
Media is too big
VIEW IN TELEGRAM
neuroplanets
took from the channel https://t.iss.one/NeuralShit
full video: https://www.youtube.com/watch?v=tPyPwW7W1GM
took from the channel https://t.iss.one/NeuralShit
full video: https://www.youtube.com/watch?v=tPyPwW7W1GM
👍1
Pie chart naming in different languages.
Credit: https://twitter.com/ElephantEating/status/1360988590814023683
Credit: https://twitter.com/ElephantEating/status/1360988590814023683
Forwarded from Towards NLP🇺🇦
2020 in ML and NLP publications
By conferences, countries, companies, universities and most productive scientists:
https://www.marekrei.com/blog/ml-and-nlp-publications-in-2020/
By conferences, countries, companies, universities and most productive scientists:
https://www.marekrei.com/blog/ml-and-nlp-publications-in-2020/
Marek Rei
ML and NLP Publications in 2020 - Marek Rei
I ran my paper analysis pipeline once again in order to get statistics for 2020. It certainly was an unusual year. While ML and NLP…
🔥1
Introducing Model Search: An Open Source Platform for Finding Optimal ML Models
#Google has released an open source #AutoML framework capable of hyperparameter tuning and ensembling.
Blog post: https://ai.googleblog.com/2021/02/introducing-model-search-open-source.html
Repo: https://github.com/google/model_search
#Google has released an open source #AutoML framework capable of hyperparameter tuning and ensembling.
Blog post: https://ai.googleblog.com/2021/02/introducing-model-search-open-source.html
Repo: https://github.com/google/model_search
👍1
Towards Causal Representation Learning
Work on how neural networks derive casual variables from low-level observations.
Link: https://arxiv.org/abs/2102.11107
#casuallearning #bengio #nn #DL
Work on how neural networks derive casual variables from low-level observations.
Link: https://arxiv.org/abs/2102.11107
#casuallearning #bengio #nn #DL
Real-World Super-Resolution of Face-Images from Surveillance Cameras
Most SR methods are trained on LR (low resolution) data, which is downsampled from HR (high resolution) data using bicubic interpolation, but real-life LR images are usually different, so models work worse on them. In this paper, the authors suggest using blur kernels, noise, and JPEG compression artifacts to generate LR images similar to the original ones.
Another suggested improvement is using ESRGAN and replacing VGG-loss with LPIPS-loss, as well as adding PatchGAN.
In addition, the authors show that NIMA metric better correlates with human perception (mean opinion rank) than traditional Image Quality Assessment methods.
Paper: https://arxiv.org/abs/2102.03113
#deeplearning #superresolution #gan #facesuperresolution
Most SR methods are trained on LR (low resolution) data, which is downsampled from HR (high resolution) data using bicubic interpolation, but real-life LR images are usually different, so models work worse on them. In this paper, the authors suggest using blur kernels, noise, and JPEG compression artifacts to generate LR images similar to the original ones.
Another suggested improvement is using ESRGAN and replacing VGG-loss with LPIPS-loss, as well as adding PatchGAN.
In addition, the authors show that NIMA metric better correlates with human perception (mean opinion rank) than traditional Image Quality Assessment methods.
Paper: https://arxiv.org/abs/2102.03113
#deeplearning #superresolution #gan #facesuperresolution
{kind=link}
👍1
Forwarded from Spark in me (Alexander)
Ukrainian Open STT 1000 Hours
Following the path of Open STT in Russian, now you can enjoy a similar dataset in Ukrainian:
- Torrent Link
- GitHub Link
Congratulations to our Ukrainian friends for finally publishing a diverse easily downloadable dataset!
Their pages / dataset UX is still a bit rough on the edges, but compared how fast for example Common Voice accumulates data (130 hours for Russian and 43 hours for Ukrainian), UA Open STT and Open STT remain the best resource for respective languages to date.
Also unlike the majority of STT datasets which are (i) behind a paywall or sponsored by corporations (ii) have limited scope / domains (iii) fit some sort of agenda (i.e. use more GPUs than necessary, use our bloated tools, etc), this dataset is legit made by real people.
Also recently corporations have taken up the trend of rehashing publicly available data, which is cool, but unique data is still nowhere to be seen for obvious reasons (except for Common Voice, which is decent only for English).
#dataset
Following the path of Open STT in Russian, now you can enjoy a similar dataset in Ukrainian:
- Torrent Link
- GitHub Link
Congratulations to our Ukrainian friends for finally publishing a diverse easily downloadable dataset!
Their pages / dataset UX is still a bit rough on the edges, but compared how fast for example Common Voice accumulates data (130 hours for Russian and 43 hours for Ukrainian), UA Open STT and Open STT remain the best resource for respective languages to date.
Also unlike the majority of STT datasets which are (i) behind a paywall or sponsored by corporations (ii) have limited scope / domains (iii) fit some sort of agenda (i.e. use more GPUs than necessary, use our bloated tools, etc), this dataset is legit made by real people.
Also recently corporations have taken up the trend of rehashing publicly available data, which is cool, but unique data is still nowhere to be seen for obvious reasons (except for Common Voice, which is decent only for English).
#dataset
GitHub
GitHub - snakers4/open_stt: Open STT
Open STT. Contribute to snakers4/open_stt development by creating an account on GitHub.
👍1
Forwarded from Towards NLP🇺🇦
Recent Advances in Language Model Fine-tuning
By Sebastian Ruder:
https://ruder.io/recent-advances-lm-fine-tuning/
By Sebastian Ruder:
https://ruder.io/recent-advances-lm-fine-tuning/
ruder.io
Recent Advances in Language Model Fine-tuning
This post provides an overview of recent methods to fine-tune large pre-trained language models.
Forwarded from Towards NLP🇺🇦
MIT Introduction to Deep Learning
And specifically, lecture about RNN and its modifications:
https://youtu.be/qjrad0V0uJE
The course is excellent as well, but more about image processing. For NLP beginners, such clear and elegant survey about RNNs will be quite useful. So, a lot of architectures in NLP models came from image processing tasks. If you want to recap some theory or get understanding of basics of DL — strong recommendation!
And specifically, lecture about RNN and its modifications:
https://youtu.be/qjrad0V0uJE
The course is excellent as well, but more about image processing. For NLP beginners, such clear and elegant survey about RNNs will be quite useful. So, a lot of architectures in NLP models came from image processing tasks. If you want to recap some theory or get understanding of basics of DL — strong recommendation!
YouTube
MIT 6.S191 (2021): Recurrent Neural Networks
MIT Introduction to Deep Learning 6.S191: Lecture 2
Recurrent Neural Networks
Lecturer: Ava Soleimany
January 2021
For all lectures, slides, and lab materials: https://introtodeeplearning.com
Lecture Outline
0:00 - Introduction
2:37 - Sequence modeling…
Recurrent Neural Networks
Lecturer: Ava Soleimany
January 2021
For all lectures, slides, and lab materials: https://introtodeeplearning.com
Lecture Outline
0:00 - Introduction
2:37 - Sequence modeling…
SEER: The start of a more powerful, flexible, and accessible era for computer vision
#SEER stands for SElf-supERvised architecture which follows the vision of Yan LeCunn that real breakthrough in quality of models is possible only with #selfsupervised learning.
And here it is — model which was trained using some enormous amount of data achieves 84.2 percent top-1 accuracy on ImageNet.
Paramus: 1.3B
Dataset: 1B random images
Hardware: 512 GPUs (unspecified)
Blogpost: https://ai.facebook.com/blog/seer-the-start-of-a-more-powerful-flexible-and-accessible-era-for-computer-vision
ArXiV: https://arxiv.org/pdf/2103.01988.pdf
#facebook #fair #cv #dl
#SEER stands for SElf-supERvised architecture which follows the vision of Yan LeCunn that real breakthrough in quality of models is possible only with #selfsupervised learning.
And here it is — model which was trained using some enormous amount of data achieves 84.2 percent top-1 accuracy on ImageNet.
Paramus: 1.3B
Dataset: 1B random images
Hardware: 512 GPUs (unspecified)
Blogpost: https://ai.facebook.com/blog/seer-the-start-of-a-more-powerful-flexible-and-accessible-era-for-computer-vision
ArXiV: https://arxiv.org/pdf/2103.01988.pdf
#facebook #fair #cv #dl
Meta
SEER: The start of a more powerful, flexible, and accessible era for computer vision
The future of AI is in creating systems that can learn directly from whatever information they’re given — whether it’s text, images, or another type of data — without relying on carefully curated and labeled data sets to teach them how to recognize objects…
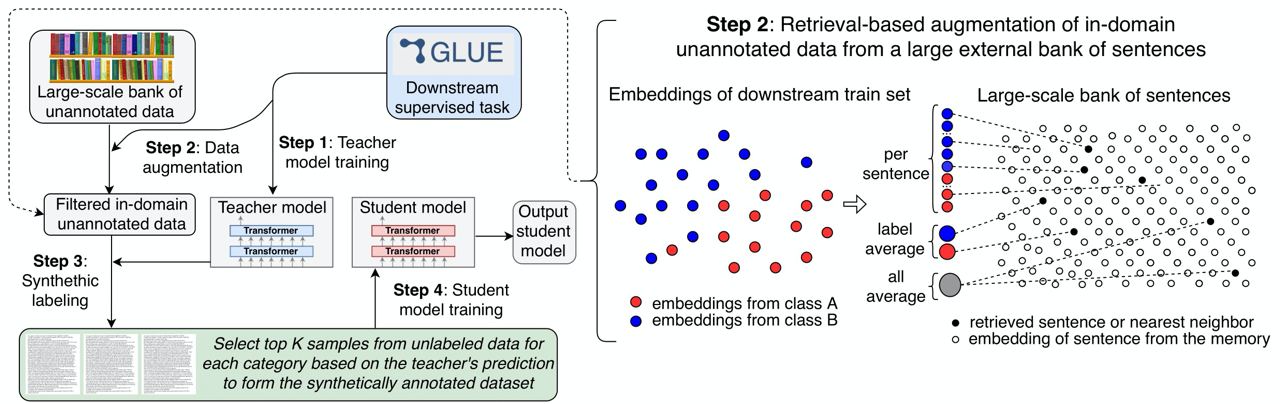
Self-training improves pretraining for natural language understanding
Authors suggested another way to leverage unlabeled data through semi-supervised learning. They use #SOTA sentence embeddings to structure the information of a very large bank of sentences.
Code: https://github.com/facebookresearch/SentAugment
Link: https://arxiv.org/abs/2010.02194
Authors suggested another way to leverage unlabeled data through semi-supervised learning. They use #SOTA sentence embeddings to structure the information of a very large bank of sentences.
Code: https://github.com/facebookresearch/SentAugment
Link: https://arxiv.org/abs/2010.02194
{kind=link}
Contrastive Semi-supervised Learning for ASR
Nowadays, pseudo-labeling is the most common method for pre-training automatic speech recognition (ASR) models, but in the case of low-resource setups and domain transfer, it suffers from a supervised teacher model’s degrading quality. The authors of this paper suggest using contrastive learning to overcome this problem.
CSL approach (Contrastive Semi-supervised Learning) uses teacher-generated predictions to select positive and negative examples instead of using pseudo-labels directly.
Experiments show that CSL has lower WER not only in comparison with standard CE-PL (Cross-Entropy pseudo-labeling) but also under low-resource and out-of-domain conditions.
To demonstrate its resilience to pseudo-labeling noise, the authors apply CSL pre-training in a low-resource setup with only 10hr of labeled data, where it reduces WER by 8% compared to the standard cross-entropy pseudo-labeling (CE-PL). This WER reduction increase to 19% with a teacher trained only on 1hr of labels and 17% for out-of-domain conditions.
Paper: https://arxiv.org/abs/2103.05149
#deeplearning #asr #contrastivelearning #semisupervised
Nowadays, pseudo-labeling is the most common method for pre-training automatic speech recognition (ASR) models, but in the case of low-resource setups and domain transfer, it suffers from a supervised teacher model’s degrading quality. The authors of this paper suggest using contrastive learning to overcome this problem.
CSL approach (Contrastive Semi-supervised Learning) uses teacher-generated predictions to select positive and negative examples instead of using pseudo-labels directly.
Experiments show that CSL has lower WER not only in comparison with standard CE-PL (Cross-Entropy pseudo-labeling) but also under low-resource and out-of-domain conditions.
To demonstrate its resilience to pseudo-labeling noise, the authors apply CSL pre-training in a low-resource setup with only 10hr of labeled data, where it reduces WER by 8% compared to the standard cross-entropy pseudo-labeling (CE-PL). This WER reduction increase to 19% with a teacher trained only on 1hr of labels and 17% for out-of-domain conditions.
Paper: https://arxiv.org/abs/2103.05149
#deeplearning #asr #contrastivelearning #semisupervised
{kind=link}
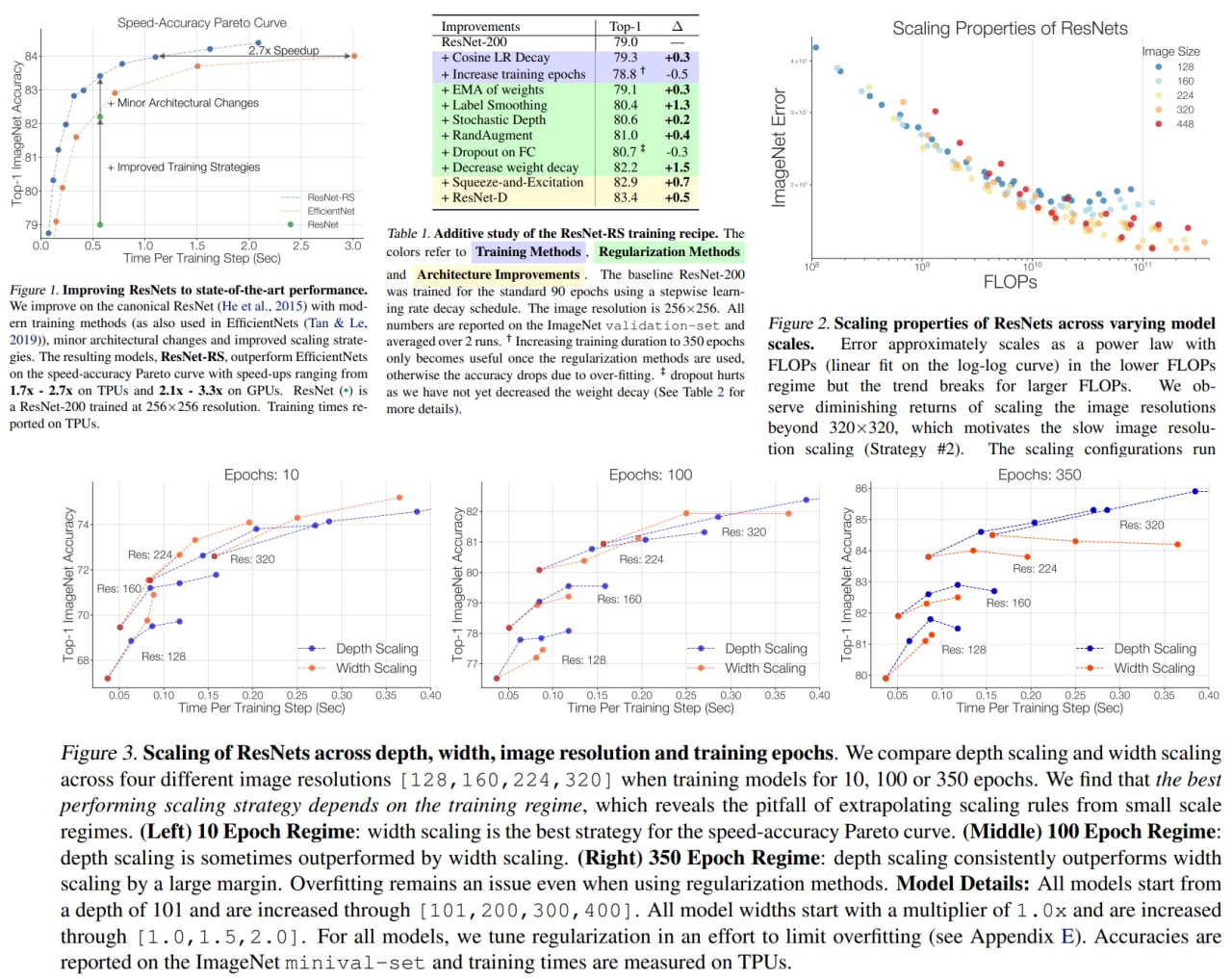
Revisiting ResNets: Improved Training and Scaling Strategies
The authors of the paper (from Google Brain and UC Berkeley) have decided to analyze the effects of the model architecture, training, and scaling strategies separately and concluded that these strategies might have a higher impact on the score than the architecture.
They offer two new strategies:
- scale model depth if overfitting is possible, scale model width otherwise
- increase image resolution slower than recommended in previous papers
Based on these ideas, the new architecture ResNet-RS was developed. It is 2.1x–3.3x faster than EfficientNets on GPU while reaching similar accuracy on ImageNet.
In semi-supervised learning, ResNet-RS achieves 86.2% top-1 ImageNet accuracy while being 4.7x faster than EfficientNet-NoisyStudent.
Transfer learning on downstream tasks also has improved performance.
The authors suggest using these ResNet-RS as a baseline for further research.
Paper: https://arxiv.org/abs/2103.07579
Code and checkpoints are available in TensorFlow:
https://github.com/tensorflow/models/tree/master/official/vision/beta
https://github.com/tensorflow/tpu/tree/master/models/official/resnet/resnet_rs
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-resnetsr
#deeplearning #computervision #sota
The authors of the paper (from Google Brain and UC Berkeley) have decided to analyze the effects of the model architecture, training, and scaling strategies separately and concluded that these strategies might have a higher impact on the score than the architecture.
They offer two new strategies:
- scale model depth if overfitting is possible, scale model width otherwise
- increase image resolution slower than recommended in previous papers
Based on these ideas, the new architecture ResNet-RS was developed. It is 2.1x–3.3x faster than EfficientNets on GPU while reaching similar accuracy on ImageNet.
In semi-supervised learning, ResNet-RS achieves 86.2% top-1 ImageNet accuracy while being 4.7x faster than EfficientNet-NoisyStudent.
Transfer learning on downstream tasks also has improved performance.
The authors suggest using these ResNet-RS as a baseline for further research.
Paper: https://arxiv.org/abs/2103.07579
Code and checkpoints are available in TensorFlow:
https://github.com/tensorflow/models/tree/master/official/vision/beta
https://github.com/tensorflow/tpu/tree/master/models/official/resnet/resnet_rs
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-resnetsr
#deeplearning #computervision #sota
{kind=link}
LightningDOT: Pre-training Visual-Semantic Embeddings for Real-Time Image-Text Retrieval
Pre-training transformers simultaneously on text and images proved to work quite well for model performance on multiple tasks, but such models usually have a low inference speed due to cross-modal attention. As a result, in practice, these models can hardly be used when low latency is required.
The authors of the paper offer a solution to this problem:
- pre-training on three new learning objectives
- extracting feature indexes offline
- using dot-product matching
- further re-ranking with a separate model
LightningDOT outperforms the previous state-of-the-art while significantly speeding up inference time by 600-2000× on Flickr30K and COCO image-text retrieval benchmarks.
Paper: https://arxiv.org/abs/2103.08784
Code and checkpoints will be available here:
https://github.com/intersun/LightningDOT
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-lightningdot
#pretraining #realtime #ranking #deeplearning
Pre-training transformers simultaneously on text and images proved to work quite well for model performance on multiple tasks, but such models usually have a low inference speed due to cross-modal attention. As a result, in practice, these models can hardly be used when low latency is required.
The authors of the paper offer a solution to this problem:
- pre-training on three new learning objectives
- extracting feature indexes offline
- using dot-product matching
- further re-ranking with a separate model
LightningDOT outperforms the previous state-of-the-art while significantly speeding up inference time by 600-2000× on Flickr30K and COCO image-text retrieval benchmarks.
Paper: https://arxiv.org/abs/2103.08784
Code and checkpoints will be available here:
https://github.com/intersun/LightningDOT
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-lightningdot
#pretraining #realtime #ranking #deeplearning
{kind=link}
👍2
Forwarded from Gradient Dude
Finetuning Pretrained Transformers into RNNs
Microsoft+Deepmind+...
Transformers is the current SOTA in language modeling. But they come with significant computational overhead, as the attention mechanism scales quadratically in sequence length. The memory consumption also grows linearly as the sequence becomes longer. This bottleneck limits the usage of large-scale pretrained generation models, such as GPT-3 or Image transformers.
Several efficient transformer variants have been proposed recently. For example, a linear-complexity recurrent variant has proven well suited for an autoregressive generation. It approximates the softmax attention with randomized or heuristic feature maps but can be difficult to train or yield suboptimal accuracy.
This work converts a pretrained transformer into its efficient linear-complexity recurrent counterpart with a learned feature map to improve the efficiency while retaining the accuracy. To achieve this, they replace the softmax attention in an off-the-shelf pretrained transformer with its linear-complexity recurrent alternative and then finetune.
➕ Pros:
+ The finetuning process requires much less GPU time than training the recurrent variants from scratch
+ Converting a large off-the-shelf transformer to a lightweight inference model w/o repeating the whole training procedure is very handy in many downstream applications.
📝 arxiv.org/abs/2103.13076
Microsoft+Deepmind+...
Transformers is the current SOTA in language modeling. But they come with significant computational overhead, as the attention mechanism scales quadratically in sequence length. The memory consumption also grows linearly as the sequence becomes longer. This bottleneck limits the usage of large-scale pretrained generation models, such as GPT-3 or Image transformers.
Several efficient transformer variants have been proposed recently. For example, a linear-complexity recurrent variant has proven well suited for an autoregressive generation. It approximates the softmax attention with randomized or heuristic feature maps but can be difficult to train or yield suboptimal accuracy.
This work converts a pretrained transformer into its efficient linear-complexity recurrent counterpart with a learned feature map to improve the efficiency while retaining the accuracy. To achieve this, they replace the softmax attention in an off-the-shelf pretrained transformer with its linear-complexity recurrent alternative and then finetune.
➕ Pros:
+ The finetuning process requires much less GPU time than training the recurrent variants from scratch
+ Converting a large off-the-shelf transformer to a lightweight inference model w/o repeating the whole training procedure is very handy in many downstream applications.
📝 arxiv.org/abs/2103.13076
{kind=link}
👍2
Predicting body movement based on data from socks
Researchers from #MIT has opened a new vector of opportunity for #techwear by making smart socks.
Website: https://www.csail.mit.edu/news/smart-clothes-can-measure-your-movements
Video: https://senstextile.csail.mit.edu/file/overview.mp4
Paper: https://www.nature.com/articles/s41928-021-00558-0
Researchers from #MIT has opened a new vector of opportunity for #techwear by making smart socks.
Website: https://www.csail.mit.edu/news/smart-clothes-can-measure-your-movements
Video: https://senstextile.csail.mit.edu/file/overview.mp4
Paper: https://www.nature.com/articles/s41928-021-00558-0
Forwarded from Silero News (Alexander)
Silero TTS Released
Surprise! A quick pre-release of Silero Text-to-Speech models!
Speakers
10 voices (each available in 16 kHz and 8 kHz):
- 6 Russian voices;
- 1 English voice;
- 1 German voice, 1 Spanish voice, 1 French voice;
Why is this Different?
- One-line usage;
- A large library of voices;
- A fully end-to-end pipeline;
- Naturally sounding speech;
- No GPU or training required;
- Minimalism and lack of dependencies;
- Faster than real-time on one CPU thread (!!!);
- Support for
Links
- Try our TTS models here;
- Quick summary;
- Performance benchmarks;
Stay tuned for much more detailed PR releases and
Surprise! A quick pre-release of Silero Text-to-Speech models!
Speakers
10 voices (each available in 16 kHz and 8 kHz):
- 6 Russian voices;
- 1 English voice;
- 1 German voice, 1 Spanish voice, 1 French voice;
Why is this Different?
- One-line usage;
- A large library of voices;
- A fully end-to-end pipeline;
- Naturally sounding speech;
- No GPU or training required;
- Minimalism and lack of dependencies;
- Faster than real-time on one CPU thread (!!!);
- Support for
16kHz and 8kHz out of the box;Links
- Try our TTS models here;
- Quick summary;
- Performance benchmarks;
Stay tuned for much more detailed PR releases and
torch.hub release soon!GitHub
GitHub - snakers4/silero-models: Silero Models: pre-trained text-to-speech models made embarrassingly simple
Silero Models: pre-trained text-to-speech models made embarrassingly simple - snakers4/silero-models
Few-Shot Text Classification with Triplet Networks, Data Augmentation, and Curriculum Learning
Few-shot text classification is a fundamental NLP task in which a model aims to classify text into a large number of categories, given only a few training examples per category.
The authors suggest several practical ideas to improving model performance on this task:
- using augmentations (synonym replacement, random insertion, random swap, random deletion) together with triplet loss
- using curriculum learning (two-stage and gradual)
Paper: https://arxiv.org/abs/2103.07552
Code: https://github.com/jasonwei20/triplet-loss
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-nlptriplettricks
#deeplearning #nlp #fewshotlearning #augmentation #curriculumlreaning
Few-shot text classification is a fundamental NLP task in which a model aims to classify text into a large number of categories, given only a few training examples per category.
The authors suggest several practical ideas to improving model performance on this task:
- using augmentations (synonym replacement, random insertion, random swap, random deletion) together with triplet loss
- using curriculum learning (two-stage and gradual)
Paper: https://arxiv.org/abs/2103.07552
Code: https://github.com/jasonwei20/triplet-loss
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-nlptriplettricks
#deeplearning #nlp #fewshotlearning #augmentation #curriculumlreaning
{kind=link}
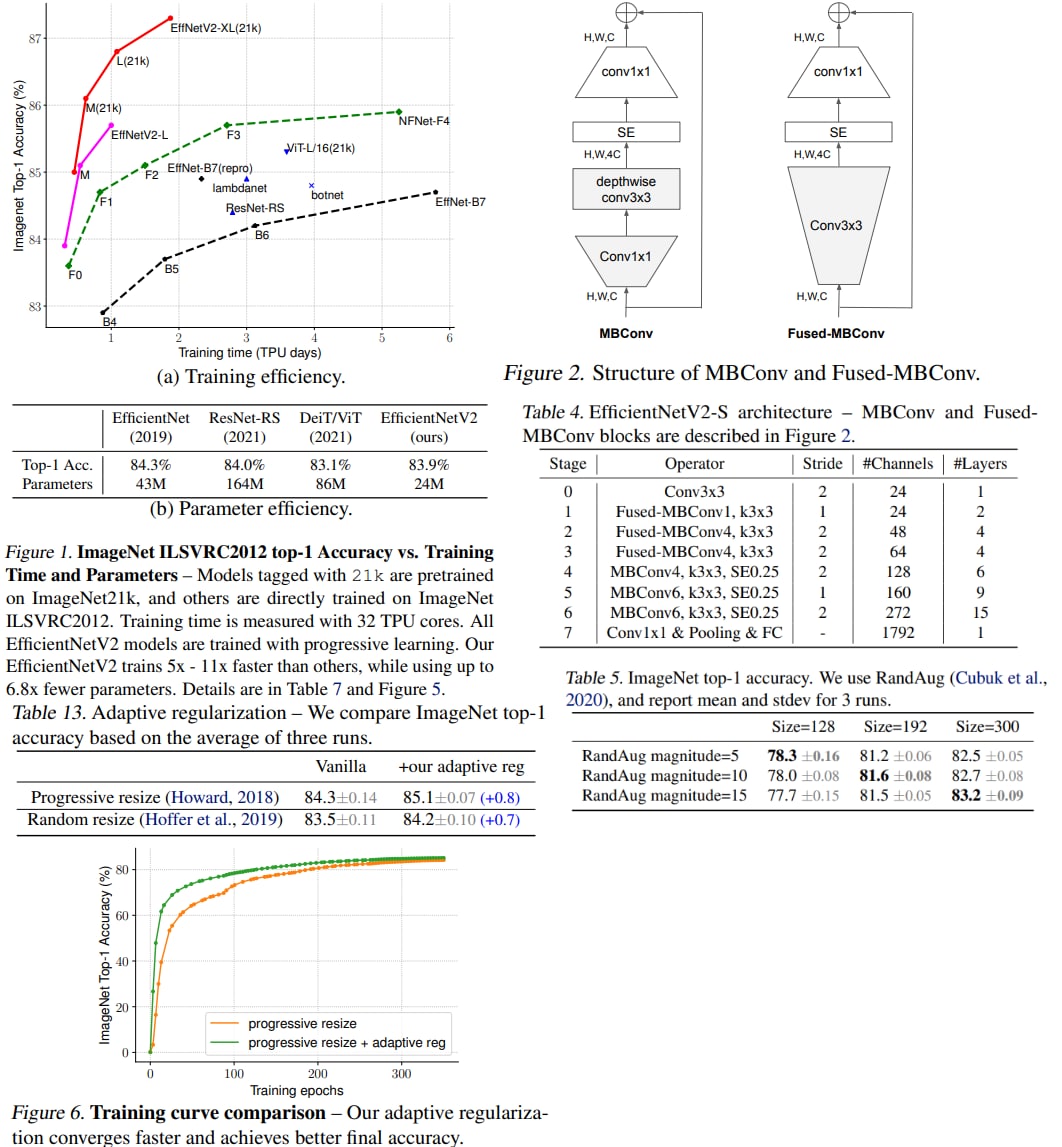
EfficientNetV2: Smaller Models and Faster Training
A new paper from Google Brain with a new SOTA architecture called EfficientNetV2. The authors develop a new family of CNN models that are optimized both for accuracy and training speed. The main improvements are:
- an improved training-aware neural architecture search with new building blocks and ideas to jointly optimize training speed and parameter efficiency;
- a new approach to progressive learning that adjusts regularization along with the image size;
As a result, the new approach can reach SOTA results while training faster (up to 11x) and smaller (up to 6.8x).
Paper: https://arxiv.org/abs/2104.00298
Code will be available here:
https://github.com/google/automl/tree/master/efficientnetv2
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-effnetv2
#cv #sota #nas #deeplearning
A new paper from Google Brain with a new SOTA architecture called EfficientNetV2. The authors develop a new family of CNN models that are optimized both for accuracy and training speed. The main improvements are:
- an improved training-aware neural architecture search with new building blocks and ideas to jointly optimize training speed and parameter efficiency;
- a new approach to progressive learning that adjusts regularization along with the image size;
As a result, the new approach can reach SOTA results while training faster (up to 11x) and smaller (up to 6.8x).
Paper: https://arxiv.org/abs/2104.00298
Code will be available here:
https://github.com/google/automl/tree/master/efficientnetv2
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-effnetv2
#cv #sota #nas #deeplearning
{kind=link}
👍1
🏥Self-supervised Learning for Medical images
Due to standard imaging procedures, medical images (X-ray, CT scans, etc) are usually well aligned.
This paper gives an opportunity to utilize such an alignment to automatically connect similar pairs of images for training.
GitHub: https://github.com/fhaghighi/TransVW
ArXiV: https://arxiv.org/abs/2102.10680
#biolearning #medical #dl #pytorch #keras
Due to standard imaging procedures, medical images (X-ray, CT scans, etc) are usually well aligned.
This paper gives an opportunity to utilize such an alignment to automatically connect similar pairs of images for training.
GitHub: https://github.com/fhaghighi/TransVW
ArXiV: https://arxiv.org/abs/2102.10680
#biolearning #medical #dl #pytorch #keras
GitHub
GitHub - fhaghighi/TransVW: Official Keras & PyTorch Implementation and Pre-trained Models for TransVW
Official Keras & PyTorch Implementation and Pre-trained Models for TransVW - fhaghighi/TransVW
👍2