
Today @ 🕙11:00 CET.
☕️ 🥐🇫🇷 Parisian Data Breakfast will be held online 🌐! See you soon at
https://spatial.chat/s/DataBreakfast
☕️ 🥐🇫🇷 Parisian Data Breakfast will be held online 🌐! See you soon at
https://spatial.chat/s/DataBreakfast
app.spatial.chat
SpatialChat
Virtual space platform to help remote teams collaborate.
Forwarded from Self Supervised Boy
Self-supervision paper from arxiv for histopathology CV.
Authors draw inspiration from the process of how histopathologists tend to review the images, and how those images are stored. Histopathology images are multiscale slices of enormous size (tens of thousands pixels by one side), and area experts constantly move through different levels of magnification to keep in mind both fine and coarse structures of the tissue.
Therefore, in this paper the loss is proposed to capture relation between different magnification levels. Authors propose to train network to order concentric patches by their magnification level. They organise it as the classification task — network to predict id of the order permutation instead of predicting order itself.
Also, authors proposed specific architecture for this task and appended self-training procedure, as it was shown to boost results even after pre-training.
All this allows them to reach quality increase even in high-data regime.
My description of the architecture and loss expanded here.
Source of the work here.
Authors draw inspiration from the process of how histopathologists tend to review the images, and how those images are stored. Histopathology images are multiscale slices of enormous size (tens of thousands pixels by one side), and area experts constantly move through different levels of magnification to keep in mind both fine and coarse structures of the tissue.
Therefore, in this paper the loss is proposed to capture relation between different magnification levels. Authors propose to train network to order concentric patches by their magnification level. They organise it as the classification task — network to predict id of the order permutation instead of predicting order itself.
Also, authors proposed specific architecture for this task and appended self-training procedure, as it was shown to boost results even after pre-training.
All this allows them to reach quality increase even in high-data regime.
My description of the architecture and loss expanded here.
Source of the work here.
swanky-pleasure-bcf on Notion
Self-supervised driven consistency training for annotation efficient histopathology image analysis | Notion
In this paper authors gain insight for the new loss from the way histopathologists work with images. Since the enormous scale of the images for histopathological research it is stored in pyramid-like structure with different zoom level, so researches tend…
👍3
Unsupervised 3D Neural Rendering of Minecraft Worlds
Work on unsupervised neural rendering framework for generating photorealistic images of Minecraft (or any large 3D block worlds).
Why this is cool: this is a step towards better graphics for games.
Project Page: https://nvlabs.github.io/GANcraft/
YouTube: https://www.youtube.com/watch?v=1Hky092CGFQ&t=2s
#GAN #Nvidia #Minecraft
Work on unsupervised neural rendering framework for generating photorealistic images of Minecraft (or any large 3D block worlds).
Why this is cool: this is a step towards better graphics for games.
Project Page: https://nvlabs.github.io/GANcraft/
YouTube: https://www.youtube.com/watch?v=1Hky092CGFQ&t=2s
#GAN #Nvidia #Minecraft
Forwarded from Graph Machine Learning
Awesome graph repos
Collections of methods and papers for specific graph topics.
Graph-based Deep Learning Literature — Links to Conference Publications and the top 10 most-cited publications, Related workshops, Surveys / Literature Reviews / Books in graph-based deep learning.
awesome-graph-classification — A collection of graph classification methods, covering embedding, deep learning, graph kernel and factorization papers with reference implementations.
Awesome-Graph-Neural-Networks — A collection of resources related with graph neural networks..
awesome-graph — A curated list of resources for graph databases and graph computing tools
awesome-knowledge-graph — A curated list of Knowledge Graph related learning materials, databases, tools and other resources.
awesome-knowledge-graph — A curated list of awesome knowledge graph tutorials, projects and communities.
Awesome-GNN-Recommendation — graph mining for recommender systems.
awesome-graph-attack-papers — links to works about adversarial attacks and defenses on graph data or GNNs.
Graph-Adversarial-Learning — Attack-related papers, Defense-related papers, Robustness Certification papers, etc., ranging from 2017 to 2021.
awesome-self-supervised-gnn — Papers about self-supervised learning on GNNs.
awesome-self-supervised-learning-for-graphs — A curated list for awesome self-supervised graph representation learning resources.
Awesome-Graph-Contrastive-Learning — Collection of resources related with Graph Contrastive Learning.
Collections of methods and papers for specific graph topics.
Graph-based Deep Learning Literature — Links to Conference Publications and the top 10 most-cited publications, Related workshops, Surveys / Literature Reviews / Books in graph-based deep learning.
awesome-graph-classification — A collection of graph classification methods, covering embedding, deep learning, graph kernel and factorization papers with reference implementations.
Awesome-Graph-Neural-Networks — A collection of resources related with graph neural networks..
awesome-graph — A curated list of resources for graph databases and graph computing tools
awesome-knowledge-graph — A curated list of Knowledge Graph related learning materials, databases, tools and other resources.
awesome-knowledge-graph — A curated list of awesome knowledge graph tutorials, projects and communities.
Awesome-GNN-Recommendation — graph mining for recommender systems.
awesome-graph-attack-papers — links to works about adversarial attacks and defenses on graph data or GNNs.
Graph-Adversarial-Learning — Attack-related papers, Defense-related papers, Robustness Certification papers, etc., ranging from 2017 to 2021.
awesome-self-supervised-gnn — Papers about self-supervised learning on GNNs.
awesome-self-supervised-learning-for-graphs — A curated list for awesome self-supervised graph representation learning resources.
Awesome-Graph-Contrastive-Learning — Collection of resources related with Graph Contrastive Learning.
GitHub
GitHub - naganandy/graph-based-deep-learning-literature: links to conference publications in graph-based deep learning
links to conference publications in graph-based deep learning - naganandy/graph-based-deep-learning-literature
👍1
Data Science by ODS.ai 🦜
Starting -1 Data Science Breakfast as an audio chat
Starting 0 Data Breakfast as an audio chat in this channel in 15 minutes.
This is an informal online event where you can discuss anything related to Data Science (even vaguely related).
This is an informal online event where you can discuss anything related to Data Science (even vaguely related).
Forwarded from Gradient Dude
This media is not supported in your browser
VIEW IN TELEGRAM
Researchers from Berkeley rolled out VideoGPT - a transformer that generates videos.
The results are not super "WOW", but the architecture is quite simple and now it can be a starting point for all future work in this direction. As you know, GPT-3 for text generation was also not built right away. So let's will wait for method acceleration and quality improvement.
📝Paper
⚙️Code
🌐Project page
🃏Demo
The results are not super "WOW", but the architecture is quite simple and now it can be a starting point for all future work in this direction. As you know, GPT-3 for text generation was also not built right away. So let's will wait for method acceleration and quality improvement.
📝Paper
⚙️Code
🌐Project page
🃏Demo

For almost 5 years channel picture beared arbitrary picture found in google and now we updated it with a proper new channel logo generated by neural network. Do you like it?

Okay, what about this one?
Anonymous Poll
39%
Better
11%
Love it!
51%
Can generate better (suggest in comments)
Forwarded from Towards NLP🇺🇦
The Annotated Transformer
3 years ago Alexander Rush created an incredible notebook supported the "Attention is All You Need" paper giving a possibility to dive in the implementation details and obtain your own transformer :)
We, SkoltechNLP group, within our Neual NLP 2021 course revisited this notebook for adapting it as a seminar. Of course, the original code was created 3 years ago and in some places is incompatible with new versions of required libraries. As a result, we created "runnable with 'Run all Cells' for April 2021" version of this notebook:
https://github.com/skoltech-nlp/annotated-transformer
So if you want to learn the Transformer and run an example in your computer or Colab, you can save your time and use current version of this great notebook. Also, we add some links to the amazing resources about Transformers that emerged during these years:
* Seq2Seq and Attention by Lena Voita;
* The Illustrated Transformer.
Enjoy your Transformer! And be free to ask any questions and leave comments.
3 years ago Alexander Rush created an incredible notebook supported the "Attention is All You Need" paper giving a possibility to dive in the implementation details and obtain your own transformer :)
We, SkoltechNLP group, within our Neual NLP 2021 course revisited this notebook for adapting it as a seminar. Of course, the original code was created 3 years ago and in some places is incompatible with new versions of required libraries. As a result, we created "runnable with 'Run all Cells' for April 2021" version of this notebook:
https://github.com/skoltech-nlp/annotated-transformer
So if you want to learn the Transformer and run an example in your computer or Colab, you can save your time and use current version of this great notebook. Also, we add some links to the amazing resources about Transformers that emerged during these years:
* Seq2Seq and Attention by Lena Voita;
* The Illustrated Transformer.
Enjoy your Transformer! And be free to ask any questions and leave comments.
GitHub
GitHub - s-nlp/annotated-transformer: https://nlp.seas.harvard.edu/2018/04/03/attention.html
https://nlp.seas.harvard.edu/2018/04/03/attention.html - s-nlp/annotated-transformer
MDETR: Modulated Detection for End-to-End Multi-Modal Understanding
Multi-modal reasoning systems rely on a pre-trained object detector to extract regions of interest from the image. However, this crucial module is typically used as a black box, trained independently of the downstream task and on a fixed vocabulary of objects and attributes.
The authors present an end-to-end approach to multi-modal reasoning systems, which works much better than using a separate pre-trained decoder.
They pre-train the network on 1.3M text-image pairs, mined from pre-existing multi-modal datasets having explicit alignment between phrases in text and objects in the image.
Fine-tuning this model achieves new SOTA results on phrase grounding, referring expression comprehension, and segmentation tasks. The approach could be extended to visual question answering.
Furthermore, the model is capable of handling the long tail of object categories.
Paper: https://arxiv.org/abs/2104.12763
Code: https://github.com/ashkamath/mdetr
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-mdetr
#deeplearning #multimodalreasoning #transformer
Multi-modal reasoning systems rely on a pre-trained object detector to extract regions of interest from the image. However, this crucial module is typically used as a black box, trained independently of the downstream task and on a fixed vocabulary of objects and attributes.
The authors present an end-to-end approach to multi-modal reasoning systems, which works much better than using a separate pre-trained decoder.
They pre-train the network on 1.3M text-image pairs, mined from pre-existing multi-modal datasets having explicit alignment between phrases in text and objects in the image.
Fine-tuning this model achieves new SOTA results on phrase grounding, referring expression comprehension, and segmentation tasks. The approach could be extended to visual question answering.
Furthermore, the model is capable of handling the long tail of object categories.
Paper: https://arxiv.org/abs/2104.12763
Code: https://github.com/ashkamath/mdetr
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-mdetr
#deeplearning #multimodalreasoning #transformer
{kind=link}
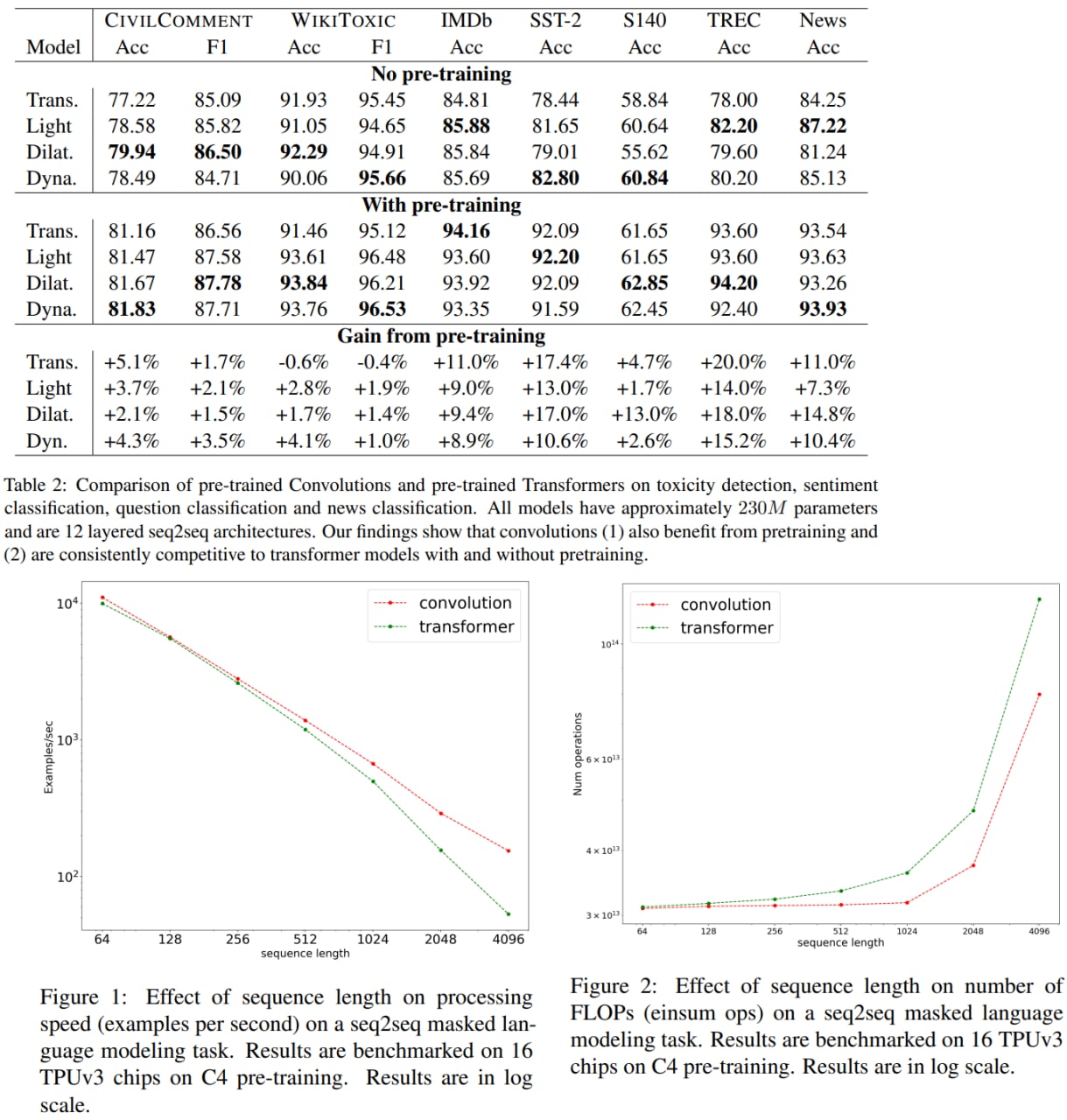
Are Pre-trained Convolutions Better than Pre-trained Transformers?
In this paper, the authors from Google Research wanted to investigate whether CNN architectures can be competitive compared to transformers on NLP problems. It turns out that pre-trained CNN models outperform pre-trained Transformers on some tasks; they also train faster and scale better to longer sequences.
Overall, the findings outlined in this paper suggest that conflating pre-training and architectural advances is misguided and that both advances should be considered independently. The authors believe their research paves the way for a healthy amount of optimism in alternative architectures.
Paper: https://arxiv.org/abs/2105.03322
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-cnnbettertransformers
#nlp #deeplearning #cnn #transformer #pretraining
In this paper, the authors from Google Research wanted to investigate whether CNN architectures can be competitive compared to transformers on NLP problems. It turns out that pre-trained CNN models outperform pre-trained Transformers on some tasks; they also train faster and scale better to longer sequences.
Overall, the findings outlined in this paper suggest that conflating pre-training and architectural advances is misguided and that both advances should be considered independently. The authors believe their research paves the way for a healthy amount of optimism in alternative architectures.
Paper: https://arxiv.org/abs/2105.03322
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-cnnbettertransformers
#nlp #deeplearning #cnn #transformer #pretraining
{kind=link}
Forwarded from Machinelearning
⚽️ Advancing sports analytics through AI research
🔥 Deepmind blog : https://deepmind.com/blog/article/advancing-sports-analytics-through-ai
A Dataset and Benchmarks: https://soccer-net.org/
Dataset: https://github.com/statsbomb/open-data
Paper: https://sites.google.com/view/ijcai-aisa-2021/
@ai_machinelearning_big_data
🔥 Deepmind blog : https://deepmind.com/blog/article/advancing-sports-analytics-through-ai
A Dataset and Benchmarks: https://soccer-net.org/
Dataset: https://github.com/statsbomb/open-data
Paper: https://sites.google.com/view/ijcai-aisa-2021/
@ai_machinelearning_big_data
{kind=link}
👍2
Data Fest returns! 🎉 And pretty soon
📅 Starting May 22nd and until June 19th we host an Online Fest just like we did last year:
🔸Our YouTube livestream return to a zoo-forest with 🦙🦌 and this time 🐻a bear cub! (RU)
🔸Unlimited networking in our spatial.chat - May 22nd will be the real community maelstrom (RU & EN)
🔸Tracks on our ODS.AI platform, with new types of activities and tons of new features (RU & EN)
Registration is live! Check out Data Fest 2021 website for the astonishing tracks we have in our programme and all the details 🤩
📅 Starting May 22nd and until June 19th we host an Online Fest just like we did last year:
🔸Our YouTube livestream return to a zoo-forest with 🦙🦌 and this time 🐻a bear cub! (RU)
🔸Unlimited networking in our spatial.chat - May 22nd will be the real community maelstrom (RU & EN)
🔸Tracks on our ODS.AI platform, with new types of activities and tons of new features (RU & EN)
Registration is live! Check out Data Fest 2021 website for the astonishing tracks we have in our programme and all the details 🤩
GAN Prior Embedded Network for Blind Face Restoration in the Wild
New proposed method allowed authors to improve the quality of old photoes
ArXiV: https://arxiv.org/abs/2105.06070
Github: https://github.com/yangxy/GPEN
#GAN #GPEN #blind_face_restoration #CV #DL
New proposed method allowed authors to improve the quality of old photoes
ArXiV: https://arxiv.org/abs/2105.06070
Github: https://github.com/yangxy/GPEN
#GAN #GPEN #blind_face_restoration #CV #DL
👍2