
Yandex Team Talk at NeurIPS. Talk will be most interesting for those who are working on critical aspects of successful data collection and labeling.
Moderation team will focus on:
- Remoteness. A discussion about effectiveness and efficiency of remote work on crowdsourcing platforms.
- Fairness. How the working environment (e.g., a crowdsourcing platform) may help provide executors flexibility in choosing/switching tasks and working hours.
- Mechanisms. Discussion on bilateral mechanisms that not only provide flexibility to the performers, but also guarantee the quality of the result and the efficiency of the process to the customers.
Toloka's workshop info: https://clck.ru/SNwi3
#NeurIPS2020 #labeling #Yandex
Moderation team will focus on:
- Remoteness. A discussion about effectiveness and efficiency of remote work on crowdsourcing platforms.
- Fairness. How the working environment (e.g., a crowdsourcing platform) may help provide executors flexibility in choosing/switching tasks and working hours.
- Mechanisms. Discussion on bilateral mechanisms that not only provide flexibility to the performers, but also guarantee the quality of the result and the efficiency of the process to the customers.
Toloka's workshop info: https://clck.ru/SNwi3
#NeurIPS2020 #labeling #Yandex
Toloka: Data solutions to drive AI
Crowd Science Workshop at NeurIPS 2020
Remoteness, fairness, and mechanisms as challenges of data supply by humans for automation.
Supporting content decision makers with machine learning
#Netflix shared a post providing information about how they research and prepare data for new title production.
Link: https://netflixtechblog.com/supporting-content-decision-makers-with-machine-learning-995b7b76006f
#NLU #NLP #recommendation #embeddings
#Netflix shared a post providing information about how they research and prepare data for new title production.
Link: https://netflixtechblog.com/supporting-content-decision-makers-with-machine-learning-995b7b76006f
#NLU #NLP #recommendation #embeddings
{kind=link}
🔥Everything You Always Wanted To Know About GitHub (But Were Afraid To Ask)
ClickHouse team provided extensive statistics on GitHub, including but not limited to distribution of repositories by star count, top repositories by stars, affinity list, top labels etc.
All the data is available for download with instructions for ClickHouse import
Link: https://gh.clickhouse.tech/explorer/
#GitHub #ClickHouse #Yandex #statistics #EDA #engineerketing
ClickHouse team provided extensive statistics on GitHub, including but not limited to distribution of repositories by star count, top repositories by stars, affinity list, top labels etc.
All the data is available for download with instructions for ClickHouse import
Link: https://gh.clickhouse.tech/explorer/
#GitHub #ClickHouse #Yandex #statistics #EDA #engineerketing
If you know someone who might like our channel @opendatascience, please invite them or share this post
Forwarded from Graph Machine Learning
GML Newsletter - Issue #5: Was 2020 a good year for graph research?
My new newsletter is out! 🔥 Talking about my predictions for 2020, NeurIPS recordings, ICLR submissions and a few links that you probably have seen already, my friends!
My new newsletter is out! 🔥 Talking about my predictions for 2020, NeurIPS recordings, ICLR submissions and a few links that you probably have seen already, my friends!
Forwarded from Karim Iskakov - канал (Karim Iskakov)
Media is too big
VIEW IN TELEGRAM
New method to create relightable 3D selfies from Samsung AI (Moscow). You have: single smartphone video of a head with blinking flash. You get: sharp renderings under any lighting and from any viewpoint.
🌐 saic-violet.github.io/relightable-portrait
📝 arxiv.org/abs/2012.09963
📉 @loss_function_porn
🌐 saic-violet.github.io/relightable-portrait
📝 arxiv.org/abs/2012.09963
📉 @loss_function_porn
Hey, fellow researchers, engineers and students.
We can recommend you another great frequently updated channel, covering Machine and Deep Learning: @ai_machinelearning_big_data
We can recommend you another great frequently updated channel, covering Machine and Deep Learning: @ai_machinelearning_big_data
Forwarded from Machinelearning
YolactEdge: Real-time Instance Segmentation on the Edge
Github: https://github.com/haotian-liu/yolact_edge
Demo: https://www.youtube.com/watch?v=GBCK9SrcCLM
Paper: https://arxiv.org/abs/2012.12259
@ai_machinelearning_big_data
Github: https://github.com/haotian-liu/yolact_edge
Demo: https://www.youtube.com/watch?v=GBCK9SrcCLM
Paper: https://arxiv.org/abs/2012.12259
@ai_machinelearning_big_data
QVMix and QVMix-Max: Extending the Deep Quality-Value Family of Algorithms to Cooperative Multi-Agent Reinforcement Learning
Paper extends the Deep Quality-Value (DQV) family of al-
gorithms to multi-agent reinforcement learning and outperforms #SOTA
ArXiV: https://arxiv.org/abs/2012.12062
#DQV #RL #Starcraft
Paper extends the Deep Quality-Value (DQV) family of al-
gorithms to multi-agent reinforcement learning and outperforms #SOTA
ArXiV: https://arxiv.org/abs/2012.12062
#DQV #RL #Starcraft
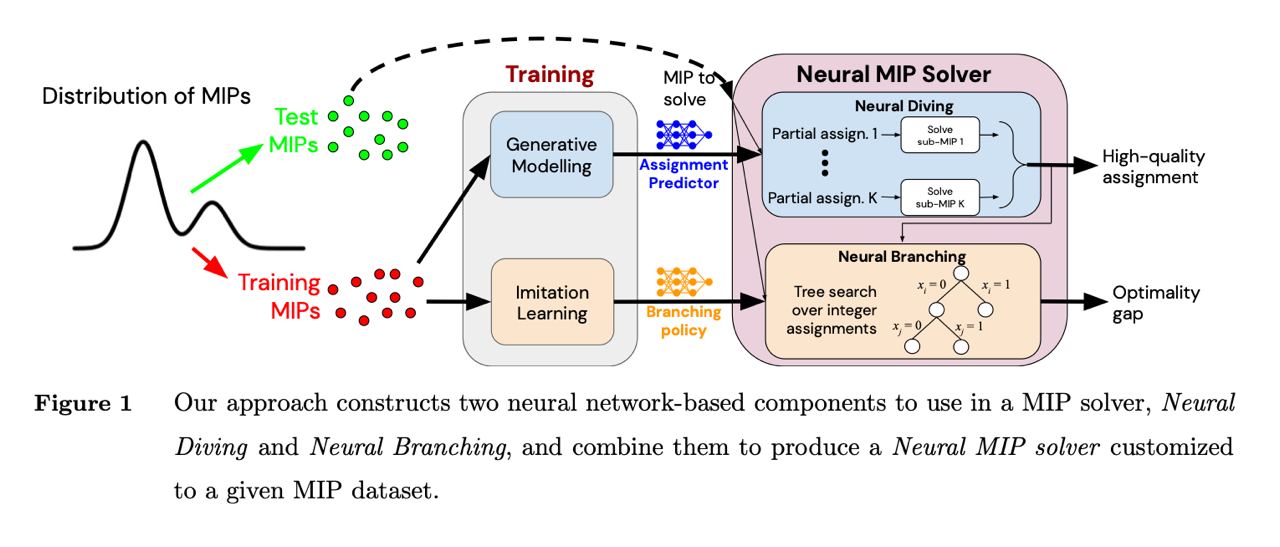
Solving Mixed Integer Programs Using Neural Networks
Article on speeding up Mixed Integer Programs with ML. Mixed Integer Programs are usually NP-hard problems:
- Problems solved with linear programming
- Production planning (pipeline optimization)
- Scheduling / Dispatching
Or any problems where integers represent various decisions (including some of the graph problems).
ArXiV: https://arxiv.org/abs/2012.13349
Wikipedia on Mixed Integer Programming: https://en.wikipedia.org/wiki/Integer_programming
#NPhard #MILP #DeepMind #productionml #linearprogramming #optimizationproblem
Article on speeding up Mixed Integer Programs with ML. Mixed Integer Programs are usually NP-hard problems:
- Problems solved with linear programming
- Production planning (pipeline optimization)
- Scheduling / Dispatching
Or any problems where integers represent various decisions (including some of the graph problems).
ArXiV: https://arxiv.org/abs/2012.13349
Wikipedia on Mixed Integer Programming: https://en.wikipedia.org/wiki/Integer_programming
#NPhard #MILP #DeepMind #productionml #linearprogramming #optimizationproblem
{kind=link}
{kind=link}
Forwarded from Machinelearning
🧠 2020: A Year Full of Amazing AI Papers — A Review
https://www.kdnuggets.com/2020/12/2020-amazing-ai-papers.html
@ai_machinelearning_big_data
https://www.kdnuggets.com/2020/12/2020-amazing-ai-papers.html
@ai_machinelearning_big_data
🔥New breakthrough on text2image generation by #OpenAI
DALL·E: Creating Images from Text
This architecture is capable of understanding style descriptions as well as complex relationship between objects in context.
That opens whole new perspective for digital agencies, potentially threatening stock photo sites and new opportunies for regulations and lawers to work on.
Interesting times!
Website: https://openai.com/blog/dall-e/
#GAN #GPT3 #openai #dalle #DL
DALL·E: Creating Images from Text
This architecture is capable of understanding style descriptions as well as complex relationship between objects in context.
That opens whole new perspective for digital agencies, potentially threatening stock photo sites and new opportunies for regulations and lawers to work on.
Interesting times!
Website: https://openai.com/blog/dall-e/
#GAN #GPT3 #openai #dalle #DL
{kind=link}
Forwarded from Towards NLP🇺🇦
🤗 multilingual datasets
- 611 datasets you can download in one line of python;
- 467 languages covered, 99 with at least 10 datasets;
- efficient pre-processing to free you from memory constraints;
https://github.com/huggingface/datasets
- 611 datasets you can download in one line of python;
- 467 languages covered, 99 with at least 10 datasets;
- efficient pre-processing to free you from memory constraints;
https://github.com/huggingface/datasets
GitHub
GitHub - huggingface/datasets: 🤗 The largest hub of ready-to-use datasets for AI models with fast, easy-to-use and efficient data…
🤗 The largest hub of ready-to-use datasets for AI models with fast, easy-to-use and efficient data manipulation tools - huggingface/datasets
Open Software Packaging for Science
#opensource alternative to #conda.
Mamba (drop-in replacement) direct link: https://github.com/TheSnakePit/mamba
Link: https://medium.com/@QuantStack/open-software-packaging-for-science-61cecee7fc23
#python #packagemanagement
#opensource alternative to #conda.
Mamba (drop-in replacement) direct link: https://github.com/TheSnakePit/mamba
Link: https://medium.com/@QuantStack/open-software-packaging-for-science-61cecee7fc23
#python #packagemanagement
GitHub
GitHub - mamba-org/mamba: The Fast Cross-Platform Package Manager
The Fast Cross-Platform Package Manager. Contribute to mamba-org/mamba development by creating an account on GitHub.
👍1
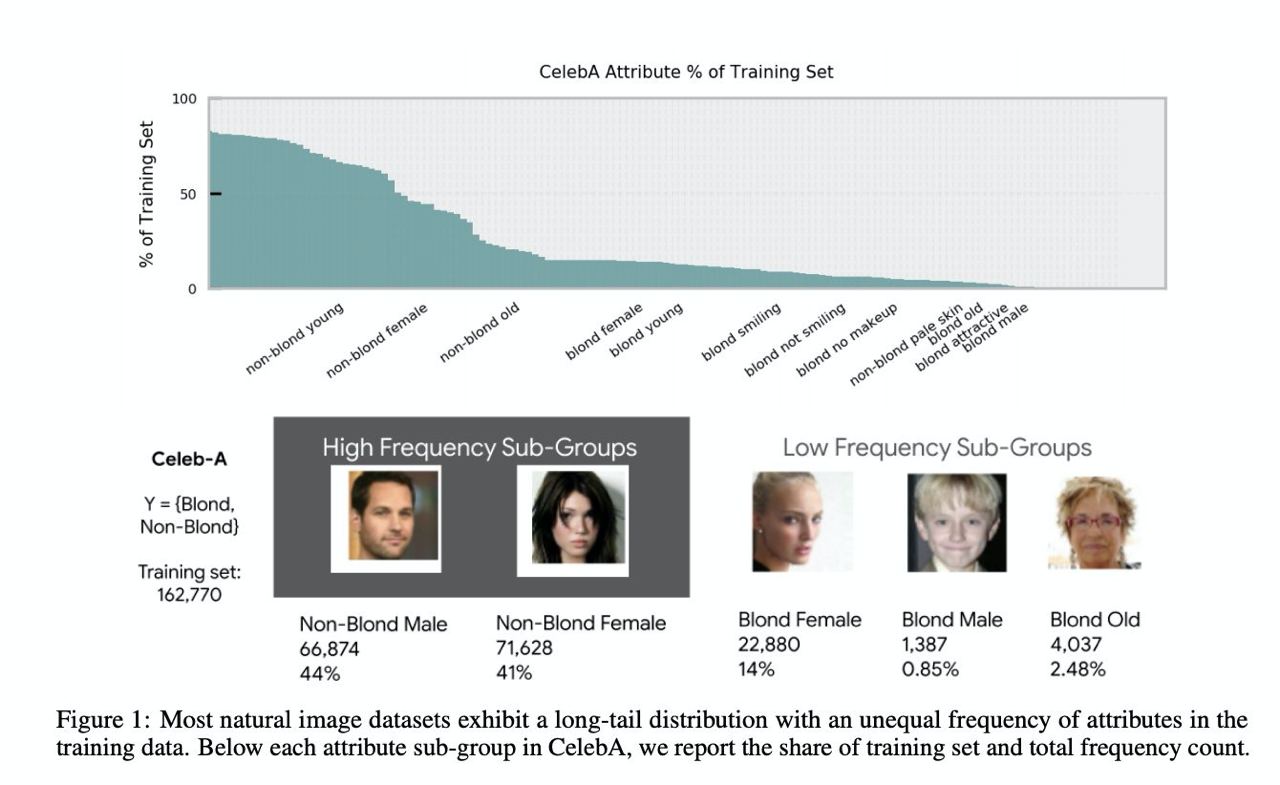
Characterising Bias in Compressed Models
Popular compression techniques turned out to amplify bias in deep neural networks.
ArXiV: https://arxiv.org/abs/2010.03058
#NN #DL #bias
Popular compression techniques turned out to amplify bias in deep neural networks.
ArXiV: https://arxiv.org/abs/2010.03058
#NN #DL #bias
{kind=link}
Interactive and explorable explanations
Collection of links to different explanations of how things work.
Link: https://explorabl.es
How network effect (ideas, diseases) works: https://meltingasphalt.com/interactive/going-critical/
How trust works: https://ncase.me/trust/
#howstuffworks #explanations
Collection of links to different explanations of how things work.
Link: https://explorabl.es
How network effect (ideas, diseases) works: https://meltingasphalt.com/interactive/going-critical/
How trust works: https://ncase.me/trust/
#howstuffworks #explanations
❤1
Forwarded from Towards NLP🇺🇦
Choosing Transfer Languages for Cross-Lingual Learning
Given a particular task low-resource language and NLP task, how can we determine which languages we should be performing transfer from?
If we train models on the top K transfer languages suggested by the ranking model and pick the best one, how good is the best model expected to be?
In the era of transfer learning now we have a possibility not to collect the massive data for each language, but using already pretrained model achieve good scores training on smaller data. But how should we choose the language from which we can transfer knowledge? Will it be okay to transfer from English to Chinese or from Russian to Turkish?
The paper investigate on this question. The features the authors created to detect the best transfer language are the follows:
* Dataset Size: as simple as it is — do we have enough data in transfer language with respect to ratio to train language?
* Type-Token Ratio: diversity of both languages;
* Word Overlap and Subword Overlap: kind of similarity of languages; it is very good if both languages have as much the same words as possible;
* Geographic distance: are the languages from the territories that are close on the Earth surface?
* Genetic distance: are they close to each other in terms of language genealogical tree?
* Inventory distance: are they sound familiar?
The idea is pretty simple and clear but very important for studies of multilingual models.
The post is based on reading task from Multilingual NLP course by CMU (from the post).
Given a particular task low-resource language and NLP task, how can we determine which languages we should be performing transfer from?
If we train models on the top K transfer languages suggested by the ranking model and pick the best one, how good is the best model expected to be?
In the era of transfer learning now we have a possibility not to collect the massive data for each language, but using already pretrained model achieve good scores training on smaller data. But how should we choose the language from which we can transfer knowledge? Will it be okay to transfer from English to Chinese or from Russian to Turkish?
The paper investigate on this question. The features the authors created to detect the best transfer language are the follows:
* Dataset Size: as simple as it is — do we have enough data in transfer language with respect to ratio to train language?
* Type-Token Ratio: diversity of both languages;
* Word Overlap and Subword Overlap: kind of similarity of languages; it is very good if both languages have as much the same words as possible;
* Geographic distance: are the languages from the territories that are close on the Earth surface?
* Genetic distance: are they close to each other in terms of language genealogical tree?
* Inventory distance: are they sound familiar?
The idea is pretty simple and clear but very important for studies of multilingual models.
The post is based on reading task from Multilingual NLP course by CMU (from the post).
Telegram
Towards NLP
Multilingual NLP
Сейчас время начинать (или вспомнить, что забросили) новые учебные курсы. И, если честно, сейчас онлайн курсов невероятное количество и по классическому ML, и по deeplearning, и по NLP. Так, fast.ai перезапустили свой курс по глубокому обучению…
Сейчас время начинать (или вспомнить, что забросили) новые учебные курсы. И, если честно, сейчас онлайн курсов невероятное количество и по классическому ML, и по deeplearning, и по NLP. Так, fast.ai перезапустили свой курс по глубокому обучению…