
Forwarded from South HUB
Вашей компании нужен герой — и он уже среди ваших разработчиков!
(#соавтор South HUB, Денис Макрушин.)
Если кто-то до сих пор слышит и соглашается с тезисом «безопасность замедляет разработку и душит инновации», то он плохо осознает с какой скоростью двигается прогресс. Раньше управленец C-level в технологической компании мог надеяться, что его бизнес или продукт не будут интересны кибер-преступникам, и они обойдут его стороной. Теперь же, когда злодеи повсеместно используют автоматизацию и регулярно мониторят возможности запрыгнуть в инфраструктуру компании любого масштаба — нельзя надеяться на «да кому я нужен».
Атаки, утечки и различные кибер-инциденты реально тормозят развитие. Иногда останавливают его полностью. Потому что когда «зашифрован прод», а данные клиентов текут в паблик — это не про развитие. А еще, оказывается, что недостаточно завернуть в свой пайплайн все необходимые security-инструменты. Недостаточно даже их правильно настроить и получать только важные результаты их работы.
Как обычно, секретный соус кибербезопасной компании — в ее людях и культуре. Уязвимость всегда проще и дешевле исправлять, когда она обнаружена в IDE разработчика, а не в проде у клиента. Практики и инструменты ИБ нужно двигать «влево» — ближе к началу жизненного цикла системы. Ближе к тому этапу, на которых рождается идея, гипотеза, бизнес-план, дизайн системы. А для этого, нужно понимать “кибербез” на уровне культуры топ-менеджмента и разработки.
В индустрии есть такое термин: Security-чемпион. Это не всегда выделенная роль. Это может быть сотрудник, который прокачивает себя в вопросах ИБ и приземляет экспертизу в своих повседневных задачах. Например, разработчик или тим лид, который понимает риски некачественного кода. CTO, который не ждет, когда появится CISO и принесет контроли в SDLC. CEO и CPO, которые знают, для чего проводить дополнительные security design review.
Чтобы запустить чемпионскую программу в своих командах разработки, нужно предварительно ответить на ключевые вопросы вопроса:
1. Как я создам внутреннюю мотивацию? Что будет драйвить разработчика развиваться в направлении безопасной разработки?
2. Какой ресурс я выделю для реализации программы? Смогу ли обеспечить реальное влияние security-чемпионов на SDLC-процессы?
3. Как буду постоянно развивать и поддерживать сообщество security-чемпионов?
И как только появятся конкретные ответы на эти вопросы, можно будет приступать к тактике. Кстати, отправной точкой для запуска программы может стать вот этот плейбук, подготовленный моим товарищем и поддержанный сообществом OWASP.
Культивируете ли чемпионов в своих командах?
(#соавтор South HUB, Денис Макрушин.)
Если кто-то до сих пор слышит и соглашается с тезисом «безопасность замедляет разработку и душит инновации», то он плохо осознает с какой скоростью двигается прогресс. Раньше управленец C-level в технологической компании мог надеяться, что его бизнес или продукт не будут интересны кибер-преступникам, и они обойдут его стороной. Теперь же, когда злодеи повсеместно используют автоматизацию и регулярно мониторят возможности запрыгнуть в инфраструктуру компании любого масштаба — нельзя надеяться на «да кому я нужен».
Атаки, утечки и различные кибер-инциденты реально тормозят развитие. Иногда останавливают его полностью. Потому что когда «зашифрован прод», а данные клиентов текут в паблик — это не про развитие. А еще, оказывается, что недостаточно завернуть в свой пайплайн все необходимые security-инструменты. Недостаточно даже их правильно настроить и получать только важные результаты их работы.
Как обычно, секретный соус кибербезопасной компании — в ее людях и культуре. Уязвимость всегда проще и дешевле исправлять, когда она обнаружена в IDE разработчика, а не в проде у клиента. Практики и инструменты ИБ нужно двигать «влево» — ближе к началу жизненного цикла системы. Ближе к тому этапу, на которых рождается идея, гипотеза, бизнес-план, дизайн системы. А для этого, нужно понимать “кибербез” на уровне культуры топ-менеджмента и разработки.
В индустрии есть такое термин: Security-чемпион. Это не всегда выделенная роль. Это может быть сотрудник, который прокачивает себя в вопросах ИБ и приземляет экспертизу в своих повседневных задачах. Например, разработчик или тим лид, который понимает риски некачественного кода. CTO, который не ждет, когда появится CISO и принесет контроли в SDLC. CEO и CPO, которые знают, для чего проводить дополнительные security design review.
Чтобы запустить чемпионскую программу в своих командах разработки, нужно предварительно ответить на ключевые вопросы вопроса:
1. Как я создам внутреннюю мотивацию? Что будет драйвить разработчика развиваться в направлении безопасной разработки?
2. Какой ресурс я выделю для реализации программы? Смогу ли обеспечить реальное влияние security-чемпионов на SDLC-процессы?
3. Как буду постоянно развивать и поддерживать сообщество security-чемпионов?
И как только появятся конкретные ответы на эти вопросы, можно будет приступать к тактике. Кстати, отправной точкой для запуска программы может стать вот этот плейбук, подготовленный моим товарищем и поддержанный сообществом OWASP.
Культивируете ли чемпионов в своих командах?
👍7❤4🔥2😭2😁1🏆1
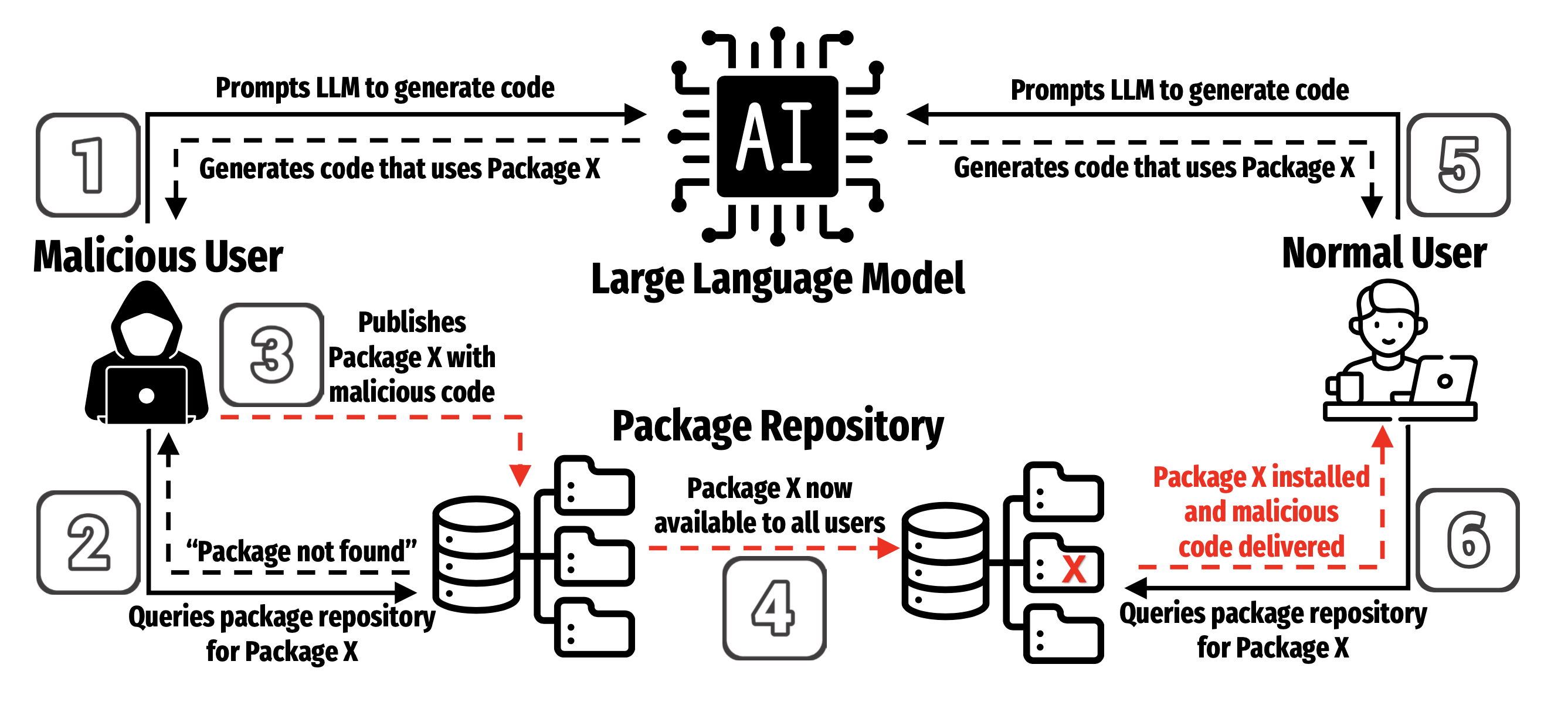
Глюк-пакеты: как названия пакетов, придуманные ИИ, становятся угрозой
Помним про старые атаки typosquatting, которые актуальны до сих пор. Typosquatting в разработке - это загрузка в репозиторий вредоносного пакета с именем, похожим на название популярного и уже существующего пакета.
В свежей академической статье авторы проверяли гипотезу, что галюцинации пакетов являются распространенным явлением при генерации кода с использованием больших языковых моделей (LLM), и что это явление представляет собой новую угрозу для цепочки поставок в разработке ПО.
Для проверки этой гипотезы исследователи выполнили три задачи:
1. определили частоту, с которой LLM генерируют несуществующие или ошибочные названия пакетов при генерации кода на Python и JavaScript, и то, как настройки модели влияют на возникновение галлюцинаций;
2. определили повторяемость галлюцинаций;
3. выявили семантические особенности сгенерированных пакетов.
Методика исследования состояла из нескольких этапов. Сначала авторы сгенерировали датасет из входных запросов (промптов) для генерации кода. Затем передали этот набор запросов для каждой из 16 выбранных LLM. И уже на сгенерированном коде применили правила для поиска фрагментов кода, в которых производится подключение сторонних пакетов.
Каждый полученный пакет сравнивался с актуальным списком настоящих пакетов. Если этот пакет отсутствовал в списке, то помечался авторами как галлюцинация. Галлюцинаций накопилось аж 205474 штук. Большинство галлюцинированных названий пакетов не были семантически схожи с существующими популярными пакетами. Это значит, что название глюк-пакета было мало похоже на оригинальное название. То есть, эти названия не являются простыми опечатками.
После изучения исследования у меня остался один вопрос: как злоумышленник может эффективно использовать эту особенность ИИ в своих атаках? Очевидная схема: «нагенерировать» с помощью LLM подобные галлюцинации, и использовать полученный словарь для регистрации вредоносных пакетов. Но далеко не факт, что подобные галлюцинации LLM воспроизведет у разработчика. Поэтому злодею остается стрелять «из пушки по воробьям»: регистрировать как можно больше названий, напоминающих названия для легитимных зависимостей.
Помним про старые атаки typosquatting, которые актуальны до сих пор. Typosquatting в разработке - это загрузка в репозиторий вредоносного пакета с именем, похожим на название популярного и уже существующего пакета.
В свежей академической статье авторы проверяли гипотезу, что галюцинации пакетов являются распространенным явлением при генерации кода с использованием больших языковых моделей (LLM), и что это явление представляет собой новую угрозу для цепочки поставок в разработке ПО.
Для проверки этой гипотезы исследователи выполнили три задачи:
1. определили частоту, с которой LLM генерируют несуществующие или ошибочные названия пакетов при генерации кода на Python и JavaScript, и то, как настройки модели влияют на возникновение галлюцинаций;
2. определили повторяемость галлюцинаций;
3. выявили семантические особенности сгенерированных пакетов.
Методика исследования состояла из нескольких этапов. Сначала авторы сгенерировали датасет из входных запросов (промптов) для генерации кода. Затем передали этот набор запросов для каждой из 16 выбранных LLM. И уже на сгенерированном коде применили правила для поиска фрагментов кода, в которых производится подключение сторонних пакетов.
Каждый полученный пакет сравнивался с актуальным списком настоящих пакетов. Если этот пакет отсутствовал в списке, то помечался авторами как галлюцинация. Галлюцинаций накопилось аж 205474 штук. Большинство галлюцинированных названий пакетов не были семантически схожи с существующими популярными пакетами. Это значит, что название глюк-пакета было мало похоже на оригинальное название. То есть, эти названия не являются простыми опечатками.
После изучения исследования у меня остался один вопрос: как злоумышленник может эффективно использовать эту особенность ИИ в своих атаках? Очевидная схема: «нагенерировать» с помощью LLM подобные галлюцинации, и использовать полученный словарь для регистрации вредоносных пакетов. Но далеко не факт, что подобные галлюцинации LLM воспроизведет у разработчика. Поэтому злодею остается стрелять «из пушки по воробьям»: регистрировать как можно больше названий, напоминающих названия для легитимных зависимостей.
{kind=link}
❤6😱2
Продолжаю дежурить в сообществе South HUB, которое объявило месяц безопасности для топ-менеджеров в IT.
На этих выходных подняли тему безопасности цепочки поставок при создании продуктов. Пока в том канале знакомятся с угрозами, здесь мы изучим дайджест исследований, которые попали в мою подборку на этой неделе. Следим за историями в канале.
На этих выходных подняли тему безопасности цепочки поставок при создании продуктов. Пока в том канале знакомятся с угрозами, здесь мы изучим дайджест исследований, которые попали в мою подборку на этой неделе. Следим за историями в канале.
Telegram
South HUB
Привет! На связи Денис Макрушин и в этом месяце я отвечаю за безопасность в South HUB.
Если в прошлый раз, текст был направлен на тех, кто преисполнился в вопросах безопасности, то сегодняшний лонгрид будет адресован тем, кто еще только подступается к этому…
Если в прошлый раз, текст был направлен на тех, кто преисполнился в вопросах безопасности, то сегодняшний лонгрид будет адресован тем, кто еще только подступается к этому…
👍2❤1🔥1
Веб-ханипот, чтобы изучить атакующего
Интересная библиотека, которую разработчик веб-приложения может добавить в свой проект и наблюдать, кто и как пытается проэксплуатировать уязвимости.
Ханипот поднимает API-эндпоинты, которые имитируют разные уязвимости. В результате, если атакующий использует сканер, то получает ложные срабатывания и тратит свое время на их анализ. А владелец веб-приложения получает дополнительное время, чтобы принять меры.
Если пишешь свои веб-приложения на Go/Python/JS и хочешь знать, кто пробует твои проекты на прочность, то подключай эту библиотеку - уверен, что соберешь много инсайтов.
Интересная библиотека, которую разработчик веб-приложения может добавить в свой проект и наблюдать, кто и как пытается проэксплуатировать уязвимости.
Ханипот поднимает API-эндпоинты, которые имитируют разные уязвимости. В результате, если атакующий использует сканер, то получает ложные срабатывания и тратит свое время на их анализ. А владелец веб-приложения получает дополнительное время, чтобы принять меры.
Если пишешь свои веб-приложения на Go/Python/JS и хочешь знать, кто пробует твои проекты на прочность, то подключай эту библиотеку - уверен, что соберешь много инсайтов.
{kind=link}
👍7🔥2💯1
Последняя миля для исследователя
Итог любого исследования - это отчет. Не найденная уязвимость, не новая техника атаки и даже не прототип. Заключительным этапом является опубликованный репорт, и об этом мы говорили в комментариях к посту, из которого родилась статья “Как провести свое первое security-исследование”.
Эта последняя миля иногда составляет более 50% от всего объема исследовательской работы. Нужно не только подготовить отчет, но и доставить его до целевой аудитории. В этот период доставки, ресерчер превращается в героя компьютерной игры Death Stranding и, как курьер, перемещается со своим докладом и материалами между различными регионами и конференциями.
Локальных конференций, на которых исследователь-практик может представить доклад, можно пересчитать по пальцам одной руки. А мероприятий, организаторы которых еще и могут дать экспертную обратную связь о ресерче - еще меньше.
Pentest Award - это отраслевая награда для специалистов по тестированию на проникновение, которую ежегодно вручают мои коллеги из компании Авилликс. Основная задача: выделить лучших специалистов и показать их вклад в развитие российского пентеста. Слежу за этим мероприятием уже третий год подряд и вижу, как площадка постепенно набирает свое сообщество и увеличивает количество номинаций в направлении наступательной безопасности. Если ты занимаешься анализом защищенности и нашел что-то нетривиальное, то точно стоит поделиться.
Отмечай это событие точкой на карте своего карьерного пути.
Итог любого исследования - это отчет. Не найденная уязвимость, не новая техника атаки и даже не прототип. Заключительным этапом является опубликованный репорт, и об этом мы говорили в комментариях к посту, из которого родилась статья “Как провести свое первое security-исследование”.
Эта последняя миля иногда составляет более 50% от всего объема исследовательской работы. Нужно не только подготовить отчет, но и доставить его до целевой аудитории. В этот период доставки, ресерчер превращается в героя компьютерной игры Death Stranding и, как курьер, перемещается со своим докладом и материалами между различными регионами и конференциями.
Локальных конференций, на которых исследователь-практик может представить доклад, можно пересчитать по пальцам одной руки. А мероприятий, организаторы которых еще и могут дать экспертную обратную связь о ресерче - еще меньше.
Pentest Award - это отраслевая награда для специалистов по тестированию на проникновение, которую ежегодно вручают мои коллеги из компании Авилликс. Основная задача: выделить лучших специалистов и показать их вклад в развитие российского пентеста. Слежу за этим мероприятием уже третий год подряд и вижу, как площадка постепенно набирает свое сообщество и увеличивает количество номинаций в направлении наступательной безопасности. Если ты занимаешься анализом защищенности и нашел что-то нетривиальное, то точно стоит поделиться.
Отмечай это событие точкой на карте своего карьерного пути.
{kind=link}
👍5🔥3❤1
LLM может автономно проводить целевой фишинг
Открытие, которое сейчас мало кого удивит: полностью автоматизированные фишинг-атаки с помощью ИИ так же успешны, как и организованные людьми. За последний год способности LLM в проведении атак значительно улучшились, и это подтверждают новые тесты:
* на фишинговые письма, созданные ИИ, кликнули 54% пользователей из контрольной группы
* на письма, созданные экспертами-людьми, кликнули 54% - ровно столько же пользователей.
Только человек тратил 34 минуты на составление письма, а LLM делала это за 2 минуты и 41 секунду. Экономически эффективно. Даже посчитана точка безубыточности: ИИ-фишинг становится более прибыльным, чем «человеческий», при атаке на группы размером от 2859 до 54123 человек.
Модели стали хитрее, а у атакующего появляются маркетинговые параметры, с которыми можно работать в автоматическом режиме: воронка, A/B-тесты и product-market fit.
Открытие, которое сейчас мало кого удивит: полностью автоматизированные фишинг-атаки с помощью ИИ так же успешны, как и организованные людьми. За последний год способности LLM в проведении атак значительно улучшились, и это подтверждают новые тесты:
* на фишинговые письма, созданные ИИ, кликнули 54% пользователей из контрольной группы
* на письма, созданные экспертами-людьми, кликнули 54% - ровно столько же пользователей.
Только человек тратил 34 минуты на составление письма, а LLM делала это за 2 минуты и 41 секунду. Экономически эффективно. Даже посчитана точка безубыточности: ИИ-фишинг становится более прибыльным, чем «человеческий», при атаке на группы размером от 2859 до 54123 человек.
Модели стали хитрее, а у атакующего появляются маркетинговые параметры, с которыми можно работать в автоматическом режиме: воронка, A/B-тесты и product-market fit.
{kind=link}
👍8🏆3🔥2❤1
Break Glass на PHDays
Break Glass - это механизм, который включается в критических, нестандартных ситуациях. Когда пропал доступ к ключевым ресурсам. Когда требуется оперативное восстановление. Когда случилась авария.
Завтра где-то в Лужниках вместе с Евгением Фрикиным мы посмотрим на фундаментальные недостатки технологии аварийного доступа к инфраструктуре. Рассмотрим идею, как исключить из реализации этого доступа ключевые элементы: пароли и предустановленные учетные записи. Обсудим архитектуру, опубликуем вайтпейпер, поделимся прототипом.
Если завтра ты тоже будешь неподалеку, добавляй доклад в календарь и приходи пообщаться.
Break Glass - это механизм, который включается в критических, нестандартных ситуациях. Когда пропал доступ к ключевым ресурсам. Когда требуется оперативное восстановление. Когда случилась авария.
Завтра где-то в Лужниках вместе с Евгением Фрикиным мы посмотрим на фундаментальные недостатки технологии аварийного доступа к инфраструктуре. Рассмотрим идею, как исключить из реализации этого доступа ключевые элементы: пароли и предустановленные учетные записи. Обсудим архитектуру, опубликуем вайтпейпер, поделимся прототипом.
Если завтра ты тоже будешь неподалеку, добавляй доклад в календарь и приходи пообщаться.
🔥11🏆1
Погружаем в безопасность приложений на PHDays
Для тех, кто сегодня будет в Лужниках, мы вместе с Александром Чуфистовым покажем, как использовать основные инструменты в коллекции исследователя, чтобы прокачать навыки в безопасности приложений. Поищем уязвимости, поделимся своими техниками и приправим это автоматизацией с использованием LLM. В качестве объекта для атаки будем использовать приложение, которое Саша подготовил специально для воркшопа и упаковал в контейнер. Поэтому выпустим наших слушателей с порцией инсайтов и задачами для домашней работы.
Спонсор воркшопа: наш курс AppSec🙂
Для тех, кто сегодня будет в Лужниках, мы вместе с Александром Чуфистовым покажем, как использовать основные инструменты в коллекции исследователя, чтобы прокачать навыки в безопасности приложений. Поищем уязвимости, поделимся своими техниками и приправим это автоматизацией с использованием LLM. В качестве объекта для атаки будем использовать приложение, которое Саша подготовил специально для воркшопа и упаковал в контейнер. Поэтому выпустим наших слушателей с порцией инсайтов и задачами для домашней работы.
Спонсор воркшопа: наш курс AppSec
Please open Telegram to view this post
VIEW IN TELEGRAM
👍7🔥1🤣1🏆1
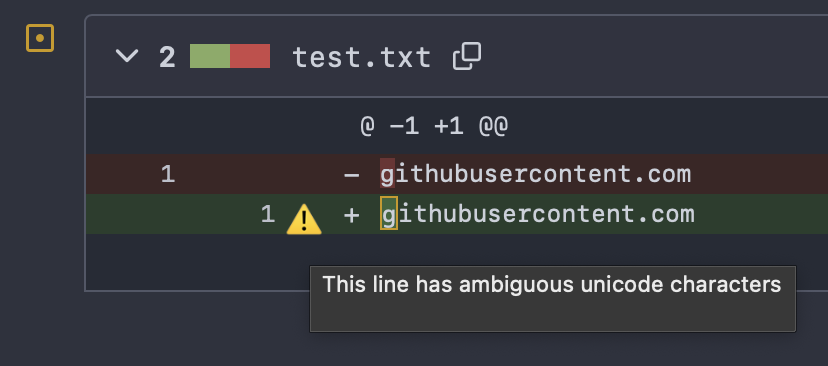
Один символ, который ломает код
Видишь что-то подозрительное в этом участке кода?
Буква “a” - кириллическая, а не латинская .
Это пример homoglyph-атаки - визуального обмана, при котором используются визуально похожие символы (гомоглифы), но из разных кодировок. Часто используется в фишинге для регистрации доменов, реже - для компрометации исходного кода, чтобы ввести в заблуждение код-ревьюверов.
Недавно исследователь провел эксперимент для крупного проекта curl: отправил pull request, в котором помимо основного полезного кода были заменены ASCII-сиволы на их похожие Unicode-альтернативы. Никто из ревьюверов не заметил этих изменений.
С тех пор Github стал подсвечивать измененные символы, но если ревьювишь код, то на всякий случай попроси свою LLM посмотреть его на гомоглифы.
Видишь что-то подозрительное в этом участке кода?
user = "admin"
if user == "аdmin":
grant_access()
Это пример homoglyph-атаки - визуального обмана, при котором используются визуально похожие символы (гомоглифы), но из разных кодировок. Часто используется в фишинге для регистрации доменов, реже - для компрометации исходного кода, чтобы ввести в заблуждение код-ревьюверов.
Недавно исследователь провел эксперимент для крупного проекта curl: отправил pull request, в котором помимо основного полезного кода были заменены ASCII-сиволы на их похожие Unicode-альтернативы. Никто из ревьюверов не заметил этих изменений.
С тех пор Github стал подсвечивать измененные символы, но если ревьювишь код, то на всякий случай попроси свою LLM посмотреть его на гомоглифы.
{kind=link}
🔥7❤6🍌2🌭1🏆1💊1
Атака на Dependabot: внедрение вредоносного кода через Github-бота
Есть такой Dependabot - популярный бот на Github, который регулярно проверяет проекты на наличие устаревших зависимостей. Если он находит обновления, то создает pull request (PR), в котором предлагает внести изменения в код для обновления.
Есть разработчики - они обычно настраивают рабочий процесс так, чтобы автоматически объединять все PR от Dependabot. Проверка происходит через переменную
И есть злоумышленники. Они знают, что
* создает форк целевого репозитория, у которого разработчики выставили настройки автоматического приема PR от Dependabot;
* добавляет свой вредоносный код в основную ветку своего форка;
* активирует Dependabot в своем форке и добавляет какую-нибудь устаревшую зависимость, чтобы привлечь внимание бота. Dependabot создает свою ветку обновлений в форке, и поскольку она основана на основной ветке форка, то содержит вредоносный код злодея.
* создает PR в целевом репозитории жертвы, используя ветку бота
* и ничего не получается, ведь в созданном PR значение
И вот на этом этапе происходит магия: когда Dependabot сам пересоздает и принудительно отправляет изменения, он становится «исполнителем» этого последнего события. Значение
PR с вредоносным кодом оказывается в целевом репозитории.
Нетривиальная атака. Поэтому попадает в коллекцию атак на разработчиков, о которой на следующей неделе расскажу на мероприятии IT IS Conf в Екатеринбурге.
Есть такой Dependabot - популярный бот на Github, который регулярно проверяет проекты на наличие устаревших зависимостей. Если он находит обновления, то создает pull request (PR), в котором предлагает внести изменения в код для обновления.
Есть разработчики - они обычно настраивают рабочий процесс так, чтобы автоматически объединять все PR от Dependabot. Проверка происходит через переменную
github.actor. Если ее значение = dependabot[bot], то происходит слияние кода. И есть злоумышленники. Они знают, что
github.actor не всегда указывает на того, кто изначально создал PR, и существует возможность для атаки confused deputy. Для этого злодей выполняет следующие действия:* создает форк целевого репозитория, у которого разработчики выставили настройки автоматического приема PR от Dependabot;
* добавляет свой вредоносный код в основную ветку своего форка;
* активирует Dependabot в своем форке и добавляет какую-нибудь устаревшую зависимость, чтобы привлечь внимание бота. Dependabot создает свою ветку обновлений в форке, и поскольку она основана на основной ветке форка, то содержит вредоносный код злодея.
* создает PR в целевом репозитории жертвы, используя ветку бота
* и ничего не получается, ведь в созданном PR значение
github.actor (инициатор) все еще принадлежит злодею, поэтому он возвращается к оригинальному PR от Dependabot и комментирует: @dependabot recreate
* Dependabot выполняет команду: пересоздает свою ветку и принудительно отправляет в нее изменения (force-push). Принудительная отправка изменений в ветку повторно запускает процесс слияния в целевом репозитории (репозитории-жертве). И вот на этом этапе происходит магия: когда Dependabot сам пересоздает и принудительно отправляет изменения, он становится «исполнителем» этого последнего события. Значение
github.actor меняется и условие для автослияния выполняется:if: ${{ github.actor == ‘dependabot[bot]’ }}
PR с вредоносным кодом оказывается в целевом репозитории.
Нетривиальная атака. Поэтому попадает в коллекцию атак на разработчиков, о которой на следующей неделе расскажу на мероприятии IT IS Conf в Екатеринбурге.
{kind=link}
🔥6❤2🏆2✍1👍1🤯1
Материалы для погружения в AppSec
На связи Саша Чуфистов. По следам воркшопа, совместно с Денисом, мы собрали материалы для дальнейшего погружения в тему безопасности веб-приложений.
1. Теория и кейсы, с которых стоит начать практику:
* Фреймворк для автоматизации активной и пассивной разведки сэкономит часы ручной работы при поиске точек входа в исследуемое приложение.
* Много полезных oneliners для избавления от рутинных действий при поиске базовых уязвимостей вроде XSS или SSRF.
2. Практика:
* Для участников воркшопа я подготовил уязвимое приложение и готовый образ.
amd64:
arm64:
Также можно собрать его самостоятельно, по инструкции из данного репозитория.
3. Уязвимости, которые мы разбирали:
1. Полный гайд по xss.
2. Полный гайд по lfi.
3. Полный гайд по idor.
Если нужно больше практики, но вы еще не заглядывали на portswigger labs, то вы найдете там все, что было рассмотрено на воркшопе, и не только👉
На связи Саша Чуфистов. По следам воркшопа, совместно с Денисом, мы собрали материалы для дальнейшего погружения в тему безопасности веб-приложений.
1. Теория и кейсы, с которых стоит начать практику:
* Фреймворк для автоматизации активной и пассивной разведки сэкономит часы ручной работы при поиске точек входа в исследуемое приложение.
* Много полезных oneliners для избавления от рутинных действий при поиске базовых уязвимостей вроде XSS или SSRF.
2. Практика:
* Для участников воркшопа я подготовил уязвимое приложение и готовый образ.
amd64:
docker pull achuf/phd_workshop_app:latest
arm64:
docker pull achuf/phd_workshop_app_arm64:latest
Также можно собрать его самостоятельно, по инструкции из данного репозитория.
3. Уязвимости, которые мы разбирали:
1. Полный гайд по xss.
2. Полный гайд по lfi.
3. Полный гайд по idor.
Если нужно больше практики, но вы еще не заглядывали на portswigger labs, то вы найдете там все, что было рассмотрено на воркшопе, и не только
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥5❤1👍1🏆1
Чтобы не заплыть в аналитике, роадмапах, продуктовых стратегиях, security-исследованиях и докладах собираем палатку, посуду, фонарик, любимый транспорт и выезжаем в оффлайн.
Если где-то поймаю связь и буду мерзнуть ночью, то подготовлю подборку материалов, которые изучим на следующей неделе. Бодрых выходных.
Если где-то поймаю связь и буду мерзнуть ночью, то подготовлю подборку материалов, которые изучим на следующей неделе. Бодрых выходных.
🔥5❤🔥3🏆2😎1
Makrushin
Если где-то поймаю связь и буду мерзнуть ночью
«Секретные» материалы, которые изучим на следующей неделе
Было холодно, поэтому подготовил подборку:
* Применение малых языковых моделей (SLM) для поиска секретов.
Доклад, в котором исследователи достигли точности 86% в задаче обнаружения секретов с помощью Llama 3.2 1B. Интересно изучить методологию и посмотреть бенчмарки.
* А этот пост уже про то, какие секреты удалось найти на Github. Месяц сканирования публичных репозиториев, новые типы секретов (связанные с ИИ-провайдерами) - новые находки старыми способами.
* В контексте архитектуры MCP (Model Context Protocol) секреты имеют новое значение. Можно забирать кейс для личных исследований.
* Велопоходное фото.
#дайджест
Было холодно, поэтому подготовил подборку:
* Применение малых языковых моделей (SLM) для поиска секретов.
Доклад, в котором исследователи достигли точности 86% в задаче обнаружения секретов с помощью Llama 3.2 1B. Интересно изучить методологию и посмотреть бенчмарки.
* А этот пост уже про то, какие секреты удалось найти на Github. Месяц сканирования публичных репозиториев, новые типы секретов (связанные с ИИ-провайдерами) - новые находки старыми способами.
* В контексте архитектуры MCP (Model Context Protocol) секреты имеют новое значение. Можно забирать кейс для личных исследований.
* Велопоходное фото.
#дайджест
🔥7👍2🤣2🏆1
Повышение эффективности обнаружения секретов в коде
Год другой, но те же тактики: в 2025 украденные учетные записи являются главными “фигурантами” инцидентов. Атакующие все чаще используют учетки от “non-human identities” (NHI): секреты от всевозможных сервисных аккаунтов, ботов, ИИ-агентов. Один из ключевых источников, который хранит в себе эти секреты - код.
В 2020 году рассматривали методы для поиска секретов в коде. С тех пор, к анализу энтропии, регулярным выражениям и сигнатурам, которые часто ошибались и путали строку пароля с названием функции, добавились большие языковые модели (LLM). Но у LLM есть ключевое ограничение в задаче поиска секрета: они требуют значительных вычислительных ресурсов. Это приводит к значительным временным задержкам в процессе поиска.
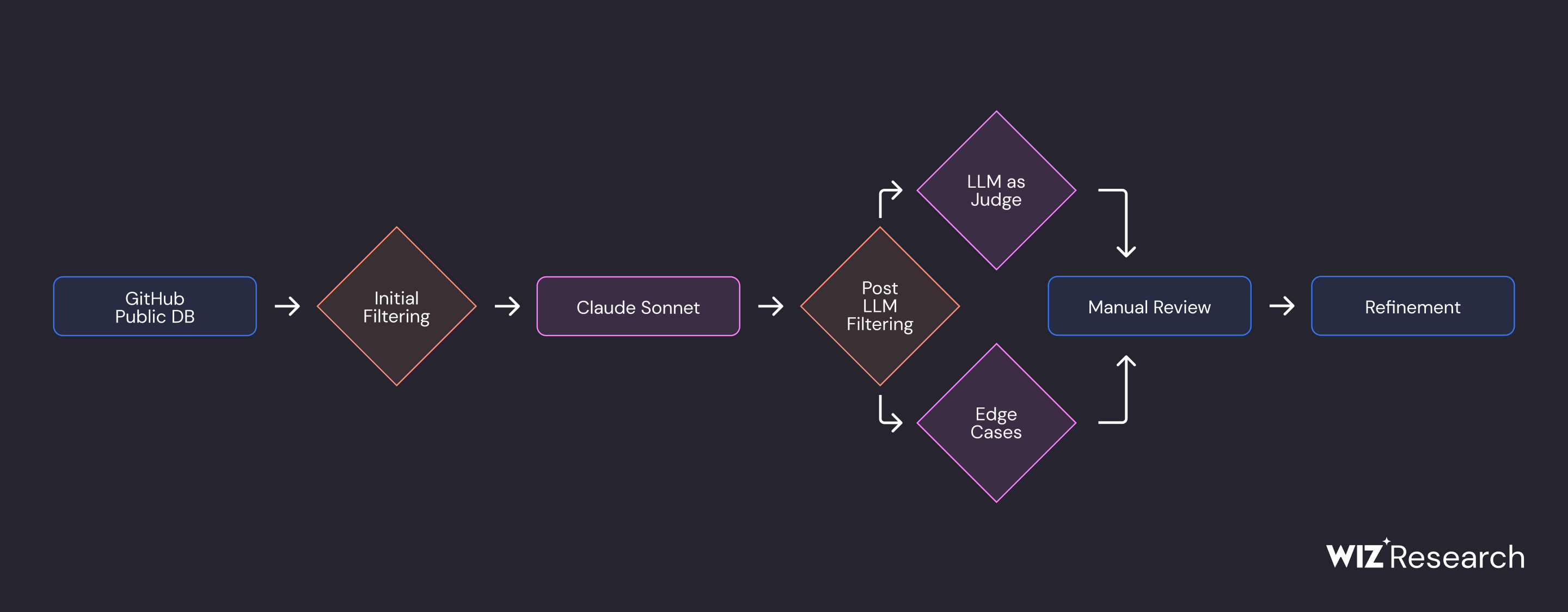
Исследователи подтвердили гипотезу, что SLM эффективнее в этой задаче. Рецепт, который привел к 86% точности (выявленный секрет действительно является секретом) и 82% полноты (доля обнаруженных секретов от всех существующих секретов в коде):
1️⃣ готовим данные для обучения модели: с помощью LLM проводим обнаружение и классификация секретов из публичных Github-репозиториев. Можно использовать вторую LLM для оценки результата.
2️⃣ Для повышения качества полученного датасета применяем алгоритмы MinHash и LSH (Locality Sensitive Hashing) для кластеризации полученных данных: объединяем похожие фрагменты кода в один кластер и убираем дубликаты.
3️⃣ Выбираем модель, которую будем дообучать. Наша цель: не более 10 секунд на поиск секрета (доступный ресурс: однопоточная машинка с ARM). В качестве базовой модели для этого выбираем LLAMA-3.2-1B.
4️⃣ Добавляем наши “фильтры” к исходной модели: дообучаем небольшие матрицы внутри выбранной модели с помощью метода LoRA.
5️⃣ Охапку дров и плов готов:Оцениваем результаты: следим за совпадениями на уровне файла (есть ли в нем секреты?) и совпадениями на уровне секрета (какой это тип секрета?).
Полученный результат не отменяет эффективность сигнатурных методов. Модель работает как дополнение к существующим правилам.
Год другой, но те же тактики: в 2025 украденные учетные записи являются главными “фигурантами” инцидентов. Атакующие все чаще используют учетки от “non-human identities” (NHI): секреты от всевозможных сервисных аккаунтов, ботов, ИИ-агентов. Один из ключевых источников, который хранит в себе эти секреты - код.
В 2020 году рассматривали методы для поиска секретов в коде. С тех пор, к анализу энтропии, регулярным выражениям и сигнатурам, которые часто ошибались и путали строку пароля с названием функции, добавились большие языковые модели (LLM). Но у LLM есть ключевое ограничение в задаче поиска секрета: они требуют значительных вычислительных ресурсов. Это приводит к значительным временным задержкам в процессе поиска.
Исследователи подтвердили гипотезу, что SLM эффективнее в этой задаче. Рецепт, который привел к 86% точности (выявленный секрет действительно является секретом) и 82% полноты (доля обнаруженных секретов от всех существующих секретов в коде):
Полученный результат не отменяет эффективность сигнатурных методов. Модель работает как дополнение к существующим правилам.
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
🔥2🏆1
Поиск секретов в коде с помощью LLM: подход GitHub
Исследователи Wiz пришли к выводу, что языковые модели лучше справляется с поиском секретов, чем традиционные регулярки. Исследователи команды GitHub тоже пришли к этому выводу, но только с помощью LLM.
Обычные регулярки хороши только там, где формат строк строго определен (ключи, API-токены), но не учитывают многообразие структур строк паролей. LLM снижает количество шума, потому что учитывает контекст. Ожидаемо, использование LLM требует линейного увеличения вычислительных ресурсов с каждым новым клиентом. И чтобы сэкономить немного ресурса, команде пришлось исключить из проверок все медиафайлы или файлы, которые содержали в названии “test”, “mock”, “spec”.
Если занимаешься поиском секретов в репозиториях, то из исследования можно позаимствовать следующие инсайты:
⭐️ Регулярные выражения - это база для выявления детерминированных строк, но она сильно шумит при поиске паролей.
⭐️ LLM снижает шум и хорошо справляются с задачей поиска за счет анализа контекста. При этом использовать LLM для активных и крупных репозиториев - дорого.
⭐️ Чтобы экономить ресурсы можно выбрать два пути: сокращать размер базы для анализа (как GitHub) или оптимизировать использование вычислительных ресурсов для анализа (как Wiz). Еще лучше использовать оба подхода.
⭐️ Стратегии подсказок (промптов) для LLM влияют на точность обнаружения и на количество потребляемых ресурсов. GitHub попробовал стратегии Zero-Shot (дать модели только задачу, без примеров), Chain-of-Thought (попросить модель прийти к ответу через цепочку рассуждений), Fill-in-the-Middle (дать контекст “до” и контекст “после”, затем попросить дополнить середину) и MetaReflection (после первого ответа модели попросить ее проанализировать и доработать собственный ответ). В итоге MetaReflection дала лучшую точность.
Исследователи Wiz пришли к выводу, что языковые модели лучше справляется с поиском секретов, чем традиционные регулярки. Исследователи команды GitHub тоже пришли к этому выводу, но только с помощью LLM.
Обычные регулярки хороши только там, где формат строк строго определен (ключи, API-токены), но не учитывают многообразие структур строк паролей. LLM снижает количество шума, потому что учитывает контекст. Ожидаемо, использование LLM требует линейного увеличения вычислительных ресурсов с каждым новым клиентом. И чтобы сэкономить немного ресурса, команде пришлось исключить из проверок все медиафайлы или файлы, которые содержали в названии “test”, “mock”, “spec”.
Если занимаешься поиском секретов в репозиториях, то из исследования можно позаимствовать следующие инсайты:
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
2✍2🤩1🏆1
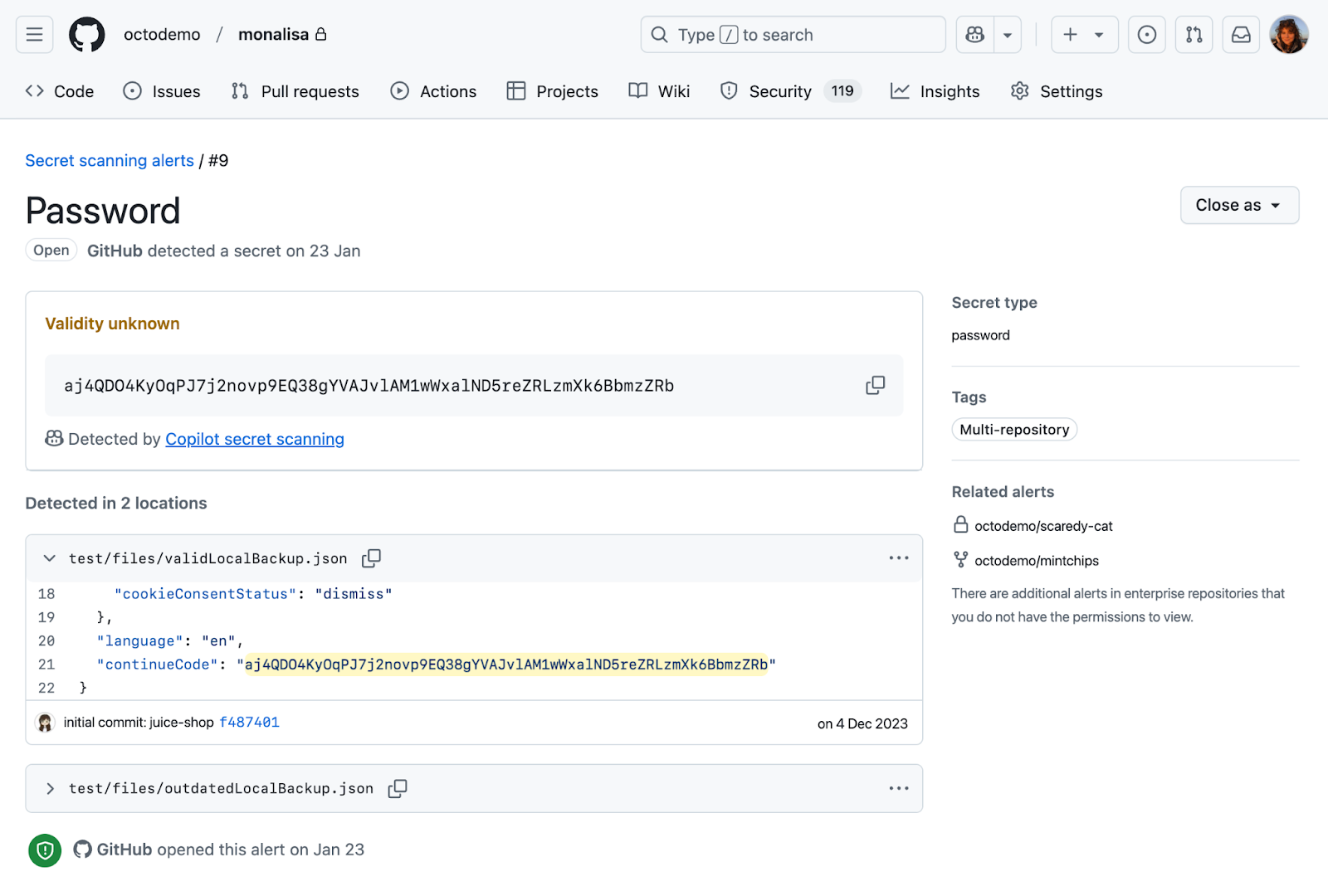
Новый и супер-быстрый инструмент для поиска секретов в коде
Чтобы оценить инструменты поиска секретов исследователи подготовили специальный датасет SecretBench и провели на его основе сравнение популярных проектов. Лидером среди opensource стал gitleaks: у него 46% точности и 88% полноты. А еще авторы сделали ключевой вывод:
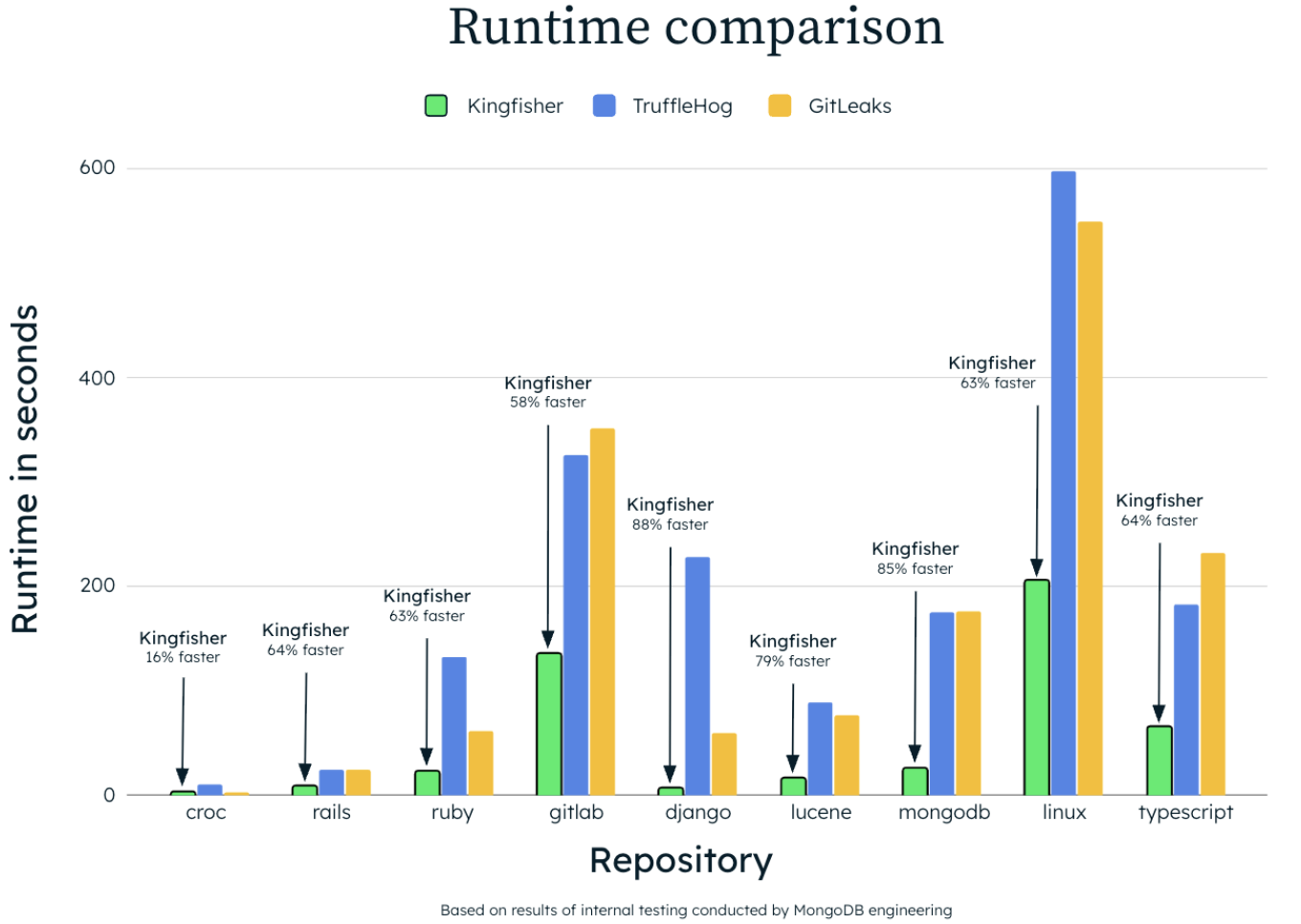
Недавно команда mongodb опубликовала инструмент Kingfisher, который обладает рядом преимуществ относительно других опенсорс-проектов:
💡 написан на Rust, а значит, есть преимущества перед Golang-тулами за счет ускорения потока обработки. Это дает ощутимый выигрыш в производительности при сканировании больших объемов кода, например, монорепозиториев или всей истории коммитов.
💡 использует Hyperscan - быстрый движок для поиска по регулярным выражениям, который может одновременно обрабатывать тысячи шаблонов за один прогон. Regex matching занимает до 90% от всего времени сканирования, поэтому наличие этого движка позволяет отбросить gitleaks, который использует стандартные regex-средства в Go.
💡 кроме regex-движка еще использует инструмент для синтаксического анализа кода - Tree-Sitter. Строит AST-дерево, чтобы понимать, где в коде находятся строки, комментарии, переменные и проводить поиск только в нужных местах. Это помогает лучше понимать контекст, в котором находится секрет и точнее его интерпретировать. Но эту функцию также лучше применять для больших файлов.
Результаты внутренних тестов Kingfisher от авторов показывают кратное преимущество в скорости. Интересно, как инструмент ведет себя в точности и скорости для небольших проектов. 🧐
Чтобы оценить инструменты поиска секретов исследователи подготовили специальный датасет SecretBench и провели на его основе сравнение популярных проектов. Лидером среди opensource стал gitleaks: у него 46% точности и 88% полноты. А еще авторы сделали ключевой вывод:
На данный момент нет ни одного инструмента, который обладал бы одновременно высокими показателями точности и полноты.
Недавно команда mongodb опубликовала инструмент Kingfisher, который обладает рядом преимуществ относительно других опенсорс-проектов:
Результаты внутренних тестов Kingfisher от авторов показывают кратное преимущество в скорости. Интересно, как инструмент ведет себя в точности и скорости для небольших проектов. 🧐
Please open Telegram to view this post
VIEW IN TELEGRAM
{kind=link}
🏆3
Ретроспектива ПМЭФ: безопасность киберфизических систем
Задача: выйти из ящика ИБ-конференций и мероприятий для разработчиков и запрыгнуть в совершенно другой контекст, чтобы поискать свежие идеи. Решение: посетить ПМЭФ (спасибо PT-товарищам за приглашение), принести с собой кибербез и поискать тренды, которые повлияют на него в ближайшее время.
Делюсь заметками, которые закидывал в телефон, пока слушал доклады и общался с коллегами:
⭐️ Безопасность киберфизических систем - это приоритет для крупных предприятий и производств. Особенно с появлением автономных ИИ-агентов. Разница между скоростью исправления уязвимостей в таких системах и скоростью приземления в них агентов настолько большая, что кажется, кибератаки совсем потеряют приставку “кибер”. Можно даже рассмотреть свежий пример: уязвимость в стандарте связи, который используется в поездах. Используя SDR-устройство, редиска может перехватывать и подделывать трафик в грузовых поездах и отправить команду активации тормоза. Это может привести к сходу с рельсов. Уязвимость не исправлена до сих пор.
⭐️ Безопасность ИИ. Понятно, что тема актуальная. И понятно, что защитные меры нужно двигать максимально “влево” в жизненном цикле этих систем. Интересно, с какой скоростью MLSecOps повторяет путь DevSecOps.
⭐️ Рынок труда и образование в ИБ меняются быстрее, чем образовательные стандарты. Частота, с которой Дима обновляет схему карьерных треков, как бы намекает, что подход к обучению трансформируется из контентно-центричного в проектно-центричный. Главное, не забыть про математику.
Задача: выйти из ящика ИБ-конференций и мероприятий для разработчиков и запрыгнуть в совершенно другой контекст, чтобы поискать свежие идеи. Решение: посетить ПМЭФ (спасибо PT-товарищам за приглашение), принести с собой кибербез и поискать тренды, которые повлияют на него в ближайшее время.
Делюсь заметками, которые закидывал в телефон, пока слушал доклады и общался с коллегами:
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥6🏆2❤1
Исследуем способы точного и быстрого поиска секретов
В процессе создания платформы безопасной разработки мы провели исследование актуальных инструментов поиска секретов в исходном коде. В статье “Секретные ингредиенты безопасной разработки” поделились критериями выбора движков для анализа, особенностями их работы и результатами сравнительных тестов.
AppSec-инженеры и DevSecOps-специалисты, которые строят безопасный конвейер разработки, найдут в материале подсказки, какие проекты с открытым исходным кодом стоит рассмотреть для внедрения. Исследователи безопасности и охотники за ошибками, возможно, откроют новые утилиты и нюансы их использования на больших объемах данных. Владельцы продуктов и разработчики еще раз получат напоминание и рецепт поиска секретов в своем коде.
В процессе создания платформы безопасной разработки мы провели исследование актуальных инструментов поиска секретов в исходном коде. В статье “Секретные ингредиенты безопасной разработки” поделились критериями выбора движков для анализа, особенностями их работы и результатами сравнительных тестов.
AppSec-инженеры и DevSecOps-специалисты, которые строят безопасный конвейер разработки, найдут в материале подсказки, какие проекты с открытым исходным кодом стоит рассмотреть для внедрения. Исследователи безопасности и охотники за ошибками, возможно, откроют новые утилиты и нюансы их использования на больших объемах данных. Владельцы продуктов и разработчики еще раз получат напоминание и рецепт поиска секретов в своем коде.
{kind=link}
👀6👍2🏆2