
#вопросы_с_собеседований
В чем разница между машинным обучением с учителем и без учителя?
В чем разница между машинным обучением с учителем и без учителя?
Для обучения с учителем требуются данные, помеченные для обучения. Например, чтобы провести классификацию (задача обучения с учителем), вам нужно сначала пометить данные, которые вы будете использовать для обучения модели, для классификации данных по помеченным группам; в то же время обучение без учителя не требует явной маркировки данных.
#вопросы_с_собеседований
Почему ReLU лучше и чаще используется в нейронных сетях, чем сигмоида?
Почему ReLU лучше и чаще используется в нейронных сетях, чем сигмоида?
👍1
#вопросы_с_собеседований
Что такое нормализация данных и зачем она нам нужна?
Нормализация данных - очень важный этап предварительной обработки, используемый для изменения масштаба значений, чтобы они соответствовали определенному диапазону, чтобы обеспечить лучшую сходимость во время обратного распространения ошибки. В общем случае она сводится к вычитанию среднего значения и делению на стандартное отклонение.
Если этого не сделать, некоторые признаки будут иметь более высокий вес в функции стоимости. Нормализация позволяет сделать все признаки одинаково взвешенными.
Что такое нормализация данных и зачем она нам нужна?
Нормализация данных - очень важный этап предварительной обработки, используемый для изменения масштаба значений, чтобы они соответствовали определенному диапазону, чтобы обеспечить лучшую сходимость во время обратного распространения ошибки. В общем случае она сводится к вычитанию среднего значения и делению на стандартное отклонение.
Если этого не сделать, некоторые признаки будут иметь более высокий вес в функции стоимости. Нормализация позволяет сделать все признаки одинаково взвешенными.
👍1
#вопросы_с_собеседований
Что такое аугментация данных? Можете привести примеры?
Под аугментацией данных понимается увеличение выборки данных для обучения через модификацию существующих данных. Компьютерное зрение - одна из областей, где очень полезно увеличение объема данных. Есть много модификаций, которые мы можем сделать с изображениями:
— Изменить размер
— Горизонтально или вертикально перевернуть
— Добавить шум
— Деформировать
— Изменить цвета
Что такое аугментация данных? Можете привести примеры?
Под аугментацией данных понимается увеличение выборки данных для обучения через модификацию существующих данных. Компьютерное зрение - одна из областей, где очень полезно увеличение объема данных. Есть много модификаций, которые мы можем сделать с изображениями:
— Изменить размер
— Горизонтально или вертикально перевернуть
— Добавить шум
— Деформировать
— Изменить цвета
👍2
#вопросы_с_собеседований
Как рассчитать точность прогноза, используя матрицу ошибок?
В матрице ошибок есть значения для общего количества данных, истинных значений и прогнозируемых значений.
Как рассчитать точность прогноза, используя матрицу ошибок?
В матрице ошибок есть значения для общего количества данных, истинных значений и прогнозируемых значений.
Представьте, что ваш набор данных наверняка линейно разделим и вам нужно гарантировать сходимость и наибольшее число итераций/шагов в вашем алгоритме (из-за вычислительных ресурсов).
Выбрали ли бы вы в таком случае градиентный спуск? Что можно выбрать? (Подсказка: какой простой алгоритм с гарантией обеспечивает нахождение решения?)
Выбрали ли бы вы в таком случае градиентный спуск? Что можно выбрать? (Подсказка: какой простой алгоритм с гарантией обеспечивает нахождение решения?)
Простая выгрузка случайной выборки из обучающего набора данных в обучающую и проверочную выборку хорошо подходит для задачи регрессии. А что может пойти не так с этим подходом для задачи классификации? Что с этим можно сделать? (Подсказка: все ли классы преобладают в одной и той же степени?)
Что такое уменьшение размерности? Почему и как?
Снижение размерности - это уменьшение размерности (количества функций) данных перед подгонкой модели.
Проклятие размерности является основной причиной уменьшения размерности. Проклятие размерности говорит о том, что, когда размерность увеличивается, первое, что связано с интенсивным использованием данных, уменьшается в каждом измерении, а второе, более высокая размерность, облегчает переоснащение модели.
В зависимости от проблемы существуют разные методы уменьшения размерности. Самый строгий прямой способ выполнить анализ главных компонентов (PCA), который представляет собой алгоритм машинного обучения без учителя, который сохраняет только некоррелированные функции с наибольшей дисперсией.
Во время анализа текста обычно требуется уменьшить размерность, поскольку векторизованная матрица является разреженной матрицей. HashingVectorizer уменьшит размерность перед подгонкой данных в модель.
Это все двадцать вопросов, связанных с машинным обучением, для подготовки к собеседованию. Вы можете использовать их в качестве контрольного списка при подготовке к собеседованию или в качестве учебного пособия, которое поможет вам лучше понять основы машинного обучения. Я написал другие руководства по собеседованию для вопросов по статистике:
Снижение размерности - это уменьшение размерности (количества функций) данных перед подгонкой модели.
Проклятие размерности является основной причиной уменьшения размерности. Проклятие размерности говорит о том, что, когда размерность увеличивается, первое, что связано с интенсивным использованием данных, уменьшается в каждом измерении, а второе, более высокая размерность, облегчает переоснащение модели.
В зависимости от проблемы существуют разные методы уменьшения размерности. Самый строгий прямой способ выполнить анализ главных компонентов (PCA), который представляет собой алгоритм машинного обучения без учителя, который сохраняет только некоррелированные функции с наибольшей дисперсией.
Во время анализа текста обычно требуется уменьшить размерность, поскольку векторизованная матрица является разреженной матрицей. HashingVectorizer уменьшит размерность перед подгонкой данных в модель.
Это все двадцать вопросов, связанных с машинным обучением, для подготовки к собеседованию. Вы можете использовать их в качестве контрольного списка при подготовке к собеседованию или в качестве учебного пособия, которое поможет вам лучше понять основы машинного обучения. Я написал другие руководства по собеседованию для вопросов по статистике:
👍3
Что делать с несбалансированным набором данных?
Несбалансированный набор данных приводит к тому, что обычные показатели классификации, такие как точность, не работают. Есть несколько способов справиться с несбалансированным набором данных:
1, выберите различные метрики для оценки модели в зависимости от проблемы: оценка F, отзыв, точность и т. Д.
2, исключить некоторые наблюдения из большего набора: уменьшить выборку большего набора путем случайного отбрасывания некоторых данных из этого набора.
3, увеличьте количество наблюдений для меньшего набора: увеличьте выборку меньшего набора либо путем создания нескольких копий точек данных в меньшем наборе (может привести к переобучению модели), либо с помощью создания синтетических данных, таких как SMOTE, где мы используйте существующие данные в меньшем наборе, чтобы создать новые точки данных, которые выглядят как существующие.
Несбалансированный набор данных приводит к тому, что обычные показатели классификации, такие как точность, не работают. Есть несколько способов справиться с несбалансированным набором данных:
1, выберите различные метрики для оценки модели в зависимости от проблемы: оценка F, отзыв, точность и т. Д.
2, исключить некоторые наблюдения из большего набора: уменьшить выборку большего набора путем случайного отбрасывания некоторых данных из этого набора.
3, увеличьте количество наблюдений для меньшего набора: увеличьте выборку меньшего набора либо путем создания нескольких копий точек данных в меньшем наборе (может привести к переобучению модели), либо с помощью создания синтетических данных, таких как SMOTE, где мы используйте существующие данные в меньшем наборе, чтобы создать новые точки данных, которые выглядят как существующие.
Что делать с отсутствующими данными?
Ответ сильно зависит от конкретных сценариев, но вот несколько вариантов:
1, удалите недостающие строки / столбцы, если размер набора данных существенно не уменьшится, если их фильтрация не приведет к смещению выборки.
2, используйте среднее значение / медиана / режим для замены отсутствующего значения: это может быть проблематичным, поскольку оно уменьшает дисперсию функции и игнорирует корреляцию между этой функцией и другими функциями.
3, спрогнозируйте значение, построив интерполятор или предсказав их на основе других функций.
4, используйте пропущенное значение как отдельную функцию: возможно, некоторые значения отсутствуют по определенным причинам, которые могут быть полезны для анализа данных.
Ответ сильно зависит от конкретных сценариев, но вот несколько вариантов:
1, удалите недостающие строки / столбцы, если размер набора данных существенно не уменьшится, если их фильтрация не приведет к смещению выборки.
2, используйте среднее значение / медиана / режим для замены отсутствующего значения: это может быть проблематичным, поскольку оно уменьшает дисперсию функции и игнорирует корреляцию между этой функцией и другими функциями.
3, спрогнозируйте значение, построив интерполятор или предсказав их на основе других функций.
4, используйте пропущенное значение как отдельную функцию: возможно, некоторые значения отсутствуют по определенным причинам, которые могут быть полезны для анализа данных.
Что такое нормализация данных и почему?
Нормализация (или масштабирование) данных позволяет всем непрерывным функциям иметь более согласованный диапазон значений. Для каждой функции мы вычитаем ее среднее значение и делим на стандартную ошибку или диапазон. Цель состоит в том, чтобы все непрерывные объекты находились в одном масштабе. Нормализация данных полезна как минимум в трех случаях:
1, для алгоритмов, использующих евклидово расстояние: Kmeans, KNN: разные масштабы искажают расчет расстояния.
2, для алгоритмов, которые оптимизируются с помощью градиентного спуска: функции в разных масштабах затрудняют сходимость градиентного спуска.
3, для уменьшения размерности (PCA): находит комбинации функций, которые имеют наибольшую дисперсию
Нормализация (или масштабирование) данных позволяет всем непрерывным функциям иметь более согласованный диапазон значений. Для каждой функции мы вычитаем ее среднее значение и делим на стандартную ошибку или диапазон. Цель состоит в том, чтобы все непрерывные объекты находились в одном масштабе. Нормализация данных полезна как минимум в трех случаях:
1, для алгоритмов, использующих евклидово расстояние: Kmeans, KNN: разные масштабы искажают расчет расстояния.
2, для алгоритмов, которые оптимизируются с помощью градиентного спуска: функции в разных масштабах затрудняют сходимость градиентного спуска.
3, для уменьшения размерности (PCA): находит комбинации функций, которые имеют наибольшую дисперсию
👍2🥰2
Какой метод перекрестной проверки следует использовать для набора данных временных рядов?
Методы перекрестной проверки по умолчанию перемешивают данные перед их разделением на разные группы, что нежелательно для анализа временных рядов. Порядок данных временных рядов имеет значение, и мы не хотим обучаться на будущих данных и тестировать на прошлых данных. Вместо этого нам нужно сохранять порядок и тренироваться только на прошлом.
Есть два метода: «скользящее окно» и «прямая цепочка». Во-первых, мы сохраняем порядок наших данных и разрезаем их на разные сгибы. В скользящем окне мы тренируемся на сгибе 1 и тестируем на сгибе 2. Затем мы тренируемся на сгибе 2 и тестируем на сгибе 3. Мы закончим, пока не проверим последний сгиб. В прямой цепочке мы тренируемся на сгибе 1, тестируем на сгибе 2. Затем мы тренируемся на сгибе 1 + 2, тестируем на сгибе 3. Затем тренируемся на сгибе 1 + 2 + 3, тестируем на сгибе 4. Мы остановимся, пока не будем проверить последнюю складку.
@machinelearning_interview
Методы перекрестной проверки по умолчанию перемешивают данные перед их разделением на разные группы, что нежелательно для анализа временных рядов. Порядок данных временных рядов имеет значение, и мы не хотим обучаться на будущих данных и тестировать на прошлых данных. Вместо этого нам нужно сохранять порядок и тренироваться только на прошлом.
Есть два метода: «скользящее окно» и «прямая цепочка». Во-первых, мы сохраняем порядок наших данных и разрезаем их на разные сгибы. В скользящем окне мы тренируемся на сгибе 1 и тестируем на сгибе 2. Затем мы тренируемся на сгибе 2 и тестируем на сгибе 3. Мы закончим, пока не проверим последний сгиб. В прямой цепочке мы тренируемся на сгибе 1, тестируем на сгибе 2. Затем мы тренируемся на сгибе 1 + 2, тестируем на сгибе 3. Затем тренируемся на сгибе 1 + 2 + 3, тестируем на сгибе 4. Мы остановимся, пока не будем проверить последнюю складку.
@machinelearning_interview
👍4
Что такое упаковка и повышение? Почему мы их используем?
Бэггинг - это параллельная тренировка моделей ансамбля. У нас есть набор идентичных моделей обучения со случайно выбранными подвыборками (с заменой) и функциями. Окончательный прогноз объединяет прогнозы всех моделей. Для задач классификации требуется большинство голосов. В то время как для задач регрессии требуется среднее значение всех прогнозов модели. Бэггинг обычно используется для борьбы с переобучением, и Random Forest - отличный тому пример.
Boosting - это вертикальное обучение моделей. Требуется серия моделей, каждая из которых повторяет результат предыдущей. Он обучен на данных, повторно взвешенных, чтобы сосредоточиться на данных, которые предыдущие модели ошибались. Окончательные прогнозы затем объединяются в средневзвешенное значение в конце. Повышение - это техника, которая борется с недостаточной подгонкой, и деревья принятия решений с градиентным усилением - отличный тому пример.
@machinelearning_interview
Бэггинг - это параллельная тренировка моделей ансамбля. У нас есть набор идентичных моделей обучения со случайно выбранными подвыборками (с заменой) и функциями. Окончательный прогноз объединяет прогнозы всех моделей. Для задач классификации требуется большинство голосов. В то время как для задач регрессии требуется среднее значение всех прогнозов модели. Бэггинг обычно используется для борьбы с переобучением, и Random Forest - отличный тому пример.
Boosting - это вертикальное обучение моделей. Требуется серия моделей, каждая из которых повторяет результат предыдущей. Он обучен на данных, повторно взвешенных, чтобы сосредоточиться на данных, которые предыдущие модели ошибались. Окончательные прогнозы затем объединяются в средневзвешенное значение в конце. Повышение - это техника, которая борется с недостаточной подгонкой, и деревья принятия решений с градиентным усилением - отличный тому пример.
@machinelearning_interview
👎6❤1
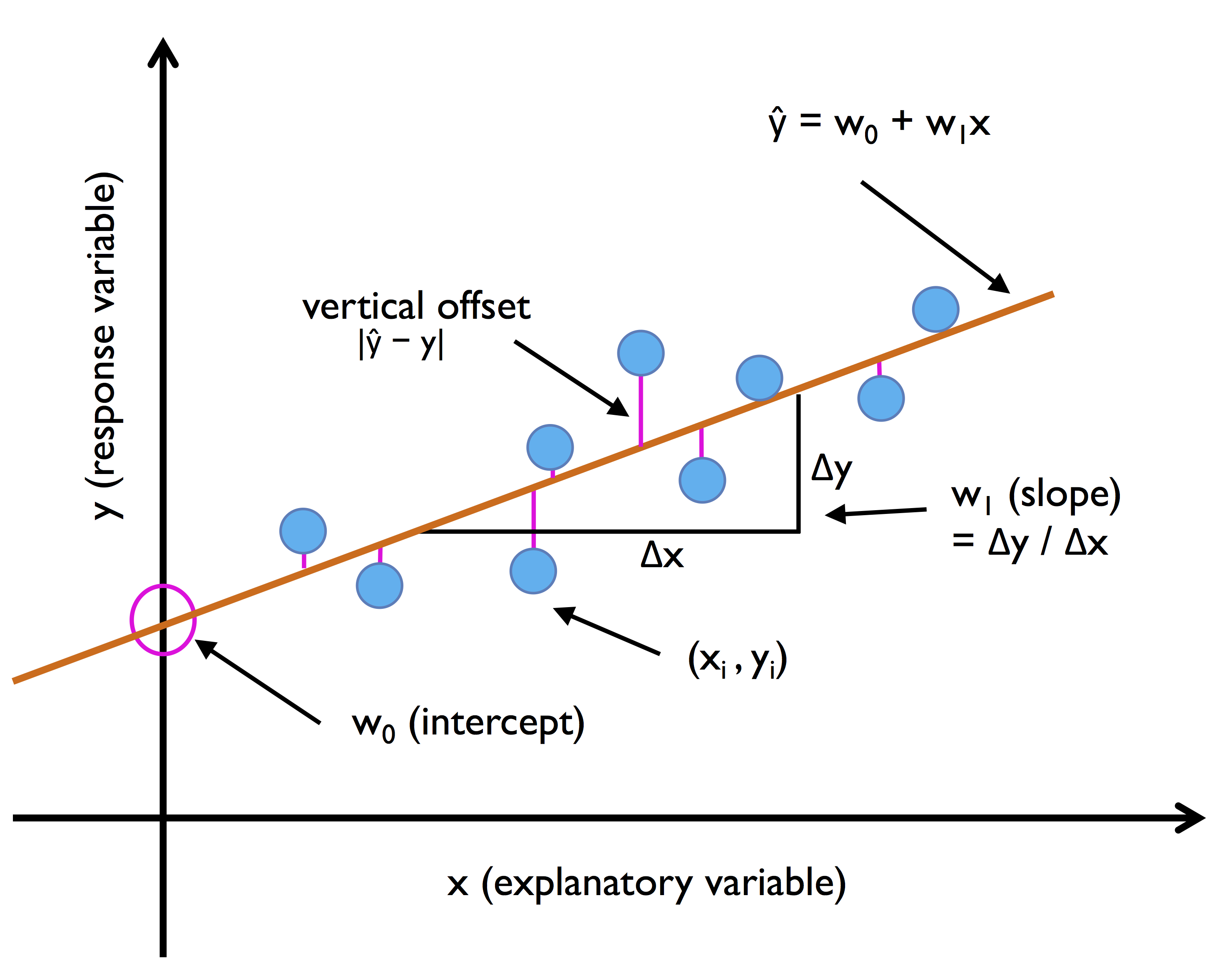
Как оценивать модели линейной регрессии?
Есть несколько способов оценить модели линейной регрессии. Для оценки модели мы можем использовать такие показатели, как средняя абсолютная ошибка (MAE), среднеквадратичная ошибка (MSE), среднеквадратичная ошибка (RMSE). Обратите внимание: если вы не хотите, чтобы выбросы влияли на производительность вашей модели, вам следует использовать MAE, а не MSE. В дополнение к этим показателям мы также можем использовать R-квадрат или скорректированный R-квадрат (R2). R-Squared - это мера, которая сравнивает модель, которую вы построили, с базовой моделью, где базовая модель все время предсказывает среднее значение y.
Если ваша модель хуже, чем базовая модель, R-Squared может быть меньше нуля. Скорректированный R-Squared корректирует R-Squared в зависимости от того, сколько функций ваша модель использовала для прогнозирования. Если увеличение одной функции не улучшает производительность модели, чем ожидалось, скорректированный R-Squared будет уменьшаться.
Обратите внимание, что MAE и MSE трудно интерпретировать без контекста, потому что они зависят от масштаба данных. Однако, поскольку R-Squared имеет фиксированный диапазон, значение, близкое к 1, всегда означает, что модель достаточно хорошо соответствует данным.
@machinelearning_interview
Есть несколько способов оценить модели линейной регрессии. Для оценки модели мы можем использовать такие показатели, как средняя абсолютная ошибка (MAE), среднеквадратичная ошибка (MSE), среднеквадратичная ошибка (RMSE). Обратите внимание: если вы не хотите, чтобы выбросы влияли на производительность вашей модели, вам следует использовать MAE, а не MSE. В дополнение к этим показателям мы также можем использовать R-квадрат или скорректированный R-квадрат (R2). R-Squared - это мера, которая сравнивает модель, которую вы построили, с базовой моделью, где базовая модель все время предсказывает среднее значение y.
Если ваша модель хуже, чем базовая модель, R-Squared может быть меньше нуля. Скорректированный R-Squared корректирует R-Squared в зависимости от того, сколько функций ваша модель использовала для прогнозирования. Если увеличение одной функции не улучшает производительность модели, чем ожидалось, скорректированный R-Squared будет уменьшаться.
Обратите внимание, что MAE и MSE трудно интерпретировать без контекста, потому что они зависят от масштаба данных. Однако, поскольку R-Squared имеет фиксированный диапазон, значение, близкое к 1, всегда означает, что модель достаточно хорошо соответствует данным.
@machinelearning_interview
{kind=link}
👍4🥰1
Как оценивать регрессионные модели и как оценивать модели классификации? (также укажите эффективность)
Чтобы оценить модель, нам необходимо оценить ее технические и практические характеристики. С технической точки зрения, в зависимости от сценариев, мы используем MSE, MAE, RMSE и т. Д. Для оценки регрессионных моделей и используем точность, отзыв, прецизионность, оценку F, AUC для оценки моделей классификации. У меня есть статья, в которой описывается выбор метрик для оценки моделей классификации:
С практической стороны нам нужно оценить, готова ли модель к развертыванию и использованию бизнес-метрик в этом случае. Если мы улучшаем старую модель, мы можем просто сравнить метрики методов между старой моделью и новой моделью, чтобы увидеть, имеет ли новая модель лучшую производительность. Если это лучшая модель, которую вы строите, вам необходимо определить «хорошую производительность» с помощью бизнес-показателей. Например, сколько будет потерь, если мы будем следовать неверным прогнозам модели, и это сильно зависит от бизнес-сценариев. Если отправка рекламы обходится дешево, то модель все равно имеет низкую точность. Однако, если отправка рекламы стоит дорого, нам нужна более высокая точность.
@machinelearning_interview
Чтобы оценить модель, нам необходимо оценить ее технические и практические характеристики. С технической точки зрения, в зависимости от сценариев, мы используем MSE, MAE, RMSE и т. Д. Для оценки регрессионных моделей и используем точность, отзыв, прецизионность, оценку F, AUC для оценки моделей классификации. У меня есть статья, в которой описывается выбор метрик для оценки моделей классификации:
С практической стороны нам нужно оценить, готова ли модель к развертыванию и использованию бизнес-метрик в этом случае. Если мы улучшаем старую модель, мы можем просто сравнить метрики методов между старой моделью и новой моделью, чтобы увидеть, имеет ли новая модель лучшую производительность. Если это лучшая модель, которую вы строите, вам необходимо определить «хорошую производительность» с помощью бизнес-показателей. Например, сколько будет потерь, если мы будем следовать неверным прогнозам модели, и это сильно зависит от бизнес-сценариев. Если отправка рекламы обходится дешево, то модель все равно имеет низкую точность. Однако, если отправка рекламы стоит дорого, нам нужна более высокая точность.
@machinelearning_interview
{kind=link}
🔥5
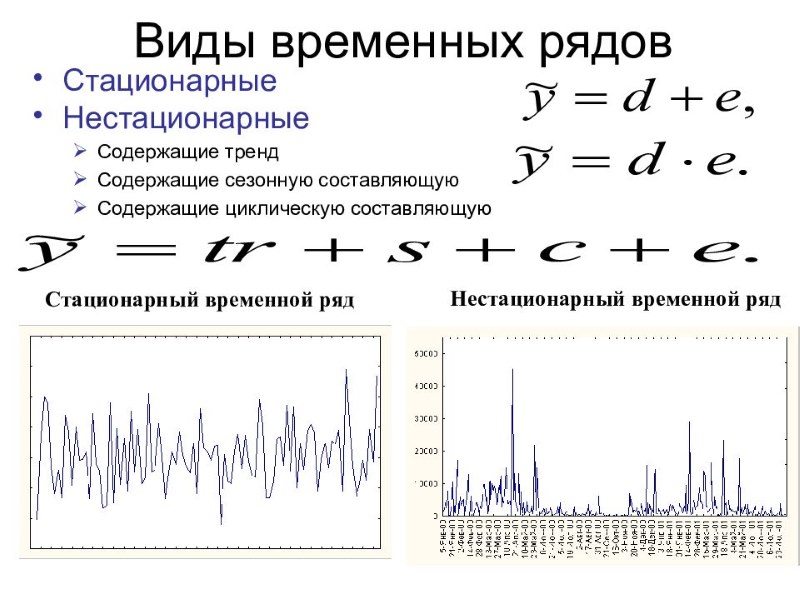
Какой метод перекрёстной проверки вы бы использовали для набора данных временных рядов?
Нормальная k-кратная процедура перекрёстной проверки может быть проблематичной для временных рядов.
Наиболее результативный подход для временных рядов — это прямая цепочка, где процедура выглядит примерно так:
сгиб 1: тренировка [1], тест [2];
сгиб 2: тренировка [1 2], тест [3];
сгиб 3: тренировка [1 2 3], тест [4];
сгиб 4: тренировка [1 2 3 4], тест [5];
сгиб 5: тренировка [1 2 3 4 5], тест [6].
Это более точно показывает ситуацию, где можно моделировать прошлые данные и прогнозировать прогнозные данные.
@machinelearning_interview
Нормальная k-кратная процедура перекрёстной проверки может быть проблематичной для временных рядов.
Наиболее результативный подход для временных рядов — это прямая цепочка, где процедура выглядит примерно так:
сгиб 1: тренировка [1], тест [2];
сгиб 2: тренировка [1 2], тест [3];
сгиб 3: тренировка [1 2 3], тест [4];
сгиб 4: тренировка [1 2 3 4], тест [5];
сгиб 5: тренировка [1 2 3 4 5], тест [6].
Это более точно показывает ситуацию, где можно моделировать прошлые данные и прогнозировать прогнозные данные.
@machinelearning_interview
{kind=link}
👍7
"Что такое мешающий фактор?"
Это посторонние факторы статистической модели, которые прямо или обратно пропорционально коррелируют как с зависимой, так и с независимой переменной. Оценка не учитывает мешающий фактор, зато сама профессия Data Scientist предусматривает его изучение.
@machinelearning_interview
Это посторонние факторы статистической модели, которые прямо или обратно пропорционально коррелируют как с зависимой, так и с независимой переменной. Оценка не учитывает мешающий фактор, зато сама профессия Data Scientist предусматривает его изучение.
@machinelearning_interview
👍5
#вопросы_с_собеседований
Что такое Random Forest?
Random Forest, или случайный лес, — это один из немногих универсальных алгоритмов обучения, который способен выполнять задачи классификации, регрессии и кластеризации.
Случайный лес состоит из большого количества отдельных деревьев решений, которые по сути являются ансамблем методов. Каждое дерево в случайном лесу возвращает прогноз класса, и класс с наибольшим количеством голосов становится прогнозом леса.
Что такое Random Forest?
Random Forest, или случайный лес, — это один из немногих универсальных алгоритмов обучения, который способен выполнять задачи классификации, регрессии и кластеризации.
Случайный лес состоит из большого количества отдельных деревьев решений, которые по сути являются ансамблем методов. Каждое дерево в случайном лесу возвращает прогноз класса, и класс с наибольшим количеством голосов становится прогнозом леса.
👍9❤1