
(Re)Discovering Protein Structure and Function Through Language Modeling
Trained solely on unsupervised language modeling, the Transformer's attention mechanism recovers high-level structural (folding) and functional properties of proteins!
Why this is important: traditional protein modelling requires lots of computational power. This might be a key to more efficient structure modelling. Protein structure => function. Function => faster drug research and understanding of diseases mechanisms.
Blog: https://blog.einstein.ai/provis/
Paper: https://arxiv.org/abs/2006.15222
Code: https://github.com/salesforce/provis
#DL #NLU #proteinmodelling #bio #biolearning #insilico
Trained solely on unsupervised language modeling, the Transformer's attention mechanism recovers high-level structural (folding) and functional properties of proteins!
Why this is important: traditional protein modelling requires lots of computational power. This might be a key to more efficient structure modelling. Protein structure => function. Function => faster drug research and understanding of diseases mechanisms.
Blog: https://blog.einstein.ai/provis/
Paper: https://arxiv.org/abs/2006.15222
Code: https://github.com/salesforce/provis
#DL #NLU #proteinmodelling #bio #biolearning #insilico
🎙Mozilla’s Common Voice project
Mozilla launched a project to make digitalization of human voice more open and accessable. Anyone is eligible to download the dataset to use it for building #voicerecognition or #voicegeneration ML systems.
Most importantly, anyone can take a part in the project and make sure that her/his voice with all the accents and personal manner of speech features such as altitude, speed, clarity and timbre are accounted for in the models are to built.
Why is that important: if you have speech defects and you are not happy how machine speech translation works for you, or how well #Alexa or #Siri gets you, you should spend some time recording your voice for the Common Voice, to increase the probability of upcoming voice recognition model working great for you.
Project: https://voice.mozilla.org
Venturebeat article: https://venturebeat.com/2020/07/01/mozilla-common-voice-updates-will-help-train-the-hey-firefox-wakeword-for-voice-based-web-browsing/
#open #SpeechToText #TextToSpeech #DL #mozilla #audiolearning #voicerecognition
Mozilla launched a project to make digitalization of human voice more open and accessable. Anyone is eligible to download the dataset to use it for building #voicerecognition or #voicegeneration ML systems.
Most importantly, anyone can take a part in the project and make sure that her/his voice with all the accents and personal manner of speech features such as altitude, speed, clarity and timbre are accounted for in the models are to built.
Why is that important: if you have speech defects and you are not happy how machine speech translation works for you, or how well #Alexa or #Siri gets you, you should spend some time recording your voice for the Common Voice, to increase the probability of upcoming voice recognition model working great for you.
Project: https://voice.mozilla.org
Venturebeat article: https://venturebeat.com/2020/07/01/mozilla-common-voice-updates-will-help-train-the-hey-firefox-wakeword-for-voice-based-web-browsing/
#open #SpeechToText #TextToSpeech #DL #mozilla #audiolearning #voicerecognition
👍1
Data Science by ODS.ai 🦜
🎙Mozilla’s Common Voice project Mozilla launched a project to make digitalization of human voice more open and accessable. Anyone is eligible to download the dataset to use it for building #voicerecognition or #voicegeneration ML systems. Most importantly…
Please share this message to your friends, especially to those who speak funny, strange. If you have a friend, whom you can’t understand sometimes when she/he is anxious / excited, you will help them a lot.
And if you ever heard from someone that they can’t get you, you are speaking to fast, slow, or losing sounds, you should definately record some pieces for this project.
And if you ever heard from someone that they can’t get you, you are speaking to fast, slow, or losing sounds, you should definately record some pieces for this project.
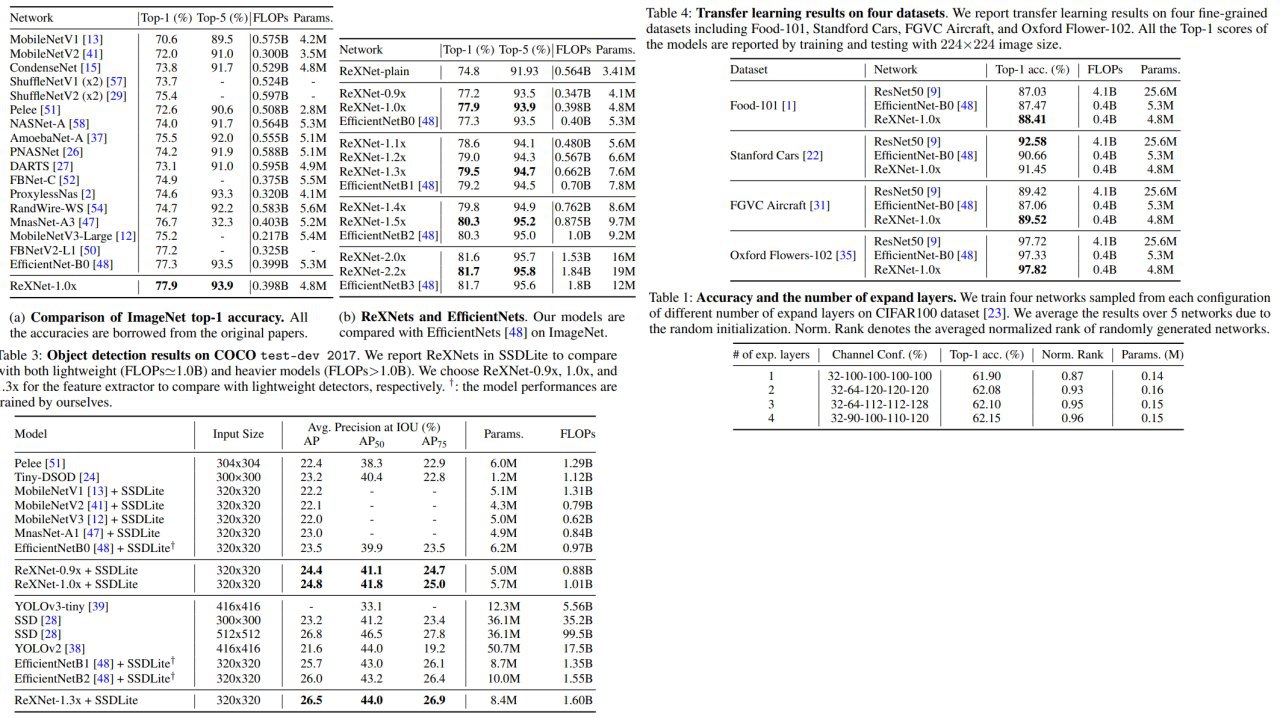
ReXNet: Diminishing Representational Bottleneck on Convolutional Neural Network
The authors propose a set of design principles that improves model performance significantly based on the analysis of representation bottlenecks.
Authors think that commonly used architectures have a representation bottleneck and try to fix it by expanding channel size, using more expand layers, and better activation functions. This also improves the performance of models on ImageNet and good results on transfer learning on classification and object detection.
Authors hope that their design ideas could be used by NAS to create even better models.
Paper: https://arxiv.org/abs/2007.00992
Code: https://github.com/clovaai/rexnet
#deeplearning #pretraining #transferlearning #computervision #pytorch
The authors propose a set of design principles that improves model performance significantly based on the analysis of representation bottlenecks.
Authors think that commonly used architectures have a representation bottleneck and try to fix it by expanding channel size, using more expand layers, and better activation functions. This also improves the performance of models on ImageNet and good results on transfer learning on classification and object detection.
Authors hope that their design ideas could be used by NAS to create even better models.
Paper: https://arxiv.org/abs/2007.00992
Code: https://github.com/clovaai/rexnet
#deeplearning #pretraining #transferlearning #computervision #pytorch
{kind=link}
👍1
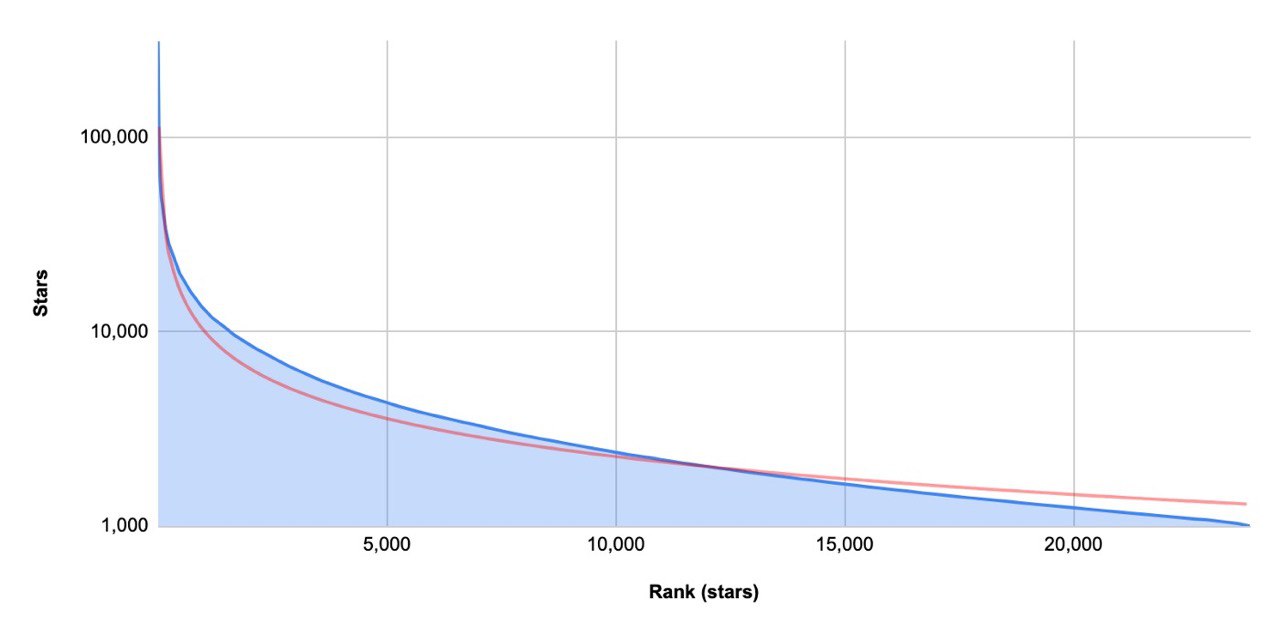
Overview of Open Source projects growth metrics
Quantative analytics of top starred repositories.
Link: https://medium.com/runacapital/open-source-growth-benchmarks-and-the-20-fastest-growing-oss-startups-d3556a669fe6
#opensource #analytics #statistics #growth
Quantative analytics of top starred repositories.
Link: https://medium.com/runacapital/open-source-growth-benchmarks-and-the-20-fastest-growing-oss-startups-d3556a669fe6
#opensource #analytics #statistics #growth
{kind=link}
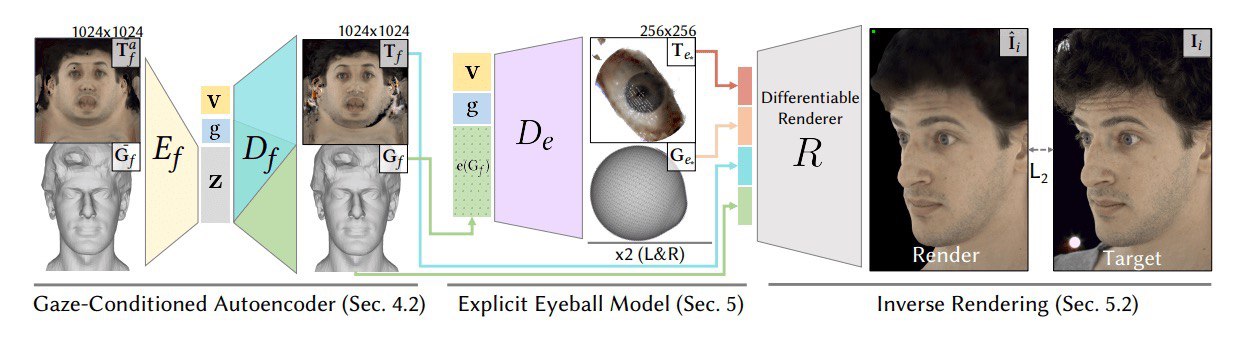
Making Animoji or any other 3D avatar more human-like
#Facebook researchers suggested an approach for more precise facial and gaze expression tracking.
Review: https://syncedreview.com/2020/07/07/facebook-introduces-integrated-eye-face-model-for-3d-immersion-in-remote-communication/
Paper: https://research.fb.com/wp-content/uploads/2020/06/The-Eyes-Have-It-An-Integrated-Eye-and-Face-Model-for-Photorealistic-Facial-Animation.pdf
#eyetracking #cv #dl #3davatar #videolearning #facerecognition
#Facebook researchers suggested an approach for more precise facial and gaze expression tracking.
Review: https://syncedreview.com/2020/07/07/facebook-introduces-integrated-eye-face-model-for-3d-immersion-in-remote-communication/
Paper: https://research.fb.com/wp-content/uploads/2020/06/The-Eyes-Have-It-An-Integrated-Eye-and-Face-Model-for-Photorealistic-Facial-Animation.pdf
#eyetracking #cv #dl #3davatar #videolearning #facerecognition
{kind=link}
Soon we will give a try to certain solution which will allow commenting on the posts in this channel.
Therefore, we will at first release the Ultimate Post on #wheretostart with Data Science, describing various entry points, books and courses. We want to provide extensive and thorough manual (just check out the name we chose), so we would be grateful if you can submit any resourses on getting starting with DS (any sphere) through our bot @opendatasciencebot (make sure you add your username, so we can reach you back)
You are most welcome to share:
Favourite books, youtube playlists, courses or even success stories.
Therefore, we will at first release the Ultimate Post on #wheretostart with Data Science, describing various entry points, books and courses. We want to provide extensive and thorough manual (just check out the name we chose), so we would be grateful if you can submit any resourses on getting starting with DS (any sphere) through our bot @opendatasciencebot (make sure you add your username, so we can reach you back)
You are most welcome to share:
Favourite books, youtube playlists, courses or even success stories.
A new SOTA on voice separation model that distinguishes multiple speakers simultaneously
Pandemic given a sufficient rise to new technologies covering voice communication. Noise cancelling is required more than ever and now #Facebook introduced a new method for separating as many as five voices speaking simultaneously into a single microphone. It pushes state of the art on multiple benchmarks, including ones with challenging noise and reverberations.
Blogpost: https://ai.facebook.com/blog/a-new-state-of-the-art-voice-separation-model-that-distinguishes-multiple-speakers-simultaneously
Paper: https://arxiv.org/pdf/2003.01531.pdf
#SOTA #FacebookAI #voicerecognition #soundlearning #DL
Pandemic given a sufficient rise to new technologies covering voice communication. Noise cancelling is required more than ever and now #Facebook introduced a new method for separating as many as five voices speaking simultaneously into a single microphone. It pushes state of the art on multiple benchmarks, including ones with challenging noise and reverberations.
Blogpost: https://ai.facebook.com/blog/a-new-state-of-the-art-voice-separation-model-that-distinguishes-multiple-speakers-simultaneously
Paper: https://arxiv.org/pdf/2003.01531.pdf
#SOTA #FacebookAI #voicerecognition #soundlearning #DL
Forwarded from Graph Machine Learning
Knowledge Graphs at ACL 2020
Another brilliant post by Michael Galkin on usage of knowledge graphs in NLP at ACL 2020.
"Knowledge graphs demonstrate better capabilities to reveal higher-order interdependencies in otherwise unstructured data."
Content:
1. Question Answering over Structured Data
2. KG Embeddings: Hyperbolic and Hyper-relational
3. Data-to-text NLG: Prepare your Transformer
4. Conversational AI: Improving Goal-Oriented Bots
5. Information Extraction: OpenIE and Link Prediction
Another brilliant post by Michael Galkin on usage of knowledge graphs in NLP at ACL 2020.
"Knowledge graphs demonstrate better capabilities to reveal higher-order interdependencies in otherwise unstructured data."
Content:
1. Question Answering over Structured Data
2. KG Embeddings: Hyperbolic and Hyper-relational
3. Data-to-text NLG: Prepare your Transformer
4. Conversational AI: Improving Goal-Oriented Bots
5. Information Extraction: OpenIE and Link Prediction
Medium
Knowledge Graphs in Natural Language Processing @ ACL 2020
This post commemorates the first anniversary of the series where we examine advancements in NLP and Graph ML powered by knowledge graphs…
👍1
Ultimate post on where to start learning DS
Most common request we received through the years was to share insights and advices on how to start career in data science and to recommend decent cources. Apparently, using hashtag #wheretostart wasn't enough so we were sharing some general advices.
So we assembled a through guide on how to start learning machine learning and created another #ultimatepost (in a form of a github repo, so it will be keep updated and anyone can submit worthy piece of advice to it).
We welcome you to share your stories and advices on how to start rolling into data science, as well as to spread the link to the repo to those your friends who might benefit from it.
Link: Ultimate post
#entrylevel #beginner #junior #MOOC #learndatascience #courses #mlcourse #opensource
Most common request we received through the years was to share insights and advices on how to start career in data science and to recommend decent cources. Apparently, using hashtag #wheretostart wasn't enough so we were sharing some general advices.
So we assembled a through guide on how to start learning machine learning and created another #ultimatepost (in a form of a github repo, so it will be keep updated and anyone can submit worthy piece of advice to it).
We welcome you to share your stories and advices on how to start rolling into data science, as well as to spread the link to the repo to those your friends who might benefit from it.
Link: Ultimate post
#entrylevel #beginner #junior #MOOC #learndatascience #courses #mlcourse #opensource
{kind=link}
👍13😁2❤1
GPT-3 application for website form generation
Turns out #GPT3 model is capable of generating #JSX code (which is HTML layout for #React ) given the description of the required blocks to generate.
Author reports that there are exceptions, given current output limit of the model of 512 tokens.
Why this is important: one might suppose that in the future programmers will just write specifications and tests for the AI to generate the code. Given the speed of progress that won’t be surprising at all.
And probably the more sophisticated models will be capable of using hard output limit to produce a code for the output generation but that obviously is still an area for active research.
More realistic evaluation is that the upcoming code generation tools is that it will just allow more people to build products, following #nocode movement.
Twitter thread: https://twitter.com/sharifshameem/status/1282676454690451457
#codegeneration #NLU
Turns out #GPT3 model is capable of generating #JSX code (which is HTML layout for #React ) given the description of the required blocks to generate.
Author reports that there are exceptions, given current output limit of the model of 512 tokens.
Why this is important: one might suppose that in the future programmers will just write specifications and tests for the AI to generate the code. Given the speed of progress that won’t be surprising at all.
And probably the more sophisticated models will be capable of using hard output limit to produce a code for the output generation but that obviously is still an area for active research.
More realistic evaluation is that the upcoming code generation tools is that it will just allow more people to build products, following #nocode movement.
Twitter thread: https://twitter.com/sharifshameem/status/1282676454690451457
#codegeneration #NLU
❤1
Forwarded from Находки в опенсорсе
Voila turns Jupyter notebooks into standalone web applications.
Unlike the usual HTML converted notebooks, each user connecting to the Voila tornado application gets a dedicated Jupyter kernel which can execute the callbacks to changes in Jupyter interactive widgets.
- By default, Voila disallows execute requests from the front-end, preventing execution of arbitrary code.
- By default, Voila runs with the
https://github.com/voila-dashboards/voila
#python
Unlike the usual HTML converted notebooks, each user connecting to the Voila tornado application gets a dedicated Jupyter kernel which can execute the callbacks to changes in Jupyter interactive widgets.
- By default, Voila disallows execute requests from the front-end, preventing execution of arbitrary code.
- By default, Voila runs with the
strip_source option, which strips out the input cells from the rendered notebook.https://github.com/voila-dashboards/voila
#python
Data Science by ODS.ai 🦜
GPT-3 application for website form generation Turns out #GPT3 model is capable of generating #JSX code (which is HTML layout for #React ) given the description of the required blocks to generate. Author reports that there are exceptions, given current…
This media is not supported in your browser
VIEW IN TELEGRAM
Sharif Shameem improved the original app, which is now capable of generating real applications, as he demostrates with a simple ToDo app.
#GPT3 #codegeneration
#GPT3 #codegeneration
The Reformer – Pushing the limits of language modeling
Patrick von Platen @ huggingface
The Reformer model was introduced by Kitaev, Kaiser et al. `20 – it is one of the most memory-efficient transformer models for long sequence modeling as of today.
The goal of this blog post is to give an in-depth understanding of each of the next four Reformer features:
[0] reformer self-attention layer – how to efficiently implement self-attention without being restricted to a local context?
[1] chunked feed forward layers – how to get a better time-memory trade-off for large feed forward layers?
[2] reversible residual layers – how to drastically reduce memory consumption in training by a smart residual architecture?
[3] axial positional encodings – how to make positional encodings usable for extremely large input sequences?
This long blog post can better allow you to understand how the model works to correctly set configurations
blog post: https://huggingface.co/blog/reformer
#nlp #reformer #huggingface #transformers
Patrick von Platen @ huggingface
The Reformer model was introduced by Kitaev, Kaiser et al. `20 – it is one of the most memory-efficient transformer models for long sequence modeling as of today.
The goal of this blog post is to give an in-depth understanding of each of the next four Reformer features:
[0] reformer self-attention layer – how to efficiently implement self-attention without being restricted to a local context?
[1] chunked feed forward layers – how to get a better time-memory trade-off for large feed forward layers?
[2] reversible residual layers – how to drastically reduce memory consumption in training by a smart residual architecture?
[3] axial positional encodings – how to make positional encodings usable for extremely large input sequences?
This long blog post can better allow you to understand how the model works to correctly set configurations
blog post: https://huggingface.co/blog/reformer
#nlp #reformer #huggingface #transformers
huggingface.co
The Reformer - Pushing the limits of language modeling
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
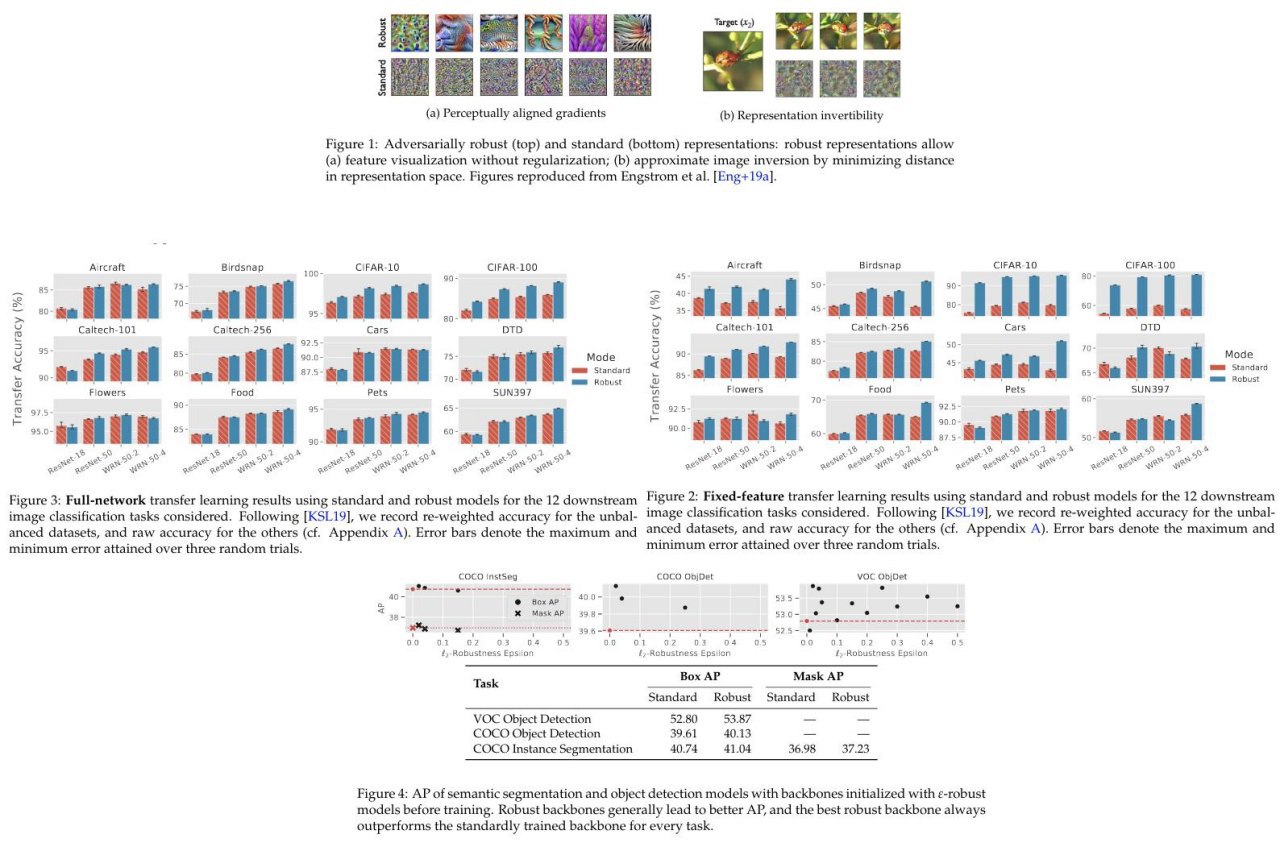
Do Adversarially Robust ImageNet Models Transfer Better?
TLDR - Yes.
Authors decide to check will adversarial trained network performed better on transfer learning tasks despite on worst accuracy on the trained dataset (ImageNet of course). And it is true.
They tested this idea on a frozen pre-trained feature extractor and trained only linear classifier that outperformed classic counterpart. And they tested on a full unfrozen fine-tuned network, that outperformed too on transfer learning tasks.
On pre-train task they use the adversarial robustness prior, that refers to a model’s invariance to small (often imperceptible) perturbations of its inputs.
They show also that such an approach gives better future representation properties of the networks.
They did many experiments (14 pages of graphics) and an ablation study.
paper: https://arxiv.org/abs/2007.08489
code: https://github.com/Microsoft/robust-models-transfer
#transfer_learning #SOTA #adversarial
TLDR - Yes.
Authors decide to check will adversarial trained network performed better on transfer learning tasks despite on worst accuracy on the trained dataset (ImageNet of course). And it is true.
They tested this idea on a frozen pre-trained feature extractor and trained only linear classifier that outperformed classic counterpart. And they tested on a full unfrozen fine-tuned network, that outperformed too on transfer learning tasks.
On pre-train task they use the adversarial robustness prior, that refers to a model’s invariance to small (often imperceptible) perturbations of its inputs.
They show also that such an approach gives better future representation properties of the networks.
They did many experiments (14 pages of graphics) and an ablation study.
paper: https://arxiv.org/abs/2007.08489
code: https://github.com/Microsoft/robust-models-transfer
#transfer_learning #SOTA #adversarial
{kind=link}
how gpt3 works. a visual thread
short thread with cool animations how gpt-3 works by jay alammar
collected twitter thread: https://threader.app/thread/1285498971960598529
#nlp #transformers #gpt3 #jayalammar
short thread with cool animations how gpt-3 works by jay alammar
collected twitter thread: https://threader.app/thread/1285498971960598529
#nlp #transformers #gpt3 #jayalammar
#GPT3 attracted lots of attention. Let’s try new format of discussing the matter in the comments, provided by peerboard.
For accessing the comments, just click the link below ⬇️⬇️⬇️, authorize with the telegram and follow the discussion.
For accessing the comments, just click the link below ⬇️⬇️⬇️, authorize with the telegram and follow the discussion.
(Rich Sutton, author of https://www.incompleteideas.net/IncIdeas/BitterLesson.html is on the right)
Data Science by ODS.ai 🦜 pinned «Ultimate post on where to start learning DS Most common request we received through the years was to share insights and advices on how to start career in data science and to recommend decent cources. Apparently, using hashtag #wheretostart wasn't enough…»