
Forwarded from Artificial Intelligence
🔍 Exploiting Explainable Metrics for Augmented SGD
A new explainability metrics that measure the redundant information in a network's layers and exploit this information to augment the Stochastic Gradient Descent
Project
Code: https://github.com/mahdihosseini/rmsgd
Paper: https://arxiv.org/pdf/2203.16723v1.pdf
Dataset: https://paperswithcode.com/dataset/mhist
@ArtificialIntelligencedl
A new explainability metrics that measure the redundant information in a network's layers and exploit this information to augment the Stochastic Gradient Descent
Project
Code: https://github.com/mahdihosseini/rmsgd
Paper: https://arxiv.org/pdf/2203.16723v1.pdf
Dataset: https://paperswithcode.com/dataset/mhist
@ArtificialIntelligencedl
👍28❤1
Big step after first DALL·E — DALL·E 2
In January 2021, OpenAI introduced DALL·E. One year later, their newest system, DALL·E 2, generates more realistic and accurate images with 4x greater resolution.
The first DALL·E is a transformer model. It receives both the text and the image as a single stream of data containing up to 1280 tokens, and is trained using maximum likelihood to generate all of the tokens, one after another. This training procedure allows DALL·E to not only generate an image from scratch, but also to regenerate any rectangular region of an existing image that extends to the bottom-right corner, in a way that is consistent with the text prompt.
In the second DALL·E they reformated method and now it is CLIP + diffusion model.
CLIP to encode text prior and diffusion model to decode resulting embeding to high resolution image.
So it’s simply GLIDE, but with some tweaks. To generate high resolution images, they train two diffusion upsampler models.
But the results are amazing. Despite that it is cherry picks of course :))
- paper
- blog with images and demos
- video
In January 2021, OpenAI introduced DALL·E. One year later, their newest system, DALL·E 2, generates more realistic and accurate images with 4x greater resolution.
The first DALL·E is a transformer model. It receives both the text and the image as a single stream of data containing up to 1280 tokens, and is trained using maximum likelihood to generate all of the tokens, one after another. This training procedure allows DALL·E to not only generate an image from scratch, but also to regenerate any rectangular region of an existing image that extends to the bottom-right corner, in a way that is consistent with the text prompt.
In the second DALL·E they reformated method and now it is CLIP + diffusion model.
CLIP to encode text prior and diffusion model to decode resulting embeding to high resolution image.
So it’s simply GLIDE, but with some tweaks. To generate high resolution images, they train two diffusion upsampler models.
But the results are amazing. Despite that it is cherry picks of course :))
- paper
- blog with images and demos
- video
{kind=link}
🔥41👍16😁2🤔1
Forwarded from Silero News (Alexander)
Silero TTS V3 Finally Released
We have just released a brand new Russian speech synthesis model.
We have made a number of promises we kept:
- Model size reduced 2x;
- New models are 10x faster (!);
- We added flags to control stress;
- Now the models can make proper pauses;
- High quality voice added (and unlimited "random" voices);
- All speakers squeezed into the same model;
- Input length limitations lifted, now models can work with paragraphs of text;
- Pauses, speed and pitch can be controlled via SSML;
- Sampling rates of 8, 24 or 48 kHz are supported;
- Models are much more stable — they do not omit words anymore;
Next steps:
- Release models for the CIS languages, English, some European languages and Hindic languages
- Even further 2-4x speed up
- Updated stress model
- Phonemes support and and built-in voice transfer
Links:
- GitHub - https://github.com/snakers4/silero-models#text-to-speech
- Colab - https://colab.research.google.com/github/snakers4/silero-models/blob/master/examples_tts.ipynb
- Russian article - https://habr.com/ru/post/660565/
- English article - https://habr.com/ru/post/660571/
We have just released a brand new Russian speech synthesis model.
We have made a number of promises we kept:
- Model size reduced 2x;
- New models are 10x faster (!);
- We added flags to control stress;
- Now the models can make proper pauses;
- High quality voice added (and unlimited "random" voices);
- All speakers squeezed into the same model;
- Input length limitations lifted, now models can work with paragraphs of text;
- Pauses, speed and pitch can be controlled via SSML;
- Sampling rates of 8, 24 or 48 kHz are supported;
- Models are much more stable — they do not omit words anymore;
Next steps:
- Release models for the CIS languages, English, some European languages and Hindic languages
- Even further 2-4x speed up
- Updated stress model
- Phonemes support and and built-in voice transfer
Links:
- GitHub - https://github.com/snakers4/silero-models#text-to-speech
- Colab - https://colab.research.google.com/github/snakers4/silero-models/blob/master/examples_tts.ipynb
- Russian article - https://habr.com/ru/post/660565/
- English article - https://habr.com/ru/post/660571/
GitHub
GitHub - snakers4/silero-models: Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly…
Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly simple - snakers4/silero-models
👍58🤔2👎1
Imagen — new neural network for picture generation from Google
TLDR: Competitor of DALLE was released.
Imagen — text-to-image diffusion model with an unprecedented degree of photorealism and a deep level of language understanding. Imagen builds on the power of large transformer language models in understanding text and hinges on the strength of diffusion models in high-fidelity image generation. #Google key discovery is that generic large language models (e.g. T5), pretrained on text-only corpora, are surprisingly effective at encoding text for image synthesis: increasing the size of the language model in Imagen boosts both sample fidelity and image-text alignment much more than increasing the size of the image diffusion model.
Website: https://imagen.research.google
#GAN #CV #DL #Dalle
TLDR: Competitor of DALLE was released.
Imagen — text-to-image diffusion model with an unprecedented degree of photorealism and a deep level of language understanding. Imagen builds on the power of large transformer language models in understanding text and hinges on the strength of diffusion models in high-fidelity image generation. #Google key discovery is that generic large language models (e.g. T5), pretrained on text-only corpora, are surprisingly effective at encoding text for image synthesis: increasing the size of the language model in Imagen boosts both sample fidelity and image-text alignment much more than increasing the size of the image diffusion model.
Website: https://imagen.research.google
#GAN #CV #DL #Dalle
🔥38👍23🤯3❤2😱1
Hi, our friends @mike0sv and @agusch1n just open-sourced MLEM - a tool that helps you deploy your ML models as part of the DVC ecosystem
It’s a Python library + Command line tool.
TLDR:
📦 MLEM can package an ML model into a Docker image or a Python package, and deploy it to Heroku (we made them promise to add SageMaker, K8s and Seldon-core soon :parrot:).
⚙️ MLEM saves all model metadata to a human-readable text file: Python environment, model methods, model input & output data schema and more.
💅 MLEM helps you turn your Git repository into a Model Registry with features like ML model lifecycle management.
Read more in release blogpost: https://dvc.org/blog/MLEM-release
Also, check out the project: https://github.com/iterative/mlem
And the website: https://mlem.ai
Guys are happy to hear your feedback, discuss how this could be helpful for you, how MLEM compares to MLflow, etc.
Ask in the comments!
#mlops #opensource #deployment #dvc
It’s a Python library + Command line tool.
TLDR:
📦 MLEM can package an ML model into a Docker image or a Python package, and deploy it to Heroku (we made them promise to add SageMaker, K8s and Seldon-core soon :parrot:).
⚙️ MLEM saves all model metadata to a human-readable text file: Python environment, model methods, model input & output data schema and more.
💅 MLEM helps you turn your Git repository into a Model Registry with features like ML model lifecycle management.
Read more in release blogpost: https://dvc.org/blog/MLEM-release
Also, check out the project: https://github.com/iterative/mlem
And the website: https://mlem.ai
Guys are happy to hear your feedback, discuss how this could be helpful for you, how MLEM compares to MLflow, etc.
Ask in the comments!
#mlops #opensource #deployment #dvc
🔥32👍13👎3🤔1
Forwarded from Spark in me (Alexander)
The Cat is on the Mat
Interesting approach to be combined with Ngram embeddings when span boundaries are fuzzy.
I guess can be used downstream with existing sentence parsers.
Such models can be rough and dirty, cheap to train and robust.
- https://explosion.ai/blog/spancat
Interesting approach to be combined with Ngram embeddings when span boundaries are fuzzy.
I guess can be used downstream with existing sentence parsers.
Such models can be rough and dirty, cheap to train and robust.
- https://explosion.ai/blog/spancat
explosion.ai
Spancat: a new approach for span labeling · Explosion
The SpanCategorizer is a spaCy component that answers the NLP community's need to
have structured annotation for a wide variety of labeled spans, including long
phrases, non-named entities, or overlapping annotations. In this blog post, we're
excited to talk…
have structured annotation for a wide variety of labeled spans, including long
phrases, non-named entities, or overlapping annotations. In this blog post, we're
excited to talk…
👍18👏2🤔1
Forwarded from Spark in me (Alexander)
DALL-E Mini Explained with Demo
Tech report:
- Financed by Google Cloud and HF, essentially an advertising campaign for JAX, 8 person team
- 27x smaller than the original, trained on a single TPU v3-8 for only 3 days + ~3 weeks for experiments, 400M params
- 30m image-text pairs, only 2m used to fine-tune the VQGAN encoder
- Could use preemptible TPU instances
- Pre-trained BART Encoder
- Pre-trained VQGAN encoder
- Pre-trained CLIP is used to select the best generated images
- (so the actual cost probably is actually ~1-2 orders of magnitude higher)
- (compare with 20k GPU days stipulated by Sber)
- The report is expertly written and easy to read
Tech report:
- Financed by Google Cloud and HF, essentially an advertising campaign for JAX, 8 person team
- 27x smaller than the original, trained on a single TPU v3-8 for only 3 days + ~3 weeks for experiments, 400M params
- 30m image-text pairs, only 2m used to fine-tune the VQGAN encoder
- Could use preemptible TPU instances
- Pre-trained BART Encoder
- Pre-trained VQGAN encoder
- Pre-trained CLIP is used to select the best generated images
- (so the actual cost probably is actually ~1-2 orders of magnitude higher)
- (compare with 20k GPU days stipulated by Sber)
- The report is expertly written and easy to read
W&B
DALL-E Mini Explained
Generate images from a text prompt in this interactive report: DALL-E Mini Explained, a reproduction of OpenAI DALL·E. Made by Boris Dayma using W&B
👍13❤1
Forwarded from Machinelearning
💬 Yandex: An Open-source Yet another Language Model 100B
YaLM 100B is trained for 2 terabyte of text: dataset the Pile and web-pages, including not only Wikipedia, news articles, and books, but also Github and arxiv.org. Yandex has applied the generative neural networks YaLM in the recent Y1 search update. Now they are already helping to give answers to searches in Yandex and Alice.
Github: https://github.com/yandex/YaLM-100B
@ai_machinelearning_big_data
YaLM 100B is trained for 2 terabyte of text: dataset the Pile and web-pages, including not only Wikipedia, news articles, and books, but also Github and arxiv.org. Yandex has applied the generative neural networks YaLM in the recent Y1 search update. Now they are already helping to give answers to searches in Yandex and Alice.
Github: https://github.com/yandex/YaLM-100B
@ai_machinelearning_big_data
👍18🤔17👎6🔥6
In 15 minutes, start the last section of DataFestOnline 2022.
[language of presentations - Russian]
Mikhail Neretin - Topic management in Kafka
Evgeniy Sorokin - Human and ML => collaboration
Olga Filippova - Data drift & Concept drift: How to monitor ML models in production
Dmitry Beloborodov - Matrix factorizations with embeddings of variable dimension
Stanislav Yarkin - Summarization Is All You Need: summarization in RecSys
Artem Trofimov - MLOps by DS forces
Possible: Secret Speaker - MLEM: Version and deploy your ML models following Hitops principles
Start at 11:00 MSK (UTC+3)
There is an opportunity to ask a question to the speaker
Where?
Come to the session -> https://live.ods.ai/
Room: Last chance
Password: followthepinkparrot
[language of presentations - Russian]
Mikhail Neretin - Topic management in Kafka
Evgeniy Sorokin - Human and ML => collaboration
Olga Filippova - Data drift & Concept drift: How to monitor ML models in production
Dmitry Beloborodov - Matrix factorizations with embeddings of variable dimension
Stanislav Yarkin - Summarization Is All You Need: summarization in RecSys
Artem Trofimov - MLOps by DS forces
Possible: Secret Speaker - MLEM: Version and deploy your ML models following Hitops principles
Start at 11:00 MSK (UTC+3)
There is an opportunity to ask a question to the speaker
Where?
Come to the session -> https://live.ods.ai/
Room: Last chance
Password: followthepinkparrot
👍21
Forwarded from Binary Tree
Today mimesis has been designated as a critical project on PyPI.
It's ain't much, but I feel warm when I think about how many people use think I built.
Thank you everyone!
P.S If you don't know what the hell mimesis is, then go and check it out. Maybe you'll find it useful for you.
#mimesis #pypi #python
It's ain't much, but I feel warm when I think about how many people use think I built.
Thank you everyone!
P.S If you don't know what the hell mimesis is, then go and check it out. Maybe you'll find it useful for you.
#mimesis #pypi #python
👍32❤4😁1
No Language Left Behind
Scaling Human-Centered Machine Translation
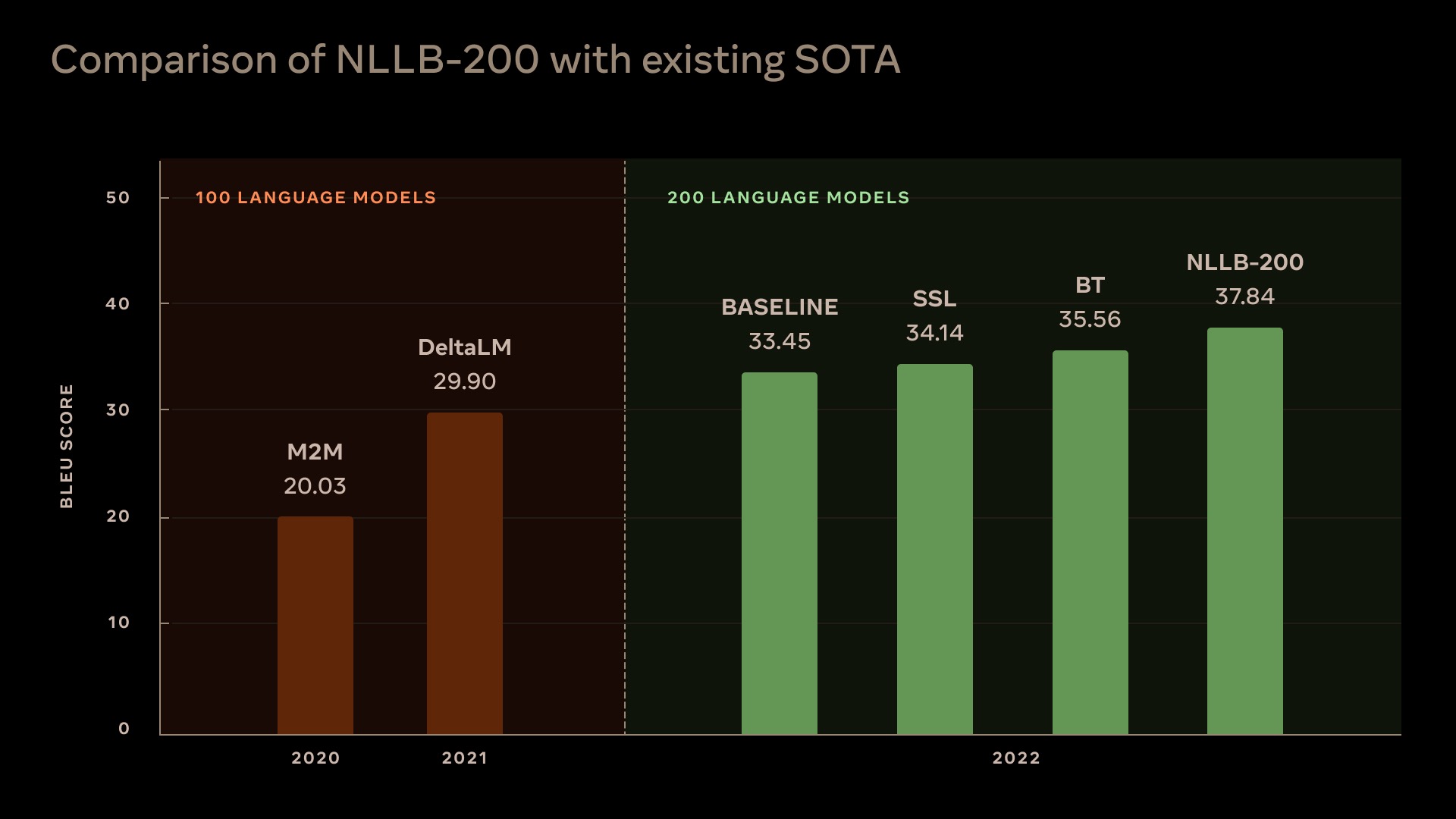
No Language Left Behind (NLLB) is a first-of-its-kind, AI breakthrough project that open-sources models capable of delivering high-quality translations directly between any pair of 200+ languages — including low-resource languages like Asturian, Luganda, Urdu and more. It aims to help people communicate with anyone, anywhere, regardless of their language preferences.
To enable the community to leverage and build on top of NLLB, the lab open source all they evaluation benchmarks (FLORES-200, NLLB-MD, Toxicity-200), LID models and training code, LASER3 encoders, data mining code, MMT training and inference code and our final NLLB-200 models and their smaller distilled versions, for easier use and adoption by the research community.
Paper: https://research.facebook.com/publications/no-language-left-behind/
Blog: https://ai.facebook.com/blog/nllb-200-high-quality-machine-translation/
GitHub: https://github.com/facebookresearch/fairseq/tree/26d62ae8fbf3deccf01a138d704be1e5c346ca9a
#nlp #translations #dl #datasets
Scaling Human-Centered Machine Translation
No Language Left Behind (NLLB) is a first-of-its-kind, AI breakthrough project that open-sources models capable of delivering high-quality translations directly between any pair of 200+ languages — including low-resource languages like Asturian, Luganda, Urdu and more. It aims to help people communicate with anyone, anywhere, regardless of their language preferences.
To enable the community to leverage and build on top of NLLB, the lab open source all they evaluation benchmarks (FLORES-200, NLLB-MD, Toxicity-200), LID models and training code, LASER3 encoders, data mining code, MMT training and inference code and our final NLLB-200 models and their smaller distilled versions, for easier use and adoption by the research community.
Paper: https://research.facebook.com/publications/no-language-left-behind/
Blog: https://ai.facebook.com/blog/nllb-200-high-quality-machine-translation/
GitHub: https://github.com/facebookresearch/fairseq/tree/26d62ae8fbf3deccf01a138d704be1e5c346ca9a
#nlp #translations #dl #datasets
{kind=link}
👍39👎1
{kind=link}
Data Science by ODS.ai 🦜
Big step after first DALL·E — DALL·E 2 In January 2021, OpenAI introduced DALL·E. One year later, their newest system, DALL·E 2, generates more realistic and accurate images with 4x greater resolution. The first DALL·E is a transformer model. It receives…
DALL·E Now Available in Beta
#Dalle by #openai was released for public (though obviously moderated) access. Join waitlist to play around.
Images are also available for commercial use.
By default user can generate 460 images, further generations (or variations on generated images) will be available on paid plan.
Link: https://openai.com/blog/dall-e-now-available-in-beta/
#image #CV #GAN #generation #generatinveart
#Dalle by #openai was released for public (though obviously moderated) access. Join waitlist to play around.
Images are also available for commercial use.
By default user can generate 460 images, further generations (or variations on generated images) will be available on paid plan.
Link: https://openai.com/blog/dall-e-now-available-in-beta/
#image #CV #GAN #generation #generatinveart
Openai
DALL·E now available in beta
We’ll invite 1 million people from our waitlist over the coming weeks. Users can create with DALL·E using free credits that refill every month, and buy additional credits in 115-generation increments for $15.
👍14❤9🤮2
Data Science by ODS.ai 🦜
DALL·E Now Available in Beta #Dalle by #openai was released for public (though obviously moderated) access. Join waitlist to play around. Images are also available for commercial use. By default user can generate 460 images, further generations (or variations…
Images, generated by #dalle on the input
#openai #generatinveart #generation
Illustration for dalle-2 beta release post, courtesy of @stas_kulesh.#openai #generatinveart #generation
👍9
Data Science by ODS.ai 🦜
Experimenting with CLIP+VQGAN to Create AI Generated Art Tips and tricks on prompts to #vqclip. TLDR: * Adding rendered in unreal engine, trending on artstation, top of /r/art improves image quality significally. * Using the pipe to split a prompt into…
Some stats to get the perspective of the development of #dalle
«Used 1000 prompts in Dalle over the last 2 days, about 9 hours each day. Of those, saved ~300. 50 I like enough to share w/ socials. 12 enough to rework for future projects. 3 were perfect, may mint someday. Curation is *1* step of AI art. I used to finish physicals in less time.»
Source: https://twitter.com/clairesilver12/status/1550709299797577729
#visualization #gan #generation #generatinveart #aiart #artgentips
«Used 1000 prompts in Dalle over the last 2 days, about 9 hours each day. Of those, saved ~300. 50 I like enough to share w/ socials. 12 enough to rework for future projects. 3 were perfect, may mint someday. Curation is *1* step of AI art. I used to finish physicals in less time.»
Source: https://twitter.com/clairesilver12/status/1550709299797577729
#visualization #gan #generation #generatinveart #aiart #artgentips
👍6👏2
Next-ViT: Next Generation Vision Transformer for Efficient Deployment in Realistic Industrial Scenarios
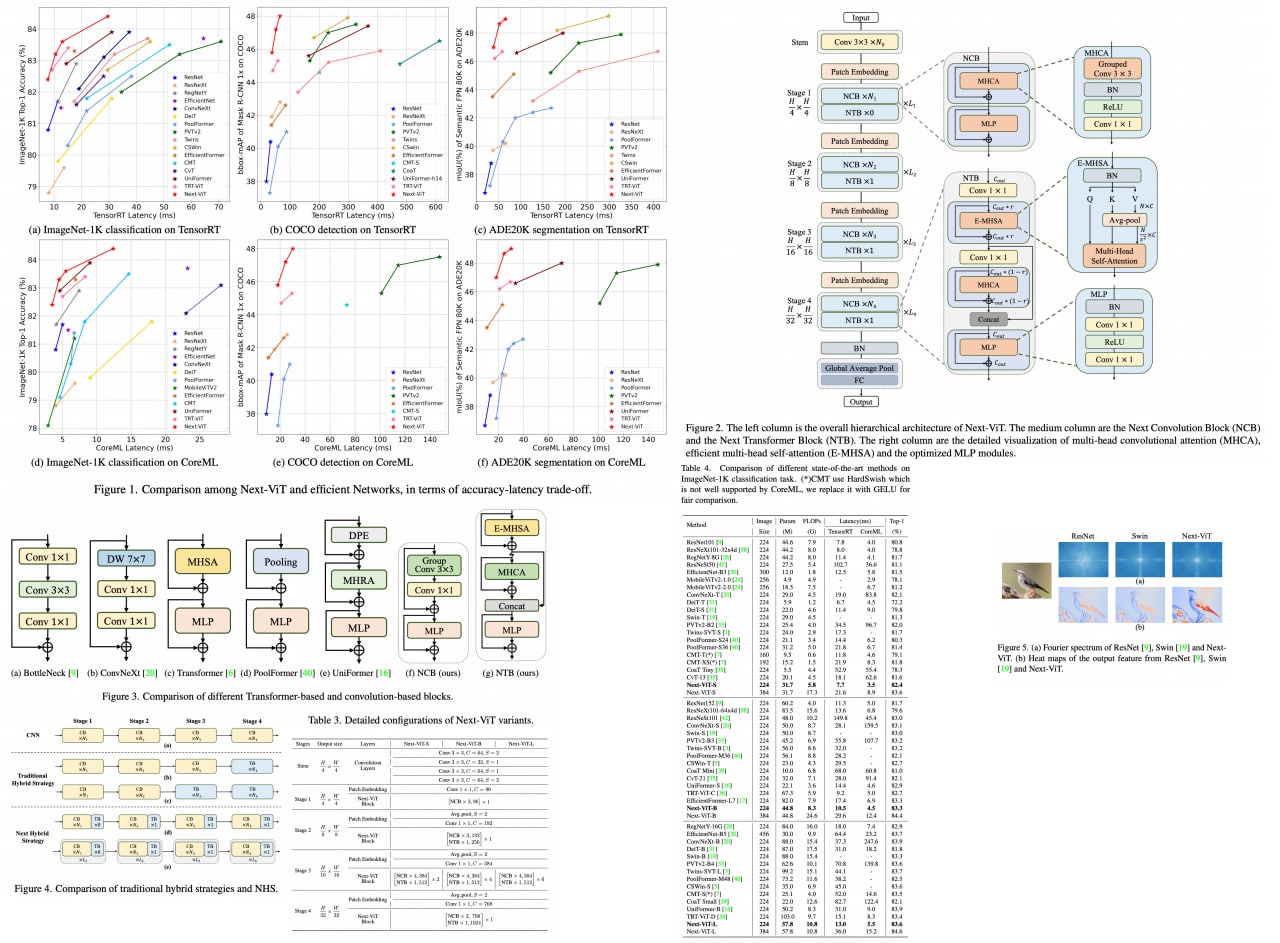
While vision transformers demostrate high performance, they can't be deployed as efficiently as CNNs in realistic industrial deployment scenarios, e. g. TensorRT or CoreML.
The authors propose Next-ViT, which has a higher latency/accuracy trade-off than existing CNN and ViT models. They develop two new architecture blocks and a new paradigm to stack them. As a result, On TensorRT, Next-ViT surpasses ResNet by 5.4 mAP (from 40.4 to 45.8) on COCO detection and 8.2% mIoU (from 38.8% to 47.0%) on ADE20K segmentation. Also, it achieves comparable performance with CSWin, while the inference speed is accelerated by
3.6×. On CoreML, Next-ViT surpasses EfficientFormer by 4.6 mAP (from 42.6 to 47.2) on COCO detection and 3.5% mIoU (from 45.2% to 48.7%) on ADE20K segmentation under similar latency.
Paper: https://arxiv.org/abs/2207.05501
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-next-vit
#deeplearning #cv #transformer #computervision
While vision transformers demostrate high performance, they can't be deployed as efficiently as CNNs in realistic industrial deployment scenarios, e. g. TensorRT or CoreML.
The authors propose Next-ViT, which has a higher latency/accuracy trade-off than existing CNN and ViT models. They develop two new architecture blocks and a new paradigm to stack them. As a result, On TensorRT, Next-ViT surpasses ResNet by 5.4 mAP (from 40.4 to 45.8) on COCO detection and 8.2% mIoU (from 38.8% to 47.0%) on ADE20K segmentation. Also, it achieves comparable performance with CSWin, while the inference speed is accelerated by
3.6×. On CoreML, Next-ViT surpasses EfficientFormer by 4.6 mAP (from 42.6 to 47.2) on COCO detection and 3.5% mIoU (from 45.2% to 48.7%) on ADE20K segmentation under similar latency.
Paper: https://arxiv.org/abs/2207.05501
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-next-vit
#deeplearning #cv #transformer #computervision
{kind=link}
👍24❤2😁2🔥1👏1
Forwarded from gonzo-обзоры ML статей
Now it is official.
I've started writing a book on JAX. This seems to be the first book ever on this topic.
For those who don't know, JAX is an exceptionally cool numeric computations library from Google, a kind of NumPy on steroids, with autodiff, XLA compilation, and hardware acceleration on TPU/GPU. JAX also brings the functional programming paradigm to deep learning.
JAX is heavily used for deep learning and already pretends to be the deep learning framework #3. Some companies, like DeepMind, have already switched to JAX internally. There are rumors that Google also switches to JAX.
JAX ecosystem is constantly growing. There are a lot of high-quality deep learning-related modules. But JAX is not limited to deep learning. There are many exciting applications and libraries on top of JAX for physics, including molecular dynamics, fluid dynamics, rigid body simulation, quantum computing, astrophysics, ocean modeling, and so on. There are libraries for distributed matrix factorization, streaming data processing, protein folding, and chemical modeling, with other new applications emerging constantly.
Anyway, it's a perfect time to start learning JAX!
The book is available today as a part of the Manning Early Access Program (MEAP), so you can read the book as I write it 🙂 This is a very smart way of learning something new, you do not have to wait until the complete book is ready. You can start learning right away, and at the moment the book is published, you already know everything. Your feedback will also be very valuable, and you can influence how the book is made.
Here's a link to the book: https://mng.bz/QvAG
If you want a decent discount, use the discount code mlsapunov. It will provide you with 40% off, and it's valid through August 11th.
I've started writing a book on JAX. This seems to be the first book ever on this topic.
For those who don't know, JAX is an exceptionally cool numeric computations library from Google, a kind of NumPy on steroids, with autodiff, XLA compilation, and hardware acceleration on TPU/GPU. JAX also brings the functional programming paradigm to deep learning.
JAX is heavily used for deep learning and already pretends to be the deep learning framework #3. Some companies, like DeepMind, have already switched to JAX internally. There are rumors that Google also switches to JAX.
JAX ecosystem is constantly growing. There are a lot of high-quality deep learning-related modules. But JAX is not limited to deep learning. There are many exciting applications and libraries on top of JAX for physics, including molecular dynamics, fluid dynamics, rigid body simulation, quantum computing, astrophysics, ocean modeling, and so on. There are libraries for distributed matrix factorization, streaming data processing, protein folding, and chemical modeling, with other new applications emerging constantly.
Anyway, it's a perfect time to start learning JAX!
The book is available today as a part of the Manning Early Access Program (MEAP), so you can read the book as I write it 🙂 This is a very smart way of learning something new, you do not have to wait until the complete book is ready. You can start learning right away, and at the moment the book is published, you already know everything. Your feedback will also be very valuable, and you can influence how the book is made.
Here's a link to the book: https://mng.bz/QvAG
If you want a decent discount, use the discount code mlsapunov. It will provide you with 40% off, and it's valid through August 11th.
🔥34👍27❤4👎1
Frankfurt Data Science welcome you back to the onsite event in Frankfurt-am-Main! As usual special - a demo of the new #dalle2 model by statworx team, Sebastian Heinz and Fabian Müller, socialising time, and a cocktail bar with free cocktails. Frankfurt DS Community thanks SAS for supporting and TechQuartier for hosting! They are looking for more supporters.
Event details:
Date: 24th August 2022
Time: 6PM - 11PM
Location: TechQuartier, Frankfurt
Register here
Event details:
Date: 24th August 2022
Time: 6PM - 11PM
Location: TechQuartier, Frankfurt
Register here
👍27❤17🔥1