
Forwarded from Silero News (Alexander)
Silero TTS Released
Surprise! A quick pre-release of Silero Text-to-Speech models!
Speakers
10 voices (each available in 16 kHz and 8 kHz):
- 6 Russian voices;
- 1 English voice;
- 1 German voice, 1 Spanish voice, 1 French voice;
Why is this Different?
- One-line usage;
- A large library of voices;
- A fully end-to-end pipeline;
- Naturally sounding speech;
- No GPU or training required;
- Minimalism and lack of dependencies;
- Faster than real-time on one CPU thread (!!!);
- Support for
Links
- Try our TTS models here;
- Quick summary;
- Performance benchmarks;
Stay tuned for much more detailed PR releases and
Surprise! A quick pre-release of Silero Text-to-Speech models!
Speakers
10 voices (each available in 16 kHz and 8 kHz):
- 6 Russian voices;
- 1 English voice;
- 1 German voice, 1 Spanish voice, 1 French voice;
Why is this Different?
- One-line usage;
- A large library of voices;
- A fully end-to-end pipeline;
- Naturally sounding speech;
- No GPU or training required;
- Minimalism and lack of dependencies;
- Faster than real-time on one CPU thread (!!!);
- Support for
16kHz and 8kHz out of the box;Links
- Try our TTS models here;
- Quick summary;
- Performance benchmarks;
Stay tuned for much more detailed PR releases and
torch.hub release soon!GitHub
GitHub - snakers4/silero-models: Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly…
Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly simple - snakers4/silero-models
Few-Shot Text Classification with Triplet Networks, Data Augmentation, and Curriculum Learning
Few-shot text classification is a fundamental NLP task in which a model aims to classify text into a large number of categories, given only a few training examples per category.
The authors suggest several practical ideas to improving model performance on this task:
- using augmentations (synonym replacement, random insertion, random swap, random deletion) together with triplet loss
- using curriculum learning (two-stage and gradual)
Paper: https://arxiv.org/abs/2103.07552
Code: https://github.com/jasonwei20/triplet-loss
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-nlptriplettricks
#deeplearning #nlp #fewshotlearning #augmentation #curriculumlreaning
Few-shot text classification is a fundamental NLP task in which a model aims to classify text into a large number of categories, given only a few training examples per category.
The authors suggest several practical ideas to improving model performance on this task:
- using augmentations (synonym replacement, random insertion, random swap, random deletion) together with triplet loss
- using curriculum learning (two-stage and gradual)
Paper: https://arxiv.org/abs/2103.07552
Code: https://github.com/jasonwei20/triplet-loss
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-nlptriplettricks
#deeplearning #nlp #fewshotlearning #augmentation #curriculumlreaning
{kind=link}
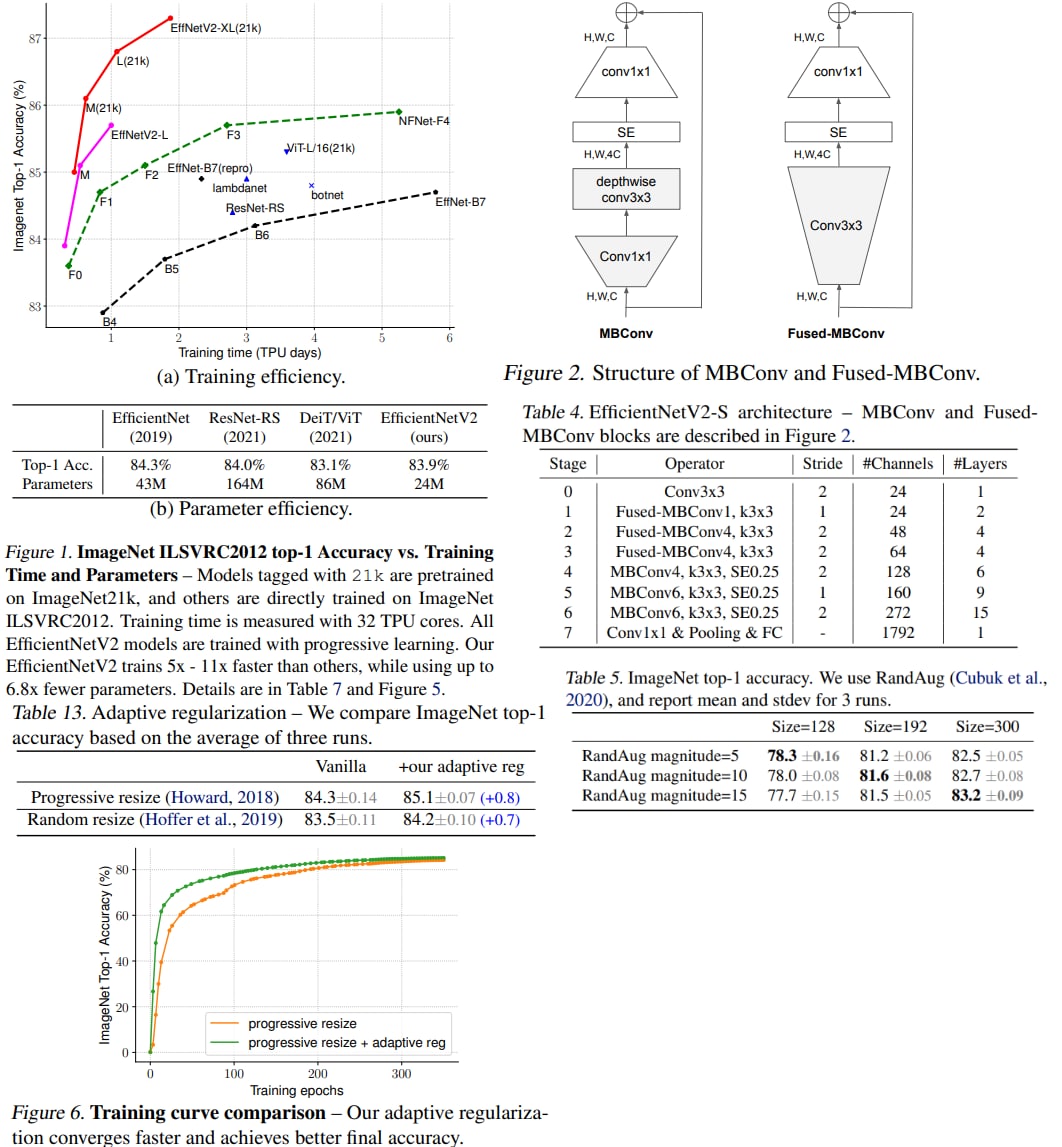
EfficientNetV2: Smaller Models and Faster Training
A new paper from Google Brain with a new SOTA architecture called EfficientNetV2. The authors develop a new family of CNN models that are optimized both for accuracy and training speed. The main improvements are:
- an improved training-aware neural architecture search with new building blocks and ideas to jointly optimize training speed and parameter efficiency;
- a new approach to progressive learning that adjusts regularization along with the image size;
As a result, the new approach can reach SOTA results while training faster (up to 11x) and smaller (up to 6.8x).
Paper: https://arxiv.org/abs/2104.00298
Code will be available here:
https://github.com/google/automl/tree/master/efficientnetv2
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-effnetv2
#cv #sota #nas #deeplearning
A new paper from Google Brain with a new SOTA architecture called EfficientNetV2. The authors develop a new family of CNN models that are optimized both for accuracy and training speed. The main improvements are:
- an improved training-aware neural architecture search with new building blocks and ideas to jointly optimize training speed and parameter efficiency;
- a new approach to progressive learning that adjusts regularization along with the image size;
As a result, the new approach can reach SOTA results while training faster (up to 11x) and smaller (up to 6.8x).
Paper: https://arxiv.org/abs/2104.00298
Code will be available here:
https://github.com/google/automl/tree/master/efficientnetv2
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-effnetv2
#cv #sota #nas #deeplearning
{kind=link}
👍1
🏥Self-supervised Learning for Medical images
Due to standard imaging procedures, medical images (X-ray, CT scans, etc) are usually well aligned.
This paper gives an opportunity to utilize such an alignment to automatically connect similar pairs of images for training.
GitHub: https://github.com/fhaghighi/TransVW
ArXiV: https://arxiv.org/abs/2102.10680
#biolearning #medical #dl #pytorch #keras
Due to standard imaging procedures, medical images (X-ray, CT scans, etc) are usually well aligned.
This paper gives an opportunity to utilize such an alignment to automatically connect similar pairs of images for training.
GitHub: https://github.com/fhaghighi/TransVW
ArXiV: https://arxiv.org/abs/2102.10680
#biolearning #medical #dl #pytorch #keras
GitHub
GitHub - fhaghighi/TransVW: Official Keras & PyTorch Implementation and Pre-trained Models for TransVW
Official Keras & PyTorch Implementation and Pre-trained Models for TransVW - fhaghighi/TransVW
👍2
Forwarded from Gradient Dude
LatentCLR: A Contrastive Learning Approach for Unsupervised Discovery of Interpretable Directions
A framework that learns meaningful directions in GANs' latent space using unsupervised contrastive learning. Instead of discovering fixed directions such as in previous work, this method can discover non-linear directions in pretrained StyleGAN2 and BigGAN models. The discovered directions may be used for image manipulation.
Authors use the differences caused by an edit operation on the feature activations to optimize the identifiability of each direction. The edit operations are modeled by several separate neural nets
📝 Paper
🛠 Code (next week)
#paper_tldr #cv #gan
A framework that learns meaningful directions in GANs' latent space using unsupervised contrastive learning. Instead of discovering fixed directions such as in previous work, this method can discover non-linear directions in pretrained StyleGAN2 and BigGAN models. The discovered directions may be used for image manipulation.
Authors use the differences caused by an edit operation on the feature activations to optimize the identifiability of each direction. The edit operations are modeled by several separate neural nets
∆_i(z) and learning. Given a latent code z and its generated image x = G(z), we seek to find edit operations ∆_i(z) such that the image x' = G(∆_i(z)) has semantically meaningful changes over x while still preserving the identity of x.📝 Paper
🛠 Code (next week)
#paper_tldr #cv #gan
Forwarded from Towards NLP🇺🇦
Conversational AI Reading List
List of interesting papers as well as some link to the lectures from Conversational AI course for Columbia University:
https://docs.google.com/spreadsheets/u/0/d/1nSKcnM5r9x82BdyPgn-obN1sRUlLC7zZ082a0132Igk/htmlview#gid=1523499517
List of interesting papers as well as some link to the lectures from Conversational AI course for Columbia University:
https://docs.google.com/spreadsheets/u/0/d/1nSKcnM5r9x82BdyPgn-obN1sRUlLC7zZ082a0132Igk/htmlview#gid=1523499517
Forwarded from Sysadmin Tools 🇺🇦
Advanced Database Systems
#database #db #sql #nosql
This course is a comprehensive study of the internals of modern database management systems. It will cover the core concepts and fundamentals of the components that are used in both high-performance transaction processing systems (OLTP) and large-scale analytical systems (OLAP).YouTube Playlist
#database #db #sql #nosql
CMU 15-721
Schedule - CMU 15-721 :: Advanced Database Systems (Spring 2020)
Course schedule with slides, lecture notes, and videos.
Generating Furry Cars: Disentangling Object Shape and Appearance across Multiple Domains
This is an interesting paper about learning and combining representations of object shape and appearance from the different domains (for example, dogs and cars). This allows to create a model, which borrows different properties from each domain and generates images, which don't exist in a single domain.
The main idea is the following:
- use FineGAN as a base model;
- represent object appearance with a differentiable histogram of visual features;
- optimize the generator so that images with different shapes but similar appearances produce similar histograms;
Paper: https://openreview.net/forum?id=M88oFvqp_9
Project link: https://utkarshojha.github.io/inter-domain-gan/
Code will be available here: https://github.com/utkarshojha/inter-domain-gan
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-furrycars
#cv #gan #deeplearning #contrastivelearning
This is an interesting paper about learning and combining representations of object shape and appearance from the different domains (for example, dogs and cars). This allows to create a model, which borrows different properties from each domain and generates images, which don't exist in a single domain.
The main idea is the following:
- use FineGAN as a base model;
- represent object appearance with a differentiable histogram of visual features;
- optimize the generator so that images with different shapes but similar appearances produce similar histograms;
Paper: https://openreview.net/forum?id=M88oFvqp_9
Project link: https://utkarshojha.github.io/inter-domain-gan/
Code will be available here: https://github.com/utkarshojha/inter-domain-gan
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-furrycars
#cv #gan #deeplearning #contrastivelearning
OpenReview
Generating Furry Cars: Disentangling Object Shape and Appearance...
We consider the novel task of learning disentangled representations of object shape and appearance across multiple domains (e.g., dogs and cars). The goal is to learn a generative model that...
Today @ 🕙11:00 CET.
☕️ 🥐🇫🇷 Parisian Data Breakfast will be held online 🌐! See you soon at
https://spatial.chat/s/DataBreakfast
☕️ 🥐🇫🇷 Parisian Data Breakfast will be held online 🌐! See you soon at
https://spatial.chat/s/DataBreakfast
app.spatial.chat
SpatialChat
Virtual space platform to help remote teams collaborate.
Forwarded from Self Supervised Boy
Self-supervision paper from arxiv for histopathology CV.
Authors draw inspiration from the process of how histopathologists tend to review the images, and how those images are stored. Histopathology images are multiscale slices of enormous size (tens of thousands pixels by one side), and area experts constantly move through different levels of magnification to keep in mind both fine and coarse structures of the tissue.
Therefore, in this paper the loss is proposed to capture relation between different magnification levels. Authors propose to train network to order concentric patches by their magnification level. They organise it as the classification task — network to predict id of the order permutation instead of predicting order itself.
Also, authors proposed specific architecture for this task and appended self-training procedure, as it was shown to boost results even after pre-training.
All this allows them to reach quality increase even in high-data regime.
My description of the architecture and loss expanded here.
Source of the work here.
Authors draw inspiration from the process of how histopathologists tend to review the images, and how those images are stored. Histopathology images are multiscale slices of enormous size (tens of thousands pixels by one side), and area experts constantly move through different levels of magnification to keep in mind both fine and coarse structures of the tissue.
Therefore, in this paper the loss is proposed to capture relation between different magnification levels. Authors propose to train network to order concentric patches by their magnification level. They organise it as the classification task — network to predict id of the order permutation instead of predicting order itself.
Also, authors proposed specific architecture for this task and appended self-training procedure, as it was shown to boost results even after pre-training.
All this allows them to reach quality increase even in high-data regime.
My description of the architecture and loss expanded here.
Source of the work here.
swanky-pleasure-bcf on Notion
Self-supervised driven consistency training for annotation efficient histopathology image analysis | Notion
In this paper authors gain insight for the new loss from the way histopathologists work with images. Since the enormous scale of the images for histopathological research it is stored in pyramid-like structure with different zoom level, so researches tend…
👍3
Unsupervised 3D Neural Rendering of Minecraft Worlds
Work on unsupervised neural rendering framework for generating photorealistic images of Minecraft (or any large 3D block worlds).
Why this is cool: this is a step towards better graphics for games.
Project Page: https://nvlabs.github.io/GANcraft/
YouTube: https://www.youtube.com/watch?v=1Hky092CGFQ&t=2s
#GAN #Nvidia #Minecraft
Work on unsupervised neural rendering framework for generating photorealistic images of Minecraft (or any large 3D block worlds).
Why this is cool: this is a step towards better graphics for games.
Project Page: https://nvlabs.github.io/GANcraft/
YouTube: https://www.youtube.com/watch?v=1Hky092CGFQ&t=2s
#GAN #Nvidia #Minecraft
Forwarded from Graph Machine Learning
Awesome graph repos
Collections of methods and papers for specific graph topics.
Graph-based Deep Learning Literature — Links to Conference Publications and the top 10 most-cited publications, Related workshops, Surveys / Literature Reviews / Books in graph-based deep learning.
awesome-graph-classification — A collection of graph classification methods, covering embedding, deep learning, graph kernel and factorization papers with reference implementations.
Awesome-Graph-Neural-Networks — A collection of resources related with graph neural networks..
awesome-graph — A curated list of resources for graph databases and graph computing tools
awesome-knowledge-graph — A curated list of Knowledge Graph related learning materials, databases, tools and other resources.
awesome-knowledge-graph — A curated list of awesome knowledge graph tutorials, projects and communities.
Awesome-GNN-Recommendation — graph mining for recommender systems.
awesome-graph-attack-papers — links to works about adversarial attacks and defenses on graph data or GNNs.
Graph-Adversarial-Learning — Attack-related papers, Defense-related papers, Robustness Certification papers, etc., ranging from 2017 to 2021.
awesome-self-supervised-gnn — Papers about self-supervised learning on GNNs.
awesome-self-supervised-learning-for-graphs — A curated list for awesome self-supervised graph representation learning resources.
Awesome-Graph-Contrastive-Learning — Collection of resources related with Graph Contrastive Learning.
Collections of methods and papers for specific graph topics.
Graph-based Deep Learning Literature — Links to Conference Publications and the top 10 most-cited publications, Related workshops, Surveys / Literature Reviews / Books in graph-based deep learning.
awesome-graph-classification — A collection of graph classification methods, covering embedding, deep learning, graph kernel and factorization papers with reference implementations.
Awesome-Graph-Neural-Networks — A collection of resources related with graph neural networks..
awesome-graph — A curated list of resources for graph databases and graph computing tools
awesome-knowledge-graph — A curated list of Knowledge Graph related learning materials, databases, tools and other resources.
awesome-knowledge-graph — A curated list of awesome knowledge graph tutorials, projects and communities.
Awesome-GNN-Recommendation — graph mining for recommender systems.
awesome-graph-attack-papers — links to works about adversarial attacks and defenses on graph data or GNNs.
Graph-Adversarial-Learning — Attack-related papers, Defense-related papers, Robustness Certification papers, etc., ranging from 2017 to 2021.
awesome-self-supervised-gnn — Papers about self-supervised learning on GNNs.
awesome-self-supervised-learning-for-graphs — A curated list for awesome self-supervised graph representation learning resources.
Awesome-Graph-Contrastive-Learning — Collection of resources related with Graph Contrastive Learning.
GitHub
GitHub - naganandy/graph-based-deep-learning-literature: links to conference publications in graph-based deep learning
links to conference publications in graph-based deep learning - naganandy/graph-based-deep-learning-literature
👍1
Data Science by ODS.ai 🦜
Starting -1 Data Science Breakfast as an audio chat
Starting 0 Data Breakfast as an audio chat in this channel in 15 minutes.
This is an informal online event where you can discuss anything related to Data Science (even vaguely related).
This is an informal online event where you can discuss anything related to Data Science (even vaguely related).
Forwarded from Gradient Dude
This media is not supported in your browser
VIEW IN TELEGRAM
Researchers from Berkeley rolled out VideoGPT - a transformer that generates videos.
The results are not super "WOW", but the architecture is quite simple and now it can be a starting point for all future work in this direction. As you know, GPT-3 for text generation was also not built right away. So let's will wait for method acceleration and quality improvement.
📝Paper
⚙️Code
🌐Project page
🃏Demo
The results are not super "WOW", but the architecture is quite simple and now it can be a starting point for all future work in this direction. As you know, GPT-3 for text generation was also not built right away. So let's will wait for method acceleration and quality improvement.
📝Paper
⚙️Code
🌐Project page
🃏Demo