
For almost 5 years channel picture beared arbitrary picture found in google and now we updated it with a proper new channel logo generated by neural network. Do you like it?

Okay, what about this one?
Anonymous Poll
39%
Better
11%
Love it!
51%
Can generate better (suggest in comments)
Forwarded from Towards NLP🇺🇦
The Annotated Transformer
3 years ago Alexander Rush created an incredible notebook supported the "Attention is All You Need" paper giving a possibility to dive in the implementation details and obtain your own transformer :)
We, SkoltechNLP group, within our Neual NLP 2021 course revisited this notebook for adapting it as a seminar. Of course, the original code was created 3 years ago and in some places is incompatible with new versions of required libraries. As a result, we created "runnable with 'Run all Cells' for April 2021" version of this notebook:
https://github.com/skoltech-nlp/annotated-transformer
So if you want to learn the Transformer and run an example in your computer or Colab, you can save your time and use current version of this great notebook. Also, we add some links to the amazing resources about Transformers that emerged during these years:
* Seq2Seq and Attention by Lena Voita;
* The Illustrated Transformer.
Enjoy your Transformer! And be free to ask any questions and leave comments.
3 years ago Alexander Rush created an incredible notebook supported the "Attention is All You Need" paper giving a possibility to dive in the implementation details and obtain your own transformer :)
We, SkoltechNLP group, within our Neual NLP 2021 course revisited this notebook for adapting it as a seminar. Of course, the original code was created 3 years ago and in some places is incompatible with new versions of required libraries. As a result, we created "runnable with 'Run all Cells' for April 2021" version of this notebook:
https://github.com/skoltech-nlp/annotated-transformer
So if you want to learn the Transformer and run an example in your computer or Colab, you can save your time and use current version of this great notebook. Also, we add some links to the amazing resources about Transformers that emerged during these years:
* Seq2Seq and Attention by Lena Voita;
* The Illustrated Transformer.
Enjoy your Transformer! And be free to ask any questions and leave comments.
GitHub
GitHub - s-nlp/annotated-transformer: https://nlp.seas.harvard.edu/2018/04/03/attention.html
https://nlp.seas.harvard.edu/2018/04/03/attention.html - s-nlp/annotated-transformer
MDETR: Modulated Detection for End-to-End Multi-Modal Understanding
Multi-modal reasoning systems rely on a pre-trained object detector to extract regions of interest from the image. However, this crucial module is typically used as a black box, trained independently of the downstream task and on a fixed vocabulary of objects and attributes.
The authors present an end-to-end approach to multi-modal reasoning systems, which works much better than using a separate pre-trained decoder.
They pre-train the network on 1.3M text-image pairs, mined from pre-existing multi-modal datasets having explicit alignment between phrases in text and objects in the image.
Fine-tuning this model achieves new SOTA results on phrase grounding, referring expression comprehension, and segmentation tasks. The approach could be extended to visual question answering.
Furthermore, the model is capable of handling the long tail of object categories.
Paper: https://arxiv.org/abs/2104.12763
Code: https://github.com/ashkamath/mdetr
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-mdetr
#deeplearning #multimodalreasoning #transformer
Multi-modal reasoning systems rely on a pre-trained object detector to extract regions of interest from the image. However, this crucial module is typically used as a black box, trained independently of the downstream task and on a fixed vocabulary of objects and attributes.
The authors present an end-to-end approach to multi-modal reasoning systems, which works much better than using a separate pre-trained decoder.
They pre-train the network on 1.3M text-image pairs, mined from pre-existing multi-modal datasets having explicit alignment between phrases in text and objects in the image.
Fine-tuning this model achieves new SOTA results on phrase grounding, referring expression comprehension, and segmentation tasks. The approach could be extended to visual question answering.
Furthermore, the model is capable of handling the long tail of object categories.
Paper: https://arxiv.org/abs/2104.12763
Code: https://github.com/ashkamath/mdetr
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-mdetr
#deeplearning #multimodalreasoning #transformer
{kind=link}
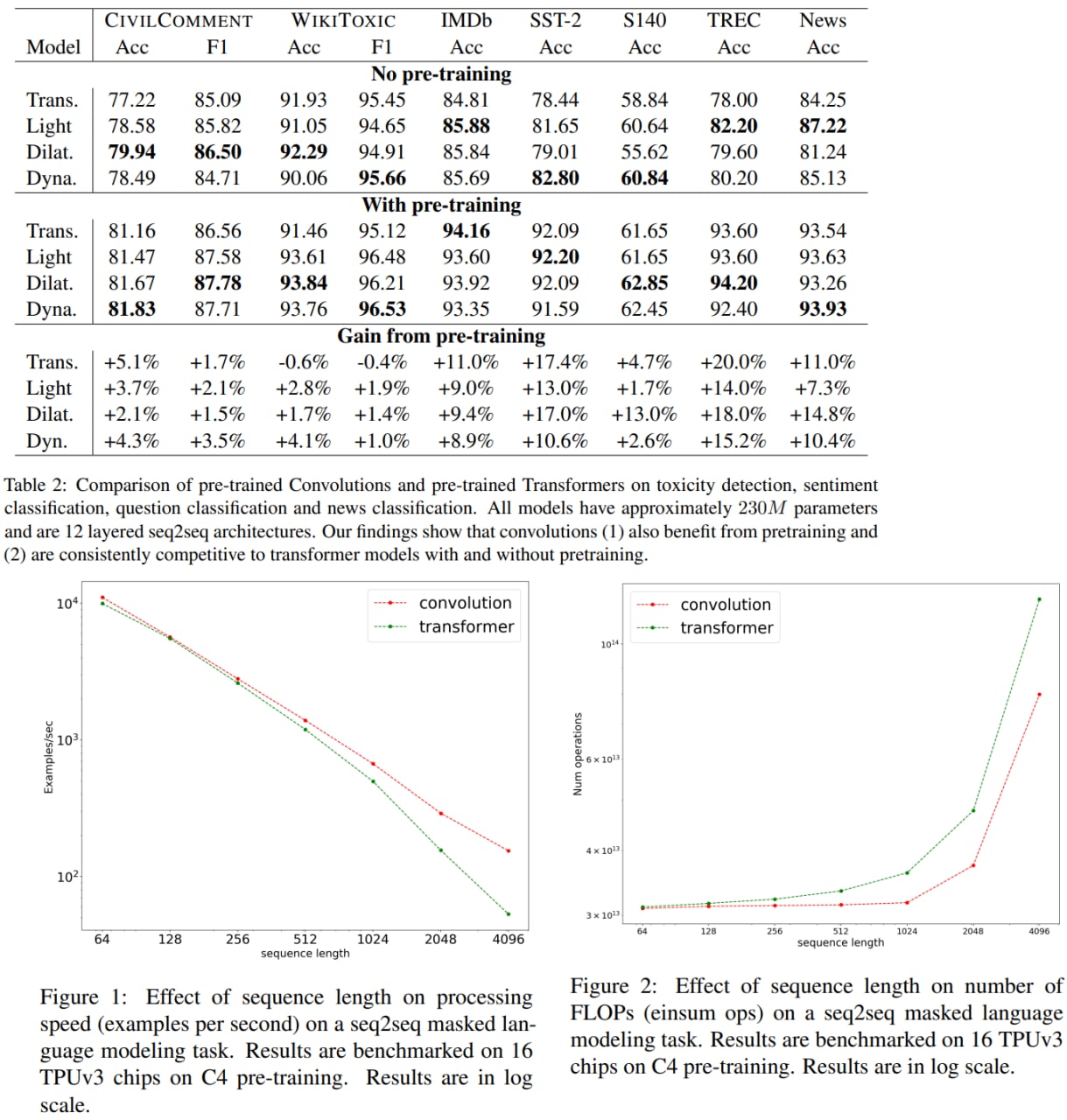
Are Pre-trained Convolutions Better than Pre-trained Transformers?
In this paper, the authors from Google Research wanted to investigate whether CNN architectures can be competitive compared to transformers on NLP problems. It turns out that pre-trained CNN models outperform pre-trained Transformers on some tasks; they also train faster and scale better to longer sequences.
Overall, the findings outlined in this paper suggest that conflating pre-training and architectural advances is misguided and that both advances should be considered independently. The authors believe their research paves the way for a healthy amount of optimism in alternative architectures.
Paper: https://arxiv.org/abs/2105.03322
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-cnnbettertransformers
#nlp #deeplearning #cnn #transformer #pretraining
In this paper, the authors from Google Research wanted to investigate whether CNN architectures can be competitive compared to transformers on NLP problems. It turns out that pre-trained CNN models outperform pre-trained Transformers on some tasks; they also train faster and scale better to longer sequences.
Overall, the findings outlined in this paper suggest that conflating pre-training and architectural advances is misguided and that both advances should be considered independently. The authors believe their research paves the way for a healthy amount of optimism in alternative architectures.
Paper: https://arxiv.org/abs/2105.03322
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-cnnbettertransformers
#nlp #deeplearning #cnn #transformer #pretraining
{kind=link}
Forwarded from Machinelearning
⚽️ Advancing sports analytics through AI research
🔥 Deepmind blog : https://deepmind.com/blog/article/advancing-sports-analytics-through-ai
A Dataset and Benchmarks: https://soccer-net.org/
Dataset: https://github.com/statsbomb/open-data
Paper: https://sites.google.com/view/ijcai-aisa-2021/
@ai_machinelearning_big_data
🔥 Deepmind blog : https://deepmind.com/blog/article/advancing-sports-analytics-through-ai
A Dataset and Benchmarks: https://soccer-net.org/
Dataset: https://github.com/statsbomb/open-data
Paper: https://sites.google.com/view/ijcai-aisa-2021/
@ai_machinelearning_big_data
{kind=link}
👍2
Data Fest returns! 🎉 And pretty soon
📅 Starting May 22nd and until June 19th we host an Online Fest just like we did last year:
🔸Our YouTube livestream return to a zoo-forest with 🦙🦌 and this time 🐻a bear cub! (RU)
🔸Unlimited networking in our spatial.chat - May 22nd will be the real community maelstrom (RU & EN)
🔸Tracks on our ODS.AI platform, with new types of activities and tons of new features (RU & EN)
Registration is live! Check out Data Fest 2021 website for the astonishing tracks we have in our programme and all the details 🤩
📅 Starting May 22nd and until June 19th we host an Online Fest just like we did last year:
🔸Our YouTube livestream return to a zoo-forest with 🦙🦌 and this time 🐻a bear cub! (RU)
🔸Unlimited networking in our spatial.chat - May 22nd will be the real community maelstrom (RU & EN)
🔸Tracks on our ODS.AI platform, with new types of activities and tons of new features (RU & EN)
Registration is live! Check out Data Fest 2021 website for the astonishing tracks we have in our programme and all the details 🤩
GAN Prior Embedded Network for Blind Face Restoration in the Wild
New proposed method allowed authors to improve the quality of old photoes
ArXiV: https://arxiv.org/abs/2105.06070
Github: https://github.com/yangxy/GPEN
#GAN #GPEN #blind_face_restoration #CV #DL
New proposed method allowed authors to improve the quality of old photoes
ArXiV: https://arxiv.org/abs/2105.06070
Github: https://github.com/yangxy/GPEN
#GAN #GPEN #blind_face_restoration #CV #DL
👍2
Forwarded from Binary Tree
Testing Python Applications with Pytest.
Pytest is a testing framework and test runner for Python. In this guide we will have a look at the most useful and common configuration and usage, including several pytest plugins and external libraries. Although Python comes with a unittest module in the standard library and there are other Python test frameworks like nose2 or Ward, pytest remains my favourite. The beauty of using simple functions instead of class hierarchies, one simple
#guide #testing #python #pytest
Pytest is a testing framework and test runner for Python. In this guide we will have a look at the most useful and common configuration and usage, including several pytest plugins and external libraries. Although Python comes with a unittest module in the standard library and there are other Python test frameworks like nose2 or Ward, pytest remains my favourite. The beauty of using simple functions instead of class hierarchies, one simple
assert instead of many different assert functions, built-in parametrized testing, a nice system of fixtures and the number of available plugins makes it a pleasure to use.#guide #testing #python #pytest
🥰2
Last Call: register to participate in the EMERGENCY DATAHACK
Online-hackathon for data-scientists and specialists in the fields of machine-learning, geography and geology.
Best solutions designed by the contestants during the event will be later utilized by the Ministry of the Russian Federation for Civil Defence, Emergencies and Elimination of Consequences of Natural Disasters (EMERCOM).
The contestants will be able to research and analyze data, for the first time provided by the Ministry. Also, the contestants will be able to work with data provided by the partners of the event: the Federal Service for Hydrometeorology (Roshydromet), the Federal Road Agency (Rosavtodor), GLONASS BDD, Tele2, Rostelecom, the Federal Water Resources Agency (Rosvodresources), the Main Directorate for Traffic Safety of Russia.
Date: May 28 – 30
Format: online
Registration: open until May 24 (the date is inclusive)
Link: https://emergencydatahack.ru
The aggregated prize fund for the event – 12 200 USD (in the national currency).
Online-hackathon for data-scientists and specialists in the fields of machine-learning, geography and geology.
Best solutions designed by the contestants during the event will be later utilized by the Ministry of the Russian Federation for Civil Defence, Emergencies and Elimination of Consequences of Natural Disasters (EMERCOM).
The contestants will be able to research and analyze data, for the first time provided by the Ministry. Also, the contestants will be able to work with data provided by the partners of the event: the Federal Service for Hydrometeorology (Roshydromet), the Federal Road Agency (Rosavtodor), GLONASS BDD, Tele2, Rostelecom, the Federal Water Resources Agency (Rosvodresources), the Main Directorate for Traffic Safety of Russia.
Date: May 28 – 30
Format: online
Registration: open until May 24 (the date is inclusive)
Link: https://emergencydatahack.ru
The aggregated prize fund for the event – 12 200 USD (in the national currency).
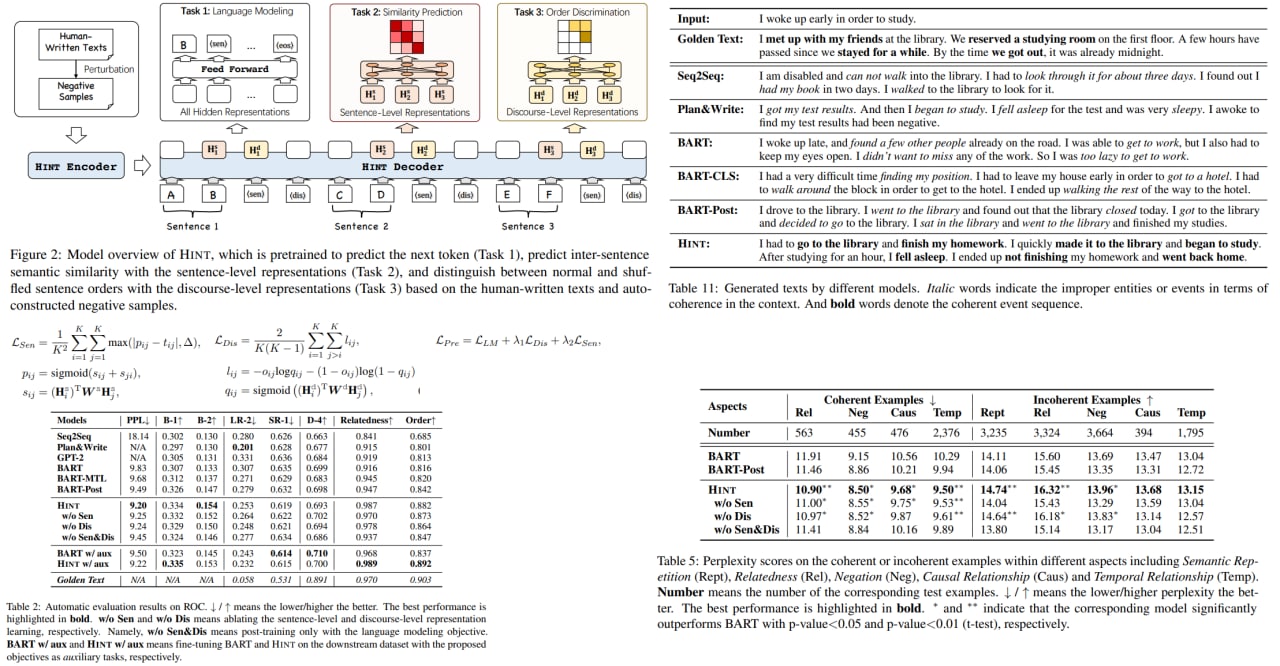
Long Text Generation by Modeling Sentence-Level and Discourse-Level Coherence
Modern NLP models still struggle with generating long and coherent texts, especially for open-ended dialogues such as story generation. The authors of the paper suggest a new model architecture HINT (a generation model equipped with HIgh-level representations for loNg Text generation) with two pre-training objectives to improve the language generation models: predicting inter-sentence semantic similarity and distinguishing between normal and shuffled sentence orders. Experiments and ablation studies show that these improvements result in more coherent texts than state-of-the-art baselines.
Paper: https://arxiv.org/abs/2105.08963
Code: https://github.com/thu-coai/HINT
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-hint
#deeplearning #nlp #nlg #pretraining
Modern NLP models still struggle with generating long and coherent texts, especially for open-ended dialogues such as story generation. The authors of the paper suggest a new model architecture HINT (a generation model equipped with HIgh-level representations for loNg Text generation) with two pre-training objectives to improve the language generation models: predicting inter-sentence semantic similarity and distinguishing between normal and shuffled sentence orders. Experiments and ablation studies show that these improvements result in more coherent texts than state-of-the-art baselines.
Paper: https://arxiv.org/abs/2105.08963
Code: https://github.com/thu-coai/HINT
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-hint
#deeplearning #nlp #nlg #pretraining
{kind=link}
👍1
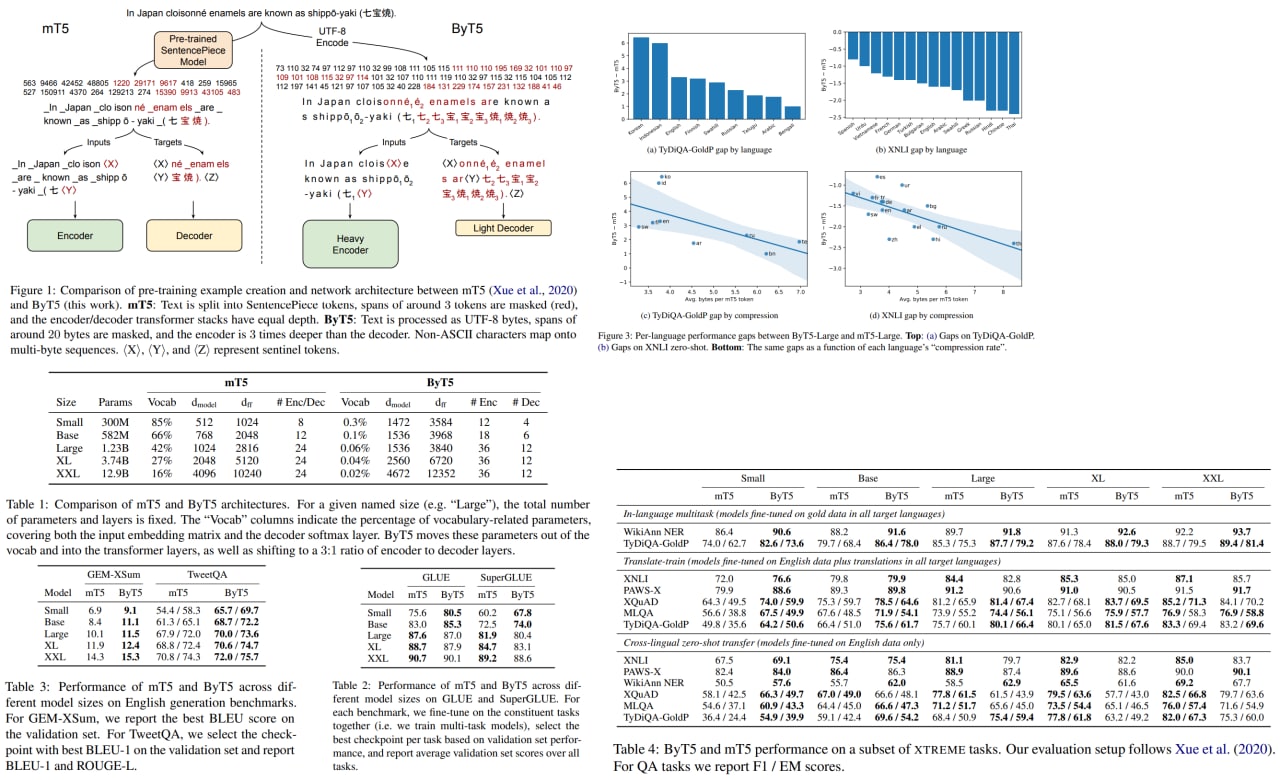
ByT5: Towards a token-free future with pre-trained byte-to-byte models
Pre-trained language models usually operate on the sequences of tokens, which are based on words or subword units.
Token-free models operate directly on the raw text (characters or bytes) instead. They can work with any language, are more robust to the noise, and don’t require preprocessing.
The authors use a modified mT5 architecture and show that their approach is competitive with token-level models.
Paper: https://arxiv.org/abs/2105.13626
Code: https://github.com/google-research/byt5
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-byt5
#nlp #deeplearning #transformer #pretraining
Pre-trained language models usually operate on the sequences of tokens, which are based on words or subword units.
Token-free models operate directly on the raw text (characters or bytes) instead. They can work with any language, are more robust to the noise, and don’t require preprocessing.
The authors use a modified mT5 architecture and show that their approach is competitive with token-level models.
Paper: https://arxiv.org/abs/2105.13626
Code: https://github.com/google-research/byt5
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-byt5
#nlp #deeplearning #transformer #pretraining
{kind=link}
Implementing original #UNet paper using #PyTorch
Video tutorial on how to code your own neural network from scratch.
Link: https://www.youtube.com/watch?v=u1loyDCoGbE&t=1s
Paper: https://arxiv.org/abs/1505.04597
Video tutorial on how to code your own neural network from scratch.
Link: https://www.youtube.com/watch?v=u1loyDCoGbE&t=1s
Paper: https://arxiv.org/abs/1505.04597
YouTube
Implementing original U-Net from scratch using PyTorch
In this video, I show you how to implement original UNet paper using PyTorch. UNet paper can be found here: https://arxiv.org/abs/1505.04597
Please subscribe and like the video to help me keep motivated to make awesome videos like this one. :)
To buy my…
Please subscribe and like the video to help me keep motivated to make awesome videos like this one. :)
To buy my…
👍2❤1
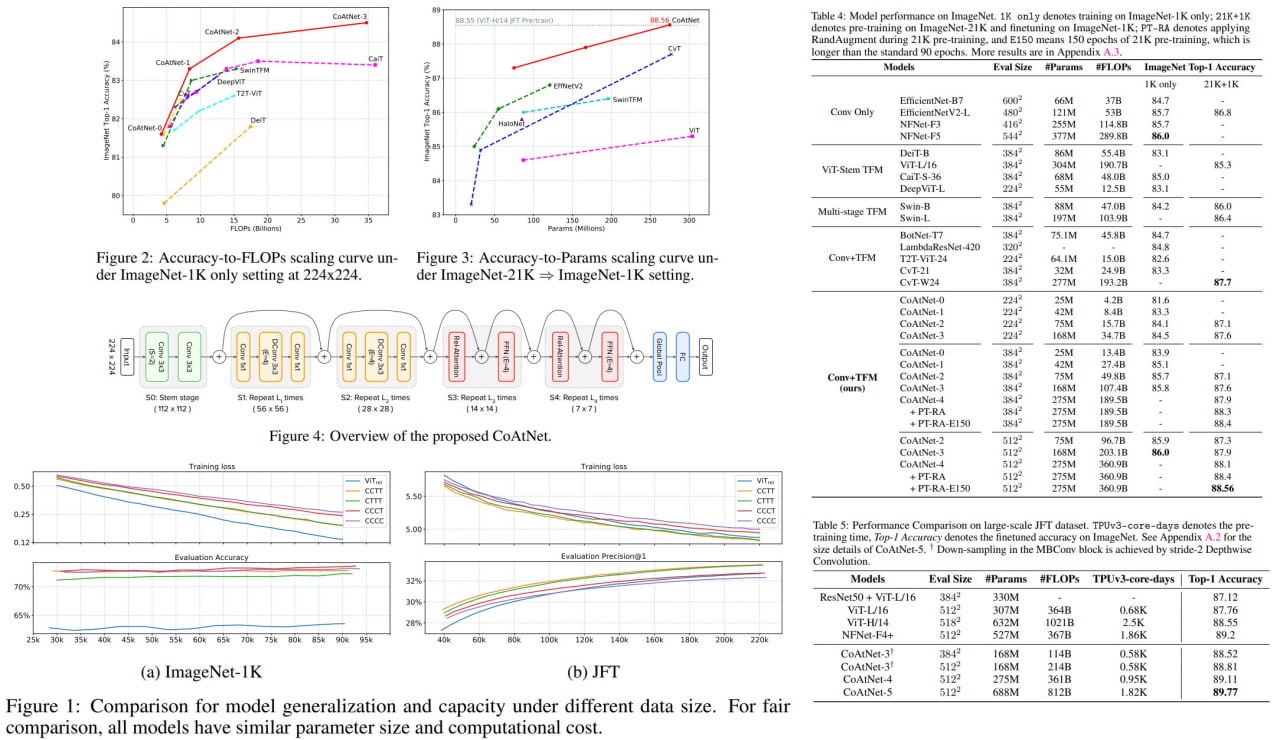
CoAtNet: Marrying Convolution and Attention for All Data Sizes
This is a paper on combining CNN and attention for Computer Vision tasks by Google Research.
The authors unify depthwise convolutions and self-attention via relative attention and vertically stack attention and convolutional layers in a specific way.
Resulting CoAtNets have good generalization, capacity and efficiency.
CoAtNet achieves 86.0% ImageNet top-1 accuracy without extra data and 89.77% with extra JFT data, outperforming the prior state of the art of both convolutional networks and Transformers. Notably, when pre-trained with 13M images from ImageNet-21K, CoAtNet achieves 88.56% top-1 accuracy, matching ViT-huge pre-trained with 300M images from JFT while using 23x less data.
Paper: https://arxiv.org/abs/2106.04803
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-coatnet
#cv #deeplearning #transformer #pretraining
This is a paper on combining CNN and attention for Computer Vision tasks by Google Research.
The authors unify depthwise convolutions and self-attention via relative attention and vertically stack attention and convolutional layers in a specific way.
Resulting CoAtNets have good generalization, capacity and efficiency.
CoAtNet achieves 86.0% ImageNet top-1 accuracy without extra data and 89.77% with extra JFT data, outperforming the prior state of the art of both convolutional networks and Transformers. Notably, when pre-trained with 13M images from ImageNet-21K, CoAtNet achieves 88.56% top-1 accuracy, matching ViT-huge pre-trained with 300M images from JFT while using 23x less data.
Paper: https://arxiv.org/abs/2106.04803
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-coatnet
#cv #deeplearning #transformer #pretraining
{kind=link}
Forwarded from opendatasciencebot
Microsoft's FLAML - Fast and Lightweight AutoML
Github: https://github.com/microsoft/FLAML
Code: https://github.com/microsoft/FLAML/tree/main/notebook/
Paper: https://arxiv.org/abs/2106.04815v1
@a
Github: https://github.com/microsoft/FLAML
Code: https://github.com/microsoft/FLAML/tree/main/notebook/
Paper: https://arxiv.org/abs/2106.04815v1
@a
👍1
Forwarded from Gradient Dude
Chinese researchers are very fond of doing extensive surveys of a particular sub-field of machine learning, listing the main works and the major breakthrough ideas. There are so many articles published every day, and it is impossible to read everything. Therefore, such reviews are valuable (if they are well written, of course, which is quite rare).
Recently there was a very good paper reviewing various variants of Transformers with a focus on language modeling (NLP). This is a must-read for anyone getting into the world of NLP and interested in Transformers. The paper discusses the basic principles of self-attention and such details of modern variants of Transformers as architecture modifications, pre-training, and various applications.
📝Paper: A Survey of Transformers.
Recently there was a very good paper reviewing various variants of Transformers with a focus on language modeling (NLP). This is a must-read for anyone getting into the world of NLP and interested in Transformers. The paper discusses the basic principles of self-attention and such details of modern variants of Transformers as architecture modifications, pre-training, and various applications.
📝Paper: A Survey of Transformers.