
Дайте Определение Коллаборативной Фильтрации.
Коллаборативная фильтрация, как понятно из названия, является процессом фильтрации, который используют многие рекомендательные системы. Этот тип фильтрации используется для поиска и категоризации определённых паттернов.
Коллаборативная фильтрация — это способ создания автоматических прогнозов (фильтрации) об интересах пользователя с помощью сбора информации о предпочтениях и вкусе многих пользователей.
@machinelearning_interview
Коллаборативная фильтрация, как понятно из названия, является процессом фильтрации, который используют многие рекомендательные системы. Этот тип фильтрации используется для поиска и категоризации определённых паттернов.
Коллаборативная фильтрация — это способ создания автоматических прогнозов (фильтрации) об интересах пользователя с помощью сбора информации о предпочтениях и вкусе многих пользователей.
@machinelearning_interview
👎11🔥7👍2🤯2
Делимся с вами подкастом Рандомные Дрова, который делает команда @ozon_tech. Они рассказывают о разном из мира DS и DA, в частности, про собесы, кейсы, обучение, тех.интервью.
В этом эпизоде встретились Ван Хачатрян (Head of ML Ozon), Денис Нечитайло (Head of Product Analytics Ozon) и Сергей Юдин (COO Яндекс Кью).
Обсудили, где пролегает граница между дата-сайентистами и дата-аналитиками, поговорили о том, что нужно дата-сайентисту и что пригодится аналитику данных, рассказали, откуда взялась мода на дата-сайентистов (спойлер: по одной изверсий, с этой статьи «Дата-сайентист – самая сексуальная профессия»).
Послушать можно тут :
🎧Яндекс
🎧Apple
🎧Google
🎧Vk
В этом эпизоде встретились Ван Хачатрян (Head of ML Ozon), Денис Нечитайло (Head of Product Analytics Ozon) и Сергей Юдин (COO Яндекс Кью).
Обсудили, где пролегает граница между дата-сайентистами и дата-аналитиками, поговорили о том, что нужно дата-сайентисту и что пригодится аналитику данных, рассказали, откуда взялась мода на дата-сайентистов (спойлер: по одной изверсий, с этой статьи «Дата-сайентист – самая сексуальная профессия»).
Послушать можно тут :
🎧Яндекс
🎧Apple
🎧Vk
👍13🔥2
Вы летите в Казань, и хотите решить, стоит ли брать зонт. Вы звоните трем случайным казанцам и спрашиваете, идет ли дождь. Каждый из них говорит правду с вероятностью 2/3, а с вероятностью 1/3 обманывает вас. Все трое говорят, что дождь идет. Какова вероятность, что он идет на самом деле?
Поскольку последнее предложение фактически спрашивает: «какова вероятность A при условии, что верно B?», можно сразу сказать, что здесь нужна теорема Байеса. Нам потребуется информация о вероятности дождя в Казани в произвольный день, не связанный с полетом Допустим, она равна 25%.
P(A) = вероятность дождя = 25%
P(B) = вероятность, что все три казанца говорят, что идет дождь.
P(A|B) = вероятность дождя, при условии, что все трое говорят, что он идет.
P(B|A) = вероятность, что все трое говорят, что идет дождь, при условии, что он действительно идет = (2/3)3=8/27.
Шаг 1. Находим P(B)
Формулу Байеса P(A|B) = P(B|A) * P(A) / P(B) можно переписать в виде
P(B) = P(B|A) * P(A) + P(B| не А) * P(не A)
P(B) = (2/3)3*0.25 + (1/3)3*0.75 = 0.25*8/27 + 0.75*1/27.
Шаг 2. Находим P(A|B)
P(A|B) = 0.25*(8/27) / (0.25*8/27 + 0.75*1/27) = 8 / (8+3) = 8/11.
Таким образом, если все три казанца говорят, что идет дождь, то он действительно идет с вероятностью 8/11.
@machinelearning_interview
Поскольку последнее предложение фактически спрашивает: «какова вероятность A при условии, что верно B?», можно сразу сказать, что здесь нужна теорема Байеса. Нам потребуется информация о вероятности дождя в Казани в произвольный день, не связанный с полетом Допустим, она равна 25%.
P(A) = вероятность дождя = 25%
P(B) = вероятность, что все три казанца говорят, что идет дождь.
P(A|B) = вероятность дождя, при условии, что все трое говорят, что он идет.
P(B|A) = вероятность, что все трое говорят, что идет дождь, при условии, что он действительно идет = (2/3)3=8/27.
Шаг 1. Находим P(B)
Формулу Байеса P(A|B) = P(B|A) * P(A) / P(B) можно переписать в виде
P(B) = P(B|A) * P(A) + P(B| не А) * P(не A)
P(B) = (2/3)3*0.25 + (1/3)3*0.75 = 0.25*8/27 + 0.75*1/27.
Шаг 2. Находим P(A|B)
P(A|B) = 0.25*(8/27) / (0.25*8/27 + 0.75*1/27) = 8 / (8+3) = 8/11.
Таким образом, если все три казанца говорят, что идет дождь, то он действительно идет с вероятностью 8/11.
@machinelearning_interview
👍19🤯5🔥2
Как уменьшить количество ошибок выборки?
Ответ
Два простых метода – это рандомизация, при которой наблюдения выбираются случайным образом, и случайная выборка, при которой каждое наблюдение имеет равный шанс попасть в выборку.
Подробнее
@machinelearning_interview
Ответ
Два простых метода – это рандомизация, при которой наблюдения выбираются случайным образом, и случайная выборка, при которой каждое наблюдение имеет равный шанс попасть в выборку.
Подробнее
@machinelearning_interview
👍10🔥1
Выборка 9 человек из интересующей нас популяции выявила средний объем мозга = 1100 куб.см. со стандартным отклоненим 30 куб.см. Каким будет 95% Т-доверительный интервал Стьюдента для среднего объема мозга в этой популяции?
Ответ
Используем формулу доверительного интервала для выборки (картинка)
Учитывая уровень доверительности 95% и количество степеней свободы, равное 8, t-оценка = 2.306.
Доверительный интервал = 1100 +/- 2.306*(30/3) = [1076.94, 1123.06].
38. Девять испытуемых получали диетические пилюли на протяжении 6 недель. Средняя потеря веса составила -2 кг. Каким должно быть стандартное отклонение потери веса, чтобы верхняя граница 95% Т-доверительного интервала была равна 0?
Верхняя граница = среднее + t-оценка * (стандартное отклонение / квадратный корень из размера выборки).
0 = -2 + 2.306*(s/3)
2 = 2.306 * s / 3
s = 2.601903
Таким образом, стандартное отклонение должно быть примерно 2.60, чтобы Т-доверительный интервал заканчивался в нуле.
@machinelearning_interview
Ответ
Используем формулу доверительного интервала для выборки (картинка)
Учитывая уровень доверительности 95% и количество степеней свободы, равное 8, t-оценка = 2.306.
Доверительный интервал = 1100 +/- 2.306*(30/3) = [1076.94, 1123.06].
38. Девять испытуемых получали диетические пилюли на протяжении 6 недель. Средняя потеря веса составила -2 кг. Каким должно быть стандартное отклонение потери веса, чтобы верхняя граница 95% Т-доверительного интервала была равна 0?
Верхняя граница = среднее + t-оценка * (стандартное отклонение / квадратный корень из размера выборки).
0 = -2 + 2.306*(s/3)
2 = 2.306 * s / 3
s = 2.601903
Таким образом, стандартное отклонение должно быть примерно 2.60, чтобы Т-доверительный интервал заканчивался в нуле.
@machinelearning_interview
👍18🔥1
Количество убийств в Шотландии упало со 115 до 99. Является ли это изменение значимым?
Ответ
Эта задача аналогична предыдущей – зесь тоже используется распределение Пуассона. Доверительный интервал равен 115 +/- 21.45 = [93.55, 136.45]. Поскольку 99 находится в этом доверительном интервале, мы можем сделать вывод, что это изменение не является значимым.
@machinelearning_interview
Ответ
Эта задача аналогична предыдущей – зесь тоже используется распределение Пуассона. Доверительный интервал равен 115 +/- 21.45 = [93.55, 136.45]. Поскольку 99 находится в этом доверительном интервале, мы можем сделать вывод, что это изменение не является значимым.
@machinelearning_interview
🔥13🤔3👍2
КОГДА ЛУЧШЕ ИСПОЛЬЗОВАТЬ TENSORFLOW [ИЛИ ДРУГУЮ БИБЛИОТЕКУ, ТЕХНОЛОГИЮ ИЛИ ПОДХОД]?
Когда дело доходит до машинного обучения (или даже собеседований по науке о данных для тех, кто хочет получить работу в C-Suite), ожидайте вопросов, которые проверят, насколько вы в курсе текущих технологий и тенденций. Сюда входят вопросы, связанные с библиотеками Python, такими как TensorFlow. Бабич, которому однажды пришлось нанять семь кандидатов наук в области науки о данных для трехмесячного проекта (то есть он провел более 100 собеседований), любит разбрасывать подобные вопросы между более математическими. «Мне очень нравятся вопросы о современных технологиях и подходах».
Итог: не бойтесь высказывать свое мнение, если вы можете его обосновать.
Краткое описание популярных мл библиотек
@machinelearning_interview
Когда дело доходит до машинного обучения (или даже собеседований по науке о данных для тех, кто хочет получить работу в C-Suite), ожидайте вопросов, которые проверят, насколько вы в курсе текущих технологий и тенденций. Сюда входят вопросы, связанные с библиотеками Python, такими как TensorFlow. Бабич, которому однажды пришлось нанять семь кандидатов наук в области науки о данных для трехмесячного проекта (то есть он провел более 100 собеседований), любит разбрасывать подобные вопросы между более математическими. «Мне очень нравятся вопросы о современных технологиях и подходах».
Итог: не бойтесь высказывать свое мнение, если вы можете его обосновать.
Краткое описание популярных мл библиотек
@machinelearning_interview
👍10
Рассмотрим эпидемию инфлюэнцы для гетеросексуальных семей с двумя родителями. Предположим, что вероятность заражения хотя бы одного родителя 17%. Вероятность заражения отца 12%, а заражения обоих родителей – 6%. Какова вероятность заражения матери?
Ответ
Используем общее правило сложения вероятностей:
P(мать или отец) = P(мать) + P(отец) – P(мать и отец)
P(мать) = P(мать или отец) + P(мать и отец) – P(отец) = 0.17 + 0.06 – 0.12 = 0.11
Правила сложения вероятностей
@machinelearning_interview
Ответ
Используем общее правило сложения вероятностей:
P(мать или отец) = P(мать) + P(отец) – P(мать и отец)
P(мать) = P(мать или отец) + P(мать и отец) – P(отец) = 0.17 + 0.06 – 0.12 = 0.11
Правила сложения вероятностей
@machinelearning_interview
👍22🔥6🤔3👎1
Случайная величина X распределена нормально со средним значением 1020 и стандартным отклонением 50. Вычислите P(X>1200).
Ответ
Используем Excel: p = 1-norm.dist(1200, 1020, 50, true). Получаем p=0.000159.
@machinelearning_interview
Ответ
Используем Excel: p = 1-norm.dist(1200, 1020, 50, true). Получаем p=0.000159.
@machinelearning_interview
👍19🔥3
Назовите жизненные этапы разработки модели в проекте машинного обучения.
Ответ
Разработка модели машинного обучения проходит в следующие этапы:
1 Определить бизнес-задачу: понять бизнес-цели и преобразовать задачу ИТ-аналитики
Конструирование данных: определение необходимых источников данных, извлечение и агрегирование данных на необходимом уровне.
2 Исследовательский анализ: понимание данных, проверка переменных на наличие ошибок, выбросов и пропущенных значений. Определите взаимосвязь между различными типами переменных. Проверьте предположения.
3 Подготовка данных: исключения, преобразование типов, обработка выбросов, обработка пропущенных значений. Создайте новые гипотетически релевантные переменные, например max, min, sum, change, ratio. Группирование переменных, создание фиктивных переменных и т. Д.
4 Разработка функций: Избегайте мультиколлинеарности и оптимизируйте сложность модели за счет сокращения количества входных переменных – кластера переменных, корреляции, факторного анализа, RFE и т. Д.
5 Разделение данных: разделите данные на обучающую и тестовую выборки.
6 Построение модели: подгонка, проверка точности, перекрестная проверка и настройка модели с помощью параметров и гиперпараметров.
7 Тестирование модели: проверьте модель на тестовом образце, запустите диагностику и при необходимости повторите модель.
8 Реализация модели: Подготовьте окончательные результаты модели – представьте модель. Определите ограничения модели. Реализуйте модель (преобразование решения машинного обучения в рабочую среду).
9 Отслеживание производительности: периодически отслеживайте производительность модели и обновляйте ее по мере необходимости. В условиях развивающейся бизнес-среды производительность любой модели машинного обучения может со временем ухудшиться.
@machinelearning_interview
Ответ
Разработка модели машинного обучения проходит в следующие этапы:
1 Определить бизнес-задачу: понять бизнес-цели и преобразовать задачу ИТ-аналитики
Конструирование данных: определение необходимых источников данных, извлечение и агрегирование данных на необходимом уровне.
2 Исследовательский анализ: понимание данных, проверка переменных на наличие ошибок, выбросов и пропущенных значений. Определите взаимосвязь между различными типами переменных. Проверьте предположения.
3 Подготовка данных: исключения, преобразование типов, обработка выбросов, обработка пропущенных значений. Создайте новые гипотетически релевантные переменные, например max, min, sum, change, ratio. Группирование переменных, создание фиктивных переменных и т. Д.
4 Разработка функций: Избегайте мультиколлинеарности и оптимизируйте сложность модели за счет сокращения количества входных переменных – кластера переменных, корреляции, факторного анализа, RFE и т. Д.
5 Разделение данных: разделите данные на обучающую и тестовую выборки.
6 Построение модели: подгонка, проверка точности, перекрестная проверка и настройка модели с помощью параметров и гиперпараметров.
7 Тестирование модели: проверьте модель на тестовом образце, запустите диагностику и при необходимости повторите модель.
8 Реализация модели: Подготовьте окончательные результаты модели – представьте модель. Определите ограничения модели. Реализуйте модель (преобразование решения машинного обучения в рабочую среду).
9 Отслеживание производительности: периодически отслеживайте производительность модели и обновляйте ее по мере необходимости. В условиях развивающейся бизнес-среды производительность любой модели машинного обучения может со временем ухудшиться.
@machinelearning_interview
👍24🔥6❤1👏1
Когда нам следует использовать SVM?
SVM означает машины опорных векторов; это контролируемый алгоритм машинного обучения, который может использоваться для решения проблем, связанных с классификацией и регрессией. В классификации он используется для различения нескольких групп или классов, а в регрессии он используется для получения математической модели, которая могла бы предсказывать вещи. Одним из очень больших преимуществ использования SVM является то, что его можно использовать как в линейных, так и в нелинейных задачах.
➡️ SVM. Подробный разбор метода опорных векторов
@machinelearning_interview
SVM означает машины опорных векторов; это контролируемый алгоритм машинного обучения, который может использоваться для решения проблем, связанных с классификацией и регрессией. В классификации он используется для различения нескольких групп или классов, а в регрессии он используется для получения математической модели, которая могла бы предсказывать вещи. Одним из очень больших преимуществ использования SVM является то, что его можно использовать как в линейных, так и в нелинейных задачах.
➡️ SVM. Подробный разбор метода опорных векторов
@machinelearning_interview
🔥12👍4👎4❤1
👨💻 Перечислите основнные методы уменьшения размерностей.
- Многомерное шкалирование (MDS)
- Метод главных компонент (PCA)
- Визуализация многомерных пространств
- Применение Автоэнкодеров
- Isomap
- CA, MCA
- LDA (Linear Discriminant Analysis), DCA (Discriminant - Correspondence Analysis)
- tSNE (t-Distributed Stochastic Neighbor Embedding)
и другие
➡️ Читать подробнее
@machinelearning_interview
- Многомерное шкалирование (MDS)
- Метод главных компонент (PCA)
- Визуализация многомерных пространств
- Применение Автоэнкодеров
- Isomap
- CA, MCA
- LDA (Linear Discriminant Analysis), DCA (Discriminant - Correspondence Analysis)
- tSNE (t-Distributed Stochastic Neighbor Embedding)
и другие
➡️ Читать подробнее
@machinelearning_interview
👍14🔥2
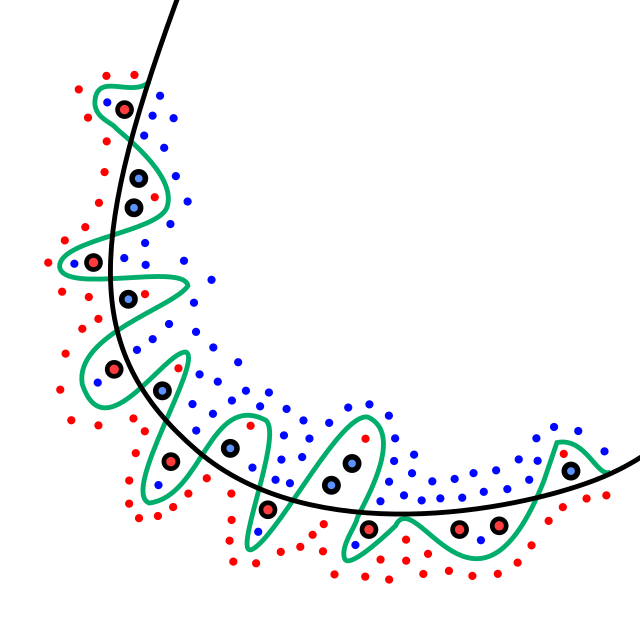
Как решить проблему переобучения модели ?
Ответ
Переобучение — противоположный недообучению эффект, когда модель слишком сложная и универсальная. Например, сейчас много говорят о моделях нейронных сетей, которые содержат миллионы параметров, но самые продвинутые нейронные сети содержат сотни миллионов параметров.
Такие сети обучаются на больших данных, поэтому иногда объема данных может не хватить, чтобы одновременно хорошо настроить все параметры. В момент переобучения наблюдается ситуация, когда мы пытаемся определить оптимальные параметры модели, которые хорошо описывают наши данные, но потом на новых данных эта модель начинает часто ошибаться. Проблема переобучения часто встречается, и связана она с тем, что мы пытаемся сделать выбор по неполной информации. Наша выборка всегда не полностью описывает искомую зависимость, которую мы мечтаем построить, затем мы пытаемся зависимость по неполной информации, но это невозможно.
Как решить проблему переобучения
Первый вариант решения проблемы переобучения — хорошо угадать модель, но это очень редкая ситуация. Если у нас есть хорошая модель явления, которое мы пытаемся описать и потом спрогнозировать, то проблем с переобучением может не возникнуть. Простые модели, которые мы изобретаем в физике или хорошо изученных предметных областях, — это здорово, но машинное обучение является той областью, где хороших моделей просто не существует.
Другой универсальный рецепт решения проблемы переобучения — скользящий контроль, или кросс-проверка. Модель всегда оценивают по тестовой выборке, а не по данным, на которых она обучалась. Данные, которые есть изначально, делят на две части: обучающую и тестовую. В итоге после двух этапов можно просто выбрать наилучшую модель из некоторого количества моделей, которые мы изобрели.
Главная проблема этого подхода — возможное переобучение экспериментатора. Процедура выбора лучшей функции из параметрического семейства функций — это численный метод, поэтому мы доверяем этот выбор компьютеру, алгоритму. Когда мы начинаем перебирать разные модели и выбирать лучшую по тестовой выборке, мы превращаем этот процесс в такую же оптимизацию, но выполняется она не алгоритмом, а умом человека. Экспериментатор совершает тот же самый выбор по неполной информации и тоже может переобучиться.
Еще один вариант решения проблемы переобучения — регуляризация. Если спросить специалистов по анализу данных (data scientists) о том, какие методы регуляризации им известны, то они сходу скажут: L1-регуляризация и L2-регуляризация. Все data scientists хорошо понимают и знают эти методы. Такие методы регуляризации используют на линейных моделях регрессии и классификации. В теории часто пишут, что при создании линейной модели всегда надо приближать вектор коэффициентов модели к нулевому вектору. Если этого не делать, то может возникнуть эффект переобучения, когда вы смотрите на модель и видите там большие значения коэффициентов, но одни отрицательные, а другие положительные. Кажется, что в сумме они компенсируют друг друга, на обучающей выборке это работает хорошо, а на тестовых данных работает отвратительно. Для устранения этого эффекта вектор коэффициентов приближают к нулю, и делает это регуляризация.
Распространить подход регуляризации с линейных моделей на общие классы моделей непросто, поэтому для этого используют байесовский подход, который связан с вводом априорного распределения вероятностей в пространстве параметров модели. Байесовский подход сложно воплотить, потому что априорное распределение надо откуда-то взять, а значит, необходимо примерно понимать тип зависимости, которую мы хотим восстановить.
➡️ Подробнее
@machinelearning_interview
Ответ
Переобучение — противоположный недообучению эффект, когда модель слишком сложная и универсальная. Например, сейчас много говорят о моделях нейронных сетей, которые содержат миллионы параметров, но самые продвинутые нейронные сети содержат сотни миллионов параметров.
Такие сети обучаются на больших данных, поэтому иногда объема данных может не хватить, чтобы одновременно хорошо настроить все параметры. В момент переобучения наблюдается ситуация, когда мы пытаемся определить оптимальные параметры модели, которые хорошо описывают наши данные, но потом на новых данных эта модель начинает часто ошибаться. Проблема переобучения часто встречается, и связана она с тем, что мы пытаемся сделать выбор по неполной информации. Наша выборка всегда не полностью описывает искомую зависимость, которую мы мечтаем построить, затем мы пытаемся зависимость по неполной информации, но это невозможно.
Как решить проблему переобучения
Первый вариант решения проблемы переобучения — хорошо угадать модель, но это очень редкая ситуация. Если у нас есть хорошая модель явления, которое мы пытаемся описать и потом спрогнозировать, то проблем с переобучением может не возникнуть. Простые модели, которые мы изобретаем в физике или хорошо изученных предметных областях, — это здорово, но машинное обучение является той областью, где хороших моделей просто не существует.
Другой универсальный рецепт решения проблемы переобучения — скользящий контроль, или кросс-проверка. Модель всегда оценивают по тестовой выборке, а не по данным, на которых она обучалась. Данные, которые есть изначально, делят на две части: обучающую и тестовую. В итоге после двух этапов можно просто выбрать наилучшую модель из некоторого количества моделей, которые мы изобрели.
Главная проблема этого подхода — возможное переобучение экспериментатора. Процедура выбора лучшей функции из параметрического семейства функций — это численный метод, поэтому мы доверяем этот выбор компьютеру, алгоритму. Когда мы начинаем перебирать разные модели и выбирать лучшую по тестовой выборке, мы превращаем этот процесс в такую же оптимизацию, но выполняется она не алгоритмом, а умом человека. Экспериментатор совершает тот же самый выбор по неполной информации и тоже может переобучиться.
Еще один вариант решения проблемы переобучения — регуляризация. Если спросить специалистов по анализу данных (data scientists) о том, какие методы регуляризации им известны, то они сходу скажут: L1-регуляризация и L2-регуляризация. Все data scientists хорошо понимают и знают эти методы. Такие методы регуляризации используют на линейных моделях регрессии и классификации. В теории часто пишут, что при создании линейной модели всегда надо приближать вектор коэффициентов модели к нулевому вектору. Если этого не делать, то может возникнуть эффект переобучения, когда вы смотрите на модель и видите там большие значения коэффициентов, но одни отрицательные, а другие положительные. Кажется, что в сумме они компенсируют друг друга, на обучающей выборке это работает хорошо, а на тестовых данных работает отвратительно. Для устранения этого эффекта вектор коэффициентов приближают к нулю, и делает это регуляризация.
Распространить подход регуляризации с линейных моделей на общие классы моделей непросто, поэтому для этого используют байесовский подход, который связан с вводом априорного распределения вероятностей в пространстве параметров модели. Байесовский подход сложно воплотить, потому что априорное распределение надо откуда-то взять, а значит, необходимо примерно понимать тип зависимости, которую мы хотим восстановить.
➡️ Подробнее
@machinelearning_interview
{kind=link}
👍13🤔5🔥3❤1
Что вы понимаете под термином «нормальное распределение»?
Нормальное распределение — одно из основных распределений вероятности.
Плотность нормального распределения выражается функцией Гаусса.
Примеры нормального распределения: погрешности измерений, отклонения при стрельбе, показатели живых популяций в природе.
@machinelearning_interview
Нормальное распределение — одно из основных распределений вероятности.
Плотность нормального распределения выражается функцией Гаусса.
Примеры нормального распределения: погрешности измерений, отклонения при стрельбе, показатели живых популяций в природе.
@machinelearning_interview
👍14👎3❤1
Как выполняется мониторинг Docker в производственных окружениях?
Для мониторинга есть инструменты Docker stats и Docker events. С их помощью можно получить отчеты по важной статистике. Если запустить stats с некоторым идентификатором контейнера, он вернет использование оперативной памяти и процессорного времени в контейнере. Это схоже с использованием команды top. С другой стороны есть events, показывающая список активностей в процессе работы сервиса Docker. Вот некоторые из них: подключение к консоли контейнера, commit, переименование, удаление и т.п., а также есть возможность фильтрации нужных событий.
Шпаргалка с командами Docker
#middle
@machinelearning_interview
Для мониторинга есть инструменты Docker stats и Docker events. С их помощью можно получить отчеты по важной статистике. Если запустить stats с некоторым идентификатором контейнера, он вернет использование оперативной памяти и процессорного времени в контейнере. Это схоже с использованием команды top. С другой стороны есть events, показывающая список активностей в процессе работы сервиса Docker. Вот некоторые из них: подключение к консоли контейнера, commit, переименование, удаление и т.п., а также есть возможность фильтрации нужных событий.
Шпаргалка с командами Docker
#middle
@machinelearning_interview
👍10🔥4
Что такое обучение вероятно приближённо корректное обучение ?
Ответ
Вероятно приближённо корректное обучение (ВПК-обучение, англ. Probably Approximately Correct learning, PAC learning) — схема машинного обучения, использующая понятия асимптотической достоверности и вычислительной сложности.
В этой схеме учитель получает выборки и должен выбрать обобщающую функцию (называемую гипотезой) из определённого класса возможных функций. Целью является функция, которая с большой вероятностью (откуда «вероятно» в названии) будет иметь низкую ошибку обобщения (откуда «приближенно корректное» в названии). Учитель должен быть способен обучить концепт, дающее произвольный коэффициент аппроксимации, вероятность успеха или распределения выборок.
Модель была позднее расширена для обработки шума (некорректно классифицируемых выборок).
Важным нововведением схемы ВПК является использование понятия о вычислительной сложности машинного обучения. В частности, ожидается, что учитель находит эффективные функции (которые ограничены по времени выполнения и требуемому пространству многочленом от размера выборки), и учитель должен реализовать эффективную процедуру (запрашивая размер примера, ограниченный многочленом от размера концепта, модифицированного границами приближения и правдоподобия).
@machinelearning_interview
Ответ
Вероятно приближённо корректное обучение (ВПК-обучение, англ. Probably Approximately Correct learning, PAC learning) — схема машинного обучения, использующая понятия асимптотической достоверности и вычислительной сложности.
В этой схеме учитель получает выборки и должен выбрать обобщающую функцию (называемую гипотезой) из определённого класса возможных функций. Целью является функция, которая с большой вероятностью (откуда «вероятно» в названии) будет иметь низкую ошибку обобщения (откуда «приближенно корректное» в названии). Учитель должен быть способен обучить концепт, дающее произвольный коэффициент аппроксимации, вероятность успеха или распределения выборок.
Модель была позднее расширена для обработки шума (некорректно классифицируемых выборок).
Важным нововведением схемы ВПК является использование понятия о вычислительной сложности машинного обучения. В частности, ожидается, что учитель находит эффективные функции (которые ограничены по времени выполнения и требуемому пространству многочленом от размера выборки), и учитель должен реализовать эффективную процедуру (запрашивая размер примера, ограниченный многочленом от размера концепта, модифицированного границами приближения и правдоподобия).
@machinelearning_interview
👍13👎2
Сравните профилирование данных и интеллектуальный анализ данных.
Ответ
Сравнение и противопоставление двух предметов позволяет вам продемонстрировать знание обоих. Вот как можно говорить о профилировании и интеллектуальном анализе данных.
Пример: «Вот черты интеллектуального анализа данных и профилирования данных, которые можно сравнить:
*Профилирование данных. При профилировании данных анализ выполняется на уровне экземпляра, что позволяет получить представление о качествах каждого экземпляра.*
* Интеллектуальный анализ данных. Интеллектуальный анализ данных делает упор на разрешение кластеров данных, ищет такие вещи, как единообразие, взаимосвязи и многое другое».
@machinelearning_interview
Ответ
Сравнение и противопоставление двух предметов позволяет вам продемонстрировать знание обоих. Вот как можно говорить о профилировании и интеллектуальном анализе данных.
Пример: «Вот черты интеллектуального анализа данных и профилирования данных, которые можно сравнить:
*Профилирование данных. При профилировании данных анализ выполняется на уровне экземпляра, что позволяет получить представление о качествах каждого экземпляра.*
* Интеллектуальный анализ данных. Интеллектуальный анализ данных делает упор на разрешение кластеров данных, ищет такие вещи, как единообразие, взаимосвязи и многое другое».
@machinelearning_interview
👍6🔥1
Как вы создаете аналитический проект?
Ответ на этот вопрос позволит вам продемонстрировать социальные навыки, такие как аккуратность и организованность, которые важны для роли аналитика данных.
Пример: «В аналитическом проекте есть определенные шаги, которые можно повторять. Когда вы начинаете аналитический проект, вы должны выполнить следующие шаги:
Определите проблему.
Исследуйте существующие данные и исследуйте новые данные для поддержки решений.
Подготовьте данные для хранения данных.
Выберите привлекательную модель данных, которая подходит для аналитики, которую вы хотите получить.
Подтвердите данные.
Внедрите модель данных и просмотрите аналитику».
@machinelearning_interview
Ответ на этот вопрос позволит вам продемонстрировать социальные навыки, такие как аккуратность и организованность, которые важны для роли аналитика данных.
Пример: «В аналитическом проекте есть определенные шаги, которые можно повторять. Когда вы начинаете аналитический проект, вы должны выполнить следующие шаги:
Определите проблему.
Исследуйте существующие данные и исследуйте новые данные для поддержки решений.
Подготовьте данные для хранения данных.
Выберите привлекательную модель данных, которая подходит для аналитики, которую вы хотите получить.
Подтвердите данные.
Внедрите модель данных и просмотрите аналитику».
@machinelearning_interview
👍8👎2🔥1
🤖 Расскажите о наивном байесовсом алгоритме какие у него преимущества и недостатки?
Ответ
Наивный байесовский классификатор (Naive Bayes classifier) – это очень популярный в машинном обучении алгоритм, который в основном используется для получения базовой точности набора данных. Изучим его преимущества и недостатки, а также реализацию на языке Python.
Плюсы
Алгоритм легко и быстро предсказывает класс тестового набора данных. Он также хорошо справляется с многоклассовым прогнозированием.
Производительность наивного байесовского классификатора лучше, чем у других простых алгоритмов, таких как логистическая регрессия. Более того, вам требуется меньше обучающих данных.
Он хорошо работает с категориальными признаками(по сравнению с числовыми). Для числовых признаков предполагается нормальное распределение, что может быть серьезным допущением в точности нашего алгоритма.
Минусы
Если переменная имеет категорию (в тестовом наборе данных), которая не наблюдалась в обучающем наборе данных, то модель присвоит 0 (нулевую) вероятность и не сможет сделать предсказание. Это часто называют нулевой частотой. Чтобы решить эту проблему, мы можем использовать технику сглаживания. Один из самых простых методов сглаживания называется оценкой Лапласа.
Значения спрогнозированных вероятностей, возвращенные методом predict_proba, не всегда являются достаточно точными.
Ограничением данного алгоритма является предположение о независимости признаков. Однако в реальных задачах полностью независимые признаки встречаются крайне редко.
➡️ Читать подробнее
@machinelearning_interview
Ответ
Наивный байесовский классификатор (Naive Bayes classifier) – это очень популярный в машинном обучении алгоритм, который в основном используется для получения базовой точности набора данных. Изучим его преимущества и недостатки, а также реализацию на языке Python.
Плюсы
Алгоритм легко и быстро предсказывает класс тестового набора данных. Он также хорошо справляется с многоклассовым прогнозированием.
Производительность наивного байесовского классификатора лучше, чем у других простых алгоритмов, таких как логистическая регрессия. Более того, вам требуется меньше обучающих данных.
Он хорошо работает с категориальными признаками(по сравнению с числовыми). Для числовых признаков предполагается нормальное распределение, что может быть серьезным допущением в точности нашего алгоритма.
Минусы
Если переменная имеет категорию (в тестовом наборе данных), которая не наблюдалась в обучающем наборе данных, то модель присвоит 0 (нулевую) вероятность и не сможет сделать предсказание. Это часто называют нулевой частотой. Чтобы решить эту проблему, мы можем использовать технику сглаживания. Один из самых простых методов сглаживания называется оценкой Лапласа.
Значения спрогнозированных вероятностей, возвращенные методом predict_proba, не всегда являются достаточно точными.
Ограничением данного алгоритма является предположение о независимости признаков. Однако в реальных задачах полностью независимые признаки встречаются крайне редко.
➡️ Читать подробнее
@machinelearning_interview
👍14🔥4
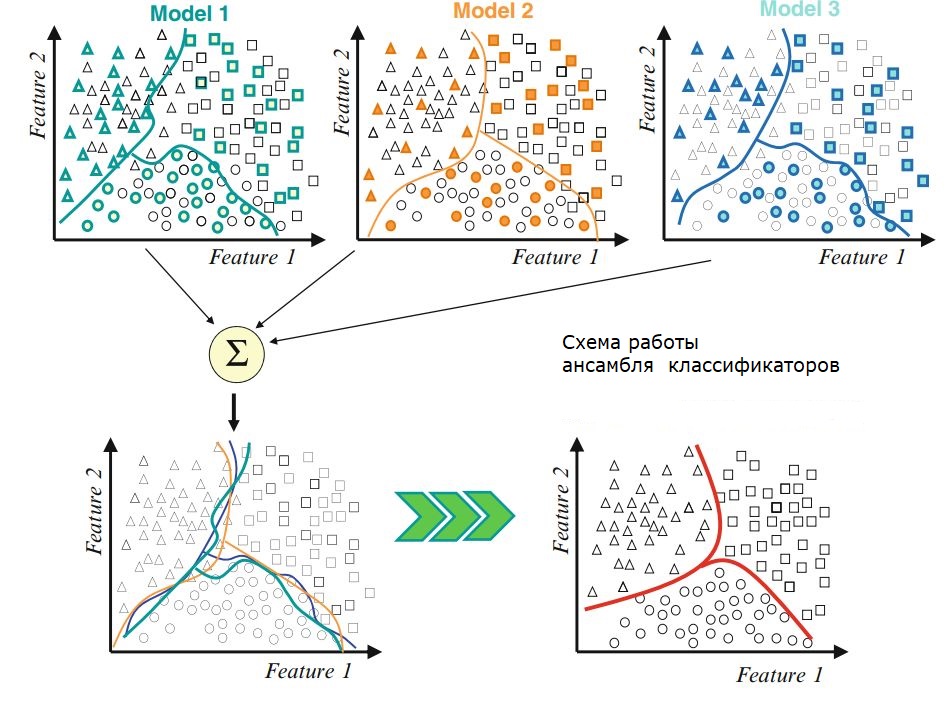
Рассакажите о градиентном бустинг. Опишите логику, которуюа стоит за градиентым бустингом.
Ответ
Градиентный бустинг — это техника машинного обучения для задач классификации и регрессии, которая строит модель предсказания в форме ансамбля слабых предсказывающих моделей, обычно деревьев решений.
Интуиция за градиентным бустингом
Логика, что стоит за градиентым бустингом, проста, ее можно понять интуитивно, без математического формализма. Предполагается, что читатель знаком с простой линейной регрессией.
Первое предположение линейной регресии, что сумма отклонений = 0, т.е. отклонения должны быть случайно распределены в окрестности нуля.
Теперь давайте думать о отклонениях, как об ошибках, сделанных нашей моделью. Хотя в моделях основанных на деревьях не делается такого предположения, если мы будем размышлять об этом предположении логически (не статистически), мы можем понять, что увидив принцип распределения отклонений, сможем использовать данный паттерн для модели.
Итак, интуиция за алгоритмом градиентного бустинга — итеративно применять паттерны отклонений и улучшать предсказания. Как только мы достигли момента, когда отклонения не имеют никакого паттерна, мы прекращаем достраивать нашу модель (иначе это может привести к переобучению). Алгоритмически, мы минимизируем нашу функцию потерь.
В итоге,
Сначала строим простые модели и анализируем ошибки;
Определяем точки, которые не вписываются в простую модель;
Добавляем модели, которые обрабатывают сложные случаи, которые были выявлены на начальной модели;
Собираем все построенные модели, определяя вес каждого предсказателя.
➡️ Подробное описание с примерами кода
@machinelearning_interview
Ответ
Градиентный бустинг — это техника машинного обучения для задач классификации и регрессии, которая строит модель предсказания в форме ансамбля слабых предсказывающих моделей, обычно деревьев решений.
Интуиция за градиентным бустингом
Логика, что стоит за градиентым бустингом, проста, ее можно понять интуитивно, без математического формализма. Предполагается, что читатель знаком с простой линейной регрессией.
Первое предположение линейной регресии, что сумма отклонений = 0, т.е. отклонения должны быть случайно распределены в окрестности нуля.
Теперь давайте думать о отклонениях, как об ошибках, сделанных нашей моделью. Хотя в моделях основанных на деревьях не делается такого предположения, если мы будем размышлять об этом предположении логически (не статистически), мы можем понять, что увидив принцип распределения отклонений, сможем использовать данный паттерн для модели.
Итак, интуиция за алгоритмом градиентного бустинга — итеративно применять паттерны отклонений и улучшать предсказания. Как только мы достигли момента, когда отклонения не имеют никакого паттерна, мы прекращаем достраивать нашу модель (иначе это может привести к переобучению). Алгоритмически, мы минимизируем нашу функцию потерь.
В итоге,
Сначала строим простые модели и анализируем ошибки;
Определяем точки, которые не вписываются в простую модель;
Добавляем модели, которые обрабатывают сложные случаи, которые были выявлены на начальной модели;
Собираем все построенные модели, определяя вес каждого предсказателя.
➡️ Подробное описание с примерами кода
@machinelearning_interview
{kind=link}
👍15👎3🔥1