type annotation does a lot of work. No need to duplicate models in SQLAlchemy and Pydantic.
https://github.com/tiangolo/sqlmodel
{kind=link}
🔥1
Forwarded from Silero News (Alexander)
New German V4 Model and English V5 Models
New and improved models in Silero-models! Community edition versions available here: https://github.com/snakers4/silero-models
Huge performance improvements for two new models:
- English V5 (quality)
- German V3 (quality)
The models currently are available in the following flavors:
- English V5
The quality growth visualization:
New and improved models in Silero-models! Community edition versions available here: https://github.com/snakers4/silero-models
Huge performance improvements for two new models:
- English V5 (quality)
- German V3 (quality)
The models currently are available in the following flavors:
- English V5
jit (small), onnx (small), jit_q (small, quantized), jit_xlarge, onnx_xlarge
- German V3 jit_large, onnx_large
The xsmall model family for English in on the way.The quality growth visualization:
GitHub
GitHub - snakers4/silero-models: Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly…
Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly simple - snakers4/silero-models
👍2