
КАКОВА ЦЕЛЬ A / B ТЕСТИРОВАНИЯ?
Ответ
Вичорек добавляет этот вопрос в смесь, которую она описывает как «тест на общие знания». Для этого и всех собеседований по машинному обучению и науке о данных убедитесь, что вы знаете лучшие практики в своей области. Вас спросят о них.
Итог: знайте общие области машинного обучения и / или науки о данных, а также каковы текущие стандарты, а также почему они являются стандартами.
Подробнее
@machinelearning_interview
Ответ
Вичорек добавляет этот вопрос в смесь, которую она описывает как «тест на общие знания». Для этого и всех собеседований по машинному обучению и науке о данных убедитесь, что вы знаете лучшие практики в своей области. Вас спросят о них.
Итог: знайте общие области машинного обучения и / или науки о данных, а также каковы текущие стандарты, а также почему они являются стандартами.
Подробнее
@machinelearning_interview
👍4
Data Science SQL Интервью Вопрос и ответ Airbnd
https://www.youtube.com/watch?v=gZ7OmLgNglU
@machinelearning_interview
https://www.youtube.com/watch?v=gZ7OmLgNglU
@machinelearning_interview
YouTube
Data Science SQL Interview Question and Answer | Airbnb
🚀 Prep SQL with https://www.datainterview.com/sqlpad
====== ✅ Details ======
Love it or hate it - solving the SQL question correctly with speed can make or break your interview success.
That's why in this video, I share:
👉 Three tips that helped clients…
====== ✅ Details ======
Love it or hate it - solving the SQL question correctly with speed can make or break your interview success.
That's why in this video, I share:
👉 Three tips that helped clients…
🔥5
Не кажется ли вам, что временной ряд — это очень простая задача линейной регрессии с единственной переменной отклика и с единственным предиктором — временем? В чём проблема метода линейной регрессии (необязательно с единственным линейным членом, с многочленами тоже) в случае данных временного ряда? (Подсказка: прошлое указывает на будущее…)
@machinelearning_interview
@machinelearning_interview
👍5👎1
8 вопросов для интервью по визуализации данных с примерами ответовa
Читать дальше
@machinelearning_interview
Читать дальше
@machinelearning_interview
BUOM
8 вопросов для интервью по визуализации данных с примерами ответов • BUOM
26 августа 2021 г.
👍6👎1🔥1
Обработка null-значений, синтаксических ошибок, дубликатов столбцов и строк
От незаполненных полей в датасете никуда не деться. Каждое влияет на погрешность по-своему. Существует целая область, изучающая методы работы с null-полями. Однажды на собеседовании меня просили в деталях рассказать о каждом из них.
Синтаксические ошибки возникают, когда данные в датасет добавлялись вручную, например через форму. Из-за этого можно получить ненужные уровни категорий, как «Горячий», «ГоРяЧий» и «горячий/n» и т. д.
Напоследок о дубликатах. Повторяющиеся столбцы бесполезны, а вот повторение строк искажает баланс данных в сторону одного класса.
@machinelearning_interview
От незаполненных полей в датасете никуда не деться. Каждое влияет на погрешность по-своему. Существует целая область, изучающая методы работы с null-полями. Однажды на собеседовании меня просили в деталях рассказать о каждом из них.
Синтаксические ошибки возникают, когда данные в датасет добавлялись вручную, например через форму. Из-за этого можно получить ненужные уровни категорий, как «Горячий», «ГоРяЧий» и «горячий/n» и т. д.
Напоследок о дубликатах. Повторяющиеся столбцы бесполезны, а вот повторение строк искажает баланс данных в сторону одного класса.
@machinelearning_interview
🔥9👍4
Есть данные о длительности звонков в колл-центр. Разработайте план кодирования и анализа этих данных. Приведите пример, как может выглядеть распределение этих данных. Как бы вы могли проверить, хотя бы графически, подтверждаются ли ваши ожидания?
Ответ
Чтобы очистить, исследовать и представить данные, я бы провел EDA – Exploratory Data Analysis (разведочный анализ данных). В процессе EDA я бы построил гистограмму длительности звонков, чтобы увидеть их распределение.
Можно предположить, что длительность звонков следует логнормальному распределению. Длительность звонка не может быть отрицательной, так что нижнее значение равно 0. На другом конце гистограммы будет небольшое количество очень длинных звонков.
Пример логнормального распределения
Пример логнормального распределения
Чтобы подтвердить, распределена длительность звонков логнормально или нет, мы могли бы использовать график КК (QQPlot).
@machinelearning_interview
Ответ
Чтобы очистить, исследовать и представить данные, я бы провел EDA – Exploratory Data Analysis (разведочный анализ данных). В процессе EDA я бы построил гистограмму длительности звонков, чтобы увидеть их распределение.
Можно предположить, что длительность звонков следует логнормальному распределению. Длительность звонка не может быть отрицательной, так что нижнее значение равно 0. На другом конце гистограммы будет небольшое количество очень длинных звонков.
Пример логнормального распределения
Пример логнормального распределения
Чтобы подтвердить, распределена длительность звонков логнормально или нет, мы могли бы использовать график КК (QQPlot).
@machinelearning_interview
👍11🔥1
Счетчик Гейгера записывает 100 радиоактивных распадов за 5 минут. Найдите приблизительный 95% интервал для количества распадов в час.
Ответ
Поскольку это задача на распределение Пуассона, среднее = лямбда = дисперсия, что также означает, что стандартное отклонение = квадратному корню из среднего.
Доверительный интервал 95% соответствует z-оценке 1.96.
Одно стандартное отклонение = 10.
То есть, доверительный интервал равен
100 +/- 19.6 = [964.8, 1435.2].
@machinelearning_interview
Ответ
Поскольку это задача на распределение Пуассона, среднее = лямбда = дисперсия, что также означает, что стандартное отклонение = квадратному корню из среднего.
Доверительный интервал 95% соответствует z-оценке 1.96.
Одно стандартное отклонение = 10.
То есть, доверительный интервал равен
100 +/- 19.6 = [964.8, 1435.2].
@machinelearning_interview
👍14🔥5👎2
Вопрос с собеседования на DS. "Для чего нужна повторная выборка?"
Ответ
Повторная выборка выполняется в любом из этих случаев:
*Оценка точности статистических данных выборок путем использования подмножеств доступных данных или рисования случайным образом с заменой из набора точек данных.
*Подстановка меток в точках данных при выполнении тестов значимости.
*Проверка моделей с использованием случайных подмножеств (самонастройка, перекрестная проверка).
#собес
@machinelearning_interview
Ответ
Повторная выборка выполняется в любом из этих случаев:
*Оценка точности статистических данных выборок путем использования подмножеств доступных данных или рисования случайным образом с заменой из набора точек данных.
*Подстановка меток в точках данных при выполнении тестов значимости.
*Проверка моделей с использованием случайных подмножеств (самонастройка, перекрестная проверка).
#собес
@machinelearning_interview
👍13🔥4
Расскажите, какой обычно бывает разница между административным набором данных и данными, полученными в результате эксперимента? Какие проблемы обычно встречаются в административных данных? Как экспериментальные данные позволяют справиться с этими проблемами, и какие проблемы они могут принести?
Административные наборы данных – это обычно наборы, используемые правительством или иными организациями для нужд, не связанных со статистикой.
Административные данные обычно больше, и их дешевле получить, чем экспериментальные данные. Вместе с тем, административные наборы данных часто не содержат всех данных, которые могут понадобиться, и могут храниться в неудобном формате. В них также встречаются ошибки и пропуски.
@machinelearning_interview
Административные наборы данных – это обычно наборы, используемые правительством или иными организациями для нужд, не связанных со статистикой.
Административные данные обычно больше, и их дешевле получить, чем экспериментальные данные. Вместе с тем, административные наборы данных часто не содержат всех данных, которые могут понадобиться, и могут храниться в неудобном формате. В них также встречаются ошибки и пропуски.
@machinelearning_interview
👍15🔥1
Что такое ошибка отбора (в отношении данных), и почему она важна? Как предварительная обработка данных может ухудшить ситуацию?
Ответ
Ошибка отбора – это выбор для анализа людей, групп или данных методом, не обеспечивающим должную рандомизацию, в результате чего выборка не является репрезентативной.
Существуют следующие виды ошибок отбора:
ошибка выборки: выборка, полученная не в результате случайного отбора.
интервал времени: выбор особого интервала времени, поддерживающего желаемый вывод – например, исследование продаж перед Рождеством.
воздействие: включает клиническую уязвимость, протопатическую ошибку и ошибку показателей (подробнее см. здесь).
ошибка данных: выборочное представление фактов, избирательный подход, выборочное цитирование.
ошибка истощения: включает «ошибку выжившего», когда в анализ включаются только те, кто «пережил» длительный процесс и «ошибку неудачников», когда в анализ включаются только те, кто потерпел неудачу.
Обработка пропущенных данных может усилить влияние ошибок отбора. Например, если вы заменяете значения null на средние значения, вы добавляете в данные ошибку, поскольку считаете, что данные не имеют такого разброса, который они могут иметь на самом деле.
@machinelearning_interview
Ответ
Ошибка отбора – это выбор для анализа людей, групп или данных методом, не обеспечивающим должную рандомизацию, в результате чего выборка не является репрезентативной.
Существуют следующие виды ошибок отбора:
ошибка выборки: выборка, полученная не в результате случайного отбора.
интервал времени: выбор особого интервала времени, поддерживающего желаемый вывод – например, исследование продаж перед Рождеством.
воздействие: включает клиническую уязвимость, протопатическую ошибку и ошибку показателей (подробнее см. здесь).
ошибка данных: выборочное представление фактов, избирательный подход, выборочное цитирование.
ошибка истощения: включает «ошибку выжившего», когда в анализ включаются только те, кто «пережил» длительный процесс и «ошибку неудачников», когда в анализ включаются только те, кто потерпел неудачу.
Обработка пропущенных данных может усилить влияние ошибок отбора. Например, если вы заменяете значения null на средние значения, вы добавляете в данные ошибку, поскольку считаете, что данные не имеют такого разброса, который они могут иметь на самом деле.
@machinelearning_interview
👍6🔥3
Data Study - канал с полезными и практическими материалами про аналитику данных, бизнес-анализ и развитие soft-навыков от ведущего BI аналитика.
На канале Даниил также организовывает бесплатные вокршопы по обсуждению аналитических тем.
Воркшоп по теме создания data-продуктов в компания
Статья на habr про оконные функции простым языком
Шаблон оформления документации про профайлинге нового data-источника
Материалы канала помогут улучшить профессиональные навыки в аналитике.
🎁 Большой бонус: бесплатный гайд по профессии аналитика данных, чтобы еще лучше погрузиться в специализацию аналитика
Подписаться 👨💻
На канале Даниил также организовывает бесплатные вокршопы по обсуждению аналитических тем.
Воркшоп по теме создания data-продуктов в компания
Статья на habr про оконные функции простым языком
Шаблон оформления документации про профайлинге нового data-источника
Материалы канала помогут улучшить профессиональные навыки в аналитике.
🎁 Большой бонус: бесплатный гайд по профессии аналитика данных, чтобы еще лучше погрузиться в специализацию аналитика
Подписаться 👨💻
🔥10
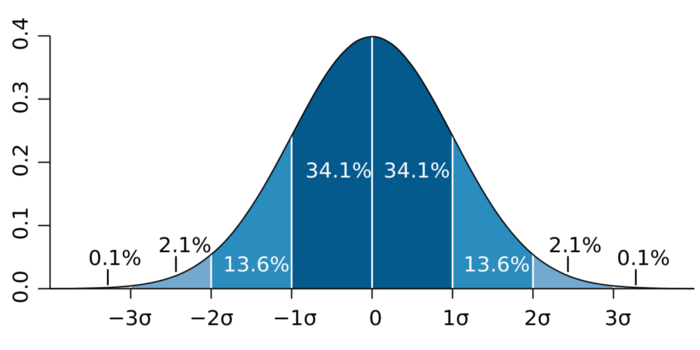
Что такое выброс и внутренняя ошибка? Объясните, как их обнаружить, и что бы вы делали, если нашли их в наборе данных?
Ответ
Выброс (англ. outlier) – это значение в данных, существенно отличающееся от прочих наблюдений.
В зависимости от причины выбросов, они могут быть плохими с точки зрения машинного обучения, поскольку ухудшают точность модели. Если выброс вызван ошибкой измерения, важно удалить его из набора данных. Есть пара способов обнаружения выбросов.
1) Z-оценка/стандартные отклонения: если мы знаем, что 99.7% данных в наборе лежат в пределах тройного стандартного отклонения, мы можем найти элементы данных, выходящие за эти пределы. Точно так же, мы можем рассчитать z-оценку каждого элемента, и если она равна +/- 3, это выброс.
Внимание
При использовании указанного метода надо принимать во внимание обстоятельства: данные должны быть нормально распределены, метод неприменим для малых наборов данных, а слишком большое количество выбросов может исказить z-оценку.
2) Межквартильное расстояние (Inter-Quartile Range, IQR) – концепция, положенная в основу ящиков с усами (box plots), которую также можно использовать для нахождения выбросов. МКР – это расстояние между 3-м и 1-м квартилями. После его расчета можно считать значение выбросом, если оно меньше Q1-1.5*IQR или больше Q3+1.5*IQR. Это составляет примерно 2.7 стандартных отклонений.
Другие методы включают кластеризацию DBScan, Лес Изоляции и устойчивый случайно-обрубленный лес.
Внутренняя ошибка (inlier) – это наблюдение, лежащее в пределах общего набора данных, но необычное либо ошибочное. Поскольку оно находится там же, где остальные данные, его труднее идентифицировать, чем выброс. Внутренние ошибки обычно можно просто удалить из набора данных.
@machinelearning_interview
Ответ
Выброс (англ. outlier) – это значение в данных, существенно отличающееся от прочих наблюдений.
В зависимости от причины выбросов, они могут быть плохими с точки зрения машинного обучения, поскольку ухудшают точность модели. Если выброс вызван ошибкой измерения, важно удалить его из набора данных. Есть пара способов обнаружения выбросов.
1) Z-оценка/стандартные отклонения: если мы знаем, что 99.7% данных в наборе лежат в пределах тройного стандартного отклонения, мы можем найти элементы данных, выходящие за эти пределы. Точно так же, мы можем рассчитать z-оценку каждого элемента, и если она равна +/- 3, это выброс.
Внимание
При использовании указанного метода надо принимать во внимание обстоятельства: данные должны быть нормально распределены, метод неприменим для малых наборов данных, а слишком большое количество выбросов может исказить z-оценку.
2) Межквартильное расстояние (Inter-Quartile Range, IQR) – концепция, положенная в основу ящиков с усами (box plots), которую также можно использовать для нахождения выбросов. МКР – это расстояние между 3-м и 1-м квартилями. После его расчета можно считать значение выбросом, если оно меньше Q1-1.5*IQR или больше Q3+1.5*IQR. Это составляет примерно 2.7 стандартных отклонений.
Другие методы включают кластеризацию DBScan, Лес Изоляции и устойчивый случайно-обрубленный лес.
Внутренняя ошибка (inlier) – это наблюдение, лежащее в пределах общего набора данных, но необычное либо ошибочное. Поскольку оно находится там же, где остальные данные, его труднее идентифицировать, чем выброс. Внутренние ошибки обычно можно просто удалить из набора данных.
@machinelearning_interview
{kind=link}
👍19🔥1
Что Лучше – Хорошие Данные Или Хорошие Модели?
Это можно назвать одним из самых популярных вопросов по Big data, несмотря на то, что он также подпадает под категорию вопросов по Data science.
Ответ на этот вопрос на самом деле субъективен и зависит от ситуации. Крупные компании могут предпочесть хорошие данные, так как они являются основой для любого успешного бизнеса. С другой стороны, хорошие модели не могут быть созданы без хороших данных.
Вы должны ответить на этот вопрос в соответствии с вашими предпочтениями – здесь нет неправильного или правильного ответа (если конечно компания сама не пытается его найти).
@machinelearning_interview
Это можно назвать одним из самых популярных вопросов по Big data, несмотря на то, что он также подпадает под категорию вопросов по Data science.
Ответ на этот вопрос на самом деле субъективен и зависит от ситуации. Крупные компании могут предпочесть хорошие данные, так как они являются основой для любого успешного бизнеса. С другой стороны, хорошие модели не могут быть созданы без хороших данных.
Вы должны ответить на этот вопрос в соответствии с вашими предпочтениями – здесь нет неправильного или правильного ответа (если конечно компания сама не пытается его найти).
@machinelearning_interview
👍10🔥1
Что Такое Кластерная Выборка?
Кластерная выборка относится к типу метода выборки. С кластерной выборкой, исследователь делит популяцию на несколько отдельных групп под названием кластеры. Затем, из популяции выбирается простой случайный образец кластеров. Исследователь проводит свой анализ данных на основе выбранных кластеров.
@machinelearning_interview
Кластерная выборка относится к типу метода выборки. С кластерной выборкой, исследователь делит популяцию на несколько отдельных групп под названием кластеры. Затем, из популяции выбирается простой случайный образец кластеров. Исследователь проводит свой анализ данных на основе выбранных кластеров.
@machinelearning_interview
🔥8
Как Много Стандартных Форматов Ввода Hadoop Существует? Какие Они?
Один из вопросов для аналитика данных, который также может быть задан. Он довольно сложный, так как вам не только нужно знать число, но и сам формат.
Всего существует три распространённых формата ввода Hadoop. Это: формат key-value, sequence file и text.
@machinelearning_interview
Один из вопросов для аналитика данных, который также может быть задан. Он довольно сложный, так как вам не только нужно знать число, но и сам формат.
Всего существует три распространённых формата ввода Hadoop. Это: формат key-value, sequence file и text.
@machinelearning_interview
👍10🔥1
В Чём Различие Между Двумерным, Многомерным и Одномерным Анализом?
Двумерный (bivariate) анализ касается двух переменных одновременно, тогда как многомерный (multivariate) анализ имеет дело с несколькими переменными. Одномерный (univariate) анализ является самой простой формой анализа данных. “Uni” означает “один“, другими словами, ваши данные имеют только одну переменную. Он не имеет отношения к причинам или отношениям (в отличие от регрессии), и его главная цель – описать; он берёт данные, суммирует эти данные и находит шаблоны в данных.
@machinelearning_interview
Двумерный (bivariate) анализ касается двух переменных одновременно, тогда как многомерный (multivariate) анализ имеет дело с несколькими переменными. Одномерный (univariate) анализ является самой простой формой анализа данных. “Uni” означает “один“, другими словами, ваши данные имеют только одну переменную. Он не имеет отношения к причинам или отношениям (в отличие от регрессии), и его главная цель – описать; он берёт данные, суммирует эти данные и находит шаблоны в данных.
@machinelearning_interview
🔥11👍1
Что Такое fsck?
Дата сайентист должен знать, что fsck является аббревиатурой для “File System Check” или “Проверки Файловой Системы”. Это тип команды, который ищет возможные ошибки внутри файла и при их нахождении сообщает об этом в распределённую файловую систему Hadoop.
@machinelearning_interview
Дата сайентист должен знать, что fsck является аббревиатурой для “File System Check” или “Проверки Файловой Системы”. Это тип команды, который ищет возможные ошибки внутри файла и при их нахождении сообщает об этом в распределённую файловую систему Hadoop.
@machinelearning_interview
🔥8👎5👍1
Приведите три примера распределений с длинным хвостом. Почему они важны в задачах классификации и регрессии?
Три практических примера: степенной закон, закон Парето и продажи продуктов (например, продукты-бестселлеры против обычных).
При решении задач классификации и регрессии важно не забывать о распределении с длинным хвостом, поскольку редко встречающиеся значения составляют существенную часть выборки. Это влияет на выбор метода обработки выбросов. Кроме того, некоторые методики машинного обучения предполагают, что данные распределены нормально.
@machinelearning_interview
Три практических примера: степенной закон, закон Парето и продажи продуктов (например, продукты-бестселлеры против обычных).
При решении задач классификации и регрессии важно не забывать о распределении с длинным хвостом, поскольку редко встречающиеся значения составляют существенную часть выборки. Это влияет на выбор метода обработки выбросов. Кроме того, некоторые методики машинного обучения предполагают, что данные распределены нормально.
@machinelearning_interview
👍14🔥1
Дайте Определение Коллаборативной Фильтрации.
Коллаборативная фильтрация, как понятно из названия, является процессом фильтрации, который используют многие рекомендательные системы. Этот тип фильтрации используется для поиска и категоризации определённых паттернов.
Коллаборативная фильтрация — это способ создания автоматических прогнозов (фильтрации) об интересах пользователя с помощью сбора информации о предпочтениях и вкусе многих пользователей.
@machinelearning_interview
Коллаборативная фильтрация, как понятно из названия, является процессом фильтрации, который используют многие рекомендательные системы. Этот тип фильтрации используется для поиска и категоризации определённых паттернов.
Коллаборативная фильтрация — это способ создания автоматических прогнозов (фильтрации) об интересах пользователя с помощью сбора информации о предпочтениях и вкусе многих пользователей.
@machinelearning_interview
👎11🔥7👍2🤯2
Делимся с вами подкастом Рандомные Дрова, который делает команда @ozon_tech. Они рассказывают о разном из мира DS и DA, в частности, про собесы, кейсы, обучение, тех.интервью.
В этом эпизоде встретились Ван Хачатрян (Head of ML Ozon), Денис Нечитайло (Head of Product Analytics Ozon) и Сергей Юдин (COO Яндекс Кью).
Обсудили, где пролегает граница между дата-сайентистами и дата-аналитиками, поговорили о том, что нужно дата-сайентисту и что пригодится аналитику данных, рассказали, откуда взялась мода на дата-сайентистов (спойлер: по одной изверсий, с этой статьи «Дата-сайентист – самая сексуальная профессия»).
Послушать можно тут :
🎧Яндекс
🎧Apple
🎧Google
🎧Vk
В этом эпизоде встретились Ван Хачатрян (Head of ML Ozon), Денис Нечитайло (Head of Product Analytics Ozon) и Сергей Юдин (COO Яндекс Кью).
Обсудили, где пролегает граница между дата-сайентистами и дата-аналитиками, поговорили о том, что нужно дата-сайентисту и что пригодится аналитику данных, рассказали, откуда взялась мода на дата-сайентистов (спойлер: по одной изверсий, с этой статьи «Дата-сайентист – самая сексуальная профессия»).
Послушать можно тут :
🎧Яндекс
🎧Apple
🎧Vk
👍13🔥2