
SEER: The start of a more powerful, flexible, and accessible era for computer vision
#SEER stands for SElf-supERvised architecture which follows the vision of Yan LeCunn that real breakthrough in quality of models is possible only with #selfsupervised learning.
And here it is — model which was trained using some enormous amount of data achieves 84.2 percent top-1 accuracy on ImageNet.
Paramus: 1.3B
Dataset: 1B random images
Hardware: 512 GPUs (unspecified)
Blogpost: https://ai.facebook.com/blog/seer-the-start-of-a-more-powerful-flexible-and-accessible-era-for-computer-vision
ArXiV: https://arxiv.org/pdf/2103.01988.pdf
#facebook #fair #cv #dl
#SEER stands for SElf-supERvised architecture which follows the vision of Yan LeCunn that real breakthrough in quality of models is possible only with #selfsupervised learning.
And here it is — model which was trained using some enormous amount of data achieves 84.2 percent top-1 accuracy on ImageNet.
Paramus: 1.3B
Dataset: 1B random images
Hardware: 512 GPUs (unspecified)
Blogpost: https://ai.facebook.com/blog/seer-the-start-of-a-more-powerful-flexible-and-accessible-era-for-computer-vision
ArXiV: https://arxiv.org/pdf/2103.01988.pdf
#facebook #fair #cv #dl
Meta
SEER: The start of a more powerful, flexible, and accessible era for computer vision
The future of AI is in creating systems that can learn directly from whatever information they’re given — whether it’s text, images, or another type of data — without relying on carefully curated and labeled data sets to teach them how to recognize objects…
Self-training improves pretraining for natural language understanding
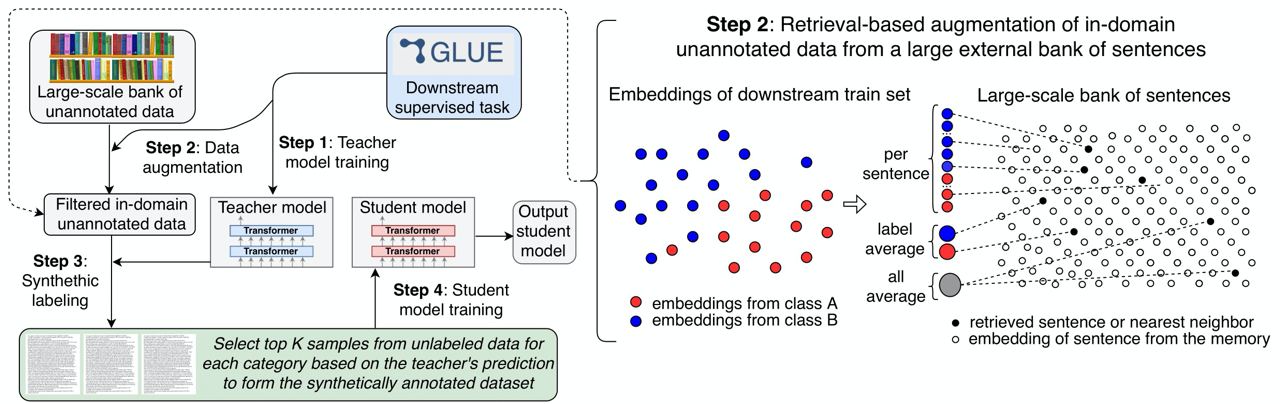
Authors suggested another way to leverage unlabeled data through semi-supervised learning. They use #SOTA sentence embeddings to structure the information of a very large bank of sentences.
Code: https://github.com/facebookresearch/SentAugment
Link: https://arxiv.org/abs/2010.02194
Authors suggested another way to leverage unlabeled data through semi-supervised learning. They use #SOTA sentence embeddings to structure the information of a very large bank of sentences.
Code: https://github.com/facebookresearch/SentAugment
Link: https://arxiv.org/abs/2010.02194
{kind=link}
Contrastive Semi-supervised Learning for ASR
Nowadays, pseudo-labeling is the most common method for pre-training automatic speech recognition (ASR) models, but in the case of low-resource setups and domain transfer, it suffers from a supervised teacher model’s degrading quality. The authors of this paper suggest using contrastive learning to overcome this problem.
CSL approach (Contrastive Semi-supervised Learning) uses teacher-generated predictions to select positive and negative examples instead of using pseudo-labels directly.
Experiments show that CSL has lower WER not only in comparison with standard CE-PL (Cross-Entropy pseudo-labeling) but also under low-resource and out-of-domain conditions.
To demonstrate its resilience to pseudo-labeling noise, the authors apply CSL pre-training in a low-resource setup with only 10hr of labeled data, where it reduces WER by 8% compared to the standard cross-entropy pseudo-labeling (CE-PL). This WER reduction increase to 19% with a teacher trained only on 1hr of labels and 17% for out-of-domain conditions.
Paper: https://arxiv.org/abs/2103.05149
#deeplearning #asr #contrastivelearning #semisupervised
Nowadays, pseudo-labeling is the most common method for pre-training automatic speech recognition (ASR) models, but in the case of low-resource setups and domain transfer, it suffers from a supervised teacher model’s degrading quality. The authors of this paper suggest using contrastive learning to overcome this problem.
CSL approach (Contrastive Semi-supervised Learning) uses teacher-generated predictions to select positive and negative examples instead of using pseudo-labels directly.
Experiments show that CSL has lower WER not only in comparison with standard CE-PL (Cross-Entropy pseudo-labeling) but also under low-resource and out-of-domain conditions.
To demonstrate its resilience to pseudo-labeling noise, the authors apply CSL pre-training in a low-resource setup with only 10hr of labeled data, where it reduces WER by 8% compared to the standard cross-entropy pseudo-labeling (CE-PL). This WER reduction increase to 19% with a teacher trained only on 1hr of labels and 17% for out-of-domain conditions.
Paper: https://arxiv.org/abs/2103.05149
#deeplearning #asr #contrastivelearning #semisupervised
{kind=link}
Revisiting ResNets: Improved Training and Scaling Strategies
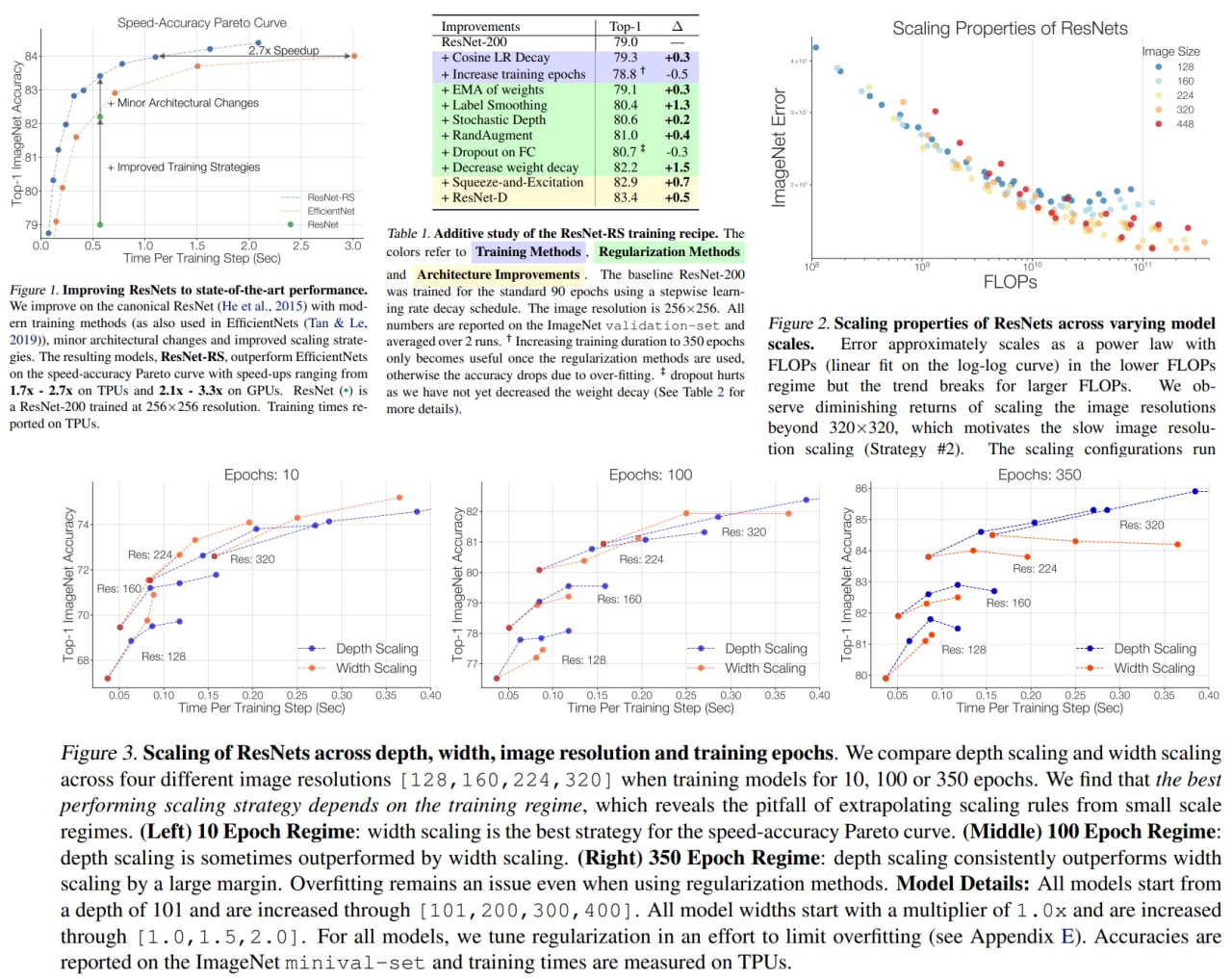
The authors of the paper (from Google Brain and UC Berkeley) have decided to analyze the effects of the model architecture, training, and scaling strategies separately and concluded that these strategies might have a higher impact on the score than the architecture.
They offer two new strategies:
- scale model depth if overfitting is possible, scale model width otherwise
- increase image resolution slower than recommended in previous papers
Based on these ideas, the new architecture ResNet-RS was developed. It is 2.1x–3.3x faster than EfficientNets on GPU while reaching similar accuracy on ImageNet.
In semi-supervised learning, ResNet-RS achieves 86.2% top-1 ImageNet accuracy while being 4.7x faster than EfficientNet-NoisyStudent.
Transfer learning on downstream tasks also has improved performance.
The authors suggest using these ResNet-RS as a baseline for further research.
Paper: https://arxiv.org/abs/2103.07579
Code and checkpoints are available in TensorFlow:
https://github.com/tensorflow/models/tree/master/official/vision/beta
https://github.com/tensorflow/tpu/tree/master/models/official/resnet/resnet_rs
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-resnetsr
#deeplearning #computervision #sota
The authors of the paper (from Google Brain and UC Berkeley) have decided to analyze the effects of the model architecture, training, and scaling strategies separately and concluded that these strategies might have a higher impact on the score than the architecture.
They offer two new strategies:
- scale model depth if overfitting is possible, scale model width otherwise
- increase image resolution slower than recommended in previous papers
Based on these ideas, the new architecture ResNet-RS was developed. It is 2.1x–3.3x faster than EfficientNets on GPU while reaching similar accuracy on ImageNet.
In semi-supervised learning, ResNet-RS achieves 86.2% top-1 ImageNet accuracy while being 4.7x faster than EfficientNet-NoisyStudent.
Transfer learning on downstream tasks also has improved performance.
The authors suggest using these ResNet-RS as a baseline for further research.
Paper: https://arxiv.org/abs/2103.07579
Code and checkpoints are available in TensorFlow:
https://github.com/tensorflow/models/tree/master/official/vision/beta
https://github.com/tensorflow/tpu/tree/master/models/official/resnet/resnet_rs
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-resnetsr
#deeplearning #computervision #sota
{kind=link}
LightningDOT: Pre-training Visual-Semantic Embeddings for Real-Time Image-Text Retrieval
Pre-training transformers simultaneously on text and images proved to work quite well for model performance on multiple tasks, but such models usually have a low inference speed due to cross-modal attention. As a result, in practice, these models can hardly be used when low latency is required.
The authors of the paper offer a solution to this problem:
- pre-training on three new learning objectives
- extracting feature indexes offline
- using dot-product matching
- further re-ranking with a separate model
LightningDOT outperforms the previous state-of-the-art while significantly speeding up inference time by 600-2000× on Flickr30K and COCO image-text retrieval benchmarks.
Paper: https://arxiv.org/abs/2103.08784
Code and checkpoints will be available here:
https://github.com/intersun/LightningDOT
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-lightningdot
#pretraining #realtime #ranking #deeplearning
Pre-training transformers simultaneously on text and images proved to work quite well for model performance on multiple tasks, but such models usually have a low inference speed due to cross-modal attention. As a result, in practice, these models can hardly be used when low latency is required.
The authors of the paper offer a solution to this problem:
- pre-training on three new learning objectives
- extracting feature indexes offline
- using dot-product matching
- further re-ranking with a separate model
LightningDOT outperforms the previous state-of-the-art while significantly speeding up inference time by 600-2000× on Flickr30K and COCO image-text retrieval benchmarks.
Paper: https://arxiv.org/abs/2103.08784
Code and checkpoints will be available here:
https://github.com/intersun/LightningDOT
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-lightningdot
#pretraining #realtime #ranking #deeplearning
{kind=link}
👍2
Forwarded from Gradient Dude
Finetuning Pretrained Transformers into RNNs
Microsoft+Deepmind+...
Transformers is the current SOTA in language modeling. But they come with significant computational overhead, as the attention mechanism scales quadratically in sequence length. The memory consumption also grows linearly as the sequence becomes longer. This bottleneck limits the usage of large-scale pretrained generation models, such as GPT-3 or Image transformers.
Several efficient transformer variants have been proposed recently. For example, a linear-complexity recurrent variant has proven well suited for an autoregressive generation. It approximates the softmax attention with randomized or heuristic feature maps but can be difficult to train or yield suboptimal accuracy.
This work converts a pretrained transformer into its efficient linear-complexity recurrent counterpart with a learned feature map to improve the efficiency while retaining the accuracy. To achieve this, they replace the softmax attention in an off-the-shelf pretrained transformer with its linear-complexity recurrent alternative and then finetune.
➕ Pros:
+ The finetuning process requires much less GPU time than training the recurrent variants from scratch
+ Converting a large off-the-shelf transformer to a lightweight inference model w/o repeating the whole training procedure is very handy in many downstream applications.
📝 arxiv.org/abs/2103.13076
Microsoft+Deepmind+...
Transformers is the current SOTA in language modeling. But they come with significant computational overhead, as the attention mechanism scales quadratically in sequence length. The memory consumption also grows linearly as the sequence becomes longer. This bottleneck limits the usage of large-scale pretrained generation models, such as GPT-3 or Image transformers.
Several efficient transformer variants have been proposed recently. For example, a linear-complexity recurrent variant has proven well suited for an autoregressive generation. It approximates the softmax attention with randomized or heuristic feature maps but can be difficult to train or yield suboptimal accuracy.
This work converts a pretrained transformer into its efficient linear-complexity recurrent counterpart with a learned feature map to improve the efficiency while retaining the accuracy. To achieve this, they replace the softmax attention in an off-the-shelf pretrained transformer with its linear-complexity recurrent alternative and then finetune.
➕ Pros:
+ The finetuning process requires much less GPU time than training the recurrent variants from scratch
+ Converting a large off-the-shelf transformer to a lightweight inference model w/o repeating the whole training procedure is very handy in many downstream applications.
📝 arxiv.org/abs/2103.13076
{kind=link}
👍2
Predicting body movement based on data from socks
Researchers from #MIT has opened a new vector of opportunity for #techwear by making smart socks.
Website: https://www.csail.mit.edu/news/smart-clothes-can-measure-your-movements
Video: https://senstextile.csail.mit.edu/file/overview.mp4
Paper: https://www.nature.com/articles/s41928-021-00558-0
Researchers from #MIT has opened a new vector of opportunity for #techwear by making smart socks.
Website: https://www.csail.mit.edu/news/smart-clothes-can-measure-your-movements
Video: https://senstextile.csail.mit.edu/file/overview.mp4
Paper: https://www.nature.com/articles/s41928-021-00558-0
Forwarded from Silero News (Alexander)
Silero TTS Released
Surprise! A quick pre-release of Silero Text-to-Speech models!
Speakers
10 voices (each available in 16 kHz and 8 kHz):
- 6 Russian voices;
- 1 English voice;
- 1 German voice, 1 Spanish voice, 1 French voice;
Why is this Different?
- One-line usage;
- A large library of voices;
- A fully end-to-end pipeline;
- Naturally sounding speech;
- No GPU or training required;
- Minimalism and lack of dependencies;
- Faster than real-time on one CPU thread (!!!);
- Support for
Links
- Try our TTS models here;
- Quick summary;
- Performance benchmarks;
Stay tuned for much more detailed PR releases and
Surprise! A quick pre-release of Silero Text-to-Speech models!
Speakers
10 voices (each available in 16 kHz and 8 kHz):
- 6 Russian voices;
- 1 English voice;
- 1 German voice, 1 Spanish voice, 1 French voice;
Why is this Different?
- One-line usage;
- A large library of voices;
- A fully end-to-end pipeline;
- Naturally sounding speech;
- No GPU or training required;
- Minimalism and lack of dependencies;
- Faster than real-time on one CPU thread (!!!);
- Support for
16kHz and 8kHz out of the box;Links
- Try our TTS models here;
- Quick summary;
- Performance benchmarks;
Stay tuned for much more detailed PR releases and
torch.hub release soon!GitHub
GitHub - snakers4/silero-models: Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly…
Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly simple - snakers4/silero-models
Few-Shot Text Classification with Triplet Networks, Data Augmentation, and Curriculum Learning
Few-shot text classification is a fundamental NLP task in which a model aims to classify text into a large number of categories, given only a few training examples per category.
The authors suggest several practical ideas to improving model performance on this task:
- using augmentations (synonym replacement, random insertion, random swap, random deletion) together with triplet loss
- using curriculum learning (two-stage and gradual)
Paper: https://arxiv.org/abs/2103.07552
Code: https://github.com/jasonwei20/triplet-loss
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-nlptriplettricks
#deeplearning #nlp #fewshotlearning #augmentation #curriculumlreaning
Few-shot text classification is a fundamental NLP task in which a model aims to classify text into a large number of categories, given only a few training examples per category.
The authors suggest several practical ideas to improving model performance on this task:
- using augmentations (synonym replacement, random insertion, random swap, random deletion) together with triplet loss
- using curriculum learning (two-stage and gradual)
Paper: https://arxiv.org/abs/2103.07552
Code: https://github.com/jasonwei20/triplet-loss
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-nlptriplettricks
#deeplearning #nlp #fewshotlearning #augmentation #curriculumlreaning
{kind=link}
EfficientNetV2: Smaller Models and Faster Training
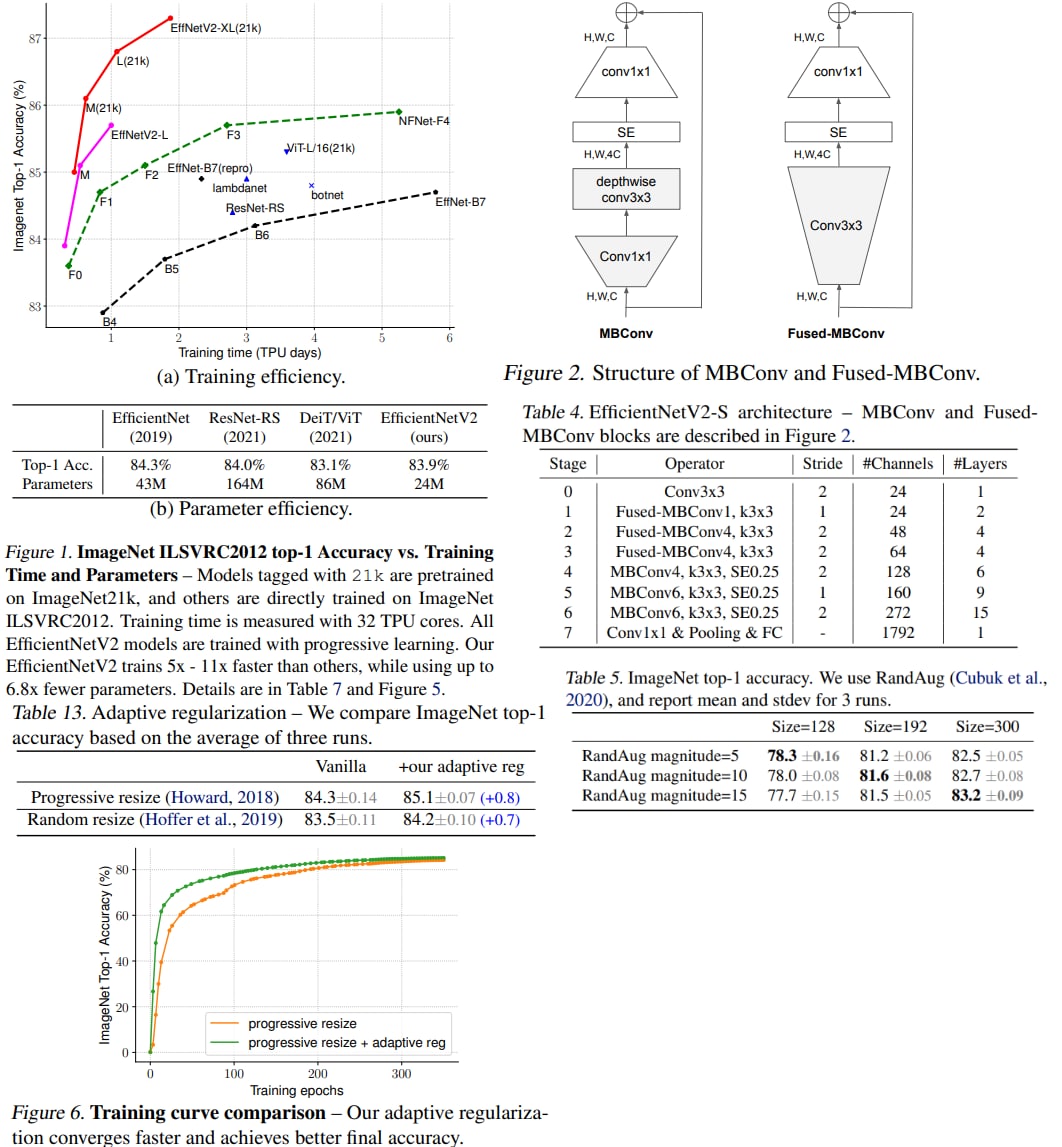
A new paper from Google Brain with a new SOTA architecture called EfficientNetV2. The authors develop a new family of CNN models that are optimized both for accuracy and training speed. The main improvements are:
- an improved training-aware neural architecture search with new building blocks and ideas to jointly optimize training speed and parameter efficiency;
- a new approach to progressive learning that adjusts regularization along with the image size;
As a result, the new approach can reach SOTA results while training faster (up to 11x) and smaller (up to 6.8x).
Paper: https://arxiv.org/abs/2104.00298
Code will be available here:
https://github.com/google/automl/tree/master/efficientnetv2
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-effnetv2
#cv #sota #nas #deeplearning
A new paper from Google Brain with a new SOTA architecture called EfficientNetV2. The authors develop a new family of CNN models that are optimized both for accuracy and training speed. The main improvements are:
- an improved training-aware neural architecture search with new building blocks and ideas to jointly optimize training speed and parameter efficiency;
- a new approach to progressive learning that adjusts regularization along with the image size;
As a result, the new approach can reach SOTA results while training faster (up to 11x) and smaller (up to 6.8x).
Paper: https://arxiv.org/abs/2104.00298
Code will be available here:
https://github.com/google/automl/tree/master/efficientnetv2
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-effnetv2
#cv #sota #nas #deeplearning
{kind=link}
👍1
🏥Self-supervised Learning for Medical images
Due to standard imaging procedures, medical images (X-ray, CT scans, etc) are usually well aligned.
This paper gives an opportunity to utilize such an alignment to automatically connect similar pairs of images for training.
GitHub: https://github.com/fhaghighi/TransVW
ArXiV: https://arxiv.org/abs/2102.10680
#biolearning #medical #dl #pytorch #keras
Due to standard imaging procedures, medical images (X-ray, CT scans, etc) are usually well aligned.
This paper gives an opportunity to utilize such an alignment to automatically connect similar pairs of images for training.
GitHub: https://github.com/fhaghighi/TransVW
ArXiV: https://arxiv.org/abs/2102.10680
#biolearning #medical #dl #pytorch #keras
GitHub
GitHub - fhaghighi/TransVW: Official Keras & PyTorch Implementation and Pre-trained Models for TransVW
Official Keras & PyTorch Implementation and Pre-trained Models for TransVW - fhaghighi/TransVW
👍2
Forwarded from Gradient Dude
LatentCLR: A Contrastive Learning Approach for Unsupervised Discovery of Interpretable Directions
A framework that learns meaningful directions in GANs' latent space using unsupervised contrastive learning. Instead of discovering fixed directions such as in previous work, this method can discover non-linear directions in pretrained StyleGAN2 and BigGAN models. The discovered directions may be used for image manipulation.
Authors use the differences caused by an edit operation on the feature activations to optimize the identifiability of each direction. The edit operations are modeled by several separate neural nets
📝 Paper
🛠 Code (next week)
#paper_tldr #cv #gan
A framework that learns meaningful directions in GANs' latent space using unsupervised contrastive learning. Instead of discovering fixed directions such as in previous work, this method can discover non-linear directions in pretrained StyleGAN2 and BigGAN models. The discovered directions may be used for image manipulation.
Authors use the differences caused by an edit operation on the feature activations to optimize the identifiability of each direction. The edit operations are modeled by several separate neural nets
∆_i(z) and learning. Given a latent code z and its generated image x = G(z), we seek to find edit operations ∆_i(z) such that the image x' = G(∆_i(z)) has semantically meaningful changes over x while still preserving the identity of x.📝 Paper
🛠 Code (next week)
#paper_tldr #cv #gan
Forwarded from Towards NLP🇺🇦
Conversational AI Reading List
List of interesting papers as well as some link to the lectures from Conversational AI course for Columbia University:
https://docs.google.com/spreadsheets/u/0/d/1nSKcnM5r9x82BdyPgn-obN1sRUlLC7zZ082a0132Igk/htmlview#gid=1523499517
List of interesting papers as well as some link to the lectures from Conversational AI course for Columbia University:
https://docs.google.com/spreadsheets/u/0/d/1nSKcnM5r9x82BdyPgn-obN1sRUlLC7zZ082a0132Igk/htmlview#gid=1523499517
Forwarded from Sysadmin Tools 🇺🇦
Advanced Database Systems
#database #db #sql #nosql
This course is a comprehensive study of the internals of modern database management systems. It will cover the core concepts and fundamentals of the components that are used in both high-performance transaction processing systems (OLTP) and large-scale analytical systems (OLAP).YouTube Playlist
#database #db #sql #nosql
CMU 15-721
Schedule - CMU 15-721 :: Advanced Database Systems (Spring 2020)
Course schedule with slides, lecture notes, and videos.
Generating Furry Cars: Disentangling Object Shape and Appearance across Multiple Domains
This is an interesting paper about learning and combining representations of object shape and appearance from the different domains (for example, dogs and cars). This allows to create a model, which borrows different properties from each domain and generates images, which don't exist in a single domain.
The main idea is the following:
- use FineGAN as a base model;
- represent object appearance with a differentiable histogram of visual features;
- optimize the generator so that images with different shapes but similar appearances produce similar histograms;
Paper: https://openreview.net/forum?id=M88oFvqp_9
Project link: https://utkarshojha.github.io/inter-domain-gan/
Code will be available here: https://github.com/utkarshojha/inter-domain-gan
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-furrycars
#cv #gan #deeplearning #contrastivelearning
This is an interesting paper about learning and combining representations of object shape and appearance from the different domains (for example, dogs and cars). This allows to create a model, which borrows different properties from each domain and generates images, which don't exist in a single domain.
The main idea is the following:
- use FineGAN as a base model;
- represent object appearance with a differentiable histogram of visual features;
- optimize the generator so that images with different shapes but similar appearances produce similar histograms;
Paper: https://openreview.net/forum?id=M88oFvqp_9
Project link: https://utkarshojha.github.io/inter-domain-gan/
Code will be available here: https://github.com/utkarshojha/inter-domain-gan
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-furrycars
#cv #gan #deeplearning #contrastivelearning
OpenReview
Generating Furry Cars: Disentangling Object Shape and Appearance...
We consider the novel task of learning disentangled representations of object shape and appearance across multiple domains (e.g., dogs and cars). The goal is to learn a generative model that...