
«Обработка естественного языка в действии»
Аврам Линкольн говорил: «Мой лучший друг — это человек, который даст мне книгу, что я не читал». А если вы, как и Линкольн, цените литературу и ищете полезный источник знаний по NLP, то вы нашли, что искали.
Книга содержит полный набор инструментов и методов для создания приложений в этой области: виртуальных помощников (чат-ботов), спам-фильтров, анализаторов тональности и многого другого.
Материал рассчитан на Python-разработчиков среднего и высокого уровня. Но даже экспертам в проектировании сложных систем она будет полезна.
#почитать #nlp #python
Аврам Линкольн говорил: «Мой лучший друг — это человек, который даст мне книгу, что я не читал». А если вы, как и Линкольн, цените литературу и ищете полезный источник знаний по NLP, то вы нашли, что искали.
Книга содержит полный набор инструментов и методов для создания приложений в этой области: виртуальных помощников (чат-ботов), спам-фильтров, анализаторов тональности и многого другого.
Материал рассчитан на Python-разработчиков среднего и высокого уровня. Но даже экспертам в проектировании сложных систем она будет полезна.
#почитать #nlp #python
👍7❤5
ИИ помог безработному пройти 20 собеседований после 5000 заявок
Инженер-программист Джулиан Джозеф остался без работы, но нашёл нестандартный выход — он воспользовался сервисом LazyApply для автоматической рассылки резюме потенциальным работодателям. Всего одним кликом мыши он разослал 5000 резюме и, несмотря на низкий процент откликов, сумел пройти около 20 собеседований
Интересно, что в конечном итоге Джулиан получил предложения от таких корпораций, как Apple и даже от Белого дома. Однако благодаря не технологиям, а своему профессионализму и личным связям.
#новости
Инженер-программист Джулиан Джозеф остался без работы, но нашёл нестандартный выход — он воспользовался сервисом LazyApply для автоматической рассылки резюме потенциальным работодателям. Всего одним кликом мыши он разослал 5000 резюме и, несмотря на низкий процент откликов, сумел пройти около 20 собеседований
Интересно, что в конечном итоге Джулиан получил предложения от таких корпораций, как Apple и даже от Белого дома. Однако благодаря не технологиям, а своему профессионализму и личным связям.
#новости
{kind=link}
😁13❤3
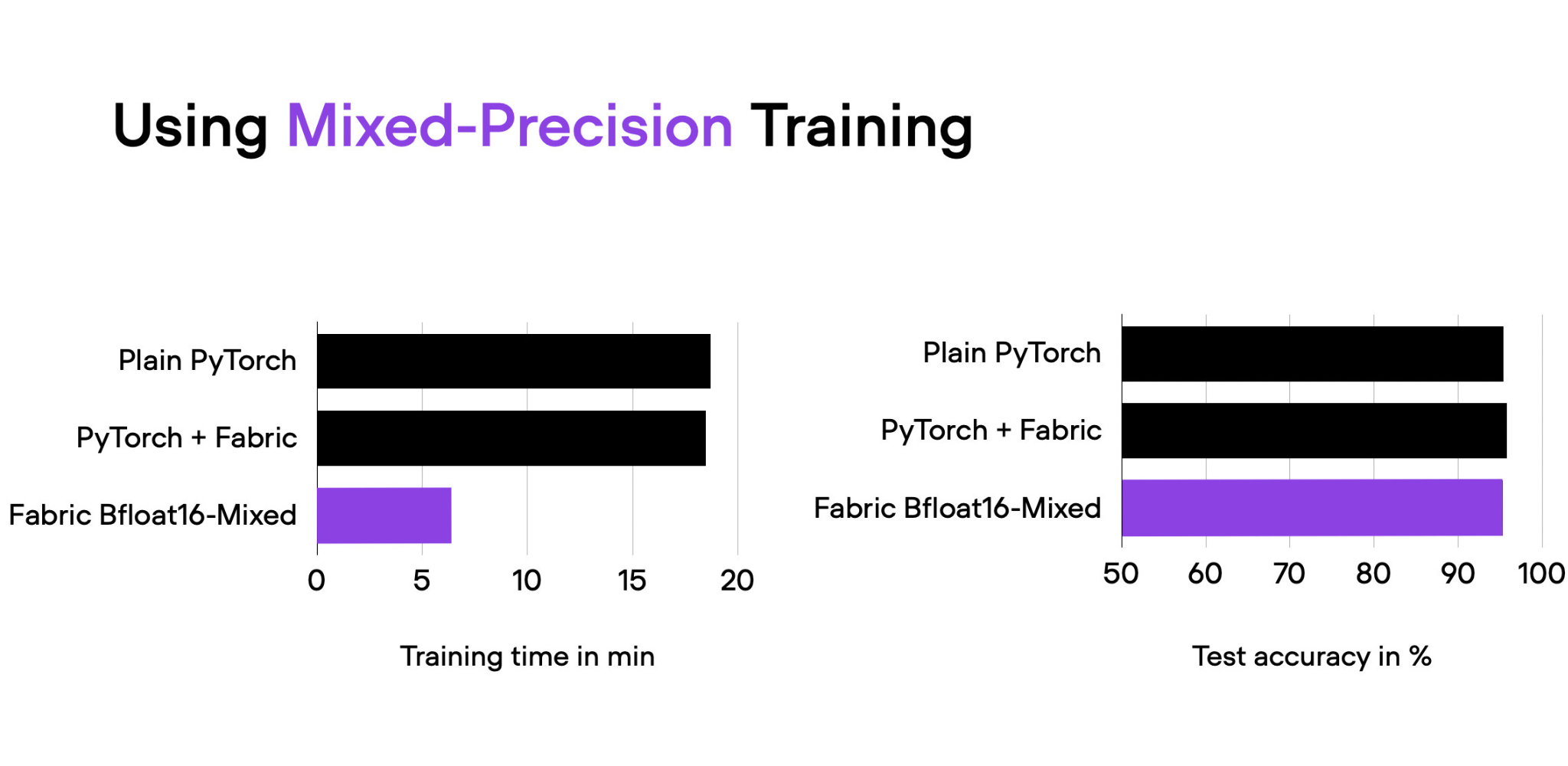
Ускорение обучения моделей PyTorch
Жизнь и без того очень скоротечна, поэтому давайте сэкономим время хотя бы на обучении и масштабировании наших моделей. А эта статья поможет вам с этим, в ней автор показывает, как с помощью библиотеки Fabric и техник вроде смешанной точности (mixed precision) можно масштабировать обучение нейросетей с минимальными изменениями кода.
Весь процесс происходит на примере простой модели Vision Transformer (ViT) для классификации изображений. Демонстрируется, что использование смешанной точности позволяет сократить время обучения в 3 раза. А если вы криптомиллионер и имеете ещё три графических процессора, то вкупе можно достичь и 10-кратного эффекта.
#статья #llm #pytorch
Жизнь и без того очень скоротечна, поэтому давайте сэкономим время хотя бы на обучении и масштабировании наших моделей. А эта статья поможет вам с этим, в ней автор показывает, как с помощью библиотеки Fabric и техник вроде смешанной точности (mixed precision) можно масштабировать обучение нейросетей с минимальными изменениями кода.
Весь процесс происходит на примере простой модели Vision Transformer (ViT) для классификации изображений. Демонстрируется, что использование смешанной точности позволяет сократить время обучения в 3 раза. А если вы криптомиллионер и имеете ещё три графических процессора, то вкупе можно достичь и 10-кратного эффекта.
#статья #llm #pytorch
{kind=link}
❤4👍2
Генеративный искусственный интеллект для начинающих
Microsoft выпустила обучающий курс, состоящий из 12 уроков, охватывающих ключевые аспекты принципов генеративного искусственного интеллекта и разработки приложений. В процессе обучения вы создадите собственный стартап по генеративному искусственному интеллекту, получив понимание того, что требуется для реализации ваших идей.
Особенно привлекательно то, что курс имеет собственный сервер в Discord, где участники могут общаться, задавать вопросы и делиться впечатлениями.
#полезности #ml
Microsoft выпустила обучающий курс, состоящий из 12 уроков, охватывающих ключевые аспекты принципов генеративного искусственного интеллекта и разработки приложений. В процессе обучения вы создадите собственный стартап по генеративному искусственному интеллекту, получив понимание того, что требуется для реализации ваших идей.
Особенно привлекательно то, что курс имеет собственный сервер в Discord, где участники могут общаться, задавать вопросы и делиться впечатлениями.
#полезности #ml
{kind=link}
👍5👏3❤1
This media is not supported in your browser
VIEW IN TELEGRAM
Бездомный мститель: противостояние ИИ
Если вы когда-либо задумывались о том, кто окажется на страже нашей безопасности, когда эпоха скайнета настигнет нас, мы радушно представляем вам первого кандидата на роль главного героя в этом противостоянии.
#ржака
Если вы когда-либо задумывались о том, кто окажется на страже нашей безопасности, когда эпоха скайнета настигнет нас, мы радушно представляем вам первого кандидата на роль главного героя в этом противостоянии.
#ржака
🤣15❤3👍1👏1
Orca 2: гигантский прорыв в области логики и рассуждения ИИ
Ранее мы уже говорили, что касатки далеко не глупые, но с того момента они стали ещё умнее. А если без шуток, то Microsoft расширила проект Orca, выпустив — Orca 2.
С общим числом параметров в 13 миллиардов она значительно превосходит модели аналогичного размера и демонстрирует производительность, сопоставимую или даже превосходящую модели в 5-10 раз большего размера.
В этом видео вы найдёте подробный анализ статьи о Orca 2 и тесты её возможностей на практике.
HuggingFace:
Orca-2-13b | Orca-2-7b
#llm #ml #orca
Ранее мы уже говорили, что касатки далеко не глупые, но с того момента они стали ещё умнее. А если без шуток, то Microsoft расширила проект Orca, выпустив — Orca 2.
С общим числом параметров в 13 миллиардов она значительно превосходит модели аналогичного размера и демонстрирует производительность, сопоставимую или даже превосходящую модели в 5-10 раз большего размера.
В этом видео вы найдёте подробный анализ статьи о Orca 2 и тесты её возможностей на практике.
HuggingFace:
Orca-2-13b | Orca-2-7b
#llm #ml #orca
Telegram
Нейроканал
Доказательство того, что косатки — очень умные животные
Правда это не совсем косатка, а Orca AI — новая языковая модель от Microsoft на 13 миллиардов параметров, обученная ChatGPT 3.5 и 4. Да-да, одни модели уже вовсю припахали учить другие.
При этом,…
Правда это не совсем косатка, а Orca AI — новая языковая модель от Microsoft на 13 миллиардов параметров, обученная ChatGPT 3.5 и 4. Да-да, одни модели уже вовсю припахали учить другие.
При этом,…
👍8❤3
10 ключевых алгоритмов машинного обучения
Эта статья описывает 10 наиболее распространённых алгоритмов ML. Среди них: линейная и логистическая регрессия, метод опорных векторов, деревья решений, случайный лес, наивный байесовский классификатор, K-ближайших соседей, K-средних, алгоритмы понижения размерности и AdaBoost.
Для каждого алгоритма приведено краткое описание работы, основные преимущества и недостатки, а также типичные сферы применения и примеры конкретных задач ML.
#статья #алгоритмы #ml
Эта статья описывает 10 наиболее распространённых алгоритмов ML. Среди них: линейная и логистическая регрессия, метод опорных векторов, деревья решений, случайный лес, наивный байесовский классификатор, K-ближайших соседей, K-средних, алгоритмы понижения размерности и AdaBoost.
Для каждого алгоритма приведено краткое описание работы, основные преимущества и недостатки, а также типичные сферы применения и примеры конкретных задач ML.
#статья #алгоритмы #ml
{kind=link}
👍8❤1
This media is not supported in your browser
VIEW IN TELEGRAM
Компания Google представила новую мультимодальную модель искусственного интеллекта под названием Gemini. Её отличительная черта — возможность обрабатывать информацию из разнообразных источников: кода, текстов, изображений, аудио и даже видео.
Gemini будет доступна в трёх версиях:
— Gemini Ultra: самая большая и мощная модель серии, которая по результатам тестирований превзошла даже GPT-4 (выйдет в начале 2024 года).
— Gemini Pro: более компактный вариант. Доступ к API откроется с 13 декабря, но вы уже сейчас можете опробовать модель в Google Bard (для этого измените язык в настройках гугла на английский и используя VPN с регионом США).
— Gemini Nano: оптимизирована для работы на мобильных устройствах.
Для дополнительной информации можете ознакомиться с техническим отчётом.
#нейроновости #llm #gemini
Gemini будет доступна в трёх версиях:
— Gemini Ultra: самая большая и мощная модель серии, которая по результатам тестирований превзошла даже GPT-4 (выйдет в начале 2024 года).
— Gemini Pro: более компактный вариант. Доступ к API откроется с 13 декабря, но вы уже сейчас можете опробовать модель в Google Bard (для этого измените язык в настройках гугла на английский и используя VPN с регионом США).
— Gemini Nano: оптимизирована для работы на мобильных устройствах.
Для дополнительной информации можете ознакомиться с техническим отчётом.
#нейроновости #llm #gemini
👍10❤4
Как говорится, дообучение моделей — свет, а неученье — тьма
Как вы уже догадались, сегодня мы обсудим тему дообучения, и данное видео поможет более глубоко погрузиться в этот вопрос.
В ролике автор демонстрирует процесс файн-тюнинга модели BART для решения задачи суммаризации текста. Главная цель — познакомить зрителей с популярными библиотеками в области обработки естественного языка (NLP) и показать, как это можно делать максимально эффективно, затрачивая минимум усилий при написании кода.
#позалипать #nlp #дообучение
Как вы уже догадались, сегодня мы обсудим тему дообучения, и данное видео поможет более глубоко погрузиться в этот вопрос.
В ролике автор демонстрирует процесс файн-тюнинга модели BART для решения задачи суммаризации текста. Главная цель — познакомить зрителей с популярными библиотеками в области обработки естественного языка (NLP) и показать, как это можно делать максимально эффективно, затрачивая минимум усилий при написании кода.
#позалипать #nlp #дообучение
YouTube
Семинар. Файнтьюнинг BART для задачи суммаризации текста
Занятие ведёт Антон Земеров
Ссылка на материалы занятия: https://colab.research.google.com/drive/1bZJ9OE7YEWkK3owKpP12Qc-RfOKeeXf2?usp=sharing
---
Deep Learning School при ФПМИ МФТИ
Каждые полгода мы запускаем новую итерацию нашего двухсеместрового практического…
Ссылка на материалы занятия: https://colab.research.google.com/drive/1bZJ9OE7YEWkK3owKpP12Qc-RfOKeeXf2?usp=sharing
---
Deep Learning School при ФПМИ МФТИ
Каждые полгода мы запускаем новую итерацию нашего двухсеместрового практического…
👍3❤2
Forwarded from Zen of Python
Сравниваем LLM-модели, чтобы потом внедрить без мороки
Сравнили в статье GPT4, LLaMA, Yandex GPT2, GigaChat c позиции разработчика-внедренца: стоимость, число параметров, вероятность цена и проч.
#факты
Сравнили в статье GPT4, LLaMA, Yandex GPT2, GigaChat c позиции разработчика-внедренца: стоимость, число параметров, вероятность цена и проч.
#факты
{kind=link}
👍5❤2👎2
This media is not supported in your browser
VIEW IN TELEGRAM
В Чили начали собирать яблоки при помощи дронов и компьютерного зрения
👍 — если бы хотел, чтобы дроны научились копать картошку на даче твоей бабушки
#нейроновости #cv
👍 — если бы хотел, чтобы дроны научились копать картошку на даче твоей бабушки
#нейроновости #cv
👍42❤3
MLOps: создание проектов производственного уровня
Freecodecamp выпустили курс по MLOps, который предоставит вам возможность прочувствовать полный цикл разработки проекта в этой области — от сбора данных до развёртывания с применением передовых инструментов.
В рамках обучения вы познакомитесь с фреймворком ZenML, MLflow и другими не менее важными инструментами.
Сам курс | Репозиторий курса
#нейровидео #mlops
Freecodecamp выпустили курс по MLOps, который предоставит вам возможность прочувствовать полный цикл разработки проекта в этой области — от сбора данных до развёртывания с применением передовых инструментов.
В рамках обучения вы познакомитесь с фреймворком ZenML, MLflow и другими не менее важными инструментами.
Сам курс | Репозиторий курса
#нейровидео #mlops
YouTube
MLOps Course – Build Machine Learning Production Grade Projects
MLOps, short for Machine Learning Operations, refers to the practice of applying DevOps principles to machine learning. This MLOps course will guide you through an end-to-end MLOps project, covering everything from data ingestion to deployment, using state…
👍5❤1
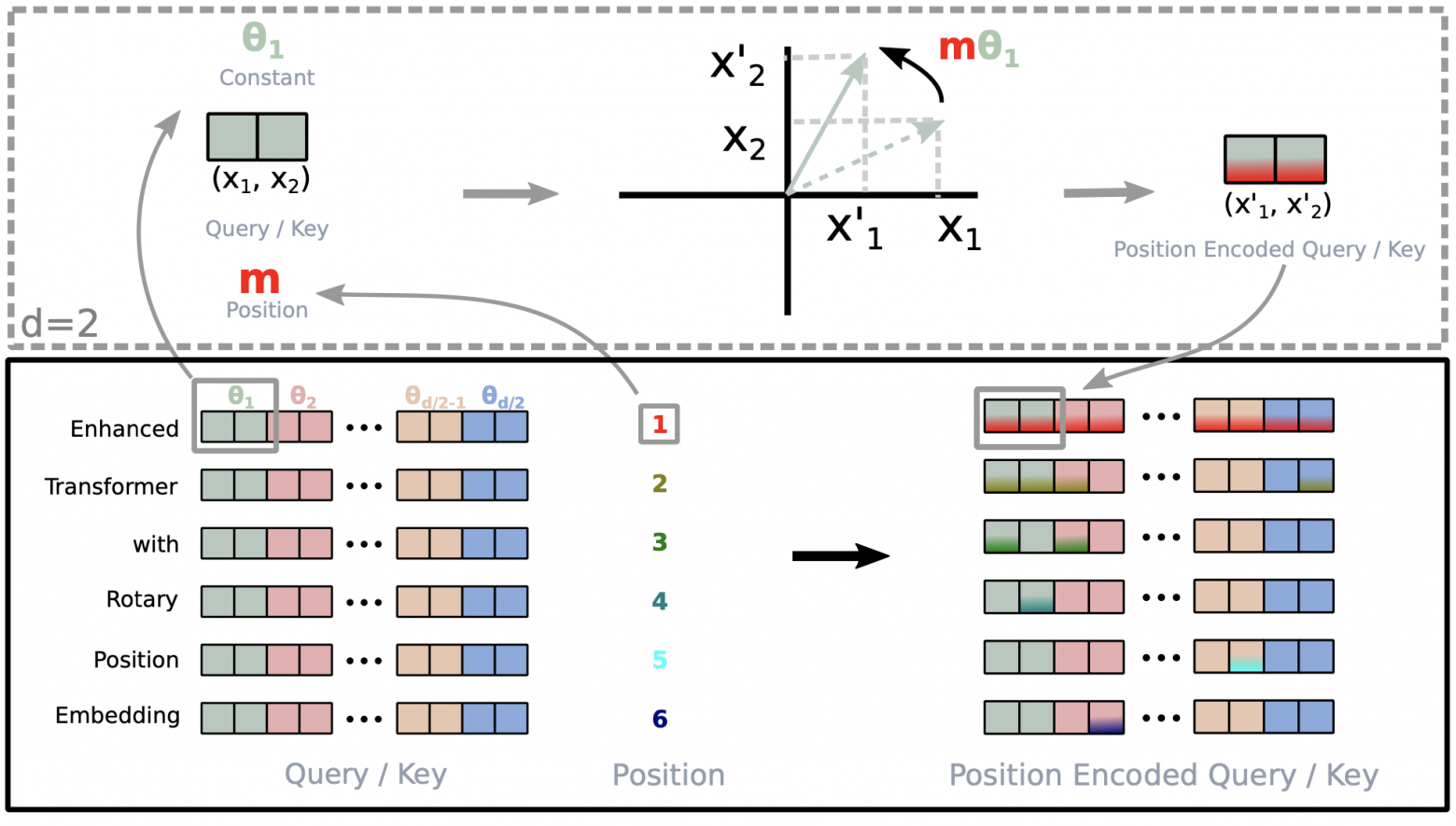
Методы позиционного кодирования в Transformer
Методы позиционного кодирования — ключевой элемент Transformer для анализа длинных текстов. Как правило, в отличие от RNN, эта архитектура обрабатывает входные векторы одновременно, и без дополнительной информации о позиции каждого токена будет рассматривать последовательность подобно «мешку со словами».
В данной статье вы найдёте основные подходы, описанные в научных работах и применяемые в известных языковых моделях.
#nlp #transformer #deeplearning
Методы позиционного кодирования — ключевой элемент Transformer для анализа длинных текстов. Как правило, в отличие от RNN, эта архитектура обрабатывает входные векторы одновременно, и без дополнительной информации о позиции каждого токена будет рассматривать последовательность подобно «мешку со словами».
В данной статье вы найдёте основные подходы, описанные в научных работах и применяемые в известных языковых моделях.
#nlp #transformer #deeplearning
{kind=link}
👍5❤2
This media is not supported in your browser
VIEW IN TELEGRAM
Пакет Python для анимации статистических данных
Недавно наткнулись на интересный проект и хоть понятно, что анимация линейных графиков обычно не имеет никакого смысла, но возможно пригодится кому на работе.
GitHub | Документация | pypi
#project
Недавно наткнулись на интересный проект и хоть понятно, что анимация линейных графиков обычно не имеет никакого смысла, но возможно пригодится кому на работе.
GitHub | Документация | pypi
#project
👍7❤6
Как стать топ-100 на Kaggle и востребованным в Data Science
Kaggle — ведущая платформа для проведения соревнований в области Data Science. Подобные соревнования не только отличный способ обучения для специалистов разного уровня, но и мощный мотиватор. Поэтому если раньше вы не слышали о Kaggle, то пора это исправлять.
В этой статье наш соотечественник, занявший 68-е место в мировом рейтинге Kaggle, делится своим рецептом успеха и рассказывает о том, какие возможности получил благодаря участию в соревнованиях. Оказывается, для входа в топ достаточно всего трёх ингредиентов: математика, программирование и щепотка безумной страсти к своему делу.
#статья #kaggle #ds
Kaggle — ведущая платформа для проведения соревнований в области Data Science. Подобные соревнования не только отличный способ обучения для специалистов разного уровня, но и мощный мотиватор. Поэтому если раньше вы не слышали о Kaggle, то пора это исправлять.
В этой статье наш соотечественник, занявший 68-е место в мировом рейтинге Kaggle, делится своим рецептом успеха и рассказывает о том, какие возможности получил благодаря участию в соревнованиях. Оказывается, для входа в топ достаточно всего трёх ингредиентов: математика, программирование и щепотка безумной страсти к своему делу.
#статья #kaggle #ds
{kind=link}
👎6❤5
Боремся с галлюцинациями: настройка языковых моделей для более точных ответов
Языковые модели часто сталкиваются с проблемой «галлюцинаций», предоставляя убедительную, но фактически неточную информацию. Это особенно актуально при использовании таких моделей для ответов на вопросы, основанные на знаниях, поскольку требует дополнительной проверки ответов.
В данной статье авторы предлагают методы точной настройки, используя оптимизацию прямых предпочтений Direct Preference Optimization (DPO), о котором упоминалось ранее, для снижения частоты галлюцинаций.
Путём точной настройки модели 7B Llama 2 с применением этого подхода они смогли уменьшить фактическую частоту ошибок на 58% по сравнению с исходной моделью чата Llama-2.
#статья #llm #dpo
Языковые модели часто сталкиваются с проблемой «галлюцинаций», предоставляя убедительную, но фактически неточную информацию. Это особенно актуально при использовании таких моделей для ответов на вопросы, основанные на знаниях, поскольку требует дополнительной проверки ответов.
В данной статье авторы предлагают методы точной настройки, используя оптимизацию прямых предпочтений Direct Preference Optimization (DPO), о котором упоминалось ранее, для снижения частоты галлюцинаций.
Путём точной настройки модели 7B Llama 2 с применением этого подхода они смогли уменьшить фактическую частоту ошибок на 58% по сравнению с исходной моделью чата Llama-2.
#статья #llm #dpo
{kind=link}
👍6❤2
This media is not supported in your browser
VIEW IN TELEGRAM
Учёные из GrapheneX-UTS разработали ии-систему, переводящую мысли в текст
Участники исследования молча читали текст, надевая специальную шапочку, регистрирующую электрическую активность мозга через кожу головы с помощью ЭЭГ.
В перспективе эта технология будет полезна тем, кто не может говорить из-за болезней или травм. А также обеспечит удобное взаимодействие с машинами, включая управление бионической рукой или роботом.
А если вас тоже манит идея чтения мыслей, то держите статью исследования и репозиторий.
#нейроновости
Участники исследования молча читали текст, надевая специальную шапочку, регистрирующую электрическую активность мозга через кожу головы с помощью ЭЭГ.
В перспективе эта технология будет полезна тем, кто не может говорить из-за болезней или травм. А также обеспечит удобное взаимодействие с машинами, включая управление бионической рукой или роботом.
А если вас тоже манит идея чтения мыслей, то держите статью исследования и репозиторий.
#нейроновости
👍10❤3👻3
Объявляем батл языков программирования открытым
2023 год близится к завершению, и пришло время подвести его итоги, запустив традиционный поединок за звание лучшего языка программирования на Tproger.
Мы уже проводили подобные голосования в 2020, 2021 и 2022 годах: первые два раза победу одержал Python, а в прошлом году — C#.
Сегодня на арене сойдутся R и Python, а также Swift и Dart. Уверены, вы уже определились, кому предоставить свой голос, поэтому дерзайте и внесите свой вклад.
#toplang2023
2023 год близится к завершению, и пришло время подвести его итоги, запустив традиционный поединок за звание лучшего языка программирования на Tproger.
Мы уже проводили подобные голосования в 2020, 2021 и 2022 годах: первые два раза победу одержал Python, а в прошлом году — C#.
Сегодня на арене сойдутся R и Python, а также Swift и Dart. Уверены, вы уже определились, кому предоставить свой голос, поэтому дерзайте и внесите свой вклад.
#toplang2023
🏆6❤2🥰2
Mixtral 8x7B: эксперт в мире открытых LLM
Компания Mistral AI в преддверии Нового года представила открытую языковую модель — Mixtral 8x7B с контекстом в 32 тысячи токенов.
Эта модель основана на архитектуре «sparse mixture of experts» (SMoE), где одна большая сеть разбита на 8 меньших подсетей-экспертов. Для каждого входного токена динамически выбираются нужный эксперт. Благодаря такому подходу, Mixtral 8x7B, содержащая 47 млрд параметров, работает с той же скоростью, что и LLaMa 7B с 7 млрд параметров.
По результатам тестов модель показала впечатляющие 8.3 балла из 10 на бенчмарке MT-bench, что сопостовимо с GPT-3.5. При этом доступ к API стоит всего $2 за миллион токенов.
Видеообзор и тесты | Разбор архитектуры | HuggingFace
#llm #nlp
Компания Mistral AI в преддверии Нового года представила открытую языковую модель — Mixtral 8x7B с контекстом в 32 тысячи токенов.
Эта модель основана на архитектуре «sparse mixture of experts» (SMoE), где одна большая сеть разбита на 8 меньших подсетей-экспертов. Для каждого входного токена динамически выбираются нужный эксперт. Благодаря такому подходу, Mixtral 8x7B, содержащая 47 млрд параметров, работает с той же скоростью, что и LLaMa 7B с 7 млрд параметров.
По результатам тестов модель показала впечатляющие 8.3 балла из 10 на бенчмарке MT-bench, что сопостовимо с GPT-3.5. При этом доступ к API стоит всего $2 за миллион токенов.
Видеообзор и тесты | Разбор архитектуры | HuggingFace
#llm #nlp
👍8❤4