
CoTracker: It is Better to Track Together
The CoTracker paper proposes a groundbreaking approach that takes video motion prediction to the next level. Traditional methods have often been limited, either tracking the motion of all points in a frame collectively using optical flow, or tracking individual points through a video. These approaches tend to overlook the crucial interrelationships between multiple points, especially when they're part of the same physical object. CoTracker flips the script by employing a transformer-based architecture to jointly track multiple points throughout a video, effectively modeling the correlations between different points in time.
What really sets CoTracker apart is its versatility and adaptability. It's engineered to handle extremely long videos through a unique sliding-window mechanism, and iteratively updates estimates for multiple trajectories. The system even allows for the addition of new tracking points on-the-fly, offering unmatched flexibility. CoTracker outshines state-of-the-art methods in nearly all benchmark tests.
Paper link: https://arxiv.org/abs/2307.07635
Code link: https://github.com/facebookresearch/co-tracker
Project link: https://co-tracker.github.io/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-cotracker
#deeplearning #cv #objecttracking
The CoTracker paper proposes a groundbreaking approach that takes video motion prediction to the next level. Traditional methods have often been limited, either tracking the motion of all points in a frame collectively using optical flow, or tracking individual points through a video. These approaches tend to overlook the crucial interrelationships between multiple points, especially when they're part of the same physical object. CoTracker flips the script by employing a transformer-based architecture to jointly track multiple points throughout a video, effectively modeling the correlations between different points in time.
What really sets CoTracker apart is its versatility and adaptability. It's engineered to handle extremely long videos through a unique sliding-window mechanism, and iteratively updates estimates for multiple trajectories. The system even allows for the addition of new tracking points on-the-fly, offering unmatched flexibility. CoTracker outshines state-of-the-art methods in nearly all benchmark tests.
Paper link: https://arxiv.org/abs/2307.07635
Code link: https://github.com/facebookresearch/co-tracker
Project link: https://co-tracker.github.io/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-cotracker
#deeplearning #cv #objecttracking
{kind=link}
👍7🔥7❤5😁1
Forwarded from Machinelearning
SAM-Med2D ➕
SAM-Med2D, the most comprehensive studies on applying SAM to medical 2D images.
🏆 Самая большая на сегодняшний день база данных по сегментации медицинских изображений (4,6 млн. изображений и 19,7 млн. масок) для обучения моделей.
🏆 Модель файнтюнинга Segment Anything Model (SAM).
🏆 Бенчмарк SAM-Med2D на крупномасштабных наборах данных.
🖥 Github: https://github.com/uni-medical/sam-med2d
🖥 Colab: https://colab.research.google.com/github/uni-medical/SAM-Med2D/blob/main/predictor_example.ipynb
📕 Paper: https://arxiv.org/abs/2308.16184
⭐️ Dataset: https://paperswithcode.com/dataset/sa-1b
ai_machinelearning_big_data
SAM-Med2D, the most comprehensive studies on applying SAM to medical 2D images.
🏆 Самая большая на сегодняшний день база данных по сегментации медицинских изображений (4,6 млн. изображений и 19,7 млн. масок) для обучения моделей.
🏆 Модель файнтюнинга Segment Anything Model (SAM).
🏆 Бенчмарк SAM-Med2D на крупномасштабных наборах данных.
ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥16👍14❤6
RecMind: Large Language Model Powered Agent For Recommendation
Recent advancements have significantly improved the capabilities of Large Language Models (LLMs) in various tasks, yet their potential in the realm of personalized recommendations has been relatively unexplored. To address this gap, a new LLM-powered autonomous recommender agent called RecMind has been developed. RecMind is designed to provide highly personalized recommendations by leveraging planning algorithms, tapping into external data sources, and using individualized data.
One standout feature of RecMind is its novel "Self-Inspiring" algorithm, which enhances the model's planning abilities. During each step of planning, the algorithm encourages the model to consider all its past actions, thereby improving its understanding and use of historical data. The performance of RecMind has been evaluated across multiple recommendation tasks like rating prediction, sequential and direct recommendation, explanation generation, and review summarization. The results show that RecMind outperforms existing LLM-based methods in these tasks and is competitive with the specialized P5 model.
Paper link: https://arxiv.org/abs/2308.14296
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-recmind
#deeplearning #nlp #llm #recommender
Recent advancements have significantly improved the capabilities of Large Language Models (LLMs) in various tasks, yet their potential in the realm of personalized recommendations has been relatively unexplored. To address this gap, a new LLM-powered autonomous recommender agent called RecMind has been developed. RecMind is designed to provide highly personalized recommendations by leveraging planning algorithms, tapping into external data sources, and using individualized data.
One standout feature of RecMind is its novel "Self-Inspiring" algorithm, which enhances the model's planning abilities. During each step of planning, the algorithm encourages the model to consider all its past actions, thereby improving its understanding and use of historical data. The performance of RecMind has been evaluated across multiple recommendation tasks like rating prediction, sequential and direct recommendation, explanation generation, and review summarization. The results show that RecMind outperforms existing LLM-based methods in these tasks and is competitive with the specialized P5 model.
Paper link: https://arxiv.org/abs/2308.14296
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-recmind
#deeplearning #nlp #llm #recommender
{kind=link}
👍17❤5🔥1
Forwarded from Data, Stories and Languages
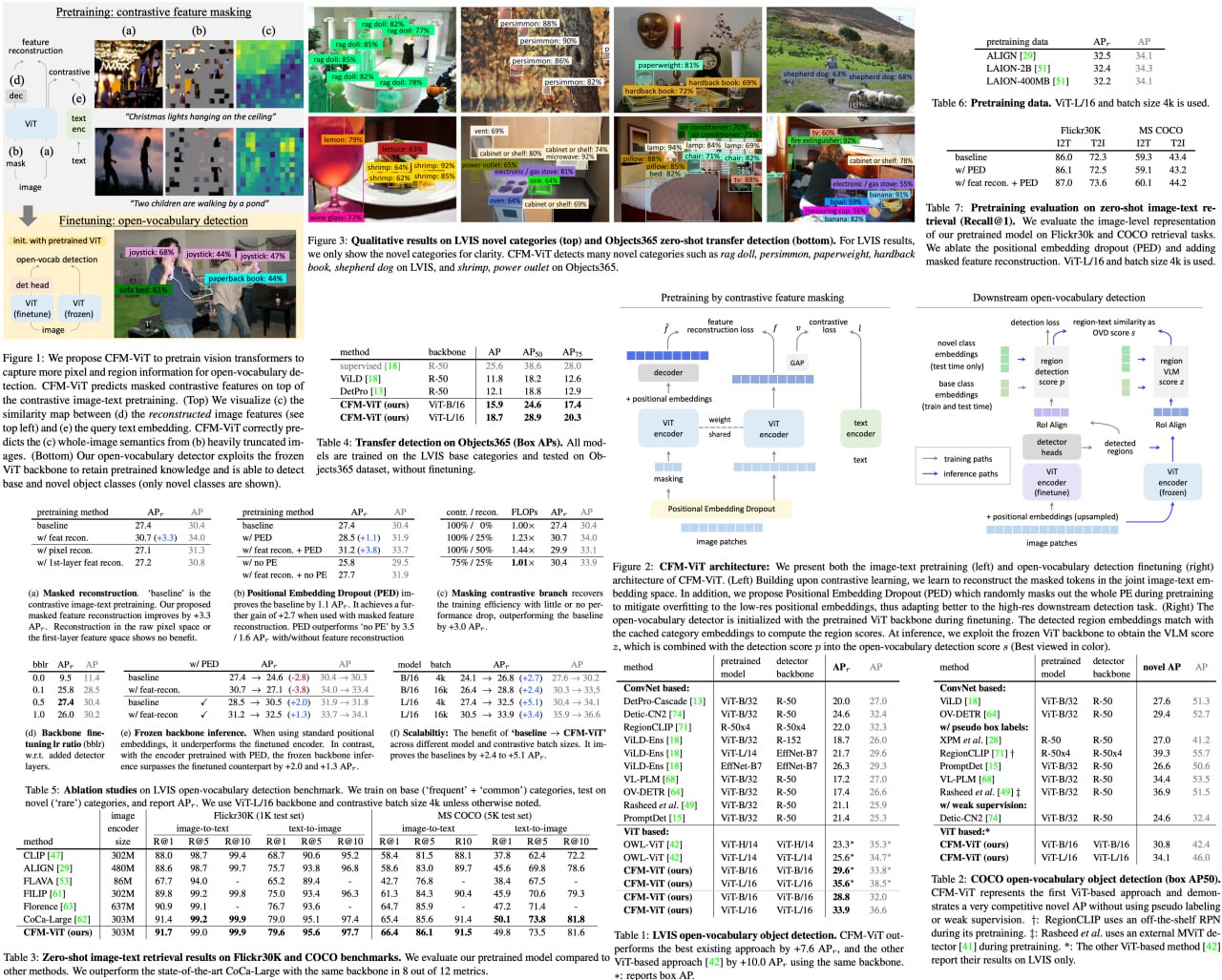
Contrastive Feature Masking Open-Vocabulary Vision Transformer
Contrastive Feature Masking Vision Transformer (CFM-ViT): a new approach for image-text pretraining that is optimized for open-vocabulary object detection. Unlike traditional masked autoencoders, which typically operate in the pixel space, CFM-ViT uses a joint image-text embedding space for reconstruction. This approach enhances the model's ability to learn region-level semantics. Additionally, the model features a Positional Embedding Dropout to better handle scale variations that occur when transitioning from image-text pretraining to detection finetuning. PED also enables the model to use a "frozen" ViT backbone as a region classifier without loss of performance.
In terms of results, CFM-ViT sets a new benchmark in open-vocabulary object detection with a 33.9 APr score on the LVIS dataset, outperforming the closest competitor by 7.6 points. The model also demonstrates strong capabilities in zero-shot detection transfer. Beyond object detection, it excels in image-text retrieval, outperforming the state of the art on 8 out of 12 key metrics. These features and results position CFM-ViT as a significant advancement in the field of computer vision and machine learning.
Paper link: https://arxiv.org/abs/2309.00775
My overview of the paper:
https://andlukyane.com/blog/paper-review-cfmvit
https://artgor.medium.com/paper-review-contrastive-feature-masking-open-vocabulary-vision-transformer-4639d1bf7043
#paperreview
Contrastive Feature Masking Vision Transformer (CFM-ViT): a new approach for image-text pretraining that is optimized for open-vocabulary object detection. Unlike traditional masked autoencoders, which typically operate in the pixel space, CFM-ViT uses a joint image-text embedding space for reconstruction. This approach enhances the model's ability to learn region-level semantics. Additionally, the model features a Positional Embedding Dropout to better handle scale variations that occur when transitioning from image-text pretraining to detection finetuning. PED also enables the model to use a "frozen" ViT backbone as a region classifier without loss of performance.
In terms of results, CFM-ViT sets a new benchmark in open-vocabulary object detection with a 33.9 APr score on the LVIS dataset, outperforming the closest competitor by 7.6 points. The model also demonstrates strong capabilities in zero-shot detection transfer. Beyond object detection, it excels in image-text retrieval, outperforming the state of the art on 8 out of 12 key metrics. These features and results position CFM-ViT as a significant advancement in the field of computer vision and machine learning.
Paper link: https://arxiv.org/abs/2309.00775
My overview of the paper:
https://andlukyane.com/blog/paper-review-cfmvit
https://artgor.medium.com/paper-review-contrastive-feature-masking-open-vocabulary-vision-transformer-4639d1bf7043
#paperreview
{kind=link}
🔥11👍10❤4
Forwarded from Data, Stories and Languages
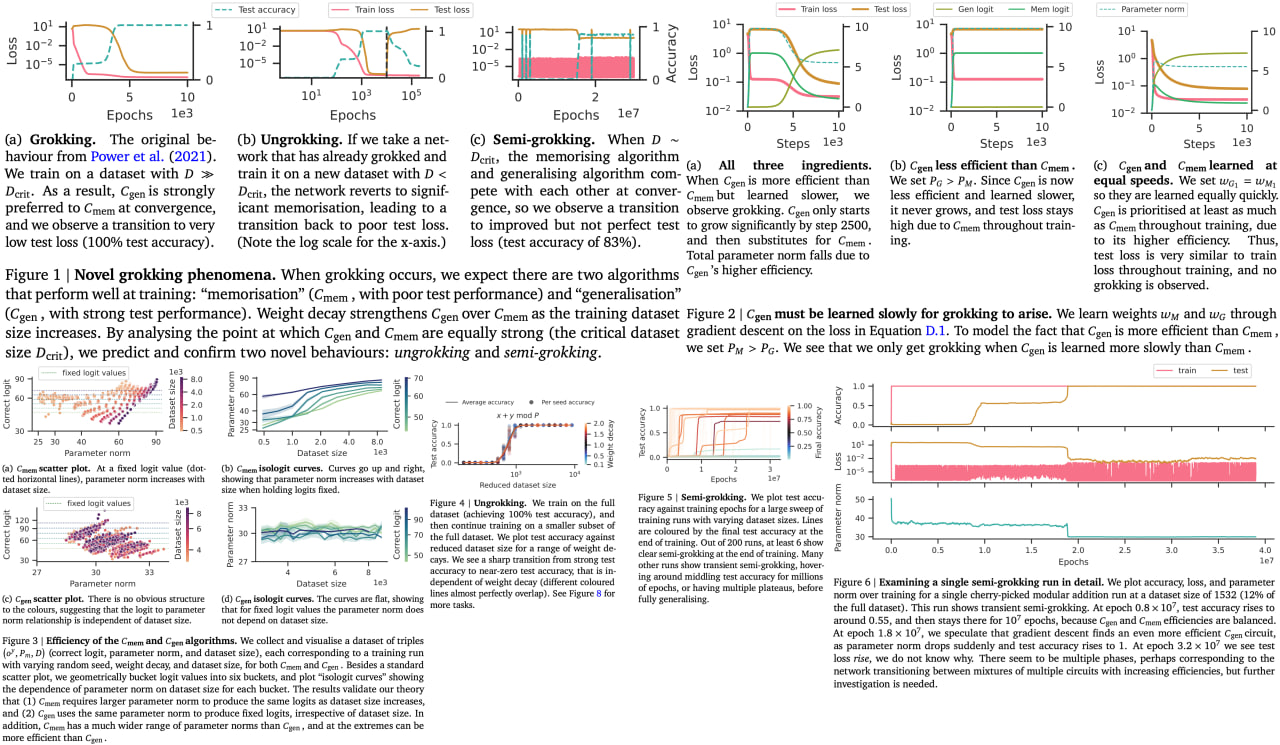
Explaining grokking through circuit efficiency
The paper explores the phenomenon of "grokking" in neural networks, where a network that initially performs poorly on new data eventually excels without any change in training setup. According to the authors, grokking occurs when two conditions are present: a memorizing solution and a generalizing solution. The generalizing solution takes longer to learn but is more efficient in terms of computational resources. The authors propose a "critical dataset size" at which the efficiencies of memorizing and generalizing are equal, providing a pivot point for the network to switch from memorization to generalization.
Furthermore, the paper introduces two new behaviors: "ungrokking" and "semi-grokking." Ungrokking describes a situation where a well-performing network reverts to poor performance when trained on a smaller dataset. Semi-grokking refers to a scenario where the network, instead of achieving full generalization, reaches a state of partial but improved performance.
Paper link: https://arxiv.org/abs/2309.02390
My overview of the paper:
https://andlukyane.com/blog/paper-review-un-semi-grokking
https://artgor.medium.com/paper-review-explaining-grokking-through-circuit-efficiency-1f420d6aea5f
#paperreview
The paper explores the phenomenon of "grokking" in neural networks, where a network that initially performs poorly on new data eventually excels without any change in training setup. According to the authors, grokking occurs when two conditions are present: a memorizing solution and a generalizing solution. The generalizing solution takes longer to learn but is more efficient in terms of computational resources. The authors propose a "critical dataset size" at which the efficiencies of memorizing and generalizing are equal, providing a pivot point for the network to switch from memorization to generalization.
Furthermore, the paper introduces two new behaviors: "ungrokking" and "semi-grokking." Ungrokking describes a situation where a well-performing network reverts to poor performance when trained on a smaller dataset. Semi-grokking refers to a scenario where the network, instead of achieving full generalization, reaches a state of partial but improved performance.
Paper link: https://arxiv.org/abs/2309.02390
My overview of the paper:
https://andlukyane.com/blog/paper-review-un-semi-grokking
https://artgor.medium.com/paper-review-explaining-grokking-through-circuit-efficiency-1f420d6aea5f
#paperreview
{kind=link}
👍22❤3😁3
Forwarded from ml4se
Releasing Persimmon-8B
Permisimmon-8B is open-source, fully permissive model. It is trained from scratch using a context size of 16K. The model has 70k unused embeddings for multimodal extensions, and has sparse activations. The inference code combines the speed of C++ implementations (e.g. FasterTransformer) with the flexibility of naive Python inference.
Hidden Size 4096
Heads 64
Layers 36
Batch Size 120
Sequence Length 16384
Training Iterations 375K
Tokens Seen 737B
Code and weights: https://github.com/persimmon-ai-labs/adept-inference
Permisimmon-8B is open-source, fully permissive model. It is trained from scratch using a context size of 16K. The model has 70k unused embeddings for multimodal extensions, and has sparse activations. The inference code combines the speed of C++ implementations (e.g. FasterTransformer) with the flexibility of naive Python inference.
Hidden Size 4096
Heads 64
Layers 36
Batch Size 120
Sequence Length 16384
Training Iterations 375K
Tokens Seen 737B
Code and weights: https://github.com/persimmon-ai-labs/adept-inference
👍5❤3
Forwarded from Machinelearning
Media is too big
VIEW IN TELEGRAM
📹 DEVA: Tracking Anything with Decoupled Video Segmentation
Decoupled video segmentation approach (DEVA), composed of task-specific image-level segmentation and class/task-agnostic bi-directional temporal propagation.
Новая модель сегментации видео для "отслеживания чего угодно" без обучения по видео для любой отдельной задачи.
🖥 Github: https://github.com/hkchengrex/Tracking-Anything-with-DEVA
🖥 Colab: https://colab.research.google.com/drive/1OsyNVoV_7ETD1zIE8UWxL3NXxu12m_YZ?usp=sharing
⏩ Project: https://hkchengrex.github.io/Tracking-Anything-with-DEVA/
📕 Paper: https://arxiv.org/abs/2309.03903v1
⭐️ Docs: https://paperswithcode.com/dataset/burst
ai_machinelearning_big_data
Decoupled video segmentation approach (DEVA), composed of task-specific image-level segmentation and class/task-agnostic bi-directional temporal propagation.
Новая модель сегментации видео для "отслеживания чего угодно" без обучения по видео для любой отдельной задачи.
ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
👍18🔥11❤6
TSMixer: An All-MLP Architecture for Time Series Forecasting
Time-series datasets in real-world scenarios are inherently multivariate and riddled with intricate dynamics. While recurrent or attention-based deep learning models have been the go-to solution to address these complexities, recent discoveries have shown that even basic univariate linear models can surpass them in performance on standard academic benchmarks. As an extension of this revelation, the paper introduces the Time-Series Mixer TSMixer. This innovative design, crafted by layering multi-layer perceptrons, hinges on mixing operations across both time and feature axes, ensuring an efficient extraction of data nuances.
Upon application, TSMixer has shown promising results. Not only does it hold its ground against specialized state-of-the-art models on well-known benchmarks, but it also trumps leading alternatives in the challenging M5 benchmark, a dataset that mirrors the intricacies of retail realities. The paper's outcomes emphasize the pivotal role of cross-variate and auxiliary data in refining time series forecasting.
Paper link: https://arxiv.org/abs/2303.06053
Code link: https://github.com/google-research/google-research/tree/master/tsmixer
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-tsmixer
#paperreview #deeplearning #timeseries #mlp
Time-series datasets in real-world scenarios are inherently multivariate and riddled with intricate dynamics. While recurrent or attention-based deep learning models have been the go-to solution to address these complexities, recent discoveries have shown that even basic univariate linear models can surpass them in performance on standard academic benchmarks. As an extension of this revelation, the paper introduces the Time-Series Mixer TSMixer. This innovative design, crafted by layering multi-layer perceptrons, hinges on mixing operations across both time and feature axes, ensuring an efficient extraction of data nuances.
Upon application, TSMixer has shown promising results. Not only does it hold its ground against specialized state-of-the-art models on well-known benchmarks, but it also trumps leading alternatives in the challenging M5 benchmark, a dataset that mirrors the intricacies of retail realities. The paper's outcomes emphasize the pivotal role of cross-variate and auxiliary data in refining time series forecasting.
Paper link: https://arxiv.org/abs/2303.06053
Code link: https://github.com/google-research/google-research/tree/master/tsmixer
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-tsmixer
#paperreview #deeplearning #timeseries #mlp
{kind=link}
👍23🔥7❤4👏2
Forwarded from Machinelearning
Diffusion model, whose text-conditional component works in a highly compressed latent space of images
Würstchen - это диффузионная модель, которой работает в сильно сжатом латентном пространстве изображений.
Почему это важно? Сжатие данных позволяет на порядки снизить вычислительные затраты как на обучение, так и на вывод модели.
Обучение на 1024×1024 изображениях гораздо затратное, чем на 32×32. Обычно в других моделях используется сравнительно небольшое сжатие, в пределах 4x - 8x пространственного сжатия.
Благодаря новой архитектуре достигается 42-кратное пространственное сжатие!
🤗 HF: https://huggingface.co/blog/wuertschen
📝 Paper: https://arxiv.org/abs/2306.00637
🚀 Demo: https://huggingface.co/spaces/warp-ai/Wuerstchen
ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
👍51❤16🔥9😁1
Hey, please boost our channel to allow us to post stories.
We solemnly swear to post only memes there.
https://t.iss.one/opendatascience?boost
We solemnly swear to post only memes there.
https://t.iss.one/opendatascience?boost
Telegram
Data Science by ODS.ai 🦜
Boost this channel to help it unlock additional features.
👎29💩18🖕17👍14😁9❤4
Here is very interesting notes about how behaves generation of stable diffusion trained on different datasets with the same noise. Seems very contrintuitive!
https://twitter.com/mokadyron/status/1706618451664474148
https://twitter.com/mokadyron/status/1706618451664474148
X (formerly Twitter)
Ron Mokady (@MokadyRon) on X
🔬Exploring Alignment in Diffusion Models - a 🧵
TL;DR: Diffusion models trained on *different datasets* can surprisingly generate similar images when fed with the same noise 🤯
[1/N]
TL;DR: Diffusion models trained on *different datasets* can surprisingly generate similar images when fed with the same noise 🤯
[1/N]
👍21❤14😁4👎2👏2😱2🔥1
🤣158👍67❤22🤯13😁6👏4👌4🔥3