
Как вы создаете аналитический проект?
Ответ на этот вопрос позволит вам продемонстрировать социальные навыки, такие как аккуратность и организованность, которые важны для роли аналитика данных.
Пример: «В аналитическом проекте есть определенные шаги, которые можно повторять. Когда вы начинаете аналитический проект, вы должны выполнить следующие шаги:
Определите проблему.
Исследуйте существующие данные и исследуйте новые данные для поддержки решений.
Подготовьте данные для хранения данных.
Выберите привлекательную модель данных, которая подходит для аналитики, которую вы хотите получить.
Подтвердите данные.
Внедрите модель данных и просмотрите аналитику».
@machinelearning_interview
Ответ на этот вопрос позволит вам продемонстрировать социальные навыки, такие как аккуратность и организованность, которые важны для роли аналитика данных.
Пример: «В аналитическом проекте есть определенные шаги, которые можно повторять. Когда вы начинаете аналитический проект, вы должны выполнить следующие шаги:
Определите проблему.
Исследуйте существующие данные и исследуйте новые данные для поддержки решений.
Подготовьте данные для хранения данных.
Выберите привлекательную модель данных, которая подходит для аналитики, которую вы хотите получить.
Подтвердите данные.
Внедрите модель данных и просмотрите аналитику».
@machinelearning_interview
👍8👎2🔥1
🤖 Расскажите о наивном байесовсом алгоритме какие у него преимущества и недостатки?
Ответ
Наивный байесовский классификатор (Naive Bayes classifier) – это очень популярный в машинном обучении алгоритм, который в основном используется для получения базовой точности набора данных. Изучим его преимущества и недостатки, а также реализацию на языке Python.
Плюсы
Алгоритм легко и быстро предсказывает класс тестового набора данных. Он также хорошо справляется с многоклассовым прогнозированием.
Производительность наивного байесовского классификатора лучше, чем у других простых алгоритмов, таких как логистическая регрессия. Более того, вам требуется меньше обучающих данных.
Он хорошо работает с категориальными признаками(по сравнению с числовыми). Для числовых признаков предполагается нормальное распределение, что может быть серьезным допущением в точности нашего алгоритма.
Минусы
Если переменная имеет категорию (в тестовом наборе данных), которая не наблюдалась в обучающем наборе данных, то модель присвоит 0 (нулевую) вероятность и не сможет сделать предсказание. Это часто называют нулевой частотой. Чтобы решить эту проблему, мы можем использовать технику сглаживания. Один из самых простых методов сглаживания называется оценкой Лапласа.
Значения спрогнозированных вероятностей, возвращенные методом predict_proba, не всегда являются достаточно точными.
Ограничением данного алгоритма является предположение о независимости признаков. Однако в реальных задачах полностью независимые признаки встречаются крайне редко.
➡️ Читать подробнее
@machinelearning_interview
Ответ
Наивный байесовский классификатор (Naive Bayes classifier) – это очень популярный в машинном обучении алгоритм, который в основном используется для получения базовой точности набора данных. Изучим его преимущества и недостатки, а также реализацию на языке Python.
Плюсы
Алгоритм легко и быстро предсказывает класс тестового набора данных. Он также хорошо справляется с многоклассовым прогнозированием.
Производительность наивного байесовского классификатора лучше, чем у других простых алгоритмов, таких как логистическая регрессия. Более того, вам требуется меньше обучающих данных.
Он хорошо работает с категориальными признаками(по сравнению с числовыми). Для числовых признаков предполагается нормальное распределение, что может быть серьезным допущением в точности нашего алгоритма.
Минусы
Если переменная имеет категорию (в тестовом наборе данных), которая не наблюдалась в обучающем наборе данных, то модель присвоит 0 (нулевую) вероятность и не сможет сделать предсказание. Это часто называют нулевой частотой. Чтобы решить эту проблему, мы можем использовать технику сглаживания. Один из самых простых методов сглаживания называется оценкой Лапласа.
Значения спрогнозированных вероятностей, возвращенные методом predict_proba, не всегда являются достаточно точными.
Ограничением данного алгоритма является предположение о независимости признаков. Однако в реальных задачах полностью независимые признаки встречаются крайне редко.
➡️ Читать подробнее
@machinelearning_interview
👍14🔥4
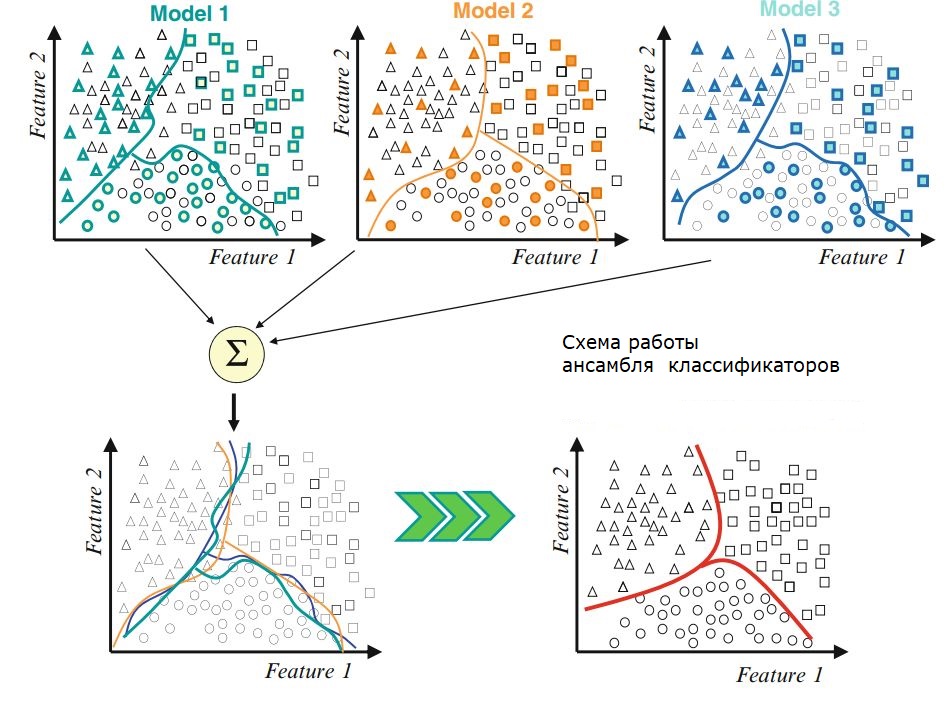
Рассакажите о градиентном бустинг. Опишите логику, которуюа стоит за градиентым бустингом.
Ответ
Градиентный бустинг — это техника машинного обучения для задач классификации и регрессии, которая строит модель предсказания в форме ансамбля слабых предсказывающих моделей, обычно деревьев решений.
Интуиция за градиентным бустингом
Логика, что стоит за градиентым бустингом, проста, ее можно понять интуитивно, без математического формализма. Предполагается, что читатель знаком с простой линейной регрессией.
Первое предположение линейной регресии, что сумма отклонений = 0, т.е. отклонения должны быть случайно распределены в окрестности нуля.
Теперь давайте думать о отклонениях, как об ошибках, сделанных нашей моделью. Хотя в моделях основанных на деревьях не делается такого предположения, если мы будем размышлять об этом предположении логически (не статистически), мы можем понять, что увидив принцип распределения отклонений, сможем использовать данный паттерн для модели.
Итак, интуиция за алгоритмом градиентного бустинга — итеративно применять паттерны отклонений и улучшать предсказания. Как только мы достигли момента, когда отклонения не имеют никакого паттерна, мы прекращаем достраивать нашу модель (иначе это может привести к переобучению). Алгоритмически, мы минимизируем нашу функцию потерь.
В итоге,
Сначала строим простые модели и анализируем ошибки;
Определяем точки, которые не вписываются в простую модель;
Добавляем модели, которые обрабатывают сложные случаи, которые были выявлены на начальной модели;
Собираем все построенные модели, определяя вес каждого предсказателя.
➡️ Подробное описание с примерами кода
@machinelearning_interview
Ответ
Градиентный бустинг — это техника машинного обучения для задач классификации и регрессии, которая строит модель предсказания в форме ансамбля слабых предсказывающих моделей, обычно деревьев решений.
Интуиция за градиентным бустингом
Логика, что стоит за градиентым бустингом, проста, ее можно понять интуитивно, без математического формализма. Предполагается, что читатель знаком с простой линейной регрессией.
Первое предположение линейной регресии, что сумма отклонений = 0, т.е. отклонения должны быть случайно распределены в окрестности нуля.
Теперь давайте думать о отклонениях, как об ошибках, сделанных нашей моделью. Хотя в моделях основанных на деревьях не делается такого предположения, если мы будем размышлять об этом предположении логически (не статистически), мы можем понять, что увидив принцип распределения отклонений, сможем использовать данный паттерн для модели.
Итак, интуиция за алгоритмом градиентного бустинга — итеративно применять паттерны отклонений и улучшать предсказания. Как только мы достигли момента, когда отклонения не имеют никакого паттерна, мы прекращаем достраивать нашу модель (иначе это может привести к переобучению). Алгоритмически, мы минимизируем нашу функцию потерь.
В итоге,
Сначала строим простые модели и анализируем ошибки;
Определяем точки, которые не вписываются в простую модель;
Добавляем модели, которые обрабатывают сложные случаи, которые были выявлены на начальной модели;
Собираем все построенные модели, определяя вес каждого предсказателя.
➡️ Подробное описание с примерами кода
@machinelearning_interview
{kind=link}
👍15👎3🔥1
Расскажите о механизмах работы ридж и лассо регрессий.
Ответ
Лассо и ридж — это модели линейной регрессии, но с поправочным (штрафным) коэффициентом, также называемым регуляризацией. Они вносят поправки в размерность бета-вектора разными способами.
Лассо-регрессия
Лассо-регрессия накладывает штраф на l1-норму бета-вектора. l1-норма вектора — это сумма абсолютных значений в этом векторе.
Это заставляет лассо-регрессию обнулять некоторые коэффициенты в бета-векторе. Детали этого процесса можно найти по ссылке.
Упрощенно назначение лассо-регрессии можно выразить так: “Постарайтесь достичь наилучшей производительности, но, обнаружив бесполезность некоторых коэффициентов, отбросьте их”.
Ридж-регрессия
Ридж-регрессия накладывает штраф на l2-норму бета-вектора. 2-норма вектора — это квадратный корень из суммы квадратов значений в векторе.
Благодаря этому, ридж-регрессия не позволяет коэффициентам бета-вектора достигать экстремальных значений (что часто происходит при чрезмерно близкой подгонке).
Простыми словами назначение ридж-регрессии можно выразить так: “Постарайтесь добиться наилучшей производительности, но ни один из коэффициентов не должен достигать экстремального значения”.
➡️ Лассо и ридж-регрессии: интуитивное сравнение
@machinelearning_interview
Ответ
Лассо и ридж — это модели линейной регрессии, но с поправочным (штрафным) коэффициентом, также называемым регуляризацией. Они вносят поправки в размерность бета-вектора разными способами.
Лассо-регрессия
Лассо-регрессия накладывает штраф на l1-норму бета-вектора. l1-норма вектора — это сумма абсолютных значений в этом векторе.
Это заставляет лассо-регрессию обнулять некоторые коэффициенты в бета-векторе. Детали этого процесса можно найти по ссылке.
Упрощенно назначение лассо-регрессии можно выразить так: “Постарайтесь достичь наилучшей производительности, но, обнаружив бесполезность некоторых коэффициентов, отбросьте их”.
Ридж-регрессия
Ридж-регрессия накладывает штраф на l2-норму бета-вектора. 2-норма вектора — это квадратный корень из суммы квадратов значений в векторе.
Благодаря этому, ридж-регрессия не позволяет коэффициентам бета-вектора достигать экстремальных значений (что часто происходит при чрезмерно близкой подгонке).
Простыми словами назначение ридж-регрессии можно выразить так: “Постарайтесь добиться наилучшей производительности, но ни один из коэффициентов не должен достигать экстремального значения”.
➡️ Лассо и ридж-регрессии: интуитивное сравнение
@machinelearning_interview
👍20🔥3
КАКОВА СВЯЗЬ МЕЖДУ АНАЛИЗОМ И ОБРАБОТКОЙ ДАННЫХ И DATAOPS?
Ответ
DataOps (операции с данными) — это новая концепция, под которой понимается методология управления корпоративными данными для эры искусственного интеллекта. Реализовав всеобъемлющую стратегию DataOps, вы можете легко связывать потребителей и создателей данных, чтобы быстро выявлять и использовать всю ценность информационных активов.
DataOps — не продукт, услуга или решение. Это методология, технологическая и культурная новация, призванная улучшить использование данных в организации за счет повышения их качества, сокращения цикла и максимально эффективного управления ими.
Очевидно, что анализ и обработка данных — ключевая концепция DataOps. DataOps охватывает весь цикл сбора и использования информации, а анализ и обработка данных направлены на применение математических и статистических методов, а также алгоритмов искусственного интеллекта и машинного обучения для осмысления данных. Анализ и обработка данных поддерживают сквозной процесс DataOps, преобразуя необработанную информацию в сведения, обладающие практической ценностью, которые помогают реализовать общую стратегию.
@machinelearning_interview
Ответ
DataOps (операции с данными) — это новая концепция, под которой понимается методология управления корпоративными данными для эры искусственного интеллекта. Реализовав всеобъемлющую стратегию DataOps, вы можете легко связывать потребителей и создателей данных, чтобы быстро выявлять и использовать всю ценность информационных активов.
DataOps — не продукт, услуга или решение. Это методология, технологическая и культурная новация, призванная улучшить использование данных в организации за счет повышения их качества, сокращения цикла и максимально эффективного управления ими.
Очевидно, что анализ и обработка данных — ключевая концепция DataOps. DataOps охватывает весь цикл сбора и использования информации, а анализ и обработка данных направлены на применение математических и статистических методов, а также алгоритмов искусственного интеллекта и машинного обучения для осмысления данных. Анализ и обработка данных поддерживают сквозной процесс DataOps, преобразуя необработанную информацию в сведения, обладающие практической ценностью, которые помогают реализовать общую стратегию.
@machinelearning_interview
👍11🔥1
Техническое собеседование для Амазон:
Есть 2 таблицы А и Б, нужно сказать сколько строк выведется при соединении.
TableA
id1
1
1
TableB
id2
1
1
1
1
NULL
Please provide the count of rows for each join for Table A and Table B:
Left join:
Right join:
inner join:
full join:
Задание 2:
Department table (id, name)
D1 Finance Dept
D2 HR Dept
D3 AR Dept
F1 AP Dept
Employee table (id, name, deptNo, sex, hireDate, Salary,effectiveDate)
E1, sample1, D1,M,01/01/2000, 5000, 01/01/2000
E1, sample1, D1,M,01/01/2000, 6000, 01/01/2001
E1, sample1, D2,M,01/01/2000, 6000, 01/02/2001
E2, sample1, D2,M,01/01/2000, 6000, 01/02/2001
E3, sample1, D1,M,01/01/2000, 5000, 01/01/2000
E3, sample1, D1,M,01/01/2000, 6000, 01/01/2001
E4, sample1, F1,M,01/01/2000, 5000, 01/01/2000
E4, sample1, D1,M,01/01/2000, 6000, 01/01/2001
E4, sample1, D3,M,01/01/2000, 8000, 01/02/2001
E5, sample1, D3,F,01/01/2001, 8000, 01/02/2001
E6, sample1, D3,F,01/01/2001, 9000, 01/02/2001
1.Write a query to display latest salary of each employee
2. Write a query to display department name where employees count in the department is
more than 2
Задание 3 (code):
Given two strings, output the words that are unique to each string.
Example:
String 1: The quick brown fox jumped over the lazy fox
String 2: The slow blue whale swam over the quick shark
Output: slow, brown, blue, fox, whale, jumped, swam, lazy, shark
Задание 4 (моделирование):
Employee Seat Assignment
Daily some employees in the organization transfer from one manager to another manager.
This transfer leads to new seat assignment at his new work location.
Can you do a data model to maintain the history of work location changes? (нужно прикинуть какой подход для моделирования использовать, какие колонки будут в таблице, как отображать историю)
@machinelearning_interview
Есть 2 таблицы А и Б, нужно сказать сколько строк выведется при соединении.
TableA
id1
1
1
TableB
id2
1
1
1
1
NULL
Please provide the count of rows for each join for Table A and Table B:
Left join:
Right join:
inner join:
full join:
Задание 2:
Department table (id, name)
D1 Finance Dept
D2 HR Dept
D3 AR Dept
F1 AP Dept
Employee table (id, name, deptNo, sex, hireDate, Salary,effectiveDate)
E1, sample1, D1,M,01/01/2000, 5000, 01/01/2000
E1, sample1, D1,M,01/01/2000, 6000, 01/01/2001
E1, sample1, D2,M,01/01/2000, 6000, 01/02/2001
E2, sample1, D2,M,01/01/2000, 6000, 01/02/2001
E3, sample1, D1,M,01/01/2000, 5000, 01/01/2000
E3, sample1, D1,M,01/01/2000, 6000, 01/01/2001
E4, sample1, F1,M,01/01/2000, 5000, 01/01/2000
E4, sample1, D1,M,01/01/2000, 6000, 01/01/2001
E4, sample1, D3,M,01/01/2000, 8000, 01/02/2001
E5, sample1, D3,F,01/01/2001, 8000, 01/02/2001
E6, sample1, D3,F,01/01/2001, 9000, 01/02/2001
1.Write a query to display latest salary of each employee
2. Write a query to display department name where employees count in the department is
more than 2
Задание 3 (code):
Given two strings, output the words that are unique to each string.
Example:
String 1: The quick brown fox jumped over the lazy fox
String 2: The slow blue whale swam over the quick shark
Output: slow, brown, blue, fox, whale, jumped, swam, lazy, shark
Задание 4 (моделирование):
Employee Seat Assignment
Daily some employees in the organization transfer from one manager to another manager.
This transfer leads to new seat assignment at his new work location.
Can you do a data model to maintain the history of work location changes? (нужно прикинуть какой подход для моделирования использовать, какие колонки будут в таблице, как отображать историю)
@machinelearning_interview
👍21🔥3
Какая метрика линейной регрессии является наиболее информативной?
Ответ
Если вы уверены, что в ваших данных нет очень больших выбросов (качественные данные, например, собранные исправными датчиками), то самой информативной является RMSE (или MSE, если не важна физическая размерность прогнозируемой величины).
Если вы ничего не знаете о ваших данных или уверены, что в них есть выбросы (некачественные данные, например, которые вводились людьми с клавиатуры), то лучше использовать MAE.
Что касается относительных метрик, которые что-то показывают в процентах или относительных единицах, то они бывают очень коварными.
Особенно коварен коэффициент детерминации R2. Сравнивать разные модели по R2 можно только на одном и том же наборе данных. Добавление новых данных или удаление части данных обрушивает всякое такое сравнение разных моделей по R2.
Например, модель с R2=0.1 может прогнозировать гораздо лучше, чем модель с R2=0.9, если первая модель прогнозирует на данных с почти горизонтальным трендом, а вторая модель прогнозирует на данных с почти вертикальным трендом.
@machinelearning_interview
Ответ
Если вы уверены, что в ваших данных нет очень больших выбросов (качественные данные, например, собранные исправными датчиками), то самой информативной является RMSE (или MSE, если не важна физическая размерность прогнозируемой величины).
Если вы ничего не знаете о ваших данных или уверены, что в них есть выбросы (некачественные данные, например, которые вводились людьми с клавиатуры), то лучше использовать MAE.
Что касается относительных метрик, которые что-то показывают в процентах или относительных единицах, то они бывают очень коварными.
Особенно коварен коэффициент детерминации R2. Сравнивать разные модели по R2 можно только на одном и том же наборе данных. Добавление новых данных или удаление части данных обрушивает всякое такое сравнение разных моделей по R2.
Например, модель с R2=0.1 может прогнозировать гораздо лучше, чем модель с R2=0.9, если первая модель прогнозирует на данных с почти горизонтальным трендом, а вторая модель прогнозирует на данных с почти вертикальным трендом.
@machinelearning_interview
👍22🔥1
Является ли метрика ROC-AUC лучшей в задачах классификации?
Ответ
Нет лучшей метрики в задачах классификации, иначе бы остальные метрики отменили. ROC-AUC отличная метрика, но она оценивает скорее устойчивость алгоритма, так как смотрит на качество работы всех порогов сразу. А так метрика всегда зависит от решаемой задачи.
@machinelearning_interview
Ответ
Нет лучшей метрики в задачах классификации, иначе бы остальные метрики отменили. ROC-AUC отличная метрика, но она оценивает скорее устойчивость алгоритма, так как смотрит на качество работы всех порогов сразу. А так метрика всегда зависит от решаемой задачи.
@machinelearning_interview
👍21🔥3
Зачем нужна сигмоида в логистической регрессии?
Ответ
1. Сигмоида переводит интервал от минус бесконечности до плюс бесконечности в (0, 1), что позволяет интерпретировать результат как вероятность и использовать метод максимального правдоподобия для обучения.
2. Сигмоиды не насыщаются от сильных сигналов. Что это значит? Пусть у нас есть объекты в одномерном пространстве. Объекты нулевого класса - (-1000, -1000, ... , -1000) - всего 100 штук, а объекты первого класса - (-999, 1000, 1000, ..., 1000) - тоже 100 штук. То есть можно разделить объекты, например, по границе -999.5. Однако если решать эту классификационную задачу линейной регрессией (никогда не делайте так), то алгоритм скажет, что границу нужно проводить в нуле, так как большое количество объектов в экстремальных значениях (-1000 и +1000) окажут на функцию ошибки существенно большее влияние, чем один элемент в точке -999. А в случае использования сигмоиды такого не происходит - влияние правильно классифицированных объектов на функцию ошибки крайне мало.
3. Градиенты сигмоид очень удобно выражаются через саму функцию, что сильно упрощает практическое применение на практике. В логистической регрессии в качестве сигмоиды используется логистическая функция f(x) = (1 + e^(-x))^(-1). А её градиент f'(x) = f(x) * (1 - f(x))
@machinelearning_interview
Ответ
1. Сигмоида переводит интервал от минус бесконечности до плюс бесконечности в (0, 1), что позволяет интерпретировать результат как вероятность и использовать метод максимального правдоподобия для обучения.
2. Сигмоиды не насыщаются от сильных сигналов. Что это значит? Пусть у нас есть объекты в одномерном пространстве. Объекты нулевого класса - (-1000, -1000, ... , -1000) - всего 100 штук, а объекты первого класса - (-999, 1000, 1000, ..., 1000) - тоже 100 штук. То есть можно разделить объекты, например, по границе -999.5. Однако если решать эту классификационную задачу линейной регрессией (никогда не делайте так), то алгоритм скажет, что границу нужно проводить в нуле, так как большое количество объектов в экстремальных значениях (-1000 и +1000) окажут на функцию ошибки существенно большее влияние, чем один элемент в точке -999. А в случае использования сигмоиды такого не происходит - влияние правильно классифицированных объектов на функцию ошибки крайне мало.
3. Градиенты сигмоид очень удобно выражаются через саму функцию, что сильно упрощает практическое применение на практике. В логистической регрессии в качестве сигмоиды используется логистическая функция f(x) = (1 + e^(-x))^(-1). А её градиент f'(x) = f(x) * (1 - f(x))
@machinelearning_interview
👍21🔥4
Что такое Active learning - активное обучение ?
Ответ
Подход, при котором алгоритм выбирает часть данных, на которых он учится. Активное обучение особенно ценно в тех случаях, когда маркированных примеров недостаточно или их получение обходится дорого. Вместо того, чтобы слепо искать в широком диапазоне помеченных примеров, алгоритм активного обучения выборочно рассматривает конкретный набор примеров, которые ему нужны для обучения.
➡️ Подробнее
@machinelearning_interview
Ответ
Подход, при котором алгоритм выбирает часть данных, на которых он учится. Активное обучение особенно ценно в тех случаях, когда маркированных примеров недостаточно или их получение обходится дорого. Вместо того, чтобы слепо искать в широком диапазоне помеченных примеров, алгоритм активного обучения выборочно рассматривает конкретный набор примеров, которые ему нужны для обучения.
➡️ Подробнее
@machinelearning_interview
👍8🔥2
Что такое квантильная регрессия?
Квантильная регрессия — это регрессия (т.е. прогноз), которая намеренно вводит смещение в результат. Вместо поиска среднего значения прогнозируемой переменной, квантильная регрессия направлена на поиск медианы и любых других квантилей (которые иногда называют процентилями). Квантили особенно полезны для оптимизации товарных запасов в качестве прямого метода для вычисления точки возобновления.
Здесь регрессия выступает синонимом прогноза. "Регрессия" делает акцент на математическом подходе, тогда как "прогноз" - на практическом использовании результата.
На графике показаны 3 обособленных прогноза:
- красным цветом отмечен 75-процентный квантильный прогноз.
- черным цветом отмечен прогноз на основе средних значений.
- зеленым цветом отмечен 25-процентный квантильный прогноз.
Визуально поведение квантилей схоже с поведением доверительных интервалов. Однако, на практике квантиль нужен лишь для процентного выражения отдельно взятых точек.
@machinelearning_interview
Квантильная регрессия — это регрессия (т.е. прогноз), которая намеренно вводит смещение в результат. Вместо поиска среднего значения прогнозируемой переменной, квантильная регрессия направлена на поиск медианы и любых других квантилей (которые иногда называют процентилями). Квантили особенно полезны для оптимизации товарных запасов в качестве прямого метода для вычисления точки возобновления.
Здесь регрессия выступает синонимом прогноза. "Регрессия" делает акцент на математическом подходе, тогда как "прогноз" - на практическом использовании результата.
На графике показаны 3 обособленных прогноза:
- красным цветом отмечен 75-процентный квантильный прогноз.
- черным цветом отмечен прогноз на основе средних значений.
- зеленым цветом отмечен 25-процентный квантильный прогноз.
Визуально поведение квантилей схоже с поведением доверительных интервалов. Однако, на практике квантиль нужен лишь для процентного выражения отдельно взятых точек.
@machinelearning_interview
👍21🤔1🤬1
Junior Data Scientist | Собеседование
0:00 Введение.
0:50 О структуре и секциях, которые входят в интервью.
Секция «Python»
2:30 Вопрос на изменяемые и неизменяемые типы данных
6:21 Задача на dict и ответ Дмитрия
8:15 Объяснение первой задачи
10:38 Задача, цель которой — сделать, чтобы дикты были разные, ответ Дмитрия
13:51 Разбор второй задачи
16:10 Вопрос о выделении и очистке памяти в Python, ответ Дмитрия
16:26 Разбор вопроса
19:00 Вопрос о генераторах, декораторах и итераторах
Секция «A/B-тесты»
20:35 Вопрос о моделировании A/B теста
30:57 Вопрос о генерации распределений
31:22 Подводка к критерию стьюдента и вопрос про ограничения его применения
32:26 О необходимости нормальности распределения
33:46 Тесты для проверки на нормальность
34:24 Как сравнить ненормальные распределения
35:02 Подводка к вопросу о нормальности распределения средних при бутстрапе
36:04 Как быть, если нет старых пользователей, и нужно провести тест только на новых
37:53 Какие еще бывают вопросы и общие рассуждения
41:19 Интерпретация Bootstrap
Секция «Работа с данными»
42:04 Вопрос про разницу Where и Having
44:20 вопрос про виды join и задания на join
45:57 подводка к задаче про group by в Python
47:49 Задача на group by в Python
Секция «ML алгоритмы»
1:06:22 Задача о линейных регрессиях
1:09:47 Вопрос о градиентном спуске
1:14:06 Вопрос о переобучении
1:22:20 Вопрос о деревьях и их построении
1:26:04 Вопрос: почему случайный лес работает хорошо и не переобучается?
1:28:20 Последний вопрос со звездочкой: в каких случаях логистическая регрессия на задачах классификации будет работать лучше, чем случайный лес
1:32:18 Конец, обратная связь
https://www.youtube.com/watch?v=Us_TKT8ZL2E
@machinelearning_interview
0:00 Введение.
0:50 О структуре и секциях, которые входят в интервью.
Секция «Python»
2:30 Вопрос на изменяемые и неизменяемые типы данных
6:21 Задача на dict и ответ Дмитрия
8:15 Объяснение первой задачи
10:38 Задача, цель которой — сделать, чтобы дикты были разные, ответ Дмитрия
13:51 Разбор второй задачи
16:10 Вопрос о выделении и очистке памяти в Python, ответ Дмитрия
16:26 Разбор вопроса
19:00 Вопрос о генераторах, декораторах и итераторах
Секция «A/B-тесты»
20:35 Вопрос о моделировании A/B теста
30:57 Вопрос о генерации распределений
31:22 Подводка к критерию стьюдента и вопрос про ограничения его применения
32:26 О необходимости нормальности распределения
33:46 Тесты для проверки на нормальность
34:24 Как сравнить ненормальные распределения
35:02 Подводка к вопросу о нормальности распределения средних при бутстрапе
36:04 Как быть, если нет старых пользователей, и нужно провести тест только на новых
37:53 Какие еще бывают вопросы и общие рассуждения
41:19 Интерпретация Bootstrap
Секция «Работа с данными»
42:04 Вопрос про разницу Where и Having
44:20 вопрос про виды join и задания на join
45:57 подводка к задаче про group by в Python
47:49 Задача на group by в Python
Секция «ML алгоритмы»
1:06:22 Задача о линейных регрессиях
1:09:47 Вопрос о градиентном спуске
1:14:06 Вопрос о переобучении
1:22:20 Вопрос о деревьях и их построении
1:26:04 Вопрос: почему случайный лес работает хорошо и не переобучается?
1:28:20 Последний вопрос со звездочкой: в каких случаях логистическая регрессия на задачах классификации будет работать лучше, чем случайный лес
1:32:18 Конец, обратная связь
https://www.youtube.com/watch?v=Us_TKT8ZL2E
@machinelearning_interview
YouTube
Junior Data Scientist | Собеседование | karpov.courses
Курс Start ML: https://bit.ly/3SdB7Am
Лучший способ подготовиться к собеседованию — пройти его в тестовом режиме.
Мы записали mock-интервью, которое состоит из 4-х секций: Python, ML, работа с данными и А/В Тесты. В независимости от уровня соискателя есть…
Лучший способ подготовиться к собеседованию — пройти его в тестовом режиме.
Мы записали mock-интервью, которое состоит из 4-х секций: Python, ML, работа с данными и А/В Тесты. В независимости от уровня соискателя есть…
👍34🔥7😁4❤2
Следует ли применять нормализацию к данным до или после разделения? Имеет ли значение при построении прогнозной модели?
Ответ
Нормализация должна выполняться после разделения данных между обучающим и тестовым наборами с использованием только данных из обучающего набора. Это связано с тем, что тестовый набор играет роль свежих невидимых данных, поэтому он не должен быть доступен на этапе обучения. Использование любой информации, полученной из тестового набора до или во время обучения, может привести к систематической ошибке при оценке производительности. При нормализации тестового набора следует применять параметры нормализации, ранее полученные из тренировочного набора как есть. Не пересчитывайте их на тестовом наборе, потому что они будут несовместимы с моделью, и это приведет к неправильным прогнозам.
@machinelearning_interview
Ответ
Нормализация должна выполняться после разделения данных между обучающим и тестовым наборами с использованием только данных из обучающего набора. Это связано с тем, что тестовый набор играет роль свежих невидимых данных, поэтому он не должен быть доступен на этапе обучения. Использование любой информации, полученной из тестового набора до или во время обучения, может привести к систематической ошибке при оценке производительности. При нормализации тестового набора следует применять параметры нормализации, ранее полученные из тренировочного набора как есть. Не пересчитывайте их на тестовом наборе, потому что они будут несовместимы с моделью, и это приведет к неправильным прогнозам.
@machinelearning_interview
👍34🔥3
🔥 Полезнейшая Подборка каналов
🦾 Machine learning
@ai_machinelearning_big_data – все о машинном обучении
@data_analysis_ml – все о анализе данных.
@machinelearning_ru – машинное обучении на русском от новичка до профессионала.
@machinelearning_interview – подготовка к собеседования Data Science
@datascienceiot – бесплатные книги Machine learning
@ArtificialIntelligencedl – канал о искусственном интеллекте
@neural – все о нейронных сетях
@machinee_learning – чат о машинном обучении
@datascienceml_jobs - работа ds, ml
☕️ Java
@javatg - Java для програмистов
@javachats Java чат
@java_library - книги Java
@android_its Android разработка
@java_quizes - тесты Java
@Java_workit - работа Java
@progersit - шпаргалки ит
💡 Javascript / front
@javascriptv - javascript изучение
@about_javascript - javascript продвинутый
@JavaScript_testit -тесты JS
@htmlcssjavas - web
@hashdev - web разработка
🦫 Golang
@golang_interview - вопросы и ответы с собеседований по Go. Для всех уровней разработчиков.
@Golang_google - go для разработчиков
@golangtests - тесты и задачи GO
@golangl - чат Golang
@GolangJobsit - вакансии и работа GO
@golang_jobsgo - чат вакансий
@golang_books - книги Golang
@golang_speak - обсуждение задач Go
🐍 Python
@pythonl – python для датасаентиста
@pro_python_code – python на русском
@python_job_interview – подготовка к Python собеседованию
@python_testit тесты на python
@pythonlbooks - книги Python
@Django_pythonl django
@python_djangojobs - работа Python
🐧 Linux
@inux_kal - чат kali linux
@inuxkalii - linux kali
@linux_read - книги linux
👷♂️ IT работа
@hr_itwork - ит-ваканнсии
🔋 SQL
@sqlhub - базы данных
@chat_sql - базы данных чат
🤡It memes
@memes_prog - ит-мемы
⚙️ Rust
@rust_code - язык программирования rust
@rust_chats - чат rust
#️⃣ c# c++
@csharp_ci - c# c++кодинг
@csharp_cplus чат
🦾 Machine learning
@ai_machinelearning_big_data – все о машинном обучении
@data_analysis_ml – все о анализе данных.
@machinelearning_ru – машинное обучении на русском от новичка до профессионала.
@machinelearning_interview – подготовка к собеседования Data Science
@datascienceiot – бесплатные книги Machine learning
@ArtificialIntelligencedl – канал о искусственном интеллекте
@neural – все о нейронных сетях
@machinee_learning – чат о машинном обучении
@datascienceml_jobs - работа ds, ml
☕️ Java
@javatg - Java для програмистов
@javachats Java чат
@java_library - книги Java
@android_its Android разработка
@java_quizes - тесты Java
@Java_workit - работа Java
@progersit - шпаргалки ит
💡 Javascript / front
@javascriptv - javascript изучение
@about_javascript - javascript продвинутый
@JavaScript_testit -тесты JS
@htmlcssjavas - web
@hashdev - web разработка
🦫 Golang
@golang_interview - вопросы и ответы с собеседований по Go. Для всех уровней разработчиков.
@Golang_google - go для разработчиков
@golangtests - тесты и задачи GO
@golangl - чат Golang
@GolangJobsit - вакансии и работа GO
@golang_jobsgo - чат вакансий
@golang_books - книги Golang
@golang_speak - обсуждение задач Go
🐍 Python
@pythonl – python для датасаентиста
@pro_python_code – python на русском
@python_job_interview – подготовка к Python собеседованию
@python_testit тесты на python
@pythonlbooks - книги Python
@Django_pythonl django
@python_djangojobs - работа Python
🐧 Linux
@inux_kal - чат kali linux
@inuxkalii - linux kali
@linux_read - книги linux
👷♂️ IT работа
@hr_itwork - ит-ваканнсии
🔋 SQL
@sqlhub - базы данных
@chat_sql - базы данных чат
🤡It memes
@memes_prog - ит-мемы
⚙️ Rust
@rust_code - язык программирования rust
@rust_chats - чат rust
#️⃣ c# c++
@csharp_ci - c# c++кодинг
@csharp_cplus чат
👍10🔥3
В каких задачах и при использовании каких алгоритмов возникает «проблема мультиколлинеарности»?
Ответ
Мультиколлинеарность - два признака называются мультиколлинеарными, если два признака сильно коррелированы/зависимы. Изменения в одном признаке влекут за собой изменения в другом признаке.
Мультиколлинеарность влияет на алгоритмы линейной регрессии, логистической регрессии, KNN и Наивного Байеса.
======================
Линейная регрессия - из-за мультиколлинеарности линейная регрессия дает неверные результаты, и производительность модели снижается.
Это может уменьшить общий коэффициент, а также значение p (известное как значение значимости) и вызвать непредсказуемую дисперсию. Это приведет к переобучению, когда модель может отлично работать на известном тренировочном наборе, но потерпит неудачу на неизвестном наборе тестов. Поскольку это приводит к более высокой стандартной ошибке с более низким значением статистической значимости, мультиколлинеарность затрудняет определение того, насколько важен признак для целевой переменной. А при более низком значении значимости невозможно отклонить нулевое значение и приведет к ошибке второго рода для проверки нашей гипотезы.
=======================
Логистическая регрессия. Логистическая регрессия — это обобщенная линейная модель регрессии, на которую также влияет мультиколлинеарность.
=======================
KNN - из-за мультиколлинеарности точки становятся очень близкими, дают неверные результаты, и это влияет на производительность.
=======================
Наивный байесовский подход — основное предположение NB состоит в том, что признаки независимы. если функции коррелированы, предположение будет ошибочным.
=======================
На мой взляд, попытка решать любую задачу в предметной области указанными методами создает потенциальную угрозу мультиколлинеарности.
@machinelearning_interview
Ответ
Мультиколлинеарность - два признака называются мультиколлинеарными, если два признака сильно коррелированы/зависимы. Изменения в одном признаке влекут за собой изменения в другом признаке.
Мультиколлинеарность влияет на алгоритмы линейной регрессии, логистической регрессии, KNN и Наивного Байеса.
======================
Линейная регрессия - из-за мультиколлинеарности линейная регрессия дает неверные результаты, и производительность модели снижается.
Это может уменьшить общий коэффициент, а также значение p (известное как значение значимости) и вызвать непредсказуемую дисперсию. Это приведет к переобучению, когда модель может отлично работать на известном тренировочном наборе, но потерпит неудачу на неизвестном наборе тестов. Поскольку это приводит к более высокой стандартной ошибке с более низким значением статистической значимости, мультиколлинеарность затрудняет определение того, насколько важен признак для целевой переменной. А при более низком значении значимости невозможно отклонить нулевое значение и приведет к ошибке второго рода для проверки нашей гипотезы.
=======================
Логистическая регрессия. Логистическая регрессия — это обобщенная линейная модель регрессии, на которую также влияет мультиколлинеарность.
=======================
KNN - из-за мультиколлинеарности точки становятся очень близкими, дают неверные результаты, и это влияет на производительность.
=======================
Наивный байесовский подход — основное предположение NB состоит в том, что признаки независимы. если функции коррелированы, предположение будет ошибочным.
=======================
На мой взляд, попытка решать любую задачу в предметной области указанными методами создает потенциальную угрозу мультиколлинеарности.
@machinelearning_interview
👍19❤2🔥1
Нужно ли увеличивать размер ядра свертки, чтобы улучшить эффект сверточной нейронной сети?
Ядро большего размера может упустить из виду функции и пропустить важные детали в изображениях, тогда как ядро меньшего размера может предоставить больше информации, что приведет к большей путанице. Таким образом, необходимо определить наиболее подходящий размер ядра/фильтра.
==============
Сверточные нейронные сети работают на двух предположениях:
Функции низкого уровня являются локальными. То, что полезно в одном месте, будет полезно и в других местах. Размер ядра должен определяться тем, насколько сильно мы верим в эти предположения для рассматриваемой проблемы. В одном крайнем случае, когда у нас есть ядра 1x1, мы, по сути, говорим, что функции низкого уровня являются попиксельными, и они вообще не влияют на соседние пиксели, и что мы должны применить одну и ту же операцию ко всем пикселям. С другой стороны, у нас есть ядра размером с весь образ. В этом случае CNN по существу становится полностью подключенным и перестает быть CNN, и мы больше не делаем никаких предположений о локальности объектов низкого уровня.
===============
На практике это часто делается, просто пробуя несколько размеров ядра и наблюдая, какой из них работает лучше всего.
@machinelearning_interview
Ядро большего размера может упустить из виду функции и пропустить важные детали в изображениях, тогда как ядро меньшего размера может предоставить больше информации, что приведет к большей путанице. Таким образом, необходимо определить наиболее подходящий размер ядра/фильтра.
==============
Сверточные нейронные сети работают на двух предположениях:
Функции низкого уровня являются локальными. То, что полезно в одном месте, будет полезно и в других местах. Размер ядра должен определяться тем, насколько сильно мы верим в эти предположения для рассматриваемой проблемы. В одном крайнем случае, когда у нас есть ядра 1x1, мы, по сути, говорим, что функции низкого уровня являются попиксельными, и они вообще не влияют на соседние пиксели, и что мы должны применить одну и ту же операцию ко всем пикселям. С другой стороны, у нас есть ядра размером с весь образ. В этом случае CNN по существу становится полностью подключенным и перестает быть CNN, и мы больше не делаем никаких предположений о локальности объектов низкого уровня.
===============
На практике это часто делается, просто пробуя несколько размеров ядра и наблюдая, какой из них работает лучше всего.
@machinelearning_interview
👍11👎4
Как можно ускорить сходимость в градиентных методах настройки нейронных сетей?
Ответ
Задача оптимизатора — сделать функцию потерь как можно меньше, чтобы найти подходящие параметры для выполнения определенной задачи. В настоящее время основными оптимизаторами, используемыми при обучении моделей, являются SGD, RMSProp, Adam, AdaDelt и так далее. Оптимизаторы SGD с импульсом широко используются в научных кругах и промышленности, поэтому большинство выпускаемых моделей обучаются с помощью оптимизатора SGD с импульсом. Но у SGD-оптимизатора с импульсом есть два недостатка: во-первых, скорость сходимости низкая, во-вторых, трудно установить начальную скорость обучения, однако, если начальная скорость обучения установлена
правильно, а модели обучены в достаточном количестве итераций. , модели, обученные SGD с помощью импульса, могут достигать более высокой точности по сравнению с моделями, обученными другими оптимизаторами. Некоторые другие оптимизаторы с адаптивной скоростью обучения, такие как Adam, RMSProp и т. д., стремятся сходиться быстрее, но окончательная точность сходимости будет немного хуже.
==========================
Концепция скорости обучения: скорость обучения — это гиперпараметр для управления скоростью обучения, чем ниже скорость обучения, тем медленнее изменяется значение потерь, хотя использование низкой скорости обучения может гарантировать, что вы не пропустите ни один локальный минимум, но это также означает, что скорость конвергенции медленная, особенно когда градиент попадает в область градиентного плато.
=========================
Нейронные сети глубокого обучения обучаются с использованием алгоритма стохастического градиентного спуска.
Стохастический градиентный спуск — это алгоритм оптимизации, который оценивает градиент ошибки для текущего состояния модели, используя примеры из обучающего набора данных, а затем обновляет веса модели, используя алгоритм обратного распространения ошибок, называемый просто обратным распространением.
Величина, на которую веса обновляются во время обучения, называется размером шага или «скоростью обучения».
============================
Задача обучения нейронных сетей глубокого обучения заключается в тщательном выборе скорости обучения. Это может быть самый важный гиперпараметр для модели.
Стратегия снижения скорости обучения: Во время обучения, если мы всегда используем одну и ту же скорость обучения, мы не можем получить модель с максимальной точностью, поэтому скорость обучения следует регулировать во время обучения. На ранней стадии обучения веса находятся в состоянии случайной инициализации, а градиенты имеют тенденцию к снижению, поэтому мы можем установить относительно большую скорость обучения для более быстрой сходимости. На поздней стадии обучения веса близки к оптимальным значениям, оптимальное значение не может быть достигнуто при относительно большой скорости обучения, поэтому следует использовать относительно меньшую скорость обучения. Во время обучения многие исследователи используют стратегию снижения скорости обучения piecewise_decay, которая представляет собой пошаговое снижение скорости обучения. Например, при обучении ResNet50 начальная скорость обучения, которую установили, равна 0,1, и скорость обучения падает до 1/10 каждые 30 эпох, общее количество эпох для обучения равно 120. Помимо кусочного_распада, многие исследователи также предлагали другие способы уменьшить скорость обучения, например, polynomial_decay, exponential_decay и cosine_decay и т. д.
ResNet50 — это вариант модели ResNet, который имеет 48 слоев свертки, а также 1 слой MaxPool и 1 средний пул. Он имеет 3,8 x 10 ^ 9 операций с плавающей запятой. Это широко используемая модель ResNet и ее архитектура хорошо известна.
Смотри также https://informatics-ege.blogspot.com/2022/06/deep-learning-neural-networks-trained.html
➡️ Подробнее
@machinelearning_interview
Ответ
Задача оптимизатора — сделать функцию потерь как можно меньше, чтобы найти подходящие параметры для выполнения определенной задачи. В настоящее время основными оптимизаторами, используемыми при обучении моделей, являются SGD, RMSProp, Adam, AdaDelt и так далее. Оптимизаторы SGD с импульсом широко используются в научных кругах и промышленности, поэтому большинство выпускаемых моделей обучаются с помощью оптимизатора SGD с импульсом. Но у SGD-оптимизатора с импульсом есть два недостатка: во-первых, скорость сходимости низкая, во-вторых, трудно установить начальную скорость обучения, однако, если начальная скорость обучения установлена
правильно, а модели обучены в достаточном количестве итераций. , модели, обученные SGD с помощью импульса, могут достигать более высокой точности по сравнению с моделями, обученными другими оптимизаторами. Некоторые другие оптимизаторы с адаптивной скоростью обучения, такие как Adam, RMSProp и т. д., стремятся сходиться быстрее, но окончательная точность сходимости будет немного хуже.
==========================
Концепция скорости обучения: скорость обучения — это гиперпараметр для управления скоростью обучения, чем ниже скорость обучения, тем медленнее изменяется значение потерь, хотя использование низкой скорости обучения может гарантировать, что вы не пропустите ни один локальный минимум, но это также означает, что скорость конвергенции медленная, особенно когда градиент попадает в область градиентного плато.
=========================
Нейронные сети глубокого обучения обучаются с использованием алгоритма стохастического градиентного спуска.
Стохастический градиентный спуск — это алгоритм оптимизации, который оценивает градиент ошибки для текущего состояния модели, используя примеры из обучающего набора данных, а затем обновляет веса модели, используя алгоритм обратного распространения ошибок, называемый просто обратным распространением.
Величина, на которую веса обновляются во время обучения, называется размером шага или «скоростью обучения».
============================
Задача обучения нейронных сетей глубокого обучения заключается в тщательном выборе скорости обучения. Это может быть самый важный гиперпараметр для модели.
Стратегия снижения скорости обучения: Во время обучения, если мы всегда используем одну и ту же скорость обучения, мы не можем получить модель с максимальной точностью, поэтому скорость обучения следует регулировать во время обучения. На ранней стадии обучения веса находятся в состоянии случайной инициализации, а градиенты имеют тенденцию к снижению, поэтому мы можем установить относительно большую скорость обучения для более быстрой сходимости. На поздней стадии обучения веса близки к оптимальным значениям, оптимальное значение не может быть достигнуто при относительно большой скорости обучения, поэтому следует использовать относительно меньшую скорость обучения. Во время обучения многие исследователи используют стратегию снижения скорости обучения piecewise_decay, которая представляет собой пошаговое снижение скорости обучения. Например, при обучении ResNet50 начальная скорость обучения, которую установили, равна 0,1, и скорость обучения падает до 1/10 каждые 30 эпох, общее количество эпох для обучения равно 120. Помимо кусочного_распада, многие исследователи также предлагали другие способы уменьшить скорость обучения, например, polynomial_decay, exponential_decay и cosine_decay и т. д.
ResNet50 — это вариант модели ResNet, который имеет 48 слоев свертки, а также 1 слой MaxPool и 1 средний пул. Он имеет 3,8 x 10 ^ 9 операций с плавающей запятой. Это широко используемая модель ResNet и ее архитектура хорошо известна.
Смотри также https://informatics-ege.blogspot.com/2022/06/deep-learning-neural-networks-trained.html
➡️ Подробнее
@machinelearning_interview
👍25👎1
Можно ли сказать, что машинное обучение - это автоматизация обработки данных?
Ответ : ML - это одна из фаз автоматизированной обработки данных
=========================
Обработка данных - это задача преобразования данных из заданной формы в гораздо более удобную и желаемую форму, то есть сделать ее более значимой и информативной.
========================
Используя алгоритмы машинного обучения, математическое моделирование и статистические знания, весь этот процесс можно автоматизировать.
========================
Результат этого полного процесса может быть в любой желаемой форме, такой как графики, видео, диаграммы, таблицы, изображения и многое другое, в зависимости от задачи, которую мы выполняем, и требований машины. Это может показаться простым, но когда дело касается крупных организаций, таких как Twitter, Facebook, административных органов, таких как парламент, ЮНЕСКО, и организаций сектора здравоохранения, весь этот процесс должен выполняться в очень структурированной манере.
Сбор:
===========
Самый важный шаг при запуске машинного обучения - получение данных хорошего качества и точности. Данные могут быть собраны из любого аутентифицированного источника, такого как data.gov.in, Kaggle или репозиторий наборов данных UCI. Например, при подготовке к конкурсному экзамену студенты изучают лучшие учебные материалы, к которым они могут получить доступ, чтобы они усваивали лучшее для получения наилучших результатов. Точно так же высококачественные и точные данные сделают процесс изучения модели проще и лучше, а во время тестирования модель будет давать самые современные результаты.
На сбор данных уходит огромное количество капитала, времени и ресурсов. Организации или исследователи должны решить, какие данные им нужны для выполнения своих задач или исследований.Пример: при работе с распознавателем выражений лица требуется множество изображений с различными человеческими выражениями. Хорошие данные гарантируют, что результаты модели верны и им можно доверять.
Подготовка :
===========
Собранные данные могут быть в необработанном виде, которые нельзя напрямую передать в машину. Итак, это процесс сбора наборов данных из разных источников, анализа этих наборов данных и последующего создания нового набора данных для дальнейшей обработки и исследования. Эта подготовка может быть выполнена вручную или в автоматическом режиме. Данные также могут быть подготовлены в числовой форме, что ускорит изучение модели.
Пример: изображение можно преобразовать в матрицу размером N X N, значение каждой ячейки будет указывать пиксель изображения.
Вход :
==========
Теперь подготовленные данные могут быть в форме, которая не может быть машиночитаемой, поэтому для преобразования этих данных в читаемую форму необходимы некоторые алгоритмы преобразования. Для выполнения этой задачи необходимы высокая точность вычислений. Пример: данные могут быть собраны из таких источников, как данные MNIST Digit (изображения), комментарии Twitter, аудиофайлы, видеоклипы.
Обработка :
==========
Это этап, на котором требуются алгоритмы и методы машинного обучения для выполнения инструкций, предоставленных для большого объема данных с точностью и оптимальным расчетом.
Выход :
На этом этапе машина получает результат осмысленным образом, который может быть легко выведен пользователем. Вывод может быть в виде отчетов, графиков, видео и т. д.
Место хранения :
Это последний шаг, на котором полученные выходные данные, данные модели данных и вся полезная информация сохраняются для использования в будущем
@machinelearning_interview
Ответ : ML - это одна из фаз автоматизированной обработки данных
=========================
Обработка данных - это задача преобразования данных из заданной формы в гораздо более удобную и желаемую форму, то есть сделать ее более значимой и информативной.
========================
Используя алгоритмы машинного обучения, математическое моделирование и статистические знания, весь этот процесс можно автоматизировать.
========================
Результат этого полного процесса может быть в любой желаемой форме, такой как графики, видео, диаграммы, таблицы, изображения и многое другое, в зависимости от задачи, которую мы выполняем, и требований машины. Это может показаться простым, но когда дело касается крупных организаций, таких как Twitter, Facebook, административных органов, таких как парламент, ЮНЕСКО, и организаций сектора здравоохранения, весь этот процесс должен выполняться в очень структурированной манере.
Сбор:
===========
Самый важный шаг при запуске машинного обучения - получение данных хорошего качества и точности. Данные могут быть собраны из любого аутентифицированного источника, такого как data.gov.in, Kaggle или репозиторий наборов данных UCI. Например, при подготовке к конкурсному экзамену студенты изучают лучшие учебные материалы, к которым они могут получить доступ, чтобы они усваивали лучшее для получения наилучших результатов. Точно так же высококачественные и точные данные сделают процесс изучения модели проще и лучше, а во время тестирования модель будет давать самые современные результаты.
На сбор данных уходит огромное количество капитала, времени и ресурсов. Организации или исследователи должны решить, какие данные им нужны для выполнения своих задач или исследований.Пример: при работе с распознавателем выражений лица требуется множество изображений с различными человеческими выражениями. Хорошие данные гарантируют, что результаты модели верны и им можно доверять.
Подготовка :
===========
Собранные данные могут быть в необработанном виде, которые нельзя напрямую передать в машину. Итак, это процесс сбора наборов данных из разных источников, анализа этих наборов данных и последующего создания нового набора данных для дальнейшей обработки и исследования. Эта подготовка может быть выполнена вручную или в автоматическом режиме. Данные также могут быть подготовлены в числовой форме, что ускорит изучение модели.
Пример: изображение можно преобразовать в матрицу размером N X N, значение каждой ячейки будет указывать пиксель изображения.
Вход :
==========
Теперь подготовленные данные могут быть в форме, которая не может быть машиночитаемой, поэтому для преобразования этих данных в читаемую форму необходимы некоторые алгоритмы преобразования. Для выполнения этой задачи необходимы высокая точность вычислений. Пример: данные могут быть собраны из таких источников, как данные MNIST Digit (изображения), комментарии Twitter, аудиофайлы, видеоклипы.
Обработка :
==========
Это этап, на котором требуются алгоритмы и методы машинного обучения для выполнения инструкций, предоставленных для большого объема данных с точностью и оптимальным расчетом.
Выход :
На этом этапе машина получает результат осмысленным образом, который может быть легко выведен пользователем. Вывод может быть в виде отчетов, графиков, видео и т. д.
Место хранения :
Это последний шаг, на котором полученные выходные данные, данные модели данных и вся полезная информация сохраняются для использования в будущем
@machinelearning_interview
👍18👎1🔥1
На ваш взгляд, что более важно при разработке модели машинного обучения: производительность модели или её точность?
Ответ
По моему мнению, точность - самая важная характеристика модели машинного обучения и искусственного интеллекта. Когда мы обсуждаем производительность модели, нам нужно сначала уточнить, является ли это производительностью обучения модели или производительностью оценки модели? Производительность модели можно улучшить с помощью распределенных вычислений и распараллеливания оцениваемых активов, тогда как точность должна быть тщательно повышена в процессе обучения модели. Часто, когда мы сравниваем время вычислений для обучения модели с временем вычисления оценки той же модели, последнее оказывается на несколько порядков меньше. Кроме того, после того, как модели развернуты в работе, обычно (пере) обучение модели выполняется гораздо реже, чем оценка результатов.
Хотя это может и зависить от конкретной цели, доминирующей при принятии решения
========================================
1.Если вы имели в виду скорость, это, конечно, очень зависит от приложения. Например, при анализе медицинских изображений для определения наличия заболевания точность чрезвычайно важна, даже если модели потребуют минуты или часы, чтобы сделать прогноз.
========================================
2.Другие приложения требуют производительности в реальном времени, даже если это происходит за счет точности. Например, представьте себе машину, которая наблюдает за быстрой конвейерной лентой, несущей помидоры, где она должна отделять зеленые от красных. Хотя случайная ошибка нежелательна, успех этой машины в большей степени определяется ее способностью выдерживать ее пропускную способность.
@machinelearning_interview
Ответ
По моему мнению, точность - самая важная характеристика модели машинного обучения и искусственного интеллекта. Когда мы обсуждаем производительность модели, нам нужно сначала уточнить, является ли это производительностью обучения модели или производительностью оценки модели? Производительность модели можно улучшить с помощью распределенных вычислений и распараллеливания оцениваемых активов, тогда как точность должна быть тщательно повышена в процессе обучения модели. Часто, когда мы сравниваем время вычислений для обучения модели с временем вычисления оценки той же модели, последнее оказывается на несколько порядков меньше. Кроме того, после того, как модели развернуты в работе, обычно (пере) обучение модели выполняется гораздо реже, чем оценка результатов.
Хотя это может и зависить от конкретной цели, доминирующей при принятии решения
========================================
1.Если вы имели в виду скорость, это, конечно, очень зависит от приложения. Например, при анализе медицинских изображений для определения наличия заболевания точность чрезвычайно важна, даже если модели потребуют минуты или часы, чтобы сделать прогноз.
========================================
2.Другие приложения требуют производительности в реальном времени, даже если это происходит за счет точности. Например, представьте себе машину, которая наблюдает за быстрой конвейерной лентой, несущей помидоры, где она должна отделять зеленые от красных. Хотя случайная ошибка нежелательна, успех этой машины в большей степени определяется ее способностью выдерживать ее пропускную способность.
@machinelearning_interview
👍20👎1🤡1